openmp1_Yaguchi_version_170530
|
|
|
- たみじろう あみおか
- 5 years ago
- Views:
Transcription
1 並列計算とは /OpenMP の初歩 (1)
2 今 の内容
3
4 なぜ並列計算が必要か?
5 スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201 天河 1 号 Jaguar Roadrunner 地球シミュレータ 1MFLOPS IBM360/95 CDC6600 スカラー / ベクトル機 並列機 (104times faster / 20 years) 年
6 TOP500 によるスーパーコンピュータ性能 較
7 2016 年 11 のリスト ( 上位 8 システム )

8 TOP500 で るアーキテクチャの変遷
9 頑張って勉強しましょう!
10
11 並列計算機のアーキテクチャ
12 SIMD と MIMD
13 共有メモリ型と分散メモリ型
14 共有メモリ型と分散メモリ型 ( 続き ) PU0 PU1 PU1 メモリメモリメモリ インターコネクト ネットワーク
15 ホモジニアス型とヘテロジニアス型



16 計算科学演習 I で使う並列計算機


17 π コンピュータ SPARC64 IXfx SPARC64 V9 + HPC-ACE コア数 16 コア 動作周波 数 1.65GHz キャッシュ L1-I L1-D 32KB/コア L2 12MB/ソケット メモリバンド幅 85GB/s 40nm CMOS, 21.9 mm 臼井英之 21.9 mm 並列計算とは/OpenMP の初歩 1
18
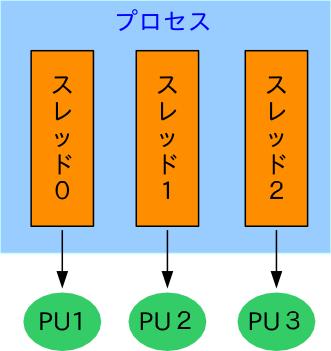
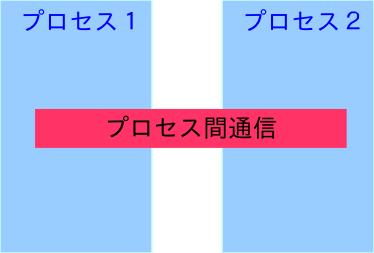
19 共有メモリ型並列計算機における並列 式
20 OpenMP


21 OpenMP の実 モデル :Fork Join モデル
22 OpenMP の構成要素
23 演習 1( 準備 ):Hello World を並列化してみよう! % mkdir enshu openmp1 % cd enshu openmp1 program hello world imp lic it none prin t, Hello World! end program % frtpx hello. f90 注意 : 計算ノードで計算を うのでコンパイル 実 法が変わります
24 型計算機上でのプログラム実 : キューイングシステム
25 演習 1( 続き ): ジョブスクリプトの作成 #!/bin/bash #PJM -N jobname #PJM -L rscgrp=small #PJM -L node=1 #PJM -L elapse=2:00 #PJM -j export OMP_NUM_THREADS=1. / a. out シェルを指定ジョブ名を指定投 先のキュー名を指定使 ノード数を指定 スレッド数を指定実 プログラム名を指定
26 演習 1( 続き ): ジョブの投 演習 pjsub ( ジョブスクリプト名 ) pjstat JOB ID JOB NAME MD ST USER START DATE ELAPSE LIM NODE REQUIRE jobname NM RUN user (05/19 16:23) 0000:02: jobname NM QUE user (05/19 16:33) 0000:02:00 1 pjdel ( ジョブ番号 ) % pjsub hello.sh [INFO] PJM 0000 pjsub Job submitted. cat
27 演習 1( これで最後 ):OpenMP を いた Hello World の並列化 program hello world imp lic it none integer :: omp_get_thread_num!$ompparallel p r i n t, My id is, omp_get_thread_num(), Hello World!!$omp end parallel end program % frtpx Kopenmp hello. f90 % pjsub hello.sh
28 プログラムの解説 program hello im plic it none!$ompparallel 並列リージョン end program
29 OpenMP 並列化プログラムの基本構成例 program main imp lic it none ( 逐次実 部分 )!$ompparallel ( 並列化したい部分 )!$omp end parallel ( 逐次実 部分 ) end program
30 マルチスレッドでの実 のイメージといくつかの 語
31 計算の並列化 (Work-Sharing 構造 ) a (1 :n) = a (1:n ) + 1
32 DO ループの分割 (!$omp do) programmain implicit none integer, parameter :: SP = kind(1.0) integer, parameter :: DP = selected_real_kind(2*precision(1.0_sp)) real(dp), dimension(100000) :: a, b integer :: i!$omp parallel!$omp do 直後の DO ループを複数のスレッド do i=1, で分割して実 せよ, という意味 b(i) = a(i) (!$omp end do は省略可 ) end do!$omp end do!$omp end parallel 2 スレッドで実 した場合 スレッド 0 do i=1,50000 b(i) = a(i) end do スレッド 1 do i=50001, b(i) = a(i) end do ( 分割の仕 はコンパイラ依存 ) end program
33 演習 2:omp do を使ってみよう!
34 演習 2 のプログラム program axpy i mp l ic i t none integer, parameter : : SP = kind (1. 0 ) integer, parameter : : DP = selected_ real_kind (2 precision ( 1. 0_SP )) r e a l (DP), dimension ( ) : : x, y, z re al (DP): : a integer : : i!! a,x,y の値を各 で 由に設定.!!$omp parallel!$omp do do i = 1, z ( i ) = a x ( i ) + y ( i ) ベクトルの加算 z = a x + y end do!$omp end do!$omp end parallel!! 経過時間の確認! p rin t, z ( 1 ) end program

35 時間計測 ジョブスクリプトの例
36 演習 3:!$omp parallel do!$ompparallel!$omp parallel do!$ompdo do i=1, do i=1, b(i) = a(i) b(i) = a(i) end do end do!$omp end parallel do!$omp end do!$omp end parallel!$omp end parallel do
37 注意 omp do は並列実 できない場合も 動的に分割してしまう! program i n v l i mp l ic i t none integer, parameter : : n = 100 integer, dimension ( n ) : : a integer : : i a ( 1 ) = 0!$omp parallel do do i =2,n a ( i ) = a ( i 1) + 1 end do! $omp end paralleldo p rin t, a (n ) end program 正しい結果 :99 2 スレッドで実 スレッド 0 do i=1,50 a(i) = a(i-1) + 1 end do スレッド 1 do i=51,100 a(i) = a(i-1) + 1 end do 本当は a(50) の結果がないと実 できない!
38 do ループの並列化のまとめ do i =2,100 x ( i ) = a x ( i 1) + b end do
39 omp workshare!$ompdo do i=1, z(i) = a x(i) + y(i) end do!$omp end do!$omp end parallel!$omp workshare z(:) = a x(:) + y(:)!$omp end workshare (!$omp end workshare は省略不可 ) C = matmul(a, B)!$omp end workshare
40 mail s 自分のアカウント名 kobeuniv.compra1@gmail.com < result.txt
41 mail s 自分のアカウント名 kobeuniv.compra1@gmail.com < result.txt
ÊÂÎó·×»»¤È¤Ï/OpenMP¤Î½éÊâ¡Ê£±¡Ë
 2015 5 21 OpenMP Hello World Do (omp do) Fortran (omp workshare) CPU Richardson s Forecast Factory 64,000 L.F. Richardson, Weather Prediction by Numerical Process, Cambridge, University Press (1922) Drawing
2015 5 21 OpenMP Hello World Do (omp do) Fortran (omp workshare) CPU Richardson s Forecast Factory 64,000 L.F. Richardson, Weather Prediction by Numerical Process, Cambridge, University Press (1922) Drawing
OpenMP¤òÍѤ¤¤¿ÊÂÎó·×»»¡Ê£±¡Ë
 2012 5 24 scalar Open MP Hello World Do (omp do) (omp workshare) (shared, private) π (reduction) PU PU PU 2 16 OpenMP FORTRAN/C/C++ MPI OpenMP 1997 FORTRAN Ver. 1.0 API 1998 C/C++ Ver. 1.0 API 2000 FORTRAN
2012 5 24 scalar Open MP Hello World Do (omp do) (omp workshare) (shared, private) π (reduction) PU PU PU 2 16 OpenMP FORTRAN/C/C++ MPI OpenMP 1997 FORTRAN Ver. 1.0 API 1998 C/C++ Ver. 1.0 API 2000 FORTRAN
OpenMP¤òÍѤ¤¤¿ÊÂÎó·×»»¡Ê£±¡Ë
 2011 5 26 scalar Open MP Hello World Do (omp do) (omp workshare) (shared, private) π (reduction) scalar magny-cours, 48 scalar scalar 1 % scp. ssh / authorized keys 133. 30. 112. 246 2 48 % ssh 133.30.112.246
2011 5 26 scalar Open MP Hello World Do (omp do) (omp workshare) (shared, private) π (reduction) scalar magny-cours, 48 scalar scalar 1 % scp. ssh / authorized keys 133. 30. 112. 246 2 48 % ssh 133.30.112.246
演習1: 演習準備
 演習 1: 演習準備 2013 年 8 月 6 日神戸大学大学院システム情報学研究科森下浩二 1 演習 1 の内容 神戸大 X10(π-omputer) について システム概要 ログイン方法 コンパイルとジョブ実行方法 OpenMP の演習 ( 入門編 ) 1. parallel 構文 実行時ライブラリ関数 2. ループ構文 3. shared 節 private 節 4. reduction 節
演習 1: 演習準備 2013 年 8 月 6 日神戸大学大学院システム情報学研究科森下浩二 1 演習 1 の内容 神戸大 X10(π-omputer) について システム概要 ログイン方法 コンパイルとジョブ実行方法 OpenMP の演習 ( 入門編 ) 1. parallel 構文 実行時ライブラリ関数 2. ループ構文 3. shared 節 private 節 4. reduction 節
OpenMP¤òÍѤ¤¤¿ÊÂÎó·×»»¡Ê£²¡Ë
 2013 5 30 (schedule) (omp sections) (omp single, omp master) (barrier, critical, atomic) program pi i m p l i c i t none integer, parameter : : SP = kind ( 1. 0 ) integer, parameter : : DP = selected real
2013 5 30 (schedule) (omp sections) (omp single, omp master) (barrier, critical, atomic) program pi i m p l i c i t none integer, parameter : : SP = kind ( 1. 0 ) integer, parameter : : DP = selected real
演習準備
 演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
I I / 47
 1 2013.07.18 1 I 2013 3 I 2013.07.18 1 / 47 A Flat MPI B 1 2 C: 2 I 2013.07.18 2 / 47 I 2013.07.18 3 / 47 #PJM -L "rscgrp=small" π-computer small: 12 large: 84 school: 24 84 16 = 1344 small school small
1 2013.07.18 1 I 2013 3 I 2013.07.18 1 / 47 A Flat MPI B 1 2 C: 2 I 2013.07.18 2 / 47 I 2013.07.18 3 / 47 #PJM -L "rscgrp=small" π-computer small: 12 large: 84 school: 24 84 16 = 1344 small school small
PowerPoint プレゼンテーション
 計算科学演習 I 第 8 回講義 MPI を用いた並列計算 (I) 2013 年 6 月 6 日 システム情報学研究科計算科学専攻 山本有作 今回の講義の概要 1. MPI とは 2. 簡単な MPI プログラムの例 (1) 3. 簡単な MPI プログラムの例 (2):1 対 1 通信 4. 簡単な MPI プログラムの例 (3): 集団通信 共有メモリ型並列計算機 ( 復習 ) 共有メモリ型並列計算機
計算科学演習 I 第 8 回講義 MPI を用いた並列計算 (I) 2013 年 6 月 6 日 システム情報学研究科計算科学専攻 山本有作 今回の講義の概要 1. MPI とは 2. 簡単な MPI プログラムの例 (1) 3. 簡単な MPI プログラムの例 (2):1 対 1 通信 4. 簡単な MPI プログラムの例 (3): 集団通信 共有メモリ型並列計算機 ( 復習 ) 共有メモリ型並列計算機
コードのチューニング
 OpenMP による並列化実装 八木学 ( 理化学研究所計算科学研究センター ) KOBE HPC Spring School 2019 2019 年 3 月 14 日 スレッド並列とプロセス並列 スレッド並列 OpenMP 自動並列化 プロセス並列 MPI プロセス プロセス プロセス スレッドスレッドスレッドスレッド メモリ メモリ プロセス間通信 Private Private Private
OpenMP による並列化実装 八木学 ( 理化学研究所計算科学研究センター ) KOBE HPC Spring School 2019 2019 年 3 月 14 日 スレッド並列とプロセス並列 スレッド並列 OpenMP 自動並列化 プロセス並列 MPI プロセス プロセス プロセス スレッドスレッドスレッドスレッド メモリ メモリ プロセス間通信 Private Private Private
Microsoft PowerPoint _MPI-01.pptx
 計算科学演習 Ⅰ MPI を いた並列計算 (I) 神戸大学大学院システム情報学研究科谷口隆晴 yaguchi@pearl.kobe-u.ac.jp この資料は昨年度担当の横川先生の資料を参考にさせて頂いています. 2016/06/23 MPI を用いた並列計算 (I) 1 講義概要 分散メモリ型計算機上のプログラミング メッセージ パシング インターフェイス (Message Passing Interface,MPI)
計算科学演習 Ⅰ MPI を いた並列計算 (I) 神戸大学大学院システム情報学研究科谷口隆晴 yaguchi@pearl.kobe-u.ac.jp この資料は昨年度担当の横川先生の資料を参考にさせて頂いています. 2016/06/23 MPI を用いた並列計算 (I) 1 講義概要 分散メモリ型計算機上のプログラミング メッセージ パシング インターフェイス (Message Passing Interface,MPI)
演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 RIKEN AICS HPC Spring School /3/5
 演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
OpenMPプログラミング
 OpenMP 基礎 岩下武史 ( 学術情報メディアセンター ) 1 2013/9/13 並列処理とは 逐次処理 CPU1 並列処理 CPU1 CPU2 CPU3 CPU4 処理 1 処理 1 処理 2 処理 3 処理 4 処理 2 処理 3 処理 4 時間 2 2 種類の並列処理方法 プロセス並列 スレッド並列 並列プログラム 並列プログラム プロセス プロセス 0 プロセス 1 プロセス間通信 スレッド
OpenMP 基礎 岩下武史 ( 学術情報メディアセンター ) 1 2013/9/13 並列処理とは 逐次処理 CPU1 並列処理 CPU1 CPU2 CPU3 CPU4 処理 1 処理 1 処理 2 処理 3 処理 4 処理 2 処理 3 処理 4 時間 2 2 種類の並列処理方法 プロセス並列 スレッド並列 並列プログラム 並列プログラム プロセス プロセス 0 プロセス 1 プロセス間通信 スレッド
OpenMP (1) 1, 12 1 UNIX (FUJITSU GP7000F model 900), 13 1 (COMPAQ GS320) FUJITSU VPP5000/64 1 (a) (b) 1: ( 1(a))
 1, 12 1 UNIX (FUJITSU GP7000F model 900), 13 1 (COMPAQ GS320) FUJITSU VPP5000/64 1 (a) (b) 1: ( 1(a))") OpenMP (1) 1, 12 1 UNIX (FUJITSU GP7000F model 900), 13 1 (COMPAQ GS320) FUJITSU VPP5000/64 1 (a) (b) 1: ( 1(a)) E-mail: {nanri,amano}@cc.kyushu-u.ac.jp 1 ( ) 1. VPP Fortran[6] HPF[3] VPP Fortran 2. MPI[5]
OpenMP (1) 1, 12 1 UNIX (FUJITSU GP7000F model 900), 13 1 (COMPAQ GS320) FUJITSU VPP5000/64 1 (a) (b) 1: ( 1(a)) E-mail: {nanri,amano}@cc.kyushu-u.ac.jp 1 ( ) 1. VPP Fortran[6] HPF[3] VPP Fortran 2. MPI[5]
スライド 1
 計算科学が拓く世界スーパーコンピュータは何故スーパーか 学術情報メディアセンター中島浩 http://www.para.media.kyoto-u.ac.jp/jp/ username=super password=computer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
計算科学が拓く世界スーパーコンピュータは何故スーパーか 学術情報メディアセンター中島浩 http://www.para.media.kyoto-u.ac.jp/jp/ username=super password=computer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
Microsoft PowerPoint - 演習2:MPI初歩.pptx
 演習 2:MPI 初歩 - 並列に計算する - 2013 年 8 月 6 日 神戸大学大学院システム情報学研究科計算科学専攻横川三津夫 MPI( メッセージ パッシング インターフェース ) を使おう! [ 演習 2 の内容 ] はじめの一歩課題 1: Hello, world を並列に出力する. 課題 2: プロセス 0 からのメッセージを受け取る (1 対 1 通信 ). 部分に分けて計算しよう課題
演習 2:MPI 初歩 - 並列に計算する - 2013 年 8 月 6 日 神戸大学大学院システム情報学研究科計算科学専攻横川三津夫 MPI( メッセージ パッシング インターフェース ) を使おう! [ 演習 2 の内容 ] はじめの一歩課題 1: Hello, world を並列に出力する. 課題 2: プロセス 0 からのメッセージを受け取る (1 対 1 通信 ). 部分に分けて計算しよう課題
スパコンに通じる並列プログラミングの基礎
 2018.09.10 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 1 / 59 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 2 / 59 Windows, Mac Unix 0444-J furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 3 / 59 Part I Unix GUI CUI:
2018.09.10 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 1 / 59 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 2 / 59 Windows, Mac Unix 0444-J furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 3 / 59 Part I Unix GUI CUI:
Microsoft Word - openmp-txt.doc
 ( 付録 A) OpenMP チュートリアル OepnMP は 共有メモリマルチプロセッサ上のマルチスレッドプログラミングのための API です 本稿では OpenMP の簡単な解説とともにプログラム例をつかって説明します 詳しくは OpenMP の規約を決めている OpenMP ARB の http://www.openmp.org/ にある仕様書を参照してください 日本語訳は http://www.hpcc.jp/omni/spec.ja/
( 付録 A) OpenMP チュートリアル OepnMP は 共有メモリマルチプロセッサ上のマルチスレッドプログラミングのための API です 本稿では OpenMP の簡単な解説とともにプログラム例をつかって説明します 詳しくは OpenMP の規約を決めている OpenMP ARB の http://www.openmp.org/ にある仕様書を参照してください 日本語訳は http://www.hpcc.jp/omni/spec.ja/
スパコンに通じる並列プログラミングの基礎
 2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
(Microsoft PowerPoint \215u\213`4\201i\221\272\210\344\201j.pptx)
") AICS 村井均 RIKEN AICS HPC Summer School 2012 8/7/2012 1 背景 OpenMP とは OpenMP の基本 OpenMP プログラミングにおける注意点 やや高度な話題 2 共有メモリマルチプロセッサシステムの普及 共有メモリマルチプロセッサシステムのための並列化指示文を共通化する必要性 各社で仕様が異なり 移植性がない そして いまやマルチコア プロセッサが主流となり
AICS 村井均 RIKEN AICS HPC Summer School 2012 8/7/2012 1 背景 OpenMP とは OpenMP の基本 OpenMP プログラミングにおける注意点 やや高度な話題 2 共有メモリマルチプロセッサシステムの普及 共有メモリマルチプロセッサシステムのための並列化指示文を共通化する必要性 各社で仕様が異なり 移植性がない そして いまやマルチコア プロセッサが主流となり
AICS 村井均 RIKEN AICS HPC Summer School /6/2013 1
 AICS 村井均 RIKEN AICS HPC Summer School 2013 8/6/2013 1 背景 OpenMP とは OpenMP の基本 OpenMP プログラミングにおける注意点 やや高度な話題 2 共有メモリマルチプロセッサシステムの普及 共有メモリマルチプロセッサシステムのための並列化指示文を共通化する必要性 各社で仕様が異なり 移植性がない そして いまやマルチコア プロセッサが主流となり
AICS 村井均 RIKEN AICS HPC Summer School 2013 8/6/2013 1 背景 OpenMP とは OpenMP の基本 OpenMP プログラミングにおける注意点 やや高度な話題 2 共有メモリマルチプロセッサシステムの普及 共有メモリマルチプロセッサシステムのための並列化指示文を共通化する必要性 各社で仕様が異なり 移植性がない そして いまやマルチコア プロセッサが主流となり
スパコンに通じる並列プログラミングの基礎
 2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
I
 I 1 2016.07.21 MPI OpenMP 84 1344 gnuplot Xming Tera term cp -r /tmp/160721 chmod 0 L x L y 0 k T (x, t) k: T t = k 2 T x 2 T t = s s : heat source 1D T (x, t) t = k 2 T (x, t) x 2 + s(x) 2D T (x,
I 1 2016.07.21 MPI OpenMP 84 1344 gnuplot Xming Tera term cp -r /tmp/160721 chmod 0 L x L y 0 k T (x, t) k: T t = k 2 T x 2 T t = s s : heat source 1D T (x, t) t = k 2 T (x, t) x 2 + s(x) 2D T (x,
NUMAの構成
 共有メモリを使ったデータ交換と同期 慶應義塾大学理工学部 天野英晴 hunga@am.ics.keio.ac.jp 同期の必要性 あるプロセッサが共有メモリに書いても 別のプロセッサにはそのことが分からない 同時に同じ共有変数に書き込みすると 結果がどうなるか分からない そもそも共有メモリって結構危険な代物 多くのプロセッサが並列に動くには何かの制御機構が要る 不可分命令 同期用メモリ バリア同期機構
共有メモリを使ったデータ交換と同期 慶應義塾大学理工学部 天野英晴 hunga@am.ics.keio.ac.jp 同期の必要性 あるプロセッサが共有メモリに書いても 別のプロセッサにはそのことが分からない 同時に同じ共有変数に書き込みすると 結果がどうなるか分からない そもそも共有メモリって結構危険な代物 多くのプロセッサが並列に動くには何かの制御機構が要る 不可分命令 同期用メモリ バリア同期機構
コードのチューニング
 ハイブリッド並列 八木学 ( 理化学研究所計算科学研究機構 ) 謝辞 松本洋介氏 ( 千葉大学 ) KOBE HPC Spring School 2017 2017 年 3 月 14 日神戸大学計算科学教育センター MPI とは Message Passing Interface 分散メモリのプロセス間の通信規格(API) SPMD(Single Program Multi Data) が基本 -
ハイブリッド並列 八木学 ( 理化学研究所計算科学研究機構 ) 謝辞 松本洋介氏 ( 千葉大学 ) KOBE HPC Spring School 2017 2017 年 3 月 14 日神戸大学計算科学教育センター MPI とは Message Passing Interface 分散メモリのプロセス間の通信規格(API) SPMD(Single Program Multi Data) が基本 -
Microsoft PowerPoint - OpenMP入門.pptx
 OpenMP 入門 須田礼仁 2009/10/30 初版 OpenMP 共有メモリ並列処理の標準化 API http://openmp.org/ 最新版は 30 3.0 バージョンによる違いはあまり大きくない サポートしているバージョンはともかく csp で動きます gcc も対応しています やっぱり SPMD Single Program Multiple Data プログラム #pragma omp
OpenMP 入門 須田礼仁 2009/10/30 初版 OpenMP 共有メモリ並列処理の標準化 API http://openmp.org/ 最新版は 30 3.0 バージョンによる違いはあまり大きくない サポートしているバージョンはともかく csp で動きます gcc も対応しています やっぱり SPMD Single Program Multiple Data プログラム #pragma omp
±é½¬£²¡§£Í£Ð£É½éÊâ
 2012 8 7 1 / 52 MPI Hello World I ( ) Hello World II ( ) I ( ) II ( ) ( sendrecv) π ( ) MPI fortran C wget http://www.na.scitec.kobe-u.ac.jp/ yaguchi/riken2012/enshu2.zip unzip enshu2.zip 2 / 52 FORTRAN
2012 8 7 1 / 52 MPI Hello World I ( ) Hello World II ( ) I ( ) II ( ) ( sendrecv) π ( ) MPI fortran C wget http://www.na.scitec.kobe-u.ac.jp/ yaguchi/riken2012/enshu2.zip unzip enshu2.zip 2 / 52 FORTRAN
内容に関するご質問は まで お願いします [Oakforest-PACS(OFP) 編 ] 第 85 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用 : 科学技術計算の効率化入門 スパコンへのログイン テストプログラム起動 東京大学情報基盤セ
![内容に関するご質問は まで お願いします [Oakforest-PACS(OFP) 編 ] 第 85 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用 : 科学技術計算の効率化入門 スパコンへのログイン テストプログラム起動 東京大学情報基盤セ](/thumbs/95/125947898.jpg "内容に関するご質問は まで お願いします [Oakforest-PACS(OFP) 編 ] 第 85 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用 : 科学技術計算の効率化入門 スパコンへのログイン テストプログラム起動 東京大学情報基盤セ") 内容に関するご質問は ida@cc.u-tokyo.ac.jp まで お願いします [Oakforest-PACS(OFP) 編 ] 第 85 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用 : 科学技術計算の効率化入門 スパコンへのログイン テストプログラム起動 東京大学情報基盤センター特任准教授伊田明弘 1 講習会 : ライブラリ利用 [FX10] スパコンへのログイン ファイル転送
内容に関するご質問は ida@cc.u-tokyo.ac.jp まで お願いします [Oakforest-PACS(OFP) 編 ] 第 85 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用 : 科学技術計算の効率化入門 スパコンへのログイン テストプログラム起動 東京大学情報基盤センター特任准教授伊田明弘 1 講習会 : ライブラリ利用 [FX10] スパコンへのログイン ファイル転送
01_OpenMP_osx.indd
 OpenMP* / 1 1... 2 2... 3 3... 5 4... 7 5... 9 5.1... 9 5.2 OpenMP* API... 13 6... 17 7... 19 / 4 1 2 C/C++ OpenMP* 3 Fortran OpenMP* 4 PC 1 1 9.0 Linux* Windows* Xeon Itanium OS 1 2 2 WEB OS OS OS 1 OS
OpenMP* / 1 1... 2 2... 3 3... 5 4... 7 5... 9 5.1... 9 5.2 OpenMP* API... 13 6... 17 7... 19 / 4 1 2 C/C++ OpenMP* 3 Fortran OpenMP* 4 PC 1 1 9.0 Linux* Windows* Xeon Itanium OS 1 2 2 WEB OS OS OS 1 OS
supercomputer2010.ppt
 nanri@cc.kyushu-u.ac.jp 1 !! : 11 12! : nanri@cc.kyushu-u.ac.jp! : Word 2 ! PC GPU) 1997 7 http://wiredvision.jp/news/200806/2008062322.html 3 !! (Cell, GPU )! 4 ! etc...! 5 !! etc. 6 !! 20km 40 km ) 340km
nanri@cc.kyushu-u.ac.jp 1 !! : 11 12! : nanri@cc.kyushu-u.ac.jp! : Word 2 ! PC GPU) 1997 7 http://wiredvision.jp/news/200806/2008062322.html 3 !! (Cell, GPU )! 4 ! etc...! 5 !! etc. 6 !! 20km 40 km ) 340km
VXPRO R1400® ご提案資料
 Intel Core i7 プロセッサ 920 Preliminary Performance Report ノード性能評価 ノード性能の評価 NAS Parallel Benchmark Class B OpenMP 版での性能評価 実行スレッド数を 4 で固定 ( デュアルソケットでは各プロセッサに 2 スレッド ) 全て 2.66GHz のコアとなるため コアあたりのピーク性能は同じ 評価システム
Intel Core i7 プロセッサ 920 Preliminary Performance Report ノード性能評価 ノード性能の評価 NAS Parallel Benchmark Class B OpenMP 版での性能評価 実行スレッド数を 4 で固定 ( デュアルソケットでは各プロセッサに 2 スレッド ) 全て 2.66GHz のコアとなるため コアあたりのピーク性能は同じ 評価システム
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
Microsoft PowerPoint - 阪大CMSI pptx
 内容に関する質問は katagiri@cc.u-tokyo.ac.jp まで 第 3 回 OpenMP の基礎 東京大学情報基盤センター 片桐孝洋 1 講義日程と内容について (1 学期 : 木曜 3 限 ) 第 1 回 : プログラム高速化の基礎 2013 年 4 月 11 日 イントロダクション ループアンローリング キャッシュブロック化 数値計算ライブラリの利用 その他第 2 回 :MPIの基礎
内容に関する質問は katagiri@cc.u-tokyo.ac.jp まで 第 3 回 OpenMP の基礎 東京大学情報基盤センター 片桐孝洋 1 講義日程と内容について (1 学期 : 木曜 3 限 ) 第 1 回 : プログラム高速化の基礎 2013 年 4 月 11 日 イントロダクション ループアンローリング キャッシュブロック化 数値計算ライブラリの利用 その他第 2 回 :MPIの基礎
新スーパーコンピュータ 「ITOシステム」利用講習会
 1 新スーパーコンピュータ ITO システム 利用講習会 九州大学情報基盤研究開発センター 2017 年 10 月 ITO システムの構成 2 3 ITO システムの特徴 最新ハードウェア技術 Intel Skylake-SP NVIDIA Pascal + NVLink Mellanox InfiniBand EDR 対話的な利用環境の拡充 合計 164 ノードのフロントエンド ノード当たりメモリ量
1 新スーパーコンピュータ ITO システム 利用講習会 九州大学情報基盤研究開発センター 2017 年 10 月 ITO システムの構成 2 3 ITO システムの特徴 最新ハードウェア技術 Intel Skylake-SP NVIDIA Pascal + NVLink Mellanox InfiniBand EDR 対話的な利用環境の拡充 合計 164 ノードのフロントエンド ノード当たりメモリ量
<4D F736F F F696E74202D D F95C097F D834F E F93FC96E5284D F96E291E85F8DE391E52E >
 SX-ACE 並列プログラミング入門 (MPI) ( 演習補足資料 ) 大阪大学サイバーメディアセンター日本電気株式会社 演習問題の構成 ディレクトリ構成 MPI/ -- practice_1 演習問題 1 -- practice_2 演習問題 2 -- practice_3 演習問題 3 -- practice_4 演習問題 4 -- practice_5 演習問題 5 -- practice_6
SX-ACE 並列プログラミング入門 (MPI) ( 演習補足資料 ) 大阪大学サイバーメディアセンター日本電気株式会社 演習問題の構成 ディレクトリ構成 MPI/ -- practice_1 演習問題 1 -- practice_2 演習問題 2 -- practice_3 演習問題 3 -- practice_4 演習問題 4 -- practice_5 演習問題 5 -- practice_6
develop
 SCore SCore 02/03/20 2 1 HA (High Availability) HPC (High Performance Computing) 02/03/20 3 HA (High Availability) Mail/Web/News/File Server HPC (High Performance Computing) Job Dispatching( ) Parallel
SCore SCore 02/03/20 2 1 HA (High Availability) HPC (High Performance Computing) 02/03/20 3 HA (High Availability) Mail/Web/News/File Server HPC (High Performance Computing) Job Dispatching( ) Parallel
スライド 1
 FMO 創薬コンソーシアム FMODD 京での FMO 計算練習会 2015 年 5 月 22 日 理化学研究所 本講習会の内容 1. 京の構成とABINIT-MPの概要 2. 京にログイン 計算環境の準備 3. ジョブの投入練習 1(TrpCageの例題を用いた基本ジョブ実行練習 ) 4. ジョブの投入練習 2(ERαの例題を用いた実践的なジョブ実行練習 ) 5. 新規作成構造のジョブの投入に関する注意点
FMO 創薬コンソーシアム FMODD 京での FMO 計算練習会 2015 年 5 月 22 日 理化学研究所 本講習会の内容 1. 京の構成とABINIT-MPの概要 2. 京にログイン 計算環境の準備 3. ジョブの投入練習 1(TrpCageの例題を用いた基本ジョブ実行練習 ) 4. ジョブの投入練習 2(ERαの例題を用いた実践的なジョブ実行練習 ) 5. 新規作成構造のジョブの投入に関する注意点
enshu5_4.key
 http://www.mmsonline.com/articles/parallel-processing-speeds-toolpath-calculations TA : 菅 新 菅沼智史 水曜 新行紗弓 馬淵隼 木曜 情報知能工学演習V (前半第4週) 政田洋平 システム情報学研究科計算科学専攻 演習 V( 前半 ) の内容 第 1 週 : 高性能計算 (High Performance Computing
http://www.mmsonline.com/articles/parallel-processing-speeds-toolpath-calculations TA : 菅 新 菅沼智史 水曜 新行紗弓 馬淵隼 木曜 情報知能工学演習V (前半第4週) 政田洋平 システム情報学研究科計算科学専攻 演習 V( 前半 ) の内容 第 1 週 : 高性能計算 (High Performance Computing
情報処理概論(第二日目)
") センター入門講習会 ~ 高性能演算サーバ PRIMERGY CX400(tatara)~ 2016 年 6 月 6 日 この資料は以下の Web ページからダウンロードできます. https://www.cc.kyushu-u.ac.jp/scp/users/lecture/ 1 並列プログラミング入門講習会のご案内 スーパーコンピュータの性能を引き出すには 並列化が不可欠! 並列プログラミング入門講習会を
センター入門講習会 ~ 高性能演算サーバ PRIMERGY CX400(tatara)~ 2016 年 6 月 6 日 この資料は以下の Web ページからダウンロードできます. https://www.cc.kyushu-u.ac.jp/scp/users/lecture/ 1 並列プログラミング入門講習会のご案内 スーパーコンピュータの性能を引き出すには 並列化が不可欠! 並列プログラミング入門講習会を
Microsoft PowerPoint - 講習 _kido.pptx[読み取り専用]
![Microsoft PowerPoint - 講習 _kido.pptx[読み取り専用]](/thumbs/79/79773151.jpg "Microsoft PowerPoint - 講習 _kido.pptx[読み取り専用]") スパコンの概要と CMC のスパコンの紹介 大阪大学サイバーメディアセンター講師木戸善之 2015/1/15 目次 1. スパコンの略歴 2. 計算機の概要 3. 並列計算 4. CMCのスパコン 1 1. スパコンの略歴 計算機ってなんだ? 計算機 計算に用いる機械 ( デジタル大辞泉 ) 計算のための機械 器具のこと コンピュータや電卓を指すことが多い (Wikipedia) 人が不得意な 正確な演算やルーチンワークを肩代わりするための道具
スパコンの概要と CMC のスパコンの紹介 大阪大学サイバーメディアセンター講師木戸善之 2015/1/15 目次 1. スパコンの略歴 2. 計算機の概要 3. 並列計算 4. CMCのスパコン 1 1. スパコンの略歴 計算機ってなんだ? 計算機 計算に用いる機械 ( デジタル大辞泉 ) 計算のための機械 器具のこと コンピュータや電卓を指すことが多い (Wikipedia) 人が不得意な 正確な演算やルーチンワークを肩代わりするための道具
02_C-C++_osx.indd
 C/C++ OpenMP* / 2 C/C++ OpenMP* OpenMP* 9.0 1... 2 2... 3 3OpenMP*... 5 3.1... 5 3.2 OpenMP*... 6 3.3 OpenMP*... 8 4OpenMP*... 9 4.1... 9 4.2 OpenMP*... 9 4.3 OpenMP*... 10 4.4... 10 5OpenMP*... 11 5.1
C/C++ OpenMP* / 2 C/C++ OpenMP* OpenMP* 9.0 1... 2 2... 3 3OpenMP*... 5 3.1... 5 3.2 OpenMP*... 6 3.3 OpenMP*... 8 4OpenMP*... 9 4.1... 9 4.2 OpenMP*... 9 4.3 OpenMP*... 10 4.4... 10 5OpenMP*... 11 5.1
GROMACS実習
 SCLS 計算機システム講習会 GHOST-MP 実習 独立行政法人理化学研究所 HPCI 計算生命科学推進プログラム SCLS 計算機システムの GHOST-MP GHOST-MP BLAST のように遠縁のホモログを検出可能なホモロジー検索ツールである GHOSTX を 京 で高速化したもの GHOST-MP ver.201311 OpenMP node 内のスレッド並列 MPI master
SCLS 計算機システム講習会 GHOST-MP 実習 独立行政法人理化学研究所 HPCI 計算生命科学推進プログラム SCLS 計算機システムの GHOST-MP GHOST-MP BLAST のように遠縁のホモログを検出可能なホモロジー検索ツールである GHOSTX を 京 で高速化したもの GHOST-MP ver.201311 OpenMP node 内のスレッド並列 MPI master
スライド 1
 計算科学が拓く世界 スーパーコンピュータは 何故スーパーか 学術情報メディアセンター 中島浩 http://www.pr.medi.kyoto-u.c.jp/jp/ usermesuper psswordcomputer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どうスーパーなのか どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
計算科学が拓く世界 スーパーコンピュータは 何故スーパーか 学術情報メディアセンター 中島浩 http://www.pr.medi.kyoto-u.c.jp/jp/ usermesuper psswordcomputer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どうスーパーなのか どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
Microsoft PowerPoint - 演習1:並列化と評価.pptx
 講義 2& 演習 1 プログラム並列化と性能評価 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 1 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 2 2 次元温度分布の計算
講義 2& 演習 1 プログラム並列化と性能評価 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 1 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 2 2 次元温度分布の計算
Oakforest-PACS 利用の手引き 2 ノートパソコンの設定 : 公開鍵の生成 登録
 Oakforest-PACS 利用の手引き 1 お試しアカウント付き 並列プログラミング講習会 Oakforest-PACS 利用の手引き 東京大学情報基盤センター Oakforest-PACS 利用の手引き 2 ノートパソコンの設定 : 公開鍵の生成 登録 Oakforest-PACS 利用の手引き 3 鍵の作成 1. ターミナルを起動する 2. 以下を入力する $ ssh-keygen t rsa
Oakforest-PACS 利用の手引き 1 お試しアカウント付き 並列プログラミング講習会 Oakforest-PACS 利用の手引き 東京大学情報基盤センター Oakforest-PACS 利用の手引き 2 ノートパソコンの設定 : 公開鍵の生成 登録 Oakforest-PACS 利用の手引き 3 鍵の作成 1. ターミナルを起動する 2. 以下を入力する $ ssh-keygen t rsa
Microsoft PowerPoint 知る集い(京都)最終.ppt
最終.ppt") 次世代スパコンについて知る集い 配布資料 世界最高性能を目指すシステム開発について ー次世代スパコンのシステム構成と施設の概要 - 平成 22 年 1 月 28 日 理化学研究所次世代スーパーコンピュータ開発実施本部横川三津夫 高性能かつ大規模システムの課題と対応 演算性能の向上 CPU のマルチコア化,SIMD( ベクトル化 ) 機構 主記憶へのアクセス頻度の削減 - CPU 性能とメモリアクセス性能のギャップ
次世代スパコンについて知る集い 配布資料 世界最高性能を目指すシステム開発について ー次世代スパコンのシステム構成と施設の概要 - 平成 22 年 1 月 28 日 理化学研究所次世代スーパーコンピュータ開発実施本部横川三津夫 高性能かつ大規模システムの課題と対応 演算性能の向上 CPU のマルチコア化,SIMD( ベクトル化 ) 機構 主記憶へのアクセス頻度の削減 - CPU 性能とメモリアクセス性能のギャップ
FX10利用準備
 π-computer(fx10) 利用準備 2018 年 3 月 14 日理化学研究所計算科学研究機構八木学 1 KOBE HPC Spring School 2018 2018/3/14 内容 本スクールの実習で利用するスーパーコンピュータ神戸大学 π-computer (FX10) について システム概要 ログイン準備 2 神戸大学 π-computer: システム概要 富士通 PRIMEHPC
π-computer(fx10) 利用準備 2018 年 3 月 14 日理化学研究所計算科学研究機構八木学 1 KOBE HPC Spring School 2018 2018/3/14 内容 本スクールの実習で利用するスーパーコンピュータ神戸大学 π-computer (FX10) について システム概要 ログイン準備 2 神戸大学 π-computer: システム概要 富士通 PRIMEHPC
Microsoft PowerPoint _MPI-03.pptx
 計算科学演習 Ⅰ ( 第 11 回 ) MPI を いた並列計算 (III) 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/07/03 計算科学演習 Ⅰ:MPI を用いた並列計算 (III) 1 2014/07/03 計算科学演習 Ⅰ:MPI を用いた並列計算 (III) 2 今週の講義の概要 1. 前回課題の解説 2. 部分配列とローカルインデックス
計算科学演習 Ⅰ ( 第 11 回 ) MPI を いた並列計算 (III) 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/07/03 計算科学演習 Ⅰ:MPI を用いた並列計算 (III) 1 2014/07/03 計算科学演習 Ⅰ:MPI を用いた並列計算 (III) 2 今週の講義の概要 1. 前回課題の解説 2. 部分配列とローカルインデックス
スライド 1
 目次 計算科学演習スーパーコンピュータ & 並列計算概論 学術情報メディアセンター情報学研究科 システム科学専攻中島浩 科目概要 目標 スケジュール スタッフ 講義資料 課題 スーパーコンピュータ概論 一般のスーパーコンピュータ 京大のスーパーコンピュータ スーパーコンピュータの構造 並列計算概論 並列計算の類型 条件 Scalng & Scalablty 問題分割 落し穴 プロセス並列 & スレッド並列
目次 計算科学演習スーパーコンピュータ & 並列計算概論 学術情報メディアセンター情報学研究科 システム科学専攻中島浩 科目概要 目標 スケジュール スタッフ 講義資料 課題 スーパーコンピュータ概論 一般のスーパーコンピュータ 京大のスーパーコンピュータ スーパーコンピュータの構造 並列計算概論 並列計算の類型 条件 Scalng & Scalablty 問題分割 落し穴 プロセス並列 & スレッド並列
資料3 今後のHPC技術に関する研究開発の方向性について(日立製作所提供資料)
") 今後の HPC 技術に関する 研究開発の方向性について 2012 年 5 月 30 日 ( 株 ) 日立製作所情報 通信システム社 IT プラットフォーム事業本部 Hitachi, Hitachi, Ltd. Ltd. Hitachi 2012. 2012. Ltd. 2012. All rights All rights All rights reserved. reserved. reserved.
今後の HPC 技術に関する 研究開発の方向性について 2012 年 5 月 30 日 ( 株 ) 日立製作所情報 通信システム社 IT プラットフォーム事業本部 Hitachi, Hitachi, Ltd. Ltd. Hitachi 2012. 2012. Ltd. 2012. All rights All rights All rights reserved. reserved. reserved.
サイバーメディアセンター 大規模計算機システムの利用
 サイバーメディアセンター 大規模計算機システムの利用 大阪大学情報推進部情報基盤課 本日のプログラム I. システムのご紹介 II. 利用方法の解説 実習 i. システムへの接続 ii. プログラムの作成 コンパイル iii. ジョブスクリプトの作成 iv. ジョブスクリプトの投入 III. 利用を希望する方へ 2/56 SX-ACE NEC 製のベクトル型スーパーコンピュータ ノード毎 1 クラスタ
サイバーメディアセンター 大規模計算機システムの利用 大阪大学情報推進部情報基盤課 本日のプログラム I. システムのご紹介 II. 利用方法の解説 実習 i. システムへの接続 ii. プログラムの作成 コンパイル iii. ジョブスクリプトの作成 iv. ジョブスクリプトの投入 III. 利用を希望する方へ 2/56 SX-ACE NEC 製のベクトル型スーパーコンピュータ ノード毎 1 クラスタ
サイバーメディアセンター 大規模計算機システムの利用
 サイバーメディアセンター 大規模計算機システムの利用 大阪大学情報推進部情報基盤課 本日のプログラム I. システムのご紹介 II. 利用方法の解説 実習 i. システムへの接続 ii. プログラムの作成 コンパイル iii. ジョブスクリプトの作成 iv. ジョブスクリプトの投入 III. 利用を希望する方へ SX-ACE NEC 製のベクトル型スーパーコンピュータ ノード毎 1 クラスタ (512
サイバーメディアセンター 大規模計算機システムの利用 大阪大学情報推進部情報基盤課 本日のプログラム I. システムのご紹介 II. 利用方法の解説 実習 i. システムへの接続 ii. プログラムの作成 コンパイル iii. ジョブスクリプトの作成 iv. ジョブスクリプトの投入 III. 利用を希望する方へ SX-ACE NEC 製のベクトル型スーパーコンピュータ ノード毎 1 クラスタ (512
Microsoft Word ●IntelクアッドコアCPUでのベンチマーク_吉岡_ _更新__ doc
 2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
05 I I / 56
 05 I 2015 2015.05.14 I 05 2015.05.14 1 / 56 I 05 2015.05.14 2 / 56 cd mkdir vis01 OK cd vis01 cp /tmp/150514/leibniz.*. I 05 2015.05.14 3 / 56 I 05 2015.05.14 4 / 56 Information visualization Data visualization,
05 I 2015 2015.05.14 I 05 2015.05.14 1 / 56 I 05 2015.05.14 2 / 56 cd mkdir vis01 OK cd vis01 cp /tmp/150514/leibniz.*. I 05 2015.05.14 3 / 56 I 05 2015.05.14 4 / 56 Information visualization Data visualization,
untitled
 RIKEN AICS Summer School 3 4 MPI 2012 8 8 1 6 MPI MPI 2 allocatable 2 Fox mpi_sendrecv 3 3 FFT mpi_alltoall MPI_PROC_NULL 4 FX10 /home/guest/guest07/school/ 5 1 A (i, j) i+j x i i y = Ax A x y y 1 y i
RIKEN AICS Summer School 3 4 MPI 2012 8 8 1 6 MPI MPI 2 allocatable 2 Fox mpi_sendrecv 3 3 FFT mpi_alltoall MPI_PROC_NULL 4 FX10 /home/guest/guest07/school/ 5 1 A (i, j) i+j x i i y = Ax A x y y 1 y i
Platypus-QM β ( )
") Platypus-QM β (2012.11.12) 1 1 1.1...................................... 1 1.1.1...................................... 1 1.1.2................................... 1 1.1.3..........................................
Platypus-QM β (2012.11.12) 1 1 1.1...................................... 1 1.1.1...................................... 1 1.1.2................................... 1 1.1.3..........................................

PowerPoint プレゼンテーション
 スーパーコンピュータのネットワーク 情報ネットワーク特論 南里豪志 ( 九州大学情報基盤研究開発センター ) 1 今日の講義内容 スーパーコンピュータとは どうやって計算機を速くするか スーパーコンピュータのネットワーク 2 スーパーコンピュータとは? " スーパー " な計算機 = その時点で 一般的な計算機の性能をはるかに超える性能を持つ計算機 スーパーコンピュータの用途 主に科学技術分野 創薬
スーパーコンピュータのネットワーク 情報ネットワーク特論 南里豪志 ( 九州大学情報基盤研究開発センター ) 1 今日の講義内容 スーパーコンピュータとは どうやって計算機を速くするか スーパーコンピュータのネットワーク 2 スーパーコンピュータとは? " スーパー " な計算機 = その時点で 一般的な計算機の性能をはるかに超える性能を持つ計算機 スーパーコンピュータの用途 主に科学技術分野 創薬
Microsoft PowerPoint - 阪大CMSI pptx
 内容に関する質問は katagiri@cc.u-tokyo.ac.jp まで 第 3 回 OpenMP の基礎 東京大学情報基盤センター 片桐孝洋 1 講義日程と内容について (1 学期 : 木曜 3 限 ) 第 1 回 : プログラム高速化の基礎 2015 年 4 月 9 日 イントロダクション ループアンローリング キャッシュブロック化 数値計算ライブラリの利用 その他第 2 回 :MPIの基礎
内容に関する質問は katagiri@cc.u-tokyo.ac.jp まで 第 3 回 OpenMP の基礎 東京大学情報基盤センター 片桐孝洋 1 講義日程と内容について (1 学期 : 木曜 3 限 ) 第 1 回 : プログラム高速化の基礎 2015 年 4 月 9 日 イントロダクション ループアンローリング キャッシュブロック化 数値計算ライブラリの利用 その他第 2 回 :MPIの基礎
修士論文
 AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
(Microsoft PowerPoint \211\211\217K3_4\201i\216R\226{_\211\272\215\342\201j.ppt [\214\335\212\267\203\202\201[\203h])
![(Microsoft PowerPoint \211\211\217K3_4\201i\216R\226{_\211\272\215\342\201j.ppt [\214\335\212\267\203\202\201[\203h])](/thumbs/101/148628642.jpg "(Microsoft PowerPoint \211\211\217K3_4\201i\216R\226{_\211\272\215\342\201j.ppt [\214\335\212\267\203\202\201[\203h])") RIKEN AICS Summer School 演習 3 4 MPI による並列計算 2012 年 8 月 8 日 神戸大学大学院システム情報学研究科山本有作理化学研究所計算科学研究機構下坂健則 1 演習の目標 講義 6 並列アルゴリズム基礎 で学んだアルゴリズムのいくつかを,MPI を用いて並列化してみる これを通じて, 基本的な並列化手法と,MPI 通信関数の使い方を身に付ける 2 取り上げる例題と学習項目
RIKEN AICS Summer School 演習 3 4 MPI による並列計算 2012 年 8 月 8 日 神戸大学大学院システム情報学研究科山本有作理化学研究所計算科学研究機構下坂健則 1 演習の目標 講義 6 並列アルゴリズム基礎 で学んだアルゴリズムのいくつかを,MPI を用いて並列化してみる これを通じて, 基本的な並列化手法と,MPI 通信関数の使い方を身に付ける 2 取り上げる例題と学習項目
Microsoft Word - 計算科学演習第1回3.doc
 スーパーコンピュータの基本的操作方法 2009 年 9 月 10 日高橋康人 1. スーパーコンピュータへのログイン方法 本演習では,X 端末ソフト Exceed on Demand を使用するが, 必要に応じて SSH クライアント putty,ftp クライアント WinSCP や FileZilla を使用して構わない Exceed on Demand を起動し, 以下のとおり設定 ( 各自のユーザ
スーパーコンピュータの基本的操作方法 2009 年 9 月 10 日高橋康人 1. スーパーコンピュータへのログイン方法 本演習では,X 端末ソフト Exceed on Demand を使用するが, 必要に応じて SSH クライアント putty,ftp クライアント WinSCP や FileZilla を使用して構わない Exceed on Demand を起動し, 以下のとおり設定 ( 各自のユーザ
XcalableMP入門
 XcalableMP 1 HPC-Phys@, 2018 8 22 XcalableMP XMP XMP Lattice QCD!2 XMP MPI MPI!3 XMP 1/2 PCXMP MPI Fortran CCoarray C++ MPIMPI XMP OpenMP http://xcalablemp.org!4 XMP 2/2 SPMD (Single Program Multiple Data)
XcalableMP 1 HPC-Phys@, 2018 8 22 XcalableMP XMP XMP Lattice QCD!2 XMP MPI MPI!3 XMP 1/2 PCXMP MPI Fortran CCoarray C++ MPIMPI XMP OpenMP http://xcalablemp.org!4 XMP 2/2 SPMD (Single Program Multiple Data)
並列プログラミング入門(OpenMP編)
") 登録施設利用促進機関 / 文科省委託事業 HPCI の運営 代表機関一般財団法人高度情報科学技術研究機構 (RIST) 1 並列プログラミング入門 (OpenMP 編 ) 2019 年 1 月 17 日 高度情報科学技術研究機構 (RIST) 山本秀喜 RIST 主催の講習会等 2 HPC プログラミングセミナー 一般 初心者向け : チューニング 並列化 (OpenMP MPI) 京 初中級者向け講習会
登録施設利用促進機関 / 文科省委託事業 HPCI の運営 代表機関一般財団法人高度情報科学技術研究機構 (RIST) 1 並列プログラミング入門 (OpenMP 編 ) 2019 年 1 月 17 日 高度情報科学技術研究機構 (RIST) 山本秀喜 RIST 主催の講習会等 2 HPC プログラミングセミナー 一般 初心者向け : チューニング 並列化 (OpenMP MPI) 京 初中級者向け講習会
PowerPoint プレゼンテーション
 OpenMP 並列解説 1 人が共同作業を行うわけ 田植えの例 重いものを持ち上げる 田おこし 代かき 苗の準備 植付 共同作業する理由 1. 短時間で作業を行うため 2. 一人ではできない作業を行うため 3. 得意分野が異なる人が協力し合うため ポイント 1. 全員が最大限働く 2. タイミングよく 3. 作業順序に注意 4. オーバーヘッドをなくす 2 倍率 効率 並列化率と並列加速率 並列化効率の関係
OpenMP 並列解説 1 人が共同作業を行うわけ 田植えの例 重いものを持ち上げる 田おこし 代かき 苗の準備 植付 共同作業する理由 1. 短時間で作業を行うため 2. 一人ではできない作業を行うため 3. 得意分野が異なる人が協力し合うため ポイント 1. 全員が最大限働く 2. タイミングよく 3. 作業順序に注意 4. オーバーヘッドをなくす 2 倍率 効率 並列化率と並列加速率 並列化効率の関係
untitled
 I 9 MPI (II) 2012 6 14 .. MPI. 1-3 sum100.f90 4 istart=myrank*25+1 iend=(myrank+1)*25 0 1 2 3 mpi_recv 3 isum1 1 isum /tmp/120614/sum100_4.f90 program sum100_4 use mpi implicit none integer :: i,istart,iend,isum,isum1,ip
I 9 MPI (II) 2012 6 14 .. MPI. 1-3 sum100.f90 4 istart=myrank*25+1 iend=(myrank+1)*25 0 1 2 3 mpi_recv 3 isum1 1 isum /tmp/120614/sum100_4.f90 program sum100_4 use mpi implicit none integer :: i,istart,iend,isum,isum1,ip
040312研究会HPC2500.ppt
 2004312 e-mail : m-aoki@jp.fujitsu.com 1 2 PRIMEPOWER VX/VPP300 VPP700 GP7000 AP3000 VPP5000 PRIMEPOWER 2000 PRIMEPOWER HPC2500 1998 1999 2000 2001 2002 2003 3 VPP5000 PRIMEPOWER ( 1 VU 9.6 GF 16GB 1 VU
2004312 e-mail : m-aoki@jp.fujitsu.com 1 2 PRIMEPOWER VX/VPP300 VPP700 GP7000 AP3000 VPP5000 PRIMEPOWER 2000 PRIMEPOWER HPC2500 1998 1999 2000 2001 2002 2003 3 VPP5000 PRIMEPOWER ( 1 VU 9.6 GF 16GB 1 VU
2 A I / 58
 2 A 2018.07.12 I 2 2018.07.12 1 / 58 I 2 2018.07.12 2 / 58 π-computer gnuplot 5/31 1 π-computer -X ssh π-computer gnuplot I 2 2018.07.12 3 / 58 gnuplot> gnuplot> plot sin(x) I 2 2018.07.12 4 / 58 cp -r
2 A 2018.07.12 I 2 2018.07.12 1 / 58 I 2 2018.07.12 2 / 58 π-computer gnuplot 5/31 1 π-computer -X ssh π-computer gnuplot I 2 2018.07.12 3 / 58 gnuplot> gnuplot> plot sin(x) I 2 2018.07.12 4 / 58 cp -r
Microsoft PowerPoint - sales2.ppt
 最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
地球シミュレータ開発の現状 平成 14 年 2 月 22 日 横川三津夫 地球シミュレータ研究開発センター 1
 地球シミュレータ開発の現状 平成 14 年 2 月 22 日 横川三津夫 地球シミュレータ研究開発センター ESRDC@JAERI 1 地球シミュレータ 計画の背景 地球規模の複雑な諸現象の理解, 予測の必要性 地球温暖化 異常気象 エルニーニョエルニーニョ,, 冷夏冷夏,, 暖冬暖冬,, 豪雨豪雨,, 豪雪豪雪,, 干ばつ干ばつ 地殻活動 地震地震,, 火山活動火山活動 大気汚染 酸性雨酸性雨,,
地球シミュレータ開発の現状 平成 14 年 2 月 22 日 横川三津夫 地球シミュレータ研究開発センター ESRDC@JAERI 1 地球シミュレータ 計画の背景 地球規模の複雑な諸現象の理解, 予測の必要性 地球温暖化 異常気象 エルニーニョエルニーニョ,, 冷夏冷夏,, 暖冬暖冬,, 豪雨豪雨,, 豪雪豪雪,, 干ばつ干ばつ 地殻活動 地震地震,, 火山活動火山活動 大気汚染 酸性雨酸性雨,,
次世代スーパーコンピュータのシステム構成案について
 6 19 4 27 1. 2. 3. 3.1 3.2 A 3.3 B 4. 5. 2007/4/27 4 1 1. 2007/4/27 4 2 NEC NHF2 18 9 19 19 2 28 10PFLOPS2.5PB 30MW 3,200 18 12 12 SimFold, GAMESS, Modylas, RSDFT, NICAM, LatticeQCD, LANS HPL, NPB-FT 19
6 19 4 27 1. 2. 3. 3.1 3.2 A 3.3 B 4. 5. 2007/4/27 4 1 1. 2007/4/27 4 2 NEC NHF2 18 9 19 19 2 28 10PFLOPS2.5PB 30MW 3,200 18 12 12 SimFold, GAMESS, Modylas, RSDFT, NICAM, LatticeQCD, LANS HPL, NPB-FT 19
2 I I / 61
 2 I 2017.07.13 I 2 2017.07.13 1 / 61 I 2 2017.07.13 2 / 61 I 2 2017.07.13 3 / 61 7/13 2 7/20 I 7/27 II I 2 2017.07.13 4 / 61 π-computer gnuplot MobaXterm Wiki PC X11 DISPLAY I 2 2017.07.13 5 / 61 Mac 1.
2 I 2017.07.13 I 2 2017.07.13 1 / 61 I 2 2017.07.13 2 / 61 I 2 2017.07.13 3 / 61 7/13 2 7/20 I 7/27 II I 2 2017.07.13 4 / 61 π-computer gnuplot MobaXterm Wiki PC X11 DISPLAY I 2 2017.07.13 5 / 61 Mac 1.
最新の並列計算事情とCAE
 1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
Microsoft Word - koubo-H26.doc
 平成 26 年度学際共同利用プログラム 計算基礎科学プロジェクト 公募要項 - 計算基礎科学連携拠点 ( 筑波大学 高エネルギー加速器研究機構 国立天文台 ) では スーパーコンピュータの学際共同利用プログラム 計算基礎科学プロジェクト を平成 22 年度から実施しております 平成 23 年度からは HPCI 戦略プログラム 分野 5 物質と宇宙の起源と構造 の協力機関である京都大学基礎物理学研究所
平成 26 年度学際共同利用プログラム 計算基礎科学プロジェクト 公募要項 - 計算基礎科学連携拠点 ( 筑波大学 高エネルギー加速器研究機構 国立天文台 ) では スーパーコンピュータの学際共同利用プログラム 計算基礎科学プロジェクト を平成 22 年度から実施しております 平成 23 年度からは HPCI 戦略プログラム 分野 5 物質と宇宙の起源と構造 の協力機関である京都大学基礎物理学研究所
平成17年度 マスターセンター補助事業
 - 1 - - 2 - - 3 - - 4 - - 5 - - 6 - - 7 - - 8 - - 9 - - 10 - - 11 - - 12 - - 13 - - 14 - - 15 - - 16 - - 17 - - 18 - - 19 - - 20 - - 21 - - 22 - - 23 - - 24 - - 25 - - 26 - - 27 - - 28 - IC IC - 29 - IT
- 1 - - 2 - - 3 - - 4 - - 5 - - 6 - - 7 - - 8 - - 9 - - 10 - - 11 - - 12 - - 13 - - 14 - - 15 - - 16 - - 17 - - 18 - - 19 - - 20 - - 21 - - 22 - - 23 - - 24 - - 25 - - 26 - - 27 - - 28 - IC IC - 29 - IT
統計数理研究所とスーパーコンピュータ
 スーパーコンピュータと統計数理研究所 統計数理研究所 統計科学技術センターセンター長 中野純司 目次 スーパーコンピュータとは いったい何? 本当に スーパー?: ノートパソコンとの比較 どのように使う?: 仕組みとソフトウェア 統計数理研究所の ( スーパー ) コンピュータ 必要性 導入の歴史 現在の統数研スパコン : A, I, C 2/44 目次 スーパーコンピュータとは いったい何? 本当に
スーパーコンピュータと統計数理研究所 統計数理研究所 統計科学技術センターセンター長 中野純司 目次 スーパーコンピュータとは いったい何? 本当に スーパー?: ノートパソコンとの比較 どのように使う?: 仕組みとソフトウェア 統計数理研究所の ( スーパー ) コンピュータ 必要性 導入の歴史 現在の統数研スパコン : A, I, C 2/44 目次 スーパーコンピュータとは いったい何? 本当に
Microsoft PowerPoint - 阪大CMSI pptx
 内容に関する質問は katagiri@cc.nagoya-u.ac.jp まで 第 4 回 Hybrid 並列化技法 (MPIとOpenMPの応用) 名古屋大学情報基盤センター 片桐孝洋 207 年度計算科学技術特論 A 講義日程と内容について 207 年度計算科学技術特論 A( 学期 : 木曜 3 限 ) 第 回 : プログラム高速化の基礎 207 年 4 月 3 日 イントロダクション ループアンローリング
内容に関する質問は katagiri@cc.nagoya-u.ac.jp まで 第 4 回 Hybrid 並列化技法 (MPIとOpenMPの応用) 名古屋大学情報基盤センター 片桐孝洋 207 年度計算科学技術特論 A 講義日程と内容について 207 年度計算科学技術特論 A( 学期 : 木曜 3 限 ) 第 回 : プログラム高速化の基礎 207 年 4 月 3 日 イントロダクション ループアンローリング
ohpr.dvi
 2003-08-04 1984 VP-1001 CPU, 250 MFLOPS, 128 MB 2004ASCI Purple (LLNL)64 CPU 197, 100 TFLOPS, 50 TB, 4.5 MW PC 2 CPU 16, 4 GFLOPS, 32 GB, 3.2 kw 20028 CPU 640, 40 TFLOPS, 10 TB, 10 MW (ASCI: Accelerated
2003-08-04 1984 VP-1001 CPU, 250 MFLOPS, 128 MB 2004ASCI Purple (LLNL)64 CPU 197, 100 TFLOPS, 50 TB, 4.5 MW PC 2 CPU 16, 4 GFLOPS, 32 GB, 3.2 kw 20028 CPU 640, 40 TFLOPS, 10 TB, 10 MW (ASCI: Accelerated
Microsoft PowerPoint - stream.ppt [互換モード]
![Microsoft PowerPoint - stream.ppt [互換モード]](/thumbs/94/118945109.jpg "Microsoft PowerPoint - stream.ppt [互換モード]") STREAM 1 Quad Opteron: ccnuma Arch. AMD Quad Opteron 2.3GHz Quad のソケット 4 1 ノード (16コア ) 各ソケットがローカルにメモリを持っている NUMA:Non-Uniform Access ローカルのメモリをアクセスして計算するようなプログラミング, データ配置, 実行時制御 (numactl) が必要 cc: cache-coherent
STREAM 1 Quad Opteron: ccnuma Arch. AMD Quad Opteron 2.3GHz Quad のソケット 4 1 ノード (16コア ) 各ソケットがローカルにメモリを持っている NUMA:Non-Uniform Access ローカルのメモリをアクセスして計算するようなプログラミング, データ配置, 実行時制御 (numactl) が必要 cc: cache-coherent
Microsoft PowerPoint _5_8_f95a_usui.pptx
 1 Fortran90/95 入門と演習 前半 担当 : 臼井英之 三宅洋平 ( 神戸大学大学院システム情報学研究科 ) 目標 本演習で用いる数値計算用プログラム言語 Fortran90/95 の基礎を習得する 参考資料 : TECS-KOBE 第二回シミュレーションスクール ( 神戸大学 ) 2010/12/6:Fortran 講義ノート ( 平尾一 ) Fortran90/95 入門 2010
1 Fortran90/95 入門と演習 前半 担当 : 臼井英之 三宅洋平 ( 神戸大学大学院システム情報学研究科 ) 目標 本演習で用いる数値計算用プログラム言語 Fortran90/95 の基礎を習得する 参考資料 : TECS-KOBE 第二回シミュレーションスクール ( 神戸大学 ) 2010/12/6:Fortran 講義ノート ( 平尾一 ) Fortran90/95 入門 2010
Microsoft PowerPoint ppt
 並列アルゴリズム 2005 年後期火曜 2 限 高見利也 ( 青柳睦 ) Aoyagi@cc.kyushu-u.ac.jp http://server-500.cc.kyushu-u.ac.jp/ 12 月 20 日 ( 火 ) 9. PC クラスタによる並列プログラミング ( 演習 ) つづき 1 もくじ 1. 序並列計算機の現状 2. 計算方式およびアーキテクチュアの分類 3. 並列計算の目的と課題
並列アルゴリズム 2005 年後期火曜 2 限 高見利也 ( 青柳睦 ) Aoyagi@cc.kyushu-u.ac.jp http://server-500.cc.kyushu-u.ac.jp/ 12 月 20 日 ( 火 ) 9. PC クラスタによる並列プログラミング ( 演習 ) つづき 1 もくじ 1. 序並列計算機の現状 2. 計算方式およびアーキテクチュアの分類 3. 並列計算の目的と課題
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日
 TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
H28 年度 SX-ACE 高速化技法の基礎 ( 演習用資料 ) 2016 年 6 月 16 日大阪大学サイバーメディアセンター日本電気株式会社
 2016 年 6 月 16 日大阪大学サイバーメディアセンター日本電気株式会社") H28 年度 SX-ACE 高速化技法の基礎 ( 演習用資料 ) 2016 年 6 月 16 日大阪大学サイバーメディアセンター日本電気株式会社 Page 2 本資料は, 東北大学サイバーサイエンスセンターと NEC の共同により作成され, 大阪大学サイバーメディアセンターの環境で実行確認を行い, 修正を加えたものです. 無断転載等は, ご遠慮下さい. SX-ACE の計算ノード構成 全 1536
H28 年度 SX-ACE 高速化技法の基礎 ( 演習用資料 ) 2016 年 6 月 16 日大阪大学サイバーメディアセンター日本電気株式会社 Page 2 本資料は, 東北大学サイバーサイエンスセンターと NEC の共同により作成され, 大阪大学サイバーメディアセンターの環境で実行確認を行い, 修正を加えたものです. 無断転載等は, ご遠慮下さい. SX-ACE の計算ノード構成 全 1536
Microsoft PowerPoint _4_26_f95a_usui.pptx
 1 Fortran90/95 入門と演習 前半 担当 : 臼井英之 三宅洋平 ( 神戸大学大学院システム情報学研究科 ) 目標 本演習で用いる数値計算用プログラム言語 Fortran90/95 の基礎を習得する 参考資料 : TECS-KOBE 第二回シミュレーションスクールションスク ( 神戸大学 ) 2010/12/6:Fortran 0/ /6 ota 講義ノート ( 平尾一 ) Fortran90/95
1 Fortran90/95 入門と演習 前半 担当 : 臼井英之 三宅洋平 ( 神戸大学大学院システム情報学研究科 ) 目標 本演習で用いる数値計算用プログラム言語 Fortran90/95 の基礎を習得する 参考資料 : TECS-KOBE 第二回シミュレーションスクールションスク ( 神戸大学 ) 2010/12/6:Fortran 0/ /6 ota 講義ノート ( 平尾一 ) Fortran90/95
Microsoft PowerPoint - scls_biogrid_lecture_v2.pptx
 スパコン コース並列プログラミング編 善之 E-mail:yoshiyuki.kido@riken.jp 理化学研究所 HPCI 計算 命科学推進プログラム企画調整グループ企画調整チームチーム員 次 1. Message Passing Interface (MPI) 2. Open MP 3. ハイブリッド並列 4. 列計算の並列化 計算機ってなんだ? 計算機 計算に いる機械 ( デジタル 辞泉
スパコン コース並列プログラミング編 善之 E-mail:yoshiyuki.kido@riken.jp 理化学研究所 HPCI 計算 命科学推進プログラム企画調整グループ企画調整チームチーム員 次 1. Message Passing Interface (MPI) 2. Open MP 3. ハイブリッド並列 4. 列計算の並列化 計算機ってなんだ? 計算機 計算に いる機械 ( デジタル 辞泉
nakao
 Fortran+Python 4 Fortran, 2018 12 12 !2 Python!3 Python 2018 IEEE spectrum https://spectrum.ieee.org/static/interactive-the-top-programming-languages-2018!4 Python print("hello World!") if x == 10: print
Fortran+Python 4 Fortran, 2018 12 12 !2 Python!3 Python 2018 IEEE spectrum https://spectrum.ieee.org/static/interactive-the-top-programming-languages-2018!4 Python print("hello World!") if x == 10: print
2012年度HPCサマーセミナー_多田野.pptx
 ! CCS HPC! I " tadano@cs.tsukuba.ac.jp" " 1 " " " " " " " 2 3 " " Ax = b" " " 4 Ax = b" A = a 11 a 12... a 1n a 21 a 22... a 2n...... a n1 a n2... a nn, x = x 1 x 2. x n, b = b 1 b 2. b n " " 5 Gauss LU
! CCS HPC! I " tadano@cs.tsukuba.ac.jp" " 1 " " " " " " " 2 3 " " Ax = b" " " 4 Ax = b" A = a 11 a 12... a 1n a 21 a 22... a 2n...... a n1 a n2... a nn, x = x 1 x 2. x n, b = b 1 b 2. b n " " 5 Gauss LU
I I / 68
 2013.07.04 I 2013 3 I 2013.07.04 1 / 68 I 2013.07.04 2 / 68 I 2013.07.04 3 / 68 heat1.f90 heat2.f90 /tmp/130704/heat2.f90 I 2013.07.04 4 / 68 diff heat1.f90 heat2.f90!! heat2. f 9 0! c m > NGRID! c nmax
2013.07.04 I 2013 3 I 2013.07.04 1 / 68 I 2013.07.04 2 / 68 I 2013.07.04 3 / 68 heat1.f90 heat2.f90 /tmp/130704/heat2.f90 I 2013.07.04 4 / 68 diff heat1.f90 heat2.f90!! heat2. f 9 0! c m > NGRID! c nmax
スライド 1
 計算科学演習 スーパーコンピュータ & 並列計算 概論 学術情報メディアセンター 情報学研究科 システム科学専攻 中島浩 目次 科目概要 目標 スケジュール スタッフ 講義資料 課題 スーパーコンピュータ概論 一般のスーパーコンピュータ 京大のスーパーコンピュータ スーパーコンピュータの構造 並列計算概論 並列計算の類型 条件 Scaling & Scalability 問題分割 落し穴 プロセス並列
計算科学演習 スーパーコンピュータ & 並列計算 概論 学術情報メディアセンター 情報学研究科 システム科学専攻 中島浩 目次 科目概要 目標 スケジュール スタッフ 講義資料 課題 スーパーコンピュータ概論 一般のスーパーコンピュータ 京大のスーパーコンピュータ スーパーコンピュータの構造 並列計算概論 並列計算の類型 条件 Scaling & Scalability 問題分割 落し穴 プロセス並列
Microsoft Word - HOKUSAI_system_overview_ja.docx
 HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
 10 117 5 1 121841 4 15 12 7 27 12 6 31856 8 21 1983-2 - 321899 12 21656 2 45 9 2 131816 4 91812 11 20 1887 461971 11 3 2 161703 11 13 98 3 16201700-3 - 2 35 6 7 8 9 12 13 12 481973 12 2 571982 161703 11
10 117 5 1 121841 4 15 12 7 27 12 6 31856 8 21 1983-2 - 321899 12 21656 2 45 9 2 131816 4 91812 11 20 1887 461971 11 3 2 161703 11 13 98 3 16201700-3 - 2 35 6 7 8 9 12 13 12 481973 12 2 571982 161703 11
0.45m1.00m 1.00m 1.00m 0.33m 0.33m 0.33m 0.45m 1.00m 2
 24 11 10 24 12 10 30 1 0.45m1.00m 1.00m 1.00m 0.33m 0.33m 0.33m 0.45m 1.00m 2 23% 29% 71% 67% 6% 4% n=1525 n=1137 6% +6% -4% -2% 21% 30% 5% 35% 6% 6% 11% 40% 37% 36 172 166 371 213 226 177 54 382 704 216
24 11 10 24 12 10 30 1 0.45m1.00m 1.00m 1.00m 0.33m 0.33m 0.33m 0.45m 1.00m 2 23% 29% 71% 67% 6% 4% n=1525 n=1137 6% +6% -4% -2% 21% 30% 5% 35% 6% 6% 11% 40% 37% 36 172 166 371 213 226 177 54 382 704 216
生物情報実験法 (オンライン, 4/20)
") 生物情報実験法 (7/23) 笠原雅弘 (mkasa@cb.k.u-tokyo.ac.jp) Table of Contents スレッドの使い方 OpenMP プログラミング Deadline The deadline is Aug 5 23:59 Your e-mail must have reached my e-mail box at the deadline time. It may take
生物情報実験法 (7/23) 笠原雅弘 (mkasa@cb.k.u-tokyo.ac.jp) Table of Contents スレッドの使い方 OpenMP プログラミング Deadline The deadline is Aug 5 23:59 Your e-mail must have reached my e-mail box at the deadline time. It may take
九州大学学術情報リポジトリ Kyushu University Institutional Repository 将来 (2010 年前後を想定 ) のペタフロップス超級スパコンセンターとの連携について 村上, 和彰九州大学大学院システム情報科学研究院 九州大学情報基盤センター
 のペタフロップス超級スパコンセンターとの連携について 村上, 和彰九州大学大学院システム情報科学研究院 九州大学情報基盤センター") 九州大学学術情報リポジトリ Kyushu University Institutional Repository 将来 (2010 年前後を想定 ) のペタフロップス超級スパコンセンターとの連携について 村上, 和彰九州大学大学院システム情報科学研究院 九州大学情報基盤センター http://hdl.handle.net/2324/9112 出版情報 :SLRC プレゼンテーション, 2005-03-08
九州大学学術情報リポジトリ Kyushu University Institutional Repository 将来 (2010 年前後を想定 ) のペタフロップス超級スパコンセンターとの連携について 村上, 和彰九州大学大学院システム情報科学研究院 九州大学情報基盤センター http://hdl.handle.net/2324/9112 出版情報 :SLRC プレゼンテーション, 2005-03-08
4.7講義.key
 スーパーコンピュータとアプリケーションの性能 2016 年 4 月 国立研究開発法人理化学研究所 計算科学研究機構 運用技術部門 ソフトウェア技術チーム チームヘッド 南 一生 minami_kaz@riken.jp RIKEN ADVANCED INSTITUTE FOR COMPUTATIONAL SCIENCE 講義の概要 スーパーコンピュータとアプリケーションの性能 アプリケーションの性能最適化
スーパーコンピュータとアプリケーションの性能 2016 年 4 月 国立研究開発法人理化学研究所 計算科学研究機構 運用技術部門 ソフトウェア技術チーム チームヘッド 南 一生 minami_kaz@riken.jp RIKEN ADVANCED INSTITUTE FOR COMPUTATIONAL SCIENCE 講義の概要 スーパーコンピュータとアプリケーションの性能 アプリケーションの性能最適化
IPSJ SIG Technical Report Vol.2014-HPC-144 No /5/26 ES2 1,a) 1,b) 1,c) (ES2) The system architecture and operation results of the Earth Simulato
 1,b) 1,c) (ES2) The system architecture and operation results of the Earth Simulato") ES2 1,a) 1,b) 1,c) (ES2) The system architecture and operation results of the Earth Simulator (ES2) Ken ichi Itakura 1,a) Hitoshi Uehara 1,b) Toshiyuki Asano 1,c) Abstract: This paper describes the system
ES2 1,a) 1,b) 1,c) (ES2) The system architecture and operation results of the Earth Simulator (ES2) Ken ichi Itakura 1,a) Hitoshi Uehara 1,b) Toshiyuki Asano 1,c) Abstract: This paper describes the system
CPU Levels in the memory hierarchy Level 1 Level 2... Increasing distance from the CPU in access time Level n Size of the memory at each level 1: 2.2
 FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
内容 イントロダクション スカラチューニング OpenMPによる並列化 最近のHPC分野の動向 まとめ
 スカラチューニングと OpenMPによるコードの高速化 松本洋介 千葉大学 謝辞 C言語への対応 簑島敬 JAMSTEC 宇宙磁気流体 プラズマシミュレーションサマースクール 2013年8月6日 千葉大学統合情報センター 内容 イントロダクション スカラチューニング OpenMPによる並列化 最近のHPC分野の動向 まとめ イントロダクション CPUの作り \ Fujitsu SPARC64TM VIIIfx
スカラチューニングと OpenMPによるコードの高速化 松本洋介 千葉大学 謝辞 C言語への対応 簑島敬 JAMSTEC 宇宙磁気流体 プラズマシミュレーションサマースクール 2013年8月6日 千葉大学統合情報センター 内容 イントロダクション スカラチューニング OpenMPによる並列化 最近のHPC分野の動向 まとめ イントロダクション CPUの作り \ Fujitsu SPARC64TM VIIIfx
インテル(R) Visual Fortran Composer XE 2013 Windows版 入門ガイド
 Visual Fortran Composer XE 2013 Windows版 入門ガイド") Visual Fortran Composer XE 2013 Windows* エクセルソフト株式会社 www.xlsoft.com Rev. 1.1 (2012/12/10) Copyright 1998-2013 XLsoft Corporation. All Rights Reserved. 1 / 53 ... 3... 4... 4... 5 Visual Studio... 9...
Visual Fortran Composer XE 2013 Windows* エクセルソフト株式会社 www.xlsoft.com Rev. 1.1 (2012/12/10) Copyright 1998-2013 XLsoft Corporation. All Rights Reserved. 1 / 53 ... 3... 4... 4... 5 Visual Studio... 9...
目次 LS-DYNA 利用の手引き 1 1. はじめに 利用できるバージョン 概要 1 2. TSUBAME での利用方法 使用可能な LS-DYNA の実行 4 (1) TSUBAMEにログイン 4 (2) バージョンの切り替え 4 (3) インタラ
 TSUBAMEにログイン 4 (2) バージョンの切り替え 4 (3) インタラ") LS-DYNA 利用の手引 東京工業大学学術国際情報センター 2016.04 version 1.10 目次 LS-DYNA 利用の手引き 1 1. はじめに 1 1.1 利用できるバージョン 1 1.2 概要 1 2. TSUBAME での利用方法 1 2.1 使用可能な 1 2.2 LS-DYNA の実行 4 (1) TSUBAMEにログイン 4 (2) バージョンの切り替え 4 (3) インタラクティブ実行
LS-DYNA 利用の手引 東京工業大学学術国際情報センター 2016.04 version 1.10 目次 LS-DYNA 利用の手引き 1 1. はじめに 1 1.1 利用できるバージョン 1 1.2 概要 1 2. TSUBAME での利用方法 1 2.1 使用可能な 1 2.2 LS-DYNA の実行 4 (1) TSUBAMEにログイン 4 (2) バージョンの切り替え 4 (3) インタラクティブ実行