GPU CUDA CUDA 2010/06/28 1
|
|
|
- としみ ちとく
- 5 years ago
- Views:
Transcription
1 GPU CUDA CUDA 2010/06/28 1
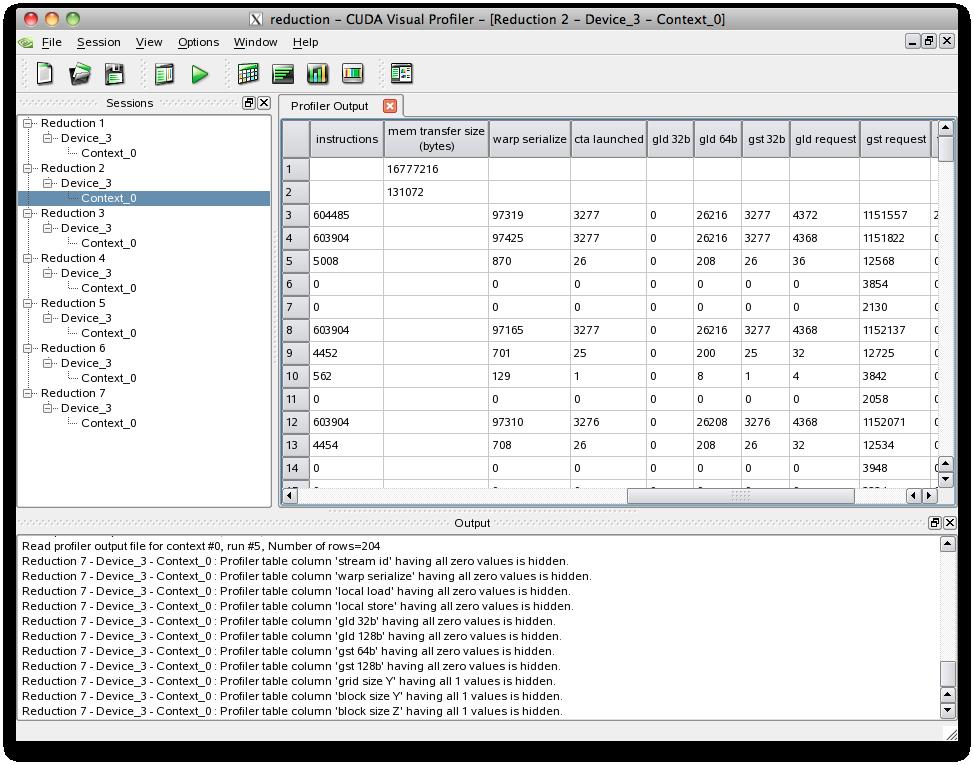
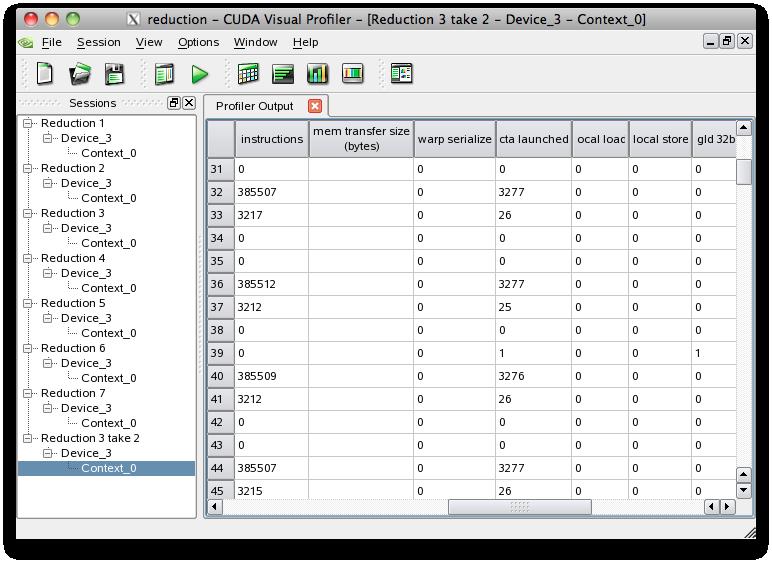
2 GPU NVIDIA Mark Harris, Optimizing Parallel Reduction in CUDA compute/cuda/1_1/website/data- Parallel_Algorithms.html#reduction CUDA SDK reduction 2010/06/28 2
3 /work/nmaruyam/gpu-tutorial/reduction CUDA SDK $ cp r /work/nmaruyam/gpu-tutorial/reduction ~ $ cd ~/reduction $ cd projects/reduction $ make $ cd../.. $./bin/linux/release/reduction 2010/06/28 3
4 GPU /06/28 4
5 log(n) CUDA /06/28 5
6 FLOPS TSUBAME Tesla GPU (S1070): 102 GB/s 2010/06/28 6
7 Reduction #1 global void reduce0(int *g_idata, int *g_odata) { extern shared int sdata[]; // unsigned int tid = threadidx.x; unsigned int i = blockidx.x*blockdim.x + threadidx.x; sdata[tid] = g_idata[i]; syncthreads(); // for(unsigned int s=1; s < blockdim.x; s *= 2) { if (tid % (2*s) == 0) { sdata[tid] += sdata[tid + s]; syncthreads(); // if (tid == 0) g_odata[blockidx.x] = sdata[0]; 2010/06/28 7
8 Values (shared memory) Step 1 Stride 1 Step 2 Stride 2 Step 3 Stride 4 Step 4 Stride 8 IDs Values IDs Values IDs Values IDs Values /06/28 8
9 Kernel ms 4.77 GB/s 4.6 % TSUBAME S1070 GPU 2010/06/28 9
10 # global void reduce0(int *g_idata, int *g_odata) { extern shared int sdata[]; // unsigned int tid = threadidx.x; unsigned int i = blockidx.x*blockdim.x + threadidx.x; sdata[tid] = g_idata[i]; syncthreads(); // for(unsigned int s=1; s < blockdim.x; s *= 2) { if (tid % (2*s) == 0) { sdata[tid] += sdata[tid + s]; syncthreads(); % // if (tid == 0) g_odata[blockidx.x] = sdata[0]; 2010/06/28 10
11 CUDA C/Fortran if, while, for, do-while GPU CPU 2010/06/28 11
12 CUDA 2010/06/28 12
13 Time Mask Warp T T T T T T T x = z - k; if (x > 0) { t = y * x a; else { s = y * y; t = 2 * x + a; s = x * y; a[i] = t * s; 2010/06/28 13
14 Time Mask Warp T T T T T T T x = z - k; if (x > 0) { t = y * x a; else { s = y * y; t = 2 * x + a; s = x * y; a[i] = t * s; 2010/06/28 14
15 Time Mask Warp T T T T T T T x = z - k; if (x > 0) { t = y * x a; else { s = y * y; t = 2 * x + a; s = x * y; a[i] = t * s; 2010/06/28 15
16 Time Mask Warp T T T T T T T T T F T F F T x = z - k; if (x > 0) { t = y * x a; else { s = y * y; t = 2 * x + a; s = x * y; a[i] = t * s; 2010/06/28 16
17 Time Mask Warp T T F T F F T T T F T F F T x = z - k; if (x > 0) { t = y * x a; else { s = y * y; t = 2 * x + a; s = x * y; a[i] = t * s; 2010/06/28 17
18 Time Mask Warp T T F T F F T T T F T F F T x = z - k; if (x > 0) { t = y * x a; else { s = y * y; t = 2 * x + a; s = x * y; a[i] = t * s; 2010/06/28 18
19 Time Mask Warp T T F T F F T T T F T F F T x = z - k; if (x > 0) { t = y * x a; else { s = y * y; t = 2 * x + a; s = x * y; a[i] = t * s; 2010/06/28 19
20 Time Mask Warp F F T F T T F T T F T F F T x = z - k; if (x > 0) { t = y * x a; else { s = y * y; t = 2 * x + a; s = x * y; a[i] = t * s; 2010/06/28 20
21 Time Mask Warp F F T F T T F T T F T F F T x = z - k; if (x > 0) { t = y * x a; else { s = y * y; t = 2 * x + a; s = x * y; a[i] = t * s; 2010/06/28 21
22 Time Mask Warp F F T F T T F T T F T F F T x = z - k; if (x > 0) { t = y * x a; else { s = y * y; t = 2 * x + a; s = x * y; a[i] = t * s; 2010/06/28 22
23 Time Mask Warp T T T T T T T T T F T F F T x = z - k; if (x > 0) { t = y * x a; else { s = y * y; t = 2 * x + a; s = x * y; a[i] = t * s; 2010/06/28 23
24 Time Mask Warp F F T F T T F T T F T F F T x = z - k; if (x > 0) { t = y * x a; else { s = y * y; t = 2 * x + a; s = x * y; a[i] = t * s; 2010/06/28 24
25 #2 for (unsigned int s=1; s < blockdim.x; s *= 2) { if (tid % (2*s) == 0) { sdata[tid] += sdata[tid + s]; syncthreads(); for (unsigned int s=1; s < blockdim.x; s *= 2) { int index = 2 * s * tid; if (index < blockdim.x) { sdata[index] += sdata[index + s]; syncthreads(); 2010/06/28 25
26 #2 Values (shared memory) Step 1 Stride 1 Step 2 Stride 2 Step 3 Stride 4 Step 4 Stride 8 IDs Values IDs Values IDs Values IDs Values /06/28 26
27 % MAX Kernel ms 4.77 GB/s Kernel ms 10.4 GB/s 4.6 % 10.1 % 2.2x 2.2x 2010/06/28 27
28 #2 Values (shared memory) 2 Step 1 Stride 1 4 Step 2 Stride 2 8 Step 3 Stride 4 16 Step 4 Stride 8 IDs Values IDs Values IDs Values IDs Values /06/28 28


29 2010/06/28 29
30 GPU 1 CUDA Bank 0 Bank 1 Bank 2 Bank 3 Bank 4 Bank 5 Bank 6 Bank 7 Bank /06/28 30
31 No Bank Conflicts Linear addressing stride == 1 Bank 0 Bank 1 Bank 2 Bank 3 Bank 4 Bank 5 Bank 6 Bank 7 No Bank Conflicts Random 1:1 Permutation Bank 0 Bank 1 Bank 2 Bank 3 Bank 4 Bank 5 Bank 6 Bank 7 15 Bank Bank /06/28 31
32 2-way Bank Conflicts Linear addressing stride == 2 Bank 0 Bank 1 Bank 2 Bank 3 Bank 4 Bank 5 Bank 6 Bank 7 Bank 15 8-way Bank Conflicts Linear addressing stride == 8 x8 x8 Bank 0 Bank 1 Bank 2 Bank 7 Bank 8 Bank 9 Bank /06/28 32
33 Values (shared memory) Step 1 Stride 8 Step 2 Stride 4 Step 3 Stride 2 Step 4 Stride 1 IDs Values IDs Values IDs Values IDs Values /06/28 33
34 # for (unsigned int s=1; s < blockdim.x; s *= 2) { int index = 2 * s * tid; if (index < blockdim.x) { sdata[index] += sdata[index + s]; syncthreads(); for (unsigned int s=blockdim.x/2; s>0; s>>=1) { if (tid < s) { sdata[tid] += sdata[tid + s]; syncthreads(); 2010/06/28 34
35 % MAX Kernel ms 4.77 GB/s Kernel ms 10.4 GB/s Kernel ms 20.7 GB/s 4.6 % 10.1 % 2.2x 2.2x 20.2 % 2.0x 4.3x 2010/06/28 35



36 2010/06/28 36
37 #3 for (unsigned int s=blockdim.x/2; s>0; s>>=1) { if (tid < s) { sdata[tid] += sdata[tid + s]; syncthreads(); /06/28 OK 37
; // 2 // unsigned int tid = threadidx.x; unsigned int i = blockidx.x*(blockdim.x*2) + threadidx.")
38 #4 1 // unsigned int tid = threadidx.x; unsigned int i = blockidx.x*blockdim.x + threadidx.x; sdata[tid] = g_idata[i]; syncthreads(); // 2 // unsigned int tid = threadidx.x; unsigned int i = blockidx.x*(blockdim.x*2) + threadidx.x; sdata[tid] = g_idata[i] + g_idata[i+blockdim.x]; syncthreads(); 2010/06/28 38
39 % MAX Kernel ms 4.77 GB/s Kernel ms 10.4 GB/s Kernel ms 20.7 GB/s Kernel ms 36.0 GB/s 4.6 % 10.1 % 2.2x 2.2x 20.2 % 2.0x 4.3x 35.2 % 1.7x 7.5x 35% 2010/06/28 39
 { if (tid < s) { sdata[tid] += sdata[tid + s]; syncthreads(); if (tid < 32) { sdata[tid] += sdata[tid + 32]; sdata[tid] += sdata[tid + 16];")
40 for (unsigned int s=blockdim.x/2; s>32; s>>=1) { if (tid < s) { sdata[tid] += sdata[tid + s]; syncthreads(); if (tid < 32) { sdata[tid] += sdata[tid + 32]; sdata[tid] += sdata[tid + 16]; sdata[tid] += sdata[tid + 8]; sdata[tid] += sdata[tid + 4]; sdata[tid] += sdata[tid + 2]; sdata[tid] += sdata[tid + 1]; 6 syncthreads() 2010/06/28 40
41 % MAX Kernel ms 4.77 GB/s Kernel ms 10.4 GB/s Kernel ms 20.7 GB/s Kernel ms 36.0 GB/s Kernel ms 58.1 GB/s 4.6 % 10.1 % 2.2x 2.2x 20.2 % 2.0x 4.3x 35.2 % 1.7x 7.5x 57.0 % 1.7x 12.5x 2010/06/28 41
 { if (tid < s) { sdata[tid] += sdata[tid + s]; syncthreads(); if (tid < 32) { sdata[tid] += sdata[tid + 32]; sdata[tid] += sdata[tid + 16]; sdata[tid]")
42 for (unsigned int s=blockdim.x/2; s>32; s>>=1) { if (tid < s) { sdata[tid] += sdata[tid + s]; syncthreads(); if (tid < 32) { sdata[tid] += sdata[tid + 32]; sdata[tid] += sdata[tid + 16]; sdata[tid] += sdata[tid + 8]; sdata[tid] += sdata[tid + 4]; sdata[tid] += sdata[tid + 2]; sdata[tid] += sdata[tid + 1]; 512 s 64, 128, /06/28 42
43 #6 if (blocksize >= 512) { if (tid < 256) { sdata[tid] += sdata[tid + 256]; syncthreads(); if (blocksize >= 256) { if (tid < 128) { sdata[tid] += sdata[tid + 128]; syncthreads(); if (blocksize >= 128) { if (tid < 64) { sdata[tid] += sdata[tid + 64]; syncthreads(); if (tid < 32) { if (blocksize >= 64) sdata[tid] += sdata[tid + 32]; if (blocksize >= 32) sdata[tid] += sdata[tid + 16]; if (blocksize >= 16) sdata[tid] += sdata[tid + 8]; if (blocksize >= 8) sdata[tid] += sdata[tid + 4]; if (blocksize >= 4) sdata[tid] += sdata[tid + 2]; if (blocksize >= 2) sdata[tid] += sdata[tid + 1]; 2010/06/28 43
44 % MAX Kernel ms 4.77 GB/s 4.6 % Kernel ms 10.4 GB/s 10.1 % 2.2x 2.2x Kernel ms 20.7 GB/s 20.2 % 2.0x 4.3x Kernel ms 36.0 GB/s 35.2 % 1.7x 7.5x Kernel ms 58.1 GB/s 57.0 % 1.7x 12.5x Kernel ms 66.2 GB/s 65.0 % 1.13x 14.0x 2010/06/28 44
45 template <unsigned int blocksize> global void reduce6(int *g_idata, int *g_odata, unsigned int n) { extern shared int sdata[]; unsigned int tid = threadidx.x; unsigned int i = blockidx.x*(blocksize*2) + tid; unsigned int gridsize = blocksize*2*griddim.x; sdata[tid] = 0; while (i < n) { sdata[tid] += g_idata[i] + g_idata[i+blocksize]; i += gridsize; syncthreads(); if (blocksize >= 512) { if (tid < 256) { sdata[tid] += sdata[tid + 256]; syncthreads(); if (blocksize >= 256) { if (tid < 128) { sdata[tid] += sdata[tid + 128]; syncthreads(); if (blocksize >= 128) { if (tid < 64) { sdata[tid] += sdata[tid + 64]; syncthreads(); if (tid < 32) { if (blocksize >= 64) sdata[tid] += sdata[tid + 32]; if (blocksize >= 32) sdata[tid] += sdata[tid + 16]; if (blocksize >= 16) sdata[tid] += sdata[tid + 8]; if (blocksize >= 8) sdata[tid] += sdata[tid + 4]; if (blocksize >= 4) sdata[tid] += sdata[tid + 2]; if (blocksize >= 2) sdata[tid] += sdata[tid + 1]; 1 if (tid == 0) g_odata[blockidx.x] = sdata[0]; 45
46 % MAX Kernel ms 4.77 GB/s 4.6 % Kernel ms 10.4 GB/s 10.1 % 2.2x 2.2x Kernel ms 20.7 GB/s 20.2 % 2.0x 4.3x Kernel ms 36.0 GB/s 35.2 % 1.7x 7.5x Kernel ms 58.1 GB/s 57.0 % 1.7x 12.5x Kernel ms 66.2 GB/s 65.0 % 1.13x 14.0x Kernel ms 76.1 GB/s 74.6 % 1.14x 16.0x 2010/06/28 46
47 CUDA CUDA CUI GUI CUI CUDA_PROFILE 1 CUDA_Profiler.txt GUI ssh -Y $ export LD_LIBRARY_PATH=/opt/cuda2.3/cudaprof/bin:$LD_LIBRARY_PATH $ export PATH=/opt/cuda2.3/cudaprof/bin:$PATH $ cudaprof 2010/06/28 47
untitled
 CUDA Vol II: CUDA : NVIDIA Q2 2008 CUDA...1 CUDA...3 CUDA...16...40...63 CUDA CUDA ( ) CUDA 2 NVIDIA Corporation 2008 2 CUDA CUDA GPU GPU CPU NVIDIA Corporation 2008 4 V V d call put 1 2 = S CND( d ) X
CUDA Vol II: CUDA : NVIDIA Q2 2008 CUDA...1 CUDA...3 CUDA...16...40...63 CUDA CUDA ( ) CUDA 2 NVIDIA Corporation 2008 2 CUDA CUDA GPU GPU CPU NVIDIA Corporation 2008 4 V V d call put 1 2 = S CND( d ) X
( CUDA CUDA CUDA CUDA ( NVIDIA CUDA I
 GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
GPU GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1
 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1") GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
Slide 1
 CUDA プログラミングの基本 パート II - カーネル CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パート II カーネルの起動 GPUコードの具体像 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください GPU 上でのコードの実行 カーネルは C 関数 + 多少の制約 ホストメモリはアクセスできない戻り値型は
CUDA プログラミングの基本 パート II - カーネル CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パート II カーネルの起動 GPUコードの具体像 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください GPU 上でのコードの実行 カーネルは C 関数 + 多少の制約 ホストメモリはアクセスできない戻り値型は
07-二村幸孝・出口大輔.indd
 GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
untitled
 GPGPU NVIDACUDA Learn More about CUDA - NVIDIA http://www.nvidia.co.jp/object/cuda_education_jp.html NVIDIA CUDA programming Guide CUDA http://www.sintef.no/upload/ikt/9011/simoslo/evita/2008/seland.pdf
GPGPU NVIDACUDA Learn More about CUDA - NVIDIA http://www.nvidia.co.jp/object/cuda_education_jp.html NVIDIA CUDA programming Guide CUDA http://www.sintef.no/upload/ikt/9011/simoslo/evita/2008/seland.pdf
3次多項式パラメタ推定計算の CUDAを用いた実装 (CUDAプログラミングの練習として) Implementation of the Estimation of the parameters of 3rd-order-Polynomial with CUDA
 Implementation of the Estimation of the parameters of 3rd-order-Polynomial with CUDA") 3 次多項式パラメタ推定計算の CUDA を用いた実装 (CUDA プログラミングの練習として ) Estimating the Parameters of 3rd-order-Polynomial with CUDA ISS 09/11/12 問題の選択 目的 CUDA プログラミングを経験 ( 試行錯誤と習得 ) 実際に CPU のみの場合と比べて高速化されることを体験 問題 ( インプリメントする内容
3 次多項式パラメタ推定計算の CUDA を用いた実装 (CUDA プログラミングの練習として ) Estimating the Parameters of 3rd-order-Polynomial with CUDA ISS 09/11/12 問題の選択 目的 CUDA プログラミングを経験 ( 試行錯誤と習得 ) 実際に CPU のみの場合と比べて高速化されることを体験 問題 ( インプリメントする内容
NUMAの構成
 GPU のプログラム 天野 アクセラレータとは? 特定の性質のプログラムを高速化するプロセッサ 典型的なアクセラレータ GPU(Graphic Processing Unit) Xeon Phi FPGA(Field Programmable Gate Array) 最近出て来た Deep Learning 用ニューロチップなど Domain Specific Architecture 1GPGPU:General
GPU のプログラム 天野 アクセラレータとは? 特定の性質のプログラムを高速化するプロセッサ 典型的なアクセラレータ GPU(Graphic Processing Unit) Xeon Phi FPGA(Field Programmable Gate Array) 最近出て来た Deep Learning 用ニューロチップなど Domain Specific Architecture 1GPGPU:General
1206_Cray_PE_Overview+Roadmap_JPN
 Cray プログラミング環境の開発と現状 寺西慶太 Cray Inc. Cray のプログラミング環境へのビジョン Crayはアプリケーション性能を最大限に向アプリケーション性能を最大限に向上させることを目標にプログラミング環境を研究開発 コンパイラ ライブラリ ツールの統合されたプログラミング環境で HPC プログラミングの複雑さを克服 スケーラービリティ 機能の拡張と自動化による使いやすさの向上
Cray プログラミング環境の開発と現状 寺西慶太 Cray Inc. Cray のプログラミング環境へのビジョン Crayはアプリケーション性能を最大限に向アプリケーション性能を最大限に向上させることを目標にプログラミング環境を研究開発 コンパイラ ライブラリ ツールの統合されたプログラミング環境で HPC プログラミングの複雑さを克服 スケーラービリティ 機能の拡張と自動化による使いやすさの向上
IPSJ SIG Technical Report Vol.2013-HPC-138 No /2/21 GPU CRS 1,a) 2,b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla
 2,b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla") GPU CRS 1,a),b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla K0 CUDA5.0 cusparse CRS SpMV 00 1.86 177 1. SpMV SpMV CRS Compressed Row Storage *1 SpMV GPU GPU NVIDIA Kepler
GPU CRS 1,a),b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla K0 CUDA5.0 cusparse CRS SpMV 00 1.86 177 1. SpMV SpMV CRS Compressed Row Storage *1 SpMV GPU GPU NVIDIA Kepler
CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン
 CUDA 画像処理入門 エヌビディアジャパン CUDA エンジニア森野慎也 GTC Japan 2014 CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン RGB Y( 輝度 ) 変換 カラー画像から グレイスケールへの変換 Y = 0.299 R + 0.587
CUDA 画像処理入門 エヌビディアジャパン CUDA エンジニア森野慎也 GTC Japan 2014 CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン RGB Y( 輝度 ) 変換 カラー画像から グレイスケールへの変換 Y = 0.299 R + 0.587
untitled
 A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU.....
 CPU GPU N Q07-065 2011 2 17 1 1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU...........................................
CPU GPU N Q07-065 2011 2 17 1 1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU...........................................
MPI または CUDA を用いた将棋評価関数学習プログラムの並列化 2009/06/30
 MPI または CUDA を用いた将棋評価関数学習プログラムの並列化 2009/06/30 目次 1. まえがき 3 2. 計算方法 4 3. MPI を用いた並列化 6 4. CUDA を用いた並列化 11 5. 計算結果 20 6. まとめ 24 2 1. まえがき 目的将棋の評価関数を棋譜から学習するボナンザメソッドの簡易版を作成し それを MPI または CUDA を用いて並列化し 計算時間を短縮することを目的とする
MPI または CUDA を用いた将棋評価関数学習プログラムの並列化 2009/06/30 目次 1. まえがき 3 2. 計算方法 4 3. MPI を用いた並列化 6 4. CUDA を用いた並列化 11 5. 計算結果 20 6. まとめ 24 2 1. まえがき 目的将棋の評価関数を棋譜から学習するボナンザメソッドの簡易版を作成し それを MPI または CUDA を用いて並列化し 計算時間を短縮することを目的とする
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
Microsoft PowerPoint - GPGPU実践基礎工学(web).pptx
.pptx") GPU のメモリ階層 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のメモリ階層 グローバルメモリ 共有メモリ モザイク処理への適用 コンスタントメモリ 空間フィルタへの適用 577 GPU の主要部品 基盤 GPU( チップ )+ 冷却部品 画面出力端子 電源入力端子 メモリ 特性の把握が重要 電源入力端子 画面出力端子 メモリ チップ PCI Ex 端子 http://www.geforce.com/whats
GPU のメモリ階層 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のメモリ階層 グローバルメモリ 共有メモリ モザイク処理への適用 コンスタントメモリ 空間フィルタへの適用 577 GPU の主要部品 基盤 GPU( チップ )+ 冷却部品 画面出力端子 電源入力端子 メモリ 特性の把握が重要 電源入力端子 画面出力端子 メモリ チップ PCI Ex 端子 http://www.geforce.com/whats
CUDA 連携とライブラリの活用 2
 1 09:30-10:00 受付 10:00-12:00 Reedbush-H ログイン GPU 入門 13:30-15:00 OpenACC 入門 15:15-16:45 OpenACC 最適化入門と演習 17:00-18:00 OpenACC の活用 (CUDA 連携とライブラリの活用 ) CUDA 連携とライブラリの活用 2 3 OpenACC 簡単にGPUプログラムが作成できる それなりの性能が得られる
1 09:30-10:00 受付 10:00-12:00 Reedbush-H ログイン GPU 入門 13:30-15:00 OpenACC 入門 15:15-16:45 OpenACC 最適化入門と演習 17:00-18:00 OpenACC の活用 (CUDA 連携とライブラリの活用 ) CUDA 連携とライブラリの活用 2 3 OpenACC 簡単にGPUプログラムが作成できる それなりの性能が得られる


CuPy とは何か?
 GTC Japan 2018 CuPy NumPy 互換 GPU ライブラリによる Python での高速計算 Preferred Networks 取締役最高技術責任者奥田遼介 okuta@preferred.jp CuPy とは何か? CuPy とは GPU を使って NumPy 互換の機能を提供するライブラリ import numpy as np X_cpu = np.zeros((10,))
GTC Japan 2018 CuPy NumPy 互換 GPU ライブラリによる Python での高速計算 Preferred Networks 取締役最高技術責任者奥田遼介 okuta@preferred.jp CuPy とは何か? CuPy とは GPU を使って NumPy 互換の機能を提供するライブラリ import numpy as np X_cpu = np.zeros((10,))
untitled
 A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }




P072-076.indd
 3 STEP0 STEP1 STEP2 STEP3 STEP4 072 3STEP4 STEP3 STEP2 STEP1 STEP0 073 3 STEP0 STEP1 STEP2 STEP3 STEP4 074 3STEP4 STEP3 STEP2 STEP1 STEP0 075 3 STEP0 STEP1 STEP2 STEP3 STEP4 076 3STEP4 STEP3 STEP2 STEP1
3 STEP0 STEP1 STEP2 STEP3 STEP4 072 3STEP4 STEP3 STEP2 STEP1 STEP0 073 3 STEP0 STEP1 STEP2 STEP3 STEP4 074 3STEP4 STEP3 STEP2 STEP1 STEP0 075 3 STEP0 STEP1 STEP2 STEP3 STEP4 076 3STEP4 STEP3 STEP2 STEP1

1
 1 2 3 4 5 6 7 8 9 0 1 2 6 3 1 2 3 4 5 6 7 8 9 0 5 4 STEP 02 STEP 01 STEP 03 STEP 04 1F 1F 2F 2F 2F 1F 1 2 3 4 5 http://smarthouse-center.org/sdk/ http://smarthouse-center.org/inquiries/ http://sh-center.org/
1 2 3 4 5 6 7 8 9 0 1 2 6 3 1 2 3 4 5 6 7 8 9 0 5 4 STEP 02 STEP 01 STEP 03 STEP 04 1F 1F 2F 2F 2F 1F 1 2 3 4 5 http://smarthouse-center.org/sdk/ http://smarthouse-center.org/inquiries/ http://sh-center.org/





 STEP1 STEP3 STEP2 STEP4 STEP6 STEP5 STEP7 10,000,000 2,060 38 0 0 0 1978 4 1 2015 9 30 15,000,000 2,060 38 0 0 0 197941 2016930 10,000,000 2,060 38 0 0 0 197941 2016930 3 000 000 0 0 0 600 15
STEP1 STEP3 STEP2 STEP4 STEP6 STEP5 STEP7 10,000,000 2,060 38 0 0 0 1978 4 1 2015 9 30 15,000,000 2,060 38 0 0 0 197941 2016930 10,000,000 2,060 38 0 0 0 197941 2016930 3 000 000 0 0 0 600 15

TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日
 TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
DO 時間積分 START 反変速度の計算 contravariant_velocity 移流項の計算 advection_adams_bashforth_2nd DO implicit loop( 陰解法 ) 速度勾配, 温度勾配の計算 gradient_cell_center_surface 速
 速度勾配, 温度勾配の計算 gradient_cell_center_surface 速") 1 1, 2 1, 2 3 2, 3 4 GP LES ASUCA LES NVIDIA CUDA LES 1. Graphics Processing Unit GP General-Purpose SIMT Single Instruction Multiple Threads 1 2 3 4 1),2) LES Large Eddy Simulation 3) ASUCA 4) LES LES
1 1, 2 1, 2 3 2, 3 4 GP LES ASUCA LES NVIDIA CUDA LES 1. Graphics Processing Unit GP General-Purpose SIMT Single Instruction Multiple Threads 1 2 3 4 1),2) LES Large Eddy Simulation 3) ASUCA 4) LES LES
 H24.12.23")
1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境 Lin
 Windows で始める CUDA 入門 GTC 2013 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境
Windows で始める CUDA 入門 GTC 2013 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境
(search: ) [1] ( ) 2 (linear search) (sequential search) 1
![(search: ) [1] ( ) 2 (linear search) (sequential search) 1](/thumbs/97/131825822.jpg "(search: ) [1] ( ) 2 (linear search) (sequential search) 1") 2005 11 14 1 1.1 2 1.2 (search:) [1] () 2 (linear search) (sequential search) 1 2.1 2.1.1 List 2-1(p.37) 1 1 13 n
2005 11 14 1 1.1 2 1.2 (search:) [1] () 2 (linear search) (sequential search) 1 2.1 2.1.1 List 2-1(p.37) 1 1 13 n







 001 No.3/12 1 1 2 3 4 5 6 4 8 13 27 33 39 001 No.3/12 4 001 No.3/12 5 001 No.3/12 6 001 No.3/12 7 001 8 No.3/12 001 No.3/12 9 001 10 No.3/12 001 No.3/12 11 Index 1 2 3 14 18 21 001 No.3/12 14 001 No.3/12
001 No.3/12 1 1 2 3 4 5 6 4 8 13 27 33 39 001 No.3/12 4 001 No.3/12 5 001 No.3/12 6 001 No.3/12 7 001 8 No.3/12 001 No.3/12 9 001 10 No.3/12 001 No.3/12 11 Index 1 2 3 14 18 21 001 No.3/12 14 001 No.3/12
証券協会_p56
 INDEX P.02-19 P.20-31 P.32-34 1 STEP1 STEP2 STEP3 STEP4 P.03-06 P.07-10 P.11-12 P.11-14 P.15-16 P.15-18 P.19 202 STEP 1 3 4 5 10 25 200 30 1,000 2,500 20 30 40 50 60 5 1 80.4 356.7 66.3 461.7 452.7 802.7
INDEX P.02-19 P.20-31 P.32-34 1 STEP1 STEP2 STEP3 STEP4 P.03-06 P.07-10 P.11-12 P.11-14 P.15-16 P.15-18 P.19 202 STEP 1 3 4 5 10 25 200 30 1,000 2,500 20 30 40 50 60 5 1 80.4 356.7 66.3 461.7 452.7 802.7
2 09:00-09:30 受付 09:30-12:00 GPU 入門,CUDA 入門 13:00-14:30 OpenACC 入門 + HA-PACS ログイン 14:45-16:15 OpenACC 最適化入門と演習 16:30-18:00 CUDA 最適化入門と演習
 担当 大島聡史 ( 助教 ) ohshima@cc.u-tokyo.ac.jp 星野哲也 ( 助教 ) hoshino@cc.u-tokyo.ac.jp 質問やサンプルプログラムの提供についてはメールでお問い合わせください 1 2016 年 6 月 8 日 ( 水 ) 東京大学情報基盤センター 2 09:00-09:30 受付 09:30-12:00 GPU 入門,CUDA 入門 13:00-14:30
担当 大島聡史 ( 助教 ) ohshima@cc.u-tokyo.ac.jp 星野哲也 ( 助教 ) hoshino@cc.u-tokyo.ac.jp 質問やサンプルプログラムの提供についてはメールでお問い合わせください 1 2016 年 6 月 8 日 ( 水 ) 東京大学情報基盤センター 2 09:00-09:30 受付 09:30-12:00 GPU 入門,CUDA 入門 13:00-14:30


XACCの概要
 2 global void kernel(int a[max], int llimit, int ulimit) {... } : int main(int argc, char *argv[]){ MPI_Int(&argc, &argc); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); dx
2 global void kernel(int a[max], int llimit, int ulimit) {... } : int main(int argc, char *argv[]){ MPI_Int(&argc, &argc); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); dx
Microsoft PowerPoint - GPU_computing_2013_01.pptx
 GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格
GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格

1 OpenCL OpenCL 1 OpenCL GPU ( ) 1 OpenCL Compute Units Elements OpenCL OpenCL SPMD (Single-Program, Multiple-Data) SPMD OpenCL work-item work-group N
 1 OpenCL Compute Units Elements OpenCL OpenCL SPMD (Single-Program, Multiple-Data) SPMD OpenCL work-item work-group N") GPU 1 1 2 1, 3 2, 3 (Graphics Unit: GPU) GPU GPU GPU Evaluation of GPU Computing Based on An Automatic Program Generation Technology Makoto Sugawara, 1 Katsuto Sato, 1 Kazuhiko Komatsu, 2 Hiroyuki Takizawa
GPU 1 1 2 1, 3 2, 3 (Graphics Unit: GPU) GPU GPU GPU Evaluation of GPU Computing Based on An Automatic Program Generation Technology Makoto Sugawara, 1 Katsuto Sato, 1 Kazuhiko Komatsu, 2 Hiroyuki Takizawa
GPGPUクラスタの性能評価
 2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
OpenMP¤òÍѤ¤¤¿ÊÂÎó·×»»¡Ê£±¡Ë
 2011 5 26 scalar Open MP Hello World Do (omp do) (omp workshare) (shared, private) π (reduction) scalar magny-cours, 48 scalar scalar 1 % scp. ssh / authorized keys 133. 30. 112. 246 2 48 % ssh 133.30.112.246
2011 5 26 scalar Open MP Hello World Do (omp do) (omp workshare) (shared, private) π (reduction) scalar magny-cours, 48 scalar scalar 1 % scp. ssh / authorized keys 133. 30. 112. 246 2 48 % ssh 133.30.112.246
Microsoft PowerPoint - GPGPU実践基礎工学(web).pptx
.pptx") GPU のプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU プログラミング環境 (CUDA) GPU プログラムの実行の流れ CUDA によるプログラムの記述 カーネル (GPU で処理する関数 ) の構造 記述方法とその理由 GPU 固有のパラメータの確認 405 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ
GPU のプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU プログラミング環境 (CUDA) GPU プログラムの実行の流れ CUDA によるプログラムの記述 カーネル (GPU で処理する関数 ) の構造 記述方法とその理由 GPU 固有のパラメータの確認 405 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ


TSUBAME2.0におけるGPUの 活用方法
 GPU プログラミング 基礎編 東京工業大学学術国際情報センター 1. GPU コンピューティングと TSUBAME2.0 スーパーコンピュータ GPU コンピューティングとは グラフィックプロセッサ (GPU) は グラフィック ゲームの画像計算のために 進化を続けてきた 現在 CPU のコア数は 2~12 個に対し GPU 中には数百コア その GPU を一般アプリケーションの高速化に利用! GPGPU
GPU プログラミング 基礎編 東京工業大学学術国際情報センター 1. GPU コンピューティングと TSUBAME2.0 スーパーコンピュータ GPU コンピューティングとは グラフィックプロセッサ (GPU) は グラフィック ゲームの画像計算のために 進化を続けてきた 現在 CPU のコア数は 2~12 個に対し GPU 中には数百コア その GPU を一般アプリケーションの高速化に利用! GPGPU
の設立に伴う包装変更のご案内")



17. (1) 18. (1) 19. (1) 20. (1) 21. (1) (3) 22. (1) (3) 23. (1) (3) (1) (3) 25. (1) (3) 26. (1) 27. (1) (3) 28. (1) 29. (1) 2
 18. (1) 19. (1) 20. (1) 21. (1) (3) 22. (1) (3) 23. (1) (3) (1) (3) 25. (1) (3) 26. (1) 27. (1) (3) 28. (1) 29. (1) 2") 1. (1) 2. 2 (1) 4. (1) 5. (1) 6. (1) 7. (1) 8. (1) 9. (1) 10. (1) 11. (1) 12. (1) 13. (1) 14. (1) 15. (1) (3) 16. (1) 1 17. (1) 18. (1) 19. (1) 20. (1) 21. (1) (3) 22. (1) (3) 23. (1) (3) 24. 1 (1) (3)
1. (1) 2. 2 (1) 4. (1) 5. (1) 6. (1) 7. (1) 8. (1) 9. (1) 10. (1) 11. (1) 12. (1) 13. (1) 14. (1) 15. (1) (3) 16. (1) 1 17. (1) 18. (1) 19. (1) 20. (1) 21. (1) (3) 22. (1) (3) 23. (1) (3) 24. 1 (1) (3)
(MIRU2010) NTT Graphic Processor Unit GPU graphi
 NTT Graphic Processor Unit GPU graphi") (MIRU2010) 2010 7 889 2192 1-1 905 2171 905 NTT 243 0124 3-1 E-mail: ac094608@edu.okinawa-ct.ac.jp, akisato@ieee.org Graphic Processor Unit GPU graphic processor unit CUDA Fully automatic extraction of
(MIRU2010) 2010 7 889 2192 1-1 905 2171 905 NTT 243 0124 3-1 E-mail: ac094608@edu.okinawa-ct.ac.jp, akisato@ieee.org Graphic Processor Unit GPU graphic processor unit CUDA Fully automatic extraction of
いまからはじめる組み込みGPU実装
 いまからはじめる組み込み GPU 実装 ~ コンピュータービジョン ディープラーニング編 ~ MathWorks Japan アプリケーションエンジニアリング部シニアアプリケーションエンジニア大塚慶太郎 2017 The MathWorks, Inc. 1 コンピュータービジョン ディープラーニングによる 様々な可能性 自動運転 ロボティクス 予知保全 ( 製造設備 ) セキュリティ 2 転移学習を使った画像分類
いまからはじめる組み込み GPU 実装 ~ コンピュータービジョン ディープラーニング編 ~ MathWorks Japan アプリケーションエンジニアリング部シニアアプリケーションエンジニア大塚慶太郎 2017 The MathWorks, Inc. 1 コンピュータービジョン ディープラーニングによる 様々な可能性 自動運転 ロボティクス 予知保全 ( 製造設備 ) セキュリティ 2 転移学習を使った画像分類
概要 目的 CUDA Fortran の利用に関する基本的なノウハウを提供する 本チュートリアル受講後は Web 上で公開されている資料等を参照しながら独力で CUDA Fortran が利用できることが目標 対象 CUDA Fortran の利用に興味を抱いている方 前提とする知識 Fortran
 CUDA Fortran チュートリアル 2010 年 9 月 29 日 NEC 概要 目的 CUDA Fortran の利用に関する基本的なノウハウを提供する 本チュートリアル受講後は Web 上で公開されている資料等を参照しながら独力で CUDA Fortran が利用できることが目標 対象 CUDA Fortran の利用に興味を抱いている方 前提とする知識 Fortran を用いた Linux
CUDA Fortran チュートリアル 2010 年 9 月 29 日 NEC 概要 目的 CUDA Fortran の利用に関する基本的なノウハウを提供する 本チュートリアル受講後は Web 上で公開されている資料等を参照しながら独力で CUDA Fortran が利用できることが目標 対象 CUDA Fortran の利用に興味を抱いている方 前提とする知識 Fortran を用いた Linux
GPU Computing on Business
 GPU Computing on Business 2010 Numerical Technologies Incorporated http://www.numtech.com/ 1 2 3 4 5 6 7 8 9 GPU Computing $$$ Revenue Total Cost low BEP Quantity 10 11 12 13 14 15 GPU Computing $$$ Revenue
GPU Computing on Business 2010 Numerical Technologies Incorporated http://www.numtech.com/ 1 2 3 4 5 6 7 8 9 GPU Computing $$$ Revenue Total Cost low BEP Quantity 10 11 12 13 14 15 GPU Computing $$$ Revenue
GPU 画像 動画処理用ハードウェア 低性能なプロセッサがたくさん詰まっている ピーク性能が非常に高い GPUを数値計算に用いるのがGPGPU Graphics Processing Unit General Purpose GPU TSUBAME2.0: GPUスパコン 本演習ではNVIDIA社の
 演習II (連続系アルゴリズム) 第2回: GPGPU 須田研究室 M1 本谷 徹 motoya@is.s.u-tokyo.ac.jp 2012/10/19 GPU 画像 動画処理用ハードウェア 低性能なプロセッサがたくさん詰まっている ピーク性能が非常に高い GPUを数値計算に用いるのがGPGPU Graphics Processing Unit General Purpose GPU TSUBAME2.0:
演習II (連続系アルゴリズム) 第2回: GPGPU 須田研究室 M1 本谷 徹 motoya@is.s.u-tokyo.ac.jp 2012/10/19 GPU 画像 動画処理用ハードウェア 低性能なプロセッサがたくさん詰まっている ピーク性能が非常に高い GPUを数値計算に用いるのがGPGPU Graphics Processing Unit General Purpose GPU TSUBAME2.0:
‚æ4›ñ
 ( ) ( ) ( ) A B C D E F G H I J K L M N O P Q R S T U V W X Y Z a b c d e f g h i j k l m n o p q r s t u v w x y z 0 1 2 3 4 5 6 7 8 9 (OUS) 9 26 1 / 28 ( ) ( ) ( ) A B C D Z a b c d z 0 1 2 9 (OUS) 9
( ) ( ) ( ) A B C D E F G H I J K L M N O P Q R S T U V W X Y Z a b c d e f g h i j k l m n o p q r s t u v w x y z 0 1 2 3 4 5 6 7 8 9 (OUS) 9 26 1 / 28 ( ) ( ) ( ) A B C D Z a b c d z 0 1 2 9 (OUS) 9
Cell/B.E. BlockLib
 Cell/B.E. BlockLib 17 17115080 21 2 10 i Cell/B.E. BlockLib SIMD CELL SIMD Cell Cell BlockLib BlockLib NestStep libspe1 Cell SDK 3.1 libspe2 BlockLib Cell SDK 3.1 NestStep libspe2 BlockLib BlockLib libspe1
Cell/B.E. BlockLib 17 17115080 21 2 10 i Cell/B.E. BlockLib SIMD CELL SIMD Cell Cell BlockLib BlockLib NestStep libspe1 Cell SDK 3.1 libspe2 BlockLib Cell SDK 3.1 NestStep libspe2 BlockLib BlockLib libspe1
OpenMP¤òÍѤ¤¤¿ÊÂÎó·×»»¡Ê£²¡Ë
 2013 5 30 (schedule) (omp sections) (omp single, omp master) (barrier, critical, atomic) program pi i m p l i c i t none integer, parameter : : SP = kind ( 1. 0 ) integer, parameter : : DP = selected real
2013 5 30 (schedule) (omp sections) (omp single, omp master) (barrier, critical, atomic) program pi i m p l i c i t none integer, parameter : : SP = kind ( 1. 0 ) integer, parameter : : DP = selected real





OpenMP¤òÍѤ¤¤¿ÊÂÎó·×»»¡Ê£±¡Ë
 2012 5 24 scalar Open MP Hello World Do (omp do) (omp workshare) (shared, private) π (reduction) PU PU PU 2 16 OpenMP FORTRAN/C/C++ MPI OpenMP 1997 FORTRAN Ver. 1.0 API 1998 C/C++ Ver. 1.0 API 2000 FORTRAN
2012 5 24 scalar Open MP Hello World Do (omp do) (omp workshare) (shared, private) π (reduction) PU PU PU 2 16 OpenMP FORTRAN/C/C++ MPI OpenMP 1997 FORTRAN Ver. 1.0 API 1998 C/C++ Ver. 1.0 API 2000 FORTRAN
02_C-C++_osx.indd
 C/C++ OpenMP* / 2 C/C++ OpenMP* OpenMP* 9.0 1... 2 2... 3 3OpenMP*... 5 3.1... 5 3.2 OpenMP*... 6 3.3 OpenMP*... 8 4OpenMP*... 9 4.1... 9 4.2 OpenMP*... 9 4.3 OpenMP*... 10 4.4... 10 5OpenMP*... 11 5.1
C/C++ OpenMP* / 2 C/C++ OpenMP* OpenMP* 9.0 1... 2 2... 3 3OpenMP*... 5 3.1... 5 3.2 OpenMP*... 6 3.3 OpenMP*... 8 4OpenMP*... 9 4.1... 9 4.2 OpenMP*... 9 4.3 OpenMP*... 10 4.4... 10 5OpenMP*... 11 5.1
Microsoft PowerPoint - suda.pptx
 GPU の HWアーキテクチャと高性能化手法 須田礼仁 ( 東京大学 ) 2011/03/22 GPU 高性能プログラミング GPU のハードウェアを理解する CUDA のソフトウェアを理解する CUDA でプログラムを書くのは難しくないが, CUDA で高速なプログラムを書くのは難しい どうすれば遅くなるかを理解する! 効果が大きいものから順に説明します 1 高性能プログラミングの手順 1. 現在のコードの,
GPU の HWアーキテクチャと高性能化手法 須田礼仁 ( 東京大学 ) 2011/03/22 GPU 高性能プログラミング GPU のハードウェアを理解する CUDA のソフトウェアを理解する CUDA でプログラムを書くのは難しくないが, CUDA で高速なプログラムを書くのは難しい どうすれば遅くなるかを理解する! 効果が大きいものから順に説明します 1 高性能プログラミングの手順 1. 現在のコードの,

N 体問題 長岡技術科学大学電気電子情報工学専攻出川智啓
 N 体問題 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 天体の運動方程式 天体運動の GPU 実装 最適化による性能変化 #pragma unroll 855 計算の種類 画像処理, 差分法 空間に固定された観測点を配置 観測点 ( 固定 ) 観測点上で物理量がどのように変化するかを追跡 Euler 型 多粒子の運動 観測点を配置せず, 観測点が粒子と共に移動 Lagrange 型 観測点
N 体問題 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 天体の運動方程式 天体運動の GPU 実装 最適化による性能変化 #pragma unroll 855 計算の種類 画像処理, 差分法 空間に固定された観測点を配置 観測点 ( 固定 ) 観測点上で物理量がどのように変化するかを追跡 Euler 型 多粒子の運動 観測点を配置せず, 観測点が粒子と共に移動 Lagrange 型 観測点
Java updated
 Java 2003.07.14 updated 3 1 Java 5 1.1 Java................................. 5 1.2 Java..................................... 5 1.3 Java................................ 6 1.3.1 Java.......................
Java 2003.07.14 updated 3 1 Java 5 1.1 Java................................. 5 1.2 Java..................................... 5 1.3 Java................................ 6 1.3.1 Java.......................
Slide 1
 CUDA プログラミングの基本 パート I - ソフトウェアスタックとメモリ管理 CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パートII カーネルの起動 GPUコードの具体項目 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください CUDA インストレーション CUDA インストレーションの構成
CUDA プログラミングの基本 パート I - ソフトウェアスタックとメモリ管理 CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パートII カーネルの起動 GPUコードの具体項目 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください CUDA インストレーション CUDA インストレーションの構成
e-tax e-tax e-tax e-tax OK 2e-Tax
 e-tax e-tax 3-1 e-tax...31 3-2...34...34...35 3-3...36...36...39...40...41...42...44 3-4 e-tax...45 3-5...46...46 2...48 e-tax e-tax e-tax e-tax OK 2e-Tax e-tax e-tax 4-1 16 4 30 e-tax 2 4-2 e-tax e-tax
e-tax e-tax 3-1 e-tax...31 3-2...34...34...35 3-3...36...36...39...40...41...42...44 3-4 e-tax...45 3-5...46...46 2...48 e-tax e-tax e-tax e-tax OK 2e-Tax e-tax e-tax 4-1 16 4 30 e-tax 2 4-2 e-tax e-tax
EGunGPU
 Super Computing in Accelerator simulations - Electron Gun simulation using GPGPU - K. Ohmi, KEK-Accel Accelerator Physics seminar 2009.11.19 Super computers in KEK HITACHI SR11000 POWER5 16 24GB 16 134GFlops,
Super Computing in Accelerator simulations - Electron Gun simulation using GPGPU - K. Ohmi, KEK-Accel Accelerator Physics seminar 2009.11.19 Super computers in KEK HITACHI SR11000 POWER5 16 24GB 16 134GFlops,
GPUコンピューティング講習会パート1
 GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
/* do-while */ #include <stdio.h> #include <math.h> int main(void) double val1, val2, arith_mean, geo_mean; printf( \n ); do printf( ); scanf( %lf, &v
 double val1, val2, arith_mean, geo_mean; printf( \n ); do printf( ); scanf( %lf, &v") 1 http://www7.bpe.es.osaka-u.ac.jp/~kota/classes/jse.html kota@fbs.osaka-u.ac.jp /* do-while */ #include #include int main(void) double val1, val2, arith_mean, geo_mean; printf( \n );
1 http://www7.bpe.es.osaka-u.ac.jp/~kota/classes/jse.html kota@fbs.osaka-u.ac.jp /* do-while */ #include #include int main(void) double val1, val2, arith_mean, geo_mean; printf( \n );
KBLAS[7] *1., CUBLAS.,,, Byte/flop., [13] 1 2. (AT). GPU AT,, GPU SYMV., SYMV CUDABLAS., (double, float) (cu- FloatComplex, cudoublecomplex).,, DD(dou
![KBLAS[7] *1., CUBLAS.,,, Byte/flop., [13] 1 2. (AT). GPU AT,, GPU SYMV., SYMV CUDABLAS., (double, float) (cu- FloatComplex, cudoublecomplex).,, DD(dou](/thumbs/71/64446865.jpg "KBLAS[7] *1., CUBLAS.,,, Byte/flop., [13] 1 2. (AT). GPU AT,, GPU SYMV., SYMV CUDABLAS., (double, float) (cu- FloatComplex, cudoublecomplex).,, DD(dou") Vol.214-HPC-146 No.14 214/1/3 CUDA-xSYMV 1,3,a) 1 2,3 2,3 (SYMV)., (GEMV) 2.,, mutex., CUBLAS., 1 2,. (AT). 2, SYMV GPU., SSYMV( SYMV), GeForce GTXTitan Black 211GFLOPS( 62.8%)., ( ) (, ) DD(double-double),
Vol.214-HPC-146 No.14 214/1/3 CUDA-xSYMV 1,3,a) 1 2,3 2,3 (SYMV)., (GEMV) 2.,, mutex., CUBLAS., 1 2,. (AT). 2, SYMV GPU., SSYMV( SYMV), GeForce GTXTitan Black 211GFLOPS( 62.8%)., ( ) (, ) DD(double-double),
明解Javaによるアルゴリズムとデータ構造
 74 searching 3 key Fig.3-1 75 2を探索 53を探索 3-1 5 2 1 4 3 7 4 を探索 Fig.3-1 76 3 linear searchsequential search 2 Fig.3-2 0 ❶ ❷ ❸ 配列の要素を先頭から順に走査していく 探索すべき値と等しい要素を発見 Fig.3-2 6 4 3 2 3-2Fig.3-3 77 5 Fig.3-3 0
74 searching 3 key Fig.3-1 75 2を探索 53を探索 3-1 5 2 1 4 3 7 4 を探索 Fig.3-1 76 3 linear searchsequential search 2 Fig.3-2 0 ❶ ❷ ❸ 配列の要素を先頭から順に走査していく 探索すべき値と等しい要素を発見 Fig.3-2 6 4 3 2 3-2Fig.3-3 77 5 Fig.3-3 0
25 2 ) 15 (W 力電 idle FMA(1) FMA(N) 実行コード Memcopy matmul 1 N occupancy gridsize N=256 Memcopy blocksize 288x288 (matmu
 15 (W 力電 idle FMA(1) FMA(N) 実行コード Memcopy matmul 1 N occupancy gridsize N=256 Memcopy blocksize 288x288 (matmu") GPU 1, 2 1, 2 1, 2 1, 2 1, 2, 3 GPU NVIDIA GeForce GTX285 Tesla S17 1 GPU GPU GPU 2W CPU GPU GPU GPU GPGPU 92.8% GPU GPU Correlative Analysis of Performance Counters and Power Consumption on GPUs Hitoshi
GPU 1, 2 1, 2 1, 2 1, 2 1, 2, 3 GPU NVIDIA GeForce GTX285 Tesla S17 1 GPU GPU GPU 2W CPU GPU GPU GPU GPGPU 92.8% GPU GPU Correlative Analysis of Performance Counters and Power Consumption on GPUs Hitoshi
HPEハイパフォーマンスコンピューティング ソリューション
 HPE HPC / AI Page 2 No.1 * 24.8% No.1 * HPE HPC / AI HPC AI SGIHPE HPC / AI GPU TOP500 50th edition Nov. 2017 HPE No.1 124 www.top500.org HPE HPC / AI TSUBAME 3.0 2017 7 AI TSUBAME 3.0 HPE SGI 8600 System
HPE HPC / AI Page 2 No.1 * 24.8% No.1 * HPE HPC / AI HPC AI SGIHPE HPC / AI GPU TOP500 50th edition Nov. 2017 HPE No.1 124 www.top500.org HPE HPC / AI TSUBAME 3.0 2017 7 AI TSUBAME 3.0 HPE SGI 8600 System
Microsoft Word - C.....u.K...doc
 C uwêííôöðöõ Ð C ÔÖÐÖÕ ÐÊÉÌÊ C ÔÖÐÖÕÊ C ÔÖÐÖÕÊ Ç Ê Æ ~ if eíè ~ for ÒÑÒ ÌÆÊÉÉÊ ~ switch ÉeÍÈ ~ while ÒÑÒ ÊÍÍÔÖÐÖÕÊ ~ 1 C ÔÖÐÖÕ ÐÊÉÌÊ uê~ ÏÒÏÑ Ð ÓÏÖ CUI Ô ÑÊ ÏÒÏÑ ÔÖÐÖÕÎ d ÈÍÉÇÊ ÆÒ Ö ÒÐÑÒ ÊÔÎÏÖÎ d ÉÇÍÊ
C uwêííôöðöõ Ð C ÔÖÐÖÕ ÐÊÉÌÊ C ÔÖÐÖÕÊ C ÔÖÐÖÕÊ Ç Ê Æ ~ if eíè ~ for ÒÑÒ ÌÆÊÉÉÊ ~ switch ÉeÍÈ ~ while ÒÑÒ ÊÍÍÔÖÐÖÕÊ ~ 1 C ÔÖÐÖÕ ÐÊÉÌÊ uê~ ÏÒÏÑ Ð ÓÏÖ CUI Ô ÑÊ ÏÒÏÑ ÔÖÐÖÕÎ d ÈÍÉÇÊ ÆÒ Ö ÒÐÑÒ ÊÔÎÏÖÎ d ÉÇÍÊ
HPC146
 2 3 4 5 6 int array[16]; #pragma xmp nodes p(4) #pragma xmp template t(0:15) #pragma xmp distribute t(block) on p #pragma xmp align array[i] with t(i) array[16] 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Node
2 3 4 5 6 int array[16]; #pragma xmp nodes p(4) #pragma xmp template t(0:15) #pragma xmp distribute t(block) on p #pragma xmp align array[i] with t(i) array[16] 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Node
N08
 CPU のキモチ C.John 自己紹介 英語きらい 絵かけない 人の話を素直に信じない CPUにキモチなんてない お詫び 予告ではCとC# とありましたがやる気と時間の都合上 C++のみを対象とします 今日のネタ元 MSDN マガジン 2010 年 10 月号 http://msdn.microsoft.com/ja-jp/magazine/cc850829.aspx Windows と C++
CPU のキモチ C.John 自己紹介 英語きらい 絵かけない 人の話を素直に信じない CPUにキモチなんてない お詫び 予告ではCとC# とありましたがやる気と時間の都合上 C++のみを対象とします 今日のネタ元 MSDN マガジン 2010 年 10 月号 http://msdn.microsoft.com/ja-jp/magazine/cc850829.aspx Windows と C++
C言語によるアルゴリズムとデータ構造
 Algorithms and Data Structures in C 4 algorithm List - /* */ #include List - int main(void) { int a, b, c; int max; /* */ Ÿ 3Ÿ 2Ÿ 3 printf(""); printf(""); printf(""); scanf("%d", &a); scanf("%d",
Algorithms and Data Structures in C 4 algorithm List - /* */ #include List - int main(void) { int a, b, c; int max; /* */ Ÿ 3Ÿ 2Ÿ 3 printf(""); printf(""); printf(""); scanf("%d", &a); scanf("%d",
main
 14 1. 12 5 main 1.23 3 1.230000 3 1.860867 1 2. 1988 1925 1911 1867 void JPcalendar(int x) 1987 1 64 1 1 1 while(1) Ctrl C void JPcalendar(int x){ if (x > 1988) printf(" %d %d \n", x, x-1988); else if(x
14 1. 12 5 main 1.23 3 1.230000 3 1.860867 1 2. 1988 1925 1911 1867 void JPcalendar(int x) 1987 1 64 1 1 1 while(1) Ctrl C void JPcalendar(int x){ if (x > 1988) printf(" %d %d \n", x, x-1988); else if(x