PowerPoint Presentation
|
|
|
- あかり ありの
- 5 years ago
- Views:
Transcription

1 インテル Xeon Phi プロセッサー ( 開発コード名 : Knights Landing) とインテル Distribution for Python* による高速化 エクセルソフト株式会社ソリューション事業部マネージャー黒澤一平
2 言語と環境について 対応言語 環境プロセスインテル ソフトウェア開発製品機能 C C++ Fortran 言語 コンパイル / リンク インテル Parallel Studio XE 全エディションに含まれるインテル C++ Fortran コンパイラー 最適化 性能解析インテル VTune Amplifier XE パフォーマンス問題解析 ベクトル化 並列化インテル Advisor 高速化アドバイス提供 MPI コンパイル / リンク インテル Parallel Studio XE 全エディションに含まれる インテル C++ Fortran コンパイラー + インテル MPI ライブラリー 最適化 性能解析インテル Trace Analyzer & Collector MPI パフォーマンス問題解析 ベクトル化 並列化インテル Advisor 高速化アドバイス提供 Python* 実行環境 インテル Distribution for Python* + インテル MKL + インテル コンパイラー (Cython) 最適化された Python* 実行環境 性能解析インテル VTune Amplifier XE パフォーマンス問題解析 Java* 性能解析インテル VTune Amplifier XE パフォーマンス問題解析 Hadoop*/Spark* 実行環境 インテル DAAL マシン / ディープラーニング用の 最適化された関数 Caffe 実行環境インテル MKL 最適化された関数 2
3 考慮するべき並列性 ベクトル化 コアの命令セットを利用 1 コアごとの性能向上 複数のデータ要素を同時に処理 (SIMD) スレッド並列化 複数コアを利用 1 プロセッサーの性能向上 複数タスクの同時実行 MPI 並列化 複数マシンを利用 複数のマシンを使用 複数プロセスの同時実行 3
 2012 インテル Xeon プロセッサー E5-2600 製品ファミリー ( 開発コード名 Sandy Bridge) 2013 インテル Xeon プロセッサー E5-2600 v2 製品ファミリー ( 開発コード名 Ivy Bridge) 2014 インテル Xeon プロセッサー E5-2600")
4 1 秒あたりの 2 項オプション SP ( 値が大きいほうが良い ) ベクトル化とマルチスレッド化 最適化の効果マルチスレッド化 + ベクトル化はより良い効果が得られる ベクトル化とスレッド化 179 倍 2007 インテル Xeon プロセッサー X5472 ( 開発コード名 Harpertown) 2009 インテル Xeon プロセッサー X5570 ( 開発コード名 Nehalem) 2010 インテル Xeon プロセッサー X5680 ( 開発コード名 Westmere) 2012 インテル Xeon プロセッサー E 製品ファミリー ( 開発コード名 Sandy Bridge) 2013 インテル Xeon プロセッサー E v2 製品ファミリー ( 開発コード名 Ivy Bridge) 2014 インテル Xeon プロセッサー E v3 製品ファミリー ( 開発コード名 Haswell) スレッド化ベクトル化シリアル 性能に関するテストに使用されるソフトウェアとワークロードは 性能がインテル マイクロプロセッサー用に最適化されていることがあります SYSmark* や MobileMark* などの性能テストは 特定のコンピューター システム コンポーネント ソフトウェア 操作 機能に基づいて行ったものです 結果はこれらの要因によって異なります 製品の購入を検討される場合は 他の製品と組み合わせた場合の本製品の性能など ほかの情報や性能テストも参考にして パフォーマンスを総合的に評価することをお勧めします 詳細については ( 英語 ) を参照してください 4

5 Common Instruction Set インテル AVX-512 対応コンパイラーオプションインテル Xeon Phi プロセッサー ( 開発コード名 : Knights Landing 以下 KNL ) と将来のインテル Xeon プロセッサーとの違い MPX,SHA, コンパイラー オプション ターゲット AVX-512VL -xmic-avx512 KNL のみ AVX-512PR AVX- 512BW -xcore-avx512 -xcommon-avx512 将来のインテル Xeon プロセッサーのみ KNL および将来のインテル Xeon プロセッサーのみ AVX2 AVX-512ER AVX- 512CD AVX-512F AVX2* AVX- 512DQ AVX-512CD AVX-512F AVX2 開発コード名 NHM: Nehalem SNB: Sandy Bridge HSW: Haswell KNL: Knights Landing SSE: インテル ストリーミング SIMD 拡張 ( インテル SSE) AVX: インテル アドバンスト ベクトル エクステンション ( インテル AVX) AVX2: インテル アドバンスト ベクトル エクステンション 2 ( インテル AVX2) AVX-512: インテル アドバンスト ベクトル エクステンション 512 ( インテル AVX-512) SSE* NHM AVX SSE* SNB AVX SSE* HSW AVX SSE* KNL AVX SSE* Future Intel Xeon Processor 5
 Intel64 (64bit) 15")
 AVX-512 (2014 KNL) 8 x 256bit 16 x 256bit 8 x 512bit 32")
6 0 インテル AVX-512 インテル AVX-512 インテル AVX2 インテル SSE YMM bytes XMM bytes Vector Registers IA32 (32bit) Intel64 (64bit) 15 SSE (1999) 8 x 128bit 16 x 128bit 31 ZMM bytes AVX and AVX-2 (2011 / 2013) AVX-512 (2014 KNL) 8 x 256bit 16 x 256bit 8 x 512bit 32 x 512bit 6
 コンパイラーへ伝える ベクトル化の判断 自動的に解釈 ベクトル化のヒントを解釈 SIMD 対応関数 SIMD プラグマ / ディレクティブ 最適化とコード生成インテル SSE ~ インテル AVX-512 出力 :")
7 ベクトル化におけるインテル コンパイラーの役割 ベクトル化可能な処理を自動的にベクトル化する新しい SIMD 命令セットへの対応の労力を最小限にする 入力 : ソースコード 汎用的なプログラミング方法 特定のアーキテクチャーへの依存度を小さくする プログラマーの意図を適切に ( かつ容易に ) コンパイラーへ伝える ベクトル化の判断 自動的に解釈 ベクトル化のヒントを解釈 SIMD 対応関数 SIMD プラグマ / ディレクティブ 最適化とコード生成インテル SSE ~ インテル AVX-512 出力 : バイナリー 7
8 インテル Distribution for Python* 8
9 インテル ソフトウェア開発製品の Python* 開発環境 インテル Distribution for Python* NumPy SciPy など インテル MKL Cython インテル コンパイラー Hadoop* インテル DAAL Spark* 性能解析 インテル VTune Amplifier XE 9
 Python* インテル Distribution for Python* Python* 実行時 numpy から呼ばれる ATLAS などの BLAS 関数 インテル Distribution for Python* 実行時 インテル MKL の BLAS 関数")
10 インテル Distribution for Python* 内のインテル MKL # Python* コード例 C = numpy.dot(a, B) Python* インテル Distribution for Python* Python* 実行時 numpy から呼ばれる ATLAS などの BLAS 関数 インテル Distribution for Python* 実行時 インテル MKL の BLAS 関数 対応関数が使用されると インテル Distribution for Python* は自動的にインテル MKL を呼び出します ソースコードを変更することなく より高速な演算を行うことができます 10
11 Performance (GFlops) Performance (GFlops) インテル MKL はインテル アーキテクチャーの性能を最大化 200 DGEMM Performance Boost by using Intel MKL vs. ATLAS* Intel Core Processor i7-4770k 1500 Intel Xeon Processor E v Matrix size (M = 10000, N = 6000, K = 64,80,96,, 384) Intel MKL - 1 thread Intel MKL - 2 threads Intel MKL - 4 threads ATLAS - 1 thread ATLAS - 2 threads ATLAS - 4 threads Matrix size (M = N) Intel MKL - 1 thread Intel MKL - 18 threads Intel MKL - 36 threads ATLAS - 1 thread ATLAS - 18 threads ATLAS - 36 threads Configuration Info - Versions: Intel Math Kernel Library (Intel MKL) 11.3, ATLAS* ; Hardware: Intel Xeon Processor E5-2699v3, 2 Eighteen-core CPUs (45MB LLC, 2.3GHz), 64GB of RAM; Intel Core Processor i7-4770k, Quad-core CPU (8MB LLC, 3.5GHz), 8GB of RAM; Operating System: RHEL 6.4 GA x86_64; Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. * Other brands and names are the property of their respective owners. Benchmark Source: Intel Corporation Optimization Notice: Intel s compilers may or may not optimize to the same degree for non-intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice revision #
12 インテル Distribution for Python* との比較 DBN-Kyoto ( $ time./run.sh < 略 > 2000x loading data Load Data set: dataset1.pkl Data set permutation Data purge invariance Data scaling Data shape after preprocessing: (248195, 1864)... building the model... getting the pretraining functions... pre-training the model The pretraining code for file DBN_benchmark.py ran for 0.00m... getting the finetuning functions... finetuning the model epoch 1, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:3 Time: epoch 2, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:4 Time: epoch 3, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:5 Time: epoch 4, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:6 Time: epoch 5, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:7 Time: epoch 6, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:8 Time: epoch 7, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:9 Time: epoch 8, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:10 Time: epoch 9, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:11 Time: epoch 10, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:12 Time: Optimization complete with best test performance % obtained at iteration The fine tuning code for file DBN_benchmark.py ran for m 通常の Python* real 712m21.525s user 1230m50.721s sys 178m34.818s 12
13 インテル Distribution for Python* との比較 DBN-Kyoto ( $ time./run.sh 2000x loading data Load Data set: dataset1.pkl Data set permutation Data purge invariance Data scaling Data shape after preprocessing: (248195, 1864)... building the model... getting the pretraining functions... pre-training the model The pretraining code for file DBN_benchmark.py ran for 0.00m... getting the finetuning functions... finetuning the model epoch 1, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:3 Time: epoch 2, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:4 Time: epoch 3, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:5 Time: epoch 4, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:6 Time: epoch 5, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:7 Time: epoch 6, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:8 Time: epoch 7, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:9 Time: epoch 8, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:10 Time: epoch 9, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:11 Time: epoch 10, minibatch 19855/19855, test error % Stat Layers:3 LayerSize:2000 BatchSize:10 PreTrainingLayer:12 Time: Optimization complete with best test performance % obtained at iteration The fine tuning code for file DBN_benchmark.py ran for m real 335m22.928s user 3821m14.855s sys 193m43.648s インテル Distribution for Python* さらに Cython + インテル コンパイラーを使用することでさらなる高速化 インテル Xeon プロセッサー E v2 製品ファミリー 2 CPU 32GB メモリー CentOS* 7.2 インテル Distribution for Python* 2017 Beta 13
14 インテル MKL (Math Kernel Library) インテル DAAL (Data Analytics Acceleration Library) 14
15 ディープ ニューラル ネットワーク (DNN) 人間の脳細胞を模倣した学習システム 深い階層の処理層において異なる演算を行う 従来の方式 従来のニューラル ネットワークでは判断基準を教える必要がある例 : 猫の画像を認識 人間が猫の特徴を教える DNN DNN ではコンピューター自身が判断基準を学習することができる例 : 猫の画像を認識 自動的に猫の特徴を学習 15
16 Caffe にインテル MKL の DNN を用いる Caffe: ディープ ラーニング フレームワーク Caffe のコンフィグファイルでインテル MKL を設定することで インテル MKL の数学関数を利用することができるようになります USE_MKL2017_AS_DEFAULT_ENGINE := 1 出典 : 16
")
17 インテル MKL の DNN 関数による Caffe の高速化 2 つの処理を高速化 ベクトル化と並列化により 学習スピードの最適化 特徴の分類スピードの最適化 インテル AVX2 以上の命令セットを有するプロセッサーをサポート ( 開発コード名 Haswell 以降 ) 17



18 インテル DAAL データ分析で行われるすべてのステージをカバー データソース ビジネス科学工学 Web/SNS すべてのステージに対して最適化されたアルゴリズムを提供 18
19 インテル DAAL の性能 さまざまなインテル プロセッサー向けに最適化済み 次世代プロセッサーへの移行を簡略化 対応プロセッサー - インテル Atom プロセッサー - インテル Core i3/i5/i7 プロセッサー ファミリー - インテル Xeon プロセッサー - インテル Xeon Phi プロセッサー ( 開発コード名 : Knights Landing) インテル DAAL の内部実装はインテル IPP とインテル MKL が提供する関数 19

20 インテル DAAL 対応言語と環境 Python* C++ Java* 言語に対応 Python* や Java* などのマネージドコード環境でも ネイティブコードの性能が得られます Python* C++ Java* ALGORITHMS ADVANCED DATA MINING MACHINE/DEEP LARNING SUMMARY STATISTICS インテル DAAL Spark Hadoop Cassandra Storm MPI Cluster インテル アーキテクチャーのプロセッサー 20
21 Speedup Computing Correlation Matrix Using Intel DAAL vs. KDB Computing correlation matrices using Intel DAAL with KDB data source X X K x K x 1000 Table size Configuration Info - Versions: Intel Data Analytics Acceleration Library 2017 Beta update 1, KDB+ version 3.3 (Parallel mode); Hardware: Intel Xeon Processor X5650, 2 Six-core CPUs (12MB LLC, 2.67GHz), 72GB of RAM; Operating System: RHEL 7.0 x86_64. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. * Other brands and names are the property of their respective owners. Benchmark Source: Intel Corporation Optimization Notice: Intel s compilers may or may not optimize to the same degree for non-intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice revision #
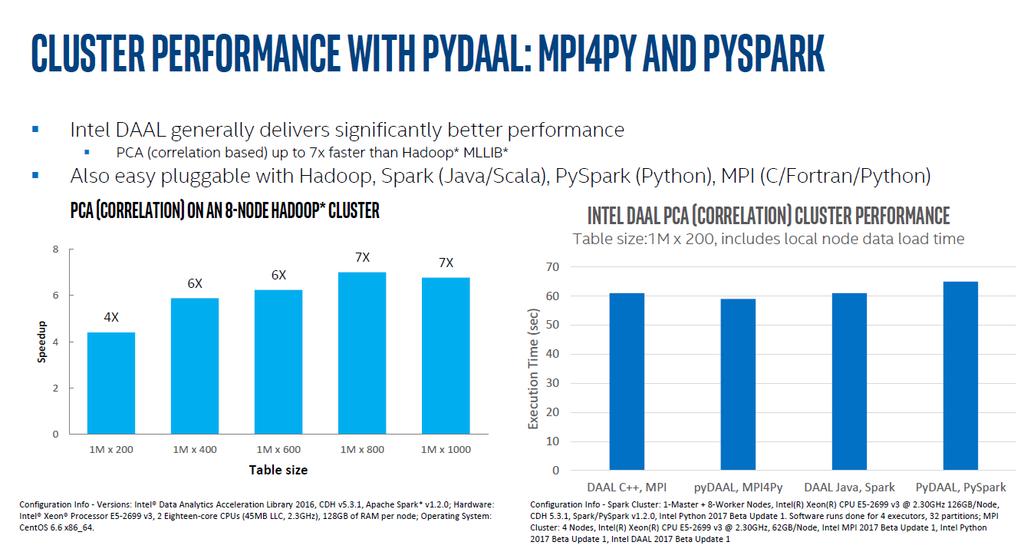
22 Speedup Computing PCA Using Intel DAAL vs. Spark* MLLib PCA (correlation method) on an 8-node Hadoop* cluster based on Intel Xeon Processors E v X 6X 7X 7X 4X M x 200 1M x 400 1M x 600 1M x 800 1M x 1000 Table size Configuration Info - Versions: Intel Data Analytics Acceleration Library 2016, CDH v5.3.1, Apache Spark* v1.2.0; Hardware: Intel Xeon Processor E v3, 2 Eighteen-core CPUs (45MB LLC, 2.3GHz), 128GB of RAM per node; Operating System: CentOS 6.6 x86_64. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. * Other brands and names are the property of their respective owners. Benchmark Source: Intel Corporation Optimization Notice: Intel s compilers may or may not optimize to the same degree for non-intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice revision #
23 23
24 ソースコードの近代化 24
25 ネイティブコードについて KNL に向けた準備 作業対応ツール実施内容 コンパイル / リンクインテル コンパイラーインテル Xeon プロセッベクトル化インテル コンパイラーサーの場合と同じようにコンインテル Advisor パイル 実装 解析することができます マルチスレッド化 ベクトル / マルチスレッド性能解析 MPI 性能解析 インテル コンパイラーインテル Advisor インテル Advisor インテル VTune Amplifier XE インテル Trace Analyzer & Collector ただし 512 ビットのベクトル化と 高並列性を目指す必要があります インテル ソフトウェア開発製品は初心者でも上級者に近い最適化を行えるようなさまざまな補助機能を提供します 開発コード名 25
26 ソフトウェア開発者が考慮するべき並列性 ベクトル化 コアの命令セットを利用 1 コアごとの性能向上 複数のデータ要素を同時に処理 (SIMD) スレッド並列化 複数コアを利用 1 プロセッサーの性能向上 複数タスクの同時実行 MPI 並列化 複数マシンを利用 複数のマシンを使用 複数プロセスの同時実行 26
27 1 秒あたりの 2 項オプション SP ( 値が大きいほうが良い ) ベクトル化とマルチスレッド化 最適化の効果マルチスレッド化 + ベクトル化はより良い効果が得られる ベクトル化とスレッド化 179 倍 2007 インテル Xeon プロセッサー X5472 ( 開発コード名 Harpertown) 2009 インテル Xeon プロセッサー X5570 ( 開発コード名 Nehalem) 2010 インテル Xeon プロセッサー X5680 ( 開発コード名 Westmere) 2012 インテル Xeon プロセッサー E 製品ファミリー ( 開発コード名 Sandy Bridge) 2013 インテル Xeon プロセッサー E v2 製品ファミリー ( 開発コード名 Ivy Bridge) 2014 インテル Xeon プロセッサー E v3 製品ファミリー ( 開発コード名 Haswell) スレッド化ベクトル化シリアル 性能に関するテストに使用されるソフトウェアとワークロードは 性能がインテル マイクロプロセッサー用に最適化されていることがあります SYSmark* や MobileMark* などの性能テストは 特定のコンピューター システム コンポーネント ソフトウェア 操作 機能に基づいて行ったものです 結果はこれらの要因によって異なります 製品の購入を検討される場合は 他の製品と組み合わせた場合の本製品の性能など ほかの情報や性能テストも参考にして パフォーマンスを総合的に評価することをお勧めします 詳細については ( 英語 ) を参照してください 27
28 メモリー帯域幅による制約 演算が並列化されると 帯域幅の利用率が高まる コアコアコアコア 処理自体の工夫も必要となる 処理 A 処理 B 処理 C メモリー上のデータ メモリー ループ (A, B, C) 例 : 複数処理のループをまとめて 処理間で再利用されるデータについてのメモリーアクセス回数を減らす 28
29 最適化例 インテル コンパイラー インテル VTune Amplifier XE インテル Advisor を用いて最適化を行います 依存関係の削除 メモリージャンプの削除 ベクトル化 マルチスレッド化 マイクロアーキテクチャー レベルの最適化 インテル ソフトウェア開発製品のアドバイス機能や解析結果を用いることで 初心者でも上級者のように 上級者はより早く最適化を行うことができるようになります 29


30 OpenMP* アドバイス機能 インテル VTune Amplifier XE の OpenMP* 解析機能を使用することで OpenMP* を用いたマルチスレッド化のパフォーマンス問題と 改善点を確認することができ 修正した場合のパフォーマンスの向上度合いが表示されます 30


31 HPC 向けの新しい解析タイプ HPC Performance Characterization Analysis は HPC 分野で有用な情報である GFLOPs や 関数 / ループごとの CPU 使用率や CPU 使用効率 メモリー / キャッシュに関する情報 1 サイクルあたりの FLOPs ベクトル化状況を確認することができます 31
32 インテル AVX-512 向けの最適化 インテル Xeon Phi プロセッサー ( 開発コード名 : Knights Landing) を始めに 今後多くのインテル AVX-512 命令セットをサポートするプロセッサーがリリースされていきます 今日 コードの近代化を行うことでインテル AVX-512 命令セットや多くのコアが搭載されたプロセッサー向けの 将来にも有効な最適化を行うことができます 必要な作業はベクトル化 + マルチスレッド化 32
33 高速なコードを素早く開発 : インテル Advisor 最新プロセッサーで性能を出すためにはベクトル化とマルチスレッド化が必須 ベクトル化でおきる問題 : インテル AVX-512 を使用したのに速くならない そもそもどこをベクトル化すれば良い? 最新プロセッサー用の組込み関数を使用する必要がある? コンパイラーのベクトル化レポートのどこを見れば良い? マルチスレッド化でおきる問題 : マルチスレッド化したけれど速くならない スレッド数を増やしたら性能劣化する マルチスレッド化に時間がかかってしまう これらの問題 疑問をインテル Advisor が解決 33
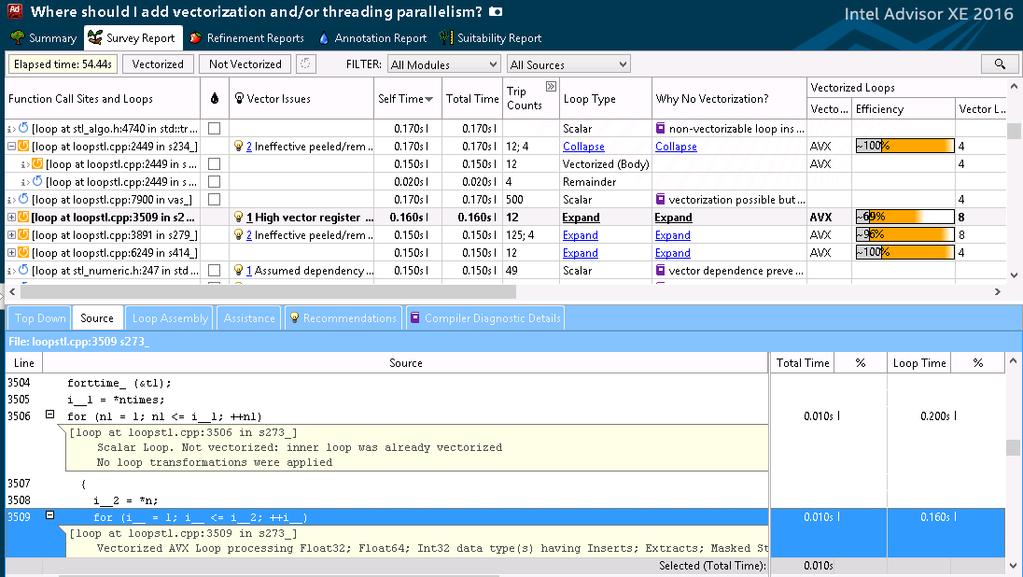
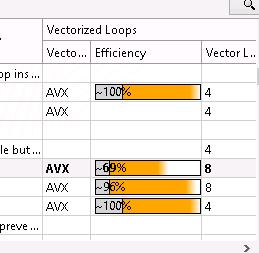
34 ベクトル化したコードの効率性をインテル Advisor で評価 34


35 インテル Advisor によるアドバイス機能 エイリアスによる依存関係の可能性がベクトル化を妨げている場合 インテル Advisor は修正案を提供します ここでは #pragma simd や #pragma ivdep の使用を提案されました 35
36 法務上の注意書きと最適化に関する注意事項 本資料の情報は 現状のまま提供され 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスも許諾するものではありません 製品に付属の売買契約書 Intel's Terms and Conditions of Sale に規定されている場合を除き インテルはいかなる責任を負うものではなく またインテル製品の販売や使用に関する明示または黙示の保証 ( 特定目的への適合性 商品性に関する保証 第三者の特許権 著作権 その他 知的財産権の侵害への保証を含む ) をするものではありません 性能に関するテストに使用されるソフトウェアとワークロードは 性能がインテル マイクロプロセッサー用に最適化されていることがあります SYSmark* や MobileMark* などの性能テストは 特定のコンピューター システム コンポーネント ソフトウェア 操作 機能に基づいて行ったものです 結果はこれらの要因によって異なります 製品の購入を検討される場合は 他の製品と組み合わせた場合の本製品の性能など ほかの情報や性能テストも参考にして パフォーマンスを総合的に評価することをお勧めします 2016 Intel Corporation. 無断での引用 転載を禁じます Intel インテル Intel ロゴ Intel Core Intel Atom Xeon Intel Xeon Phi VTune は アメリカ合衆国および / またはその他の国における Intel Corporation の商標です * その他の社名 製品名などは 一般に各社の商標または登録商標です 最適化に関する注意事項 インテル コンパイラーでは インテル マイクロプロセッサーに限定されない最適化に関して 他社製マイクロプロセッサー用に同等の最適化を行えないことがあります これには インテル ストリーミング SIMD 拡張命令 2 インテル ストリーミング SIMD 拡張命令 3 インテル ストリーミング SIMD 拡張命令 3 補足命令などの最適化が該当します インテルは 他社製マイクロプロセッサーに関して いかなる最適化の利用 機能 または効果も保証いたしません 本製品のマイクロプロセッサー依存の最適化は インテル マイクロプロセッサーでの使用を前提としています インテル マイクロアーキテクチャーに限定されない最適化のなかにも インテル マイクロプロセッサー用のものがあります この注意事項で言及した命令セットの詳細については 該当する製品のユーザー リファレンス ガイドを参照してください 注意事項の改訂 #
37 補足資料 : 2 項オプション SP のシステム構成 システム構成 最適化に関する注意事項インテル コンパイラーでは インテル マイクロプロセッサーに限定されない最適化に関して 他社製マイクロプロセッサー用に同等の最適化を行えないことがあります これには インテル ストリーミング SIMD 拡張命令 2 インテル ストリーミング SIMD 拡張命令 3 インテル ストリーミング SIMD 拡張命令 3 補足命令などの最適化が該当します インテルは 他社製マイクロプロセッサーに関して いかなる最適化の利用 機能 または効果も保証いたしません 本製品のマイクロプロセッサー依存の最適化は インテル マイクロプロセッサーでの使用を前提としています インテル マイクロアーキテクチャーに限定されない最適化のなかにも インテル マイクロプロセッサー用のものがあります この注意事項で言及した命令セットの詳細については 該当する製品のユーザー リファレンス ガイドを参照してください 注意事項の改訂 # インテル社内での測定値 スケーリング されていないコアクロックの コア / ソケット L1 データ L1 命令 L2 L3 H/W メモリーメモリープリフェッチ HT ターボ C コンパイラー プラットフォーム 周波数 ソケット 数 キャッシュキャッシュキャッシュキャッシュメモリー 周波数 アクセス 有効 有効 有効 ステート OS カーネル バージョン インテル Xeon Fedora* プロセッサー GHz K 32K 12MB なし 32GB 800MHz UMA Y N N 無効 fc20 icc インテル Xeon プロセッサー X GHz K 32K 256K 8MB 48GB 1333MHz NUMA Y Y Y 無効 Fedora* fc20 icc インテル Xeon プロセッサー X GHz K 32K 256K 12MB 48MB 1333MHz NUMA Y Y Y 無効 Fedora* fc20 icc インテル Xeon プロセッサー E 製品ファミリー 2.90GHz K 32K 256K 20MB 64GB 1600MHz NUMA Y Y Y 無効 Fedora* fc20 icc インテル Xeon プロセッサー E v2 製品ファミリー 2.70GHz K 32K 256K 30MB 64GB 1867MHz NUMA Y Y Y 無効 Fedora* fc20 icc 開発コード名 Haswell 2.20GHz K 32K 256K 35MB 64GB 2133MHz NUMA Y Y Y 無効 Fedora* fc20 icc

38
PowerPoint Presentation
 インテル ソフトウェア開発製品によるソースコードの近代化 エクセルソフト株式会社黒澤一平 ソースコードの近代化 インテル Xeon Phi プロセッサーや 将来のインテル Xeon プロセッサー上での実行に向けた準備と適用 インテル ソフトウェア製品 名称インテル Composer XE for Fortran and C++ インテル VTune Amplifier XE インテル Advisor
インテル ソフトウェア開発製品によるソースコードの近代化 エクセルソフト株式会社黒澤一平 ソースコードの近代化 インテル Xeon Phi プロセッサーや 将来のインテル Xeon プロセッサー上での実行に向けた準備と適用 インテル ソフトウェア製品 名称インテル Composer XE for Fortran and C++ インテル VTune Amplifier XE インテル Advisor
Product Brief 高速なコードを素早く開発 インテル Parallel Studio XE 2017 インテル ソフトウェア開発ツール 概要 高速なコード : 現在および次世代のプロセッサーでスケーリングする優れたアプリケーション パフォーマンスを実現します 迅速に開発 : 高速かつ安定し
 Product Brief 高速なコードを素早く開発 インテル Parallel Studio XE 2017 インテル ソフトウェア開発ツール 概要 高速なコード : 現在および次世代のプロセッサーでスケーリングする優れたアプリケーション パフォーマンスを実現します 迅速に開発 : 高速かつ安定した並列コードの作成を簡略化するツールセットです : 最先端のコンパイラー ライブラリー 並列モデル インテル
Product Brief 高速なコードを素早く開発 インテル Parallel Studio XE 2017 インテル ソフトウェア開発ツール 概要 高速なコード : 現在および次世代のプロセッサーでスケーリングする優れたアプリケーション パフォーマンスを実現します 迅速に開発 : 高速かつ安定した並列コードの作成を簡略化するツールセットです : 最先端のコンパイラー ライブラリー 並列モデル インテル
インテル® Parallel Studio XE 2013 Linux* 版インストール・ガイドおよびリリースノート
 インテル Parallel Studio XE 2013 Linux* 版インストール ガイドおよびリリースノート 資料番号 : 323804-003JA 2012 年 7 月 30 日 目次 1 概要... 2 1.1 新機能... 2 1.1.1 インテル Parallel Studio XE 2011 からの変更点... 2 1.2 製品の内容... 2 1.3 動作環境... 2 1.4 ドキュメント...
インテル Parallel Studio XE 2013 Linux* 版インストール ガイドおよびリリースノート 資料番号 : 323804-003JA 2012 年 7 月 30 日 目次 1 概要... 2 1.1 新機能... 2 1.1.1 インテル Parallel Studio XE 2011 からの変更点... 2 1.2 製品の内容... 2 1.3 動作環境... 2 1.4 ドキュメント...
インテル® Parallel Studio XE 2013 Windows* 版インストール・ガイドおよびリリースノート
 インテル Parallel Studio XE 2013 Windows* 版インストール ガイドおよびリリースノート 資料番号 : 323803-003JA 2012 年 8 月 8 日 目次 1 概要... 2 1.1 新機能... 2 1.1.1 インテル Parallel Studio XE 2011 からの変更点... 2 1.2 製品の内容... 2 1.3 動作環境... 2 1.4
インテル Parallel Studio XE 2013 Windows* 版インストール ガイドおよびリリースノート 資料番号 : 323803-003JA 2012 年 8 月 8 日 目次 1 概要... 2 1.1 新機能... 2 1.1.1 インテル Parallel Studio XE 2011 からの変更点... 2 1.2 製品の内容... 2 1.3 動作環境... 2 1.4
インテル® Parallel Studio XE 2015 Composer Edition for Linux* インストール・ガイドおよびリリースノート
 インテル Parallel Studio XE 2015 Composer Edition for Linux* インストール ガイドおよびリリースノート 2014 年 10 月 14 日 目次 1 概要... 1 1.1 製品の内容... 2 1.2 インテル デバッガー (IDB) を削除... 2 1.3 動作環境... 2 1.3.1 SuSE Enterprise Linux 10* のサポートを終了...
インテル Parallel Studio XE 2015 Composer Edition for Linux* インストール ガイドおよびリリースノート 2014 年 10 月 14 日 目次 1 概要... 1 1.1 製品の内容... 2 1.2 インテル デバッガー (IDB) を削除... 2 1.3 動作環境... 2 1.3.1 SuSE Enterprise Linux 10* のサポートを終了...
Click to edit title
 インテル VTune Amplifier 2018 を 使用した最適化手法 ( 初級編 ) 久保寺 陽子 内容 アプリケーション最適化のプロセス インテル VTune Amplifier の紹介 インテル VTune Amplifier の新機能 インテル VTune Amplifier を用いた最適化例 (1) インテル VTune Amplifier を用いた最適化例 (2) まとめ 2 インテル
インテル VTune Amplifier 2018 を 使用した最適化手法 ( 初級編 ) 久保寺 陽子 内容 アプリケーション最適化のプロセス インテル VTune Amplifier の紹介 インテル VTune Amplifier の新機能 インテル VTune Amplifier を用いた最適化例 (1) インテル VTune Amplifier を用いた最適化例 (2) まとめ 2 インテル
インテル® Fortran Studio XE 2011 SP1 Windows* 版インストール・ガイドおよびリリースノート
 インテル Fortran Studio XE 2011 SP1 Windows* 版インストール ガイドおよびリリースノート 資料番号 : 325583-001JA 2011 年 8 月 5 日 目次 1 概要... 1 1.1 新機能... 2 1.2 製品の内容... 2 1.3 動作環境... 2 1.3.1 Microsoft* Visual Studio* 2005 のサポート終了予定...
インテル Fortran Studio XE 2011 SP1 Windows* 版インストール ガイドおよびリリースノート 資料番号 : 325583-001JA 2011 年 8 月 5 日 目次 1 概要... 1 1.1 新機能... 2 1.2 製品の内容... 2 1.3 動作環境... 2 1.3.1 Microsoft* Visual Studio* 2005 のサポート終了予定...
Click to edit title
 コードの現代化と最適化 ソフトウェアの最適化において注目すべきこと 2019 年 4 月 isus 編集部すがわらきよふみ 目的 ソフトウェア開発時の最適化において注目すべき点を理解します ソフトウェアの要件を理解します ソフトウェアに影響するハードウェアの機能を評価します 2 盲目の男たちと象 ヒィンドスタンに 盲目の 6 人の男たちがいました 学ぼうという気持ちが強く 象を見に出かけました 全員
コードの現代化と最適化 ソフトウェアの最適化において注目すべきこと 2019 年 4 月 isus 編集部すがわらきよふみ 目的 ソフトウェア開発時の最適化において注目すべき点を理解します ソフトウェアの要件を理解します ソフトウェアに影響するハードウェアの機能を評価します 2 盲目の男たちと象 ヒィンドスタンに 盲目の 6 人の男たちがいました 学ぼうという気持ちが強く 象を見に出かけました 全員
PowerPoint Presentation
 2016 年 11 月 マシンラーニング ソフトウェアの課題 オープンソースのマシンラーニング フレームワークやライブラリーは最新のインテル アーキテクチャー ベースのシステム向けに最適化されていないことがある フレームワークは設定および利用が困難 データセンターでのモデルの訓練からエンドポイント システムの配備までヘテロジニアス ハードウェアをターゲットにする必要がある データセンター エンドポイント
2016 年 11 月 マシンラーニング ソフトウェアの課題 オープンソースのマシンラーニング フレームワークやライブラリーは最新のインテル アーキテクチャー ベースのシステム向けに最適化されていないことがある フレームワークは設定および利用が困難 データセンターでのモデルの訓練からエンドポイント システムの配備までヘテロジニアス ハードウェアをターゲットにする必要がある データセンター エンドポイント
インテル® Parallel Studio XE 2019 Composer Edition for Fortran Windows : インストール・ガイド
 インテル Parallel Studio XE 2019 Composer Edition for Fortran Windows インストール ガイド エクセルソフト株式会社 Version 1.0.0-20180918 目次 1. はじめに....................................................................................
インテル Parallel Studio XE 2019 Composer Edition for Fortran Windows インストール ガイド エクセルソフト株式会社 Version 1.0.0-20180918 目次 1. はじめに....................................................................................
Intel_ParallelStudioXE2013_ClusterStudioXE2013_Introduction.pptx
 Parallel Studio XE 2013 Cluster Studio XE 2013 ) ( Intel s Terms and Conditions of Sale Sandy Bridge SYSmark MobileMark http://www.intel.com/performance/ Intel Intel Intel Atom Intel Core Intel Xeon Phi
Parallel Studio XE 2013 Cluster Studio XE 2013 ) ( Intel s Terms and Conditions of Sale Sandy Bridge SYSmark MobileMark http://www.intel.com/performance/ Intel Intel Intel Atom Intel Core Intel Xeon Phi
インテル® VTune™ Amplifier XE を使用したストレージ向けの パフォーマンス最適化
 インテル VTune Amplifier XE を使用したストレージ向けのパフォーマンス最適化 2016 年 10 月 12 日 Day2 トラック D-2 (14:55 15:40) すがわらきよふみ isus 編集長 本日の内容 インテル VTune Amplifier XE 2017 概要 ストレージ解析向けのインテル VTune Amplifier XE の新機能 メモリー解析向けのインテル
インテル VTune Amplifier XE を使用したストレージ向けのパフォーマンス最適化 2016 年 10 月 12 日 Day2 トラック D-2 (14:55 15:40) すがわらきよふみ isus 編集長 本日の内容 インテル VTune Amplifier XE 2017 概要 ストレージ解析向けのインテル VTune Amplifier XE の新機能 メモリー解析向けのインテル
インテル® Parallel Studio XE 2019 Composer Edition for Fortran Windows 日本語版 : インストール・ガイド
 インテル Parallel Studio XE 2019 Composer Edition for Fortran Windows 日本語版インストール ガイド エクセルソフト株式会社 Version 2.1.0-20190405 目次 1. はじめに.................................................................................
インテル Parallel Studio XE 2019 Composer Edition for Fortran Windows 日本語版インストール ガイド エクセルソフト株式会社 Version 2.1.0-20190405 目次 1. はじめに.................................................................................
Mission Statement
 インテルのグリーンIT への 取 り 組 み インテル 株 式 会 社 マーケティング 本 部 田 口 栄 治 2011 年 7 月 1 2010 Intel Corporation. 無 断 での 引 用 転 載 を 禁 じます エネルギー 効 率 化 へのアプローチ プロセッサー プラットフォーム データーセンター 業 界 のリーダーシップ 包 括 的 な 取 り 組 み 2 Intel インテル
インテルのグリーンIT への 取 り 組 み インテル 株 式 会 社 マーケティング 本 部 田 口 栄 治 2011 年 7 月 1 2010 Intel Corporation. 無 断 での 引 用 転 載 を 禁 じます エネルギー 効 率 化 へのアプローチ プロセッサー プラットフォーム データーセンター 業 界 のリーダーシップ 包 括 的 な 取 り 組 み 2 Intel インテル
議題 プロセッサーの動向とコード モダナイゼーション インテル アドバンスト ベクトル エクステンション 512 ( インテル AVX-512) 命令と演算性能 ベクトル化を支援するインテル Advisor ループの性能を可視化するルーフライン表示 姫野ベンチマークを用いたインテル Xeon Phi
 命令と演算性能 ベクトル化を支援するインテル Advisor ループの性能を可視化するルーフライン表示 姫野ベンチマークを用いたインテル Xeon Phi") 最新のインテル Parallel Studio XE を用いた迅速なベクトル化と並列化手法 インテル株式会社 技術本部ソフトウェア技術統括部 シニア スタッフ エンジニア 池井 満 議題 プロセッサーの動向とコード モダナイゼーション インテル アドバンスト ベクトル エクステンション 512 ( インテル AVX-512) 命令と演算性能 ベクトル化を支援するインテル Advisor ループの性能を可視化するルーフライン表示
最新のインテル Parallel Studio XE を用いた迅速なベクトル化と並列化手法 インテル株式会社 技術本部ソフトウェア技術統括部 シニア スタッフ エンジニア 池井 満 議題 プロセッサーの動向とコード モダナイゼーション インテル アドバンスト ベクトル エクステンション 512 ( インテル AVX-512) 命令と演算性能 ベクトル化を支援するインテル Advisor ループの性能を可視化するルーフライン表示
CPU Levels in the memory hierarchy Level 1 Level 2... Increasing distance from the CPU in access time Level n Size of the memory at each level 1: 2.2
 FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
目次 1 はじめに 製品に含まれるコンポーネント 動作環境... 4 オペレーティング システム... 4 Microsoft Visual Studio* 製品 製品のダウンロード 製品版をインストールする場合 評価版を
 インテル Parallel Studio XE 2018 Composer Edition for Fortran Windows* インストール ガイド Rev. 2. 0 (2017/11/22) エクセルソフト株式会社 www.xlsoft.com 目次 1 はじめに... 3 2 製品に含まれるコンポーネント... 3 3 動作環境... 4 オペレーティング システム... 4 Microsoft
インテル Parallel Studio XE 2018 Composer Edition for Fortran Windows* インストール ガイド Rev. 2. 0 (2017/11/22) エクセルソフト株式会社 www.xlsoft.com 目次 1 はじめに... 3 2 製品に含まれるコンポーネント... 3 3 動作環境... 4 オペレーティング システム... 4 Microsoft
(速報) Xeon E 系モデル 新プロセッサ性能について
 Xeon E 系モデル 新プロセッサ性能について") ( 速報 ) Xeon E5-2600 系モデル新プロセッサ性能について 2012 年 3 月 16 日 富士通株式会社 2012 年 3 月 7 日 インテル社より最新 CPU インテル Xeon E5 ファミリー の発表がありました この最新 CPU について PC クラスタシステムの観点から性能検証を行いましたので 概要を速報いたします プロセッサインテル Xeon プロセッサ E5-2690
( 速報 ) Xeon E5-2600 系モデル新プロセッサ性能について 2012 年 3 月 16 日 富士通株式会社 2012 年 3 月 7 日 インテル社より最新 CPU インテル Xeon E5 ファミリー の発表がありました この最新 CPU について PC クラスタシステムの観点から性能検証を行いましたので 概要を速報いたします プロセッサインテル Xeon プロセッサ E5-2690
Microsoft* Windows* 10 における新しい命令セットの利用
 Microsoft* Windows* 10 における新しい命令セットの利用 この記事は インテル デベロッパー ゾーンに公開されている Follow-Up: How does Microsoft Windows 10 Use New Instruction Sets? の日本語参考訳です 以前のブログ ソフトウェアは実際に新しい命令セットを使用しているのか? ( 英語 ) では いくつかの異なる
Microsoft* Windows* 10 における新しい命令セットの利用 この記事は インテル デベロッパー ゾーンに公開されている Follow-Up: How does Microsoft Windows 10 Use New Instruction Sets? の日本語参考訳です 以前のブログ ソフトウェアは実際に新しい命令セットを使用しているのか? ( 英語 ) では いくつかの異なる
インテル® Xeon Phi™ プロセッサー上で MPI for Python* (mpi4py) を使用する
 を使用する") インテル Xeon Phi プロセッサー上で MPI for Python* (mpi4py) を使用する この記事は インテル デベロッパー ゾーンに公開されている Exploring MPI for Python* on Intel Xeon Phi Processor の日本語参考訳です はじめに メッセージ パッシング インターフェイス (MPI) ( 英語 ) は 分散メモリー プログラミング向けに標準化されたメッセージ
インテル Xeon Phi プロセッサー上で MPI for Python* (mpi4py) を使用する この記事は インテル デベロッパー ゾーンに公開されている Exploring MPI for Python* on Intel Xeon Phi Processor の日本語参考訳です はじめに メッセージ パッシング インターフェイス (MPI) ( 英語 ) は 分散メモリー プログラミング向けに標準化されたメッセージ
スレッド化されていないアプリケーションでも大幅なパフォーマンス向上を容易に実現
 はじめに 本ガイドは インテル Parallel Studio XE を使用してアプリケーション中の hotspot ( 多くの時間を費やしているコード領域 ) を見つけ それらの領域を再コンパイルすることでアプリケーション全体のパフォーマンスを向上する方法について説明します 1 つのファイルを再コンパイルするだけで違いが出るのでしょうか? はい 多くの場合 インテル Parallel Studio
はじめに 本ガイドは インテル Parallel Studio XE を使用してアプリケーション中の hotspot ( 多くの時間を費やしているコード領域 ) を見つけ それらの領域を再コンパイルすることでアプリケーション全体のパフォーマンスを向上する方法について説明します 1 つのファイルを再コンパイルするだけで違いが出るのでしょうか? はい 多くの場合 インテル Parallel Studio
インテル C++ および Fortran コンパイラー for Linux*/OS X*/Windows
 および Fortran コンパイラー for Linux*/OS X*/Windows インテル Parallel Studio XE の主要コンポーネント ソフトウェア開発者にとって重要なポイント課題インテル コンパイラーの利点 パフォーマンス高速なアプリケーションを開発する必要がある 最新のハードウェア イノベーションを利用しなければならない 最新の x86 互換プロセッサーと命令セットを最大限に利用できる
および Fortran コンパイラー for Linux*/OS X*/Windows インテル Parallel Studio XE の主要コンポーネント ソフトウェア開発者にとって重要なポイント課題インテル コンパイラーの利点 パフォーマンス高速なアプリケーションを開発する必要がある 最新のハードウェア イノベーションを利用しなければならない 最新の x86 互換プロセッサーと命令セットを最大限に利用できる
Intel Software Presentation Template
 最新のヘテロジニアス システムにおけるビデオ解析環境 久保寺陽子 Internet of things Internet of things (IOT) は生活へ浸透 接続しているデバイスの数は急増 良く利用されるデバイスセンサーはカメラ データは爆発的に増加しているが 少ししか利用されていない 一般には 従来通りのそれぞれのやり方で使用 人間がすべてを網羅するのは無理 より賢い自動システムを構築する必要がある
最新のヘテロジニアス システムにおけるビデオ解析環境 久保寺陽子 Internet of things Internet of things (IOT) は生活へ浸透 接続しているデバイスの数は急増 良く利用されるデバイスセンサーはカメラ データは爆発的に増加しているが 少ししか利用されていない 一般には 従来通りのそれぞれのやり方で使用 人間がすべてを網羅するのは無理 より賢い自動システムを構築する必要がある
Microsoft PowerPoint - Intel Parallel Studio XE 2019 for Live
 HPC エンタープライズ クラウド アプリケーションを高速化 インテル Parallel Studio XE のコンポーネント包括的なソフトウェア開発ツールスイート Composer Edition ビルドコンパイラーとライブラリー Professional Edition 解析解析ツール Cluster Edition スケールクラスターツール インテル C/C++ コンパイラー最適化コンパイラー
HPC エンタープライズ クラウド アプリケーションを高速化 インテル Parallel Studio XE のコンポーネント包括的なソフトウェア開発ツールスイート Composer Edition ビルドコンパイラーとライブラリー Professional Edition 解析解析ツール Cluster Edition スケールクラスターツール インテル C/C++ コンパイラー最適化コンパイラー
内容 インテル Advisor ベクトル化アドバイザー入門ガイド Version インテル Advisor の利用 ワークフロー... 3 STEP1. 必要条件の設定... 4 STEP2. インテル Advisor の起動... 5 STEP3. プロジェクトの作成
 内容 インテル Advisor ベクトル化アドバイザー入門ガイド Version 1.0 1. インテル Advisor の利用... 2 2. ワークフロー... 3 STEP1. 必要条件の設定... 4 STEP2. インテル Advisor の起動... 5 STEP3. プロジェクトの作成と設定... 7 STEP4. ベクトル化に関する情報を取得する... 9 STEP5. ループ処理の詳細を取得する...
内容 インテル Advisor ベクトル化アドバイザー入門ガイド Version 1.0 1. インテル Advisor の利用... 2 2. ワークフロー... 3 STEP1. 必要条件の設定... 4 STEP2. インテル Advisor の起動... 5 STEP3. プロジェクトの作成と設定... 7 STEP4. ベクトル化に関する情報を取得する... 9 STEP5. ループ処理の詳細を取得する...
インテル Parallel Studio XE 2017 Composer Edition for Fortran Windows* インストール ガイド Rev (2017/06/08) エクセルソフト株式会社
 エクセルソフト株式会社") インテル Parallel Studio XE 2017 Composer Edition for Fortran Windows* インストール ガイド Rev. 2. 1 (2017/06/08) エクセルソフト株式会社 www.xlsoft.com 目次 1 はじめに... 3 2 製品に含まれるコンポーネント... 3 3 動作環境... 4 オペレーティング システム... 4 Microsoft
インテル Parallel Studio XE 2017 Composer Edition for Fortran Windows* インストール ガイド Rev. 2. 1 (2017/06/08) エクセルソフト株式会社 www.xlsoft.com 目次 1 はじめに... 3 2 製品に含まれるコンポーネント... 3 3 動作環境... 4 オペレーティング システム... 4 Microsoft
Parallel Studio XE Parallel Studio XE hotspot ( )
") Parallel Studio XE Parallel Studio XE hotspot ( ) 1 つのファイルを再コンパイルするだけで違いが出るのでしょうか? はい 多くの場合 Parallel Studio XE の最適化コンパイラーを使用して 1 つのファイルを再コンパイルするだけでパフォーマンスが大幅に向上します 必ずしもアプリケーション全体を再コンパイルする必要はありません これは シリアル
Parallel Studio XE Parallel Studio XE hotspot ( ) 1 つのファイルを再コンパイルするだけで違いが出るのでしょうか? はい 多くの場合 Parallel Studio XE の最適化コンパイラーを使用して 1 つのファイルを再コンパイルするだけでパフォーマンスが大幅に向上します 必ずしもアプリケーション全体を再コンパイルする必要はありません これは シリアル
ベース0516.indd
 QlikView QlikView 2012 2 qlikview.com Business Discovery QlikTech QlikView QlikView QlikView QlikView 1 QlikView Server QlikTech QlikView Scaling Up vs. Scaling Out in a QlikView Environment 2 QlikView
QlikView QlikView 2012 2 qlikview.com Business Discovery QlikTech QlikView QlikView QlikView QlikView 1 QlikView Server QlikTech QlikView Scaling Up vs. Scaling Out in a QlikView Environment 2 QlikView
Microsoft Word - HOKUSAI_system_overview_ja.docx
 HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
インテル(R) Visual Fortran Composer XE
 Visual Fortran Composer XE") Visual Fortran Composer XE 1. 2. 3. 4. 5. Visual Studio 6. Visual Studio 7. 8. Compaq Visual Fortran 9. Visual Studio 10. 2 https://registrationcenter.intel.com/regcenter/ w_fcompxe_all_jp_2013_sp1.1.139.exe
Visual Fortran Composer XE 1. 2. 3. 4. 5. Visual Studio 6. Visual Studio 7. 8. Compaq Visual Fortran 9. Visual Studio 10. 2 https://registrationcenter.intel.com/regcenter/ w_fcompxe_all_jp_2013_sp1.1.139.exe
appli_HPhi_install
 2018/3/7 HΦ version 3.0.0 インストール手順書 (Linux 64 ビット版 ) 目次 1. アプリケーション概要...- 1-2. システム環境...- 1-3. 必要なツール ライブラリのインストール...- 1-1 cmake...- 2-2 numpy...- 3-4. アプリケーションのインストール...- 4-5. 動作確認の実施...- 5 - 本手順書は HΦ
2018/3/7 HΦ version 3.0.0 インストール手順書 (Linux 64 ビット版 ) 目次 1. アプリケーション概要...- 1-2. システム環境...- 1-3. 必要なツール ライブラリのインストール...- 1-1 cmake...- 2-2 numpy...- 3-4. アプリケーションのインストール...- 4-5. 動作確認の実施...- 5 - 本手順書は HΦ
VXPRO R1400® ご提案資料
 Intel Core i7 プロセッサ 920 Preliminary Performance Report ノード性能評価 ノード性能の評価 NAS Parallel Benchmark Class B OpenMP 版での性能評価 実行スレッド数を 4 で固定 ( デュアルソケットでは各プロセッサに 2 スレッド ) 全て 2.66GHz のコアとなるため コアあたりのピーク性能は同じ 評価システム
Intel Core i7 プロセッサ 920 Preliminary Performance Report ノード性能評価 ノード性能の評価 NAS Parallel Benchmark Class B OpenMP 版での性能評価 実行スレッド数を 4 で固定 ( デュアルソケットでは各プロセッサに 2 スレッド ) 全て 2.66GHz のコアとなるため コアあたりのピーク性能は同じ 評価システム
Microsoft PowerPoint Quality-sama_Seminar.pptx
 インテル vpro テクノロジー ~ 革新と継続的な進化 ~ インテル株式会社マーケティング本部 2010 年 11 月 2010年の新プロセッサー: 更なるパフォーマンスを スマート に実現 ユーザーのワークロードに合わせて プロセッサーの周波数を動的に向上 インテル インテル ターボ ブースト テクノロジー* ターボ ブースト テクノロジー* 暗号化処理を高速化 保護する 新しいプロセッサー命令
インテル vpro テクノロジー ~ 革新と継続的な進化 ~ インテル株式会社マーケティング本部 2010 年 11 月 2010年の新プロセッサー: 更なるパフォーマンスを スマート に実現 ユーザーのワークロードに合わせて プロセッサーの周波数を動的に向上 インテル インテル ターボ ブースト テクノロジー* ターボ ブースト テクノロジー* 暗号化処理を高速化 保護する 新しいプロセッサー命令
高速なコードを素早く開発 インテル Parallel Studio XE 設計 ビルド 検証 チューニング C++ C Fortran Python* Java* 標準規格に基づく並列モデル : OpenMP* MPI インテル TBB バージョン 2017 の主な機能 インテル Distribut
 高速なコードを 素早く開発 インテル Parallel Studio XE 2017 インテル株式会社ソフトウェア技術統括部池井満 パフォーマンスを最大限に引き出そう 高速なコードを素早く開発 インテル Parallel Studio XE 設計 ビルド 検証 チューニング C++ C Fortran Python* Java* 標準規格に基づく並列モデル : OpenMP* MPI インテル TBB
高速なコードを 素早く開発 インテル Parallel Studio XE 2017 インテル株式会社ソフトウェア技術統括部池井満 パフォーマンスを最大限に引き出そう 高速なコードを素早く開発 インテル Parallel Studio XE 設計 ビルド 検証 チューニング C++ C Fortran Python* Java* 標準規格に基づく並列モデル : OpenMP* MPI インテル TBB
高速なコードを 素早く開発 インテル Parallel Studio XE 2017 最適化に関する注意事項 2016 Intel Corporation. 無断での引用 転載を禁じます * その他の社名 製品名などは 一般に各社の表示 商標または登録商標です パフォーマンスを最大限に引き出そう
 高速なコードを 素早く開発 インテル Parallel Studio XE 2017 パフォーマンスを最大限に引き出そう 高速なコードを素早く開発 インテル Parallel Studio XE 設計 ビルド 検証 チューニング C++ C Fortran Python* Java* 標準規格に基づく並列モデル : OpenMP* MPI インテル TBB バージョン 2017 の主な機能 インテル
高速なコードを 素早く開発 インテル Parallel Studio XE 2017 パフォーマンスを最大限に引き出そう 高速なコードを素早く開発 インテル Parallel Studio XE 設計 ビルド 検証 チューニング C++ C Fortran Python* Java* 標準規格に基づく並列モデル : OpenMP* MPI インテル TBB バージョン 2017 の主な機能 インテル
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
バトルカードでゲーマーやエンスージアストへの販売促進
 究極のメガタスク 4K ビデオの編集 3D 効果のレンダリング サウンドトラックの作曲を システム パフォーマンスを低下させずに同時に実行 4K ビデオの編集を 最大 2.4 倍 ビデオのトランスコードを 最大 高速化¹ Adobe* Premiere* Pro CC と インテル Core i7-7700k で比較 2.3 倍 高速化² - Handbrake* を使用し インテル Core i7-7700k
究極のメガタスク 4K ビデオの編集 3D 効果のレンダリング サウンドトラックの作曲を システム パフォーマンスを低下させずに同時に実行 4K ビデオの編集を 最大 2.4 倍 ビデオのトランスコードを 最大 高速化¹ Adobe* Premiere* Pro CC と インテル Core i7-7700k で比較 2.3 倍 高速化² - Handbrake* を使用し インテル Core i7-7700k
Jackson Marusarz 開発製品部門
 Jackson Marusarz 開発製品部門 内容 インテル TBB の概要 ヘテロジニアスの課題とそれらに対応するための概念 課題に対応するためのインテル TBB の進化 2 インテル TBB threadingbuildingblocks.org 汎用並列アルゴリズム ゼロから始めることなく マルチコアの能力を活かす効率的でスケーラブルな方法を提供 フローグラフ 並列処理を計算の依存性やデータフロー
Jackson Marusarz 開発製品部門 内容 インテル TBB の概要 ヘテロジニアスの課題とそれらに対応するための概念 課題に対応するためのインテル TBB の進化 2 インテル TBB threadingbuildingblocks.org 汎用並列アルゴリズム ゼロから始めることなく マルチコアの能力を活かす効率的でスケーラブルな方法を提供 フローグラフ 並列処理を計算の依存性やデータフロー
高速なコードを 迅速に開発 インテル Parallel Studio XE 2016 最適化に関する注意事項 2015 Intel Corporation. 無断での引用 転載を禁じます * その他の社名 製品名などは 一般に各社の表示 商標または登録商標です パフォーマンスを最大限に引き出そう
 高速なコードを 迅速に開発 インテル Parallel Studio XE 2016 パフォーマンスを最大限に引き出そう 高速なコードを迅速に開発 インテル Parallel Studio XE 設計 ビルド 検証 チューニング C++ C Fortran Java* バージョン 2016 の新機能 インテル Data Analytics Acceleration Library ( インテル DAAL)
高速なコードを 迅速に開発 インテル Parallel Studio XE 2016 パフォーマンスを最大限に引き出そう 高速なコードを迅速に開発 インテル Parallel Studio XE 設計 ビルド 検証 チューニング C++ C Fortran Java* バージョン 2016 の新機能 インテル Data Analytics Acceleration Library ( インテル DAAL)
インテル(R) Visual Fortran コンパイラ 10.0
 Visual Fortran コンパイラ 10.0") インテル (R) Visual Fortran コンパイラー 10.0 日本語版スペシャル エディション 入門ガイド 目次 概要インテル (R) Visual Fortran コンパイラーの設定はじめに検証用ソースファイル適切なインストールの確認コンパイラーの起動 ( コマンドライン ) コンパイル ( 最適化オプションなし ) 実行 / プログラムの検証コンパイル ( 最適化オプションあり ) 実行
インテル (R) Visual Fortran コンパイラー 10.0 日本語版スペシャル エディション 入門ガイド 目次 概要インテル (R) Visual Fortran コンパイラーの設定はじめに検証用ソースファイル適切なインストールの確認コンパイラーの起動 ( コマンドライン ) コンパイル ( 最適化オプションなし ) 実行 / プログラムの検証コンパイル ( 最適化オプションあり ) 実行
untitled
 SUBJECT: Applied Biosystems Data Collection Software v2.0 v3.0 Windows 2000 OS : 30 45 Cancel Data Collection - Applied Biosystems Sequencing Analysis Software v5.2 - Applied Biosystems SeqScape Software
SUBJECT: Applied Biosystems Data Collection Software v2.0 v3.0 Windows 2000 OS : 30 45 Cancel Data Collection - Applied Biosystems Sequencing Analysis Software v5.2 - Applied Biosystems SeqScape Software
修士論文
 AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
Microsoft PowerPoint - handai.pptx
 インテル Xeon Phi のプログラミングモデルと アプリケーション分野 インテル Xeon Phi が高性能を低消費電力で実現でき る超並列のプログラミングモデルとその適用可能なアプリ ケーションについて紹介する 内容 インテル Xeon プロセッサーとインテル Xeon Phi コプロセッサー Phi コプロセッサーの高並列アーキテクチャ Phi コプロセッサーに適したアプリ領域とプログラミング環境
インテル Xeon Phi のプログラミングモデルと アプリケーション分野 インテル Xeon Phi が高性能を低消費電力で実現でき る超並列のプログラミングモデルとその適用可能なアプリ ケーションについて紹介する 内容 インテル Xeon プロセッサーとインテル Xeon Phi コプロセッサー Phi コプロセッサーの高並列アーキテクチャ Phi コプロセッサーに適したアプリ領域とプログラミング環境
AI 人工知能 高度なプログラミングをすることなく 人間の心理と関連した認識機能を実行するために 経験を基にした機械の学習する能力 人工知能 マシンラーニング長期間にわたってより多くのデータを使用することにより 性能が向上するアルゴリズム ディープラーニング多層ニューラル ネットワークが膨大な量のデ
 AI 人工知能 高度なプログラミングをすることなく 人間の心理と関連した認識機能を実行するために 経験を基にした機械の学習する能力 人工知能 マシンラーニング長期間にわたってより多くのデータを使用することにより 性能が向上するアルゴリズム ディープラーニング多層ニューラル ネットワークが膨大な量のデータから学ぶマシンラーニングのサブセット 2 マシンラーニング技術の分析 訓練モデル構築のための訓練
AI 人工知能 高度なプログラミングをすることなく 人間の心理と関連した認識機能を実行するために 経験を基にした機械の学習する能力 人工知能 マシンラーニング長期間にわたってより多くのデータを使用することにより 性能が向上するアルゴリズム ディープラーニング多層ニューラル ネットワークが膨大な量のデータから学ぶマシンラーニングのサブセット 2 マシンラーニング技術の分析 訓練モデル構築のための訓練
Intel® Compilers Professional Editions
 2007 6 10.0 * 10.0 6 5 Software &Solutions group 10.0 (SV) C++ Fortran OpenMP* OpenMP API / : 200 C/C++ Fortran : OpenMP : : : $ cat -n main.cpp 1 #include 2 int foo(const char *); 3 int main()
2007 6 10.0 * 10.0 6 5 Software &Solutions group 10.0 (SV) C++ Fortran OpenMP* OpenMP API / : 200 C/C++ Fortran : OpenMP : : : $ cat -n main.cpp 1 #include 2 int foo(const char *); 3 int main()
2.1 インテル マイクロアーキテクチャー Haswell インテル マイクロアーキテクチャー Haswell は インテル マイクロアーキテクチャー Sandy Bridge とインテル マイクロアーキテクチャー Ivy Bridge の成功を受けて開発された この新しいマイクロアーキテクチャーの
 2 章インテル 64 プロセッサー アーキテクチャーと IA-32 プロセッサー アーキテクチャー 本章では 最新世代のインテル 64 プロセッサーと IA-32 プロセッサー ( インテル マイクロアーキテクチャー Haswell インテル マイクロアーキテクチャー Ivy Bridge インテル マイクロアーキテクチャー Sandy Bridge ベースのプロセッサーと インテル Core マイクロアーキテクチャー
2 章インテル 64 プロセッサー アーキテクチャーと IA-32 プロセッサー アーキテクチャー 本章では 最新世代のインテル 64 プロセッサーと IA-32 プロセッサー ( インテル マイクロアーキテクチャー Haswell インテル マイクロアーキテクチャー Ivy Bridge インテル マイクロアーキテクチャー Sandy Bridge ベースのプロセッサーと インテル Core マイクロアーキテクチャー
Hundreds of Thousands of Customers in 190 Countries
 高性能インスタンスで実現する HPC クラウドの実力 アマゾンデータサービスジャパンソリューションアーキテクト松尾康博 matsuoy@amazon.co.jp Wifi は全セッション会場展示会場にて ご利用いただけます SSID: awssummit #awssummit 自己紹介 名前 松尾康博 ( matusoy@amazon.co.jp ) 仕事 ソリューションアーキテクト HPC ビッグデータに関するお客様を担当
高性能インスタンスで実現する HPC クラウドの実力 アマゾンデータサービスジャパンソリューションアーキテクト松尾康博 matsuoy@amazon.co.jp Wifi は全セッション会場展示会場にて ご利用いただけます SSID: awssummit #awssummit 自己紹介 名前 松尾康博 ( matusoy@amazon.co.jp ) 仕事 ソリューションアーキテクト HPC ビッグデータに関するお客様を担当
for (int x = 0; x < X_MAX; x++) { /* これらの 3 つの行は外部ループの自己データと * 合計データの両方にカウントされます */ bar[x * 2] = x * ; bar[(x * 2) - 1] = (x - 1.0) *
![for (int x = 0; x < X_MAX; x++) { /* これらの 3 つの行は外部ループの自己データと * 合計データの両方にカウントされます */ bar[x * 2] = x * ; bar[(x * 2) - 1] = (x - 1.0) *](/thumbs/91/105660328.jpg "for (int x = 0; x < X_MAX; x++) { /* これらの 3 つの行は外部ループの自己データと * 合計データの両方にカウントされます */ bar[x * 2] = x * ; bar[(x * 2) - 1] = (x - 1.0) *") コールスタックを利用したルーフライン Alexandra S. (Intel) 2017 年 12 月 1 日公開 この記事は 2017 年 12 月 18 日時点の インテル デベロッパー ゾーンに公開されている Roofline with Callstacks の日本語訳です 注 : この記事の一部のスクリーンショットにはオレンジ色の点が表示されています デフォルト設定では これらの点は赤または黄色になります
コールスタックを利用したルーフライン Alexandra S. (Intel) 2017 年 12 月 1 日公開 この記事は 2017 年 12 月 18 日時点の インテル デベロッパー ゾーンに公開されている Roofline with Callstacks の日本語訳です 注 : この記事の一部のスクリーンショットにはオレンジ色の点が表示されています デフォルト設定では これらの点は赤または黄色になります
Microsoft PowerPoint - 1_コンパイラ入門セミナー.ppt
 インテルコンパイラー 入門セミナー [ 対象製品 ] インテル C++ コンパイラー 9.1 Windows* 版インテル Visual Fortran コンパイラー 9.1 Windows* 版 資料作成 : エクセルソフト株式会社 Copyright 1998-2007 XLsoft Corporation. All Rights Reserved. 1 インテル コンパイラー入門 本セミナーの内容
インテルコンパイラー 入門セミナー [ 対象製品 ] インテル C++ コンパイラー 9.1 Windows* 版インテル Visual Fortran コンパイラー 9.1 Windows* 版 資料作成 : エクセルソフト株式会社 Copyright 1998-2007 XLsoft Corporation. All Rights Reserved. 1 インテル コンパイラー入門 本セミナーの内容
Tutorial-GettingStarted
 インテル HTML5 開発環境 チュートリアル インテル XDK 入門ガイド V2.02 : 05.09.2013 著作権と商標について 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスを許諾するものではありません 製品に付属の売買契約書 Intel's Terms
インテル HTML5 開発環境 チュートリアル インテル XDK 入門ガイド V2.02 : 05.09.2013 著作権と商標について 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスを許諾するものではありません 製品に付属の売買契約書 Intel's Terms
目次 1 はじめに 製品コンポーネント 動作環境 インストールを行う前に 製品版と評価版 製品のインストール手順 製品の登録 製品のダウンロード ライセンスファイルの取得
 インテル Parallel Studio XE 2016 Composer Edition for Fortran Windows* - インストール ガイド - エクセルソフト株式会社 www.xlsoft.com Rev. 1.0 (2015/10/05) 目次 1 はじめに... 1 2 製品コンポーネント... 1 3 動作環境... 2 4 インストールを行う前に... 3 5 製品版と評価版...
インテル Parallel Studio XE 2016 Composer Edition for Fortran Windows* - インストール ガイド - エクセルソフト株式会社 www.xlsoft.com Rev. 1.0 (2015/10/05) 目次 1 はじめに... 1 2 製品コンポーネント... 1 3 動作環境... 2 4 インストールを行う前に... 3 5 製品版と評価版...
インテル(R) C++ Composer XE 2011 Windows版 入門ガイド
 C++ Composer XE 2011 Windows版 入門ガイド") C++ Composer XE 2011 Windows* エクセルソフト株式会社 www.xlsoft.com Rev. 1.2 (2011/05/03) Copyright 1998-2011 XLsoft Corporation. All Rights Reserved. 1 / 70 ... 4... 5... 6... 8 /... 8... 10 /... 11... 11 /... 13
C++ Composer XE 2011 Windows* エクセルソフト株式会社 www.xlsoft.com Rev. 1.2 (2011/05/03) Copyright 1998-2011 XLsoft Corporation. All Rights Reserved. 1 / 70 ... 4... 5... 6... 8 /... 8... 10 /... 11... 11 /... 13
untitled
 AMD HPC GP-GPU Opteron HPC 2 1 AMD Opteron 85 FLOPS 10,480 TOP500 16 T2K 95 FLOPS 10,800 140 FLOPS 15,200 61 FLOPS 7,200 3 Barcelona 4 2 AMD Opteron CPU!! ( ) L1 5 2003 2004 2005 2006 2007 2008 2009 2010
AMD HPC GP-GPU Opteron HPC 2 1 AMD Opteron 85 FLOPS 10,480 TOP500 16 T2K 95 FLOPS 10,800 140 FLOPS 15,200 61 FLOPS 7,200 3 Barcelona 4 2 AMD Opteron CPU!! ( ) L1 5 2003 2004 2005 2006 2007 2008 2009 2010
Microsoft Word - quick_start_guide_16 1_ja.docx
 Quartus Prime ソフトウェア ダウンロードおよびインストール クイック スタート ガイド 2016 Intel Corporation. All rights reserved. Intel, the Intel logo, Intel FPGA, Arria, Cyclone, Enpirion, MAX, Megacore, NIOS, Quartus and Stratix words
Quartus Prime ソフトウェア ダウンロードおよびインストール クイック スタート ガイド 2016 Intel Corporation. All rights reserved. Intel, the Intel logo, Intel FPGA, Arria, Cyclone, Enpirion, MAX, Megacore, NIOS, Quartus and Stratix words
2D/3D CAD データ管理導入手法実践セミナー Autodesk Vault 最新バージョン情報 Presenter Name 2013 年 4 月 2013 Autodesk
 2D/3D CAD データ管理導入手法実践セミナー Autodesk Vault 最新バージョン情報 Presenter Name 2013 年 4 月 2013 Autodesk Autodesk Vault 2014 新機能 操作性向上 Inventor ファイルを Vault にチェックインすることなくステータス変更を実行できるようになりました 履歴テーブルの版管理を柔軟に設定できるようになりました
2D/3D CAD データ管理導入手法実践セミナー Autodesk Vault 最新バージョン情報 Presenter Name 2013 年 4 月 2013 Autodesk Autodesk Vault 2014 新機能 操作性向上 Inventor ファイルを Vault にチェックインすることなくステータス変更を実行できるようになりました 履歴テーブルの版管理を柔軟に設定できるようになりました
Presentation title
 インテル Xeon Phi コプロセッサー搭載システムの紹介およびオフロード プログラミングとネイティブ実行の概要 インテル ソフトウェア開発製品の紹介 インテル ソフトウェア開発製品 Advanced Performance C++ および Fortran コンパイラーインテル MKL/ インテル IPP ライブラリーと解析ツール IA ベース マルチコア ノード上の Windows* および Linux*
インテル Xeon Phi コプロセッサー搭載システムの紹介およびオフロード プログラミングとネイティブ実行の概要 インテル ソフトウェア開発製品の紹介 インテル ソフトウェア開発製品 Advanced Performance C++ および Fortran コンパイラーインテル MKL/ インテル IPP ライブラリーと解析ツール IA ベース マルチコア ノード上の Windows* および Linux*
PowerPoint Presentation
 インテル Xeon Phi プロセッサーの 高帯域幅メモリーを活用するコードの作成 Ruchira Sasanka Karthik Raman 開発ツール Web セミナー 2016 年 10 月 11 日 法務上の注意書き 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスも許諾するものではありません
インテル Xeon Phi プロセッサーの 高帯域幅メモリーを活用するコードの作成 Ruchira Sasanka Karthik Raman 開発ツール Web セミナー 2016 年 10 月 11 日 法務上の注意書き 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスも許諾するものではありません
TOOLS for UR44 Release Notes for Windows
 TOOLS for UR44 V2.1.2 for Windows Release Notes TOOLS for UR44 V2.1.2 for Windows consists of the following programs. - V1.9.9 - Steinberg UR44 Applications V2.1.1 - Basic FX Suite V1.0.1 Steinberg UR44
TOOLS for UR44 V2.1.2 for Windows Release Notes TOOLS for UR44 V2.1.2 for Windows consists of the following programs. - V1.9.9 - Steinberg UR44 Applications V2.1.1 - Basic FX Suite V1.0.1 Steinberg UR44
Zinstall WinWin 日本語ユーザーズガイド
 Zinstall WinWin User Guide Thank you for purchasing Zinstall WinWin. If you have any questions, issues or problems, please contact us: Toll-free phone: (877) 444-1588 International callers: +1-877-444-1588
Zinstall WinWin User Guide Thank you for purchasing Zinstall WinWin. If you have any questions, issues or problems, please contact us: Toll-free phone: (877) 444-1588 International callers: +1-877-444-1588
スライド 1
 Nehalem 新マイクロアーキテクチャ スケーラブルシステムズ株式会社 はじめに 現在も続く x86 マイクロプロセッサマーケットでの競合において Intel と AMD という 2 つの会社は 常に新しい技術 製品を提供し マーケットでのシェアの獲得を目指しています この技術開発と製品開発では この 2 社はある時は 他社に対して優位な技術を開発し 製品面での優位性を示すことに成功してきましたが
Nehalem 新マイクロアーキテクチャ スケーラブルシステムズ株式会社 はじめに 現在も続く x86 マイクロプロセッサマーケットでの競合において Intel と AMD という 2 つの会社は 常に新しい技術 製品を提供し マーケットでのシェアの獲得を目指しています この技術開発と製品開発では この 2 社はある時は 他社に対して優位な技術を開発し 製品面での優位性を示すことに成功してきましたが
65pt Intel Clear PRO Presentation Title
 インテル株式会社 データセンター プロダクト マーケティング Xeon プラットフォーム マーケティング マネージャー横川弘 Legal Disclaimers Intel technologies features and benefits depend on system configuration and may require enabled hardware, software or service
インテル株式会社 データセンター プロダクト マーケティング Xeon プラットフォーム マーケティング マネージャー横川弘 Legal Disclaimers Intel technologies features and benefits depend on system configuration and may require enabled hardware, software or service
ムーアの法則 : インテルでは順調に存続中 65nm 2005 製造中 45nm nm nm 2011 * 開発中 15nm 2013 * リサーチ 11nm 2015 * 8nm 2017 * インテルの革新的技術を順次適用予定 2 インテル製品は 予告なく
 HPC 向け次世代 Intel プロセッサ / ツールの紹介 インテル株式会社 ソフトウェア & サービス統括部 池井満 1 2010,IntelCorporation. 無断での引用 転載を禁じます ムーアの法則 : インテルでは順調に存続中 65nm 2005 製造中 45nm 2007 32nm 2009 22nm 2011 * 開発中 15nm 2013 * リサーチ 11nm 2015 *
HPC 向け次世代 Intel プロセッサ / ツールの紹介 インテル株式会社 ソフトウェア & サービス統括部 池井満 1 2010,IntelCorporation. 無断での引用 転載を禁じます ムーアの法則 : インテルでは順調に存続中 65nm 2005 製造中 45nm 2007 32nm 2009 22nm 2011 * 開発中 15nm 2013 * リサーチ 11nm 2015 *
インテル® Parallel Studio XE 2017 Composer Edition for Fortran Windows - インストール・ガイド -
 インテル Parallel Studio XE 2017 Composer Edition for Fortran Windows - インストール ガイド - エクセルソフト株式会社 www.xlsoft.com Rev. 2. 0 (2016/10/20) 目次 1 はじめに... 4 2 製品に含まれるコンポーネント... 4 3 動作環境... 5 オペレーティング システム... 5 Microsoft
インテル Parallel Studio XE 2017 Composer Edition for Fortran Windows - インストール ガイド - エクセルソフト株式会社 www.xlsoft.com Rev. 2. 0 (2016/10/20) 目次 1 はじめに... 4 2 製品に含まれるコンポーネント... 4 3 動作環境... 5 オペレーティング システム... 5 Microsoft
本文ALL.indd
 Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法河辺峻田口成美古谷英祐 Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法 Performance Measurement Method of Cache Coherency Effects on an Intel Xeon Processor System 河辺峻田口成美古谷英祐
Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法河辺峻田口成美古谷英祐 Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法 Performance Measurement Method of Cache Coherency Effects on an Intel Xeon Processor System 河辺峻田口成美古谷英祐
Microsoft Word - IVF15.0.1J_Install.doc
 Parallel Studio XE 2015 Composer Edition for Fortran Windows* www.xlsoft.com Rev. 1.0 (2014/11/18) 1 / 17 目次 1. はじめに... 3 2. 製品コンポーネント... 3 3. 動作環境... 4 4. インストールする前に... 5 5. 製品購入者と評価ユーザー... 6 6. インストール手順...
Parallel Studio XE 2015 Composer Edition for Fortran Windows* www.xlsoft.com Rev. 1.0 (2014/11/18) 1 / 17 目次 1. はじめに... 3 2. 製品コンポーネント... 3 3. 動作環境... 4 4. インストールする前に... 5 5. 製品購入者と評価ユーザー... 6 6. インストール手順...
PowerPoint プレゼンテーション
 vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
1重谷.PDF
 RSCC RSCC RSCC BMT 1 6 3 3000 3000 200310 1994 19942 VPP500/32PE 19992 VPP700E/128PE 160PE 20043 2 2 PC Linux 2048 CPU Intel Xeon 3.06GHzDual) 12.5 TFLOPS SX-7 32CPU/256GB 282.5 GFLOPS Linux 3 PC 1999
RSCC RSCC RSCC BMT 1 6 3 3000 3000 200310 1994 19942 VPP500/32PE 19992 VPP700E/128PE 160PE 20043 2 2 PC Linux 2048 CPU Intel Xeon 3.06GHzDual) 12.5 TFLOPS SX-7 32CPU/256GB 282.5 GFLOPS Linux 3 PC 1999
1 つのツールを実行するだけで違いが出るのでしょうか? はい 多くの場合 複雑なバグを発見して アプリケーションの安定性を向上させることができます このガイドでは インテル Inspector XE 解析ツールを使用して コードの問題を排除する方法を説明します これにより コードの信頼性が向上し 開
 インテル Parallel Studio 評価ガイド メモリーエラーの排除と プログラムの安定性の向上 インテル Parallel Studio XE 1 つのツールを実行するだけで違いが出るのでしょうか? はい 多くの場合 複雑なバグを発見して アプリケーションの安定性を向上させることができます このガイドでは インテル Inspector XE 解析ツールを使用して コードの問題を排除する方法を説明します
インテル Parallel Studio 評価ガイド メモリーエラーの排除と プログラムの安定性の向上 インテル Parallel Studio XE 1 つのツールを実行するだけで違いが出るのでしょうか? はい 多くの場合 複雑なバグを発見して アプリケーションの安定性を向上させることができます このガイドでは インテル Inspector XE 解析ツールを使用して コードの問題を排除する方法を説明します
テクノロジーのビッグトレンド 180 nm nm nm nm nm On 2007 Track 32 nm には 150 億台の端末がネットワーク接続 * * "Gantz, John. "The Embedded
 ホワイトスペースに対するインテルの期待 インテルコーポレーション セールス & マーケティング統括本部副社長 吉田和正 テクノロジーのビッグトレンド 180 nm 1999 130 nm 2001 90 nm 2003 65 nm 2005 45 nm On 2007 Track 32 nm 2009 2015 には 150 億台の端末がネットワーク接続 * * "Gantz, John. "The
ホワイトスペースに対するインテルの期待 インテルコーポレーション セールス & マーケティング統括本部副社長 吉田和正 テクノロジーのビッグトレンド 180 nm 1999 130 nm 2001 90 nm 2003 65 nm 2005 45 nm On 2007 Track 32 nm 2009 2015 には 150 億台の端末がネットワーク接続 * * "Gantz, John. "The
システム imac 21.5 インチディスプレイ 3.6GHz i5 Dual core / HT 2.8GHz i7 Quad core / HT ATI Radeon 4850 ATI Radeon HD はいいいえいいえはいいいえ ATI はいいいえ
 Composer 6 および Symphony 6 認定 Apple Mac システム システム Mac デスクトップ Mac Pro dual 6-Core 2.66GHz "Westmere" Core 2.66GHz および 2.93GHz "Nehalem" Core 2.26GHz "Nehalem" Core 3.0GHz および 3.2GHz "Harpertown" Geforce
Composer 6 および Symphony 6 認定 Apple Mac システム システム Mac デスクトップ Mac Pro dual 6-Core 2.66GHz "Westmere" Core 2.66GHz および 2.93GHz "Nehalem" Core 2.26GHz "Nehalem" Core 3.0GHz および 3.2GHz "Harpertown" Geforce
IntelR Compilers Professional Editions
 June 2007 インテル コンパイラー プロフェッショナル エディション Phil De La Zerda 公開が禁止された情報が含まれています 本資料に含まれるインテル コンパイラー 10.0 についての情報は 6 月 5 日まで公開が禁止されています グローバル ビジネス デベロップメント ディレクター Intel Corporation マルチコア プロセッサーがもたらす変革 これまでは
June 2007 インテル コンパイラー プロフェッショナル エディション Phil De La Zerda 公開が禁止された情報が含まれています 本資料に含まれるインテル コンパイラー 10.0 についての情報は 6 月 5 日まで公開が禁止されています グローバル ビジネス デベロップメント ディレクター Intel Corporation マルチコア プロセッサーがもたらす変革 これまでは
目次 1 はじめに 本文書の概要 PVF ソフトウェアと VISUAL STUDIO PVF ソフトウェアの種類 MICROSOFT VISUAL STUDIO の日本語化について VISUAL STUDIO
 PGI Visual Fortran のための Microsoft Visual Studio 導入ガイド 2016 年版 日本語環境の Visual Studio の構築について PGI インストール関係の日本語ドキュメントは 以下の URL に全てアーカイブしてありま す オンラインでご覧になりたい場合は 以下の URL にアクセスしてください http://www.softek.co.jp/spg/pgi/inst_document.html
PGI Visual Fortran のための Microsoft Visual Studio 導入ガイド 2016 年版 日本語環境の Visual Studio の構築について PGI インストール関係の日本語ドキュメントは 以下の URL に全てアーカイブしてありま す オンラインでご覧になりたい場合は 以下の URL にアクセスしてください http://www.softek.co.jp/spg/pgi/inst_document.html
$ cmake --version $ make --version $ gcc --version 環境が無いあるいはバージョンが古い場合は yum などを用いて導入 最新化を行う 4. 圧縮ファイルを解凍する $ tar xzvf gromacs tar.gz 5. cmake を用
 本マニュアルの目的 Linux サーバー版 Gromacs インストールマニュアル 2015/10/28 本マニュアルでは 単独ユーザが独占的に Linux サーバー (CentOS 6.6) を使用して Gromacs ジョブを実行するための環境構築方法と Winmostar のリモートジョブ機能による計算手順を示しています つまり複数ユーザが共同使用する計算サーバー等は対象外です そのため計算環境は全てユーザのホームディレクトリ配下で行う構築することを想定しています
本マニュアルの目的 Linux サーバー版 Gromacs インストールマニュアル 2015/10/28 本マニュアルでは 単独ユーザが独占的に Linux サーバー (CentOS 6.6) を使用して Gromacs ジョブを実行するための環境構築方法と Winmostar のリモートジョブ機能による計算手順を示しています つまり複数ユーザが共同使用する計算サーバー等は対象外です そのため計算環境は全てユーザのホームディレクトリ配下で行う構築することを想定しています
インテル® VTune™ Amplifier : Windows 環境向けスタートガイド
 インテル VTune Amplifier Windows 環境向けスタートガイド エクセルソフト株式会社 Version 1.0.0-20180829 目次 1. インテル VTune Amplifier の使用.......................................................... 1 2. インテル VTune Amplifier の基本..........................................................
インテル VTune Amplifier Windows 環境向けスタートガイド エクセルソフト株式会社 Version 1.0.0-20180829 目次 1. インテル VTune Amplifier の使用.......................................................... 1 2. インテル VTune Amplifier の基本..........................................................
MATLAB® における並列・分散コンピューティング ~ Parallel Computing Toolbox™ & MATLAB Distributed Computing Server™ ~
 MATLAB における並列 分散コンピューティング ~ Parallel Computing Toolbox & MATLAB Distributed Computing Server ~ MathWorks Japan Application Engineering Group Takashi Yoshida 2016 The MathWorks, Inc. 1 System Configuration
MATLAB における並列 分散コンピューティング ~ Parallel Computing Toolbox & MATLAB Distributed Computing Server ~ MathWorks Japan Application Engineering Group Takashi Yoshida 2016 The MathWorks, Inc. 1 System Configuration
インテル(R) Visual Fortran Composer XE 2013 Windows版 入門ガイド
 Visual Fortran Composer XE 2013 Windows版 入門ガイド") Visual Fortran Composer XE 2013 Windows* エクセルソフト株式会社 www.xlsoft.com Rev. 1.1 (2012/12/10) Copyright 1998-2013 XLsoft Corporation. All Rights Reserved. 1 / 53 ... 3... 4... 4... 5 Visual Studio... 9...
Visual Fortran Composer XE 2013 Windows* エクセルソフト株式会社 www.xlsoft.com Rev. 1.1 (2012/12/10) Copyright 1998-2013 XLsoft Corporation. All Rights Reserved. 1 / 53 ... 3... 4... 4... 5 Visual Studio... 9...
Introduction to OpenMP* 4.0 for SIMD and Affinity Features with Intel® Xeon® Processors and Intel® Xeon Phi™ Coprocessors
 OpenMP* 4.0 における SIMD およびアフィニティー機能の導入 法務上の注意書きと最適化に関する注意事項 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスを許諾するものではありません 製品に付属の売買契約書 Intel's Terms and Conditions
OpenMP* 4.0 における SIMD およびアフィニティー機能の導入 法務上の注意書きと最適化に関する注意事項 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスを許諾するものではありません 製品に付属の売買契約書 Intel's Terms and Conditions
1
 PE-Expert4 統合開発環境 PE-ViewX 及び パワエレ専用ライブラリ PEOS バージョンアップのお知らせ Myway プラス株式会社 220-0022 神奈川県横浜市西区花咲町 6-145 横浜花咲ビル TEL.045-548-8836 FAX.045-548-8832 http://www.myway.co.jp/ E-mail: sales@myway.co.jp 拝啓貴社ますますご清栄のこととお喜び申し上げます
PE-Expert4 統合開発環境 PE-ViewX 及び パワエレ専用ライブラリ PEOS バージョンアップのお知らせ Myway プラス株式会社 220-0022 神奈川県横浜市西区花咲町 6-145 横浜花咲ビル TEL.045-548-8836 FAX.045-548-8832 http://www.myway.co.jp/ E-mail: sales@myway.co.jp 拝啓貴社ますますご清栄のこととお喜び申し上げます
ワークステーション推奨スペック Avid Avid Nitris Mojo SDI Fibre 及び Adrenaline MC ソフトウェア 3.5 以降のバージョンが必要です Dual 2.26 GHz Quad Core Intel 構成のに関しては Configuration Guideli
 ワークステーション推奨スペック Avid Avid Nitris Mojo SDI Fibre 及び Adrenaline MC/Symphony ソフトウェア 5.0.3 以降のバージョンが必要です Two 2.66 GHz 6-Core *Mojo SDI 及び Adrenaline サポート Intel Xeon (12 コア ) 32-bit カーネルで実 して下さい 64-bit カーネルは対応していません
ワークステーション推奨スペック Avid Avid Nitris Mojo SDI Fibre 及び Adrenaline MC/Symphony ソフトウェア 5.0.3 以降のバージョンが必要です Two 2.66 GHz 6-Core *Mojo SDI 及び Adrenaline サポート Intel Xeon (12 コア ) 32-bit カーネルで実 して下さい 64-bit カーネルは対応していません
DPD Software Development Products Overview
 2 2007 Intel Corporation. Core 2 Core 2 Duo 2006/07/27 Core 2 precise VTune Core 2 Quad 2006/11/14 VTune Core 2 ( ) 1 David Levinthal 3 2007 Intel Corporation. PC Core 2 Extreme QX6800 2.93GHz, 1066MHz
2 2007 Intel Corporation. Core 2 Core 2 Duo 2006/07/27 Core 2 precise VTune Core 2 Quad 2006/11/14 VTune Core 2 ( ) 1 David Levinthal 3 2007 Intel Corporation. PC Core 2 Extreme QX6800 2.93GHz, 1066MHz
インテル MKL を使用した小行列乗算の高速化 インテル MKL チーム
 インテル MKL を使用した小行列乗算の高速化 インテル MKL チーム 内容 インテル MKL の概要 インテル MKL の新機能 行列 - 行列乗算 小行列のパフォーマンスの課題 小行列のパフォーマンスを向上するインテル MKL のソリューション MKL_DIRECT_CALL バッチ API コンパクト API パックド API パフォーマンスのヒントと測定 サマリーおよびインテル MKL 関連情報
インテル MKL を使用した小行列乗算の高速化 インテル MKL チーム 内容 インテル MKL の概要 インテル MKL の新機能 行列 - 行列乗算 小行列のパフォーマンスの課題 小行列のパフォーマンスを向上するインテル MKL のソリューション MKL_DIRECT_CALL バッチ API コンパクト API パックド API パフォーマンスのヒントと測定 サマリーおよびインテル MKL 関連情報
Introducing Intel® Parallel Studio XE 2015
 インテル Parallel Studio XE 205 の概要 James Reinders インテルコーポレーションのソフトウェア エバンジェリスト兼ディレクター james.r.reinders@intel.com 高速なコードを迅速に開発インテル Parallel Studio XE 205 高速なコード 明示的なベクトル プログラミングでより多くのコードをスピードアップ インテル Xeon
インテル Parallel Studio XE 205 の概要 James Reinders インテルコーポレーションのソフトウェア エバンジェリスト兼ディレクター james.r.reinders@intel.com 高速なコードを迅速に開発インテル Parallel Studio XE 205 高速なコード 明示的なベクトル プログラミングでより多くのコードをスピードアップ インテル Xeon
インテル® キャッシュ・アクセラレーション・ソフトウェア (インテル® CAS) Linux* 版 v2.8 (GA)
 Linux* 版 v2.8 (GA)") 改訂 001 ドキュメント番号 :328499-001 注 : 本書には開発の設計段階の製品に関する情報が記述されています この情報は予告なく変更されることがあります この情報だけに基づいて設計を最終的なものとしないでください 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスも許諾するものではありません
改訂 001 ドキュメント番号 :328499-001 注 : 本書には開発の設計段階の製品に関する情報が記述されています この情報は予告なく変更されることがあります この情報だけに基づいて設計を最終的なものとしないでください 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスも許諾するものではありません
PowerPoint プレゼンテーション
 Foundation アプライアンス スケーラブルシステムズ株式会社 サーバ クラスタの課題 複数のシステムを一つの だけで容易に管理することは出来ないだろうか? アプリケーションがより多くのメモリを必要とするのだけど ハードウエアの増設なしで対応出来ないだろうか? 現在の利用環境のまま 利用できるコア数やメモリサイズの増強を図ることは出来ないだろうか? 短時間で導入可能で また 必要に応じて 柔軟にシステム構成の変更が可能なソリューションは無いだろうか?...
Foundation アプライアンス スケーラブルシステムズ株式会社 サーバ クラスタの課題 複数のシステムを一つの だけで容易に管理することは出来ないだろうか? アプリケーションがより多くのメモリを必要とするのだけど ハードウエアの増設なしで対応出来ないだろうか? 現在の利用環境のまま 利用できるコア数やメモリサイズの増強を図ることは出来ないだろうか? 短時間で導入可能で また 必要に応じて 柔軟にシステム構成の変更が可能なソリューションは無いだろうか?...
Microsoft PowerPoint - sales2.ppt
 最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
Introduction Purpose This training course describes the configuration and session features of the High-performance Embedded Workshop (HEW), a key tool
, a key tool") Introduction Purpose This training course describes the configuration and session features of the High-performance Embedded Workshop (HEW), a key tool for developing software for embedded systems that
Introduction Purpose This training course describes the configuration and session features of the High-performance Embedded Workshop (HEW), a key tool for developing software for embedded systems that
インテル Advisor Python* API を使用したパ フォーマンス向上の考察 この記事は Tech.Decoded に公開されている Gaining Performance Insights Using the Intel Advisor Python* API の日本語参考訳です コード
 インテル Advisor Python* API を使用したパ フォーマンス向上の考察 この記事は Tech.Decoded に公開されている Gaining Performance Insights Using the Intel Advisor Python* API の日本語参考訳です コードのチューニング方法を決定する適切なデータの取得 インテルコーポレーション テクニカル コンサルティング
インテル Advisor Python* API を使用したパ フォーマンス向上の考察 この記事は Tech.Decoded に公開されている Gaining Performance Insights Using the Intel Advisor Python* API の日本語参考訳です コードのチューニング方法を決定する適切なデータの取得 インテルコーポレーション テクニカル コンサルティング
hotspot の特定と最適化
 1 1? 1 1 2 1. hotspot : hotspot hotspot Parallel Amplifier 1? 2. hotspot : (1 ) Parallel Composer 1 Microsoft* Ticker Tape Smoke 1.0 PiSolver 66 / 64 / 2.76 ** 84 / 27% ** 75 / 17% ** 1.46 89% Microsoft*
1 1? 1 1 2 1. hotspot : hotspot hotspot Parallel Amplifier 1? 2. hotspot : (1 ) Parallel Composer 1 Microsoft* Ticker Tape Smoke 1.0 PiSolver 66 / 64 / 2.76 ** 84 / 27% ** 75 / 17% ** 1.46 89% Microsoft*
Veritas System Recovery 16 Management Solution Readme
 Veritas System Recovery 16 Management Solution Readme この README について Veritas System Recovery 16 のソフトウェア配信ポリシーのシステム要件 Veritas System Recovery 16 Management Solution のシステム要件 Veritas System Recovery 16 Management
Veritas System Recovery 16 Management Solution Readme この README について Veritas System Recovery 16 のソフトウェア配信ポリシーのシステム要件 Veritas System Recovery 16 Management Solution のシステム要件 Veritas System Recovery 16 Management
チュートリアル: インテル® MPI ライブラリー向け MPI Tuner (Windows*)
") チュートリアル : インテル MPI ライブラリー向け MPI Tuner バージョン 5.1 Update 3 (Windows*) 著作権と商標について 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスも許諾するものではありません インテルは 明示されているか否かにかかわらず いかなる保証もいたしません ここにいう保証には 商品適格性
チュートリアル : インテル MPI ライブラリー向け MPI Tuner バージョン 5.1 Update 3 (Windows*) 著作権と商標について 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスも許諾するものではありません インテルは 明示されているか否かにかかわらず いかなる保証もいたしません ここにいう保証には 商品適格性
Microsoft Word ●IntelクアッドコアCPUでのベンチマーク_吉岡_ _更新__ doc
 2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
 VQT3A26-1 DMR-T2000R μ μ μ ! R ! l l l [HDD] [BD-RE] [BD-R] [BD-V] [RAM] [-R] [-R]DL] [-RW] [DVD-V] [CD] [SD] [USB] [RAM AVCREC ] [-R AVCREC ] [-R]DL AVCREC ] [RAM VR ][-R VR ] [-R]DL VR ] [-RW VR ]
VQT3A26-1 DMR-T2000R μ μ μ ! R ! l l l [HDD] [BD-RE] [BD-R] [BD-V] [RAM] [-R] [-R]DL] [-RW] [DVD-V] [CD] [SD] [USB] [RAM AVCREC ] [-R AVCREC ] [-R]DL AVCREC ] [RAM VR ][-R VR ] [-R]DL VR ] [-RW VR ]
基本操作ガイド
 HT7-0022-000-V.4.0 Copyright 2004 CANON INC. ALL RIGHTS RESERVED 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 4 1 1 2 3 4 5 1 2 1 2 3 1 2 3 1 2 3 1 2 3 4 1 2 3 4 1 2 3 4 5 6 1 2 3 4 5 6 7 1 2 3 4
HT7-0022-000-V.4.0 Copyright 2004 CANON INC. ALL RIGHTS RESERVED 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 4 1 1 2 3 4 5 1 2 1 2 3 1 2 3 1 2 3 1 2 3 4 1 2 3 4 1 2 3 4 5 6 1 2 3 4 5 6 7 1 2 3 4
ストリーミング SIMD 拡張命令2 (SSE2) を使用した SAXPY/DAXPY
 を使用した SAXPY/DAXPY") SIMD 2(SSE2) SAXPY/DAXPY 2.0 2000 7 : 248600J-001 01/12/06 1 305-8603 115 Fax: 0120-47-8832 * Copyright Intel Corporation 1999, 2000 01/12/06 2 1...5 2 SAXPY DAXPY...5 2.1 SAXPY DAXPY...6 2.1.1 SIMD C++...6
SIMD 2(SSE2) SAXPY/DAXPY 2.0 2000 7 : 248600J-001 01/12/06 1 305-8603 115 Fax: 0120-47-8832 * Copyright Intel Corporation 1999, 2000 01/12/06 2 1...5 2 SAXPY DAXPY...5 2.1 SAXPY DAXPY...6 2.1.1 SIMD C++...6
 μ μ DMR-BZT700 DMR-BZT600 μ TM VQT3C03-2B ! ! l l l [HDD] [BD-RE] [BD-R] [DVD-V] [BD-V] [RAM] [CD] [SD] [-R] [USB] [-RW] [RAM AVCREC ] [-R AVCREC ] [RAM VR ][-R VR ] [-RW VR ] [-R V ] [-RW V ] [DVD-V]
μ μ DMR-BZT700 DMR-BZT600 μ TM VQT3C03-2B ! ! l l l [HDD] [BD-RE] [BD-R] [DVD-V] [BD-V] [RAM] [CD] [SD] [-R] [USB] [-RW] [RAM AVCREC ] [-R AVCREC ] [RAM VR ][-R VR ] [-RW VR ] [-R V ] [-RW V ] [DVD-V]
 VQT2P76 DMR-BWT2000 DMR-BWT1000 μ μ μ ! R ! l l l [HDD] [BD-RE] [BD-R] [BD-V] [RAM] [-R] [-R]DL] [-RW] [DVD-V] [CD] [SD] [USB] [RAM AVCREC ] [-R AVCREC ] [-R]DL AVCREC ] [RAM VR ][-R VR ] [-R]DL VR
VQT2P76 DMR-BWT2000 DMR-BWT1000 μ μ μ ! R ! l l l [HDD] [BD-RE] [BD-R] [BD-V] [RAM] [-R] [-R]DL] [-RW] [DVD-V] [CD] [SD] [USB] [RAM AVCREC ] [-R AVCREC ] [-R]DL AVCREC ] [RAM VR ][-R VR ] [-R]DL VR
 VQT3G14-2 DMR-BR585 μ μ μ VQT3G14.book 3 ページ 2010年10月1日 金曜日 午前10時29分 ご案内 3 本書では 本機の操作方法を説明しています 別冊の 取扱説明書 準備編 や かんたん操作ガイド もあわせてご覧ください 連携機器情報などの詳しい情報は 当社ホームページ 本機を使用していただくための サポート情報を掲載しています 接続機器に合わせた 接続方法
VQT3G14-2 DMR-BR585 μ μ μ VQT3G14.book 3 ページ 2010年10月1日 金曜日 午前10時29分 ご案内 3 本書では 本機の操作方法を説明しています 別冊の 取扱説明書 準備編 や かんたん操作ガイド もあわせてご覧ください 連携機器情報などの詳しい情報は 当社ホームページ 本機を使用していただくための サポート情報を掲載しています 接続機器に合わせた 接続方法
基本操作ガイド
 HT7-0199-000-V.5.0 1. 2. 3. 4. 5. 6. 7. 8. 9. Copyright 2004 CANON INC. ALL RIGHTS RESERVED 1 2 3 1 1 2 3 4 1 2 1 2 3 1 2 3 1 2 3 1 2 3 4 1 2 3 4 1 2 3 4 5 AB AB Step 1 Step
HT7-0199-000-V.5.0 1. 2. 3. 4. 5. 6. 7. 8. 9. Copyright 2004 CANON INC. ALL RIGHTS RESERVED 1 2 3 1 1 2 3 4 1 2 1 2 3 1 2 3 1 2 3 1 2 3 4 1 2 3 4 1 2 3 4 5 AB AB Step 1 Step
HP Workstation 総合カタログ
 HP Workstation Z HP 6 Z HP HP Z840 Workstation P.9 HP Z640 Workstation & CPU P.10 HP Z440 Workstation P.11 17.3in WIDE HP ZBook 17 G2 Mobile Workstation P.15 15.6in WIDE HP ZBook 15 G2 Mobile Workstation
HP Workstation Z HP 6 Z HP HP Z840 Workstation P.9 HP Z640 Workstation & CPU P.10 HP Z440 Workstation P.11 17.3in WIDE HP ZBook 17 G2 Mobile Workstation P.15 15.6in WIDE HP ZBook 15 G2 Mobile Workstation
システムソリューションのご紹介
 HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ