untitled
|
|
|
- けいざぶろう とこたに
- 6 years ago
- Views:
Transcription
1
2 A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X


3 GPGPU
4
5
6 A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i }
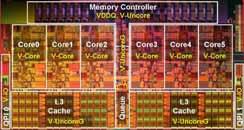
7 A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i } 2mn 2 m 3
8 3 3 A (k) := (I αww T ) A (k) = A (k) αw (w T A (k) ) Rank-1 level-2 BLAS rank k A (k) 0 0 Level-2 BLAS
9 K M 100M G Byte/Flop : 1 < 1
10 BLAS BLAS Basic Linear Algebra Subprograms BLAS Level-1 BLAS: c := x T y AXPYy: = ax + y Level-2 BLAS: A = y := Ax rank-1a := A + xy T A = A Level-3 BLAS: C := AB C = A B
11 BLAS Level-1 BLAS O(N) O(N) O(N/p) N p Level-2 BLAS O(N 2 ) O(N 2 ) O(N 2 /p) A A A Level-3 BLAS O(N 3 ) O(N 2 ) O(N) C Byte/Flop O(N 3 /p) A B level-3 BLAS
12 Level-3 BLAS 3 Bischof et al., 93 A L C 3 T n 0 0 (4/3)n 3 0 6n 2 L 0 A C L T 3 level-3 BLAS level-2 BLAS O(n 2 L)
13 H = I WαW T H H K H K R 0 H K L 0 L
14 Level-3 BLAS n A A {v i } L (4/3)n 3 0 C 0 6n 2 L 2mn 2 C 2mn 2 {w i } 0 0 T T {u i } QR DC MR 3 { i } O(n 3 ) level-3 BLAS 4mn 2 2 level-3
15 n : 9000 L : Level-3 BLAS Fortran LAPACK Xeon 8 Xeon X5355 (2.66GHz, Quad-core 2 Intel Fortran Compiler 9, Intel Math Kernel Library HX600 1 Opteron (2.5GHz, Quad-core 4 Xeon 24 Xeon E7460 (2.4 GHz, 6, L3$ 12MB 4 Intel Fortran Compiler 11, Intel Math Kernel Library
16 Xeon 8 n = 9000 L = 100 8Level-3 LAPACK 2.1 Level-3
17 HX600 n = 9000 L = 50
18 Xeon 24 n = 9000 L = 200 Level-3 BLAS 24 LAPACK Level-3 BLAS 40%
19 Xeon 24 n = 9000 Level-3 BLAS L = level-3 BLAS
20 Xeon 24 level-3 BLAS DSYMM: DSYR2K: rank-l DSYMM
21 3 level-2 BLAS Level-3 BLAS level-3 BLAS Xeon 24 level-3 BLAS
22 GPU GPU
23
24 QR Step 1 : A = H Step 2 : Step 3 : QR H T Step 4 : T A 23
25 Step 1 4 Step 1 Level-2 3 BLAS Level-2 Step 4 Level-1 BLAS : CPU : Core i7 920 (2.66 GHz) Memory: 6.0GB 24
26 GPU GPU (Graphics Processing Unit) GPU GPU NVIDIA CUDA CUBLAS CUFFT GPU Step 1 25
27
28
29 =H (H T = H, H T H = HH T = I ) for i = 1, N -2
30 for i= 1, N -2 Rank-1 O(N 2 ) O(N 2 ) CPU
31 1 N B N B O(N 2 ), O(N 2 N B )
32 2 for k = 1, N / N B for i = 1, N B N B (1) t i,v i O(N) (2) w i T v i T A O(N 2 ) (3) O(N N B ) end for end for (4) O(N 2 N B ) ()
 t i, v i")
33 (4) (3) (2) w it =t i v it A (1) t i, v i GPU
34 2 (a) BLAS GPU A Send Receive N B for k =1, N/N B A i for i = 1, N B t i,v i t i,v i BLAS CPU t i v i w it v i T A end for end for Receive A Send
35 (a) N = 5120
 O(N N B ) O(N 2 ) O(N) (2)(3) BLAS GPU")
36 (a) N = 5120 (4) (3) (2) w it =t i v it A (1) t i, v i O(N 2 N B ) O(N N B ) O(N 2 ) O(N) (2)(3) BLAS GPU
37 2 (b) BLAS CPU A Send Receive for k =1, N/N B N B for i = 1, N B t i,v i Receive end for w i T GPU CPU CPU end for A Send v i T A
38 (c) CPU GPU A Send Receive N B CPU t i,v i w i T for k =1, N/N B for i = 1, N B w i T Receive end for end for A Send
39 (a) (b) (c) BLAS GPU BLAS CPU BLAS CPU GPU (1) t i,v i CPU CPU CPU (2) w i T GPU GPU CPU+GPU (3) (4) GPU CPU CPU GPU GPU CPU+GPU
40 A N = 1024, 2048,, CPU 4 (a), (b), (c) N B = 32 (c) CPU N CPU 24/32 10/32 8/32 6/32 5/32 5/32 5/32 5/32

41 CPU (c) N=
 t i,")
42 N = 5120 (4) (3) (2) w it =t i v it A (1) t i, v i
43 GPU GPU CUBLAS BLAS CPU BLAS CPU GPU Tesla C1060 Core i
44 BLAS MAGMA GPU
untitled
 A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS /1/18 a a 1 a 2 a 3 a a GPU Graphics Processing Unit GPU CPU GPU GPGPU G
 211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS211 211/1/18 GPU 4 8 BLAS 4 8 BLAS Basic Linear Algebra Subprograms GPU Graphics Processing Unit 4 8 double 2 4 double-double DD 4 4 8 quad-double
211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS211 211/1/18 GPU 4 8 BLAS 4 8 BLAS Basic Linear Algebra Subprograms GPU Graphics Processing Unit 4 8 double 2 4 double-double DD 4 4 8 quad-double
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司
![4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司](/thumbs/97/131936032.jpg "4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司") 4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
CPU Levels in the memory hierarchy Level 1 Level 2... Increasing distance from the CPU in access time Level n Size of the memory at each level 1: 2.2
 FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
 iphone GPGPU GPU OpenCL Mac OS X Snow LeopardOpenCL iphone OpenCL OpenCL NVIDIA GPU CUDA GPU GPU GPU 15 GPU GPU CPU GPU iii OpenMP MPI CPU OpenCL CUDA OpenCL CPU OpenCL GPU NVIDIA Fermi GPU Fermi GPU GPU
iphone GPGPU GPU OpenCL Mac OS X Snow LeopardOpenCL iphone OpenCL OpenCL NVIDIA GPU CUDA GPU GPU GPU 15 GPU GPU CPU GPU iii OpenMP MPI CPU OpenCL CUDA OpenCL CPU OpenCL GPU NVIDIA Fermi GPU Fermi GPU GPU
GPU n Graphics Processing Unit CG CAD
 GPU 2016/06/27 第 20 回 GPU コンピューティング講習会 ( 東京工業大学 ) 1 GPU n Graphics Processing Unit CG CAD www.nvidia.co.jp www.autodesk.co.jp www.pixar.com GPU n GPU ü n NVIDIA CUDA ü NVIDIA GPU ü OS Linux, Windows, Mac
GPU 2016/06/27 第 20 回 GPU コンピューティング講習会 ( 東京工業大学 ) 1 GPU n Graphics Processing Unit CG CAD www.nvidia.co.jp www.autodesk.co.jp www.pixar.com GPU n GPU ü n NVIDIA CUDA ü NVIDIA GPU ü OS Linux, Windows, Mac
07-二村幸孝・出口大輔.indd
 GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
マルチコアPCクラスタ環境におけるBDD法のハイブリッド並列実装
 2010 GPGPU 2010 9 29 MPI/Pthread (DDM) DDM CPU CPU CPU CPU FEM GPU FEM CPU Mult - NUMA Multprocessng Cell GPU Accelerator, GPU CPU Heterogeneous computng L3 cache L3 cache CPU CPU + GPU GPU L3 cache 4
2010 GPGPU 2010 9 29 MPI/Pthread (DDM) DDM CPU CPU CPU CPU FEM GPU FEM CPU Mult - NUMA Multprocessng Cell GPU Accelerator, GPU CPU Heterogeneous computng L3 cache L3 cache CPU CPU + GPU GPU L3 cache 4
rank ”«‘‚“™z‡Ì GPU ‡É‡æ‡éŁÀŠñ›»
 rank GPU ERATO 2011 11 1 1 / 26 GPU rank/select wavelet tree balanced parenthesis GPU rank 2 / 26 GPU rank/select wavelet tree balanced parenthesis GPU rank 2 / 26 GPU rank/select wavelet tree balanced
rank GPU ERATO 2011 11 1 1 / 26 GPU rank/select wavelet tree balanced parenthesis GPU rank 2 / 26 GPU rank/select wavelet tree balanced parenthesis GPU rank 2 / 26 GPU rank/select wavelet tree balanced
! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2
![! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2](/thumbs/88/115445009.jpg "! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2") ! OpenCL [Open Computing Language] 言 [OpenCL C 言 ] CPU, GPU, Cell/B.E.,DSP 言 行行 [OpenCL Runtime] OpenCL C 言 API Khronos OpenCL Working Group AMD Broadcom Blizzard Apple ARM Codeplay Electronic Arts Freescale
! OpenCL [Open Computing Language] 言 [OpenCL C 言 ] CPU, GPU, Cell/B.E.,DSP 言 行行 [OpenCL Runtime] OpenCL C 言 API Khronos OpenCL Working Group AMD Broadcom Blizzard Apple ARM Codeplay Electronic Arts Freescale
numb.dvi
 11 Poisson kanenko@mbkniftycom alexeikanenko@docomonejp http://wwwkanenkocom/ , u = f, ( u = u+f u t, u = f t ) 1 D R 2 L 2 (D) := {f(x,y) f(x,y) 2 dxdy < )} D D f,g L 2 (D) (f,g) := f(x,y)g(x,y)dxdy (L
11 Poisson kanenko@mbkniftycom alexeikanenko@docomonejp http://wwwkanenkocom/ , u = f, ( u = u+f u t, u = f t ) 1 D R 2 L 2 (D) := {f(x,y) f(x,y) 2 dxdy < )} D D f,g L 2 (D) (f,g) := f(x,y)g(x,y)dxdy (L
ad bc A A A = ad bc ( d ) b c a n A n A n A A det A A ( ) a b A = c d det A = ad bc σ {,,,, n} {,,, } {,,, } {,,, } ( ) σ = σ() = σ() = n sign σ sign(
 b c a n A n A n A A det A A ( ) a b A = c d det A = ad bc σ {,,,, n} {,,, } {,,, } {,,, } ( ) σ = σ() = σ() = n sign σ sign(") I n n A AX = I, YA = I () n XY A () X = IX = (YA)X = Y(AX) = YI = Y X Y () XY A A AB AB BA (AB)(B A ) = A(BB )A = AA = I (BA)(A B ) = B(AA )B = BB = I (AB) = B A (BA) = A B A B A = B = 5 5 A B AB BA A
I n n A AX = I, YA = I () n XY A () X = IX = (YA)X = Y(AX) = YI = Y X Y () XY A A AB AB BA (AB)(B A ) = A(BB )A = AA = I (BA)(A B ) = B(AA )B = BB = I (AB) = B A (BA) = A B A B A = B = 5 5 A B AB BA A
(Basic Theory of Information Processing) 1
 1") (Basic Theory of Information Processing) 1 10 (p.178) Java a[0] = 1; 1 a[4] = 7; i = 2; j = 8; a[i] = j; b[0][0] = 1; 2 b[2][3] = 10; b[i][j] = a[2] * 3; x = a[2]; a[2] = b[i][3] * x; 2 public class Array0
(Basic Theory of Information Processing) 1 10 (p.178) Java a[0] = 1; 1 a[4] = 7; i = 2; j = 8; a[i] = j; b[0][0] = 1; 2 b[2][3] = 10; b[i][j] = a[2] * 3; x = a[2]; a[2] = b[i][3] * x; 2 public class Array0
1 OpenCL OpenCL 1 OpenCL GPU ( ) 1 OpenCL Compute Units Elements OpenCL OpenCL SPMD (Single-Program, Multiple-Data) SPMD OpenCL work-item work-group N
 1 OpenCL Compute Units Elements OpenCL OpenCL SPMD (Single-Program, Multiple-Data) SPMD OpenCL work-item work-group N") GPU 1 1 2 1, 3 2, 3 (Graphics Unit: GPU) GPU GPU GPU Evaluation of GPU Computing Based on An Automatic Program Generation Technology Makoto Sugawara, 1 Katsuto Sato, 1 Kazuhiko Komatsu, 2 Hiroyuki Takizawa
GPU 1 1 2 1, 3 2, 3 (Graphics Unit: GPU) GPU GPU GPU Evaluation of GPU Computing Based on An Automatic Program Generation Technology Makoto Sugawara, 1 Katsuto Sato, 1 Kazuhiko Komatsu, 2 Hiroyuki Takizawa
main.dvi
 PC 1 1 [1][2] [3][4] ( ) GPU(Graphics Processing Unit) GPU PC GPU PC ( 2 GPU ) GPU Harris Corner Detector[5] CPU ( ) ( ) CPU GPU 2 3 GPU 4 5 6 7 1 toyohiro@isc.kyutech.ac.jp 45 2 ( ) CPU ( ) ( ) () 2.1
PC 1 1 [1][2] [3][4] ( ) GPU(Graphics Processing Unit) GPU PC GPU PC ( 2 GPU ) GPU Harris Corner Detector[5] CPU ( ) ( ) CPU GPU 2 3 GPU 4 5 6 7 1 toyohiro@isc.kyutech.ac.jp 45 2 ( ) CPU ( ) ( ) () 2.1
理研スーパーコンピュータ・システム
 線形代数演算ライブラリ BLAS と LAPACK の基礎と実践 2 理化学研究所情報基盤センター 2013/5/30 13:00- 大阪大学基礎工学部 中田真秀 この授業の目的 対象者 - 研究用プログラムを高速化したい人 - LAPACK についてよく知らない人 この講習会の目的 - コンピュータの簡単な仕組みについて - 今後 どうやってプログラムを高速化するか - BLAS, LAPACK
線形代数演算ライブラリ BLAS と LAPACK の基礎と実践 2 理化学研究所情報基盤センター 2013/5/30 13:00- 大阪大学基礎工学部 中田真秀 この授業の目的 対象者 - 研究用プログラムを高速化したい人 - LAPACK についてよく知らない人 この講習会の目的 - コンピュータの簡単な仕組みについて - 今後 どうやってプログラムを高速化するか - BLAS, LAPACK
1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU
![1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU](/thumbs/89/99132402.jpg "1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU") GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
GPU GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1
 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1") GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
倍々精度RgemmのnVidia C2050上への実装と応用
 .. maho@riken.jp http://accc.riken.jp/maho/,,, 2011/2/16 1 - : GPU : SDPA-DD 10 1 - Rgemm : 4 (32 ) nvidia C2050, GPU CPU 150, 24GFlops 25 20 GFLOPS 15 10 QuadAdd Cray, QuadMul Sloppy Kernel QuadAdd Cray,
.. maho@riken.jp http://accc.riken.jp/maho/,,, 2011/2/16 1 - : GPU : SDPA-DD 10 1 - Rgemm : 4 (32 ) nvidia C2050, GPU CPU 150, 24GFlops 25 20 GFLOPS 15 10 QuadAdd Cray, QuadMul Sloppy Kernel QuadAdd Cray,
HPC (pay-as-you-go) HPC Web 2
 HPC Web 2") ,, 1 HPC (pay-as-you-go) HPC Web 2 HPC Amazon EC2 OpenFOAM GPU EC2 3 HPC MPI MPI Courant 1 GPGPU MPI 4 AMAZON EC2 GPU CLUSTER COMPUTE INSTANCE EC2 GPU (cg1.4xlarge) ( N. Virgina ) Quadcore Intel Xeon 5570
,, 1 HPC (pay-as-you-go) HPC Web 2 HPC Amazon EC2 OpenFOAM GPU EC2 3 HPC MPI MPI Courant 1 GPGPU MPI 4 AMAZON EC2 GPU CLUSTER COMPUTE INSTANCE EC2 GPU (cg1.4xlarge) ( N. Virgina ) Quadcore Intel Xeon 5570

インテル(R) Visual Fortran Composer XE
 Visual Fortran Composer XE") Visual Fortran Composer XE 1. 2. 3. 4. 5. Visual Studio 6. Visual Studio 7. 8. Compaq Visual Fortran 9. Visual Studio 10. 2 https://registrationcenter.intel.com/regcenter/ w_fcompxe_all_jp_2013_sp1.1.139.exe
Visual Fortran Composer XE 1. 2. 3. 4. 5. Visual Studio 6. Visual Studio 7. 8. Compaq Visual Fortran 9. Visual Studio 10. 2 https://registrationcenter.intel.com/regcenter/ w_fcompxe_all_jp_2013_sp1.1.139.exe
FIT2013( 第 12 回情報科学技術フォーラム ) I-032 Acceleration of Adaptive Bilateral Filter base on Spatial Decomposition and Symmetry of Weights 1. Taiki Makishi Ch
 I-032 Acceleration of Adaptive Bilateral Filter base on Spatial Decomposition and Symmetry of Weights 1. Taiki Makishi Ch") I-032 Acceleration of Adaptive Bilateral Filter base on Spatial Decomposition and Symmetry of Weights 1. Taiki Makishi Chikatoshi Yamada Shuichi Ichikawa Gaussian Filter GF GF Bilateral Filter BF CG [1]
I-032 Acceleration of Adaptive Bilateral Filter base on Spatial Decomposition and Symmetry of Weights 1. Taiki Makishi Chikatoshi Yamada Shuichi Ichikawa Gaussian Filter GF GF Bilateral Filter BF CG [1]
 2 4 8 13 18 24 29 34 39 44 46 48 1 2 3 4 5 6 7 18 11 11 15 10 16 10 8 9 10 1. 2. 3. 4. 5. 6. 7. 1. 2. 3. 4. 5. 6. 7. 11 1. 2. 3. 4. 5. 6. 7. 12 13 18 12 11 16 25 18 00 CPU Central Processing Unit 14 MUST-CAN-WILL
2 4 8 13 18 24 29 34 39 44 46 48 1 2 3 4 5 6 7 18 11 11 15 10 16 10 8 9 10 1. 2. 3. 4. 5. 6. 7. 1. 2. 3. 4. 5. 6. 7. 11 1. 2. 3. 4. 5. 6. 7. 12 13 18 12 11 16 25 18 00 CPU Central Processing Unit 14 MUST-CAN-WILL
Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]
![Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]](/thumbs/102/156675429.jpg "Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]") 200/0/9 数値流体解析の並列効率とその GPU による高速化の試み 清水建設 ( 株 ) 技術研究所 PHAM VAN PHUC ( ファムバンフック ) 流体計算時間短縮と GPU の活用の試み 現 CPUとの比較によりGPU 活用の可能性 現 CPU の最大利用 ノード内の最大計算資源の利用 すべてCPUコアの利用 適切なアルゴリズムの利用 CPU コア性能の何倍? GPU の利用の試み
200/0/9 数値流体解析の並列効率とその GPU による高速化の試み 清水建設 ( 株 ) 技術研究所 PHAM VAN PHUC ( ファムバンフック ) 流体計算時間短縮と GPU の活用の試み 現 CPUとの比較によりGPU 活用の可能性 現 CPU の最大利用 ノード内の最大計算資源の利用 すべてCPUコアの利用 適切なアルゴリズムの利用 CPU コア性能の何倍? GPU の利用の試み
1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU.....
 CPU GPU N Q07-065 2011 2 17 1 1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU...........................................
CPU GPU N Q07-065 2011 2 17 1 1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU...........................................
Microsoft PowerPoint - GPU_computing_2013_01.pptx
 GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格
GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日
 TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
it-ken_open.key
 深層学習技術の進展 ImageNet Classification 画像認識 音声認識 自然言語処理 機械翻訳 深層学習技術は これらの分野において 特に圧倒的な強みを見せている Figure (Left) Eight ILSVRC-2010 test Deep images and the cited4: from: ``ImageNet Classification with Networks et
深層学習技術の進展 ImageNet Classification 画像認識 音声認識 自然言語処理 機械翻訳 深層学習技術は これらの分野において 特に圧倒的な強みを見せている Figure (Left) Eight ILSVRC-2010 test Deep images and the cited4: from: ``ImageNet Classification with Networks et
Second-semi.PDF
 PC 2000 2 18 2 HPC Agenda PC Linux OS UNIX OS Linux Linux OS HPC 1 1CPU CPU Beowulf PC (PC) PC CPU(Pentium ) Beowulf: NASA Tomas Sterling Donald Becker 2 (PC ) Beowulf PC!! Linux Cluster (1) Level 1:
PC 2000 2 18 2 HPC Agenda PC Linux OS UNIX OS Linux Linux OS HPC 1 1CPU CPU Beowulf PC (PC) PC CPU(Pentium ) Beowulf: NASA Tomas Sterling Donald Becker 2 (PC ) Beowulf PC!! Linux Cluster (1) Level 1:
HPC pdf
 GPU 1 1 2 2 1 1024 3 GPUGraphics Unit1024 3 GPU GPU GPU GPU 1024 3 Tesla S1070-400 1 GPU 2.6 Accelerating Out-of-core Cone Beam Reconstruction Using GPU Yusuke Okitsu, 1 Fumihiko Ino, 1 Taketo Kishi, 2
GPU 1 1 2 2 1 1024 3 GPUGraphics Unit1024 3 GPU GPU GPU GPU 1024 3 Tesla S1070-400 1 GPU 2.6 Accelerating Out-of-core Cone Beam Reconstruction Using GPU Yusuke Okitsu, 1 Fumihiko Ino, 1 Taketo Kishi, 2
2
 ( ) 1 2 3 1.CPU, 2.,,,,,, 3. register, register, 4.L1, L2, (L3), (L4) 4 register L1 cache L2 cache Main Memory,, L2, L1 CPU L2, L1, CPU 5 , 6 dgem2vu 7 ? Wiedemann algorithm u 0, w 0, s i, s i = u 0 Ai
( ) 1 2 3 1.CPU, 2.,,,,,, 3. register, register, 4.L1, L2, (L3), (L4) 4 register L1 cache L2 cache Main Memory,, L2, L1 CPU L2, L1, CPU 5 , 6 dgem2vu 7 ? Wiedemann algorithm u 0, w 0, s i, s i = u 0 Ai
 EASYCOLOR!2 EASYCOLOR!3 EASYCOLOR!2 Mac OS X 版動作確認実施情報 EASYCOLOR!3(Ver 3.0.10.0) 動作確認 PC 環境 CPU GPU OS バージョン MacBook Pro (MB604J/A) Mac Pro (MC560J/A) MacBook Pro (Z0GP00520) Mac mini (MC816J/A)
EASYCOLOR!2 EASYCOLOR!3 EASYCOLOR!2 Mac OS X 版動作確認実施情報 EASYCOLOR!3(Ver 3.0.10.0) 動作確認 PC 環境 CPU GPU OS バージョン MacBook Pro (MB604J/A) Mac Pro (MC560J/A) MacBook Pro (Z0GP00520) Mac mini (MC816J/A)
Microsoft Word - HOKUSAI_system_overview_ja.docx
 HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
GPGPU
 GPGPU 2013 1008 2015 1 23 Abstract In recent years, with the advance of microscope technology, the alive cells have been able to observe. On the other hand, from the standpoint of image processing, the
GPGPU 2013 1008 2015 1 23 Abstract In recent years, with the advance of microscope technology, the alive cells have been able to observe. On the other hand, from the standpoint of image processing, the
チューニング講習会 初級編
 GPU のしくみ RICC での使い方 およびベンチマーク 理化学研究所情報基盤センター 2013/6/27 17:00 17:30 中田真秀 RICC の GPU が高速に! ( 旧 C1060 比約 6.6 倍高速 ) RICCのGPUがC2075になりました! C1060 比 6.6 倍高速 倍精度 515GFlops UPCに100 枚導入 : 合計 51.5TFlops うまく行くと5 倍程度高速化
GPU のしくみ RICC での使い方 およびベンチマーク 理化学研究所情報基盤センター 2013/6/27 17:00 17:30 中田真秀 RICC の GPU が高速に! ( 旧 C1060 比約 6.6 倍高速 ) RICCのGPUがC2075になりました! C1060 比 6.6 倍高速 倍精度 515GFlops UPCに100 枚導入 : 合計 51.5TFlops うまく行くと5 倍程度高速化
2ndD3.eps
 CUDA GPGPU 2012 UDX 12/5/24 p. 1 FDTD GPU FDTD GPU FDTD FDTD FDTD PGI Acceralator CUDA OpenMP Fermi GPU (Tesla C2075/C2070, GTX 580) GT200 GPU (Tesla C1060, GTX 285) PC GPGPU 2012 UDX 12/5/24 p. 2 FDTD
CUDA GPGPU 2012 UDX 12/5/24 p. 1 FDTD GPU FDTD GPU FDTD FDTD FDTD PGI Acceralator CUDA OpenMP Fermi GPU (Tesla C2075/C2070, GTX 580) GT200 GPU (Tesla C1060, GTX 285) PC GPGPU 2012 UDX 12/5/24 p. 2 FDTD
fortranfunction2.qxd
 Fortran Numerical Library Function Catalog IMSL TM Fortran Numerical Library Function Catalog IMSL Fortran 4 8 9 10 IMSL Java TM C 12 IMSL Math / Library 13 13 21 23 27 28 29 31 32 34 40 41 IMSL Math /
Fortran Numerical Library Function Catalog IMSL TM Fortran Numerical Library Function Catalog IMSL Fortran 4 8 9 10 IMSL Java TM C 12 IMSL Math / Library 13 13 21 23 27 28 29 31 32 34 40 41 IMSL Math /

HP High Performance Computing(HPC)
") ACCELERATE HP High Performance Computing HPC HPC HPC HPC HPC 1000 HPHPC HPC HP HPC HPC HPC HP HPCHP HP HPC 1 HPC HP 2 HPC HPC HP ITIDC HP HPC 1HPC HPC No.1 HPC TOP500 2010 11 HP 159 32% HP HPCHP 2010 Q1-Q4
ACCELERATE HP High Performance Computing HPC HPC HPC HPC HPC 1000 HPHPC HPC HP HPC HPC HPC HP HPCHP HP HPC 1 HPC HP 2 HPC HPC HP ITIDC HP HPC 1HPC HPC No.1 HPC TOP500 2010 11 HP 159 32% HP HPCHP 2010 Q1-Q4

 N N 1,, N 2 N N N N N 1,, N 2 N N N N N 1,, N 2 N N N 8 1 6 3 5 7 4 9 2 1 12 13 8 15 6 3 10 4 9 16 5 14 7 2 11 7 11 23 5 19 3 20 9 12 21 14 22 1 18 10 16 8 15 24 2 25 4 17 6 13 8 1 6 3 5 7 4 9 2 1 12 13
N N 1,, N 2 N N N N N 1,, N 2 N N N N N 1,, N 2 N N N 8 1 6 3 5 7 4 9 2 1 12 13 8 15 6 3 10 4 9 16 5 14 7 2 11 7 11 23 5 19 3 20 9 12 21 14 22 1 18 10 16 8 15 24 2 25 4 17 6 13 8 1 6 3 5 7 4 9 2 1 12 13

")
MBLAS¤ÈMLAPACK; ¿ÇÜĹÀºÅÙÈǤÎBLAS/LAPACK¤ÎºîÀ®
 MBLAS MLAPACK; BLAS/LAPACK maho@riken.jp February 23, 2009 MPACK(MBLAS/MLAPACK) ( ) (2007 ) ( ) http://accc.riken.jp/maho/ BLAS/LAPACK http://mplapack.sourceforge.net/ BLAS (Basic Linear Algebra Subprograms)
MBLAS MLAPACK; BLAS/LAPACK maho@riken.jp February 23, 2009 MPACK(MBLAS/MLAPACK) ( ) (2007 ) ( ) http://accc.riken.jp/maho/ BLAS/LAPACK http://mplapack.sourceforge.net/ BLAS (Basic Linear Algebra Subprograms)
(2) ( 61129) 117, ,678 10,000 10,000 6 ( 7530) 149, ,218 10,000 10,000 7 ( 71129) 173, ,100 10,000 10,000 8 ( 8530) 14
 ( 61129) 117, ,678 10,000 10,000 6 ( 7530) 149, ,218 10,000 10,000 7 ( 71129) 173, ,100 10,000 10,000 8 ( 8530) 14") 16 8 26 MMF 23 25 5 16 7 16 16 8 1 7 16 8 2 16 8 26 16 8 26 P19 (1) 16630 16,999,809,767 55.69 4,499,723,571 14.74 9,024,172,452 29.56 30,523,705,790 100.00 1 (2) 16 6 30 1 1 5 ( 61129) 117,671 117,678
16 8 26 MMF 23 25 5 16 7 16 16 8 1 7 16 8 2 16 8 26 16 8 26 P19 (1) 16630 16,999,809,767 55.69 4,499,723,571 14.74 9,024,172,452 29.56 30,523,705,790 100.00 1 (2) 16 6 30 1 1 5 ( 61129) 117,671 117,678
11050427-0_Vol16No3.indd
 2599 チュートリアル BLAS, LAPACK 2 2 GPU BLAS, LAPACKチュートリアル パート2 (GPU 編 ) 中 田 真 秀 1 はじめに GPU Graphics Processing Unit BLAS, LAPACK GPU GPU NVIDIA AMD AMD RADEON HD NVIDIA NVIDIA GPU NVIDIA C2050 BLAS, LAPACK
2599 チュートリアル BLAS, LAPACK 2 2 GPU BLAS, LAPACKチュートリアル パート2 (GPU 編 ) 中 田 真 秀 1 はじめに GPU Graphics Processing Unit BLAS, LAPACK GPU GPU NVIDIA AMD AMD RADEON HD NVIDIA NVIDIA GPU NVIDIA C2050 BLAS, LAPACK
EGunGPU
 Super Computing in Accelerator simulations - Electron Gun simulation using GPGPU - K. Ohmi, KEK-Accel Accelerator Physics seminar 2009.11.19 Super computers in KEK HITACHI SR11000 POWER5 16 24GB 16 134GFlops,
Super Computing in Accelerator simulations - Electron Gun simulation using GPGPU - K. Ohmi, KEK-Accel Accelerator Physics seminar 2009.11.19 Super computers in KEK HITACHI SR11000 POWER5 16 24GB 16 134GFlops,
( ) a C n ( R n ) R a R C n. a C n (or R n ) a 0 2. α C( R ) a C n αa = α a 3. a, b C n a + b a + b ( ) p 8..2 (p ) a = [a a n ] T C n p n a
![( ) a C n ( R n ) R a R C n. a C n (or R n ) a 0 2. α C( R ) a C n αa = α a 3. a, b C n a + b a + b ( ) p 8..2 (p ) a = [a a n ] T C n p n a](/thumbs/91/106692724.jpg "( ) a C n ( R n ) R a R C n. a C n (or R n ) a 0 2. α C( R ) a C n αa = α a 3. a, b C n a + b a + b ( ) p 8..2 (p ) a = [a a n ] T C n p n a") 9 8 m n mn N.J.Nigham, Accuracy and Stability of Numerical Algorithms 2nd ed., (SIAM) x x = x2 + y 2 = x + y = max( x, y ) x y x () (norm) (condition number) 8. R C a, b C a b 0 a, b a = a 0 0 0 n C n
9 8 m n mn N.J.Nigham, Accuracy and Stability of Numerical Algorithms 2nd ed., (SIAM) x x = x2 + y 2 = x + y = max( x, y ) x y x () (norm) (condition number) 8. R C a, b C a b 0 a, b a = a 0 0 0 n C n


直交座標系の回転
 b T.Koama x l x, Lx i ij j j xi i i i, x L T L L, L ± x L T xax axx, ( a a ) i, j ij i j ij ji λ λ + λ + + λ i i i x L T T T x ( L) L T xax T ( T L T ) A( L) T ( LAL T ) T ( L AL) λ ii L AL Λ λi i axx
b T.Koama x l x, Lx i ij j j xi i i i, x L T L L, L ± x L T xax axx, ( a a ) i, j ij i j ij ji λ λ + λ + + λ i i i x L T T T x ( L) L T xax T ( T L T ) A( L) T ( LAL T ) T ( L AL) λ ii L AL Λ λi i axx
supercomputer2010.ppt
 nanri@cc.kyushu-u.ac.jp 1 !! : 11 12! : nanri@cc.kyushu-u.ac.jp! : Word 2 ! PC GPU) 1997 7 http://wiredvision.jp/news/200806/2008062322.html 3 !! (Cell, GPU )! 4 ! etc...! 5 !! etc. 6 !! 20km 40 km ) 340km
nanri@cc.kyushu-u.ac.jp 1 !! : 11 12! : nanri@cc.kyushu-u.ac.jp! : Word 2 ! PC GPU) 1997 7 http://wiredvision.jp/news/200806/2008062322.html 3 !! (Cell, GPU )! 4 ! etc...! 5 !! etc. 6 !! 20km 40 km ) 340km




P072-076.indd
 3 STEP0 STEP1 STEP2 STEP3 STEP4 072 3STEP4 STEP3 STEP2 STEP1 STEP0 073 3 STEP0 STEP1 STEP2 STEP3 STEP4 074 3STEP4 STEP3 STEP2 STEP1 STEP0 075 3 STEP0 STEP1 STEP2 STEP3 STEP4 076 3STEP4 STEP3 STEP2 STEP1
3 STEP0 STEP1 STEP2 STEP3 STEP4 072 3STEP4 STEP3 STEP2 STEP1 STEP0 073 3 STEP0 STEP1 STEP2 STEP3 STEP4 074 3STEP4 STEP3 STEP2 STEP1 STEP0 075 3 STEP0 STEP1 STEP2 STEP3 STEP4 076 3STEP4 STEP3 STEP2 STEP1





 STEP1 STEP3 STEP2 STEP4 STEP6 STEP5 STEP7 10,000,000 2,060 38 0 0 0 1978 4 1 2015 9 30 15,000,000 2,060 38 0 0 0 197941 2016930 10,000,000 2,060 38 0 0 0 197941 2016930 3 000 000 0 0 0 600 15
STEP1 STEP3 STEP2 STEP4 STEP6 STEP5 STEP7 10,000,000 2,060 38 0 0 0 1978 4 1 2015 9 30 15,000,000 2,060 38 0 0 0 197941 2016930 10,000,000 2,060 38 0 0 0 197941 2016930 3 000 000 0 0 0 600 15

1
 1 2 3 4 5 6 7 8 9 0 1 2 6 3 1 2 3 4 5 6 7 8 9 0 5 4 STEP 02 STEP 01 STEP 03 STEP 04 1F 1F 2F 2F 2F 1F 1 2 3 4 5 http://smarthouse-center.org/sdk/ http://smarthouse-center.org/inquiries/ http://sh-center.org/
1 2 3 4 5 6 7 8 9 0 1 2 6 3 1 2 3 4 5 6 7 8 9 0 5 4 STEP 02 STEP 01 STEP 03 STEP 04 1F 1F 2F 2F 2F 1F 1 2 3 4 5 http://smarthouse-center.org/sdk/ http://smarthouse-center.org/inquiries/ http://sh-center.org/

n ( (
 1 2 27 6 1 1 m-mat@mathscihiroshima-uacjp 2 http://wwwmathscihiroshima-uacjp/~m-mat/teach/teachhtml 2 1 3 11 3 111 3 112 4 113 n 4 114 5 115 5 12 7 121 7 122 9 123 11 124 11 125 12 126 2 2 13 127 15 128
1 2 27 6 1 1 m-mat@mathscihiroshima-uacjp 2 http://wwwmathscihiroshima-uacjp/~m-mat/teach/teachhtml 2 1 3 11 3 111 3 112 4 113 n 4 114 5 115 5 12 7 121 7 122 9 123 11 124 11 125 12 126 2 2 13 127 15 128
線形代数演算ライブラリBLASとLAPACKの 基礎と実践1
 1 / 50 BLAS LAPACK 1, 2015/05/21 CMSI A 2 / 50 BLAS LAPACK (I) BLAS, LAPACK BLAS : - LAPACK : 3 / 50 ( ) 1000 ( ; 1 2 ) :... 3 / 50 ( ) 1000 ( ; 1 2 ) :... 3 / 50 ( ) 1000 ( ; 1 2 ) :... 3 / 50 ( ) 1000
1 / 50 BLAS LAPACK 1, 2015/05/21 CMSI A 2 / 50 BLAS LAPACK (I) BLAS, LAPACK BLAS : - LAPACK : 3 / 50 ( ) 1000 ( ; 1 2 ) :... 3 / 50 ( ) 1000 ( ; 1 2 ) :... 3 / 50 ( ) 1000 ( ; 1 2 ) :... 3 / 50 ( ) 1000
<4D F736F F F696E74202D2091E63489F15F436F6D C982E682E992B48D8291AC92B489B F090CD2888F38DFC E B8CDD8
 Web キャンパス資料 超音波シミュレーションの基礎 ~ 第 4 回 ComWAVEによる超高速超音波解析 ~ 科学システム開発部 Copyright (c)2006 ITOCHU Techno-Solutions Corporation 本日の説明内容 ComWAVEの概要および特徴 GPGPUとは GPGPUによる解析事例 CAE POWER 超音波研究会開催 (10 月 3 日 ) のご紹介
Web キャンパス資料 超音波シミュレーションの基礎 ~ 第 4 回 ComWAVEによる超高速超音波解析 ~ 科学システム開発部 Copyright (c)2006 ITOCHU Techno-Solutions Corporation 本日の説明内容 ComWAVEの概要および特徴 GPGPUとは GPGPUによる解析事例 CAE POWER 超音波研究会開催 (10 月 3 日 ) のご紹介
GPGPU によるアクセラレーション環境について
 GPGPU によるアクセラレーション環境について 長屋貴量 自然科学研究機構分子科学研究所技術課計算科学技術班 概要 GPGPU とは 単純で画一的なデータを一度に大量に処理することに特化したグラフィックカードの演算資源を 画像処理以外の汎用的な目的に応用する技術の一つである 近年 その演算能力は CPU で通常言われるムーアの法則に則った場合とは異なり 飛躍的に向上しており その演算性能に魅力を感じた各分野での応用が広がってきている
GPGPU によるアクセラレーション環境について 長屋貴量 自然科学研究機構分子科学研究所技術課計算科学技術班 概要 GPGPU とは 単純で画一的なデータを一度に大量に処理することに特化したグラフィックカードの演算資源を 画像処理以外の汎用的な目的に応用する技術の一つである 近年 その演算能力は CPU で通常言われるムーアの法則に則った場合とは異なり 飛躍的に向上しており その演算性能に魅力を感じた各分野での応用が広がってきている
a n a n ( ) (1) a m a n = a m+n (2) (a m ) n = a mn (3) (ab) n = a n b n (4) a m a n = a m n ( m > n ) m n 4 ( ) 552
 (1) a m a n = a m+n (2) (a m ) n = a mn (3) (ab) n = a n b n (4) a m a n = a m n ( m > n ) m n 4 ( ) 552") 3 3.0 a n a n ( ) () a m a n = a m+n () (a m ) n = a mn (3) (ab) n = a n b n (4) a m a n = a m n ( m > n ) m n 4 ( ) 55 3. (n ) a n n a n a n 3 4 = 8 8 3 ( 3) 4 = 8 3 8 ( ) ( ) 3 = 8 8 ( ) 3 n n 4 n n
3 3.0 a n a n ( ) () a m a n = a m+n () (a m ) n = a mn (3) (ab) n = a n b n (4) a m a n = a m n ( m > n ) m n 4 ( ) 55 3. (n ) a n n a n a n 3 4 = 8 8 3 ( 3) 4 = 8 3 8 ( ) ( ) 3 = 8 8 ( ) 3 n n 4 n n
untitled
 20 7 1 22 7 1 1 2 3 7 8 9 10 11 13 14 15 17 18 19 21 22 - 1 - - 2 - - 3 - - 4 - 50 200 50 200-5 - 50 200 50 200 50 200 - 6 - - 7 - () - 8 - (XY) - 9 - 112-10 - - 11 - - 12 - - 13 - - 14 - - 15 - - 16 -
20 7 1 22 7 1 1 2 3 7 8 9 10 11 13 14 15 17 18 19 21 22 - 1 - - 2 - - 3 - - 4 - 50 200 50 200-5 - 50 200 50 200 50 200 - 6 - - 7 - () - 8 - (XY) - 9 - 112-10 - - 11 - - 12 - - 13 - - 14 - - 15 - - 16 -
untitled
 19 1 19 19 3 8 1 19 1 61 2 479 1965 64 1237 148 1272 58 183 X 1 X 2 12 2 15 A B 5 18 B 29 X 1 12 10 31 A 1 58 Y B 14 1 25 3 31 1 5 5 15 Y B 1 232 Y B 1 4235 14 11 8 5350 2409 X 1 15 10 10 B Y Y 2 X 1 X
19 1 19 19 3 8 1 19 1 61 2 479 1965 64 1237 148 1272 58 183 X 1 X 2 12 2 15 A B 5 18 B 29 X 1 12 10 31 A 1 58 Y B 14 1 25 3 31 1 5 5 15 Y B 1 232 Y B 1 4235 14 11 8 5350 2409 X 1 15 10 10 B Y Y 2 X 1 X

XACCの概要
 2 global void kernel(int a[max], int llimit, int ulimit) {... } : int main(int argc, char *argv[]){ MPI_Int(&argc, &argc); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); dx
2 global void kernel(int a[max], int llimit, int ulimit) {... } : int main(int argc, char *argv[]){ MPI_Int(&argc, &argc); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); dx
HPC可視化_小野2.pptx
 大 小 二 生 高 方 目 大 方 方 方 Rank Site Processors RMax Processor System Model 1 DOE/NNSA/LANL 122400 1026000 PowerXCell 8i BladeCenter QS22 Cluster 2 DOE/NNSA/LLNL 212992 478200 PowerPC 440 BlueGene/L 3 Argonne
大 小 二 生 高 方 目 大 方 方 方 Rank Site Processors RMax Processor System Model 1 DOE/NNSA/LANL 122400 1026000 PowerXCell 8i BladeCenter QS22 Cluster 2 DOE/NNSA/LLNL 212992 478200 PowerPC 440 BlueGene/L 3 Argonne
システムソリューションのご紹介
 HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
Part y mx + n mt + n m 1 mt n + n t m 2 t + mn 0 t m 0 n 18 y n n a 7 3 ; x α α 1 7α +t t 3 4α + 3t t x α x α y mx + n
 Part2 47 Example 161 93 1 T a a 2 M 1 a 1 T a 2 a Point 1 T L L L T T L L T L L L T T L L T detm a 1 aa 2 a 1 2 + 1 > 0 11 T T x x M λ 12 y y x y λ 2 a + 1λ + a 2 2a + 2 0 13 D D a + 1 2 4a 2 2a + 2 a
Part2 47 Example 161 93 1 T a a 2 M 1 a 1 T a 2 a Point 1 T L L L T T L L T L L L T T L L T detm a 1 aa 2 a 1 2 + 1 > 0 11 T T x x M λ 12 y y x y λ 2 a + 1λ + a 2 2a + 2 0 13 D D a + 1 2 4a 2 2a + 2 a
II
 II 16 16.0 2 1 15 x α 16 x n 1 17 (x α) 2 16.1 16.1.1 2 x P (x) P (x) = 3x 3 4x + 4 369 Q(x) = x 4 ax + b ( ) 1 P (x) x Q(x) x P (x) x P (x) x = a P (a) P (x) = x 3 7x + 4 P (2) = 2 3 7 2 + 4 = 8 14 +
II 16 16.0 2 1 15 x α 16 x n 1 17 (x α) 2 16.1 16.1.1 2 x P (x) P (x) = 3x 3 4x + 4 369 Q(x) = x 4 ax + b ( ) 1 P (x) x Q(x) x P (x) x P (x) x = a P (a) P (x) = x 3 7x + 4 P (2) = 2 3 7 2 + 4 = 8 14 +
GPU CUDA CUDA 2010/06/28 1
 GPU CUDA CUDA 2010/06/28 1 GPU NVIDIA Mark Harris, Optimizing Parallel Reduction in CUDA http://developer.download.nvidia.com/ compute/cuda/1_1/website/data- Parallel_Algorithms.html#reduction CUDA SDK
GPU CUDA CUDA 2010/06/28 1 GPU NVIDIA Mark Harris, Optimizing Parallel Reduction in CUDA http://developer.download.nvidia.com/ compute/cuda/1_1/website/data- Parallel_Algorithms.html#reduction CUDA SDK
フカシギおねえさん問題の高速計算アルゴリズム
 JST ERATO 2013/7/26 Joint work with 1 / 37 1 2 3 4 5 6 2 / 37 1 2 3 4 5 6 3 / 37 : 4 / 37 9 9 6 10 10 25 5 / 37 9 9 6 10 10 25 Bousquet-Mélou (2005) 19 19 3 1GHz Alpha 8 Iwashita (Sep 2012) 21 21 3 2.67GHz
JST ERATO 2013/7/26 Joint work with 1 / 37 1 2 3 4 5 6 2 / 37 1 2 3 4 5 6 3 / 37 : 4 / 37 9 9 6 10 10 25 5 / 37 9 9 6 10 10 25 Bousquet-Mélou (2005) 19 19 3 1GHz Alpha 8 Iwashita (Sep 2012) 21 21 3 2.67GHz
 () 1 1 2 2 3 2 3 308,000 308,000 308,000 199,200 253,000 308,000 77,100 115,200 211,000 308,000 211,200 62,200 185,000 308,000 154,000 308,000 2 () 308,000 308,000 253,000 308,000 77,100 211,000 308,000
() 1 1 2 2 3 2 3 308,000 308,000 308,000 199,200 253,000 308,000 77,100 115,200 211,000 308,000 211,200 62,200 185,000 308,000 154,000 308,000 2 () 308,000 308,000 253,000 308,000 77,100 211,000 308,000
: : : : ) ) 1. d ij f i e i x i v j m a ij m f ij n x i =
 ) 1. d ij f i e i x i v j m a ij m f ij n x i =") 1 1980 1) 1 2 3 19721960 1965 2) 1999 1 69 1980 1972: 55 1999: 179 2041999: 210 211 1999: 211 3 2003 1987 92 97 3) 1960 1965 1970 1985 1990 1995 4) 1. d ij f i e i x i v j m a ij m f ij n x i = n d ij
1 1980 1) 1 2 3 19721960 1965 2) 1999 1 69 1980 1972: 55 1999: 179 2041999: 210 211 1999: 211 3 2003 1987 92 97 3) 1960 1965 1970 1985 1990 1995 4) 1. d ij f i e i x i v j m a ij m f ij n x i = n d ij
1 (bit ) ( ) PC WS CPU IEEE754 standard ( 24bit) ( 53bit)
 ( ) PC WS CPU IEEE754 standard ( 24bit) ( 53bit)") GNU MP BNCpack tkouya@cs.sist.ac.jp 2002 9 20 ( ) Linux Conference 2002 1 1 (bit ) ( ) PC WS CPU IEEE754 standard ( 24bit) ( 53bit) 10 2 2 3 4 5768:9:; = %? @BADCEGFH-I:JLKNMNOQP R )TSVU!" # %$ & " #
GNU MP BNCpack tkouya@cs.sist.ac.jp 2002 9 20 ( ) Linux Conference 2002 1 1 (bit ) ( ) PC WS CPU IEEE754 standard ( 24bit) ( 53bit) 10 2 2 3 4 5768:9:; = %? @BADCEGFH-I:JLKNMNOQP R )TSVU!" # %$ & " #
A11 (1993,1994) 29 A12 (1994) 29 A13 Trefethen and Bau Numerical Linear Algebra (1997) 29 A14 (1999) 30 A15 (2003) 30 A16 (2004) 30 A17 (2007) 30 A18
 29 A12 (1994) 29 A13 Trefethen and Bau Numerical Linear Algebra (1997) 29 A14 (1999) 30 A15 (2003) 30 A16 (2004) 30 A17 (2007) 30 A18") 2013 8 29y, 2016 10 29 1 2 2 Jordan 3 21 3 3 Jordan (1) 3 31 Jordan 4 32 Jordan 4 33 Jordan 6 34 Jordan 8 35 9 4 Jordan (2) 10 41 x 11 42 x 12 43 16 44 19 441 19 442 20 443 25 45 25 5 Jordan 26 A 26 A1
2013 8 29y, 2016 10 29 1 2 2 Jordan 3 21 3 3 Jordan (1) 3 31 Jordan 4 32 Jordan 4 33 Jordan 6 34 Jordan 8 35 9 4 Jordan (2) 10 41 x 11 42 x 12 43 16 44 19 441 19 442 20 443 25 45 25 5 Jordan 26 A 26 A1
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];

 1 z q w e r t y x c q w 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 R R 32 33 34 35 36 MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR
1 z q w e r t y x c q w 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 R R 32 33 34 35 36 MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR MR
線形代数演算ライブラリBLASとLAPACKの 基礎と実践1
 .. BLAS LAPACK 1, 2013/05/23 CMSI A 1 / 43 BLAS LAPACK (I) BLAS, LAPACK BLAS : - LAPACK : 2 / 43 : 3 / 43 (wikipedia) V : f : V u, v u + v u + v V α K u V αu V V x, y f (x + y) = f (x) + f (y) V x K α
.. BLAS LAPACK 1, 2013/05/23 CMSI A 1 / 43 BLAS LAPACK (I) BLAS, LAPACK BLAS : - LAPACK : 2 / 43 : 3 / 43 (wikipedia) V : f : V u, v u + v u + v V α K u V αu V V x, y f (x + y) = f (x) + f (y) V x K α
![Œ{Ł¶/1ŒÊ −ªfiª„¾ [ 1…y†[…W ]](/thumbs/50/26134150.jpg "Œ{Ł¶/1ŒÊ −ªfiª„¾ [ 1…y†[…W ]")



平成20年5月 協会創立50年の歩み 海の安全と環境保全を目指して 友國八郎 海上保安庁 長官 岩崎貞二 日本船主協会 会長 前川弘幸 JF全国漁業協同組合連合会 代表理事会長 服部郁弘 日本船長協会 会長 森本靖之 日本船舶機関士協会 会長 大内博文 航海訓練所 練習船船長 竹本孝弘 第二管区海上保安本部長 梅田宜弘





高性能計算研究室の紹介 High Performance Computing Lab.
 高性能計算研究室 (HPC Lab) の紹介 High Performance Computing Lab. 静岡理工科大学総合情報学部コンピュータシステム学科 ( 兼 Web デザイン特別プログラム ) 幸谷智紀 543 研究室 幸谷研究室 @ 静岡 検索 概要 1. 幸谷智紀 個人の研究テーマ 2. 3 年生ゼミ ( 情報セミナー II) 3. 卒研テーマ 4. 過去の卒研 5. 今後について
高性能計算研究室 (HPC Lab) の紹介 High Performance Computing Lab. 静岡理工科大学総合情報学部コンピュータシステム学科 ( 兼 Web デザイン特別プログラム ) 幸谷智紀 543 研究室 幸谷研究室 @ 静岡 検索 概要 1. 幸谷智紀 個人の研究テーマ 2. 3 年生ゼミ ( 情報セミナー II) 3. 卒研テーマ 4. 過去の卒研 5. 今後について