Amazon Relational Database Service (Amazon RDS)
|
|
|
- ちかこ ちゅうか
- 5 years ago
- Views:
Transcription

1 Amazon Aurora AWS Black Belt Online Seminar 2016 アマゾンウェブサービスジャパン株式会社ソリューションアーキテクト星野豊
 火曜 12:00~13:00 主にAWSのソリューションや 業界カットでの使いどころなどを紹介 (例 ネットワーク IoT 金融業界向け etc.) 最新の情報は下記をご確認下さい オンラインセミナーのスケジュール&申し込みサイト http://aws.amazon.")
2 AWS Black Belt Online Seminar とは AWSJのTechメンバがAWSに関する様々な事を紹介するオンラインセミナーです 水曜 18:00~19:00 主にAWSサービスの紹介や アップデートの解説 (例 EC2 RDS Lambda etc.) 火曜 12:00~13:00 主にAWSのソリューションや 業界カットでの使いどころなどを紹介 (例 ネットワーク IoT 金融業界向け etc.) 最新の情報は下記をご確認下さい オンラインセミナーのスケジュール&申し込みサイト
3 内容についての注意点 本資料では 2016 年 7 月 29 日時点のサービス内容および価格についてご説明しています 最新の情報は AWS 公式ウェブサイト ( ) にてご確認ください 資料作成には十分注意しておりますが 資料内の価格と AWS 公式ウェブサイト記載の価格に相違があった場合 AWS 公式ウェブサイトの価格を優先とさせていただきます 価格は税抜表記となっています 日本居住者のお客様が東京リージョンを使用する場合 別途消費税をご請求させていただきます AWS does not offer binding price quotes. AWS pricing is publicly available and is subject to change in accordance with the AWS Customer Agreement available at Any pricing information included in this document is provided only as an estimate of usage charges for AWS services based on certain information that you have provided. Monthly charges will be based on your actual use of AWS services, and may vary from the estimates provided.
4 今回お話する内容は 2016/7/29 現在の情報です

5 Amazon Aurora
6 データベース管理を簡単に データベースを数分で作成可能 自動でパッチの適用 数クリックするだけでスケールアウト可能 S3への継続的なバックアップ 障害の自動検知と自動フェールオーバ DBAが本来行うべき作業に注力して頂けるように スキーマ設計 チューニング クエリ設計 チューニング などなど Amazon RDS
7 Virginia / Oregon / Ireland / Sydney / Tokyo / Seoul / Mumbai リージョン






8 Amazon Aurora の特徴 ハイパフォーマンス スケーラブル MySQL5.6 互換 セキュリティにも配慮 フルマネージド 高可用性 高耐久性

9 リレーショナルデータベースをもう一度考える 今 データベースを再度実装するならどうする か 少なくとも1970年代の方法で実装はしない AWSサービスを活かすことができ スケールアウトが簡単で セルフヒーリングが出来るようなデータベースを作りたいと考 えた

10 MySQL のエコシステムをそのまま活用可能 Amazon Aurora に対してコンパチビリティを確認するテストスイートを実施し 全て完璧に動作を行うことが確認出来ました - Dan Jewett, Vice President of Product Management at Tableau Business Intelligence Data Integration Query and Monitoring SI and Consulting Source: Amazon

11 多くのサードパーティ監視ツールが利用可能
12 Memory インスタンスタイプ 244GB r3.8xl 122GB r3.4xl 60GB r3.2xl 32GB r3.xl 16GB r3.large 8GB 4GB 1GB 1core 2core 4core 8core 16core 32core vcpu
13 アーキテクチャ
14 Service Oriented Architecture Data Plane ログとストレージレイヤをシー ムレスにスケールするストレー ジサービスに移動 EC2, Amazon DynamoDB, Amazon SWFなどのAWSサー ビスを管理コンポーネントに採 用 Amazon S3を利用して %の耐久性でス トリーミングバックアップ Control Plane SQL Transactions Amazon DynamoDB Caching Logging + Storage Amazon S3 Amazon SWF Amazon Route 53
15 キャッシュレイヤの分離 キャッシュをデータベースプロセ ス外に移動 データベースプロセスのリスター トが発生してもキャッシュが残っ た状態を維持可能 サービスにすぐデータベースを戻 すことが出来る 高速なクラッシュリカバリ + 保持 可能なキャッシュ = DB障害から 高速に復帰可能 キャッシュプロセスをDBプロセス外におくことで DBプロセスの再起動でもキャッシュが残る SQL SQL SQL Transactions Transactions Transactions Caching Caching Caching
16 セキュリティ Application データの暗号化 AES-256 (ハードウエア支援) ディスクとAmazon S3に置かれている全ブロックを暗号化 AWS KMSを利用したキー管理 SSLを利用したデータ通信の保護 標準でAmazon VPCを使ったネットワークの分 離 SQL Transactions Caching Storage ノードへ直接アクセスは不可能 Amazon S3
17 Auroraのストレージ AZ 1 SSDを利用したシームレス にスケールするストレージ AZ 2 SQL Transactions Caching 標準で高可用性を実現 Log structured Storage Amazon S3 AZ 3
18 Auroraのストレージの特徴 リードレプリカもマスタと同じストレージを参照 継続的なS3へ増分バックアップ パフォーマンスへの影響なし 64TBまで自動でストレージがシームレスにスケールアッ プ パフォーマンスや可用性に影響無し 利用開始時のプロビジョニング不要 自動で再ストライピング ミラー修復 ホットスポット 管理 暗号化

19 ディスク障害検知と修復 2つのコピーに障害が起こっても 読み書きに影響は無い 3つのコピーに障害が発生しても読み込みは可能 自動検知 修復 AZ 1 AZ 2 SQL AZ 3 AZ 1 AZ 2 SQL Transactio n Transaction Caching Caching 読み込み可能 読み書き可能 AZ 3
20 IO traffic in Aurora ( ストレージノード ) STORAGE NODE IO FLOW Primary instance Peer storage nodes LOG RECORDS 4 ACK INCOMING QUEUE 2 PEER-TO-PEER GOSSIP SORT GROUP UPDATE QUEUE HOT LOG 3 1 COALESCE 5 POINT IN TIME SNAPSHOT 6 S3 BACKUP GC DATA BLOCKS 7 SCRUB 8 1 レコードを受信しインメモリのキューに追加 2 レコードを SSD に永続化して ACK 3 レコードを整理してギャップを把握 4 ピアと通信して穴埋め 5 ログレコードを新しいバージョンのデータブロックに合体 6 定期的にログと新しいバージョンのブロックを S3 に転送 7 定期的に古いバージョンのガベージコレクションを実施 8 定期的にブロックの CRC を検証 OBSERVATIONS 全てのステップは非同期ステップ 1 と 2 だけがフォアグラウンドのレイテンシーに影響インプットキューは MySQL の 1/46 (unamplified, per node) レイテンシーにセンシティブな操作に向くディスク領域をバッファーに使ってスパイクに対処
21 レプリケーション MySQL Master シングルスレッド でBinlog適用 MySQL Replica Aurora Replica PAGE CACHE UPDATE 70% Write 70% Write 70% Write 30% Read 30% New Reads 30% Read Data Volume Data Volume MySQL read scaling Aurora Master レプリケーションにはbinlog / relay logが必要 レプリケーションはマスターへ負荷がかかる レプリケーション遅延が増加していくケースが ある フェイルオーバでデータロスの可能性がある 100% New Reads Shared Multi-AZ Storage
22 コスト比較 : Aurora vs. RDS for MySQL Primary r3.8xl $1.33/hr Replica r3.8xl $1.33/hr Replica R3.8XL $1.33/hr Storage 6 TB / 10 K PIOP $2,42/hr Storage 6 TB / 5 K PIOP $2,42/hr Storage 6 TB / 5 K PIOP $2,42/hr Standby r3.8xl $1.33/hr Instance cost: Storage cost: $5.32 / hr $8.30 / hr Storage 6 TB / 10 K PIOP $2,42/hr Total cost: $13.62 / hr

23 コスト比較 : Aurora vs. RDS for MySQL $1.62 / hr $1.62 / hr $1.62 / hr スタンバイインスタンスのコストが不要 Primary r3.8xl Replica r3.8xl Replica R3.8XL 1 つの共有ストレージ $4.43 / hr No POIPs pay for use I/O Storage / 6 TB Instance cost: Storage cost: Total cost: $4.86 / hr $4.43 / hr $9.29 / hr 31.8% Savings
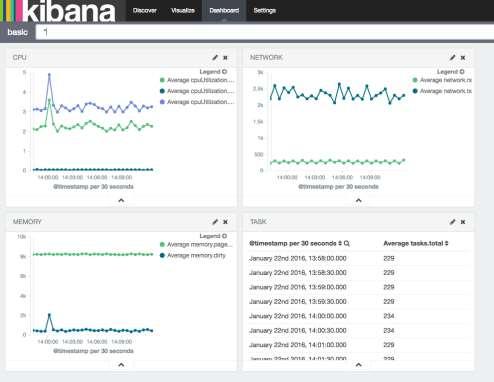
24 新しいメトリクス画面 Throughput Select Commit DML/DDL Select Commit DML/DDL Buffer Cache Result Set Latency Cache Hit Ratio Deadlocks Login Failures Blocked Transactions
25 新しいメトリクス画面 課金に関わるディスク利用量やIOPS Billed storage Billed read operations Billed write operations
26 フェイルオーバとリカバリ
27 フェイルオーバ と リプレース リードレプリカが存在する場合は1分程でフェイル オーバ可能 RDS for MySQLよりも高速にフェイルオーバ可能 リードレプリカが存在しない場合は15分程 Multi-AZ配置として別AZで起動する RDS for MySQLと違いリードアクセス可能
28 クラスタエンドポイント WriterとReaderのセットをクラスタと呼び クラスタで常にWriter(マスタ)を指すクラ スタエンドポイントが存在する 各Auroraノードは個別にエンドポイントを持っている(虫眼鏡タブ内のEndpointで確認可 能) Writer Reader
29 クラスタエンドポイント 各Auroraノードは個別 にエンドポイントを 持っている VPC subnet Write VPC subnet クラスタエンドポイン トは その時アクティ ブなAurora Writerノー ドのCNAME クラスタエンドポイント Aurora Writer VPC subnet Availability Zone A Aurora Reader VPC subnet Availability Zone B Readは各Readerを参 照する
30 クラスタエンドポイント VPC subnet Write VPC subnet クラスタエンドポイント Aurora Writer VPC subnet Availability Zone A Aurora Writer VPC subnet Availability Zone B フェイルオーバが発 生すると Aurora ノードの昇格が行わ れ クラスタエンド ポイントの指し先が 変わる

31 フェイルオーバー時の注意点 Auroraのフェイルオーバーの仕組みにより RDS MySQLよりも高速にフェイルオーバーが行われる フェイルオーバー実行時に新WriterとReaderの キャッシュの整合性をとるため各ReaderのAuroraプ ロセスもリスタートされる 数秒アクセスが出来なくなるため Readerのインスタンス障害に 備える意味でも アプリケーションやドライバ側でクエリのリトラ イ処理を入れることを推薦
32 高速でより予測可能なフェイルオーバー時間 MySQL DB failure Failure detection DNS propagation App running Recovery Recovery AURORA WITH MARIADB DRIVER DB failure Failure detection DNS propagation s e c Recovery s e c App running
33 Streaming snapshotとpitr Amazon Auroraでは各セグメント毎にAmazon S3 へ継続的に増分バックアップを取得している Backup retention periodでバックアップを残す期間を指定可能 Amazon Auroraが使用しているディスクの仕組み によりパフォーマンスへ影響を与えない PITRで5分前からBackup Retention Periodまでの 任意の位置に秒単位で復元可能
34 高速なデータ修復 既存のデータベース Amazon Aurora 最後のチェックポイントからロ グを適用していく Disk readの一環として オンデ マンドでredo logの適用を行う MySQLではシングルスレッドな ため適用完了までの時間が増加 並列 分散 非同期で行われる T0 でクラッシュが発生すると 最後のチェックポイントからの ログを適用する必要がある Checkpointed Data T0 でクラッシュが発生するとredo を並列で分散して非同期でログの適用を行う Redo Log T0 T0
35 SQLによるフェイルオーバーのテスト SQLによりノード ディスク ネットワーク障害をシミュレーション可能 データベースノードのクラッシュをシミュレート: レプリケーション障害をシミュレート: 他にも ディスク障害をシミュレート ディスクコンジェスションをシミュレート ALTER SYSTEM CRASH [{INSTANCE DISPATCHER NODE}] ALTER SYSTEM SIMULATE percentage_of_failure PERCENT READ REPLICA FAILURE [ TO ALL TO "replica name" ] FOR INTERVAL quantity [ YEAR QUARTER MONTH WEEK DAY HOUR MINUTE SECOND ];
36 チューニングとパフォーマンス
37 5X faster than RDS MySQL 5.6 & 5.7 WRITE PERFORMANCE READ PERFORMANCE 700, , , , , , ,000 75, ,000 50, ,000 25, , MySQL SysBench results R3.8XL: 32 cores / 244 GB RAM Aurora MySQL 5.6 MySQL 5.7 SysBenchを用いたベンチマークにおいて MySQLと比較して 5倍高いスループットを計測
38 インスタンスサイズによるスケール WRITE PERFORMANCE READ PERFORMANCE Aurora MySQL 5.6 MySQL 5.7 Aurora は Read/Write パフォーマンス共にインスタンスサイズに比例してスケール
39 Beyond benchmarks もしも 実環境のアプリケーションがベンチマークと 同様のパフォーマンスを出すのであれば 新しい データベースを作る必要は無かった POSSIBLE DISTORTIONS 実環境のリクエストは相互に影響がある 実環境のメタデータがディクショナリーキャッシュに収まり続けるの は稀である 実環境のデータがバッファキャッシュに収まり続けるのは稀である 実本番環境のデータデータベースはHA構成で動かす必要がある
40 チューニング指針 Amazon AuroraはMySQLと比較してインスタンスリ ソースを効率的に最大限利用する設計 CPUやメモリの利用率が高めだが パフォーマンスに影響が出ない限 りは過度な心配は必要ない Amazon Auroraは実際のワークロードで性能が発揮でき るように開発 チューニングが行われている ベンチマークテストでは無く実際のワークロードでテストを行う 監視項目もインスタンスリソースでは無く 実際のパフォーマンステス トを元にクエリレイテンシやスループット buffer poolのcache hitレー トに注目
41 チューニング指針 まずはデフォルトのパラメータグループを使用 Amazon Auroraはデフォルトの設定でパフォーマンスを発揮できる ようにチューニング済み 適切なインスタンスタイプを選択することが大切 それでも性能が出ない場合にパラメータグループの変更を検討
42 性能向上のために行っていること DO LESS WORK I/Oを減らすネットワークパケットを最小限にする結果をキャッシュしておくデータベースエンジンをオフロードする BE MORE EFFICIENT 非同期で処理するレイテンシーの通り道を減らすロックフリーなデータ構造を使うバッチ操作を同時に行う データベースは I/O が全て ネットワーク接続したストレージは PACKETS/SECOND が全て 高スループットの処理にコンテキストスイッチは許されない
43 IO traffic in RDS MySQL MYSQL WITH STANDBY AZ 1 AZ 2 3 IO FLOW EBS に書き込み EBS がミラーへ複製し 両方終了後 ack スタンバイインスタンス側の EBS に書き込み Primary instance Standby instance OBSERVATIONS 1 Amazon Elastic Block Store (EBS) EBS 4 ステップ 1, 3, 5 はシーケンシャルかつ同期それによりレイテンシーもパフォーマンスのゆらぎも増加各ユーザー操作には様々な書き込みタイプがある書き込み破損を避けるためにデータブロックを 2 回書く必要性 Amazon S3 2 EBS mirror EBS mirror 5 T YPE OF WRIT E PERFORMANCE 780K トランザクション 100 万トランザクション当たり 7,388K I/Os ( ミラー, スタンバイを除く ) 平均 1 トランザクション当たり 7.4 I/Os 30 minute SysBench write-only workload, 100 GB data set, RDS SingleAZ, 30K PIOPS LOG BINLOG DATA DOUBLE-WRITE FRM FILES
44 IO traffic in Aurora ( データベース ) AMAZON AURORA AZ 1 AZ 2 AZ 3 Primary instance Replica instance IO FLOW REDO ログレコードをまとめる 完全に LSN 順に並ぶ適切なセグメントに分割する 部分ごとに並ぶストレージノードへまとめて書き込む ASYNC 4/6 QUORUM Amazon S3 DISTRIBUTED WRITES OBSERVATIONS REDO ログレコードのみ書き込む ; 全てのステップは非同期データブロックは書かない ( チェックポイント, キャッシュ置換時 ) 6 倍のログ書き込みだが, 1/9 のネットワークトラフィックネットワークとストレージのレイテンシー異常時の耐性 PERFORMANCE 27,378K トランザクション 35X MORE 100 万トランザクション当たり 950K I/Os 7.7X LESS (6X amplification) 30 minute SysBench write-only workload, 100 GB data set LOG T YPE OF WRIT E BINLOG DATA DOUBLE-WRITE FRM FILES
45 スレッドプール Amazon Auroraはスレッドプールが実装されてい る MariaDBやMySQL EEで提供されているような機能だが Amazon Auroraに実装されているものはオリジナル実装 パラメータグループに項目があるが 設定変更は不可能 MySQL Client Thread Aurora Client Thread Client Thread Thread Thread Thread Client Thread Thread Thread Pool
46 Adaptive Thread Pool CLIENT CONNECTION CLIENT CONNECTION epoll() MYSQL THREAD MODEL AURORA THREAD MODEL LATCH FREE TASK QUEUE Standard MySQL コネクション毎に1 コネクション数に応じてスケールしない MySQL EE スレッドプール毎にコネクションをアサイン しきい値を慎重に設定する必要がある アクティブなスレッドに複数のコネクションを収容 スレッドプールの数は動的に調整される r3.8xlインスタンスのamazon Auroraで5,000 同時コネクションを扱える
47 非同期グループコミット TRANSACTIONS T1 Read Read Write Read Commit T1 Read Read Write Read Commit TIME TRADITIONAL APPROACH Tn Read Read Write Read Commit ディスクへ書き込むためののログバッファを管理 Commit (T8) Commit (T7) Commit (T6) Commit (T5) Commit (T4) Commit (T3) Commit (T2) Commit (T1) バッファが一杯になるか書き込み待ち時間を超過すると書き込みを実行 書き込み頻度が少ない場合は最初の書き込みが遅くなる LSN 50 LSN 47 LSN 41 LSN 34 LSN 30 LSN 22 LSN 12 LSN 10 COMMIT QUEUE Pending commits in LSN order GROUP COMMIT LSN 20 LSN 49 LSN GROWTH Durable LSN at head-node AMAZON AURORA 最初の書き込みと同時にI/Oリクエストを実行 書き込みが実行されるまでバッファを埋める 6 つの内 4 つのストレージノードから ACK が返ってきた時点で堅牢性のある書き込みが完了
48 過去数ヶ月で改善したこと ロック競合 ホットな行競合ディクショナリ統計小さなトランザクションのコードパスクエリーキャッシュのread/write 競合ディクショナリシステムのmutex 顧客フィードバック binlogと分散トランザクションロックの圧縮先読み (read-ahead) バッチ操作 書き込みバッチサイズのチューニング read/write I/O 要求送信の非同期化パージスレッドのパフォーマンスバルクインサートのパフォーマンス その他 フェイルオーバー時間の短縮 mallocの削減システムコールの削減 Undoスロットのキャッシュパターン協調したログ適用
49 Amazon Aurora の使いどころ
50 クエリ同時実行数やテーブルサイズが大きい Amazon Auroraに移行することで クエリスル ープットの向上などが見込まれる マルチコア環境でCPUを効率的に利用 分散ロック機構やQuery Cacheの改善による性能向上 ディスク データ量の増加に応じてディスク容量を気にする必要が無い 性能に影響を及ばさずバックアップ
51 複数のサーバにシャーディングしている 複数の小さいDBを1つにまとめる コスト効果増大と管理コストの軽減 シャーディングをするデータベースを減らすことでアプリケー ションの設計を簡略化出来る 障害時の影響を考慮する必要はある
52 新機能
53 MySQLスナップショットバックアップからの移行 Percona Xtrabackupを利用して作成したバックアップデータを 利用してオンプレミス環境やAmazon EC2上のMySQLから Amazon Auroraクラスへ移行する mysqldumpと比較したテストで約20倍高速に移行可能 バックアップデータをS3にアップロードし そのデータを利用 アップロードにはManagement ConsoleやCLI tools データサイズが大きい場合は AWS Import/Export Snowballを利用してS3へ転送する MySQLからAmazon Auroraへレプリケーションを行う機能と合 わせて利用することで アプリケーションのダウンタイムを短 縮可能
 バイナリログを利用したリージョン間レプリケーションのため")
54 クロスリージョンレプリケーション対応 リージョン間でWriterとReaderを配置可能 クロスリージョンレプリケーションのセットアップなどは全て マネージド コンソールやAPI経由で簡単に構築可能 DRや他リージョンへDBを移設する場合などに利用 注意点 機能を有効にする前に必ず最新のパッチを適用して下さい バイナリログを利用したレプリケーションのため 設定前にDB パラメータグループでbinlog_formatを設定(MIXED推薦) バイナリログを利用したリージョン間レプリケーションのため 大きめのレプリカラグが発生しやすい
に共有も可能 同一リージョンの他のAWSアカウントで起動しているAuroraス ナップショットからデータベースをリストア可能 用途 環境の分離")
55 Auroraでアカウント間でスナップショットを共有可能 に Auroraスナップショットを共有可能に スナップショットは他のAWSアカウントと共有するだけではな く パブリック(全ユーザ)に共有も可能 同一リージョンの他のAWSアカウントで起動しているAuroraス ナップショットからデータベースをリストア可能 用途 環境の分離 データの共同利用
56 Auroraで暗号化されていないSnapshotから暗号化ク ラスタを作成可能に 暗号化されていないAuroraクラスタを KMSで 暗号化されたAuroraクラスタへ簡単に移行可能 Snapshotからrestoreを行う 既存のSnapshotからrestoreする際にEnable EncryptionをYesに設定し使用するKeyを選択
57 ローカルタイムゾーン対応 time_zoneパラメータにより任意のタイムゾー ンに設定可能 RDS MySQL, RDS MariaDBでは既に対応済み
58 フェイルオーバー順の指定 Amazon Auroraのフェイルオーバーの順位を任 意に設定可能 フェイルオーバーで昇格させるReaderの順番を指定可能 優先的にフェイルオーバー先に指定するReaderを設定可能なため バッチや集計用途などで利用している サービスに組み込みたくな いReaderを作ることも可能 優先度: Tier 0 > Tier 1 > > Tier 15 同じ優先度のReaderが存在する場合 Writerよりも大きいインスタンス 優先度もインスタンスサイズも同じ場合は 同じ優先度のReaderから 任意に選択される

59 Cluster View Amazon Aurora Cluster の情報専用の画面 Cluster 毎に情報を参照出来る 例 : Cluster Snapshot からリカバリを行ったり Cluster 内の DB インスタンスを全て削除した場合 Cluster 定義のみが残るので Instance View には表示されないが Cluster View には表示される

60 拡張モニタリング Process list Metrics list
61 重要なシステム /OS メトリクスに対応 CPU Utilization User System Wait IRQ Idle Network Rx per declared ethn Tx per declared ethn Processes Num processes Num interruptible Num non-interruptible Num zombie Process List Process ID Process name VSS Res Mem % consumed CPU % used CPU time Parent ID Memory MemTotal MemFree Buffers Cached SwapCached Active Inactive SwapTotal SwapFree Dirty Writeback Mapped Slab Device IO TPS Blk_read Blk_wrtn read_kb read_ios read_size write_kb write_ios write_size avg_rw_size avg_queue_len File System Free capacity Used % Used

62 拡張モニタリング CloudWatch LogsからElasticsearch Service

63 Encryption at Rest 格納時暗号化 Key Management Service(KMS)を利用し 透過的な暗 号化と復号を行う 暗号化指定はAuroraクラスタ起動時のみ ストレージ内やSnapshotが暗号化される 暗号化されたSnapshotを暗号化が無効なAuroraクラスタに復元は出来ない Diskに書き込まれるタイミングで自動的に実施 テーブルの中身を暗号化するものでは無い点注意 実施する場合はアプリケーションなどで実施 (KMSを活用可能)
 モニタリング用にGlobal変数を追加 aurora_fast_insert_cache_hits: キャッシュのcursorにヒットした aurora_fast_insert_cache_misses: ヒットせずindexを走査した Parallel Read Ahead")
64 パフォーマンスの改善 Large dataset read performance スケジューラの改善により IO/CPUヘビーなワークロードでAuroraが動的に処 理スレッド数を調整することでIO数/CPU利用率のバランスがとれ 性能を向上 させる Fast Insert Primary keyで並んでいるデータを LOAD DATA や INSERT INTO... SELECT で 並列に実行した場合の速度を改善 (将来的には他のワークロードにも適用予定) モニタリング用にGlobal変数を追加 aurora_fast_insert_cache_hits: キャッシュのcursorにヒットした aurora_fast_insert_cache_misses: ヒットせずindexを走査した Parallel Read Ahead B-Treeスキャン性能を向上させる Disk pageの読み込みパターンを自動的に判 断し 事前にフェッチしバッファキャッシュに載せることで速度改善を行う 現在は Writerで有効になっており 今後Readerにも適用を行う シーケンシャルアクセスのパフォーマンスを大幅に改善

65 Lab mode 今後提供予定の機能を試すことが可能 DBパラメータグループ aurora_lab_mode 変数で設定可能 開発チームでテストがされておりますが 開発中の機能なので 本番適用ではなく検証目的でお使い下さい Production用途で利用可能なクオリティではありますが 正式公開 に向けて多くのワークロードで安定して性能を出せるように最後の 調整が行われているステータスです パラメータをOFFにすることで直ぐに無効化できるためテストしや すい フィードバックをお待ちしています
66 まとめ
67 Amazon Aurora クラウド時代に Amazon が再設計した RDBMS MySQL5.6 と互換があり既存の資産を活かしやすい 高いクエリ実行並列度 データサイズが大きい環境で性能を発揮 Amazon Aurora はコネクション数やテーブル数が多い環境で優位性を発揮 高可用性 高速なフェイルオーバー 実環境での性能向上を実現するための多くのチャレンジ
68 Webinar資料の配置場所 AWS クラウドサービス活用資料集 過去の資料が分かりやすくまとめられています AWS Solutions Architect ブログ 最新の情報 セミナー中のQ&A等が掲載されています
69 Q&A [ 導入に関しての問い合わせ ] [ 課金 請求内容 またはアカウントに関するお問い合わせ ]

70 Webinar資料の配置場所 AWS クラウドサービス活用資料集

71 公式 Twitter/Facebook AWS 検索 もしくは 最新技術情報 イベント情報 お役立ち情報 お得なキャンペーン情報などを日々更新しています!

72
PowerPoint Presentation
 Amazon Aurora deep dive 性能向上の仕組みと最新アップデート Yutaka Hoshino, Solutions Architect Amazon Web Services Japan K.K. 2016/6/2 自己紹介 星野 豊 (ほしの ゆたか) @con_mame conmame ソリューションアーキテクト DB Specialized SA メディア系のお客様や大規模なWebサービス企業様を担当
Amazon Aurora deep dive 性能向上の仕組みと最新アップデート Yutaka Hoshino, Solutions Architect Amazon Web Services Japan K.K. 2016/6/2 自己紹介 星野 豊 (ほしの ゆたか) @con_mame conmame ソリューションアーキテクト DB Specialized SA メディア系のお客様や大規模なWebサービス企業様を担当
Presentation Title Here
 AWS Black Belt Online Seminar Amazon Pinpoint 2017.04.26 アマゾンウェブサービスジャパン株式会社ソリューションアーキテクト清水崇之 0 自己紹介 清水崇之 ソリューションアーキテクト ( 西日本担当 ) 大阪から沖縄まで 西日本のお客様にもプライム対応で参上します AWS 芸人 ( 詳しくは https://www.slideshare.net/shimy_net/)
AWS Black Belt Online Seminar Amazon Pinpoint 2017.04.26 アマゾンウェブサービスジャパン株式会社ソリューションアーキテクト清水崇之 0 自己紹介 清水崇之 ソリューションアーキテクト ( 西日本担当 ) 大阪から沖縄まで 西日本のお客様にもプライム対応で参上します AWS 芸人 ( 詳しくは https://www.slideshare.net/shimy_net/)
Amazon Aurora for PostgreSQL アーキテクチャ・特長と移行
 Amazon Aurora PostgreSQL Mark Porter, General Manager Amazon Aurora PostgreSQL Amazon RDS for PostgreSQL Amazon RDS Platform Amazon RDS Operations markpor@amazon.com May 31, 2017 2017, Amazon Web Services,
Amazon Aurora PostgreSQL Mark Porter, General Manager Amazon Aurora PostgreSQL Amazon RDS for PostgreSQL Amazon RDS Platform Amazon RDS Operations markpor@amazon.com May 31, 2017 2017, Amazon Web Services,
Presentation Title Here
 AWS Black Belt Online Seminar AWS Well Architected Program https://aws.amazon.com/well-architected アマゾンウェブサービスジャパン株式会社 ソリューションアーキテクト荒木靖宏 2017.03.14 自己紹介 名前 荒木靖宏 所属 アマゾンウェブサービスジャパン株式会社 技術本部レディネスソリューション部シニアマネージャプリンシパルソリューションアーキテクト
AWS Black Belt Online Seminar AWS Well Architected Program https://aws.amazon.com/well-architected アマゾンウェブサービスジャパン株式会社 ソリューションアーキテクト荒木靖宏 2017.03.14 自己紹介 名前 荒木靖宏 所属 アマゾンウェブサービスジャパン株式会社 技術本部レディネスソリューション部シニアマネージャプリンシパルソリューションアーキテクト
Amazon Aurora (MySQL-compatible edition) Deep Dive
 Deep Dive") Amazon Aurora (MySQL-compatible edition) Deep Dive Amazon Web Services Japan K.K. Yutaka Hoshino, Database Specialist SA 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. 内容についての注意点
Amazon Aurora (MySQL-compatible edition) Deep Dive Amazon Web Services Japan K.K. Yutaka Hoshino, Database Specialist SA 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. 内容についての注意点
SRA OSS, Inc. のご紹介 1999 年より PostgreSQL サポートを中心に OSS ビジネスを開始 2005 年に現在の形に至る 主なビジネス PostgreSQL, Zabbix などの OSS のサポート コンサルティング 導入構築 PowerGres ファミリーの開発 販売
 Amazon Aurora with PostgreSQL Compatibility を評価して SRA OSS, Inc. 日本支社 取締役支社長 石井達夫 SRA OSS, Inc. のご紹介 1999 年より PostgreSQL サポートを中心に OSS ビジネスを開始 2005 年に現在の形に至る 主なビジネス PostgreSQL, Zabbix などの OSS のサポート コンサルティング
Amazon Aurora with PostgreSQL Compatibility を評価して SRA OSS, Inc. 日本支社 取締役支社長 石井達夫 SRA OSS, Inc. のご紹介 1999 年より PostgreSQL サポートを中心に OSS ビジネスを開始 2005 年に現在の形に至る 主なビジネス PostgreSQL, Zabbix などの OSS のサポート コンサルティング
Microsoft PowerPoint - MySQL-backup.ppt
 MySQL バックアップ リカバリ概要 オープンソース コンピテンシコンピテンシ センター日本ヒューレットパッカードヒューレットパッカード株式会社 2006 年 12 月 6 日 2006 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice
MySQL バックアップ リカバリ概要 オープンソース コンピテンシコンピテンシ センター日本ヒューレットパッカードヒューレットパッカード株式会社 2006 年 12 月 6 日 2006 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice
PowerPoint Presentation
 2-H1-1-13 AWS のデータベース入門 片岡光康 Solutions Architect, Amazon Web Services Japan K.K. 自己紹介 片岡光康 ( かたおかみつやす ) アマゾンウェブサービスジャパン株式会社 技術本部西日本担当 ソリューションアーキテクト 好きな AWS サービス Amazon Simple Storage Service (S3) Amazon
2-H1-1-13 AWS のデータベース入門 片岡光康 Solutions Architect, Amazon Web Services Japan K.K. 自己紹介 片岡光康 ( かたおかみつやす ) アマゾンウェブサービスジャパン株式会社 技術本部西日本担当 ソリューションアーキテクト 好きな AWS サービス Amazon Simple Storage Service (S3) Amazon
Slide 1
 Microsoft SharePoint Server on AWS リファレンスアーキテクチャー 2012/5/24 アマゾンデータサービスジャパン株式会社 Amazon における SharePoint の利用事例 AWS 利用によるメリット インフラの調達時間 4~6 週間から数分に短縮 サーバのイメージコピー作成 手動で半日から 自動化を実現 年間のインフラコスト オンプレミスと比較して 22%
Microsoft SharePoint Server on AWS リファレンスアーキテクチャー 2012/5/24 アマゾンデータサービスジャパン株式会社 Amazon における SharePoint の利用事例 AWS 利用によるメリット インフラの調達時間 4~6 週間から数分に短縮 サーバのイメージコピー作成 手動で半日から 自動化を実現 年間のインフラコスト オンプレミスと比較して 22%
使ってみよう!データベースとストレージ ~ Getting Started with AWS Database and Storage Services ~
 AWS Cloud Roadshow 2017 阪 使ってみよう! データベースとストレージ Getting Started with AWS Database and Storage Services Amazon Web Services Japan テクニカルトレーナー 村幸敬 1 本セッションの概要 AWS におけるデータストアの使い分けについて解説します Ø データストアの役割 Ø AWSのストレージサービス
AWS Cloud Roadshow 2017 阪 使ってみよう! データベースとストレージ Getting Started with AWS Database and Storage Services Amazon Web Services Japan テクニカルトレーナー 村幸敬 1 本セッションの概要 AWS におけるデータストアの使い分けについて解説します Ø データストアの役割 Ø AWSのストレージサービス
データベースの近代化:シンプルなクロスプラットフォーム、最小のダウンタイムで実現するクラウド移行
 AWS Database Migration Service ダウンタイムを最小限に抑えたデータベースモダナイゼーション John Winford Sr. Technical Program Manager May 31, 2017 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. アジェンダ クラウドはどのように役立つか?
AWS Database Migration Service ダウンタイムを最小限に抑えたデータベースモダナイゼーション John Winford Sr. Technical Program Manager May 31, 2017 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. アジェンダ クラウドはどのように役立つか?
Enterprise Cloud + 紹介資料
 Oracle Exadata の AWS 移行事例のご紹介 Oracle Exadata の移行 アジェンダ お客様の声 PoC フェーズ 移行診断 環境構築 データ移行 チューニング 移行フェーズ 業務 / データ整理 運用管理 まとめ 2 お客様の声 性能改修規模コスト移行方式運用環境 移行しても現状のデータベースと同等のパフォーマンスを出せるのか利用システムは どの程度改修が必要なのかコスト
Oracle Exadata の AWS 移行事例のご紹介 Oracle Exadata の移行 アジェンダ お客様の声 PoC フェーズ 移行診断 環境構築 データ移行 チューニング 移行フェーズ 業務 / データ整理 運用管理 まとめ 2 お客様の声 性能改修規模コスト移行方式運用環境 移行しても現状のデータベースと同等のパフォーマンスを出せるのか利用システムは どの程度改修が必要なのかコスト
PowerPoint Presentation
 AWS AWS AWS AWS AWS AWS AWS オンプレミス データセンター AWS Storage Gateway Amazon Kinesis Firehose EFS File Sync S3 Transfer Acceleration AWS Direct Connect Amazon Macie AWS QuickSight AWS Lambda AWS CloudFormation
AWS AWS AWS AWS AWS AWS AWS オンプレミス データセンター AWS Storage Gateway Amazon Kinesis Firehose EFS File Sync S3 Transfer Acceleration AWS Direct Connect Amazon Macie AWS QuickSight AWS Lambda AWS CloudFormation
Presentation Title Here
 AWS Black Belt Online Seminar AWS Mobile Hub 2017.08.23 アマゾンウェブサービスジャパン株式会社ソリューションアーキテクト清水崇之プロフェッショナルサービス塚越啓介 0 登壇者の紹介 清水崇之 塚越啓介 ソリューションアーキテクト AWS 芸人 Like: Amazon Connect ( カスタマーセンターのサービス ) プロフェッショナルサービス
AWS Black Belt Online Seminar AWS Mobile Hub 2017.08.23 アマゾンウェブサービスジャパン株式会社ソリューションアーキテクト清水崇之プロフェッショナルサービス塚越啓介 0 登壇者の紹介 清水崇之 塚越啓介 ソリューションアーキテクト AWS 芸人 Like: Amazon Connect ( カスタマーセンターのサービス ) プロフェッショナルサービス
PassSureExam Best Exam Questions & Valid Exam Torrent & Pass for Sure
 PassSureExam http://www.passsureexam.com Best Exam Questions & Valid Exam Torrent & Pass for Sure Exam : 1z0-950-JPN Title : Oracle Data Management Cloud Service 2018 Associate Vendor : Oracle Version
PassSureExam http://www.passsureexam.com Best Exam Questions & Valid Exam Torrent & Pass for Sure Exam : 1z0-950-JPN Title : Oracle Data Management Cloud Service 2018 Associate Vendor : Oracle Version
PowerPoint Presentation
 AWS Black Belt Online Seminar AWS 大阪ローカルリージョンの活用と AWSで実現するDisaster Recovery アマゾンウェブサービスジャパン株式会社テクニカルソリューションアーキテクト舟崎健治パートナーソリューションアーキテクト市崎洋平 2018.7.17 AWS Black Belt Online Seminar とは AWSJ の Tech メンバが AWS
AWS Black Belt Online Seminar AWS 大阪ローカルリージョンの活用と AWSで実現するDisaster Recovery アマゾンウェブサービスジャパン株式会社テクニカルソリューションアーキテクト舟崎健治パートナーソリューションアーキテクト市崎洋平 2018.7.17 AWS Black Belt Online Seminar とは AWSJ の Tech メンバが AWS
SIOS Protection Suite for Linux v9.3.2 AWS Direct Connect 接続クイックスタートガイド 2019 年 4 月
 SIOS Protection Suite for Linux v9.3.2 AWS Direct Connect 接続クイックスタートガイド 2019 年 4 月 本書およびその内容は SIOS Technology Corp.( 旧称 SteelEye Technology, Inc.) の所有物であり 許可なき使用および複製は禁止されています SIOS Technology Corp. は本書の内容に関していかなる保証も行いません
SIOS Protection Suite for Linux v9.3.2 AWS Direct Connect 接続クイックスタートガイド 2019 年 4 月 本書およびその内容は SIOS Technology Corp.( 旧称 SteelEye Technology, Inc.) の所有物であり 許可なき使用および複製は禁止されています SIOS Technology Corp. は本書の内容に関していかなる保証も行いません
組込み Linux の起動高速化 株式会社富士通コンピュータテクノロジーズ 亀山英司 1218ka01 Copyright 2013 FUJITSU COMPUTER TECHNOLOGIES LIMITED
 組込み Linux の起動高速化 株式会社富士通コンピュータテクノロジーズ 亀山英司 1218ka01 組込み Linux における起動高速化 組込み Linux の起動時間短縮について依頼あり スペック CPU : Cortex-A9 ( 800MB - single) RAM: 500MB 程度 要件 起動時間 画出し 5 秒 音出し 3 秒 終了時間 数 ms で電源断 1 課題と対策 問題点
組込み Linux の起動高速化 株式会社富士通コンピュータテクノロジーズ 亀山英司 1218ka01 組込み Linux における起動高速化 組込み Linux の起動時間短縮について依頼あり スペック CPU : Cortex-A9 ( 800MB - single) RAM: 500MB 程度 要件 起動時間 画出し 5 秒 音出し 3 秒 終了時間 数 ms で電源断 1 課題と対策 問題点
Microsoft Word - JP-AppLabs-MySQL_Update.doc
 アダプテック MaxIQ SSD キャッシュパフォーマンスソリューション MySQL 分析 September 22, 2009 はじめにアダプテックは Adaptec 5445Z ストレージコントローラでアダプテック MaxIQ SSD キャッシュパフォーマンスソリューション使用した場合のパフォーマンス評価を依頼しました アダプテックは 5 シリーズコントローラ全製品において MaxIQ をサポートしています
アダプテック MaxIQ SSD キャッシュパフォーマンスソリューション MySQL 分析 September 22, 2009 はじめにアダプテックは Adaptec 5445Z ストレージコントローラでアダプテック MaxIQ SSD キャッシュパフォーマンスソリューション使用した場合のパフォーマンス評価を依頼しました アダプテックは 5 シリーズコントローラ全製品において MaxIQ をサポートしています
スライド 1
 Zabbix のデータベース ベンチマークレポート PostgreSQL vs MySQL Yoshiharu Mori SRA OSS Inc. Japan Agenda はじめに Simple test 大量のアイテムを設定 Partitioning test パーティションイングを利用して計測 Copyright 2013 SRA OSS, Inc. Japan All rights reserved.
Zabbix のデータベース ベンチマークレポート PostgreSQL vs MySQL Yoshiharu Mori SRA OSS Inc. Japan Agenda はじめに Simple test 大量のアイテムを設定 Partitioning test パーティションイングを利用して計測 Copyright 2013 SRA OSS, Inc. Japan All rights reserved.
Presentation Title Here
 AWS Black Belt Online Seminar Amazon Elastic File System アマゾンウェブサービスジャパン株式会社西日本担当ソリューションアーキテクト辻義一 2016.07.27 自己紹介 辻義一 ( つじよしかず ) 西日本担当ソリューションアーキテクト簡単な経歴 大阪生まれの大阪育ち 独立系 SIerでインフラエンジニア AWSのすきな所 安い 早い おもしろい
AWS Black Belt Online Seminar Amazon Elastic File System アマゾンウェブサービスジャパン株式会社西日本担当ソリューションアーキテクト辻義一 2016.07.27 自己紹介 辻義一 ( つじよしかず ) 西日本担当ソリューションアーキテクト簡単な経歴 大阪生まれの大阪育ち 独立系 SIerでインフラエンジニア AWSのすきな所 安い 早い おもしろい
スライド 1
 CROOZ,Inc. 1 モバイルゲームの全世界オンライン対戦を実現する方法を考察する クルーズ株式会社 田沢知志 CROOZ って何やってる会社? CROOZ,Inc. CROOZ は ソーシャルゲームやネット通販を中心に 世界中にインターネットサービスを提供するエンターテインメント企業です アジェンダ CROOZ,Inc. 3 クラウド導入の一般的な考慮点(LAMP 環境 ) ストレージI/Oの考慮点
CROOZ,Inc. 1 モバイルゲームの全世界オンライン対戦を実現する方法を考察する クルーズ株式会社 田沢知志 CROOZ って何やってる会社? CROOZ,Inc. CROOZ は ソーシャルゲームやネット通販を中心に 世界中にインターネットサービスを提供するエンターテインメント企業です アジェンダ CROOZ,Inc. 3 クラウド導入の一般的な考慮点(LAMP 環境 ) ストレージI/Oの考慮点
pg_monz 監視アイテム一覧 :Template App PostgreSQL Template App PostgreSQL アプリケーション LLD アイテムトリガー監視タイプ更新間隔ヒストリトレンドデフォルト説明ステータス pg.get pgsql.get.pg.bgwriter Zabb
 pg_monz 監視アイテム一覧 :Template App PostgreSQL Template App PostgreSQL アプリケーション LLD アイテムトリガー監視タイプ更新間隔ヒストリトレンドデフォルト説明 pg.get pgsql.get.pg.bgwriter 60 90 365 無効 pg.bgwriterアプリケーションの監視アイテムの取得を行う pg.get pgsql.get.pg.transactions
pg_monz 監視アイテム一覧 :Template App PostgreSQL Template App PostgreSQL アプリケーション LLD アイテムトリガー監視タイプ更新間隔ヒストリトレンドデフォルト説明 pg.get pgsql.get.pg.bgwriter 60 90 365 無効 pg.bgwriterアプリケーションの監視アイテムの取得を行う pg.get pgsql.get.pg.transactions
PowerPoint Presentation
 AWS Black Belt Online Seminar Amazon Container Services Ryosuke Iwanaga, Solutions Architect Amazon Web Services Japan K.K. 2018.02.20 自己紹介 Ryosuke Iwanaga ( 岩永亮介 ) Twitter/GitHub @riywo Amazon Web Services
AWS Black Belt Online Seminar Amazon Container Services Ryosuke Iwanaga, Solutions Architect Amazon Web Services Japan K.K. 2018.02.20 自己紹介 Ryosuke Iwanaga ( 岩永亮介 ) Twitter/GitHub @riywo Amazon Web Services
今さら聞けない!? Oracle入門 ~後編~
 Oracle Direct Seminar 今さら聞けない!? Oracle 入門 ~ 後編 ~ 日本オラクル株式会社 Agenda 1. Oracle の基本動作 2. Oracle のファイル群 3. Oracle のプロセス群と専用メモリ領域. データベース内部動作 今さら聞けない!? オラクル入門 ~ 後編 ~. データベース内部動作 検索時の動作更新時の動作バックアップについて
Oracle Direct Seminar 今さら聞けない!? Oracle 入門 ~ 後編 ~ 日本オラクル株式会社 Agenda 1. Oracle の基本動作 2. Oracle のファイル群 3. Oracle のプロセス群と専用メモリ領域. データベース内部動作 今さら聞けない!? オラクル入門 ~ 後編 ~. データベース内部動作 検索時の動作更新時の動作バックアップについて
~~~~~~~~~~~~~~~~~~ wait Call CPU time 1, latch: library cache 7, latch: library cache lock 4, job scheduler co
 072 DB Magazine 2007 September ~~~~~~~~~~~~~~~~~~ wait Call CPU time 1,055 34.7 latch: library cache 7,278 750 103 24.7 latch: library cache lock 4,194 465 111 15.3 job scheduler coordinator slave wait
072 DB Magazine 2007 September ~~~~~~~~~~~~~~~~~~ wait Call CPU time 1,055 34.7 latch: library cache 7,278 750 103 24.7 latch: library cache lock 4,194 465 111 15.3 job scheduler coordinator slave wait
D. Amazon EC2 のインスタンスストアボリュームへ 1 時間ごとに DB のバックアップ取得を行うと共に Amazon S3 に 5 分ごとのトランザクションログを保管する 正解 = C 会社のマーケティング担当ディレクターから " 何気ない親切 " と思われる善行を目にしたら 80 文字
 あなたの会社にあるオンプレミス環境のコンテンツマネージメントシステムは以下のアーキテクチャを採用しています アプリケーション層 JBoss アプリケーションサーバー上で動作する Java コード データベース層 Oracle RMAN バックアップユーティリティを使用して定期的に S3 にバックアップされる Oracle データベース 静的コンテンツ iscsi インターフェース経由でアプリケーションサーバにアタッチされた
あなたの会社にあるオンプレミス環境のコンテンツマネージメントシステムは以下のアーキテクチャを採用しています アプリケーション層 JBoss アプリケーションサーバー上で動作する Java コード データベース層 Oracle RMAN バックアップユーティリティを使用して定期的に S3 にバックアップされる Oracle データベース 静的コンテンツ iscsi インターフェース経由でアプリケーションサーバにアタッチされた
PowerPoint プレゼンテーション
 AWS クラウドデザインパターン -E コマース編 - 自己紹介 名前 北迫清訓 ( きたさこきよのり ) 所属 アマゾンデータサービスジャパン株式会社ソリューションアーキテクト ID Facebook: Kiyonori Kitasako 好きなAWSサービス Amazon Glacier 好きなCDP Web Storage Archiveパターン AWS クラウドデザインパターンとは... AWS
AWS クラウドデザインパターン -E コマース編 - 自己紹介 名前 北迫清訓 ( きたさこきよのり ) 所属 アマゾンデータサービスジャパン株式会社ソリューションアーキテクト ID Facebook: Kiyonori Kitasako 好きなAWSサービス Amazon Glacier 好きなCDP Web Storage Archiveパターン AWS クラウドデザインパターンとは... AWS
よくある問題を解決する~ 5 分でそのままつかえるソリューション by AWS ソリューションズビルダチーム
 すぐに利用できる状態のソリューションを使って一般的な問題を 5 分以内に解決 Steve Morad Senior Manager, Solutions Builder Team AWS Solution Architecture May 31, 2017 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
すぐに利用できる状態のソリューションを使って一般的な問題を 5 分以内に解決 Steve Morad Senior Manager, Solutions Builder Team AWS Solution Architecture May 31, 2017 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Presentation Title Here
 AWS re:invent 2016 で発表された 新サービス 新機能の紹介パート 2 前半 アマゾンウェブサービスジャパン株式会社 ソリューションアーキテクト舘岡守 2016.12.08 自己紹介舘岡守 ( たておかまもる ) エンタープライズソリューション部 ソリューションアーキテクト 主に大企業のお客様を担当 AWS の導入を支援 前職は某 AWS 専業インテグレーター (CIer) 好きな
AWS re:invent 2016 で発表された 新サービス 新機能の紹介パート 2 前半 アマゾンウェブサービスジャパン株式会社 ソリューションアーキテクト舘岡守 2016.12.08 自己紹介舘岡守 ( たておかまもる ) エンタープライズソリューション部 ソリューションアーキテクト 主に大企業のお客様を担当 AWS の導入を支援 前職は某 AWS 専業インテグレーター (CIer) 好きな
PowerPoint Presentation
 Amazon EBS ボリュームの性能特性と構成方法を習得する! 松本大樹 (Matsumoto Hiroki) 2014 Amazon.com, Inc. and its affiliates. All rights reserved. May not be copied, modified, or distributed in whole or in part without the express
Amazon EBS ボリュームの性能特性と構成方法を習得する! 松本大樹 (Matsumoto Hiroki) 2014 Amazon.com, Inc. and its affiliates. All rights reserved. May not be copied, modified, or distributed in whole or in part without the express
2D/3D CAD データ管理導入手法実践セミナー Autodesk Vault 最新バージョン情報 Presenter Name 2013 年 4 月 2013 Autodesk
 2D/3D CAD データ管理導入手法実践セミナー Autodesk Vault 最新バージョン情報 Presenter Name 2013 年 4 月 2013 Autodesk Autodesk Vault 2014 新機能 操作性向上 Inventor ファイルを Vault にチェックインすることなくステータス変更を実行できるようになりました 履歴テーブルの版管理を柔軟に設定できるようになりました
2D/3D CAD データ管理導入手法実践セミナー Autodesk Vault 最新バージョン情報 Presenter Name 2013 年 4 月 2013 Autodesk Autodesk Vault 2014 新機能 操作性向上 Inventor ファイルを Vault にチェックインすることなくステータス変更を実行できるようになりました 履歴テーブルの版管理を柔軟に設定できるようになりました
PowerPoint Presentation
 AWS Black Belt Online Seminar AWS Support アマゾンウェブサービスジャパン株式会社技術支援本部クラウドサポートチームリード滝口開資 2018.06.20 自己紹介 名前 : 滝口開資 ( はるよし ) 所属 : アマゾンウェブサービスジャパン株式会社技術支援本部クラウドサポートチームリード クラウドサポートチームのリーダーとして AWS サポートにお問い合わせいただく全てのお客様にお届けする価値を最大化できるよう
AWS Black Belt Online Seminar AWS Support アマゾンウェブサービスジャパン株式会社技術支援本部クラウドサポートチームリード滝口開資 2018.06.20 自己紹介 名前 : 滝口開資 ( はるよし ) 所属 : アマゾンウェブサービスジャパン株式会社技術支援本部クラウドサポートチームリード クラウドサポートチームのリーダーとして AWS サポートにお問い合わせいただく全てのお客様にお届けする価値を最大化できるよう
PowerPoint Presentation
 AWS Black Belt Online Seminar Amazon DocumentDB アマゾンウェブサービスジャパン株式会社ソリューションアーキテクト桑野章弘 2019.06.25 自己紹介 桑野章弘 ( くわのあきひろ ) ソリューションアーキテクト主にメディア系のお客様を担当しております元渋谷のインフラエンジニア好きなAWSのサービス :DocumentDB Aurora Route53
AWS Black Belt Online Seminar Amazon DocumentDB アマゾンウェブサービスジャパン株式会社ソリューションアーキテクト桑野章弘 2019.06.25 自己紹介 桑野章弘 ( くわのあきひろ ) ソリューションアーキテクト主にメディア系のお客様を担当しております元渋谷のインフラエンジニア好きなAWSのサービス :DocumentDB Aurora Route53
Elastic MapReduce bootcamp
 EMR Controls, Debugging, Monitoring アマゾンデータサービスジャパン株式会社 このセッションの目的 EMR 環境の運用方法を講義とハンズオンを通して理解する デバッグ 調査の方法 モニタリングの方法 Copyright 2012 Amazon Web Services アジェンダ デバッグ 調査 ログの仕様 ログ確認方法モニタリング Management Console
EMR Controls, Debugging, Monitoring アマゾンデータサービスジャパン株式会社 このセッションの目的 EMR 環境の運用方法を講義とハンズオンを通して理解する デバッグ 調査の方法 モニタリングの方法 Copyright 2012 Amazon Web Services アジェンダ デバッグ 調査 ログの仕様 ログ確認方法モニタリング Management Console
新製品 Arcserve Backup r17.5 のご紹介 (SP1 対応版 ) Arcserve Japan Rev. 1.4
 Arcserve Japan Rev. 1.4") 新製品 Arcserve Backup r17.5 のご紹介 ( 対応版 ) Arcserve Japan Rev. 1.4 クラウドストレージへの直接バックアップ バックアップ クラウドストレージ * クラウドサーバ 一時領域 バックアップ 一時領域 一時領域 HDD 不要 災害対策コストの削減 オンプレミスサーバ * 利用可能なクラウドストレージは動作要件をご確認ください https://support.arcserve.com/s/article/218380243?language=ja
新製品 Arcserve Backup r17.5 のご紹介 ( 対応版 ) Arcserve Japan Rev. 1.4 クラウドストレージへの直接バックアップ バックアップ クラウドストレージ * クラウドサーバ 一時領域 バックアップ 一時領域 一時領域 HDD 不要 災害対策コストの削減 オンプレミスサーバ * 利用可能なクラウドストレージは動作要件をご確認ください https://support.arcserve.com/s/article/218380243?language=ja
AWSにおけるデータベース・サービスの活用
 AWS における データベース サービスの活用 アマゾンデータサービスジャパン株式会社 八木橋徹平 自己紹介 セッションの目的 AWS 上の様々なデータベース サービスの概要と使い分を事例を交えてご紹介し システム構築時における活用方法をご理解いただく アジェンダ データベース サービスの概要 AWS のデータベース サービス Amazon RDS Amazon Redshift Amazon ElastiCache
AWS における データベース サービスの活用 アマゾンデータサービスジャパン株式会社 八木橋徹平 自己紹介 セッションの目的 AWS 上の様々なデータベース サービスの概要と使い分を事例を交えてご紹介し システム構築時における活用方法をご理解いただく アジェンダ データベース サービスの概要 AWS のデータベース サービス Amazon RDS Amazon Redshift Amazon ElastiCache
【Cosminexus V9】クラウドサービスプラットフォーム Cosminexus
 http://www.hitachi.co.jp/soft/ask/ http://www.hitachi.co.jp/cosminexus/ Printed in Japan(H) 2014.2 CA-884R データ管 タ管理 理 ノンストップデータベース データ管 タ管理 理 インメモリデータグリッド HiRDB Version 9 ucosminexus Elastic Application
http://www.hitachi.co.jp/soft/ask/ http://www.hitachi.co.jp/cosminexus/ Printed in Japan(H) 2014.2 CA-884R データ管 タ管理 理 ノンストップデータベース データ管 タ管理 理 インメモリデータグリッド HiRDB Version 9 ucosminexus Elastic Application
データセンターの効率的な資源活用のためのデータ収集・照会システムの設計
 データセンターの効率的な 資源活用のためのデータ収集 照会システムの設計 株式会社ネットワーク応用通信研究所前田修吾 2014 年 11 月 20 日 本日のテーマ データセンターの効率的な資源活用のためのデータ収集 照会システムの設計 時系列データを効率的に扱うための設計 1 システムの目的 データセンター内の機器のセンサーなどからデータを取集し その情報を元に機器の制御を行うことで 電力消費量を抑制する
データセンターの効率的な 資源活用のためのデータ収集 照会システムの設計 株式会社ネットワーク応用通信研究所前田修吾 2014 年 11 月 20 日 本日のテーマ データセンターの効率的な資源活用のためのデータ収集 照会システムの設計 時系列データを効率的に扱うための設計 1 システムの目的 データセンター内の機器のセンサーなどからデータを取集し その情報を元に機器の制御を行うことで 電力消費量を抑制する
Microsoft PowerPoint - AWS-RatesSystem-JP_201310.pptx
 AWSの 課 体 系 2013 年 10 AWS does not offer binding price quotes. AWS pricing is publicly available and is subject to change in accordance with the AWS Customer Agreement available at http://aws.amazon.com/agreement/.
AWSの 課 体 系 2013 年 10 AWS does not offer binding price quotes. AWS pricing is publicly available and is subject to change in accordance with the AWS Customer Agreement available at http://aws.amazon.com/agreement/.
AWS 上でのサーバーレスアーキテクチャ 入 門 AWS Black Belt Online Seminar 2016 アマゾンウェブサービスジャパン株式会社 ソリューションアーキテクト清 水崇之 , Amazon Web Services, Inc. or its Aff
 AWS 上でのサーバーレスアーキテクチャ 入 門 AWS Black Belt Online Seminar 2016 アマゾンウェブサービスジャパン株式会社 ソリューションアーキテクト清 水崇之 2016.8.9 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved. 内容についての注意点 本資料料では 2016
AWS 上でのサーバーレスアーキテクチャ 入 門 AWS Black Belt Online Seminar 2016 アマゾンウェブサービスジャパン株式会社 ソリューションアーキテクト清 水崇之 2016.8.9 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved. 内容についての注意点 本資料料では 2016
Presentation Title Here
 AWS Black Belt Online Seminar AWS Certificate Manager アマゾンウェブサービスジャパン株式会社プロフェッショナルサービスセキュリティコンサルタント松本照吾 2016.07.13 自己紹介 名前 : 松本照吾 所属 : アマゾンウェブサービスジャパン株式会社プロフェッショナルサービス本部セキュリティコンサルタント 経歴 : セキュリティコンサルタント
AWS Black Belt Online Seminar AWS Certificate Manager アマゾンウェブサービスジャパン株式会社プロフェッショナルサービスセキュリティコンサルタント松本照吾 2016.07.13 自己紹介 名前 : 松本照吾 所属 : アマゾンウェブサービスジャパン株式会社プロフェッショナルサービス本部セキュリティコンサルタント 経歴 : セキュリティコンサルタント
PowerPoint プレゼンテーション
 AWS のいろは 株式会社神戸デジタル ラボ開発管理部情報システムチーム戎秀和 自己紹介 Hidekazu Ebisu ( 戎秀和 ) - 4 年目 - 情シス - わんこ 本日おはなしする内容 AWS について メリット セキュリティ コスト 3 本日おはなしする内容 AWS について メリット セキュリティ コスト 4 本日おはなしする内容 http://aws.amazon.com/jp/aws_history/
AWS のいろは 株式会社神戸デジタル ラボ開発管理部情報システムチーム戎秀和 自己紹介 Hidekazu Ebisu ( 戎秀和 ) - 4 年目 - 情シス - わんこ 本日おはなしする内容 AWS について メリット セキュリティ コスト 3 本日おはなしする内容 AWS について メリット セキュリティ コスト 4 本日おはなしする内容 http://aws.amazon.com/jp/aws_history/
PowerPoint Presentation
 ミッションクリティカルな業務システムを AWS クラウドで実現するポイント ~ SAP 編 ~ Kazuhide Inoue, Amazon Data Services Japan July 17 th, 2014 Session #TA-05 2014 Amazon.com, Inc. and its affiliates. All rights reserved. May not be copied,
ミッションクリティカルな業務システムを AWS クラウドで実現するポイント ~ SAP 編 ~ Kazuhide Inoue, Amazon Data Services Japan July 17 th, 2014 Session #TA-05 2014 Amazon.com, Inc. and its affiliates. All rights reserved. May not be copied,
今さら聞けない!? Oracle入門 ~前編~
 Oracle Direct Seminar 今さら聞けない!? Oracle 入門 ~ 前編 ~ 日本オラクル株式会社 Agenda 1. Oracle の基本動作 2. Oracle のファイル群 3. Oracle のプロセス群と専用メモリ領域 4. データベース内部動作 今さら聞けない!? オラクル入門 ~ 後編 ~ 4. データベース内部動作
Oracle Direct Seminar 今さら聞けない!? Oracle 入門 ~ 前編 ~ 日本オラクル株式会社 Agenda 1. Oracle の基本動作 2. Oracle のファイル群 3. Oracle のプロセス群と専用メモリ領域 4. データベース内部動作 今さら聞けない!? オラクル入門 ~ 後編 ~ 4. データベース内部動作
Web 環境におけるレイヤー別負荷の 2 違い DB サーバ AP サーバ 後ろのレイヤーほど負荷が高く ボトルネックになりやすい
 pgpool-ii 最新情報 開発中のメモリキャッシュ機能 について SRA OSS, Inc. 日本支社石井達夫 Web 環境におけるレイヤー別負荷の 2 違い DB サーバ AP サーバ 後ろのレイヤーほど負荷が高く ボトルネックになりやすい 3 キャッシュを活用して負荷を軽減 AP サーバ DB サーバ AP サーバで結果をキャッシュして返す DB サーバで結果をキャッシュして返す 4 キャッシュの実装例
pgpool-ii 最新情報 開発中のメモリキャッシュ機能 について SRA OSS, Inc. 日本支社石井達夫 Web 環境におけるレイヤー別負荷の 2 違い DB サーバ AP サーバ 後ろのレイヤーほど負荷が高く ボトルネックになりやすい 3 キャッシュを活用して負荷を軽減 AP サーバ DB サーバ AP サーバで結果をキャッシュして返す DB サーバで結果をキャッシュして返す 4 キャッシュの実装例
Presentation Title Here
 AWS Black Belt Online Seminar AWS Database Migration Service アマゾンウェブサービスジャパン株式会社 ソリューションアーキテクト柴田竜典 2017.09.19 自己紹介 柴田竜典 [ シバタツ ] データベース関連の相談ごと何でも担当 AWS への移行を機に Aurora や Redshift に乗り換えたい オンプレミス商用 DB 製品を
AWS Black Belt Online Seminar AWS Database Migration Service アマゾンウェブサービスジャパン株式会社 ソリューションアーキテクト柴田竜典 2017.09.19 自己紹介 柴田竜典 [ シバタツ ] データベース関連の相談ごと何でも担当 AWS への移行を機に Aurora や Redshift に乗り換えたい オンプレミス商用 DB 製品を
スライド 1
 による のレプリケーション構成の支援 SRA OSS, Inc. 日本支社 開発者北川俊広 2 とは 専用のクラスタ管理ツールの一つ オープンソースソフトウェア (BSD ライセンス ) pgpool Global Development Group が開発 多彩な機能 同期レプリケーション ロードバランス 自動フェイルオーバー コネクションプーリングなど 他のレプリケーションツールとの連携 Streaming
による のレプリケーション構成の支援 SRA OSS, Inc. 日本支社 開発者北川俊広 2 とは 専用のクラスタ管理ツールの一つ オープンソースソフトウェア (BSD ライセンス ) pgpool Global Development Group が開発 多彩な機能 同期レプリケーション ロードバランス 自動フェイルオーバー コネクションプーリングなど 他のレプリケーションツールとの連携 Streaming
スライド 1
 Zabbix で PostgreSQL の監視を行おう ~pg_monz のご紹介 ~ SRA OSS,Inc. 日本支社盛宣陽 Copyright 2014 SRA OSS,Inc.Japan All rights reserved. 1 PostgreSQL の課題 DB としての基本機能 性能は商用 DB と比べても引けをとらない 運用面には課題あり どのようにして運用するのか? 効果的な監視方法は?
Zabbix で PostgreSQL の監視を行おう ~pg_monz のご紹介 ~ SRA OSS,Inc. 日本支社盛宣陽 Copyright 2014 SRA OSS,Inc.Japan All rights reserved. 1 PostgreSQL の課題 DB としての基本機能 性能は商用 DB と比べても引けをとらない 運用面には課題あり どのようにして運用するのか? 効果的な監視方法は?
PowerPoint プレゼンテーション
 Oracle GRID Center Flash SSD + 最新ストレージと Oracle Database で実現するデータベース統合の新しい形 2011 年 2 月 23 日日本オラクル Grid Center エンジニア岩本知博 進化し続けるストレージ関連技術 高速ストレージネットワークの多様化 低価格化 10GbE FCoE 8Gb FC ディスクドライブの多様化および大容量 / 低価格化
Oracle GRID Center Flash SSD + 最新ストレージと Oracle Database で実現するデータベース統合の新しい形 2011 年 2 月 23 日日本オラクル Grid Center エンジニア岩本知博 進化し続けるストレージ関連技術 高速ストレージネットワークの多様化 低価格化 10GbE FCoE 8Gb FC ディスクドライブの多様化および大容量 / 低価格化
10年オンプレで運用したmixiをAWSに移行した10の理由
 10 年オンプレで運用した mixi を AWS に移行した 10 の理由 AWS Summit Tokyo 2016 株式会社ミクシィ オレンジスタジオ mixi システム部北村聖児 自己紹介 2 名前 北村聖児 所属 株式会社ミクシィオレンジスタジオ mixiシステム部 担当サービス SNS mixi 今日話すこと 3 mixi を AWS に移行した話 mixi 2004 年 3 月 3 日にオフィシャルオープンした
10 年オンプレで運用した mixi を AWS に移行した 10 の理由 AWS Summit Tokyo 2016 株式会社ミクシィ オレンジスタジオ mixi システム部北村聖児 自己紹介 2 名前 北村聖児 所属 株式会社ミクシィオレンジスタジオ mixiシステム部 担当サービス SNS mixi 今日話すこと 3 mixi を AWS に移行した話 mixi 2004 年 3 月 3 日にオフィシャルオープンした
Oracle Real Application Clusters 10g: 第4世代
 Oracle Real Application Clusters 10g: Angelo Pruscino, Oracle Gordon Smith, Oracle Oracle Real Application Clusters RAC 10g Oracle RAC 10g Oracle Database 10g Oracle RAC 10g 4 Oracle Database 10g Oracle
Oracle Real Application Clusters 10g: Angelo Pruscino, Oracle Gordon Smith, Oracle Oracle Real Application Clusters RAC 10g Oracle RAC 10g Oracle Database 10g Oracle RAC 10g 4 Oracle Database 10g Oracle
PowerPoint_template_v1.3.pptx / パワーポイントテンプレート
 オンプレから Aurora へ 移行する 3 つの手法 ~ mysqldump, xtrabackup, DMS ~ #AuroraMatsuri 2017/07/05 アジェンダ はじめに 自己紹介 funplex 紹介 funplex のシステム移行 オンプレから Aurora へ移行 mysqldump XtraBackup DMS さいごに はじめに 自己紹介 名前 出身 パクジョンウン 経歴
オンプレから Aurora へ 移行する 3 つの手法 ~ mysqldump, xtrabackup, DMS ~ #AuroraMatsuri 2017/07/05 アジェンダ はじめに 自己紹介 funplex 紹介 funplex のシステム移行 オンプレから Aurora へ移行 mysqldump XtraBackup DMS さいごに はじめに 自己紹介 名前 出身 パクジョンウン 経歴
MATLAB® における並列・分散コンピューティング ~ Parallel Computing Toolbox™ & MATLAB Distributed Computing Server™ ~
 MATLAB における並列 分散コンピューティング ~ Parallel Computing Toolbox & MATLAB Distributed Computing Server ~ MathWorks Japan Application Engineering Group Takashi Yoshida 2016 The MathWorks, Inc. 1 System Configuration
MATLAB における並列 分散コンピューティング ~ Parallel Computing Toolbox & MATLAB Distributed Computing Server ~ MathWorks Japan Application Engineering Group Takashi Yoshida 2016 The MathWorks, Inc. 1 System Configuration
Arcserve Replication/High Availability 製品の仕組み
 目次 1. Arcserve Replication/High Availability 共通の仕組み 1-1: 同期とレプリケーションについて 1-2: 同期の仕組み ファイルレベル同期 ブロックレベル同期 オフライン同期 1-3: レプリケーションの仕組み 2. Arcserve High Availability スイッチオーバーの仕組み 2-1: IP 移動 2-2: コンピュータ名の切り替え
目次 1. Arcserve Replication/High Availability 共通の仕組み 1-1: 同期とレプリケーションについて 1-2: 同期の仕組み ファイルレベル同期 ブロックレベル同期 オフライン同期 1-3: レプリケーションの仕組み 2. Arcserve High Availability スイッチオーバーの仕組み 2-1: IP 移動 2-2: コンピュータ名の切り替え
タイトルを1~2行で入力 (長文の場合はフォントサイズを縮小)
") SAP システム クラウド移行と運用の勘所 株式会社 BeeX 代表取締役広木太 どう進めるか? Copyright 2018 BeeX Inc. All Rights Reserved. 出典 : https://medium.com/aws-enterprise-collection/cloud-native-or-lift-and-shift-99970053b25b 3 Copyright
SAP システム クラウド移行と運用の勘所 株式会社 BeeX 代表取締役広木太 どう進めるか? Copyright 2018 BeeX Inc. All Rights Reserved. 出典 : https://medium.com/aws-enterprise-collection/cloud-native-or-lift-and-shift-99970053b25b 3 Copyright
PowerPoint Presentation
 AWS ビッグデータサービス Deep Dive アマゾンデータサービスジャパンソリューションアーキテクト蒋逸峰 July 17, 2014 Session #TA-01 2014 Amazon.com, Inc. and its affiliates. All rights reserved. May not be copied, modified, or distributed in whole
AWS ビッグデータサービス Deep Dive アマゾンデータサービスジャパンソリューションアーキテクト蒋逸峰 July 17, 2014 Session #TA-01 2014 Amazon.com, Inc. and its affiliates. All rights reserved. May not be copied, modified, or distributed in whole
スライド 1
 オンライン セミナー Bluemix いつでも Webinar シリーズ第 18 回 Cloudant & dashdb 日本アイ ビー エム株式会社 IBM アナリティクス事業部肥後智彦 Bluemix で使用できるデータベース サービス 2 2014 IBM Corporation Bluemix で使用できるデータベース サービス 3 2014 IBM Corporation 4 2013 IBM
オンライン セミナー Bluemix いつでも Webinar シリーズ第 18 回 Cloudant & dashdb 日本アイ ビー エム株式会社 IBM アナリティクス事業部肥後智彦 Bluemix で使用できるデータベース サービス 2 2014 IBM Corporation Bluemix で使用できるデータベース サービス 3 2014 IBM Corporation 4 2013 IBM
アジェンダ はクラウド上でも十分使えます 1. の概要 とは の導入事例 で利用される構成 2. をクラウドで使う クラウドサービスの分類 Amazon Web Services による構成例 2
 をクラウドで利用しよう オープンソースミドルウェア最新技術セミナー 2014/03/25 14:10-14:40 SRA OSS, Inc. 日本支社 技術開発部 正野 裕大 1 アジェンダ はクラウド上でも十分使えます 1. の概要 とは の導入事例 で利用される構成 2. をクラウドで使う クラウドサービスの分類 Amazon Web Services による構成例 2 をクラウドで利用しよう
をクラウドで利用しよう オープンソースミドルウェア最新技術セミナー 2014/03/25 14:10-14:40 SRA OSS, Inc. 日本支社 技術開発部 正野 裕大 1 アジェンダ はクラウド上でも十分使えます 1. の概要 とは の導入事例 で利用される構成 2. をクラウドで使う クラウドサービスの分類 Amazon Web Services による構成例 2 をクラウドで利用しよう
第 7 章 ユーザー データ用表領域の管理 この章では 表や索引を格納するユーザー データ用表領域の作成や 作成後のメンテナンスに ついて解説します 1. ユーザー データ用表領域の管理概要 2. ユーザー データ用表領域作成時の考慮事項 3. ユーザー データ用表領域の作成 4. ユーザー データ
 はじめに コース概要と目的 効率良く Oracle データベースを使用するための運用管理について 管理タスクを行う上での考慮事項や注意 点を実習を通して習得します 受講対象者 データベース管理者 前提条件 データベース アーキテクチャ コースを受講された方 もしくは Oracle システム構成とデータベース構 造に関する知識をお持ちの方 テキスト内の記述について 構文 [ ] 省略可能 { A B
はじめに コース概要と目的 効率良く Oracle データベースを使用するための運用管理について 管理タスクを行う上での考慮事項や注意 点を実習を通して習得します 受講対象者 データベース管理者 前提条件 データベース アーキテクチャ コースを受講された方 もしくは Oracle システム構成とデータベース構 造に関する知識をお持ちの方 テキスト内の記述について 構文 [ ] 省略可能 { A B
Microsoft PowerPoint - AWS紹介-VIOPS2 [互換モード]
![Microsoft PowerPoint - AWS紹介-VIOPS2 [互換モード]](/thumbs/99/141158402.jpg "Microsoft PowerPoint - AWS紹介-VIOPS2 [互換モード]") Amazon Web Services (AWS) の紹介 JAWS JAWS UG 肝付兼続 Amazon Web Services (AWS) http://aws.amazon.com/ Amazon Web Services (AWS) Amazon Web Services LLC が提供しているパイオニア的な IaaS クラウドサービスサーバホスティング (VPS, 専用サーバ ) 的に利用ハードウェア資産を持たずに情報システムを外部
Amazon Web Services (AWS) の紹介 JAWS JAWS UG 肝付兼続 Amazon Web Services (AWS) http://aws.amazon.com/ Amazon Web Services (AWS) Amazon Web Services LLC が提供しているパイオニア的な IaaS クラウドサービスサーバホスティング (VPS, 専用サーバ ) 的に利用ハードウェア資産を持たずに情報システムを外部
利用約款別紙 SkyCDP for AWS 基本サービス仕様書 この仕様書は SkyCDP for AWS の基本サービスに関する内容 方法について記述したものです 尚 SkyCDP for AWS オプションサービスをご利用のお客様は各 SkyCDP for AWS オプションサービスのご契約内容
 利用約款別紙 SkyCDP for AWS 基本サービス仕様書 この仕様書は SkyCDP for AWS の基本サービスに関する内容 方法について記述したものです 尚 SkyCDP for AWS オプションサービスをご利用のお客様は各 SkyCDP for AWS オプションサービスのご契約内容が優先されま す サーバに関する基本サービス仕様 システム仕様 OS Amazon Linux2 or
利用約款別紙 SkyCDP for AWS 基本サービス仕様書 この仕様書は SkyCDP for AWS の基本サービスに関する内容 方法について記述したものです 尚 SkyCDP for AWS オプションサービスをご利用のお客様は各 SkyCDP for AWS オプションサービスのご契約内容が優先されま す サーバに関する基本サービス仕様 システム仕様 OS Amazon Linux2 or
Zabbix で PostgreSQL を監視! pg_monz のご紹介 Zabbix Conference Japan 年 11 月 20 日 SRA OSS, Inc. 日本支社マーケティング部
 Zabbix で PostgreSQL を監視! pg_monz のご紹介 Zabbix Conference Japan 2015 2015 年 11 月 20 日 SRA OSS, Inc. 日本支社マーケティング部 http://www.sraoss.co.jp/ 会社概要 社名 : SRA OSS, Inc. 日本支社設立 : 2005 年 7 月支社長 : 石井達夫資本金 :100 万米国ドル事業内容
Zabbix で PostgreSQL を監視! pg_monz のご紹介 Zabbix Conference Japan 2015 2015 年 11 月 20 日 SRA OSS, Inc. 日本支社マーケティング部 http://www.sraoss.co.jp/ 会社概要 社名 : SRA OSS, Inc. 日本支社設立 : 2005 年 7 月支社長 : 石井達夫資本金 :100 万米国ドル事業内容
Amazon RDS 入門
 Amazon Relational Database Service (RDS) 入門 アマゾン ウェブ サービス ジャパン株式会社 ソリューションアーキテクト 山内 晃 2017年5月31日 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. 本セッションの Feedback をお願いします 受付でお配りしたアンケートに本セッションの満足度やご感想などをご記入くださいアンケートをご提出いただきました方には
Amazon Relational Database Service (RDS) 入門 アマゾン ウェブ サービス ジャパン株式会社 ソリューションアーキテクト 山内 晃 2017年5月31日 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. 本セッションの Feedback をお願いします 受付でお配りしたアンケートに本セッションの満足度やご感想などをご記入くださいアンケートをご提出いただきました方には
サンのオープンソースへの 取り組み
 の高可用性構成 日本オラクル株式会社 Global Business Unit 以下の事項は 弊社の一般的な製品の方向性に関する概要を説明するものです また 情報提供を唯一の目的とするものであり いかなる契約にも組み込むことはできません 以下の事項は マテリアルやコード 機能を提供することをコミットメント ( 確約 ) するものではないため 購買決定を行う際の判断材料になさらないで下さい
の高可用性構成 日本オラクル株式会社 Global Business Unit 以下の事項は 弊社の一般的な製品の方向性に関する概要を説明するものです また 情報提供を唯一の目的とするものであり いかなる契約にも組み込むことはできません 以下の事項は マテリアルやコード 機能を提供することをコミットメント ( 確約 ) するものではないため 購買決定を行う際の判断材料になさらないで下さい
平成20年度成果報告書
 ベンチマークレポート - データグリッド Caché 編 - 平成 22 年 9 月 グリッド協議会先端金融テクノロジー研究会ベンチマーク WG - i - 目次 1. CACHÉ (INTERSYSTEMS)... 1 1.1 Caché の機能概要... 1 1.2 Caché の評価結果... 2 1.2.1 ベンチマーク実行環境... 2 1.2.2 評価シナリオ: 事前テスト... 3 -
ベンチマークレポート - データグリッド Caché 編 - 平成 22 年 9 月 グリッド協議会先端金融テクノロジー研究会ベンチマーク WG - i - 目次 1. CACHÉ (INTERSYSTEMS)... 1 1.1 Caché の機能概要... 1 1.2 Caché の評価結果... 2 1.2.1 ベンチマーク実行環境... 2 1.2.2 評価シナリオ: 事前テスト... 3 -
ネットアップクラウドデータサービス
 ネットアップクラウドデータサービス ネットアップのクラウドデータサービス IT ネットアップのクラウドデータサービスによってもたらされる効果 ネットアップのクラウド戦略 INSPIRE Innovation with the Cloud クラウドに安定性と信頼性をもたらし お客様のクラウド活用を強力に支援 ネットアップのクラウドデータサービスの主なユースケース ファイルサービス DevOps バックアップとディザスタリカバリ
ネットアップクラウドデータサービス ネットアップのクラウドデータサービス IT ネットアップのクラウドデータサービスによってもたらされる効果 ネットアップのクラウド戦略 INSPIRE Innovation with the Cloud クラウドに安定性と信頼性をもたらし お客様のクラウド活用を強力に支援 ネットアップのクラウドデータサービスの主なユースケース ファイルサービス DevOps バックアップとディザスタリカバリ
はじめに コース概要と目的 Oracle データベースのパフォーマンス問題の分析方法 解決方法を説明します 受講対象者 データベース管理者の方を対象としています 前提条件 データベース アーキテクチャ データベース マネジメント を受講された方 もしくは同等の知識 をお持ちの方 テキスト内の記述につ
 はじめに コース概要と目的 Oracle データベースのパフォーマンス問題の分析方法 解決方法を説明します 受講対象者 データベース管理者の方を対象としています 前提条件 データベース アーキテクチャ データベース マネジメント を受講された方 もしくは同等の知識 をお持ちの方 テキスト内の記述について 構文 [ ] 省略可能 { A B } A または B のどちらかを選択 n _ 数値の指定 デフォルト値
はじめに コース概要と目的 Oracle データベースのパフォーマンス問題の分析方法 解決方法を説明します 受講対象者 データベース管理者の方を対象としています 前提条件 データベース アーキテクチャ データベース マネジメント を受講された方 もしくは同等の知識 をお持ちの方 テキスト内の記述について 構文 [ ] 省略可能 { A B } A または B のどちらかを選択 n _ 数値の指定 デフォルト値
PostgreSQL による クラスタ構成の可能性 SRA OSS, Inc. 日本支社 取締役支社長 石井達夫
 PostgreSQL による クラスタ構成の可能性 SRA OSS, Inc. 日本支社 取締役支社長 石井達夫 SRA OSS, Inc. のご紹介 PostgreSQLを中心とした OSSへの様々なサービスを提供 サポートサービス コンサルティング パッケージ製品 PowerGres, libtextconv, Sylpheed Pro 教育サービス トレーニング 技術者認定制度 (PostgreSQL
PostgreSQL による クラスタ構成の可能性 SRA OSS, Inc. 日本支社 取締役支社長 石井達夫 SRA OSS, Inc. のご紹介 PostgreSQLを中心とした OSSへの様々なサービスを提供 サポートサービス コンサルティング パッケージ製品 PowerGres, libtextconv, Sylpheed Pro 教育サービス トレーニング 技術者認定制度 (PostgreSQL
UNIVERGE SG3000 から SG3600 Ver.6.2(2012 年モデル ) への 移行手順 All Rights Reserved, Copyright(C) NEC Corporation 2017 年 11 月 4 版
 への 移行手順 All Rights Reserved, Copyright(C) NEC Corporation 2017 年 11 月 4 版") UNIVERGE SG3000 から SG3600 Ver.6.2(2012 年モデル ) への 移行手順 2017 年 11 月 4 版 目次 1. はじめに... 1 2. 事前準備... 2 2.1 バックアップデータの移行に必要なもの... 2 2.2 事前準備... 3 3. 移行手順... 5 3.1 初期設定の実行... 5 3.2 バックアップデータのリストア... 5 4. 注意制限事項...
UNIVERGE SG3000 から SG3600 Ver.6.2(2012 年モデル ) への 移行手順 2017 年 11 月 4 版 目次 1. はじめに... 1 2. 事前準備... 2 2.1 バックアップデータの移行に必要なもの... 2 2.2 事前準備... 3 3. 移行手順... 5 3.1 初期設定の実行... 5 3.2 バックアップデータのリストア... 5 4. 注意制限事項...
スライド 1
 pgpool-ii によるオンメモリクエリキャッシュの実装 SRA OSS, Inc. 日本支社 pgpool-ii とは PostgreSQL 専用のミドルウェア OSS プロジェクト (BSD ライセンス ) proxy のように アプリケーションと PostgreSQL の間に入って様々な機能を提供 コネクションプーリング 負荷分散 自動フェイルオーバー レプリケーション クエリキャッシュ 導入事例
pgpool-ii によるオンメモリクエリキャッシュの実装 SRA OSS, Inc. 日本支社 pgpool-ii とは PostgreSQL 専用のミドルウェア OSS プロジェクト (BSD ライセンス ) proxy のように アプリケーションと PostgreSQL の間に入って様々な機能を提供 コネクションプーリング 負荷分散 自動フェイルオーバー レプリケーション クエリキャッシュ 導入事例
PowerPoint Presentation
 グローバルバンクにおける最新クラウド活用事例 AWS で実現する ハイパフォーマンスコンピューティング Pawan Agnihotri Global Financial Services Solutions Architect 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. 金融サービスにおけるリスク管理
グローバルバンクにおける最新クラウド活用事例 AWS で実現する ハイパフォーマンスコンピューティング Pawan Agnihotri Global Financial Services Solutions Architect 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. 金融サービスにおけるリスク管理
第 3 章 メディア障害とバックアップ リカバリ この章では メディア障害の発生に備えたバックアップ方法と 障害時の基本的なリカバリ方法につい て説明します 1. メディア リカバリ概要 2. ファイルの多重化 3. アーカイブ モードの設定 4. バックアップ概要 5. 一貫性バックアップ ( オ
 はじめに コース概要と目的 データベースのバックアップの取得方法 障害発生時のリカバリ方法について習得します 受講対象者 データベース管理者の方 前提条件 データベース アーキテクチャ および データベース マネジメント コースを受講された方 または 同等の知識をお持ちの方 テキスト内の記述について 構文 [ ] 省略可能 { A B } A または B のどちらかを選択 n _ 数値の指定 デフォルト値
はじめに コース概要と目的 データベースのバックアップの取得方法 障害発生時のリカバリ方法について習得します 受講対象者 データベース管理者の方 前提条件 データベース アーキテクチャ および データベース マネジメント コースを受講された方 または 同等の知識をお持ちの方 テキスト内の記述について 構文 [ ] 省略可能 { A B } A または B のどちらかを選択 n _ 数値の指定 デフォルト値
PowerPoint プレゼンテーション
 vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
自己紹介 1982 年 4 月に日商エレクトロニクス株式会社入社 Sybase を使った銀行系システムの開発 保守を担当 Oracle データベースを使ったアプリケーション設計 開発 保守 およびパフォーマンス チューニングなどのコンサルティング業務を担当 Oracle データベースのデータ移行 再
 PCIe SSD を用いた MySQL 5.6 と 5.7 のパフォーマンス対決![+α 版 ] ~ MySQL の性能は どこまで向上するのか ~ 日商エレクトロニクス株式会社マーケティング本部 SODC グループ長井伸次 自己紹介 1982 年 4 月に日商エレクトロニクス株式会社入社 Sybase を使った銀行系システムの開発 保守を担当 Oracle データベースを使ったアプリケーション設計
PCIe SSD を用いた MySQL 5.6 と 5.7 のパフォーマンス対決![+α 版 ] ~ MySQL の性能は どこまで向上するのか ~ 日商エレクトロニクス株式会社マーケティング本部 SODC グループ長井伸次 自己紹介 1982 年 4 月に日商エレクトロニクス株式会社入社 Sybase を使った銀行系システムの開発 保守を担当 Oracle データベースを使ったアプリケーション設計
OPENSQUARE
 HGST ServerCache ~ 高性能 SSD+RAM キャッシュソフトウェア ~ 株式会社 OPENスクエア東京都千代田区神田紺屋町 17 番 SIA 神田スクエア2F お問合せ先 : info_os@opensquare.co.jp 2014 年 12 月 3 日 http://www.opensquare.co.jp Copyright OPENSQUARE. All rights reserved
HGST ServerCache ~ 高性能 SSD+RAM キャッシュソフトウェア ~ 株式会社 OPENスクエア東京都千代田区神田紺屋町 17 番 SIA 神田スクエア2F お問合せ先 : info_os@opensquare.co.jp 2014 年 12 月 3 日 http://www.opensquare.co.jp Copyright OPENSQUARE. All rights reserved
スライド 1
 1 MySQL パフォーマンス機能改善点紹介 日本オラクル株式会社山崎由章 / MySQL Senior Sales Consultant, Asia Pacific and Japan 2 以下の事項は 弊社の一般的な製品の方向性に関する概要を説明するものです また 情報提供を唯一の目的とするものであり いかなる契約にも組み込むことはできません 以下の事項は マテリアルやコード 機能を提供することをコミットメント
1 MySQL パフォーマンス機能改善点紹介 日本オラクル株式会社山崎由章 / MySQL Senior Sales Consultant, Asia Pacific and Japan 2 以下の事項は 弊社の一般的な製品の方向性に関する概要を説明するものです また 情報提供を唯一の目的とするものであり いかなる契約にも組み込むことはできません 以下の事項は マテリアルやコード 機能を提供することをコミットメント
…l…b…g…‘†[…N…v…“…O…›…~…fi…OfiÁŸ_
 13 : Web : RDB (MySQL ) DB (memcached ) 1: MySQL ( ) 2: : /, 3: : Google, 1 / 23 testmysql.rb: mysql ruby testmem.rb: memcached ruby 2 / 23 ? Web / 3 ( ) Web s ( ) MySQL PostgreSQL SQLite MariaDB (MySQL
13 : Web : RDB (MySQL ) DB (memcached ) 1: MySQL ( ) 2: : /, 3: : Google, 1 / 23 testmysql.rb: mysql ruby testmem.rb: memcached ruby 2 / 23 ? Web / 3 ( ) Web s ( ) MySQL PostgreSQL SQLite MariaDB (MySQL
更新履歴 Document No. Date Comments 次 D JP 2017/05/01 初版 1. 概要 はじめに 情報源 A10 Lightning Application Delivery Service(ADS) 導 構成 動作概要 構築概要 2. 事
 導 構成 動作概要 構築概要 2. 事") A10 Lightning Application Delivery Service AWS での Application 展開 複数 Availability Zone での Auto Scaling Document Number : D-030-01-0079-01-JP この 書及びその内容に関し如何なる保証をするものではありません 記載されている事項は予告なしに変更されることがあります and/or
A10 Lightning Application Delivery Service AWS での Application 展開 複数 Availability Zone での Auto Scaling Document Number : D-030-01-0079-01-JP この 書及びその内容に関し如何なる保証をするものではありません 記載されている事項は予告なしに変更されることがあります and/or
PowerPoint Presentation
 MySQL Workbench を使ったデータベース開発 日本オラクル株式会社山崎由章 / MySQL Senior Sales Consultant, Asia Pacific and Japan 1 Copyright 2013, Oracle and/or its affiliates. All rights reserved. 以下の事項は 弊社の一般的な製品の方向性に関する概要を説明するものです
MySQL Workbench を使ったデータベース開発 日本オラクル株式会社山崎由章 / MySQL Senior Sales Consultant, Asia Pacific and Japan 1 Copyright 2013, Oracle and/or its affiliates. All rights reserved. 以下の事項は 弊社の一般的な製品の方向性に関する概要を説明するものです
Microsoft Word - nvsi_050110jp_netvault_vtl_on_dothill_sannetII.doc
 Article ID: NVSI-050110JP Created: 2005/10/19 Revised: - NetVault 仮想テープ ライブラリのパフォーマンス検証 : dothill SANnetⅡSATA 編 1. 検証の目的 ドットヒルシステムズ株式会社の SANnetll SATA は 安価な SATA ドライブを使用した大容量ストレージで ディスクへのバックアップを行う際の対象デバイスとして最適と言えます
Article ID: NVSI-050110JP Created: 2005/10/19 Revised: - NetVault 仮想テープ ライブラリのパフォーマンス検証 : dothill SANnetⅡSATA 編 1. 検証の目的 ドットヒルシステムズ株式会社の SANnetll SATA は 安価な SATA ドライブを使用した大容量ストレージで ディスクへのバックアップを行う際の対象デバイスとして最適と言えます
Oracle Data Pumpのパラレル機能
 Oracle Data Pump のパラレル機能 Carol Palmer オラクル社 Principal Product Manager はじめに Oracle Database 10g 上の Oracle Data Pump により 異なるデータベース間のデータとメタデータを高速で移動できます Data Pump の最も便利な機能の 1 つは エクスポート ジョブとインポート ジョブをパラレルに実行しパフォーマンスを高める機能です
Oracle Data Pump のパラレル機能 Carol Palmer オラクル社 Principal Product Manager はじめに Oracle Database 10g 上の Oracle Data Pump により 異なるデータベース間のデータとメタデータを高速で移動できます Data Pump の最も便利な機能の 1 つは エクスポート ジョブとインポート ジョブをパラレルに実行しパフォーマンスを高める機能です
Oracle Database 11g Oracle Real Application Testing
 Oracle Database 11g Real Application Testing 1 2 Oracle Real Application Testing 価値 テクノロジの迅速な導入 テスト品質の向上 ビジネス上の利点 低コスト 低リスク テスト 変更 修正 配置 機動的なビジネスのためのソリューション 3 Database Replay 4 Database Replay の必要性 ビジネスに相応しい価値を付加する新しいテクノロジの導入
Oracle Database 11g Real Application Testing 1 2 Oracle Real Application Testing 価値 テクノロジの迅速な導入 テスト品質の向上 ビジネス上の利点 低コスト 低リスク テスト 変更 修正 配置 機動的なビジネスのためのソリューション 3 Database Replay 4 Database Replay の必要性 ビジネスに相応しい価値を付加する新しいテクノロジの導入
Microsoft Word - nvsi_050090jp_oracle10g_vlm.doc
 Article ID: NVSI-050090JP Created: 2005/04/20 Revised: Oracle Database10g VLM 環境での NetVault 動作検証 1. 検証目的 Linux 上で稼動する Oracle Database10g を大容量メモリ搭載環境で動作させる場合 VLM に対応したシステム設定を行います その環境において NetVault を使用し
Article ID: NVSI-050090JP Created: 2005/04/20 Revised: Oracle Database10g VLM 環境での NetVault 動作検証 1. 検証目的 Linux 上で稼動する Oracle Database10g を大容量メモリ搭載環境で動作させる場合 VLM に対応したシステム設定を行います その環境において NetVault を使用し
Automation for Everyone <デモ で実感できる、組織全体で活用できるAnsible Tower>
 Mixed-OSS における PostgreSQL の活用 2018 年 8 月 24 日三菱総研 DCS 株式会社 三菱総研 DCS の会社概要 IT コンサルティングからシステムの設計 開発 運用 処理まで すべての局面でサービスを提供できる IT トータルソリューションを実現しています 東京本社 ( 品川 ) 千葉情報センター 東京ビジネスセンター ( 木場 ) 商号設立資本金代表取締役社長株主
Mixed-OSS における PostgreSQL の活用 2018 年 8 月 24 日三菱総研 DCS 株式会社 三菱総研 DCS の会社概要 IT コンサルティングからシステムの設計 開発 運用 処理まで すべての局面でサービスを提供できる IT トータルソリューションを実現しています 東京本社 ( 品川 ) 千葉情報センター 東京ビジネスセンター ( 木場 ) 商号設立資本金代表取締役社長株主
_AWS-Blackbelt-Organizations
 AWS Black Belt Online Seminar AWS Organizations アマゾンウェブサービスジャパン株式会社ソリューションアーキテクト辻義一 2018.02.14 自己紹介 辻義一 ( つじよしかず ) 西日本担当ソリューションアーキテクト簡単な経歴 大阪生まれの大阪育ち 独立系 SIerでインフラエンジニア AWSのすきな所 安い 早い おもしろい 内容についての注意点
AWS Black Belt Online Seminar AWS Organizations アマゾンウェブサービスジャパン株式会社ソリューションアーキテクト辻義一 2018.02.14 自己紹介 辻義一 ( つじよしかず ) 西日本担当ソリューションアーキテクト簡単な経歴 大阪生まれの大阪育ち 独立系 SIerでインフラエンジニア AWSのすきな所 安い 早い おもしろい 内容についての注意点
Microsoft Word - eRecovery v3-1.doc
 Acer erecovery Management Acer erecovery Management は コンピュータを ハードディスクドライブの隠しパーティション 第二パーティション または光ディスクに保存されている画像から 工場出荷時設定あるいはユーザが設定したシステム設定に復元するための高速で安定した 安全な方法を提供します また Acer erecovery Management は システム設定
Acer erecovery Management Acer erecovery Management は コンピュータを ハードディスクドライブの隠しパーティション 第二パーティション または光ディスクに保存されている画像から 工場出荷時設定あるいはユーザが設定したシステム設定に復元するための高速で安定した 安全な方法を提供します また Acer erecovery Management は システム設定
April 2014 Flash-aware MySQL フラッシュが MySQL を変える Takeshi Hasegawa Senior Sales Engineer APAC Japan Fusion-io
 April 2014 Flash-aware MySQL フラッシュが MySQL を変える Takeshi Hasegawa Senior Sales Engineer APAC Japan Fusion-io 不揮発メモリ (NVM) の登場 フラッシュ (NAND) デバイスあたり数百 GB 10TBの容量 フラッシュ技術のトレンド 大容量化 GB 単価コスト 書き込み回数の減少 セルの多値化
April 2014 Flash-aware MySQL フラッシュが MySQL を変える Takeshi Hasegawa Senior Sales Engineer APAC Japan Fusion-io 不揮発メモリ (NVM) の登場 フラッシュ (NAND) デバイスあたり数百 GB 10TBの容量 フラッシュ技術のトレンド 大容量化 GB 単価コスト 書き込み回数の減少 セルの多値化
Microsoft Word - nvsi_080188jp_r1_netvault_oracle_rac_backup_complemental_guide_j_174x217.doc
 Oracle RAC 環境における NetVault Backup バックアップ & リストア補足資料 バックボーン ソフトウエア株式会社 Doc# NVSI-080188JP Copyrights 著作権 2009 BakBone Software Oracle RAC 環境における NetVault Backup バックアップ & リストア補足資料 Version 1.1 本ガイドは Oracle
Oracle RAC 環境における NetVault Backup バックアップ & リストア補足資料 バックボーン ソフトウエア株式会社 Doc# NVSI-080188JP Copyrights 著作権 2009 BakBone Software Oracle RAC 環境における NetVault Backup バックアップ & リストア補足資料 Version 1.1 本ガイドは Oracle
スライド 1
 期間限定販売プログラム vsmp Foundation クラスタを仮想化して運用と管理の容易なシングルシステムを構築様々なリソースを柔軟に統合化 Panasas ActiveStor 研究開発やエンタープライズクラスのワークロードに理想的なハイブリッドスケールアウト NAS アプライアンス 販売プログラム PANASAS ACTIVESTORE 仮想化ソフトウエア無償提供 2 販売プログラムの内容
期間限定販売プログラム vsmp Foundation クラスタを仮想化して運用と管理の容易なシングルシステムを構築様々なリソースを柔軟に統合化 Panasas ActiveStor 研究開発やエンタープライズクラスのワークロードに理想的なハイブリッドスケールアウト NAS アプライアンス 販売プログラム PANASAS ACTIVESTORE 仮想化ソフトウエア無償提供 2 販売プログラムの内容
PowerPoint プレゼンテーション
 ROOM G Web 開発者のためのクラウド活用 ~ Windows Azure 基本の " き " 日本マイクロソフト株式会社デベロッパー & プラットフォーム統括本部エバンジェリスト大森彩子 http://blogs.msdn.com/bluesky Azure 青い空 http://itpro.nikkeibp.co.jp Azure 基礎 Agenda Windows Azure Web サイトの概要
ROOM G Web 開発者のためのクラウド活用 ~ Windows Azure 基本の " き " 日本マイクロソフト株式会社デベロッパー & プラットフォーム統括本部エバンジェリスト大森彩子 http://blogs.msdn.com/bluesky Azure 青い空 http://itpro.nikkeibp.co.jp Azure 基礎 Agenda Windows Azure Web サイトの概要
AWSストレージ関連サービスの正しい理解と使い方講座
 AWSストレージ関連サービスの正しい理解と使い方講座 アマゾンデータサービスジャパンソリューションアーキテクト小林正人 本セッションの目的 AWS が提供する様々なストレージ関連サービスの特徴についておさらいする サービス毎の機能概要やユースケースを正しく理解する ユースケースに応じて最適なストレージサービスを選択できるようにする 自己紹介 AWS のストレージ関連サービス EBS S3 Glacier
AWSストレージ関連サービスの正しい理解と使い方講座 アマゾンデータサービスジャパンソリューションアーキテクト小林正人 本セッションの目的 AWS が提供する様々なストレージ関連サービスの特徴についておさらいする サービス毎の機能概要やユースケースを正しく理解する ユースケースに応じて最適なストレージサービスを選択できるようにする 自己紹介 AWS のストレージ関連サービス EBS S3 Glacier
Leveraging Cloud Computing to launch Python apps
 (Twitter: @KenTamagawa) v 1.1 - July 21st, 2011 (Ken Tamagawa) Twitter: @KenTamagawa 2011 8 6 Japan Innovation Leaders Summit IT IT AWS 90% AWS 90% アーキテクチャ設計 Intro }7 Intro 1 2 3 4 5 6 7 Intro 1 2 3 4
(Twitter: @KenTamagawa) v 1.1 - July 21st, 2011 (Ken Tamagawa) Twitter: @KenTamagawa 2011 8 6 Japan Innovation Leaders Summit IT IT AWS 90% AWS 90% アーキテクチャ設計 Intro }7 Intro 1 2 3 4 5 6 7 Intro 1 2 3 4
PowerPoint プレゼンテーション
 BrightSignNetwork クイックスタートガイド 1 この度は BrightSignNetwork サブスクリプションパックをお買い上げいただき 誠にありがとうございます このクイックスタートガイドは BrightSignNetwork を使って 遠隔地に設置した BrightSign プレイヤーのプレゼンテーションを管理するための手順をご説明します ジャパンマテリアル株式会社 Rev.
BrightSignNetwork クイックスタートガイド 1 この度は BrightSignNetwork サブスクリプションパックをお買い上げいただき 誠にありがとうございます このクイックスタートガイドは BrightSignNetwork を使って 遠隔地に設置した BrightSign プレイヤーのプレゼンテーションを管理するための手順をご説明します ジャパンマテリアル株式会社 Rev.
本資料の関連資料は下記をクリックして PDF 一覧からお入り下さい IT ライブラリー (pdf 100 冊 ) 目次番号 453 番 AWS 詳細解説全 33 冊計 6,100 ページ 2
 目次番号 453 番 AWS 詳細解説全 33 冊計 6,100 ページ 2") IT ライブラリーより (pdf 100 冊 ) http://www.geocities.jp/ittaizen/itlib1/ AWS Storage Gateway ( 全 120 ページ ) 解説 本資料の関連資料は下記をクリックして PDF 一覧からお入り下さい IT ライブラリー (pdf 100 冊 ) http://www.geocities.jp/ittaizen/itlib1/
IT ライブラリーより (pdf 100 冊 ) http://www.geocities.jp/ittaizen/itlib1/ AWS Storage Gateway ( 全 120 ページ ) 解説 本資料の関連資料は下記をクリックして PDF 一覧からお入り下さい IT ライブラリー (pdf 100 冊 ) http://www.geocities.jp/ittaizen/itlib1/
PowerPoint プレゼンテーション
 大規模環境における Ruby on Rails on AWS での最適化事例 ~ 200ms 100ms への歩み ~ 2018/06/01 AWS Summit 2018 株式会社アカツキエンジニア長井昭裕 1 自己紹介 長井昭裕 (Akihiro Nagai) 経歴: 2016年にアカツキに入社 モバイルゲームの インフラ構築 運用(AWS, GCP), サーバサイドアプリケーション開発(Rails),
大規模環境における Ruby on Rails on AWS での最適化事例 ~ 200ms 100ms への歩み ~ 2018/06/01 AWS Summit 2018 株式会社アカツキエンジニア長井昭裕 1 自己紹介 長井昭裕 (Akihiro Nagai) 経歴: 2016年にアカツキに入社 モバイルゲームの インフラ構築 運用(AWS, GCP), サーバサイドアプリケーション開発(Rails),
pgpool-ii で PostgreSQL のクラスタを楽々運用しよう OSC Tokyo 2014/12/12 SRA OSS, Inc. 日本支社マーケティング部 OSS 技術グループ 長田 悠吾
 pgpool-ii で PostgreSQL のクラスタを楽々運用しよう OSC 2014.Enterprise @ Tokyo 2014/12/12 SRA OSS, Inc. 日本支社マーケティング部 OSS 技術グループ 長田 悠吾 自己紹介 長田悠吾 ( ナガタユウゴ ) SRA OSS, Inc. 日本支社 マーケティング部 OSS 技術グループ pgpool-ii 開発者 PostgreSQL
pgpool-ii で PostgreSQL のクラスタを楽々運用しよう OSC 2014.Enterprise @ Tokyo 2014/12/12 SRA OSS, Inc. 日本支社マーケティング部 OSS 技術グループ 長田 悠吾 自己紹介 長田悠吾 ( ナガタユウゴ ) SRA OSS, Inc. 日本支社 マーケティング部 OSS 技術グループ pgpool-ii 開発者 PostgreSQL
版 HinemosVM クラウド管理機能のご紹介 NTT データ先端技術株式会社 2019 NTT DATA INTELLILINK Corporation
 201907 版 HinemosVM クラウド管理機能のご紹介 NTT データ先端技術株式会社 2019 NTT DATA INTELLILINK Corporation 背景 クラウドが一般的に しかしクラウド運用が課題に 法人分野早期からクラウド導入が進む金融分野某メガバンクのAWS 戦略公共分野デジタル ガバメント実行計画 準拠法および裁判地とも日本法適用へ クラウドのメリットを享受するにはクリアすべき運用課題が
201907 版 HinemosVM クラウド管理機能のご紹介 NTT データ先端技術株式会社 2019 NTT DATA INTELLILINK Corporation 背景 クラウドが一般的に しかしクラウド運用が課題に 法人分野早期からクラウド導入が進む金融分野某メガバンクのAWS 戦略公共分野デジタル ガバメント実行計画 準拠法および裁判地とも日本法適用へ クラウドのメリットを享受するにはクリアすべき運用課題が
Title Slide with Name
 自習 & ハンズオントレーニング資料 Backup Exec 15 BE15-07 データライフサイクル管理 (DLM) ベリタステクノロジーズ合同会社 テクノロジーセールス & サービス統括本部セールスエンジニアリング本部パートナー SE 部 免責事項 ベリタステクノロジーズ合同会社は この文書の著作権を留保します また 記載された内容の無謬性を保証しません VERITAS の製品は将来に渡って仕様を変更する可能性を常に含み
自習 & ハンズオントレーニング資料 Backup Exec 15 BE15-07 データライフサイクル管理 (DLM) ベリタステクノロジーズ合同会社 テクノロジーセールス & サービス統括本部セールスエンジニアリング本部パートナー SE 部 免責事項 ベリタステクノロジーズ合同会社は この文書の著作権を留保します また 記載された内容の無謬性を保証しません VERITAS の製品は将来に渡って仕様を変更する可能性を常に含み
AWS Simple Monthly Calculator (簡易見積ツール) 使い方説明
 使い方説明") AWS Simple Monthly Calculator ( 簡易見積ツール ) 使用方法ご説明資料 目次 AWS Simple Monthly Calculatorとは AWS Simple Monthly Calculatorを利用するには基本設定 Amazon Elastic Compute Cloud (EC2) Amazon Elastic Block Store (EBS) その他 EC2/EBS
AWS Simple Monthly Calculator ( 簡易見積ツール ) 使用方法ご説明資料 目次 AWS Simple Monthly Calculatorとは AWS Simple Monthly Calculatorを利用するには基本設定 Amazon Elastic Compute Cloud (EC2) Amazon Elastic Block Store (EBS) その他 EC2/EBS