議題 プロセッサーの動向とコード モダナイゼーション インテル アドバンスト ベクトル エクステンション 512 ( インテル AVX-512) 命令と演算性能 ベクトル化を支援するインテル Advisor ループの性能を可視化するルーフライン表示 姫野ベンチマークを用いたインテル Xeon Phi
|
|
|
- てるえ じゅふく
- 5 years ago
- Views:
Transcription


1 最新のインテル Parallel Studio XE を用いた迅速なベクトル化と並列化手法 インテル株式会社 技術本部ソフトウェア技術統括部 シニア スタッフ エンジニア 池井 満
2 議題 プロセッサーの動向とコード モダナイゼーション インテル アドバンスト ベクトル エクステンション 512 ( インテル AVX-512) 命令と演算性能 ベクトル化を支援するインテル Advisor ループの性能を可視化するルーフライン表示 姫野ベンチマークを用いたインテル Xeon Phi プロセッサー上でのケーススタディー 並列化とベクトル化の検討 インテル VTune Amplifier によるメモリー使用表示 メモリー階層 ( 高速メモリー ) の影響 NUMA 構成 ( クラスター ) の影響 まとめ 2


3 予測に沿った半導体の微細化ムーアの法則に沿って製造を続ける 高機能で複雑な新しい製品を 電力 価格 大きさを制御しながら提供する ストレインド シリコン Hi-K メタルゲート 3D トランジスター 90nm 65nm 45nm 32nm 22nm 14nm 10nm 7nm 3











4 より多いコア数. より幅広いベクトル. コプロセッサー性能を活かすにはすべての並列性を利用することが必要 Images do not reflect actual die sizes インテル Xeon プロセッサー 64-bit インテル Xeon プロセッサー 5100 シリーズ インテル Xeon プロセッサー 5600 シリーズ インテル Xeon プロセッサー E (Sandy Bridge ) インテル Xeon プロセッサー E v2 (Ivy Bridge ) インテル Xeon プロセッサー E v3 (Haswell ) インテル Xeon Platinum 81xx プロセッサー (Skylake ) インテル Xeon Phi コプロセッサー Knights Landing 3+ Tflops コア数 スレッド数 SIMD 幅 インテル SSE2 インテル SSSE3 インテル SSE4.2 インテル AVX インテル AVX インテル AVX2 FMA インテル AVX-512 IMCI インテル AVX-512 開発コード名 4
5 より多いコア数. より幅広いベクトル. コプロセッサー性能を活かすにはすべての並列性を利用することが必要 単精度数 16 個の FMA 演算を 2 個同時に計算できる Images do not reflect actual die sizes 64 SP 演算 インテル Xeon プロセッサー 64-bit インテル Xeon プロセッサー 5100 シリーズ インテル Xeon プロセッサー 5600 シリーズ インテル Xeon プロセッサー E (Sandy Bridge ) インテル Xeon プロセッサー E v2 (Ivy Bridge ) 28 コア = 17 インテル インテル Xeon 92Xeon プロセッサー E v3 (Haswell ) Platinum 81xx プロセッサー (Skylake ) インテル Xeon Phi コプロセッサー Knights Landing 3+ Tflops コア数 スレッド数 SIMD 幅 インテル SSE2 インテル SSSE3 インテル SSE4.2 インテル AVX インテル AVX インテル AVX2 FMA インテル AVX-512 IMCI インテル AVX-512 開発コード名 5
6 プログラミング方法の再検討コード モダナイゼーション 数コアのプロセッサーから始まって一貫したモデル 言語 ツールや手法でメニーコアに対応することで 持続的な価値を生み出すことができる アプリケーションは利用できるすべての並列性を活用する - 命令レベル : コアの特性を知り 考慮 - データレベル : SIMD 命令を用いるようにベクトル化 - スレッドレベル : OpenMP* などの標準ツールで並列化 - クラスターレベル : MPI などの標準ツールで並列化 専門家がプロセッサーに最適化した標準ライブラリーや言語を利用する ヘテロジニティーまで考慮した最適化を検討する 6
7 インテル Parallel Studio XE 高速なコードを素早く開発 Composer Edition ビルドコンパイラーとライブラリー Professional Edition 解析解析ツール Cluster Edition スケールクラスターツール インテル C/C++ コンパイラー最適化コンパイラー インテル Fortran コンパイラー最適化コンパイラー インテル TBB 2 C++ スレッド ライブラリー インテル MKL 3 高速なマス カーネル ライブラリー インテル IPP 4 画像 信号 データ処理 インテル DAAL 5 データ解析 マシンラーニング ライブラリー インテル Distribution for Python* ハイパフォーマンスなスクリプト インテル アーキテクチャー ベースのプラットフォーム オペレーティング システム : Windows* Linux* macos* 1 インテル VTune Amplifier パフォーマンス プロファイラー インテル Inspector メモリー / スレッドのデバッガー インテル Advisor ベクトル化の最適化とスレッドのプロトライプ生成 インテル MPI ライブラリーメッセージ パッシング インターフェイス ライブラリー インテル Trace Analyzer & Collector MPI チューニングと解析 インテル Cluster Checker クラスター診断エキスパート システム コードを強力に支援 - isus.jp/intel-parallel-studio-xe/ 1 Composer Edition でのみ利用可能 2 インテル スレッディング ビルディング ブロック 3 インテル マス カーネル ライブラリー 4 インテル インテグレーテッド パフォーマンス プリミティブ 5 インテル データ アナリティクス アクセラレーション ライブラリー 7


8 インテル Parallel Studio XE 高速なコードを素早く開発 Composer Edition SIMD 命令を活用するためビルドの強力なツールコンパイラーとライブラリー C/C++ インテル MKL インテル 3 コンパイラー Advisor 最適化コンパイラー インテル Fortran コンパイラー最適化コンパイラー インテル TBB 2 C++ スレッド ライブラリー 高速なマス カーネル ライブラリー インテル IPP 4 画像 信号 データ処理 インテル DAAL 5 データ解析 マシンラーニング ライブラリー インテル Distribution for Python* ハイパフォーマンスなスクリプト Professional Edition 解析解析ツール インテル VTune Amplifier パフォーマンス プロファイラー インテル Inspector メモリー / スレッドのデバッガー インテル Advisor ベクトル化の最適化とスレッドのプロトライプ生成 Cluster Edition スケールクラスターツール インテル MPI ライブラリーメッセージ パッシング インターフェイス ライブラリー インテル Trace Analyzer & Collector MPI チューニングと解析 インテル Cluster Checker クラスター診断エキスパート システム インテル アーキテクチャー ベースのプラットフォーム オペレーティング システム : Windows* Linux* macos* 1 コードを強力に支援 - isus.jp/intel-parallel-studio-xe/ 1 Composer Edition でのみ利用可能 2 インテル スレッディング ビルディング ブロック 3 インテル マス カーネル ライブラリー 4 インテル インテグレーテッド パフォーマンス プリミティブ 5 インテル データ アナリティクス アクセラレーション ライブラリー 8
9 新機能 : ルーフライン 高速な解析 ほか インテル Advisor ベクトル化の最適化 ルーフライン解析により効率良く最適化 影響の大きい最適化されていないループを見つける キャッシュまたはベクトル化の最適化が必要か? 演算負荷の高いアルゴリズムのほうが良いか? 高速なデータ収集 モジュールでフィルター 必要なもののみ計算 詳細な解析を追跡 すべてのサイトが実行されたら停止する より多くのデータと推奨事項により的確な判断が可能 インテル MKL フレンドリー コードが最適化されているか? 最適なバージョンが使用されているか? トリップカウントと関数呼び出しカウント 上位 5 つの推奨事項をサマリーに表示 動的な命令ミックス エキスパート機能により各命令の正確なカウントを表示 簡単に MPI を起動 コマンドライン ダイアログで MPI をサポート 9
 HPC 向け SIMD サポートパフォーマンス / ワットにおいて業界のリーダーシップ AVX2 AVX512F AVX2 AVX512F AVX2 AVX AVX AVX AVX SSE* SSE* SSE* SSE* SSE* SKL: インテル Xeon スケーラブル")
10 インテル Xeon プロセッサーとインテル Xeon Phi プロセッサー向け命令セット アーキテクチャー (ISA) 大きいコア低レイテンシーに注力 / マルチスレッド シングルスレッドエンタープライズ HPC 向け SIMD サポートベスト パフォーマンスで一般的なワークロードのパフォーマンスを最適化 Pftchwt1 AVX512PF AVX512ER AVX512VL AVX512BW AVX512DQ AVX512CD AVX512CD 小さいコアスループットに注力 / 多くのスレッド ( メニーコア ) HPC 向け SIMD サポートパフォーマンス / ワットにおいて業界のリーダーシップ AVX2 AVX512F AVX2 AVX512F AVX2 AVX AVX AVX AVX SSE* SSE* SSE* SSE* SSE* SKL: インテル Xeon スケーラブル プロセッサー ( 開発コード名 Skylake) KNL: インテル Xeon Phi プロセッサー ( 開発コード名 Knights Landing) HSW: 開発コード名 Haswell SNB: 開発コード名 Sandy Bridge NHM: 開発コード名 Nehalem NHM SNB HSW KNL SKL インテル インテル Xeon Phi Xeon プロセッサースケーラブル プロセッサー開発コード名 10
11 論理レジスターファイルの拡張 汎用レジスター (32/64) EAX EBX RAX RBX インテル MMX テクノロジーおよび浮動小数点レジスター (64) MM0/ST0 MM1/ST1 インテル SSE (128)/ インテル AVX (256)/ インテル AVX (512) レジスター XMM0 XMM1 XMM2 ZMM0 ZMM1 ZMM2 ECX EDX EBP ESI EDI ESP RCX RDX RBP RSI RDI RSP MM2/ST2 MM3/ST3 MM4/ST4 MM5/ST5 MM6/ST6 MM7/ST7 MASK レジスター (64) K0 K1 K2 K3 XMM3 XMM4 XMM5 XMM6 XMM7 XMM8 XMM9 XMM10 XMM11 ZMM3 ZMM4 ZMM5 ZMM6 ZMM7 ZMM8 ZMM9 ZMM10 ZMM11 ZMM16 ZMM17 ZMM18 ZMM19 ZMM20 R8 R9 K4 K5 XMM12 XMM13 XMM14 ZMM12 ZMM13 ZMM14 ZMM21 ZMM22 ZMM23 R10 R11 EFLAGS K6 K7 XMM15 ZMM15 ZMM24 ZMM25 R12 ZMM26 R13 R14 R15 プログラムカウンター (32/64) RIP ZMM27 ZMM28 ZMM9 ZMM30 ZMM31 インテル SSE: インテル ストリーミング SIMD 拡張命令インテル AVX : インテル アドバンスト ベクトル エクステンション 11

12 単一のベクトルレーンを使用しない! ベクトル化およびスレッド化されていないソフトウェアは パフォーマンスを得られません 12
13 SIMD (Single Instruction Multiple Data) 命令 for(i = 0; i <= MAX; i++) c[i] = a[i] + b[i]; for(i = 0; i <= MAX; i+8) c[i:8] = a[i:8] + b[i:8]; a[i] + b[i] a[i] b[i] a[i+1] a[i+2] a[i+3] a[i+4] a[i+5] a[i+6] a[i+7] + b[i+1] b[i+2] b[i+3] b[i+4] b[i+5] b[i+6] b[i+7] c[i] c[i] c[i+1] c[i+2] c[i+3] c[i+4] c[i+5] c[i+6] c[i+7] 13
14 一般的なループのベクトル化の問題 ループの反復 ( イテレーション ) 間に依存性があってはならない 一部の依存ループはベクトル化が可能 ループ内の変数は明確でなければならない 多くの関数呼び出しはベクトル化できない 条件分岐はベクトル化を妨げる 比較的単純な IF 文はマスクによりベクトル化可能 ループはカウント可能でなければならない ネストするループの外部ループはベクトル化できない 混在データ型はベクトル化できない 14
15 インテル Advisor スレッド化とベクトル化によるアプリケーションのパフォーマンスを向上 コンパイラーは常にコードをベクトル化するとは限りません インテル Advisor を使用してループ伝搬依存をチェック ベクトル化を強制しても問題ないか? C++: pragma simd Fortran: SIMD ディレクティブ ベクトル化が常に効率的とは限りません ストライド 1 はストライド 2 よりもキャッシュに効率的インテル Advisor で解析 データ配置の再構成を検討 SIMD Data Layout Templates が有効 構造体配列はデータを直観的に構成するには優れていますが 配列構造体ほど効率的ではありません SIMD Data Layout Templates (SDLT) を使用して ベクトル化に効率良いデータにマッピングします 15

16 高速なコードを迅速に開発 : インテル Advisor ベクトル化の最適化 問題 : インテル AVX2 向けの再コンパイルでは わずかなゲイン どこをベクトル化するか? 新しいアーキテクチャー向けに組込み関数を使用すべきか? コンパイラー レポートの内容が分からない? データ主導型のベクトル化 : 最も効率良いベクトル化の候補は? ベクトル化を妨げているものは? その原因? ループはベクトル化に適しているか? データの再構成でパフォーマンスを改善可能か? 単純に pragma simd を使用しても安全か? インテル Advisor のベクトル化アドバイザーは 開発者が本来行うべき作業に集中することを可能にします 最適化に費やすことができる時間が限られている場合 非常に有効です ハイエンド コンピューティング アイルランド センターシニア ソフトウェア アーキテクト Gilles Civario 16
17 姫野ベンチマークでの試行 姫野ベンチマークは 理化学研究所情報基盤センターのセンター である姫野龍太郎氏が非圧縮流体解析コードの性能評価のために考えたもので ポアソン方程式解法をヤコビの反復法で解く場合に主要なループの処理速度を計るものです 非圧縮流体解析のポアソン方程式をヤコビの反復法で解く場合に使用する主要なループの処理速度を測定 (19 点ステンシルコード ) 単精度の MFLOPS を性能として比較する C または Fortran77/90 のソースコードで供給 クラスターシステム用に MPI を またマルチプロセッサー用に OpenMP* のものを準備 17
18 ステンシルの例 (6 点 ) 全格子点について k i j A_new(I,J,K) = F( A(I-1,J,K), A(I+1,J,K), A(I,J-1,K), A(I,J+1,K), A(I,J,K+1), A(I,J,K-1) ) 18
19 姫野ベンチマーク ( 279 #pragma omp parallel shared(a,p,b,c,bnd,wrk1,wrk2,nn,imax,jmax,kmax,omega,gosa) private(i,j,k,s0,ss,gosa1,n) 280 { 281 for(n=0 ; n<nn ; n++){ 282 #pragma omp barrier 283 #pragma omp master 284 { 285 gosa = 0.0; 286 } 287 gosa1= 0.0; 288 #pragma omp for nowait 289 for(i=1 ; i<imax; i++) 290 for(j=1 ; j<jmax ; j++) 291 for(k=1 ; k<kmax ; k++){ 292 s0= MR(a,0,i,j,k)*MR(p,0,i+1,j, k) MR(a,1,i,j,k)*MR(p,0,i, j+1,k) MR(a,2,i,j,k)*MR(p,0,i, j, k+1) MR(b,0,i,j,k) 296 *( MR(p,0,i+1,j+1,k) - MR(p,0,i+1,j-1,k) MR(p,0,i-1,j+1,k) + MR(p,0,i-1,j-1,k) ) MR(b,1,i,j,k) 300 *( MR(p,0,i,j+1,k+1) - MR(p,0,i,j-1,k+1) 19
20 逐次プログラム版のコンパイル $ icc -g -O2../himenoBMTxpa.c -o hime.ser../himenobmtxpa.c(279): 警告 #3180: 識別できない OpenMP プラグマです #pragma omp parallel shared(a,p,b,c,bnd,wrk1,wrk2,nn,imax,jmax,kmax,omega,gosa) private(i,j,k,s0,ss,gosa1,n) ^../himenobmtxpa.c(282): 警告 #3180: 識別できない OpenMP プラグマです #pragma omp barrier $./hime.ser Xl 20
21 逐次プログラム版の実行 $./hime.ser Xl Grid-size = Xl mimax = 512 mjmax = 512 mkmax = 1024 imax = 511 jmax = 511 kmax =1023 Start rehearsal measurement process. Measure the performance in 3 times. MFLOPS: time(s): e-05 cpu : sec. Loop executed for 3 times Gosa : e-05 MFLOPS measured : Score based on Pentium III 600MHz using Fortran 77:
22 OpenMP* 版のコンパイルと実行 $ icc -g -O3 -qopenmp -qopt-streaming-stores always./himenobmtxpa.c -o hime.par $./hime.par Xl mimax = 512 mjmax = 512 mkmax = 1024 imax = 511 jmax = 511 kmax =1023 Start rehearsal measurement process. Measure the performance in 3 times. MFLOPS: time(s): e-04 cpu : sec. Loop executed for 40 times Gosa : e-04 MFLOPS measured : Score based on Pentium III 600MHz using Fortran 77:
23 性能解析ツールの実行 ( インテル VTune Amplifier とインテル Advisor) $ amplxe-gui もしくは $ amplxe-cl -collect hotspots -app-working-dir himeno/openmp -- himeno/openmp/hime.par Xl $ advixe-gui もしくは $ advixe-cl -collect survey -no-support-multi-isa-binaries -interval=10 -data-limit=100 -resume-after=0 -project-dir micperf/himeno -- micperf/himeno/openmp/hime.par Xl 23
24 PLATINUM 81xx
25 PLATINUM 81xx 25
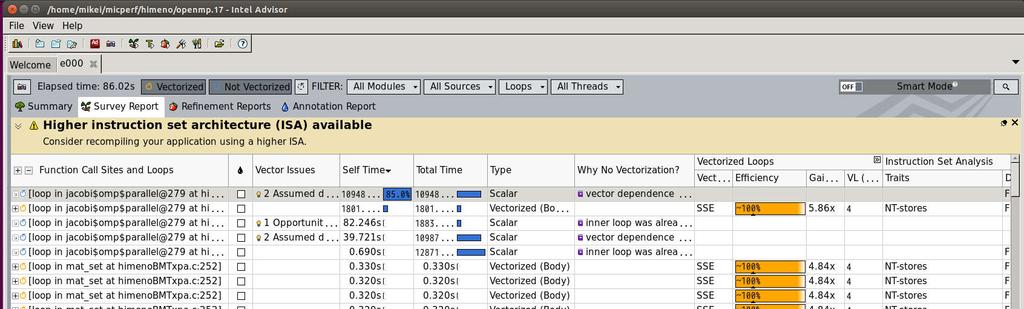
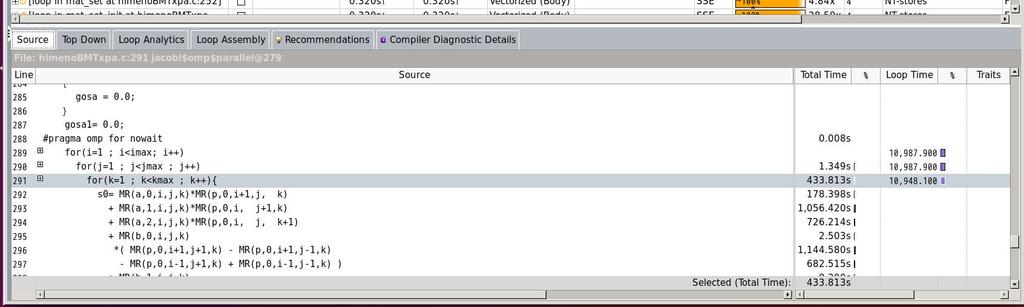
26 PLATINUM 81xx 最も時間を要しているループがベクトル化されていない!! ベクトル化されているループも 128 ビットのインテル SSE 命令!! 26
27 ベクトル化のために pragma を追加 279 #pragma omp parallel shared(a,p,b,c,bnd,wrk1,wrk2,nn,imax,jmax,kmax,omega,gosa) private(i,j,k,s0,ss,gosa1,n) 280 { 281 for(n=0 ; n<nn ; n++){ 282 #pragma omp barrier 283 #pragma omp master 284 { 285 gosa = 0.0; 286 } 287 gosa1= 0.0; 288 #pragma omp for nowait 289 for(i=1 ; i<imax; i++) 290 for(j=1 ; j<jmax ; j++) 291 #pragma omp simd reduction(+:gosa1) 292 for(k=1 ; k<kmax ; k++){ 293 s0= MR(a,0,i,j,k)*MR(p,0,i+1,j, k) MR(a,1,i,j,k)*MR(p,0,i, j+1,k) MR(a,2,i,j,k)*MR(p,0,i, j, k+1) MR(b,0,i,j,k) 297 *( MR(p,0,i+1,j+1,k) - MR(p,0,i+1,j-1,k) 27
28 インテル AVX-512 版のコンパイルと実行 $ icc -g -O2 -qopenmp -xmic-avx512 -qopt-streaming-stores always himeno2.c -o hime2.avx $./hime2.avx Xl Wait for a while cpu : sec. Loop executed for 138 times Gosa : e-04 MFLOPS measured : Score based on Pentium III 600MHz using Fortran 77:
29 インテル Xeon プロセッサーとインテル Xeon Phi プロセッサー向け命令セット アーキテクチャー (ISA) 大きいコア低レイテンシーに注力 / マルチスレッド シングルスレッドエンタープライズ HPC 向け SIMD サポートベスト パフォーマンスで一般的なワークロードのパフォーマンスを最適化 Pftchwt1 AVX512PF AVX512ER AVX512VL AVX512BW AVX512DQ AVX512CD AVX512CD 小さいコアスループットに注力 / 多くのスレッド ( メニーコア ) HPC 向け SIMD サポートパフォーマンス / ワットにおいて業界のリーダーシップ AVX2 AVX512F AVX2 AVX512F AVX2 AVX AVX AVX AVX SSE* SSE* SSE* SSE* SSE* SKL: インテル Xeon スケーラブル プロセッサー ( 開発コード名 Skylake) KNL: インテル Xeon Phi プロセッサー ( 開発コード名 Knights Landing) HSW: 開発コード名 Haswell SNB: 開発コード名 Sandy Bridge NHM: 開発コード名 Nehalem NHM SNB HSW KNL SKL インテル インテル Xeon Phi Xeon プロセッサースケーラブル プロセッサー開発コード名 29
30 インテル C/C++ コンパイラー 18.0 コンパイラー オプション インテル Xeon スケーラブル プロセッサー対応コンパイラー オプション一覧 オプション -xcore-avx512 -xcore-avx512 qopt-zmm-usage=high -xcommon-avx512 説明 xcore-avx2 からのスムーズな移行 ( エンタープライズ向け ) 512 ビット命令のメリットが大きいアプリケーション (HPC 向け ) 512 ビット命令のメリットが大きくインテル Xeon Phi プロセッサー (KNL ) とバイナリー互換が必要なアプリケーション -xcore-avx2 クライアント アプリケーション インテル Xeon プロセッサー E5 v4 ファミリー (Broadwell ) と互換性またはインテル Xeon Phi プロセッサー (KNL ) と互換性が必要な場合 [OpenMP* 4.5] #pragma omp simd simdlen() simdlen を追加し SIMD チャンクごと必要な反復数を指定 #pragma omp declare simd simdlen(16) 開発コード名 30
31 31
32 最も時間を要しているループがインテル AVX-512 でベクトル化された 32







33 Knights Landing 本当のブレークスルーに向けての統合的な取り組みシステムメモリー計算最大 384GB DDR4 (6 ch > 90GB/S, 2400 T/S) 以上のコア インテル Xeon プロセッサーとバイナリー互換 3+ TFLOPS 1, 3X ST 2 ( 単一スレッド ) KNC の性能比 2D メッシュ Out-of-Order コア パッケージ内メモリー 5x 以上 STREAM vs. DDR4 3 最大 16GB (>450GB/S) 内蔵インテル Omni-Path ファブリック プロセッサー パッケージ I/O 最大 36 PCIe* 3.0 レーン インテル Omni-Path ファブリック ( オプション ) 最初の統合化したインテル プロセッサー 開発コード名 33


34 メモリーモード キャッシュモード ブート時に設定する 3 つのモード フラットモード ハイブリッド モード 16GB MCDRAM DDR 16GB MCDRAM DDR 物理的アドレス空間 4 か 8GB MCDRAM 8 か 12GB MCDRAM DDR 物理的アドレス空間 SW 的には MCDRAM を意識しない 64 バイト ラインのダイレクトマップ タグをライン中に持つ DDR のすべてのメモリー空間をカバー MCDRAM をメモリーとして使用 SW で明示的に制御 MCDRAM と DDR は同じメモリー空間 34
35 Knights Landing ブロック図 MCDRAM MCDRAM DRAM DRAM コア + 2 VPU CHA コア + 2 VPU 共用キャッシュ 1MB MCDRAM MCDRAM タイルの構成 開発コード名 35
36 メモリー階層の確認 $ numactl -H available: 2 nodes (0-1) node 0 cpus: node 0 size: MB node 0 free: MB node 1 cpus: node 1 size: MB node 1 free: MB node distances: node 0 1 0: :
37 メモリー階層の確認 $ numactl -H available: 2 nodes (0-1) node 0 cpus: node 0 size: MB DDR メモリーがノード 0 node 0 free: MB node 1 cpus: node 1 size: MB node 1 free: MB 16GB の MCDRAM はノード 1 node distances: node 0 1 0: :
38 インテル AVX-512 版のコンパイルと実行 $ icc -g -O2 -qopenmp -xmic-avx512 -qopt-streaming-stores always himeno2.c -o hime2.avx $./hime2.avx Xl Wait for a while cpu : sec. Loop executed for 138 times Gosa : e-04 MFLOPS measured : Score based on Pentium III 600MHz using Fortran 77:
39 PLATINUM 81xx 39
40 DDR メモリーで 89GB/s PLATINUM 81xx 40
41 PLATINUM 81xx コア周波数の変動 41
42 ルーフライン モデルとは? どれくらい高速化できるか理解しているか? バークレーの研究者により提唱された パフォーマンスは 計算式 / 実装およびコード生成 / ハードウェアにより制限されます 2 つのハードウェア要件 ピーク FLOPS ピーク帯域幅 アプリケーションのパフォーマンスは ハードウェアの仕様により制限されます算術密度 (Flop/ バイト ) GFLOPS= 42
43 プラットフォームのピーク FLOPS 1 秒あたりの浮動小数点演算数 GFLOPS= 理論値は仕様によって算出可能例 ) 2 ソケットのインテル Xeon プロセッサー E v2 ピーク FLOP = 2 x 2.7 x 12 x 8 x 2 = GFLOPS ソケット数 コア周波数 コア数 1 つのポートを加算に もう 1 つを乗算に SIMD レジスター中の単精度要素の数 より現実的な値は Linpack を実行して求めることができます =~ 930 GFLOPS (2 ソケットのインテル Xeon プロセッサー E v2) 43
44 プラットフォームのピーク帯域幅 1 秒あたりの転送バイト数 GLOPS = 理論値は仕様によって算出可能例 ) 2 ソケットのインテル Xeon プロセッサー E v2 ピーク BW = 2 x x 8 x 4 = 119GB/ 秒 ソケット数 メモリー周波数チャネルあたりのバイト数 メモリーチャネル数 より現実的な値は Stream を実行して求めることができます =~ 100 Gflop/ 秒 (2 ソケットのインテル Xeon プロセッサー E v2) 44
45 ルーフラインを描く限界を定義 GFLOPS = 2 ソケットのインテル Xeon プロセッサー E v2 ピーク Flops = 1036 GFLOPS ピーク BW = 119GB/ 秒 1036 GFLOPS AI [Flop/ バイト ]
46 ルーフラインを描く限界を定義 GFLOPS = 2 ソケットのインテル Xeon プロセッサー E v2 ピーク Flops = 1036 GFLOPS ピーク BW = 119GB/ 秒 1036 GFLOPS AI [Flop/ バイト ]
47 秒 インテル Advisor のルーフライン : 実際の値 ユーザ モード サンプリング ルートアクセスは不要 Performance = Flops/seconds ルーフラインの実行プロファイル : Y 座標 : FLOPS = #FLOP ( マスクを考慮 ) / #Seconds X 座標 : AI = #FLOP / #Bytes ルーフ マイクロベンチマーク現状のコンフィグの実際のピーク値 #FLOP バイナリー インストルメンテーション CPU のカウンターは不使用 AI = Flop/ バイト バイト バイナリー インストルメンテーションオペランドの大きさを加算 ( キャッシュラインではない ) 47
48 48
49 メモリー階層の確認 $ numactl -H available: 2 nodes (0-1) node 0 cpus: node 0 size: MB DDR メモリーがノード 0 node 0 free: MB node 1 cpus: node 1 size: MB node 1 free: MB 16GBの MCDRAM はノード 1 node distances: node 0 1 0: :
50 DDR メモリーで 89GB/s PLATINUM 81xx 50
51 高速メモリーでの実行 $ numactl -m 1./hime2.avx Xl mimax = 512 mjmax = 512 mkmax = 1024 imax = 511 jmax = 511 kmax =1023 Start rehearsal measurement process. Measure the performance in 3 times. cpu : sec. Loop executed for 354 times Gosa : e-04 MFLOPS measured : Score based on Pentium III 600MHz using Fortran 77:
52 高速メモリーでの実行 $ numactl -m 1./hime2.avx Xl mimax = 512 mjmax = 512 mkmax = 1024 imax = 511 jmax = 511 kmax =1023 Start rehearsal measurement process. Measure the performance in 3 times. cpu : sec. Loop executed for 354 times Gosa : e-04 MFLOPS measured : Score based on Pentium III 600MHz using Fortran 77:
53 53
54 MCDRAM メモリーで 327GB/s 54
55 Skylake 1 上での実行 $ icc -g -O2 -qopenmp -xcore-avx512 -qopt-streaming-stores always -qopt-streaming-cache-evict=0 himeno2.c -o himeno2 $./himeno2 Xl mimax = 512 mjmax = 512 mkmax = 1024 imax = 511 jmax = 511 kmax =1023 Start rehearsal measurement process. Measure the performance in 3 times. 1 開発コード名インテル Xeon Platinum GHz 26 コア cpu : sec. Loop executed for 185 times Gosa : e-04 MFLOPS measured : Score based on Pentium III 600MHz using Fortran 77:
56 56
57 57
58 58

59 Sub NUMA クラスター 3. SNC-4: 4 ソケットのマシン ( コア数は 4 分の 1) として見える MCDRAM MCDRAM MCDRAM MCDRAM $ numactl -H available: 8 nodes (0-7) node 0 cpus: node 0 size: MB node 0 free: MB node 1 cpus: node 1 size: MB node 1 free: MB node 2 cpus: node 2 size: MB node 2 free: MB node 3 cpus: node 4 cpus: node 4 size: 4096 MB node 4 free: 3982 MB node 5 cpus: node 7 cpus: node 7 size: 4096 MB node 7 free: 3982 MB 59
60 MPI 版の姫野プログラムをハイブリッドに 370 integer,intent(in) :: nn 371 real(4),intent(inout) :: gosa 372 integer :: i,j,k,loop,ierr 373 real(4) :: s0,ss,wgosa 374! 375 do loop=1,nn 376 gosa= wgosa= !$OMP PARALLEL DO SHARED (kmax,jmax,imax,nn,a,p,b,c,bnd,wrk1,wrk2) & 379!$OMP PRIVATE (k,i,j,s0,ss) REDUCTION (+:wgosa) 380 do k=2,kmax do j=2,jmax do i=2,imax s0=a(i,j,k,1)*p(i+1,j,k) & 384 +a(i,j,k,2)*p(i,j+1,k) & 385 +a(i,j,k,3)*p(i,j,k+1) & 386 +b(i,j,k,1)*(p(i+1,j+1,k)-p(i+1,j-1,k) & 387 -p(i-1,j+1,k)+p(i-1,j-1,k)) & 388 +b(i,j,k,2)*(p(i,j+1,k+1)-p(i,j-1,k+1) & 389 -p(i,j+1,k-1)+p(i,j-1,k-1)) & 60
61 ハイブリッド版のコンパイルと実行 $ mpiifort -g -O3 -xmic_avx512 -qopenmp -qopt-streaming-stores always himeno4.f90 -o himeno4.avx $ export OMP_NUM_THREADS=2 $ numactl -m 4,5,6,7 mpiexec.hydra -n 64./himeno4.avx The loop will be excuted in 1008 times. This will take about one minute. Wait for a while. Loop executed for 1008 times Gosa : E-04 MFLOPS: time(s): Score based on Pentium III 600MHz :




62 MCDRAM メモリーで 386GB/s 62
63 高速メモリーをプログラムから使用する方法 (F90) module pres implicit none real(4),dimension(:,:,:),allocatable :: p!dec$ ATTRIBUTES FASTMEM :: p end module pres! module mtrx implicit none real(4),dimension(:,:,:,:),allocatable :: a,b,c!dec$ ATTRIBUTES FASTMEM :: a,b,c end module mtrx! 63
64 高速メモリーをプログラムから使用する方法 (C) #include <hbwmalloc.h> Mat->m= NULL; Mat->m= (float*) hbw_malloc(mnums * mrows * mcols * mdeps * sizeof(float)); } return(mat->m!= NULL)? 1:0; void clearmat(matrix* Mat) { if(mat->m) hbw_free(mat->m); Mat->m= NULL; Mat->mnums= 0; 64
65 コード モダナイゼーションのまとめ 項目利用するツールなど考察 1. スレッド化 OpenMP* OpenMP* を使用してコア数 4 のスレッドを 活用 2. ベクトル化 SIMD pragma インテル AVX-512 により 512b の VPU を活用 3. ブロック化 (MPI による分割 ) 4. キャッシュ クラスターモード フラットかキャッシュか? AllToAll Quadrant SNC4? 5. ファブリック MPI インテル Omni Path アーキテクチャーなどの 高速ファブリックを利用 6. データレイアウト メモリー階層 Numactl や FASTMEM HBMMALLOC を利用 65
66 結論 プロセッサーのコア数と SIMD 幅が広がり 並列化 = コード モダナイゼーションは必須 インテル AVX-512 命令でベクトル化の重要性が大きく インテル Advisor により 重要なループを効果的にベクトル化 キャッシュやパッケージメモリーなどのメモリーの階層構造の演算性能への影響も大きく インテル VTune Amplifier でメモリー性能を可視化 インテル Advisor のルーフライン表示によりループ性能を可視化 より高性能で複雑になる IA アーキテクチャー上でもインテル Parallel Studio XE で迅速なプログラムの最適化を実現 66
67 法務上の注意書きと最適化に関する注意事項 本資料の情報は 現状のまま提供され 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスも許諾するものではありません 製品に付属の売買契約書 Intel's Terms and Conditions of Sale に規定されている場合を除き インテルはいかなる責任を負うものではなく またインテル製品の販売や使用に関する明示または黙示の保証 ( 特定目的への適合性 商品性に関する保証 第三者の特許権 著作権 その他 知的財産権の侵害への保証を含む ) をするものではありません 性能に関するテストに使用されるソフトウェアとワークロードは 性能がインテル マイクロプロセッサー用に最適化されていることがあります SYSmark* や MobileMark* などの性能テストは 特定のコンピューター システム コンポーネント ソフトウェア 操作 機能に基づいて行ったものです 結果はこれらの要因によって異なります 製品の購入を検討される場合は 他の製品と組み合わせた場合の本製品の性能など ほかの情報や性能テストも参考にして パフォーマンスを総合的に評価することをお勧めします 2017 Intel Corporation. 無断での引用 転載を禁じます Intel インテル Intel ロゴ Intel Inside Intel Inside ロゴ Intel Core Xeon Intel Xeon Phi VTune は アメリカ合衆国および / またはその他の国における Intel Corporation の商標です 最適化に関する注意事項 インテル コンパイラーでは インテル マイクロプロセッサーに限定されない最適化に関して 他社製マイクロプロセッサー用に同等の最適化を行えないことがあります これには インテル ストリーミング SIMD 拡張命令 2 インテル ストリーミング SIMD 拡張命令 3 インテル ストリーミング SIMD 拡張命令 3 補足命令などの最適化が該当します インテルは 他社製マイクロプロセッサーに関して いかなる最適化の利用 機能 または効果も保証いたしません 本製品のマイクロプロセッサー依存の最適化は インテル マイクロプロセッサーでの使用を前提としています インテル マイクロアーキテクチャーに限定されない最適化のなかにも インテル マイクロプロセッサー用のものがあります この注意事項で言及した命令セットの詳細については 該当する製品のユーザー リファレンス ガイドを参照してください 注意事項の改訂 #

68
Product Brief 高速なコードを素早く開発 インテル Parallel Studio XE 2017 インテル ソフトウェア開発ツール 概要 高速なコード : 現在および次世代のプロセッサーでスケーリングする優れたアプリケーション パフォーマンスを実現します 迅速に開発 : 高速かつ安定し
 Product Brief 高速なコードを素早く開発 インテル Parallel Studio XE 2017 インテル ソフトウェア開発ツール 概要 高速なコード : 現在および次世代のプロセッサーでスケーリングする優れたアプリケーション パフォーマンスを実現します 迅速に開発 : 高速かつ安定した並列コードの作成を簡略化するツールセットです : 最先端のコンパイラー ライブラリー 並列モデル インテル
Product Brief 高速なコードを素早く開発 インテル Parallel Studio XE 2017 インテル ソフトウェア開発ツール 概要 高速なコード : 現在および次世代のプロセッサーでスケーリングする優れたアプリケーション パフォーマンスを実現します 迅速に開発 : 高速かつ安定した並列コードの作成を簡略化するツールセットです : 最先端のコンパイラー ライブラリー 並列モデル インテル
PowerPoint Presentation
 インテル ソフトウェア開発製品によるソースコードの近代化 エクセルソフト株式会社黒澤一平 ソースコードの近代化 インテル Xeon Phi プロセッサーや 将来のインテル Xeon プロセッサー上での実行に向けた準備と適用 インテル ソフトウェア製品 名称インテル Composer XE for Fortran and C++ インテル VTune Amplifier XE インテル Advisor
インテル ソフトウェア開発製品によるソースコードの近代化 エクセルソフト株式会社黒澤一平 ソースコードの近代化 インテル Xeon Phi プロセッサーや 将来のインテル Xeon プロセッサー上での実行に向けた準備と適用 インテル ソフトウェア製品 名称インテル Composer XE for Fortran and C++ インテル VTune Amplifier XE インテル Advisor
インテル® Parallel Studio XE 2013 Linux* 版インストール・ガイドおよびリリースノート
 インテル Parallel Studio XE 2013 Linux* 版インストール ガイドおよびリリースノート 資料番号 : 323804-003JA 2012 年 7 月 30 日 目次 1 概要... 2 1.1 新機能... 2 1.1.1 インテル Parallel Studio XE 2011 からの変更点... 2 1.2 製品の内容... 2 1.3 動作環境... 2 1.4 ドキュメント...
インテル Parallel Studio XE 2013 Linux* 版インストール ガイドおよびリリースノート 資料番号 : 323804-003JA 2012 年 7 月 30 日 目次 1 概要... 2 1.1 新機能... 2 1.1.1 インテル Parallel Studio XE 2011 からの変更点... 2 1.2 製品の内容... 2 1.3 動作環境... 2 1.4 ドキュメント...
インテル® Parallel Studio XE 2013 Windows* 版インストール・ガイドおよびリリースノート
 インテル Parallel Studio XE 2013 Windows* 版インストール ガイドおよびリリースノート 資料番号 : 323803-003JA 2012 年 8 月 8 日 目次 1 概要... 2 1.1 新機能... 2 1.1.1 インテル Parallel Studio XE 2011 からの変更点... 2 1.2 製品の内容... 2 1.3 動作環境... 2 1.4
インテル Parallel Studio XE 2013 Windows* 版インストール ガイドおよびリリースノート 資料番号 : 323803-003JA 2012 年 8 月 8 日 目次 1 概要... 2 1.1 新機能... 2 1.1.1 インテル Parallel Studio XE 2011 からの変更点... 2 1.2 製品の内容... 2 1.3 動作環境... 2 1.4
Click to edit title
 インテル VTune Amplifier 2018 を 使用した最適化手法 ( 初級編 ) 久保寺 陽子 内容 アプリケーション最適化のプロセス インテル VTune Amplifier の紹介 インテル VTune Amplifier の新機能 インテル VTune Amplifier を用いた最適化例 (1) インテル VTune Amplifier を用いた最適化例 (2) まとめ 2 インテル
インテル VTune Amplifier 2018 を 使用した最適化手法 ( 初級編 ) 久保寺 陽子 内容 アプリケーション最適化のプロセス インテル VTune Amplifier の紹介 インテル VTune Amplifier の新機能 インテル VTune Amplifier を用いた最適化例 (1) インテル VTune Amplifier を用いた最適化例 (2) まとめ 2 インテル
インテル® Parallel Studio XE 2015 Composer Edition for Linux* インストール・ガイドおよびリリースノート
 インテル Parallel Studio XE 2015 Composer Edition for Linux* インストール ガイドおよびリリースノート 2014 年 10 月 14 日 目次 1 概要... 1 1.1 製品の内容... 2 1.2 インテル デバッガー (IDB) を削除... 2 1.3 動作環境... 2 1.3.1 SuSE Enterprise Linux 10* のサポートを終了...
インテル Parallel Studio XE 2015 Composer Edition for Linux* インストール ガイドおよびリリースノート 2014 年 10 月 14 日 目次 1 概要... 1 1.1 製品の内容... 2 1.2 インテル デバッガー (IDB) を削除... 2 1.3 動作環境... 2 1.3.1 SuSE Enterprise Linux 10* のサポートを終了...
インテル® Fortran Studio XE 2011 SP1 Windows* 版インストール・ガイドおよびリリースノート
 インテル Fortran Studio XE 2011 SP1 Windows* 版インストール ガイドおよびリリースノート 資料番号 : 325583-001JA 2011 年 8 月 5 日 目次 1 概要... 1 1.1 新機能... 2 1.2 製品の内容... 2 1.3 動作環境... 2 1.3.1 Microsoft* Visual Studio* 2005 のサポート終了予定...
インテル Fortran Studio XE 2011 SP1 Windows* 版インストール ガイドおよびリリースノート 資料番号 : 325583-001JA 2011 年 8 月 5 日 目次 1 概要... 1 1.1 新機能... 2 1.2 製品の内容... 2 1.3 動作環境... 2 1.3.1 Microsoft* Visual Studio* 2005 のサポート終了予定...
PowerPoint Presentation
 インテル Xeon Phi プロセッサー ( 開発コード名 : Knights Landing) とインテル Distribution for Python* による高速化 エクセルソフト株式会社ソリューション事業部マネージャー黒澤一平 言語と環境について 対応言語 環境プロセスインテル ソフトウェア開発製品機能 C C++ Fortran 言語 コンパイル / リンク インテル Parallel
インテル Xeon Phi プロセッサー ( 開発コード名 : Knights Landing) とインテル Distribution for Python* による高速化 エクセルソフト株式会社ソリューション事業部マネージャー黒澤一平 言語と環境について 対応言語 環境プロセスインテル ソフトウェア開発製品機能 C C++ Fortran 言語 コンパイル / リンク インテル Parallel
Microsoft PowerPoint - Intel Parallel Studio XE 2019 for Live
 HPC エンタープライズ クラウド アプリケーションを高速化 インテル Parallel Studio XE のコンポーネント包括的なソフトウェア開発ツールスイート Composer Edition ビルドコンパイラーとライブラリー Professional Edition 解析解析ツール Cluster Edition スケールクラスターツール インテル C/C++ コンパイラー最適化コンパイラー
HPC エンタープライズ クラウド アプリケーションを高速化 インテル Parallel Studio XE のコンポーネント包括的なソフトウェア開発ツールスイート Composer Edition ビルドコンパイラーとライブラリー Professional Edition 解析解析ツール Cluster Edition スケールクラスターツール インテル C/C++ コンパイラー最適化コンパイラー
インテル® VTune™ Amplifier XE を使用したストレージ向けの パフォーマンス最適化
 インテル VTune Amplifier XE を使用したストレージ向けのパフォーマンス最適化 2016 年 10 月 12 日 Day2 トラック D-2 (14:55 15:40) すがわらきよふみ isus 編集長 本日の内容 インテル VTune Amplifier XE 2017 概要 ストレージ解析向けのインテル VTune Amplifier XE の新機能 メモリー解析向けのインテル
インテル VTune Amplifier XE を使用したストレージ向けのパフォーマンス最適化 2016 年 10 月 12 日 Day2 トラック D-2 (14:55 15:40) すがわらきよふみ isus 編集長 本日の内容 インテル VTune Amplifier XE 2017 概要 ストレージ解析向けのインテル VTune Amplifier XE の新機能 メモリー解析向けのインテル
Microsoft Word ●IntelクアッドコアCPUでのベンチマーク_吉岡_ _更新__ doc
 2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
Microsoft* Windows* 10 における新しい命令セットの利用
 Microsoft* Windows* 10 における新しい命令セットの利用 この記事は インテル デベロッパー ゾーンに公開されている Follow-Up: How does Microsoft Windows 10 Use New Instruction Sets? の日本語参考訳です 以前のブログ ソフトウェアは実際に新しい命令セットを使用しているのか? ( 英語 ) では いくつかの異なる
Microsoft* Windows* 10 における新しい命令セットの利用 この記事は インテル デベロッパー ゾーンに公開されている Follow-Up: How does Microsoft Windows 10 Use New Instruction Sets? の日本語参考訳です 以前のブログ ソフトウェアは実際に新しい命令セットを使用しているのか? ( 英語 ) では いくつかの異なる
VXPRO R1400® ご提案資料
 Intel Core i7 プロセッサ 920 Preliminary Performance Report ノード性能評価 ノード性能の評価 NAS Parallel Benchmark Class B OpenMP 版での性能評価 実行スレッド数を 4 で固定 ( デュアルソケットでは各プロセッサに 2 スレッド ) 全て 2.66GHz のコアとなるため コアあたりのピーク性能は同じ 評価システム
Intel Core i7 プロセッサ 920 Preliminary Performance Report ノード性能評価 ノード性能の評価 NAS Parallel Benchmark Class B OpenMP 版での性能評価 実行スレッド数を 4 で固定 ( デュアルソケットでは各プロセッサに 2 スレッド ) 全て 2.66GHz のコアとなるため コアあたりのピーク性能は同じ 評価システム
Click to edit title
 コードの現代化と最適化 ソフトウェアの最適化において注目すべきこと 2019 年 4 月 isus 編集部すがわらきよふみ 目的 ソフトウェア開発時の最適化において注目すべき点を理解します ソフトウェアの要件を理解します ソフトウェアに影響するハードウェアの機能を評価します 2 盲目の男たちと象 ヒィンドスタンに 盲目の 6 人の男たちがいました 学ぼうという気持ちが強く 象を見に出かけました 全員
コードの現代化と最適化 ソフトウェアの最適化において注目すべきこと 2019 年 4 月 isus 編集部すがわらきよふみ 目的 ソフトウェア開発時の最適化において注目すべき点を理解します ソフトウェアの要件を理解します ソフトウェアに影響するハードウェアの機能を評価します 2 盲目の男たちと象 ヒィンドスタンに 盲目の 6 人の男たちがいました 学ぼうという気持ちが強く 象を見に出かけました 全員
Microsoft Word - HOKUSAI_system_overview_ja.docx
 HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
インテル® Xeon Phi™ プロセッサー上で MPI for Python* (mpi4py) を使用する
 を使用する") インテル Xeon Phi プロセッサー上で MPI for Python* (mpi4py) を使用する この記事は インテル デベロッパー ゾーンに公開されている Exploring MPI for Python* on Intel Xeon Phi Processor の日本語参考訳です はじめに メッセージ パッシング インターフェイス (MPI) ( 英語 ) は 分散メモリー プログラミング向けに標準化されたメッセージ
インテル Xeon Phi プロセッサー上で MPI for Python* (mpi4py) を使用する この記事は インテル デベロッパー ゾーンに公開されている Exploring MPI for Python* on Intel Xeon Phi Processor の日本語参考訳です はじめに メッセージ パッシング インターフェイス (MPI) ( 英語 ) は 分散メモリー プログラミング向けに標準化されたメッセージ
PowerPoint Presentation
 インテル Xeon Phi プロセッサーの 高帯域幅メモリーを活用するコードの作成 Ruchira Sasanka Karthik Raman 開発ツール Web セミナー 2016 年 10 月 11 日 法務上の注意書き 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスも許諾するものではありません
インテル Xeon Phi プロセッサーの 高帯域幅メモリーを活用するコードの作成 Ruchira Sasanka Karthik Raman 開発ツール Web セミナー 2016 年 10 月 11 日 法務上の注意書き 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスも許諾するものではありません
内容 インテル Advisor ベクトル化アドバイザー入門ガイド Version インテル Advisor の利用 ワークフロー... 3 STEP1. 必要条件の設定... 4 STEP2. インテル Advisor の起動... 5 STEP3. プロジェクトの作成
 内容 インテル Advisor ベクトル化アドバイザー入門ガイド Version 1.0 1. インテル Advisor の利用... 2 2. ワークフロー... 3 STEP1. 必要条件の設定... 4 STEP2. インテル Advisor の起動... 5 STEP3. プロジェクトの作成と設定... 7 STEP4. ベクトル化に関する情報を取得する... 9 STEP5. ループ処理の詳細を取得する...
内容 インテル Advisor ベクトル化アドバイザー入門ガイド Version 1.0 1. インテル Advisor の利用... 2 2. ワークフロー... 3 STEP1. 必要条件の設定... 4 STEP2. インテル Advisor の起動... 5 STEP3. プロジェクトの作成と設定... 7 STEP4. ベクトル化に関する情報を取得する... 9 STEP5. ループ処理の詳細を取得する...
Intel_ParallelStudioXE2013_ClusterStudioXE2013_Introduction.pptx
 Parallel Studio XE 2013 Cluster Studio XE 2013 ) ( Intel s Terms and Conditions of Sale Sandy Bridge SYSmark MobileMark http://www.intel.com/performance/ Intel Intel Intel Atom Intel Core Intel Xeon Phi
Parallel Studio XE 2013 Cluster Studio XE 2013 ) ( Intel s Terms and Conditions of Sale Sandy Bridge SYSmark MobileMark http://www.intel.com/performance/ Intel Intel Intel Atom Intel Core Intel Xeon Phi
インテル C++ および Fortran コンパイラー for Linux*/OS X*/Windows
 および Fortran コンパイラー for Linux*/OS X*/Windows インテル Parallel Studio XE の主要コンポーネント ソフトウェア開発者にとって重要なポイント課題インテル コンパイラーの利点 パフォーマンス高速なアプリケーションを開発する必要がある 最新のハードウェア イノベーションを利用しなければならない 最新の x86 互換プロセッサーと命令セットを最大限に利用できる
および Fortran コンパイラー for Linux*/OS X*/Windows インテル Parallel Studio XE の主要コンポーネント ソフトウェア開発者にとって重要なポイント課題インテル コンパイラーの利点 パフォーマンス高速なアプリケーションを開発する必要がある 最新のハードウェア イノベーションを利用しなければならない 最新の x86 互換プロセッサーと命令セットを最大限に利用できる
for (int x = 0; x < X_MAX; x++) { /* これらの 3 つの行は外部ループの自己データと * 合計データの両方にカウントされます */ bar[x * 2] = x * ; bar[(x * 2) - 1] = (x - 1.0) *
![for (int x = 0; x < X_MAX; x++) { /* これらの 3 つの行は外部ループの自己データと * 合計データの両方にカウントされます */ bar[x * 2] = x * ; bar[(x * 2) - 1] = (x - 1.0) *](/thumbs/91/105660328.jpg "for (int x = 0; x < X_MAX; x++) { /* これらの 3 つの行は外部ループの自己データと * 合計データの両方にカウントされます */ bar[x * 2] = x * ; bar[(x * 2) - 1] = (x - 1.0) *") コールスタックを利用したルーフライン Alexandra S. (Intel) 2017 年 12 月 1 日公開 この記事は 2017 年 12 月 18 日時点の インテル デベロッパー ゾーンに公開されている Roofline with Callstacks の日本語訳です 注 : この記事の一部のスクリーンショットにはオレンジ色の点が表示されています デフォルト設定では これらの点は赤または黄色になります
コールスタックを利用したルーフライン Alexandra S. (Intel) 2017 年 12 月 1 日公開 この記事は 2017 年 12 月 18 日時点の インテル デベロッパー ゾーンに公開されている Roofline with Callstacks の日本語訳です 注 : この記事の一部のスクリーンショットにはオレンジ色の点が表示されています デフォルト設定では これらの点は赤または黄色になります
Presentation title
 インテル Xeon Phi コプロセッサー搭載システムの紹介およびオフロード プログラミングとネイティブ実行の概要 インテル ソフトウェア開発製品の紹介 インテル ソフトウェア開発製品 Advanced Performance C++ および Fortran コンパイラーインテル MKL/ インテル IPP ライブラリーと解析ツール IA ベース マルチコア ノード上の Windows* および Linux*
インテル Xeon Phi コプロセッサー搭載システムの紹介およびオフロード プログラミングとネイティブ実行の概要 インテル ソフトウェア開発製品の紹介 インテル ソフトウェア開発製品 Advanced Performance C++ および Fortran コンパイラーインテル MKL/ インテル IPP ライブラリーと解析ツール IA ベース マルチコア ノード上の Windows* および Linux*
バトルカードでゲーマーやエンスージアストへの販売促進
 究極のメガタスク 4K ビデオの編集 3D 効果のレンダリング サウンドトラックの作曲を システム パフォーマンスを低下させずに同時に実行 4K ビデオの編集を 最大 2.4 倍 ビデオのトランスコードを 最大 高速化¹ Adobe* Premiere* Pro CC と インテル Core i7-7700k で比較 2.3 倍 高速化² - Handbrake* を使用し インテル Core i7-7700k
究極のメガタスク 4K ビデオの編集 3D 効果のレンダリング サウンドトラックの作曲を システム パフォーマンスを低下させずに同時に実行 4K ビデオの編集を 最大 2.4 倍 ビデオのトランスコードを 最大 高速化¹ Adobe* Premiere* Pro CC と インテル Core i7-7700k で比較 2.3 倍 高速化² - Handbrake* を使用し インテル Core i7-7700k
Intel Software Presentation Template
 最新のヘテロジニアス システムにおけるビデオ解析環境 久保寺陽子 Internet of things Internet of things (IOT) は生活へ浸透 接続しているデバイスの数は急増 良く利用されるデバイスセンサーはカメラ データは爆発的に増加しているが 少ししか利用されていない 一般には 従来通りのそれぞれのやり方で使用 人間がすべてを網羅するのは無理 より賢い自動システムを構築する必要がある
最新のヘテロジニアス システムにおけるビデオ解析環境 久保寺陽子 Internet of things Internet of things (IOT) は生活へ浸透 接続しているデバイスの数は急増 良く利用されるデバイスセンサーはカメラ データは爆発的に増加しているが 少ししか利用されていない 一般には 従来通りのそれぞれのやり方で使用 人間がすべてを網羅するのは無理 より賢い自動システムを構築する必要がある
2.1 インテル マイクロアーキテクチャー Haswell インテル マイクロアーキテクチャー Haswell は インテル マイクロアーキテクチャー Sandy Bridge とインテル マイクロアーキテクチャー Ivy Bridge の成功を受けて開発された この新しいマイクロアーキテクチャーの
 2 章インテル 64 プロセッサー アーキテクチャーと IA-32 プロセッサー アーキテクチャー 本章では 最新世代のインテル 64 プロセッサーと IA-32 プロセッサー ( インテル マイクロアーキテクチャー Haswell インテル マイクロアーキテクチャー Ivy Bridge インテル マイクロアーキテクチャー Sandy Bridge ベースのプロセッサーと インテル Core マイクロアーキテクチャー
2 章インテル 64 プロセッサー アーキテクチャーと IA-32 プロセッサー アーキテクチャー 本章では 最新世代のインテル 64 プロセッサーと IA-32 プロセッサー ( インテル マイクロアーキテクチャー Haswell インテル マイクロアーキテクチャー Ivy Bridge インテル マイクロアーキテクチャー Sandy Bridge ベースのプロセッサーと インテル Core マイクロアーキテクチャー
開発者用 Knights Landing✝ ガイド - 第 2 世代インテル® Xeon Phi™ プロセッサーの概要
 開発者用 Knights Landing ガイド 第 2 世代インテル Xeon Phi プロセッサーの概要 Colfax International @colfaxintl 2016 年 4 月 - 改訂 1.2 colfaxresearch.com/knl-webinar ようこそ Colfax International, 2013 2016 このドキュメントについて このドキュメントは Colfax
開発者用 Knights Landing ガイド 第 2 世代インテル Xeon Phi プロセッサーの概要 Colfax International @colfaxintl 2016 年 4 月 - 改訂 1.2 colfaxresearch.com/knl-webinar ようこそ Colfax International, 2013 2016 このドキュメントについて このドキュメントは Colfax
openmp1_Yaguchi_version_170530
 並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
インテル® Parallel Studio XE 2019 Composer Edition for Fortran Windows : インストール・ガイド
 インテル Parallel Studio XE 2019 Composer Edition for Fortran Windows インストール ガイド エクセルソフト株式会社 Version 1.0.0-20180918 目次 1. はじめに....................................................................................
インテル Parallel Studio XE 2019 Composer Edition for Fortran Windows インストール ガイド エクセルソフト株式会社 Version 1.0.0-20180918 目次 1. はじめに....................................................................................
スレッド化されていないアプリケーションでも大幅なパフォーマンス向上を容易に実現
 はじめに 本ガイドは インテル Parallel Studio XE を使用してアプリケーション中の hotspot ( 多くの時間を費やしているコード領域 ) を見つけ それらの領域を再コンパイルすることでアプリケーション全体のパフォーマンスを向上する方法について説明します 1 つのファイルを再コンパイルするだけで違いが出るのでしょうか? はい 多くの場合 インテル Parallel Studio
はじめに 本ガイドは インテル Parallel Studio XE を使用してアプリケーション中の hotspot ( 多くの時間を費やしているコード領域 ) を見つけ それらの領域を再コンパイルすることでアプリケーション全体のパフォーマンスを向上する方法について説明します 1 つのファイルを再コンパイルするだけで違いが出るのでしょうか? はい 多くの場合 インテル Parallel Studio
目次 1 はじめに 製品に含まれるコンポーネント 動作環境... 4 オペレーティング システム... 4 Microsoft Visual Studio* 製品 製品のダウンロード 製品版をインストールする場合 評価版を
 インテル Parallel Studio XE 2018 Composer Edition for Fortran Windows* インストール ガイド Rev. 2. 0 (2017/11/22) エクセルソフト株式会社 www.xlsoft.com 目次 1 はじめに... 3 2 製品に含まれるコンポーネント... 3 3 動作環境... 4 オペレーティング システム... 4 Microsoft
インテル Parallel Studio XE 2018 Composer Edition for Fortran Windows* インストール ガイド Rev. 2. 0 (2017/11/22) エクセルソフト株式会社 www.xlsoft.com 目次 1 はじめに... 3 2 製品に含まれるコンポーネント... 3 3 動作環境... 4 オペレーティング システム... 4 Microsoft
Parallel Studio XE Parallel Studio XE hotspot ( )
") Parallel Studio XE Parallel Studio XE hotspot ( ) 1 つのファイルを再コンパイルするだけで違いが出るのでしょうか? はい 多くの場合 Parallel Studio XE の最適化コンパイラーを使用して 1 つのファイルを再コンパイルするだけでパフォーマンスが大幅に向上します 必ずしもアプリケーション全体を再コンパイルする必要はありません これは シリアル
Parallel Studio XE Parallel Studio XE hotspot ( ) 1 つのファイルを再コンパイルするだけで違いが出るのでしょうか? はい 多くの場合 Parallel Studio XE の最適化コンパイラーを使用して 1 つのファイルを再コンパイルするだけでパフォーマンスが大幅に向上します 必ずしもアプリケーション全体を再コンパイルする必要はありません これは シリアル
高速なコードを素早く開発 インテル Parallel Studio XE 設計 ビルド 検証 チューニング C++ C Fortran Python* Java* 標準規格に基づく並列モデル : OpenMP* MPI インテル TBB バージョン 2017 の主な機能 インテル Distribut
 高速なコードを 素早く開発 インテル Parallel Studio XE 2017 インテル株式会社ソフトウェア技術統括部池井満 パフォーマンスを最大限に引き出そう 高速なコードを素早く開発 インテル Parallel Studio XE 設計 ビルド 検証 チューニング C++ C Fortran Python* Java* 標準規格に基づく並列モデル : OpenMP* MPI インテル TBB
高速なコードを 素早く開発 インテル Parallel Studio XE 2017 インテル株式会社ソフトウェア技術統括部池井満 パフォーマンスを最大限に引き出そう 高速なコードを素早く開発 インテル Parallel Studio XE 設計 ビルド 検証 チューニング C++ C Fortran Python* Java* 標準規格に基づく並列モデル : OpenMP* MPI インテル TBB
インテル® Parallel Studio XE 2019 Composer Edition for Fortran Windows 日本語版 : インストール・ガイド
 インテル Parallel Studio XE 2019 Composer Edition for Fortran Windows 日本語版インストール ガイド エクセルソフト株式会社 Version 2.1.0-20190405 目次 1. はじめに.................................................................................
インテル Parallel Studio XE 2019 Composer Edition for Fortran Windows 日本語版インストール ガイド エクセルソフト株式会社 Version 2.1.0-20190405 目次 1. はじめに.................................................................................
Code Modernization Online training plan
 Windows* 環境での MPI プログラムの作成と実行 2016 年 4 月 内容 必要要件と各ツール インストール コンパイルと実行 必要なツールと環境 プロセッサーと Windows* OS コンパイラーとリンカー MPI ライブラリー クラスター診断 / 最適化ツール プロセッサーと Windows* OS インテル 64 アーキテクチャー ベースのシステム 1 コアあたり 1GB のメモリーと
Windows* 環境での MPI プログラムの作成と実行 2016 年 4 月 内容 必要要件と各ツール インストール コンパイルと実行 必要なツールと環境 プロセッサーと Windows* OS コンパイラーとリンカー MPI ライブラリー クラスター診断 / 最適化ツール プロセッサーと Windows* OS インテル 64 アーキテクチャー ベースのシステム 1 コアあたり 1GB のメモリーと
PowerPoint プレゼンテーション
 vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
Jackson Marusarz 開発製品部門
 Jackson Marusarz 開発製品部門 内容 インテル TBB の概要 ヘテロジニアスの課題とそれらに対応するための概念 課題に対応するためのインテル TBB の進化 2 インテル TBB threadingbuildingblocks.org 汎用並列アルゴリズム ゼロから始めることなく マルチコアの能力を活かす効率的でスケーラブルな方法を提供 フローグラフ 並列処理を計算の依存性やデータフロー
Jackson Marusarz 開発製品部門 内容 インテル TBB の概要 ヘテロジニアスの課題とそれらに対応するための概念 課題に対応するためのインテル TBB の進化 2 インテル TBB threadingbuildingblocks.org 汎用並列アルゴリズム ゼロから始めることなく マルチコアの能力を活かす効率的でスケーラブルな方法を提供 フローグラフ 並列処理を計算の依存性やデータフロー
製品価格 ( 新規購入 ) INT6531 インテル VTune Amplifier XE 2017 for Windows Floating 1-275, ,000 INT6532 インテル VTune Amplifier XE 2017 for Linux Floating 1-27
 INT6531 インテル VTune Amplifier XE 2017 for Windows Floating 1-275, ,000 INT6532 インテル VTune Amplifier XE 2017 for Linux Floating 1-27") 製品価格 ( 新規購入 ) INT6499 インテル Parallel Studio XE 2017 Cluster Edition for Windows Floating 2- INT6500 インテル Parallel Studio XE 2017 Cluster Edition for Windows Floating 5-2,478,000 2,676,240 INT6501 インテル Parallel
製品価格 ( 新規購入 ) INT6499 インテル Parallel Studio XE 2017 Cluster Edition for Windows Floating 2- INT6500 インテル Parallel Studio XE 2017 Cluster Edition for Windows Floating 5-2,478,000 2,676,240 INT6501 インテル Parallel
インテル Parallel Studio XE 2017 Composer Edition for Fortran Windows* インストール ガイド Rev (2017/06/08) エクセルソフト株式会社
 エクセルソフト株式会社") インテル Parallel Studio XE 2017 Composer Edition for Fortran Windows* インストール ガイド Rev. 2. 1 (2017/06/08) エクセルソフト株式会社 www.xlsoft.com 目次 1 はじめに... 3 2 製品に含まれるコンポーネント... 3 3 動作環境... 4 オペレーティング システム... 4 Microsoft
インテル Parallel Studio XE 2017 Composer Edition for Fortran Windows* インストール ガイド Rev. 2. 1 (2017/06/08) エクセルソフト株式会社 www.xlsoft.com 目次 1 はじめに... 3 2 製品に含まれるコンポーネント... 3 3 動作環境... 4 オペレーティング システム... 4 Microsoft
インテル Advisor Python* API を使用したパ フォーマンス向上の考察 この記事は Tech.Decoded に公開されている Gaining Performance Insights Using the Intel Advisor Python* API の日本語参考訳です コード
 インテル Advisor Python* API を使用したパ フォーマンス向上の考察 この記事は Tech.Decoded に公開されている Gaining Performance Insights Using the Intel Advisor Python* API の日本語参考訳です コードのチューニング方法を決定する適切なデータの取得 インテルコーポレーション テクニカル コンサルティング
インテル Advisor Python* API を使用したパ フォーマンス向上の考察 この記事は Tech.Decoded に公開されている Gaining Performance Insights Using the Intel Advisor Python* API の日本語参考訳です コードのチューニング方法を決定する適切なデータの取得 インテルコーポレーション テクニカル コンサルティング
Introduction to OpenMP* 4.0 for SIMD and Affinity Features with Intel® Xeon® Processors and Intel® Xeon Phi™ Coprocessors
 OpenMP* 4.0 における SIMD およびアフィニティー機能の導入 法務上の注意書きと最適化に関する注意事項 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスを許諾するものではありません 製品に付属の売買契約書 Intel's Terms and Conditions
OpenMP* 4.0 における SIMD およびアフィニティー機能の導入 法務上の注意書きと最適化に関する注意事項 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスを許諾するものではありません 製品に付属の売買契約書 Intel's Terms and Conditions
(速報) Xeon E 系モデル 新プロセッサ性能について
 Xeon E 系モデル 新プロセッサ性能について") ( 速報 ) Xeon E5-2600 系モデル新プロセッサ性能について 2012 年 3 月 16 日 富士通株式会社 2012 年 3 月 7 日 インテル社より最新 CPU インテル Xeon E5 ファミリー の発表がありました この最新 CPU について PC クラスタシステムの観点から性能検証を行いましたので 概要を速報いたします プロセッサインテル Xeon プロセッサ E5-2690
( 速報 ) Xeon E5-2600 系モデル新プロセッサ性能について 2012 年 3 月 16 日 富士通株式会社 2012 年 3 月 7 日 インテル社より最新 CPU インテル Xeon E5 ファミリー の発表がありました この最新 CPU について PC クラスタシステムの観点から性能検証を行いましたので 概要を速報いたします プロセッサインテル Xeon プロセッサ E5-2690
Itanium2ベンチマーク
 HPC CPU mhori@ile.osaka-u.ac.jp Special thanks Timur Esirkepov HPC 2004 2 25 1 1. CPU 2. 3. Itanium 2 HPC 2 1 Itanium2 CPU CPU 3 ( ) Intel Itanium2 NEC SX-6 HP Alpha Server ES40 PRIMEPOWER SR8000 Intel
HPC CPU mhori@ile.osaka-u.ac.jp Special thanks Timur Esirkepov HPC 2004 2 25 1 1. CPU 2. 3. Itanium 2 HPC 2 1 Itanium2 CPU CPU 3 ( ) Intel Itanium2 NEC SX-6 HP Alpha Server ES40 PRIMEPOWER SR8000 Intel
インテル(R) Visual Fortran Composer XE 2013 Windows版 入門ガイド
 Visual Fortran Composer XE 2013 Windows版 入門ガイド") Visual Fortran Composer XE 2013 Windows* エクセルソフト株式会社 www.xlsoft.com Rev. 1.1 (2012/12/10) Copyright 1998-2013 XLsoft Corporation. All Rights Reserved. 1 / 53 ... 3... 4... 4... 5 Visual Studio... 9...
Visual Fortran Composer XE 2013 Windows* エクセルソフト株式会社 www.xlsoft.com Rev. 1.1 (2012/12/10) Copyright 1998-2013 XLsoft Corporation. All Rights Reserved. 1 / 53 ... 3... 4... 4... 5 Visual Studio... 9...
IntelR Compilers Professional Editions
 June 2007 インテル コンパイラー プロフェッショナル エディション Phil De La Zerda 公開が禁止された情報が含まれています 本資料に含まれるインテル コンパイラー 10.0 についての情報は 6 月 5 日まで公開が禁止されています グローバル ビジネス デベロップメント ディレクター Intel Corporation マルチコア プロセッサーがもたらす変革 これまでは
June 2007 インテル コンパイラー プロフェッショナル エディション Phil De La Zerda 公開が禁止された情報が含まれています 本資料に含まれるインテル コンパイラー 10.0 についての情報は 6 月 5 日まで公開が禁止されています グローバル ビジネス デベロップメント ディレクター Intel Corporation マルチコア プロセッサーがもたらす変革 これまでは
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
インテルソウトウェア開発製品アカデミック版特定ユーザーライセンス標準価格表 株式会社アークブレイン 2016 年 5 月 10 日 ~ 製品型番 アカデミック版特定ユーザーライセンス 税別標準価格 税込標準価格 INT5744 インテル Parallel Studio XE 2016 Cluster
 インテルソウトウェア開発製品アカデミック版特定ユーザーライセンス標準価格表 株式会社アークブレイン 2016 年 5 月 10 日 ~ アカデミック版特定ユーザーライセンス INT5744 インテル Parallel Studio XE 2016 Cluster Edition 273,000 for 294 Win INT5745 インテル Parallel Studio XE 2016 Cluster
インテルソウトウェア開発製品アカデミック版特定ユーザーライセンス標準価格表 株式会社アークブレイン 2016 年 5 月 10 日 ~ アカデミック版特定ユーザーライセンス INT5744 インテル Parallel Studio XE 2016 Cluster Edition 273,000 for 294 Win INT5745 インテル Parallel Studio XE 2016 Cluster
インテル® ソフトウェア・カンファレンス福岡 インテル® コンパイラーを使用する際に直面するよくある問題と課題
 コードの現代化 ( 最適化 ) 1-2-3 インテル コンパイラーを使用する際に直面するよくある問題と課題 2017 年 7 月 isus 編集長 すがわらきよふみ このセッションの内容 ベクトル化と命令セット ベクトル化を支援するコンパイラーの機能 インテル Advisor を使用した最適化のステップ 複数ソケットシステム (NUMA) 環境での留意点 このセッションで使用する機材 : インテル
コードの現代化 ( 最適化 ) 1-2-3 インテル コンパイラーを使用する際に直面するよくある問題と課題 2017 年 7 月 isus 編集長 すがわらきよふみ このセッションの内容 ベクトル化と命令セット ベクトル化を支援するコンパイラーの機能 インテル Advisor を使用した最適化のステップ 複数ソケットシステム (NUMA) 環境での留意点 このセッションで使用する機材 : インテル
The 3 key challenges in programming for MC
 Aug 3 06 Software &Solutions group Intel Intel Centrino Intel NetBurst Intel XScale Itanium Pentium Xeon Intel Core VTune Intel Corporation Intel NetBurst Pentium Xeon Pentium M Core 64 2 Intel Software
Aug 3 06 Software &Solutions group Intel Intel Centrino Intel NetBurst Intel XScale Itanium Pentium Xeon Intel Core VTune Intel Corporation Intel NetBurst Pentium Xeon Pentium M Core 64 2 Intel Software
Microsoft PowerPoint - 1_コンパイラ入門セミナー.ppt
 インテルコンパイラー 入門セミナー [ 対象製品 ] インテル C++ コンパイラー 9.1 Windows* 版インテル Visual Fortran コンパイラー 9.1 Windows* 版 資料作成 : エクセルソフト株式会社 Copyright 1998-2007 XLsoft Corporation. All Rights Reserved. 1 インテル コンパイラー入門 本セミナーの内容
インテルコンパイラー 入門セミナー [ 対象製品 ] インテル C++ コンパイラー 9.1 Windows* 版インテル Visual Fortran コンパイラー 9.1 Windows* 版 資料作成 : エクセルソフト株式会社 Copyright 1998-2007 XLsoft Corporation. All Rights Reserved. 1 インテル コンパイラー入門 本セミナーの内容
製品型番 商用版特定ユーザーライセンス INT7001 インテル System Studio 2018 FreeBSD \163,080 INT6673 インテル Media Server Studio 2017 Essentials \84,000 \90,720 Edit INT6674 インテ
 インテルソウトウェア開発製品 2018 (C++ Fotran コンパイラ ) 商用版特定ユーザーライセンス標準価格表 株式会社アークブレイン 2017 年 12 月 7 日 ~ 製品型番 商用版特定ユーザーライセンス INT6759 インテル Parallel Studio XE 2018 Cluster \495,000 \534,600 Edition INT6760 インテル Parallel
インテルソウトウェア開発製品 2018 (C++ Fotran コンパイラ ) 商用版特定ユーザーライセンス標準価格表 株式会社アークブレイン 2017 年 12 月 7 日 ~ 製品型番 商用版特定ユーザーライセンス INT6759 インテル Parallel Studio XE 2018 Cluster \495,000 \534,600 Edition INT6760 インテル Parallel
インテル® Parallel Studio XE 2017 for Linux* インストール・ガイド
 インテル Parallel Studio XE 2017 Linux* インストール ガイド 2016 年 7 月 15 日 内容 1 概要... 2 1.1 ライセンス情報... 2 2 必要条件... 2 2.1 クラスター インストールの注意事項... 3 2.1.1 インストール方法の選択... 3 2.1.2 セキュアシェル接続の確立... 4 3 インストール... 5 3.1 オンライン
インテル Parallel Studio XE 2017 Linux* インストール ガイド 2016 年 7 月 15 日 内容 1 概要... 2 1.1 ライセンス情報... 2 2 必要条件... 2 2.1 クラスター インストールの注意事項... 3 2.1.1 インストール方法の選択... 3 2.1.2 セキュアシェル接続の確立... 4 3 インストール... 5 3.1 オンライン
Tutorial-GettingStarted
 インテル HTML5 開発環境 チュートリアル インテル XDK 入門ガイド V2.02 : 05.09.2013 著作権と商標について 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスを許諾するものではありません 製品に付属の売買契約書 Intel's Terms
インテル HTML5 開発環境 チュートリアル インテル XDK 入門ガイド V2.02 : 05.09.2013 著作権と商標について 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスを許諾するものではありません 製品に付属の売買契約書 Intel's Terms
コードのチューニング
 OpenMP による並列化実装 八木学 ( 理化学研究所計算科学研究センター ) KOBE HPC Spring School 2019 2019 年 3 月 14 日 スレッド並列とプロセス並列 スレッド並列 OpenMP 自動並列化 プロセス並列 MPI プロセス プロセス プロセス スレッドスレッドスレッドスレッド メモリ メモリ プロセス間通信 Private Private Private
OpenMP による並列化実装 八木学 ( 理化学研究所計算科学研究センター ) KOBE HPC Spring School 2019 2019 年 3 月 14 日 スレッド並列とプロセス並列 スレッド並列 OpenMP 自動並列化 プロセス並列 MPI プロセス プロセス プロセス スレッドスレッドスレッドスレッド メモリ メモリ プロセス間通信 Private Private Private
01_OpenMP_osx.indd
 OpenMP* / 1 1... 2 2... 3 3... 5 4... 7 5... 9 5.1... 9 5.2 OpenMP* API... 13 6... 17 7... 19 / 4 1 2 C/C++ OpenMP* 3 Fortran OpenMP* 4 PC 1 1 9.0 Linux* Windows* Xeon Itanium OS 1 2 2 WEB OS OS OS 1 OS
OpenMP* / 1 1... 2 2... 3 3... 5 4... 7 5... 9 5.1... 9 5.2 OpenMP* API... 13 6... 17 7... 19 / 4 1 2 C/C++ OpenMP* 3 Fortran OpenMP* 4 PC 1 1 9.0 Linux* Windows* Xeon Itanium OS 1 2 2 WEB OS OS OS 1 OS
演習1: 演習準備
 演習 1: 演習準備 2013 年 8 月 6 日神戸大学大学院システム情報学研究科森下浩二 1 演習 1 の内容 神戸大 X10(π-omputer) について システム概要 ログイン方法 コンパイルとジョブ実行方法 OpenMP の演習 ( 入門編 ) 1. parallel 構文 実行時ライブラリ関数 2. ループ構文 3. shared 節 private 節 4. reduction 節
演習 1: 演習準備 2013 年 8 月 6 日神戸大学大学院システム情報学研究科森下浩二 1 演習 1 の内容 神戸大 X10(π-omputer) について システム概要 ログイン方法 コンパイルとジョブ実行方法 OpenMP の演習 ( 入門編 ) 1. parallel 構文 実行時ライブラリ関数 2. ループ構文 3. shared 節 private 節 4. reduction 節
インテル(R) Visual Fortran Composer XE
 Visual Fortran Composer XE") Visual Fortran Composer XE 1. 2. 3. 4. 5. Visual Studio 6. Visual Studio 7. 8. Compaq Visual Fortran 9. Visual Studio 10. 2 https://registrationcenter.intel.com/regcenter/ w_fcompxe_all_jp_2013_sp1.1.139.exe
Visual Fortran Composer XE 1. 2. 3. 4. 5. Visual Studio 6. Visual Studio 7. 8. Compaq Visual Fortran 9. Visual Studio 10. 2 https://registrationcenter.intel.com/regcenter/ w_fcompxe_all_jp_2013_sp1.1.139.exe
修士論文
 AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
1重谷.PDF
 RSCC RSCC RSCC BMT 1 6 3 3000 3000 200310 1994 19942 VPP500/32PE 19992 VPP700E/128PE 160PE 20043 2 2 PC Linux 2048 CPU Intel Xeon 3.06GHzDual) 12.5 TFLOPS SX-7 32CPU/256GB 282.5 GFLOPS Linux 3 PC 1999
RSCC RSCC RSCC BMT 1 6 3 3000 3000 200310 1994 19942 VPP500/32PE 19992 VPP700E/128PE 160PE 20043 2 2 PC Linux 2048 CPU Intel Xeon 3.06GHzDual) 12.5 TFLOPS SX-7 32CPU/256GB 282.5 GFLOPS Linux 3 PC 1999
Introducing Intel® Parallel Studio XE 2015
 インテル Parallel Studio XE 205 の概要 James Reinders インテルコーポレーションのソフトウェア エバンジェリスト兼ディレクター james.r.reinders@intel.com 高速なコードを迅速に開発インテル Parallel Studio XE 205 高速なコード 明示的なベクトル プログラミングでより多くのコードをスピードアップ インテル Xeon
インテル Parallel Studio XE 205 の概要 James Reinders インテルコーポレーションのソフトウェア エバンジェリスト兼ディレクター james.r.reinders@intel.com 高速なコードを迅速に開発インテル Parallel Studio XE 205 高速なコード 明示的なベクトル プログラミングでより多くのコードをスピードアップ インテル Xeon
テクノロジーのビッグトレンド 180 nm nm nm nm nm On 2007 Track 32 nm には 150 億台の端末がネットワーク接続 * * "Gantz, John. "The Embedded
 ホワイトスペースに対するインテルの期待 インテルコーポレーション セールス & マーケティング統括本部副社長 吉田和正 テクノロジーのビッグトレンド 180 nm 1999 130 nm 2001 90 nm 2003 65 nm 2005 45 nm On 2007 Track 32 nm 2009 2015 には 150 億台の端末がネットワーク接続 * * "Gantz, John. "The
ホワイトスペースに対するインテルの期待 インテルコーポレーション セールス & マーケティング統括本部副社長 吉田和正 テクノロジーのビッグトレンド 180 nm 1999 130 nm 2001 90 nm 2003 65 nm 2005 45 nm On 2007 Track 32 nm 2009 2015 には 150 億台の端末がネットワーク接続 * * "Gantz, John. "The
インテル® キャッシュ・アクセラレーション・ソフトウェア (インテル® CAS) Linux* 版 v2.8 (GA)
 Linux* 版 v2.8 (GA)") 改訂 001 ドキュメント番号 :328499-001 注 : 本書には開発の設計段階の製品に関する情報が記述されています この情報は予告なく変更されることがあります この情報だけに基づいて設計を最終的なものとしないでください 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスも許諾するものではありません
改訂 001 ドキュメント番号 :328499-001 注 : 本書には開発の設計段階の製品に関する情報が記述されています この情報は予告なく変更されることがあります この情報だけに基づいて設計を最終的なものとしないでください 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスも許諾するものではありません
インテル(R) Visual Fortran コンパイラ 10.0
 Visual Fortran コンパイラ 10.0") インテル (R) Visual Fortran コンパイラー 10.0 日本語版スペシャル エディション 入門ガイド 目次 概要インテル (R) Visual Fortran コンパイラーの設定はじめに検証用ソースファイル適切なインストールの確認コンパイラーの起動 ( コマンドライン ) コンパイル ( 最適化オプションなし ) 実行 / プログラムの検証コンパイル ( 最適化オプションあり ) 実行
インテル (R) Visual Fortran コンパイラー 10.0 日本語版スペシャル エディション 入門ガイド 目次 概要インテル (R) Visual Fortran コンパイラーの設定はじめに検証用ソースファイル適切なインストールの確認コンパイラーの起動 ( コマンドライン ) コンパイル ( 最適化オプションなし ) 実行 / プログラムの検証コンパイル ( 最適化オプションあり ) 実行
PowerPoint プレゼンテーション
 Dell PowerEdge C6320 スケーラブルサーバアプライアンス 仮想化アプライアンスサーバ 最新のプロセッサを搭載したサーバプラットフォーム vsmp Foundation によるサーバ仮想化と統合化の適用 システムはセットアップを完了した状態でご提供 基本構成ではバックプレーン用のスイッチなどが不要 各ノード間を直接接続 冗長性の高いバックプレーン構成 利用するサーバプラットフォームは
Dell PowerEdge C6320 スケーラブルサーバアプライアンス 仮想化アプライアンスサーバ 最新のプロセッサを搭載したサーバプラットフォーム vsmp Foundation によるサーバ仮想化と統合化の適用 システムはセットアップを完了した状態でご提供 基本構成ではバックプレーン用のスイッチなどが不要 各ノード間を直接接続 冗長性の高いバックプレーン構成 利用するサーバプラットフォームは
Microsoft PowerPoint - OpenMP入門.pptx
 OpenMP 入門 須田礼仁 2009/10/30 初版 OpenMP 共有メモリ並列処理の標準化 API http://openmp.org/ 最新版は 30 3.0 バージョンによる違いはあまり大きくない サポートしているバージョンはともかく csp で動きます gcc も対応しています やっぱり SPMD Single Program Multiple Data プログラム #pragma omp
OpenMP 入門 須田礼仁 2009/10/30 初版 OpenMP 共有メモリ並列処理の標準化 API http://openmp.org/ 最新版は 30 3.0 バージョンによる違いはあまり大きくない サポートしているバージョンはともかく csp で動きます gcc も対応しています やっぱり SPMD Single Program Multiple Data プログラム #pragma omp
KSforWindowsServerのご紹介
 Kaspersky Security for Windows Server のご紹介 ランサムウェアに対抗する アンチクリプター を搭載 株式会社カスペルスキー 製品本部 目次 1. サーバーセキュリティがなぜ重要か? 2. Kaspesky Security for Windows Server の概要 Kaspersky Security for Windows Server の特長 導入の効果
Kaspersky Security for Windows Server のご紹介 ランサムウェアに対抗する アンチクリプター を搭載 株式会社カスペルスキー 製品本部 目次 1. サーバーセキュリティがなぜ重要か? 2. Kaspesky Security for Windows Server の概要 Kaspersky Security for Windows Server の特長 導入の効果
インテル® Parallel Studio XE 2016 Update 1 for Linux* インストール・ガイド
 インテル Parallel Studio XE 2016 Update 1 Linux* インストール ガイド 2015 年 10 月 16 日 内容 1 概要... 2 1.1 ライセンス情報... 2 2 必要条件... 3 2.1 クラスター インストールの注意事項... 3 2.1.1 インストール方法の選択... 3 2.1.2 セキュアシェル接続の確立... 4 3 インストール...
インテル Parallel Studio XE 2016 Update 1 Linux* インストール ガイド 2015 年 10 月 16 日 内容 1 概要... 2 1.1 ライセンス情報... 2 2 必要条件... 3 2.1 クラスター インストールの注意事項... 3 2.1.1 インストール方法の選択... 3 2.1.2 セキュアシェル接続の確立... 4 3 インストール...
Microsoft PowerPoint - sales2.ppt
 最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
The Parallel Universe 1 インテル MPI ライブラリーのマルチ EP によりハイブリッド アプリケーションのパフォーマンスを向上 最小限のコード変更でエクサスケール時代に備える Rama Kishan Malladi インテルコーポレーショングラフィックス パフォーマンス モ
 1 インテル MPI ライブラリーのマルチ EP によりハイブリッド アプリケーションのパフォーマンスを向上 最小限のコード変更でエクサスケール時代に備える Rama Kishan Malladi インテルコーポレーショングラフィックス パフォーマンス モデリング エンジニア Dr. Amarpal Singh Kapoor インテルコーポレーションテクニカル コンサルティング エンジニア 1990
1 インテル MPI ライブラリーのマルチ EP によりハイブリッド アプリケーションのパフォーマンスを向上 最小限のコード変更でエクサスケール時代に備える Rama Kishan Malladi インテルコーポレーショングラフィックス パフォーマンス モデリング エンジニア Dr. Amarpal Singh Kapoor インテルコーポレーションテクニカル コンサルティング エンジニア 1990
Microsoft PowerPoint Quality-sama_Seminar.pptx
 インテル vpro テクノロジー ~ 革新と継続的な進化 ~ インテル株式会社マーケティング本部 2010 年 11 月 2010年の新プロセッサー: 更なるパフォーマンスを スマート に実現 ユーザーのワークロードに合わせて プロセッサーの周波数を動的に向上 インテル インテル ターボ ブースト テクノロジー* ターボ ブースト テクノロジー* 暗号化処理を高速化 保護する 新しいプロセッサー命令
インテル vpro テクノロジー ~ 革新と継続的な進化 ~ インテル株式会社マーケティング本部 2010 年 11 月 2010年の新プロセッサー: 更なるパフォーマンスを スマート に実現 ユーザーのワークロードに合わせて プロセッサーの周波数を動的に向上 インテル インテル ターボ ブースト テクノロジー* ターボ ブースト テクノロジー* 暗号化処理を高速化 保護する 新しいプロセッサー命令
Microsoft Word - IVF15.0.1J_Install.doc
 Parallel Studio XE 2015 Composer Edition for Fortran Windows* www.xlsoft.com Rev. 1.0 (2014/11/18) 1 / 17 目次 1. はじめに... 3 2. 製品コンポーネント... 3 3. 動作環境... 4 4. インストールする前に... 5 5. 製品購入者と評価ユーザー... 6 6. インストール手順...
Parallel Studio XE 2015 Composer Edition for Fortran Windows* www.xlsoft.com Rev. 1.0 (2014/11/18) 1 / 17 目次 1. はじめに... 3 2. 製品コンポーネント... 3 3. 動作環境... 4 4. インストールする前に... 5 5. 製品購入者と評価ユーザー... 6 6. インストール手順...
NUMAの構成
 共有メモリを使ったデータ交換と同期 慶應義塾大学理工学部 天野英晴 hunga@am.ics.keio.ac.jp 同期の必要性 あるプロセッサが共有メモリに書いても 別のプロセッサにはそのことが分からない 同時に同じ共有変数に書き込みすると 結果がどうなるか分からない そもそも共有メモリって結構危険な代物 多くのプロセッサが並列に動くには何かの制御機構が要る 不可分命令 同期用メモリ バリア同期機構
共有メモリを使ったデータ交換と同期 慶應義塾大学理工学部 天野英晴 hunga@am.ics.keio.ac.jp 同期の必要性 あるプロセッサが共有メモリに書いても 別のプロセッサにはそのことが分からない 同時に同じ共有変数に書き込みすると 結果がどうなるか分からない そもそも共有メモリって結構危険な代物 多くのプロセッサが並列に動くには何かの制御機構が要る 不可分命令 同期用メモリ バリア同期機構
GPGPUクラスタの性能評価
 2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
02_C-C++_osx.indd
 C/C++ OpenMP* / 2 C/C++ OpenMP* OpenMP* 9.0 1... 2 2... 3 3OpenMP*... 5 3.1... 5 3.2 OpenMP*... 6 3.3 OpenMP*... 8 4OpenMP*... 9 4.1... 9 4.2 OpenMP*... 9 4.3 OpenMP*... 10 4.4... 10 5OpenMP*... 11 5.1
C/C++ OpenMP* / 2 C/C++ OpenMP* OpenMP* 9.0 1... 2 2... 3 3OpenMP*... 5 3.1... 5 3.2 OpenMP*... 6 3.3 OpenMP*... 8 4OpenMP*... 9 4.1... 9 4.2 OpenMP*... 9 4.3 OpenMP*... 10 4.4... 10 5OpenMP*... 11 5.1
PowerPoint プレゼンテーション
 各種計算機アプリケーション性能比較 目次. はじめに. 行列積計算.QDR 積計算 4.N 体問題計算 5. 多次元積分計算 5. 次元積分計算 5. 次元積分計算 5. 4 次元積分計算 5.4 5 次元積分計算 5.5 6 次元積分計算 平成 6 年度第 四半期 . はじめに 今までと少し性質の異なるグラフィックボードが使用できる様になったので従来のアプリケーションで性能比較を実施しました 主に使用した計算機は以下のものです
各種計算機アプリケーション性能比較 目次. はじめに. 行列積計算.QDR 積計算 4.N 体問題計算 5. 多次元積分計算 5. 次元積分計算 5. 次元積分計算 5. 4 次元積分計算 5.4 5 次元積分計算 5.5 6 次元積分計算 平成 6 年度第 四半期 . はじめに 今までと少し性質の異なるグラフィックボードが使用できる様になったので従来のアプリケーションで性能比較を実施しました 主に使用した計算機は以下のものです
Microsoft Word - Dolphin Expressによる10Gbpソケット通信.docx
 Dolphin Express による 10Gbps ソケット通信 Dolphin Express は 標準的な低価格のサーバを用いて 強力なクラスタリングシステムが構築できる ハードウェアとソフトウェアによる通信用アーキテクチャです 本資料では Dolphin Express 製品の概要と 実際にどの程度の性能が出るのか市販 PC での実験結果をご紹介します Dolphin Express 製品体系
Dolphin Express による 10Gbps ソケット通信 Dolphin Express は 標準的な低価格のサーバを用いて 強力なクラスタリングシステムが構築できる ハードウェアとソフトウェアによる通信用アーキテクチャです 本資料では Dolphin Express 製品の概要と 実際にどの程度の性能が出るのか市販 PC での実験結果をご紹介します Dolphin Express 製品体系
Microsoft PowerPoint - CCS学際共同boku-08b.ppt
 マルチコア / マルチソケットノードに おけるメモリ性能のインパクト 研究代表者朴泰祐筑波大学システム情報工学研究科 taisuke@cs.tsukuba.ac.jp アウトライン 近年の高性能 PC クラスタの傾向と問題 multi-core/multi-socket ノードとメモリ性能 メモリバンド幅に着目した性能測定 multi-link network 性能評価 まとめ 近年の高性能 PC
マルチコア / マルチソケットノードに おけるメモリ性能のインパクト 研究代表者朴泰祐筑波大学システム情報工学研究科 taisuke@cs.tsukuba.ac.jp アウトライン 近年の高性能 PC クラスタの傾向と問題 multi-core/multi-socket ノードとメモリ性能 メモリバンド幅に着目した性能測定 multi-link network 性能評価 まとめ 近年の高性能 PC
N08
 CPU のキモチ C.John 自己紹介 英語きらい 絵かけない 人の話を素直に信じない CPUにキモチなんてない お詫び 予告ではCとC# とありましたがやる気と時間の都合上 C++のみを対象とします 今日のネタ元 MSDN マガジン 2010 年 10 月号 http://msdn.microsoft.com/ja-jp/magazine/cc850829.aspx Windows と C++
CPU のキモチ C.John 自己紹介 英語きらい 絵かけない 人の話を素直に信じない CPUにキモチなんてない お詫び 予告ではCとC# とありましたがやる気と時間の都合上 C++のみを対象とします 今日のネタ元 MSDN マガジン 2010 年 10 月号 http://msdn.microsoft.com/ja-jp/magazine/cc850829.aspx Windows と C++
並列アプリケーション向けインテル® TBB スケーラブル・メモリー・アロケーターの活用
 並列アプリケーション向けインテル TBB スケーラブル メモリー アロケーターの活用インテル スレッディング ビルディング ブロック ( インテル TBB) 2019 インテルコーポレーションソフトウェア開発エンジニア Nikita Ponomarev アプリケーションの想定 高速な malloc/free クロススレッドはそこまで速くないかもしれないが忘れないようにする ローカルキャッシュでホットなオブジェクトを取得する
並列アプリケーション向けインテル TBB スケーラブル メモリー アロケーターの活用インテル スレッディング ビルディング ブロック ( インテル TBB) 2019 インテルコーポレーションソフトウェア開発エンジニア Nikita Ponomarev アプリケーションの想定 高速な malloc/free クロススレッドはそこまで速くないかもしれないが忘れないようにする ローカルキャッシュでホットなオブジェクトを取得する
Microsoft PowerPoint - 03_What is OpenMP 4.0 other_Jan18
 OpenMP* 4.x における拡張 OpenMP 4.0 と 4.5 の機能拡張 内容 OpenMP* 3.1 から 4.0 への拡張 OpenMP* 4.0 から 4.5 への拡張 2 追加された機能 (3.1 -> 4.0) C/C++ 配列シンタックスの拡張 SIMD と SIMD 対応関数 デバイスオフロード task 構 の依存性 taskgroup 構 cancel 句と cancellation
OpenMP* 4.x における拡張 OpenMP 4.0 と 4.5 の機能拡張 内容 OpenMP* 3.1 から 4.0 への拡張 OpenMP* 4.0 から 4.5 への拡張 2 追加された機能 (3.1 -> 4.0) C/C++ 配列シンタックスの拡張 SIMD と SIMD 対応関数 デバイスオフロード task 構 の依存性 taskgroup 構 cancel 句と cancellation
性能を強化した 第 12 世代 Dell PowerEdge サーバの RAID コントローラ Dell PERC H800 と PERC H810 の OLTP ワークロード性能比較 ソリューション性能分析グループ Luis Acosta アドバンストストレージエンジニアリング Joe Noyol
 性能を強化した 第 12 世代 Dell PowerEdge サーバの RAID コントローラ Dell PERC H800 と PERC H810 の OLTP ワークロード性能比較 ソリューション性能分析グループ Luis Acosta アドバンストストレージエンジニアリング Joe Noyola 目次 要旨... 3 はじめに... 3 主なテスト結果... 3 OLTP データベース性能 :
性能を強化した 第 12 世代 Dell PowerEdge サーバの RAID コントローラ Dell PERC H800 と PERC H810 の OLTP ワークロード性能比較 ソリューション性能分析グループ Luis Acosta アドバンストストレージエンジニアリング Joe Noyola 目次 要旨... 3 はじめに... 3 主なテスト結果... 3 OLTP データベース性能 :
CPU Levels in the memory hierarchy Level 1 Level 2... Increasing distance from the CPU in access time Level n Size of the memory at each level 1: 2.2
 FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
Oracle Real Application Clusters 10g: 第4世代
 Oracle Real Application Clusters 10g: Angelo Pruscino, Oracle Gordon Smith, Oracle Oracle Real Application Clusters RAC 10g Oracle RAC 10g Oracle Database 10g Oracle RAC 10g 4 Oracle Database 10g Oracle
Oracle Real Application Clusters 10g: Angelo Pruscino, Oracle Gordon Smith, Oracle Oracle Real Application Clusters RAC 10g Oracle RAC 10g Oracle Database 10g Oracle RAC 10g 4 Oracle Database 10g Oracle
ビッグデータやクラウドのシステム基盤向けに処理性能を強化した「BladeSymphony」および「HA8000シリーズ」の新製品を販売開始
 2013 年 9 月 19 日 株式会社日立製作所 ビッグデータやクラウドのシステム基盤向けに処理性能を強化した BladeSymphony および HA8000 シリーズ の新製品を販売開始 運用管理工数の削減を実現するサーバ管理ソフトウェア Hitachi Compute Systems Manager を標準添付 BS520H サーバブレード / PCI 拡張ブレード HA8000/RS220-h
2013 年 9 月 19 日 株式会社日立製作所 ビッグデータやクラウドのシステム基盤向けに処理性能を強化した BladeSymphony および HA8000 シリーズ の新製品を販売開始 運用管理工数の削減を実現するサーバ管理ソフトウェア Hitachi Compute Systems Manager を標準添付 BS520H サーバブレード / PCI 拡張ブレード HA8000/RS220-h
<4D F736F F D20332E322E332E819C97AC91CC89F090CD82A982E78CA982E9466F E393082CC8D5C91A291CC90AB945C955D89BF5F8D8296D85F F8D F5F E646F63>
 3.2.3. 流体解析から見る Fortran90 の構造体性能評価 宇宙航空研究開発機構 高木亮治 1. はじめに Fortran90 では 構造体 動的配列 ポインターなど様々な便利な機能が追加され ユーザーがプログラムを作成する際に選択の幅が広がりより便利になった 一方で 実際のアプリケーションプログラムを開発する際には 解析対象となる物理現象を記述する数学モデルやそれらを解析するための計算手法が内包する階層構造を反映したプログラムを作成できるかどうかは一つの重要な観点であると考えられる
3.2.3. 流体解析から見る Fortran90 の構造体性能評価 宇宙航空研究開発機構 高木亮治 1. はじめに Fortran90 では 構造体 動的配列 ポインターなど様々な便利な機能が追加され ユーザーがプログラムを作成する際に選択の幅が広がりより便利になった 一方で 実際のアプリケーションプログラムを開発する際には 解析対象となる物理現象を記述する数学モデルやそれらを解析するための計算手法が内包する階層構造を反映したプログラムを作成できるかどうかは一つの重要な観点であると考えられる
PowerPoint プレゼンテーション
 Foundation アプライアンス スケーラブルシステムズ株式会社 サーバ クラスタの課題 複数のシステムを一つの だけで容易に管理することは出来ないだろうか? アプリケーションがより多くのメモリを必要とするのだけど ハードウエアの増設なしで対応出来ないだろうか? 現在の利用環境のまま 利用できるコア数やメモリサイズの増強を図ることは出来ないだろうか? 短時間で導入可能で また 必要に応じて 柔軟にシステム構成の変更が可能なソリューションは無いだろうか?...
Foundation アプライアンス スケーラブルシステムズ株式会社 サーバ クラスタの課題 複数のシステムを一つの だけで容易に管理することは出来ないだろうか? アプリケーションがより多くのメモリを必要とするのだけど ハードウエアの増設なしで対応出来ないだろうか? 現在の利用環境のまま 利用できるコア数やメモリサイズの増強を図ることは出来ないだろうか? 短時間で導入可能で また 必要に応じて 柔軟にシステム構成の変更が可能なソリューションは無いだろうか?...
hotspot の特定と最適化
 1 1? 1 1 2 1. hotspot : hotspot hotspot Parallel Amplifier 1? 2. hotspot : (1 ) Parallel Composer 1 Microsoft* Ticker Tape Smoke 1.0 PiSolver 66 / 64 / 2.76 ** 84 / 27% ** 75 / 17% ** 1.46 89% Microsoft*
1 1? 1 1 2 1. hotspot : hotspot hotspot Parallel Amplifier 1? 2. hotspot : (1 ) Parallel Composer 1 Microsoft* Ticker Tape Smoke 1.0 PiSolver 66 / 64 / 2.76 ** 84 / 27% ** 75 / 17% ** 1.46 89% Microsoft*
Microsoft PowerPoint - handai.pptx
 インテル Xeon Phi のプログラミングモデルと アプリケーション分野 インテル Xeon Phi が高性能を低消費電力で実現でき る超並列のプログラミングモデルとその適用可能なアプリ ケーションについて紹介する 内容 インテル Xeon プロセッサーとインテル Xeon Phi コプロセッサー Phi コプロセッサーの高並列アーキテクチャ Phi コプロセッサーに適したアプリ領域とプログラミング環境
インテル Xeon Phi のプログラミングモデルと アプリケーション分野 インテル Xeon Phi が高性能を低消費電力で実現でき る超並列のプログラミングモデルとその適用可能なアプリ ケーションについて紹介する 内容 インテル Xeon プロセッサーとインテル Xeon Phi コプロセッサー Phi コプロセッサーの高並列アーキテクチャ Phi コプロセッサーに適したアプリ領域とプログラミング環境
チュートリアル: インテル® MPI ライブラリー向け MPI Tuner (Windows*)
") チュートリアル : インテル MPI ライブラリー向け MPI Tuner バージョン 5.1 Update 3 (Windows*) 著作権と商標について 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスも許諾するものではありません インテルは 明示されているか否かにかかわらず いかなる保証もいたしません ここにいう保証には 商品適格性
チュートリアル : インテル MPI ライブラリー向け MPI Tuner バージョン 5.1 Update 3 (Windows*) 著作権と商標について 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスも許諾するものではありません インテルは 明示されているか否かにかかわらず いかなる保証もいたしません ここにいう保証には 商品適格性
サーバプラットフォーム「BladeSymphony」、「HA8000シリーズ」の新モデルを販売開始
 006 年 6 月 6 日 サーバプラットフォーム BladeSymphony シリーズ の新モデルを販売開始 最新のデュアルコアプロセッサーを採用 同時に シリーズ ではラインアップを一新 /70W /30W BladeSymphony BS30 日立製作所情報 通信グループ ( グループ長 &CEO: 篠本学 以下 日立 ) は 統合サービスプラットフォーム BladeSymphony およびアドバンストサーバ
006 年 6 月 6 日 サーバプラットフォーム BladeSymphony シリーズ の新モデルを販売開始 最新のデュアルコアプロセッサーを採用 同時に シリーズ ではラインアップを一新 /70W /30W BladeSymphony BS30 日立製作所情報 通信グループ ( グループ長 &CEO: 篠本学 以下 日立 ) は 統合サービスプラットフォーム BladeSymphony およびアドバンストサーバ
アカ版特定ユーザーライセンス INT7006 INT7007 INT7008 INT6685 インテル System Studio 2018 Ultimate on \217,080 r インテル System Studio 2018 Ultimate on \217,080 r インテル Syst
 インテルソウトウェア開発製品 2018 (C++ Fotran コンパイラ ) アカ版特定ユーザーライセンス標準価格表 株式会社アークブレイン 2017 年 12 月 7 日 ~ 製品型番 アカ版特定ユーザーライセンス INT6794 インテル Parallel Studio XE 2018 Cluster \252,000 \272,160 on INT6795 インテル Parallel Studio
インテルソウトウェア開発製品 2018 (C++ Fotran コンパイラ ) アカ版特定ユーザーライセンス標準価格表 株式会社アークブレイン 2017 年 12 月 7 日 ~ 製品型番 アカ版特定ユーザーライセンス INT6794 インテル Parallel Studio XE 2018 Cluster \252,000 \272,160 on INT6795 インテル Parallel Studio
Microsoft Word - openmp-txt.doc
 ( 付録 A) OpenMP チュートリアル OepnMP は 共有メモリマルチプロセッサ上のマルチスレッドプログラミングのための API です 本稿では OpenMP の簡単な解説とともにプログラム例をつかって説明します 詳しくは OpenMP の規約を決めている OpenMP ARB の http://www.openmp.org/ にある仕様書を参照してください 日本語訳は http://www.hpcc.jp/omni/spec.ja/
( 付録 A) OpenMP チュートリアル OepnMP は 共有メモリマルチプロセッサ上のマルチスレッドプログラミングのための API です 本稿では OpenMP の簡単な解説とともにプログラム例をつかって説明します 詳しくは OpenMP の規約を決めている OpenMP ARB の http://www.openmp.org/ にある仕様書を参照してください 日本語訳は http://www.hpcc.jp/omni/spec.ja/
インテル® VTune™ Amplifier : Windows 環境向けスタートガイド
 インテル VTune Amplifier Windows 環境向けスタートガイド エクセルソフト株式会社 Version 1.0.0-20180829 目次 1. インテル VTune Amplifier の使用.......................................................... 1 2. インテル VTune Amplifier の基本..........................................................
インテル VTune Amplifier Windows 環境向けスタートガイド エクセルソフト株式会社 Version 1.0.0-20180829 目次 1. インテル VTune Amplifier の使用.......................................................... 1 2. インテル VTune Amplifier の基本..........................................................
スライド 1
 計算科学が拓く世界スーパーコンピュータは何故スーパーか 学術情報メディアセンター中島浩 http://www.para.media.kyoto-u.ac.jp/jp/ username=super password=computer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
計算科学が拓く世界スーパーコンピュータは何故スーパーか 学術情報メディアセンター中島浩 http://www.para.media.kyoto-u.ac.jp/jp/ username=super password=computer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
Microsoft Word - PCOMM V6.0_FAQ.doc
 日本 IBM システムズ エンジニアリング メインフレーム サーバー部 2012 年 3 月 目次 1 サポートされる環境について... 3 1.1 接続先ホスト (System z, IBM i) の OS のバージョンに制約がありますか?... 3 1.2 PCOMM を導入する PC のスペックの推奨はありますか?... 3 1.3 PCOMM は Windows 7 に対応していますか?...
日本 IBM システムズ エンジニアリング メインフレーム サーバー部 2012 年 3 月 目次 1 サポートされる環境について... 3 1.1 接続先ホスト (System z, IBM i) の OS のバージョンに制約がありますか?... 3 1.2 PCOMM を導入する PC のスペックの推奨はありますか?... 3 1.3 PCOMM は Windows 7 に対応していますか?...
本文ALL.indd
 Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法河辺峻田口成美古谷英祐 Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法 Performance Measurement Method of Cache Coherency Effects on an Intel Xeon Processor System 河辺峻田口成美古谷英祐
Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法河辺峻田口成美古谷英祐 Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法 Performance Measurement Method of Cache Coherency Effects on an Intel Xeon Processor System 河辺峻田口成美古谷英祐
インテル MKL を使用した小行列乗算の高速化 インテル MKL チーム
 インテル MKL を使用した小行列乗算の高速化 インテル MKL チーム 内容 インテル MKL の概要 インテル MKL の新機能 行列 - 行列乗算 小行列のパフォーマンスの課題 小行列のパフォーマンスを向上するインテル MKL のソリューション MKL_DIRECT_CALL バッチ API コンパクト API パックド API パフォーマンスのヒントと測定 サマリーおよびインテル MKL 関連情報
インテル MKL を使用した小行列乗算の高速化 インテル MKL チーム 内容 インテル MKL の概要 インテル MKL の新機能 行列 - 行列乗算 小行列のパフォーマンスの課題 小行列のパフォーマンスを向上するインテル MKL のソリューション MKL_DIRECT_CALL バッチ API コンパクト API パックド API パフォーマンスのヒントと測定 サマリーおよびインテル MKL 関連情報
AI 人工知能 高度なプログラミングをすることなく 人間の心理と関連した認識機能を実行するために 経験を基にした機械の学習する能力 人工知能 マシンラーニング長期間にわたってより多くのデータを使用することにより 性能が向上するアルゴリズム ディープラーニング多層ニューラル ネットワークが膨大な量のデ
 AI 人工知能 高度なプログラミングをすることなく 人間の心理と関連した認識機能を実行するために 経験を基にした機械の学習する能力 人工知能 マシンラーニング長期間にわたってより多くのデータを使用することにより 性能が向上するアルゴリズム ディープラーニング多層ニューラル ネットワークが膨大な量のデータから学ぶマシンラーニングのサブセット 2 マシンラーニング技術の分析 訓練モデル構築のための訓練
AI 人工知能 高度なプログラミングをすることなく 人間の心理と関連した認識機能を実行するために 経験を基にした機械の学習する能力 人工知能 マシンラーニング長期間にわたってより多くのデータを使用することにより 性能が向上するアルゴリズム ディープラーニング多層ニューラル ネットワークが膨大な量のデータから学ぶマシンラーニングのサブセット 2 マシンラーニング技術の分析 訓練モデル構築のための訓練
インテル® Parallel Studio XE 2019 Update 4 リリースノート
 インテル Parallel Studio XE 2019 2019 年 4 月 22 日 内容 1 概要... 2 2 製品の内容... 3 2.1 インテルが提供するデバッグ ソリューションの追加情報... 5 2.2 インテル Visual Fortran コンパイラー用 Microsoft* Visual Studio* Shell の追加情報... 5 2.3 インテル Software Manager...
インテル Parallel Studio XE 2019 2019 年 4 月 22 日 内容 1 概要... 2 2 製品の内容... 3 2.1 インテルが提供するデバッグ ソリューションの追加情報... 5 2.2 インテル Visual Fortran コンパイラー用 Microsoft* Visual Studio* Shell の追加情報... 5 2.3 インテル Software Manager...
HPC143
 研究背景 GPUクラスタ 高性能 高いエネルギー効率 低価格 様々なHPCアプリケーションで用いられている TCA (Tightly Coupled Accelerators) 密結合並列演算加速機構 筑波大学HA-PACSクラスタ アクセラレータ GPU 間の直接通信 低レイテンシ 今後のHPCアプリは強スケーリングも重要 TCAとアクセラレータを搭載したシステムに おけるプログラミングモデル 例
研究背景 GPUクラスタ 高性能 高いエネルギー効率 低価格 様々なHPCアプリケーションで用いられている TCA (Tightly Coupled Accelerators) 密結合並列演算加速機構 筑波大学HA-PACSクラスタ アクセラレータ GPU 間の直接通信 低レイテンシ 今後のHPCアプリは強スケーリングも重要 TCAとアクセラレータを搭載したシステムに おけるプログラミングモデル 例
ムーアの法則 : インテルでは順調に存続中 65nm 2005 製造中 45nm nm nm 2011 * 開発中 15nm 2013 * リサーチ 11nm 2015 * 8nm 2017 * インテルの革新的技術を順次適用予定 2 インテル製品は 予告なく
 HPC 向け次世代 Intel プロセッサ / ツールの紹介 インテル株式会社 ソフトウェア & サービス統括部 池井満 1 2010,IntelCorporation. 無断での引用 転載を禁じます ムーアの法則 : インテルでは順調に存続中 65nm 2005 製造中 45nm 2007 32nm 2009 22nm 2011 * 開発中 15nm 2013 * リサーチ 11nm 2015 *
HPC 向け次世代 Intel プロセッサ / ツールの紹介 インテル株式会社 ソフトウェア & サービス統括部 池井満 1 2010,IntelCorporation. 無断での引用 転載を禁じます ムーアの法則 : インテルでは順調に存続中 65nm 2005 製造中 45nm 2007 32nm 2009 22nm 2011 * 開発中 15nm 2013 * リサーチ 11nm 2015 *