untitled
|
|
|
- てるえ あくや
- 5 years ago
- Views:
Transcription
1 GPGPU
2 NVIDACUDA Learn More about CUDA - NVIDIA NVIDIA CUDA programming Guide CUDA CUDA OpenCL NVIDIA Weekly NVIDIAG KhronosGDCGPUCell B.E.OpenCL )
3 GPU Computing GPGPU - General-Purpose Graphic Processing Unit GPU CUDA Compute Unified Device Architecture GPUNVIDIA GPU GPGPUCUDA CPU GPGPU price!!!

4 NVIDIA NVIDIA
5 CPUGPU CPU memory PCIe GPGPU Graphic memory PCIexpress
. The multiprocessor maps each thread to one scalar processor core, and each scalar thread executes independently with its own instruction address and register state.")
6 NVIDIA GPGPU multiprocessor eight Scalar Processor (SP) cores, two special function units for transcendentals a multithreaded instruction unit on-chip shared Memory SIMT (single-instruction, multiplethread). The multiprocessor maps each thread to one scalar processor core, and each scalar thread executes independently with its own instruction address and register state. creates, manages, schedules, and executes threads in groups of 32 parallel threads called warps. Device Memory (Global Memory) Shared Memory Constant Cache Texture Cache
7 CUDA (Compute Unified Device Architecture) C programming language on GPUs Requires no knowledge of graphics APIs or GPU programming Access to native instructions and memory Easy to get started and to get real performance benefit Designed and developed by NVIDIA Requires an NVIDIA GPU (GeForce 8xxx/Tesla/Quadro) Stable, available (for free), documented and supported For both Windows and Linux
8 CUDA (1/2) GPUCPU(host)co-processorcompute device compute intensivedevice off-load body devicekernel kerneldevice kerneldevice host (CPU)device(GPU)host memory device memory CPU memory PCIe GPGPU Graphic memory

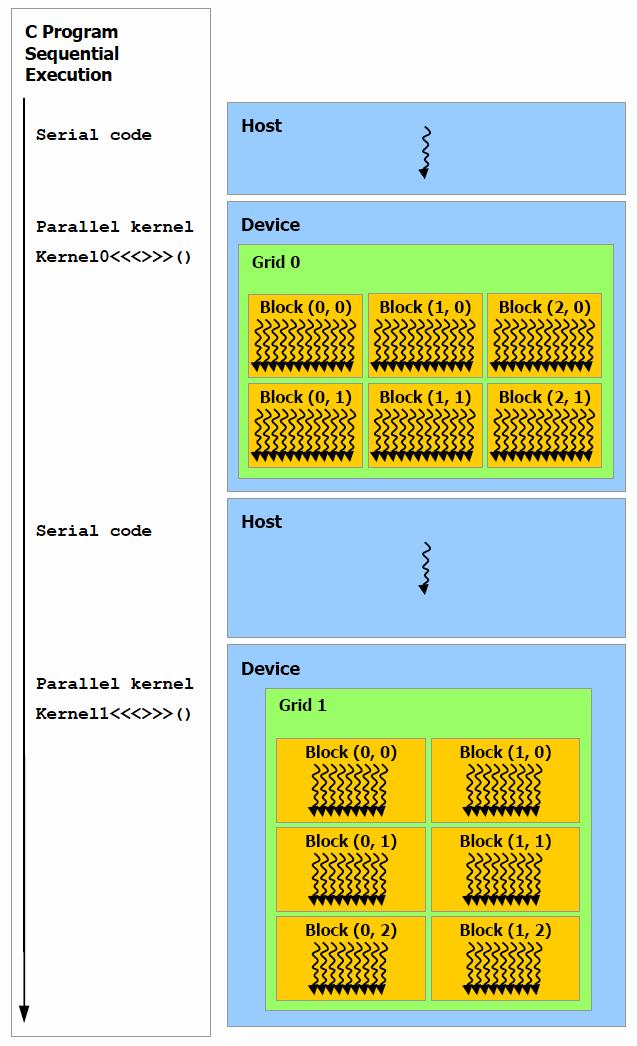
9 CUDA (2/2) (computational Grid) thread Block thread block kernel kernel computational Gridblock1,2,3 blockidthreadid
10 Element-wise Matrix Add void add_matrix ( float* a, float* b, float* c, int N ) { int index; for ( int i = 0; i < N; ++i ) for ( int j = 0; j < N; ++j ) { index = i + j*n; c[index] = a[index] + b[index]; } } CUDA program int main() { add_matrix( a, b, c, N ); global global add_matrix add_matrix } ( ( float* float* a, a, float* float* b, b, float* float* c, c, int int N N ) ) { { CPU program int int i i = = blockidx.x blockidx.x * * blockdim.x blockdim.x + + threadidx.x; threadidx.x; int int j j = = blockidx.y blockidx.y * * blockdim.y blockdim.y + + threadidx.y; threadidx.y; int int index index = = i i + + j*n; j*n; if if ( ( i i < < N N && && j j < < N N ) ) c[index] c[index] = = a[index] a[index] + + b[index]; b[index]; } } int int main() main() { { dim3 dim3 dimblock( dimblock( blocksize, blocksize, blocksize blocksize ); ); dim3 dim3 dimgrid( dimgrid( N/dimBlock.x, N/dimBlock.x, N/dimBlock.y N/dimBlock.y ); ); add_matrix<<<dimgrid, add_matrix<<<dimgrid, dimblock>>>( dimblock>>>( a, a, b, b, c, c, N N ); ); } }
")
11 SM (Streaming Multiprocessor) SM8processor
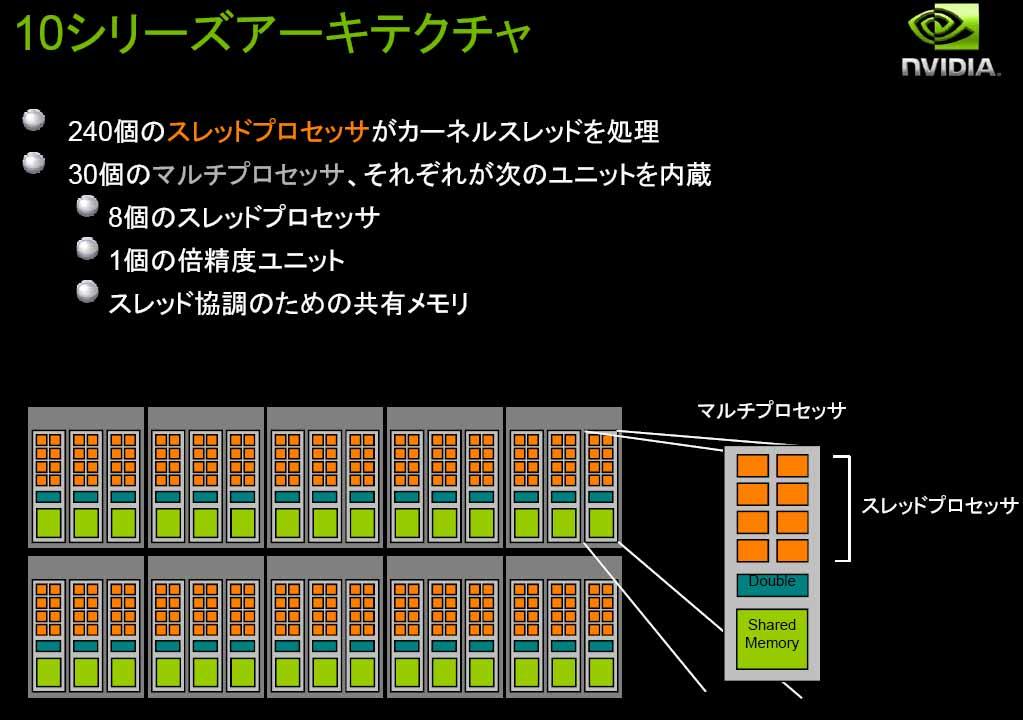
12 GPGPU
 () : : 78GFlops")

13 Tesla C1060 : : : : 1.3GHz 1.3GHz : : 4GB 4GB : : 933GFlops 933GFlops () () : : 78GFlops 78GFlops () () : : 102GB/sec 102GB/sec : : 187.8W 187.8W : : IEEE IEEE / / : : PCI PCI Express Express x16 x16 (PCI-E2.0) (PCI-E2.0)
14 kernel<<<dim3 grid, dim3 block, shmem_size>>>( ) <<< >>> : xy : xyz dim3 grid(16 16); dim3 block(16,16); kernel<<<grid, block>>>(...); kernel<<<32, 512>>>(...);
15 CUDA 11 CUDACPU CUDA CUDA CPU
16
17
18 CPUGPU CPUGPU CPU cudamalloc(void ** pointer, size_t nbytes) cudamemset(void * pointer, int value, size_t count) cudafree(void* pointer) int n = 1024; int nbytes = 1024*sizeof(int); int *d_a = 0; cudamalloc( (void**)&d_a nbytes ); cudamemset( d_a, 0, nbytes); cudafree(d_a);
19 cudamemcpy(void *dst, void *src, size_t nbytes, enum cudamemcpykind direction); directionsrcdst CPU: CUDA enum cudamemcpykind cudamemcpyhosttodevice cudamemcpydevicetohost cudamemcpydevicetodevice
20 GPU C GPU void varargs static CPUGPU
21 global : CPU GPUvoid device : GPU CPU host : CPU host device : CPUGPU
22 CUDA global device dim3 griddim; 2 dim3 blockdim; dim3 blockidx; dim3 threadidx;
23 global void minimal( int* d_a) { *d_a = 13; } global void assign( int* d_a, int value) { int idx = blockdim.x * blockidx.x + threadidx.x; d_a[idx] = value; }
24 global void assign2d(int* d_a, int w, int h, int value) { int iy = blockdim.y * blockidx.y + threadidx.y; int ix = blockdim.x * blockidx.x + threadidx.x; int idx = iy * w + ix; d_a[idx] = value; }... assign2d<<<dim3(64, 64), dim3(16, 16)>>>(...);
25 CPU void inc_cpu(int*a, intn) { int idx; for (idx =0;idx<N;idx++) a[idx]=a[idx] + 1; } voidmain() {... inc_cpu(a, N); } CUDA global void inc_gpu(int*a_d, intn){ int idx = blockidx.x* blockdim.x +threadidx.x; if (idx < N) a_d[idx] = a_d[idx] + 1; } void main() { dim3dimblock (blocksize); dim3dimgrid(ceil(n/ (float)blocksize)); inc_gpu<<<dimgrid, dimblock>>>(a_d, N); }
26 // int numbytes = N * sizeof(float) float* h_a = (float*) malloc(numbytes); // // float* d_a = 0; cudamalloc((void**)&d_a, numbytes); // cudamemcpy(d_a, h_a, numbytes, cudamemcpyhosttodevice); // increment_gpu<<< N/blockSize, blocksize>>>(d_a, b); // cudamemcpy(h_a, d_a, numbytes, cudamemcpydevicetohost); // cudafree(d_a);
27 int main() { float *a = new float[n*n]; float *b = new float[n*n]; float *c = new float[n*n]; for ( int i = 0; i < N*N; ++i ) { a[i] = 1.0f; b[i] = 3.5f; } float *ad, *bd, *cd; const int size = N*N*sizeof(float); cudamalloc( (void**)&ad, size ); cudamalloc( (void**)&bd, size ); cudamalloc( (void**)&cd, size ); cudamemcpy( ad, a, size, cudamemcpyhosttodevice ); cudamemcpy( bd, b, size, cudamemcpyhosttodevice ); dim3 dimblock( blocksize, blocksize ); dim3 dimgrid( N/dimBlock.x, N/dimBlock.y ); add_matrix<<<dimgrid, dimblock>>>( ad, bd, cd, N ); cudamemcpy( c, cd, size, cudamemcpydevicetohost ); } cudafree( ad ); cudafree( bd ); cudafree( cd ); delete[] a; delete[] b; delete[] c; return EXIT_SUCCESS;
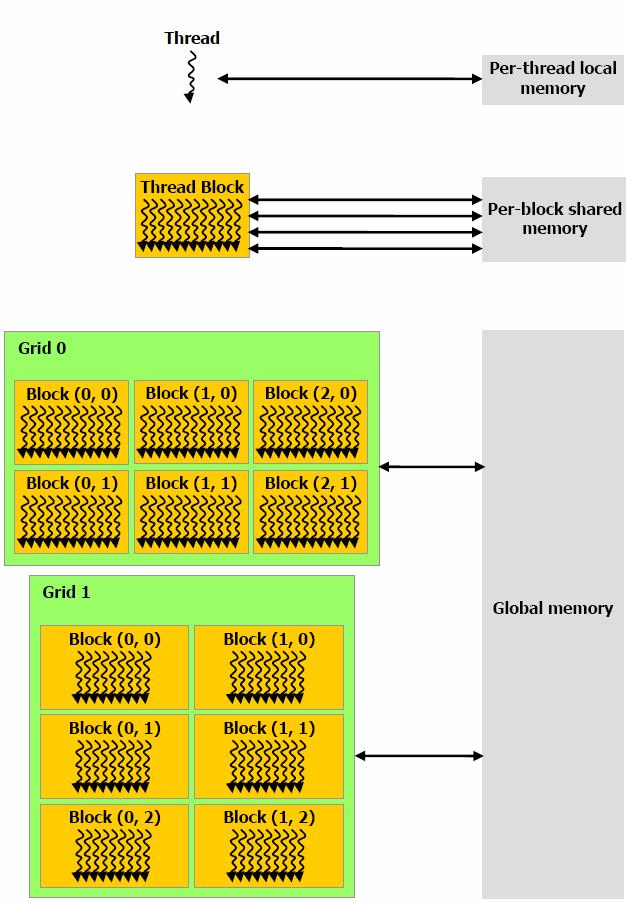
28 device cudamalloc device : shared : 5
29 global void kernel( ) { shared float sdata[256]; } int main(void) { kernel<<<nblocks,blocksize>>>( ); } global void kernel( ) { extern shared float sdata[]; } int main(void) { smbytes = blocksize*sizeof(float); kernel<<<nblocks, blocksize, smbytes>>>( ); }
30 void syncthreads(); GPU RAW WAR WAW

31 CUDA nvcc nvcc cudaccg++cl nvcc CCPU PTX CUDA CUDAcuda CUDAcudart APICUDA
32 GPU GPU GPU
33 1 vs. =
34 Constant memory: Quite small, < 20K As fast as register access if all threads in a warp access the same location Texture memory: Spatially cached Optimized for 2D locality Neighboring threads should read neighboring addresses No need to think about coalescing Constraint: These memories can only be updated from the CPU
35 4 cycles to issue on memory fetch but cycles of latency The equivalent of 100 MADs Likely to be a performance bottleneck Order of magnitude speedups possible Coalesce memory access Use shared memory to re-order non-coalesced addressing
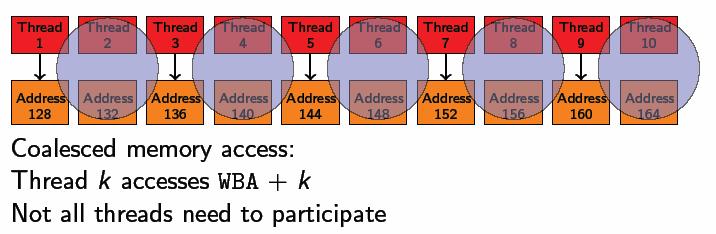
36 coalesce coalesce 16 : 64- intfloat 128- int2float int4float4 float3align (Warp base address (WBA)) 16*sizeof(type) kk

37

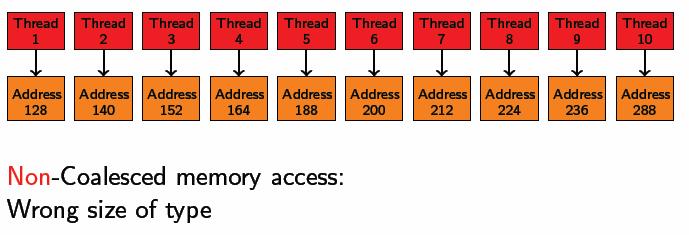
38
 { unsigned int idx_in = xidx + w * yidx; unsigned int idx_out = yidx + h * xidx; } } out[idx_out] = in[idx_in]; read(in) write(out) http://www.sintef.")
39 Matrix Transpose global void transpose_naive( float *out, float *in, int w, int h ) { unsigned int xidx = blockdim.x * blockidx.x + threadidx.x; unsigned int yidx = blockdim.y * blockidx.y + threadidx.y; if ( xidx < w && yidx < h ) { unsigned int idx_in = xidx + w * yidx; unsigned int idx_out = yidx + h * xidx; } } out[idx_out] = in[idx_in]; read(in) write(out)

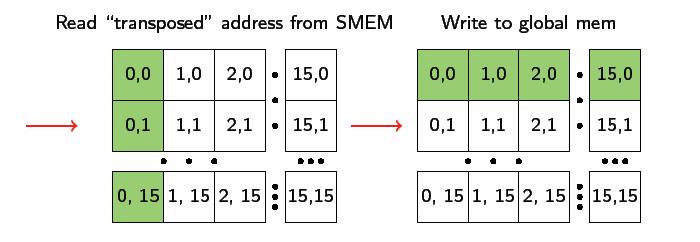
40 16 x 16 thread block Matrix 16 x 16 write
41 ( global void transpose( float *out, float *in, int w, int h ) { shared float block[block_dim*block_dim]; unsigned int xblock = blockdim.x * blockidx.x; unsigned int yblock = blockdim.y * blockidx.y; unsigned int xindex = xblock + threadidx.x; unsigned int yindex = yblock + threadidx.y; unsigned int index_out, index_transpose; if ( xindex < width && yindex < height ) { unsigned int index_in = width * yindex + xindex; unsigned int index_block = threadidx.y * BLOCK_DIM + threadidx.x; block[index_block] = in[index_in]; index_transpose = threadidx.x * BLOCK_DIM + threadidx.y; index_out = height * (xblock + threadidx.y) + yblock + threadidx.x; } synchthreads(); if ( xindex < width && yindex < height ) { out[index_out] = block[index_transpose]; } }
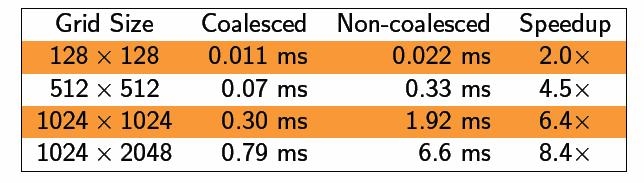
42
43 4GB/s PCIe x vs.76 GB/s Tesla C870 cudamemcpyasync(dst, src, size, direction, 0);
44 CPU CUDA cudamemcpy() CPU CUDA cudathreadsynchronize() CUDA
45 OpenCL GPU NVIDIAC for CUDA NVIDIAAMD(ATI)GPUCPUCell Broadband Engine(Cell B.E.)(Larrabee ) GPU CPU CUDAkernel

46 xxx kernel
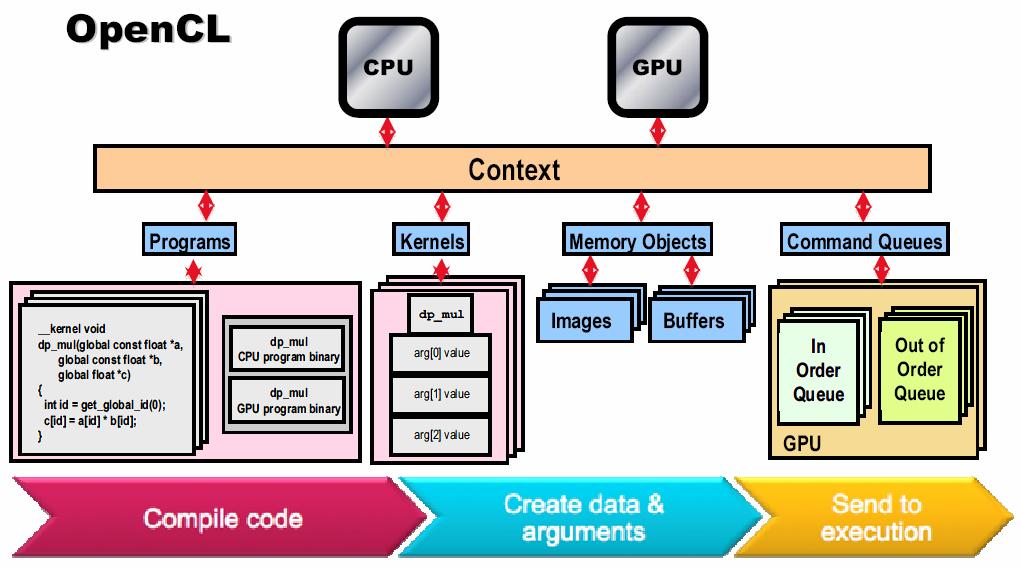
47 OpenCL
48 GPGPU 1GPU CUDA kernel local view GPUGPU GPU -- GPU
Slide 1
 CUDA プログラミングの基本 パート II - カーネル CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パート II カーネルの起動 GPUコードの具体像 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください GPU 上でのコードの実行 カーネルは C 関数 + 多少の制約 ホストメモリはアクセスできない戻り値型は
CUDA プログラミングの基本 パート II - カーネル CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パート II カーネルの起動 GPUコードの具体像 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください GPU 上でのコードの実行 カーネルは C 関数 + 多少の制約 ホストメモリはアクセスできない戻り値型は
07-二村幸孝・出口大輔.indd
 GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境 Lin
 Windows で始める CUDA 入門 GTC 2013 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境
Windows で始める CUDA 入門 GTC 2013 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境
Slide 1
 CUDA プログラミングの基本 パート I - ソフトウェアスタックとメモリ管理 CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パートII カーネルの起動 GPUコードの具体項目 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください CUDA インストレーション CUDA インストレーションの構成
CUDA プログラミングの基本 パート I - ソフトウェアスタックとメモリ管理 CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パートII カーネルの起動 GPUコードの具体項目 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください CUDA インストレーション CUDA インストレーションの構成
1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU.....
 CPU GPU N Q07-065 2011 2 17 1 1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU...........................................
CPU GPU N Q07-065 2011 2 17 1 1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU...........................................
CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン
 CUDA 画像処理入門 エヌビディアジャパン CUDA エンジニア森野慎也 GTC Japan 2014 CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン RGB Y( 輝度 ) 変換 カラー画像から グレイスケールへの変換 Y = 0.299 R + 0.587
CUDA 画像処理入門 エヌビディアジャパン CUDA エンジニア森野慎也 GTC Japan 2014 CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン RGB Y( 輝度 ) 変換 カラー画像から グレイスケールへの変換 Y = 0.299 R + 0.587
( CUDA CUDA CUDA CUDA ( NVIDIA CUDA I
 GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
GPU GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1
 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1") GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
GPGPU
 GPGPU 2013 1008 2015 1 23 Abstract In recent years, with the advance of microscope technology, the alive cells have been able to observe. On the other hand, from the standpoint of image processing, the
GPGPU 2013 1008 2015 1 23 Abstract In recent years, with the advance of microscope technology, the alive cells have been able to observe. On the other hand, from the standpoint of image processing, the
NUMAの構成
 GPU のプログラム 天野 アクセラレータとは? 特定の性質のプログラムを高速化するプロセッサ 典型的なアクセラレータ GPU(Graphic Processing Unit) Xeon Phi FPGA(Field Programmable Gate Array) 最近出て来た Deep Learning 用ニューロチップなど Domain Specific Architecture 1GPGPU:General
GPU のプログラム 天野 アクセラレータとは? 特定の性質のプログラムを高速化するプロセッサ 典型的なアクセラレータ GPU(Graphic Processing Unit) Xeon Phi FPGA(Field Programmable Gate Array) 最近出て来た Deep Learning 用ニューロチップなど Domain Specific Architecture 1GPGPU:General
GPU CUDA CUDA 2010/06/28 1
 GPU CUDA CUDA 2010/06/28 1 GPU NVIDIA Mark Harris, Optimizing Parallel Reduction in CUDA http://developer.download.nvidia.com/ compute/cuda/1_1/website/data- Parallel_Algorithms.html#reduction CUDA SDK
GPU CUDA CUDA 2010/06/28 1 GPU NVIDIA Mark Harris, Optimizing Parallel Reduction in CUDA http://developer.download.nvidia.com/ compute/cuda/1_1/website/data- Parallel_Algorithms.html#reduction CUDA SDK
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
Microsoft PowerPoint - GPU_computing_2013_01.pptx
 GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格
GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格
TSUBAME2.0におけるGPUの 活用方法
 GPU プログラミング 基礎編 東京工業大学学術国際情報センター 1. GPU コンピューティングと TSUBAME2.0 スーパーコンピュータ GPU コンピューティングとは グラフィックプロセッサ (GPU) は グラフィック ゲームの画像計算のために 進化を続けてきた 現在 CPU のコア数は 2~12 個に対し GPU 中には数百コア その GPU を一般アプリケーションの高速化に利用! GPGPU
GPU プログラミング 基礎編 東京工業大学学術国際情報センター 1. GPU コンピューティングと TSUBAME2.0 スーパーコンピュータ GPU コンピューティングとは グラフィックプロセッサ (GPU) は グラフィック ゲームの画像計算のために 進化を続けてきた 現在 CPU のコア数は 2~12 個に対し GPU 中には数百コア その GPU を一般アプリケーションの高速化に利用! GPGPU
CUDA基礎1
 CUDA 基礎 1 東京工業大学 学術国際情報センター 黄遠雄 2016/6/27 第 20 回 GPU コンピューティング講習会 1 ヘテロジニアス コンピューティング ヘテロジニアス コンピューティング (CPU + GPU) は広く使われている Financial Analysis Scientific Simulation Engineering Simulation Data Intensive
CUDA 基礎 1 東京工業大学 学術国際情報センター 黄遠雄 2016/6/27 第 20 回 GPU コンピューティング講習会 1 ヘテロジニアス コンピューティング ヘテロジニアス コンピューティング (CPU + GPU) は広く使われている Financial Analysis Scientific Simulation Engineering Simulation Data Intensive
GPU 画像 動画処理用ハードウェア 低性能なプロセッサがたくさん詰まっている ピーク性能が非常に高い GPUを数値計算に用いるのがGPGPU Graphics Processing Unit General Purpose GPU TSUBAME2.0: GPUスパコン 本演習ではNVIDIA社の
 演習II (連続系アルゴリズム) 第2回: GPGPU 須田研究室 M1 本谷 徹 motoya@is.s.u-tokyo.ac.jp 2012/10/19 GPU 画像 動画処理用ハードウェア 低性能なプロセッサがたくさん詰まっている ピーク性能が非常に高い GPUを数値計算に用いるのがGPGPU Graphics Processing Unit General Purpose GPU TSUBAME2.0:
演習II (連続系アルゴリズム) 第2回: GPGPU 須田研究室 M1 本谷 徹 motoya@is.s.u-tokyo.ac.jp 2012/10/19 GPU 画像 動画処理用ハードウェア 低性能なプロセッサがたくさん詰まっている ピーク性能が非常に高い GPUを数値計算に用いるのがGPGPU Graphics Processing Unit General Purpose GPU TSUBAME2.0:
概要 目的 CUDA Fortran の利用に関する基本的なノウハウを提供する 本チュートリアル受講後は Web 上で公開されている資料等を参照しながら独力で CUDA Fortran が利用できることが目標 対象 CUDA Fortran の利用に興味を抱いている方 前提とする知識 Fortran
 CUDA Fortran チュートリアル 2010 年 9 月 29 日 NEC 概要 目的 CUDA Fortran の利用に関する基本的なノウハウを提供する 本チュートリアル受講後は Web 上で公開されている資料等を参照しながら独力で CUDA Fortran が利用できることが目標 対象 CUDA Fortran の利用に興味を抱いている方 前提とする知識 Fortran を用いた Linux
CUDA Fortran チュートリアル 2010 年 9 月 29 日 NEC 概要 目的 CUDA Fortran の利用に関する基本的なノウハウを提供する 本チュートリアル受講後は Web 上で公開されている資料等を参照しながら独力で CUDA Fortran が利用できることが目標 対象 CUDA Fortran の利用に興味を抱いている方 前提とする知識 Fortran を用いた Linux
Microsoft PowerPoint - GPGPU実践基礎工学(web).pptx
.pptx") GPU のプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU プログラミング環境 (CUDA) GPU プログラムの実行の流れ CUDA によるプログラムの記述 カーネル (GPU で処理する関数 ) の構造 記述方法とその理由 GPU 固有のパラメータの確認 405 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ
GPU のプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU プログラミング環境 (CUDA) GPU プログラムの実行の流れ CUDA によるプログラムの記述 カーネル (GPU で処理する関数 ) の構造 記述方法とその理由 GPU 固有のパラメータの確認 405 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ
1 OpenCL OpenCL 1 OpenCL GPU ( ) 1 OpenCL Compute Units Elements OpenCL OpenCL SPMD (Single-Program, Multiple-Data) SPMD OpenCL work-item work-group N
 1 OpenCL Compute Units Elements OpenCL OpenCL SPMD (Single-Program, Multiple-Data) SPMD OpenCL work-item work-group N") GPU 1 1 2 1, 3 2, 3 (Graphics Unit: GPU) GPU GPU GPU Evaluation of GPU Computing Based on An Automatic Program Generation Technology Makoto Sugawara, 1 Katsuto Sato, 1 Kazuhiko Komatsu, 2 Hiroyuki Takizawa
GPU 1 1 2 1, 3 2, 3 (Graphics Unit: GPU) GPU GPU GPU Evaluation of GPU Computing Based on An Automatic Program Generation Technology Makoto Sugawara, 1 Katsuto Sato, 1 Kazuhiko Komatsu, 2 Hiroyuki Takizawa
23 Fig. 2: hwmodulev2 3. Reconfigurable HPC 3.1 hw/sw hw/sw hw/sw FPGA PC FPGA PC FPGA HPC FPGA FPGA hw/sw hw/sw hw- Module FPGA hwmodule hw/sw FPGA h
 23 FPGA CUDA Performance Comparison of FPGA Array with CUDA on Poisson Equation (lijiang@sekine-lab.ei.tuat.ac.jp), (kazuki@sekine-lab.ei.tuat.ac.jp), (takahashi@sekine-lab.ei.tuat.ac.jp), (tamukoh@cc.tuat.ac.jp),
23 FPGA CUDA Performance Comparison of FPGA Array with CUDA on Poisson Equation (lijiang@sekine-lab.ei.tuat.ac.jp), (kazuki@sekine-lab.ei.tuat.ac.jp), (takahashi@sekine-lab.ei.tuat.ac.jp), (tamukoh@cc.tuat.ac.jp),
DO 時間積分 START 反変速度の計算 contravariant_velocity 移流項の計算 advection_adams_bashforth_2nd DO implicit loop( 陰解法 ) 速度勾配, 温度勾配の計算 gradient_cell_center_surface 速
 速度勾配, 温度勾配の計算 gradient_cell_center_surface 速") 1 1, 2 1, 2 3 2, 3 4 GP LES ASUCA LES NVIDIA CUDA LES 1. Graphics Processing Unit GP General-Purpose SIMT Single Instruction Multiple Threads 1 2 3 4 1),2) LES Large Eddy Simulation 3) ASUCA 4) LES LES
1 1, 2 1, 2 3 2, 3 4 GP LES ASUCA LES NVIDIA CUDA LES 1. Graphics Processing Unit GP General-Purpose SIMT Single Instruction Multiple Threads 1 2 3 4 1),2) LES Large Eddy Simulation 3) ASUCA 4) LES LES
1. マシンビジョンにおける GPU の活用
 CUDA 画像処理入門 GTC 213 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. マシンビジョンにおける GPU の活用 1. 医用画像処理における GPU の活用 CT や MRI から画像を受信して三次元画像の構築をするシステム 2 次元スキャンデータから 3 次元 4 次元イメージの高速生成 CUDA 化により画像処理速度を約 2 倍に高速化 1. CUDA で画像処理
CUDA 画像処理入門 GTC 213 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. マシンビジョンにおける GPU の活用 1. 医用画像処理における GPU の活用 CT や MRI から画像を受信して三次元画像の構築をするシステム 2 次元スキャンデータから 3 次元 4 次元イメージの高速生成 CUDA 化により画像処理速度を約 2 倍に高速化 1. CUDA で画像処理
CUDA 連携とライブラリの活用 2
 1 09:30-10:00 受付 10:00-12:00 Reedbush-H ログイン GPU 入門 13:30-15:00 OpenACC 入門 15:15-16:45 OpenACC 最適化入門と演習 17:00-18:00 OpenACC の活用 (CUDA 連携とライブラリの活用 ) CUDA 連携とライブラリの活用 2 3 OpenACC 簡単にGPUプログラムが作成できる それなりの性能が得られる
1 09:30-10:00 受付 10:00-12:00 Reedbush-H ログイン GPU 入門 13:30-15:00 OpenACC 入門 15:15-16:45 OpenACC 最適化入門と演習 17:00-18:00 OpenACC の活用 (CUDA 連携とライブラリの活用 ) CUDA 連携とライブラリの活用 2 3 OpenACC 簡単にGPUプログラムが作成できる それなりの性能が得られる
1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU
![1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU](/thumbs/89/99132402.jpg "1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU") GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2
![! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2](/thumbs/88/115445009.jpg "! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2") ! OpenCL [Open Computing Language] 言 [OpenCL C 言 ] CPU, GPU, Cell/B.E.,DSP 言 行行 [OpenCL Runtime] OpenCL C 言 API Khronos OpenCL Working Group AMD Broadcom Blizzard Apple ARM Codeplay Electronic Arts Freescale
! OpenCL [Open Computing Language] 言 [OpenCL C 言 ] CPU, GPU, Cell/B.E.,DSP 言 行行 [OpenCL Runtime] OpenCL C 言 API Khronos OpenCL Working Group AMD Broadcom Blizzard Apple ARM Codeplay Electronic Arts Freescale
IPSJ SIG Technical Report Vol.2013-HPC-138 No /2/21 GPU CRS 1,a) 2,b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla
 2,b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla") GPU CRS 1,a),b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla K0 CUDA5.0 cusparse CRS SpMV 00 1.86 177 1. SpMV SpMV CRS Compressed Row Storage *1 SpMV GPU GPU NVIDIA Kepler
GPU CRS 1,a),b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla K0 CUDA5.0 cusparse CRS SpMV 00 1.86 177 1. SpMV SpMV CRS Compressed Row Storage *1 SpMV GPU GPU NVIDIA Kepler
熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date Type URL Presentation
 榎本, 昌一 Citation Issue date Type URL Presentation") 熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date 2011-03-17 Type URL Presentation http://hdl.handle.net/2298/23539 Right GPGPU による高速演算について 榎本昌一 東京大学大学院工学系研究科システム創成学専攻
熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date 2011-03-17 Type URL Presentation http://hdl.handle.net/2298/23539 Right GPGPU による高速演算について 榎本昌一 東京大学大学院工学系研究科システム創成学専攻
main.dvi
 PC 1 1 [1][2] [3][4] ( ) GPU(Graphics Processing Unit) GPU PC GPU PC ( 2 GPU ) GPU Harris Corner Detector[5] CPU ( ) ( ) CPU GPU 2 3 GPU 4 5 6 7 1 toyohiro@isc.kyutech.ac.jp 45 2 ( ) CPU ( ) ( ) () 2.1
PC 1 1 [1][2] [3][4] ( ) GPU(Graphics Processing Unit) GPU PC GPU PC ( 2 GPU ) GPU Harris Corner Detector[5] CPU ( ) ( ) CPU GPU 2 3 GPU 4 5 6 7 1 toyohiro@isc.kyutech.ac.jp 45 2 ( ) CPU ( ) ( ) () 2.1
CPU Levels in the memory hierarchy Level 1 Level 2... Increasing distance from the CPU in access time Level n Size of the memory at each level 1: 2.2
 FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
GPU のアーキテクチャとプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓
 GPU のアーキテクチャとプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のアーキテクチャ CUDA CUDA によるプログラミング 58 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ チップ単体では販売されていない PCI Ex カードで販売 ( チップ単体と区別せずに GPU と呼ぶことも多い
GPU のアーキテクチャとプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のアーキテクチャ CUDA CUDA によるプログラミング 58 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ チップ単体では販売されていない PCI Ex カードで販売 ( チップ単体と区別せずに GPU と呼ぶことも多い
HPC pdf
 GPU 1 1 2 2 1 1024 3 GPUGraphics Unit1024 3 GPU GPU GPU GPU 1024 3 Tesla S1070-400 1 GPU 2.6 Accelerating Out-of-core Cone Beam Reconstruction Using GPU Yusuke Okitsu, 1 Fumihiko Ino, 1 Taketo Kishi, 2
GPU 1 1 2 2 1 1024 3 GPUGraphics Unit1024 3 GPU GPU GPU GPU 1024 3 Tesla S1070-400 1 GPU 2.6 Accelerating Out-of-core Cone Beam Reconstruction Using GPU Yusuke Okitsu, 1 Fumihiko Ino, 1 Taketo Kishi, 2
いまからはじめる組み込みGPU実装
 いまからはじめる組み込み GPU 実装 ~ コンピュータービジョン ディープラーニング編 ~ MathWorks Japan アプリケーションエンジニアリング部シニアアプリケーションエンジニア大塚慶太郎 2017 The MathWorks, Inc. 1 コンピュータービジョン ディープラーニングによる 様々な可能性 自動運転 ロボティクス 予知保全 ( 製造設備 ) セキュリティ 2 転移学習を使った画像分類
いまからはじめる組み込み GPU 実装 ~ コンピュータービジョン ディープラーニング編 ~ MathWorks Japan アプリケーションエンジニアリング部シニアアプリケーションエンジニア大塚慶太郎 2017 The MathWorks, Inc. 1 コンピュータービジョン ディープラーニングによる 様々な可能性 自動運転 ロボティクス 予知保全 ( 製造設備 ) セキュリティ 2 転移学習を使った画像分類
(MIRU2010) NTT Graphic Processor Unit GPU graphi
 NTT Graphic Processor Unit GPU graphi") (MIRU2010) 2010 7 889 2192 1-1 905 2171 905 NTT 243 0124 3-1 E-mail: ac094608@edu.okinawa-ct.ac.jp, akisato@ieee.org Graphic Processor Unit GPU graphic processor unit CUDA Fully automatic extraction of
(MIRU2010) 2010 7 889 2192 1-1 905 2171 905 NTT 243 0124 3-1 E-mail: ac094608@edu.okinawa-ct.ac.jp, akisato@ieee.org Graphic Processor Unit GPU graphic processor unit CUDA Fully automatic extraction of
untitled
 CUDA Vol II: CUDA : NVIDIA Q2 2008 CUDA...1 CUDA...3 CUDA...16...40...63 CUDA CUDA ( ) CUDA 2 NVIDIA Corporation 2008 2 CUDA CUDA GPU GPU CPU NVIDIA Corporation 2008 4 V V d call put 1 2 = S CND( d ) X
CUDA Vol II: CUDA : NVIDIA Q2 2008 CUDA...1 CUDA...3 CUDA...16...40...63 CUDA CUDA ( ) CUDA 2 NVIDIA Corporation 2008 2 CUDA CUDA GPU GPU CPU NVIDIA Corporation 2008 4 V V d call put 1 2 = S CND( d ) X
untitled
 CUDA Vol I: CUDA : NVIDIA Q2 2008 GPU...1 CUDA...10 CUDA...25...56 G8x...62...67...105...115 CUDA...128 CUBLAS...130 CUFFT...142 CUDA...157 CUDA...159 CUDA Fortran...168 CUDA API...173...174 CUDA...176
CUDA Vol I: CUDA : NVIDIA Q2 2008 GPU...1 CUDA...10 CUDA...25...56 G8x...62...67...105...115 CUDA...128 CUBLAS...130 CUFFT...142 CUDA...157 CUDA...159 CUDA Fortran...168 CUDA API...173...174 CUDA...176
Microsoft PowerPoint - suda.pptx
 GPU の HWアーキテクチャと高性能化手法 須田礼仁 ( 東京大学 ) 2011/03/22 GPU 高性能プログラミング GPU のハードウェアを理解する CUDA のソフトウェアを理解する CUDA でプログラムを書くのは難しくないが, CUDA で高速なプログラムを書くのは難しい どうすれば遅くなるかを理解する! 効果が大きいものから順に説明します 1 高性能プログラミングの手順 1. 現在のコードの,
GPU の HWアーキテクチャと高性能化手法 須田礼仁 ( 東京大学 ) 2011/03/22 GPU 高性能プログラミング GPU のハードウェアを理解する CUDA のソフトウェアを理解する CUDA でプログラムを書くのは難しくないが, CUDA で高速なプログラムを書くのは難しい どうすれば遅くなるかを理解する! 効果が大きいものから順に説明します 1 高性能プログラミングの手順 1. 現在のコードの,
IPSJ SIG Technical Report Vol.2013-ARC-203 No /2/1 SMYLE OpenCL (NEDO) IT FPGA SMYLEref SMYLE OpenCL SMYLE OpenCL FPGA 1
 IT FPGA SMYLEref SMYLE OpenCL SMYLE OpenCL FPGA 1") SMYLE OpenCL 128 1 1 1 1 1 2 2 3 3 3 (NEDO) IT FPGA SMYLEref SMYLE OpenCL SMYLE OpenCL FPGA 128 SMYLEref SMYLE OpenCL SMYLE OpenCL Implementation and Evaluations on 128 Cores Takuji Hieda 1 Noriko Etani
SMYLE OpenCL 128 1 1 1 1 1 2 2 3 3 3 (NEDO) IT FPGA SMYLEref SMYLE OpenCL SMYLE OpenCL FPGA 128 SMYLEref SMYLE OpenCL SMYLE OpenCL Implementation and Evaluations on 128 Cores Takuji Hieda 1 Noriko Etani
untitled
 A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
16.16%
 2017 (411824) 16.16% Abstract Multi-core processor is common technique for high computing performance. In many multi-core processor architectures, all processors share L2 and last level cache memory. Thus,
2017 (411824) 16.16% Abstract Multi-core processor is common technique for high computing performance. In many multi-core processor architectures, all processors share L2 and last level cache memory. Thus,
supercomputer2010.ppt
 nanri@cc.kyushu-u.ac.jp 1 !! : 11 12! : nanri@cc.kyushu-u.ac.jp! : Word 2 ! PC GPU) 1997 7 http://wiredvision.jp/news/200806/2008062322.html 3 !! (Cell, GPU )! 4 ! etc...! 5 !! etc. 6 !! 20km 40 km ) 340km
nanri@cc.kyushu-u.ac.jp 1 !! : 11 12! : nanri@cc.kyushu-u.ac.jp! : Word 2 ! PC GPU) 1997 7 http://wiredvision.jp/news/200806/2008062322.html 3 !! (Cell, GPU )! 4 ! etc...! 5 !! etc. 6 !! 20km 40 km ) 340km
 iphone GPGPU GPU OpenCL Mac OS X Snow LeopardOpenCL iphone OpenCL OpenCL NVIDIA GPU CUDA GPU GPU GPU 15 GPU GPU CPU GPU iii OpenMP MPI CPU OpenCL CUDA OpenCL CPU OpenCL GPU NVIDIA Fermi GPU Fermi GPU GPU
iphone GPGPU GPU OpenCL Mac OS X Snow LeopardOpenCL iphone OpenCL OpenCL NVIDIA GPU CUDA GPU GPU GPU 15 GPU GPU CPU GPU iii OpenMP MPI CPU OpenCL CUDA OpenCL CPU OpenCL GPU NVIDIA Fermi GPU Fermi GPU GPU
ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014
 ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014 コンカレントな処理の実行 システム内部の複数の処理を 平行に実行する CPU GPU メモリ転送 カーネル実行 複数のカーネル間 ストリーム GPU 上の処理キュー カーネル実行 メモリ転送の並列性 実行順序 DEFAULT STREAM Stream : GPU
ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014 コンカレントな処理の実行 システム内部の複数の処理を 平行に実行する CPU GPU メモリ転送 カーネル実行 複数のカーネル間 ストリーム GPU 上の処理キュー カーネル実行 メモリ転送の並列性 実行順序 DEFAULT STREAM Stream : GPU
GPU n Graphics Processing Unit CG CAD
 GPU 2016/06/27 第 20 回 GPU コンピューティング講習会 ( 東京工業大学 ) 1 GPU n Graphics Processing Unit CG CAD www.nvidia.co.jp www.autodesk.co.jp www.pixar.com GPU n GPU ü n NVIDIA CUDA ü NVIDIA GPU ü OS Linux, Windows, Mac
GPU 2016/06/27 第 20 回 GPU コンピューティング講習会 ( 東京工業大学 ) 1 GPU n Graphics Processing Unit CG CAD www.nvidia.co.jp www.autodesk.co.jp www.pixar.com GPU n GPU ü n NVIDIA CUDA ü NVIDIA GPU ü OS Linux, Windows, Mac
Vol.214-HPC-145 No /7/3 C #pragma acc directive-name [clause [[,] clause] ] new-line structured block Fortran!$acc directive-name [clause [[,] c
![Vol.214-HPC-145 No /7/3 C #pragma acc directive-name [clause [[,] clause] ] new-line structured block Fortran!$acc directive-name [clause [[,] c](/thumbs/83/88091581.jpg "Vol.214-HPC-145 No /7/3 C #pragma acc directive-name [clause [[,] clause] ] new-line structured block Fortran!$acc directive-name [clause [[,] c") Vol.214-HPC-145 No.45 214/7/3 OpenACC 1 3,1,2 1,2 GPU CUDA OpenCL OpenACC OpenACC High-level OpenACC CPU Intex Xeon Phi K2X GPU Intel Xeon Phi 27% K2X GPU 24% 1. TSUBAME2.5 CPU GPU CUDA OpenCL CPU OpenMP
Vol.214-HPC-145 No.45 214/7/3 OpenACC 1 3,1,2 1,2 GPU CUDA OpenCL OpenACC OpenACC High-level OpenACC CPU Intex Xeon Phi K2X GPU Intel Xeon Phi 27% K2X GPU 24% 1. TSUBAME2.5 CPU GPU CUDA OpenCL CPU OpenMP
untitled
 A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
10D16.dvi
 D IEEJ Transactions on Industry Applications Vol.136 No.10 pp.686 691 DOI: 10.1541/ieejias.136.686 NW Accelerating Techniques for Sequence Alignment based on an Extended NW Algorithm Jin Okaze, Non-member,
D IEEJ Transactions on Industry Applications Vol.136 No.10 pp.686 691 DOI: 10.1541/ieejias.136.686 NW Accelerating Techniques for Sequence Alignment based on an Extended NW Algorithm Jin Okaze, Non-member,
2011 年 3 月 3 日 GPGPU ハンズオンプログラミング演習 株式会社クロスアビリティ ability.jp 3 Mar 2011 Copyright (C) 2011 X-Ability Co.,Ltd. All rights reserved.
 2011 X-Ability Co.,Ltd. All rights reserved.") 2011 年 3 月 3 日 GPGPU ハンズオンプログラミング演習 株式会社クロスアビリティ rkoga@x ability.jp 講師 : 古賀良太 / 古川祐貴 取締役計算化学ソルバー XA CHEM SUITE の開発 コンサルティングパートナー 並列ソフトウェアの開発 ビルド サーバ販売 ソフトウェア代理店 会社紹介 社名株式会社クロスアビリティ (X Ability Co.,Ltd)
2011 年 3 月 3 日 GPGPU ハンズオンプログラミング演習 株式会社クロスアビリティ rkoga@x ability.jp 講師 : 古賀良太 / 古川祐貴 取締役計算化学ソルバー XA CHEM SUITE の開発 コンサルティングパートナー 並列ソフトウェアの開発 ビルド サーバ販売 ソフトウェア代理店 会社紹介 社名株式会社クロスアビリティ (X Ability Co.,Ltd)
Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ 3.7x faster P100 V100 P10
 NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
Microsoft PowerPoint - GPGPU実践基礎工学(web).pptx
.pptx") GPU のメモリ階層 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のメモリ階層 グローバルメモリ 共有メモリ モザイク処理への適用 コンスタントメモリ 空間フィルタへの適用 577 GPU の主要部品 基盤 GPU( チップ )+ 冷却部品 画面出力端子 電源入力端子 メモリ 特性の把握が重要 電源入力端子 画面出力端子 メモリ チップ PCI Ex 端子 http://www.geforce.com/whats
GPU のメモリ階層 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のメモリ階層 グローバルメモリ 共有メモリ モザイク処理への適用 コンスタントメモリ 空間フィルタへの適用 577 GPU の主要部品 基盤 GPU( チップ )+ 冷却部品 画面出力端子 電源入力端子 メモリ 特性の把握が重要 電源入力端子 画面出力端子 メモリ チップ PCI Ex 端子 http://www.geforce.com/whats
211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS /1/18 a a 1 a 2 a 3 a a GPU Graphics Processing Unit GPU CPU GPU GPGPU G
 211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS211 211/1/18 GPU 4 8 BLAS 4 8 BLAS Basic Linear Algebra Subprograms GPU Graphics Processing Unit 4 8 double 2 4 double-double DD 4 4 8 quad-double
211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS211 211/1/18 GPU 4 8 BLAS 4 8 BLAS Basic Linear Algebra Subprograms GPU Graphics Processing Unit 4 8 double 2 4 double-double DD 4 4 8 quad-double
GPGPUクラスタの性能評価
 2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
PowerPoint Presentation
 ヘテロジニアスな環境におけるソフトウェア開発 Agenda 今日の概要 ヘテロジニアスな環境の登場 ホモジニアスからヘテロジニアスへ ヘテロジニアスなアーキテクチャ GPU CUDA OpenACC, XeonPhi 自分のプログラムを理解するために デバッガ 共通の操作体験 TotalView 続きはブースで より速く ホモジーニアスな並列 HPC 銀河生成 金融のリスク計算 車の衝突解析 製薬
ヘテロジニアスな環境におけるソフトウェア開発 Agenda 今日の概要 ヘテロジニアスな環境の登場 ホモジニアスからヘテロジニアスへ ヘテロジニアスなアーキテクチャ GPU CUDA OpenACC, XeonPhi 自分のプログラムを理解するために デバッガ 共通の操作体験 TotalView 続きはブースで より速く ホモジーニアスな並列 HPC 銀河生成 金融のリスク計算 車の衝突解析 製薬
EGunGPU
 Super Computing in Accelerator simulations - Electron Gun simulation using GPGPU - K. Ohmi, KEK-Accel Accelerator Physics seminar 2009.11.19 Super computers in KEK HITACHI SR11000 POWER5 16 24GB 16 134GFlops,
Super Computing in Accelerator simulations - Electron Gun simulation using GPGPU - K. Ohmi, KEK-Accel Accelerator Physics seminar 2009.11.19 Super computers in KEK HITACHI SR11000 POWER5 16 24GB 16 134GFlops,
GPGPUイントロダクション
 大島聡史 ( 並列計算分科会主査 東京大学情報基盤センター助教 ) GPGPU イントロダクション 1 目的 昨今注目を集めている GPGPU(GPU コンピューティング ) について紹介する GPGPU とは何か? 成り立ち 特徴 用途 ( ソフトウェアや研究例の紹介 ) 使い方 ( ライブラリ 言語 ) CUDA GPGPU における課題 2 GPGPU とは何か? GPGPU General-Purpose
大島聡史 ( 並列計算分科会主査 東京大学情報基盤センター助教 ) GPGPU イントロダクション 1 目的 昨今注目を集めている GPGPU(GPU コンピューティング ) について紹介する GPGPU とは何か? 成り立ち 特徴 用途 ( ソフトウェアや研究例の紹介 ) 使い方 ( ライブラリ 言語 ) CUDA GPGPU における課題 2 GPGPU とは何か? GPGPU General-Purpose
Nios® II HAL API を使用したソフトウェア・サンプル集 「Modular Scatter-Gather DMA Core」
 ALTIMA Company, MACNICA, Inc Nios II HAL API Modular Scatter-Gather DMA Core Ver.17.1 2018 8 Rev.1 Nios II HAL API Modular Scatter-Gather DMA Core...3...3...4... 4... 5 3-2-1. msgdma... 6 3-2-2. On-Chip
ALTIMA Company, MACNICA, Inc Nios II HAL API Modular Scatter-Gather DMA Core Ver.17.1 2018 8 Rev.1 Nios II HAL API Modular Scatter-Gather DMA Core...3...3...4... 4... 5 3-2-1. msgdma... 6 3-2-2. On-Chip
MPI または CUDA を用いた将棋評価関数学習プログラムの並列化 2009/06/30
 MPI または CUDA を用いた将棋評価関数学習プログラムの並列化 2009/06/30 目次 1. まえがき 3 2. 計算方法 4 3. MPI を用いた並列化 6 4. CUDA を用いた並列化 11 5. 計算結果 20 6. まとめ 24 2 1. まえがき 目的将棋の評価関数を棋譜から学習するボナンザメソッドの簡易版を作成し それを MPI または CUDA を用いて並列化し 計算時間を短縮することを目的とする
MPI または CUDA を用いた将棋評価関数学習プログラムの並列化 2009/06/30 目次 1. まえがき 3 2. 計算方法 4 3. MPI を用いた並列化 6 4. CUDA を用いた並列化 11 5. 計算結果 20 6. まとめ 24 2 1. まえがき 目的将棋の評価関数を棋譜から学習するボナンザメソッドの簡易版を作成し それを MPI または CUDA を用いて並列化し 計算時間を短縮することを目的とする
スライド 1
 GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
3次多項式パラメタ推定計算の CUDAを用いた実装 (CUDAプログラミングの練習として) Implementation of the Estimation of the parameters of 3rd-order-Polynomial with CUDA
 Implementation of the Estimation of the parameters of 3rd-order-Polynomial with CUDA") 3 次多項式パラメタ推定計算の CUDA を用いた実装 (CUDA プログラミングの練習として ) Estimating the Parameters of 3rd-order-Polynomial with CUDA ISS 09/11/12 問題の選択 目的 CUDA プログラミングを経験 ( 試行錯誤と習得 ) 実際に CPU のみの場合と比べて高速化されることを体験 問題 ( インプリメントする内容
3 次多項式パラメタ推定計算の CUDA を用いた実装 (CUDA プログラミングの練習として ) Estimating the Parameters of 3rd-order-Polynomial with CUDA ISS 09/11/12 問題の選択 目的 CUDA プログラミングを経験 ( 試行錯誤と習得 ) 実際に CPU のみの場合と比べて高速化されることを体験 問題 ( インプリメントする内容
/ SCHEDULE /06/07(Tue) / Basic of Programming /06/09(Thu) / Fundamental structures /06/14(Tue) / Memory Management /06/1
 / Basic of Programming /06/09(Thu) / Fundamental structures /06/14(Tue) / Memory Management /06/1") I117 II I117 PROGRAMMING PRACTICE II 2 MEMORY MANAGEMENT 2 Research Center for Advanced Computing Infrastructure (RCACI) / Yasuhiro Ohara yasu@jaist.ac.jp / SCHEDULE 1. 2011/06/07(Tue) / Basic of Programming
I117 II I117 PROGRAMMING PRACTICE II 2 MEMORY MANAGEMENT 2 Research Center for Advanced Computing Infrastructure (RCACI) / Yasuhiro Ohara yasu@jaist.ac.jp / SCHEDULE 1. 2011/06/07(Tue) / Basic of Programming
WebGL OpenGL GLSL Kageyama (Kobe Univ.) Visualization / 57
 Visualization / 57") WebGL 2014.04.15 X021 2014 3 1F Kageyama (Kobe Univ.) Visualization 2014.04.15 1 / 57 WebGL OpenGL GLSL Kageyama (Kobe Univ.) Visualization 2014.04.15 2 / 57 WebGL Kageyama (Kobe Univ.) Visualization 2014.04.15
WebGL 2014.04.15 X021 2014 3 1F Kageyama (Kobe Univ.) Visualization 2014.04.15 1 / 57 WebGL OpenGL GLSL Kageyama (Kobe Univ.) Visualization 2014.04.15 2 / 57 WebGL Kageyama (Kobe Univ.) Visualization 2014.04.15
GPUコンピューティング講習会パート1
 GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
rank ”«‘‚“™z‡Ì GPU ‡É‡æ‡éŁÀŠñ›»
 rank GPU ERATO 2011 11 1 1 / 26 GPU rank/select wavelet tree balanced parenthesis GPU rank 2 / 26 GPU rank/select wavelet tree balanced parenthesis GPU rank 2 / 26 GPU rank/select wavelet tree balanced
rank GPU ERATO 2011 11 1 1 / 26 GPU rank/select wavelet tree balanced parenthesis GPU rank 2 / 26 GPU rank/select wavelet tree balanced parenthesis GPU rank 2 / 26 GPU rank/select wavelet tree balanced
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日
 TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
TSUBAMEのTeslaを用いたGPGPU(CUDAの基礎)
") GPU コンピューティング (CUDA) 講習会 CUDA によるプログラミング基礎 丸山直也 2009/11/25 1 はじめに 本講習では時間の関係上ごくごく基礎的な内容のみをとりあげます ただし 資料の後半にはメモリアクセスなどに関するチューニングに向けた情報をのせてあります それらは講習時間内には取り上げません チューニングやよりアドバンストな内容の講習会は今後 ( 基礎編の需要が一段落してから
GPU コンピューティング (CUDA) 講習会 CUDA によるプログラミング基礎 丸山直也 2009/11/25 1 はじめに 本講習では時間の関係上ごくごく基礎的な内容のみをとりあげます ただし 資料の後半にはメモリアクセスなどに関するチューニングに向けた情報をのせてあります それらは講習時間内には取り上げません チューニングやよりアドバンストな内容の講習会は今後 ( 基礎編の需要が一段落してから
Microsoft Word - 0_0_表紙.doc
 2km Local Forecast Model; LFM Local Analysis; LA 2010 11 2.1.1 2010a LFM 2.1.1 2011 3 11 2.1.1 2011 5 2010 6 1 8 3 1 LFM LFM MSM LFM FT=2 2009; 2010 MSM RMSE RMSE MSM RMSE 2010 1 8 3 2010 6 2010 6 8 2010
2km Local Forecast Model; LFM Local Analysis; LA 2010 11 2.1.1 2010a LFM 2.1.1 2011 3 11 2.1.1 2011 5 2010 6 1 8 3 1 LFM LFM MSM LFM FT=2 2009; 2010 MSM RMSE RMSE MSM RMSE 2010 1 8 3 2010 6 2010 6 8 2010
,4) 1 P% P%P=2.5 5%!%! (1) = (2) l l Figure 1 A compilation flow of the proposing sampling based architecture simulation
 1 P% P%P=2.5 5%!%! (1) = (2) l l Figure 1 A compilation flow of the proposing sampling based architecture simulation") 1 1 1 1 SPEC CPU 2000 EQUAKE 1.6 50 500 A Parallelizing Compiler Cooperative Multicore Architecture Simulator with Changeover Mechanism of Simulation Modes GAKUHO TAGUCHI 1 YOUICHI ABE 1 KEIJI KIMURA 1
1 1 1 1 SPEC CPU 2000 EQUAKE 1.6 50 500 A Parallelizing Compiler Cooperative Multicore Architecture Simulator with Changeover Mechanism of Simulation Modes GAKUHO TAGUCHI 1 YOUICHI ABE 1 KEIJI KIMURA 1
untitled
 PC murakami@cc.kyushu-u.ac.jp muscle server blade server PC PC + EHPC/Eric (Embedded HPC with Eric) 1216 Compact PCI Compact PCIPC Compact PCISH-4 Compact PCISH-4 Eric Eric EHPC/Eric EHPC/Eric Gigabit
PC murakami@cc.kyushu-u.ac.jp muscle server blade server PC PC + EHPC/Eric (Embedded HPC with Eric) 1216 Compact PCI Compact PCIPC Compact PCISH-4 Compact PCISH-4 Eric Eric EHPC/Eric EHPC/Eric Gigabit
,,,,., C Java,,.,,.,., ,,.,, i
 24 Development of the programming s learning tool for children be derived from maze 1130353 2013 3 1 ,,,,., C Java,,.,,.,., 1 6 1 2.,,.,, i Abstract Development of the programming s learning tool for children
24 Development of the programming s learning tool for children be derived from maze 1130353 2013 3 1 ,,,,., C Java,,.,,.,., 1 6 1 2.,,.,, i Abstract Development of the programming s learning tool for children
GPGPUによる高速画像処理
 GPGPU による高速画像処理 ~ リアルタイム画像処理への挑戦 ~ 名古屋大学大学院情報科学研究科 出口大輔 リアルタイム画像処理 2 3 発表の流れ GPGPU を始める前に GPGPU の基礎知識 CUDA の使い方 CUDA を使う前に プログラミングの予備知識 CUDA を使って Hello World GPGPU にチャレンジ 行列積の計算 テンプレートマッチング ガウシアンフィルタ SIFT
GPGPU による高速画像処理 ~ リアルタイム画像処理への挑戦 ~ 名古屋大学大学院情報科学研究科 出口大輔 リアルタイム画像処理 2 3 発表の流れ GPGPU を始める前に GPGPU の基礎知識 CUDA の使い方 CUDA を使う前に プログラミングの予備知識 CUDA を使って Hello World GPGPU にチャレンジ 行列積の計算 テンプレートマッチング ガウシアンフィルタ SIFT
マルチコアPCクラスタ環境におけるBDD法のハイブリッド並列実装
 2010 GPGPU 2010 9 29 MPI/Pthread (DDM) DDM CPU CPU CPU CPU FEM GPU FEM CPU Mult - NUMA Multprocessng Cell GPU Accelerator, GPU CPU Heterogeneous computng L3 cache L3 cache CPU CPU + GPU GPU L3 cache 4
2010 GPGPU 2010 9 29 MPI/Pthread (DDM) DDM CPU CPU CPU CPU FEM GPU FEM CPU Mult - NUMA Multprocessng Cell GPU Accelerator, GPU CPU Heterogeneous computng L3 cache L3 cache CPU CPU + GPU GPU L3 cache 4
25 2 ) 15 (W 力電 idle FMA(1) FMA(N) 実行コード Memcopy matmul 1 N occupancy gridsize N=256 Memcopy blocksize 288x288 (matmu
 15 (W 力電 idle FMA(1) FMA(N) 実行コード Memcopy matmul 1 N occupancy gridsize N=256 Memcopy blocksize 288x288 (matmu") GPU 1, 2 1, 2 1, 2 1, 2 1, 2, 3 GPU NVIDIA GeForce GTX285 Tesla S17 1 GPU GPU GPU 2W CPU GPU GPU GPU GPGPU 92.8% GPU GPU Correlative Analysis of Performance Counters and Power Consumption on GPUs Hitoshi
GPU 1, 2 1, 2 1, 2 1, 2 1, 2, 3 GPU NVIDIA GeForce GTX285 Tesla S17 1 GPU GPU GPU 2W CPU GPU GPU GPU GPGPU 92.8% GPU GPU Correlative Analysis of Performance Counters and Power Consumption on GPUs Hitoshi
単位、情報量、デジタルデータ、CPUと高速化 ~ICT用語集~
 CPU ICT mizutani@ic.daito.ac.jp 2014 SI: Systèm International d Unités SI SI 10 1 da 10 1 d 10 2 h 10 2 c 10 3 k 10 3 m 10 6 M 10 6 µ 10 9 G 10 9 n 10 12 T 10 12 p 10 15 P 10 15 f 10 18 E 10 18 a 10 21
CPU ICT mizutani@ic.daito.ac.jp 2014 SI: Systèm International d Unités SI SI 10 1 da 10 1 d 10 2 h 10 2 c 10 3 k 10 3 m 10 6 M 10 6 µ 10 9 G 10 9 n 10 12 T 10 12 p 10 15 P 10 15 f 10 18 E 10 18 a 10 21
GPUコンピューティング講習会パート1
 GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 理化学研究所 共通コードプロジェクト
 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 理化学研究所 共通コードプロジェクト") GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 勉強会 @ 理化学研究所 共通コードプロジェクト Contents Hands On 環境について Introduction to GPU computing Introduction
GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 勉強会 @ 理化学研究所 共通コードプロジェクト Contents Hands On 環境について Introduction to GPU computing Introduction
KBLAS[7] *1., CUBLAS.,,, Byte/flop., [13] 1 2. (AT). GPU AT,, GPU SYMV., SYMV CUDABLAS., (double, float) (cu- FloatComplex, cudoublecomplex).,, DD(dou
![KBLAS[7] *1., CUBLAS.,,, Byte/flop., [13] 1 2. (AT). GPU AT,, GPU SYMV., SYMV CUDABLAS., (double, float) (cu- FloatComplex, cudoublecomplex).,, DD(dou](/thumbs/71/64446865.jpg "KBLAS[7] *1., CUBLAS.,,, Byte/flop., [13] 1 2. (AT). GPU AT,, GPU SYMV., SYMV CUDABLAS., (double, float) (cu- FloatComplex, cudoublecomplex).,, DD(dou") Vol.214-HPC-146 No.14 214/1/3 CUDA-xSYMV 1,3,a) 1 2,3 2,3 (SYMV)., (GEMV) 2.,, mutex., CUBLAS., 1 2,. (AT). 2, SYMV GPU., SSYMV( SYMV), GeForce GTXTitan Black 211GFLOPS( 62.8%)., ( ) (, ) DD(double-double),
Vol.214-HPC-146 No.14 214/1/3 CUDA-xSYMV 1,3,a) 1 2,3 2,3 (SYMV)., (GEMV) 2.,, mutex., CUBLAS., 1 2,. (AT). 2, SYMV GPU., SSYMV( SYMV), GeForce GTXTitan Black 211GFLOPS( 62.8%)., ( ) (, ) DD(double-double),
TSUBAMEのTeslaを用いたGPGPU(CUDAの基礎)
") GPU コンピューティング (CUDA) 講習会 CUDA によるプログラミング基礎 丸山直也 2009/10/28 1 はじめに 本講習会では時間の関係上ごくごく基礎的なことのみをとりあげます ただし 資料の後半にはメモリアクセスなどに関するチューニングに向けた情報をのせてあります それらは講習時間内には取り上げません チューニングやよりアドバンストな内容の講習会は今後 ( 基礎編の需要が一段落してから
GPU コンピューティング (CUDA) 講習会 CUDA によるプログラミング基礎 丸山直也 2009/10/28 1 はじめに 本講習会では時間の関係上ごくごく基礎的なことのみをとりあげます ただし 資料の後半にはメモリアクセスなどに関するチューニングに向けた情報をのせてあります それらは講習時間内には取り上げません チューニングやよりアドバンストな内容の講習会は今後 ( 基礎編の需要が一段落してから
strtok-count.eps
 IoT FPGA 2016/12/1 IoT FPGA 200MHz 32 ASCII PCI Express FPGA OpenCL (Volvox) Volvox CPU 10 1 IoT (Internet of Things) 2020 208 [1] IoT IoT HTTP JSON ( Python Ruby) IoT IoT IoT (Hadoop [2] ) AI (Artificial
IoT FPGA 2016/12/1 IoT FPGA 200MHz 32 ASCII PCI Express FPGA OpenCL (Volvox) Volvox CPU 10 1 IoT (Internet of Things) 2020 208 [1] IoT IoT HTTP JSON ( Python Ruby) IoT IoT IoT (Hadoop [2] ) AI (Artificial
TSUBAMEのTeslaを用いたGPGPU(CUDAの基礎)
") GPU コンピューティング (CUDA) 講習会 CUDA プログラミング基礎 丸山直也 2010/09/13 1 はじめに 本講習では時間の関係上ごくごく基礎的な内容のみをとりあげます ただし 資料の後半にはメモリアクセスなどに関するチューニングに向けた情報をのせてあります それらは講習時間内には取り上げません チューニングやよりアドバンストな内容の講習会は別途開催しております 本講習で取り上げる概念等は基礎的なものに限られるため
GPU コンピューティング (CUDA) 講習会 CUDA プログラミング基礎 丸山直也 2010/09/13 1 はじめに 本講習では時間の関係上ごくごく基礎的な内容のみをとりあげます ただし 資料の後半にはメモリアクセスなどに関するチューニングに向けた情報をのせてあります それらは講習時間内には取り上げません チューニングやよりアドバンストな内容の講習会は別途開催しております 本講習で取り上げる概念等は基礎的なものに限られるため
2 09:00-09:30 受付 09:30-12:00 GPU 入門,CUDA 入門 13:00-14:30 OpenACC 入門 + HA-PACS ログイン 14:45-16:15 OpenACC 最適化入門と演習 16:30-18:00 CUDA 最適化入門と演習
 担当 大島聡史 ( 助教 ) ohshima@cc.u-tokyo.ac.jp 星野哲也 ( 助教 ) hoshino@cc.u-tokyo.ac.jp 質問やサンプルプログラムの提供についてはメールでお問い合わせください 1 2016 年 6 月 8 日 ( 水 ) 東京大学情報基盤センター 2 09:00-09:30 受付 09:30-12:00 GPU 入門,CUDA 入門 13:00-14:30
担当 大島聡史 ( 助教 ) ohshima@cc.u-tokyo.ac.jp 星野哲也 ( 助教 ) hoshino@cc.u-tokyo.ac.jp 質問やサンプルプログラムの提供についてはメールでお問い合わせください 1 2016 年 6 月 8 日 ( 水 ) 東京大学情報基盤センター 2 09:00-09:30 受付 09:30-12:00 GPU 入門,CUDA 入門 13:00-14:30
XACCの概要
 2 global void kernel(int a[max], int llimit, int ulimit) {... } : int main(int argc, char *argv[]){ MPI_Int(&argc, &argc); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); dx
2 global void kernel(int a[max], int llimit, int ulimit) {... } : int main(int argc, char *argv[]){ MPI_Int(&argc, &argc); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); dx
FabHetero FabHetero FabHetero FabCache FabCache SPEC2000INT IPC FabCache 0.076%
 2013 (409812) FabHetero FabHetero FabHetero FabCache FabCache SPEC2000INT 6 1000 IPC FabCache 0.076% Abstract Single-ISA heterogeneous multi-core processors are increasing importance in the processor architecture.
2013 (409812) FabHetero FabHetero FabHetero FabCache FabCache SPEC2000INT 6 1000 IPC FabCache 0.076% Abstract Single-ISA heterogeneous multi-core processors are increasing importance in the processor architecture.
4.1 % 7.5 %
 2018 (412837) 4.1 % 7.5 % Abstract Recently, various methods for improving computial performance have been proposed. One of these various methods is Multi-core. Multi-core can execute processes in parallel
2018 (412837) 4.1 % 7.5 % Abstract Recently, various methods for improving computial performance have been proposed. One of these various methods is Multi-core. Multi-core can execute processes in parallel
Shonan Institute of Technology MEMOIRS OF SHONAN INSTITUTE OF TECHNOLOGY Vol. 41, No. 1, 2007 Ships1 * ** ** ** Development of a Small-Mid Range Paral
 MEMOIRS OF SHONAN INSTITUTE OF TECHNOLOGY Vol. 41, No. 1, 2007 Ships1 * ** ** ** Development of a Small-Mid Range Parallel Computer Ships1 Makoto OYA*, Hiroto MATSUBARA**, Kazuyoshi SAKURAI** and Yu KATO**
MEMOIRS OF SHONAN INSTITUTE OF TECHNOLOGY Vol. 41, No. 1, 2007 Ships1 * ** ** ** Development of a Small-Mid Range Parallel Computer Ships1 Makoto OYA*, Hiroto MATSUBARA**, Kazuyoshi SAKURAI** and Yu KATO**
はじめに
 IT 1 NPO (IPEC) 55.7 29.5 Web TOEIC Nice to meet you. How are you doing? 1 type (2002 5 )66 15 1 IT Java (IZUMA, Tsuyuki) James Robinson James James James Oh, YOU are Tsuyuki! Finally, huh? What's going
IT 1 NPO (IPEC) 55.7 29.5 Web TOEIC Nice to meet you. How are you doing? 1 type (2002 5 )66 15 1 IT Java (IZUMA, Tsuyuki) James Robinson James James James Oh, YOU are Tsuyuki! Finally, huh? What's going
OpenGL GLSL References Kageyama (Kobe Univ.) Visualization / 58
 Visualization / 58") WebGL *1 2013.04.23 *1 X021 2013 LR301 Kageyama (Kobe Univ.) Visualization 2013.04.23 1 / 58 OpenGL GLSL References Kageyama (Kobe Univ.) Visualization 2013.04.23 2 / 58 Kageyama (Kobe Univ.) Visualization
WebGL *1 2013.04.23 *1 X021 2013 LR301 Kageyama (Kobe Univ.) Visualization 2013.04.23 1 / 58 OpenGL GLSL References Kageyama (Kobe Univ.) Visualization 2013.04.23 2 / 58 Kageyama (Kobe Univ.) Visualization
tutorial_lc.dvi
 00 Linux v.s. RT Linux v.s. ART-Linux Linux RT-Linux ART-Linux Linux kumagai@emura.mech.tohoku.ac.jp 1 1.1 Linux Yes, No.,. OS., Yes. Linux,.,, Linux., Linux.,, Linux. Linux.,,. Linux,.,, 0..,. RT-Linux
00 Linux v.s. RT Linux v.s. ART-Linux Linux RT-Linux ART-Linux Linux kumagai@emura.mech.tohoku.ac.jp 1 1.1 Linux Yes, No.,. OS., Yes. Linux,.,, Linux., Linux.,, Linux. Linux.,,. Linux,.,, 0..,. RT-Linux
Microsoft Word - paper.docx
 による高速画像処理 名古屋大学大学院情報科学研究科出口大輔, 井手一郎, 村瀬洋 概要 : 本発表では, 近年注目を集めている GP(General Purpose computing on s) の技術に着目し,GP を利用するための開発環境の使い方やプログラミングのノウハウを分かりやすく解説する. GP は を汎用計算に利用しようという試みであり, 現在では物理シミュレーション, 数値計算, 信号解析,
による高速画像処理 名古屋大学大学院情報科学研究科出口大輔, 井手一郎, 村瀬洋 概要 : 本発表では, 近年注目を集めている GP(General Purpose computing on s) の技術に着目し,GP を利用するための開発環境の使い方やプログラミングのノウハウを分かりやすく解説する. GP は を汎用計算に利用しようという試みであり, 現在では物理シミュレーション, 数値計算, 信号解析,
untitled
 AMD HPC GP-GPU Opteron HPC 2 1 AMD Opteron 85 FLOPS 10,480 TOP500 16 T2K 95 FLOPS 10,800 140 FLOPS 15,200 61 FLOPS 7,200 3 Barcelona 4 2 AMD Opteron CPU!! ( ) L1 5 2003 2004 2005 2006 2007 2008 2009 2010
AMD HPC GP-GPU Opteron HPC 2 1 AMD Opteron 85 FLOPS 10,480 TOP500 16 T2K 95 FLOPS 10,800 140 FLOPS 15,200 61 FLOPS 7,200 3 Barcelona 4 2 AMD Opteron CPU!! ( ) L1 5 2003 2004 2005 2006 2007 2008 2009 2010
HP Workstation 総合カタログ
 HP Workstation Z HP 6 Z HP HP Z840 Workstation P.9 HP Z640 Workstation & CPU P.10 HP Z440 Workstation P.11 17.3in WIDE HP ZBook 17 G2 Mobile Workstation P.15 15.6in WIDE HP ZBook 15 G2 Mobile Workstation
HP Workstation Z HP 6 Z HP HP Z840 Workstation P.9 HP Z640 Workstation & CPU P.10 HP Z440 Workstation P.11 17.3in WIDE HP ZBook 17 G2 Mobile Workstation P.15 15.6in WIDE HP ZBook 15 G2 Mobile Workstation
1 Table 1: Identification by color of voxel Voxel Mode of expression Nothing Other 1 Orange 2 Blue 3 Yellow 4 SSL Humanoid SSL-Vision 3 3 [, 21] 8 325
![1 Table 1: Identification by color of voxel Voxel Mode of expression Nothing Other 1 Orange 2 Blue 3 Yellow 4 SSL Humanoid SSL-Vision 3 3 [, 21] 8 325](/thumbs/91/105378470.jpg "1 Table 1: Identification by color of voxel Voxel Mode of expression Nothing Other 1 Orange 2 Blue 3 Yellow 4 SSL Humanoid SSL-Vision 3 3 [, 21] 8 325") 社団法人人工知能学会 Japanese Society for Artificial Intelligence 人工知能学会研究会資料 JSAI Technical Report SIG-Challenge-B3 (5/5) RoboCup SSL Humanoid A Proposal and its Application of Color Voxel Server for RoboCup SSL
社団法人人工知能学会 Japanese Society for Artificial Intelligence 人工知能学会研究会資料 JSAI Technical Report SIG-Challenge-B3 (5/5) RoboCup SSL Humanoid A Proposal and its Application of Color Voxel Server for RoboCup SSL
cpp1.dvi
 2017 c 1 C++ (1) C C++, C++, C 11, 12 13 (1) 14 (2) 11 1 n C++ //, [List 11] 1: #include // C 2: 3: int main(void) { 4: std::cout
2017 c 1 C++ (1) C C++, C++, C 11, 12 13 (1) 14 (2) 11 1 n C++ //, [List 11] 1: #include // C 2: 3: int main(void) { 4: std::cout
GPUを用いたN体計算
 単精度 190Tflops GPU クラスタ ( 長崎大 ) の紹介 長崎大学工学部超高速メニーコアコンピューティングセンターテニュアトラック助教濱田剛 1 概要 GPU (Graphics Processing Unit) について簡単に説明します. GPU クラスタが得意とする応用問題を議論し 長崎大学での GPU クラスタによる 取組方針 N 体計算の高速化に関する研究内容 を紹介します. まとめ
単精度 190Tflops GPU クラスタ ( 長崎大 ) の紹介 長崎大学工学部超高速メニーコアコンピューティングセンターテニュアトラック助教濱田剛 1 概要 GPU (Graphics Processing Unit) について簡単に説明します. GPU クラスタが得意とする応用問題を議論し 長崎大学での GPU クラスタによる 取組方針 N 体計算の高速化に関する研究内容 を紹介します. まとめ
IPSJ SIG Technical Report Vol.2012-ARC-202 No.13 Vol.2012-HPC-137 No /12/13 Tightly Coupled Accelerators 1,a) 1,b) 1,c) 1,d) GPU HA-PACS
 1,b) 1,c) 1,d) GPU HA-PACS") Tightly Coupled Accelerators 1,a) 1,b) 1,c) 1,d) HA-PACS 2012 2 HA-PACS TCA (Tightly Coupled Accelerators) TCA PEACH2 1. (Graphics Processing Unit) HPC GP(General Purpose ) TOP500 [1] CPU PCI Express (PCIe)
Tightly Coupled Accelerators 1,a) 1,b) 1,c) 1,d) HA-PACS 2012 2 HA-PACS TCA (Tightly Coupled Accelerators) TCA PEACH2 1. (Graphics Processing Unit) HPC GP(General Purpose ) TOP500 [1] CPU PCI Express (PCIe)
Fig. 3 Coordinate system and notation Fig. 1 The hydrodynamic force and wave measured system Fig. 2 Apparatus of model testing
 The Hydrodynamic Force Acting on the Ship in a Following Sea (1 St Report) Summary by Yutaka Terao, Member Broaching phenomena are most likely to occur in a following sea to relative small and fast craft
The Hydrodynamic Force Acting on the Ship in a Following Sea (1 St Report) Summary by Yutaka Terao, Member Broaching phenomena are most likely to occur in a following sea to relative small and fast craft
2
 8 23 32A950S 30 38 43 52 2 3 23 40 10 33 33 11 52 4 52 7 28 26 7 8 8 18 5 6 7 9 8 17 7 7 7 38 10 12 9 23 22 22 8 53 8 8 8 8 1 2 3 17 11 52 52 19 23 29 71 29 41 55 22 22 22 22 22 55 8 18 31 9 9 54 71 44
8 23 32A950S 30 38 43 52 2 3 23 40 10 33 33 11 52 4 52 7 28 26 7 8 8 18 5 6 7 9 8 17 7 7 7 38 10 12 9 23 22 22 8 53 8 8 8 8 1 2 3 17 11 52 52 19 23 29 71 29 41 55 22 22 22 22 22 55 8 18 31 9 9 54 71 44
Slide 1
 電子情報通信学会研究会組込みシステム研究会 (IPSJ-EMB) 2010 年 1 月 28 日 超並列マルチコア GPU を用いた高速演算処理の実用化 NVIDIA Solution Architect 馬路徹 目次 なぜ今 GPU コンピューティングか? CPUの性能向上速度が減速 性能向上 = 並列処理 にGPUコンピューティングが応える CUDAシステムアーキテクチャによる超並列処理の実現
電子情報通信学会研究会組込みシステム研究会 (IPSJ-EMB) 2010 年 1 月 28 日 超並列マルチコア GPU を用いた高速演算処理の実用化 NVIDIA Solution Architect 馬路徹 目次 なぜ今 GPU コンピューティングか? CPUの性能向上速度が減速 性能向上 = 並列処理 にGPUコンピューティングが応える CUDAシステムアーキテクチャによる超並列処理の実現
1 OpenCL Work-Item Private Memory Workgroup Local Memory Compute Device Global/Constant Memory Host Host Memory OpenCL CUDA CUDA Compute Unit MP Proce
 GPGPU (VI) GPGPU 1 GPGPU CUDA CUDA GPGPU GPGPU CUDA GPGPU ( ) CUDA GPGPU 2 OpenCL OpenCL GPGPU Apple Khronos Group OpenCL Working Group [1] CUDA GPU NVIDIA GPU *1 OpenCL NVIDIA AMD GPU CPU DSP(Digital
GPGPU (VI) GPGPU 1 GPGPU CUDA CUDA GPGPU GPGPU CUDA GPGPU ( ) CUDA GPGPU 2 OpenCL OpenCL GPGPU Apple Khronos Group OpenCL Working Group [1] CUDA GPU NVIDIA GPU *1 OpenCL NVIDIA AMD GPU CPU DSP(Digital
on PS3 Linux Core 2 Quad (GHz) SMs 7 SPEs 1 OS 4 1 Hz 1 (GFLOPS) SM PPE SPE bit
 SMs 7 SPEs 1 OS 4 1 Hz 1 (GFLOPS) SM PPE SPE bit") vs. 1 1 1 GPU TFLOPS GPU GPU GPGPU GPGPU 1 SIMD MFLOPS HPC GPU FFTZIP HPC Challenge RandomAccess Levenshtein 6 vs. Ryōhei NISHIMURA, 1 Hidetsugu IRIE 1 and Kei HIRAKI 1 Recently, on the one hand, performance
vs. 1 1 1 GPU TFLOPS GPU GPU GPGPU GPGPU 1 SIMD MFLOPS HPC GPU FFTZIP HPC Challenge RandomAccess Levenshtein 6 vs. Ryōhei NISHIMURA, 1 Hidetsugu IRIE 1 and Kei HIRAKI 1 Recently, on the one hand, performance
RX600 & RX200シリーズ アプリケーションノート RX用仮想EEPROM
 R01AN0724JU0170 Rev.1.70 MCU EEPROM RX MCU 1 RX MCU EEPROM VEE VEE API MCU MCU API RX621 RX62N RX62T RX62G RX630 RX631 RX63N RX63T RX210 R01AN0724JU0170 Rev.1.70 Page 1 of 33 1.... 3 1.1... 3 1.2... 3
R01AN0724JU0170 Rev.1.70 MCU EEPROM RX MCU 1 RX MCU EEPROM VEE VEE API MCU MCU API RX621 RX62N RX62T RX62G RX630 RX631 RX63N RX63T RX210 R01AN0724JU0170 Rev.1.70 Page 1 of 33 1.... 3 1.1... 3 1.2... 3