今回 次回の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ Danger!! (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか これは次回)
|
|
|
- ちかこ むこやま
- 5 years ago
- Views:
Transcription
1 生態学の時系列データ解析でよく見る あぶない モデリング 久保拓弥 statistical model for time-series data kubostat2017 (h) 1/59
2 今回 次回の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ Danger!! (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか これは次回)
3 (危 1) 時系列データを GLM で Do NOT apply GLM to time-series data!
4 Danger! time-series Y ~ time-series X (危 2) 時系列Yt 時系列 Xt 見せかけの回帰 spurious regression No! Time_series y ~ Time_series x
5 時系列データの統計モデリング 安易に 回帰 してはいけない ランダムウォークモデルが基本 統計モデルが生成する時系列 パターンを意識する 階層ベイズモデルで推定 Use state-space models kubostat2017 (h) 状態空間モデル 5/59
6 (危 1) 時系列データを GLM で
7 このような時系列データがあったとしましょう y y は何か連続値と しましょう (今日でてくる y は 連続値ばかり と いうことで) t kubostat2017 (h) 7/59
8 時系列データの統計モデリング入門 y glm(y ~ t) とモデル をあてはめてみた t kubostat2017 (h) 8/59
9 やったーゆーいだ!!?? > summary(glm(formula = y ~ t)) Deviance Residuals: Min 1Q Median Q Max Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) e-06 t e-06 これはまちがい glm(時系列y ~ 時間 t) kubostat2017 (h) 9/59

10 時系列の各点は独立ではない time autocorrelation among data points! ゆーいな傾き (偽 が ぞろぞろ でます 傾きの検定やめて AIC モデル選択 しても同様になる 検定とかモデル選択とかそういう問題ではない 統計モデルがおかしい? kubostat2017 (h) 10/59
11 時系列の ずれ auto-correlation GLM のずれ no correlation to adjacent points! ずれかたが ちがってる? kubostat2017 (h) 11/59
12 時系列の ずれ GLM のずれ 直線からのずれがちがう! 時間的自己相関がある 時間的自己相関がない kubostat2017 (h) 12/59
13 時系列の基本モデルのひとつ ランダムウォーク (乱歩)
14 変数 Y Random walk model Y1 Y1 Y ランダムウォーク もっとも単純な モデル 正規分布 Y2 Y2 Y3 kubostat2017 (h) t 時間 14/59
15 ランダムウォークなサンプル時系列 とりあえず 1000 本ほど生成してみました Generate 1000 time-series using random walk model 長さ kubostat2017 (h) 15/59
16 例外的な時系列というのはありえる たとえば t = 100 でかなり外れている 50 本 exceptional 50 time-series data? めったにない ランダムウォーク?? kubostat2017 (h) 16/59

17 しかし直線回帰 GLM あてはめると ほとんどすべての場合で ゆーい! significant? no! 統計モデルがおかしい 時間 t を説明変数とする GLM はダメそう kubostat2017 (h) 17/59
18 ちょっとでも傾いてたら ゆーい 各データ点が 独立ではない 実際には こんなデータ なのに 情報が少ない R の glm() は こんなデータ だとみなしている 情報が多い kubostat2017 (h) 18/59
19 temporal auto-correlation coefficient 時間的自己相関 (略称:自己相関 時間相関) を調べたらいいの?
20 R の ts クラス: 時系列をあつかう plot(ts(y)) これはたんなる 100 個の正規乱数 plot(acf(ts(y))) 自己相関ない kubostat2017 (h) 20/59
21 自己相関減衰の様子を図示 plot(ts(y)) plot(acf(ts(y))) 自己相関あり kubostat2017 (h) 21/59
22 変数 Y 時間相関がある とは? Y1 Y1 Y と は 似ている! 正規分布 Y2 Y2 Y3 kubostat2017 (h) t 時間 22/59
23 temporal auto-correlation coefficient 時間的自己相関 いつも役にたつわけではない?
24 各点独立のデータをナナメにすると? plot(ts(y)) これを ナナメに したもの なんだけど plot(acf(ts(y))) 自己相関あり え? kubostat2017 (h) 24/59
25 各点独立のデータをナナメにすると? plot(ts(y)) これを ナナメに したもの plot(acf(ts(y))) 自己相関あり kubostat2017 (h) 25/59
26 自己相関係数みても区別がつかない 傾向のある変化 を推定する手段がない (これは下とは区別つくけど) 統計モデル を選べないから kubostat2017 (h) 26/59
27 変数 Y Y1 Y1 Y ランダムウォーク もっとも単純な モデル 正規分布 Y2 Y2 Y3 kubostat2017 (h) t 時間 27/59
28 状態空間モデルでたちむかう 時系列データ解析 いろいろな時系列データを 統一的にあつかえないか?
29 変数 Y Y1 Y1 Y ランダムウォーク もっとも単純な モデル 正規分布 Y2 Y2 Y3 kubostat2017 (h) t 時間 29/59
30 状態空間モデル 観測の誤差 観測データY y1 二種類のσをもつ Y2 1 y2 Y3 y3 状態変数の変化 y4 t 時間 観測できない世界 (状態空間) kubostat2017 (h) 30/59
31 State-space model! 大 小 小 大 kubostat2017 (h) 31/59
32 状態空間モデルは state-space model is... 階層ベイズモデルだ! a hierarchical Bayesian model!
33 階層ベイズモデルとは? 多数の 似たようなパラメーター たちに 適切 な制約を加えて推定できる 全データ 個体 33 のデータ のデータ 個体 個体 33 のデータ のデータ 時刻 時刻 2 のデータ 時刻 1 のデータ {y1, y2, y3,..., y100} 局所的パラメータ 大域的パラメータ 一定の時間変化 時系列のばらつき (たくさんの時点 個体 調査地 ) kubostat2017 (h) 33/59
 library(kfas)")
34 どうやてモデルをあてはめる? R の状態空間モデルの package いろいろある library(dlm) library(kfas) しかしより一般化したモデルに ついての理解が必要かも kubostat2017 (h) 34/59

35 こういう問題も JAGS で BUGS 言語でこの単純な 階層ベイズモデルを記述できる kubostat2017 (h) 35/59
36 model { Tau.Noninformative < Y[1] ~ dnorm(y[1], tau[2]) y[1] ~ dnorm(0, Tau.Noninformative) for (t in 2:N.Y) { Y[t] ~ dnorm(y[t], tau[2]) y[t] ~ dnorm(m[t], tau[1]) m[t] < delta + y[t 1] } delta ~ dnorm(0, Tau.Noninformative) for (k in 1:2) { tau[k] < 1 / (s[k] * s[k]) s[k] ~ dunif(0, 10000) } } kubostat2017 (h) 36/59
37 状態空間モデルを使う利点 ばらばら解析 の回避 気象庁のデータ解析 An example: time change of yearly temperature
38 long-term change of yearly temperature 気象庁の長期変化傾向 トレンド の解説 /59


39 気象庁の長期変化傾向 トレンド の解説 /59
40 downloaded data 公開データをダウンロード /59
41 Do NOT apply GLM! とりあえず 直線回帰 の危険性 > summary(glm(gl ~ year, data = d)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) 1.41e e <2e 16 year 7.03e e <2e 年 あたり 時間相関その他ばらつきを 無視して 長期傾向 を推定 確率 1京ぶんの 2? 41/59
42 Do NOT apply GLM! 直線あてはめ (GLM) が予測した 温暖化 > summary(glm(gl ~ year, data = d)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) 1.41e e <2e 16 year 7.03e e <2e 年 あたり /59
43 状態空間モデル すべてを同時に推定 Hierarchical Bayesian state-space model ランダムウォーク+各年独立なノイズ kubostat2016i 43/59
44 状態空間モデル すべてを同時に推定 ランダムウォーク+各年独立なノイズ Y1 Y2 Y3 + trend Y3 Y Y2 trend δ kubostat2016i 時間 44/59
45 状態空間モデル すべてを同時に推定 Y[1] ~ dnorm(y[1], tau[2]) y[1] ~ dnorm(0.0, Tau.Noninformative) for (t in 2:N.Y) { Y[t] ~ dnorm(y[t], tau[2]) y[t] ~ dnorm(m[t], tau[1]) m[t] < delta + y[t 1] } delta ~ dnorm(0, Tau.Noninformative) for (k in 1:2) { tau[k] < 1.0 / (s[k] * s[k]) s[k] ~ dunif(0, 1.0E+4) } Y3 Y Y2 trend δ kubostat2016i 時間 45/59
46 GLM under-estimates standard-errors! 状態空間モデルが予測した 温暖化 > summary(glm(gl ~ year, data = d)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) 1.41e e <2e 16 year 7.03e e <2e 年 あたり 状態空間モデル 100 年あたり0.84 事後分布の95%区間 内にゼロあり GLM 46/59
47 観測値間に相関あり サンプルサイズが小さくなる 100年 あたり 状態空間モデル 100 年あたり0.84 事後分布の95%区間 内にゼロあり GLM 47/59
48 疑わしい回帰 spurious regression 時系列どうしの回帰 time series Y ~ time series X
49 時系列データの統計モデリング でやめたほうがいいこと GLM: Y(t) ~ t とか Y(t) ~ X(t) 段階的解析:観測値の四則演算 残差 の再解析 対応 の無視 再測は時系列 kubostat2016i 49/59
50 見せかけの回帰 spurious regression yt xt Time_series1 ~ Time_series kubostat2016i 50/59
51 ノイズの大きな時系列にうもれたワナ 時間的自己相関のない時系列 X Y ゆーい に なりやすい しかし glm(y ~ X) とすると /59
52 疑わしい回帰 spurious regression 状態空間モデル (SSM)で あつかえないか?

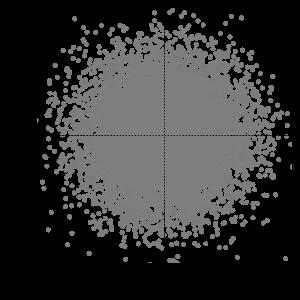
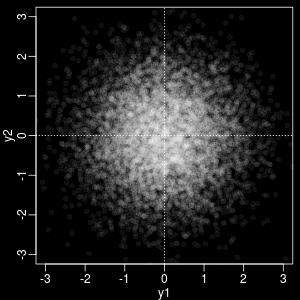
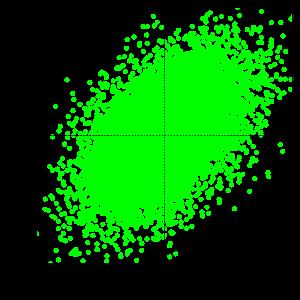
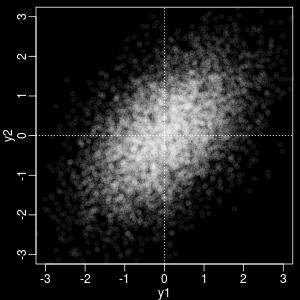
53 二変量正規分布とランダムウォーク ρ = 0.0 ρ = /59
 2016-08-09")
54 二変量正規分布を部品とする状態空間モデル (R で実演) /59

55 階層ベイズモデルである 状態空間モデル から得られた事後分布 ふたつの時系列データの変動が 相関しているかどうかを特定できる /59
56 おわりに
57 時間的な相関はデータの 情報量を減少させる 空間相関も 時系列の ずれ kubostat2017 (h) GLM のずれ 57/59
58 時系列データの統計モデリング 安易に 回帰 してはいけない ランダムウォークモデルが基本 統計モデルが生成する時系列 パターンを意識する 階層ベイズモデルで推定 状態空間モデル kubostat2017 (h) 58/59
59 おしまい The Evolution of Linear Models Hierarchical Bayesian Model (HBM) Parameter Estimation MCMC Generalized Linear Mixed Model (GLMM) MLE データ解析は 階層ベイズモデルで Generalized Linear Model (GLM) MSE Linear Model /59
今日の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか
 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか") 時系列データ解析でよく見る あぶない モデリング 久保拓弥 (北海道大 環境科学) 1/56 今日の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか (危 1) 時系列データを GLM で (危 2) 時系列Yt 時系列 Xt 相関は因果関係ではない 問題の一部
時系列データ解析でよく見る あぶない モデリング 久保拓弥 (北海道大 環境科学) 1/56 今日の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか (危 1) 時系列データを GLM で (危 2) 時系列Yt 時系列 Xt 相関は因果関係ではない 問題の一部
kubostat2018a p.1 統計モデリング入門 2018 (a) The main language of this class is 生物多様性学特論 Japanese Sorry An overview: Statistical Modeling 観測されたパターンを説明する統計モデル
 The main language of this class is 生物多様性学特論 Japanese Sorry An overview: Statistical Modeling 観測されたパターンを説明する統計モデル") p.1 統計モデリング入門 2018 (a) The main language of this class is 生物多様性学特論 Japanese Sorry An overview: Statistical Modeling 観測されたパターンを説明する統計モデル 久保拓弥 (北海道大 環境科学) Why in Japanese? because even in Japanese, statistics
p.1 統計モデリング入門 2018 (a) The main language of this class is 生物多様性学特論 Japanese Sorry An overview: Statistical Modeling 観測されたパターンを説明する統計モデル 久保拓弥 (北海道大 環境科学) Why in Japanese? because even in Japanese, statistics
統計モデリング入門 2018 (a) 生物多様性学特論 An overview: Statistical Modeling 観測されたパターンを説明する統計モデル 久保拓弥 (北海道大 環境科学) 統計モデリング入門 2018a 1
 生物多様性学特論 An overview: Statistical Modeling 観測されたパターンを説明する統計モデル 久保拓弥 (北海道大 環境科学) 統計モデリング入門 2018a 1") 統計モデリング入門 2018 (a) 生物多様性学特論 An overview: Statistical Modeling 観測されたパターンを説明する統計モデル 久保拓弥 (北海道大 環境科学) kubo@ees.hokudai.ac.jp 1/56 The main language of this class is Japanese Sorry Why in Japanese? because
統計モデリング入門 2018 (a) 生物多様性学特論 An overview: Statistical Modeling 観測されたパターンを説明する統計モデル 久保拓弥 (北海道大 環境科学) kubo@ees.hokudai.ac.jp 1/56 The main language of this class is Japanese Sorry Why in Japanese? because
kubostat2017c p (c) Poisson regression, a generalized linear model (GLM) : :
 Poisson regression, a generalized linear model (GLM) : :") kubostat2017c p.1 2017 (c), a generalized linear model (GLM) : kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2017 11 14 : 2017 11 07 15:43 kubostat2017c (http://goo.gl/76c4i) 2017 (c) 2017 11 14 1 / 47 agenda
kubostat2017c p.1 2017 (c), a generalized linear model (GLM) : kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2017 11 14 : 2017 11 07 15:43 kubostat2017c (http://goo.gl/76c4i) 2017 (c) 2017 11 14 1 / 47 agenda
kubostat7f p GLM! logistic regression as usual? N? GLM GLM doesn t work! GLM!! probabilit distribution binomial distribution : : β + β x i link functi
 kubostat7f p statistaical models appeared in the class 7 (f) kubo@eeshokudaiacjp https://googl/z9cjy 7 : 7 : The development of linear models Hierarchical Baesian Model Be more flexible Generalized Linear
kubostat7f p statistaical models appeared in the class 7 (f) kubo@eeshokudaiacjp https://googl/z9cjy 7 : 7 : The development of linear models Hierarchical Baesian Model Be more flexible Generalized Linear
kubostat2017j p.2 CSV CSV (!) d2.csv d2.csv,, 286,0,A 85,0,B 378,1,A 148,1,B ( :27 ) 10/ 51 kubostat2017j (http://goo.gl/76c4i
 d2.csv d2.csv,, 286,0,A 85,0,B 378,1,A 148,1,B ( :27 ) 10/ 51 kubostat2017j (http://goo.gl/76c4i") kubostat2017j p.1 2017 (j) Categorical Data Analsis kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2017 11 15 : 2017 11 08 17:11 kubostat2017j (http://goo.gl/76c4i) 2017 (j) 2017 11 15 1 / 63 A B C D E F G
kubostat2017j p.1 2017 (j) Categorical Data Analsis kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2017 11 15 : 2017 11 08 17:11 kubostat2017j (http://goo.gl/76c4i) 2017 (j) 2017 11 15 1 / 63 A B C D E F G
kubostat2015e p.2 how to specify Poisson regression model, a GLM GLM how to specify model, a GLM GLM logistic probability distribution Poisson distrib
 kubostat2015e p.1 I 2015 (e) GLM kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2015 07 22 2015 07 21 16:26 kubostat2015e (http://goo.gl/76c4i) 2015 (e) 2015 07 22 1 / 42 1 N k 2 binomial distribution logit
kubostat2015e p.1 I 2015 (e) GLM kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2015 07 22 2015 07 21 16:26 kubostat2015e (http://goo.gl/76c4i) 2015 (e) 2015 07 22 1 / 42 1 N k 2 binomial distribution logit
/ *1 *1 c Mike Gonzalez, October 14, Wikimedia Commons.
 2010 05 22 1/ 35 2010 2010 05 22 *1 kubo@ees.hokudai.ac.jp *1 c Mike Gonzalez, October 14, 2007. Wikimedia Commons. 2010 05 22 2/ 35 1. 2. 3. 2010 05 22 3/ 35 : 1.? 2. 2010 05 22 4/ 35 1. 2010 05 22 5/
2010 05 22 1/ 35 2010 2010 05 22 *1 kubo@ees.hokudai.ac.jp *1 c Mike Gonzalez, October 14, 2007. Wikimedia Commons. 2010 05 22 2/ 35 1. 2. 3. 2010 05 22 3/ 35 : 1.? 2. 2010 05 22 4/ 35 1. 2010 05 22 5/
kubostat2017e p.1 I 2017 (e) GLM logistic regression : : :02 1 N y count data or
 GLM logistic regression : : :02 1 N y count data or") kubostat207e p. I 207 (e) GLM kubo@ees.hokudai.ac.jp https://goo.gl/z9ycjy 207 4 207 6:02 N y 2 binomial distribution logit link function 3 4! offset kubostat207e (https://goo.gl/z9ycjy) 207 (e) 207 4
kubostat207e p. I 207 (e) GLM kubo@ees.hokudai.ac.jp https://goo.gl/z9ycjy 207 4 207 6:02 N y 2 binomial distribution logit link function 3 4! offset kubostat207e (https://goo.gl/z9ycjy) 207 (e) 207 4
60 (W30)? 1. ( ) 2. ( ) web site URL ( :41 ) 1/ 77
? 1. ( ) 2. ( ) web site URL ( :41 ) 1/ 77") 60 (W30)? 1. ( ) kubo@ees.hokudai.ac.jp 2. ( ) web site URL http://goo.gl/e1cja!! 2013 03 07 (2013 03 07 17 :41 ) 1/ 77 ! : :? 2013 03 07 (2013 03 07 17 :41 ) 2/ 77 2013 03 07 (2013 03 07 17 :41 ) 3/ 77!!
60 (W30)? 1. ( ) kubo@ees.hokudai.ac.jp 2. ( ) web site URL http://goo.gl/e1cja!! 2013 03 07 (2013 03 07 17 :41 ) 1/ 77 ! : :? 2013 03 07 (2013 03 07 17 :41 ) 2/ 77 2013 03 07 (2013 03 07 17 :41 ) 3/ 77!!
kubo2015ngt6 p.2 ( ( (MLE 8 y i L(q q log L(q q 0 ˆq log L(q / q = 0 q ˆq = = = * ˆq = 0.46 ( 8 y 0.46 y y y i kubo (ht
 kubo2015ngt6 p.1 2015 (6 MCMC kubo@ees.hokudai.ac.jp, @KuboBook http://goo.gl/m8hsbm 1 ( 2 3 4 5 JAGS : 2015 05 18 16:48 kubo (http://goo.gl/m8hsbm 2015 (6 1 / 70 kubo (http://goo.gl/m8hsbm 2015 (6 2 /
kubo2015ngt6 p.1 2015 (6 MCMC kubo@ees.hokudai.ac.jp, @KuboBook http://goo.gl/m8hsbm 1 ( 2 3 4 5 JAGS : 2015 05 18 16:48 kubo (http://goo.gl/m8hsbm 2015 (6 1 / 70 kubo (http://goo.gl/m8hsbm 2015 (6 2 /
kubostat2017b p.1 agenda I 2017 (b) probability distribution and maximum likelihood estimation :
 probability distribution and maximum likelihood estimation :") kubostat2017b p.1 agenda I 2017 (b) probabilit distribution and maimum likelihood estimation kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2017 11 14 : 2017 11 07 15:43 1 : 2 3? 4 kubostat2017b (http://goo.gl/76c4i)
kubostat2017b p.1 agenda I 2017 (b) probabilit distribution and maimum likelihood estimation kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2017 11 14 : 2017 11 07 15:43 1 : 2 3? 4 kubostat2017b (http://goo.gl/76c4i)
講義のーと : データ解析のための統計モデリング. 第5回
 Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
一般化線形 (混合) モデル (2) - ロジスティック回帰と GLMM
 モデル (2) - ロジスティック回帰と GLMM") .. ( ) (2) GLMM kubo@ees.hokudai.ac.jp I http://goo.gl/rrhzey 2013 08 27 : 2013 08 27 08:29 kubostat2013ou2 (http://goo.gl/rrhzey) ( ) (2) 2013 08 27 1 / 74 I.1 N k.2 binomial distribution logit link function.3.4!
.. ( ) (2) GLMM kubo@ees.hokudai.ac.jp I http://goo.gl/rrhzey 2013 08 27 : 2013 08 27 08:29 kubostat2013ou2 (http://goo.gl/rrhzey) ( ) (2) 2013 08 27 1 / 74 I.1 N k.2 binomial distribution logit link function.3.4!
Microsoft PowerPoint - GLMMexample_ver pptx
 Linear Mixed Model ( 以下 混合モデル ) の短い解説 この解説のPDFは http://www.lowtem.hokudai.ac.jp/plantecol/akihiro/sumida-index.html の お勉強 のページにあります. ver 20121121 と との間に次のような関係が見つかったとしよう 全体的な傾向に対する回帰直線を点線で示した ところが これらのデータは実は異なる
Linear Mixed Model ( 以下 混合モデル ) の短い解説 この解説のPDFは http://www.lowtem.hokudai.ac.jp/plantecol/akihiro/sumida-index.html の お勉強 のページにあります. ver 20121121 と との間に次のような関係が見つかったとしよう 全体的な傾向に対する回帰直線を点線で示した ところが これらのデータは実は異なる
スライド 1
 データ解析特論第 10 回 ( 全 15 回 ) 2012 年 12 月 11 日 ( 火 ) 情報エレクトロニクス専攻横田孝義 1 終了 11/13 11/20 重回帰分析をしばらくやります 12/4 12/11 12/18 2 前回から回帰分析について学習しています 3 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える
データ解析特論第 10 回 ( 全 15 回 ) 2012 年 12 月 11 日 ( 火 ) 情報エレクトロニクス専攻横田孝義 1 終了 11/13 11/20 重回帰分析をしばらくやります 12/4 12/11 12/18 2 前回から回帰分析について学習しています 3 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える
スライド 1
 データ解析特論重回帰分析編 2017 年 7 月 10 日 ( 月 )~ 情報エレクトロニクスコース横田孝義 1 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える 具体的には y = a + bx という回帰直線 ( モデル ) でデータを代表させる このためにデータからこの回帰直線の切片 (a) と傾き (b) を最小
データ解析特論重回帰分析編 2017 年 7 月 10 日 ( 月 )~ 情報エレクトロニクスコース横田孝義 1 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える 具体的には y = a + bx という回帰直線 ( モデル ) でデータを代表させる このためにデータからこの回帰直線の切片 (a) と傾き (b) を最小
自由集会時系列part2web.key
 spurious correlation spurious regression xt=xt-1+n(0,σ^2) yt=yt-1+n(0,σ^2) n=20 type1error(5%)=0.4703 no trend 0 1000 2000 3000 4000 p for r xt=xt-1+n(0,σ^2) random walk random walk variable -5 0 5 variable
spurious correlation spurious regression xt=xt-1+n(0,σ^2) yt=yt-1+n(0,σ^2) n=20 type1error(5%)=0.4703 no trend 0 1000 2000 3000 4000 p for r xt=xt-1+n(0,σ^2) random walk random walk variable -5 0 5 variable
kubostat1g p. MCMC binomial distribution q MCMC : i N i y i p(y i q = ( Ni y i q y i (1 q N i y i, q {y i } q likelihood q L(q {y i } = i=1 p(y i q 1
 kubostat1g p.1 1 (g Hierarchical Bayesian Model kubo@ees.hokudai.ac.jp http://goo.gl/7ci The development of linear models Hierarchical Bayesian Model Be more flexible Generalized Linear Mixed Model (GLMM
kubostat1g p.1 1 (g Hierarchical Bayesian Model kubo@ees.hokudai.ac.jp http://goo.gl/7ci The development of linear models Hierarchical Bayesian Model Be more flexible Generalized Linear Mixed Model (GLMM
日心TWS
 2017.09.22 (15:40~17:10) 日本心理学会第 81 回大会 TWS ベイジアンデータ解析入門 回帰分析を例に ベイジアンデータ解析 を体験してみる 広島大学大学院教育学研究科平川真 ベイジアン分析のステップ (p.24) 1) データの特定 2) モデルの定義 ( 解釈可能な ) モデルの作成 3) パラメタの事前分布の設定 4) ベイズ推論を用いて パラメタの値に確信度を再配分ベイズ推定
2017.09.22 (15:40~17:10) 日本心理学会第 81 回大会 TWS ベイジアンデータ解析入門 回帰分析を例に ベイジアンデータ解析 を体験してみる 広島大学大学院教育学研究科平川真 ベイジアン分析のステップ (p.24) 1) データの特定 2) モデルの定義 ( 解釈可能な ) モデルの作成 3) パラメタの事前分布の設定 4) ベイズ推論を用いて パラメタの値に確信度を再配分ベイズ推定
> usdata01 と打ち込んでエンター キーを押すと V1 V2 V : : : : のように表示され 読み込まれていることがわかる ここで V1, V2, V3 は R が列のデータに自 動的につけた変数名である ( variable
 R による回帰分析 ( 最小二乗法 ) この資料では 1. データを読み込む 2. 最小二乗法によってパラメーターを推定する 3. データをプロットし 回帰直線を書き込む 4. いろいろなデータの読み込み方について簡単に説明する 1. データを読み込む 以下では read.table( ) 関数を使ってテキストファイル ( 拡張子が.txt のファイル ) のデー タの読み込み方を説明する 1.1
R による回帰分析 ( 最小二乗法 ) この資料では 1. データを読み込む 2. 最小二乗法によってパラメーターを推定する 3. データをプロットし 回帰直線を書き込む 4. いろいろなデータの読み込み方について簡単に説明する 1. データを読み込む 以下では read.table( ) 関数を使ってテキストファイル ( 拡張子が.txt のファイル ) のデー タの読み込み方を説明する 1.1
今回用いる例データ lh( 小文字のエル ) ある女性の血液中の黄体ホルモンを 10 分間隔で測定した時系列データ UKgas 1960 年 ~1986 年のイギリスのガス消費量を四半期ごとに観測した時系列データ ldeaths 1974 年 ~1979 年のイギリスで喘息 気管支炎 肺気腫による死
 ある女性の血液中の黄体ホルモンを 10 分間隔で測定した時系列データ UKgas 1960 年 ~1986 年のイギリスのガス消費量を四半期ごとに観測した時系列データ ldeaths 1974 年 ~1979 年のイギリスで喘息 気管支炎 肺気腫による死") 12 章 - 時系列分析 1296603c 埴岡瞬 今回用いる例データ lh( 小文字のエル ) ある女性の血液中の黄体ホルモンを 10 分間隔で測定した時系列データ UKgas 1960 年 ~1986 年のイギリスのガス消費量を四半期ごとに観測した時系列データ ldeaths 1974 年 ~1979 年のイギリスで喘息 気管支炎 肺気腫による死亡数を月ごとに記録した時系列データ mdeaths
12 章 - 時系列分析 1296603c 埴岡瞬 今回用いる例データ lh( 小文字のエル ) ある女性の血液中の黄体ホルモンを 10 分間隔で測定した時系列データ UKgas 1960 年 ~1986 年のイギリスのガス消費量を四半期ごとに観測した時系列データ ldeaths 1974 年 ~1979 年のイギリスで喘息 気管支炎 肺気腫による死亡数を月ごとに記録した時系列データ mdeaths
講義のーと : データ解析のための統計モデリング. 第3回
 Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
Use R
 Use R! 2008/05/23( ) Index Introduction (GLM) ( ) R. Introduction R,, PLS,,, etc. 2. Correlation coefficient (Pearson s product moment correlation) r = Sxy Sxx Syy :, Sxy, Sxx= X, Syy Y 1.96 95% R cor(x,
Use R! 2008/05/23( ) Index Introduction (GLM) ( ) R. Introduction R,, PLS,,, etc. 2. Correlation coefficient (Pearson s product moment correlation) r = Sxy Sxx Syy :, Sxy, Sxx= X, Syy Y 1.96 95% R cor(x,
kubostat2018d p.2 :? bod size x and fertilization f change seed number? : a statistical model for this example? i response variable seed number : { i
 kubostat2018d p.1 I 2018 (d) model selection and kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2018 06 25 : 2018 06 21 17:45 1 2 3 4 :? AIC : deviance model selection misunderstanding kubostat2018d (http://goo.gl/76c4i)
kubostat2018d p.1 I 2018 (d) model selection and kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2018 06 25 : 2018 06 21 17:45 1 2 3 4 :? AIC : deviance model selection misunderstanding kubostat2018d (http://goo.gl/76c4i)
k2 ( :35 ) ( k2) (GLM) web web 1 :
 ( k2) (GLM) web web 1 :") 2012 11 01 k2 (2012-10-26 16:35 ) 1 6 2 (2012 11 01 k2) (GLM) kubo@ees.hokudai.ac.jp web http://goo.gl/wijx2 web http://goo.gl/ufq2 1 : 2 2 4 3 7 4 9 5 : 11 5.1................... 13 6 14 6.1......................
2012 11 01 k2 (2012-10-26 16:35 ) 1 6 2 (2012 11 01 k2) (GLM) kubo@ees.hokudai.ac.jp web http://goo.gl/wijx2 web http://goo.gl/ufq2 1 : 2 2 4 3 7 4 9 5 : 11 5.1................... 13 6 14 6.1......................
kubo2017sep16a p.1 ( 1 ) : : :55 kubo ( ( 1 ) / 10
 : : :55 kubo ( ( 1 ) / 10") kubo2017sep16a p.1 ( 1 ) kubo@ees.hokudai.ac.jp 2017 09 16 : http://goo.gl/8je5wh : 2017 09 13 16:55 kubo (http://goo.gl/ufq2) ( 1 ) 2017 09 16 1 / 106 kubo (http://goo.gl/ufq2) ( 1 ) 2017 09 16 2 / 106
kubo2017sep16a p.1 ( 1 ) kubo@ees.hokudai.ac.jp 2017 09 16 : http://goo.gl/8je5wh : 2017 09 13 16:55 kubo (http://goo.gl/ufq2) ( 1 ) 2017 09 16 1 / 106 kubo (http://goo.gl/ufq2) ( 1 ) 2017 09 16 2 / 106
PowerPoint プレゼンテーション
 1/X Chapter 9: Linear correlation Cohen, B. H. (2007). In B. H. Cohen (Ed.), Explaining Psychological Statistics (3rd ed.) (pp. 255-285). NJ: Wiley. 概要 2/X 相関係数とは何か 相関係数の数式 検定 注意点 フィッシャーのZ 変換 信頼区間 相関係数の差の検定
1/X Chapter 9: Linear correlation Cohen, B. H. (2007). In B. H. Cohen (Ed.), Explaining Psychological Statistics (3rd ed.) (pp. 255-285). NJ: Wiley. 概要 2/X 相関係数とは何か 相関係数の数式 検定 注意点 フィッシャーのZ 変換 信頼区間 相関係数の差の検定
1 環境統計学ぷらす 第 5 回 一般 ( 化 ) 線形混合モデル 高木俊 2013/11/21
 線形混合モデル 高木俊 2013/11/21") 1 環境統計学ぷらす 第 5 回 一般 ( 化 ) 線形混合モデル 高木俊 shun.takagi@sci.toho-u.ac.jp 2013/11/21 2 予定 第 1 回 : Rの基礎と仮説検定 第 2 回 : 分散分析と回帰 第 3 回 : 一般線形モデル 交互作用 第 4.1 回 : 一般化線形モデル 第 4.2 回 : モデル選択 (11/29?) 第 5 回 : 一般化線形混合モデル
1 環境統計学ぷらす 第 5 回 一般 ( 化 ) 線形混合モデル 高木俊 shun.takagi@sci.toho-u.ac.jp 2013/11/21 2 予定 第 1 回 : Rの基礎と仮説検定 第 2 回 : 分散分析と回帰 第 3 回 : 一般線形モデル 交互作用 第 4.1 回 : 一般化線形モデル 第 4.2 回 : モデル選択 (11/29?) 第 5 回 : 一般化線形混合モデル
/22 R MCMC R R MCMC? 3. Gibbs sampler : kubo/
 2006-12-09 1/22 R MCMC R 1. 2. R MCMC? 3. Gibbs sampler : kubo@ees.hokudai.ac.jp http://hosho.ees.hokudai.ac.jp/ kubo/ 2006-12-09 2/22 : ( ) : : ( ) : (?) community ( ) 2006-12-09 3/22 :? 1. ( ) 2. ( )
2006-12-09 1/22 R MCMC R 1. 2. R MCMC? 3. Gibbs sampler : kubo@ees.hokudai.ac.jp http://hosho.ees.hokudai.ac.jp/ kubo/ 2006-12-09 2/22 : ( ) : : ( ) : (?) community ( ) 2006-12-09 3/22 :? 1. ( ) 2. ( )
Microsoft PowerPoint - 統計科学研究所_R_重回帰分析_変数選択_2.ppt
 重回帰分析 残差分析 変数選択 1 内容 重回帰分析 残差分析 歯の咬耗度データの分析 R で変数選択 ~ step 関数 ~ 2 重回帰分析と単回帰分析 体重を予測する問題 分析 1 身長 のみから体重を予測 分析 2 身長 と ウエスト の両方を用いて体重を予測 分析 1 と比べて大きな改善 体重 に関する推測では 身長 だけでは不十分 重回帰分析における問題 ~ モデルの構築 ~ 適切なモデルで分析しているか?
重回帰分析 残差分析 変数選択 1 内容 重回帰分析 残差分析 歯の咬耗度データの分析 R で変数選択 ~ step 関数 ~ 2 重回帰分析と単回帰分析 体重を予測する問題 分析 1 身長 のみから体重を予測 分析 2 身長 と ウエスト の両方を用いて体重を予測 分析 1 と比べて大きな改善 体重 に関する推測では 身長 だけでは不十分 重回帰分析における問題 ~ モデルの構築 ~ 適切なモデルで分析しているか?
. 分析内容及びデータ () 分析内容中長期の代表的金利である円金利スワップを題材に 年 -5 年物のイールドスプレッドの変動を自己回帰誤差モデル * により時系列分析を行った * ) 自己回帰誤差モデル一般に自己回帰モデルは線形回帰モデルと同様な考え方で 外生変数の無いT 期間だけ遅れのある従属変
 分析内容中長期の代表的金利である円金利スワップを題材に 年 -5 年物のイールドスプレッドの変動を自己回帰誤差モデル * により時系列分析を行った * ) 自己回帰誤差モデル一般に自己回帰モデルは線形回帰モデルと同様な考え方で 外生変数の無いT 期間だけ遅れのある従属変") () 現在データは最大 5 営業日前までの自己データが受けたショック ( 変動要因 ) の影響を受け 易い ( 情報の有効性 ) 現在の金利変動は 過去のどのタイミングでのショック ( 変動要因 ) を引きずり変動しているのかの推測 ( 偏自己相関 ) また 将来の変動を予測する上で 政策金利変更等の ショックの持続性 はどの程度 将来の変動に影響を与えるか等の判別に役に立つ可能性がある (2) その中でも
() 現在データは最大 5 営業日前までの自己データが受けたショック ( 変動要因 ) の影響を受け 易い ( 情報の有効性 ) 現在の金利変動は 過去のどのタイミングでのショック ( 変動要因 ) を引きずり変動しているのかの推測 ( 偏自己相関 ) また 将来の変動を予測する上で 政策金利変更等の ショックの持続性 はどの程度 将来の変動に影響を与えるか等の判別に役に立つ可能性がある (2) その中でも
回帰分析 単回帰
 回帰分析 単回帰 麻生良文 単回帰モデル simple regression model = α + β + u 従属変数 (dependent variable) 被説明変数 (eplained variable) 独立変数 (independent variable) 説明変数 (eplanator variable) u 誤差項 (error term) 撹乱項 (disturbance term)
回帰分析 単回帰 麻生良文 単回帰モデル simple regression model = α + β + u 従属変数 (dependent variable) 被説明変数 (eplained variable) 独立変数 (independent variable) 説明変数 (eplanator variable) u 誤差項 (error term) 撹乱項 (disturbance term)
集中理論談話会 #9 Bhat, C.R., Sidharthan, R.: A simulation evaluation of the maximum approximate composite marginal likelihood (MACML) estimator for mixed mu
 estimator for mixed mu") 集中理論談話会 #9 Bhat, C.R., Sidharthan, R.: A simulation evaluation of the maximum approximate composite marginal likelihood (MACML) estimator for mixed multinomial probit models, Transportation Research Part
集中理論談話会 #9 Bhat, C.R., Sidharthan, R.: A simulation evaluation of the maximum approximate composite marginal likelihood (MACML) estimator for mixed multinomial probit models, Transportation Research Part
Microsoft PowerPoint - 資料04 重回帰分析.ppt
 04. 重回帰分析 京都大学 加納学 Division of Process Control & Process Sstems Engineering Department of Chemical Engineering, Koto Universit manabu@cheme.koto-u.ac.jp http://www-pse.cheme.koto-u.ac.jp/~kano/ Outline
04. 重回帰分析 京都大学 加納学 Division of Process Control & Process Sstems Engineering Department of Chemical Engineering, Koto Universit manabu@cheme.koto-u.ac.jp http://www-pse.cheme.koto-u.ac.jp/~kano/ Outline
統計的データ解析
 統計的データ解析 011 011.11.9 林田清 ( 大阪大学大学院理学研究科 ) 連続確率分布の平均値 分散 比較のため P(c ) c 分布 自由度 の ( カイ c 平均値 0, 標準偏差 1の正規分布 に従う変数 xの自乗和 c x =1 が従う分布を自由度 の分布と呼ぶ 一般に自由度の分布は f /1 c / / ( c ) {( c ) e }/ ( / ) 期待値 二乗 ) 分布 c
統計的データ解析 011 011.11.9 林田清 ( 大阪大学大学院理学研究科 ) 連続確率分布の平均値 分散 比較のため P(c ) c 分布 自由度 の ( カイ c 平均値 0, 標準偏差 1の正規分布 に従う変数 xの自乗和 c x =1 が従う分布を自由度 の分布と呼ぶ 一般に自由度の分布は f /1 c / / ( c ) {( c ) e }/ ( / ) 期待値 二乗 ) 分布 c
12/1 ( ) GLM, R MCMC, WinBUGS 12/2 ( ) WinBUGS WinBUGS 12/2 ( ) : 12/3 ( ) :? ( :51 ) 2/ 71
 GLM, R MCMC, WinBUGS 12/2 ( ) WinBUGS WinBUGS 12/2 ( ) : 12/3 ( ) :? ( :51 ) 2/ 71") 2010-12-02 (2010 12 02 10 :51 ) 1/ 71 GCOE 2010-12-02 WinBUGS kubo@ees.hokudai.ac.jp http://goo.gl/bukrb 12/1 ( ) GLM, R MCMC, WinBUGS 12/2 ( ) WinBUGS WinBUGS 12/2 ( ) : 12/3 ( ) :? 2010-12-02 (2010 12
2010-12-02 (2010 12 02 10 :51 ) 1/ 71 GCOE 2010-12-02 WinBUGS kubo@ees.hokudai.ac.jp http://goo.gl/bukrb 12/1 ( ) GLM, R MCMC, WinBUGS 12/2 ( ) WinBUGS WinBUGS 12/2 ( ) : 12/3 ( ) :? 2010-12-02 (2010 12
Microsoft Word - eviews6_
 6 章 : 共和分と誤差修正モデル 2017/11/22 新谷元嗣 藪友良 石原卓弥 教科書 6 章 5 節のデータを用いて エングル = グレンジャーの方法 誤差修正モデル ヨハンセンの方法を学んでいこう 1. データの読み込みと単位根検定 COINT6.XLS のデータを Workfile に読み込む このファイルは教科書の表 6.1 の式から 生成された人工的なデータである ( 下表参照 )
6 章 : 共和分と誤差修正モデル 2017/11/22 新谷元嗣 藪友良 石原卓弥 教科書 6 章 5 節のデータを用いて エングル = グレンジャーの方法 誤差修正モデル ヨハンセンの方法を学んでいこう 1. データの読み込みと単位根検定 COINT6.XLS のデータを Workfile に読み込む このファイルは教科書の表 6.1 の式から 生成された人工的なデータである ( 下表参照 )
3. みせかけの相関単位根系列が注目されるのは これを持つ変数同士の回帰には意味がないためだ 単位根系列で代表的なドリフト付きランダムウォークを発生させてそれを確かめてみよう yと xという変数名の系列をを作成する yt=0.5+yt-1+et xt=0.1+xt-1+et 初期値を y は 10
 第 10 章 くさりのない犬 はじめにこの章では 単位根検定や 共和分検定を説明する データが単位根を持つ系列の場合 見せかけの相関をする場合があり 推計結果が信用できなくなる 経済分析の手順として 系列が定常系列か単位根を持つ非定常系列かを見極め 定常系列であればそのまま推計し 非定常系列であれば階差をとって推計するのが一般的である 1. ランダムウオーク 最も簡単な単位根を持つ系列としてランダムウオークがある
第 10 章 くさりのない犬 はじめにこの章では 単位根検定や 共和分検定を説明する データが単位根を持つ系列の場合 見せかけの相関をする場合があり 推計結果が信用できなくなる 経済分析の手順として 系列が定常系列か単位根を持つ非定常系列かを見極め 定常系列であればそのまま推計し 非定常系列であれば階差をとって推計するのが一般的である 1. ランダムウオーク 最も簡単な単位根を持つ系列としてランダムウオークがある
講義のーと : データ解析のための統計モデリング. 第2回
 Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
EBNと疫学
 推定と検定 57 ( 復習 ) 記述統計と推測統計 統計解析は大きく 2 つに分けられる 記述統計 推測統計 記述統計 観察集団の特性を示すもの 代表値 ( 平均値や中央値 ) や ばらつきの指標 ( 標準偏差など ) 図表を効果的に使う 推測統計 観察集団のデータから母集団の特性を 推定 する 平均 / 分散 / 係数値などの推定 ( 点推定 ) 点推定値のばらつきを調べる ( 区間推定 ) 検定統計量を用いた検定
推定と検定 57 ( 復習 ) 記述統計と推測統計 統計解析は大きく 2 つに分けられる 記述統計 推測統計 記述統計 観察集団の特性を示すもの 代表値 ( 平均値や中央値 ) や ばらつきの指標 ( 標準偏差など ) 図表を効果的に使う 推測統計 観察集団のデータから母集団の特性を 推定 する 平均 / 分散 / 係数値などの推定 ( 点推定 ) 点推定値のばらつきを調べる ( 区間推定 ) 検定統計量を用いた検定
1.民営化
 参考資料 最小二乗法 数学的性質 経済統計分析 3 年度秋学期 回帰分析と最小二乗法 被説明変数 の動きを説明変数 の動きで説明 = 回帰分析 説明変数がつ 単回帰 説明変数がつ以上 重回帰 被説明変数 従属変数 係数 定数項傾き 説明変数 独立変数 残差... で説明できる部分 説明できない部分 説明できない部分が小さくなるように回帰式の係数 を推定する有力な方法 = 最小二乗法 最小二乗法による回帰の考え方
参考資料 最小二乗法 数学的性質 経済統計分析 3 年度秋学期 回帰分析と最小二乗法 被説明変数 の動きを説明変数 の動きで説明 = 回帰分析 説明変数がつ 単回帰 説明変数がつ以上 重回帰 被説明変数 従属変数 係数 定数項傾き 説明変数 独立変数 残差... で説明できる部分 説明できない部分 説明できない部分が小さくなるように回帰式の係数 を推定する有力な方法 = 最小二乗法 最小二乗法による回帰の考え方
DVIOUT-ar
 1 4 μ=0, σ=1 5 μ=2, σ=1 5 μ=0, σ=2 3 2 1 0-1 -2-3 0 10 20 30 40 50 60 70 80 90 4 3 2 1 0-1 0 10 20 30 40 50 60 70 80 90 4 3 2 1 0-1 -2-3 -4-5 0 10 20 30 40 50 60 70 80 90 8 μ=2, σ=2 5 μ=1, θ 1 =0.5, σ=1
1 4 μ=0, σ=1 5 μ=2, σ=1 5 μ=0, σ=2 3 2 1 0-1 -2-3 0 10 20 30 40 50 60 70 80 90 4 3 2 1 0-1 0 10 20 30 40 50 60 70 80 90 4 3 2 1 0-1 -2-3 -4-5 0 10 20 30 40 50 60 70 80 90 8 μ=2, σ=2 5 μ=1, θ 1 =0.5, σ=1
J1順位と得点者数の関係分析
 2015 年度 S-PLUS & Visual R Platform 学生研究奨励賞応募 J1 順位と得点者数の関係分析 -J リーグの得点数の現状 - 目次 1. はじめに 2. 研究目的 データについて 3.J1 リーグの得点数の現状 4. 分析 5. まとめ 6. 今後の課題 - 参考文献 - 東海大学情報通信学部 経営システム工学科 山田貴久 1. はじめに 1993 年 5 月 15 日に
2015 年度 S-PLUS & Visual R Platform 学生研究奨励賞応募 J1 順位と得点者数の関係分析 -J リーグの得点数の現状 - 目次 1. はじめに 2. 研究目的 データについて 3.J1 リーグの得点数の現状 4. 分析 5. まとめ 6. 今後の課題 - 参考文献 - 東海大学情報通信学部 経営システム工学科 山田貴久 1. はじめに 1993 年 5 月 15 日に
多変量解析 ~ 重回帰分析 ~ 2006 年 4 月 21 日 ( 金 ) 南慶典
 南慶典") 多変量解析 ~ 重回帰分析 ~ 2006 年 4 月 21 日 ( 金 ) 南慶典 重回帰分析とは? 重回帰分析とは複数の説明変数から目的変数との関係性を予測 評価説明変数 ( 数量データ ) は目的変数を説明するのに有効であるか得られた関係性より未知のデータの妥当性を判断する これを重回帰分析という つまり どんなことをするのか? 1 最小 2 乗法により重回帰モデルを想定 2 自由度調整済寄与率を求め
多変量解析 ~ 重回帰分析 ~ 2006 年 4 月 21 日 ( 金 ) 南慶典 重回帰分析とは? 重回帰分析とは複数の説明変数から目的変数との関係性を予測 評価説明変数 ( 数量データ ) は目的変数を説明するのに有効であるか得られた関係性より未知のデータの妥当性を判断する これを重回帰分析という つまり どんなことをするのか? 1 最小 2 乗法により重回帰モデルを想定 2 自由度調整済寄与率を求め
1 15 R Part : website:
 1 15 R Part 4 2017 7 24 4 : website: email: http://www3.u-toyama.ac.jp/kkarato/ kkarato@eco.u-toyama.ac.jp 1 2 2 3 2.1............................... 3 2.2 2................................. 4 2.3................................
1 15 R Part 4 2017 7 24 4 : website: email: http://www3.u-toyama.ac.jp/kkarato/ kkarato@eco.u-toyama.ac.jp 1 2 2 3 2.1............................... 3 2.2 2................................. 4 2.3................................
Microsoft PowerPoint - H17-5時限(パターン認識).ppt
.ppt") パターン認識早稲田大学講義 平成 7 年度 独 産業技術総合研究所栗田多喜夫 赤穂昭太郎 統計的特徴抽出 パターン認識過程 特徴抽出 認識対象から何らかの特徴量を計測 抽出 する必要がある 認識に有効な情報 特徴 を抽出し 次元を縮小した効率の良い空間を構成する過程 文字認識 : スキャナ等で取り込んだ画像から文字の識別に必要な本質的な特徴のみを抽出 例 文字線の傾き 曲率 面積など 識別 与えられた未知の対象を
パターン認識早稲田大学講義 平成 7 年度 独 産業技術総合研究所栗田多喜夫 赤穂昭太郎 統計的特徴抽出 パターン認識過程 特徴抽出 認識対象から何らかの特徴量を計測 抽出 する必要がある 認識に有効な情報 特徴 を抽出し 次元を縮小した効率の良い空間を構成する過程 文字認識 : スキャナ等で取り込んだ画像から文字の識別に必要な本質的な特徴のみを抽出 例 文字線の傾き 曲率 面積など 識別 与えられた未知の対象を
Microsoft Word - å“Ÿåłžå¸°173.docx
 回帰分析 ( その 3) 経済情報処理 価格弾力性の推定ある商品について その購入量を w 単価を p とし それぞれの変化量を w p で表 w w すことにする この時 この商品の価格弾力性 は により定義される これ p p は p が 1 パーセント変化した場合に w が何パーセント変化するかを示したものである ここで p を 0 に近づけていった極限を考えると d ln w 1 dw dw
回帰分析 ( その 3) 経済情報処理 価格弾力性の推定ある商品について その購入量を w 単価を p とし それぞれの変化量を w p で表 w w すことにする この時 この商品の価格弾力性 は により定義される これ p p は p が 1 パーセント変化した場合に w が何パーセント変化するかを示したものである ここで p を 0 に近づけていった極限を考えると d ln w 1 dw dw
Dependent Variable: LOG(GDP00/(E*HOUR)) Date: 02/27/06 Time: 16:39 Sample (adjusted): 1994Q1 2005Q3 Included observations: 47 after adjustments C -1.5
) Date: 02/27/06 Time: 16:39 Sample (adjusted): 1994Q1 2005Q3 Included observations: 47 after adjustments C -1.5") 第 4 章 この章では 最小二乗法をベースにして 推計上のさまざまなテクニックを検討する 変数のバリエーション 係数の制約係数にあらかじめ制約がある場合がある たとえばマクロの生産関数は 次のように表すことができる 生産要素は資本と労働である 稼動資本は資本ストックに稼働率をかけることで計算でき 労働投入量は 就業者数に総労働時間をかけることで計算できる 制約を掛けずに 推計すると次の結果が得られる
第 4 章 この章では 最小二乗法をベースにして 推計上のさまざまなテクニックを検討する 変数のバリエーション 係数の制約係数にあらかじめ制約がある場合がある たとえばマクロの生産関数は 次のように表すことができる 生産要素は資本と労働である 稼動資本は資本ストックに稼働率をかけることで計算でき 労働投入量は 就業者数に総労働時間をかけることで計算できる 制約を掛けずに 推計すると次の結果が得られる
201711grade2.pdf
 2017 11 26 1 2 28 3 90 4 5 A 1 2 3 4 Web Web 6 B 10 3 10 3 7 34 8 23 9 10 1 2 3 1 (A) 3 32.14 0.65 2.82 0.93 7.48 (B) 4 6 61.30 54.68 34.86 5.25 19.07 (C) 7 13 5.89 42.18 56.51 35.80 50.28 (D) 14 20 0.35
2017 11 26 1 2 28 3 90 4 5 A 1 2 3 4 Web Web 6 B 10 3 10 3 7 34 8 23 9 10 1 2 3 1 (A) 3 32.14 0.65 2.82 0.93 7.48 (B) 4 6 61.30 54.68 34.86 5.25 19.07 (C) 7 13 5.89 42.18 56.51 35.80 50.28 (D) 14 20 0.35
Microsoft PowerPoint - 時系列解析(10)_講義用.pptx
_講義用.pptx") 時系列解析 () 季節調整モデルと成分分解 信号抽出 東京 学数理 情報教育研究センター 北川源四郎 東京 学北川源四郎数理 法 VII ( 時系列解析 ) 季節調整とは.5 WHARD 月次データ.3..9.7 5 49 73 97 45 何らかの原因で特定の周期で繰り返す成分を除去して本質的な現象を抽出する方法 東京 学北川源四郎数理 法 VII ( 時系列解析 ) 季節調整モデル 観測モデル
時系列解析 () 季節調整モデルと成分分解 信号抽出 東京 学数理 情報教育研究センター 北川源四郎 東京 学北川源四郎数理 法 VII ( 時系列解析 ) 季節調整とは.5 WHARD 月次データ.3..9.7 5 49 73 97 45 何らかの原因で特定の周期で繰り返す成分を除去して本質的な現象を抽出する方法 東京 学北川源四郎数理 法 VII ( 時系列解析 ) 季節調整モデル 観測モデル
/ 60 : 1. GLM? 2. A: (pwer functin) x y?
 x y?") 2009-03-17 1/ 60 (2009-03-17) GLM 1. GLM :, link,, deviance (20 ) 2. GLM : (60 ) 3. GLM ( ): ffset (40 ) http://hsh.ees.hkudai.ac.jp/ kub/ce/ecsj2009.html 2009-03-17 2/ 60 : 1. GLM? 2. A: (pwer functin)
2009-03-17 1/ 60 (2009-03-17) GLM 1. GLM :, link,, deviance (20 ) 2. GLM : (60 ) 3. GLM ( ): ffset (40 ) http://hsh.ees.hkudai.ac.jp/ kub/ce/ecsj2009.html 2009-03-17 2/ 60 : 1. GLM? 2. A: (pwer functin)
14 化学実験法 II( 吉村 ( 洋 mmol/l の半分だったから さんの測定値は くんの測定値の 4 倍の重みがあり 推定値 としては 0.68 mmol/l その標準偏差は mmol/l 程度ということになる 測定値を 特徴づけるパラメータ t を推定するこの手
 14 化学実験法 II( 吉村 ( 洋 014.6.1. 最小 乗法のはなし 014.6.1. 内容 最小 乗法のはなし...1 最小 乗法の考え方...1 最小 乗法によるパラメータの決定... パラメータの信頼区間...3 重みの異なるデータの取扱い...4 相関係数 決定係数 ( 最小 乗法を語るもう一つの立場...5 実験条件の誤差の影響...5 問題...6 最小 乗法の考え方 飲料水中のカルシウム濃度を
14 化学実験法 II( 吉村 ( 洋 014.6.1. 最小 乗法のはなし 014.6.1. 内容 最小 乗法のはなし...1 最小 乗法の考え方...1 最小 乗法によるパラメータの決定... パラメータの信頼区間...3 重みの異なるデータの取扱い...4 相関係数 決定係数 ( 最小 乗法を語るもう一つの立場...5 実験条件の誤差の影響...5 問題...6 最小 乗法の考え方 飲料水中のカルシウム濃度を
Microsoft PowerPoint - e-stat(OLS).pptx
.pptx") 経済統計学 ( 補足 ) 最小二乗法について 担当 : 小塚匡文 2015 年 11 月 19 日 ( 改訂版 ) 神戸大学経済学部 2015 年度後期開講授業 補足 : 最小二乗法 ( 単回帰分析 ) 1.( 単純 ) 回帰分析とは? 標本サイズTの2 変数 ( ここではXとY) のデータが存在 YをXで説明する回帰方程式を推定するための方法 Y: 被説明変数 ( または従属変数 ) X: 説明変数
経済統計学 ( 補足 ) 最小二乗法について 担当 : 小塚匡文 2015 年 11 月 19 日 ( 改訂版 ) 神戸大学経済学部 2015 年度後期開講授業 補足 : 最小二乗法 ( 単回帰分析 ) 1.( 単純 ) 回帰分析とは? 標本サイズTの2 変数 ( ここではXとY) のデータが存在 YをXで説明する回帰方程式を推定するための方法 Y: 被説明変数 ( または従属変数 ) X: 説明変数
情報工学概論
 確率と統計 中山クラス 第 11 週 0 本日の内容 第 3 回レポート解説 第 5 章 5.6 独立性の検定 ( カイ二乗検定 ) 5.7 サンプルサイズの検定結果への影響練習問題 (4),(5) 第 4 回レポート課題の説明 1 演習問題 ( 前回 ) の解説 勉強時間と定期試験の得点の関係を無相関検定により調べる. データ入力 > aa
確率と統計 中山クラス 第 11 週 0 本日の内容 第 3 回レポート解説 第 5 章 5.6 独立性の検定 ( カイ二乗検定 ) 5.7 サンプルサイズの検定結果への影響練習問題 (4),(5) 第 4 回レポート課題の説明 1 演習問題 ( 前回 ) の解説 勉強時間と定期試験の得点の関係を無相関検定により調べる. データ入力 > aa
2. 時系列分析 プラットフォームの使用法 JMP の 時系列分析 プラットフォームでは 一変量の時系列に対する分析を行うことができます この章では JMP のサンプルデ ータを用いて このプラットフォームの使用法をご説明します JMP のメニューバーより [ ヘルプ ] > [ サンプルデータ ]
![2. 時系列分析 プラットフォームの使用法 JMP の 時系列分析 プラットフォームでは 一変量の時系列に対する分析を行うことができます この章では JMP のサンプルデ ータを用いて このプラットフォームの使用法をご説明します JMP のメニューバーより [ ヘルプ ] > [ サンプルデータ ]](/thumbs/49/25514951.jpg "2. 時系列分析 プラットフォームの使用法 JMP の 時系列分析 プラットフォームでは 一変量の時系列に対する分析を行うことができます この章では JMP のサンプルデ ータを用いて このプラットフォームの使用法をご説明します JMP のメニューバーより [ ヘルプ ] > [ サンプルデータ ]") JMP を用いた ARIMA モデルのあてはめ SAS Institute Japan 株式会社 JMP ジャパン事業部 2013 年 2 月作成 1. はじめに JMP の時系列分析では 一変量の時系列データに対する分析や予測を行うことができ 時系列データに対するグラフ表示 時系列モデルのあてはめ モデルの評価 予測まで 対話的に分析を実行することができます 時系列データにあてはめるモデルとしては
JMP を用いた ARIMA モデルのあてはめ SAS Institute Japan 株式会社 JMP ジャパン事業部 2013 年 2 月作成 1. はじめに JMP の時系列分析では 一変量の時系列データに対する分析や予測を行うことができ 時系列データに対するグラフ表示 時系列モデルのあてはめ モデルの評価 予測まで 対話的に分析を実行することができます 時系列データにあてはめるモデルとしては
解析センターを知っていただく キャンペーン
 005..5 SAS 問題設定 目的 PKパラメータ (AUC,Cmax,Tmaxなど) の推定 PKパラメータの群間比較 PKパラメータのバラツキの評価! データの特徴 非反復測定値 個体につき 個の測定値しか得られない plasma concentration 非反復測定値のイメージ図 測定時点間で個体の対応がない 着目する状況 plasma concentration 経時反復測定値のイメージ図
005..5 SAS 問題設定 目的 PKパラメータ (AUC,Cmax,Tmaxなど) の推定 PKパラメータの群間比較 PKパラメータのバラツキの評価! データの特徴 非反復測定値 個体につき 個の測定値しか得られない plasma concentration 非反復測定値のイメージ図 測定時点間で個体の対応がない 着目する状況 plasma concentration 経時反復測定値のイメージ図
(lm) lm AIC 2 / 1
 lm AIC 2 / 1") W707 s-taiji@is.titech.ac.jp 1 / 1 (lm) lm AIC 2 / 1 : y = β 1 x 1 + β 2 x 2 + + β d x d + β d+1 + ϵ (ϵ N(0, σ 2 )) y R: x R d : β i (i = 1,..., d):, β d+1 : ( ) (d = 1) y = β 1 x 1 + β 2 + ϵ (d > 1) y
W707 s-taiji@is.titech.ac.jp 1 / 1 (lm) lm AIC 2 / 1 : y = β 1 x 1 + β 2 x 2 + + β d x d + β d+1 + ϵ (ϵ N(0, σ 2 )) y R: x R d : β i (i = 1,..., d):, β d+1 : ( ) (d = 1) y = β 1 x 1 + β 2 + ϵ (d > 1) y
スライド 1
 担当 : 田中冬彦 016 年 4 月 19 日 @ 統計モデリング 統計モデリング 第二回配布資料 文献 : A. J. Dobson and A. G. Barnett: An Introduction to Generalized Linear Models 3rd ed., CRC Press. 配布資料の PDF は以下からも DL できます. 短縮 URL http://tinyurl.com/lxb7kb8
担当 : 田中冬彦 016 年 4 月 19 日 @ 統計モデリング 統計モデリング 第二回配布資料 文献 : A. J. Dobson and A. G. Barnett: An Introduction to Generalized Linear Models 3rd ed., CRC Press. 配布資料の PDF は以下からも DL できます. 短縮 URL http://tinyurl.com/lxb7kb8
まず y t を定数項だけに回帰する > levelmod = lm(topixrate~1) 次にこの出力を使って先ほどのレジームスイッチングモデルを推定する 以下のように入力する > levelswmod = msmfit(levelmod,k=,p=0,sw=c(t,t)) ここで k はレジ
 次にこの出力を使って先ほどのレジームスイッチングモデルを推定する 以下のように入力する > levelswmod = msmfit(levelmod,k=,p=0,sw=c(t,t)) ここで k はレジ") マルコフレジームスイッチングモデルの推定 1. マルコフレジームスイッチング (MS) モデルを推定する 1.1 パッケージ MSwM インスツールする MS モデルを推定するために R のパッケージ MSwM をインスツールする パッケージとは通常の R には含まれていない 追加的な R のコマンドの集まりのようなものである R には追加的に 600 以上のパッケージが用意されており それぞれ分析の目的に応じて標準の
マルコフレジームスイッチングモデルの推定 1. マルコフレジームスイッチング (MS) モデルを推定する 1.1 パッケージ MSwM インスツールする MS モデルを推定するために R のパッケージ MSwM をインスツールする パッケージとは通常の R には含まれていない 追加的な R のコマンドの集まりのようなものである R には追加的に 600 以上のパッケージが用意されており それぞれ分析の目的に応じて標準の
カイ二乗フィット検定、パラメータの誤差
 統計的データ解析 008 008.. 林田清 ( 大阪大学大学院理学研究科 ) 問題 C (, ) ( x xˆ) ( y yˆ) σ x πσ σ y y Pabx (, ;,,, ) ˆ y σx σ y = dx exp exp πσx ただし xy ˆ ˆ はyˆ = axˆ+ bであらわされる直線モデル上の点 ( ˆ) ( ˆ ) ( ) x x y ax b y ax b Pabx (,
統計的データ解析 008 008.. 林田清 ( 大阪大学大学院理学研究科 ) 問題 C (, ) ( x xˆ) ( y yˆ) σ x πσ σ y y Pabx (, ;,,, ) ˆ y σx σ y = dx exp exp πσx ただし xy ˆ ˆ はyˆ = axˆ+ bであらわされる直線モデル上の点 ( ˆ) ( ˆ ) ( ) x x y ax b y ax b Pabx (,
スライド 1
 205 年 4 月 28 日 @ 統計モデリング 統計モデリング 第三回配布資料 文献 : A. J. Dobso ad A. G. Barett: A Itroducto to Geeralzed Lear Models. 3rd ed., CRC Press. J. J. Faraway: Etedg the Lear Model wth R. CRC Press. 配布資料の PDF は以下からも
205 年 4 月 28 日 @ 統計モデリング 統計モデリング 第三回配布資料 文献 : A. J. Dobso ad A. G. Barett: A Itroducto to Geeralzed Lear Models. 3rd ed., CRC Press. J. J. Faraway: Etedg the Lear Model wth R. CRC Press. 配布資料の PDF は以下からも
DAA09
 > summary(dat.lm1) Call: lm(formula = sales ~ price, data = dat) Residuals: Min 1Q Median 3Q Max -55.719-19.270 4.212 16.143 73.454 Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) 237.1326
> summary(dat.lm1) Call: lm(formula = sales ~ price, data = dat) Residuals: Min 1Q Median 3Q Max -55.719-19.270 4.212 16.143 73.454 Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) 237.1326
Probit , Mixed logit
 Probit, Mixed logit 2016/5/16 スタートアップゼミ #5 B4 後藤祥孝 1 0. 目次 Probit モデルについて 1. モデル概要 2. 定式化と理解 3. 推定 Mixed logit モデルについて 4. モデル概要 5. 定式化と理解 6. 推定 2 1.Probit 概要 プロビットモデルとは. 効用関数の誤差項に多変量正規分布を仮定したもの. 誤差項には様々な要因が存在するため,
Probit, Mixed logit 2016/5/16 スタートアップゼミ #5 B4 後藤祥孝 1 0. 目次 Probit モデルについて 1. モデル概要 2. 定式化と理解 3. 推定 Mixed logit モデルについて 4. モデル概要 5. 定式化と理解 6. 推定 2 1.Probit 概要 プロビットモデルとは. 効用関数の誤差項に多変量正規分布を仮定したもの. 誤差項には様々な要因が存在するため,
Microsoft Word - HM-RAJ doc
 NIST 及び DIEHARD テストによる RPG100 乱数評価 FDK( 株 )RPG 推進室 2003/12/16 導入 RPG100 から生成される乱数を 2 つの有名なテストを用いて評価します 一方は米国機関 NIST により公開されている資料に基づくテストで 他方は Marsaglia 博士により提供されているテストです 乱数を一度テストしただけでは それが常にテストを満足する乱数性を持っていることを確認できないことから
NIST 及び DIEHARD テストによる RPG100 乱数評価 FDK( 株 )RPG 推進室 2003/12/16 導入 RPG100 から生成される乱数を 2 つの有名なテストを用いて評価します 一方は米国機関 NIST により公開されている資料に基づくテストで 他方は Marsaglia 博士により提供されているテストです 乱数を一度テストしただけでは それが常にテストを満足する乱数性を持っていることを確認できないことから
Microsoft PowerPoint - 時系列解析(11)_講義用.pptx
_講義用.pptx") 時系列解析 () ボラティリティ 時変係数 AR モデル 東京 学数理 情報教育研究センター 北川源四郎 概要. 分散 定常モデル : 線形化 正規近似. 共分散 定常モデル : 時変係数モデル 3. 線形 ガウス型状態空間モデル 分散 共分散 定常 3 地震波 経 5 定常時系列のモデル 4. 平均 定常 トレンド, 季節調整. 分散 定常 線形 ガウスモデル ( カルマンフィルタ ) で推定するためには
時系列解析 () ボラティリティ 時変係数 AR モデル 東京 学数理 情報教育研究センター 北川源四郎 概要. 分散 定常モデル : 線形化 正規近似. 共分散 定常モデル : 時変係数モデル 3. 線形 ガウス型状態空間モデル 分散 共分散 定常 3 地震波 経 5 定常時系列のモデル 4. 平均 定常 トレンド, 季節調整. 分散 定常 線形 ガウスモデル ( カルマンフィルタ ) で推定するためには
Excelにおける回帰分析(最小二乗法)の手順と出力
の手順と出力") Microsoft Excel Excel 1 1 x y x y y = a + bx a b a x 1 3 x 0 1 30 31 y b log x α x α x β 4 version.01 008 3 30 Website:http://keijisaito.info, E-mail:master@keijisaito.info 1 Excel Excel.1 Excel Excel
Microsoft Excel Excel 1 1 x y x y y = a + bx a b a x 1 3 x 0 1 30 31 y b log x α x α x β 4 version.01 008 3 30 Website:http://keijisaito.info, E-mail:master@keijisaito.info 1 Excel Excel.1 Excel Excel
第 3 回講義の項目と概要 統計的手法入門 : 品質のばらつきを解析する 平均と標準偏差 (P30) a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均
 a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均") 第 3 回講義の項目と概要 016.8.9 1.3 統計的手法入門 : 品質のばらつきを解析する 1.3.1 平均と標準偏差 (P30) a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均 :AVERAGE 関数, 標準偏差 :STDEVP 関数とSTDEVという関数 1 取得したデータそのものの標準偏差
第 3 回講義の項目と概要 016.8.9 1.3 統計的手法入門 : 品質のばらつきを解析する 1.3.1 平均と標準偏差 (P30) a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均 :AVERAGE 関数, 標準偏差 :STDEVP 関数とSTDEVという関数 1 取得したデータそのものの標準偏差
相関分析・偏相関分析
 相関分析 偏相関分析 教育学研究科修士課程 1 回生 田中友香理 MENU 相関とは 相関分析とは ' パラメトリックな手法 ( Pearsonの相関係数について SPSSによる相関係数 偏相関係数 SPSSによる偏相関係数 順位相関係数とは ' ノンパラメトリックな手法 ( SPSS による順位相関係数 おまけ ' 時間があれば ( 回帰分析で2 変数間の関係を出す 曲線回帰分析を行う 相関とは
相関分析 偏相関分析 教育学研究科修士課程 1 回生 田中友香理 MENU 相関とは 相関分析とは ' パラメトリックな手法 ( Pearsonの相関係数について SPSSによる相関係数 偏相関係数 SPSSによる偏相関係数 順位相関係数とは ' ノンパラメトリックな手法 ( SPSS による順位相関係数 おまけ ' 時間があれば ( 回帰分析で2 変数間の関係を出す 曲線回帰分析を行う 相関とは
スライド 1
 WinBUGS 入門 水産資源学におけるベイズ統計の応用ワークショップ 2007 年 8 月 2-3 日, 中央水研 遠洋水産研究所外洋資源部 鯨類管理研究室 岡村寛 WinBUGS とは BUGS (Bayesian Inference Using Gibbs Sampling) の Windows バージョン フリーのソフトウェア Gibbs samplingを利用した事後確率からのサンプリングを行う
WinBUGS 入門 水産資源学におけるベイズ統計の応用ワークショップ 2007 年 8 月 2-3 日, 中央水研 遠洋水産研究所外洋資源部 鯨類管理研究室 岡村寛 WinBUGS とは BUGS (Bayesian Inference Using Gibbs Sampling) の Windows バージョン フリーのソフトウェア Gibbs samplingを利用した事後確率からのサンプリングを行う
<4D F736F F D20939D8C7689F090CD985F93C18EEA8D758B E646F63>
 Gretl OLS omitted variable omitted variable AIC,BIC a) gretl gretl sample file Greene greene8_3 Add Define new variable l_g_percapita=log(g/pop) Pg,Y,Pnc,Puc,Ppt,Pd,Pn,Ps Add logs of selected variables
Gretl OLS omitted variable omitted variable AIC,BIC a) gretl gretl sample file Greene greene8_3 Add Define new variable l_g_percapita=log(g/pop) Pg,Y,Pnc,Puc,Ppt,Pd,Pn,Ps Add logs of selected variables
Microsoft Word - Time Series Basic - Modeling.doc
 時系列解析入門 モデリング. 確率分布と統計的モデル が確率変数 (radom varable のとき すべての実数 R に対して となる確 率 Prob( が定められる これを の関数とみなして G( Prob ( とあらわすとき G( を確率変数 の分布関数 (probablt dstrbuto ucto と呼 ぶ 時系列解析で用いられる確率変数は通常連続型と呼ばれるもので その分布関数は (
時系列解析入門 モデリング. 確率分布と統計的モデル が確率変数 (radom varable のとき すべての実数 R に対して となる確 率 Prob( が定められる これを の関数とみなして G( Prob ( とあらわすとき G( を確率変数 の分布関数 (probablt dstrbuto ucto と呼 ぶ 時系列解析で用いられる確率変数は通常連続型と呼ばれるもので その分布関数は (
0 スペクトル 時系列データの前処理 法 平滑化 ( スムージング ) と微分 明治大学理 学部応用化学科 データ化学 学研究室 弘昌
 と微分 明治大学理 学部応用化学科 データ化学 学研究室 弘昌") 0 スペクトル 時系列データの前処理 法 平滑化 ( スムージング ) と微分 明治大学理 学部応用化学科 データ化学 学研究室 弘昌 スペクトルデータの特徴 1 波 ( 波数 ) が近いと 吸光度 ( 強度 ) の値も似ている ノイズが含まれる 吸光度 ( 強度 ) の極大値 ( ピーク ) 以外のデータも重要 時系列データの特徴 2 時刻が近いと プロセス変数の値も似ている ノイズが含まれる プロセス変数の極大値
0 スペクトル 時系列データの前処理 法 平滑化 ( スムージング ) と微分 明治大学理 学部応用化学科 データ化学 学研究室 弘昌 スペクトルデータの特徴 1 波 ( 波数 ) が近いと 吸光度 ( 強度 ) の値も似ている ノイズが含まれる 吸光度 ( 強度 ) の極大値 ( ピーク ) 以外のデータも重要 時系列データの特徴 2 時刻が近いと プロセス変数の値も似ている ノイズが含まれる プロセス変数の極大値
ビジネス統計 統計基礎とエクセル分析 正誤表
 ビジネス統計統計基礎とエクセル分析 ビジネス統計スペシャリスト エクセル分析スペシャリスト 公式テキスト正誤表と学習用データ更新履歴 平成 30 年 5 月 14 日現在 公式テキスト正誤表 頁場所誤正修正 6 知識編第 章 -3-3 最頻値の解説内容 たとえば, 表.1 のデータであれば, 最頻値は 167.5cm というたとえば, 表.1 のデータであれば, 最頻値は 165.0cm ということになります
ビジネス統計統計基礎とエクセル分析 ビジネス統計スペシャリスト エクセル分析スペシャリスト 公式テキスト正誤表と学習用データ更新履歴 平成 30 年 5 月 14 日現在 公式テキスト正誤表 頁場所誤正修正 6 知識編第 章 -3-3 最頻値の解説内容 たとえば, 表.1 のデータであれば, 最頻値は 167.5cm というたとえば, 表.1 のデータであれば, 最頻値は 165.0cm ということになります
ベイズ統計入門
 ベイズ統計入門 条件付確率 事象 F が起こったことが既知であるという条件の下で E が起こる確率を条件付確率 (codtoal probablt) という P ( E F ) P ( E F ) P( F ) 定義式を変形すると 確率の乗法公式となる ( E F ) P( F ) P( E F ) P( E) P( F E) P 事象の独立 ある事象の生起する確率が 他のある事象が生起するかどうかによって変化しないとき
ベイズ統計入門 条件付確率 事象 F が起こったことが既知であるという条件の下で E が起こる確率を条件付確率 (codtoal probablt) という P ( E F ) P ( E F ) P( F ) 定義式を変形すると 確率の乗法公式となる ( E F ) P( F ) P( E F ) P( E) P( F E) P 事象の独立 ある事象の生起する確率が 他のある事象が生起するかどうかによって変化しないとき
: Bradley-Terry Burczyk
 58 (W15) 2011 03 09 kubo@ees.hokudai.ac.jp http://goo.gl/edzle 2011 03 09 (2011 03 09 19 :32 ) : Bradley-Terry Burczyk ? ( ) 1999 2010 9 R : 7 (1) 8 7??! 15 http://www.atmarkit.co.jp/fcoding/articles/stat/07/stat07a.html
58 (W15) 2011 03 09 kubo@ees.hokudai.ac.jp http://goo.gl/edzle 2011 03 09 (2011 03 09 19 :32 ) : Bradley-Terry Burczyk ? ( ) 1999 2010 9 R : 7 (1) 8 7??! 15 http://www.atmarkit.co.jp/fcoding/articles/stat/07/stat07a.html
最小2乗法
 2 2012 4 ( ) 2 2012 4 1 / 42 X Y Y = f (X ; Z) linear regression model X Y slope X 1 Y (X, Y ) 1 (X, Y ) ( ) 2 2012 4 2 / 42 1 β = β = β (4.2) = β 0 + β (4.3) ( ) 2 2012 4 3 / 42 = β 0 + β + (4.4) ( )
2 2012 4 ( ) 2 2012 4 1 / 42 X Y Y = f (X ; Z) linear regression model X Y slope X 1 Y (X, Y ) 1 (X, Y ) ( ) 2 2012 4 2 / 42 1 β = β = β (4.2) = β 0 + β (4.3) ( ) 2 2012 4 3 / 42 = β 0 + β + (4.4) ( )
International Classification of Diseases (ICD) について :[3][4] Standard diagnostic tool for epidemiology, health management and clinical purposes. This i
![International Classification of Diseases (ICD) について :[3][4] Standard diagnostic tool for epidemiology, health management and clinical purposes. This i](/thumbs/59/42972277.jpg "International Classification of Diseases (ICD) について :[3][4] Standard diagnostic tool for epidemiology, health management and clinical purposes. This i") 季節性インフルエンザの疾病負荷推定 Estimating the disease burden associated with seasonal influenza in Japan 東京大学大学院 総合文化研究科水本憲治 Kenji Mizumoto Graduate School of Arts and Sciences, The University of Tokyo はじめに インフルエンザは毎年流行し
季節性インフルエンザの疾病負荷推定 Estimating the disease burden associated with seasonal influenza in Japan 東京大学大学院 総合文化研究科水本憲治 Kenji Mizumoto Graduate School of Arts and Sciences, The University of Tokyo はじめに インフルエンザは毎年流行し
Medical3
 Chapter 1 1.4.1 1 元配置分散分析と多重比較の実行 3つの治療法による測定値に有意な差が認められるかどうかを分散分析で調べます この例では 因子が1つだけ含まれるため1 元配置分散分析 one-way ANOVA の適用になります また 多重比較法 multiple comparison procedure を用いて 具体的のどの治療法の間に有意差が認められるかを検定します 1. 分析メニュー
Chapter 1 1.4.1 1 元配置分散分析と多重比較の実行 3つの治療法による測定値に有意な差が認められるかどうかを分散分析で調べます この例では 因子が1つだけ含まれるため1 元配置分散分析 one-way ANOVA の適用になります また 多重比較法 multiple comparison procedure を用いて 具体的のどの治療法の間に有意差が認められるかを検定します 1. 分析メニュー
当し 図 6. のように 2 分類 ( 疾患の有無 ) のデータを直線の代わりにシグモイド曲線 (S 字状曲線 ) で回帰する手法である ちなみに 直線で回帰する手法はコクラン アーミテージの傾向検定 疾患の確率 x : リスクファクター 図 6. ロジスティック曲線と回帰直線 疾患が発
 のデータを直線の代わりにシグモイド曲線 (S 字状曲線 ) で回帰する手法である ちなみに 直線で回帰する手法はコクラン アーミテージの傾向検定 疾患の確率 x : リスクファクター 図 6. ロジスティック曲線と回帰直線 疾患が発") 6.. ロジスティック回帰分析 6. ロジスティック回帰分析の原理 ロジスティック回帰分析は判別分析を前向きデータ用にした手法 () ロジスティックモデル 疾患が発症するかどうかをリスクファクターから予想したいまたは疾患のリスクファクターを検討したい 判別分析は後ろ向きデータ用だから前向きデータ用にする必要がある ロジスティック回帰分析を適用ロジスティック回帰分析 ( ロジット回帰分析 ) は 判別分析をロジスティック曲線によって前向き研究から得られたデータ用にした手法
6.. ロジスティック回帰分析 6. ロジスティック回帰分析の原理 ロジスティック回帰分析は判別分析を前向きデータ用にした手法 () ロジスティックモデル 疾患が発症するかどうかをリスクファクターから予想したいまたは疾患のリスクファクターを検討したい 判別分析は後ろ向きデータ用だから前向きデータ用にする必要がある ロジスティック回帰分析を適用ロジスティック回帰分析 ( ロジット回帰分析 ) は 判別分析をロジスティック曲線によって前向き研究から得られたデータ用にした手法
Microsoft PowerPoint - SDF2007_nakanishi_2.ppt[読み取り専用]
![Microsoft PowerPoint - SDF2007_nakanishi_2.ppt[読み取り専用]](/thumbs/94/118227082.jpg "Microsoft PowerPoint - SDF2007_nakanishi_2.ppt[読み取り専用]") ばらつきの計測と解析技術 7 年 月 日設計基盤開発部先端回路技術グループ中西甚吾 内容. はじめに. DMA(Device Matrix Array)-TEG. チップ間 チップ内ばらつきの比較. ばらつきの成分分離. 各ばらつき成分の解析. まとめ . はじめに 背景 スケーリングにともない さまざまなばらつきの現象が顕著化しており この先ますます設計困難化が予想される EDA ツール 回路方式
ばらつきの計測と解析技術 7 年 月 日設計基盤開発部先端回路技術グループ中西甚吾 内容. はじめに. DMA(Device Matrix Array)-TEG. チップ間 チップ内ばらつきの比較. ばらつきの成分分離. 各ばらつき成分の解析. まとめ . はじめに 背景 スケーリングにともない さまざまなばらつきの現象が顕著化しており この先ますます設計困難化が予想される EDA ツール 回路方式
ファイナンスのための数学基礎 第1回 オリエンテーション、ベクトル
 時系列分析 変量時系列モデルとその性質 担当 : 長倉大輔 ( ながくらだいすけ 時系列モデル 時系列モデルとは時系列データを生み出すメカニズムとなるものである これは実際には未知である 私たちにできるのは観測された時系列データからその背後にある時系列モデルを推測 推定するだけである 以下ではいくつかの代表的な時系列モデルを考察する 自己回帰モデル (Auoregressive Model もっとも頻繁に使われる時系列モデルは自己回帰モデル
時系列分析 変量時系列モデルとその性質 担当 : 長倉大輔 ( ながくらだいすけ 時系列モデル 時系列モデルとは時系列データを生み出すメカニズムとなるものである これは実際には未知である 私たちにできるのは観測された時系列データからその背後にある時系列モデルを推測 推定するだけである 以下ではいくつかの代表的な時系列モデルを考察する 自己回帰モデル (Auoregressive Model もっとも頻繁に使われる時系列モデルは自己回帰モデル
R による共和分分析 1. 共和分分析を行う 1.1 パッケージ urca インスツールする 共和分分析をするために R のパッケージ urca をインスツールする パッケージとは通常の R には含まれていない 追加的な R のコマンドの集まりのようなものである R には追加的に 600 以上のパッ
 R による共和分分析 1. 共和分分析を行う 1.1 パッケージ urca インスツールする 共和分分析をするために R のパッケージ urca をインスツールする パッケージとは通常の R には含まれていない 追加的な R のコマンドの集まりのようなものである R には追加的に 600 以上のパッケージが用意されており それぞれ分析の目的に応じて標準の R にパッケージを追加していくことになる インターネットに接続してあるパソコンで
R による共和分分析 1. 共和分分析を行う 1.1 パッケージ urca インスツールする 共和分分析をするために R のパッケージ urca をインスツールする パッケージとは通常の R には含まれていない 追加的な R のコマンドの集まりのようなものである R には追加的に 600 以上のパッケージが用意されており それぞれ分析の目的に応じて標準の R にパッケージを追加していくことになる インターネットに接続してあるパソコンで
Microsoft Word - 計量研修テキスト_第5版).doc
.doc") Q9-1 テキスト P166 2)VAR の推定 注 ) 各変数について ADF 検定を行った結果 和文の次数はすべて 1 である 作業手順 4 情報量基準 (AIC) によるラグ次数の選択 VAR Lag Order Selection Criteria Endogenous variables: D(IG9S) D(IP9S) D(CP9S) Exogenous variables: C Date:
Q9-1 テキスト P166 2)VAR の推定 注 ) 各変数について ADF 検定を行った結果 和文の次数はすべて 1 である 作業手順 4 情報量基準 (AIC) によるラグ次数の選択 VAR Lag Order Selection Criteria Endogenous variables: D(IG9S) D(IP9S) D(CP9S) Exogenous variables: C Date:
横浜市環境科学研究所
 周期時系列の統計解析 単回帰分析 io 8 年 3 日 周期時系列に季節調整を行わないで単回帰分析を適用すると, 回帰係数には周期成分の影響が加わる. ここでは, 周期時系列をコサイン関数モデルで近似し単回帰分析によりモデルの回帰係数を求め, 周期成分の影響を検討した. また, その結果を気温時系列に当てはめ, 課題等について考察した. 気温時系列とコサイン関数モデル第 報の結果を利用するので, その一部を再掲する.
周期時系列の統計解析 単回帰分析 io 8 年 3 日 周期時系列に季節調整を行わないで単回帰分析を適用すると, 回帰係数には周期成分の影響が加わる. ここでは, 周期時系列をコサイン関数モデルで近似し単回帰分析によりモデルの回帰係数を求め, 周期成分の影響を検討した. また, その結果を気温時系列に当てはめ, 課題等について考察した. 気温時系列とコサイン関数モデル第 報の結果を利用するので, その一部を再掲する.
Microsoft PowerPoint - Econometrics pptx
 計量経済学講義 第 4 回回帰モデルの診断と選択 Part 07 年 ( ) 限 担当教員 : 唐渡 広志 研究室 : 経済学研究棟 4 階 43 号室 emal: kkarato@eco.u-toyama.ac.p webste: http://www3.u-toyama.ac.p/kkarato/ 講義の目的 誤差項の分散が不均 である場合や, 系列相関を持つ場合についての検定 法と修正 法を学びます
計量経済学講義 第 4 回回帰モデルの診断と選択 Part 07 年 ( ) 限 担当教員 : 唐渡 広志 研究室 : 経済学研究棟 4 階 43 号室 emal: kkarato@eco.u-toyama.ac.p webste: http://www3.u-toyama.ac.p/kkarato/ 講義の目的 誤差項の分散が不均 である場合や, 系列相関を持つ場合についての検定 法と修正 法を学びます
第11回:線形回帰モデルのOLS推定
 11 OLS 2018 7 13 1 / 45 1. 2. 3. 2 / 45 n 2 ((y 1, x 1 ), (y 2, x 2 ),, (y n, x n )) linear regression model y i = β 0 + β 1 x i + u i, E(u i x i ) = 0, E(u i u j x i ) = 0 (i j), V(u i x i ) = σ 2, i
11 OLS 2018 7 13 1 / 45 1. 2. 3. 2 / 45 n 2 ((y 1, x 1 ), (y 2, x 2 ),, (y n, x n )) linear regression model y i = β 0 + β 1 x i + u i, E(u i x i ) = 0, E(u i u j x i ) = 0 (i j), V(u i x i ) = σ 2, i
スライド 1
 ベイジアンモデルによる地域人口予測モデルの可能性について 片桐智志 1 山下諭史 1 ( 1 ネイチャーインサイト株式会社 ) The possibility of regional population forecasting model by Bayesian model KATAGIRI, Satoshi 1 YAMASHITA, Satoshi 1 1 Nature Insight Co.,
ベイジアンモデルによる地域人口予測モデルの可能性について 片桐智志 1 山下諭史 1 ( 1 ネイチャーインサイト株式会社 ) The possibility of regional population forecasting model by Bayesian model KATAGIRI, Satoshi 1 YAMASHITA, Satoshi 1 1 Nature Insight Co.,

解答のポイント 第 1 章問 1 ポイント仮に1 年生全員の数が 100 人であったとする.100 人全員に数学の試験を課して, それらの 100 人の個人個人の点数が母集団となる. 問 2 ポイント仮に10 人を抽出するとする. 学生に1から 100 までの番号を割り当てたとする. 箱の中に番号札
 解答のポイント 第 1 章問 1 ポイント仮に1 年生全員の数が 100 人であったとする.100 人全員に数学の試験を課して, それらの 100 人の個人個人の点数が母集団となる. 問 2 ポイント仮に10 人を抽出するとする. 学生に1から 100 までの番号を割り当てたとする. 箱の中に番号札を入れまず1 枚取り出す ( 仮に1 番とする ). 最初に1 番の学生を選ぶ. その1 番の札を箱の中に戻し,
解答のポイント 第 1 章問 1 ポイント仮に1 年生全員の数が 100 人であったとする.100 人全員に数学の試験を課して, それらの 100 人の個人個人の点数が母集団となる. 問 2 ポイント仮に10 人を抽出するとする. 学生に1から 100 までの番号を割り当てたとする. 箱の中に番号札を入れまず1 枚取り出す ( 仮に1 番とする ). 最初に1 番の学生を選ぶ. その1 番の札を箱の中に戻し,
スライド 1
 計測工学第 12 回以降 測定値の誤差と精度編 2014 年 7 月 2 日 ( 水 )~7 月 16 日 ( 水 ) 知能情報工学科 横田孝義 1 授業計画 4/9 4/16 4/23 5/7 5/14 5/21 5/28 6/4 6/11 6/18 6/25 7/2 7/9 7/16 7/23 2 誤差とその取扱い 3 誤差 = 測定値 真の値 相対誤差 = 誤差 / 真の値 4 誤差 (error)
計測工学第 12 回以降 測定値の誤差と精度編 2014 年 7 月 2 日 ( 水 )~7 月 16 日 ( 水 ) 知能情報工学科 横田孝義 1 授業計画 4/9 4/16 4/23 5/7 5/14 5/21 5/28 6/4 6/11 6/18 6/25 7/2 7/9 7/16 7/23 2 誤差とその取扱い 3 誤差 = 測定値 真の値 相対誤差 = 誤差 / 真の値 4 誤差 (error)
みっちりGLM
 2015/3/27 12:00-13:00 日本草地学会若手 R 統計企画 ( 信州大学農学部 ) R と一般化線形モデル入門 山梨県富士山科学研究所 安田泰輔 謝辞 : 日本草地学会若手の会の皆様 発表の機会を頂き たいへんありがとうございます! 茨城大学 学生時代 自己紹介 ベータ二項分布を用いた種の空間分布の解析 所属 : 山梨県富士山科学研究所 最近の研究テーマ 近接リモートセンシングによる半自然草地のモニタリング手法開発
2015/3/27 12:00-13:00 日本草地学会若手 R 統計企画 ( 信州大学農学部 ) R と一般化線形モデル入門 山梨県富士山科学研究所 安田泰輔 謝辞 : 日本草地学会若手の会の皆様 発表の機会を頂き たいへんありがとうございます! 茨城大学 学生時代 自己紹介 ベータ二項分布を用いた種の空間分布の解析 所属 : 山梨県富士山科学研究所 最近の研究テーマ 近接リモートセンシングによる半自然草地のモニタリング手法開発
と入力する すると最初の 25 行が表示される 1 行目は変数の名前であり 2 列目は企業番号 (1,,10),3 列目は西暦 (1935,,1954) を表している ( 他のパネルデータを分析する際もデ ータをこのように並べておかなくてはならない つまりまず i=1 を固定し i=1 の t に関
,3 列目は西暦 (1935,,1954) を表している ( 他のパネルデータを分析する際もデ ータをこのように並べておかなくてはならない つまりまず i=1 を固定し i=1 の t に関") R によるパネルデータモデルの推定 R を用いて 静学的パネルデータモデルに対して Pooled OLS, LSDV (Least Squares Dummy Variable) 推定 F 検定 ( 個別効果なしの F 検定 ) GLS(Generalized Least Square : 一般化最小二乗 ) 法による推定 およびハウスマン検定を行うやり方を 動学的パネルデータモデルに対して 1 階階差
R によるパネルデータモデルの推定 R を用いて 静学的パネルデータモデルに対して Pooled OLS, LSDV (Least Squares Dummy Variable) 推定 F 検定 ( 個別効果なしの F 検定 ) GLS(Generalized Least Square : 一般化最小二乗 ) 法による推定 およびハウスマン検定を行うやり方を 動学的パネルデータモデルに対して 1 階階差
PowerPoint プレゼンテーション
 データ解析 第 7 回 : 時系列分析 渡辺澄夫 過去から未来を予測する 観測データ 回帰 判別分析 解析方法 主成分 因子 クラスタ分析 時系列予測 時系列を予測する 無限個の確率変数 ( 確率変数が作る無限数列 ){X(t) ; t は整数 } を生成する情報源を考える {X(t)} を確率過程という 確率過程に ついて過去の値から未来を予測するにはどうしたらよいだろうか X(t-K),X(t-K+1),,X(t-1)
データ解析 第 7 回 : 時系列分析 渡辺澄夫 過去から未来を予測する 観測データ 回帰 判別分析 解析方法 主成分 因子 クラスタ分析 時系列予測 時系列を予測する 無限個の確率変数 ( 確率変数が作る無限数列 ){X(t) ; t は整数 } を生成する情報源を考える {X(t)} を確率過程という 確率過程に ついて過去の値から未来を予測するにはどうしたらよいだろうか X(t-K),X(t-K+1),,X(t-1)
Chapter 1 Epidemiological Terminology
 Appendix Real examples of statistical analysis 検定 偶然を超えた差なら有意差という P
Appendix Real examples of statistical analysis 検定 偶然を超えた差なら有意差という P
要旨 1. 始めに PCA 2. 不偏分散, 分散, 共分散 N N 49
 要旨 1. 始めに PCA 2. 不偏分散, 分散, 共分散 N N 49 N N Web x x y x x x y x y x y N 三井信宏 : 統計の落とし穴と蜘蛛の糸,https://www.yodosha.co.jp/jikkenigaku/statistics_pitfall/pitfall_.html 50 標本分散 不偏分散 図 1: 不偏分散のほうが母集団の分散に近付くことを示すシミュレーション
要旨 1. 始めに PCA 2. 不偏分散, 分散, 共分散 N N 49 N N Web x x y x x x y x y x y N 三井信宏 : 統計の落とし穴と蜘蛛の糸,https://www.yodosha.co.jp/jikkenigaku/statistics_pitfall/pitfall_.html 50 標本分散 不偏分散 図 1: 不偏分散のほうが母集団の分散に近付くことを示すシミュレーション
アダストリア売り上げデータによる 現状把握と今後の方針 東海大学情報通信学部経営システム工学科佐藤健太
 アダストリア売り上げデータによる 現状把握と今後の方針 東海大学情報通信学部経営システム工学科佐藤健太 目次 1. 研究背景 2. 研究目的 3. データ概要 4. 分析手順 5. 分析結果 6. 戦略予想 7. まとめ 8. 今後の課題 参考文献 2016/10/27 2016 年 S-PLUS &Visual R Platform 学生研究奨励賞 1 1. 研究背景 Ⅰ アダストリア (¹) とは,
アダストリア売り上げデータによる 現状把握と今後の方針 東海大学情報通信学部経営システム工学科佐藤健太 目次 1. 研究背景 2. 研究目的 3. データ概要 4. 分析手順 5. 分析結果 6. 戦略予想 7. まとめ 8. 今後の課題 参考文献 2016/10/27 2016 年 S-PLUS &Visual R Platform 学生研究奨励賞 1 1. 研究背景 Ⅰ アダストリア (¹) とは,
スライド 1
 2016 年 4 月 26 日 @ 統計モデリング 統計モデリング 第三回配布資料 文献 : A. J. Dobson and A. G. Barnett: An Introducton to Generalzed Lnear Models. 3rd ed., CRC Press. J. J. Farawa: Extendng the Lnear Model wth R. CRC Press. 配布資料の
2016 年 4 月 26 日 @ 統計モデリング 統計モデリング 第三回配布資料 文献 : A. J. Dobson and A. G. Barnett: An Introducton to Generalzed Lnear Models. 3rd ed., CRC Press. J. J. Farawa: Extendng the Lnear Model wth R. CRC Press. 配布資料の
Stata11 whitepapers mwp-037 regress - regress regress. regress mpg weight foreign Source SS df MS Number of obs = 74 F(
 mwp-037 regress - regress 1. 1.1 1.2 1.3 2. 3. 4. 5. 1. regress. regress mpg weight foreign Source SS df MS Number of obs = 74 F( 2, 71) = 69.75 Model 1619.2877 2 809.643849 Prob > F = 0.0000 Residual
mwp-037 regress - regress 1. 1.1 1.2 1.3 2. 3. 4. 5. 1. regress. regress mpg weight foreign Source SS df MS Number of obs = 74 F( 2, 71) = 69.75 Model 1619.2877 2 809.643849 Prob > F = 0.0000 Residual
2 値データの Intraclass Correlation Coefficient の推定マクロプログラム 稲葉洋介 1 田中紀子 1 1 国立国際医療研究センターデータサイエンス部生物統計研究室 Macro program for calculating Intraclass Correlati
 2 値データの Intraclass Correlation Coefficient の推定マクロプログラム 稲葉洋介 1 田中紀子 1 1 国立国際医療研究センターデータサイエンス部生物統計研究室 Macro program for calculating Intraclass Correlation Coefficient for binary data Yosuke Inaba, Noriko
2 値データの Intraclass Correlation Coefficient の推定マクロプログラム 稲葉洋介 1 田中紀子 1 1 国立国際医療研究センターデータサイエンス部生物統計研究室 Macro program for calculating Intraclass Correlation Coefficient for binary data Yosuke Inaba, Noriko