WinHPC ppt
|
|
|
- けいしょう とりこし
- 5 years ago
- Views:
Transcription
1 MPI.NET C#
2 MPI.NET MPI.NET C#
3 MPI.NET C# MPI MPI.NET 1 1 MPI.NET C# Hello World
4 MPI.NET.NET Framework.NET C# API
5 C# Microsoft.NET java.net (Visual Basic.NET Visual C++)
; } }")
6 C# class Helloworld // { public static void Main() // { // System.Console.Write( Hello World\n ); } }
7 MPI Message Passing Interface MPI MPI-1 MPI-2 2 MPI.NET MPICH MPICH2 LAM/MPI MS-MPI Ver NET C# C, C++, fortran

8 MPI 1 1 ID
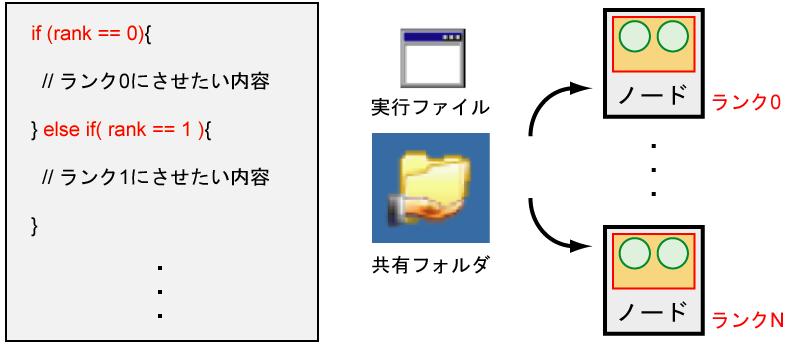
9 1 if else
10 C# Visual Studio 2008 Visual C# 2008 Express Edition.NET.NET Framework 3.5 MPI.NET MPI.NET SDK 1.0 OS Windows HPC Server 2008 HPC Pack 2008 SDK Microsoft Compute Cluster Server 2003 Microsoft Compute Cluster Pack SDK
11 MPI.NET 1 1 Send Receive ImmediateSend ImmediateReceive Barrier Gather Broadcast Reduce
12 Send Receive ImmediateSend ImmediateReceive
13 Send public void Send<T>(value, dest, tag) value dest tag int if (comm.rank == 0) { string value = Windows ; comm.send(value, 1, 9); }
14 Receive public T Receive<T>(source, tag) source tag int if (comm.rank == 0) { string value = Windows ; comm.send(value, 1, 9); } else if(comm.rank == 1) { string msg = comm.receive<string>(0, 9); } Console.Write(msg);

15 (1/2) 1. Visual Studio > ->

16 (2/2) Message Passing Interface
17 1 1 (1/2) HelloWorld 0 1 using System; using MPI; // MPI class Helloworld { static void Main(string[] args) { // MPI using (new MPI.Environment(ref args)) { MPI } } }
18 1 1 (2/2) // Intracommunicator comm = Communicator.world; int tag = 9; // if (comm.rank == 0) { comm.send( HelloWorld, 1, tag); // 1 } else if(comm.rank == 1) { string msg = comm.receive<string>(0, tag); // 0 Console.Write(msg); }
 /numcores:( ) /workdir:( )")
19 & Shift + F6 -> PowerShell > job submit /scheduler:( ) /numcores:( ) /workdir:( ) mpiexec ( )
20 C mpich (1/2) #include <stdio.h> #include <string.h> #include <mpi.h> // using MPI int main(int argc, char *argv[]) { char msg[20]; // int rank; // int tag = 9; // new MPI.Environment(ref args) MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank);
21 C mpich (2/2) if (rank == 0) { sprintf(msg, HelloWorld ); MPI_Send(msg, strlen(msg), MPI_CHAR, 1, tag, MPI_COMM_WORLD); } else if(rank == 1) { MPI_Status status; MPI_Recv(msg, 20, MPI_CHAR, 0, tag, MPI_COMM_WORLD, &status); } } printf( %s\n, msg); MPI_Finalize(); return 0;
22 MPI.NET mpich MPI.NET comm.send(value, dest, tag) 3 4 mpich MPI_Send(void *msg, int count, MPI_Datatype datatype, int dest, int tag, MPI_COMM comm) msg count MPI_Datatype dest tag comm 6
23 for(i=0; i<num; i++){ comm.send( HelloWorld, i, tag); } MPI one-to-all, all-to-one, all-to-all
 1 ref T")
24 : one to all public void Broadcast<T>(ref T value, root) 1 ref T value root root
25 : all to one public T[] Gather<T>(value, root) value root root
26 : Reduction( ) public T Reduce<T>(value, Operation, root) value Opration root root

27 (1/3) -1 1 = 4
28 (2/3) Reduce 3. 0 Reduce
29 (3/3) Random random = new Random(comm.Rank); // int num = 10000; // int count = 0; // for (int i = 0; i < num; ++i) { double x = (random.nextdouble() - 0.5) * 2; double y = (random.nextdouble() - 0.5) * 2; if (x * x + y * y <= 1.0) ++ count; } int total = comm.reduce(count, Operation<int>.Add, 0); if (comm.rank == 0) Pi = 4*(double) total/(comm.size*(double)num));
30 C# MPI.NET MPI.NET MPI.NET C#
31 MPI.NET( ) MPI.NET ation/reference/current/index.html
MPI MPI MPI.NET C# MPI Version2
 MPI.NET C# 2 2009 2 27 MPI MPI MPI.NET C# MPI Version2 MPI (Message Passing Interface) MPI MPI Version 1 1994 1 1 1 1 ID MPI MPI_Send MPI_Recv if(rank == 0){ // 0 MPI_Send(); } else if(rank == 1){ // 1
MPI.NET C# 2 2009 2 27 MPI MPI MPI.NET C# MPI Version2 MPI (Message Passing Interface) MPI MPI Version 1 1994 1 1 1 1 ID MPI MPI_Send MPI_Recv if(rank == 0){ // 0 MPI_Send(); } else if(rank == 1){ // 1
目 目 用方 用 用 方
 大 生 大 工 目 目 用方 用 用 方 用 方 MS-MPI MPI.NET MPICH MPICH2 LAM/MPI Ver. 2 2 1 2 1 C C++ Fortan.NET C# C C++ Fortan 用 行 用 用 用 行 用 言 言 言 行 生 方 方 一 行 高 行 行 文 用 行 If ( rank == 0 ) { // 0 } else if (rank == 1) {
大 生 大 工 目 目 用方 用 用 方 用 方 MS-MPI MPI.NET MPICH MPICH2 LAM/MPI Ver. 2 2 1 2 1 C C++ Fortan.NET C# C C++ Fortan 用 行 用 用 用 行 用 言 言 言 行 生 方 方 一 行 高 行 行 文 用 行 If ( rank == 0 ) { // 0 } else if (rank == 1) {
NUMAの構成
 メッセージパッシング プログラミング 天野 共有メモリ対メッセージパッシング 共有メモリモデル 共有変数を用いた単純な記述自動並列化コンパイラ簡単なディレクティブによる並列化 :OpenMP メッセージパッシング 形式検証が可能 ( ブロッキング ) 副作用がない ( 共有変数は副作用そのもの ) コストが小さい メッセージパッシングモデル 共有変数は使わない 共有メモリがないマシンでも実装可能 クラスタ
メッセージパッシング プログラミング 天野 共有メモリ対メッセージパッシング 共有メモリモデル 共有変数を用いた単純な記述自動並列化コンパイラ簡単なディレクティブによる並列化 :OpenMP メッセージパッシング 形式検証が可能 ( ブロッキング ) 副作用がない ( 共有変数は副作用そのもの ) コストが小さい メッセージパッシングモデル 共有変数は使わない 共有メモリがないマシンでも実装可能 クラスタ
para02-2.dvi
 2002 2 2002 4 23 : MPI MPI 1 MPI MPI(Message Passing Interface) MPI UNIX Windows Machintosh OS, MPI 2 1 1 2 2.1 1 1 1 1 1 1 Fig. 1 A B C F Fig. 2 A B F Fig. 1 1 1 Fig. 2 2.2 Fig. 3 1 . Fig. 4 Fig. 3 Fig.
2002 2 2002 4 23 : MPI MPI 1 MPI MPI(Message Passing Interface) MPI UNIX Windows Machintosh OS, MPI 2 1 1 2 2.1 1 1 1 1 1 1 Fig. 1 A B C F Fig. 2 A B F Fig. 1 1 1 Fig. 2 2.2 Fig. 3 1 . Fig. 4 Fig. 3 Fig.
Microsoft PowerPoint - KHPCSS pptx
 KOBE HPC サマースクール 2018( 初級 ) 9. 1 対 1 通信関数, 集団通信関数 2018/8/8 KOBE HPC サマースクール 2018 1 2018/8/8 KOBE HPC サマースクール 2018 2 MPI プログラム (M-2):1 対 1 通信関数 問題 1 から 100 までの整数の和を 2 並列で求めなさい. プログラムの方針 プロセス0: 1から50までの和を求める.
KOBE HPC サマースクール 2018( 初級 ) 9. 1 対 1 通信関数, 集団通信関数 2018/8/8 KOBE HPC サマースクール 2018 1 2018/8/8 KOBE HPC サマースクール 2018 2 MPI プログラム (M-2):1 対 1 通信関数 問題 1 から 100 までの整数の和を 2 並列で求めなさい. プログラムの方針 プロセス0: 1から50までの和を求める.
2 T 1 N n T n α = T 1 nt n (1) α = 1 100% OpenMP MPI OpenMP OpenMP MPI (Message Passing Interface) MPI MPICH OpenMPI 1 OpenMP MPI MPI (trivial p
 α = 1 100% OpenMP MPI OpenMP OpenMP MPI (Message Passing Interface) MPI MPICH OpenMPI 1 OpenMP MPI MPI (trivial p") 22 6 22 MPI MPI 1 1 2 2 3 MPI 3 4 7 4.1.................................. 7 4.2 ( )................................ 10 4.3 (Allreduce )................................. 12 5 14 5.1........................................
22 6 22 MPI MPI 1 1 2 2 3 MPI 3 4 7 4.1.................................. 7 4.2 ( )................................ 10 4.3 (Allreduce )................................. 12 5 14 5.1........................................
±é½¬£²¡§£Í£Ð£É½éÊâ
 2012 8 7 1 / 52 MPI Hello World I ( ) Hello World II ( ) I ( ) II ( ) ( sendrecv) π ( ) MPI fortran C wget http://www.na.scitec.kobe-u.ac.jp/ yaguchi/riken2012/enshu2.zip unzip enshu2.zip 2 / 52 FORTRAN
2012 8 7 1 / 52 MPI Hello World I ( ) Hello World II ( ) I ( ) II ( ) ( sendrecv) π ( ) MPI fortran C wget http://www.na.scitec.kobe-u.ac.jp/ yaguchi/riken2012/enshu2.zip unzip enshu2.zip 2 / 52 FORTRAN
スライド 1
 目次 2.MPI プログラミング入門 この資料は, スーパーコン 10 で使用したものである. ごく基本的な内容なので, 現在でも十分利用できると思われるものなので, ここに紹介させて頂く. ただし, 古い情報も含まれているので注意が必要である. 今年度版の解説は, 本選の初日に配布する予定である. 1/20 2.MPI プログラミング入門 (1) 基本 説明 MPI (message passing
目次 2.MPI プログラミング入門 この資料は, スーパーコン 10 で使用したものである. ごく基本的な内容なので, 現在でも十分利用できると思われるものなので, ここに紹介させて頂く. ただし, 古い情報も含まれているので注意が必要である. 今年度版の解説は, 本選の初日に配布する予定である. 1/20 2.MPI プログラミング入門 (1) 基本 説明 MPI (message passing
44 6 MPI 4 : #LIB=-lmpich -lm 5 : LIB=-lmpi -lm 7 : mpi1: mpi1.c 8 : $(CC) -o mpi1 mpi1.c $(LIB) 9 : 10 : clean: 11 : -$(DEL) mpi1 make mpi1 1 % mpiru
 -o mpi1 mpi1.c $(LIB) 9 : 10 : clean: 11 : -$(DEL) mpi1 make mpi1 1 % mpiru") 43 6 MPI MPI(Message Passing Interface) MPI 1CPU/1 PC Cluster MPICH[5] 6.1 MPI MPI MPI 1 : #include 2 : #include 3 : #include 4 : 5 : #include "mpi.h" 7 : int main(int argc,
43 6 MPI MPI(Message Passing Interface) MPI 1CPU/1 PC Cluster MPICH[5] 6.1 MPI MPI MPI 1 : #include 2 : #include 3 : #include 4 : 5 : #include "mpi.h" 7 : int main(int argc,
Microsoft PowerPoint - 演習2:MPI初歩.pptx
 演習 2:MPI 初歩 - 並列に計算する - 2013 年 8 月 6 日 神戸大学大学院システム情報学研究科計算科学専攻横川三津夫 MPI( メッセージ パッシング インターフェース ) を使おう! [ 演習 2 の内容 ] はじめの一歩課題 1: Hello, world を並列に出力する. 課題 2: プロセス 0 からのメッセージを受け取る (1 対 1 通信 ). 部分に分けて計算しよう課題
演習 2:MPI 初歩 - 並列に計算する - 2013 年 8 月 6 日 神戸大学大学院システム情報学研究科計算科学専攻横川三津夫 MPI( メッセージ パッシング インターフェース ) を使おう! [ 演習 2 の内容 ] はじめの一歩課題 1: Hello, world を並列に出力する. 課題 2: プロセス 0 からのメッセージを受け取る (1 対 1 通信 ). 部分に分けて計算しよう課題
MPI usage
 MPI (Version 0.99 2006 11 8 ) 1 1 MPI ( Message Passing Interface ) 1 1.1 MPI................................. 1 1.2............................... 2 1.2.1 MPI GATHER.......................... 2 1.2.2
MPI (Version 0.99 2006 11 8 ) 1 1 MPI ( Message Passing Interface ) 1 1.1 MPI................................. 1 1.2............................... 2 1.2.1 MPI GATHER.......................... 2 1.2.2
演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 RIKEN AICS HPC Spring School /3/5
 演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
Microsoft PowerPoint - 講義:片方向通信.pptx
 MPI( 片方向通信 ) 09 年 3 月 5 日 神戸大学大学院システム情報学研究科計算科学専攻横川三津夫 09/3/5 KOBE HPC Spring School 09 分散メモリ型並列計算機 複数のプロセッサがネットワークで接続されており, れぞれのプロセッサ (PE) が, メモリを持っている. 各 PE が自分のメモリ領域のみアクセス可能 特徴数千から数万 PE 規模の並列システムが可能
MPI( 片方向通信 ) 09 年 3 月 5 日 神戸大学大学院システム情報学研究科計算科学専攻横川三津夫 09/3/5 KOBE HPC Spring School 09 分散メモリ型並列計算機 複数のプロセッサがネットワークで接続されており, れぞれのプロセッサ (PE) が, メモリを持っている. 各 PE が自分のメモリ領域のみアクセス可能 特徴数千から数万 PE 規模の並列システムが可能
chap2.ppt
 2. メッセージ通信計算 2.1 メッセージ通信プログラミングの基本 プログラミングの選択肢 特別な並列プログラミング言語を設計する occam (Inmos, 1984, 1986) 既存の逐次言語の文法 / 予約語をメッセージ通信を処理できるように拡張する 既存の逐次言語を用い メッセージ通信のための拡張手続のライブラリを用意する どのプロセスを実行するのか メッセージ通信のタイミング 中身を明示的に指定する必要がある
2. メッセージ通信計算 2.1 メッセージ通信プログラミングの基本 プログラミングの選択肢 特別な並列プログラミング言語を設計する occam (Inmos, 1984, 1986) 既存の逐次言語の文法 / 予約語をメッセージ通信を処理できるように拡張する 既存の逐次言語を用い メッセージ通信のための拡張手続のライブラリを用意する どのプロセスを実行するのか メッセージ通信のタイミング 中身を明示的に指定する必要がある
Microsoft PowerPoint - 講義:コミュニケータ.pptx
 コミュニケータとデータタイプ (Communicator and Datatype) 2019 年 3 月 15 日 神戸大学大学院システム情報学研究科横川三津夫 2019/3/15 Kobe HPC Spring School 2019 1 講義の内容 コミュニケータ (Communicator) データタイプ (Datatype) 演習問題 2019/3/15 Kobe HPC Spring School
コミュニケータとデータタイプ (Communicator and Datatype) 2019 年 3 月 15 日 神戸大学大学院システム情報学研究科横川三津夫 2019/3/15 Kobe HPC Spring School 2019 1 講義の内容 コミュニケータ (Communicator) データタイプ (Datatype) 演習問題 2019/3/15 Kobe HPC Spring School
演習 II 2 つの講義の演習 奇数回 : 連続系アルゴリズム 部分 偶数回 : 計算量理論 部分 連続系アルゴリズム部分は全 8 回を予定 前半 2 回 高性能計算 後半 6 回 数値計算 4 回以上の課題提出 ( プログラム + 考察レポート ) で単位
 で単位") 演習 II ( 連続系アルゴリズム ) 第 1 回 : MPI 須田研究室 M2 本谷徹 motoya@is.s.u-tokyo.ac.jp 2012/10/05 2012/10/18 補足 訂正 演習 II 2 つの講義の演習 奇数回 : 連続系アルゴリズム 部分 偶数回 : 計算量理論 部分 連続系アルゴリズム部分は全 8 回を予定 前半 2 回 高性能計算 後半 6 回 数値計算 4 回以上の課題提出
演習 II ( 連続系アルゴリズム ) 第 1 回 : MPI 須田研究室 M2 本谷徹 motoya@is.s.u-tokyo.ac.jp 2012/10/05 2012/10/18 補足 訂正 演習 II 2 つの講義の演習 奇数回 : 連続系アルゴリズム 部分 偶数回 : 計算量理論 部分 連続系アルゴリズム部分は全 8 回を予定 前半 2 回 高性能計算 後半 6 回 数値計算 4 回以上の課題提出
1.ppt
 /* * Program name: hello.c */ #include int main() { printf( hello, world\n ); return 0; /* * Program name: Hello.java */ import java.io.*; class Hello { public static void main(string[] arg)
/* * Program name: hello.c */ #include int main() { printf( hello, world\n ); return 0; /* * Program name: Hello.java */ import java.io.*; class Hello { public static void main(string[] arg)
Microsoft PowerPoint 並列アルゴリズム04.ppt
 並列アルゴリズム 2005 年後期火曜 2 限 青柳睦 Aoyagi@cc.kyushu-u.ac.jp http://server-500.cc.kyushu-u.ac.jp/ 11 月 8 日 ( 火 ) 5. MPI の基礎 6. 並列処理の性能評価 1 もくじ 1. 序並列計算機の現状 2. 計算方式およびアーキテクチュアの分類 3. 並列計算の目的と課題 4. 数値計算における各種の並列化
並列アルゴリズム 2005 年後期火曜 2 限 青柳睦 Aoyagi@cc.kyushu-u.ac.jp http://server-500.cc.kyushu-u.ac.jp/ 11 月 8 日 ( 火 ) 5. MPI の基礎 6. 並列処理の性能評価 1 もくじ 1. 序並列計算機の現状 2. 計算方式およびアーキテクチュアの分類 3. 並列計算の目的と課題 4. 数値計算における各種の並列化
ex01.dvi
 ,. 0. 0.0. C () /******************************* * $Id: ex_0_0.c,v.2 2006-04-0 3:37:00+09 naito Exp $ * * 0. 0.0 *******************************/ #include int main(int argc, char **argv) double
,. 0. 0.0. C () /******************************* * $Id: ex_0_0.c,v.2 2006-04-0 3:37:00+09 naito Exp $ * * 0. 0.0 *******************************/ #include int main(int argc, char **argv) double
115 9 MPIBNCpack 9.1 BNCpack 1CPU X = , B =
 115 9 MPIBNCpack 9.1 BNCpack 1CPU 1 2 3 4 5 25 24 23 22 21 6 7 8 9 10 20 19 18 17 16 X = 11 12 13 14 15, B = 15 14 13 12 11 16 17 18 19 20 10 9 8 7 6 21 22 23 24 25 5 4 3 2 1 C = XB X dmat1 B dmat2 C dmat
115 9 MPIBNCpack 9.1 BNCpack 1CPU 1 2 3 4 5 25 24 23 22 21 6 7 8 9 10 20 19 18 17 16 X = 11 12 13 14 15, B = 15 14 13 12 11 16 17 18 19 20 10 9 8 7 6 21 22 23 24 25 5 4 3 2 1 C = XB X dmat1 B dmat2 C dmat
¥Ñ¥Ã¥±¡¼¥¸ Rhpc ¤Î¾õ¶·
 Rhpc COM-ONE 2015 R 27 12 5 1 / 29 1 2 Rhpc 3 forign MPI 4 Windows 5 2 / 29 1 2 Rhpc 3 forign MPI 4 Windows 5 3 / 29 Rhpc, R HPC Rhpc, ( ), snow..., Rhpc worker call Rhpc lapply 4 / 29 1 2 Rhpc 3 forign
Rhpc COM-ONE 2015 R 27 12 5 1 / 29 1 2 Rhpc 3 forign MPI 4 Windows 5 2 / 29 1 2 Rhpc 3 forign MPI 4 Windows 5 3 / 29 Rhpc, R HPC Rhpc, ( ), snow..., Rhpc worker call Rhpc lapply 4 / 29 1 2 Rhpc 3 forign
<4D F736F F F696E74202D C097F B A E B93C782DD8EE682E890EA97705D>
 並列アルゴリズム 2005 年後期火曜 2 限 青柳睦 Aoyagi@cc.kyushu-u.ac.jp http://server-500.cc.kyushu-u.ac.jp/ 10 月 18( 火 ) 4. 数値計算における各種の並列化 5. MPI の基礎 1 講義の概要 並列計算機や計算機クラスターなどの分散環境における並列処理の概論 MPI および OpenMP による並列計算 理工学分野の並列計算アルゴリズム
並列アルゴリズム 2005 年後期火曜 2 限 青柳睦 Aoyagi@cc.kyushu-u.ac.jp http://server-500.cc.kyushu-u.ac.jp/ 10 月 18( 火 ) 4. 数値計算における各種の並列化 5. MPI の基礎 1 講義の概要 並列計算機や計算機クラスターなどの分散環境における並列処理の概論 MPI および OpenMP による並列計算 理工学分野の並列計算アルゴリズム
コードのチューニング
 ハイブリッド並列 八木学 ( 理化学研究所計算科学研究機構 ) 謝辞 松本洋介氏 ( 千葉大学 ) KOBE HPC Spring School 2017 2017 年 3 月 14 日神戸大学計算科学教育センター MPI とは Message Passing Interface 分散メモリのプロセス間の通信規格(API) SPMD(Single Program Multi Data) が基本 -
ハイブリッド並列 八木学 ( 理化学研究所計算科学研究機構 ) 謝辞 松本洋介氏 ( 千葉大学 ) KOBE HPC Spring School 2017 2017 年 3 月 14 日神戸大学計算科学教育センター MPI とは Message Passing Interface 分散メモリのプロセス間の通信規格(API) SPMD(Single Program Multi Data) が基本 -
<4D F736F F F696E74202D C097F B A E B93C782DD8EE682E890EA97705D>
 並列アルゴリズム 2005 年後期火曜 2 限青柳睦 Aoyagi@cc.kyushu-u.ac.jp http//server-500.cc.kyushu-u.ac.jp/ 11 月 29( 火 ) 7. 集団通信 (Collective Communication) 8. 領域分割 (Domain Decomposition) 1 もくじ 1. 序並列計算機の現状 2. 計算方式およびアーキテクチュアの分類
並列アルゴリズム 2005 年後期火曜 2 限青柳睦 Aoyagi@cc.kyushu-u.ac.jp http//server-500.cc.kyushu-u.ac.jp/ 11 月 29( 火 ) 7. 集団通信 (Collective Communication) 8. 領域分割 (Domain Decomposition) 1 もくじ 1. 序並列計算機の現状 2. 計算方式およびアーキテクチュアの分類
 main() {... } main() { main() { main() {......... } } } main() { main() { main() {......... } } } main() { if(rank==)... } main() { if(rank==)... } main() { if(rank==x)... } P(N) P(N) / P(M) * ( M / N
main() {... } main() { main() { main() {......... } } } main() { main() { main() {......... } } } main() { if(rank==)... } main() { if(rank==)... } main() { if(rank==x)... } P(N) P(N) / P(M) * ( M / N
58 7 MPI 7 : main(int argc, char *argv[]) 8 : { 9 : int num_procs, myrank; 10 : double a, b; 11 : int tag = 0; 12 : MPI_Status status; 13 : 1 MPI_Init
![58 7 MPI 7 : main(int argc, char *argv[]) 8 : { 9 : int num_procs, myrank; 10 : double a, b; 11 : int tag = 0; 12 : MPI_Status status; 13 : 1 MPI_Init](/thumbs/57/39896772.jpg "58 7 MPI 7 : main(int argc, char *argv[]) 8 : { 9 : int num_procs, myrank; 10 : double a, b; 11 : int tag = 0; 12 : MPI_Status status; 13 : 1 MPI_Init") 57 7 MPI MPI 1 1 7.1 Bcast( ) allocate Bcast a=1 PE0 a=1 PE1 a=1 PE2 a=1 PE3 7.1: Bcast 58 7 MPI 7 : main(int argc, char *argv[]) 8 : { 9 : int num_procs, myrank; 10 : double a, b; 11 : int tag = 0; 12
57 7 MPI MPI 1 1 7.1 Bcast( ) allocate Bcast a=1 PE0 a=1 PE1 a=1 PE2 a=1 PE3 7.1: Bcast 58 7 MPI 7 : main(int argc, char *argv[]) 8 : { 9 : int num_procs, myrank; 10 : double a, b; 11 : int tag = 0; 12
86
 86 86 86 main() {... } main() { main() { main() {......... } } } 86 main() { main() { main() {......... } } } main() { if(rank==)... } main() { if(rank==)... } main() { if(rank==x)... } 86 P(N) P(N) /
86 86 86 main() {... } main() { main() { main() {......... } } } 86 main() { main() { main() {......... } } } main() { if(rank==)... } main() { if(rank==)... } main() { if(rank==x)... } 86 P(N) P(N) /
10/ / /30 3. ( ) 11/ 6 4. UNIX + C socket 11/13 5. ( ) C 11/20 6. http, CGI Perl 11/27 7. ( ) Perl 12/ 4 8. Windows Winsock 12/11 9. JAV
 11/ 6 4. UNIX + C socket 11/13 5. ( ) C 11/20 6. http, CGI Perl 11/27 7. ( ) Perl 12/ 4 8. Windows Winsock 12/11 9. JAV") tutimura@mist.i.u-tokyo.ac.jp kaneko@ipl.t.u-tokyo.ac.jp http://www.misojiro.t.u-tokyo.ac.jp/ tutimura/sem3/ 2002 12 11 p.1/33 10/16 1. 10/23 2. 10/30 3. ( ) 11/ 6 4. UNIX + C socket 11/13 5. ( ) C 11/20
tutimura@mist.i.u-tokyo.ac.jp kaneko@ipl.t.u-tokyo.ac.jp http://www.misojiro.t.u-tokyo.ac.jp/ tutimura/sem3/ 2002 12 11 p.1/33 10/16 1. 10/23 2. 10/30 3. ( ) 11/ 6 4. UNIX + C socket 11/13 5. ( ) C 11/20
: : : TSTank 2
 Java (8) 2008-05-20 Lesson6 Lesson5 Java 1 Lesson 6: TSTank1, TSTank2, TSTank3 java 2 car1 car2 Car car1 = new Car(); Car car2 = new Car(); car1.setcolor(red); car2.setcolor(blue); car2.changeengine(jet);
Java (8) 2008-05-20 Lesson6 Lesson5 Java 1 Lesson 6: TSTank1, TSTank2, TSTank3 java 2 car1 car2 Car car1 = new Car(); Car car2 = new Car(); car1.setcolor(red); car2.setcolor(blue); car2.changeengine(jet);
ex01.dvi
 ,. 0. 0.0. C () /******************************* * $Id: ex_0_0.c,v.2 2006-04-0 3:37:00+09 naito Exp $ * * 0. 0.0 *******************************/ #include int main(int argc, char **argv) { double
,. 0. 0.0. C () /******************************* * $Id: ex_0_0.c,v.2 2006-04-0 3:37:00+09 naito Exp $ * * 0. 0.0 *******************************/ #include int main(int argc, char **argv) { double
A B 1: Ex. MPICH-G2 C.f. NXProxy [Tanaka] 2:
![A B 1: Ex. MPICH-G2 C.f. NXProxy [Tanaka] 2:](/thumbs/92/109494506.jpg "A B 1: Ex. MPICH-G2 C.f. NXProxy [Tanaka] 2:") Java Jojo ( ) ( ) A B 1: Ex. MPICH-G2 C.f. NXProxy [Tanaka] 2: Java Jojo Jojo (1) :Globus GRAM ssh rsh GRAM ssh GRAM A rsh B Jojo (2) ( ) Jojo Java VM JavaRMI (Sun) Horb(ETL) ( ) JPVM,mpiJava etc. Send,
Java Jojo ( ) ( ) A B 1: Ex. MPICH-G2 C.f. NXProxy [Tanaka] 2: Java Jojo Jojo (1) :Globus GRAM ssh rsh GRAM ssh GRAM A rsh B Jojo (2) ( ) Jojo Java VM JavaRMI (Sun) Horb(ETL) ( ) JPVM,mpiJava etc. Send,
3 Java 3.1 Hello World! Hello World public class HelloWorld { public static void main(string[] args) { System.out.println("Hello World");
![3 Java 3.1 Hello World! Hello World public class HelloWorld { public static void main(string[] args) { System.out.println(Hello World);](/thumbs/78/78512594.jpg "3 Java 3.1 Hello World! Hello World public class HelloWorld { public static void main(string[] args) { System.out.println(Hello World);") (Basic Theory of Information Processing) Java (eclipse ) Hello World! eclipse Java 1 3 Java 3.1 Hello World! Hello World public class HelloWorld { public static void main(string[] args) { System.out.println("Hello
(Basic Theory of Information Processing) Java (eclipse ) Hello World! eclipse Java 1 3 Java 3.1 Hello World! Hello World public class HelloWorld { public static void main(string[] args) { System.out.println("Hello
スライド 1
 Parallel Programming in MPI part 2 1 1 Today's Topic ノンブロッキング通信 Non-Blocking Communication 通信の完了を待つ間に他の処理を行う Execute other instructions while waiting for the completion of a communication. 集団通信関数の実装 Implementation
Parallel Programming in MPI part 2 1 1 Today's Topic ノンブロッキング通信 Non-Blocking Communication 通信の完了を待つ間に他の処理を行う Execute other instructions while waiting for the completion of a communication. 集団通信関数の実装 Implementation
Java updated
 Java 2003.07.14 updated 3 1 Java 5 1.1 Java................................. 5 1.2 Java..................................... 5 1.3 Java................................ 6 1.3.1 Java.......................
Java 2003.07.14 updated 3 1 Java 5 1.1 Java................................. 5 1.2 Java..................................... 5 1.3 Java................................ 6 1.3.1 Java.......................
DKA ( 1) 1 n i=1 α i c n 1 = 0 ( 1) 2 n i 1 <i 2 α i1 α i2 c n 2 = 0 ( 1) 3 n i 1 <i 2 <i 3 α i1 α i2 α i3 c n 3 = 0. ( 1) n 1 n i 1 <i 2 < <i
 1 n i=1 α i c n 1 = 0 ( 1) 2 n i 1 <i 2 α i1 α i2 c n 2 = 0 ( 1) 3 n i 1 <i 2 <i 3 α i1 α i2 α i3 c n 3 = 0. ( 1) n 1 n i 1 <i 2 < <i") 149 11 DKA IEEE754 11.1 DKA n p(x) = a n x n + a n 1 x n 1 + + a 0 (11.1) p(x) = 0 (11.2) p n (x) q n (x) = x n + c n 1 x n 1 + + c 1 x + c 0 q n (x) = 0 (11.3) c i = a i a n (i = 0, 1,..., n 1) (11.3)
149 11 DKA IEEE754 11.1 DKA n p(x) = a n x n + a n 1 x n 1 + + a 0 (11.1) p(x) = 0 (11.2) p n (x) q n (x) = x n + c n 1 x n 1 + + c 1 x + c 0 q n (x) = 0 (11.3) c i = a i a n (i = 0, 1,..., n 1) (11.3)
tuat1.dvi
 ( 1 ) http://ist.ksc.kwansei.ac.jp/ tutimura/ 2012 6 23 ( 1 ) 1 / 58 C ( 1 ) 2 / 58 2008 9 2002 2005 T E X ptetex3, ptexlive pt E X UTF-8 xdvi-jp 3 ( 1 ) 3 / 58 ( 1 ) 4 / 58 C,... ( 1 ) 5 / 58 6/23( )
( 1 ) http://ist.ksc.kwansei.ac.jp/ tutimura/ 2012 6 23 ( 1 ) 1 / 58 C ( 1 ) 2 / 58 2008 9 2002 2005 T E X ptetex3, ptexlive pt E X UTF-8 xdvi-jp 3 ( 1 ) 3 / 58 ( 1 ) 4 / 58 C,... ( 1 ) 5 / 58 6/23( )
K227 Java 2
 1 K227 Java 2 3 4 5 6 Java 7 class Sample1 { public static void main (String args[]) { System.out.println( Java! ); } } 8 > javac Sample1.java 9 10 > java Sample1 Java 11 12 13 http://java.sun.com/j2se/1.5.0/ja/download.html
1 K227 Java 2 3 4 5 6 Java 7 class Sample1 { public static void main (String args[]) { System.out.println( Java! ); } } 8 > javac Sample1.java 9 10 > java Sample1 Java 11 12 13 http://java.sun.com/j2se/1.5.0/ja/download.html
情報処理演習 II
 2004 年 6 月 15 日 長谷川秀彦 情報処理演習 II Parallel Computing on Distributed Memory Machine 1. 分散メモリ方式並列計算の基礎 複数の CPU がそれぞれのメモリを持ち 独立に動作するコンピュータを分散メモリ方式並列コンピュータ 正確には Distributed Memory Parallel Computer という これには複数の
2004 年 6 月 15 日 長谷川秀彦 情報処理演習 II Parallel Computing on Distributed Memory Machine 1. 分散メモリ方式並列計算の基礎 複数の CPU がそれぞれのメモリを持ち 独立に動作するコンピュータを分散メモリ方式並列コンピュータ 正確には Distributed Memory Parallel Computer という これには複数の
XMPによる並列化実装2
 2 3 C Fortran Exercise 1 Exercise 2 Serial init.c init.f90 XMP xmp_init.c xmp_init.f90 Serial laplace.c laplace.f90 XMP xmp_laplace.c xmp_laplace.f90 #include int a[10]; program init integer
2 3 C Fortran Exercise 1 Exercise 2 Serial init.c init.f90 XMP xmp_init.c xmp_init.f90 Serial laplace.c laplace.f90 XMP xmp_laplace.c xmp_laplace.f90 #include int a[10]; program init integer
I. Backus-Naur BNF S + S S * S S x S +, *, x BNF S (parse tree) : * x + x x S * S x + S S S x x (1) * x x * x (2) * + x x x (3) + x * x + x x (4) * *
 : * x + x x S * S x + S S S x x (1) * x x * x (2) * + x x x (3) + x * x + x x (4) * *") 2015 2015 07 30 10:30 12:00 I. I VI II. III. IV. a d V. VI. 80 100 60 1 I. Backus-Naur BNF S + S S * S S x S +, *, x BNF S (parse tree) : * x + x x S * S x + S S S x x (1) * x x * x (2) * + x x x (3) +
2015 2015 07 30 10:30 12:00 I. I VI II. III. IV. a d V. VI. 80 100 60 1 I. Backus-Naur BNF S + S S * S S x S +, *, x BNF S (parse tree) : * x + x x S * S x + S S S x x (1) * x x * x (2) * + x x x (3) +
I. Backus-Naur BNF : N N 0 N N N N N N 0, 1 BNF N N 0 11 (parse tree) 11 (1) (2) (3) (4) II. 0(0 101)* (
 11 (1) (2) (3) (4) II. 0(0 101)* (") 2016 2016 07 28 10:30 12:00 I. I VI II. III. IV. a d V. VI. 80 100 60 1 I. Backus-Naur BNF : 11011 N N 0 N N 11 1001 N N N N 0, 1 BNF N N 0 11 (parse tree) 11 (1) 1100100 (2) 1111011 (3) 1110010 (4) 1001011
2016 2016 07 28 10:30 12:00 I. I VI II. III. IV. a d V. VI. 80 100 60 1 I. Backus-Naur BNF : 11011 N N 0 N N 11 1001 N N N N 0, 1 BNF N N 0 11 (parse tree) 11 (1) 1100100 (2) 1111011 (3) 1110010 (4) 1001011
II ( ) prog8-1.c s1542h017%./prog8-1 1 => 35 Hiroshi 2 => 23 Koji 3 => 67 Satoshi 4 => 87 Junko 5 => 64 Ichiro 6 => 89 Mari 7 => 73 D
 prog8-1.c s1542h017%./prog8-1 1 => 35 Hiroshi 2 => 23 Koji 3 => 67 Satoshi 4 => 87 Junko 5 => 64 Ichiro 6 => 89 Mari 7 => 73 D") II 8 2003 11 12 1 6 ( ) prog8-1.c s1542h017%./prog8-1 1 => 35 Hiroshi 2 => 23 Koji 3 => 67 Satoshi 4 => 87 Junko 5 => 64 Ichiro 6 => 89 Mari 7 => 73 Daisuke 8 =>. 73 Daisuke 35 Hiroshi 64 Ichiro 87 Junko
II 8 2003 11 12 1 6 ( ) prog8-1.c s1542h017%./prog8-1 1 => 35 Hiroshi 2 => 23 Koji 3 => 67 Satoshi 4 => 87 Junko 5 => 64 Ichiro 6 => 89 Mari 7 => 73 Daisuke 8 =>. 73 Daisuke 35 Hiroshi 64 Ichiro 87 Junko
A/B (2018/10/19) Ver kurino/2018/soft/soft.html A/B
 Ver kurino/2018/soft/soft.html A/B") A/B (2018/10/19) Ver. 1.0 kurino@math.cst.nihon-u.ac.jp http://edu-gw2.math.cst.nihon-u.ac.jp/ kurino/2018/soft/soft.html 2018 10 19 A/B 1 2018 10 19 2 1 1 1.1 OHP.................................... 1
A/B (2018/10/19) Ver. 1.0 kurino@math.cst.nihon-u.ac.jp http://edu-gw2.math.cst.nihon-u.ac.jp/ kurino/2018/soft/soft.html 2018 10 19 A/B 1 2018 10 19 2 1 1 1.1 OHP.................................... 1
XcalableMP入門
 XcalableMP 1 HPC-Phys@, 2018 8 22 XcalableMP XMP XMP Lattice QCD!2 XMP MPI MPI!3 XMP 1/2 PCXMP MPI Fortran CCoarray C++ MPIMPI XMP OpenMP http://xcalablemp.org!4 XMP 2/2 SPMD (Single Program Multiple Data)
XcalableMP 1 HPC-Phys@, 2018 8 22 XcalableMP XMP XMP Lattice QCD!2 XMP MPI MPI!3 XMP 1/2 PCXMP MPI Fortran CCoarray C++ MPIMPI XMP OpenMP http://xcalablemp.org!4 XMP 2/2 SPMD (Single Program Multiple Data)
XACC講習会
 www.xcalablemp.org 1 4, int array[max]; #pragma xmp nodes p(*) #pragma xmp template t(0:max-1) #pragma xmp distribute t(block) onto p #pragma xmp align array[i] with t(i) int array[max]; main(int argc,
www.xcalablemp.org 1 4, int array[max]; #pragma xmp nodes p(*) #pragma xmp template t(0:max-1) #pragma xmp distribute t(block) onto p #pragma xmp align array[i] with t(i) int array[max]; main(int argc,
joho07-1.ppt
 0xbffffc5c 0xbffffc60 xxxxxxxx xxxxxxxx 00001010 00000000 00000000 00000000 01100011 00000000 00000000 00000000 xxxxxxxx x y 2 func1 func2 double func1(double y) { y = y + 5.0; return y; } double func2(double*
0xbffffc5c 0xbffffc60 xxxxxxxx xxxxxxxx 00001010 00000000 00000000 00000000 01100011 00000000 00000000 00000000 xxxxxxxx x y 2 func1 func2 double func1(double y) { y = y + 5.0; return y; } double func2(double*
<4D F736F F F696E74202D C097F B A E B93C782DD8EE682E890EA97705D>
 並列アルゴリズム 2005 年後期火曜 2 限 青柳睦 Aoyagi@cc.kyushu-u.ac.jp http://server-500.cc.kyushu-u.ac.jp/ 10 月 11 日 ( 火 ) 1. 序並列計算機の現状 2. 計算方式およびアーキテクチュアの分類 ( 途中から ) 3. 並列計算の目的と課題 4. 数値計算における各種の並列化 1 講義の概要 並列計算機や計算機クラスターなどの分散環境における並列処理の概論
並列アルゴリズム 2005 年後期火曜 2 限 青柳睦 Aoyagi@cc.kyushu-u.ac.jp http://server-500.cc.kyushu-u.ac.jp/ 10 月 11 日 ( 火 ) 1. 序並列計算機の現状 2. 計算方式およびアーキテクチュアの分類 ( 途中から ) 3. 並列計算の目的と課題 4. 数値計算における各種の並列化 1 講義の概要 並列計算機や計算機クラスターなどの分散環境における並列処理の概論
86 8 MPIBNCpack 15 : int n, myid, numprocs, i; 16 : double pi, start_x, end_x; 17 : double startwtime = 0.0, endwtime; 18 : int namelen; 19 : char pro
 85 8 MPIBNCpack 1CPU BNCpack MPIBNCpack 1 1 8.1 5.2 (5.1) f (a), f (b), f (x i ) PE reduce 1 0 1 1 + x 2 dx = π 4 mpi-int.c mpi-int-gmp.c mpi-int.c 2 : #include 3 : #include "mpi.h" 5 : 6 : #include
85 8 MPIBNCpack 1CPU BNCpack MPIBNCpack 1 1 8.1 5.2 (5.1) f (a), f (b), f (x i ) PE reduce 1 0 1 1 + x 2 dx = π 4 mpi-int.c mpi-int-gmp.c mpi-int.c 2 : #include 3 : #include "mpi.h" 5 : 6 : #include
Java (7) Lesson = (1) 1 m 3 /s m 2 5 m 2 4 m 2 1 m 3 m 1 m 0.5 m 3 /ms 0.3 m 3 /ms 0.6 m 3 /ms 1 1 3
 Lesson = (1) 1 m 3 /s m 2 5 m 2 4 m 2 1 m 3 m 1 m 0.5 m 3 /ms 0.3 m 3 /ms 0.6 m 3 /ms 1 1 3") Java (7) 2008-05-20 1 Lesson 5 1.1 5 3 = (1) 1 m 3 /s 1 2 3 10 m 2 5 m 2 4 m 2 1 m 3 m 1 m 0.5 m 3 /ms 0.3 m 3 /ms 0.6 m 3 /ms 1 1 3 1.2 java 2 1. 2. 3. 4. 3 2 1.3 i =1, 2, 3 V i (t) 1 t h i (t) i F, k
Java (7) 2008-05-20 1 Lesson 5 1.1 5 3 = (1) 1 m 3 /s 1 2 3 10 m 2 5 m 2 4 m 2 1 m 3 m 1 m 0.5 m 3 /ms 0.3 m 3 /ms 0.6 m 3 /ms 1 1 3 1.2 java 2 1. 2. 3. 4. 3 2 1.3 i =1, 2, 3 V i (t) 1 t h i (t) i F, k
Microsoft PowerPoint - 演習1:並列化と評価.pptx
 講義 2& 演習 1 プログラム並列化と性能評価 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 1 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 2 2 次元温度分布の計算
講義 2& 演習 1 プログラム並列化と性能評価 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 1 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 2 2 次元温度分布の計算
untitled
 RIKEN AICS Summer School 3 4 MPI 2012 8 8 1 6 MPI MPI 2 allocatable 2 Fox mpi_sendrecv 3 3 FFT mpi_alltoall MPI_PROC_NULL 4 FX10 /home/guest/guest07/school/ 5 1 A (i, j) i+j x i i y = Ax A x y y 1 y i
RIKEN AICS Summer School 3 4 MPI 2012 8 8 1 6 MPI MPI 2 allocatable 2 Fox mpi_sendrecv 3 3 FFT mpi_alltoall MPI_PROC_NULL 4 FX10 /home/guest/guest07/school/ 5 1 A (i, j) i+j x i i y = Ax A x y y 1 y i
120802_MPI.ppt
 CPU CPU CPU CPU CPU SMP Symmetric MultiProcessing CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CP OpenMP MPI MPI CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU MPI MPI+OpenMP CPU CPU CPU CPU CPU CPU CPU CP
CPU CPU CPU CPU CPU SMP Symmetric MultiProcessing CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CP OpenMP MPI MPI CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU MPI MPI+OpenMP CPU CPU CPU CPU CPU CPU CPU CP
:30 12:00 I. I VI II. III. IV. a d V. VI
 2017 2017 08 03 10:30 12:00 I. I VI II. III. IV. a d V. VI. 80 100 60 1 I. Backus-Naur BNF X [ S ] a S S ; X X X, S [, a, ], ; BNF X (parse tree) (1) [a;a] (2) [[a]] (3) [a;[a]] (4) [[a];a] : [a] X 2 222222
2017 2017 08 03 10:30 12:00 I. I VI II. III. IV. a d V. VI. 80 100 60 1 I. Backus-Naur BNF X [ S ] a S S ; X X X, S [, a, ], ; BNF X (parse tree) (1) [a;a] (2) [[a]] (3) [a;[a]] (4) [[a];a] : [a] X 2 222222
Microsoft PowerPoint MPI.v...O...~...O.e.L.X.g(...Q..)
") MPI プログラミング Information Initiative Center, Hokkaido Univ. MPI ライブラリを利用した分散メモリ型並列プログラミング 分散メモリ型並列処理 : 基礎 分散メモリマルチコンピュータの構成 プロセッサエレメントが専用のメモリ ( ローカルメモリ ) を搭載 スケーラビリティが高い 例 :HITACHI SR8000 Interconnection
MPI プログラミング Information Initiative Center, Hokkaido Univ. MPI ライブラリを利用した分散メモリ型並列プログラミング 分散メモリ型並列処理 : 基礎 分散メモリマルチコンピュータの構成 プロセッサエレメントが専用のメモリ ( ローカルメモリ ) を搭載 スケーラビリティが高い 例 :HITACHI SR8000 Interconnection
C/C++ FORTRAN FORTRAN MPI MPI MPI UNIX Windows (SIMD Single Instruction Multipule Data) SMP(Symmetric Multi Processor) MPI (thread) OpenMP[5]
![C/C++ FORTRAN FORTRAN MPI MPI MPI UNIX Windows (SIMD Single Instruction Multipule Data) SMP(Symmetric Multi Processor) MPI (thread) OpenMP[5]](/thumbs/73/69613550.jpg "C/C++ FORTRAN FORTRAN MPI MPI MPI UNIX Windows (SIMD Single Instruction Multipule Data) SMP(Symmetric Multi Processor) MPI (thread) OpenMP[5]") MPI ( ) snozawa@env.sci.ibaraki.ac.jp 1 ( ) MPI MPI Message Passing Interface[2] MPI MPICH[3],LAM/MPI[4] (MIMDMultiple Instruction Multipule Data) Message Passing ( ) (MPI (rank) PE(Processing Element)
MPI ( ) snozawa@env.sci.ibaraki.ac.jp 1 ( ) MPI MPI Message Passing Interface[2] MPI MPICH[3],LAM/MPI[4] (MIMDMultiple Instruction Multipule Data) Message Passing ( ) (MPI (rank) PE(Processing Element)
講義の流れ 並列プログラムの概要 通常のプログラムと並列プログラムの違い 並列プログラム作成手段と並列計算機の構造 OpenMP による並列プログラム作成 処理を複数コアに分割して並列実行する方法 MPI による並列プログラム作成 ( 午後 ) プロセス間通信による並列処理 処理の分割 + データの
 プロセス間通信による並列処理 処理の分割 + データの") ( 財 ) 計算科学振興財団 大学院 GP 大学連合による計算科学の最先端人材育成 第 1 回社会人向けスパコン実践セミナー資料 29 年 2 月 17 日 13:15~14:45 九州大学情報基盤研究開発センター 南里豪志 1 講義の流れ 並列プログラムの概要 通常のプログラムと並列プログラムの違い 並列プログラム作成手段と並列計算機の構造 OpenMP による並列プログラム作成 処理を複数コアに分割して並列実行する方法
( 財 ) 計算科学振興財団 大学院 GP 大学連合による計算科学の最先端人材育成 第 1 回社会人向けスパコン実践セミナー資料 29 年 2 月 17 日 13:15~14:45 九州大学情報基盤研究開発センター 南里豪志 1 講義の流れ 並列プログラムの概要 通常のプログラムと並列プログラムの違い 並列プログラム作成手段と並列計算機の構造 OpenMP による並列プログラム作成 処理を複数コアに分割して並列実行する方法
スライド 1
 計算科学演習 MPI 基礎 学術情報メディアセンター情報学研究科 システム科学専攻中島浩 目次 プログラミングモデル SPMD 同期通信 / 非同期通信 MPI 概論 プログラム構造 Communicator & rank データ型 タグ 一対一通信関数 1 次元分割並列化 : 基本 基本的考え方 配列宣言 割付 部分領域交換 結果出力 1 次元分割並列化 : 高速化 通信 計算のオーバーラップ 通信回数削減
計算科学演習 MPI 基礎 学術情報メディアセンター情報学研究科 システム科学専攻中島浩 目次 プログラミングモデル SPMD 同期通信 / 非同期通信 MPI 概論 プログラム構造 Communicator & rank データ型 タグ 一対一通信関数 1 次元分割並列化 : 基本 基本的考え方 配列宣言 割付 部分領域交換 結果出力 1 次元分割並列化 : 高速化 通信 計算のオーバーラップ 通信回数削減
課題 S1 解説 C 言語編 中島研吾 東京大学情報基盤センター
 課題 S1 解説 C 言語編 中島研吾 東京大学情報基盤センター 内容 課題 S1 /a1.0~a1.3, /a2.0~a2.3 から局所ベクトル情報を読み込み, 全体ベクトルのノルム ( x ) を求めるプログラムを作成する (S1-1) file.f,file2.f をそれぞれ参考にする 下記の数値積分の結果を台形公式によって求めるプログラムを作成する
課題 S1 解説 C 言語編 中島研吾 東京大学情報基盤センター 内容 課題 S1 /a1.0~a1.3, /a2.0~a2.3 から局所ベクトル情報を読み込み, 全体ベクトルのノルム ( x ) を求めるプログラムを作成する (S1-1) file.f,file2.f をそれぞれ参考にする 下記の数値積分の結果を台形公式によって求めるプログラムを作成する
01_OpenMP_osx.indd
 OpenMP* / 1 1... 2 2... 3 3... 5 4... 7 5... 9 5.1... 9 5.2 OpenMP* API... 13 6... 17 7... 19 / 4 1 2 C/C++ OpenMP* 3 Fortran OpenMP* 4 PC 1 1 9.0 Linux* Windows* Xeon Itanium OS 1 2 2 WEB OS OS OS 1 OS
OpenMP* / 1 1... 2 2... 3 3... 5 4... 7 5... 9 5.1... 9 5.2 OpenMP* API... 13 6... 17 7... 19 / 4 1 2 C/C++ OpenMP* 3 Fortran OpenMP* 4 PC 1 1 9.0 Linux* Windows* Xeon Itanium OS 1 2 2 WEB OS OS OS 1 OS
Microsoft Word - C.....u.K...doc
 C uwêííôöðöõ Ð C ÔÖÐÖÕ ÐÊÉÌÊ C ÔÖÐÖÕÊ C ÔÖÐÖÕÊ Ç Ê Æ ~ if eíè ~ for ÒÑÒ ÌÆÊÉÉÊ ~ switch ÉeÍÈ ~ while ÒÑÒ ÊÍÍÔÖÐÖÕÊ ~ 1 C ÔÖÐÖÕ ÐÊÉÌÊ uê~ ÏÒÏÑ Ð ÓÏÖ CUI Ô ÑÊ ÏÒÏÑ ÔÖÐÖÕÎ d ÈÍÉÇÊ ÆÒ Ö ÒÐÑÒ ÊÔÎÏÖÎ d ÉÇÍÊ
C uwêííôöðöõ Ð C ÔÖÐÖÕ ÐÊÉÌÊ C ÔÖÐÖÕÊ C ÔÖÐÖÕÊ Ç Ê Æ ~ if eíè ~ for ÒÑÒ ÌÆÊÉÉÊ ~ switch ÉeÍÈ ~ while ÒÑÒ ÊÍÍÔÖÐÖÕÊ ~ 1 C ÔÖÐÖÕ ÐÊÉÌÊ uê~ ÏÒÏÑ Ð ÓÏÖ CUI Ô ÑÊ ÏÒÏÑ ÔÖÐÖÕÎ d ÈÍÉÇÊ ÆÒ Ö ÒÐÑÒ ÊÔÎÏÖÎ d ÉÇÍÊ
A/B (2018/06/08) Ver kurino/2018/soft/soft.html A/B
 Ver kurino/2018/soft/soft.html A/B") A/B (2018/06/08) Ver. 1.0 kurino@math.cst.nihon-u.ac.jp http://edu-gw2.math.cst.nihon-u.ac.jp/ kurino/2018/soft/soft.html 2018 6 8 A/B 1 2018 6 8 2 1 1 1.1 OHP.................................... 1 1.2
A/B (2018/06/08) Ver. 1.0 kurino@math.cst.nihon-u.ac.jp http://edu-gw2.math.cst.nihon-u.ac.jp/ kurino/2018/soft/soft.html 2018 6 8 A/B 1 2018 6 8 2 1 1 1.1 OHP.................................... 1 1.2
かし, 異なったプロセス間でデータを共有するためには, プロセス間通信や特殊な共有メモリ領域を 利用する必要がある. このためマルチプロセッサマシンの利点を最大に引き出すことができない. こ の問題はマルチスレッドを用いることで解決できる. マルチスレッドとは,1 つのプロセスの中に複 数のスレッド
 0 並列計算について 0.1 並列プログラミングライブラリのメッセージパッシングモデル並列プログラムにはメモリモデルで分類すると, 共有メモリモデルと分散メモリモデルの 2 つに分けられる. それぞれ次のような特徴がある. 共有メモリモデル複数のプロセスやスレッドが事項する主体となり, 互いに通信や同期を取りながら計算が継続される. スレッド間の実行順序をプログラマが保証してやらないと, 思った結果が得られない.
0 並列計算について 0.1 並列プログラミングライブラリのメッセージパッシングモデル並列プログラムにはメモリモデルで分類すると, 共有メモリモデルと分散メモリモデルの 2 つに分けられる. それぞれ次のような特徴がある. 共有メモリモデル複数のプロセスやスレッドが事項する主体となり, 互いに通信や同期を取りながら計算が継続される. スレッド間の実行順序をプログラマが保証してやらないと, 思った結果が得られない.
Microsoft PowerPoint - 講習 _kido.pptx[読み取り専用]
![Microsoft PowerPoint - 講習 _kido.pptx[読み取り専用]](/thumbs/79/79773151.jpg "Microsoft PowerPoint - 講習 _kido.pptx[読み取り専用]") スパコンの概要と CMC のスパコンの紹介 大阪大学サイバーメディアセンター講師木戸善之 2015/1/15 目次 1. スパコンの略歴 2. 計算機の概要 3. 並列計算 4. CMCのスパコン 1 1. スパコンの略歴 計算機ってなんだ? 計算機 計算に用いる機械 ( デジタル大辞泉 ) 計算のための機械 器具のこと コンピュータや電卓を指すことが多い (Wikipedia) 人が不得意な 正確な演算やルーチンワークを肩代わりするための道具
スパコンの概要と CMC のスパコンの紹介 大阪大学サイバーメディアセンター講師木戸善之 2015/1/15 目次 1. スパコンの略歴 2. 計算機の概要 3. 並列計算 4. CMCのスパコン 1 1. スパコンの略歴 計算機ってなんだ? 計算機 計算に用いる機械 ( デジタル大辞泉 ) 計算のための機械 器具のこと コンピュータや電卓を指すことが多い (Wikipedia) 人が不得意な 正確な演算やルーチンワークを肩代わりするための道具
r07.dvi
 19 7 ( ) 2019.4.20 1 1.1 (data structure ( (dynamic data structure 1 malloc C free C (garbage collection GC C GC(conservative GC 2 1.2 data next p 3 5 7 9 p 3 5 7 9 p 3 5 7 9 1 1: (single linked list 1
19 7 ( ) 2019.4.20 1 1.1 (data structure ( (dynamic data structure 1 malloc C free C (garbage collection GC C GC(conservative GC 2 1.2 data next p 3 5 7 9 p 3 5 7 9 p 3 5 7 9 1 1: (single linked list 1
Microsoft PowerPoint _MPI-01.pptx
 計算科学演習 Ⅰ MPI を いた並列計算 (I) 神戸大学大学院システム情報学研究科谷口隆晴 yaguchi@pearl.kobe-u.ac.jp この資料は昨年度担当の横川先生の資料を参考にさせて頂いています. 2016/06/23 MPI を用いた並列計算 (I) 1 講義概要 分散メモリ型計算機上のプログラミング メッセージ パシング インターフェイス (Message Passing Interface,MPI)
計算科学演習 Ⅰ MPI を いた並列計算 (I) 神戸大学大学院システム情報学研究科谷口隆晴 yaguchi@pearl.kobe-u.ac.jp この資料は昨年度担当の横川先生の資料を参考にさせて頂いています. 2016/06/23 MPI を用いた並列計算 (I) 1 講義概要 分散メモリ型計算機上のプログラミング メッセージ パシング インターフェイス (Message Passing Interface,MPI)
1-4 int a; std::cin >> a; std::cout << "a = " << a << std::endl; C++( 1-4 ) stdio.h iostream iostream.h C++ include.h 1-4 scanf() std::cin >>
 stdio.h iostream iostream.h C++ include.h 1-4 scanf() std::cin >>") 1 C++ 1.1 C C++ C++ C C C++ 1.1.1 C printf() scanf() C++ C hello world printf() 1-1 #include printf( "hello world\n" ); C++ 1-2 std::cout
1 C++ 1.1 C C++ C++ C C C++ 1.1.1 C printf() scanf() C++ C hello world printf() 1-1 #include printf( "hello world\n" ); C++ 1-2 std::cout
とても使いやすい Boost の serialization
 とても使いやすい Boost の serialization Zegrahm シリアライズ ( 直列化 ) シリアライズ ( 直列化 ) とは何か? オブジェクトデータをバイト列や XML フォーマットに変換すること もう少しわかりやすく表現すると オブジェクトの状態を表す変数 ( フィールド ) とオブジェクトの種類を表す何らかの識別子をファイル化出来るようなバイト列 XML フォーマット形式で書き出す事を言う
とても使いやすい Boost の serialization Zegrahm シリアライズ ( 直列化 ) シリアライズ ( 直列化 ) とは何か? オブジェクトデータをバイト列や XML フォーマットに変換すること もう少しわかりやすく表現すると オブジェクトの状態を表す変数 ( フィールド ) とオブジェクトの種類を表す何らかの識別子をファイル化出来るようなバイト列 XML フォーマット形式で書き出す事を言う
ohp07.dvi
 19 7 ( ) 2019.4.20 1 (data structure) ( ) (dynamic data structure) 1 malloc C free 1 (static data structure) 2 (2) C (garbage collection GC) C GC(conservative GC) 2 2 conservative GC 3 data next p 3 5
19 7 ( ) 2019.4.20 1 (data structure) ( ) (dynamic data structure) 1 malloc C free 1 (static data structure) 2 (2) C (garbage collection GC) C GC(conservative GC) 2 2 conservative GC 3 data next p 3 5
2 p.2 2 Java Hello0.class JVM Hello0 java > java Hello0.class Hello World! javac Java JVM java JVM : Java > javac 2> Q Foo.java Java : Q B
 2 p.1 2 Java Java JDK Sun Microsystems JDK javac Java java JVM appletviewer IDESun Microsystems NetBeans, IBM 1 Eclipse 2 IDE GUI JDK Java 2.1 Hello World! 2.1.1 Java 2.1.1 Hello World Emacs Hello0.java
2 p.1 2 Java Java JDK Sun Microsystems JDK javac Java java JVM appletviewer IDESun Microsystems NetBeans, IBM 1 Eclipse 2 IDE GUI JDK Java 2.1 Hello World! 2.1.1 Java 2.1.1 Hello World Emacs Hello0.java
C C UNIX C ( ) 4 1 HTML 1
 4 1 HTML 1") C 2007 4 18 C UNIX 1 2 1 1.1 C ( ) 4 1 HTML 1 はじめ mkdir work 作業用ディレクトリーの作成 emacs hoge.c& エディターによりソースプログラム作成 gcc -o fuga hoge.c コンパイルにより機械語に変換 コンパイルエラー./fuga 実行 実行時エラー 完成 1: work hooge.c fuga 1 4 4 1 1.
C 2007 4 18 C UNIX 1 2 1 1.1 C ( ) 4 1 HTML 1 はじめ mkdir work 作業用ディレクトリーの作成 emacs hoge.c& エディターによりソースプログラム作成 gcc -o fuga hoge.c コンパイルにより機械語に変換 コンパイルエラー./fuga 実行 実行時エラー 完成 1: work hooge.c fuga 1 4 4 1 1.
コードのチューニング
 MPI による並列化実装 ~ ハイブリッド並列 ~ 八木学 ( 理化学研究所計算科学研究センター ) KOBE HPC Spring School 2019 2019 年 3 月 14 日 MPI とは Message Passing Interface 分散メモリのプロセス間の通信規格(API) SPMD(Single Program Multi Data) が基本 - 各プロセスが 同じことをやる
MPI による並列化実装 ~ ハイブリッド並列 ~ 八木学 ( 理化学研究所計算科学研究センター ) KOBE HPC Spring School 2019 2019 年 3 月 14 日 MPI とは Message Passing Interface 分散メモリのプロセス間の通信規格(API) SPMD(Single Program Multi Data) が基本 - 各プロセスが 同じことをやる
& & a a * * ptr p int a ; int *a ; int a ; int a int *a
 int a = 123; a 123 :100 a 123 int *ptr = & a; a ptr ptr a 100 a 123 200 *ptr 200 a & & a a * * ptr p --------------------------------------------------------------------------------------------- int a
int a = 123; a 123 :100 a 123 int *ptr = & a; a ptr ptr a 100 a 123 200 *ptr 200 a & & a a * * ptr p --------------------------------------------------------------------------------------------- int a
2002 avidemux MPEG-4 : : : G99P045-1
 2002 avidemux MPEG-4 : 2003 2 5 : : G99P045-1 MPEG-4 MPEG-4 PC MPEG-4 MPI XviD MPEG-4 MPEG avidemux MPI MPEG-4 PE 1 1 1.1........................... 1 1.2................................ 1 2 2 2.1 MPEG-4............................
2002 avidemux MPEG-4 : 2003 2 5 : : G99P045-1 MPEG-4 MPEG-4 PC MPEG-4 MPI XviD MPEG-4 MPEG avidemux MPI MPEG-4 PE 1 1 1.1........................... 1 1.2................................ 1 2 2 2.1 MPEG-4............................
1.overview
 村井均 ( 理研 ) 2 はじめに 規模シミュレーションなどの計算を うためには クラスタのような分散メモリシステムの利 が 般的 並列プログラミングの現状 半は MPI (Message Passing Interface) を利 MPI はプログラミングコストが きい 標 性能と 産性を兼ね備えた並列プログラミング 語の開発 3 並列プログラミング 語 XcalableMP 次世代並列プログラミング
村井均 ( 理研 ) 2 はじめに 規模シミュレーションなどの計算を うためには クラスタのような分散メモリシステムの利 が 般的 並列プログラミングの現状 半は MPI (Message Passing Interface) を利 MPI はプログラミングコストが きい 標 性能と 産性を兼ね備えた並列プログラミング 語の開発 3 並列プログラミング 語 XcalableMP 次世代並列プログラミング
 #include #include #include int gcd( int a, int b) { if ( b == 0 ) return a; else { int c = a % b; return gcd( b, c); } /* if */ } int main() { int a = 60; int b = 45; int
#include #include #include int gcd( int a, int b) { if ( b == 0 ) return a; else { int c = a % b; return gcd( b, c); } /* if */ } int main() { int a = 60; int b = 45; int
Microsoft PowerPoint - scls_biogrid_lecture_v2.pptx
 スパコン コース並列プログラミング編 善之 E-mail:yoshiyuki.kido@riken.jp 理化学研究所 HPCI 計算 命科学推進プログラム企画調整グループ企画調整チームチーム員 次 1. Message Passing Interface (MPI) 2. Open MP 3. ハイブリッド並列 4. 列計算の並列化 計算機ってなんだ? 計算機 計算に いる機械 ( デジタル 辞泉
スパコン コース並列プログラミング編 善之 E-mail:yoshiyuki.kido@riken.jp 理化学研究所 HPCI 計算 命科学推進プログラム企画調整グループ企画調整チームチーム員 次 1. Message Passing Interface (MPI) 2. Open MP 3. ハイブリッド並列 4. 列計算の並列化 計算機ってなんだ? 計算機 計算に いる機械 ( デジタル 辞泉
Krylov (b) x k+1 := x k + α k p k (c) r k+1 := r k α k Ap k ( := b Ax k+1 ) (d) β k := r k r k 2 2 (e) : r k 2 / r 0 2 < ε R (f) p k+1 :=
 x k+1 := x k + α k p k (c) r k+1 := r k α k Ap k ( := b Ax k+1 ) (d) β k := r k r k 2 2 (e) : r k 2 / r 0 2 < ε R (f) p k+1 :=") 127 10 Krylov Krylov (Conjugate-Gradient (CG ), Krylov ) MPIBNCpack 10.1 CG (Conjugate-Gradient CG ) A R n n a 11 a 12 a 1n a 21 a 22 a 2n A T = =... a n1 a n2 a nn n a 11 a 21 a n1 a 12 a 22 a n2 = A...
127 10 Krylov Krylov (Conjugate-Gradient (CG ), Krylov ) MPIBNCpack 10.1 CG (Conjugate-Gradient CG ) A R n n a 11 a 12 a 1n a 21 a 22 a 2n A T = =... a n1 a n2 a nn n a 11 a 21 a n1 a 12 a 22 a n2 = A...
( CUDA CUDA CUDA CUDA ( NVIDIA CUDA I
 GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
£Ã¥×¥í¥°¥é¥ß¥ó¥°(2018) - Âè11²ó – ½ÉÂꣲ¤Î²òÀ⡤±é½¬£² –
 - Âè11²ó – ½ÉÂꣲ¤Î²òÀ⡤±é½¬£² –") (2018) 11 2018 12 13 2 g v dv x dt = bv x, dv y dt = g bv y (1) b v 0 θ x(t) = v 0 cos θ ( 1 e bt) (2) b y(t) = 1 ( v 0 sin θ + g ) ( 1 e bt) g b b b t (3) 11 ( ) p14 2 1 y 4 t m y > 0 y < 0 t m1 h = 0001
(2018) 11 2018 12 13 2 g v dv x dt = bv x, dv y dt = g bv y (1) b v 0 θ x(t) = v 0 cos θ ( 1 e bt) (2) b y(t) = 1 ( v 0 sin θ + g ) ( 1 e bt) g b b b t (3) 11 ( ) p14 2 1 y 4 t m y > 0 y < 0 t m1 h = 0001
ohp03.dvi
 19 3 ( ) 2019.4.20 CS 1 (comand line arguments) Unix./a.out aa bbb ccc ( ) C main void int main(int argc, char *argv[]) {... 2 (2) argc argv argc ( ) argv (C char ) ( 1) argc 4 argv NULL. / a. o u t \0
19 3 ( ) 2019.4.20 CS 1 (comand line arguments) Unix./a.out aa bbb ccc ( ) C main void int main(int argc, char *argv[]) {... 2 (2) argc argv argc ( ) argv (C char ) ( 1) argc 4 argv NULL. / a. o u t \0
スライド 1
 計算科学演習 MPI 基礎 学術情報メディアセンター 情報学研究科 システム科学専攻 中島浩 目次 プログラミングモデル SPMD 同期通信 / 非同期通信 MPI 概論 プログラム構造 Communicator & rank データ型 タグ 一対一通信関数 1 次元分割並列化 : 基本 基本的考え方 配列宣言 割付 部分領域交換 結果出力 1 次元分割並列化 : 高速化 通信 計算のオーバーラップ
計算科学演習 MPI 基礎 学術情報メディアセンター 情報学研究科 システム科学専攻 中島浩 目次 プログラミングモデル SPMD 同期通信 / 非同期通信 MPI 概論 プログラム構造 Communicator & rank データ型 タグ 一対一通信関数 1 次元分割並列化 : 基本 基本的考え方 配列宣言 割付 部分領域交換 結果出力 1 次元分割並列化 : 高速化 通信 計算のオーバーラップ
r08.dvi
 19 8 ( ) 019.4.0 1 1.1 (linked list) ( ) next ( 1) (head) (tail) ( ) top head tail head data next 1: NULL nil ( ) NULL ( NULL ) ( 1 ) (double linked list ) ( ) 1 next 1 prev 1 head cur tail head cur prev
19 8 ( ) 019.4.0 1 1.1 (linked list) ( ) next ( 1) (head) (tail) ( ) top head tail head data next 1: NULL nil ( ) NULL ( NULL ) ( 1 ) (double linked list ) ( ) 1 next 1 prev 1 head cur tail head cur prev
Gfarm/MPI-IOの 概要と使い方
 MPI-IO/Gfarm のご紹介と現在の開発状況 鷹津冬将 2018/3/2 Gfarm ワークショップ 2018 1 目次 MPI-IO/Gfarm 概要 MPI-IO/Gfarm の開発状況 MVAPICH2 向け MPI-IO/Gfarm MPI-IO/Gfarm の使い方 かんたんなサンプルプログラムと動作確認の方法 既知の不具合 まとめと今後の展望 2018/3/2 Gfarm ワークショップ
MPI-IO/Gfarm のご紹介と現在の開発状況 鷹津冬将 2018/3/2 Gfarm ワークショップ 2018 1 目次 MPI-IO/Gfarm 概要 MPI-IO/Gfarm の開発状況 MVAPICH2 向け MPI-IO/Gfarm MPI-IO/Gfarm の使い方 かんたんなサンプルプログラムと動作確認の方法 既知の不具合 まとめと今後の展望 2018/3/2 Gfarm ワークショップ
MPI
 筑波大学計算科学研究センター CCS HPC サマーセミナー MPI 建部修見 tatebe@cs.tsukuba.ac.jp 筑波大学大学院システム情報工学研究科計算科学研究センター 分散メモリ型並列計算機 (PC クラスタ ) 計算ノードはプロセッサとメモリで構成され, 相互結合網で接続 ノード内のメモリは直接アクセス 他ノードとはネットワーク通信により情報交換 いわゆるPCクラスタ 相互結合網
筑波大学計算科学研究センター CCS HPC サマーセミナー MPI 建部修見 tatebe@cs.tsukuba.ac.jp 筑波大学大学院システム情報工学研究科計算科学研究センター 分散メモリ型並列計算機 (PC クラスタ ) 計算ノードはプロセッサとメモリで構成され, 相互結合網で接続 ノード内のメモリは直接アクセス 他ノードとはネットワーク通信により情報交換 いわゆるPCクラスタ 相互結合網
untitled
 Visual Basic.NET 1 ... P.3 Visual Studio.NET... P.4 2-1 Visual Studio.NET... P.4 2-2... P.5 2-3... P.6 2-4 VS.NET(VB.NET)... P.9 2-5.NET... P.9 2-6 MSDN... P.11 Visual Basic.NET... P.12 3-1 Visual Basic.NET...
Visual Basic.NET 1 ... P.3 Visual Studio.NET... P.4 2-1 Visual Studio.NET... P.4 2-2... P.5 2-3... P.6 2-4 VS.NET(VB.NET)... P.9 2-5.NET... P.9 2-6 MSDN... P.11 Visual Basic.NET... P.12 3-1 Visual Basic.NET...
main
 14 1. 12 5 main 1.23 3 1.230000 3 1.860867 1 2. 1988 1925 1911 1867 void JPcalendar(int x) 1987 1 64 1 1 1 while(1) Ctrl C void JPcalendar(int x){ if (x > 1988) printf(" %d %d \n", x, x-1988); else if(x
14 1. 12 5 main 1.23 3 1.230000 3 1.860867 1 2. 1988 1925 1911 1867 void JPcalendar(int x) 1987 1 64 1 1 1 while(1) Ctrl C void JPcalendar(int x){ if (x > 1988) printf(" %d %d \n", x, x-1988); else if(x
untitled
 II yacc 005 : 1, 1 1 1 %{ int lineno=0; 3 int wordno=0; 4 int charno=0; 5 6 %} 7 8 %% 9 [ \t]+ { charno+=strlen(yytext); } 10 "\n" { lineno++; charno++; } 11 [^ \t\n]+ { wordno++; charno+=strlen(yytext);}
II yacc 005 : 1, 1 1 1 %{ int lineno=0; 3 int wordno=0; 4 int charno=0; 5 6 %} 7 8 %% 9 [ \t]+ { charno+=strlen(yytext); } 10 "\n" { lineno++; charno++; } 11 [^ \t\n]+ { wordno++; charno+=strlen(yytext);}
£Ã¥×¥í¥°¥é¥ß¥ó¥°ÆþÌç (2018) - Â裵²ó ¨¡ À©¸æ¹½Â¤¡§¾ò·ïʬ´ô ¨¡
 - Â裵²ó ¨¡ À©¸æ¹½Â¤¡§¾ò·ïʬ´ô ¨¡") (2018) 2018 5 17 0 0 if switch if if ( ) if ( 0) if ( ) if ( 0) if ( ) (0) if ( 0) if ( ) (0) ( ) ; if else if ( ) 1 else 2 if else ( 0) 1 if ( ) 1 else 2 if else ( 0) 1 if ( ) 1 else 2 (0) 2 if else
(2018) 2018 5 17 0 0 if switch if if ( ) if ( 0) if ( ) if ( 0) if ( ) (0) if ( 0) if ( ) (0) ( ) ; if else if ( ) 1 else 2 if else ( 0) 1 if ( ) 1 else 2 if else ( 0) 1 if ( ) 1 else 2 (0) 2 if else
P06.ppt
 p.130 p.198 p.208 2 1 double weight[num]; double min, max; min = max = weight[0]; for( i= 1; i < NUM; i++ ) if ( weight[i] > max ) max = weight[i]: if ( weight[i] < min ) min = weight[i]: weight 3 maxof(a,
p.130 p.198 p.208 2 1 double weight[num]; double min, max; min = max = weight[0]; for( i= 1; i < NUM; i++ ) if ( weight[i] > max ) max = weight[i]: if ( weight[i] < min ) min = weight[i]: weight 3 maxof(a,
ohp08.dvi
 19 8 ( ) 2019.4.20 1 (linked list) ( ) next ( 1) (head) (tail) ( ) top head tail head data next 1: 2 (2) NULL nil ( ) NULL ( NULL ) ( 1 ) (double linked list ) ( 2) 3 (3) head cur tail head cur prev data
19 8 ( ) 2019.4.20 1 (linked list) ( ) next ( 1) (head) (tail) ( ) top head tail head data next 1: 2 (2) NULL nil ( ) NULL ( NULL ) ( 1 ) (double linked list ) ( 2) 3 (3) head cur tail head cur prev data
8 if switch for while do while 2
 (Basic Theory of Information Processing) ( ) if for while break continue 1 8 if switch for while do while 2 8.1 if (p.52) 8.1.1 if 1 if ( ) 2; 3 1 true 2 3 false 2 3 3 8.1.2 if-else (p.54) if ( ) 1; else
(Basic Theory of Information Processing) ( ) if for while break continue 1 8 if switch for while do while 2 8.1 if (p.52) 8.1.1 if 1 if ( ) 2; 3 1 true 2 3 false 2 3 3 8.1.2 if-else (p.54) if ( ) 1; else
10K pdf
 #1 #2 Java class Circle { double x; // x double y; // y double radius; // void set(double tx, double ty){ x = tx; y = ty; void set(double tx, double ty, double r) { x = tx; y = ty; radius = r; // Circle
#1 #2 Java class Circle { double x; // x double y; // y double radius; // void set(double tx, double ty){ x = tx; y = ty; void set(double tx, double ty, double r) { x = tx; y = ty; radius = r; // Circle
1) OOP 2) ( ) 3.2) printf Number3-2.cpp #include <stdio.h> class Number Number(); // ~Number(); // void setnumber(float n); float getnumber();
 OOP 2) ( ) 3.2) printf Number3-2.cpp #include <stdio.h> class Number Number(); // ~Number(); // void setnumber(float n); float getnumber();") : : :0757230G :2008/07/18 2008/08/17 1) OOP 2) ( ) 3.2) printf Number3-2.cpp #include class Number Number(); // ~Number(); // void setnumber(float n); float getnumber(); private: float num; ;
: : :0757230G :2008/07/18 2008/08/17 1) OOP 2) ( ) 3.2) printf Number3-2.cpp #include class Number Number(); // ~Number(); // void setnumber(float n); float getnumber(); private: float num; ;
TOEIC
 TOEIC 1 1 3 1.1.............................................. 3 1.2 C#........................................... 3 2 Visual Studio.NET Windows 5 2.1....................................... 5 2.2..........................................
TOEIC 1 1 3 1.1.............................................. 3 1.2 C#........................................... 3 2 Visual Studio.NET Windows 5 2.1....................................... 5 2.2..........................................
:30 12:00 I. I VI II. III. IV. a d V. VI
 2018 2018 08 02 10:30 12:00 I. I VI II. III. IV. a d V. VI. 80 100 60 1 I. Backus-Naur BNF N N y N x N xy yx : yxxyxy N N x, y N (parse tree) (1) yxyyx (2) xyxyxy (3) yxxyxyy (4) yxxxyxxy N y N x N yx
2018 2018 08 02 10:30 12:00 I. I VI II. III. IV. a d V. VI. 80 100 60 1 I. Backus-Naur BNF N N y N x N xy yx : yxxyxy N N x, y N (parse tree) (1) yxyyx (2) xyxyxy (3) yxxyxyy (4) yxxxyxxy N y N x N yx
Excel97関数編
 Excel97 SUM Microsoft Excel 97... 1... 1... 1... 2... 3... 3... 4... 5... 6... 6... 7 SUM... 8... 11 Microsoft Excel 97 AVERAGE MIN MAX SUM IF 2 RANK TODAY ROUND COUNT INT VLOOKUP 1/15 Excel A B C A B
Excel97 SUM Microsoft Excel 97... 1... 1... 1... 2... 3... 3... 4... 5... 6... 6... 7 SUM... 8... 11 Microsoft Excel 97 AVERAGE MIN MAX SUM IF 2 RANK TODAY ROUND COUNT INT VLOOKUP 1/15 Excel A B C A B
超初心者用
 3 1999 10 13 1. 2. hello.c printf( Hello, world! n ); cc hello.c a.out./a.out Hello, world printf( Hello, world! n ); 2 Hello, world printf n printf 3. ( ) int num; num = 100; num 100 100 num int num num
3 1999 10 13 1. 2. hello.c printf( Hello, world! n ); cc hello.c a.out./a.out Hello, world printf( Hello, world! n ); 2 Hello, world printf n printf 3. ( ) int num; num = 100; num 100 100 num int num num
oop1
 public class Car{ int num; double gas; // double distance; String maker; // // // void drive(){ System.out.println(""); Car.java void curve(){ System.out.println(""); void stop(){ System.out.println("");
public class Car{ int num; double gas; // double distance; String maker; // // // void drive(){ System.out.println(""); Car.java void curve(){ System.out.println(""); void stop(){ System.out.println("");
(Eclipse\202\305\212w\202\324Java2\215\374.pdf)
") C H A P T E R 11 11-1 1 Sample9_4 package sample.sample11; public class Sample9_4 { 2 public static void main(string[] args) { int[] points = new int[30]; initializearray(points); double averagepoint =
C H A P T E R 11 11-1 1 Sample9_4 package sample.sample11; public class Sample9_4 { 2 public static void main(string[] args) { int[] points = new int[30]; initializearray(points); double averagepoint =
(OnePoint) ( URL Web Copyright 2005 Microsoft Corporation. All rights reserved. Microsoft Windows Visual Basic Visual Studio Microsoft Corporation
 ( URL Web Copyright 2005 Microsoft Corporation. All rights reserved. Microsoft Windows Visual Basic Visual Studio Microsoft Corporation") Microsoft Microsoft Visual Basic.NET (OnePoint) ( URL Web Copyright 2005 Microsoft Corporation. All rights reserved. Microsoft Windows Visual Basic Visual Studio Microsoft Corporation Microsoft Microsoft
Microsoft Microsoft Visual Basic.NET (OnePoint) ( URL Web Copyright 2005 Microsoft Corporation. All rights reserved. Microsoft Windows Visual Basic Visual Studio Microsoft Corporation Microsoft Microsoft