演習1: 演習準備
|
|
|
- きよはる とりこし
- 4 years ago
- Views:
Transcription
1 演習 1: 演習準備 2013 年 8 月 6 日神戸大学大学院システム情報学研究科森下浩二 1
2 演習 1 の内容 神戸大 X10(π-omputer) について システム概要 ログイン方法 コンパイルとジョブ実行方法 OpenMP の演習 ( 入門編 ) 1. parallel 構文 実行時ライブラリ関数 2. ループ構文 3. shared 節 private 節 4. reduction 節 2
3 神戸大 X10(π-omputer) について 3
4 神戸大 X10(π-omputer) 富士通 PRIMEHP X10:1 ラック SPAR64 TM IXfx プロセッサ x 96 ノード 総理論演算性能 :20.2TLOPS 総主記憶容量 :3TByte 1 ノード諸元表 ( 京との比較 ) X10 (SPAR64 TM IXfx ) 京 (SPAR64 TM VIIIfx ) コア数 16 8 L1 キャッシュ ( コア ) 32KB(D)/32KB(I) 共有 L2 キャッシュ 12MB 6MB 動作周波数 1.65GHz 2.0GHz 理論演算性能 211.2Glops 128Glops メモリ容量 32GB 16GB 4
5 X10 へのログイン方法 公開鍵認証によりログイン 手順の詳細は別紙を参照 1. 鍵ペア ( 公開鍵 秘密鍵 ) の作成 2. 仮の鍵ペアでログイン 3. 自身の公開鍵を登録 4. 自身の鍵ペアでログイン出来ることを確認 5. 仮の公開鍵を削除 5
6 コンパイル方法 逐次プログラム $ frtpx sample.f90 :ortran : 言語 $ fccpx sample.c OpenMP $ frtpx Kopenmp sample.f90 $ fccpx Kopenmp sample.c 自動並列化 ( ノード内スレッド並列 ) $ frtpx Kparallel sample.f90 $ fccpx Kparallel sample.c 6

7 ジョブ実行方法 ジョブスクリプトの作成 single.sh: 逐次ジョブ #!/bin/sh #PJM -L "rscgrp=school" #PJM -L "node=1" #PJM -L "elapse=10:00" #PJM -j #./a.out シェルを指定 利用リソースグループ名 利用ノード数 最大経過時間 (hh:mm:ss) 標準エラー出力をマージして出力 プログラムの実行 7 ジョブの投入 $ pjsub single.sh

 標準エラー出力をマージして出力 OpenMP")
8 ジョブ実行方法 ジョブスクリプトの作成 thread_omp.sh: スレッド並列 (OpenMP) ジョブ #!/bin/sh #PJM -L "rscgrp=school" #PJM -L "node=1" #PJM -L "elapse=10:00" #PJM -j # export OMP_NUM_THREADS=16./a.out シェルを指定 利用リソースグループ名 利用ノード数 最大経過時間 (hh:mm:ss) 標準エラー出力をマージして出力 OpenMP 並列数を指定 プログラムの実行 環境変数 OMP_NUM_THREADS に OpenMP 並列数を設定 8
![ジョブの管理 ジョブの状態表示 $ pjstat [option] -v オプション : 詳細なジョブ情報を表示 -H オプション : 終了したジョブ情報を表示 -A オプション :](/docs-images/101/148629117/images/9-4.jpg "全ユーザのジョブ情報を表示 ジョブのキャンセル $ pjdel [JOB_ID] [JOB_ID] は pjstat で表示されるものを指定 例 ) [JOB_ID] が 12345 のジョブをキャンセル $")
9 ジョブの管理 ジョブの状態表示 $ pjstat [option] -v オプション : 詳細なジョブ情報を表示 -H オプション : 終了したジョブ情報を表示 -A オプション : 全ユーザのジョブ情報を表示 ジョブのキャンセル $ pjdel [JOB_ID] [JOB_ID] は pjstat で表示されるものを指定 例 ) [JOB_ID] が のジョブをキャンセル $ pjdel
10 ジョブ結果の確認 バッチジョブの実行が終了すると 標準出力ファイルと標準エラー出力ファイルがジョブ投入ディレクトリに出力される 標準出力ファイル : ジョブ名.oXXXXX 標準エラー出力ファイル : ジョブ名.eXXXXX デフォルトのジョブ名はジョブスクリプトのファイル名 XXXXX には [JOB_ID] が入る ジョブスクリプト内で #PJM -j を指定した場合には 標準エラー出力はマージされ標準出力ファイルのみ出力される 例 )p.7 の thread_omp.sh を投入し [JOB_ID] に が割り当てられた場合 : thread_omp.sh.o12345 が出力 10
11 OpenMP の演習 ( 入門編 ) 11



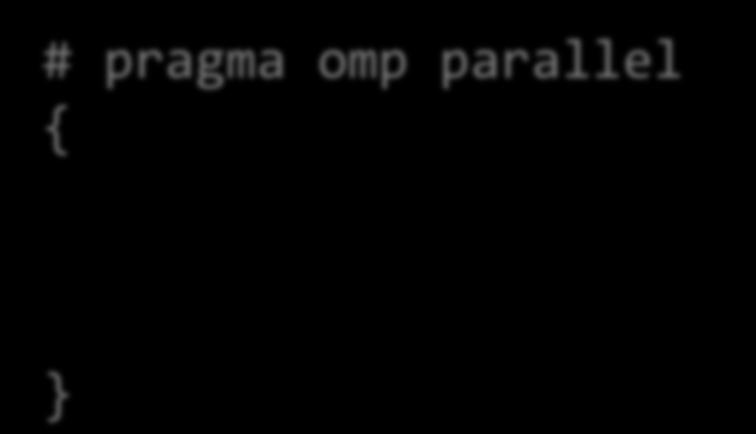
12 OpenMP 復習 ( ノード内 ) スレッド並列のためのAPI 仕様 逐次プログラムに指示文を挿入 parallel 構文 複数のスレッドにより並列実行するリージョンを指定!$ omp parallel 並列リージョン!$ omp end parallel # pragma omp parallel { 並列リージョン 12
 自身のスレッド番号 ( 整数 ) omp_get_num_threads() 総スレッド数 ( 整数 ) omp_get_wtime() 経過時間 ( 秒 :")
13 OpenMP 演習 1: 実行時ライブラリ関数 並列計算を行う際にプログラムの管理がしやすくなる 関数を利用するには以下の文を追加 include "omp_lib.h" もしくは use omp_lib #include <omp.h> 実行時ライブラリ関数の例 関数名 戻り値 omp_get_thread_num() 自身のスレッド番号 ( 整数 ) omp_get_num_threads() 総スレッド数 ( 整数 ) omp_get_wtime() 経過時間 ( 秒 : 倍精度実数 ) 13
,\"of\",omp_get_num_threads()!")
14 OpenMP 演習 1: 実行時ライブラリ関数 プログラム :omp1.f90 program omp1 use omp_lib implicit none real(8) :: t1, t2 t1 = omp_get_wtime()!$omp parallel print *, "#ID:",omp_get_thread_num(),"of",omp_get_num_threads()!$omp end parallel t2 = omp_get_wtime() print *, "#time:", t2-t1 end program omp1 演習 1 上記のプログラムを作成し コンパイル ジョブ実行し 結果を確認してください 14
{ double t1, t2; t1 = omp_get_wtime(); #pragma omp parallel { printf(\"#id: %d of %d n\",omp_get_thread_num(),omp_get_num_threads()); t2 =")
15 OpenMP 演習 1: 実行時ライブラリ関数 プログラム :omp1.c #include <stdio.h> #include <omp.h> int main(void){ double t1, t2; t1 = omp_get_wtime(); #pragma omp parallel { printf("#id: %d of %d n",omp_get_thread_num(),omp_get_num_threads()); t2 = omp_get_wtime(); printf("#time: %le n",t2-t1); return 0; 演習 1 上記のプログラムを作成し コンパイル ジョブ実行し 結果を確認してください 15

16 OpenMP 演習 1: 実行時ライブラリ関数 実行結果の例 #ID: 11 of 16 #ID: 13 of 16 #ID: 9 of 16 #ID: 1 of 16 #ID: 10 of 16 #ID: 0 of 16 #ID: 5 of 16 #ID: 15 of 16 #ID: 4 of 16 #ID: 6 of 16 #ID: 7 of 16 #ID: 8 of 16 #ID: 2 of 16 #ID: 12 of 16 #ID: 3 of 16 #ID: 14 of 16 #time: E-02 16




17 OpenMP 演習 2: ループ構文 do ループおよび for ループの並列処理!$omp parallel!$omp do do i = 1, n... end do!$omp end do!$omp end parallel #pragma omp parallel { #pragma omp for for(i = 0; i < n; i++){... 又は まとめて!$omp parallel do do i = 1, n... end do!$omp end parallel do #pragma omp parallel for for(i = 0; i < n; i++){... 17
18 OpenMP 演習 2: ループ構文 プログラム :omp2.f90 program omp2 implicit none integer, parameter :: n = real(8) :: x(n), y(n), pi, dx integer :: i pi = 4.0d0*atan(1.0d0) dx = 2.0d0*pi/n do i = 1, n x(i) = dx*i y(i) = sin(x(i)) end do print *, y(1), y(n) end program omp2 演習 2 1. 上記プログラムのdoループ部分をOpenMPで並列化する 2. doループ部分の計算時間を計測 出力し 並列数を変え たときに計算時間がどう変わるかを確認する 18
19 OpenMP 演習 2: ループ構文 プログラム :omp2.c #include <stdio.h> #include <math.h> int main(void){ int n = , i; double x[n], y[n], pi, dx; pi = 4.0*atan(1.0); dx = 2.0*pi/n; for(i = 0; i < n; i++){ x[i] = dx*(i+1); y[i] = sin(x[i]); printf("%le %le n", y[0], y[n-1]); return 0; 演習 2 1. 上記プログラムのforループ部分をOpenMPで並列化する 2. forループ部分の計算時間を計測 出力し 並列数を変 えたときに計算時間がどう変わるかを確認する 19
20 OpenMP 演習 3:shared 節 private 節 データ共有属性 並列リージョン内での変数の共有属性 shared 節 例 ) 変数 a はスレッド間で共有される ( 共有変数 ) private 節 例 )!$omp parallel shared(a) #pragma omp parallel shared(a)!$omp parallel private(b) #pragma omp parallel private(b) 変数 b は各スレッド固有となる ( プライベート変数 ) デフォルトではループ制御変数は private それ以外は shared 20
 = sin(x) end do print *, y(1), y(n) end program omp3 演習 3 1. 上記プログラムのdoループ部分をOpenMPで並列化する 2. その際 shared, private を明示的に指定してみる 3.")
21 OpenMP 演習 3:shared 節 private 節 プログラム :omp3.f90 program omp3 implicit none integer, parameter :: n = real(8) :: x, y(n), pi, dx integer :: i pi = 4.0d0*atan(1.0d0) dx = 2.0d0*pi/n do i = 1, n x = dx*i y(i) = sin(x) end do print *, y(1), y(n) end program omp3 演習 3 1. 上記プログラムのdoループ部分をOpenMPで並列化する 2. その際 shared, private を明示的に指定してみる 3. 不適切な指定をした場合 どうなるかやってみる 21
![OpenMP 演習 3:shared 節 private 節 プログラム :omp3.c #include <stdio.h> #include <math.h> int main(void){ int n = 100000000, i; double x, y[n], pi, dx; pi = 4.0*atan(1.0); dx = 2.](/docs-images/101/148629117/images/22-1.jpg "0*pi/n; for(i = 0; i < n; i++){ x = dx*(i+1); y[i] = sin(x); printf(\"%le %le n\", y[0], y[n-1]); return 0; 演習 3 1. 上記プログラムのdoループ部分をOpenMPで並列化する 2. その際 shared, private を明示的に指定してみる 3.")
22 OpenMP 演習 3:shared 節 private 節 プログラム :omp3.c #include <stdio.h> #include <math.h> int main(void){ int n = , i; double x, y[n], pi, dx; pi = 4.0*atan(1.0); dx = 2.0*pi/n; for(i = 0; i < n; i++){ x = dx*(i+1); y[i] = sin(x); printf("%le %le n", y[0], y[n-1]); return 0; 演習 3 1. 上記プログラムのdoループ部分をOpenMPで並列化する 2. その際 shared, private を明示的に指定してみる 3. 不適切な指定をした場合 どうなるかやってみる 22
23 OpenMP 演習 4:reduction 節 データ共有属性 reduction 節 例 )!$omp parallel reduction(+:c) #pragma omp parallel reduction(+:c) 変数 c は private と同様各スレッド固有であるが 並列リージョン終了時に全スレッドについて総和 (+) がとられる 指定した演算で各スレッドの値を集計した結果が代入される 演算子 : +, -, * 等 一部組み込み関数 (ortran): max, min 等 23
 :: x(n), y(n), pi, dx, z, l1, l2")
*y(i) l1 = l1 + z*dx l2 = l2 + z*(1.")
24 OpenMP 演習 4:reduction 節 プログラム :omp4.f90 program omp4 implicit none integer, parameter :: n = real(8) :: x(n), y(n), pi, dx, z, l1, l2 integer :: i pi = 4.0d0*atan(1.0d0) dx = 2.0d0*pi/n do i = 1, n x(i) = dx*i y(i) = sin(x(i)) end do l1 = 0.0d0 l2 = 0.0d0 do i = 1, n z = x(i)*y(i) l1 = l1 + z*dx l2 = l2 + z*(1.0d0-z)*dx end do print *, l1, l2 end program omp4 演習 4 1. 上記プログラムの 2 つの do ループ部分を OpenMP で並列化する 2. reduction の指定が不適切な場合 どうなるかやってみる 24
![OpenMP 演習 4:reduction 節 プログラム :omp4.c #include <stdio.h> #include <math.h> int main(void){ int n = 100000000, i; double x[n], y[n], pi, dx, z, l1, l2; pi = 4.0*atan(1.0); dx = 2.](/docs-images/101/148629117/images/25-0.jpg "0*pi/n; for(i = 0; i < n; i++){ x[i] = dx*(i+1); y[i] = sin(x[i]); l1 = 0.0; l2 = 0.0; for(i = 0; i < n; i++){ z = x[i]*y[i]; l1 += z*dx; l2 += z*(1.")
25 OpenMP 演習 4:reduction 節 プログラム :omp4.c #include <stdio.h> #include <math.h> int main(void){ int n = , i; double x[n], y[n], pi, dx, z, l1, l2; pi = 4.0*atan(1.0); dx = 2.0*pi/n; for(i = 0; i < n; i++){ x[i] = dx*(i+1); y[i] = sin(x[i]); l1 = 0.0; l2 = 0.0; for(i = 0; i < n; i++){ z = x[i]*y[i]; l1 += z*dx; l2 += z*(1.0-z)*dx; printf("%le %le n", l1, l2); return 0; 演習 4 1. 上記プログラムの 2 つの for ループ部分を OpenMP で並列化する 2. reduction の指定が不適切な場合 どうなるかやってみる 25
演習準備
 演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 RIKEN AICS HPC Spring School /3/5
 演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
openmp1_Yaguchi_version_170530
 並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
FX10利用準備
 π-computer(fx10) 利用準備 2018 年 3 月 14 日理化学研究所計算科学研究機構八木学 1 KOBE HPC Spring School 2018 2018/3/14 内容 本スクールの実習で利用するスーパーコンピュータ神戸大学 π-computer (FX10) について システム概要 ログイン準備 2 神戸大学 π-computer: システム概要 富士通 PRIMEHPC
π-computer(fx10) 利用準備 2018 年 3 月 14 日理化学研究所計算科学研究機構八木学 1 KOBE HPC Spring School 2018 2018/3/14 内容 本スクールの実習で利用するスーパーコンピュータ神戸大学 π-computer (FX10) について システム概要 ログイン準備 2 神戸大学 π-computer: システム概要 富士通 PRIMEHPC
コードのチューニング
 OpenMP による並列化実装 八木学 ( 理化学研究所計算科学研究センター ) KOBE HPC Spring School 2019 2019 年 3 月 14 日 スレッド並列とプロセス並列 スレッド並列 OpenMP 自動並列化 プロセス並列 MPI プロセス プロセス プロセス スレッドスレッドスレッドスレッド メモリ メモリ プロセス間通信 Private Private Private
OpenMP による並列化実装 八木学 ( 理化学研究所計算科学研究センター ) KOBE HPC Spring School 2019 2019 年 3 月 14 日 スレッド並列とプロセス並列 スレッド並列 OpenMP 自動並列化 プロセス並列 MPI プロセス プロセス プロセス スレッドスレッドスレッドスレッド メモリ メモリ プロセス間通信 Private Private Private
Microsoft PowerPoint - 演習2:MPI初歩.pptx
 演習 2:MPI 初歩 - 並列に計算する - 2013 年 8 月 6 日 神戸大学大学院システム情報学研究科計算科学専攻横川三津夫 MPI( メッセージ パッシング インターフェース ) を使おう! [ 演習 2 の内容 ] はじめの一歩課題 1: Hello, world を並列に出力する. 課題 2: プロセス 0 からのメッセージを受け取る (1 対 1 通信 ). 部分に分けて計算しよう課題
演習 2:MPI 初歩 - 並列に計算する - 2013 年 8 月 6 日 神戸大学大学院システム情報学研究科計算科学専攻横川三津夫 MPI( メッセージ パッシング インターフェース ) を使おう! [ 演習 2 の内容 ] はじめの一歩課題 1: Hello, world を並列に出力する. 課題 2: プロセス 0 からのメッセージを受け取る (1 対 1 通信 ). 部分に分けて計算しよう課題
Microsoft PowerPoint - OpenMP入門.pptx
 OpenMP 入門 須田礼仁 2009/10/30 初版 OpenMP 共有メモリ並列処理の標準化 API http://openmp.org/ 最新版は 30 3.0 バージョンによる違いはあまり大きくない サポートしているバージョンはともかく csp で動きます gcc も対応しています やっぱり SPMD Single Program Multiple Data プログラム #pragma omp
OpenMP 入門 須田礼仁 2009/10/30 初版 OpenMP 共有メモリ並列処理の標準化 API http://openmp.org/ 最新版は 30 3.0 バージョンによる違いはあまり大きくない サポートしているバージョンはともかく csp で動きます gcc も対応しています やっぱり SPMD Single Program Multiple Data プログラム #pragma omp
NUMAの構成
 共有メモリを使ったデータ交換と同期 慶應義塾大学理工学部 天野英晴 hunga@am.ics.keio.ac.jp 同期の必要性 あるプロセッサが共有メモリに書いても 別のプロセッサにはそのことが分からない 同時に同じ共有変数に書き込みすると 結果がどうなるか分からない そもそも共有メモリって結構危険な代物 多くのプロセッサが並列に動くには何かの制御機構が要る 不可分命令 同期用メモリ バリア同期機構
共有メモリを使ったデータ交換と同期 慶應義塾大学理工学部 天野英晴 hunga@am.ics.keio.ac.jp 同期の必要性 あるプロセッサが共有メモリに書いても 別のプロセッサにはそのことが分からない 同時に同じ共有変数に書き込みすると 結果がどうなるか分からない そもそも共有メモリって結構危険な代物 多くのプロセッサが並列に動くには何かの制御機構が要る 不可分命令 同期用メモリ バリア同期機構
Microsoft Word - openmp-txt.doc
 ( 付録 A) OpenMP チュートリアル OepnMP は 共有メモリマルチプロセッサ上のマルチスレッドプログラミングのための API です 本稿では OpenMP の簡単な解説とともにプログラム例をつかって説明します 詳しくは OpenMP の規約を決めている OpenMP ARB の http://www.openmp.org/ にある仕様書を参照してください 日本語訳は http://www.hpcc.jp/omni/spec.ja/
( 付録 A) OpenMP チュートリアル OepnMP は 共有メモリマルチプロセッサ上のマルチスレッドプログラミングのための API です 本稿では OpenMP の簡単な解説とともにプログラム例をつかって説明します 詳しくは OpenMP の規約を決めている OpenMP ARB の http://www.openmp.org/ にある仕様書を参照してください 日本語訳は http://www.hpcc.jp/omni/spec.ja/
OpenMP¤òÍѤ¤¤¿ÊÂÎó·×»»¡Ê£±¡Ë
 2012 5 24 scalar Open MP Hello World Do (omp do) (omp workshare) (shared, private) π (reduction) PU PU PU 2 16 OpenMP FORTRAN/C/C++ MPI OpenMP 1997 FORTRAN Ver. 1.0 API 1998 C/C++ Ver. 1.0 API 2000 FORTRAN
2012 5 24 scalar Open MP Hello World Do (omp do) (omp workshare) (shared, private) π (reduction) PU PU PU 2 16 OpenMP FORTRAN/C/C++ MPI OpenMP 1997 FORTRAN Ver. 1.0 API 1998 C/C++ Ver. 1.0 API 2000 FORTRAN
OpenMP (1) 1, 12 1 UNIX (FUJITSU GP7000F model 900), 13 1 (COMPAQ GS320) FUJITSU VPP5000/64 1 (a) (b) 1: ( 1(a))
 1, 12 1 UNIX (FUJITSU GP7000F model 900), 13 1 (COMPAQ GS320) FUJITSU VPP5000/64 1 (a) (b) 1: ( 1(a))") OpenMP (1) 1, 12 1 UNIX (FUJITSU GP7000F model 900), 13 1 (COMPAQ GS320) FUJITSU VPP5000/64 1 (a) (b) 1: ( 1(a)) E-mail: {nanri,amano}@cc.kyushu-u.ac.jp 1 ( ) 1. VPP Fortran[6] HPF[3] VPP Fortran 2. MPI[5]
OpenMP (1) 1, 12 1 UNIX (FUJITSU GP7000F model 900), 13 1 (COMPAQ GS320) FUJITSU VPP5000/64 1 (a) (b) 1: ( 1(a)) E-mail: {nanri,amano}@cc.kyushu-u.ac.jp 1 ( ) 1. VPP Fortran[6] HPF[3] VPP Fortran 2. MPI[5]
OpenMP¤òÍѤ¤¤¿ÊÂÎó·×»»¡Ê£±¡Ë
 2011 5 26 scalar Open MP Hello World Do (omp do) (omp workshare) (shared, private) π (reduction) scalar magny-cours, 48 scalar scalar 1 % scp. ssh / authorized keys 133. 30. 112. 246 2 48 % ssh 133.30.112.246
2011 5 26 scalar Open MP Hello World Do (omp do) (omp workshare) (shared, private) π (reduction) scalar magny-cours, 48 scalar scalar 1 % scp. ssh / authorized keys 133. 30. 112. 246 2 48 % ssh 133.30.112.246
OpenMP¤òÍѤ¤¤¿ÊÂÎó·×»»¡Ê£²¡Ë
 2013 5 30 (schedule) (omp sections) (omp single, omp master) (barrier, critical, atomic) program pi i m p l i c i t none integer, parameter : : SP = kind ( 1. 0 ) integer, parameter : : DP = selected real
2013 5 30 (schedule) (omp sections) (omp single, omp master) (barrier, critical, atomic) program pi i m p l i c i t none integer, parameter : : SP = kind ( 1. 0 ) integer, parameter : : DP = selected real
Microsoft Word - 計算科学演習第1回3.doc
 スーパーコンピュータの基本的操作方法 2009 年 9 月 10 日高橋康人 1. スーパーコンピュータへのログイン方法 本演習では,X 端末ソフト Exceed on Demand を使用するが, 必要に応じて SSH クライアント putty,ftp クライアント WinSCP や FileZilla を使用して構わない Exceed on Demand を起動し, 以下のとおり設定 ( 各自のユーザ
スーパーコンピュータの基本的操作方法 2009 年 9 月 10 日高橋康人 1. スーパーコンピュータへのログイン方法 本演習では,X 端末ソフト Exceed on Demand を使用するが, 必要に応じて SSH クライアント putty,ftp クライアント WinSCP や FileZilla を使用して構わない Exceed on Demand を起動し, 以下のとおり設定 ( 各自のユーザ
I I / 47
 1 2013.07.18 1 I 2013 3 I 2013.07.18 1 / 47 A Flat MPI B 1 2 C: 2 I 2013.07.18 2 / 47 I 2013.07.18 3 / 47 #PJM -L "rscgrp=small" π-computer small: 12 large: 84 school: 24 84 16 = 1344 small school small
1 2013.07.18 1 I 2013 3 I 2013.07.18 1 / 47 A Flat MPI B 1 2 C: 2 I 2013.07.18 2 / 47 I 2013.07.18 3 / 47 #PJM -L "rscgrp=small" π-computer small: 12 large: 84 school: 24 84 16 = 1344 small school small
PowerPoint プレゼンテーション
 計算科学演習 I 第 8 回講義 MPI を用いた並列計算 (I) 2013 年 6 月 6 日 システム情報学研究科計算科学専攻 山本有作 今回の講義の概要 1. MPI とは 2. 簡単な MPI プログラムの例 (1) 3. 簡単な MPI プログラムの例 (2):1 対 1 通信 4. 簡単な MPI プログラムの例 (3): 集団通信 共有メモリ型並列計算機 ( 復習 ) 共有メモリ型並列計算機
計算科学演習 I 第 8 回講義 MPI を用いた並列計算 (I) 2013 年 6 月 6 日 システム情報学研究科計算科学専攻 山本有作 今回の講義の概要 1. MPI とは 2. 簡単な MPI プログラムの例 (1) 3. 簡単な MPI プログラムの例 (2):1 対 1 通信 4. 簡単な MPI プログラムの例 (3): 集団通信 共有メモリ型並列計算機 ( 復習 ) 共有メモリ型並列計算機
enshu5_4.key
 http://www.mmsonline.com/articles/parallel-processing-speeds-toolpath-calculations TA : 菅 新 菅沼智史 水曜 新行紗弓 馬淵隼 木曜 情報知能工学演習V (前半第4週) 政田洋平 システム情報学研究科計算科学専攻 演習 V( 前半 ) の内容 第 1 週 : 高性能計算 (High Performance Computing
http://www.mmsonline.com/articles/parallel-processing-speeds-toolpath-calculations TA : 菅 新 菅沼智史 水曜 新行紗弓 馬淵隼 木曜 情報知能工学演習V (前半第4週) 政田洋平 システム情報学研究科計算科学専攻 演習 V( 前半 ) の内容 第 1 週 : 高性能計算 (High Performance Computing
(Microsoft PowerPoint \215u\213`4\201i\221\272\210\344\201j.pptx)
") AICS 村井均 RIKEN AICS HPC Summer School 2012 8/7/2012 1 背景 OpenMP とは OpenMP の基本 OpenMP プログラミングにおける注意点 やや高度な話題 2 共有メモリマルチプロセッサシステムの普及 共有メモリマルチプロセッサシステムのための並列化指示文を共通化する必要性 各社で仕様が異なり 移植性がない そして いまやマルチコア プロセッサが主流となり
AICS 村井均 RIKEN AICS HPC Summer School 2012 8/7/2012 1 背景 OpenMP とは OpenMP の基本 OpenMP プログラミングにおける注意点 やや高度な話題 2 共有メモリマルチプロセッサシステムの普及 共有メモリマルチプロセッサシステムのための並列化指示文を共通化する必要性 各社で仕様が異なり 移植性がない そして いまやマルチコア プロセッサが主流となり
OpenMPプログラミング
 OpenMP 基礎 岩下武史 ( 学術情報メディアセンター ) 1 2013/9/13 並列処理とは 逐次処理 CPU1 並列処理 CPU1 CPU2 CPU3 CPU4 処理 1 処理 1 処理 2 処理 3 処理 4 処理 2 処理 3 処理 4 時間 2 2 種類の並列処理方法 プロセス並列 スレッド並列 並列プログラム 並列プログラム プロセス プロセス 0 プロセス 1 プロセス間通信 スレッド
OpenMP 基礎 岩下武史 ( 学術情報メディアセンター ) 1 2013/9/13 並列処理とは 逐次処理 CPU1 並列処理 CPU1 CPU2 CPU3 CPU4 処理 1 処理 1 処理 2 処理 3 処理 4 処理 2 処理 3 処理 4 時間 2 2 種類の並列処理方法 プロセス並列 スレッド並列 並列プログラム 並列プログラム プロセス プロセス 0 プロセス 1 プロセス間通信 スレッド
内容に関するご質問は まで お願いします [Oakforest-PACS(OFP) 編 ] 第 85 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用 : 科学技術計算の効率化入門 スパコンへのログイン テストプログラム起動 東京大学情報基盤セ
![内容に関するご質問は まで お願いします [Oakforest-PACS(OFP) 編 ] 第 85 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用 : 科学技術計算の効率化入門 スパコンへのログイン テストプログラム起動 東京大学情報基盤セ](/thumbs/95/125947898.jpg "内容に関するご質問は まで お願いします [Oakforest-PACS(OFP) 編 ] 第 85 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用 : 科学技術計算の効率化入門 スパコンへのログイン テストプログラム起動 東京大学情報基盤セ") 内容に関するご質問は ida@cc.u-tokyo.ac.jp まで お願いします [Oakforest-PACS(OFP) 編 ] 第 85 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用 : 科学技術計算の効率化入門 スパコンへのログイン テストプログラム起動 東京大学情報基盤センター特任准教授伊田明弘 1 講習会 : ライブラリ利用 [FX10] スパコンへのログイン ファイル転送
内容に関するご質問は ida@cc.u-tokyo.ac.jp まで お願いします [Oakforest-PACS(OFP) 編 ] 第 85 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用 : 科学技術計算の効率化入門 スパコンへのログイン テストプログラム起動 東京大学情報基盤センター特任准教授伊田明弘 1 講習会 : ライブラリ利用 [FX10] スパコンへのログイン ファイル転送
±é½¬£²¡§£Í£Ð£É½éÊâ
 2012 8 7 1 / 52 MPI Hello World I ( ) Hello World II ( ) I ( ) II ( ) ( sendrecv) π ( ) MPI fortran C wget http://www.na.scitec.kobe-u.ac.jp/ yaguchi/riken2012/enshu2.zip unzip enshu2.zip 2 / 52 FORTRAN
2012 8 7 1 / 52 MPI Hello World I ( ) Hello World II ( ) I ( ) II ( ) ( sendrecv) π ( ) MPI fortran C wget http://www.na.scitec.kobe-u.ac.jp/ yaguchi/riken2012/enshu2.zip unzip enshu2.zip 2 / 52 FORTRAN
Microsoft PowerPoint _MPI-01.pptx
 計算科学演習 Ⅰ MPI を いた並列計算 (I) 神戸大学大学院システム情報学研究科谷口隆晴 yaguchi@pearl.kobe-u.ac.jp この資料は昨年度担当の横川先生の資料を参考にさせて頂いています. 2016/06/23 MPI を用いた並列計算 (I) 1 講義概要 分散メモリ型計算機上のプログラミング メッセージ パシング インターフェイス (Message Passing Interface,MPI)
計算科学演習 Ⅰ MPI を いた並列計算 (I) 神戸大学大学院システム情報学研究科谷口隆晴 yaguchi@pearl.kobe-u.ac.jp この資料は昨年度担当の横川先生の資料を参考にさせて頂いています. 2016/06/23 MPI を用いた並列計算 (I) 1 講義概要 分散メモリ型計算機上のプログラミング メッセージ パシング インターフェイス (Message Passing Interface,MPI)
Microsoft PowerPoint - 演習1:並列化と評価.pptx
 講義 2& 演習 1 プログラム並列化と性能評価 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 1 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 2 2 次元温度分布の計算
講義 2& 演習 1 プログラム並列化と性能評価 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 1 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 2 2 次元温度分布の計算
演習1
 神戸市立工業高等専門学校電気工学科 / 電子工学科専門科目 数値解析 2019.5.10 演習 1 山浦剛 (tyamaura@riken.jp) 講義資料ページ http://r-ccs-climate.riken.jp/members/yamaura/numerical_analysis.html Fortran とは? Fortran(= FORmula TRANslation ) は 1950
神戸市立工業高等専門学校電気工学科 / 電子工学科専門科目 数値解析 2019.5.10 演習 1 山浦剛 (tyamaura@riken.jp) 講義資料ページ http://r-ccs-climate.riken.jp/members/yamaura/numerical_analysis.html Fortran とは? Fortran(= FORmula TRANslation ) は 1950
コードのチューニング
 ハイブリッド並列 八木学 ( 理化学研究所計算科学研究機構 ) 謝辞 松本洋介氏 ( 千葉大学 ) KOBE HPC Spring School 2017 2017 年 3 月 14 日神戸大学計算科学教育センター MPI とは Message Passing Interface 分散メモリのプロセス間の通信規格(API) SPMD(Single Program Multi Data) が基本 -
ハイブリッド並列 八木学 ( 理化学研究所計算科学研究機構 ) 謝辞 松本洋介氏 ( 千葉大学 ) KOBE HPC Spring School 2017 2017 年 3 月 14 日神戸大学計算科学教育センター MPI とは Message Passing Interface 分散メモリのプロセス間の通信規格(API) SPMD(Single Program Multi Data) が基本 -
ÊÂÎó·×»»¤È¤Ï/OpenMP¤Î½éÊâ¡Ê£±¡Ë
 2015 5 21 OpenMP Hello World Do (omp do) Fortran (omp workshare) CPU Richardson s Forecast Factory 64,000 L.F. Richardson, Weather Prediction by Numerical Process, Cambridge, University Press (1922) Drawing
2015 5 21 OpenMP Hello World Do (omp do) Fortran (omp workshare) CPU Richardson s Forecast Factory 64,000 L.F. Richardson, Weather Prediction by Numerical Process, Cambridge, University Press (1922) Drawing
新スーパーコンピュータ 「ITOシステム」利用講習会
 1 新スーパーコンピュータ ITO システム 利用講習会 九州大学情報基盤研究開発センター 2017 年 10 月 ITO システムの構成 2 3 ITO システムの特徴 最新ハードウェア技術 Intel Skylake-SP NVIDIA Pascal + NVLink Mellanox InfiniBand EDR 対話的な利用環境の拡充 合計 164 ノードのフロントエンド ノード当たりメモリ量
1 新スーパーコンピュータ ITO システム 利用講習会 九州大学情報基盤研究開発センター 2017 年 10 月 ITO システムの構成 2 3 ITO システムの特徴 最新ハードウェア技術 Intel Skylake-SP NVIDIA Pascal + NVLink Mellanox InfiniBand EDR 対話的な利用環境の拡充 合計 164 ノードのフロントエンド ノード当たりメモリ量
8 / 0 1 i++ i 1 i-- i C !!! C 2
 C 2006 5 2 printf() 1 [1] 5 8 C 5 ( ) 6 (auto) (static) 7 (=) 1 8 / 0 1 i++ i 1 i-- i 1 2 2.1 C 4 5 3 13!!! C 2 2.2 C ( ) 4 1 HTML はじめ mkdir work 作業用ディレクトリーの作成 emacs hoge.c& エディターによりソースプログラム作成 gcc -o fuga
C 2006 5 2 printf() 1 [1] 5 8 C 5 ( ) 6 (auto) (static) 7 (=) 1 8 / 0 1 i++ i 1 i-- i 1 2 2.1 C 4 5 3 13!!! C 2 2.2 C ( ) 4 1 HTML はじめ mkdir work 作業用ディレクトリーの作成 emacs hoge.c& エディターによりソースプログラム作成 gcc -o fuga
<4D F736F F F696E74202D D F95C097F D834F E F93FC96E5284D F96E291E85F8DE391E52E >
 SX-ACE 並列プログラミング入門 (MPI) ( 演習補足資料 ) 大阪大学サイバーメディアセンター日本電気株式会社 演習問題の構成 ディレクトリ構成 MPI/ -- practice_1 演習問題 1 -- practice_2 演習問題 2 -- practice_3 演習問題 3 -- practice_4 演習問題 4 -- practice_5 演習問題 5 -- practice_6
SX-ACE 並列プログラミング入門 (MPI) ( 演習補足資料 ) 大阪大学サイバーメディアセンター日本電気株式会社 演習問題の構成 ディレクトリ構成 MPI/ -- practice_1 演習問題 1 -- practice_2 演習問題 2 -- practice_3 演習問題 3 -- practice_4 演習問題 4 -- practice_5 演習問題 5 -- practice_6
enshu5_6.key
 情報知能工学演習V (前半第6週) 政田洋平 システム情報学研究科計算科学専攻 TA : 菅 新 菅沼智史 水曜 新行紗弓 馬淵隼 木曜 演習 V( 前半 ) の内容 第 1 週 : 高性能計算 (High Performance Computing = HPC) 向けプログラミングの基礎 第 2 週 : シミュレーションの基礎 第 3 週 : 波の移流方程式のシミュレーション 第 4,5 週 :
情報知能工学演習V (前半第6週) 政田洋平 システム情報学研究科計算科学専攻 TA : 菅 新 菅沼智史 水曜 新行紗弓 馬淵隼 木曜 演習 V( 前半 ) の内容 第 1 週 : 高性能計算 (High Performance Computing = HPC) 向けプログラミングの基礎 第 2 週 : シミュレーションの基礎 第 3 週 : 波の移流方程式のシミュレーション 第 4,5 週 :
01_OpenMP_osx.indd
 OpenMP* / 1 1... 2 2... 3 3... 5 4... 7 5... 9 5.1... 9 5.2 OpenMP* API... 13 6... 17 7... 19 / 4 1 2 C/C++ OpenMP* 3 Fortran OpenMP* 4 PC 1 1 9.0 Linux* Windows* Xeon Itanium OS 1 2 2 WEB OS OS OS 1 OS
OpenMP* / 1 1... 2 2... 3 3... 5 4... 7 5... 9 5.1... 9 5.2 OpenMP* API... 13 6... 17 7... 19 / 4 1 2 C/C++ OpenMP* 3 Fortran OpenMP* 4 PC 1 1 9.0 Linux* Windows* Xeon Itanium OS 1 2 2 WEB OS OS OS 1 OS
AICS 村井均 RIKEN AICS HPC Summer School /6/2013 1
 AICS 村井均 RIKEN AICS HPC Summer School 2013 8/6/2013 1 背景 OpenMP とは OpenMP の基本 OpenMP プログラミングにおける注意点 やや高度な話題 2 共有メモリマルチプロセッサシステムの普及 共有メモリマルチプロセッサシステムのための並列化指示文を共通化する必要性 各社で仕様が異なり 移植性がない そして いまやマルチコア プロセッサが主流となり
AICS 村井均 RIKEN AICS HPC Summer School 2013 8/6/2013 1 背景 OpenMP とは OpenMP の基本 OpenMP プログラミングにおける注意点 やや高度な話題 2 共有メモリマルチプロセッサシステムの普及 共有メモリマルチプロセッサシステムのための並列化指示文を共通化する必要性 各社で仕様が異なり 移植性がない そして いまやマルチコア プロセッサが主流となり
2. OpenMP OpenMP OpenMP OpenMP #pragma#pragma omp #pragma omp parallel #pragma omp single #pragma omp master #pragma omp for #pragma omp critica
 C OpenMP 1. OpenMP OpenMP Architecture Review BoardARB OpenMP OpenMP OpenMP OpenMP OpenMP Version 2.0 Version 2.0 OpenMP Fortran C/C++ C C++ 1997 10 OpenMP Fortran API 1.0 1998 10 OpenMP C/C++ API 1.0
C OpenMP 1. OpenMP OpenMP Architecture Review BoardARB OpenMP OpenMP OpenMP OpenMP OpenMP Version 2.0 Version 2.0 OpenMP Fortran C/C++ C C++ 1997 10 OpenMP Fortran API 1.0 1998 10 OpenMP C/C++ API 1.0
並列計算導入.pptx
 並列計算の基礎 MPI を用いた並列計算 並列計算の環境 並列計算 複数の計算ユニット(PU, ore, Pなど を使用して 一つの問題 計算 を行わせる 近年 並列計算を手軽に使用できる環境が急速に整いつつある >通常のP PU(entral Processing Unit)上に計算装置であるoreが 複数含まれている Intel ore i7 シリーズ: 4つの計算装置(ore) 通常のプログラム
並列計算の基礎 MPI を用いた並列計算 並列計算の環境 並列計算 複数の計算ユニット(PU, ore, Pなど を使用して 一つの問題 計算 を行わせる 近年 並列計算を手軽に使用できる環境が急速に整いつつある >通常のP PU(entral Processing Unit)上に計算装置であるoreが 複数含まれている Intel ore i7 シリーズ: 4つの計算装置(ore) 通常のプログラム
Microsoft PowerPoint - 阪大CMSI pptx
 内容に関する質問は katagiri@cc.u-tokyo.ac.jp まで 第 3 回 OpenMP の基礎 東京大学情報基盤センター 片桐孝洋 1 講義日程と内容について (1 学期 : 木曜 3 限 ) 第 1 回 : プログラム高速化の基礎 2013 年 4 月 11 日 イントロダクション ループアンローリング キャッシュブロック化 数値計算ライブラリの利用 その他第 2 回 :MPIの基礎
内容に関する質問は katagiri@cc.u-tokyo.ac.jp まで 第 3 回 OpenMP の基礎 東京大学情報基盤センター 片桐孝洋 1 講義日程と内容について (1 学期 : 木曜 3 限 ) 第 1 回 : プログラム高速化の基礎 2013 年 4 月 11 日 イントロダクション ループアンローリング キャッシュブロック化 数値計算ライブラリの利用 その他第 2 回 :MPIの基礎
Microsoft PowerPoint - 03_What is OpenMP 4.0 other_Jan18
 OpenMP* 4.x における拡張 OpenMP 4.0 と 4.5 の機能拡張 内容 OpenMP* 3.1 から 4.0 への拡張 OpenMP* 4.0 から 4.5 への拡張 2 追加された機能 (3.1 -> 4.0) C/C++ 配列シンタックスの拡張 SIMD と SIMD 対応関数 デバイスオフロード task 構 の依存性 taskgroup 構 cancel 句と cancellation
OpenMP* 4.x における拡張 OpenMP 4.0 と 4.5 の機能拡張 内容 OpenMP* 3.1 から 4.0 への拡張 OpenMP* 4.0 から 4.5 への拡張 2 追加された機能 (3.1 -> 4.0) C/C++ 配列シンタックスの拡張 SIMD と SIMD 対応関数 デバイスオフロード task 構 の依存性 taskgroup 構 cancel 句と cancellation
PowerPoint プレゼンテーション
 2018/10/05 竹島研究室創成課題 第 2 回 C 言語演習 変数と演算 東京工科大学 加納徹 前回の復習 Hello, world! と表示するプログラム 1 #include 2 3 int main(void) { 4 printf("hello, world! n"); 5 return 0; 6 } 2 プログラム実行の流れ 1. 作業ディレクトリへの移動 $ cd
2018/10/05 竹島研究室創成課題 第 2 回 C 言語演習 変数と演算 東京工科大学 加納徹 前回の復習 Hello, world! と表示するプログラム 1 #include 2 3 int main(void) { 4 printf("hello, world! n"); 5 return 0; 6 } 2 プログラム実行の流れ 1. 作業ディレクトリへの移動 $ cd
Microsoft PowerPoint - KHPCSS pptx
 KOBE HPC サマースクール 2018( 初級 ) 9. 1 対 1 通信関数, 集団通信関数 2018/8/8 KOBE HPC サマースクール 2018 1 2018/8/8 KOBE HPC サマースクール 2018 2 MPI プログラム (M-2):1 対 1 通信関数 問題 1 から 100 までの整数の和を 2 並列で求めなさい. プログラムの方針 プロセス0: 1から50までの和を求める.
KOBE HPC サマースクール 2018( 初級 ) 9. 1 対 1 通信関数, 集団通信関数 2018/8/8 KOBE HPC サマースクール 2018 1 2018/8/8 KOBE HPC サマースクール 2018 2 MPI プログラム (M-2):1 対 1 通信関数 問題 1 から 100 までの整数の和を 2 並列で求めなさい. プログラムの方針 プロセス0: 1から50までの和を求める.
情報処理概論(第二日目)
") センター入門講習会 ~ 高性能演算サーバ PRIMERGY CX400(tatara)~ 2016 年 6 月 6 日 この資料は以下の Web ページからダウンロードできます. https://www.cc.kyushu-u.ac.jp/scp/users/lecture/ 1 並列プログラミング入門講習会のご案内 スーパーコンピュータの性能を引き出すには 並列化が不可欠! 並列プログラミング入門講習会を
センター入門講習会 ~ 高性能演算サーバ PRIMERGY CX400(tatara)~ 2016 年 6 月 6 日 この資料は以下の Web ページからダウンロードできます. https://www.cc.kyushu-u.ac.jp/scp/users/lecture/ 1 並列プログラミング入門講習会のご案内 スーパーコンピュータの性能を引き出すには 並列化が不可欠! 並列プログラミング入門講習会を
並列プログラミング入門(OpenMP編)
") 登録施設利用促進機関 / 文科省委託事業 HPCI の運営 代表機関一般財団法人高度情報科学技術研究機構 (RIST) 1 並列プログラミング入門 (OpenMP 編 ) 2019 年 1 月 17 日 高度情報科学技術研究機構 (RIST) 山本秀喜 RIST 主催の講習会等 2 HPC プログラミングセミナー 一般 初心者向け : チューニング 並列化 (OpenMP MPI) 京 初中級者向け講習会
登録施設利用促進機関 / 文科省委託事業 HPCI の運営 代表機関一般財団法人高度情報科学技術研究機構 (RIST) 1 並列プログラミング入門 (OpenMP 編 ) 2019 年 1 月 17 日 高度情報科学技術研究機構 (RIST) 山本秀喜 RIST 主催の講習会等 2 HPC プログラミングセミナー 一般 初心者向け : チューニング 並列化 (OpenMP MPI) 京 初中級者向け講習会
この時お使いの端末の.ssh ディレクトリ配下にある known_hosts ファイルから fx.cc.nagoya-u.ac.jp に関する行を削除して再度ログインを行って下さい
 20150901 FX10 システムから FX100 システムへの変更点について 共通... 1 Fortran の変更点... 2 C/C++ の変更点... 4 C の変更点... 5 C++ の変更点... 7 共通 1. プログラミング支援ツールの更新 -FX システムについて旧バージョンのプログラミング支援ツールは利用できません 下記からダウンロードの上新規インストールが必要です https://fx.cc.nagoya-u.ac.jp/fsdtfx100/install/index.html
20150901 FX10 システムから FX100 システムへの変更点について 共通... 1 Fortran の変更点... 2 C/C++ の変更点... 4 C の変更点... 5 C++ の変更点... 7 共通 1. プログラミング支援ツールの更新 -FX システムについて旧バージョンのプログラミング支援ツールは利用できません 下記からダウンロードの上新規インストールが必要です https://fx.cc.nagoya-u.ac.jp/fsdtfx100/install/index.html
02_C-C++_osx.indd
 C/C++ OpenMP* / 2 C/C++ OpenMP* OpenMP* 9.0 1... 2 2... 3 3OpenMP*... 5 3.1... 5 3.2 OpenMP*... 6 3.3 OpenMP*... 8 4OpenMP*... 9 4.1... 9 4.2 OpenMP*... 9 4.3 OpenMP*... 10 4.4... 10 5OpenMP*... 11 5.1
C/C++ OpenMP* / 2 C/C++ OpenMP* OpenMP* 9.0 1... 2 2... 3 3OpenMP*... 5 3.1... 5 3.2 OpenMP*... 6 3.3 OpenMP*... 8 4OpenMP*... 9 4.1... 9 4.2 OpenMP*... 9 4.3 OpenMP*... 10 4.4... 10 5OpenMP*... 11 5.1
プログラミング基礎
 C プログラミング Ⅰ 授業ガイダンス C 言語の概要プログラム作成 実行方法 授業内容について 授業目的 C 言語によるプログラミングの基礎を学ぶこと 学習内容 C 言語の基礎的な文法 入出力, 変数, 演算, 条件分岐, 繰り返し, 配列,( 関数 ) C 言語による簡単な計算処理プログラムの開発 到達目標 C 言語の基礎的な文法を理解する 簡単な計算処理プログラムを作成できるようにする 授業ガイダンス
C プログラミング Ⅰ 授業ガイダンス C 言語の概要プログラム作成 実行方法 授業内容について 授業目的 C 言語によるプログラミングの基礎を学ぶこと 学習内容 C 言語の基礎的な文法 入出力, 変数, 演算, 条件分岐, 繰り返し, 配列,( 関数 ) C 言語による簡単な計算処理プログラムの開発 到達目標 C 言語の基礎的な文法を理解する 簡単な計算処理プログラムを作成できるようにする 授業ガイダンス
PowerPoint プレゼンテーション
 OpenMP 並列解説 1 人が共同作業を行うわけ 田植えの例 重いものを持ち上げる 田おこし 代かき 苗の準備 植付 共同作業する理由 1. 短時間で作業を行うため 2. 一人ではできない作業を行うため 3. 得意分野が異なる人が協力し合うため ポイント 1. 全員が最大限働く 2. タイミングよく 3. 作業順序に注意 4. オーバーヘッドをなくす 2 倍率 効率 並列化率と並列加速率 並列化効率の関係
OpenMP 並列解説 1 人が共同作業を行うわけ 田植えの例 重いものを持ち上げる 田おこし 代かき 苗の準備 植付 共同作業する理由 1. 短時間で作業を行うため 2. 一人ではできない作業を行うため 3. 得意分野が異なる人が協力し合うため ポイント 1. 全員が最大限働く 2. タイミングよく 3. 作業順序に注意 4. オーバーヘッドをなくす 2 倍率 効率 並列化率と並列加速率 並列化効率の関係
C プログラミング演習 1( 再 ) 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ
 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ") C プログラミング演習 1( 再 ) 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ 今回のプログラミングの課題 次のステップによって 徐々に難易度の高いプログラムを作成する ( 参照用の番号は よくわかる C 言語 のページ番号 ) 1. キーボード入力された整数 10 個の中から最大のものを答える 2. 整数を要素とする配列 (p.57-59) に初期値を与えておき
C プログラミング演習 1( 再 ) 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ 今回のプログラミングの課題 次のステップによって 徐々に難易度の高いプログラムを作成する ( 参照用の番号は よくわかる C 言語 のページ番号 ) 1. キーボード入力された整数 10 個の中から最大のものを答える 2. 整数を要素とする配列 (p.57-59) に初期値を与えておき
研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI, MPICH, MVAPICH, MPI.NET プログラミングコストが高いため 生産性が悪い 新しい並
 XcalableMPによる NAS Parallel Benchmarksの実装と評価 中尾 昌広 李 珍泌 朴 泰祐 佐藤 三久 筑波大学 計算科学研究センター 筑波大学大学院 システム情報工学研究科 研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI,
XcalableMPによる NAS Parallel Benchmarksの実装と評価 中尾 昌広 李 珍泌 朴 泰祐 佐藤 三久 筑波大学 計算科学研究センター 筑波大学大学院 システム情報工学研究科 研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI,
I
 I 1 2016.07.21 MPI OpenMP 84 1344 gnuplot Xming Tera term cp -r /tmp/160721 chmod 0 L x L y 0 k T (x, t) k: T t = k 2 T x 2 T t = s s : heat source 1D T (x, t) t = k 2 T (x, t) x 2 + s(x) 2D T (x,
I 1 2016.07.21 MPI OpenMP 84 1344 gnuplot Xming Tera term cp -r /tmp/160721 chmod 0 L x L y 0 k T (x, t) k: T t = k 2 T x 2 T t = s s : heat source 1D T (x, t) t = k 2 T (x, t) x 2 + s(x) 2D T (x,
スライド 1
 FMO 創薬コンソーシアム FMODD 京での FMO 計算練習会 2015 年 5 月 22 日 理化学研究所 本講習会の内容 1. 京の構成とABINIT-MPの概要 2. 京にログイン 計算環境の準備 3. ジョブの投入練習 1(TrpCageの例題を用いた基本ジョブ実行練習 ) 4. ジョブの投入練習 2(ERαの例題を用いた実践的なジョブ実行練習 ) 5. 新規作成構造のジョブの投入に関する注意点
FMO 創薬コンソーシアム FMODD 京での FMO 計算練習会 2015 年 5 月 22 日 理化学研究所 本講習会の内容 1. 京の構成とABINIT-MPの概要 2. 京にログイン 計算環境の準備 3. ジョブの投入練習 1(TrpCageの例題を用いた基本ジョブ実行練習 ) 4. ジョブの投入練習 2(ERαの例題を用いた実践的なジョブ実行練習 ) 5. 新規作成構造のジョブの投入に関する注意点
Microsoft PowerPoint - 阪大CMSI pptx
 内容に関する質問は katagiri@cc.u-tokyo.ac.jp まで 第 3 回 OpenMP の基礎 東京大学情報基盤センター 片桐孝洋 1 講義日程と内容について (1 学期 : 木曜 3 限 ) 第 1 回 : プログラム高速化の基礎 2015 年 4 月 9 日 イントロダクション ループアンローリング キャッシュブロック化 数値計算ライブラリの利用 その他第 2 回 :MPIの基礎
内容に関する質問は katagiri@cc.u-tokyo.ac.jp まで 第 3 回 OpenMP の基礎 東京大学情報基盤センター 片桐孝洋 1 講義日程と内容について (1 学期 : 木曜 3 限 ) 第 1 回 : プログラム高速化の基礎 2015 年 4 月 9 日 イントロダクション ループアンローリング キャッシュブロック化 数値計算ライブラリの利用 その他第 2 回 :MPIの基礎
about MPI
 本日 (4/16) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
本日 (4/16) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
sim98-8.dvi
 8 12 12.1 12.2 @u @t = @2 u (1) @x 2 u(x; 0) = (x) u(0;t)=u(1;t)=0fort 0 1x, 1t N1x =1 x j = j1x, t n = n1t u(x j ;t n ) Uj n U n+1 j 1t 0 U n j =1t=(1x) 2 = U n j+1 0 2U n j + U n j01 (1x) 2 (2) U n+1
8 12 12.1 12.2 @u @t = @2 u (1) @x 2 u(x; 0) = (x) u(0;t)=u(1;t)=0fort 0 1x, 1t N1x =1 x j = j1x, t n = n1t u(x j ;t n ) Uj n U n+1 j 1t 0 U n j =1t=(1x) 2 = U n j+1 0 2U n j + U n j01 (1x) 2 (2) U n+1
ゲームエンジンの構成要素
 cp-3. 計算 (C プログラムの書き方を, パソコン演習で学ぶシリーズ ) https://www.kkaneko.jp/cc/adp/index.html 金子邦彦 1 本日の内容 例題 1. 自由落下距離四則演算例題 2. 三角形の面積浮動小数の変数, 入力文, 出力文, 代入文例題 3. sin 関数による三角形の面積ライブラリ関数 2 今日の到達目標 プログラムを使って, 自分の思い通りの計算ができるようになる
cp-3. 計算 (C プログラムの書き方を, パソコン演習で学ぶシリーズ ) https://www.kkaneko.jp/cc/adp/index.html 金子邦彦 1 本日の内容 例題 1. 自由落下距離四則演算例題 2. 三角形の面積浮動小数の変数, 入力文, 出力文, 代入文例題 3. sin 関数による三角形の面積ライブラリ関数 2 今日の到達目標 プログラムを使って, 自分の思い通りの計算ができるようになる
 名古屋大学教育研究用高性能コンピュータシステム利用者マニュアル (FX100,CX400) 2018 年 1 月 31 日 本マニュアルは 名古屋大学情報基盤センタースーパーコンピュータシステムの利用手引です 新スーパーコンピュータでは 利用方法が大きく変わっています 別冊 FX10 システムから FX100 システムへの変更点について に変更点等があります ご参考お願いいたします なお ご不明な点やご質問がございましたら
名古屋大学教育研究用高性能コンピュータシステム利用者マニュアル (FX100,CX400) 2018 年 1 月 31 日 本マニュアルは 名古屋大学情報基盤センタースーパーコンピュータシステムの利用手引です 新スーパーコンピュータでは 利用方法が大きく変わっています 別冊 FX10 システムから FX100 システムへの変更点について に変更点等があります ご参考お願いいたします なお ご不明な点やご質問がございましたら
C
 C 1 2 1.1........................... 2 1.2........................ 2 1.3 make................................................ 3 1.4....................................... 5 1.4.1 strip................................................
C 1 2 1.1........................... 2 1.2........................ 2 1.3 make................................................ 3 1.4....................................... 5 1.4.1 strip................................................
バイオプログラミング第 1 榊原康文 佐藤健吾 慶應義塾大学理工学部生命情報学科
 バイオプログラミング第 1 榊原康文 佐藤健吾 慶應義塾大学理工学部生命情報学科 ポインタ変数の扱い方 1 ポインタ変数の宣言 int *p; double *q; 2 ポインタ変数へのアドレスの代入 int *p; と宣言した時,p がポインタ変数 int x; と普通に宣言した変数に対して, p = &x; は x のアドレスのポインタ変数 p への代入 ポインタ変数の扱い方 3 間接参照 (
バイオプログラミング第 1 榊原康文 佐藤健吾 慶應義塾大学理工学部生命情報学科 ポインタ変数の扱い方 1 ポインタ変数の宣言 int *p; double *q; 2 ポインタ変数へのアドレスの代入 int *p; と宣言した時,p がポインタ変数 int x; と普通に宣言した変数に対して, p = &x; は x のアドレスのポインタ変数 p への代入 ポインタ変数の扱い方 3 間接参照 (
生物情報実験法 (オンライン, 4/20)
") 生物情報実験法 (7/23) 笠原雅弘 (mkasa@cb.k.u-tokyo.ac.jp) Table of Contents スレッドの使い方 OpenMP プログラミング Deadline The deadline is Aug 5 23:59 Your e-mail must have reached my e-mail box at the deadline time. It may take
生物情報実験法 (7/23) 笠原雅弘 (mkasa@cb.k.u-tokyo.ac.jp) Table of Contents スレッドの使い方 OpenMP プログラミング Deadline The deadline is Aug 5 23:59 Your e-mail must have reached my e-mail box at the deadline time. It may take
Oakforest-PACS 利用の手引き 2 ノートパソコンの設定 : 公開鍵の生成 登録
 Oakforest-PACS 利用の手引き 1 お試しアカウント付き 並列プログラミング講習会 Oakforest-PACS 利用の手引き 東京大学情報基盤センター Oakforest-PACS 利用の手引き 2 ノートパソコンの設定 : 公開鍵の生成 登録 Oakforest-PACS 利用の手引き 3 鍵の作成 1. ターミナルを起動する 2. 以下を入力する $ ssh-keygen t rsa
Oakforest-PACS 利用の手引き 1 お試しアカウント付き 並列プログラミング講習会 Oakforest-PACS 利用の手引き 東京大学情報基盤センター Oakforest-PACS 利用の手引き 2 ノートパソコンの設定 : 公開鍵の生成 登録 Oakforest-PACS 利用の手引き 3 鍵の作成 1. ターミナルを起動する 2. 以下を入力する $ ssh-keygen t rsa
情報処理概論(第二日目)
") 実習資料 Linux 入門講習会 九州大学情報基盤研究開発センター 注意 : この内容は najima.cc.kyushu-u.ac.jp の任意の ID で利用できますが, ファイルの削除等を含んでいるので各コマンドの意味を理解するまでは講習会用 ID で利用することをお勧めします. 1 実習 1 ログイン ファイル操作 ディレクトリの作成 ファイルの移動, コピー, 削除 ログアウト 2 ログイン
実習資料 Linux 入門講習会 九州大学情報基盤研究開発センター 注意 : この内容は najima.cc.kyushu-u.ac.jp の任意の ID で利用できますが, ファイルの削除等を含んでいるので各コマンドの意味を理解するまでは講習会用 ID で利用することをお勧めします. 1 実習 1 ログイン ファイル操作 ディレクトリの作成 ファイルの移動, コピー, 削除 ログアウト 2 ログイン
情報処理概論(第二日目)
") 実習資料 Linux 入門講習会 九州大学情報基盤研究開発センター 注意 : この内容は najima.cc.kyushu-u.ac.jp の任意の ID で利用できますが, ファイルの削除等を含んでいるので各コマンドの意味を理解するまでは講習会用 ID で利用することをお勧めします. 1 実習 1 ログイン ファイル操作 ディレクトリの作成 ファイルの移動, コピー, 削除 ログアウト 2 ログイン
実習資料 Linux 入門講習会 九州大学情報基盤研究開発センター 注意 : この内容は najima.cc.kyushu-u.ac.jp の任意の ID で利用できますが, ファイルの削除等を含んでいるので各コマンドの意味を理解するまでは講習会用 ID で利用することをお勧めします. 1 実習 1 ログイン ファイル操作 ディレクトリの作成 ファイルの移動, コピー, 削除 ログアウト 2 ログイン
PowerPoint Presentation
 工学部 6 7 8 9 10 組 ( 奇数学籍番号 ) 担当 : 長谷川英之 情報処理演習 第 7 回 2010 年 11 月 18 日 1 今回のテーマ 1: ポインタ 変数に値を代入 = 記憶プログラムの記憶領域として使用されるものがメモリ ( パソコンの仕様書における 512 MB RAM などの記述はこのメモリの量 ) RAM は多数のコンデンサの集合体 : 電荷がたまっている (1)/ いない
工学部 6 7 8 9 10 組 ( 奇数学籍番号 ) 担当 : 長谷川英之 情報処理演習 第 7 回 2010 年 11 月 18 日 1 今回のテーマ 1: ポインタ 変数に値を代入 = 記憶プログラムの記憶領域として使用されるものがメモリ ( パソコンの仕様書における 512 MB RAM などの記述はこのメモリの量 ) RAM は多数のコンデンサの集合体 : 電荷がたまっている (1)/ いない
情報工学実験 C コンパイラ第 2 回説明資料 (2017 年度 ) 担当 : 笹倉 佐藤
 担当 : 笹倉 佐藤") 情報工学実験 C コンパイラ第 2 回説明資料 (2017 年度 ) 担当 : 笹倉 佐藤 2017.12.7 前回の演習問題の解答例 1. 四則演算のできる計算機のプログラム ( 括弧も使える ) 2. 実数の扱える四則演算の計算機のプログラム ( 実数 も というより実数 が が正しかったです ) 3. 変数も扱える四則演算の計算機のプログラム ( 変数と実数が扱える ) 演習問題 1 で行うべきこと
情報工学実験 C コンパイラ第 2 回説明資料 (2017 年度 ) 担当 : 笹倉 佐藤 2017.12.7 前回の演習問題の解答例 1. 四則演算のできる計算機のプログラム ( 括弧も使える ) 2. 実数の扱える四則演算の計算機のプログラム ( 実数 も というより実数 が が正しかったです ) 3. 変数も扱える四則演算の計算機のプログラム ( 変数と実数が扱える ) 演習問題 1 で行うべきこと
Microsoft PowerPoint - 計算機言語 第7回.ppt
 計算機言語第 7 回 長宗高樹 目的 関数について理解する. 入力 X 関数 f 出力 Y Y=f(X) 関数の例 関数の型 #include int tasu(int a, int b); main(void) int x1, x2, y; x1 = 2; x2 = 3; y = tasu(x1,x2); 実引数 printf( %d + %d = %d, x1, x2, y);
計算機言語第 7 回 長宗高樹 目的 関数について理解する. 入力 X 関数 f 出力 Y Y=f(X) 関数の例 関数の型 #include int tasu(int a, int b); main(void) int x1, x2, y; x1 = 2; x2 = 3; y = tasu(x1,x2); 実引数 printf( %d + %d = %d, x1, x2, y);
演習2
 神戸市立工業高等専門学校電気工学科 / 電子工学科専門科目 数値解析 2017.6.2 演習 2 山浦剛 (tyamaura@riken.jp) 講義資料ページ h t t p://clim ate.aic s. riken. jp/m embers/yamaura/num erical_analysis. html 曲線の推定 N 次多項式ラグランジュ補間 y = p N x = σ N x x
神戸市立工業高等専門学校電気工学科 / 電子工学科専門科目 数値解析 2017.6.2 演習 2 山浦剛 (tyamaura@riken.jp) 講義資料ページ h t t p://clim ate.aic s. riken. jp/m embers/yamaura/num erical_analysis. html 曲線の推定 N 次多項式ラグランジュ補間 y = p N x = σ N x x
プログラミング基礎
 C プログラミング Ⅰ 条件分岐 if~else if~else 文,switch 文 条件分岐 if~else if~else 文 if~else if~else 文 複数の条件で処理を分ける if~else if~else 文の書式 if( 条件式 1){ 文 1-1; 文 1-2; else if( 条件式 2){ 文 2-1; 文 2-2; else { 文 3-1; 文 3-2; 真条件式
C プログラミング Ⅰ 条件分岐 if~else if~else 文,switch 文 条件分岐 if~else if~else 文 if~else if~else 文 複数の条件で処理を分ける if~else if~else 文の書式 if( 条件式 1){ 文 1-1; 文 1-2; else if( 条件式 2){ 文 2-1; 文 2-2; else { 文 3-1; 文 3-2; 真条件式
C C UNIX C ( ) 4 1 HTML 1
 4 1 HTML 1") C 2007 4 18 C UNIX 1 2 1 1.1 C ( ) 4 1 HTML 1 はじめ mkdir work 作業用ディレクトリーの作成 emacs hoge.c& エディターによりソースプログラム作成 gcc -o fuga hoge.c コンパイルにより機械語に変換 コンパイルエラー./fuga 実行 実行時エラー 完成 1: work hooge.c fuga 1 4 4 1 1.
C 2007 4 18 C UNIX 1 2 1 1.1 C ( ) 4 1 HTML 1 はじめ mkdir work 作業用ディレクトリーの作成 emacs hoge.c& エディターによりソースプログラム作成 gcc -o fuga hoge.c コンパイルにより機械語に変換 コンパイルエラー./fuga 実行 実行時エラー 完成 1: work hooge.c fuga 1 4 4 1 1.
Microsoft PowerPoint - 説明2_演算と型(C_guide2)【2015新教材対応確認済み】.pptx
【2015新教材対応確認済み】.pptx") 情報ネットワーク導入ユニット Ⅰ C 言語 演算と型 演算 代入 演算と型 +,-,*,/,% = C 言語では 代入 の意味 vx = a + b; //a+b の結果を vx に代入 型 : int 型 ( 整数 ) double 型 ( 実数 ) 演算での型変換 ( 整数, 実数の混在 ) キャスト演算子 型を一時的に変更 書式指定 :printf("%6d n", a); 加減, 剰余演算
情報ネットワーク導入ユニット Ⅰ C 言語 演算と型 演算 代入 演算と型 +,-,*,/,% = C 言語では 代入 の意味 vx = a + b; //a+b の結果を vx に代入 型 : int 型 ( 整数 ) double 型 ( 実数 ) 演算での型変換 ( 整数, 実数の混在 ) キャスト演算子 型を一時的に変更 書式指定 :printf("%6d n", a); 加減, 剰余演算
情報処理概論(第二日目)
") 情報処理概論 工学部物質科学工学科応用化学コース機能物質化学クラス 第 8 回 2005 年 6 月 9 日 前回の演習の解答例 多項式の計算 ( 前半 ): program poly implicit none integer, parameter :: number = 5 real(8), dimension(0:number) :: a real(8) :: x, total integer
情報処理概論 工学部物質科学工学科応用化学コース機能物質化学クラス 第 8 回 2005 年 6 月 9 日 前回の演習の解答例 多項式の計算 ( 前半 ): program poly implicit none integer, parameter :: number = 5 real(8), dimension(0:number) :: a real(8) :: x, total integer
1 return main() { main main C 1 戻り値の型 関数名 引数 関数ブロックをあらわす中括弧 main() 関数の定義 int main(void){ printf("hello World!!\n"); return 0; 戻り値 1: main() 2.2 C main
 { main main C 1 戻り値の型 関数名 引数 関数ブロックをあらわす中括弧 main() 関数の定義 int main(void){ printf(hello World!!\n); return 0; 戻り値 1: main() 2.2 C main") C 2007 5 29 C 1 11 2 2.1 main() 1 FORTRAN C main() main main() main() 1 return 1 1 return main() { main main C 1 戻り値の型 関数名 引数 関数ブロックをあらわす中括弧 main() 関数の定義 int main(void){ printf("hello World!!\n"); return
C 2007 5 29 C 1 11 2 2.1 main() 1 FORTRAN C main() main main() main() 1 return 1 1 return main() { main main C 1 戻り値の型 関数名 引数 関数ブロックをあらわす中括弧 main() 関数の定義 int main(void){ printf("hello World!!\n"); return
3. :, c, ν. 4. Burgers : t + c x = ν 2 u x 2, (3), ν. 5. : t + u x = ν 2 u x 2, (4), c. 2 u t 2 = c2 2 u x 2, (5) (1) (4), (1 Navier Stokes,., ν. t +
, ν. 5. : t + u x = ν 2 u x 2, (4), c. 2 u t 2 = c2 2 u x 2, (5) (1) (4), (1 Navier Stokes,., ν. t +") B: 2016 12 2, 9, 16, 2017 1 6 1,.,,,,.,.,,,., 1,. 1. :, ν. 2. : t = ν 2 u x 2, (1), c. t + c x = 0, (2). e-mail: iwayama@kobe-u.ac.jp,. 1 3. :, c, ν. 4. Burgers : t + c x = ν 2 u x 2, (3), ν. 5. : t +
B: 2016 12 2, 9, 16, 2017 1 6 1,.,,,,.,.,,,., 1,. 1. :, ν. 2. : t = ν 2 u x 2, (1), c. t + c x = 0, (2). e-mail: iwayama@kobe-u.ac.jp,. 1 3. :, c, ν. 4. Burgers : t + c x = ν 2 u x 2, (3), ν. 5. : t +
Microsoft PowerPoint ppt
 基礎演習 3 C 言語の基礎 (5) 第 05 回 (20 年 07 月 07 日 ) メモリとポインタの概念 ビットとバイト 計算機内部では データは2 進数で保存している 計算機は メモリにデータを蓄えている bit 1bit 0 もしくは 1 のどちらかを保存 byte 1byte 1bitが8つ集まっている byte が メモリの基本単位として使用される メモリとアドレス メモリは 1byte
基礎演習 3 C 言語の基礎 (5) 第 05 回 (20 年 07 月 07 日 ) メモリとポインタの概念 ビットとバイト 計算機内部では データは2 進数で保存している 計算機は メモリにデータを蓄えている bit 1bit 0 もしくは 1 のどちらかを保存 byte 1byte 1bitが8つ集まっている byte が メモリの基本単位として使用される メモリとアドレス メモリは 1byte
3. 標準入出力
 Linux にログインして待っていること以下のサイトを開いておくこと http://www-it.sci.waseda.ac.jp/teachers/w483692/cpr1/ 4. 条件分岐 制御構文 (1) C プログラミング入門基幹 2 ( 月 4) 制御構造 control flow 逐次実行 o 関数は ブロック内の文を書かれた順に実行する 条件分岐 o 変数などがある条件を満たす場合だけ実行する
Linux にログインして待っていること以下のサイトを開いておくこと http://www-it.sci.waseda.ac.jp/teachers/w483692/cpr1/ 4. 条件分岐 制御構文 (1) C プログラミング入門基幹 2 ( 月 4) 制御構造 control flow 逐次実行 o 関数は ブロック内の文を書かれた順に実行する 条件分岐 o 変数などがある条件を満たす場合だけ実行する
Microsoft Word - HOKUSAI_system_overview_ja.docx
 HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
Microsoft PowerPoint _5_8_f95a_usui.pptx
 1 Fortran90/95 入門と演習 前半 担当 : 臼井英之 三宅洋平 ( 神戸大学大学院システム情報学研究科 ) 目標 本演習で用いる数値計算用プログラム言語 Fortran90/95 の基礎を習得する 参考資料 : TECS-KOBE 第二回シミュレーションスクール ( 神戸大学 ) 2010/12/6:Fortran 講義ノート ( 平尾一 ) Fortran90/95 入門 2010
1 Fortran90/95 入門と演習 前半 担当 : 臼井英之 三宅洋平 ( 神戸大学大学院システム情報学研究科 ) 目標 本演習で用いる数値計算用プログラム言語 Fortran90/95 の基礎を習得する 参考資料 : TECS-KOBE 第二回シミュレーションスクール ( 神戸大学 ) 2010/12/6:Fortran 講義ノート ( 平尾一 ) Fortran90/95 入門 2010
Microsoft PowerPoint _4_26_f95a_usui.pptx
 1 Fortran90/95 入門と演習 前半 担当 : 臼井英之 三宅洋平 ( 神戸大学大学院システム情報学研究科 ) 目標 本演習で用いる数値計算用プログラム言語 Fortran90/95 の基礎を習得する 参考資料 : TECS-KOBE 第二回シミュレーションスクールションスク ( 神戸大学 ) 2010/12/6:Fortran 0/ /6 ota 講義ノート ( 平尾一 ) Fortran90/95
1 Fortran90/95 入門と演習 前半 担当 : 臼井英之 三宅洋平 ( 神戸大学大学院システム情報学研究科 ) 目標 本演習で用いる数値計算用プログラム言語 Fortran90/95 の基礎を習得する 参考資料 : TECS-KOBE 第二回シミュレーションスクールションスク ( 神戸大学 ) 2010/12/6:Fortran 0/ /6 ota 講義ノート ( 平尾一 ) Fortran90/95
資料
 PC PC C VMwareをインストールする Tips: VmwareFusion *.vmx vhv.enable = TRUE Tips: Windows Hyper-V -rwxr-xr-x 1 masakazu staff 8552 7 29 13:18 a.out* -rw------- 1 masakazu staff 8552 7 29
PC PC C VMwareをインストールする Tips: VmwareFusion *.vmx vhv.enable = TRUE Tips: Windows Hyper-V -rwxr-xr-x 1 masakazu staff 8552 7 29 13:18 a.out* -rw------- 1 masakazu staff 8552 7 29
kiso2-09.key
 座席指定はありません 計算機基礎実習II 2018 のウェブページか 第9回 ら 以下の課題に自力で取り組んで下さい 計算機基礎実習II 第7回の復習課題(rev07) 第9回の基本課題(base09) 第8回試験の結果 中間試験に関するコメント コンパイルできない不完全なプログラムなど プログラミングに慣れていない あるいは複雑な問題は 要件 をバラして段階的にプログラムを作成する exam08-2.c
座席指定はありません 計算機基礎実習II 2018 のウェブページか 第9回 ら 以下の課題に自力で取り組んで下さい 計算機基礎実習II 第7回の復習課題(rev07) 第9回の基本課題(base09) 第8回試験の結果 中間試験に関するコメント コンパイルできない不完全なプログラムなど プログラミングに慣れていない あるいは複雑な問題は 要件 をバラして段階的にプログラムを作成する exam08-2.c
< 中略 > 24 0 NNE 次に 指定した日時の時間降水量と気温を 観測地点の一覧表に載っているすべての地点について出力するプログラムを作成してみます 観測地点の一覧表は index.txt というファイルで与えられています このファイルを読みこむためのサブルーチンが AMD
 気象観測データの解析 1 AMeDAS データの解析 研究を進めるにあたって データ解析用のプログラムを自分で作成する必要が生じることがあります ここでは 自分で FORTRAN または C でプログラムを作成し CD-ROM に入った気象観測データ ( 気象庁による AMeDAS の観測データ ) を読みこんで解析します データを読みこむためのサブルーチンや関数はあらかじめ作成してあります それらのサブルーチンや関数を使って自分でプログラムを書いてデータを解析していきます
気象観測データの解析 1 AMeDAS データの解析 研究を進めるにあたって データ解析用のプログラムを自分で作成する必要が生じることがあります ここでは 自分で FORTRAN または C でプログラムを作成し CD-ROM に入った気象観測データ ( 気象庁による AMeDAS の観測データ ) を読みこんで解析します データを読みこむためのサブルーチンや関数はあらかじめ作成してあります それらのサブルーチンや関数を使って自分でプログラムを書いてデータを解析していきます
Taro-ポインタ変数Ⅰ(公開版).j
.j") 0. 目次 1. ポインタ変数と変数 2. ポインタ変数と配列 3. ポインタ変数と構造体 4. ポインタ変数と線形リスト 5. 問題 問題 1 問題 2-1 - 1. ポインタ変数と変数 ポインタ変数には 記憶領域の番地が格納されている 通常の変数にはデータが格納されている 宣言 int *a; float *b; char *c; 意味ポインタ変数 aは 整数型データが保存されている番地を格納している
0. 目次 1. ポインタ変数と変数 2. ポインタ変数と配列 3. ポインタ変数と構造体 4. ポインタ変数と線形リスト 5. 問題 問題 1 問題 2-1 - 1. ポインタ変数と変数 ポインタ変数には 記憶領域の番地が格納されている 通常の変数にはデータが格納されている 宣言 int *a; float *b; char *c; 意味ポインタ変数 aは 整数型データが保存されている番地を格納している
num2.dvi
 kanenko@mbk.nifty.com http://kanenko.a.la9.jp/ 16 32...... h 0 h = ε () 0 ( ) 0 1 IEEE754 (ieee754.c Kerosoft Ltd.!) 1 2 : OS! : WindowsXP ( ) : X Window xcalc.. (,.) C double 10,??? 3 :, ( ) : BASIC,
kanenko@mbk.nifty.com http://kanenko.a.la9.jp/ 16 32...... h 0 h = ε () 0 ( ) 0 1 IEEE754 (ieee754.c Kerosoft Ltd.!) 1 2 : OS! : WindowsXP ( ) : X Window xcalc.. (,.) C double 10,??? 3 :, ( ) : BASIC,
Microsoft Word - 3new.doc
 プログラミング演習 II 講義資料 3 ポインタ I - ポインタの基礎 1 ポインタとは ポインタとはポインタは, アドレス ( データが格納されている場所 ) を扱うデータ型です つまり, アドレスを通してデータを間接的に処理します ポインタを使用する場合の, 処理の手順は以下のようになります 1 ポインタ変数を宣言する 2 ポインタ変数へアドレスを割り当てる 3 ポインタ変数を用いて処理 (
プログラミング演習 II 講義資料 3 ポインタ I - ポインタの基礎 1 ポインタとは ポインタとはポインタは, アドレス ( データが格納されている場所 ) を扱うデータ型です つまり, アドレスを通してデータを間接的に処理します ポインタを使用する場合の, 処理の手順は以下のようになります 1 ポインタ変数を宣言する 2 ポインタ変数へアドレスを割り当てる 3 ポインタ変数を用いて処理 (
Microsoft PowerPoint - 説明3_if文switch文(C_guide3)【2015新教材対応確認済み】.pptx
【2015新教材対応確認済み】.pptx") 情報ネットワーク導入ユニット Ⅰ C 言語 if 文 switch 文 3 章 : プログラムの流れの分岐 if 文 if( 条件 ) 条件が成立すれば実行 if( 条件 ) ~ else 場合分け ( 成立, 不成立 ) if( 条件 A) ~ else if( 条件 B) ~ else if( 条件 C) ~ else 場合分け ( 複数の条件での場合分け ) 等価演算子 : == ( 等しい
情報ネットワーク導入ユニット Ⅰ C 言語 if 文 switch 文 3 章 : プログラムの流れの分岐 if 文 if( 条件 ) 条件が成立すれば実行 if( 条件 ) ~ else 場合分け ( 成立, 不成立 ) if( 条件 A) ~ else if( 条件 B) ~ else if( 条件 C) ~ else 場合分け ( 複数の条件での場合分け ) 等価演算子 : == ( 等しい
Microsoft Word - appli_SMASH_tutorial_2.docx
 チュートリアル SMASH version 2.2.0 (Linux 64 ビット版 ) 本チュートリアルでは 量子化学計算ソフトウェア SMASH バージョン 2.2.0 について ソフトウェアの入手 / 実行モジュール作成 / 計算実行 / 可視化処理までを例示します 1. ソフトウェアの入手以下の URL よりダウンロードします https://sourceforge.net/projects/smash-qc/files/smash-2.2.0.tgz/download
チュートリアル SMASH version 2.2.0 (Linux 64 ビット版 ) 本チュートリアルでは 量子化学計算ソフトウェア SMASH バージョン 2.2.0 について ソフトウェアの入手 / 実行モジュール作成 / 計算実行 / 可視化処理までを例示します 1. ソフトウェアの入手以下の URL よりダウンロードします https://sourceforge.net/projects/smash-qc/files/smash-2.2.0.tgz/download
enshu5_1.key
 情報知能工学演習V (前半第1週) 政田洋平 システム情報学研究科計算科学専攻 TA : 菅 新 菅沼智史 水曜 新行紗弓 馬淵隼 木曜 演習 V( 前半 ) の内容 第 1 週 : 高性能計算 (High Performance Computing = HPC) 向けプログラミングの基礎 第 2 週 : シミュレーションの基礎 第 3 週 : 波の移流方程式のシミュレーション 第 4,5 週 :
情報知能工学演習V (前半第1週) 政田洋平 システム情報学研究科計算科学専攻 TA : 菅 新 菅沼智史 水曜 新行紗弓 馬淵隼 木曜 演習 V( 前半 ) の内容 第 1 週 : 高性能計算 (High Performance Computing = HPC) 向けプログラミングの基礎 第 2 週 : シミュレーションの基礎 第 3 週 : 波の移流方程式のシミュレーション 第 4,5 週 :
char int float double の変数型はそれぞれ 文字あるいは小さな整数 整数 実数 より精度の高い ( 数値のより大きい より小さい ) 実数 を扱う時に用いる 備考 : 基本型の説明に示した 浮動小数点 とは数値を指数表現で表す方法である 例えば は指数表現で 3 書く
 実数 を扱う時に用いる 備考 : 基本型の説明に示した 浮動小数点 とは数値を指数表現で表す方法である 例えば は指数表現で 3 書く") 変数 入出力 演算子ここまでに C 言語プログラミングの様子を知ってもらうため printf 文 変数 scanf 文 if 文を使った簡単なプログラムを紹介した 今回は変数の詳細について習い それに併せて使い方が増える入出力処理の方法を習う また 演算子についての復習と供に新しい演算子を紹介する 変数の宣言プログラムでデータを取り扱う場合には対象となるデータを保存する必要がでてくる このデータを保存する場所のことを
変数 入出力 演算子ここまでに C 言語プログラミングの様子を知ってもらうため printf 文 変数 scanf 文 if 文を使った簡単なプログラムを紹介した 今回は変数の詳細について習い それに併せて使い方が増える入出力処理の方法を習う また 演算子についての復習と供に新しい演算子を紹介する 変数の宣言プログラムでデータを取り扱う場合には対象となるデータを保存する必要がでてくる このデータを保存する場所のことを
Microsoft PowerPoint - compsys2-06.ppt
 情報基盤センター天野浩文 前回のおさらい (1) 並列処理のやり方 何と何を並列に行うのか コントロール並列プログラミング 同時に実行できる多数の処理を, 多数のノードに分配して同時に処理させる しかし, 同時に実行できる多数の処理 を見つけるのは難しい データ並列プログラミング 大量のデータを多数の演算ノードに分配して, それらに同じ演算を同時に適用する コントロール並列よりも, 多数の演算ノードを利用しやすい
情報基盤センター天野浩文 前回のおさらい (1) 並列処理のやり方 何と何を並列に行うのか コントロール並列プログラミング 同時に実行できる多数の処理を, 多数のノードに分配して同時に処理させる しかし, 同時に実行できる多数の処理 を見つけるのは難しい データ並列プログラミング 大量のデータを多数の演算ノードに分配して, それらに同じ演算を同時に適用する コントロール並列よりも, 多数の演算ノードを利用しやすい
Microsoft PowerPoint - 講義10改.pptx
 計算機プログラミング ( 後半組 ) Computer Programming (2nd half group) 担当 : 城﨑知至 Instructor: Tomoyuki JOHZAKI 第 9 回ファイルの入出力 Lesson 9 input/output statements 教科書 7.3 章 1 ファイル入出力 : サンプル 1 下記プログラムを outin1.f90 として作成し コンパイル実
計算機プログラミング ( 後半組 ) Computer Programming (2nd half group) 担当 : 城﨑知至 Instructor: Tomoyuki JOHZAKI 第 9 回ファイルの入出力 Lesson 9 input/output statements 教科書 7.3 章 1 ファイル入出力 : サンプル 1 下記プログラムを outin1.f90 として作成し コンパイル実
スライド 1
 本日 (4/25) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
本日 (4/25) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
PowerPoint プレゼンテーション
 各種計算機アプリケーション性能比較 目次. はじめに. 行列積計算.QDR 積計算 4.N 体問題計算 5. 多次元積分計算 5. 次元積分計算 5. 次元積分計算 5. 4 次元積分計算 5.4 5 次元積分計算 5.5 6 次元積分計算 平成 6 年度第 四半期 . はじめに 今までと少し性質の異なるグラフィックボードが使用できる様になったので従来のアプリケーションで性能比較を実施しました 主に使用した計算機は以下のものです
各種計算機アプリケーション性能比較 目次. はじめに. 行列積計算.QDR 積計算 4.N 体問題計算 5. 多次元積分計算 5. 次元積分計算 5. 次元積分計算 5. 4 次元積分計算 5.4 5 次元積分計算 5.5 6 次元積分計算 平成 6 年度第 四半期 . はじめに 今までと少し性質の異なるグラフィックボードが使用できる様になったので従来のアプリケーションで性能比較を実施しました 主に使用した計算機は以下のものです
RX ファミリ用 C/C++ コンパイラ V.1.00 Release 02 ご使用上のお願い RX ファミリ用 C/C++ コンパイラの使用上の注意事項 4 件を連絡します #pragma option 使用時の 1 または 2 バイトの整数型の関数戻り値に関する注意事項 (RXC#012) 共用
 共用") RX ファミリ用 C/C++ コンパイラ V.1.00 Release 02 ご使用上のお願い RX ファミリ用 C/C++ コンパイラの使用上の注意事項 4 件を連絡します #pragma option 使用時の 1 または 2 バイトの整数型の関数戻り値に関する注意事項 (RXC#012) 共用体型のローカル変数を文字列操作関数で操作する場合の注意事項 (RXC#013) 配列型構造体または共用体の配列型メンバから読み出した値を動的初期化に用いる場合の注意事項
RX ファミリ用 C/C++ コンパイラ V.1.00 Release 02 ご使用上のお願い RX ファミリ用 C/C++ コンパイラの使用上の注意事項 4 件を連絡します #pragma option 使用時の 1 または 2 バイトの整数型の関数戻り値に関する注意事項 (RXC#012) 共用体型のローカル変数を文字列操作関数で操作する場合の注意事項 (RXC#013) 配列型構造体または共用体の配列型メンバから読み出した値を動的初期化に用いる場合の注意事項
情報処理演習 B8クラス
 予定スケジュール ( 全 15 回 ) 1 1. 終了 プログラミング言語の基礎 2. 終了 演算と型 3. 終了 プログラムの流れの分岐 (if 文,switch 文など ) 4. 終了 プログラムの流れの繰返し (do, while, for 文など ) 5. 終了 中間レポート1 6. 終了 配列 7. 終了 関数 8. 終了 文字列 ( 文字列の配列, 文字列の操作 ) 9. 終了 ポインタ
予定スケジュール ( 全 15 回 ) 1 1. 終了 プログラミング言語の基礎 2. 終了 演算と型 3. 終了 プログラムの流れの分岐 (if 文,switch 文など ) 4. 終了 プログラムの流れの繰返し (do, while, for 文など ) 5. 終了 中間レポート1 6. 終了 配列 7. 終了 関数 8. 終了 文字列 ( 文字列の配列, 文字列の操作 ) 9. 終了 ポインタ
3. :, c, ν. 4. Burgers : u t + c u x = ν 2 u x 2, (3), ν. 5. : u t + u u x = ν 2 u x 2, (4), c. 2 u t 2 = c2 2 u x 2, (5) (1) (4), (1 Navier Stokes,.,
, ν. 5. : u t + u u x = ν 2 u x 2, (4), c. 2 u t 2 = c2 2 u x 2, (5) (1) (4), (1 Navier Stokes,.,") B:,, 2017 12 1, 8, 15, 22 1,.,,,,.,.,,,., 1,. 1. :, ν. 2. : u t = ν 2 u x 2, (1), c. u t + c u x = 0, (2), ( ). 1 3. :, c, ν. 4. Burgers : u t + c u x = ν 2 u x 2, (3), ν. 5. : u t + u u x = ν 2 u x 2,
B:,, 2017 12 1, 8, 15, 22 1,.,,,,.,.,,,., 1,. 1. :, ν. 2. : u t = ν 2 u x 2, (1), c. u t + c u x = 0, (2), ( ). 1 3. :, c, ν. 4. Burgers : u t + c u x = ν 2 u x 2, (3), ν. 5. : u t + u u x = ν 2 u x 2,
XMPによる並列化実装2
 2 3 C Fortran Exercise 1 Exercise 2 Serial init.c init.f90 XMP xmp_init.c xmp_init.f90 Serial laplace.c laplace.f90 XMP xmp_laplace.c xmp_laplace.f90 #include int a[10]; program init integer
2 3 C Fortran Exercise 1 Exercise 2 Serial init.c init.f90 XMP xmp_init.c xmp_init.f90 Serial laplace.c laplace.f90 XMP xmp_laplace.c xmp_laplace.f90 #include int a[10]; program init integer
2 A I / 58
 2 A 2018.07.12 I 2 2018.07.12 1 / 58 I 2 2018.07.12 2 / 58 π-computer gnuplot 5/31 1 π-computer -X ssh π-computer gnuplot I 2 2018.07.12 3 / 58 gnuplot> gnuplot> plot sin(x) I 2 2018.07.12 4 / 58 cp -r
2 A 2018.07.12 I 2 2018.07.12 1 / 58 I 2 2018.07.12 2 / 58 π-computer gnuplot 5/31 1 π-computer -X ssh π-computer gnuplot I 2 2018.07.12 3 / 58 gnuplot> gnuplot> plot sin(x) I 2 2018.07.12 4 / 58 cp -r
Microsoft PowerPoint - CproNt02.ppt [互換モード]
![Microsoft PowerPoint - CproNt02.ppt [互換モード]](/thumbs/95/124866096.jpg "Microsoft PowerPoint - CproNt02.ppt [互換モード]") 第 2 章 C プログラムの書き方 CPro:02-01 概要 C プログラムの構成要素は関数 ( プログラム = 関数の集まり ) 関数は, ヘッダと本体からなる 使用する関数は, プログラムの先頭 ( 厳密には, 使用場所より前 ) で型宣言 ( プロトタイプ宣言 ) する 関数は仮引数を用いることができる ( なくてもよい ) 関数には戻り値がある ( なくてもよい void 型 ) コメント
第 2 章 C プログラムの書き方 CPro:02-01 概要 C プログラムの構成要素は関数 ( プログラム = 関数の集まり ) 関数は, ヘッダと本体からなる 使用する関数は, プログラムの先頭 ( 厳密には, 使用場所より前 ) で型宣言 ( プロトタイプ宣言 ) する 関数は仮引数を用いることができる ( なくてもよい ) 関数には戻り値がある ( なくてもよい void 型 ) コメント
kiso2-03.key
 座席指定はありません Linux を起動して下さい 第3回 計算機基礎実習II 2018 のウェブページか ら 以下の課題に自力で取り組んで下さい 計算機基礎実習II 第2回の復習課題(rev02) 第3回の基本課題(base03) 第2回課題の回答例 ex02-2.c include int main { int l int v, s; /* 一辺の長さ */ /* 体積 v
座席指定はありません Linux を起動して下さい 第3回 計算機基礎実習II 2018 のウェブページか ら 以下の課題に自力で取り組んで下さい 計算機基礎実習II 第2回の復習課題(rev02) 第3回の基本課題(base03) 第2回課題の回答例 ex02-2.c include int main { int l int v, s; /* 一辺の長さ */ /* 体積 v
cp-7. 配列
 cp-7. 配列 (C プログラムの書き方を, パソコン演習で学ぶシリーズ ) https://www.kkaneko.jp/cc/adp/index.html 金子邦彦 1 本日の内容 例題 1. 月の日数配列とは. 配列の宣言. 配列の添え字. 例題 2. ベクトルの内積例題 3. 合計点と平均点例題 4. 棒グラフを描く配列と繰り返し計算の関係例題 5. 行列の和 2 次元配列 2 今日の到達目標
cp-7. 配列 (C プログラムの書き方を, パソコン演習で学ぶシリーズ ) https://www.kkaneko.jp/cc/adp/index.html 金子邦彦 1 本日の内容 例題 1. 月の日数配列とは. 配列の宣言. 配列の添え字. 例題 2. ベクトルの内積例題 3. 合計点と平均点例題 4. 棒グラフを描く配列と繰り返し計算の関係例題 5. 行列の和 2 次元配列 2 今日の到達目標
memo
 計数工学プログラミング演習 ( 第 3 回 ) 2017/04/25 DEPARTMENT OF MATHEMATICAL INFORMATICS 1 内容 ポインタの続き 引数の値渡しと参照渡し 構造体 2 ポインタで指されるメモリへのアクセス double **R; 型 R[i] と *(R+i) は同じ意味 意味 R double ** ポインタの配列 ( の先頭 ) へのポインタ R[i]
計数工学プログラミング演習 ( 第 3 回 ) 2017/04/25 DEPARTMENT OF MATHEMATICAL INFORMATICS 1 内容 ポインタの続き 引数の値渡しと参照渡し 構造体 2 ポインタで指されるメモリへのアクセス double **R; 型 R[i] と *(R+i) は同じ意味 意味 R double ** ポインタの配列 ( の先頭 ) へのポインタ R[i]
Platypus-QM β ( )
") Platypus-QM β (2012.11.12) 1 1 1.1...................................... 1 1.1.1...................................... 1 1.1.2................................... 1 1.1.3..........................................
Platypus-QM β (2012.11.12) 1 1 1.1...................................... 1 1.1.1...................................... 1 1.1.2................................... 1 1.1.3..........................................
Microsoft Word - 資料 (テイラー級数と数値積分).docx
.docx") δx δx n x=0 sin x = x x3 3 + x5 5 x7 7 +... x ak = (-mod(k,2))**(k/2) / fact_k ( ) = a n δ x n f x 0 + δ x a n = f ( n) ( x 0 ) n f ( x) = sin x n=0 58 I = b a ( ) f x dx ΔS = f ( x)h I = f a h h I = h
δx δx n x=0 sin x = x x3 3 + x5 5 x7 7 +... x ak = (-mod(k,2))**(k/2) / fact_k ( ) = a n δ x n f x 0 + δ x a n = f ( n) ( x 0 ) n f ( x) = sin x n=0 58 I = b a ( ) f x dx ΔS = f ( x)h I = f a h h I = h