bioinfo-jags2
|
|
|
- らむ いいはた
- 2 years ago
- Views:
Transcription
1 藤 博幸
2 ベイズ統計で実践モデリング では MCMC による パラメータ推定 と モデル選択 が われている この講義でもその順番で進める
3 率を推定する 率の差 共通の 率を推論する
4 ベイズ統計で実践モデリング 3.1 率を推定する 第 3 章 項分布を使った推論
5 n 回コイントスをして k 回表が出たコインの表が出る割合 θ を求める θ の事後分布を求める
6 θ コインは θ の割合で表が出る k 回表が観測 k n n 回コイントス
7 連続値 離散値 観測変数 ( 確率変数 ) 観測変数 依存関係
8 θ k n θ が与えられた時 n 回のコイントス中 k 回表が出る確率 ( 尤度 ) は 項分布に従う k~b n, θ = n! k! n k! θ* 1 θ,-* θ がどのような値をとるのかの情報がない 様分布を無情報事前分布として いるベータ分布 Beta(1,1) は 様分布になる θ θ~beta(1,1)
9 beta x; α, β = 9:;< =-9 >;< B(α, β) はベータ関数パラメータ α, β (0 x 1) Rでベータ分布の密度関数をパラメータの値を変えてプロットしてみる code2.1.r
10 x <- seq(0,1.0, 0.01) alpha <- 5 beta <- 1 y1 <- dbeta(x, alpha, beta) alpha <- 1 beta <- 3 y2 <- dbeta(x, alpha, beta) alpha <- 2 beta <- 2 y3 <- dbeta(x, alpha, beta) alpha<- 1 beta <- 1 y4 <- dbeta(x, alpha, beta) plot(x, y1, ty='l') par(new=t) plot(x, y2, col="red", ty='l', ylim=c(0,2.5), yaxt="n") par(new=t) plot(x, y3, col="yellow", ty='l', ylim=c(0,2.5), yaxt="n") par(new=t) plot(x, y4, col="green", ty='l', ylim=c(0,2.5), yaxt="n")
11
12 Jags でのモデルの記述 Rate_1.txt 事前分布 # Inferring a Rate model{ # Prior Distribution for Rate Theta theta ~ dbeta(1,1) # Observed Counts k ~ dbin(theta,n) 尤度 } θ k n
13 Rate_1_jags.R 変数のクリア # clears workspace: rm(list=ls()) Rate_1.txt と Rate_1_jags.R のあるディレクトリへの移動 # sets working directories: setwd("/users/toh/desktop/code/parameterestimation/binomial") library(r2jags) パッケージの読み込み k <- 5 n <- 10 data <- list("k", "n") # to be passed on to JAGS 観測変数の設定
14 θ の初期値の設定 myinits <- list( list(theta = 0.1), #chain 1 starting value list(theta = 0.9)) #chain 2 starting value # parameters to be monitored: parameters <- c("theta") モニターするパラメータの設定 # The following command calls JAGS with specific options. # For a detailed description see the R2jags documentation. samples <- jags(data, inits=myinits, parameters, model.file ="Rate_1.txt", n.chains=2, n.iter=20000, n.burnin=1, n.thin=1, DIC=T) Jags を呼び出して θ をサンプリング
15 samples <- jags(data, inits=myinits, parameters, model.file ="Rate_1.txt", n.chains=2, n.iter=20000, n.burnin=1, n.thin=1, DIC=T) data: 観測値 inits: 初期値 parameters: モニタするパラメータ model.file: Jagsのモデルの指定 n.chains: 2 回 MCMC 異なる初期値からMCMCを行う n.iter:1 回のMCMCのサンプリングの回数 n.burnin: burn inのサイズ n.thin: thiningのサイズ DIC: 逸脱情報量基準 (Deviance Information Criterion) モデル選択の時に用いるが ベイズ統計家でも必ずしも受け入れられている訳ではない TRUEで計算される
16 # The commands below are useful for a quick overview: print(samples) # a rough summary traceplot(samples) # traceplot (press <enter> repeatedly to see the chains) # Collect posterior samples across all chains: theta <- samples$bugsoutput$sims.list$theta # Now let's plot a histogram for theta. # First, some options to make the plot look better: par(cex.main = 1.5, mar = c(5, 6, 4, 5) + 0.1, mgp = c(3.5, 1, 0), cex.lab = 1.5, font.lab = 2, cex.axis = 1.3, bty = "n", las=1) Nbreaks <- 80 y <- hist(theta, Nbreaks, plot=f) mixing の確認 2 つの chain でサンプルされた θ を つにまとめる θ の事後分布の表 plot(c(y$breaks, max(y$breaks)), c(0,y$density,0), type="s", lwd=2, lty=1, xlim=c(0,1), ylim=c(0,10), xlab="rate", ylab="posterior Density") # NB. ylim=c(0,10) defines the range of the y-axis. Adjust the upper value # in case your posterior distribution falls partly outside this range. max(c(samples$bugsoutput$sims.array[,1,][,2], samples$bugsoutput$sims.array[,2,][1,2])) min(c(samples$bugsoutput$sims.array[,1,][,2], samples$bugsoutput$sims.array[,2,][1,2])) summary(c(samples$bugsoutput$sims.array[,1,][,2], samples$bugsoutput$sims.array[,2,][,2 2 つの chain それぞれについての解析
17 > print(samples) # a rough summary Inference for Bugs model at "Rate_1.txt", fit using jags, 2 chains, each with iterations (first 1 discarded) n.sims = iterations saved mu.vect sd.vect 2.5% 25% 50% 75% 97.5% Rhat n.eff theta deviance For each parameter, n.eff is a crude measure of effective sample size, and Rhat is the potential scale reduction factor (at convergence, Rhat=1). DIC info (using the rule, pd = var(deviance)/2) pd = 0.7 and DIC = つの chain をまとめた θ の要約

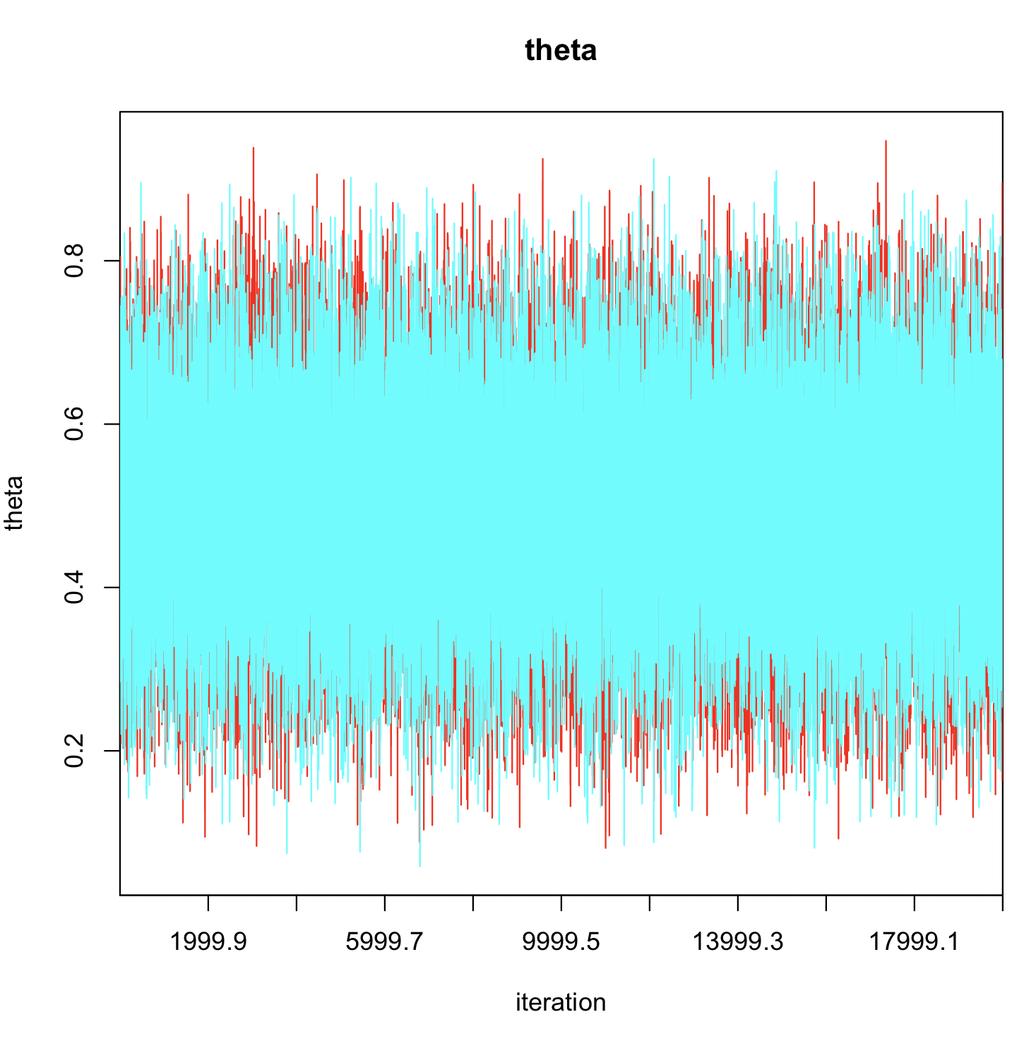
18 traceplot は R2jags の関数
19 > summary(theta) V1 Min. : st Qu.: Median : Mean : rd Qu.: Max. : chain1 の θ chain2 の θ > max(c(samples$bugsoutput$sims.array[,1,][,2], samples$bugsoutput$sims.array[,2,][1,2])) [1] > min(c(samples$bugsoutput$sims.array[,1,][,2], samples$bugsoutput$sims.array[,2,][,2])) [1] > summary(c(samples$bugsoutput$sims.array[,1,][,2], samples$bugsoutput$sims.array[,2,][,2 Min. 1st Qu. Median Mean 3rd Qu. Max
20 ベイズ統計で実践モデリング 3.2 2つの 率の差 第 3 章 項分布を使った推論
21 違うコインでそれぞれコイントス n 1 回トス, k 1 回表が出る n 2 回トス, k 2 回表が出る 表が出る 率 θ 1 表が出る 率 θ 2
22 δ k = ~B n =, θ = k E ~B n E, θ E 尤度 θ 1 θ 2 θ = ~Beta(1,1) θ E ~Beta(1,1) 事前分布 k 1 k 2 δ θ = θ E 率の差 n 1 n 2 確定変数 (deterministic variable) を表すノード
23 Rate_2.txt # Difference Between Two Rates model{ # Observed Counts } k1 ~ dbin(theta1,n1) k2 ~ dbin(theta2,n2) # Prior on Rates theta1 ~ dbeta(1,1) theta2 ~ dbeta(1,1) 尤度 事前分布 # Difference Between Rates delta <- theta1-theta2
24 R2jags による MCMC サンプリング Rate_2_jags.R 変数のクリア # clears workspace: rm(list=ls()) Rate_2.txt と Rate_2_jags.R のあるディレクトリへの移動 # sets working directories: setwd("/users/toh/desktop/code/parameterestimation/binomial") library(r2jags) パッケージの読み込み k1 <- 5 k2 <- 7 n1 <- 10 n2 <- 10 data <- list("k1", "k2", "n1", "n2") # to be passed on to JAGS 観測変数の設定
25 θ 1 と θ 2 の初期値の設定何故 list(list()) となっているのか? ヒント :n.chains の設定 myinits <- list( list(theta1 = 0.1, theta2 = 0.9)) # parameters to be monitored: parameters <- c("delta", "theta1", "theta2") モニターするパラメータの設定 # The following command calls JAGS with specific options. # For a detailed description see the R2jags documentation. samples <- jags(data, inits=myinits, parameters, model.file ="Rate_2.txt", n.chains=1, n.iter=10000, n.burnin=1, n.thin=1, DIC=T) Jags を呼び出して θ をサンプリング
26 サンプリングされた δ( 率の差 ) を取り出して その事後分布を作成 delta <- samples$bugsoutput$sims.list$delta # Now let's plot a histogram for delta. # First, some options to make the plot look better: par(cex.main = 1.5, mar = c(5, 6, 4, 5) + 0.1, mgp = c(3.5, 1, 0), cex.lab = 1.5, font.lab = 2, cex.axis = 1.3, bty = "n", las=1) Nbreaks <- 80 y <- hist(delta, Nbreaks, plot=f) plot(c(y$breaks, max(y$breaks)), c(0,y$density,0), type="s", lwd=2, lty=1, xlim=c(-1,1), ylim=c(0,10), xlab="difference in Rates", ylab="posterior Density")
27
28 δ の点推定, 区間推定 # mean of delta: mean(delta) # median of delta: median(delta) # mode of delta, estimated from the "density" smoother: density(delta)$x[which(density(delta)$y==max(density(delta)$y))] # 95% credible interval for delta: quantile(delta, c(.025,.975))
29 > mean(delta) [1] 平均 > median(delta) [1] メジアン > density(delta)$x[which(density(delta)$y==max(density(delta)$y))] [1] モード > quantile(delta, c(.025,.975)) 2.5% 97.5% % 信 区間
30 ベイズ統計で実践モデリング 3.3 共通の 率を推論する 第 3 章 項分布を使った推論
31 同じコインを 2 が独 にコイントス n 1 回トス, k 1 回表が出る n 2 回トス, k 2 回表が出る 表が出る 率 θ
32 θ k = ~B n =, θ k E ~B n E, θ 尤度 k 1 k 2 θ~beta(1,1) 事前分布 n 1 n 2
33 θ k i k H ~B n H, θ θ~beta(1,1) 尤度 事前分布 n i i 独 なグラフの繰り返しを閉じた 形で囲んで表す for ループのような表現
34 Rate_3.txt # Inferring a Common Rate model{ # Observed Counts k1 ~ dbin(theta,n1) 尤度 k2 ~ dbin(theta,n2) # Prior on Single Rate Theta theta ~ dbeta(1,1) 事前分布 }
35 Rate_3_jags.R 変数のクリア # clears workspace: rm(list=ls()) Rate_2.txt と Rate_2_jags.R のあるディレクトリへの移動 # sets working directories: setwd("/users/toh/desktop/code/parameterestimation/binomial") library(r2jags) パッケージの読み込み k1 <- 5 k2 <- 7 n1 <- 10 n2 <- 10 data <- list("k1", "k2", "n1", "n2") # to be passed on to JAGS 観測変数の設定
36 θ の初期値の設定 myinits <- list( list(theta = 0.5)) # parameters to be monitored: parameters <- c("theta") モニターするパラメータの設定 # The following command calls JAGS with specific options. # For a detailed description see the R2jags documentation. samples <- jags(data, inits=myinits, parameters, model.file ="Rate_3.txt", n.chains=1, n.iter=1000, n.burnin=1, n.thin=1, DIC=T) Jags を呼び出して θ をサンプリング
37 samples の中から θ のサンプルを取り出す theta <- samples$bugsoutput$sims.list$theta # Now let's plot a histogram for theta. # First, some options to make the plot look better: par(cex.main = 1.5, mar = c(5, 6, 4, 5) + 0.1, mgp = c(3.5, 1, 0), cex.lab = 1.5, font.lab = 2, cex.axis = 1.3, bty = "n", las=1) Nbreaks <- 80 y <- hist(theta, Nbreaks, plot=f) plot(c(y$breaks, max(y$breaks)), c(0,y$density,0), type="s", lwd=2, lty=1, xlim=c(0,1), ylim=c(0,10), xlab="rate", ylab="posterior Density") θ の事後分布をプロット
38
39 > mean(theta) [1] > median(theta) [1] > density(theta)$x[which(density(theta)$y==max(density(theta)$y))] [1] > quantile(theta, c(.025,.975)) 2.5% 97.5%
40 まとめ 問題からグラフィカルモデルを作る グラフィカルモデルから jags のモデルを記述する R のスクリプトを記述 (1) ワークスペースへの移動 (2) ワークスペースのクリア (3)R2jags の読み込み (4) 観測データの記述 (5) パラメータの初期値の設定 (6) モニターするパラメータの設定 (7)Jags を実 し MCMC によるサンプリングを実 (8) サンプリング結果を可視化 点推定 区間推定
バイオインフォマティクス特論12
 藤 博幸 事後予測分布 パラメータの事後分布に従って モデルがどんなデータを期待するかを予測する 予測分布が観測されたデータと 致するかを確認することで モデルの適切さを確認できる 前回と同じ問題で事後予測を う 3-1-1. 個 差を考えない場合 3-1-2. 完全な個 差を考える場合 3-1-3. 構造化された個 差を考える場合 ベイズ統計で実践モデリング 10.1 個 差を考えない場合 第 10
藤 博幸 事後予測分布 パラメータの事後分布に従って モデルがどんなデータを期待するかを予測する 予測分布が観測されたデータと 致するかを確認することで モデルの適切さを確認できる 前回と同じ問題で事後予測を う 3-1-1. 個 差を考えない場合 3-1-2. 完全な個 差を考える場合 3-1-3. 構造化された個 差を考える場合 ベイズ統計で実践モデリング 10.1 個 差を考えない場合 第 10
バイオインフォマティクス特論4
 藤 博幸 1-3-1. ピアソン相関係数 1-3-2. 致性のカッパ係数 1-3-3. 時系列データにおける変化検出 ベイズ統計で実践モデリング 5.1 ピアソン係数 第 5 章データ解析の例 データは n ペアの独 な観測値の対例 : 特定の薬剤の投与量と投与から t 時間後の注 する遺伝 の発現量 2 つの変数間の線形の関係性はピアソンの積率相関係数 r で表現される t 時間後の注 する遺伝
藤 博幸 1-3-1. ピアソン相関係数 1-3-2. 致性のカッパ係数 1-3-3. 時系列データにおける変化検出 ベイズ統計で実践モデリング 5.1 ピアソン係数 第 5 章データ解析の例 データは n ペアの独 な観測値の対例 : 特定の薬剤の投与量と投与から t 時間後の注 する遺伝 の発現量 2 つの変数間の線形の関係性はピアソンの積率相関係数 r で表現される t 時間後の注 する遺伝
kubo2015ngt6 p.2 ( ( (MLE 8 y i L(q q log L(q q 0 ˆq log L(q / q = 0 q ˆq = = = * ˆq = 0.46 ( 8 y 0.46 y y y i kubo (ht
 kubo2015ngt6 p.1 2015 (6 MCMC kubo@ees.hokudai.ac.jp, @KuboBook http://goo.gl/m8hsbm 1 ( 2 3 4 5 JAGS : 2015 05 18 16:48 kubo (http://goo.gl/m8hsbm 2015 (6 1 / 70 kubo (http://goo.gl/m8hsbm 2015 (6 2 /
kubo2015ngt6 p.1 2015 (6 MCMC kubo@ees.hokudai.ac.jp, @KuboBook http://goo.gl/m8hsbm 1 ( 2 3 4 5 JAGS : 2015 05 18 16:48 kubo (http://goo.gl/m8hsbm 2015 (6 1 / 70 kubo (http://goo.gl/m8hsbm 2015 (6 2 /
12/1 ( ) GLM, R MCMC, WinBUGS 12/2 ( ) WinBUGS WinBUGS 12/2 ( ) : 12/3 ( ) :? ( :51 ) 2/ 71
 GLM, R MCMC, WinBUGS 12/2 ( ) WinBUGS WinBUGS 12/2 ( ) : 12/3 ( ) :? ( :51 ) 2/ 71") 2010-12-02 (2010 12 02 10 :51 ) 1/ 71 GCOE 2010-12-02 WinBUGS kubo@ees.hokudai.ac.jp http://goo.gl/bukrb 12/1 ( ) GLM, R MCMC, WinBUGS 12/2 ( ) WinBUGS WinBUGS 12/2 ( ) : 12/3 ( ) :? 2010-12-02 (2010 12
2010-12-02 (2010 12 02 10 :51 ) 1/ 71 GCOE 2010-12-02 WinBUGS kubo@ees.hokudai.ac.jp http://goo.gl/bukrb 12/1 ( ) GLM, R MCMC, WinBUGS 12/2 ( ) WinBUGS WinBUGS 12/2 ( ) : 12/3 ( ) :? 2010-12-02 (2010 12
2014ESJ.key
 http://www001.upp.so-net.ne.jp/ito-hi/stat/2014esj/ Statistical Software for State Space Models Commandeur et al. (2011) Journal of Statistical Software 41(1) State Space Models in R Petris & Petrone (2011)
http://www001.upp.so-net.ne.jp/ito-hi/stat/2014esj/ Statistical Software for State Space Models Commandeur et al. (2011) Journal of Statistical Software 41(1) State Space Models in R Petris & Petrone (2011)
Microsoft PowerPoint - R-stat-intro_20.ppt [互換モード]
![Microsoft PowerPoint - R-stat-intro_20.ppt [互換モード]](/thumbs/95/123289731.jpg "Microsoft PowerPoint - R-stat-intro_20.ppt [互換モード]") と WinBUGS R で統計解析入門 (20) ベイズ統計 超 入門 WinBUGS と R2WinBUGS のセットアップ 1. 本資料で使用するデータを以下からダウンロードする http://www.cwk.zaq.ne.jp/fkhud708/files/r-intro/r-stat-intro_data.zip 2. WinBUGS のホームページから下記ファイルをダウンロードし WinBUGS14.exe
と WinBUGS R で統計解析入門 (20) ベイズ統計 超 入門 WinBUGS と R2WinBUGS のセットアップ 1. 本資料で使用するデータを以下からダウンロードする http://www.cwk.zaq.ne.jp/fkhud708/files/r-intro/r-stat-intro_data.zip 2. WinBUGS のホームページから下記ファイルをダウンロードし WinBUGS14.exe
kubostat1g p. MCMC binomial distribution q MCMC : i N i y i p(y i q = ( Ni y i q y i (1 q N i y i, q {y i } q likelihood q L(q {y i } = i=1 p(y i q 1
 kubostat1g p.1 1 (g Hierarchical Bayesian Model kubo@ees.hokudai.ac.jp http://goo.gl/7ci The development of linear models Hierarchical Bayesian Model Be more flexible Generalized Linear Mixed Model (GLMM
kubostat1g p.1 1 (g Hierarchical Bayesian Model kubo@ees.hokudai.ac.jp http://goo.gl/7ci The development of linear models Hierarchical Bayesian Model Be more flexible Generalized Linear Mixed Model (GLMM
日心TWS
 2017.09.22 (15:40~17:10) 日本心理学会第 81 回大会 TWS ベイジアンデータ解析入門 回帰分析を例に ベイジアンデータ解析 を体験してみる 広島大学大学院教育学研究科平川真 ベイジアン分析のステップ (p.24) 1) データの特定 2) モデルの定義 ( 解釈可能な ) モデルの作成 3) パラメタの事前分布の設定 4) ベイズ推論を用いて パラメタの値に確信度を再配分ベイズ推定
2017.09.22 (15:40~17:10) 日本心理学会第 81 回大会 TWS ベイジアンデータ解析入門 回帰分析を例に ベイジアンデータ解析 を体験してみる 広島大学大学院教育学研究科平川真 ベイジアン分析のステップ (p.24) 1) データの特定 2) モデルの定義 ( 解釈可能な ) モデルの作成 3) パラメタの事前分布の設定 4) ベイズ推論を用いて パラメタの値に確信度を再配分ベイズ推定
k2 ( :35 ) ( k2) (GLM) web web 1 :
 ( k2) (GLM) web web 1 :") 2012 11 01 k2 (2012-10-26 16:35 ) 1 6 2 (2012 11 01 k2) (GLM) kubo@ees.hokudai.ac.jp web http://goo.gl/wijx2 web http://goo.gl/ufq2 1 : 2 2 4 3 7 4 9 5 : 11 5.1................... 13 6 14 6.1......................
2012 11 01 k2 (2012-10-26 16:35 ) 1 6 2 (2012 11 01 k2) (GLM) kubo@ees.hokudai.ac.jp web http://goo.gl/wijx2 web http://goo.gl/ufq2 1 : 2 2 4 3 7 4 9 5 : 11 5.1................... 13 6 14 6.1......................
講義のーと : データ解析のための統計モデリング. 第5回
 Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
講義のーと : データ解析のための統計モデリング. 第3回
 Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
Stanによるハミルトニアンモンテカルロ法を用いたサンプリングについて
 Stan によるハミルトニアンモンテカルロ法を用いたサンプリングについて 10 月 22 日中村文士 1 目次 1.STANについて 2.RでSTANをするためのインストール 3.STANのコード記述方法 4.STANによるサンプリングの例 2 1.STAN について ハミルトニアンモンテカルロ法に基づいた事後分布からのサンプリングなどができる STAN の HP: mc-stan.org 3 由来
Stan によるハミルトニアンモンテカルロ法を用いたサンプリングについて 10 月 22 日中村文士 1 目次 1.STANについて 2.RでSTANをするためのインストール 3.STANのコード記述方法 4.STANによるサンプリングの例 2 1.STAN について ハミルトニアンモンテカルロ法に基づいた事後分布からのサンプリングなどができる STAN の HP: mc-stan.org 3 由来
kubostat2018d p.2 :? bod size x and fertilization f change seed number? : a statistical model for this example? i response variable seed number : { i
 kubostat2018d p.1 I 2018 (d) model selection and kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2018 06 25 : 2018 06 21 17:45 1 2 3 4 :? AIC : deviance model selection misunderstanding kubostat2018d (http://goo.gl/76c4i)
kubostat2018d p.1 I 2018 (d) model selection and kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2018 06 25 : 2018 06 21 17:45 1 2 3 4 :? AIC : deviance model selection misunderstanding kubostat2018d (http://goo.gl/76c4i)
kubo2017sep16a p.1 ( 1 ) : : :55 kubo ( ( 1 ) / 10
 : : :55 kubo ( ( 1 ) / 10") kubo2017sep16a p.1 ( 1 ) kubo@ees.hokudai.ac.jp 2017 09 16 : http://goo.gl/8je5wh : 2017 09 13 16:55 kubo (http://goo.gl/ufq2) ( 1 ) 2017 09 16 1 / 106 kubo (http://goo.gl/ufq2) ( 1 ) 2017 09 16 2 / 106
kubo2017sep16a p.1 ( 1 ) kubo@ees.hokudai.ac.jp 2017 09 16 : http://goo.gl/8je5wh : 2017 09 13 16:55 kubo (http://goo.gl/ufq2) ( 1 ) 2017 09 16 1 / 106 kubo (http://goo.gl/ufq2) ( 1 ) 2017 09 16 2 / 106
スライド 1
 2019 年 5 月 7 日 @ 統計モデリング 統計モデリング 第四回配布資料 ( 予習用 ) 文献 : a) A. J. Dobson and A. G. Barnett: An Introduction to Generalized Linear Models. 3rd ed., CRC Press. b) H. Dung, et al: Monitoring the Transmission
2019 年 5 月 7 日 @ 統計モデリング 統計モデリング 第四回配布資料 ( 予習用 ) 文献 : a) A. J. Dobson and A. G. Barnett: An Introduction to Generalized Linear Models. 3rd ed., CRC Press. b) H. Dung, et al: Monitoring the Transmission
「統 計 数 学 3」
 関数の使い方 1 関数と引数 関数の構造 関数名 ( 引数 1, 引数 2, 引数 3, ) 例 : マハラノビス距離を求める関数 mahalanobis(data,m,v) 引数名を指定して記述する場合 mahalanobis(x=data, center=m, cov=v) 2 関数についてのヘルプ 基本的な関数のヘルプの呼び出し? 関数名 例 :?mean 例 :?mahalanobis 指定できる引数を確認する関数
関数の使い方 1 関数と引数 関数の構造 関数名 ( 引数 1, 引数 2, 引数 3, ) 例 : マハラノビス距離を求める関数 mahalanobis(data,m,v) 引数名を指定して記述する場合 mahalanobis(x=data, center=m, cov=v) 2 関数についてのヘルプ 基本的な関数のヘルプの呼び出し? 関数名 例 :?mean 例 :?mahalanobis 指定できる引数を確認する関数
kubostat2015e p.2 how to specify Poisson regression model, a GLM GLM how to specify model, a GLM GLM logistic probability distribution Poisson distrib
 kubostat2015e p.1 I 2015 (e) GLM kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2015 07 22 2015 07 21 16:26 kubostat2015e (http://goo.gl/76c4i) 2015 (e) 2015 07 22 1 / 42 1 N k 2 binomial distribution logit
kubostat2015e p.1 I 2015 (e) GLM kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2015 07 22 2015 07 21 16:26 kubostat2015e (http://goo.gl/76c4i) 2015 (e) 2015 07 22 1 / 42 1 N k 2 binomial distribution logit
講義のーと : データ解析のための統計モデリング. 第2回
 Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
DAA04
 # plot(x,y, ) plot(dat$shoesize, dat$h, main="relationship b/w shoesize and height, xlab = 'shoesize, ylab='height, pch=19, col='red ) Relationship b/w shoesize and height height 150 160 170 180 21 22
# plot(x,y, ) plot(dat$shoesize, dat$h, main="relationship b/w shoesize and height, xlab = 'shoesize, ylab='height, pch=19, col='red ) Relationship b/w shoesize and height height 150 160 170 180 21 22
DAA03
 par(mfrow=c(1,2)) # figure Dist. of Height for Female Participants Dist. of Height for Male Participants Density 0.00 0.02 0.04 0.06 0.08 Density 0.00 0.02 0.04 0.06 0.08 140 150 160 170 180 190 Height
par(mfrow=c(1,2)) # figure Dist. of Height for Female Participants Dist. of Height for Male Participants Density 0.00 0.02 0.04 0.06 0.08 Density 0.00 0.02 0.04 0.06 0.08 140 150 160 170 180 190 Height
様々なミクロ計量モデル†
 担当 : 長倉大輔 ( ながくらだいすけ ) この資料は私の講義において使用するために作成した資料です WEB ページ上で公開しており 自由に参照して頂いて構いません ただし 内容について 一応検証してありますが もし間違いがあった場合でもそれによって生じるいかなる損害 不利益について責任を負いかねますのでご了承ください 間違いは発見次第 継続的に直していますが まだ存在する可能性があります 1 カウントデータモデル
担当 : 長倉大輔 ( ながくらだいすけ ) この資料は私の講義において使用するために作成した資料です WEB ページ上で公開しており 自由に参照して頂いて構いません ただし 内容について 一応検証してありますが もし間違いがあった場合でもそれによって生じるいかなる損害 不利益について責任を負いかねますのでご了承ください 間違いは発見次第 継続的に直していますが まだ存在する可能性があります 1 カウントデータモデル
Probit , Mixed logit
 Probit, Mixed logit 2016/5/16 スタートアップゼミ #5 B4 後藤祥孝 1 0. 目次 Probit モデルについて 1. モデル概要 2. 定式化と理解 3. 推定 Mixed logit モデルについて 4. モデル概要 5. 定式化と理解 6. 推定 2 1.Probit 概要 プロビットモデルとは. 効用関数の誤差項に多変量正規分布を仮定したもの. 誤差項には様々な要因が存在するため,
Probit, Mixed logit 2016/5/16 スタートアップゼミ #5 B4 後藤祥孝 1 0. 目次 Probit モデルについて 1. モデル概要 2. 定式化と理解 3. 推定 Mixed logit モデルについて 4. モデル概要 5. 定式化と理解 6. 推定 2 1.Probit 概要 プロビットモデルとは. 効用関数の誤差項に多変量正規分布を仮定したもの. 誤差項には様々な要因が存在するため,
スライド 1
 2018 年 5 月 8 日 @ 統計モデリング 統計モデリング 第四回配布資料 文献 : a) A. J. Dobson and A. G. Barnett: An Introduction to Generalized Linear Models. 3rd ed., CRC Press. b) H. Dung, et al: Monitoring the Transmission of Schistosoma
2018 年 5 月 8 日 @ 統計モデリング 統計モデリング 第四回配布資料 文献 : a) A. J. Dobson and A. G. Barnett: An Introduction to Generalized Linear Models. 3rd ed., CRC Press. b) H. Dung, et al: Monitoring the Transmission of Schistosoma
k3 ( :07 ) 2 (A) k = 1 (B) k = 7 y x x 1 (k2)?? x y (A) GLM (k
 2 (A) k = 1 (B) k = 7 y x x 1 (k2)?? x y (A) GLM (k") 2012 11 01 k3 (2012-10-24 14:07 ) 1 6 3 (2012 11 01 k3) kubo@ees.hokudai.ac.jp web http://goo.gl/wijx2 web http://goo.gl/ufq2 1 3 2 : 4 3 AIC 6 4 7 5 8 6 : 9 7 11 8 12 8.1 (1)........ 13 8.2 (2) χ 2....................
2012 11 01 k3 (2012-10-24 14:07 ) 1 6 3 (2012 11 01 k3) kubo@ees.hokudai.ac.jp web http://goo.gl/wijx2 web http://goo.gl/ufq2 1 3 2 : 4 3 AIC 6 4 7 5 8 6 : 9 7 11 8 12 8.1 (1)........ 13 8.2 (2) χ 2....................
統計学 - 社会統計の基礎 - 正規分布 標準正規分布累積分布関数の逆関数 t 分布正規分布に従うサンプルの平均の信頼区間 担当 : 岸 康人 資料ページ :
 統計学 - 社会統計の基礎 - 正規分布 標準正規分布累積分布関数の逆関数 t 分布正規分布に従うサンプルの平均の信頼区間 担当 : 岸 康人 資料ページ : https://goo.gl/qw1djw 正規分布 ( 復習 ) 正規分布 (Normal Distribution)N (μ, σ 2 ) 別名 : ガウス分布 (Gaussian Distribution) 密度関数 Excel:= NORM.DIST
統計学 - 社会統計の基礎 - 正規分布 標準正規分布累積分布関数の逆関数 t 分布正規分布に従うサンプルの平均の信頼区間 担当 : 岸 康人 資料ページ : https://goo.gl/qw1djw 正規分布 ( 復習 ) 正規分布 (Normal Distribution)N (μ, σ 2 ) 別名 : ガウス分布 (Gaussian Distribution) 密度関数 Excel:= NORM.DIST
一般化線形 (混合) モデル (2) - ロジスティック回帰と GLMM
 モデル (2) - ロジスティック回帰と GLMM") .. ( ) (2) GLMM kubo@ees.hokudai.ac.jp I http://goo.gl/rrhzey 2013 08 27 : 2013 08 27 08:29 kubostat2013ou2 (http://goo.gl/rrhzey) ( ) (2) 2013 08 27 1 / 74 I.1 N k.2 binomial distribution logit link function.3.4!
.. ( ) (2) GLMM kubo@ees.hokudai.ac.jp I http://goo.gl/rrhzey 2013 08 27 : 2013 08 27 08:29 kubostat2013ou2 (http://goo.gl/rrhzey) ( ) (2) 2013 08 27 1 / 74 I.1 N k.2 binomial distribution logit link function.3.4!
情報工学概論
 確率と統計 中山クラス 第 11 週 0 本日の内容 第 3 回レポート解説 第 5 章 5.6 独立性の検定 ( カイ二乗検定 ) 5.7 サンプルサイズの検定結果への影響練習問題 (4),(5) 第 4 回レポート課題の説明 1 演習問題 ( 前回 ) の解説 勉強時間と定期試験の得点の関係を無相関検定により調べる. データ入力 > aa
確率と統計 中山クラス 第 11 週 0 本日の内容 第 3 回レポート解説 第 5 章 5.6 独立性の検定 ( カイ二乗検定 ) 5.7 サンプルサイズの検定結果への影響練習問題 (4),(5) 第 4 回レポート課題の説明 1 演習問題 ( 前回 ) の解説 勉強時間と定期試験の得点の関係を無相関検定により調べる. データ入力 > aa
kubostat2017c p (c) Poisson regression, a generalized linear model (GLM) : :
 Poisson regression, a generalized linear model (GLM) : :") kubostat2017c p.1 2017 (c), a generalized linear model (GLM) : kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2017 11 14 : 2017 11 07 15:43 kubostat2017c (http://goo.gl/76c4i) 2017 (c) 2017 11 14 1 / 47 agenda
kubostat2017c p.1 2017 (c), a generalized linear model (GLM) : kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2017 11 14 : 2017 11 07 15:43 kubostat2017c (http://goo.gl/76c4i) 2017 (c) 2017 11 14 1 / 47 agenda

kubostat2017b p.1 agenda I 2017 (b) probability distribution and maximum likelihood estimation :
 probability distribution and maximum likelihood estimation :") kubostat2017b p.1 agenda I 2017 (b) probabilit distribution and maimum likelihood estimation kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2017 11 14 : 2017 11 07 15:43 1 : 2 3? 4 kubostat2017b (http://goo.gl/76c4i)
kubostat2017b p.1 agenda I 2017 (b) probabilit distribution and maimum likelihood estimation kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2017 11 14 : 2017 11 07 15:43 1 : 2 3? 4 kubostat2017b (http://goo.gl/76c4i)
1 R Windows R 1.1 R The R project web R web Download [CRAN] CRAN Mirrors Japan Download and Install R [Windows 9
![1 R Windows R 1.1 R The R project web R web Download [CRAN] CRAN Mirrors Japan Download and Install R [Windows 9](/thumbs/99/142039515.jpg "1 R Windows R 1.1 R The R project web R web Download [CRAN] CRAN Mirrors Japan Download and Install R [Windows 9") 1 R 2007 8 19 1 Windows R 1.1 R The R project web http://www.r-project.org/ R web Download [CRAN] CRAN Mirrors Japan Download and Install R [Windows 95 and later ] [base] 2.5.1 R - 2.5.1 for Windows R
1 R 2007 8 19 1 Windows R 1.1 R The R project web http://www.r-project.org/ R web Download [CRAN] CRAN Mirrors Japan Download and Install R [Windows 95 and later ] [base] 2.5.1 R - 2.5.1 for Windows R
/22 R MCMC R R MCMC? 3. Gibbs sampler : kubo/
 2006-12-09 1/22 R MCMC R 1. 2. R MCMC? 3. Gibbs sampler : kubo@ees.hokudai.ac.jp http://hosho.ees.hokudai.ac.jp/ kubo/ 2006-12-09 2/22 : ( ) : : ( ) : (?) community ( ) 2006-12-09 3/22 :? 1. ( ) 2. ( )
2006-12-09 1/22 R MCMC R 1. 2. R MCMC? 3. Gibbs sampler : kubo@ees.hokudai.ac.jp http://hosho.ees.hokudai.ac.jp/ kubo/ 2006-12-09 2/22 : ( ) : : ( ) : (?) community ( ) 2006-12-09 3/22 :? 1. ( ) 2. ( )
 2009 5 1...1 2...3 2.1...3 2.2...3 3...10 3.1...10 3.1.1...10 3.1.2... 11 3.2...14 3.2.1...14 3.2.2...16 3.3...18 3.4...19 3.4.1...19 3.4.2...20 3.4.3...21 4...24 4.1...24 4.2...24 4.3 WinBUGS...25 4.4...28
2009 5 1...1 2...3 2.1...3 2.2...3 3...10 3.1...10 3.1.1...10 3.1.2... 11 3.2...14 3.2.1...14 3.2.2...16 3.3...18 3.4...19 3.4.1...19 3.4.2...20 3.4.3...21 4...24 4.1...24 4.2...24 4.3 WinBUGS...25 4.4...28
@i_kiwamu Bayes - -
 Bayes RStan 1 2012 12 1 R @ @i_kiwamu Bayes - - Stan / RStan Bayes Stan Development Team - Andrew Gelman, Bob Carpenter, Matt Hoffman, Ben Goodrich, Michael Malecki, Daniel Lee and Chad Scherrer Open source
Bayes RStan 1 2012 12 1 R @ @i_kiwamu Bayes - - Stan / RStan Bayes Stan Development Team - Andrew Gelman, Bob Carpenter, Matt Hoffman, Ben Goodrich, Michael Malecki, Daniel Lee and Chad Scherrer Open source
60 (W30)? 1. ( ) 2. ( ) web site URL ( :41 ) 1/ 77
? 1. ( ) 2. ( ) web site URL ( :41 ) 1/ 77") 60 (W30)? 1. ( ) kubo@ees.hokudai.ac.jp 2. ( ) web site URL http://goo.gl/e1cja!! 2013 03 07 (2013 03 07 17 :41 ) 1/ 77 ! : :? 2013 03 07 (2013 03 07 17 :41 ) 2/ 77 2013 03 07 (2013 03 07 17 :41 ) 3/ 77!!
60 (W30)? 1. ( ) kubo@ees.hokudai.ac.jp 2. ( ) web site URL http://goo.gl/e1cja!! 2013 03 07 (2013 03 07 17 :41 ) 1/ 77 ! : :? 2013 03 07 (2013 03 07 17 :41 ) 2/ 77 2013 03 07 (2013 03 07 17 :41 ) 3/ 77!!
したがって このモデルではの長さをもつ潜在履歴 latent history が存在し 同様に と指標化して扱うことができる 以下では 潜在的に起こりうる履歴を潜在履歴 latent history 実際にデ ータとして記録された履歴を記録履歴 recorded history ということにする M
 Bayesian Inference with ecological applications Chapter 10 Bayesian Inference with ecological applications 輪読会 潜在的な事象を扱うための多項分布モデル Latent Multinomial Models 本章では 記録した頻度データが多項分布に従う潜在的な変数を集約したものと考えられるときの
Bayesian Inference with ecological applications Chapter 10 Bayesian Inference with ecological applications 輪読会 潜在的な事象を扱うための多項分布モデル Latent Multinomial Models 本章では 記録した頻度データが多項分布に従う潜在的な変数を集約したものと考えられるときの
¥¤¥ó¥¿¡¼¥Í¥Ã¥È·×¬¤È¥Ç¡¼¥¿²òÀÏ Âè2²ó
 2 212 4 13 1 (4/6) : ruby 2 / 35 ( ) : gnuplot 3 / 35 ( ) 4 / 35 (summary statistics) : (mean) (median) (mode) : (range) (variance) (standard deviation) 5 / 35 (mean): x = 1 n (median): { xr+1 m, m = 2r
2 212 4 13 1 (4/6) : ruby 2 / 35 ( ) : gnuplot 3 / 35 ( ) 4 / 35 (summary statistics) : (mean) (median) (mode) : (range) (variance) (standard deviation) 5 / 35 (mean): x = 1 n (median): { xr+1 m, m = 2r
kubostat2017e p.1 I 2017 (e) GLM logistic regression : : :02 1 N y count data or
 GLM logistic regression : : :02 1 N y count data or") kubostat207e p. I 207 (e) GLM kubo@ees.hokudai.ac.jp https://goo.gl/z9ycjy 207 4 207 6:02 N y 2 binomial distribution logit link function 3 4! offset kubostat207e (https://goo.gl/z9ycjy) 207 (e) 207 4
kubostat207e p. I 207 (e) GLM kubo@ees.hokudai.ac.jp https://goo.gl/z9ycjy 207 4 207 6:02 N y 2 binomial distribution logit link function 3 4! offset kubostat207e (https://goo.gl/z9ycjy) 207 (e) 207 4
浜松医科大学紀要
 On the Statistical Bias Found in the Horse Racing Data (1) Akio NODA Mathematics Abstract: The purpose of the present paper is to report what type of statistical bias the author has found in the horse
On the Statistical Bias Found in the Horse Racing Data (1) Akio NODA Mathematics Abstract: The purpose of the present paper is to report what type of statistical bias the author has found in the horse
DAA02
 c(var1,var2,...,varn) > x x [1] 1 2 3 4 > x2 x2 [1] 1 2 3 4 5 6 7 8 c(var1,var2,...,varn) > y=c('a0','a1','b0','b1') > y [1] "a0" "a1" "b0" "b1 > z=c(x,y) > z [1] "1" "2"
c(var1,var2,...,varn) > x x [1] 1 2 3 4 > x2 x2 [1] 1 2 3 4 5 6 7 8 c(var1,var2,...,varn) > y=c('a0','a1','b0','b1') > y [1] "a0" "a1" "b0" "b1 > z=c(x,y) > z [1] "1" "2"
NLMIXED プロシジャを用いた生存時間解析 伊藤要二アストラゼネカ株式会社臨床統計 プログラミング グループグルプ Survival analysis using PROC NLMIXED Yohji Itoh Clinical Statistics & Programming Group, A
 NLMIXED プロシジャを用いた生存時間解析 伊藤要二アストラゼネカ株式会社臨床統計 プログラミング グループグルプ Survival analysis using PROC NLMIXED Yohji Itoh Clinical Statistics & Programming Group, AstraZeneca KK 要旨 : NLMIXEDプロシジャの最尤推定の機能を用いて 指数分布 Weibull
NLMIXED プロシジャを用いた生存時間解析 伊藤要二アストラゼネカ株式会社臨床統計 プログラミング グループグルプ Survival analysis using PROC NLMIXED Yohji Itoh Clinical Statistics & Programming Group, AstraZeneca KK 要旨 : NLMIXEDプロシジャの最尤推定の機能を用いて 指数分布 Weibull
¥¤¥ó¥¿¡¼¥Í¥Ã¥È·×¬¤È¥Ç¡¼¥¿²òÀÏ Âè2²ó
 2 2015 4 20 1 (4/13) : ruby 2 / 49 2 ( ) : gnuplot 3 / 49 1 1 2014 6 IIJ / 4 / 49 1 ( ) / 5 / 49 ( ) 6 / 49 (summary statistics) : (mean) (median) (mode) : (range) (variance) (standard deviation) 7 / 49
2 2015 4 20 1 (4/13) : ruby 2 / 49 2 ( ) : gnuplot 3 / 49 1 1 2014 6 IIJ / 4 / 49 1 ( ) / 5 / 49 ( ) 6 / 49 (summary statistics) : (mean) (median) (mode) : (range) (variance) (standard deviation) 7 / 49
Rによる計量分析:データ解析と可視化 - 第3回 Rの基礎とデータ操作・管理
 R 3 R 2017 Email: gito@eco.u-toyama.ac.jp October 23, 2017 (Toyama/NIHU) R ( 3 ) October 23, 2017 1 / 34 Agenda 1 2 3 4 R 5 RStudio (Toyama/NIHU) R ( 3 ) October 23, 2017 2 / 34 10/30 (Mon.) 12/11 (Mon.)
R 3 R 2017 Email: gito@eco.u-toyama.ac.jp October 23, 2017 (Toyama/NIHU) R ( 3 ) October 23, 2017 1 / 34 Agenda 1 2 3 4 R 5 RStudio (Toyama/NIHU) R ( 3 ) October 23, 2017 2 / 34 10/30 (Mon.) 12/11 (Mon.)
")
")



Microsoft Word - 計量研修テキスト_第5版).doc
.doc") Q10-2 テキスト P191 1. 記述統計量 ( 変数 :YY95) 表示変数として 平均 中央値 最大値 最小値 標準偏差 観測値 を選択 A. 都道府県別 Descriptive Statistics for YY95 Categorized by values of PREFNUM Date: 05/11/06 Time: 14:36 Sample: 1990 2002 Included
Q10-2 テキスト P191 1. 記述統計量 ( 変数 :YY95) 表示変数として 平均 中央値 最大値 最小値 標準偏差 観測値 を選択 A. 都道府県別 Descriptive Statistics for YY95 Categorized by values of PREFNUM Date: 05/11/06 Time: 14:36 Sample: 1990 2002 Included
スライド 1
 WinBUGS 入門 水産資源学におけるベイズ統計の応用ワークショップ 2007 年 8 月 2-3 日, 中央水研 遠洋水産研究所外洋資源部 鯨類管理研究室 岡村寛 WinBUGS とは BUGS (Bayesian Inference Using Gibbs Sampling) の Windows バージョン フリーのソフトウェア Gibbs samplingを利用した事後確率からのサンプリングを行う
WinBUGS 入門 水産資源学におけるベイズ統計の応用ワークショップ 2007 年 8 月 2-3 日, 中央水研 遠洋水産研究所外洋資源部 鯨類管理研究室 岡村寛 WinBUGS とは BUGS (Bayesian Inference Using Gibbs Sampling) の Windows バージョン フリーのソフトウェア Gibbs samplingを利用した事後確率からのサンプリングを行う
症例数設定? What is sample size estimation? 医療機器臨床試験のコンサルティングで最も相談件数が多いのは 症例数の設定 Many a need of consulting for device clinical trial is sample size estimat
 医療機器臨床試験における 例数設計のいろは Sample size estimation for clinical trials of devices -First education- 株式会社バイオスタティスティカルリサ - チ古川敏仁 Furukawa Toshihito, Biostatistical Research 2005 年 9 月 3 日第 2 回医療機器臨床試験研究会 Copyright(C)
医療機器臨床試験における 例数設計のいろは Sample size estimation for clinical trials of devices -First education- 株式会社バイオスタティスティカルリサ - チ古川敏仁 Furukawa Toshihito, Biostatistical Research 2005 年 9 月 3 日第 2 回医療機器臨床試験研究会 Copyright(C)
今日の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか
 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか") 時系列データ解析でよく見る あぶない モデリング 久保拓弥 (北海道大 環境科学) 1/56 今日の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか (危 1) 時系列データを GLM で (危 2) 時系列Yt 時系列 Xt 相関は因果関係ではない 問題の一部
時系列データ解析でよく見る あぶない モデリング 久保拓弥 (北海道大 環境科学) 1/56 今日の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか (危 1) 時系列データを GLM で (危 2) 時系列Yt 時系列 Xt 相関は因果関係ではない 問題の一部
スライド 1
 担当 : 田中冬彦 016 年 4 月 19 日 @ 統計モデリング 統計モデリング 第二回配布資料 文献 : A. J. Dobson and A. G. Barnett: An Introduction to Generalized Linear Models 3rd ed., CRC Press. 配布資料の PDF は以下からも DL できます. 短縮 URL http://tinyurl.com/lxb7kb8
担当 : 田中冬彦 016 年 4 月 19 日 @ 統計モデリング 統計モデリング 第二回配布資料 文献 : A. J. Dobson and A. G. Barnett: An Introduction to Generalized Linear Models 3rd ed., CRC Press. 配布資料の PDF は以下からも DL できます. 短縮 URL http://tinyurl.com/lxb7kb8
ベイズ統計入門
 ベイズ統計入門 条件付確率 事象 F が起こったことが既知であるという条件の下で E が起こる確率を条件付確率 (codtoal probablt) という P ( E F ) P ( E F ) P( F ) 定義式を変形すると 確率の乗法公式となる ( E F ) P( F ) P( E F ) P( E) P( F E) P 事象の独立 ある事象の生起する確率が 他のある事象が生起するかどうかによって変化しないとき
ベイズ統計入門 条件付確率 事象 F が起こったことが既知であるという条件の下で E が起こる確率を条件付確率 (codtoal probablt) という P ( E F ) P ( E F ) P( F ) 定義式を変形すると 確率の乗法公式となる ( E F ) P( F ) P( E F ) P( E) P( F E) P 事象の独立 ある事象の生起する確率が 他のある事象が生起するかどうかによって変化しないとき
こんにちは由美子です
 Sample size power calculation Sample Size Estimation AZTPIAIDS AIDSAZT AIDSPI AIDSRNA AZTPr (S A ) = π A, PIPr (S B ) = π B AIDS (sampling)(inference) π A, π B π A - π B = 0.20 PI 20 20AZT, PI 10 6 8 HIV-RNA
Sample size power calculation Sample Size Estimation AZTPIAIDS AIDSAZT AIDSPI AIDSRNA AZTPr (S A ) = π A, PIPr (S B ) = π B AIDS (sampling)(inference) π A, π B π A - π B = 0.20 PI 20 20AZT, PI 10 6 8 HIV-RNA
kubostat2017j p.2 CSV CSV (!) d2.csv d2.csv,, 286,0,A 85,0,B 378,1,A 148,1,B ( :27 ) 10/ 51 kubostat2017j (http://goo.gl/76c4i
 d2.csv d2.csv,, 286,0,A 85,0,B 378,1,A 148,1,B ( :27 ) 10/ 51 kubostat2017j (http://goo.gl/76c4i") kubostat2017j p.1 2017 (j) Categorical Data Analsis kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2017 11 15 : 2017 11 08 17:11 kubostat2017j (http://goo.gl/76c4i) 2017 (j) 2017 11 15 1 / 63 A B C D E F G
kubostat2017j p.1 2017 (j) Categorical Data Analsis kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2017 11 15 : 2017 11 08 17:11 kubostat2017j (http://goo.gl/76c4i) 2017 (j) 2017 11 15 1 / 63 A B C D E F G
<30315F985F95B65F90B490852E696E6464>
 Modeling for Change by Latent Difference Score Model: Adapting Process of the Student of Freshman at Half Year Intervals Kazuaki SHIMIZU and Norihiro MIHO Abstract The purpose of this paper is to present
Modeling for Change by Latent Difference Score Model: Adapting Process of the Student of Freshman at Half Year Intervals Kazuaki SHIMIZU and Norihiro MIHO Abstract The purpose of this paper is to present
(lm) lm AIC 2 / 1
 lm AIC 2 / 1") W707 s-taiji@is.titech.ac.jp 1 / 1 (lm) lm AIC 2 / 1 : y = β 1 x 1 + β 2 x 2 + + β d x d + β d+1 + ϵ (ϵ N(0, σ 2 )) y R: x R d : β i (i = 1,..., d):, β d+1 : ( ) (d = 1) y = β 1 x 1 + β 2 + ϵ (d > 1) y
W707 s-taiji@is.titech.ac.jp 1 / 1 (lm) lm AIC 2 / 1 : y = β 1 x 1 + β 2 x 2 + + β d x d + β d+1 + ϵ (ϵ N(0, σ 2 )) y R: x R d : β i (i = 1,..., d):, β d+1 : ( ) (d = 1) y = β 1 x 1 + β 2 + ϵ (d > 1) y
はじめに このドキュメントではftServerに関する障害調査を行う際に 必要となるログ データの取得方法を説明しています ログ データの取得には 初期解析用のデータの取得方法と 詳細な調査を行うときのデータ取得方法があります 特別な理由でOS 側のログが必要となった場合には RHELログの取得につ
 ftserver におけるログ取得手順 (Linux 編 ) Rev 0.5: 2017/06/08 1 はじめに このドキュメントではftServerに関する障害調査を行う際に 必要となるログ データの取得方法を説明しています ログ データの取得には 初期解析用のデータの取得方法と 詳細な調査を行うときのデータ取得方法があります 特別な理由でOS 側のログが必要となった場合には RHELログの取得について
ftserver におけるログ取得手順 (Linux 編 ) Rev 0.5: 2017/06/08 1 はじめに このドキュメントではftServerに関する障害調査を行う際に 必要となるログ データの取得方法を説明しています ログ データの取得には 初期解析用のデータの取得方法と 詳細な調査を行うときのデータ取得方法があります 特別な理由でOS 側のログが必要となった場合には RHELログの取得について
Fig. 3 Flow diagram of image processing. Black rectangle in the photo indicates the processing area (128 x 32 pixels).
.") Fig. 1 The scheme of glottal area as a function of time Fig. 3 Flow diagram of image processing. Black rectangle in the photo indicates the processing area (128 x 32 pixels). Fig, 4 Parametric representation
Fig. 1 The scheme of glottal area as a function of time Fig. 3 Flow diagram of image processing. Black rectangle in the photo indicates the processing area (128 x 32 pixels). Fig, 4 Parametric representation
Microsoft Word doc
 . 正規線形モデルのベイズ推定翠川 大竹距離減衰式 (PGA(Midorikawa, S., and Ohtake, Y. (, Attenuation relationships of peak ground acceleration and velocity considering attenuation characteristics for shallow and deeper earthquakes,
. 正規線形モデルのベイズ推定翠川 大竹距離減衰式 (PGA(Midorikawa, S., and Ohtake, Y. (, Attenuation relationships of peak ground acceleration and velocity considering attenuation characteristics for shallow and deeper earthquakes,
Microsoft Word - Meta70_Preferences.doc
 Image Windows Preferences Edit, Preferences MetaMorph, MetaVue Image Windows Preferences Edit, Preferences Image Windows Preferences 1. Windows Image Placement: Acquire Overlay at Top Left Corner: 1 Acquire
Image Windows Preferences Edit, Preferences MetaMorph, MetaVue Image Windows Preferences Edit, Preferences Image Windows Preferences 1. Windows Image Placement: Acquire Overlay at Top Left Corner: 1 Acquire
Use R
 Use R! 2008/05/23( ) Index Introduction (GLM) ( ) R. Introduction R,, PLS,,, etc. 2. Correlation coefficient (Pearson s product moment correlation) r = Sxy Sxx Syy :, Sxy, Sxx= X, Syy Y 1.96 95% R cor(x,
Use R! 2008/05/23( ) Index Introduction (GLM) ( ) R. Introduction R,, PLS,,, etc. 2. Correlation coefficient (Pearson s product moment correlation) r = Sxy Sxx Syy :, Sxy, Sxx= X, Syy Y 1.96 95% R cor(x,
Microsoft PowerPoint - 14回パラメータ推定配布用.pptx
 パラメータ推定の理論と実践 BEhavior Study for Transportation Graduate school, Univ. of Yamanashi 山梨大学佐々木邦明 最尤推定法 点推定量を求める最もポピュラーな方法 L n x n i1 f x i 右上の式を θ の関数とみなしたものが尤度関数 データ (a,b) が得られたとき, 全体の平均がいくつとするのがよいか 平均がいくつだったら
パラメータ推定の理論と実践 BEhavior Study for Transportation Graduate school, Univ. of Yamanashi 山梨大学佐々木邦明 最尤推定法 点推定量を求める最もポピュラーな方法 L n x n i1 f x i 右上の式を θ の関数とみなしたものが尤度関数 データ (a,b) が得られたとき, 全体の平均がいくつとするのがよいか 平均がいくつだったら

Microsoft PowerPoint - 統計科学研究所_R_重回帰分析_変数選択_2.ppt
 重回帰分析 残差分析 変数選択 1 内容 重回帰分析 残差分析 歯の咬耗度データの分析 R で変数選択 ~ step 関数 ~ 2 重回帰分析と単回帰分析 体重を予測する問題 分析 1 身長 のみから体重を予測 分析 2 身長 と ウエスト の両方を用いて体重を予測 分析 1 と比べて大きな改善 体重 に関する推測では 身長 だけでは不十分 重回帰分析における問題 ~ モデルの構築 ~ 適切なモデルで分析しているか?
重回帰分析 残差分析 変数選択 1 内容 重回帰分析 残差分析 歯の咬耗度データの分析 R で変数選択 ~ step 関数 ~ 2 重回帰分析と単回帰分析 体重を予測する問題 分析 1 身長 のみから体重を予測 分析 2 身長 と ウエスト の両方を用いて体重を予測 分析 1 と比べて大きな改善 体重 に関する推測では 身長 だけでは不十分 重回帰分析における問題 ~ モデルの構築 ~ 適切なモデルで分析しているか?
& 3 3 ' ' (., (Pixel), (Light Intensity) (Random Variable). (Joint Probability). V., V = {,,, V }. i x i x = (x, x,, x V ) T. x i i (State Variable),
, (Light Intensity) (Random Variable). (Joint Probability). V., V = {,,, V }. i x i x = (x, x,, x V ) T. x i i (State Variable),") .... Deeping and Expansion of Large-Scale Random Fields and Probabilistic Image Processing Kazuyuki Tanaka The mathematical frameworks of probabilistic image processing are formulated by means of Markov
.... Deeping and Expansion of Large-Scale Random Fields and Probabilistic Image Processing Kazuyuki Tanaka The mathematical frameworks of probabilistic image processing are formulated by means of Markov
Microsoft PowerPoint - stat-2014-[9] pptx
![Microsoft PowerPoint - stat-2014-[9] pptx](/thumbs/49/25555771.jpg "Microsoft PowerPoint - stat-2014-[9] pptx") 統計学 第 17 回 講義 母平均の区間推定 Part-1 014 年 6 17 ( )6-7 限 担当教員 : 唐渡 広志 ( からと こうじ ) 研究室 : 経済学研究棟 4 階 43 号室 email: kkarato@eco.u-toyama.ac.j website: htt://www3.u-toyama.ac.j/kkarato/ 1 講義の目的 標本平均は正規分布に従うという性質を
統計学 第 17 回 講義 母平均の区間推定 Part-1 014 年 6 17 ( )6-7 限 担当教員 : 唐渡 広志 ( からと こうじ ) 研究室 : 経済学研究棟 4 階 43 号室 email: kkarato@eco.u-toyama.ac.j website: htt://www3.u-toyama.ac.j/kkarato/ 1 講義の目的 標本平均は正規分布に従うという性質を
講義「○○○○」
 講義 信頼度の推定と立証 内容. 点推定と区間推定. 指数分布の点推定 区間推定 3. 指数分布 正規分布の信頼度推定 担当 : 倉敷哲生 ( ビジネスエンジニアリング専攻 ) 統計的推測 標本から得られる情報を基に 母集団に関する結論の導出が目的 測定値 x x x 3 : x 母集団 (populaio) 母集団の特性値 統計的推測 標本 (sample) 標本の特性値 分布のパラメータ ( 母数
講義 信頼度の推定と立証 内容. 点推定と区間推定. 指数分布の点推定 区間推定 3. 指数分布 正規分布の信頼度推定 担当 : 倉敷哲生 ( ビジネスエンジニアリング専攻 ) 統計的推測 標本から得られる情報を基に 母集団に関する結論の導出が目的 測定値 x x x 3 : x 母集団 (populaio) 母集団の特性値 統計的推測 標本 (sample) 標本の特性値 分布のパラメータ ( 母数
スライド 1
 205 年 4 月 28 日 @ 統計モデリング 統計モデリング 第三回配布資料 文献 : A. J. Dobso ad A. G. Barett: A Itroducto to Geeralzed Lear Models. 3rd ed., CRC Press. J. J. Faraway: Etedg the Lear Model wth R. CRC Press. 配布資料の PDF は以下からも
205 年 4 月 28 日 @ 統計モデリング 統計モデリング 第三回配布資料 文献 : A. J. Dobso ad A. G. Barett: A Itroducto to Geeralzed Lear Models. 3rd ed., CRC Press. J. J. Faraway: Etedg the Lear Model wth R. CRC Press. 配布資料の PDF は以下からも
10
 z c j = N 1 N t= j1 [ ( z t z ) ( )] z t j z q 2 1 2 r j /N j=1 1/ N J Q = N(N 2) 1 N j j=1 r j 2 2 χ J B d z t = z t d (1 B) 2 z t = (z t z t 1 ) (z t 1 z t 2 ) (1 B s )z t = z t z t s _ARIMA CONSUME
z c j = N 1 N t= j1 [ ( z t z ) ( )] z t j z q 2 1 2 r j /N j=1 1/ N J Q = N(N 2) 1 N j j=1 r j 2 2 χ J B d z t = z t d (1 B) 2 z t = (z t z t 1 ) (z t 1 z t 2 ) (1 B s )z t = z t z t s _ARIMA CONSUME
2016 年熊本地震の余震の確率予測 Probability aftershock forecasting of the M6.5 and M7.3 Kumamoto earthquakes of 2016 東京大学生産技術研究所統計数理研究所東京大学地震研究所 Institute of Indus
 2016 年熊本地震の余震の確率予測 Probability aftershock forecasting of the M6.5 and M7.3 Kumamoto earthquakes of 2016 東京大学生産技術研究所統計数理研究所東京大学地震研究所 Institute of Industrial Science, University of Tokyo The Institute of
2016 年熊本地震の余震の確率予測 Probability aftershock forecasting of the M6.5 and M7.3 Kumamoto earthquakes of 2016 東京大学生産技術研究所統計数理研究所東京大学地震研究所 Institute of Industrial Science, University of Tokyo The Institute of
RとExcelを用いた分布推定の実践例
 R Excel 1 2 1 2 2011/11/09 ( IMI) R Excel 2011/11/09 1 / 12 (1) R Excel (2) ( IMI) R Excel 2011/11/09 2 / 12 R Excel R R > library(fitdistrplus) > x fitdist(x,"norm","mle")
R Excel 1 2 1 2 2011/11/09 ( IMI) R Excel 2011/11/09 1 / 12 (1) R Excel (2) ( IMI) R Excel 2011/11/09 2 / 12 R Excel R R > library(fitdistrplus) > x fitdist(x,"norm","mle")
1 Stata SEM LightStone 4 SEM 4.. Alan C. Acock, Discovering Structural Equation Modeling Using Stata, Revised Edition, Stata Press 3.
 1 Stata SEM LightStone 4 SEM 4.. Alan C. Acock, 2013. Discovering Structural Equation Modeling Using Stata, Revised Edition, Stata Press 3. 2 4, 2. 1 2 2 Depress Conservative. 3., 3,. SES66 Alien67 Alien71,
1 Stata SEM LightStone 4 SEM 4.. Alan C. Acock, 2013. Discovering Structural Equation Modeling Using Stata, Revised Edition, Stata Press 3. 2 4, 2. 1 2 2 Depress Conservative. 3., 3,. SES66 Alien67 Alien71,
untitled
 (XFER) DISP PFLSX Windows PFLS Fe 3 O 4 Fe 2 O 3 FeO Fe 00ç Rwp=0.07933, GOF=2.000 (Fe 3 O 4 ) (FeO) Rwp=0.14558, GOF=2.821 Rwp=0.7808, GOF=1.514 RIETAN ATOMS -------------- Select a function for preferred
(XFER) DISP PFLSX Windows PFLS Fe 3 O 4 Fe 2 O 3 FeO Fe 00ç Rwp=0.07933, GOF=2.000 (Fe 3 O 4 ) (FeO) Rwp=0.14558, GOF=2.821 Rwp=0.7808, GOF=1.514 RIETAN ATOMS -------------- Select a function for preferred
kubostat7f p GLM! logistic regression as usual? N? GLM GLM doesn t work! GLM!! probabilit distribution binomial distribution : : β + β x i link functi
 kubostat7f p statistaical models appeared in the class 7 (f) kubo@eeshokudaiacjp https://googl/z9cjy 7 : 7 : The development of linear models Hierarchical Baesian Model Be more flexible Generalized Linear
kubostat7f p statistaical models appeared in the class 7 (f) kubo@eeshokudaiacjp https://googl/z9cjy 7 : 7 : The development of linear models Hierarchical Baesian Model Be more flexible Generalized Linear

1
 PalmGauss SC PGSC-5G Instruction Manual PalmGauss SC PGSC-5G Version 1.01 PalmGauss SC PGSC5G 1.... 3 2.... 3 3.... 3 3.1... 3 3.2... 3 3.3 PalmGauss... 4 3.4... 4 3.4.1 (Fig. 4)... 4 3.4.2 (Fig. 5)...
PalmGauss SC PGSC-5G Instruction Manual PalmGauss SC PGSC-5G Version 1.01 PalmGauss SC PGSC5G 1.... 3 2.... 3 3.... 3 3.1... 3 3.2... 3 3.3 PalmGauss... 4 3.4... 4 3.4.1 (Fig. 4)... 4 3.4.2 (Fig. 5)...
生命情報学
 生命情報学 5 隠れマルコフモデル 阿久津達也 京都大学化学研究所 バイオインフォマティクスセンター 内容 配列モチーフ 最尤推定 ベイズ推定 M 推定 隠れマルコフモデル HMM Verアルゴリズム EMアルゴリズム Baum-Welchアルゴリズム 前向きアルゴリズム 後向きアルゴリズム プロファイル HMM 配列モチーフ モチーフ発見 配列モチーフ : 同じ機能を持つ遺伝子配列などに見られる共通の文字列パターン
生命情報学 5 隠れマルコフモデル 阿久津達也 京都大学化学研究所 バイオインフォマティクスセンター 内容 配列モチーフ 最尤推定 ベイズ推定 M 推定 隠れマルコフモデル HMM Verアルゴリズム EMアルゴリズム Baum-Welchアルゴリズム 前向きアルゴリズム 後向きアルゴリズム プロファイル HMM 配列モチーフ モチーフ発見 配列モチーフ : 同じ機能を持つ遺伝子配列などに見られる共通の文字列パターン

 1 911 9001030 9:00 A B C D E F G H I J K L M 1A0900 1B0900 1C0900 1D0900 1E0900 1F0900 1G0900 1H0900 1I0900 1J0900 1K0900 1L0900 1M0900 9:15 1A0915 1B0915 1C0915 1D0915 1E0915 1F0915 1G0915 1H0915 1I0915
1 911 9001030 9:00 A B C D E F G H I J K L M 1A0900 1B0900 1C0900 1D0900 1E0900 1F0900 1G0900 1H0900 1I0900 1J0900 1K0900 1L0900 1M0900 9:15 1A0915 1B0915 1C0915 1D0915 1E0915 1F0915 1G0915 1H0915 1I0915
Microsoft Word - Time Series Basic - Modeling.doc
 時系列解析入門 モデリング. 確率分布と統計的モデル が確率変数 (radom varable のとき すべての実数 R に対して となる確 率 Prob( が定められる これを の関数とみなして G( Prob ( とあらわすとき G( を確率変数 の分布関数 (probablt dstrbuto ucto と呼 ぶ 時系列解析で用いられる確率変数は通常連続型と呼ばれるもので その分布関数は (
時系列解析入門 モデリング. 確率分布と統計的モデル が確率変数 (radom varable のとき すべての実数 R に対して となる確 率 Prob( が定められる これを の関数とみなして G( Prob ( とあらわすとき G( を確率変数 の分布関数 (probablt dstrbuto ucto と呼 ぶ 時系列解析で用いられる確率変数は通常連続型と呼ばれるもので その分布関数は (
塗装深み感の要因解析
 17 Analysis of Factors for Paint Depth Feeling Takashi Wada, Mikiko Kawasumi, Taka-aki Suzuki ( ) ( ) ( ) The appearance and quality of objects are controlled by paint coatings on the surfaces of the objects.
17 Analysis of Factors for Paint Depth Feeling Takashi Wada, Mikiko Kawasumi, Taka-aki Suzuki ( ) ( ) ( ) The appearance and quality of objects are controlled by paint coatings on the surfaces of the objects.

自由集会時系列part2web.key
 spurious correlation spurious regression xt=xt-1+n(0,σ^2) yt=yt-1+n(0,σ^2) n=20 type1error(5%)=0.4703 no trend 0 1000 2000 3000 4000 p for r xt=xt-1+n(0,σ^2) random walk random walk variable -5 0 5 variable
spurious correlation spurious regression xt=xt-1+n(0,σ^2) yt=yt-1+n(0,σ^2) n=20 type1error(5%)=0.4703 no trend 0 1000 2000 3000 4000 p for r xt=xt-1+n(0,σ^2) random walk random walk variable -5 0 5 variable
AD8212: 高電圧の電流シャント・モニタ
 7 V typ 7 0 V MSOP : 40 V+ V SENSE DC/DC BIAS CIRCUIT CURRENT COMPENSATION I OUT COM BIAS ALPHA 094-00 V PNP 0 7 V typ PNP PNP REV. A REVISION 007 Analog Devices, Inc. All rights reserved. 0-9 -- 0 40
7 V typ 7 0 V MSOP : 40 V+ V SENSE DC/DC BIAS CIRCUIT CURRENT COMPENSATION I OUT COM BIAS ALPHA 094-00 V PNP 0 7 V typ PNP PNP REV. A REVISION 007 Analog Devices, Inc. All rights reserved. 0-9 -- 0 40
日立金属技報 Vol.34
 Influence of Misorientation Angle between Adjacent Grains on Magnetization Reversal in Nd-Fe-B Sintered Magnet Tomohito Maki Rintaro Ishii Mitsutoshi Natsumeda Takeshi Nishiuchi Ryo Uchikoshi Masaaki Takezawa
Influence of Misorientation Angle between Adjacent Grains on Magnetization Reversal in Nd-Fe-B Sintered Magnet Tomohito Maki Rintaro Ishii Mitsutoshi Natsumeda Takeshi Nishiuchi Ryo Uchikoshi Masaaki Takezawa
青焼 1章[15-52].indd
![青焼 1章[15-52].indd](/thumbs/86/94313777.jpg "青焼 1章[15-52].indd") 1 第 1 章統計の基礎知識 1 1 なぜ統計解析が必要なのか? 人間は自分自身の経験にもとづいて 感覚的にものごとを判断しがちである 例えばある疾患に対する標準治療薬の有効率が 50% であったとする そこに新薬が登場し ある医師がその新薬を 5 人の患者に使ったところ 4 人が有効と判定されたとしたら 多くの医師はこれまでの標準治療薬よりも新薬のほうが有効性が高そうだと感じることだろう しかし
1 第 1 章統計の基礎知識 1 1 なぜ統計解析が必要なのか? 人間は自分自身の経験にもとづいて 感覚的にものごとを判断しがちである 例えばある疾患に対する標準治療薬の有効率が 50% であったとする そこに新薬が登場し ある医師がその新薬を 5 人の患者に使ったところ 4 人が有効と判定されたとしたら 多くの医師はこれまでの標準治療薬よりも新薬のほうが有効性が高そうだと感じることだろう しかし
JOURNAL OF THE JAPANESE ASSOCIATION FOR PETROLEUM TECHNOLOGY VOL. 66, NO. 6 (Nov., 2001) (Received August 10, 2001; accepted November 9, 2001) Alterna
 (Received August 10, 2001; accepted November 9, 2001) Alterna") JOURNAL OF THE JAPANESE ASSOCIATION FOR PETROLEUM TECHNOLOGY VOL. 66, NO. 6 (Nov., 2001) (Received August 10, 2001; accepted November 9, 2001) Alternative approach using the Monte Carlo simulation to evaluate
JOURNAL OF THE JAPANESE ASSOCIATION FOR PETROLEUM TECHNOLOGY VOL. 66, NO. 6 (Nov., 2001) (Received August 10, 2001; accepted November 9, 2001) Alternative approach using the Monte Carlo simulation to evaluate
今回 次回の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ Danger!! (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか これは次回)
 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか これは次回)") 生態学の時系列データ解析でよく見る あぶない モデリング 久保拓弥 mailto:kubo@ees.hokudai.ac.jp statistical model for time-series data 2017-07-03 kubostat2017 (h) 1/59 今回 次回の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ Danger!! (危 1) 時系列データの
生態学の時系列データ解析でよく見る あぶない モデリング 久保拓弥 mailto:kubo@ees.hokudai.ac.jp statistical model for time-series data 2017-07-03 kubostat2017 (h) 1/59 今回 次回の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ Danger!! (危 1) 時系列データの
2 ( ) i
 i") 25 Study on Rating System in Multi-player Games with Imperfect Information 1165069 2014 2 28 2 ( ) i ii Abstract Study on Rating System in Multi-player Games with Imperfect Information Shigehiko MORITA
25 Study on Rating System in Multi-player Games with Imperfect Information 1165069 2014 2 28 2 ( ) i ii Abstract Study on Rating System in Multi-player Games with Imperfect Information Shigehiko MORITA
スライド 1
 第 13 章系列データ 2015/9/20 夏合宿 PRML 輪読ゼミ B4 三木真理子 目次 2 1. 系列データと状態空間モデル 2. 隠れマルコフモデル 2.1 定式化とその性質 2.2 最尤推定法 2.3 潜在変数の系列を知るには 3. 線形動的システム この章の目標 : 系列データを扱う際に有効な状態空間モデルのうち 代表的な 2 例である隠れマルコフモデルと線形動的システムの性質を知り
第 13 章系列データ 2015/9/20 夏合宿 PRML 輪読ゼミ B4 三木真理子 目次 2 1. 系列データと状態空間モデル 2. 隠れマルコフモデル 2.1 定式化とその性質 2.2 最尤推定法 2.3 潜在変数の系列を知るには 3. 線形動的システム この章の目標 : 系列データを扱う際に有効な状態空間モデルのうち 代表的な 2 例である隠れマルコフモデルと線形動的システムの性質を知り
Microsoft PowerPoint - SPECTPETの原理2012.ppt [互換モード]
![Microsoft PowerPoint - SPECTPETの原理2012.ppt [互換モード]](/thumbs/94/121508518.jpg "Microsoft PowerPoint - SPECTPETの原理2012.ppt [互換モード]") 22 年国家試験解答 1,5 フーリエ変換は線形変換 FFT はデータ数に 2 の累乗数を要求するが DFT は任意のデータ数に対応 123I-IMP Brain SPECT FBP with Ramp filter 123I-IMP Brain SPECT FBP with Shepp&Logan filter 99mTc-MIBI Myocardial SPECT における ストリークアーチファクト
22 年国家試験解答 1,5 フーリエ変換は線形変換 FFT はデータ数に 2 の累乗数を要求するが DFT は任意のデータ数に対応 123I-IMP Brain SPECT FBP with Ramp filter 123I-IMP Brain SPECT FBP with Shepp&Logan filter 99mTc-MIBI Myocardial SPECT における ストリークアーチファクト

r z m ε r ε θ z rθ
 Rolling Characteristics in Three-roll-type Ring Rolling Toshifusa Nakamizo, Morihiko Nakasaki Synopsis: Hot ring rolling is a useful process for producing large seamless rings such as bearing races for
Rolling Characteristics in Three-roll-type Ring Rolling Toshifusa Nakamizo, Morihiko Nakasaki Synopsis: Hot ring rolling is a useful process for producing large seamless rings such as bearing races for
C プログラミング演習 1( 再 ) 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ
 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ") C プログラミング演習 1( 再 ) 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ 今回のプログラミングの課題 次のステップによって 徐々に難易度の高いプログラムを作成する ( 参照用の番号は よくわかる C 言語 のページ番号 ) 1. キーボード入力された整数 10 個の中から最大のものを答える 2. 整数を要素とする配列 (p.57-59) に初期値を与えておき
C プログラミング演習 1( 再 ) 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ 今回のプログラミングの課題 次のステップによって 徐々に難易度の高いプログラムを作成する ( 参照用の番号は よくわかる C 言語 のページ番号 ) 1. キーボード入力された整数 10 個の中から最大のものを答える 2. 整数を要素とする配列 (p.57-59) に初期値を与えておき
ECCS. ECCS,. ( 2. Mac Do-file Editor. Mac Do-file Editor Windows Do-file Editor Top Do-file e
 1 1 2015 4 6 1. ECCS. ECCS,. (https://ras.ecc.u-tokyo.ac.jp/guacamole/) 2. Mac Do-file Editor. Mac Do-file Editor Windows Do-file Editor Top Do-file editor, Do View Do-file Editor Execute(do). 3. Mac System
1 1 2015 4 6 1. ECCS. ECCS,. (https://ras.ecc.u-tokyo.ac.jp/guacamole/) 2. Mac Do-file Editor. Mac Do-file Editor Windows Do-file Editor Top Do-file editor, Do View Do-file Editor Execute(do). 3. Mac System
Introduction Purpose This training course describes the configuration and session features of the High-performance Embedded Workshop (HEW), a key tool
, a key tool") Introduction Purpose This training course describes the configuration and session features of the High-performance Embedded Workshop (HEW), a key tool for developing software for embedded systems that
Introduction Purpose This training course describes the configuration and session features of the High-performance Embedded Workshop (HEW), a key tool for developing software for embedded systems that
UL 746A 第 6 版の短期特性評価に関する規格について 2016 年 4 月 29 日付で比較トラッキング指数試験 (CTI) 傾斜面トラッキング試験 (IPT) 及びホットワイヤー着火試験 (HWI) について一部改定がありました 以下 参考和訳をご参照ください なお 参考和訳と原文 ( 英
 傾斜面トラッキング試験 (IPT) 及びホットワイヤー着火試験 (HWI) について一部改定がありました 以下 参考和訳をご参照ください なお 参考和訳と原文 ( 英") UL 746A 第 6 版の短期特性評価に関する規格について 2016 年 4 月 29 日付で比較トラッキング指数試験 (CTI) 傾斜面トラッキング試験 (IPT) 及びホットワイヤー着火試験 (HWI) について一部改定がありました 以下 参考和訳をご参照ください なお 参考和訳と原文 ( 英文 ) と差異のある場合は原文を優先頂くものとします 比較トラッキング指数試験 (CTI) 第 24
UL 746A 第 6 版の短期特性評価に関する規格について 2016 年 4 月 29 日付で比較トラッキング指数試験 (CTI) 傾斜面トラッキング試験 (IPT) 及びホットワイヤー着火試験 (HWI) について一部改定がありました 以下 参考和訳をご参照ください なお 参考和訳と原文 ( 英文 ) と差異のある場合は原文を優先頂くものとします 比較トラッキング指数試験 (CTI) 第 24
udc-2.dvi
 13 0.5 2 0.5 2 1 15 2001 16 2009 12 18 14 No.39, 2010 8 2009b 2009a Web Web Q&A 2006 2007a20082009 2007b200720082009 20072008 2009 2009 15 1 2 2 2.1 18 21 1 4 2 3 1(a) 1(b) 1(c) 1(d) 1) 18 16 17 21 10
13 0.5 2 0.5 2 1 15 2001 16 2009 12 18 14 No.39, 2010 8 2009b 2009a Web Web Q&A 2006 2007a20082009 2007b200720082009 20072008 2009 2009 15 1 2 2 2.1 18 21 1 4 2 3 1(a) 1(b) 1(c) 1(d) 1) 18 16 17 21 10