インテル FPGA の Deep Learning Acceleration Suite とマイクロソフトの Brainwave を HW 視点から比較してみる
|
|
|
- こうじ ひきぎ
- 4 years ago
- Views:
Transcription

1 インテル FPGA の Deep Learning Acceleration Suite とマイクロソフトの Brainwave を HW 視点から比較してみる インテル株式会社プログラマブル ソリューションズ事業本部シニア テクノロジー スペシャリスト 竹村幸尚 DA22


2 FPGA とは



3 汎用アクセラレーターとしての FPGA

4 なぜ FPGA アクセラレーションか FPGA の性能向上
5 CPU 対 FPGA 命令 命令 命令 データ 命令 データ 命令 命令 CPU 命令 FPGA FPGA: 空間計算 CPU: 時間的計算
6 FPGA アーキテクチャー : 基本エレメント FPGA の基本エレメント
 Configured to perform any 1-bit operation: AND, OR, INV, XOR,")
7 FPGA アーキテクチャー : 基本エレメント 基本エレメント 1-bit configurable operation 1-bit register (store result) Configured to perform any 1-bit operation: AND, OR, INV, XOR, etc.
")
8 FPGA アーキテクチャー : インターコネクト 基本エレメントはフレキシブルなインターコネクト ( 配線 ) に囲まれている
9 FPGA アーキテクチャー : インターコネクト カスタム回路は基本エレメントを接続することで実現できる
10 FPGA アーキテクチャー : カスタム回路 16-bit add 32-bit sqrt Your custom 64-bit bit-shuffle and encode
11 FPGA アーキテクチャー : メモリーブロック addr data_in メモリーブロック 20 Kb data_out
12 FPGA アーキテクチャー : メモリーブロック addr data_in メモリーブロック 20 Kb data_out 沢山の小型キャッシュ 大型キャッシュ

13 FPGA アーキテクチャー : 浮動小数点演算器 data_in data_out
14 FPGA アーキテクチャー : ルーティング
15 FPGA アーキテクチャー : 再構成可能な I/O
16 Project Brainwave








17 FPGA の取り組み Catapult v1 Ignite Catapult v Catapult v0 スケール v1 本番展開
18 Hardware Microservices on FPGAs [MICRO 16] Routers Hardware acceleration plane Deep neural networks SQL CPU QPI CPU FPGAs Web search ranking SDN offload Web search ranking FPGA CPUs Traditional software (CPU) server plane QSFP 40Gb/s QSFP QSFP 40Gb/s ToR

19 DNN のためのシリコンレベルの選択肢 DNN Processing Units Contr ol Unit (CU) Register s CPUs Arithmet ic Logic Unit (ALU) GPUs Soft DPU (FPGA) Hard DPU ASICs 柔軟性 効率性 BrainWave Baidu SDA Deephi Tech ESE Teradeep Etc. Cerebras Google TPU Graphcore Groq Intel Nervana Movidius Wave Computing Etc.
20 Project BrainWave l0 l1 ネットワークスイッチ l0 Instruction Decoder & Ctrl f f f FPGA f f f Neural FU Pretrained DNN モデル CNTK などで スケーラブルな DNN ハードウェアマイクロサービス BrainWave Soft DPU
21 BrainWave Stack Pretrained DNN モデルをソフト DPU にコンパイルするためのフレームワーク中立の連合コンパイラとランタイム 狭精度 DNN 推論のための適応型 ISA 変化目まぐるしい AI アルゴリズムをサポートする柔軟性と拡張性 BrainWave Soft DPU マイクロアーキテクチャ高精度 低遅延バッチに最適 FPGA 上でモデルパラメータを完全に永続化するオンチップメモリは 多数の FPGA にまたがってスケーリングすることにより 大規模なモデルをサポート Intel の FPGA をスケールする HW マイクロサービスに展開 [ マイクロ ' 16]
22 500x500 マトリックス MatMul x500 マトリックス Add500 Add dim ベクトル 分割 Sigmoid x500 マトリックス MatMul500 MatMul500 MatMul500 Sigmoid concat Add x500 マトリックス 分割 Add dim ベクトル Brainwave コンパイラとランタイム Caffe モデル CNTK モデル Tensorflow モデル フロント ポータブル IR グラフスプリッタとオプティマイザ FPGA0 FPGA1 トランスフォーム IRs ターゲットコンパイラ ターゲットコンパイラ ターゲットコンパイラ CPU-CNTK FPGA CPU- カフェ 展開パッケージ FPGA ハードウェアマイクロサービス
23 一般的なシナリオ N ウェイトカーネル 出力前のアクティベーション入力アクティベーション = = O(N 3 ) data O(N 4 K 2 ) compute O(N 2 ) data O(N 2 ) compute
24 従来の高速化アプローチ : ローカルのオフロードとストリーミング DRAM で初期化されたモデルパラメータ 2xCPU FPGA
25 従来の高速化アプローチ : ローカルのオフロードとストリーミング DRAM で初期化されたモデルパラメータ 2xCPU FPGA
26 バッチ処理による HW 使用率の向上 ハードウェア利用 (%) バッチサイズ FPGA
27 バッチ処理による HW 使用率の向上 ハードウェア利用 (%) 99 回目待ち時間 最大許可遅延 バッチサイズ バッチサイズ バッチ処理により HW の使用率が向上するが 待ち時間は増加
28 バッチ処理による HW 使用率の向上 ハードウェア利用 (%) 99 回目の待ち時間 最大許可遅延 バッチサイズ バッチサイズ バッチ処理により HW の使用率が向上するが 待ち時間が増加
29 代替 : " 永続的な " ニューラルネット 2xCPU FPGA
30 代替 : " 永続的な " ニューラルネット 観測 2xCPU
31 代替 : " 永続的な " ニューラルネット 2xCPU
32 代替 : " 永続的な " ニューラルネット 2xCPU
33 解決方法 : データセンター規模での永続化
34 Inter-Layer パイプラインの並列処理 LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM 2 CPU 2 CPU 2 CPU 2 CPU 2 CPU 2 CPU 2 CPU 2 CPU
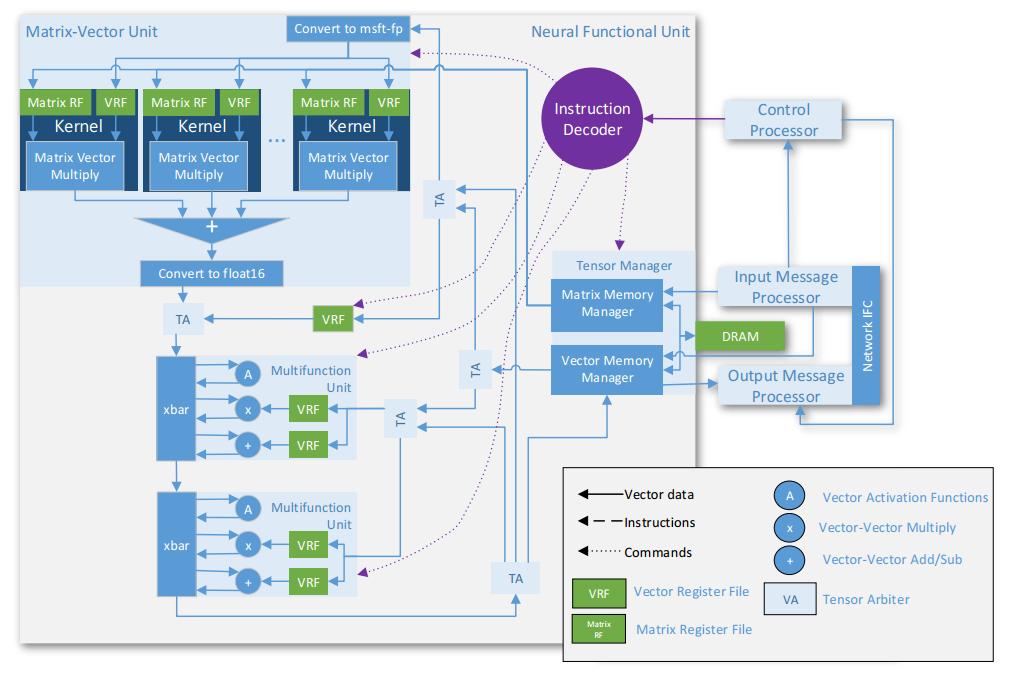
35 NPU
36 Matrix Vector Unit FPGA MVU カーネル
37 インテル OpenVINO ツールキット
38 ディープラーニング トポロジーの推論処理 head 1 インデックスの特徴ベクトル イメージ サイズの変更 / クロップ イメージ ニューラルネット 本体 ほとんどの計算は ここで実行される 特徴 head 2 タグ 物体検出 前処理 画像認識 : CNN (ResNet) 音声認識 言語翻訳 head 10 後処理
39 OpenVINO ツールキット概要 User program Algorithms OpenVINO Toolkit Libraries Inference Engine Pre-trained DL models OpenCV OpenVX Intel OVX Kernel Extensions Tools Model Optimizer ディープラーニングデプロイメント ツールキット 画像処理 画像処理とディープ ラーニングを使用した画像認識をサポートインテル アーキテクチャに最適化された ヘテロジニアス対応ライブラリ
40 推論エンジン共通 API (C++) ディープ ラーニング デプロイメント ツールキット 全インテル アーキテクチャーで訓練済のモデルをデプロイ可能 CPU GPU FPGA など 最良の実行となるよう最適化 ユーザーによる検証と調整が可能 全デバイスで使いやすいランタイム API CPU プラグイン Caffe* TensorFlow* MxNet* モデル オプティマイザー IR.xml.bin ロード 推論 GPUプラグイン FPGAプラグイン ONNX* 所定のターゲットを変換 最適化 Myriad プラグイン
41 再掲 :Brainwave コンパイラとランタイム Caffe モデル CNTK モデル Tensorflow モデル フロント ポータブル IR グラフスプリッタとオプティマイザ トランスフォーム IRs ターゲットコンパイラ CPU-CNTK ターゲットコンパイラ FPGA ターゲットコンパイラ CPU- カフェ 展開パッケージ FPGA ハードウェアマイクロサービス
42 OpenVINO における FPGA 実装
43 DDR DDR インテル FPGA DLAS の機能 一般的なトポロジーに向けた CNN アクセラレーション エンジン グラフ ループ アーキテクチャー AlexNet GoogleNet LeNet SqueezeNet VGG16 ResNet Yolo SSD LSTM など ソフトウェア デプロイメント FPGA のコンパイルは不要 ランタイムでのリコンフィグレーションが可能 カスタマイズされたハードウェア開発 パラメーターを使用したカスタム アーキテクチャーの作成 OpenCL フローを使用したカスタム プリミティブ 特徴マップキャッシュ 畳み込み PE アレイ クロスバー prim prim prim カスタム メモリー読み取り / 書き込み コンフィグレーション エンジン
44 DLA アーキテクチャー : 高パフォーマンス設計 FPGA 上で最大限の並列化を実現 Filter Parallelism ( プロセッシング エレメント ) Input-Depth Parallelism Winograd Transformation Batching Feature Stream Buffer Filter Cache FPGA ビットストリームを選択 Data Type / Design Exploration Primitive Support Convolution / Fully Connected 特徴マップキャッシュ 畳み込み PE アレイ ReLU クロスバー Norm ReLU Max Pool 実行 ストリーム バッファー メモリー読み取り / 書き込み コンフィグレーション エンジン Norm DDR DDR DDR DDR MaxPool
45 Conv ReLu Norm MaxPool Fully Conn. AlexNet Graph ストリーム バッファー Convolution / Fully Connected ReLU Norm MaxPool ブロックはランタイムでリコンフィグレーションおよびバイパスが可能
46 Conv ReLu Norm MaxPool Fully Conn. AlexNet Graph 出力 ストリーム バッファー 入力 Convolution / Fully Connected ReLU Norm MaxPool ブロックはランタイムでリコンフィグレーションおよびバイパスが可能
47 Conv ReLu Norm MaxPool Fully Conn. AlexNet Graph 入力 ストリーム バッファー出力 Convolution / Fully Connected ReLU Norm MaxPool ブロックはランタイムでリコンフィグレーションおよびバイパスが可能
48 Conv ReLu Norm MaxPool Fully Conn. AlexNet Graph 出力 ストリーム バッファー 入力 Convolution / Fully Connected ReLU ブロックはランタイムでリコンフィグレーションおよびバイパスが可能
49 Conv ReLu Norm MaxPool Fully Conn. AlexNet Graph 入力 ストリーム バッファー出力 Convolution / Fully Connected ReLU ブロックはランタイムでリコンフィグレーションおよびバイパスが可能
50 Conv ReLu Norm MaxPool Fully Conn. AlexNet Graph 出力 ストリーム バッファー 入力 Convolution / Fully Connected ReLU MaxPool ブロックはランタイムでリコンフィグレーションおよびバイパスが可能
51 Conv ReLu Norm MaxPool Fully Conn. AlexNet Graph 入力 ストリーム バッファー出力 Convolution / Fully Connected ReLU ブロックはランタイムでリコンフィグレーションおよびバイパスが可能
52 Conv ReLu Norm MaxPool Fully Conn. AlexNet Graph 出力 ストリーム バッファー 入力 Convolution / Fully Connected ReLU ブロックはランタイムでリコンフィグレーションおよびバイパスが可能
53 Conv ReLu Norm MaxPool Fully Conn. AlexNet Graph 入力 ストリーム バッファー出力 Convolution / Fully Connected ブロックはランタイムでリコンフィグレーションおよびバイパスが可能
54 アーキテクチャー詳細 DDR DDR ring interconnect Input Reader Filter Reader Output Writer 1 Bias Reader Output Writer 2 PE Sequencer Stream Buffer PE Feeder MaxPool Norm ReLU PE 1 PE 2 PE 3 PE 23 Convolution/ 全結合 (1D systolic array of 24 PEs) PE 24

55 余談 :Systolic Array feeder PE PE PE PE feeder PE PE PE PE feeder PE PE PE PE feeder PE PE PE PE Load A Arria PE Load B Drain C feeder feeder feeder feeder drain drain drain drain DDR4
")



 並列畳み込み")




56 フィルター並列処理 ( 出力深度 ) Convolution の効率的な並列処理 外部 DDR FPGA ダブルバッファー On-Chip RAM フィルター (on-chip RAM) 並列畳み込み 同じ Convolution 層の異なるフィルターが別のプロセッシング エレメント (PE) で並列的に処理されます ベクトル演算 特徴マップの深度全体 PE アレイ ジオメトリーは 既定のトポロジーのハイパーパラメーターにカスタマイズ可能です 56

57 Winograd 変換 より少ない乗算で畳み込みを実行します FPGA 上でより多くの畳み込みを可能にします 6 つの入力特徴エレメントと 3 つのフィルター エレメントを必要とします 標準的な畳み込みには 12 回の乗算が必要です 変換された畳み込みに必要な乗算は 6 回です ストリーム バッファー Winograd 変換 Convolution / Fully Connected ReLU Norm MaxPool Winograd 変換


58 フィーチャ キャッシュ 特徴データはオンチップにキャッシュ 並列処理エレメントのデイジーチェーンにストリームされる ダブルバッファー 畳み込みとキャッシュの更新が同時進行 1つのサブグラフの出力が他のサブグラフの入力に 不必要な外部メモリーへのアクセスを解消 ダブルバッファーオンチップ RAM ストリーム バッファー サイズ
59 フィルター キャッシュ フィルター ウェイトは 各プロセッシング エレメントにキャッシュ プリフェッチをサポートするためにダブルバッファーを使用 1 つのセットが出力特徴マップの計算に使用されている間 別のセットがプリフェッチされる DDR Conv DDR Conv

60 DLA アーキテクチャーの選択 必要条件を満たす最適な FPGA イメージを選択 必要に応じてカスタムの FPGA イメージを作成
61 異なるトポロジーに対するサポート 機能とパフォーマンスはトレードオフ 特徴マップキャッシュ 特徴マップキャッシュ 畳み込み PE アレイ メモリー読み取り / 書き込み vs 畳み込み PE アレイ クロスバー メモリー読み取り / 書き込み クロスバー ReLU Norm MaxPool コンフィグレーション エンジン SoftMax Reshape LRN Concat Flatten ReLU Norm Permute MaxPool コンフィグレーション エンジン
62 サポートされるプリミティブとトポロジー プリミティブ batch norm concat flatten max pool relu, leaky relu lrn normalization average pool scale softmax inner product permute prelu reshape detection output conv priorbox fully connected eltwise bias group conv depthwise conv local conv sigmoid elu power crop proporal slice depthwise conv roi pooling dilated conv tanh deconv トポロジー AlexNet GoogleNet v1 SSD ResNet18 SSD ResNet50 ResNet101 SqueezeNet SSD VGG16 Tiny Yolo LeNet サポート有 リクエストに応じてサポート有 将来的にサポートを予定
63 精度を下げてデザインを検討してみる パフォーマンスと精度はトレードオフ 精度を下げることで より多くの処理が並列的に実行可能 より小さい浮動小数点形式を使用するための ネットワークの再トレーニングは不要 FP11 は INT8/9 よりもメリットがある 再トレーニング不要 より良いパフォーマンス 精度の損失が少ない FP16 FP11 FP10 FP9 FP8 Sign 指数 5ビット 仮数 10ビット Sign 指数 5ビット 仮数 5ビット Sign 指数 5ビット 仮数 4ビット Sign 指数 5ビット 仮数 3ビット Sign 指数 5ビット 仮数 2ビット


 Intel Nervana Graph Intel")


64 経験 ツール Intel Nervana Cloud and Appliance Intel Nervana Deep Learning Studio OpenVINO Toolkit フレームワーク Mlib BigDL ライブラリ Intel Distribution for Python* Intel Data Analytics Acceleration Library (DAAL) Intel Nervana Graph Intel Math Kernel Library (Intel MKL, MKL-DNN) ハードウエア Compute CPU, igpu, VPU, FPGA, Future *Other names and brands may be claimed as the property of others. Memory and Storage Networking
65 法的注意事項および免責条項 本資料に記載されている情報は 開発中の製品 サービス プロセスに関するものです ここに記載されているすべての情報は 予告なく変更されることがあります インテルの最新の予測 スケジュール 仕様 およびロードマップをご希望の方は インテルの担当者までお問い合わせください インテル テクノロジーの機能と利点はシステム構成によって異なり 対応するハードウェアやソフトウェア またはサービスの有効化が必要となる場合があります 詳細については intel.com を参照するか OEM や販売店にお問い合わせください 絶対的なセキュリティーを提供できるコンピューター システムはありません テストでは 特定のシステムでの個々のテストにおけるコンポーネントの性能を文書化しています ハードウェア ソフトウェア システム構成などの違いにより 実際の性能は掲載された性能テストや評価とは異なる場合があります 購入を検討される場合は ほかの情報も参考にして パフォーマンスを総合的に評価することをお勧めします 性能やベンチマーク結果について さらに詳しい情報をお知りになりたい場合は ( 英語 ) を参照してください インテル テクノロジーの機能と利点はシステム構成によって異なり 対応するハードウェアやソフトウェア またはサービスの有効化が必要となる場合があります 実際の性能はシステム構成によって異なります 絶対的なセキュリティーを提供できるコンピューター システムはありません 詳細については 各システムメーカーまたは販売店にお問い合わせいただくか を参照してください 本資料は ( 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず ) いかなる知的財産権のライセンスも許諾するものではありません OpenCL および OpenCL ロゴは Apple Inc. の商標であり Khronos の許可を得て使用しています Intel インテル Intel ロゴ Intel Inside Intel Inside ロゴ Arria Avalon Cyclone Nios Stratix は アメリカ合衆国および / またはその他の国における Intel Corporation またはその子会社の商標です * その他の社名 製品名などは 一般に各所有者の表示 商標または登録商標です 2018 Intel Corporation. 無断での引用 転載を禁じます
PPT Template
 世界最大のインフラストラクチャー Norway East / West 開設発表 https://azure.microsoft.com/ja-jp/regions/ China North / East 提供開始 018.06 updates West Europe での Availability Zones 提供開始 54 100K+ 130+ 00+ REGIONS WORLDWIDE MILES
世界最大のインフラストラクチャー Norway East / West 開設発表 https://azure.microsoft.com/ja-jp/regions/ China North / East 提供開始 018.06 updates West Europe での Availability Zones 提供開始 54 100K+ 130+ 00+ REGIONS WORLDWIDE MILES
資料7 平野(拓) 構成員 御発表資料
 構成員 御発表資料") 資料 7 2 Microsoft Research Redmond Microsoft Research Station Q Microsoft Research New York City Microsoft Research New England Microsoft Research Cambridge Advanced Technology Labs Europe Advanced Technology
資料 7 2 Microsoft Research Redmond Microsoft Research Station Q Microsoft Research New York City Microsoft Research New England Microsoft Research Cambridge Advanced Technology Labs Europe Advanced Technology
Microsoft Research Redmond Microsoft Research Station Q Microsoft Research New York City Microsoft Research New Enghand Microsoft Research Cambridge A
 Microsoft Research Redmond Microsoft Research Station Q Microsoft Research New York City Microsoft Research New Enghand Microsoft Research Cambridge Advanced Technohogy Labs Europe Advanced Technohogy
Microsoft Research Redmond Microsoft Research Station Q Microsoft Research New York City Microsoft Research New Enghand Microsoft Research Cambridge Advanced Technohogy Labs Europe Advanced Technohogy
b4-deeplearning-embedded-c-mw
 ディープラーニングアプリケーション の組み込み GPU/CPU 実装 アプリケーションエンジニアリング部町田和也 2015 The MathWorks, Inc. 1 アジェンダ MATLAB Coder/GPU Coder の概要 ディープニューラルネットワークの組み込み実装ワークフロー パフォーマンスに関して まとめ 2 ディープラーニングワークフローのおさらい Application logic
ディープラーニングアプリケーション の組み込み GPU/CPU 実装 アプリケーションエンジニアリング部町田和也 2015 The MathWorks, Inc. 1 アジェンダ MATLAB Coder/GPU Coder の概要 ディープニューラルネットワークの組み込み実装ワークフロー パフォーマンスに関して まとめ 2 ディープラーニングワークフローのおさらい Application logic
Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ 3.7x faster P100 V100 P10
 NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
Intel Software Presentation Template
 最新のヘテロジニアス システムにおけるビデオ解析環境 久保寺陽子 Internet of things Internet of things (IOT) は生活へ浸透 接続しているデバイスの数は急増 良く利用されるデバイスセンサーはカメラ データは爆発的に増加しているが 少ししか利用されていない 一般には 従来通りのそれぞれのやり方で使用 人間がすべてを網羅するのは無理 より賢い自動システムを構築する必要がある
最新のヘテロジニアス システムにおけるビデオ解析環境 久保寺陽子 Internet of things Internet of things (IOT) は生活へ浸透 接続しているデバイスの数は急増 良く利用されるデバイスセンサーはカメラ データは爆発的に増加しているが 少ししか利用されていない 一般には 従来通りのそれぞれのやり方で使用 人間がすべてを網羅するのは無理 より賢い自動システムを構築する必要がある
インテル® Stratix®10 デバイスのロジック・アレイ・ブロックおよびアダプティブ・ロジック・モジュール・ユーザーガイド
 更新情報 フィードバック 最新版をウェブからダウンロード : PDF HTML 目次 目次 1 インテル Stratix デバイスの LAB および の概要... 3 2 HyperFlex レジスター... 4...5 3.1 LAB... 5 3.1.1 MLAB... 6 3.1.2 ローカル インターコネクトおよびダイレクトリンク インターコネクト...6 3.1.3 キャリーチェーンのインターコネクト...
更新情報 フィードバック 最新版をウェブからダウンロード : PDF HTML 目次 目次 1 インテル Stratix デバイスの LAB および の概要... 3 2 HyperFlex レジスター... 4...5 3.1 LAB... 5 3.1.1 MLAB... 6 3.1.2 ローカル インターコネクトおよびダイレクトリンク インターコネクト...6 3.1.3 キャリーチェーンのインターコネクト...
VOLTA TENSOR コアで 高速かつ高精度に DL モデルをトレーニングする方法 成瀬彰, シニアデベロッパーテクノロジーエンジニア, 2017/12/12
 VOLTA TENSOR コアで 高速かつ高精度に DL モデルをトレーニングする方法 成瀬彰, シニアデベロッパーテクノロジーエンジニア, 2017/12/12 アジェンダ Tensorコアとトレーニングの概要 混合精度 (Tensorコア) で FP32と同等の精度を得る方法 ウェイトをFP16とFP32を併用して更新する ロス スケーリング DLフレームワーク対応状況 ウェイトをFP16で更新する
VOLTA TENSOR コアで 高速かつ高精度に DL モデルをトレーニングする方法 成瀬彰, シニアデベロッパーテクノロジーエンジニア, 2017/12/12 アジェンダ Tensorコアとトレーニングの概要 混合精度 (Tensorコア) で FP32と同等の精度を得る方法 ウェイトをFP16とFP32を併用して更新する ロス スケーリング DLフレームワーク対応状況 ウェイトをFP16で更新する
PowerPoint Presentation
 ディープラーニングの 実践的な適用ワークフロー MathWorks Japan テクニカルコンサルティング部縣亮 2015 The MathWorks, Inc. 1 アジェンダ ディープラーニングとは?( おさらい ) ディープラーニングの適用ワークフロー ワークフローの全体像 MATLAB によるニューラルネットワークの構築 学習 検証 配布 MATLAB ではじめるメリット 試行錯誤のやりやすさ
ディープラーニングの 実践的な適用ワークフロー MathWorks Japan テクニカルコンサルティング部縣亮 2015 The MathWorks, Inc. 1 アジェンダ ディープラーニングとは?( おさらい ) ディープラーニングの適用ワークフロー ワークフローの全体像 MATLAB によるニューラルネットワークの構築 学習 検証 配布 MATLAB ではじめるメリット 試行錯誤のやりやすさ
インテル® Parallel Studio XE 2013 Windows* 版インストール・ガイドおよびリリースノート
 インテル Parallel Studio XE 2013 Windows* 版インストール ガイドおよびリリースノート 資料番号 : 323803-003JA 2012 年 8 月 8 日 目次 1 概要... 2 1.1 新機能... 2 1.1.1 インテル Parallel Studio XE 2011 からの変更点... 2 1.2 製品の内容... 2 1.3 動作環境... 2 1.4
インテル Parallel Studio XE 2013 Windows* 版インストール ガイドおよびリリースノート 資料番号 : 323803-003JA 2012 年 8 月 8 日 目次 1 概要... 2 1.1 新機能... 2 1.1.1 インテル Parallel Studio XE 2011 からの変更点... 2 1.2 製品の内容... 2 1.3 動作環境... 2 1.4
PowerPoint プレゼンテーション
 次世代 IoT に向けた AI の組み込み実装への 取り組み AI の推論機能を FPGA に実装するための技術とソリューション提案 Embedded Product Business Development Department Agenda 1. エッジAIの現状 2. 組み込みAIのニーズ 3.FPGAとエッジAI 4. 組み込み向けエッジAI 実装の特性 (GPUとFPGA) 5. エッジAI
次世代 IoT に向けた AI の組み込み実装への 取り組み AI の推論機能を FPGA に実装するための技術とソリューション提案 Embedded Product Business Development Department Agenda 1. エッジAIの現状 2. 組み込みAIのニーズ 3.FPGAとエッジAI 4. 組み込み向けエッジAI 実装の特性 (GPUとFPGA) 5. エッジAI
インテル® Parallel Studio XE 2013 Linux* 版インストール・ガイドおよびリリースノート
 インテル Parallel Studio XE 2013 Linux* 版インストール ガイドおよびリリースノート 資料番号 : 323804-003JA 2012 年 7 月 30 日 目次 1 概要... 2 1.1 新機能... 2 1.1.1 インテル Parallel Studio XE 2011 からの変更点... 2 1.2 製品の内容... 2 1.3 動作環境... 2 1.4 ドキュメント...
インテル Parallel Studio XE 2013 Linux* 版インストール ガイドおよびリリースノート 資料番号 : 323804-003JA 2012 年 7 月 30 日 目次 1 概要... 2 1.1 新機能... 2 1.1.1 インテル Parallel Studio XE 2011 からの変更点... 2 1.2 製品の内容... 2 1.3 動作環境... 2 1.4 ドキュメント...
Presentation Title
 ディープラーニングの システムへの展開 ~ エッジからクラウドまで ~ アプリケーションエンジニアリング部福本拓司 2015 The MathWorks, Inc. 1 機械学習 ディープラーニング関連セッション 2 ディープラーニング学習のイメージできましたでしょうか? カメラ データベースでのデータ取得 簡潔なコーディングで学習 & 検証 豊富なサンプルコード ユーザー成功事例 Deep Dream
ディープラーニングの システムへの展開 ~ エッジからクラウドまで ~ アプリケーションエンジニアリング部福本拓司 2015 The MathWorks, Inc. 1 機械学習 ディープラーニング関連セッション 2 ディープラーニング学習のイメージできましたでしょうか? カメラ データベースでのデータ取得 簡潔なコーディングで学習 & 検証 豊富なサンプルコード ユーザー成功事例 Deep Dream
2017 (413812)
") 2017 (413812) Deep Learning ( NN) 2012 Google ASIC(Application Specific Integrated Circuit: IC) 10 ASIC Deep Learning TPU(Tensor Processing Unit) NN 12 20 30 Abstract Multi-layered neural network(nn) has
2017 (413812) Deep Learning ( NN) 2012 Google ASIC(Application Specific Integrated Circuit: IC) 10 ASIC Deep Learning TPU(Tensor Processing Unit) NN 12 20 30 Abstract Multi-layered neural network(nn) has
HPE HPC & AI フォーラム 2018 講演資料
 2018 年 9 月 7 日インテル株式会社 HPC 事業開発マネージャー 矢澤克巳 HPC & AI の融合 エクサスケール コンピューティング AI ワークフローの融合 インテル スケーラブル システム フレームワーク AI モデリング シミュレーション 可視化 ビッグデータ アナリティクス 多種多様なワークロード 単一のフレームワーク Compute Fabric Memory / Storage
2018 年 9 月 7 日インテル株式会社 HPC 事業開発マネージャー 矢澤克巳 HPC & AI の融合 エクサスケール コンピューティング AI ワークフローの融合 インテル スケーラブル システム フレームワーク AI モデリング シミュレーション 可視化 ビッグデータ アナリティクス 多種多様なワークロード 単一のフレームワーク Compute Fabric Memory / Storage
Microsoft Word _C2H_Compiler_FAQ_J_ FINAL.doc
 Nios II C2H コンパイラに関する Q&A 全般 Q:Nios II C-to-Hardware アクセラレーション コンパイラコンパイラとはとは何ですか A:Altera Nios II C-to- Hardware アクセラレーション コンパイラ ( 以下 Nios II C2H コンパイラ ) とは Nios II ユーザ向けの生産性を高めるツールです 性能のボトルネックとなるC 言語プログラムのサブルーチンを自動的にハードウェア
Nios II C2H コンパイラに関する Q&A 全般 Q:Nios II C-to-Hardware アクセラレーション コンパイラコンパイラとはとは何ですか A:Altera Nios II C-to- Hardware アクセラレーション コンパイラ ( 以下 Nios II C2H コンパイラ ) とは Nios II ユーザ向けの生産性を高めるツールです 性能のボトルネックとなるC 言語プログラムのサブルーチンを自動的にハードウェア
Slide 1
 ディープラーニング最新動向と技術情報 なぜ GPU がディープラーニングに向いているのか エヌビディアディープラーニングソリューションアーキテクト兼 CUDAエンジニア村上真奈 ディープラーニングとは AGENDA なぜ GPU がディープラーニングに向いているか NVIDIA DIGITS 2 ディープラーニングとは 3 Google I/O 2015 基調講演 ディープラーニングのおかげで わずか一年で音声認識の誤認識率が
ディープラーニング最新動向と技術情報 なぜ GPU がディープラーニングに向いているのか エヌビディアディープラーニングソリューションアーキテクト兼 CUDAエンジニア村上真奈 ディープラーニングとは AGENDA なぜ GPU がディープラーニングに向いているか NVIDIA DIGITS 2 ディープラーニングとは 3 Google I/O 2015 基調講演 ディープラーニングのおかげで わずか一年で音声認識の誤認識率が
Microsoft PowerPoint Quality-sama_Seminar.pptx
 インテル vpro テクノロジー ~ 革新と継続的な進化 ~ インテル株式会社マーケティング本部 2010 年 11 月 2010年の新プロセッサー: 更なるパフォーマンスを スマート に実現 ユーザーのワークロードに合わせて プロセッサーの周波数を動的に向上 インテル インテル ターボ ブースト テクノロジー* ターボ ブースト テクノロジー* 暗号化処理を高速化 保護する 新しいプロセッサー命令
インテル vpro テクノロジー ~ 革新と継続的な進化 ~ インテル株式会社マーケティング本部 2010 年 11 月 2010年の新プロセッサー: 更なるパフォーマンスを スマート に実現 ユーザーのワークロードに合わせて プロセッサーの周波数を動的に向上 インテル インテル ターボ ブースト テクノロジー* ターボ ブースト テクノロジー* 暗号化処理を高速化 保護する 新しいプロセッサー命令
MATLAB® における並列・分散コンピューティング ~ Parallel Computing Toolbox™ & MATLAB Distributed Computing Server™ ~
 MATLAB における並列 分散コンピューティング ~ Parallel Computing Toolbox & MATLAB Distributed Computing Server ~ MathWorks Japan Application Engineering Group Takashi Yoshida 2016 The MathWorks, Inc. 1 System Configuration
MATLAB における並列 分散コンピューティング ~ Parallel Computing Toolbox & MATLAB Distributed Computing Server ~ MathWorks Japan Application Engineering Group Takashi Yoshida 2016 The MathWorks, Inc. 1 System Configuration
Product Brief 高速なコードを素早く開発 インテル Parallel Studio XE 2017 インテル ソフトウェア開発ツール 概要 高速なコード : 現在および次世代のプロセッサーでスケーリングする優れたアプリケーション パフォーマンスを実現します 迅速に開発 : 高速かつ安定し
 Product Brief 高速なコードを素早く開発 インテル Parallel Studio XE 2017 インテル ソフトウェア開発ツール 概要 高速なコード : 現在および次世代のプロセッサーでスケーリングする優れたアプリケーション パフォーマンスを実現します 迅速に開発 : 高速かつ安定した並列コードの作成を簡略化するツールセットです : 最先端のコンパイラー ライブラリー 並列モデル インテル
Product Brief 高速なコードを素早く開発 インテル Parallel Studio XE 2017 インテル ソフトウェア開発ツール 概要 高速なコード : 現在および次世代のプロセッサーでスケーリングする優れたアプリケーション パフォーマンスを実現します 迅速に開発 : 高速かつ安定した並列コードの作成を簡略化するツールセットです : 最先端のコンパイラー ライブラリー 並列モデル インテル
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
Microsoft Word - quick_start_guide_16 1_ja.docx
 Quartus Prime ソフトウェア ダウンロードおよびインストール クイック スタート ガイド 2016 Intel Corporation. All rights reserved. Intel, the Intel logo, Intel FPGA, Arria, Cyclone, Enpirion, MAX, Megacore, NIOS, Quartus and Stratix words
Quartus Prime ソフトウェア ダウンロードおよびインストール クイック スタート ガイド 2016 Intel Corporation. All rights reserved. Intel, the Intel logo, Intel FPGA, Arria, Cyclone, Enpirion, MAX, Megacore, NIOS, Quartus and Stratix words
インテル® Parallel Studio XE 2015 Composer Edition for Linux* インストール・ガイドおよびリリースノート
 インテル Parallel Studio XE 2015 Composer Edition for Linux* インストール ガイドおよびリリースノート 2014 年 10 月 14 日 目次 1 概要... 1 1.1 製品の内容... 2 1.2 インテル デバッガー (IDB) を削除... 2 1.3 動作環境... 2 1.3.1 SuSE Enterprise Linux 10* のサポートを終了...
インテル Parallel Studio XE 2015 Composer Edition for Linux* インストール ガイドおよびリリースノート 2014 年 10 月 14 日 目次 1 概要... 1 1.1 製品の内容... 2 1.2 インテル デバッガー (IDB) を削除... 2 1.3 動作環境... 2 1.3.1 SuSE Enterprise Linux 10* のサポートを終了...
Tutorial-GettingStarted
 インテル HTML5 開発環境 チュートリアル インテル XDK 入門ガイド V2.02 : 05.09.2013 著作権と商標について 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスを許諾するものではありません 製品に付属の売買契約書 Intel's Terms
インテル HTML5 開発環境 チュートリアル インテル XDK 入門ガイド V2.02 : 05.09.2013 著作権と商標について 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスを許諾するものではありません 製品に付属の売買契約書 Intel's Terms
はじめに AI は 感染症の早期発見と治療法の探索 交通事故死の削減 事故発生前の重大なインフラ欠陥の発見など 人類が直面する複雑な > 問題を解決するのに役立てられています AI とディープラーニング利用における 2 つの大きな課題は パフォーマンスの最大化と 絶え間なく変化する基盤技術の管理です
 技術概要 NVIDIA GPU CLOUD ディープラーニングソフトウェア 最適化されたディープラーニングコンテナーのガイド はじめに AI は 感染症の早期発見と治療法の探索 交通事故死の削減 事故発生前の重大なインフラ欠陥の発見など 人類が直面する複雑な > 問題を解決するのに役立てられています AI とディープラーニング利用における 2 つの大きな課題は パフォーマンスの最大化と 絶え間なく変化する基盤技術の管理です
技術概要 NVIDIA GPU CLOUD ディープラーニングソフトウェア 最適化されたディープラーニングコンテナーのガイド はじめに AI は 感染症の早期発見と治療法の探索 交通事故死の削減 事故発生前の重大なインフラ欠陥の発見など 人類が直面する複雑な > 問題を解決するのに役立てられています AI とディープラーニング利用における 2 つの大きな課題は パフォーマンスの最大化と 絶え間なく変化する基盤技術の管理です
インテル Media Server Studio およびインテル SDK for OpenCL* Applications でメディア ソリューション / アプリケーションを最適化
 最新のメディア環境をサポートするインテル ソフトウェア開発製品 久保寺 陽子 インテル Media Server Studio およびインテル SDK for OpenCL* Applications でメディア ソリューション / アプリケーションを最適化 コンテンツ制作者 エンドポイント レンダリングスマート IoT エンドポイント インテリジェンス クラウドサービス デジタルアートレンダリングレイトレーシング
最新のメディア環境をサポートするインテル ソフトウェア開発製品 久保寺 陽子 インテル Media Server Studio およびインテル SDK for OpenCL* Applications でメディア ソリューション / アプリケーションを最適化 コンテンツ制作者 エンドポイント レンダリングスマート IoT エンドポイント インテリジェンス クラウドサービス デジタルアートレンダリングレイトレーシング
PowerPoint プレゼンテーション
 vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
Jackson Marusarz 開発製品部門
 Jackson Marusarz 開発製品部門 内容 インテル TBB の概要 ヘテロジニアスの課題とそれらに対応するための概念 課題に対応するためのインテル TBB の進化 2 インテル TBB threadingbuildingblocks.org 汎用並列アルゴリズム ゼロから始めることなく マルチコアの能力を活かす効率的でスケーラブルな方法を提供 フローグラフ 並列処理を計算の依存性やデータフロー
Jackson Marusarz 開発製品部門 内容 インテル TBB の概要 ヘテロジニアスの課題とそれらに対応するための概念 課題に対応するためのインテル TBB の進化 2 インテル TBB threadingbuildingblocks.org 汎用並列アルゴリズム ゼロから始めることなく マルチコアの能力を活かす効率的でスケーラブルな方法を提供 フローグラフ 並列処理を計算の依存性やデータフロー
Slide 1
 GPU コンピューティング研究会ディープラーニング ハンズオン講習 エヌビディア合同会社 ディープラーニングソリューションアーキテクト兼 CUDA エンジニア村上真奈 追記 ハンズオンのおさらいを後日行いたい方へ MNIST データセットは以下からダウンロードする事が可能です (gz 形式 ) http://yann.lecun.com/exdb/mnist/ 下記スクリプトでも簡単にデータをダウンロード可能です
GPU コンピューティング研究会ディープラーニング ハンズオン講習 エヌビディア合同会社 ディープラーニングソリューションアーキテクト兼 CUDA エンジニア村上真奈 追記 ハンズオンのおさらいを後日行いたい方へ MNIST データセットは以下からダウンロードする事が可能です (gz 形式 ) http://yann.lecun.com/exdb/mnist/ 下記スクリプトでも簡単にデータをダウンロード可能です
Oracle Cloud Adapter for Oracle RightNow Cloud Service
 Oracle Cloud Adapter for Oracle RightNow Cloud Service Oracle Cloud Adapter for Oracle RightNow Cloud Service を使用すると RightNow Cloud Service をシームレスに接続および統合できるため Service Cloud プラットフォームを拡張して信頼性のある優れたカスタマ
Oracle Cloud Adapter for Oracle RightNow Cloud Service Oracle Cloud Adapter for Oracle RightNow Cloud Service を使用すると RightNow Cloud Service をシームレスに接続および統合できるため Service Cloud プラットフォームを拡張して信頼性のある優れたカスタマ
White Paper 高速部分画像検索キット(FPGA アクセラレーション)
") White Paper 高速部分画像検索キット (FPGA アクセラレーション ) White Paper 高速部分画像検索キット (FPGA アクセラレーション ) Page 1 of 7 http://www.fujitsu.com/primergy Content はじめに 3 部分画像検索とは 4 高速部分画像検索システム 5 高速部分画像検索の適用時の改善効果 6 検索結果 ( 一例 )
White Paper 高速部分画像検索キット (FPGA アクセラレーション ) White Paper 高速部分画像検索キット (FPGA アクセラレーション ) Page 1 of 7 http://www.fujitsu.com/primergy Content はじめに 3 部分画像検索とは 4 高速部分画像検索システム 5 高速部分画像検索の適用時の改善効果 6 検索結果 ( 一例 )
GTC Japan, 2018/09/14 得居誠也, Preferred Networks Chainer における 深層学習の高速化 Optimizing Deep Learning with Chainer
 GTC Japan, 2018/09/14 得居誠也, Preferred Networks Chainer における 深層学習の高速化 Optimizing Deep Learning with Chainer Chainer のミッション Deep Learning とその応用の研究開発を加速させる 環境セットアップが速い すぐ習熟 素早いコーディング 実験の高速化 結果をさっと公開 論文化
GTC Japan, 2018/09/14 得居誠也, Preferred Networks Chainer における 深層学習の高速化 Optimizing Deep Learning with Chainer Chainer のミッション Deep Learning とその応用の研究開発を加速させる 環境セットアップが速い すぐ習熟 素早いコーディング 実験の高速化 結果をさっと公開 論文化
ディープラーニングの組み込み機器実装ソリューション ~GPC/CPU編~
 ディープラーニングの組み込み機器実装ソリューション ~GPU/CPU 編 ~ MathWorks Japan アプリケーションエンジニアリング部大塚慶太郎 Kei.Otsuka@mathworks.co.jp 2018 The MathWorks, Inc. 1 自動運転 : 車 歩行者等の物体認識 白線検出 組み込み GPU への実装 モデル GPU 実装 / 配布 3 医用画像 : 腫瘍等 特定の部位の検出
ディープラーニングの組み込み機器実装ソリューション ~GPU/CPU 編 ~ MathWorks Japan アプリケーションエンジニアリング部大塚慶太郎 Kei.Otsuka@mathworks.co.jp 2018 The MathWorks, Inc. 1 自動運転 : 車 歩行者等の物体認識 白線検出 組み込み GPU への実装 モデル GPU 実装 / 配布 3 医用画像 : 腫瘍等 特定の部位の検出
スライド 1
 知能制御システム学 画像処理の高速化 OpenCV による基礎的な例 東北大学大学院情報科学研究科鏡慎吾 swk(at)ic.is.tohoku.ac.jp 2007.07.03 リアルタイム処理と高速化 リアルタイム = 高速 ではない 目標となる時間制約が定められているのがリアルタイム処理である.34 ms かかった処理が 33 ms に縮んだだけでも, それによって与えられた時間制約が満たされるのであれば,
知能制御システム学 画像処理の高速化 OpenCV による基礎的な例 東北大学大学院情報科学研究科鏡慎吾 swk(at)ic.is.tohoku.ac.jp 2007.07.03 リアルタイム処理と高速化 リアルタイム = 高速 ではない 目標となる時間制約が定められているのがリアルタイム処理である.34 ms かかった処理が 33 ms に縮んだだけでも, それによって与えられた時間制約が満たされるのであれば,
ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014
 ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014 コンカレントな処理の実行 システム内部の複数の処理を 平行に実行する CPU GPU メモリ転送 カーネル実行 複数のカーネル間 ストリーム GPU 上の処理キュー カーネル実行 メモリ転送の並列性 実行順序 DEFAULT STREAM Stream : GPU
ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014 コンカレントな処理の実行 システム内部の複数の処理を 平行に実行する CPU GPU メモリ転送 カーネル実行 複数のカーネル間 ストリーム GPU 上の処理キュー カーネル実行 メモリ転送の並列性 実行順序 DEFAULT STREAM Stream : GPU
テクノロジーのビッグトレンド 180 nm nm nm nm nm On 2007 Track 32 nm には 150 億台の端末がネットワーク接続 * * "Gantz, John. "The Embedded
 ホワイトスペースに対するインテルの期待 インテルコーポレーション セールス & マーケティング統括本部副社長 吉田和正 テクノロジーのビッグトレンド 180 nm 1999 130 nm 2001 90 nm 2003 65 nm 2005 45 nm On 2007 Track 32 nm 2009 2015 には 150 億台の端末がネットワーク接続 * * "Gantz, John. "The
ホワイトスペースに対するインテルの期待 インテルコーポレーション セールス & マーケティング統括本部副社長 吉田和正 テクノロジーのビッグトレンド 180 nm 1999 130 nm 2001 90 nm 2003 65 nm 2005 45 nm On 2007 Track 32 nm 2009 2015 には 150 億台の端末がネットワーク接続 * * "Gantz, John. "The
スピーカースライド作成前の確認シート例
 IoT に AI を組み込む ~ 最新技術と実践方法解説 AI08 IoTの開発 運用コストは AIの活用で回収する AI = Big Data Big Data from IoT Edges AI Create Excellent Value IoT は 膨大なデバイスと膨大なデータを扱う Azure で IoT+AI を実践するときの基本骨格 IoT で使われる AI 要素 IoT のスケール感
IoT に AI を組み込む ~ 最新技術と実践方法解説 AI08 IoTの開発 運用コストは AIの活用で回収する AI = Big Data Big Data from IoT Edges AI Create Excellent Value IoT は 膨大なデバイスと膨大なデータを扱う Azure で IoT+AI を実践するときの基本骨格 IoT で使われる AI 要素 IoT のスケール感
新しい 自律型データ ウェアハウス
 AUTONOMOUSDATA WAREHOUSE CLOUD 新しい自律型データウェアハウス Warehouse Cloudとは製品ツアー使用する理由まとめ始めましょう おもな機能クラウド同じ 接続 Warehouse Cloud は Oracle Database の市場をリードするパフォーマンスを備え データウェアハウスのワークロードに合わせて最適化された 完全に管理されたオラクルのデータベースです
AUTONOMOUSDATA WAREHOUSE CLOUD 新しい自律型データウェアハウス Warehouse Cloudとは製品ツアー使用する理由まとめ始めましょう おもな機能クラウド同じ 接続 Warehouse Cloud は Oracle Database の市場をリードするパフォーマンスを備え データウェアハウスのワークロードに合わせて最適化された 完全に管理されたオラクルのデータベースです
インテル® VTune™ Amplifier XE を使用したストレージ向けの パフォーマンス最適化
 インテル VTune Amplifier XE を使用したストレージ向けのパフォーマンス最適化 2016 年 10 月 12 日 Day2 トラック D-2 (14:55 15:40) すがわらきよふみ isus 編集長 本日の内容 インテル VTune Amplifier XE 2017 概要 ストレージ解析向けのインテル VTune Amplifier XE の新機能 メモリー解析向けのインテル
インテル VTune Amplifier XE を使用したストレージ向けのパフォーマンス最適化 2016 年 10 月 12 日 Day2 トラック D-2 (14:55 15:40) すがわらきよふみ isus 編集長 本日の内容 インテル VTune Amplifier XE 2017 概要 ストレージ解析向けのインテル VTune Amplifier XE の新機能 メモリー解析向けのインテル
スライド 1
 Nehalem 新マイクロアーキテクチャ スケーラブルシステムズ株式会社 はじめに 現在も続く x86 マイクロプロセッサマーケットでの競合において Intel と AMD という 2 つの会社は 常に新しい技術 製品を提供し マーケットでのシェアの獲得を目指しています この技術開発と製品開発では この 2 社はある時は 他社に対して優位な技術を開発し 製品面での優位性を示すことに成功してきましたが
Nehalem 新マイクロアーキテクチャ スケーラブルシステムズ株式会社 はじめに 現在も続く x86 マイクロプロセッサマーケットでの競合において Intel と AMD という 2 つの会社は 常に新しい技術 製品を提供し マーケットでのシェアの獲得を目指しています この技術開発と製品開発では この 2 社はある時は 他社に対して優位な技術を開発し 製品面での優位性を示すことに成功してきましたが
インテル® キャッシュ・アクセラレーション・ソフトウェア (インテル® CAS) Linux* 版 v2.8 (GA)
 Linux* 版 v2.8 (GA)") 改訂 001 ドキュメント番号 :328499-001 注 : 本書には開発の設計段階の製品に関する情報が記述されています この情報は予告なく変更されることがあります この情報だけに基づいて設計を最終的なものとしないでください 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスも許諾するものではありません
改訂 001 ドキュメント番号 :328499-001 注 : 本書には開発の設計段階の製品に関する情報が記述されています この情報は予告なく変更されることがあります この情報だけに基づいて設計を最終的なものとしないでください 本資料に掲載されている情報は インテル製品の概要説明を目的としたものです 本資料は 明示されているか否かにかかわらず また禁反言によるとよらずにかかわらず いかなる知的財産権のライセンスも許諾するものではありません
ムーアの法則後の世界 年間のマイクロプロセッサのトレンド トランジスタ数 ( 千単位 ) 年率 1.1 倍 シングルスレッド性能 年率 1.5 倍 Original data up t
 年率 1.1 倍 シングルスレッド性能 年率 1.5 倍 Original data up t") エヌビディアが加速する AI 革命 エヌビディア合同会社 エンタープライズマーケティング本部長林憲一 1 ムーアの法則後の世界 10 7 40 年間のマイクロプロセッサのトレンド 10 6 10 5 10 4 トランジスタ数 ( 千単位 ) 年率 1.1 倍 10 3 10 2 シングルスレッド性能 年率 1.5 倍 1980 1990 2000 2010 2020 Original data up
エヌビディアが加速する AI 革命 エヌビディア合同会社 エンタープライズマーケティング本部長林憲一 1 ムーアの法則後の世界 10 7 40 年間のマイクロプロセッサのトレンド 10 6 10 5 10 4 トランジスタ数 ( 千単位 ) 年率 1.1 倍 10 3 10 2 シングルスレッド性能 年率 1.5 倍 1980 1990 2000 2010 2020 Original data up
Microsoft PowerPoint - 01_Vengineer.ppt
 Software Driven Verification テストプログラムは C 言語で! SystemVerilog DPI-C を使えば こんなに便利に! 2011 年 9 月 30 日 コントローラ開発本部コントローラプラットフォーム第五開発部 宮下晴信 この資料で使用するシステム名 製品名等は一般にメーカーや 団体の登録商標などになっているものもあります なお この資料の中では トレードマーク
Software Driven Verification テストプログラムは C 言語で! SystemVerilog DPI-C を使えば こんなに便利に! 2011 年 9 月 30 日 コントローラ開発本部コントローラプラットフォーム第五開発部 宮下晴信 この資料で使用するシステム名 製品名等は一般にメーカーや 団体の登録商標などになっているものもあります なお この資料の中では トレードマーク
AI 人工知能 高度なプログラミングをすることなく 人間の心理と関連した認識機能を実行するために 経験を基にした機械の学習する能力 人工知能 マシンラーニング長期間にわたってより多くのデータを使用することにより 性能が向上するアルゴリズム ディープラーニング多層ニューラル ネットワークが膨大な量のデ
 AI 人工知能 高度なプログラミングをすることなく 人間の心理と関連した認識機能を実行するために 経験を基にした機械の学習する能力 人工知能 マシンラーニング長期間にわたってより多くのデータを使用することにより 性能が向上するアルゴリズム ディープラーニング多層ニューラル ネットワークが膨大な量のデータから学ぶマシンラーニングのサブセット 2 マシンラーニング技術の分析 訓練モデル構築のための訓練
AI 人工知能 高度なプログラミングをすることなく 人間の心理と関連した認識機能を実行するために 経験を基にした機械の学習する能力 人工知能 マシンラーニング長期間にわたってより多くのデータを使用することにより 性能が向上するアルゴリズム ディープラーニング多層ニューラル ネットワークが膨大な量のデータから学ぶマシンラーニングのサブセット 2 マシンラーニング技術の分析 訓練モデル構築のための訓練
プロセッサ・アーキテクチャ
 2. NII51002-8.0.0 Nios II Nios II Nios II 2-3 2-4 2-4 2-6 2-7 2-9 I/O 2-18 JTAG Nios II ISA ISA Nios II Nios II Nios II 2 1 Nios II Altera Corporation 2 1 2 1. Nios II Nios II Processor Core JTAG interface
2. NII51002-8.0.0 Nios II Nios II Nios II 2-3 2-4 2-4 2-6 2-7 2-9 I/O 2-18 JTAG Nios II ISA ISA Nios II Nios II Nios II 2 1 Nios II Altera Corporation 2 1 2 1. Nios II Nios II Processor Core JTAG interface
untitled
 PC murakami@cc.kyushu-u.ac.jp muscle server blade server PC PC + EHPC/Eric (Embedded HPC with Eric) 1216 Compact PCI Compact PCIPC Compact PCISH-4 Compact PCISH-4 Eric Eric EHPC/Eric EHPC/Eric Gigabit
PC murakami@cc.kyushu-u.ac.jp muscle server blade server PC PC + EHPC/Eric (Embedded HPC with Eric) 1216 Compact PCI Compact PCIPC Compact PCISH-4 Compact PCISH-4 Eric Eric EHPC/Eric EHPC/Eric Gigabit
データ移行ツール ユーザーガイド Data Migration Tool User Guide SK kynix Inc Rev 1.01
 データ移行ツール ユーザーガイド Data Migration Tool User Guide SK kynix Inc. 2014 Rev 1.01 1 免責事項 SK hynix INC は 同社の製品 情報および仕様を予告なしに変更できる権利を有しています 本資料で提示する製品および仕様は参考情報として提供しています 本資料の情報は 現状のまま 提供されるものであり 如何なる保証も行いません
データ移行ツール ユーザーガイド Data Migration Tool User Guide SK kynix Inc. 2014 Rev 1.01 1 免責事項 SK hynix INC は 同社の製品 情報および仕様を予告なしに変更できる権利を有しています 本資料で提示する製品および仕様は参考情報として提供しています 本資料の情報は 現状のまま 提供されるものであり 如何なる保証も行いません
PowerPoint Presentation
 インテル ソフトウェア開発製品によるソースコードの近代化 エクセルソフト株式会社黒澤一平 ソースコードの近代化 インテル Xeon Phi プロセッサーや 将来のインテル Xeon プロセッサー上での実行に向けた準備と適用 インテル ソフトウェア製品 名称インテル Composer XE for Fortran and C++ インテル VTune Amplifier XE インテル Advisor
インテル ソフトウェア開発製品によるソースコードの近代化 エクセルソフト株式会社黒澤一平 ソースコードの近代化 インテル Xeon Phi プロセッサーや 将来のインテル Xeon プロセッサー上での実行に向けた準備と適用 インテル ソフトウェア製品 名称インテル Composer XE for Fortran and C++ インテル VTune Amplifier XE インテル Advisor
PNopenseminar_2011_開発stack
 PROFINET Open Seminar 開発セミナー Software Stack FPGA IP core PROFINET 対応製品の開発 2 ユーザ要求要求は多種多様 複雑な規格の仕様を一から勉強するのはちょっと.. できるだけ短期間で 柔軟なスケジュールで進めたい既存のハードウェアを変更することなく PN を対応させたい将来的な仕様拡張に対してシームレスに統合したい同じハードウェアで複数の
PROFINET Open Seminar 開発セミナー Software Stack FPGA IP core PROFINET 対応製品の開発 2 ユーザ要求要求は多種多様 複雑な規格の仕様を一から勉強するのはちょっと.. できるだけ短期間で 柔軟なスケジュールで進めたい既存のハードウェアを変更することなく PN を対応させたい将来的な仕様拡張に対してシームレスに統合したい同じハードウェアで複数の
システムソリューションのご紹介
 HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
PowerPoint Presentation
 2016 年 11 月 マシンラーニング ソフトウェアの課題 オープンソースのマシンラーニング フレームワークやライブラリーは最新のインテル アーキテクチャー ベースのシステム向けに最適化されていないことがある フレームワークは設定および利用が困難 データセンターでのモデルの訓練からエンドポイント システムの配備までヘテロジニアス ハードウェアをターゲットにする必要がある データセンター エンドポイント
2016 年 11 月 マシンラーニング ソフトウェアの課題 オープンソースのマシンラーニング フレームワークやライブラリーは最新のインテル アーキテクチャー ベースのシステム向けに最適化されていないことがある フレームワークは設定および利用が困難 データセンターでのモデルの訓練からエンドポイント システムの配備までヘテロジニアス ハードウェアをターゲットにする必要がある データセンター エンドポイント
インテルが加速させるコンピューター・ビジョン
 インテルが加速させる コンピューター ビジョン AI ソリューションをあらゆる産業の あらゆるビジネスに ビジネスにおける AI 人工知能 の進化 世界は常に変化し続けています それにつれて IoT の可能性についての考え方も変化してきています モノとインターネットを結び つけることから始まった流れは 今日 接続されたモノがデータをどのように収集し そのデータを 分析することで企業がより正確で 迅速な意思決定を行うことができるのかという
インテルが加速させる コンピューター ビジョン AI ソリューションをあらゆる産業の あらゆるビジネスに ビジネスにおける AI 人工知能 の進化 世界は常に変化し続けています それにつれて IoT の可能性についての考え方も変化してきています モノとインターネットを結び つけることから始まった流れは 今日 接続されたモノがデータをどのように収集し そのデータを 分析することで企業がより正確で 迅速な意思決定を行うことができるのかという
マイクロソフトが提供するAI関連サービスとその最新事例
 Microsoft の AI 関連サービスと最新事例の紹介 本日のアジェンダ マイクロソフトの AI への取り組み マイクロソフトの AI 関連サービス お客様の導入事例 2019 Microsoft Corporation. All rights 2 Microsoft mission Empower every person and every organization on the planet
Microsoft の AI 関連サービスと最新事例の紹介 本日のアジェンダ マイクロソフトの AI への取り組み マイクロソフトの AI 関連サービス お客様の導入事例 2019 Microsoft Corporation. All rights 2 Microsoft mission Empower every person and every organization on the planet
田向研究室PPTテンプレート
 Hibikino-Musashi@Home: ホームサービスロボット開発学生プロジェクトの紹介 18/09/14 ROSCon JP 2018 Hibikino-Musashi@Home 九州工業大学田向研究室 石田裕太郎 hma@brain.kyutech.ac.jp 今日紹介するロボット RoboCup@Home に参戦するホームサービスロボット Eix@ HW: 九工大 SW: 九工大 2018
Hibikino-Musashi@Home: ホームサービスロボット開発学生プロジェクトの紹介 18/09/14 ROSCon JP 2018 Hibikino-Musashi@Home 九州工業大学田向研究室 石田裕太郎 hma@brain.kyutech.ac.jp 今日紹介するロボット RoboCup@Home に参戦するホームサービスロボット Eix@ HW: 九工大 SW: 九工大 2018
Nios II Flash Programmer ユーザ・ガイド
 ver. 8.0 2009 年 4 月 1. はじめに 本資料は Nios II 開発環境においてフラッシュメモリ または EPCS へのプログラミングを行う際の参考マニュアルです このマニュアルでは フラッシュメモリの書き込みの際に最低限必要となる情報を提供し さらに詳しい情報はアルテラ社資料 Nios II Flash Programmer User Guide( ファイル名 :ug_nios2_flash_programmer.pdf)
ver. 8.0 2009 年 4 月 1. はじめに 本資料は Nios II 開発環境においてフラッシュメモリ または EPCS へのプログラミングを行う際の参考マニュアルです このマニュアルでは フラッシュメモリの書き込みの際に最低限必要となる情報を提供し さらに詳しい情報はアルテラ社資料 Nios II Flash Programmer User Guide( ファイル名 :ug_nios2_flash_programmer.pdf)
WHITE PAPER RNN
 WHITE PAPER RNN ii 1... 1 2 RNN?... 1 2.1 ARIMA... 1 2.2... 2 2.3 RNN Recurrent Neural Network... 3 3 RNN... 5 3.1 RNN... 6 3.2 RNN... 6 3.3 RNN... 7 4 SAS Viya RNN... 8 4.1... 9 4.2... 11 4.3... 15 5...
WHITE PAPER RNN ii 1... 1 2 RNN?... 1 2.1 ARIMA... 1 2.2... 2 2.3 RNN Recurrent Neural Network... 3 3 RNN... 5 3.1 RNN... 6 3.2 RNN... 6 3.3 RNN... 7 4 SAS Viya RNN... 8 4.1... 9 4.2... 11 4.3... 15 5...
PowerPoint プレゼンテーション
 Dell PowerEdge C6320 スケーラブルサーバアプライアンス 仮想化アプライアンスサーバ 最新のプロセッサを搭載したサーバプラットフォーム vsmp Foundation によるサーバ仮想化と統合化の適用 システムはセットアップを完了した状態でご提供 基本構成ではバックプレーン用のスイッチなどが不要 各ノード間を直接接続 冗長性の高いバックプレーン構成 利用するサーバプラットフォームは
Dell PowerEdge C6320 スケーラブルサーバアプライアンス 仮想化アプライアンスサーバ 最新のプロセッサを搭載したサーバプラットフォーム vsmp Foundation によるサーバ仮想化と統合化の適用 システムはセットアップを完了した状態でご提供 基本構成ではバックプレーン用のスイッチなどが不要 各ノード間を直接接続 冗長性の高いバックプレーン構成 利用するサーバプラットフォームは
PowerPoint Presentation
 VME Embedded System ユーザーズマニュアル ~ Slim VME Embedded ~ Tecstar Page: 1 Agenda 1. VME Embedded System 概要 2. VME Embedded の特徴 3. Embedded Overview 4. VMEファイルとHEXファイルについて 5. Slim VME について 6. Deployment Toolの起動方法について
VME Embedded System ユーザーズマニュアル ~ Slim VME Embedded ~ Tecstar Page: 1 Agenda 1. VME Embedded System 概要 2. VME Embedded の特徴 3. Embedded Overview 4. VMEファイルとHEXファイルについて 5. Slim VME について 6. Deployment Toolの起動方法について
バトルカードでゲーマーやエンスージアストへの販売促進
 究極のメガタスク 4K ビデオの編集 3D 効果のレンダリング サウンドトラックの作曲を システム パフォーマンスを低下させずに同時に実行 4K ビデオの編集を 最大 2.4 倍 ビデオのトランスコードを 最大 高速化¹ Adobe* Premiere* Pro CC と インテル Core i7-7700k で比較 2.3 倍 高速化² - Handbrake* を使用し インテル Core i7-7700k
究極のメガタスク 4K ビデオの編集 3D 効果のレンダリング サウンドトラックの作曲を システム パフォーマンスを低下させずに同時に実行 4K ビデオの編集を 最大 2.4 倍 ビデオのトランスコードを 最大 高速化¹ Adobe* Premiere* Pro CC と インテル Core i7-7700k で比較 2.3 倍 高速化² - Handbrake* を使用し インテル Core i7-7700k
本ラボの目的 ディープラーニングのイントロダクション ネットワークのトレーニング トレーニングの結果を理解する コンピュータビジョン 画像分類に関するハンズオン Caffe と DIGITS を使用する 1/17/217 6
 DIGITSによるディープラーニング画像分類 森野慎也, シニアソリューションアーキテクト ディープラーニング部 エヌビディアジャパン 217/1/17 本ラボの目的 ディープラーニングのイントロダクション ネットワークのトレーニング トレーニングの結果を理解する コンピュータビジョン 画像分類に関するハンズオン Caffe と DIGITS を使用する 1/17/217 6 本ラボが意図しないこと
DIGITSによるディープラーニング画像分類 森野慎也, シニアソリューションアーキテクト ディープラーニング部 エヌビディアジャパン 217/1/17 本ラボの目的 ディープラーニングのイントロダクション ネットワークのトレーニング トレーニングの結果を理解する コンピュータビジョン 画像分類に関するハンズオン Caffe と DIGITS を使用する 1/17/217 6 本ラボが意図しないこと
Nios II - PIO を使用した I2C-Bus (2ワイヤ)マスタの実装
マスタの実装") LIM Corp. Nios II - PIO を使用した I 2 C-Bus (2 ワイヤ ) マスタの実装 ver.1.0 2010 年 6 月 ELSEN,Inc. 目次 1. はじめに... 3 2. 適用条件... 3 3. システムの構成... 3 3-1. SOPC Builder の設定... 3 3-2. PIO の設定... 4 3-2-1. シリアル クロック ライン用 PIO
LIM Corp. Nios II - PIO を使用した I 2 C-Bus (2 ワイヤ ) マスタの実装 ver.1.0 2010 年 6 月 ELSEN,Inc. 目次 1. はじめに... 3 2. 適用条件... 3 3. システムの構成... 3 3-1. SOPC Builder の設定... 3 3-2. PIO の設定... 4 3-2-1. シリアル クロック ライン用 PIO
AGENDA ディープラーニングとは Qwiklab/Jupyter notebook/digits の使い方 DIGITS による物体検出入門ハンズオン
 ハンズオンラボ2 DIGITS による物体検出入門 村上真奈 NVIDIA CUDA & Deep Learning Solution Architect NVIDIA Corporation 1 AGENDA ディープラーニングとは Qwiklab/Jupyter notebook/digits の使い方 DIGITS による物体検出入門ハンズオン ディープラーニングとは 機械学習とディープラーニングの関係
ハンズオンラボ2 DIGITS による物体検出入門 村上真奈 NVIDIA CUDA & Deep Learning Solution Architect NVIDIA Corporation 1 AGENDA ディープラーニングとは Qwiklab/Jupyter notebook/digits の使い方 DIGITS による物体検出入門ハンズオン ディープラーニングとは 機械学習とディープラーニングの関係
ホワイト ペーパー EMC VFCache により Microsoft SQL Server を高速化 EMC VFCache EMC VNX Microsoft SQL Server 2008 VFCache による SQL Server のパフォーマンスの大幅な向上 VNX によるデータ保護 E
 ホワイト ペーパー VFCache による SQL Server のパフォーマンスの大幅な向上 VNX によるデータ保護 EMC ソリューション グループ 要約 このホワイト ペーパーでは EMC VFCache と EMC VNX を組み合わせて Microsoft SQL Server 2008 環境での OLTP( オンライン トランザクション処理 ) のパフォーマンスを改善する方法について説明します
ホワイト ペーパー VFCache による SQL Server のパフォーマンスの大幅な向上 VNX によるデータ保護 EMC ソリューション グループ 要約 このホワイト ペーパーでは EMC VFCache と EMC VNX を組み合わせて Microsoft SQL Server 2008 環境での OLTP( オンライン トランザクション処理 ) のパフォーマンスを改善する方法について説明します
Touch Panel Settings Tool
 インフォメーションディスプレイ タッチパネル設定ツール取扱説明書 バージョン 2.0 対応機種 (2015 年 11 月現在 ) PN-L603A/PN-L603B/PN-L603W/PN-L703A/PN-L703B/PN-L703W/PN-L803C もくじ はじめに 3 動作条件 3 コンピューターのセットアップ 4 インストールする 4 タッチパネルの設定 5 設定のしかた 5 キャリブレーション
インフォメーションディスプレイ タッチパネル設定ツール取扱説明書 バージョン 2.0 対応機種 (2015 年 11 月現在 ) PN-L603A/PN-L603B/PN-L603W/PN-L703A/PN-L703B/PN-L703W/PN-L803C もくじ はじめに 3 動作条件 3 コンピューターのセットアップ 4 インストールする 4 タッチパネルの設定 5 設定のしかた 5 キャリブレーション
『オープンサイエンス』とAI~オープン化は人工知能研究をどう変えるか?~
 AI 研究をどう変えるか?~ KITAMOTO Asanobu http://researchmap.jp/kitamoto/ KitamotoAsanob u 2018/06/07 1 2018/06/07 2 デジタル台風とは? http://agora.ex.nii.ac.jp/digital-typhoon/ 1999 2000 P 2018/06/07 3 200813 0 1 Collaboration
AI 研究をどう変えるか?~ KITAMOTO Asanobu http://researchmap.jp/kitamoto/ KitamotoAsanob u 2018/06/07 1 2018/06/07 2 デジタル台風とは? http://agora.ex.nii.ac.jp/digital-typhoon/ 1999 2000 P 2018/06/07 3 200813 0 1 Collaboration
インテル® Parallel Studio XE 2019 Composer Edition for Fortran Windows : インストール・ガイド
 インテル Parallel Studio XE 2019 Composer Edition for Fortran Windows インストール ガイド エクセルソフト株式会社 Version 1.0.0-20180918 目次 1. はじめに....................................................................................
インテル Parallel Studio XE 2019 Composer Edition for Fortran Windows インストール ガイド エクセルソフト株式会社 Version 1.0.0-20180918 目次 1. はじめに....................................................................................
Click to edit title
 インテル VTune Amplifier 2018 を 使用した最適化手法 ( 初級編 ) 久保寺 陽子 内容 アプリケーション最適化のプロセス インテル VTune Amplifier の紹介 インテル VTune Amplifier の新機能 インテル VTune Amplifier を用いた最適化例 (1) インテル VTune Amplifier を用いた最適化例 (2) まとめ 2 インテル
インテル VTune Amplifier 2018 を 使用した最適化手法 ( 初級編 ) 久保寺 陽子 内容 アプリケーション最適化のプロセス インテル VTune Amplifier の紹介 インテル VTune Amplifier の新機能 インテル VTune Amplifier を用いた最適化例 (1) インテル VTune Amplifier を用いた最適化例 (2) まとめ 2 インテル
SimscapeプラントモデルのFPGAアクセラレーション
 Simscape TM プラントモデルの FPGA アクセラレーション MathWorks Japan アプリケーションエンジニアリング部 松本充史 2018 The MathWorks, Inc. 1 アジェンダ ユーザ事例 HILS とは? Simscape の電気系ライブラリ Simscape モデルを FPGA 実装する 2 つのアプローチ Simscape HDL Workflow Advisor
Simscape TM プラントモデルの FPGA アクセラレーション MathWorks Japan アプリケーションエンジニアリング部 松本充史 2018 The MathWorks, Inc. 1 アジェンダ ユーザ事例 HILS とは? Simscape の電気系ライブラリ Simscape モデルを FPGA 実装する 2 つのアプローチ Simscape HDL Workflow Advisor
Silk Central Connect 15.5 リリースノート
 Silk Central Connect 15.5 リリースノート Micro Focus 575 Anton Blvd., Suite 510 Costa Mesa, CA 92626 Copyright Micro Focus 2014. All rights reserved. Silk Central Connect は Borland Software Corporation に由来する成果物を含んでいます,
Silk Central Connect 15.5 リリースノート Micro Focus 575 Anton Blvd., Suite 510 Costa Mesa, CA 92626 Copyright Micro Focus 2014. All rights reserved. Silk Central Connect は Borland Software Corporation に由来する成果物を含んでいます,
計算機アーキテクチャ
 計算機アーキテクチャ 第 11 回命令実行の流れ 2014 年 6 月 20 日 電気情報工学科 田島孝治 1 授業スケジュール ( 前期 ) 2 回日付タイトル 1 4/7 コンピュータ技術の歴史と コンピュータアーキテクチャ 2 4/14 ノイマン型コンピュータ 3 4/21 コンピュータのハードウェア 4 4/28 数と文字の表現 5 5/12 固定小数点数と浮動小数点表現 6 5/19 計算アーキテクチャ
計算機アーキテクチャ 第 11 回命令実行の流れ 2014 年 6 月 20 日 電気情報工学科 田島孝治 1 授業スケジュール ( 前期 ) 2 回日付タイトル 1 4/7 コンピュータ技術の歴史と コンピュータアーキテクチャ 2 4/14 ノイマン型コンピュータ 3 4/21 コンピュータのハードウェア 4 4/28 数と文字の表現 5 5/12 固定小数点数と浮動小数点表現 6 5/19 計算アーキテクチャ
MAGNIA Storage Server Configuration Guide
 MAGNIA シリーズ システム構成ガイド Storage Server 概要編 [2012.12] 価格について 本書に記載の価格はすべて税込です 据付調整費 使用済み商品のお引き取り費は含まれておりません もくじ MAGNIA Storage Server 構成ガイド概要編 ページ 概要 2 特長 3 ネットワーク構成例 5 システム構成セレクション 6 1 MAGNIA Storage Server
MAGNIA シリーズ システム構成ガイド Storage Server 概要編 [2012.12] 価格について 本書に記載の価格はすべて税込です 据付調整費 使用済み商品のお引き取り費は含まれておりません もくじ MAGNIA Storage Server 構成ガイド概要編 ページ 概要 2 特長 3 ネットワーク構成例 5 システム構成セレクション 6 1 MAGNIA Storage Server
ModelSim-Altera - RTL シミュレーションの方法
 ALTIMA Corp. ModelSim-Altera RTL シミュレーションの方法 ver.15.1 2016 年 5 月 Rev.1 ELSENA,Inc. 目次 1. 2. 3. はじめに...3 RTL シミュレーションの手順...4 RTL シミュレーションの実施...5 3-1. 3-2. 新規プロジェクトの作成... 5 ファイルの作成と登録... 7 3-2-1. 新規ファイルの作成...
ALTIMA Corp. ModelSim-Altera RTL シミュレーションの方法 ver.15.1 2016 年 5 月 Rev.1 ELSENA,Inc. 目次 1. 2. 3. はじめに...3 RTL シミュレーションの手順...4 RTL シミュレーションの実施...5 3-1. 3-2. 新規プロジェクトの作成... 5 ファイルの作成と登録... 7 3-2-1. 新規ファイルの作成...
Presentation Title
 ディープラーニングによる画像認識の基礎と実践ワークフロー MathWorks Japan アプリケーションエンジニアリング部アプリケーションエンジニア福本拓司 2018 The MathWorks, Inc. 1 一般的におこなわれる目視による評価 製造ライン 医用データ 作業現場 インフラ 研究データ 現場での目視 大量画像の収集 専門家によるチェック 2 スマートフォンで撮影した映像をその場で評価
ディープラーニングによる画像認識の基礎と実践ワークフロー MathWorks Japan アプリケーションエンジニアリング部アプリケーションエンジニア福本拓司 2018 The MathWorks, Inc. 1 一般的におこなわれる目視による評価 製造ライン 医用データ 作業現場 インフラ 研究データ 現場での目視 大量画像の収集 専門家によるチェック 2 スマートフォンで撮影した映像をその場で評価
Microsoft Word - p2viewer_plus_jpn20.doc
 P2 Viewer Plus インストール手順書 Revision 1.04 2013.11.15 Panasonic Corporation 1. はじめに... 3 WINDOWS... 3 MACINTOSH... 3 2. インストール... 5 2.1. インストール手順 (Windows の場合 )...5 2.2. インストール手順 (Macintosh の場合 )...7 3. 起動と終了...10
P2 Viewer Plus インストール手順書 Revision 1.04 2013.11.15 Panasonic Corporation 1. はじめに... 3 WINDOWS... 3 MACINTOSH... 3 2. インストール... 5 2.1. インストール手順 (Windows の場合 )...5 2.2. インストール手順 (Macintosh の場合 )...7 3. 起動と終了...10
インテル® Parallel Studio XE 2019 Composer Edition for Fortran Windows 日本語版 : インストール・ガイド
 インテル Parallel Studio XE 2019 Composer Edition for Fortran Windows 日本語版インストール ガイド エクセルソフト株式会社 Version 2.1.0-20190405 目次 1. はじめに.................................................................................
インテル Parallel Studio XE 2019 Composer Edition for Fortran Windows 日本語版インストール ガイド エクセルソフト株式会社 Version 2.1.0-20190405 目次 1. はじめに.................................................................................
Agenda GRAPE-MPの紹介と性能評価 GRAPE-MPの概要 OpenCLによる四倍精度演算 (preliminary) 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops
 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops") Agenda GRAPE-MPの紹介と性能評価 GRAPE-MPの概要 OpenCLによる四倍精度演算 (preliminary) 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops ボードの概要 Control processor (FPGA by Altera) GRAPE-MP chip[nextreme
Agenda GRAPE-MPの紹介と性能評価 GRAPE-MPの概要 OpenCLによる四倍精度演算 (preliminary) 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops ボードの概要 Control processor (FPGA by Altera) GRAPE-MP chip[nextreme
untitled
 AMD HPC GP-GPU Opteron HPC 2 1 AMD Opteron 85 FLOPS 10,480 TOP500 16 T2K 95 FLOPS 10,800 140 FLOPS 15,200 61 FLOPS 7,200 3 Barcelona 4 2 AMD Opteron CPU!! ( ) L1 5 2003 2004 2005 2006 2007 2008 2009 2010
AMD HPC GP-GPU Opteron HPC 2 1 AMD Opteron 85 FLOPS 10,480 TOP500 16 T2K 95 FLOPS 10,800 140 FLOPS 15,200 61 FLOPS 7,200 3 Barcelona 4 2 AMD Opteron CPU!! ( ) L1 5 2003 2004 2005 2006 2007 2008 2009 2010
hpc141_shirahata.pdf
 GPU アクセラレータと不揮発性メモリ を考慮した I/O 性能の予備評価 白幡晃一 1,2 佐藤仁 1,2 松岡聡 1 1: 東京工業大学 2: JST CREST 1 GPU と不揮発性メモリを用いた 大規模データ処理 大規模データ処理 センサーネットワーク 遺伝子情報 SNS など ペタ ヨッタバイト級 高速処理が必要 スーパーコンピュータ上での大規模データ処理 GPU 高性能 高バンド幅 例
GPU アクセラレータと不揮発性メモリ を考慮した I/O 性能の予備評価 白幡晃一 1,2 佐藤仁 1,2 松岡聡 1 1: 東京工業大学 2: JST CREST 1 GPU と不揮発性メモリを用いた 大規模データ処理 大規模データ処理 センサーネットワーク 遺伝子情報 SNS など ペタ ヨッタバイト級 高速処理が必要 スーパーコンピュータ上での大規模データ処理 GPU 高性能 高バンド幅 例
SMG Field Computex 2011 New Category Update
 Intel Software Developer Day インテル メディア SDK 概要 2011 年 7 月 15 日インテル株式会社ソフトウェア & サービス統括部アプリケーション エンジニア 竹内康人 1 本日の内容 インテル メディア SDK 構成と疑似コード まとめ 2 インテル メディア SDK - 最適化されたソリューション インテル メディア SDK 共通 API を介して インテル
Intel Software Developer Day インテル メディア SDK 概要 2011 年 7 月 15 日インテル株式会社ソフトウェア & サービス統括部アプリケーション エンジニア 竹内康人 1 本日の内容 インテル メディア SDK 構成と疑似コード まとめ 2 インテル メディア SDK - 最適化されたソリューション インテル メディア SDK 共通 API を介して インテル
インテル® Fortran Studio XE 2011 SP1 Windows* 版インストール・ガイドおよびリリースノート
 インテル Fortran Studio XE 2011 SP1 Windows* 版インストール ガイドおよびリリースノート 資料番号 : 325583-001JA 2011 年 8 月 5 日 目次 1 概要... 1 1.1 新機能... 2 1.2 製品の内容... 2 1.3 動作環境... 2 1.3.1 Microsoft* Visual Studio* 2005 のサポート終了予定...
インテル Fortran Studio XE 2011 SP1 Windows* 版インストール ガイドおよびリリースノート 資料番号 : 325583-001JA 2011 年 8 月 5 日 目次 1 概要... 1 1.1 新機能... 2 1.2 製品の内容... 2 1.3 動作環境... 2 1.3.1 Microsoft* Visual Studio* 2005 のサポート終了予定...
IPSJ SIG Technical Report Vol.2013-ARC-203 No /2/1 SMYLE OpenCL (NEDO) IT FPGA SMYLEref SMYLE OpenCL SMYLE OpenCL FPGA 1
 IT FPGA SMYLEref SMYLE OpenCL SMYLE OpenCL FPGA 1") SMYLE OpenCL 128 1 1 1 1 1 2 2 3 3 3 (NEDO) IT FPGA SMYLEref SMYLE OpenCL SMYLE OpenCL FPGA 128 SMYLEref SMYLE OpenCL SMYLE OpenCL Implementation and Evaluations on 128 Cores Takuji Hieda 1 Noriko Etani
SMYLE OpenCL 128 1 1 1 1 1 2 2 3 3 3 (NEDO) IT FPGA SMYLEref SMYLE OpenCL SMYLE OpenCL FPGA 128 SMYLEref SMYLE OpenCL SMYLE OpenCL Implementation and Evaluations on 128 Cores Takuji Hieda 1 Noriko Etani
Oracle Un お問合せ : Oracle Data Integrator 11g: データ統合設定と管理 期間 ( 標準日数 ):5 コースの概要 Oracle Data Integratorは すべてのデータ統合要件 ( 大量の高パフォーマンス バッチ ローブンの統合プロセスおよ
:5 コースの概要 Oracle Data Integratorは すべてのデータ統合要件 ( 大量の高パフォーマンス バッチ ローブンの統合プロセスおよ") Oracle Un お問合せ : 0120- Oracle Data Integrator 11g: データ統合設定と管理 期間 ( 標準日数 ):5 コースの概要 Oracle Data Integratorは すべてのデータ統合要件 ( 大量の高パフォーマンス バッチ ローブンの統合プロセスおよびSOA 対応データ サービスへ ) を網羅する総合的なデータ統合プラットフォームです Oracle
Oracle Un お問合せ : 0120- Oracle Data Integrator 11g: データ統合設定と管理 期間 ( 標準日数 ):5 コースの概要 Oracle Data Integratorは すべてのデータ統合要件 ( 大量の高パフォーマンス バッチ ローブンの統合プロセスおよびSOA 対応データ サービスへ ) を網羅する総合的なデータ統合プラットフォームです Oracle
概要 単語の分散表現に基づく統計的機械翻訳の素性を提案 既存手法の FFNNLM に CNN と Gate を追加 dependency- to- string デコーダにおいて既存手法を上回る翻訳精度を達成
 Encoding Source Language with Convolu5onal Neural Network for Machine Transla5on Fandong Meng, Zhengdong Lu, Mingxuan Wang, Hang Li, Wenbin Jiang, Qun Liu, ACL- IJCNLP 2015 すずかけ読み会奥村 高村研究室博士二年上垣外英剛 概要
Encoding Source Language with Convolu5onal Neural Network for Machine Transla5on Fandong Meng, Zhengdong Lu, Mingxuan Wang, Hang Li, Wenbin Jiang, Qun Liu, ACL- IJCNLP 2015 すずかけ読み会奥村 高村研究室博士二年上垣外英剛 概要
SUALAB INTRODUCTION SUALAB Solution SUALAB は 人工知能 ( ディープラーニング ) による画像解析技術を通して 迅速 正確 そして使いやすいマシンビジョン用のディープラーニングソフトウェアライブラリーである SuaKIT を提供します これは 従来のマシン
 による画像解析技術を通して 迅速 正確 そして使いやすいマシンビジョン用のディープラーニングソフトウェアライブラリーである SuaKIT を提供します これは 従来のマシン") SuaKIT suɑ kít Deep learning S/WLibrary for MachineVision SuaKIT は ディスプレイ 太陽光 PCB 半導体など 様々な分野で使用できる メーカー独自のディープラーニングのマシンビジョンソフトウェアライブラリーです SuaKIT は 様々な産業分野から実際に取得された画像データに基づいて開発されました Samsung LG SK Hanwha
SuaKIT suɑ kít Deep learning S/WLibrary for MachineVision SuaKIT は ディスプレイ 太陽光 PCB 半導体など 様々な分野で使用できる メーカー独自のディープラーニングのマシンビジョンソフトウェアライブラリーです SuaKIT は 様々な産業分野から実際に取得された画像データに基づいて開発されました Samsung LG SK Hanwha
この方法では, 複数のアドレスが同じインデックスに対応づけられる可能性があるため, キャッシュラインのコピーと書き戻しが交互に起きる性のミスが発生する可能性がある. これを回避するために考案されたのが, 連想メモリアクセスができる形キャッシュである. この方式は, キャッシュに余裕がある限り主記憶の
 計算機システム Ⅱ 演習問題学科学籍番号氏名 1. 以下の分の空白を埋めなさい. CPUは, 命令フェッチ (F), 命令デコード (D), 実行 (E), 計算結果の書き戻し (W), の異なるステージの処理を反復実行するが, ある命令の計算結果の書き戻しをするまで, 次の命令のフェッチをしない場合, ( 単位時間当たりに実行できる命令数 ) が低くなる. これを解決するために考案されたのがパイプライン処理である.
計算機システム Ⅱ 演習問題学科学籍番号氏名 1. 以下の分の空白を埋めなさい. CPUは, 命令フェッチ (F), 命令デコード (D), 実行 (E), 計算結果の書き戻し (W), の異なるステージの処理を反復実行するが, ある命令の計算結果の書き戻しをするまで, 次の命令のフェッチをしない場合, ( 単位時間当たりに実行できる命令数 ) が低くなる. これを解決するために考案されたのがパイプライン処理である.
提案書
 アクセスログ解析ソフト Angelfish インストールについて Windows 版 2018 年 05 月 07 日 ( 月 ) 有限会社インターログ TEL: 042-354-9620 / FAX: 042-354-9621 URL: http://www.interlog.co.jp/ はじめに Angelfish のインストールに手順について説明致します 詳細は US のヘルプサイトを参照してください
アクセスログ解析ソフト Angelfish インストールについて Windows 版 2018 年 05 月 07 日 ( 月 ) 有限会社インターログ TEL: 042-354-9620 / FAX: 042-354-9621 URL: http://www.interlog.co.jp/ はじめに Angelfish のインストールに手順について説明致します 詳細は US のヘルプサイトを参照してください
インテル Parallel Studio XE 2017 Composer Edition for Fortran Windows* インストール ガイド Rev (2017/06/08) エクセルソフト株式会社
 エクセルソフト株式会社") インテル Parallel Studio XE 2017 Composer Edition for Fortran Windows* インストール ガイド Rev. 2. 1 (2017/06/08) エクセルソフト株式会社 www.xlsoft.com 目次 1 はじめに... 3 2 製品に含まれるコンポーネント... 3 3 動作環境... 4 オペレーティング システム... 4 Microsoft
インテル Parallel Studio XE 2017 Composer Edition for Fortran Windows* インストール ガイド Rev. 2. 1 (2017/06/08) エクセルソフト株式会社 www.xlsoft.com 目次 1 はじめに... 3 2 製品に含まれるコンポーネント... 3 3 動作環境... 4 オペレーティング システム... 4 Microsoft
Nios II マイコン活用ガイド Nios II マイコンボード紹介 ステップ 1 AuCE C3 製品紹介 AuCE C3 は ソフトコア プロセッサ Nios II( アルテラ社 ) を搭載可能なマイコンボードです 弊社の基本ソフトウェアをインストールし FPGA 開発者のデザインと Nios
 を搭載可能なマイコンボードです 弊社の基本ソフトウェアをインストールし FPGA 開発者のデザインと Nios") Nios II マイコン活用ガイド CHAPTER No:010Cmn 対象品 : 目次 Nios II マイコンボード紹介 2 ステップ 1 AuCE C3 製品紹介 2 ステップ 2 AuCE C3 構成 3 ステップ 3 関連ドキュメント概略 10 1 Nios II マイコン活用ガイド Nios II マイコンボード紹介 ステップ 1 AuCE C3 製品紹介 AuCE C3 は ソフトコア
Nios II マイコン活用ガイド CHAPTER No:010Cmn 対象品 : 目次 Nios II マイコンボード紹介 2 ステップ 1 AuCE C3 製品紹介 2 ステップ 2 AuCE C3 構成 3 ステップ 3 関連ドキュメント概略 10 1 Nios II マイコン活用ガイド Nios II マイコンボード紹介 ステップ 1 AuCE C3 製品紹介 AuCE C3 は ソフトコア
Windows Azure Microsoft Azure 登 場 本 セッションはここ!! 2
 プライベートクラウド 構 築 ツール ~ロードマップ~ Windows Azure Microsoft Azure 登 場 本 セッションはここ!! 2 1. Azure Pack の 今 2. Azure Stack の 前 に 最 近 の Azure 3. Azure Stack とは? 4. 今 のうちから 知 っておいてほしい 事 3 4 Microsoft Azure (パブリッククラウド)
プライベートクラウド 構 築 ツール ~ロードマップ~ Windows Azure Microsoft Azure 登 場 本 セッションはここ!! 2 1. Azure Pack の 今 2. Azure Stack の 前 に 最 近 の Azure 3. Azure Stack とは? 4. 今 のうちから 知 っておいてほしい 事 3 4 Microsoft Azure (パブリッククラウド)
strtok-count.eps
 IoT FPGA 2016/12/1 IoT FPGA 200MHz 32 ASCII PCI Express FPGA OpenCL (Volvox) Volvox CPU 10 1 IoT (Internet of Things) 2020 208 [1] IoT IoT HTTP JSON ( Python Ruby) IoT IoT IoT (Hadoop [2] ) AI (Artificial
IoT FPGA 2016/12/1 IoT FPGA 200MHz 32 ASCII PCI Express FPGA OpenCL (Volvox) Volvox CPU 10 1 IoT (Internet of Things) 2020 208 [1] IoT IoT HTTP JSON ( Python Ruby) IoT IoT IoT (Hadoop [2] ) AI (Artificial
InfiniDB最小推奨仕様ガイド
 最小推奨仕様ガイド Release 4.0 Document Version 4.0-1 www.calpont.com 1 InfiniDB 最小推奨仕様ガイド 2013 年 10 月 Copyright 本書に記載された InfiniDB Calpont InfiniDB ロゴおよびその他のすべての製品またはサービスの名称またはスローガンは Calpont およびそのサプライヤまたはライセンサの商標であり
最小推奨仕様ガイド Release 4.0 Document Version 4.0-1 www.calpont.com 1 InfiniDB 最小推奨仕様ガイド 2013 年 10 月 Copyright 本書に記載された InfiniDB Calpont InfiniDB ロゴおよびその他のすべての製品またはサービスの名称またはスローガンは Calpont およびそのサプライヤまたはライセンサの商標であり
画像分野におけるディープラーニングの新展開
 画像分野におけるディープラーニングの新展開 MathWorks Japan アプリケーションエンジニアリング部テクニカルコンピューティング 太田英司 2017 The MathWorks, Inc. 1 画像分野におけるディープラーニングの新展開 物体認識 ( 画像全体 ) 物体の検出と認識物体認識 ( ピクセル単位 ) CNN (Convolutional Neural Network) R-CNN
画像分野におけるディープラーニングの新展開 MathWorks Japan アプリケーションエンジニアリング部テクニカルコンピューティング 太田英司 2017 The MathWorks, Inc. 1 画像分野におけるディープラーニングの新展開 物体認識 ( 画像全体 ) 物体の検出と認識物体認識 ( ピクセル単位 ) CNN (Convolutional Neural Network) R-CNN
インテル® Arria®10 Avalon®-MM インターフェイスのPCI Express*デザイン例向けユーザーガイド
 更新情報 フィードバック 最新版をウェブからダウンロード : PDF HTML 目次 目次... 3 1.1 ディレクトリー構造... 4 1.2 Avalon-MM エンドポイントでのデザイン構成... 4 1.3 デザインの生成... 4 1.4 デザインのシミュレーション...5 1.5 ハードウェアでのテストとデザインの統合... 6 2 デザイン例の説明... 10 2.1 デザイン階層と一致する
更新情報 フィードバック 最新版をウェブからダウンロード : PDF HTML 目次 目次... 3 1.1 ディレクトリー構造... 4 1.2 Avalon-MM エンドポイントでのデザイン構成... 4 1.3 デザインの生成... 4 1.4 デザインのシミュレーション...5 1.5 ハードウェアでのテストとデザインの統合... 6 2 デザイン例の説明... 10 2.1 デザイン階層と一致する
it-ken_open.key
 深層学習技術の進展 ImageNet Classification 画像認識 音声認識 自然言語処理 機械翻訳 深層学習技術は これらの分野において 特に圧倒的な強みを見せている Figure (Left) Eight ILSVRC-2010 test Deep images and the cited4: from: ``ImageNet Classification with Networks et
深層学習技術の進展 ImageNet Classification 画像認識 音声認識 自然言語処理 機械翻訳 深層学習技術は これらの分野において 特に圧倒的な強みを見せている Figure (Left) Eight ILSVRC-2010 test Deep images and the cited4: from: ``ImageNet Classification with Networks et
Mastering the Game of Go without Human Knowledge ( ) AI 3 1 AI 1 rev.1 (2017/11/26) 1 6 2
 AI 3 1 AI 1 rev.1 (2017/11/26) 1 6 2") 6 2 6.1........................................... 3 6.2....................... 5 6.2.1........................... 5 6.2.2........................... 9 6.2.3................. 11 6.3.......................
6 2 6.1........................................... 3 6.2....................... 5 6.2.1........................... 5 6.2.2........................... 9 6.2.3................. 11 6.3.......................
! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2
![! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2](/thumbs/88/115445009.jpg "! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2") ! OpenCL [Open Computing Language] 言 [OpenCL C 言 ] CPU, GPU, Cell/B.E.,DSP 言 行行 [OpenCL Runtime] OpenCL C 言 API Khronos OpenCL Working Group AMD Broadcom Blizzard Apple ARM Codeplay Electronic Arts Freescale
! OpenCL [Open Computing Language] 言 [OpenCL C 言 ] CPU, GPU, Cell/B.E.,DSP 言 行行 [OpenCL Runtime] OpenCL C 言 API Khronos OpenCL Working Group AMD Broadcom Blizzard Apple ARM Codeplay Electronic Arts Freescale
PHP 開発ツール Zend Studio PHP アフ リケーションサーハ ー Zend Server OSC Tokyo/Spring /02/28 株式会社イグアスソリューション事業部
 PHP 開発ツール Zend Studio PHP アフ リケーションサーハ ー Zend Server ご紹介 @ OSC Tokyo/Spring 2015 2015/02/28 株式会社イグアスソリューション事業部 アジェンダ Eclipse ベースの PHP 開発ツール Zend Studio 11 日本語版によるアプリケーション開発について PHP アプリケーションサーバー Zend Server
PHP 開発ツール Zend Studio PHP アフ リケーションサーハ ー Zend Server ご紹介 @ OSC Tokyo/Spring 2015 2015/02/28 株式会社イグアスソリューション事業部 アジェンダ Eclipse ベースの PHP 開発ツール Zend Studio 11 日本語版によるアプリケーション開発について PHP アプリケーションサーバー Zend Server
Release Note for Recording Server Monitoring Tool V1.1.1 (Japanese)
") Recording Server Monitoring Tool リリースノート ソフトウェアバージョン 1.1.1 第 2 版 ( 最終修正日 2013 年 10 月 10 日 ) c 2013 Sony Corporation 著作権について権利者の許諾を得ることなく このソフトウェアおよび本書の内容の全部または一部を複写すること およびこのソフトウェアを賃貸に使用することは 著作権法上禁止されております
Recording Server Monitoring Tool リリースノート ソフトウェアバージョン 1.1.1 第 2 版 ( 最終修正日 2013 年 10 月 10 日 ) c 2013 Sony Corporation 著作権について権利者の許諾を得ることなく このソフトウェアおよび本書の内容の全部または一部を複写すること およびこのソフトウェアを賃貸に使用することは 著作権法上禁止されております
共通マイクロアーキテクチャ 富士通はプロセッサー設計に共通マイクロアーキテクチャを導入し メインフレーム UNIX サーバーおよびスーパーコンピューターそれぞれの要件を満たすプロセッサーの継続的かつ効率的な開発を容易にしている また この取り組みにより それぞれの固有要件を共通機能として取り込むこと
 IDC ホワイトペーパー : メインフレーム UNIX サーバー スーパーコンピューターを統合開発 : 共通マイクロプロセッサーアーキテクチャ 共通マイクロアーキテクチャ 富士通はプロセッサー設計に共通マイクロアーキテクチャを導入し メインフレーム UNIX サーバーおよびスーパーコンピューターそれぞれの要件を満たすプロセッサーの継続的かつ効率的な開発を容易にしている また この取り組みにより それぞれの固有要件を共通機能として取り込むことを可能としている
IDC ホワイトペーパー : メインフレーム UNIX サーバー スーパーコンピューターを統合開発 : 共通マイクロプロセッサーアーキテクチャ 共通マイクロアーキテクチャ 富士通はプロセッサー設計に共通マイクロアーキテクチャを導入し メインフレーム UNIX サーバーおよびスーパーコンピューターそれぞれの要件を満たすプロセッサーの継続的かつ効率的な開発を容易にしている また この取り組みにより それぞれの固有要件を共通機能として取り込むことを可能としている
Microsoft Word - HOKUSAI_system_overview_ja.docx
 HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図