3. みせかけの相関単位根系列が注目されるのは これを持つ変数同士の回帰には意味がないためだ 単位根系列で代表的なドリフト付きランダムウォークを発生させてそれを確かめてみよう yと xという変数名の系列をを作成する yt=0.5+yt-1+et xt=0.1+xt-1+et 初期値を y は 10
|
|
|
- ことこ いなおか
- 5 years ago
- Views:
Transcription
1 第 10 章 くさりのない犬 はじめにこの章では 単位根検定や 共和分検定を説明する データが単位根を持つ系列の場合 見せかけの相関をする場合があり 推計結果が信用できなくなる 経済分析の手順として 系列が定常系列か単位根を持つ非定常系列かを見極め 定常系列であればそのまま推計し 非定常系列であれば階差をとって推計するのが一般的である 1. ランダムウオーク 最も簡単な単位根を持つ系列としてランダムウオークがある ランダムウォークとは 次のような式であらわされる系列である y + e t = yt -1 t AR(1) モデルで y t-1 の係数が1の場合と考えられる 2. 時系列データの種類ランダムウォークのほか 時系列分析でよく使う概念を整理すると次の表のようになる 表でみるように 実際には同義ではないが 最初にあまり混乱しないためには次のようにまず考えるほうがよい 非定常系列 = 単位根系列 =I(1)= ランダムウオーク 時系列の種類 定常系列 平均 分散が一定 ARMAモデル I(0) ホワイトノイズ 階差をとらずに定常 非定常系列 平均または分散が一定でない発散系列経済変数にはあまりない単位根系列時間とともに分散が拡大 I(1) 階差を1 回とると定常ランダムウォークドリフト付きランダムウォークトレンド ドリフト付きランダムウオーク I(2) など階差を2 回とると定常 1
 をする誤差 項とする 次に y に x を回帰する つまり次式を推計する yt=a+bx t+e t 推計した推計結果は誤差項の発生値が違うため 以下の結果と同じならないが 1 決定係数が高い2t 値が有意 3ダービン ワトソン比が低い--といった症状を示すはずである")
2 3. みせかけの相関単位根系列が注目されるのは これを持つ変数同士の回帰には意味がないためだ 単位根系列で代表的なドリフト付きランダムウォークを発生させてそれを確かめてみよう yと xという変数名の系列をを作成する yt=0.5+yt-1+et xt=0.1+xt-1+et 初期値を y は 10 x は 100 とし e は標準正規分布 ( 平均ゼロ 標準偏差 1) をする誤差 項とする 次に y に x を回帰する つまり次式を推計する yt=a+bx t+e t 推計した推計結果は誤差項の発生値が違うため 以下の結果と同じならないが 1 決定係数が高い2t 値が有意 3ダービン ワトソン比が低い--といった症状を示すはずである xとyはランダムに発生された系列であり 本来関係のない系列である それにもかかわらず 最小二乗法の推定では ダービン ワトソン比以外は満足のいく結果となる 2
) は 階差をとると定常になる 単位根検定メニューに行くには 2 種類の方法がある ここでは実質 GDP( 系列 名 GDP95 ) の単位根検定を例にする ワークファイルで")
3 これらの系列が本来関係がないことは 両者の階差をとるとわかる 次の式を推計する ことだ y t =a+b x t +e t 4. 単位根検定 単位根検定は ある系列が定常か非定常かについて検討するものである 変数 X が次式 で表される場合 単位根を持つ系列となる Xt=Xt-1+et 単位根のある系列 (I(1)) は 階差をとると定常になる 単位根検定メニューに行くには 2 種類の方法がある ここでは実質 GDP( 系列 名 GDP95 ) の単位根検定を例にする ワークファイルで [Quick] [Series Statistics] [Unit Root Test] を選んで 系列名を入力する または GDP95 をダブルクリックして 以下のメニューを選ぶ [View ] [Unit Root Test] 次のような画面となる 3
 である 次に 1st Difference で調べ 定常になれば I(1) となる 金利は I(0) トレンドを持つようなほかの変数は I(1) になる可能性が高い Include in equation test 検定する式の形を決める trend and intercept Intercept None")
4 画面にあるオプションの内容は次の通りである Test type 単位根検定にはさまざまな種類があるが ここでは代表的なディッキーフラーテストを行う 検定する式の誤差項にラグを想定しない場合がディっキーフラーテストで ラグを想定した場合が ADF( 拡張されたディッキー フラー ) テストと呼ばれる Test for unit root in 何階の階差で定常になるかを調べる まず level で単位根検定し 定常であればその系列は I(0) である 次に 1st Difference で調べ 定常になれば I(1) となる 金利は I(0) トレンドを持つようなほかの変数は I(1) になる可能性が高い Include in equation test 検定する式の形を決める trend and intercept Intercept None yt=c+(α-1)yt-1+βtrend+e yt=c+(α-1)yt-1+e yt=(α-1)yt-1+e Laglength 誤差項のラグを何期とるかを決める ゼロの場合がディッキーフラーテストになる ラ グが 1 の場合 2 の場合は次のように書ける 4
5 1 の時 et=ρ1et-1+εt 2 の時 et=ρ1et-1+ρ2et-2+εt EViews では ラグを自動的に選択するプログラムを使うことができる (Automatic selection) ラグを選ぶ時の基準となる統計量も選べるようになっている SBIC 基準で選 ぶのが標準だ 5. ディッキーフラーテストの実行 まず 最も単純なディッキーフラーテストを実行してみよう オプションは次のものを 選択する 定数項付きで推計し ラグの長さをゼロとする Test type Augumented Dicky-Fuller Test for unit root in level Include in test equation Intercept Lag length User specified: 0 これは 次の式のαが1かどうかを検定することを目的としている yt=a+αyt-1+e αが1なら単位根を持つことになる αの分布は計算できないので 次のような形に変形して 最小二乗法で推計する yt=(1-α)yt-1+e 1 αがゼロかどうかを検定する この場合もt 分布にはならず 左側に寄った分布になるが 臨界値などは計算されるので 検定を行うことができる 5
 検定等計量は t 値 (t-statistic) だが 通常の係数の場合と臨界値が違う 10% レベルで 係数がゼロである という帰無仮説を棄却するには t 値が-2.59 よりも小さくならなければならない 推計したt 値は-1.")
6 この検定は次の式を推計して 係数である がゼロと有意に違うかどうかの検定 だ D(GDP95)= *GDP95(-1) 検定等計量は t 値 (t-statistic) だが 通常の係数の場合と臨界値が違う 10% レベルで 係数がゼロである という帰無仮説を棄却するには t 値が-2.59 よりも小さくならなければならない 推計したt 値は-1.40 であり 係数がゼロである という帰無仮説が棄却できない つまり 実質 GDP は単位根を持つという結論になる 6. コマンドやプログラムでの操作 6
7 コマンドやプログラムで使う場合は次のような書式となる コマンド uroot( オプション ) 系列名 プログラム系列名.uroot( オプション ) 代表的なオプションには次のようなものがある 検定する式の形 const trend none 検定法 adf pp 誤差のラグ数 lag= 整数標準設定では a ( 自動設定 ) 自動ラグ決定機能を使う場合の基準等計量 info=sic,aic など 結果の保存 save= 行列名 7. 共和分検定単位根を持つ系列同士でも 長期的には関係を持っている系列があり それらの系列を 共和分の関係にある と呼ぶ 共和分の検定には 1グレンジャー アングル検定 2ヨハンセンの検定 などがある 変数同士がエラーコレクションモデルの形で表現できれば共和分の関係にあることも知られている 8. グレンジャー アングル検定 変数 y と x に共和分の関係があるかどうかを調べるには 両者を回帰させた誤差が単位 根を持つかどうかを検定すればよい yt=a+bxt+ut い ut が定常系列であれば共和分の関係にあり 単位根系列であれば 共和分の関係ではな EViews の操作 まず最小二乗法で 推計する [Quick] [Esitmate Equaution] 最小二乗法のウインドウが出てくるので 次の文字列を入力する 7
![cp95 c gdp95 [OK] を押す この推計による残差を一つの系列として作成する 方程式オブジェクト :[Proc] [Make Residual Series.](/docs-images/92/108701601/images/8-0.jpg "..] 次のウインドウでは residual type は ordinary のままとし 残差に適当な名前をつける 標準では resid01 があらかじめ入っている [OK] を押すと 残差系列のオブジェクトが表示される この系列に対して単位根検定を行う ワークファイルに戻って系列オブジェクト resid01")
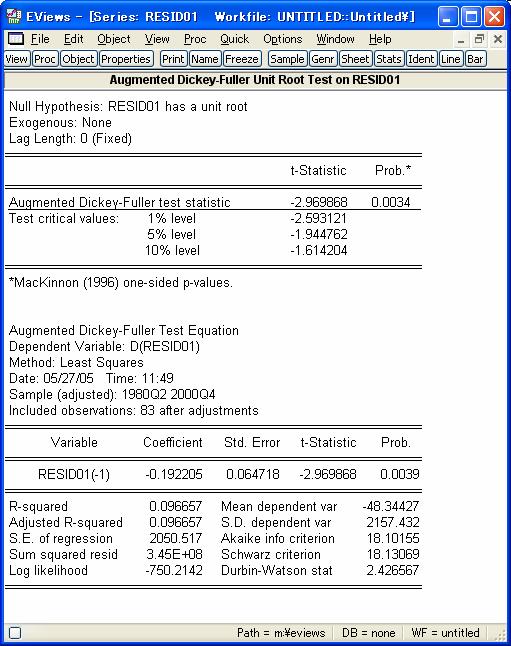
8 cp95 c gdp95 [OK] を押す この推計による残差を一つの系列として作成する 方程式オブジェクト :[Proc] [Make Residual Series...] 次のウインドウでは residual type は ordinary のままとし 残差に適当な名前をつける 標準では resid01 があらかじめ入っている [OK] を押すと 残差系列のオブジェクトが表示される この系列に対して単位根検定を行う ワークファイルに戻って系列オブジェクト resid01 をダブルクリックする 系列オブジェクト :[View] [Unit Root Test...] 残差系列は推計されたものなので 通常の単位根系列の臨界値とは異なることに注意す 8
9 る必要がある 残差の和はゼロになるので ドリフト付きやトレンド付きなどではなく 通常のランダムウォークを選ぶ ラグも考慮しなくてもよい 単位根ウインドウでの設定 Test type Test for unit root in Include in test equation Lag length Augumented Dicky-Fuller level none auto 9
10 10

11 9. エラーコレクションモデル エラーコレクションモデルは 次のようなモデルを推計するものだ yt=σ xt-γet-1+ut ( 短期的関係 ) et=yt-a-bxt ( 長期的関係 ) 実際の推計では まず長期的関係を推計し その残差を説明変数の一つとする短期的関係を推計する 長期的関係の推計は アングル グレンジャー検定の推計の際の残差の作成法と同じなので省略する 長期的関係の残差が作成できたらそれを説明変数として 短期的関係を推計する 最小二乗法のウインドウで次の文字列を入力する 残差系列の名前は resid01 とする 残差は当期でなく 一期前の変数を使うことに注意する 11
12 グレンジャー アングル検定では 共和分の関係は否定されたが エラーコレクション モデルは成り立っている 残差項の t 値は -2.5 で 有意にマイナスである プログラム equation eq1.ls cp95 c gdp95 長期的関係の推計 eq1.makeresids res01 上記方程式の残差を res01 という変数として登録 equation eq2.ls d(cp95) d(gdp95) res01(-1) 短期的関係の推計 show eq1 eq2 方程式の表示 12
13 13
Microsoft Word - eviews6_
 6 章 : 共和分と誤差修正モデル 2017/11/22 新谷元嗣 藪友良 石原卓弥 教科書 6 章 5 節のデータを用いて エングル = グレンジャーの方法 誤差修正モデル ヨハンセンの方法を学んでいこう 1. データの読み込みと単位根検定 COINT6.XLS のデータを Workfile に読み込む このファイルは教科書の表 6.1 の式から 生成された人工的なデータである ( 下表参照 )
6 章 : 共和分と誤差修正モデル 2017/11/22 新谷元嗣 藪友良 石原卓弥 教科書 6 章 5 節のデータを用いて エングル = グレンジャーの方法 誤差修正モデル ヨハンセンの方法を学んでいこう 1. データの読み込みと単位根検定 COINT6.XLS のデータを Workfile に読み込む このファイルは教科書の表 6.1 の式から 生成された人工的なデータである ( 下表参照 )
Microsoft Word - 計量研修テキスト_第5版).doc
.doc") Q8-1 テキスト P131 Engle-Granger 検定 Dependent Variable: RM2 Date: 11/04/05 Time: 15:15 Sample: 1967Q1 1999Q1 Included observations: 129 RGDP 0.012792 0.000194 65.92203 0.0000 R -95.45715 11.33648-8.420349
Q8-1 テキスト P131 Engle-Granger 検定 Dependent Variable: RM2 Date: 11/04/05 Time: 15:15 Sample: 1967Q1 1999Q1 Included observations: 129 RGDP 0.012792 0.000194 65.92203 0.0000 R -95.45715 11.33648-8.420349
Microsoft Word - eviews2_
 2018/02/02 新谷元嗣 藪友良 高尾庄吾 2 章 : 定常時系列モデル ここでは教科書 2 章 ( 定常時系列モデル ) の内容を再現する 具体的には ARMA モデルにおける同定 推定の手順 構造変化の問題を扱う 1 コレログラム Workfile を新規作成し ホームページの SIM2.xls から データを読み込もう 人工的に発生させたデータなので Date specification
2018/02/02 新谷元嗣 藪友良 高尾庄吾 2 章 : 定常時系列モデル ここでは教科書 2 章 ( 定常時系列モデル ) の内容を再現する 具体的には ARMA モデルにおける同定 推定の手順 構造変化の問題を扱う 1 コレログラム Workfile を新規作成し ホームページの SIM2.xls から データを読み込もう 人工的に発生させたデータなので Date specification
Dependent Variable: LOG(GDP00/(E*HOUR)) Date: 02/27/06 Time: 16:39 Sample (adjusted): 1994Q1 2005Q3 Included observations: 47 after adjustments C -1.5
) Date: 02/27/06 Time: 16:39 Sample (adjusted): 1994Q1 2005Q3 Included observations: 47 after adjustments C -1.5") 第 4 章 この章では 最小二乗法をベースにして 推計上のさまざまなテクニックを検討する 変数のバリエーション 係数の制約係数にあらかじめ制約がある場合がある たとえばマクロの生産関数は 次のように表すことができる 生産要素は資本と労働である 稼動資本は資本ストックに稼働率をかけることで計算でき 労働投入量は 就業者数に総労働時間をかけることで計算できる 制約を掛けずに 推計すると次の結果が得られる
第 4 章 この章では 最小二乗法をベースにして 推計上のさまざまなテクニックを検討する 変数のバリエーション 係数の制約係数にあらかじめ制約がある場合がある たとえばマクロの生産関数は 次のように表すことができる 生産要素は資本と労働である 稼動資本は資本ストックに稼働率をかけることで計算でき 労働投入量は 就業者数に総労働時間をかけることで計算できる 制約を掛けずに 推計すると次の結果が得られる
今回用いる例データ lh( 小文字のエル ) ある女性の血液中の黄体ホルモンを 10 分間隔で測定した時系列データ UKgas 1960 年 ~1986 年のイギリスのガス消費量を四半期ごとに観測した時系列データ ldeaths 1974 年 ~1979 年のイギリスで喘息 気管支炎 肺気腫による死
 ある女性の血液中の黄体ホルモンを 10 分間隔で測定した時系列データ UKgas 1960 年 ~1986 年のイギリスのガス消費量を四半期ごとに観測した時系列データ ldeaths 1974 年 ~1979 年のイギリスで喘息 気管支炎 肺気腫による死") 12 章 - 時系列分析 1296603c 埴岡瞬 今回用いる例データ lh( 小文字のエル ) ある女性の血液中の黄体ホルモンを 10 分間隔で測定した時系列データ UKgas 1960 年 ~1986 年のイギリスのガス消費量を四半期ごとに観測した時系列データ ldeaths 1974 年 ~1979 年のイギリスで喘息 気管支炎 肺気腫による死亡数を月ごとに記録した時系列データ mdeaths
12 章 - 時系列分析 1296603c 埴岡瞬 今回用いる例データ lh( 小文字のエル ) ある女性の血液中の黄体ホルモンを 10 分間隔で測定した時系列データ UKgas 1960 年 ~1986 年のイギリスのガス消費量を四半期ごとに観測した時系列データ ldeaths 1974 年 ~1979 年のイギリスで喘息 気管支炎 肺気腫による死亡数を月ごとに記録した時系列データ mdeaths
Microsoft PowerPoint - e-stat(OLS).pptx
.pptx") 経済統計学 ( 補足 ) 最小二乗法について 担当 : 小塚匡文 2015 年 11 月 19 日 ( 改訂版 ) 神戸大学経済学部 2015 年度後期開講授業 補足 : 最小二乗法 ( 単回帰分析 ) 1.( 単純 ) 回帰分析とは? 標本サイズTの2 変数 ( ここではXとY) のデータが存在 YをXで説明する回帰方程式を推定するための方法 Y: 被説明変数 ( または従属変数 ) X: 説明変数
経済統計学 ( 補足 ) 最小二乗法について 担当 : 小塚匡文 2015 年 11 月 19 日 ( 改訂版 ) 神戸大学経済学部 2015 年度後期開講授業 補足 : 最小二乗法 ( 単回帰分析 ) 1.( 単純 ) 回帰分析とは? 標本サイズTの2 変数 ( ここではXとY) のデータが存在 YをXで説明する回帰方程式を推定するための方法 Y: 被説明変数 ( または従属変数 ) X: 説明変数
Microsoft Word - eviews4_
 4 章 : トレンドモデル 2018/02/02 新谷元嗣 藪友良 高尾庄吾 教科書の 4 章の内容を確認しよう 具体的には 単位根検定として ADF 検定 ERS 検定 ペロン検定 パネル単位根検定 またトレンド分解として HP 分解を説明する 1. ADF 検定教科書の 4 章 7 節の例 ( ラグの選択 ) を通して 単位根検定の手順を確認しよう まず LAGLENGTH.XLS のデータを
4 章 : トレンドモデル 2018/02/02 新谷元嗣 藪友良 高尾庄吾 教科書の 4 章の内容を確認しよう 具体的には 単位根検定として ADF 検定 ERS 検定 ペロン検定 パネル単位根検定 またトレンド分解として HP 分解を説明する 1. ADF 検定教科書の 4 章 7 節の例 ( ラグの選択 ) を通して 単位根検定の手順を確認しよう まず LAGLENGTH.XLS のデータを
. 分析内容及びデータ () 分析内容中長期の代表的金利である円金利スワップを題材に 年 -5 年物のイールドスプレッドの変動を自己回帰誤差モデル * により時系列分析を行った * ) 自己回帰誤差モデル一般に自己回帰モデルは線形回帰モデルと同様な考え方で 外生変数の無いT 期間だけ遅れのある従属変
 分析内容中長期の代表的金利である円金利スワップを題材に 年 -5 年物のイールドスプレッドの変動を自己回帰誤差モデル * により時系列分析を行った * ) 自己回帰誤差モデル一般に自己回帰モデルは線形回帰モデルと同様な考え方で 外生変数の無いT 期間だけ遅れのある従属変") () 現在データは最大 5 営業日前までの自己データが受けたショック ( 変動要因 ) の影響を受け 易い ( 情報の有効性 ) 現在の金利変動は 過去のどのタイミングでのショック ( 変動要因 ) を引きずり変動しているのかの推測 ( 偏自己相関 ) また 将来の変動を予測する上で 政策金利変更等の ショックの持続性 はどの程度 将来の変動に影響を与えるか等の判別に役に立つ可能性がある (2) その中でも
() 現在データは最大 5 営業日前までの自己データが受けたショック ( 変動要因 ) の影響を受け 易い ( 情報の有効性 ) 現在の金利変動は 過去のどのタイミングでのショック ( 変動要因 ) を引きずり変動しているのかの推測 ( 偏自己相関 ) また 将来の変動を予測する上で 政策金利変更等の ショックの持続性 はどの程度 将来の変動に影響を与えるか等の判別に役に立つ可能性がある (2) その中でも
Microsoft Word - 訋é⁄‘組渋å�¦H29æœ�末試é¨fi解ç�fl仟㆓.docx
 07 年 8 月 日計量経済学期末試験問. 次元ベクトル x ( x..., x)', w ( w.., w )', v ( v.., v )' は非確率変数であり 一次独立である 最小二乗推定法の残差と説明変数が直交することは証明無く用いてよい 確率ベクトル e ( e... ) ' は E( e ) 0, V ( e ),cov( e j ) 0 ( j) とし 確率ベクトル y=( y...,
07 年 8 月 日計量経済学期末試験問. 次元ベクトル x ( x..., x)', w ( w.., w )', v ( v.., v )' は非確率変数であり 一次独立である 最小二乗推定法の残差と説明変数が直交することは証明無く用いてよい 確率ベクトル e ( e... ) ' は E( e ) 0, V ( e ),cov( e j ) 0 ( j) とし 確率ベクトル y=( y...,
統計的データ解析
 統計的データ解析 011 011.11.9 林田清 ( 大阪大学大学院理学研究科 ) 連続確率分布の平均値 分散 比較のため P(c ) c 分布 自由度 の ( カイ c 平均値 0, 標準偏差 1の正規分布 に従う変数 xの自乗和 c x =1 が従う分布を自由度 の分布と呼ぶ 一般に自由度の分布は f /1 c / / ( c ) {( c ) e }/ ( / ) 期待値 二乗 ) 分布 c
統計的データ解析 011 011.11.9 林田清 ( 大阪大学大学院理学研究科 ) 連続確率分布の平均値 分散 比較のため P(c ) c 分布 自由度 の ( カイ c 平均値 0, 標準偏差 1の正規分布 に従う変数 xの自乗和 c x =1 が従う分布を自由度 の分布と呼ぶ 一般に自由度の分布は f /1 c / / ( c ) {( c ) e }/ ( / ) 期待値 二乗 ) 分布 c
R による共和分分析 1. 共和分分析を行う 1.1 パッケージ urca インスツールする 共和分分析をするために R のパッケージ urca をインスツールする パッケージとは通常の R には含まれていない 追加的な R のコマンドの集まりのようなものである R には追加的に 600 以上のパッ
 R による共和分分析 1. 共和分分析を行う 1.1 パッケージ urca インスツールする 共和分分析をするために R のパッケージ urca をインスツールする パッケージとは通常の R には含まれていない 追加的な R のコマンドの集まりのようなものである R には追加的に 600 以上のパッケージが用意されており それぞれ分析の目的に応じて標準の R にパッケージを追加していくことになる インターネットに接続してあるパソコンで
R による共和分分析 1. 共和分分析を行う 1.1 パッケージ urca インスツールする 共和分分析をするために R のパッケージ urca をインスツールする パッケージとは通常の R には含まれていない 追加的な R のコマンドの集まりのようなものである R には追加的に 600 以上のパッケージが用意されており それぞれ分析の目的に応じて標準の R にパッケージを追加していくことになる インターネットに接続してあるパソコンで
ファイナンスのための数学基礎 第1回 オリエンテーション、ベクトル
 時系列分析 変量時系列モデルとその性質 担当 : 長倉大輔 ( ながくらだいすけ 時系列モデル 時系列モデルとは時系列データを生み出すメカニズムとなるものである これは実際には未知である 私たちにできるのは観測された時系列データからその背後にある時系列モデルを推測 推定するだけである 以下ではいくつかの代表的な時系列モデルを考察する 自己回帰モデル (Auoregressive Model もっとも頻繁に使われる時系列モデルは自己回帰モデル
時系列分析 変量時系列モデルとその性質 担当 : 長倉大輔 ( ながくらだいすけ 時系列モデル 時系列モデルとは時系列データを生み出すメカニズムとなるものである これは実際には未知である 私たちにできるのは観測された時系列データからその背後にある時系列モデルを推測 推定するだけである 以下ではいくつかの代表的な時系列モデルを考察する 自己回帰モデル (Auoregressive Model もっとも頻繁に使われる時系列モデルは自己回帰モデル
2. 時系列分析 プラットフォームの使用法 JMP の 時系列分析 プラットフォームでは 一変量の時系列に対する分析を行うことができます この章では JMP のサンプルデ ータを用いて このプラットフォームの使用法をご説明します JMP のメニューバーより [ ヘルプ ] > [ サンプルデータ ]
![2. 時系列分析 プラットフォームの使用法 JMP の 時系列分析 プラットフォームでは 一変量の時系列に対する分析を行うことができます この章では JMP のサンプルデ ータを用いて このプラットフォームの使用法をご説明します JMP のメニューバーより [ ヘルプ ] > [ サンプルデータ ]](/thumbs/49/25514951.jpg "2. 時系列分析 プラットフォームの使用法 JMP の 時系列分析 プラットフォームでは 一変量の時系列に対する分析を行うことができます この章では JMP のサンプルデ ータを用いて このプラットフォームの使用法をご説明します JMP のメニューバーより [ ヘルプ ] > [ サンプルデータ ]") JMP を用いた ARIMA モデルのあてはめ SAS Institute Japan 株式会社 JMP ジャパン事業部 2013 年 2 月作成 1. はじめに JMP の時系列分析では 一変量の時系列データに対する分析や予測を行うことができ 時系列データに対するグラフ表示 時系列モデルのあてはめ モデルの評価 予測まで 対話的に分析を実行することができます 時系列データにあてはめるモデルとしては
JMP を用いた ARIMA モデルのあてはめ SAS Institute Japan 株式会社 JMP ジャパン事業部 2013 年 2 月作成 1. はじめに JMP の時系列分析では 一変量の時系列データに対する分析や予測を行うことができ 時系列データに対するグラフ表示 時系列モデルのあてはめ モデルの評価 予測まで 対話的に分析を実行することができます 時系列データにあてはめるモデルとしては
スライド 1
 データ解析特論重回帰分析編 2017 年 7 月 10 日 ( 月 )~ 情報エレクトロニクスコース横田孝義 1 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える 具体的には y = a + bx という回帰直線 ( モデル ) でデータを代表させる このためにデータからこの回帰直線の切片 (a) と傾き (b) を最小
データ解析特論重回帰分析編 2017 年 7 月 10 日 ( 月 )~ 情報エレクトロニクスコース横田孝義 1 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える 具体的には y = a + bx という回帰直線 ( モデル ) でデータを代表させる このためにデータからこの回帰直線の切片 (a) と傾き (b) を最小
Microsoft Word - å“Ÿåłžå¸°173.docx
 回帰分析 ( その 3) 経済情報処理 価格弾力性の推定ある商品について その購入量を w 単価を p とし それぞれの変化量を w p で表 w w すことにする この時 この商品の価格弾力性 は により定義される これ p p は p が 1 パーセント変化した場合に w が何パーセント変化するかを示したものである ここで p を 0 に近づけていった極限を考えると d ln w 1 dw dw
回帰分析 ( その 3) 経済情報処理 価格弾力性の推定ある商品について その購入量を w 単価を p とし それぞれの変化量を w p で表 w w すことにする この時 この商品の価格弾力性 は により定義される これ p p は p が 1 パーセント変化した場合に w が何パーセント変化するかを示したものである ここで p を 0 に近づけていった極限を考えると d ln w 1 dw dw
Microsoft PowerPoint - Econometrics pptx
 計量経済学講義 第 4 回回帰モデルの診断と選択 Part 07 年 ( ) 限 担当教員 : 唐渡 広志 研究室 : 経済学研究棟 4 階 43 号室 emal: kkarato@eco.u-toyama.ac.p webste: http://www3.u-toyama.ac.p/kkarato/ 講義の目的 誤差項の分散が不均 である場合や, 系列相関を持つ場合についての検定 法と修正 法を学びます
計量経済学講義 第 4 回回帰モデルの診断と選択 Part 07 年 ( ) 限 担当教員 : 唐渡 広志 研究室 : 経済学研究棟 4 階 43 号室 emal: kkarato@eco.u-toyama.ac.p webste: http://www3.u-toyama.ac.p/kkarato/ 講義の目的 誤差項の分散が不均 である場合や, 系列相関を持つ場合についての検定 法と修正 法を学びます
して 車種に応じて一定額の補助金を支給するというものである この補助金政策は エコカー普及によるCO 2 排出量を削減することに加え 自動車販売促進によってリーマンショック後の大不況を改善するという 2 つの目的を謳って実施された しかし 白井 (2010) によると このエコカー補助金政策による
 によると このエコカー補助金政策による") 三田祭論文 乗用車販売台数からみる エコカー補助金政策の有効性 大谷駿 a, 大橋一輝 b, 小川敦士 c abc 慶應義塾大学経済学部 要旨 本稿では VAR モデルを用いて乗用車販売台数データから 2009 年に行われたエコカー補助金政策が効果的であったかを考察した その結果 エコカー補助金制度の実施は乗用車の販売台数を上昇させるが 同時に制度の終了による反動も観測できるということが示唆された
三田祭論文 乗用車販売台数からみる エコカー補助金政策の有効性 大谷駿 a, 大橋一輝 b, 小川敦士 c abc 慶應義塾大学経済学部 要旨 本稿では VAR モデルを用いて乗用車販売台数データから 2009 年に行われたエコカー補助金政策が効果的であったかを考察した その結果 エコカー補助金制度の実施は乗用車の販売台数を上昇させるが 同時に制度の終了による反動も観測できるということが示唆された
Microsoft Word - eviews1_
 1 章 : はじめての EViews 2018/02/02 新谷元嗣 藪友良 高尾庄吾 1 ここでは分析を行うにあたって 代表的なツールの 1 つとして EViews について解説しよう EViews は 時系列分析に強みを持つ統計ソフトであり その使い易さ また高度な分析に対応できることから 官公庁を中心に広く用いられている 1. データの入力と保存 EViews では データを特有のファイル形式である
1 章 : はじめての EViews 2018/02/02 新谷元嗣 藪友良 高尾庄吾 1 ここでは分析を行うにあたって 代表的なツールの 1 つとして EViews について解説しよう EViews は 時系列分析に強みを持つ統計ソフトであり その使い易さ また高度な分析に対応できることから 官公庁を中心に広く用いられている 1. データの入力と保存 EViews では データを特有のファイル形式である
PowerPoint プレゼンテーション
 データ解析 第 7 回 : 時系列分析 渡辺澄夫 過去から未来を予測する 観測データ 回帰 判別分析 解析方法 主成分 因子 クラスタ分析 時系列予測 時系列を予測する 無限個の確率変数 ( 確率変数が作る無限数列 ){X(t) ; t は整数 } を生成する情報源を考える {X(t)} を確率過程という 確率過程に ついて過去の値から未来を予測するにはどうしたらよいだろうか X(t-K),X(t-K+1),,X(t-1)
データ解析 第 7 回 : 時系列分析 渡辺澄夫 過去から未来を予測する 観測データ 回帰 判別分析 解析方法 主成分 因子 クラスタ分析 時系列予測 時系列を予測する 無限個の確率変数 ( 確率変数が作る無限数列 ){X(t) ; t は整数 } を生成する情報源を考える {X(t)} を確率過程という 確率過程に ついて過去の値から未来を予測するにはどうしたらよいだろうか X(t-K),X(t-K+1),,X(t-1)
切片 ( 定数項 ) ダミー 以下の単回帰モデルを考えよう これは賃金と就業年数の関係を分析している : ( 賃金関数 ) ここで Y i = α + β X i + u i, i =1,, n, u i ~ i.i.d. N(0, σ 2 ) Y i : 賃金の対数値, X i : 就業年数. (
 ダミー 以下の単回帰モデルを考えよう これは賃金と就業年数の関係を分析している : ( 賃金関数 ) ここで Y i = α + β X i + u i, i =1,, n, u i ~ i.i.d. N(0, σ 2 ) Y i : 賃金の対数値, X i : 就業年数. (") 統計学ダミー変数による分析 担当 : 長倉大輔 ( ながくらだいすけ ) 1 切片 ( 定数項 ) ダミー 以下の単回帰モデルを考えよう これは賃金と就業年数の関係を分析している : ( 賃金関数 ) ここで Y i = α + β X i + u i, i =1,, n, u i ~ i.i.d. N(0, σ 2 ) Y i : 賃金の対数値, X i : 就業年数. ( 実際は賃金を就業年数だけで説明するのは現実的はない
統計学ダミー変数による分析 担当 : 長倉大輔 ( ながくらだいすけ ) 1 切片 ( 定数項 ) ダミー 以下の単回帰モデルを考えよう これは賃金と就業年数の関係を分析している : ( 賃金関数 ) ここで Y i = α + β X i + u i, i =1,, n, u i ~ i.i.d. N(0, σ 2 ) Y i : 賃金の対数値, X i : 就業年数. ( 実際は賃金を就業年数だけで説明するのは現実的はない
博士学位請求論文審査報告書 申請者 : 植松良公 論文題目 :Statistical Analysis of Nonlinear Time Series 1. 論文の主題と構成経済時系列分析においては, 基礎となる理論は定常性や線形性を仮定して構築されるが, 実際の経済データにおいては, 非定常性や
 Title 非線形時系列の統計解析 Author(s) 植松, 良公 Citation Issue 2013-09-30 Date Type Thesis or Dissertation Text Version ETD URL http://doi.org/10.15057/25906 Right Hitotsubashi University Repository 博士学位請求論文審査報告書 申請者
Title 非線形時系列の統計解析 Author(s) 植松, 良公 Citation Issue 2013-09-30 Date Type Thesis or Dissertation Text Version ETD URL http://doi.org/10.15057/25906 Right Hitotsubashi University Repository 博士学位請求論文審査報告書 申請者
Microsoft PowerPoint - 資料04 重回帰分析.ppt
 04. 重回帰分析 京都大学 加納学 Division of Process Control & Process Sstems Engineering Department of Chemical Engineering, Koto Universit manabu@cheme.koto-u.ac.jp http://www-pse.cheme.koto-u.ac.jp/~kano/ Outline
04. 重回帰分析 京都大学 加納学 Division of Process Control & Process Sstems Engineering Department of Chemical Engineering, Koto Universit manabu@cheme.koto-u.ac.jp http://www-pse.cheme.koto-u.ac.jp/~kano/ Outline
スライド 1
 データ解析特論第 10 回 ( 全 15 回 ) 2012 年 12 月 11 日 ( 火 ) 情報エレクトロニクス専攻横田孝義 1 終了 11/13 11/20 重回帰分析をしばらくやります 12/4 12/11 12/18 2 前回から回帰分析について学習しています 3 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える
データ解析特論第 10 回 ( 全 15 回 ) 2012 年 12 月 11 日 ( 火 ) 情報エレクトロニクス専攻横田孝義 1 終了 11/13 11/20 重回帰分析をしばらくやります 12/4 12/11 12/18 2 前回から回帰分析について学習しています 3 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える
ビジネス統計 統計基礎とエクセル分析 正誤表
 ビジネス統計統計基礎とエクセル分析 ビジネス統計スペシャリスト エクセル分析スペシャリスト 公式テキスト正誤表と学習用データ更新履歴 平成 30 年 5 月 14 日現在 公式テキスト正誤表 頁場所誤正修正 6 知識編第 章 -3-3 最頻値の解説内容 たとえば, 表.1 のデータであれば, 最頻値は 167.5cm というたとえば, 表.1 のデータであれば, 最頻値は 165.0cm ということになります
ビジネス統計統計基礎とエクセル分析 ビジネス統計スペシャリスト エクセル分析スペシャリスト 公式テキスト正誤表と学習用データ更新履歴 平成 30 年 5 月 14 日現在 公式テキスト正誤表 頁場所誤正修正 6 知識編第 章 -3-3 最頻値の解説内容 たとえば, 表.1 のデータであれば, 最頻値は 167.5cm というたとえば, 表.1 のデータであれば, 最頻値は 165.0cm ということになります
2つの操作メニューワークファイル上での操作は 2 種類のメニューから選んで操作する 1 つはメイン画面に付いている メイン画面のメニュー でもう一つは オブジェクトごとのメニュー である 一般的なメニューは メイン画面のメニュー で選び 系列 グラフなどのオブジェクトごとに特有なメニューはオブジェク
 第 1 章 Eviews の使い方 EViews とはQMS 社が開発した計量経済学用のソフトウエアである さまざまな推計法がボタンを押したり 式を入力するだけで実行できる初心者になじみやすいソフトウエアだ そのうえ プログラム機能も有しており 複雑なデータの加工やさまざまな推計結果の出力も可能であり 上級者が使っても使いでのあるものになっている ワークファイル中心に構成 EVIews はワークファイル
第 1 章 Eviews の使い方 EViews とはQMS 社が開発した計量経済学用のソフトウエアである さまざまな推計法がボタンを押したり 式を入力するだけで実行できる初心者になじみやすいソフトウエアだ そのうえ プログラム機能も有しており 複雑なデータの加工やさまざまな推計結果の出力も可能であり 上級者が使っても使いでのあるものになっている ワークファイル中心に構成 EVIews はワークファイル
Microsoft PowerPoint - S11_1 2010Econometrics [互換モード]
![Microsoft PowerPoint - S11_1 2010Econometrics [互換モード]](/thumbs/79/79771572.jpg "Microsoft PowerPoint - S11_1 2010Econometrics [互換モード]") S11_1 計量経済学 一般化古典的回帰モデル -3 1 図 7-3 不均一分散の検定と想定の誤り 想定の誤りと不均一分散均一分散を棄却 3つの可能性 1. 不均一分散がある. 不均一分散はないがモデルの想定に誤り 3. 両者が同時に起きている 想定に誤り不均一分散を 検出 したら散布図に戻り関数形の想定や説明変数の選択を再検討 残差 残差 Y 真の関係 e e 線形回帰 X X 1 実行可能な一般化最小二乗法
S11_1 計量経済学 一般化古典的回帰モデル -3 1 図 7-3 不均一分散の検定と想定の誤り 想定の誤りと不均一分散均一分散を棄却 3つの可能性 1. 不均一分散がある. 不均一分散はないがモデルの想定に誤り 3. 両者が同時に起きている 想定に誤り不均一分散を 検出 したら散布図に戻り関数形の想定や説明変数の選択を再検討 残差 残差 Y 真の関係 e e 線形回帰 X X 1 実行可能な一般化最小二乗法

解答のポイント 第 1 章問 1 ポイント仮に1 年生全員の数が 100 人であったとする.100 人全員に数学の試験を課して, それらの 100 人の個人個人の点数が母集団となる. 問 2 ポイント仮に10 人を抽出するとする. 学生に1から 100 までの番号を割り当てたとする. 箱の中に番号札
 解答のポイント 第 1 章問 1 ポイント仮に1 年生全員の数が 100 人であったとする.100 人全員に数学の試験を課して, それらの 100 人の個人個人の点数が母集団となる. 問 2 ポイント仮に10 人を抽出するとする. 学生に1から 100 までの番号を割り当てたとする. 箱の中に番号札を入れまず1 枚取り出す ( 仮に1 番とする ). 最初に1 番の学生を選ぶ. その1 番の札を箱の中に戻し,
解答のポイント 第 1 章問 1 ポイント仮に1 年生全員の数が 100 人であったとする.100 人全員に数学の試験を課して, それらの 100 人の個人個人の点数が母集団となる. 問 2 ポイント仮に10 人を抽出するとする. 学生に1から 100 までの番号を割り当てたとする. 箱の中に番号札を入れまず1 枚取り出す ( 仮に1 番とする ). 最初に1 番の学生を選ぶ. その1 番の札を箱の中に戻し,
13章 回帰分析
 単回帰分析 つ以上の変数についての関係を見る つの 目的 被説明 変数を その他の 説明 変数を使って 予測しようというものである 因果関係とは限らない ここで勉強すること 最小 乗法と回帰直線 決定係数とは何か? 最小 乗法と回帰直線 これまで 変数の間の関係の深さについて考えてきた 相関係数 ここでは 変数に役割を与え 一方の 説明 変数を用いて他方の 目的 被説明 変数を説明することを考える
単回帰分析 つ以上の変数についての関係を見る つの 目的 被説明 変数を その他の 説明 変数を使って 予測しようというものである 因果関係とは限らない ここで勉強すること 最小 乗法と回帰直線 決定係数とは何か? 最小 乗法と回帰直線 これまで 変数の間の関係の深さについて考えてきた 相関係数 ここでは 変数に役割を与え 一方の 説明 変数を用いて他方の 目的 被説明 変数を説明することを考える
計量経済学の第一歩 田中隆一 ( 著 ) gretl で例題と実証分析問題を 再現する方法 発行所株式会社有斐閣 2015 年 12 月 20 日初版第 1 刷発行 ISBN , Ryuichi Tanaka, Printed in Japan
 gretl で例題と実証分析問題を 再現する方法 発行所株式会社有斐閣 2015 年 12 月 20 日初版第 1 刷発行 ISBN , Ryuichi Tanaka, Printed in Japan") 計量経済学の第一歩 田中隆一 ( 著 ) gretl で例題と実証分析問題を 再現する方法 発行所株式会社有斐閣 2015 年 12 月 20 日初版第 1 刷発行 ISBN 978-4-641-15028-7, Printed in Japan 第 5 章単回帰分析 本文例例 5. 1: 学歴と年収の関係 まず 5_income.csv を読み込み, メニューの モデル (M) 最小 2 乗法 (O)
計量経済学の第一歩 田中隆一 ( 著 ) gretl で例題と実証分析問題を 再現する方法 発行所株式会社有斐閣 2015 年 12 月 20 日初版第 1 刷発行 ISBN 978-4-641-15028-7, Printed in Japan 第 5 章単回帰分析 本文例例 5. 1: 学歴と年収の関係 まず 5_income.csv を読み込み, メニューの モデル (M) 最小 2 乗法 (O)
自由集会時系列part2web.key
 spurious correlation spurious regression xt=xt-1+n(0,σ^2) yt=yt-1+n(0,σ^2) n=20 type1error(5%)=0.4703 no trend 0 1000 2000 3000 4000 p for r xt=xt-1+n(0,σ^2) random walk random walk variable -5 0 5 variable
spurious correlation spurious regression xt=xt-1+n(0,σ^2) yt=yt-1+n(0,σ^2) n=20 type1error(5%)=0.4703 no trend 0 1000 2000 3000 4000 p for r xt=xt-1+n(0,σ^2) random walk random walk variable -5 0 5 variable
多変量解析 ~ 重回帰分析 ~ 2006 年 4 月 21 日 ( 金 ) 南慶典
 南慶典") 多変量解析 ~ 重回帰分析 ~ 2006 年 4 月 21 日 ( 金 ) 南慶典 重回帰分析とは? 重回帰分析とは複数の説明変数から目的変数との関係性を予測 評価説明変数 ( 数量データ ) は目的変数を説明するのに有効であるか得られた関係性より未知のデータの妥当性を判断する これを重回帰分析という つまり どんなことをするのか? 1 最小 2 乗法により重回帰モデルを想定 2 自由度調整済寄与率を求め
多変量解析 ~ 重回帰分析 ~ 2006 年 4 月 21 日 ( 金 ) 南慶典 重回帰分析とは? 重回帰分析とは複数の説明変数から目的変数との関係性を予測 評価説明変数 ( 数量データ ) は目的変数を説明するのに有効であるか得られた関係性より未知のデータの妥当性を判断する これを重回帰分析という つまり どんなことをするのか? 1 最小 2 乗法により重回帰モデルを想定 2 自由度調整済寄与率を求め
Kumamoto University Center for Multimedia and Information Technologies Lab. 熊本大学アプリケーション実験 ~ 実環境における無線 LAN 受信電波強度を用いた位置推定手法の検討 ~ InKIAI 宮崎県美郷
 熊本大学アプリケーション実験 ~ 実環境における無線 LAN 受信電波強度を用いた位置推定手法の検討 ~ InKIAI プロジェクト @ 宮崎県美郷町 熊本大学副島慶人川村諒 1 実験の目的 従来 信号の受信電波強度 (RSSI:RecevedSgnal StrengthIndcator) により 対象の位置を推定する手法として 無線 LAN の AP(AccessPont) から受信する信号の減衰量をもとに位置を推定する手法が多く検討されている
熊本大学アプリケーション実験 ~ 実環境における無線 LAN 受信電波強度を用いた位置推定手法の検討 ~ InKIAI プロジェクト @ 宮崎県美郷町 熊本大学副島慶人川村諒 1 実験の目的 従来 信号の受信電波強度 (RSSI:RecevedSgnal StrengthIndcator) により 対象の位置を推定する手法として 無線 LAN の AP(AccessPont) から受信する信号の減衰量をもとに位置を推定する手法が多く検討されている
Microsoft Word - 計量研修テキスト_第5版).doc
.doc") Q4-1 テキスト P83 多重共線性が発生する回帰 320000 280000 240000 200000 6000 4000 160000 120000 2000 0-2000 -4000 74 76 78 80 82 84 86 88 90 92 94 96 98 R e s i dual A c tual Fi tted Dependent Variable: C90 Date: 10/27/05
Q4-1 テキスト P83 多重共線性が発生する回帰 320000 280000 240000 200000 6000 4000 160000 120000 2000 0-2000 -4000 74 76 78 80 82 84 86 88 90 92 94 96 98 R e s i dual A c tual Fi tted Dependent Variable: C90 Date: 10/27/05
Microsoft Word - 計量研修テキスト_第5版).doc
.doc") Q9-1 テキスト P166 2)VAR の推定 注 ) 各変数について ADF 検定を行った結果 和文の次数はすべて 1 である 作業手順 4 情報量基準 (AIC) によるラグ次数の選択 VAR Lag Order Selection Criteria Endogenous variables: D(IG9S) D(IP9S) D(CP9S) Exogenous variables: C Date:
Q9-1 テキスト P166 2)VAR の推定 注 ) 各変数について ADF 検定を行った結果 和文の次数はすべて 1 である 作業手順 4 情報量基準 (AIC) によるラグ次数の選択 VAR Lag Order Selection Criteria Endogenous variables: D(IG9S) D(IP9S) D(CP9S) Exogenous variables: C Date:
<4D F736F F D208EC08CB18C7689E68A E F AA957A82C682948C9F92E82E646F63>
 第 7 回 t 分布と t 検定 実験計画学 A.t 分布 ( 小標本に関する平均の推定と検定 ) 前々回と前回の授業では, 標本が十分に大きいあるいは母分散が既知であることを条件に正規分布を用いて推定 検定した. しかし, 母集団が正規分布し, 標本が小さい場合には, 標本分散から母分散を推定するときの不確実さを加味したt 分布を用いて推定 検定しなければならない. t 分布は標本分散の自由度 f(
第 7 回 t 分布と t 検定 実験計画学 A.t 分布 ( 小標本に関する平均の推定と検定 ) 前々回と前回の授業では, 標本が十分に大きいあるいは母分散が既知であることを条件に正規分布を用いて推定 検定した. しかし, 母集団が正規分布し, 標本が小さい場合には, 標本分散から母分散を推定するときの不確実さを加味したt 分布を用いて推定 検定しなければならない. t 分布は標本分散の自由度 f(
経済論叢 ( 京都大学 ) 第 183 巻第 2 号,2009 年 4 月 35 ADF-GLS 検定とその用例 坂野慎哉 Ⅰ はじめに時系列データを用いて回帰分析を行うとき, 分析に先立って, 利用されるデータの系列に単位根が含まれているかどうか, 検定を行ってチェックすることが多い これは, 単
 第 183 巻第 2 号,2009 年 4 月 35 ADF-GLS 検定とその用例 坂野慎哉 Ⅰ はじめに時系列データを用いて回帰分析を行うとき, 分析に先立って, 利用されるデータの系列に単位根が含まれているかどうか, 検定を行ってチェックすることが多い これは, 単") 経済論叢 ( 京都大学 ) 第 183 巻第 2 号,2009 年 4 月 35 ADF-GLS 検定とその用例 坂野慎哉 Ⅰ はじめに時系列データを用いて回帰分析を行うとき, 分析に先立って, 利用されるデータの系列に単位根が含まれているかどうか, 検定を行ってチェックすることが多い これは, 単位根を含む時系列データを説明変数, 被説明変数として回帰分析を行った場合, たとえそれらの変数が独立であったとしても回帰係数の推定量は0に収束しないという,
経済論叢 ( 京都大学 ) 第 183 巻第 2 号,2009 年 4 月 35 ADF-GLS 検定とその用例 坂野慎哉 Ⅰ はじめに時系列データを用いて回帰分析を行うとき, 分析に先立って, 利用されるデータの系列に単位根が含まれているかどうか, 検定を行ってチェックすることが多い これは, 単位根を含む時系列データを説明変数, 被説明変数として回帰分析を行った場合, たとえそれらの変数が独立であったとしても回帰係数の推定量は0に収束しないという,
Microsoft Word - 計量研修テキスト_第5版).doc
.doc") Q3-1-1 テキスト P59 10.8.3.2.1.0 -.1 -.2 10.4 10.0 9.6 9.2 8.8 -.3 76 78 80 82 84 86 88 90 92 94 96 98 R e s i d u al A c tual Fi tte d Dependent Variable: LOG(TAXH) Date: 10/26/05 Time: 15:42 Sample: 1975
Q3-1-1 テキスト P59 10.8.3.2.1.0 -.1 -.2 10.4 10.0 9.6 9.2 8.8 -.3 76 78 80 82 84 86 88 90 92 94 96 98 R e s i d u al A c tual Fi tte d Dependent Variable: LOG(TAXH) Date: 10/26/05 Time: 15:42 Sample: 1975
Microsoft Word - appendix_b
 付録 B エクセルの使い方 藪友良 (2019/04/05) 統計学を勉強しても やはり実際に自分で使ってみないと理解は十分ではあ りません ここでは 実際に統計分析を使う方法のひとつとして Microsoft Office のエクセルの使い方を解説します B.1 分析ツールエクセルについている分析ツールという機能を使えば さまざまな統計分析が可能です まず この機能を使えるように設定をします もし
付録 B エクセルの使い方 藪友良 (2019/04/05) 統計学を勉強しても やはり実際に自分で使ってみないと理解は十分ではあ りません ここでは 実際に統計分析を使う方法のひとつとして Microsoft Office のエクセルの使い方を解説します B.1 分析ツールエクセルについている分析ツールという機能を使えば さまざまな統計分析が可能です まず この機能を使えるように設定をします もし
Excelによる統計分析検定_知識編_小塚明_5_9章.indd
 第7章57766 検定と推定 サンプリングによって得られた標本から, 母集団の統計的性質に対して推測を行うことを統計的推測といいます 本章では, 推測統計の根幹をなす仮説検定と推定の基本的な考え方について説明します 前章までの知識を用いて, 具体的な分析を行います 本章以降の知識は操作編での操作に直接関連していますので, 少し聞きなれない言葉ですが, 帰無仮説 有意水準 棄却域 などの意味を理解して,
第7章57766 検定と推定 サンプリングによって得られた標本から, 母集団の統計的性質に対して推測を行うことを統計的推測といいます 本章では, 推測統計の根幹をなす仮説検定と推定の基本的な考え方について説明します 前章までの知識を用いて, 具体的な分析を行います 本章以降の知識は操作編での操作に直接関連していますので, 少し聞きなれない言葉ですが, 帰無仮説 有意水準 棄却域 などの意味を理解して,
EBNと疫学
 推定と検定 57 ( 復習 ) 記述統計と推測統計 統計解析は大きく 2 つに分けられる 記述統計 推測統計 記述統計 観察集団の特性を示すもの 代表値 ( 平均値や中央値 ) や ばらつきの指標 ( 標準偏差など ) 図表を効果的に使う 推測統計 観察集団のデータから母集団の特性を 推定 する 平均 / 分散 / 係数値などの推定 ( 点推定 ) 点推定値のばらつきを調べる ( 区間推定 ) 検定統計量を用いた検定
推定と検定 57 ( 復習 ) 記述統計と推測統計 統計解析は大きく 2 つに分けられる 記述統計 推測統計 記述統計 観察集団の特性を示すもの 代表値 ( 平均値や中央値 ) や ばらつきの指標 ( 標準偏差など ) 図表を効果的に使う 推測統計 観察集団のデータから母集団の特性を 推定 する 平均 / 分散 / 係数値などの推定 ( 点推定 ) 点推定値のばらつきを調べる ( 区間推定 ) 検定統計量を用いた検定
回帰分析 単回帰
 回帰分析 単回帰 麻生良文 単回帰モデル simple regression model = α + β + u 従属変数 (dependent variable) 被説明変数 (eplained variable) 独立変数 (independent variable) 説明変数 (eplanator variable) u 誤差項 (error term) 撹乱項 (disturbance term)
回帰分析 単回帰 麻生良文 単回帰モデル simple regression model = α + β + u 従属変数 (dependent variable) 被説明変数 (eplained variable) 独立変数 (independent variable) 説明変数 (eplanator variable) u 誤差項 (error term) 撹乱項 (disturbance term)
0.0 Excelファイルの読み取り専用での立ち上げ手順 1) 開示 Excelファイルの知的所有権について開示する数値解析の説明用の Excel ファイルには 改変ができないようにパスワードが設定してあります しかし 読者の方には読み取り用のパスワードを開示しますので Excel ファイルを読み取
 開示 Excelファイルの知的所有権について開示する数値解析の説明用の Excel ファイルには 改変ができないようにパスワードが設定してあります しかし 読者の方には読み取り用のパスワードを開示しますので Excel ファイルを読み取") 第 1 回分 Excel ファイルの操作手順書 目次 Eexcel による数値解析準備事項 0.0 Excel ファイルの読み取り専用での立ち上げ手順 0.1 アドインのソルバーとデータ分析の有効化 ( 使えるようにする ) 第 1 回線形方程式 - 線形方程式 ( 実験式のつくり方 : 最小 2 乗法と多重回帰 )- 1.1 荷重とバネの長さの実験式 (Excelファイルのファイル名に同じ 以下同様)
第 1 回分 Excel ファイルの操作手順書 目次 Eexcel による数値解析準備事項 0.0 Excel ファイルの読み取り専用での立ち上げ手順 0.1 アドインのソルバーとデータ分析の有効化 ( 使えるようにする ) 第 1 回線形方程式 - 線形方程式 ( 実験式のつくり方 : 最小 2 乗法と多重回帰 )- 1.1 荷重とバネの長さの実験式 (Excelファイルのファイル名に同じ 以下同様)
景気指標の新しい動向
 内閣府経済社会総合研究所 経済分析 22 年第 166 号 4 時系列因子分析モデル 4.1 時系列因子分析モデル (Stock-Watson モデル の理論的解説 4.1.1 景気循環の状態空間表現 Stock and Watson (1989,1991 は観測される景気指標を状態空間表現と呼ば れるモデルで表し, 景気の状態を示す指標を開発した. 状態空間表現とは, わ れわれの目に見える実際に観測される変数は,
内閣府経済社会総合研究所 経済分析 22 年第 166 号 4 時系列因子分析モデル 4.1 時系列因子分析モデル (Stock-Watson モデル の理論的解説 4.1.1 景気循環の状態空間表現 Stock and Watson (1989,1991 は観測される景気指標を状態空間表現と呼ば れるモデルで表し, 景気の状態を示す指標を開発した. 状態空間表現とは, わ れわれの目に見える実際に観測される変数は,
14 化学実験法 II( 吉村 ( 洋 mmol/l の半分だったから さんの測定値は くんの測定値の 4 倍の重みがあり 推定値 としては 0.68 mmol/l その標準偏差は mmol/l 程度ということになる 測定値を 特徴づけるパラメータ t を推定するこの手
 14 化学実験法 II( 吉村 ( 洋 014.6.1. 最小 乗法のはなし 014.6.1. 内容 最小 乗法のはなし...1 最小 乗法の考え方...1 最小 乗法によるパラメータの決定... パラメータの信頼区間...3 重みの異なるデータの取扱い...4 相関係数 決定係数 ( 最小 乗法を語るもう一つの立場...5 実験条件の誤差の影響...5 問題...6 最小 乗法の考え方 飲料水中のカルシウム濃度を
14 化学実験法 II( 吉村 ( 洋 014.6.1. 最小 乗法のはなし 014.6.1. 内容 最小 乗法のはなし...1 最小 乗法の考え方...1 最小 乗法によるパラメータの決定... パラメータの信頼区間...3 重みの異なるデータの取扱い...4 相関係数 決定係数 ( 最小 乗法を語るもう一つの立場...5 実験条件の誤差の影響...5 問題...6 最小 乗法の考え方 飲料水中のカルシウム濃度を


Excelにおける回帰分析(最小二乗法)の手順と出力
の手順と出力") Microsoft Excel Excel 1 1 x y x y y = a + bx a b a x 1 3 x 0 1 30 31 y b log x α x α x β 4 version.01 008 3 30 Website:http://keijisaito.info, E-mail:master@keijisaito.info 1 Excel Excel.1 Excel Excel
Microsoft Excel Excel 1 1 x y x y y = a + bx a b a x 1 3 x 0 1 30 31 y b log x α x α x β 4 version.01 008 3 30 Website:http://keijisaito.info, E-mail:master@keijisaito.info 1 Excel Excel.1 Excel Excel
横浜市環境科学研究所
 周期時系列の統計解析 単回帰分析 io 8 年 3 日 周期時系列に季節調整を行わないで単回帰分析を適用すると, 回帰係数には周期成分の影響が加わる. ここでは, 周期時系列をコサイン関数モデルで近似し単回帰分析によりモデルの回帰係数を求め, 周期成分の影響を検討した. また, その結果を気温時系列に当てはめ, 課題等について考察した. 気温時系列とコサイン関数モデル第 報の結果を利用するので, その一部を再掲する.
周期時系列の統計解析 単回帰分析 io 8 年 3 日 周期時系列に季節調整を行わないで単回帰分析を適用すると, 回帰係数には周期成分の影響が加わる. ここでは, 周期時系列をコサイン関数モデルで近似し単回帰分析によりモデルの回帰係数を求め, 周期成分の影響を検討した. また, その結果を気温時系列に当てはめ, 課題等について考察した. 気温時系列とコサイン関数モデル第 報の結果を利用するので, その一部を再掲する.
非定常時系列データのVARモデル推定について
 非定常時系列データの VAR モデル推定について 明治大学大学院商学研究科辻裕行 2010 年 12 月 18 日 要旨 単位根を含んだ非定常時系列に対する VAR モデルの推定問題を検証する 伝統的理論では 単位根が存在する時系列を分析する場合 レベルの VAR モデルで推定を行うことは望ましくなく データの階差を取ったモデルで推定を行わなければならないとされてきた しかし Sims,Stock,and
非定常時系列データの VAR モデル推定について 明治大学大学院商学研究科辻裕行 2010 年 12 月 18 日 要旨 単位根を含んだ非定常時系列に対する VAR モデルの推定問題を検証する 伝統的理論では 単位根が存在する時系列を分析する場合 レベルの VAR モデルで推定を行うことは望ましくなく データの階差を取ったモデルで推定を行わなければならないとされてきた しかし Sims,Stock,and
基礎統計
 基礎統計 第 11 回講義資料 6.4.2 標本平均の差の標本分布 母平均の差 標本平均の差をみれば良い ただし, 母分散に依存するため場合分けをする 1 2 3 分散が既知分散が未知であるが等しい分散が未知であり等しいとは限らない 1 母分散が既知のとき が既知 標準化変量 2 母分散が未知であり, 等しいとき 分散が未知であるが, 等しいということは分かっているとき 標準化変量 自由度 の t
基礎統計 第 11 回講義資料 6.4.2 標本平均の差の標本分布 母平均の差 標本平均の差をみれば良い ただし, 母分散に依存するため場合分けをする 1 2 3 分散が既知分散が未知であるが等しい分散が未知であり等しいとは限らない 1 母分散が既知のとき が既知 標準化変量 2 母分散が未知であり, 等しいとき 分散が未知であるが, 等しいということは分かっているとき 標準化変量 自由度 の t
PowerPoint プレゼンテーション
 1/X Chapter 9: Linear correlation Cohen, B. H. (2007). In B. H. Cohen (Ed.), Explaining Psychological Statistics (3rd ed.) (pp. 255-285). NJ: Wiley. 概要 2/X 相関係数とは何か 相関係数の数式 検定 注意点 フィッシャーのZ 変換 信頼区間 相関係数の差の検定
1/X Chapter 9: Linear correlation Cohen, B. H. (2007). In B. H. Cohen (Ed.), Explaining Psychological Statistics (3rd ed.) (pp. 255-285). NJ: Wiley. 概要 2/X 相関係数とは何か 相関係数の数式 検定 注意点 フィッシャーのZ 変換 信頼区間 相関係数の差の検定
Medical3
 Chapter 1 1.4.1 1 元配置分散分析と多重比較の実行 3つの治療法による測定値に有意な差が認められるかどうかを分散分析で調べます この例では 因子が1つだけ含まれるため1 元配置分散分析 one-way ANOVA の適用になります また 多重比較法 multiple comparison procedure を用いて 具体的のどの治療法の間に有意差が認められるかを検定します 1. 分析メニュー
Chapter 1 1.4.1 1 元配置分散分析と多重比較の実行 3つの治療法による測定値に有意な差が認められるかどうかを分散分析で調べます この例では 因子が1つだけ含まれるため1 元配置分散分析 one-way ANOVA の適用になります また 多重比較法 multiple comparison procedure を用いて 具体的のどの治療法の間に有意差が認められるかを検定します 1. 分析メニュー
Medical3
 1.4.1 クロス集計表の作成 -l m 分割表 - 3つ以上のカテゴリを含む変数を用いて l mのクロス集計表による分析を行います この例では race( 人種 ) によってlow( 低体重出生 ) に差が認められるかどうかを分析します 人種には3つのカテゴリ 低体重出生には2つのカテゴリが含まれています 2つの変数はともにカテゴリ変数であるため クロス集計表によって分析します 1. 分析メニュー
1.4.1 クロス集計表の作成 -l m 分割表 - 3つ以上のカテゴリを含む変数を用いて l mのクロス集計表による分析を行います この例では race( 人種 ) によってlow( 低体重出生 ) に差が認められるかどうかを分析します 人種には3つのカテゴリ 低体重出生には2つのカテゴリが含まれています 2つの変数はともにカテゴリ変数であるため クロス集計表によって分析します 1. 分析メニュー
Microsoft PowerPoint - 統計科学研究所_R_重回帰分析_変数選択_2.ppt
 重回帰分析 残差分析 変数選択 1 内容 重回帰分析 残差分析 歯の咬耗度データの分析 R で変数選択 ~ step 関数 ~ 2 重回帰分析と単回帰分析 体重を予測する問題 分析 1 身長 のみから体重を予測 分析 2 身長 と ウエスト の両方を用いて体重を予測 分析 1 と比べて大きな改善 体重 に関する推測では 身長 だけでは不十分 重回帰分析における問題 ~ モデルの構築 ~ 適切なモデルで分析しているか?
重回帰分析 残差分析 変数選択 1 内容 重回帰分析 残差分析 歯の咬耗度データの分析 R で変数選択 ~ step 関数 ~ 2 重回帰分析と単回帰分析 体重を予測する問題 分析 1 身長 のみから体重を予測 分析 2 身長 と ウエスト の両方を用いて体重を予測 分析 1 と比べて大きな改善 体重 に関する推測では 身長 だけでは不十分 重回帰分析における問題 ~ モデルの構築 ~ 適切なモデルで分析しているか?
カイ二乗フィット検定、パラメータの誤差
 統計的データ解析 008 008.. 林田清 ( 大阪大学大学院理学研究科 ) 問題 C (, ) ( x xˆ) ( y yˆ) σ x πσ σ y y Pabx (, ;,,, ) ˆ y σx σ y = dx exp exp πσx ただし xy ˆ ˆ はyˆ = axˆ+ bであらわされる直線モデル上の点 ( ˆ) ( ˆ ) ( ) x x y ax b y ax b Pabx (,
統計的データ解析 008 008.. 林田清 ( 大阪大学大学院理学研究科 ) 問題 C (, ) ( x xˆ) ( y yˆ) σ x πσ σ y y Pabx (, ;,,, ) ˆ y σx σ y = dx exp exp πσx ただし xy ˆ ˆ はyˆ = axˆ+ bであらわされる直線モデル上の点 ( ˆ) ( ˆ ) ( ) x x y ax b y ax b Pabx (,
Microsoft Word - 補論3.2
 補論 3. 多変量 GARC モデル 07//6 新谷元嗣 藪友良 対数尤度関数 3 章 7 節では 変量の対数尤度を求めた ここでは多変量の場合 とくに 変量について対数尤度を求める 誤差項 は平均 0 で 次元の正規分布に従うとする 単純化のため 分散と共分散は時間を通じて一定としよう ( この仮定は後で変更される ) したがって ij から添え字 を除くことができる このとき と の尤度関数は
補論 3. 多変量 GARC モデル 07//6 新谷元嗣 藪友良 対数尤度関数 3 章 7 節では 変量の対数尤度を求めた ここでは多変量の場合 とくに 変量について対数尤度を求める 誤差項 は平均 0 で 次元の正規分布に従うとする 単純化のため 分散と共分散は時間を通じて一定としよう ( この仮定は後で変更される ) したがって ij から添え字 を除くことができる このとき と の尤度関数は
以下の内容について説明する 1. VAR モデル推定する 2. VAR モデルを用いて予測する 3. グレンジャーの因果性を検定する 4. インパルス応答関数を描く 1. VAR モデルを推定する ここでは VAR(p) モデル : R による時系列分析の方法 2 y t = c + Φ 1 y t
 モデル : R による時系列分析の方法 2 y t = c + Φ 1 y t") 以下の内容について説明する 1. VAR モデル推定する 2. VAR モデルを用いて予測する 3. グレンジャーの因果性を検定する 4. インパルス応答関数を描く 1. VAR モデルを推定する ここでは VAR(p) モデル : R による時系列分析の方法 2 y t = c + Φ 1 y t 1 + + Φ p y t p + ε t, ε t ~ W.N(Ω), を推定することを考える (
以下の内容について説明する 1. VAR モデル推定する 2. VAR モデルを用いて予測する 3. グレンジャーの因果性を検定する 4. インパルス応答関数を描く 1. VAR モデルを推定する ここでは VAR(p) モデル : R による時系列分析の方法 2 y t = c + Φ 1 y t 1 + + Φ p y t p + ε t, ε t ~ W.N(Ω), を推定することを考える (
ANOVA
 3 つ z のグループの平均を比べる ( 分散分析 : ANOVA: analysis of variance) 分散分析は 全体として 3 つ以上のグループの平均に差があるか ということしかわからないために, どのグループの間に差があったかを確かめるには 多重比較 という方法を用います これは Excel だと自分で計算しなければならないので, 分散分析には統計ソフトを使った方がよいでしょう 1.
3 つ z のグループの平均を比べる ( 分散分析 : ANOVA: analysis of variance) 分散分析は 全体として 3 つ以上のグループの平均に差があるか ということしかわからないために, どのグループの間に差があったかを確かめるには 多重比較 という方法を用います これは Excel だと自分で計算しなければならないので, 分散分析には統計ソフトを使った方がよいでしょう 1.
Microsoft PowerPoint - ch04j
 Ch.4 重回帰分析 : 推論 重回帰分析 y = 0 + 1 x 1 + 2 x 2 +... + k x k + u 2. 推論 1. OLS 推定量の標本分布 2. 1 係数の仮説検定 : t 検定 3. 信頼区間 4. 係数の線形結合への仮説検定 5. 複数線形制約の検定 : F 検定 6. 回帰結果の報告 入門計量経済学 1 入門計量経済学 2 OLS 推定量の標本分布について OLS 推定量は確率変数
Ch.4 重回帰分析 : 推論 重回帰分析 y = 0 + 1 x 1 + 2 x 2 +... + k x k + u 2. 推論 1. OLS 推定量の標本分布 2. 1 係数の仮説検定 : t 検定 3. 信頼区間 4. 係数の線形結合への仮説検定 5. 複数線形制約の検定 : F 検定 6. 回帰結果の報告 入門計量経済学 1 入門計量経済学 2 OLS 推定量の標本分布について OLS 推定量は確率変数
dae opixrae 1 Feb Mar Apr May Jun と表示される 今 必要なのは opixrae のデータだけなので > opixrae=opixdaa$opi
 R による時系列分析 4 1. GARCH モデルを推定する 1.1 パッケージ rugarch をインスツールする パッケージとは通常の R には含まれていない 追加的な R のコマンドの集まりのようなものである R には追加的に 600 以上のパッケージが用意されており それぞれ分析の目的に応じて標準の R にパッケージを追加していくことになる インターネットに接続してあるパソコンで R を起動させ
R による時系列分析 4 1. GARCH モデルを推定する 1.1 パッケージ rugarch をインスツールする パッケージとは通常の R には含まれていない 追加的な R のコマンドの集まりのようなものである R には追加的に 600 以上のパッケージが用意されており それぞれ分析の目的に応じて標準の R にパッケージを追加していくことになる インターネットに接続してあるパソコンで R を起動させ
ii 3.,. 4. F. (), ,,. 8.,. 1. (75% ) (25% ) =9 7, =9 8 (. ). 1.,, (). 3.,. 1. ( ).,.,.,.,.,. ( ) (1 2 )., ( ), 0. 2., 1., 0,.
, ,,. 8.,. 1. (75% ) (25% ) =9 7, =9 8 (. ). 1.,, (). 3.,. 1. ( ).,.,.,.,.,. ( ) (1 2 )., ( ), 0. 2., 1., 0,.") 23(2011) (1 C104) 5 11 (2 C206) 5 12 http://www.math.is.tohoku.ac.jp/~obata,.,,,.. 1. 2. 3. 4. 5. 6. 7.,,. 1., 2007 ( ). 2. P. G. Hoel, 1995. 3... 1... 2.,,. ii 3.,. 4. F. (),.. 5.. 6.. 7.,,. 8.,. 1. (75%
23(2011) (1 C104) 5 11 (2 C206) 5 12 http://www.math.is.tohoku.ac.jp/~obata,.,,,.. 1. 2. 3. 4. 5. 6. 7.,,. 1., 2007 ( ). 2. P. G. Hoel, 1995. 3... 1... 2.,,. ii 3.,. 4. F. (),.. 5.. 6.. 7.,,. 8.,. 1. (75%
Python-statistics5 Python で統計学を学ぶ (5) この内容は山田 杉澤 村井 (2008) R によるやさしい統計学 (
 この内容は山田 杉澤 村井 (2008) R によるやさしい統計学 (") http://localhost:8888/notebooks/... Python で統計学を学ぶ (5) この内容は山田 杉澤 村井 (2008) R によるやさしい統計学 (http://shop.ohmsha.co.jp/shop /shopdetail.html?brandcode=000000001781&search=978-4-274-06710-5&sort=) を参考にしています
http://localhost:8888/notebooks/... Python で統計学を学ぶ (5) この内容は山田 杉澤 村井 (2008) R によるやさしい統計学 (http://shop.ohmsha.co.jp/shop /shopdetail.html?brandcode=000000001781&search=978-4-274-06710-5&sort=) を参考にしています
Probit , Mixed logit
 Probit, Mixed logit 2016/5/16 スタートアップゼミ #5 B4 後藤祥孝 1 0. 目次 Probit モデルについて 1. モデル概要 2. 定式化と理解 3. 推定 Mixed logit モデルについて 4. モデル概要 5. 定式化と理解 6. 推定 2 1.Probit 概要 プロビットモデルとは. 効用関数の誤差項に多変量正規分布を仮定したもの. 誤差項には様々な要因が存在するため,
Probit, Mixed logit 2016/5/16 スタートアップゼミ #5 B4 後藤祥孝 1 0. 目次 Probit モデルについて 1. モデル概要 2. 定式化と理解 3. 推定 Mixed logit モデルについて 4. モデル概要 5. 定式化と理解 6. 推定 2 1.Probit 概要 プロビットモデルとは. 効用関数の誤差項に多変量正規分布を仮定したもの. 誤差項には様々な要因が存在するため,
Microsoft Word - reg2.doc
 回帰分析 重回帰 麻生良文. 前提 個の説明変数からなるモデルを考える 重回帰モデル : multple regresso model α β β β u : 被説明変数 epled vrle, 従属変数 depedet vrle, regressd :,,.., 説明変数 epltor vrle, 独立変数 depedet vrle, regressor u: 誤差項 error term, 撹乱項
回帰分析 重回帰 麻生良文. 前提 個の説明変数からなるモデルを考える 重回帰モデル : multple regresso model α β β β u : 被説明変数 epled vrle, 従属変数 depedet vrle, regressd :,,.., 説明変数 epltor vrle, 独立変数 depedet vrle, regressor u: 誤差項 error term, 撹乱項
目次 1 章 SPSS の基礎 基本 はじめに 基本操作方法 章データの編集 はじめに 値ラベルの利用 計算結果に基づく新変数の作成 値のグループ化 値の昇順
 SPSS 講習会テキスト 明治大学教育の情報化推進本部 IZM20140527 目次 1 章 SPSS の基礎 基本... 3 1.1 はじめに... 3 1.2 基本操作方法... 3 2 章データの編集... 6 2.1 はじめに... 6 2.2 値ラベルの利用... 6 2.3 計算結果に基づく新変数の作成... 7 2.4 値のグループ化... 8 2.5 値の昇順 降順... 10 3
SPSS 講習会テキスト 明治大学教育の情報化推進本部 IZM20140527 目次 1 章 SPSS の基礎 基本... 3 1.1 はじめに... 3 1.2 基本操作方法... 3 2 章データの編集... 6 2.1 はじめに... 6 2.2 値ラベルの利用... 6 2.3 計算結果に基づく新変数の作成... 7 2.4 値のグループ化... 8 2.5 値の昇順 降順... 10 3
tshaifu423
 消費 経済データ解析配布資料 011/1/1 Ⅳ 回帰分析入門 1) 変量データの記述 1. 散布図の描画 課題 0 下に示したものは 日本の実質家計可処分所得と実質家計最終消費支出のデータ ( 平成 1 年基準 単位 : 兆円 ) 1 である このデータを入力し 散布図を描いてみよう 散布図は次のような手順で描けばよい 1 B:C1 を範囲指定し リボン内にグラフのグループにある 散布図のボタンをクリックする
消費 経済データ解析配布資料 011/1/1 Ⅳ 回帰分析入門 1) 変量データの記述 1. 散布図の描画 課題 0 下に示したものは 日本の実質家計可処分所得と実質家計最終消費支出のデータ ( 平成 1 年基準 単位 : 兆円 ) 1 である このデータを入力し 散布図を描いてみよう 散布図は次のような手順で描けばよい 1 B:C1 を範囲指定し リボン内にグラフのグループにある 散布図のボタンをクリックする
今回 次回の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ Danger!! (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか これは次回)
 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか これは次回)") 生態学の時系列データ解析でよく見る あぶない モデリング 久保拓弥 mailto:kubo@ees.hokudai.ac.jp statistical model for time-series data 2017-07-03 kubostat2017 (h) 1/59 今回 次回の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ Danger!! (危 1) 時系列データの
生態学の時系列データ解析でよく見る あぶない モデリング 久保拓弥 mailto:kubo@ees.hokudai.ac.jp statistical model for time-series data 2017-07-03 kubostat2017 (h) 1/59 今回 次回の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ Danger!! (危 1) 時系列データの
(3) 検定統計量の有意確率にもとづく仮説の採否データから有意確率 (significant probability, p 値 ) を求め 有意水準と照合する 有意確率とは データの分析によって得られた統計値が偶然おこる確率のこと あらかじめ設定した有意確率より低い場合は 帰無仮説を棄却して対立仮説
 検定統計量の有意確率にもとづく仮説の採否データから有意確率 (significant probability, p 値 ) を求め 有意水準と照合する 有意確率とは データの分析によって得られた統計値が偶然おこる確率のこと あらかじめ設定した有意確率より低い場合は 帰無仮説を棄却して対立仮説") 第 3 章 t 検定 (pp. 33-42) 3-1 統計的検定 統計的検定とは 設定した仮説を検証する場合に 仮説に基づいて集めた標本を 確率論の観点から分析 検証すること 使用する標本は 母集団から無作為抽出されたものでなければならない パラメトリック検定とノンパラメトリック検定 パラメトリック検定は母集団が正規分布に従う間隔尺度あるいは比率尺度の連続データを対象とする ノンパラメトリック検定は母集団に特定の分布を仮定しない
第 3 章 t 検定 (pp. 33-42) 3-1 統計的検定 統計的検定とは 設定した仮説を検証する場合に 仮説に基づいて集めた標本を 確率論の観点から分析 検証すること 使用する標本は 母集団から無作為抽出されたものでなければならない パラメトリック検定とノンパラメトリック検定 パラメトリック検定は母集団が正規分布に従う間隔尺度あるいは比率尺度の連続データを対象とする ノンパラメトリック検定は母集団に特定の分布を仮定しない
不均一分散最小二乗法の仮定では 想定しているモデルの誤差が時間やサンプルを通じて一定であるとしている 次のような式を想定する 誤差項である ut の散らばり具合がサンプルを通じて一定であるという仮定である この仮定は均一分散と呼ばれる 不均一分散とは その仮定が満たされない場合で 推計した係数の分散
 第 5 章 さらに進んだテクニック この章では最小二乗法をそのまま適用するのが問題の場合を扱う 最小二乗法はある仮 定のもとで統計上望ましい性質を持っている のぞましい性質とは以下のものである 不偏性 不偏性とは推計された係数の期待値が 母集団の真の値と等しくなることを示している 有効性 ( 効率性 ) 有効性とは さまざまな推定値の中で 分散が最小になるように推計されたものであることを表している
第 5 章 さらに進んだテクニック この章では最小二乗法をそのまま適用するのが問題の場合を扱う 最小二乗法はある仮 定のもとで統計上望ましい性質を持っている のぞましい性質とは以下のものである 不偏性 不偏性とは推計された係数の期待値が 母集団の真の値と等しくなることを示している 有効性 ( 効率性 ) 有効性とは さまざまな推定値の中で 分散が最小になるように推計されたものであることを表している
消費 統計学基礎実習資料 2017/11/27 < 回帰分析 > 1. 準備 今回の実習では あらかじめ河田が作成した所得と消費のファイルを用いる 課題 19 統計学基礎の講義用 HP から 所得と消費のファイルをダウンロードしてみよう 手順 1 検索エンジンで 河田研究室 と入力し検索すると 河田
 消費 統計学基礎実習資料 07//7 < 回帰分析 >. 準備 今回の実習では あらかじめ河田が作成した所得と消費のファイルを用いる 課題 9 統計学基礎の講義用 HP から 所得と消費のファイルをダウンロードしてみよう 検索エンジンで 河田研究室 と入力し検索すると 河田研究室 のページにジャンプする ( ここまでの手順は http://www.tokuyama-u.ac.jp/kawada とアドレスを直接入力してもよい
消費 統計学基礎実習資料 07//7 < 回帰分析 >. 準備 今回の実習では あらかじめ河田が作成した所得と消費のファイルを用いる 課題 9 統計学基礎の講義用 HP から 所得と消費のファイルをダウンロードしてみよう 検索エンジンで 河田研究室 と入力し検索すると 河田研究室 のページにジャンプする ( ここまでの手順は http://www.tokuyama-u.ac.jp/kawada とアドレスを直接入力してもよい
象になっていた 構造的為替レートモデルの予測精度の悪さに大きな衝撃が集まったために その後の多くの研究者が多大な時間と労力をかけてさまざまな挑戦を行ってきた 3 逆に時系列モデルの予測精度の悪さにはあまり注目が集まらなかった 機械的ではあるが長い歴史と経験が蓄積されている時系列モデルは それなりの有
 時系列モデルはどれだけ為替レート変動を予測できるか How Well Can the Time Series Models Forecast Exchange Rate Changes? 橋本次郎 Jiro HASHIMOTO 要旨 1973 年以降の変動相場制以来 為替レートを説明する経済理論が数多く開発されてきた ところが 1983 年に発表されたメーシーとロゴフ (1983) の論文が それまで頼りにしていた為替レート決定理論が予測を目的にした実証分析では
時系列モデルはどれだけ為替レート変動を予測できるか How Well Can the Time Series Models Forecast Exchange Rate Changes? 橋本次郎 Jiro HASHIMOTO 要旨 1973 年以降の変動相場制以来 為替レートを説明する経済理論が数多く開発されてきた ところが 1983 年に発表されたメーシーとロゴフ (1983) の論文が それまで頼りにしていた為替レート決定理論が予測を目的にした実証分析では
まず y t を定数項だけに回帰する > levelmod = lm(topixrate~1) 次にこの出力を使って先ほどのレジームスイッチングモデルを推定する 以下のように入力する > levelswmod = msmfit(levelmod,k=,p=0,sw=c(t,t)) ここで k はレジ
 次にこの出力を使って先ほどのレジームスイッチングモデルを推定する 以下のように入力する > levelswmod = msmfit(levelmod,k=,p=0,sw=c(t,t)) ここで k はレジ") マルコフレジームスイッチングモデルの推定 1. マルコフレジームスイッチング (MS) モデルを推定する 1.1 パッケージ MSwM インスツールする MS モデルを推定するために R のパッケージ MSwM をインスツールする パッケージとは通常の R には含まれていない 追加的な R のコマンドの集まりのようなものである R には追加的に 600 以上のパッケージが用意されており それぞれ分析の目的に応じて標準の
マルコフレジームスイッチングモデルの推定 1. マルコフレジームスイッチング (MS) モデルを推定する 1.1 パッケージ MSwM インスツールする MS モデルを推定するために R のパッケージ MSwM をインスツールする パッケージとは通常の R には含まれていない 追加的な R のコマンドの集まりのようなものである R には追加的に 600 以上のパッケージが用意されており それぞれ分析の目的に応じて標準の
時系列データ解析による予測と最適化 ~エネルギー需要、発電、価格のモデリング~
 MATLAB による時系列データ解析と予測 MahWorks Japan アプリケーションエンジニアリング部テクニカルコンピューティング 中川慶子 2015 The MahWorks, Inc. 1 アジェンダ 需要予測 : 時系列データモデリング 1. データの準備 データの取得 生データの前処理 2. 機械学習 非線形重回帰 ニューラルネットワーク RNN 3. 自己回帰系モデル ARIMA/GARCHモデル
MATLAB による時系列データ解析と予測 MahWorks Japan アプリケーションエンジニアリング部テクニカルコンピューティング 中川慶子 2015 The MahWorks, Inc. 1 アジェンダ 需要予測 : 時系列データモデリング 1. データの準備 データの取得 生データの前処理 2. 機械学習 非線形重回帰 ニューラルネットワーク RNN 3. 自己回帰系モデル ARIMA/GARCHモデル
<4D F736F F D2090B695A8939D8C768A E F AA957A82C682948C9F92E8>
 第 8 回 t 分布と t 検定 生物統計学 A.t 分布 ( 小標本に関する平均の推定と検定 ) 前々回と前回の授業では, 標本が十分に大きいあるいは母分散が既知であることを条件に正規分布を用いて推定 検定した. しかし, 母集団が正規分布し, 標本が小さい場合には, 標本分散から母分散を推定するときの不確実さを加味したt 分布を用いて推定 検定しなければならない. t 分布は標本分散の自由度 f(
第 8 回 t 分布と t 検定 生物統計学 A.t 分布 ( 小標本に関する平均の推定と検定 ) 前々回と前回の授業では, 標本が十分に大きいあるいは母分散が既知であることを条件に正規分布を用いて推定 検定した. しかし, 母集団が正規分布し, 標本が小さい場合には, 標本分散から母分散を推定するときの不確実さを加味したt 分布を用いて推定 検定しなければならない. t 分布は標本分散の自由度 f(
> usdata01 と打ち込んでエンター キーを押すと V1 V2 V : : : : のように表示され 読み込まれていることがわかる ここで V1, V2, V3 は R が列のデータに自 動的につけた変数名である ( variable
 R による回帰分析 ( 最小二乗法 ) この資料では 1. データを読み込む 2. 最小二乗法によってパラメーターを推定する 3. データをプロットし 回帰直線を書き込む 4. いろいろなデータの読み込み方について簡単に説明する 1. データを読み込む 以下では read.table( ) 関数を使ってテキストファイル ( 拡張子が.txt のファイル ) のデー タの読み込み方を説明する 1.1
R による回帰分析 ( 最小二乗法 ) この資料では 1. データを読み込む 2. 最小二乗法によってパラメーターを推定する 3. データをプロットし 回帰直線を書き込む 4. いろいろなデータの読み込み方について簡単に説明する 1. データを読み込む 以下では read.table( ) 関数を使ってテキストファイル ( 拡張子が.txt のファイル ) のデー タの読み込み方を説明する 1.1
回帰分析 重回帰(3)
") 回帰分析 重回帰 (3) 内容 分散不均一性 分散不均一性とは何か 分散不均一性の検出 Heteroskedstcty robust estmator 加重最小二乗法 (Weghted Least Square) 誤差項の系列相関 多重共線性 説明変数の誤差 誤差項と説明変数の相関 回帰分析の前提 モデルの線型性 u ~N(0,s )..d. 誤差項の期待値は0 誤差項は互いに独立 ( 系列相関は無い
回帰分析 重回帰 (3) 内容 分散不均一性 分散不均一性とは何か 分散不均一性の検出 Heteroskedstcty robust estmator 加重最小二乗法 (Weghted Least Square) 誤差項の系列相関 多重共線性 説明変数の誤差 誤差項と説明変数の相関 回帰分析の前提 モデルの線型性 u ~N(0,s )..d. 誤差項の期待値は0 誤差項は互いに独立 ( 系列相関は無い
<4D F736F F F696E74202D E738A5889BB8BE688E68A4F82CC926E89BF908492E882C98AD682B782E98CA48B862E707074>
 市街化区域外の地価推定に関する研究 不動産 空間計量研究室 筑波大学第三学群社会工学類都市計画主専攻宮下将尚筑波大学大学院システム情報工学研究科社会システム工学専攻高野哲司 背景 日本の国土の区域区分 都市計画区域 市街化区域 市街化を促進する区域 市街化調整区域 市街化を抑制する区域 非線引都市計画区域 上記に属さない区域 非線引き市街化調整区域市街化区域 都市計画区域 本研究での対象区域 都市計画区域外
市街化区域外の地価推定に関する研究 不動産 空間計量研究室 筑波大学第三学群社会工学類都市計画主専攻宮下将尚筑波大学大学院システム情報工学研究科社会システム工学専攻高野哲司 背景 日本の国土の区域区分 都市計画区域 市街化区域 市街化を促進する区域 市街化調整区域 市街化を抑制する区域 非線引都市計画区域 上記に属さない区域 非線引き市街化調整区域市街化区域 都市計画区域 本研究での対象区域 都市計画区域外
4 OLS 4 OLS 4.1 nurseries dual c dual i = c + βnurseries i + ε i (1) 1. OLS Workfile Quick - Estimate Equation OK Equation specification dual c nurser
 1. OLS Workfile Quick - Estimate Equation OK Equation specification dual c nurser") 1 EViews 2 2007/5/17 2007/5/21 4 OLS 2 4.1.............................................. 2 4.2................................................ 9 4.3.............................................. 11 4.4
1 EViews 2 2007/5/17 2007/5/21 4 OLS 2 4.1.............................................. 2 4.2................................................ 9 4.3.............................................. 11 4.4
untitled
 に, 月次モデルの場合でも四半期モデルの場合でも, シミュレーション期間とは無関係に一様に RMSPE を最小にするバンドの設定法は存在しないということである 第 2 は, 表で与えた 2 つの期間及びすべての内生変数を見渡して, 全般的にパフォーマンスのよいバンドの設定法は, 最適固定バンドと最適可変バンドのうちの M 2, Q2 である いずれにしても, 以上述べた 3 つのバンド設定法は若干便宜的なものと言わざるを得ない
に, 月次モデルの場合でも四半期モデルの場合でも, シミュレーション期間とは無関係に一様に RMSPE を最小にするバンドの設定法は存在しないということである 第 2 は, 表で与えた 2 つの期間及びすべての内生変数を見渡して, 全般的にパフォーマンスのよいバンドの設定法は, 最適固定バンドと最適可変バンドのうちの M 2, Q2 である いずれにしても, 以上述べた 3 つのバンド設定法は若干便宜的なものと言わざるを得ない
PowerPoint プレゼンテーション
 学位論文作成のための疫学 統計解析の実際 徳島大学大学院 医歯薬学研究部 社会医学系 予防医学分野 有澤孝吉 (e-mail: karisawa@tokushima-u.ac.jp) 本日の講義の内容 (SPSS を用いて ) 記述統計 ( データのまとめ方 ) 代表値 ばらつき正規確率プロット 正規性の検定標準偏差 不偏標準偏差 標準誤差の区別中心極限定理母平均の区間推定 ( 母集団の標準偏差が既知の場合
学位論文作成のための疫学 統計解析の実際 徳島大学大学院 医歯薬学研究部 社会医学系 予防医学分野 有澤孝吉 (e-mail: karisawa@tokushima-u.ac.jp) 本日の講義の内容 (SPSS を用いて ) 記述統計 ( データのまとめ方 ) 代表値 ばらつき正規確率プロット 正規性の検定標準偏差 不偏標準偏差 標準誤差の区別中心極限定理母平均の区間推定 ( 母集団の標準偏差が既知の場合
PowerPoint プレゼンテーション
 復習 ) 時系列のモデリング ~a. 離散時間モデル ~ y k + a 1 z 1 y k + + a na z n ay k = b 0 u k + b 1 z 1 u k + + b nb z n bu k y k = G z 1 u k = B(z 1 ) A(z 1 u k ) ARMA モデル A z 1 B z 1 = 1 + a 1 z 1 + + a na z n a = b 0
復習 ) 時系列のモデリング ~a. 離散時間モデル ~ y k + a 1 z 1 y k + + a na z n ay k = b 0 u k + b 1 z 1 u k + + b nb z n bu k y k = G z 1 u k = B(z 1 ) A(z 1 u k ) ARMA モデル A z 1 B z 1 = 1 + a 1 z 1 + + a na z n a = b 0
Microsoft Word - 解答とヒント.doc
 ミクロ計量経済学 ヒントおよび解答 第 1 章 問 1 (1.70) 式の推計結果 (eq1) が表示されているとする.View/Residual Tests/Histogram Normality Test を選択し, 実行しなさい. 問 2 (1.70) 式の推計結果 (eq1) が表示されているとする.View/Coefficient Tests/Redundant Variables Likelihood
ミクロ計量経済学 ヒントおよび解答 第 1 章 問 1 (1.70) 式の推計結果 (eq1) が表示されているとする.View/Residual Tests/Histogram Normality Test を選択し, 実行しなさい. 問 2 (1.70) 式の推計結果 (eq1) が表示されているとする.View/Coefficient Tests/Redundant Variables Likelihood
青焼 1章[15-52].indd
![青焼 1章[15-52].indd](/thumbs/86/94313777.jpg "青焼 1章[15-52].indd") 1 第 1 章統計の基礎知識 1 1 なぜ統計解析が必要なのか? 人間は自分自身の経験にもとづいて 感覚的にものごとを判断しがちである 例えばある疾患に対する標準治療薬の有効率が 50% であったとする そこに新薬が登場し ある医師がその新薬を 5 人の患者に使ったところ 4 人が有効と判定されたとしたら 多くの医師はこれまでの標準治療薬よりも新薬のほうが有効性が高そうだと感じることだろう しかし
1 第 1 章統計の基礎知識 1 1 なぜ統計解析が必要なのか? 人間は自分自身の経験にもとづいて 感覚的にものごとを判断しがちである 例えばある疾患に対する標準治療薬の有効率が 50% であったとする そこに新薬が登場し ある医師がその新薬を 5 人の患者に使ったところ 4 人が有効と判定されたとしたら 多くの医師はこれまでの標準治療薬よりも新薬のほうが有効性が高そうだと感じることだろう しかし
データ解析
 データ解析 ( 前期 ) 最小二乗法 向井厚志 005 年度テキスト 0 データ解析 - 最小二乗法 - 目次 第 回 Σ の計算 第 回ヒストグラム 第 3 回平均と標準偏差 6 第 回誤差の伝播 8 第 5 回正規分布 0 第 6 回最尤性原理 第 7 回正規分布の 分布の幅 第 8 回最小二乗法 6 第 9 回最小二乗法の練習 8 第 0 回最小二乗法の推定誤差 0 第 回推定誤差の計算 第
データ解析 ( 前期 ) 最小二乗法 向井厚志 005 年度テキスト 0 データ解析 - 最小二乗法 - 目次 第 回 Σ の計算 第 回ヒストグラム 第 3 回平均と標準偏差 6 第 回誤差の伝播 8 第 5 回正規分布 0 第 6 回最尤性原理 第 7 回正規分布の 分布の幅 第 8 回最小二乗法 6 第 9 回最小二乗法の練習 8 第 0 回最小二乗法の推定誤差 0 第 回推定誤差の計算 第
Microsoft PowerPoint - ⑦資料2-3 【第3分冊】検討作業班(参考資料)
") 第 13 回社会保障審議会年金部会年金財政における経済前提と積立金運用のあり方に関する専門委員会平成 2 5 年 1 1 月 1 日 資料 2-3 検討作業班における議論について ( 参考資料集 ) - 第 3 分冊 - 利潤率と実質長期金利の関係について 1 1. 従来の長期金利の推計方法 平成 21 年財政検証における長期金利の設定については 長期間の平均としての国内債券の運用利回りを日本経済の長期的な見通しと整合性をとることとされた
第 13 回社会保障審議会年金部会年金財政における経済前提と積立金運用のあり方に関する専門委員会平成 2 5 年 1 1 月 1 日 資料 2-3 検討作業班における議論について ( 参考資料集 ) - 第 3 分冊 - 利潤率と実質長期金利の関係について 1 1. 従来の長期金利の推計方法 平成 21 年財政検証における長期金利の設定については 長期間の平均としての国内債券の運用利回りを日本経済の長期的な見通しと整合性をとることとされた
学習指導要領
 (1) 数と式 ア数と集合 ( ア ) 実数数を実数まで拡張する意義を理解し 簡単な無理数の四則計算をすること 絶対値の意味を理解し適切な処理することができる 例題 1-3 の絶対値をはずせ 展開公式 ( a + b ) ( a - b ) = a 2 - b 2 を利用して根号を含む分数の分母を有理化することができる 例題 5 5 + 2 の分母を有理化せよ 実数の整数部分と小数部分の表し方を理解している
(1) 数と式 ア数と集合 ( ア ) 実数数を実数まで拡張する意義を理解し 簡単な無理数の四則計算をすること 絶対値の意味を理解し適切な処理することができる 例題 1-3 の絶対値をはずせ 展開公式 ( a + b ) ( a - b ) = a 2 - b 2 を利用して根号を含む分数の分母を有理化することができる 例題 5 5 + 2 の分母を有理化せよ 実数の整数部分と小数部分の表し方を理解している
オーストラリア研究紀要 36号(P)☆/3.橋本
☆/3.橋本") 36 p.9 202010 Tourism Demand and the per capita GDP : Evidence from Australia Keiji Hashimoto Otemon Gakuin University Abstract Using Australian quarterly data1981: 2 2009: 4some time-series econometrics
36 p.9 202010 Tourism Demand and the per capita GDP : Evidence from Australia Keiji Hashimoto Otemon Gakuin University Abstract Using Australian quarterly data1981: 2 2009: 4some time-series econometrics

Microsoft Word - Stattext12.doc
 章対応のない 群間の量的データの検定. 検定手順 この章ではデータ間に 対 の対応のないつの標本から推定される母集団間の平均値や中央値の比較を行ないます 検定手法は 図. のようにまず正規に従うかどうかを調べます 但し この場合はつの群が共に正規に従うことを調べる必要があります 次に 群とも正規ならば F 検定を用いて等分散であるかどうかを調べます 等分散の場合は t 検定 等分散でない場合はウェルチ
章対応のない 群間の量的データの検定. 検定手順 この章ではデータ間に 対 の対応のないつの標本から推定される母集団間の平均値や中央値の比較を行ないます 検定手法は 図. のようにまず正規に従うかどうかを調べます 但し この場合はつの群が共に正規に従うことを調べる必要があります 次に 群とも正規ならば F 検定を用いて等分散であるかどうかを調べます 等分散の場合は t 検定 等分散でない場合はウェルチ
Microsoft Word - Stattext13.doc
 3 章対応のある 群間の量的データの検定 3. 検定手順 この章では対応がある場合の量的データの検定方法について学びます この場合も図 3. のように最初に正規に従うかどうかを調べます 正規性が認められた場合は対応がある場合の t 検定 正規性が認められない場合はウィルコクソン (Wlcoxo) の符号付き順位和検定を行ないます 章で述べた検定方法と似ていますが ここでは対応のあるデータ同士を引き算した値を用いて判断します
3 章対応のある 群間の量的データの検定 3. 検定手順 この章では対応がある場合の量的データの検定方法について学びます この場合も図 3. のように最初に正規に従うかどうかを調べます 正規性が認められた場合は対応がある場合の t 検定 正規性が認められない場合はウィルコクソン (Wlcoxo) の符号付き順位和検定を行ないます 章で述べた検定方法と似ていますが ここでは対応のあるデータ同士を引き算した値を用いて判断します
Microsoft Word - SPSS2007s5.doc
 第 5 部 SPSS によるデータ解析 : 追加編ここでは 卒論など利用されることの多いデータ処理と解析について 3つの追加をおこなう SPSS で可能なデータ解析のさまざま方法については 紹介した文献などを参照してほしい 15. 被験者の再グループ化名義尺度の反応頻度の少ない複数の反応カテゴリーをまとめて1つに置き換えることがある たとえば 調査データの出身県という変数があったとして 初期の処理の段階では
第 5 部 SPSS によるデータ解析 : 追加編ここでは 卒論など利用されることの多いデータ処理と解析について 3つの追加をおこなう SPSS で可能なデータ解析のさまざま方法については 紹介した文献などを参照してほしい 15. 被験者の再グループ化名義尺度の反応頻度の少ない複数の反応カテゴリーをまとめて1つに置き換えることがある たとえば 調査データの出身県という変数があったとして 初期の処理の段階では
Microsoft Word - econome4.docx
 : 履修登録したクラスの担当教員名を書く : 学籍番号及びが未記入のもの, また授業終了後に提出されたものは採点しないので, 注意すること. 3 単回帰分析 Tips 前回講義では, データの散らばり具合を表す偏差平方和, 分散や標準偏差, また 2 変数の関係を表す相関係数を,Excel で数回のステップに分けて求めました. 考え方を学ぶといううえでは計算手順を確認することは必要なことですが, 毎回,
: 履修登録したクラスの担当教員名を書く : 学籍番号及びが未記入のもの, また授業終了後に提出されたものは採点しないので, 注意すること. 3 単回帰分析 Tips 前回講義では, データの散らばり具合を表す偏差平方和, 分散や標準偏差, また 2 変数の関係を表す相関係数を,Excel で数回のステップに分けて求めました. 考え方を学ぶといううえでは計算手順を確認することは必要なことですが, 毎回,
2
 第 13 章 コーヒーのフィルターと役割は同じ X12-ARIMA 季節調整法である X12-ARIMA の使い方について説明する Eviews では系列ごとに 季節調整をかけるので 系列をクリックすると 系列独自のメニューが開かれる [Proc] [Seasonal Adjustment] [Census X12...] 上記手順でメニューを選ぶと X12 -ARIMA 用のウインドウが表示される
第 13 章 コーヒーのフィルターと役割は同じ X12-ARIMA 季節調整法である X12-ARIMA の使い方について説明する Eviews では系列ごとに 季節調整をかけるので 系列をクリックすると 系列独自のメニューが開かれる [Proc] [Seasonal Adjustment] [Census X12...] 上記手順でメニューを選ぶと X12 -ARIMA 用のウインドウが表示される
今回のプログラミングの課題 ( 前回の課題で取り上げた )data.txt の要素をソートして sorted.txt というファイルに書出す ソート (sort) とは : 数の場合 小さいものから大きなもの ( 昇順 ) もしくは 大きなものから小さなもの ( 降順 ) になるよう 並び替えること
data.txt の要素をソートして sorted.txt というファイルに書出す ソート (sort) とは : 数の場合 小さいものから大きなもの ( 昇順 ) もしくは 大きなものから小さなもの ( 降順 ) になるよう 並び替えること") C プログラミング演習 1( 再 ) 4 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ 今回のプログラミングの課題 ( 前回の課題で取り上げた )data.txt の要素をソートして sorted.txt というファイルに書出す ソート (sort) とは : 数の場合 小さいものから大きなもの ( 昇順 ) もしくは 大きなものから小さなもの ( 降順
C プログラミング演習 1( 再 ) 4 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ 今回のプログラミングの課題 ( 前回の課題で取り上げた )data.txt の要素をソートして sorted.txt というファイルに書出す ソート (sort) とは : 数の場合 小さいものから大きなもの ( 昇順 ) もしくは 大きなものから小さなもの ( 降順
様々なミクロ計量モデル†
 担当 : 長倉大輔 ( ながくらだいすけ ) この資料は私の講義において使用するために作成した資料です WEB ページ上で公開しており 自由に参照して頂いて構いません ただし 内容について 一応検証してありますが もし間違いがあった場合でもそれによって生じるいかなる損害 不利益について責任を負いかねますのでご了承ください 間違いは発見次第 継続的に直していますが まだ存在する可能性があります 1 カウントデータモデル
担当 : 長倉大輔 ( ながくらだいすけ ) この資料は私の講義において使用するために作成した資料です WEB ページ上で公開しており 自由に参照して頂いて構いません ただし 内容について 一応検証してありますが もし間違いがあった場合でもそれによって生じるいかなる損害 不利益について責任を負いかねますのでご了承ください 間違いは発見次第 継続的に直していますが まだ存在する可能性があります 1 カウントデータモデル
")
4.9 Hausman Test Time Fixed Effects Model vs Time Random Effects Model Two-way Fixed Effects Model
 1 EViews 5 2007 7 11 2010 5 17 1 ( ) 3 1.1........................................... 4 1.2................................... 9 2 11 3 14 3.1 Pooled OLS.............................................. 14
1 EViews 5 2007 7 11 2010 5 17 1 ( ) 3 1.1........................................... 4 1.2................................... 9 2 11 3 14 3.1 Pooled OLS.............................................. 14
Microsoft PowerPoint - R-stat-intro_12.ppt [互換モード]
![Microsoft PowerPoint - R-stat-intro_12.ppt [互換モード]](/thumbs/101/151921093.jpg "Microsoft PowerPoint - R-stat-intro_12.ppt [互換モード]") R で統計解析入門 (12) 生存時間解析 中篇 準備 : データ DEP の読み込み 1. データ DEP を以下からダウンロードする http://www.cwk.zaq.ne.jp/fkhud708/files/dep.csv /fkh /d 2. ダウンロードした場所を把握する ここでは c:/temp とする 3. R を起動し,2. 2 の場所に移動し, データを読み込む 4. データ
R で統計解析入門 (12) 生存時間解析 中篇 準備 : データ DEP の読み込み 1. データ DEP を以下からダウンロードする http://www.cwk.zaq.ne.jp/fkhud708/files/dep.csv /fkh /d 2. ダウンロードした場所を把握する ここでは c:/temp とする 3. R を起動し,2. 2 の場所に移動し, データを読み込む 4. データ
回帰分析 重回帰(1)
") 回帰分析 重回帰 (1) 項目 重回帰モデルの前提 最小二乗推定量の性質 仮説検定 ( 単一の制約 ) 決定係数 Eviews での回帰分析の実際 非線形効果 ダミー変数 定数項ダミー 傾きのダミー 3 つ以上のカテゴリー 重回帰モデル multiple regression model 説明変数が 個以上 y 1 x 1 x k x k u i y x i 他の説明変数を一定に保っておいて,x i
回帰分析 重回帰 (1) 項目 重回帰モデルの前提 最小二乗推定量の性質 仮説検定 ( 単一の制約 ) 決定係数 Eviews での回帰分析の実際 非線形効果 ダミー変数 定数項ダミー 傾きのダミー 3 つ以上のカテゴリー 重回帰モデル multiple regression model 説明変数が 個以上 y 1 x 1 x k x k u i y x i 他の説明変数を一定に保っておいて,x i