<4D F736F F F696E74202D2097AC91CC3389F196DA816995C097F18C768E5A816A2E B8CDD8AB B83685D>
|
|
|
- さみ なみこし
- 6 years ago
- Views:
Transcription
1 計算流体力学 ( 第 13 回資料 ) 2014 年 1 月 14 日 スーパーコンピュータの性能 並列計算法 (Parallel Computing) 話のポイント : 並列計算機の仕組みと並列化の方法 Flops 1Pflops 33862Tflops(2013):Tianhe Tflops(2011): 京 36Tflops(2002): 地球シミュレータ 1Tflops First Parallel Computer 1972 Massive parallel multi-proessor vetor 並列計算の目的 より大規模な問題の計算が可能となる. (n 倍のメモリー,n: プロセッサ数 ) 計算時間を大幅に短縮できる.( 計算時間 1/n) vauum tube saler transistor miro proessor 並列コンピュータの必要性 科学的に複雑な問題の解明 1980 年代末に提案されたグランド チャレンジ問題 計算流体力学と乱流 大域的な気象と環境のモデル化 物質の設計と超流動 医学, 人間の臓器と骨格のモデル化 宇宙論と宇宙物理学 : コンピュータの性能向上回路素子の進歩真空管 トランジスタ 集積回路 超大規模集積回路 シングルプロセッサの限界真空中の光の速度 ( 約 m/se) 並列計算の歴史 Rihardson( 英国 ) 1911 年 : 非線形偏微分方程式の数値解法を発表 1922 年 : 数値的方法による天気予測 大気を 5 層に分け, 水平方向にはヨーロッパ大陸をブロックに分割した 6 時間分の計算を手回し計算機で 6 週間 Rihardson の夢北半球全体を約 2,000 個のブロックに分け,32 人が一つのブロックの計算を担当すれば,6 時間先の予報を 3 時間で出来ると見積もった. (64,000 人が巨大な劇場に集合し, 指揮者のもとで一斉に計算を行えば実現できる )

 完成 (64 台の処理ユニット,1 台の中央処理ユニット :SIMD) 日本での並列コンピュータ構築研究 1977 年")
 1980 年 PACS/PAX プロジェクト筑波大学に移動 PAX-128(1983 年,4Mflops) PAX-64J(1986 年,3.")
2 Rihardson の夢 Rihardson,L.F.:Weather Predition by Numerial Proess, Cambridge University Press, London, 1922 並列コンピュータの出現 イリノイ大学 Daniel Slotni:2 種類の並列コンピュータを設計 1972 年 : 世界最初の並列計算機 ILLIAC Ⅳ(Burroughs 社 ) 完成 (64 台の処理ユニット,1 台の中央処理ユニット :SIMD) 日本での並列コンピュータ構築研究 1977 年 :PACS/PAX プロジェクトが発足星野力 ( 京都大学 筑波大学 ) PACS-9(1978 年,0.01Mflops) PAX-32(1980 年,0.5Mflops) 1980 年 PACS/PAX プロジェクト筑波大学に移動 PAX-128(1983 年,4Mflops) PAX-64J(1986 年,3.2Mflops) QCDPAX(1989 年,14Gflops) CP-PACS(1996 年,300Gflops) (1997 年,600 Gflops:2048CPU)
 8GFLOPS@5120")
 地球シミュレータ")



 世界 11 位 2843TFLOS(")


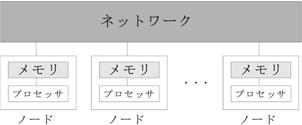
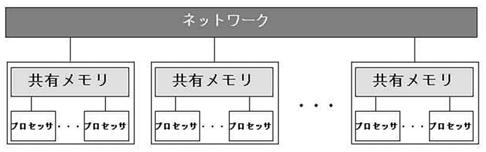
3 地球シミュレータ ( 初代 ) 640 nodes (5120 CPU) 8GFLOPS@5120 =40TFLOPS 35.86Tflops ( 実効ピーク性能 ) 地球シミュレータ ( 現在 ) 年 3 月導入の新たなシステム (NEC SX-9/E) 2002 年から 2 年半世界最高速 世界 472 位 (2013 年 11 月現在 ) 160 nodes(1280 CPU) 102.4GFLOPS@1280=131TFLOPS 122.4Tflops( 実効ピーク性能 ) TSUBAME 2.5( 東工大 ) 世界 11 位 2843TFLOS( 実効ピーク ) 次世代スパコン京 共有メモリー型と分散メモリー型 共有メモリー型 (shared memory type): すべてのプロセッサーがメモリーを共同で使用するタイプ分散メモリー型 (distributed memory type): すべてのプロセッサーが個別にメモリーを持っている 世界 4 位 (2013 年 11 月現在 ) ores(88128 CPU) 128GFLOPS@88128=11280TFLOPS 10510Tflops( 実効ピーク性能 ) 実効効率 93%



 GPGPU とは General")



 高 FLOPS")
:50,000 円程度")
4 並列計算機とプログラミングの方法 共有メモリシステム OpenMP MPI 分散メモリシステム 並列計算機とプログラミングの方法 共有分散メモリシステム (shared-distributed memory type): 大規模並列システムの場合 MPI MPI OpenMP MPI OpenMP MPI OpenMP MPI PC luster GPU を用いた汎用計算 PC(Gateway) GPGPU とは General Purpose Graphis Proessing Unit GPU を一般的な用途で利用することの総称 PCs HUB 自作も容易 OS:Linux が主流 GPU の特徴 演算能力が非常に高い 例 :GeFore GTX Titan:4.5TFlops デスクトップ PC(Win, Ma & Linux) に搭載可能. ( もちろんノート PC にも ) 高 FLOPS の割に値段が安い GeFore GTX780(4.0Tflops):50,000 円程度 数値計算専用のモデルもある (Tesla シリーズ, 搭載メモリ多い ) Tesla K40( スパコン向け )
5 GPU 計算への応用 (CUDA FORTRAN を利用 ) 並列計算機の性能向上と普及 SM: ストリーミングマルチプロセッサ 448/32=14 個 SP: ストリーミングプロセッサ SM1 つあたり 32 個 シェアードメモリ ( 超高速 ) レジスタ メモリ ( 超高速 ) ハードウエア従来のベクトルスーパーコンピュータの性能をはるかに上回る性能の実現 ( マイクロプロセッサの性能向上, 高速ネットワーク ) 超高性能並列コンピュータから PC クラスターまで 144GB/se *NVIDIA 製 GPU のアーキテクチャ ソフトウエア MPI,OpenMP などの並列プログラミング支援ツールの整備 ビデオメモリ ( グローバルメモリ ) プロセッサ メモリ17 SP 数クロック周波数 ピーク演算性能標準メモリ設定メモリバンド幅 Tesla C2075(GPU) 448 個 1147MHz GFLOPS( 単精度 ) 515GFLOPS( 倍精度 ) 6GB GDDR5 144GB/s Intel Core i7 990Xの場合 6 個 3460MHz 83.2GFLOPS 25.6GB/s 誰もが並列計算できる環境が整った ( パラダイムの変化 ) 欧米のほとんどの土木 機械系の大学院では並列計算に関する講義科目が用意されている 並列プログラミング支援ツール 1)OpenMP を用いる ( 共有メモリ型 ) プログラム構造を変更することなく指示文を挿入するだけで並列化可能 2) メッセージパッシングライブラリーを用いる ( 分散メモリ型, 共有メモリ型 ) MPI(Message Passing Interfae), ライブラリー関数群 ( 逐次言語 (Fortran,C など ) のライブラリーとして使用 ) 本格的な並列プログラミングが可能 3) 自動並列化コンパイラーを用いる ( 共有メモリ ) プログラム ( 逐次言語 ) をコンパイラーが自動並列化 OpenMP とは 共有メモリ型並列計算機に対する並列化手法 コンパイラに対して並列化の指示を行なうために, プログラム中に追加する指示行の記述方法を規定 ( Fortran や C/C++ の並列化に対する標準規格 ) 特徴 : 1) 並列化が容易逐次プログラムに指示行を挿入 2) 移植性が高い OpenMP に準拠しているコンパイラ 3) 逐次プログラムとの共存が容易並列プログラムとしても逐次プログラムとしても利用できる
6 OpenMP による並列計算 OpenMP プログラムの並列計算の概要 OpenMPの基本的な規則!$OMP :OpenMP 指示文!$ = * :OpenMP のみで実行される演算.! : コメント文. program welome_to_parallel_world_omp integer :: mythread mythread = 0 write(6,*) mythread, Hello Parallel World!$OMP parallel private( mythread ) マスタースレッド write(6,*) Hello Parallel World program hello_world_omp integer :: mythread mythread = 0!$OMP parallel private( mythread )!$ mythread = omp_get_thread_num() wirte(6,*) mythread, Hello World!$OMP end parallel end program hello_world_omp Parallel 構文 ( 並列リージョンの立上げ ) 環境変数の獲得 ( 自分が何番のスレッドなのか ) Parallel 構文 ( 並列リージョンの終了 )!$ mythread = omp_get_thread_num() write(6,*) mythread, Parallel Computing!$OMP end parallel write(6,*) mythread, Good-by end program welome_to_parallel_world_omp write(6,*) Good-by スレーブスレッド メッセージ通信によるプログラミング プロセッサ間やネットワークで結ばれたコンピュータ間の制御, 分散主記憶に分散された情報の交換を, メッセージ通信により行なう. 分散メモリー型並列計算機では, メッセージ通信によるプログラミングが最もハードウエア構成に即したプログラミングであり高性能な計算が行える ( 共有メモリー型並列計算機でも有効 ). MPI(Message Passing Interfae) が標準 (MPI-1: 基本仕様,MPI-2: 拡張機能仕様 ) 無償でダウンロードできる MPI(Message Passing Interfae) とは ノード間の情報交換をメッセージ通信で行なうライブラリ ( プログラム言語ではない ) Fortran や C などの従来の逐次プログラム言語中において, ライブラリとして引用する ( 各ノードにおいて不足する情報の交換を,MPI サブルーチンを適切に all することにより行なう ) 様々なプラットホームで利用できるフリーウェア MPI の実装 MPICH: LAM: Windows 環境で動作する MPI もある
7 MPI のサブルーチン 1) 環境管理サブルーチン MPI_INIT, MPI_COMM_SIZE, MPI_COMM_RANK MPI_FINALIZE 2) グループ通信サブルーチン MPI_REDUCE, MPI_ALLREDUCE 3)1 対 1 通信サブルーチン MPI_ISEND, MPI_IRECV, MPI_WAITALL, MPI_WAIT 4) その他 MPI_WTIME 例題 : 配列の和を求める 並列計算プログラミング 配列 A(1) から A(100) の総和を求める 配列 A 逐次プログラム do i=1,num a(i)=i end do s=0 do i=1,num s=s+a(i) end do A(1) A(2) A(3) A(100) 複数のプロセッサで並列に処理し 実行時間の短縮を図る impliit double preision (a-h,o-z) parameter ( num = 100 ) integer a(num) integer s do i=1,num a(i)=i end do s=0 do i=1,num s=s+a(i) end do write(6,100) s 100 format(3x,'sum = ', i10) stop end 並列計算プログラミング プログラム名 :single_sum.f A(1)+ A(1) A(25) PE 0 が担当 メモリー A(100),S,TS 並列計算プログラミング例 配列をプロセッサに分割する配列 A(100) の和の計算を 4 プロセッサ (PE) に分担させた A(26) A(50) PE 1 が担当 A(51) A(75) PE 2 が担当 + A(100) A(76) A(100) PE 3 が担当 部分和 + 総和 部分和 部分和 部分和 s = A(1)+ + A(25) s = A(26)+ + A(50) s = A(51)+ + A(75) s = A(76)+ + A(100) PE:0 PE:1 PE:2 PE:3 CPU CPU CPU CPU メモリー A(100), S メモリー A(100), S 総和 TS= S(PE0) + S(PE1) + S(PE2) + S(PE3) メモリー A(100), S
8 MPI プログラムの基本的構造 変数の定義, 宣言 inlude 'mpif.h' MPI プログラムのコンパイルに必要 all MPI_INIT( ierr ) MPI 環境の初期化 all MPI_COMM_RANK ( MPI_COMM_WORLD, irank, ierr ) 各プロセスのランク irank を取得 all MPI_COMM_SIZE ( MPI_COMM_WORLD, isize, ierr ) プロセス数 isize を取得 : 並列処理プログラム : all MPI_FINALIZE( ierr ) MPI の終了 stop end impliit double preision (a-h,o-z) parameter ( ip = 4 ) parameter ( num = 100 ) integer A( num ) integer S integer TS inlude 'mpif.h' MPIプログラムのコンパイルに必要 all MPI_INIT( ierr ) MPI 環境の初期化 all MPI_COMM_RANK ( MPI_COMM_WORLD, irank, ierr ) 自分のランクirankを取得 all MPI_COMM_SIZE ( MPI_COMM_WORLD, isize, ierr ) プロセス数 isizeを取得 do i = 1, num A(i) = i end do S = 0 TS = 0 ipe = num / ip ist = 1 + irank * ipe iet = ( irank + 1 ) * ipe 並列計算プログラミング例 並列計算プログラミング例 do i = ist, iet S = S + A(i) end do all MPI_REDUCE( S, TS, 1, MPI_INTEGER, MPI_SUM, 0, & MPI_COMM_WORLD, ierr ) 各プロセスの部分和 Sをプロセッサ0に集め総和を求めTSに格納 write(6,100) irank, S, TS 100 format(3x,'irank = ',i3,3x,2i10) all MPI_FINALIZE( ierr ) MPIの終了 stop 計算結果 end irank = irank = irank = irank = MPI サブルーチン引用例 all MPI_REDUCE( S, TS, 1, MPI_INTEGER, MPI_SUM, 0, & MPI_COMM_WORLD, ierr ) 各プロセスの部分和 S をプロセス 0( ランク 0) に集め総和を求め TS に格納 all MPI_REDUCE(sendbuf, revbuf, ount, datatype, op, root, omm, ierror) sendbuf: 送信バッファの先頭アドレスを指定する. revbuf: 受信バッファの先頭アドレスを指定する. ount: 整数. 送 ( 受 ) 信メッセージの要素数を指定する. datatype: 整数. 送 ( 受 ) 信メッセージのデータタイプを指定する. op: 整数. 演算の種類を指定する. root: 整数. 宛先プロセスの omm 内でのランクを指定する. omm: 整数. 送受信に参加するすべてのプロセスを含むグループのコミュニケータを指定する. ierror: 整数. 完了コードが戻る.

 1 章 OpenMP と並列計算 2 章 OpenMP によるプログラミング 3 章 OpenMP による並列数値計算 4 章付録 スピードアップ = 並列化効率 = 並列計算効率の評価指標 1 ノード使用時の実行時間 N ノード使用時の実行時間")
9 連立一次方程式の並列解法陽解法並列化の容易さ : 容易並列化効率 : 良好陰解法直接法並列化の容易さ : やや難並列化効率 : やや不良 ( 超並列には不向き ) Melosh et al., Comp. Strut., Vol.20, pp , 1985 反復法並列化の容易さ : 容易並列化効果 : 良好 ガウスの消去法が最も効率がよい. Hughes らによって提案された element-by-element 法に基づく前処理付き共役勾配法 省メモリーでかつ高効率 Barragy and Carey, Int.J.Numer.Meth.Engng., Vol.26, pp , 1988 Tezduyar et al.1992-present( 流れの並列計算に関する論文多数 ) 並列プログラミング参考書 樫山, 西村, 牛島 : 並列計算法入門, 日本計算工学会編 ( 計算力学レクチャーシリーズ 3), 丸善 (2003) 1 章計算力学における並列計算概論 2 章有限要素法における並列計算法 3 章有限差分法における並列計算法 4 章境界要素法における並列計算法 5 章 PC クラスターの構築法とグリッドコンピューティング付録並列プログラム 牛島 :OpenMP による並列プログラミングと数値計算法, 丸善 (2006) 1 章 OpenMP と並列計算 2 章 OpenMP によるプログラミング 3 章 OpenMP による並列数値計算 4 章付録 スピードアップ = 並列化効率 = 並列計算効率の評価指標 1 ノード使用時の実行時間 N ノード使用時の実行時間 スピードアップ N 並列計算における計算時間 全計算時間 = 計算時間 + 通信時間 + 同期待ち 粒度 (granularity): 並列処理の単位粗粒度 : 通信負荷に比べて計算負荷が卓越全計算時間は遅いが並列化効率は良い 細粒度 : 通信負荷が増大全計算時間は速いが並列化効率は悪い :並列計算における実行時間 実行時間 = 計算時間 + 通信時間 + 同期待ち時間 ノード 1 同期待ち時間 :計算時間通信時間 ノード n 実行時間 1 ステップあたりの実行時間
10 粒度が小さい ( 細粒度 ) と並列化効率が悪くなる理由 実行時間 高効率な並列計算を実現するには 1) 並列処理可能な部分の拡大可能な限りの処理の並列化 計算時間 ( 並列化不可能部分 ) 計算時間 ( 並列化可能部分 ) 通信時間 n 台 n1 / ノード数 1台並列化不可能並列化可能計算時間 2) 各プロセッサの計算負荷の均等化各プロセッサーに割り当てる要素数の均等化 3) プロセッサ間の通信量の最小化通信を行う節点の最小化自動領域分割法が有効 アムダールの法則 P: 並列化部分率, N: 使用するプロセッサ数 1 スピードアップ (1 P ) P / N 領域分割法 MPI に基づく並列計算では領域分割に基づく並列計算が一般的 解析領域 有限要素方程式小領域の境界自動領域分割法 (1) 小領域内での要素数の均等化 (2) 小領域間の境界上の節点数の最小化効率の良い並列計算
 節点ベース (b) 要素ベース 9")



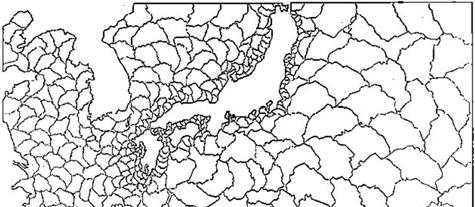
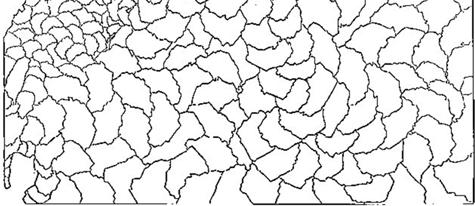
11 領域分割法伊勢湾台風による被害 (1959) (a) 節点ベース (b) 要素ベース 9 (a) 節点ベース (b) 要素ベース 要素ベースの方法 Bisetion 法 : 計算領域を次々に数学的手法を用いて 2 分していく方法. Greedy 法 : 隣接要素を記憶しておき近隣の要素を必要数だけ探索する方法. 数学理論を用いない簡便な方法 有限要素メッシュ 領域分割図 (elements:206,977,nodes:106,577) (512 sub-domain)
12 領域分割に基づく並列計算例 領域分割に基づく並列計算例 計算結果と観測結果との比較 ( 名古屋港 ) 速度向上比 (Speed-up ratio) 並列化効率 (Effiieny) 速度向上比 = 1 プロセッサ使用時の CPU 時間 N プロセッサ使用時の CPU 時間 並列化効率 = 速度向上比 N


 GPU コンピューティングのさらなる進歩 普及 商用ソフトウエアの紹介")


13 領域分割図 大気環境流れ 通信ライブラリ : MPI 自動領域分割システム :Metis 例 :64 分割図 まとめ 並列計算機環境の進歩 普及と並列化手法ついて紹介した. マルチコア CPU 登載のパソコンの普及により 誰もが並列計算可能な環境にある 共有メモリー型コンピュータの場合には OpenMP が 分散メモリー型コンピュータの場合には MPI が有効である 大規模計算には領域分割に基づく並列計算 (MPI) が並列化効率の点から一般的である 連立一次方程式の解法は反復法が並列化効率の点で優れる 今後の期待 ハイブリッド計算 (Open MP+MPI) GPU コンピューティングのさらなる進歩 普及 商用ソフトウエアの紹介 世界でもっとも使用されているソフトウエア 1 位 FLUENT 有限体積法に基づく使用実績世界 No.1の汎用熱流体解析ソフトウェア. 2 位 STAR-CD( 日本では最も使用されている ) 有限体積法に基づく汎用熱流体解析ソフトウェア. 自動車系に強い AuSolve: 有限要素法 (Galerkin/Least-Squares:GLS 法 ) による汎用熱流体解析ソフトウェア
 ソフトウェア http://ansys.")


14 AuSolve AuSolve は有限要素法による汎用熱流体解析システム 有限要素法 (Galerkin/Least-Squares:GLS) 法による汎用性と高精度な解 テトラメッシュの使用を推奨 メッシュの歪みに頑強で 実用形状のメッシュ作成工数を大幅に低減できる 反復収束が速やかで解析時間を予測できるので 製品開発設計工程での計画的な適用が可能 3 次元 CAD との連携やユーザーインターフェースのカスタマイズによって CAE オートメーションが可能 FLUENT FLUENTは 有限体積法に基づく使用実績世界 No.1のCFD( 数値流体力学 ) ソフトウェア FLUENTには豊富な物理モデルが搭載されており 化学反応 燃焼 混相流 相変化などが取扱える また 高度なカスタマイズも可能 プリプロセッサには GAMBITを標準装備 FLUENTでは連成解法および分離解法のアルゴリズムを用いて 非構造格子で離散化した質量 運動量 熱 化学種に関する支配方程式を解く 2 次元平面 2 次元軸対称 旋回を伴う2 次元軸対称 および3 次元の流れ 定常 / 非定常流 あらゆる速度域に対応 非粘性流 層流 乱流 ニュートン流体 非ニュートン流体 強制/ 自然 / 混合対流を含む熱伝達 固体 / 流体連成熱伝達 ふく射 化学種の混合 / 反応 自由表面流/ 混相流モデル 分散相のラグランジュ式追跡計算 融解/ 凝固を対象とした相変化モデル 非等方浸透性 慣性抵抗 固体熱伝導 空隙率を考慮した速度 多孔質面圧力ジャンプ条件を含む多孔質モデル ファン ラジエータ 熱交換器を対象とした集中定数モデル 移動物体周りの流れをモデル化するダイナミックメッシュ機能 慣性または非慣性座標系 複数基準座標系およびスライディングメッシュ 動静翼相互作用をモデル化する接続境界面モデル 流体騒音予測のための音響モデル 質量 運動量 熱 化学種の体積ソース項 物性値のデータベース STAR-CD STAR-CD 英国インペリアル大学のゴスマン教授を中心として開発された有限体積法非構造メッシュによる汎用熱流体解析プログラム. CD-adapo により開発 STAR-CD がカバーする解析対象は単純な熱流れ解析から, 固体熱伝導や輻射 / 太陽輻射を含んだ熱問題, 様々なタイプの混相流問題, 化学反応 / 燃焼問題, 回転機器問題, 流体騒音問題, 移動境界問題など多岐に渡り, 解析メッシュ作成機能としてもサーフェスメッシャー, サーフェスラッパー, ボリュームメッシャーなどを標準機能として提供するほか,CAD との親和性を高めた, CAD の中で STAR-CD を利用するアドオン環境 (CATIA v5, Pro/E, UG-NX, SolidWorks) も用意. 非構造 / 完全不連続メッシュ ( メッシュのつながりを意識せずにモデル化が可能 ) による複雑形状への優れた柔軟性とメッシュ作成コストの削減 ( ヘキサ, テトラ, プリズム, トリムセルを含む多面体セルに対応 ) 自動車, 航空宇宙, 重工重電, 家電, 化学, 建築, 官公庁など ( 国内 1200 ライセンス, 全世界で 3500 ライセンスを超える導入実績 )
<4D F736F F F696E74202D2097AC91CC3389F196DA816995C097F18C768E5A816A2E B8CDD8AB B83685D>
 計算流体力学 ( 第 14 回資料 ) 並列計算法 (Parallel Computing) 話のポイント : 並列計算機の仕組みと並列化の方法 2018 年 1 月 11 日 Flops スーパーコンピュータの性能 1Pflops 93015Tflops(2017):Sunway TaihuLight 33862Tflops(2015):Tianhe-2 10510Tflops(2011): 京
計算流体力学 ( 第 14 回資料 ) 並列計算法 (Parallel Computing) 話のポイント : 並列計算機の仕組みと並列化の方法 2018 年 1 月 11 日 Flops スーパーコンピュータの性能 1Pflops 93015Tflops(2017):Sunway TaihuLight 33862Tflops(2015):Tianhe-2 10510Tflops(2011): 京
Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]
![Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]](/thumbs/102/156675429.jpg "Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]") 200/0/9 数値流体解析の並列効率とその GPU による高速化の試み 清水建設 ( 株 ) 技術研究所 PHAM VAN PHUC ( ファムバンフック ) 流体計算時間短縮と GPU の活用の試み 現 CPUとの比較によりGPU 活用の可能性 現 CPU の最大利用 ノード内の最大計算資源の利用 すべてCPUコアの利用 適切なアルゴリズムの利用 CPU コア性能の何倍? GPU の利用の試み
200/0/9 数値流体解析の並列効率とその GPU による高速化の試み 清水建設 ( 株 ) 技術研究所 PHAM VAN PHUC ( ファムバンフック ) 流体計算時間短縮と GPU の活用の試み 現 CPUとの比較によりGPU 活用の可能性 現 CPU の最大利用 ノード内の最大計算資源の利用 すべてCPUコアの利用 適切なアルゴリズムの利用 CPU コア性能の何倍? GPU の利用の試み
スライド 1
 本日 (4/25) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
本日 (4/25) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
about MPI
 本日 (4/16) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
本日 (4/16) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
Microsoft PowerPoint - 演習1:並列化と評価.pptx
 講義 2& 演習 1 プログラム並列化と性能評価 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 1 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 2 2 次元温度分布の計算
講義 2& 演習 1 プログラム並列化と性能評価 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 1 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 2 2 次元温度分布の計算
並列計算導入.pptx
 並列計算の基礎 MPI を用いた並列計算 並列計算の環境 並列計算 複数の計算ユニット(PU, ore, Pなど を使用して 一つの問題 計算 を行わせる 近年 並列計算を手軽に使用できる環境が急速に整いつつある >通常のP PU(entral Processing Unit)上に計算装置であるoreが 複数含まれている Intel ore i7 シリーズ: 4つの計算装置(ore) 通常のプログラム
並列計算の基礎 MPI を用いた並列計算 並列計算の環境 並列計算 複数の計算ユニット(PU, ore, Pなど を使用して 一つの問題 計算 を行わせる 近年 並列計算を手軽に使用できる環境が急速に整いつつある >通常のP PU(entral Processing Unit)上に計算装置であるoreが 複数含まれている Intel ore i7 シリーズ: 4つの計算装置(ore) 通常のプログラム
演習準備
 演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
ParallelCalculationSeminar_imano.key
 1 OPENFOAM(R) is a registered trade mark of OpenCFD Limited, the producer of the OpenFOAM software and owner of the OPENFOAM(R) and OpenCFD(R) trade marks. 2 3 Open FOAM の歴史 1989年ー2000年 研究室のハウスコード 開発元
1 OPENFOAM(R) is a registered trade mark of OpenCFD Limited, the producer of the OpenFOAM software and owner of the OPENFOAM(R) and OpenCFD(R) trade marks. 2 3 Open FOAM の歴史 1989年ー2000年 研究室のハウスコード 開発元
openmp1_Yaguchi_version_170530
 並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
コードのチューニング
 ハイブリッド並列 八木学 ( 理化学研究所計算科学研究機構 ) 謝辞 松本洋介氏 ( 千葉大学 ) KOBE HPC Spring School 2017 2017 年 3 月 14 日神戸大学計算科学教育センター MPI とは Message Passing Interface 分散メモリのプロセス間の通信規格(API) SPMD(Single Program Multi Data) が基本 -
ハイブリッド並列 八木学 ( 理化学研究所計算科学研究機構 ) 謝辞 松本洋介氏 ( 千葉大学 ) KOBE HPC Spring School 2017 2017 年 3 月 14 日神戸大学計算科学教育センター MPI とは Message Passing Interface 分散メモリのプロセス間の通信規格(API) SPMD(Single Program Multi Data) が基本 -
Microsoft PowerPoint - KHPCSS pptx
 KOBE HPC サマースクール 2018( 初級 ) 9. 1 対 1 通信関数, 集団通信関数 2018/8/8 KOBE HPC サマースクール 2018 1 2018/8/8 KOBE HPC サマースクール 2018 2 MPI プログラム (M-2):1 対 1 通信関数 問題 1 から 100 までの整数の和を 2 並列で求めなさい. プログラムの方針 プロセス0: 1から50までの和を求める.
KOBE HPC サマースクール 2018( 初級 ) 9. 1 対 1 通信関数, 集団通信関数 2018/8/8 KOBE HPC サマースクール 2018 1 2018/8/8 KOBE HPC サマースクール 2018 2 MPI プログラム (M-2):1 対 1 通信関数 問題 1 から 100 までの整数の和を 2 並列で求めなさい. プログラムの方針 プロセス0: 1から50までの和を求める.
Microsoft Word - HOKUSAI_system_overview_ja.docx
 HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
Microsoft PowerPoint _MPI-01.pptx
 計算科学演習 Ⅰ MPI を いた並列計算 (I) 神戸大学大学院システム情報学研究科谷口隆晴 yaguchi@pearl.kobe-u.ac.jp この資料は昨年度担当の横川先生の資料を参考にさせて頂いています. 2016/06/23 MPI を用いた並列計算 (I) 1 講義概要 分散メモリ型計算機上のプログラミング メッセージ パシング インターフェイス (Message Passing Interface,MPI)
計算科学演習 Ⅰ MPI を いた並列計算 (I) 神戸大学大学院システム情報学研究科谷口隆晴 yaguchi@pearl.kobe-u.ac.jp この資料は昨年度担当の横川先生の資料を参考にさせて頂いています. 2016/06/23 MPI を用いた並列計算 (I) 1 講義概要 分散メモリ型計算機上のプログラミング メッセージ パシング インターフェイス (Message Passing Interface,MPI)
演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 RIKEN AICS HPC Spring School /3/5
 演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
NUMAの構成
 メッセージパッシング プログラミング 天野 共有メモリ対メッセージパッシング 共有メモリモデル 共有変数を用いた単純な記述自動並列化コンパイラ簡単なディレクティブによる並列化 :OpenMP メッセージパッシング 形式検証が可能 ( ブロッキング ) 副作用がない ( 共有変数は副作用そのもの ) コストが小さい メッセージパッシングモデル 共有変数は使わない 共有メモリがないマシンでも実装可能 クラスタ
メッセージパッシング プログラミング 天野 共有メモリ対メッセージパッシング 共有メモリモデル 共有変数を用いた単純な記述自動並列化コンパイラ簡単なディレクティブによる並列化 :OpenMP メッセージパッシング 形式検証が可能 ( ブロッキング ) 副作用がない ( 共有変数は副作用そのもの ) コストが小さい メッセージパッシングモデル 共有変数は使わない 共有メモリがないマシンでも実装可能 クラスタ
スライド 1
 計算科学が拓く世界スーパーコンピュータは何故スーパーか 学術情報メディアセンター中島浩 http://www.para.media.kyoto-u.ac.jp/jp/ username=super password=computer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
計算科学が拓く世界スーパーコンピュータは何故スーパーか 学術情報メディアセンター中島浩 http://www.para.media.kyoto-u.ac.jp/jp/ username=super password=computer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
<4D F736F F F696E74202D2091E63489F15F436F6D C982E682E992B48D8291AC92B489B F090CD2888F38DFC E B8CDD8
 Web キャンパス資料 超音波シミュレーションの基礎 ~ 第 4 回 ComWAVEによる超高速超音波解析 ~ 科学システム開発部 Copyright (c)2006 ITOCHU Techno-Solutions Corporation 本日の説明内容 ComWAVEの概要および特徴 GPGPUとは GPGPUによる解析事例 CAE POWER 超音波研究会開催 (10 月 3 日 ) のご紹介
Web キャンパス資料 超音波シミュレーションの基礎 ~ 第 4 回 ComWAVEによる超高速超音波解析 ~ 科学システム開発部 Copyright (c)2006 ITOCHU Techno-Solutions Corporation 本日の説明内容 ComWAVEの概要および特徴 GPGPUとは GPGPUによる解析事例 CAE POWER 超音波研究会開催 (10 月 3 日 ) のご紹介
PowerPoint Presentation
 2015 年 4 月 24 日 ( 金 ) 第 18 回 FrontISTR 研究会 FrontISTR の並列計算の基礎 奥田洋司 okuda@k.u-tokyo.ac.jp 東京大学大学院 新領域創成科学研究科 人間環境学専攻 目次 導入 計算力学とは 連続体の力学 連立 1 次方程式 FEM 構造解析の概要 なぜ並列化か? 並列アーキテクチャ 並列プログラミング FEM 計算におけるノード間並列
2015 年 4 月 24 日 ( 金 ) 第 18 回 FrontISTR 研究会 FrontISTR の並列計算の基礎 奥田洋司 okuda@k.u-tokyo.ac.jp 東京大学大学院 新領域創成科学研究科 人間環境学専攻 目次 導入 計算力学とは 連続体の力学 連立 1 次方程式 FEM 構造解析の概要 なぜ並列化か? 並列アーキテクチャ 並列プログラミング FEM 計算におけるノード間並列
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
<4D F736F F F696E74202D D F95C097F D834F E F93FC96E5284D F96E291E85F8DE391E52E >
 SX-ACE 並列プログラミング入門 (MPI) ( 演習補足資料 ) 大阪大学サイバーメディアセンター日本電気株式会社 演習問題の構成 ディレクトリ構成 MPI/ -- practice_1 演習問題 1 -- practice_2 演習問題 2 -- practice_3 演習問題 3 -- practice_4 演習問題 4 -- practice_5 演習問題 5 -- practice_6
SX-ACE 並列プログラミング入門 (MPI) ( 演習補足資料 ) 大阪大学サイバーメディアセンター日本電気株式会社 演習問題の構成 ディレクトリ構成 MPI/ -- practice_1 演習問題 1 -- practice_2 演習問題 2 -- practice_3 演習問題 3 -- practice_4 演習問題 4 -- practice_5 演習問題 5 -- practice_6
Microsoft PowerPoint - 演習2:MPI初歩.pptx
 演習 2:MPI 初歩 - 並列に計算する - 2013 年 8 月 6 日 神戸大学大学院システム情報学研究科計算科学専攻横川三津夫 MPI( メッセージ パッシング インターフェース ) を使おう! [ 演習 2 の内容 ] はじめの一歩課題 1: Hello, world を並列に出力する. 課題 2: プロセス 0 からのメッセージを受け取る (1 対 1 通信 ). 部分に分けて計算しよう課題
演習 2:MPI 初歩 - 並列に計算する - 2013 年 8 月 6 日 神戸大学大学院システム情報学研究科計算科学専攻横川三津夫 MPI( メッセージ パッシング インターフェース ) を使おう! [ 演習 2 の内容 ] はじめの一歩課題 1: Hello, world を並列に出力する. 課題 2: プロセス 0 からのメッセージを受け取る (1 対 1 通信 ). 部分に分けて計算しよう課題
課題 S1 解説 Fortran 編 中島研吾 東京大学情報基盤センター
 課題 S1 解説 Fortran 編 中島研吾 東京大学情報基盤センター 内容 課題 S1 /a1.0~a1.3, /a2.0~a2.3 から局所ベクトル情報を読み込み, 全体ベクトルのノルム ( x ) を求めるプログラムを作成する (S1-1) file.f,file2.f をそれぞれ参考にする 下記の数値積分の結果を台形公式によって求めるプログラムを作成する
課題 S1 解説 Fortran 編 中島研吾 東京大学情報基盤センター 内容 課題 S1 /a1.0~a1.3, /a2.0~a2.3 から局所ベクトル情報を読み込み, 全体ベクトルのノルム ( x ) を求めるプログラムを作成する (S1-1) file.f,file2.f をそれぞれ参考にする 下記の数値積分の結果を台形公式によって求めるプログラムを作成する
Microsoft PowerPoint - 2_FrontISTRと利用可能なソフトウェア.pptx
 東京大学本郷キャンパス 工学部8号館2階222中会議室 13:30-14:00 FrontISTRと利用可能なソフトウェア 2017年4月28日 第35回FrontISTR研究会 FrontISTRの並列計算ハンズオン 精度検証から並列性能評価まで 観測された物理現象 物理モデル ( 支配方程式 ) 連続体の運動を支配する偏微分方程式 離散化手法 ( 有限要素法, 差分法など ) 代数的な数理モデル
東京大学本郷キャンパス 工学部8号館2階222中会議室 13:30-14:00 FrontISTRと利用可能なソフトウェア 2017年4月28日 第35回FrontISTR研究会 FrontISTRの並列計算ハンズオン 精度検証から並列性能評価まで 観測された物理現象 物理モデル ( 支配方程式 ) 連続体の運動を支配する偏微分方程式 離散化手法 ( 有限要素法, 差分法など ) 代数的な数理モデル
並列・高速化を実現するための 高速化サービスの概要と事例紹介
 第 4 回 AVS 可視化フォーラム 2019 並列 高速化を実現するための 高速化サービスの概要と事例紹介 株式会社アーク情報システム営業部仮野亮ソリューション技術部佐々木竜一 2019.08.30 はじめに アーク情報システムの紹介 高速化サービスとは? 事例紹介 コンサルティングサービスについて アーク情報システムの紹介 設立 資本金 :1987 年 10 月 :3 億 600 万円 従業員数
第 4 回 AVS 可視化フォーラム 2019 並列 高速化を実現するための 高速化サービスの概要と事例紹介 株式会社アーク情報システム営業部仮野亮ソリューション技術部佐々木竜一 2019.08.30 はじめに アーク情報システムの紹介 高速化サービスとは? 事例紹介 コンサルティングサービスについて アーク情報システムの紹介 設立 資本金 :1987 年 10 月 :3 億 600 万円 従業員数
NUMAの構成
 共有メモリを使ったデータ交換と同期 慶應義塾大学理工学部 天野英晴 hunga@am.ics.keio.ac.jp 同期の必要性 あるプロセッサが共有メモリに書いても 別のプロセッサにはそのことが分からない 同時に同じ共有変数に書き込みすると 結果がどうなるか分からない そもそも共有メモリって結構危険な代物 多くのプロセッサが並列に動くには何かの制御機構が要る 不可分命令 同期用メモリ バリア同期機構
共有メモリを使ったデータ交換と同期 慶應義塾大学理工学部 天野英晴 hunga@am.ics.keio.ac.jp 同期の必要性 あるプロセッサが共有メモリに書いても 別のプロセッサにはそのことが分からない 同時に同じ共有変数に書き込みすると 結果がどうなるか分からない そもそも共有メモリって結構危険な代物 多くのプロセッサが並列に動くには何かの制御機構が要る 不可分命令 同期用メモリ バリア同期機構
スライド 0
 2012/7/11 OpeMP を用いた Fortra コードの並列化基礎セミナー 株式会社計算力学研究センター 技術 1 部三又秀行 mimata@rccm.co.jp 目次 高速化 並列化事例 PARDISO について (XLsoft 黒澤様 ) 並列化 並列化について 並列化作業の流れ 並列化の手段 OpeMP デモ OpeMP で並列計算する 円周率 p の計算 (private reductio)
2012/7/11 OpeMP を用いた Fortra コードの並列化基礎セミナー 株式会社計算力学研究センター 技術 1 部三又秀行 mimata@rccm.co.jp 目次 高速化 並列化事例 PARDISO について (XLsoft 黒澤様 ) 並列化 並列化について 並列化作業の流れ 並列化の手段 OpeMP デモ OpeMP で並列計算する 円周率 p の計算 (private reductio)
PowerPoint プレゼンテーション
 計算科学演習 I 第 8 回講義 MPI を用いた並列計算 (I) 2013 年 6 月 6 日 システム情報学研究科計算科学専攻 山本有作 今回の講義の概要 1. MPI とは 2. 簡単な MPI プログラムの例 (1) 3. 簡単な MPI プログラムの例 (2):1 対 1 通信 4. 簡単な MPI プログラムの例 (3): 集団通信 共有メモリ型並列計算機 ( 復習 ) 共有メモリ型並列計算機
計算科学演習 I 第 8 回講義 MPI を用いた並列計算 (I) 2013 年 6 月 6 日 システム情報学研究科計算科学専攻 山本有作 今回の講義の概要 1. MPI とは 2. 簡単な MPI プログラムの例 (1) 3. 簡単な MPI プログラムの例 (2):1 対 1 通信 4. 簡単な MPI プログラムの例 (3): 集団通信 共有メモリ型並列計算機 ( 復習 ) 共有メモリ型並列計算機
目次 LS-DYNA 利用の手引き 1 1. はじめに 利用できるバージョン 概要 1 2. TSUBAME での利用方法 使用可能な LS-DYNA の実行 4 (1) TSUBAMEにログイン 4 (2) バージョンの切り替え 4 (3) インタラ
 TSUBAMEにログイン 4 (2) バージョンの切り替え 4 (3) インタラ") LS-DYNA 利用の手引 東京工業大学学術国際情報センター 2016.04 version 1.10 目次 LS-DYNA 利用の手引き 1 1. はじめに 1 1.1 利用できるバージョン 1 1.2 概要 1 2. TSUBAME での利用方法 1 2.1 使用可能な 1 2.2 LS-DYNA の実行 4 (1) TSUBAMEにログイン 4 (2) バージョンの切り替え 4 (3) インタラクティブ実行
LS-DYNA 利用の手引 東京工業大学学術国際情報センター 2016.04 version 1.10 目次 LS-DYNA 利用の手引き 1 1. はじめに 1 1.1 利用できるバージョン 1 1.2 概要 1 2. TSUBAME での利用方法 1 2.1 使用可能な 1 2.2 LS-DYNA の実行 4 (1) TSUBAMEにログイン 4 (2) バージョンの切り替え 4 (3) インタラクティブ実行
スパコンに通じる並列プログラミングの基礎
 2018.09.10 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 1 / 59 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 2 / 59 Windows, Mac Unix 0444-J furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 3 / 59 Part I Unix GUI CUI:
2018.09.10 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 1 / 59 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 2 / 59 Windows, Mac Unix 0444-J furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 3 / 59 Part I Unix GUI CUI:
Microsoft PowerPoint - OS07.pptx
 この資料は 情報工学レクチャーシリーズ松尾啓志著 ( 森北出版株式会社 ) を用いて授業を行うために 名古屋工業大学松尾啓志 津邑公暁が作成しました 主記憶管理 主記憶管理基礎 パワーポイント 27 で最終版として保存しているため 変更はできませんが 授業でお使いなる場合は松尾 (matsuo@nitech.ac.jp) まで連絡いただければ 編集可能なバージョンをお渡しする事も可能です 復習 OS
この資料は 情報工学レクチャーシリーズ松尾啓志著 ( 森北出版株式会社 ) を用いて授業を行うために 名古屋工業大学松尾啓志 津邑公暁が作成しました 主記憶管理 主記憶管理基礎 パワーポイント 27 で最終版として保存しているため 変更はできませんが 授業でお使いなる場合は松尾 (matsuo@nitech.ac.jp) まで連絡いただければ 編集可能なバージョンをお渡しする事も可能です 復習 OS
スパコンに通じる並列プログラミングの基礎
 2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
Microsoft PowerPoint - 第10回講義(2015年12月22日)-1 .pptx
-1 .pptx") 非同期通信 東京大学情報基盤センター准教授片桐孝洋 1 2015 年 12 月 22 日 ( 火 )10:25-12:10 講義日程 ( 工学部共通科目 ) 10 月 6 日 : ガイダンス 1. 10 月 13 日 並列数値処理の基本演算 ( 座学 ) 2. 10 月 20 日 : スパコン利用開始 ログイン作業 テストプログラム実行 3. 10 月 27 日 高性能演算技法 1 ( ループアンローリング
非同期通信 東京大学情報基盤センター准教授片桐孝洋 1 2015 年 12 月 22 日 ( 火 )10:25-12:10 講義日程 ( 工学部共通科目 ) 10 月 6 日 : ガイダンス 1. 10 月 13 日 並列数値処理の基本演算 ( 座学 ) 2. 10 月 20 日 : スパコン利用開始 ログイン作業 テストプログラム実行 3. 10 月 27 日 高性能演算技法 1 ( ループアンローリング
Microsoft PowerPoint _MPI-03.pptx
 計算科学演習 Ⅰ ( 第 11 回 ) MPI を いた並列計算 (III) 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/07/03 計算科学演習 Ⅰ:MPI を用いた並列計算 (III) 1 2014/07/03 計算科学演習 Ⅰ:MPI を用いた並列計算 (III) 2 今週の講義の概要 1. 前回課題の解説 2. 部分配列とローカルインデックス
計算科学演習 Ⅰ ( 第 11 回 ) MPI を いた並列計算 (III) 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/07/03 計算科学演習 Ⅰ:MPI を用いた並列計算 (III) 1 2014/07/03 計算科学演習 Ⅰ:MPI を用いた並列計算 (III) 2 今週の講義の概要 1. 前回課題の解説 2. 部分配列とローカルインデックス
GeoFEM開発の経験から
 FrontISTR における並列計算のしくみ < 領域分割に基づく並列 FEM> メッシュ分割 領域分割 領域分割 ( パーティショニングツール ) 全体制御 解析制御 メッシュ hecmw_ctrl.dat 境界条件 材料物性 計算制御パラメータ 可視化パラメータ 領域分割ツール 逐次計算 並列計算 Front ISTR FEM の主な演算 FrontISTR における並列計算のしくみ < 領域分割に基づく並列
FrontISTR における並列計算のしくみ < 領域分割に基づく並列 FEM> メッシュ分割 領域分割 領域分割 ( パーティショニングツール ) 全体制御 解析制御 メッシュ hecmw_ctrl.dat 境界条件 材料物性 計算制御パラメータ 可視化パラメータ 領域分割ツール 逐次計算 並列計算 Front ISTR FEM の主な演算 FrontISTR における並列計算のしくみ < 領域分割に基づく並列
スパコンに通じる並列プログラミングの基礎
 2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
GPUを用いたN体計算
 単精度 190Tflops GPU クラスタ ( 長崎大 ) の紹介 長崎大学工学部超高速メニーコアコンピューティングセンターテニュアトラック助教濱田剛 1 概要 GPU (Graphics Processing Unit) について簡単に説明します. GPU クラスタが得意とする応用問題を議論し 長崎大学での GPU クラスタによる 取組方針 N 体計算の高速化に関する研究内容 を紹介します. まとめ
単精度 190Tflops GPU クラスタ ( 長崎大 ) の紹介 長崎大学工学部超高速メニーコアコンピューティングセンターテニュアトラック助教濱田剛 1 概要 GPU (Graphics Processing Unit) について簡単に説明します. GPU クラスタが得意とする応用問題を議論し 長崎大学での GPU クラスタによる 取組方針 N 体計算の高速化に関する研究内容 を紹介します. まとめ
パソコンシミュレータの現状
 第 2 章微分 偏微分, 写像 豊橋技術科学大学森謙一郎 2. 連続関数と微分 工学において物理現象を支配する方程式は微分方程式で表されていることが多く, 有限要素法も微分方程式を解く数値解析法であり, 定式化においては微分 積分が一般的に用いられており. 数学の基礎知識が必要になる. 図 2. に示すように, 微分は連続な関数 f() の傾きを求めることであり, 微小な に対して傾きを表し, を無限に
第 2 章微分 偏微分, 写像 豊橋技術科学大学森謙一郎 2. 連続関数と微分 工学において物理現象を支配する方程式は微分方程式で表されていることが多く, 有限要素法も微分方程式を解く数値解析法であり, 定式化においては微分 積分が一般的に用いられており. 数学の基礎知識が必要になる. 図 2. に示すように, 微分は連続な関数 f() の傾きを求めることであり, 微小な に対して傾きを表し, を無限に
コードのチューニング
 OpenMP による並列化実装 八木学 ( 理化学研究所計算科学研究センター ) KOBE HPC Spring School 2019 2019 年 3 月 14 日 スレッド並列とプロセス並列 スレッド並列 OpenMP 自動並列化 プロセス並列 MPI プロセス プロセス プロセス スレッドスレッドスレッドスレッド メモリ メモリ プロセス間通信 Private Private Private
OpenMP による並列化実装 八木学 ( 理化学研究所計算科学研究センター ) KOBE HPC Spring School 2019 2019 年 3 月 14 日 スレッド並列とプロセス並列 スレッド並列 OpenMP 自動並列化 プロセス並列 MPI プロセス プロセス プロセス スレッドスレッドスレッドスレッド メモリ メモリ プロセス間通信 Private Private Private
Microsoft Word ●IntelクアッドコアCPUでのベンチマーク_吉岡_ _更新__ doc
 2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
九州大学がスーパーコンピュータ「高性能アプリケーションサーバシステム」の本格稼働を開始
 2014 年 1 月 31 日 国立大学法人九州大学 株式会社日立製作所 九州大学がスーパーコンピュータ 高性能アプリケーションサーバシステム の本格稼働を開始 日立のテクニカルサーバ HA8000-tc/HT210 などを採用 従来システム比で 約 28 倍の性能を実現し 1TFLOPS あたりの消費電力は約 17 分の 1 に低減 九州大学情報基盤研究開発センター ( センター長 : 青柳睦 /
2014 年 1 月 31 日 国立大学法人九州大学 株式会社日立製作所 九州大学がスーパーコンピュータ 高性能アプリケーションサーバシステム の本格稼働を開始 日立のテクニカルサーバ HA8000-tc/HT210 などを採用 従来システム比で 約 28 倍の性能を実現し 1TFLOPS あたりの消費電力は約 17 分の 1 に低減 九州大学情報基盤研究開発センター ( センター長 : 青柳睦 /
研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI, MPICH, MVAPICH, MPI.NET プログラミングコストが高いため 生産性が悪い 新しい並
 XcalableMPによる NAS Parallel Benchmarksの実装と評価 中尾 昌広 李 珍泌 朴 泰祐 佐藤 三久 筑波大学 計算科学研究センター 筑波大学大学院 システム情報工学研究科 研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI,
XcalableMPによる NAS Parallel Benchmarksの実装と評価 中尾 昌広 李 珍泌 朴 泰祐 佐藤 三久 筑波大学 計算科学研究センター 筑波大学大学院 システム情報工学研究科 研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI,
RICCについて
 RICC 1 RICC 2 RICC 3 RICC GPU 1039Nodes 8312core) 93.0GFLOPS, 12GB(mem), 500GB (hdd) DDR IB!1 PC100Nodes(800core) 9.3 GPGPU 93.3TFLOPS HPSS (4PB) (550TB) 0.24 512GB 1500GB MDGRAPE33TFLOPS MDGRAPE-3 64
RICC 1 RICC 2 RICC 3 RICC GPU 1039Nodes 8312core) 93.0GFLOPS, 12GB(mem), 500GB (hdd) DDR IB!1 PC100Nodes(800core) 9.3 GPGPU 93.3TFLOPS HPSS (4PB) (550TB) 0.24 512GB 1500GB MDGRAPE33TFLOPS MDGRAPE-3 64
最新の並列計算事情とCAE
 1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
PowerPoint プレゼンテーション
 音響解析プログラム WAON 最新開発動向と適用例のご紹介 サイバネットシステム株式会社 メカニカル CAE 事業部 WAON 推進室 アジェンダ 1. 会社紹介 2. WAON とは? 3. なぜ WAON なのか? 4. 各種適用例のご紹介 5. 最新開発動向 2 1. 会社紹介サイバネットシステム ( 株 ) メカニカル CAE 事業部 音響 構造 熱 電磁場 熱流体 衝突 板成形 樹脂流動などの各種解析
音響解析プログラム WAON 最新開発動向と適用例のご紹介 サイバネットシステム株式会社 メカニカル CAE 事業部 WAON 推進室 アジェンダ 1. 会社紹介 2. WAON とは? 3. なぜ WAON なのか? 4. 各種適用例のご紹介 5. 最新開発動向 2 1. 会社紹介サイバネットシステム ( 株 ) メカニカル CAE 事業部 音響 構造 熱 電磁場 熱流体 衝突 板成形 樹脂流動などの各種解析
Microsoft PowerPoint - 講義:片方向通信.pptx
 MPI( 片方向通信 ) 09 年 3 月 5 日 神戸大学大学院システム情報学研究科計算科学専攻横川三津夫 09/3/5 KOBE HPC Spring School 09 分散メモリ型並列計算機 複数のプロセッサがネットワークで接続されており, れぞれのプロセッサ (PE) が, メモリを持っている. 各 PE が自分のメモリ領域のみアクセス可能 特徴数千から数万 PE 規模の並列システムが可能
MPI( 片方向通信 ) 09 年 3 月 5 日 神戸大学大学院システム情報学研究科計算科学専攻横川三津夫 09/3/5 KOBE HPC Spring School 09 分散メモリ型並列計算機 複数のプロセッサがネットワークで接続されており, れぞれのプロセッサ (PE) が, メモリを持っている. 各 PE が自分のメモリ領域のみアクセス可能 特徴数千から数万 PE 規模の並列システムが可能
VXPRO R1400® ご提案資料
 Intel Core i7 プロセッサ 920 Preliminary Performance Report ノード性能評価 ノード性能の評価 NAS Parallel Benchmark Class B OpenMP 版での性能評価 実行スレッド数を 4 で固定 ( デュアルソケットでは各プロセッサに 2 スレッド ) 全て 2.66GHz のコアとなるため コアあたりのピーク性能は同じ 評価システム
Intel Core i7 プロセッサ 920 Preliminary Performance Report ノード性能評価 ノード性能の評価 NAS Parallel Benchmark Class B OpenMP 版での性能評価 実行スレッド数を 4 で固定 ( デュアルソケットでは各プロセッサに 2 スレッド ) 全て 2.66GHz のコアとなるため コアあたりのピーク性能は同じ 評価システム
UNIX 初級講習会 (第一日目)
") 情報処理概論 工学部物質科学工学科応用化学コース機能物質化学クラス 第 3 回 2005 年 4 月 28 日 計算機に関する基礎知識 Fortranプログラムの基本構造 文字や数値を画面に表示する コンパイル時のエラーへの対処 ハードウェアとソフトウェア ハードウェア 計算, 記憶等を行う機械 ソフトウェア ハードウェアに対する命令 データ ソフトウェア ( 命令 ) がないとハードウェアは動かない
情報処理概論 工学部物質科学工学科応用化学コース機能物質化学クラス 第 3 回 2005 年 4 月 28 日 計算機に関する基礎知識 Fortranプログラムの基本構造 文字や数値を画面に表示する コンパイル時のエラーへの対処 ハードウェアとソフトウェア ハードウェア 計算, 記憶等を行う機械 ソフトウェア ハードウェアに対する命令 データ ソフトウェア ( 命令 ) がないとハードウェアは動かない
演習1: 演習準備
 演習 1: 演習準備 2013 年 8 月 6 日神戸大学大学院システム情報学研究科森下浩二 1 演習 1 の内容 神戸大 X10(π-omputer) について システム概要 ログイン方法 コンパイルとジョブ実行方法 OpenMP の演習 ( 入門編 ) 1. parallel 構文 実行時ライブラリ関数 2. ループ構文 3. shared 節 private 節 4. reduction 節
演習 1: 演習準備 2013 年 8 月 6 日神戸大学大学院システム情報学研究科森下浩二 1 演習 1 の内容 神戸大 X10(π-omputer) について システム概要 ログイン方法 コンパイルとジョブ実行方法 OpenMP の演習 ( 入門編 ) 1. parallel 構文 実行時ライブラリ関数 2. ループ構文 3. shared 節 private 節 4. reduction 節
演習1
 神戸市立工業高等専門学校電気工学科 / 電子工学科専門科目 数値解析 2019.5.10 演習 1 山浦剛 (tyamaura@riken.jp) 講義資料ページ http://r-ccs-climate.riken.jp/members/yamaura/numerical_analysis.html Fortran とは? Fortran(= FORmula TRANslation ) は 1950
神戸市立工業高等専門学校電気工学科 / 電子工学科専門科目 数値解析 2019.5.10 演習 1 山浦剛 (tyamaura@riken.jp) 講義資料ページ http://r-ccs-climate.riken.jp/members/yamaura/numerical_analysis.html Fortran とは? Fortran(= FORmula TRANslation ) は 1950
Microsoft PowerPoint - 高速化WS富山.pptx
 京 における 高速化ワークショップ 性能分析 チューニングの手順について 登録施設利用促進機関 一般財団法人高度情報科学技術研究機構富山栄治 一般財団法人高度情報科学技術研究機構 2 性能分析 チューニング手順 どの程度の並列数が実現可能か把握する インバランスの懸念があるか把握する タイムステップループ I/O 処理など注目すべき箇所を把握する 並列数 並列化率などの目標を設定し チューニング時の指針とする
京 における 高速化ワークショップ 性能分析 チューニングの手順について 登録施設利用促進機関 一般財団法人高度情報科学技術研究機構富山栄治 一般財団法人高度情報科学技術研究機構 2 性能分析 チューニング手順 どの程度の並列数が実現可能か把握する インバランスの懸念があるか把握する タイムステップループ I/O 処理など注目すべき箇所を把握する 並列数 並列化率などの目標を設定し チューニング時の指針とする
スライド 1
 CATIA V5 統合型デスクトップ熱流体解析ソフトウェア FloEFD.V5 < CATIA V5 統合型の熱流体解析ソフトウェア > FloEFD.Pro は Pro/ENGINEER の画面上で 3D モデルを直接解析に使用します 設計段階における設計者のさまざまなアイデアを検証し 最適な設計案を導きます 繰り返しシミュレーションを実施することで 手戻り削減 設計期間短縮 品質向上 コスト削減を可能にします
CATIA V5 統合型デスクトップ熱流体解析ソフトウェア FloEFD.V5 < CATIA V5 統合型の熱流体解析ソフトウェア > FloEFD.Pro は Pro/ENGINEER の画面上で 3D モデルを直接解析に使用します 設計段階における設計者のさまざまなアイデアを検証し 最適な設計案を導きます 繰り返しシミュレーションを実施することで 手戻り削減 設計期間短縮 品質向上 コスト削減を可能にします
HPC143
 研究背景 GPUクラスタ 高性能 高いエネルギー効率 低価格 様々なHPCアプリケーションで用いられている TCA (Tightly Coupled Accelerators) 密結合並列演算加速機構 筑波大学HA-PACSクラスタ アクセラレータ GPU 間の直接通信 低レイテンシ 今後のHPCアプリは強スケーリングも重要 TCAとアクセラレータを搭載したシステムに おけるプログラミングモデル 例
研究背景 GPUクラスタ 高性能 高いエネルギー効率 低価格 様々なHPCアプリケーションで用いられている TCA (Tightly Coupled Accelerators) 密結合並列演算加速機構 筑波大学HA-PACSクラスタ アクセラレータ GPU 間の直接通信 低レイテンシ 今後のHPCアプリは強スケーリングも重要 TCAとアクセラレータを搭載したシステムに おけるプログラミングモデル 例
PowerPoint Presentation
 FrontISTR の並列計算の基礎 奥田洋司 okuda@k.u-tokyo.ac.jp 東京大学大学院 新領域創成科学研究科 人間環境学専攻 並列有限要素法プログラム FrontISTR ( フロントアイスター ) 並列計算では, メッシュ領域分割によって分散メモリ環境に対応し, 通信ライブラリには MPI を使用 (MPI 並列 ) さらに,CPU 内は OpenMP 並列 ( スレッド並列
FrontISTR の並列計算の基礎 奥田洋司 okuda@k.u-tokyo.ac.jp 東京大学大学院 新領域創成科学研究科 人間環境学専攻 並列有限要素法プログラム FrontISTR ( フロントアイスター ) 並列計算では, メッシュ領域分割によって分散メモリ環境に対応し, 通信ライブラリには MPI を使用 (MPI 並列 ) さらに,CPU 内は OpenMP 並列 ( スレッド並列
Microsoft PowerPoint - 講義:コミュニケータ.pptx
 コミュニケータとデータタイプ (Communicator and Datatype) 2019 年 3 月 15 日 神戸大学大学院システム情報学研究科横川三津夫 2019/3/15 Kobe HPC Spring School 2019 1 講義の内容 コミュニケータ (Communicator) データタイプ (Datatype) 演習問題 2019/3/15 Kobe HPC Spring School
コミュニケータとデータタイプ (Communicator and Datatype) 2019 年 3 月 15 日 神戸大学大学院システム情報学研究科横川三津夫 2019/3/15 Kobe HPC Spring School 2019 1 講義の内容 コミュニケータ (Communicator) データタイプ (Datatype) 演習問題 2019/3/15 Kobe HPC Spring School
TopSE並行システム はじめに
 はじめに 平成 23 年 9 月 1 日 トップエスイープロジェクト 磯部祥尚 ( 産業技術総合研究所 ) 2 本講座の背景と目標 背景 : マルチコア CPU やクラウドコンピューティング等 並列 / 分散処理環境が身近なものになっている 複数のプロセス ( プログラム ) を同時に実行可能 通信等により複数のプロセスが協調可能 並行システムの構築 並行システム 通信 Proc2 プロセス ( プログラム
はじめに 平成 23 年 9 月 1 日 トップエスイープロジェクト 磯部祥尚 ( 産業技術総合研究所 ) 2 本講座の背景と目標 背景 : マルチコア CPU やクラウドコンピューティング等 並列 / 分散処理環境が身近なものになっている 複数のプロセス ( プログラム ) を同時に実行可能 通信等により複数のプロセスが協調可能 並行システムの構築 並行システム 通信 Proc2 プロセス ( プログラム
Microsoft Word - openmp-txt.doc
 ( 付録 A) OpenMP チュートリアル OepnMP は 共有メモリマルチプロセッサ上のマルチスレッドプログラミングのための API です 本稿では OpenMP の簡単な解説とともにプログラム例をつかって説明します 詳しくは OpenMP の規約を決めている OpenMP ARB の http://www.openmp.org/ にある仕様書を参照してください 日本語訳は http://www.hpcc.jp/omni/spec.ja/
( 付録 A) OpenMP チュートリアル OepnMP は 共有メモリマルチプロセッサ上のマルチスレッドプログラミングのための API です 本稿では OpenMP の簡単な解説とともにプログラム例をつかって説明します 詳しくは OpenMP の規約を決めている OpenMP ARB の http://www.openmp.org/ にある仕様書を参照してください 日本語訳は http://www.hpcc.jp/omni/spec.ja/
スライド 1
 目次 2.MPI プログラミング入門 この資料は, スーパーコン 10 で使用したものである. ごく基本的な内容なので, 現在でも十分利用できると思われるものなので, ここに紹介させて頂く. ただし, 古い情報も含まれているので注意が必要である. 今年度版の解説は, 本選の初日に配布する予定である. 1/20 2.MPI プログラミング入門 (1) 基本 説明 MPI (message passing
目次 2.MPI プログラミング入門 この資料は, スーパーコン 10 で使用したものである. ごく基本的な内容なので, 現在でも十分利用できると思われるものなので, ここに紹介させて頂く. ただし, 古い情報も含まれているので注意が必要である. 今年度版の解説は, 本選の初日に配布する予定である. 1/20 2.MPI プログラミング入門 (1) 基本 説明 MPI (message passing
4 月 東京都立蔵前工業高等学校平成 30 年度教科 ( 工業 ) 科目 ( プログラミング技術 ) 年間授業計画 教科 :( 工業 ) 科目 :( プログラミング技術 ) 単位数 : 2 単位 対象学年組 :( 第 3 学年電気科 ) 教科担当者 :( 高橋寛 三枝明夫 ) 使用教科書 :( プロ
 科目 ( プログラミング技術 ) 年間授業計画 教科 :( 工業 ) 科目 :( プログラミング技術 ) 単位数 : 2 単位 対象学年組 :( 第 3 学年電気科 ) 教科担当者 :( 高橋寛 三枝明夫 ) 使用教科書 :( プロ") 4 東京都立蔵前工業高等学校平成 30 年度教科 ( 工業 ) 科目 ( プログラミング技術 ) 年間授業計画 教科 :( 工業 ) 科目 :( プログラミング技術 ) 単位数 : 2 単位 対象学年組 :( 第 3 学年電気科 ) 教科担当者 :( 高橋寛 三枝明夫 ) 使用教科書 :( プログラミング技術 工業 333 実教出版 ) 共通 : 科目 プログラミング技術 のオリエンテーション プログラミング技術は
4 東京都立蔵前工業高等学校平成 30 年度教科 ( 工業 ) 科目 ( プログラミング技術 ) 年間授業計画 教科 :( 工業 ) 科目 :( プログラミング技術 ) 単位数 : 2 単位 対象学年組 :( 第 3 学年電気科 ) 教科担当者 :( 高橋寛 三枝明夫 ) 使用教科書 :( プログラミング技術 工業 333 実教出版 ) 共通 : 科目 プログラミング技術 のオリエンテーション プログラミング技術は
<4D F736F F F696E74202D F F8F7482CC944E89EF8AE989E6835A E6F325F8CF68A4A94C55231>
 日本原子力学会 2010 年春の年会茨城大学計算科学技術部会企画セッション シミュレーションの信頼性確保の あり方とは? (2) 海外における熱流動解析の信頼性評価の取り組み 平成 22 年 3 月 28 日東芝中田耕太郎 JNES 笠原文雄 調査対象 OECD/NEA CFD ガイドライン NEA/CSNI/R(2007)5 単相 CFD の使用に関する体系的なベストプラクティスガイドライン 原子炉安全解析に対する単相
日本原子力学会 2010 年春の年会茨城大学計算科学技術部会企画セッション シミュレーションの信頼性確保の あり方とは? (2) 海外における熱流動解析の信頼性評価の取り組み 平成 22 年 3 月 28 日東芝中田耕太郎 JNES 笠原文雄 調査対象 OECD/NEA CFD ガイドライン NEA/CSNI/R(2007)5 単相 CFD の使用に関する体系的なベストプラクティスガイドライン 原子炉安全解析に対する単相
Microsoft PowerPoint - 第7章(自然対流熱伝達 )_H27.ppt [互換モード]
![Microsoft PowerPoint - 第7章(自然対流熱伝達 )_H27.ppt [互換モード]](/thumbs/94/118222251.jpg "Microsoft PowerPoint - 第7章(自然対流熱伝達 )_H27.ppt [互換モード]") 第 7 章自然対流熱伝達 伝熱工学の基礎 : 伝熱の基本要素 フーリエの法則 ニュートンの冷却則 次元定常熱伝導 : 熱伝導率 熱通過率 熱伝導方程式 次元定常熱伝導 : ラプラスの方程式 数値解析の基礎 非定常熱伝導 : 非定常熱伝導方程式 ラプラス変換 フーリエ数とビオ数 対流熱伝達の基礎 : 熱伝達率 速度境界層と温度境界層 層流境界層と乱流境界層 境界層厚さ 混合平均温度 強制対流熱伝達 :
第 7 章自然対流熱伝達 伝熱工学の基礎 : 伝熱の基本要素 フーリエの法則 ニュートンの冷却則 次元定常熱伝導 : 熱伝導率 熱通過率 熱伝導方程式 次元定常熱伝導 : ラプラスの方程式 数値解析の基礎 非定常熱伝導 : 非定常熱伝導方程式 ラプラス変換 フーリエ数とビオ数 対流熱伝達の基礎 : 熱伝達率 速度境界層と温度境界層 層流境界層と乱流境界層 境界層厚さ 混合平均温度 強制対流熱伝達 :
第8回講義(2016年12月6日)
") 2016/12/6 スパコンプログラミング (1) (Ⅰ) 1 行列 - 行列積 (2) 東京大学情報基盤センター准教授塙敏博 2016 年 12 月 6 日 ( 火 ) 10:25-12:10 2016/11/29 講義日程 ( 工学部共通科目 ) 1. 9 月 27 日 ( 今日 ): ガイダンス 2. 10 月 4 日 l 並列数値処理の基本演算 ( 座学 ) 3. 10 月 11 日 : スパコン利用開始
2016/12/6 スパコンプログラミング (1) (Ⅰ) 1 行列 - 行列積 (2) 東京大学情報基盤センター准教授塙敏博 2016 年 12 月 6 日 ( 火 ) 10:25-12:10 2016/11/29 講義日程 ( 工学部共通科目 ) 1. 9 月 27 日 ( 今日 ): ガイダンス 2. 10 月 4 日 l 並列数値処理の基本演算 ( 座学 ) 3. 10 月 11 日 : スパコン利用開始
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司
![4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司](/thumbs/97/131936032.jpg "4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司") 4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
PowerPoint プレゼンテーション
 vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
CCS HPCサマーセミナー 並列数値計算アルゴリズム
 大規模系での高速フーリエ変換 2 高橋大介 daisuke@cs.tsukuba.ac.jp 筑波大学計算科学研究センター 2016/6/2 計算科学技術特論 B 1 講義内容 並列三次元 FFT における自動チューニング 二次元分割を用いた並列三次元 FFT アルゴリズム GPU クラスタにおける並列三次元 FFT 2016/6/2 計算科学技術特論 B 2 並列三次元 FFT における 自動チューニング
大規模系での高速フーリエ変換 2 高橋大介 daisuke@cs.tsukuba.ac.jp 筑波大学計算科学研究センター 2016/6/2 計算科学技術特論 B 1 講義内容 並列三次元 FFT における自動チューニング 二次元分割を用いた並列三次元 FFT アルゴリズム GPU クラスタにおける並列三次元 FFT 2016/6/2 計算科学技術特論 B 2 並列三次元 FFT における 自動チューニング
Microsoft PowerPoint - S1-ref-F.ppt [互換モード]
![Microsoft PowerPoint - S1-ref-F.ppt [互換モード]](/thumbs/86/94184661.jpg "Microsoft PowerPoint - S1-ref-F.ppt [互換モード]") 課題 S1 解説 Fortran 言語編 RIKEN AICS HPC Summer School 2014 中島研吾 ( 東大 情報基盤センター ) 横川三津夫 ( 神戸大 計算科学教育センター ) MPI Programming 課題 S1 (1/2) /a1.0~a1.3, /a2.0~a2.3 から局所ベクトル情報を読み込み, 全体ベクトルのノルム ( x ) を求めるプログラムを作成する
課題 S1 解説 Fortran 言語編 RIKEN AICS HPC Summer School 2014 中島研吾 ( 東大 情報基盤センター ) 横川三津夫 ( 神戸大 計算科学教育センター ) MPI Programming 課題 S1 (1/2) /a1.0~a1.3, /a2.0~a2.3 から局所ベクトル情報を読み込み, 全体ベクトルのノルム ( x ) を求めるプログラムを作成する
LS-DYNA 利用の手引 第 1 版 東京工業大学学術国際情報センター 2017 年 9 月 25 日
 LS-DYNA 利用の手引 第 1 版 東京工業大学学術国際情報センター 2017 年 9 月 25 日 目次 1. はじめに 1 1.1. 利用できるバージョン 1 1.2. 概要 1 1.3. マニュアル 1 2. TSUBAME3 での利用方法 2 2.1. LS-DYNA の実行 2 2.1.1. TSUBAME3 にログイン 2 2.1.2. バージョンの切り替え 2 2.1.3. インタラクティブノードでの
LS-DYNA 利用の手引 第 1 版 東京工業大学学術国際情報センター 2017 年 9 月 25 日 目次 1. はじめに 1 1.1. 利用できるバージョン 1 1.2. 概要 1 1.3. マニュアル 1 2. TSUBAME3 での利用方法 2 2.1. LS-DYNA の実行 2 2.1.1. TSUBAME3 にログイン 2 2.1.2. バージョンの切り替え 2 2.1.3. インタラクティブノードでの
Microsoft PowerPoint MPI.v...O...~...O.e.L.X.g(...Q..)
") MPI プログラミング Information Initiative Center, Hokkaido Univ. MPI ライブラリを利用した分散メモリ型並列プログラミング 分散メモリ型並列処理 : 基礎 分散メモリマルチコンピュータの構成 プロセッサエレメントが専用のメモリ ( ローカルメモリ ) を搭載 スケーラビリティが高い 例 :HITACHI SR8000 Interconnection
MPI プログラミング Information Initiative Center, Hokkaido Univ. MPI ライブラリを利用した分散メモリ型並列プログラミング 分散メモリ型並列処理 : 基礎 分散メモリマルチコンピュータの構成 プロセッサエレメントが専用のメモリ ( ローカルメモリ ) を搭載 スケーラビリティが高い 例 :HITACHI SR8000 Interconnection
MPI コミュニケータ操作
 コミュニケータとデータタイプ 辻田祐一 (RIKEN AICS) 講義 演習内容 MPI における重要な概念 コミュニケータ データタイプ MPI-IO 集団型 I/O MPI-IO の演習 2 コミュニケータ MPI におけるプロセスの 集団 集団的な操作などにおける操作対象となる MPI における集団的な操作とは? 集団型通信 (Collective Communication) 集団型 I/O(Collective
コミュニケータとデータタイプ 辻田祐一 (RIKEN AICS) 講義 演習内容 MPI における重要な概念 コミュニケータ データタイプ MPI-IO 集団型 I/O MPI-IO の演習 2 コミュニケータ MPI におけるプロセスの 集団 集団的な操作などにおける操作対象となる MPI における集団的な操作とは? 集団型通信 (Collective Communication) 集団型 I/O(Collective
システムソリューションのご紹介
 HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
2007年度 計算機システム演習 第3回
 2014 年度 実践的並列コンピューティング 第 10 回 MPI による分散メモリ並列プログラミング (3) 遠藤敏夫 endo@is.titech.ac.jp 1 MPI プログラムの性能を考える 前回までは MPI プログラムの挙動の正しさを議論 今回は速度性能に注目 MPIプログラムの実行時間 = プロセス内計算時間 + プロセス間通信時間 計算量 ( プロセス内 ) ボトルネック有無メモリアクセス量
2014 年度 実践的並列コンピューティング 第 10 回 MPI による分散メモリ並列プログラミング (3) 遠藤敏夫 endo@is.titech.ac.jp 1 MPI プログラムの性能を考える 前回までは MPI プログラムの挙動の正しさを議論 今回は速度性能に注目 MPIプログラムの実行時間 = プロセス内計算時間 + プロセス間通信時間 計算量 ( プロセス内 ) ボトルネック有無メモリアクセス量
Microsoft PowerPoint - 11Web.pptx
 計算機システムの基礎 ( 第 10 回配布 ) 第 7 章 2 節コンピュータの性能の推移 (1) コンピュータの歴史 (2) コンピュータの性能 (3) 集積回路の進歩 (4) アーキテクチャ 第 4 章プロセッサ (1) プロセッサの基本機能 (2) プロセッサの構成回路 (3) コンピュータアーキテクチャ 第 5 章メモリアーキテクチャ 1. コンピュータの世代 計算する機械 解析機関 by
計算機システムの基礎 ( 第 10 回配布 ) 第 7 章 2 節コンピュータの性能の推移 (1) コンピュータの歴史 (2) コンピュータの性能 (3) 集積回路の進歩 (4) アーキテクチャ 第 4 章プロセッサ (1) プロセッサの基本機能 (2) プロセッサの構成回路 (3) コンピュータアーキテクチャ 第 5 章メモリアーキテクチャ 1. コンピュータの世代 計算する機械 解析機関 by
Microsoft PowerPoint - 講習 _kido.pptx[読み取り専用]
![Microsoft PowerPoint - 講習 _kido.pptx[読み取り専用]](/thumbs/79/79773151.jpg "Microsoft PowerPoint - 講習 _kido.pptx[読み取り専用]") スパコンの概要と CMC のスパコンの紹介 大阪大学サイバーメディアセンター講師木戸善之 2015/1/15 目次 1. スパコンの略歴 2. 計算機の概要 3. 並列計算 4. CMCのスパコン 1 1. スパコンの略歴 計算機ってなんだ? 計算機 計算に用いる機械 ( デジタル大辞泉 ) 計算のための機械 器具のこと コンピュータや電卓を指すことが多い (Wikipedia) 人が不得意な 正確な演算やルーチンワークを肩代わりするための道具
スパコンの概要と CMC のスパコンの紹介 大阪大学サイバーメディアセンター講師木戸善之 2015/1/15 目次 1. スパコンの略歴 2. 計算機の概要 3. 並列計算 4. CMCのスパコン 1 1. スパコンの略歴 計算機ってなんだ? 計算機 計算に用いる機械 ( デジタル大辞泉 ) 計算のための機械 器具のこと コンピュータや電卓を指すことが多い (Wikipedia) 人が不得意な 正確な演算やルーチンワークを肩代わりするための道具
Microsoft PowerPoint ppt
 並列アルゴリズム 2005 年後期火曜 2 限 高見利也 ( 青柳睦 ) Aoyagi@cc.kyushu-u.ac.jp http://server-500.cc.kyushu-u.ac.jp/ 12 月 20 日 ( 火 ) 9. PC クラスタによる並列プログラミング ( 演習 ) つづき 1 もくじ 1. 序並列計算機の現状 2. 計算方式およびアーキテクチュアの分類 3. 並列計算の目的と課題
並列アルゴリズム 2005 年後期火曜 2 限 高見利也 ( 青柳睦 ) Aoyagi@cc.kyushu-u.ac.jp http://server-500.cc.kyushu-u.ac.jp/ 12 月 20 日 ( 火 ) 9. PC クラスタによる並列プログラミング ( 演習 ) つづき 1 もくじ 1. 序並列計算機の現状 2. 計算方式およびアーキテクチュアの分類 3. 並列計算の目的と課題
スライド 1
 GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
PowerPoint Presentation
 Embedded CFD 1D-3D 連成によるエンジンコンパートメント熱収支解析手法の提案 June 9, 2017 . アジェンダ Embedded CFD 概要 エンコパ内風流れデモモデル 他用途への適用可能性, まとめ V サイクルにおける,1D-3D シミュレーションの使い分け ( 現状 ) 1D 機能的表現 企画 & 初期設計 詳細 3D 形状情報の無い段階 1D 1D 空気流れ計算精度に限度
Embedded CFD 1D-3D 連成によるエンジンコンパートメント熱収支解析手法の提案 June 9, 2017 . アジェンダ Embedded CFD 概要 エンコパ内風流れデモモデル 他用途への適用可能性, まとめ V サイクルにおける,1D-3D シミュレーションの使い分け ( 現状 ) 1D 機能的表現 企画 & 初期設計 詳細 3D 形状情報の無い段階 1D 1D 空気流れ計算精度に限度
(Microsoft PowerPoint \215u\213`4\201i\221\272\210\344\201j.pptx)
") AICS 村井均 RIKEN AICS HPC Summer School 2012 8/7/2012 1 背景 OpenMP とは OpenMP の基本 OpenMP プログラミングにおける注意点 やや高度な話題 2 共有メモリマルチプロセッサシステムの普及 共有メモリマルチプロセッサシステムのための並列化指示文を共通化する必要性 各社で仕様が異なり 移植性がない そして いまやマルチコア プロセッサが主流となり
AICS 村井均 RIKEN AICS HPC Summer School 2012 8/7/2012 1 背景 OpenMP とは OpenMP の基本 OpenMP プログラミングにおける注意点 やや高度な話題 2 共有メモリマルチプロセッサシステムの普及 共有メモリマルチプロセッサシステムのための並列化指示文を共通化する必要性 各社で仕様が異なり 移植性がない そして いまやマルチコア プロセッサが主流となり
EnSightのご紹介
 オープン CAE シンポジウム 2014 汎用ポストプロセッサー EnSight の大規模データ対応 CEI ソフトウェア株式会社代表取締役吉川慈人 http://www.ceisoftware.co.jp/ 内容 大規模データで時間のかかる処理 クライアント サーバー機能 マルチスレッドによる並列処理 サーバーの分散処理 クライアントの分散処理 ( 分散レンダリング ) EnSightのOpenFOAMインターフェース
オープン CAE シンポジウム 2014 汎用ポストプロセッサー EnSight の大規模データ対応 CEI ソフトウェア株式会社代表取締役吉川慈人 http://www.ceisoftware.co.jp/ 内容 大規模データで時間のかかる処理 クライアント サーバー機能 マルチスレッドによる並列処理 サーバーの分散処理 クライアントの分散処理 ( 分散レンダリング ) EnSightのOpenFOAMインターフェース
製品開発の現場では 各種のセンサーや測定環境を利用したデータ解析が行われ シミュレーションや動作検証等に役立てられています しかし 日々収集されるデータ量は増加し 解析も複雑化しており データ解析の負荷は徐々に重くなっています 例えば自動車の車両計測データを解析する場合 取得したデータをそのまま解析
 ホワイトペーパー Excel と MATLAB の連携がデータ解析の課題を解決 製品開発の現場では 各種のセンサーや測定環境を利用したデータ解析が行われ シミュレーションや動作検証等に役立てられています しかし 日々収集されるデータ量は増加し 解析も複雑化しており データ解析の負荷は徐々に重くなっています 例えば自動車の車両計測データを解析する場合 取得したデータをそのまま解析に使用することはできず
ホワイトペーパー Excel と MATLAB の連携がデータ解析の課題を解決 製品開発の現場では 各種のセンサーや測定環境を利用したデータ解析が行われ シミュレーションや動作検証等に役立てられています しかし 日々収集されるデータ量は増加し 解析も複雑化しており データ解析の負荷は徐々に重くなっています 例えば自動車の車両計測データを解析する場合 取得したデータをそのまま解析に使用することはできず
120802_MPI.ppt
 CPU CPU CPU CPU CPU SMP Symmetric MultiProcessing CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CP OpenMP MPI MPI CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU MPI MPI+OpenMP CPU CPU CPU CPU CPU CPU CPU CP
CPU CPU CPU CPU CPU SMP Symmetric MultiProcessing CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CP OpenMP MPI MPI CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU MPI MPI+OpenMP CPU CPU CPU CPU CPU CPU CPU CP
Microsoft PowerPoint - compsys2-06.ppt
 情報基盤センター天野浩文 前回のおさらい (1) 並列処理のやり方 何と何を並列に行うのか コントロール並列プログラミング 同時に実行できる多数の処理を, 多数のノードに分配して同時に処理させる しかし, 同時に実行できる多数の処理 を見つけるのは難しい データ並列プログラミング 大量のデータを多数の演算ノードに分配して, それらに同じ演算を同時に適用する コントロール並列よりも, 多数の演算ノードを利用しやすい
情報基盤センター天野浩文 前回のおさらい (1) 並列処理のやり方 何と何を並列に行うのか コントロール並列プログラミング 同時に実行できる多数の処理を, 多数のノードに分配して同時に処理させる しかし, 同時に実行できる多数の処理 を見つけるのは難しい データ並列プログラミング 大量のデータを多数の演算ノードに分配して, それらに同じ演算を同時に適用する コントロール並列よりも, 多数の演算ノードを利用しやすい
Fortran 勉強会 第 5 回 辻野智紀
 Fortran 勉強会 第 5 回 辻野智紀 今回のお品書き サブルーチンの分割コンパイル ライブラリ 静的ライブラリ 動的ライブラリ モジュール その前に 以下の URL から STPK ライブラリをインストールしておいて下さい. http://www.gfd-dennou.org/library/davis/stpk 前回参加された方はインストール済みのはず. サブルーチンの分割コンパイル サブルーチンの独立化
Fortran 勉強会 第 5 回 辻野智紀 今回のお品書き サブルーチンの分割コンパイル ライブラリ 静的ライブラリ 動的ライブラリ モジュール その前に 以下の URL から STPK ライブラリをインストールしておいて下さい. http://www.gfd-dennou.org/library/davis/stpk 前回参加された方はインストール済みのはず. サブルーチンの分割コンパイル サブルーチンの独立化
ビッグデータ分析を高速化する 分散処理技術を開発 日本電気株式会社
 ビッグデータ分析を高速化する 分散処理技術を開発 日本電気株式会社 概要 NEC は ビッグデータの分析を高速化する分散処理技術を開発しました 本技術により レコメンド 価格予測 需要予測などに必要な機械学習処理を従来の 10 倍以上高速に行い 分析結果の迅速な活用に貢献します ビッグデータの分散処理で一般的なオープンソース Hadoop を利用 これにより レコメンド 価格予測 需要予測などの分析において
ビッグデータ分析を高速化する 分散処理技術を開発 日本電気株式会社 概要 NEC は ビッグデータの分析を高速化する分散処理技術を開発しました 本技術により レコメンド 価格予測 需要予測などに必要な機械学習処理を従来の 10 倍以上高速に行い 分析結果の迅速な活用に貢献します ビッグデータの分散処理で一般的なオープンソース Hadoop を利用 これにより レコメンド 価格予測 需要予測などの分析において
PowerPoint プレゼンテーション
 Foundation アプライアンス スケーラブルシステムズ株式会社 サーバ クラスタの課題 複数のシステムを一つの だけで容易に管理することは出来ないだろうか? アプリケーションがより多くのメモリを必要とするのだけど ハードウエアの増設なしで対応出来ないだろうか? 現在の利用環境のまま 利用できるコア数やメモリサイズの増強を図ることは出来ないだろうか? 短時間で導入可能で また 必要に応じて 柔軟にシステム構成の変更が可能なソリューションは無いだろうか?...
Foundation アプライアンス スケーラブルシステムズ株式会社 サーバ クラスタの課題 複数のシステムを一つの だけで容易に管理することは出来ないだろうか? アプリケーションがより多くのメモリを必要とするのだけど ハードウエアの増設なしで対応出来ないだろうか? 現在の利用環境のまま 利用できるコア数やメモリサイズの増強を図ることは出来ないだろうか? 短時間で導入可能で また 必要に応じて 柔軟にシステム構成の変更が可能なソリューションは無いだろうか?...
Stage 並列プログラミングを習得するためには : 1 計算機リテラシ, プログラミング言語 2 基本的な数値解析 3 実アプリケーション ( 例えば有限要素法, 分子動力学 ) のプログラミング 4 その並列化 という 4 つの段階 (stage) が必要である 本人材育成プログラムでは1~4を
 のプログラミング 4 その並列化 という 4 つの段階 (stage) が必要である 本人材育成プログラムでは1~4を") コンピュータ科学特別講義 科学技術計算プログラミング I ( 有限要素法 ) 中島研吾 東京大学情報基盤センター 1. はじめに本稿では,2008 年度冬学期に実施した, コンピュータ科学特別講義 I 科学技術計算プログラミング ( 有限要素法 ) について紹介する 計算科学 工学, ハードウェアの急速な進歩, 発達を背景に, 第 3 の科学 としての大規模並列シミュレーションへの期待は, 産学において一層高まっている
コンピュータ科学特別講義 科学技術計算プログラミング I ( 有限要素法 ) 中島研吾 東京大学情報基盤センター 1. はじめに本稿では,2008 年度冬学期に実施した, コンピュータ科学特別講義 I 科学技術計算プログラミング ( 有限要素法 ) について紹介する 計算科学 工学, ハードウェアの急速な進歩, 発達を背景に, 第 3 の科学 としての大規模並列シミュレーションへの期待は, 産学において一層高まっている
PowerPoint Presentation
 2016 年 6 月 10 日 ( 金 ) FrontISTR 研究会 FrontISTR の並列計算の基礎 奥田洋司 okuda@k.u-tokyo.ac.jp 東京大学大学院 新領域創成科学研究科 人間環境学専攻 目次 導入 なぜ並列化か? 並列アーキテクチャ 並列プログラミング FrontISTR における並列計算 実効性能について ノード間並列 領域分割と MPI ノード内並列 ( 単体性能
2016 年 6 月 10 日 ( 金 ) FrontISTR 研究会 FrontISTR の並列計算の基礎 奥田洋司 okuda@k.u-tokyo.ac.jp 東京大学大学院 新領域創成科学研究科 人間環境学専攻 目次 導入 なぜ並列化か? 並列アーキテクチャ 並列プログラミング FrontISTR における並列計算 実効性能について ノード間並列 領域分割と MPI ノード内並列 ( 単体性能
PowerPoint プレゼンテーション
 2011/12/2 オープンCAEシンポジウム2011 オープンCAEを活用した 大規模高速演算及び 大規模モデルの取扱 株式会社デンソー 技術管理部 CAE開発設計 促進室 野村悦治 今川洋造 背景 http://top500.org/ 2 / 27 705,024コア 数千コア FOCUSスパコン利用料金表 http://www.j-focus.or.jp/spacon/pricelist_spacon.pdf
2011/12/2 オープンCAEシンポジウム2011 オープンCAEを活用した 大規模高速演算及び 大規模モデルの取扱 株式会社デンソー 技術管理部 CAE開発設計 促進室 野村悦治 今川洋造 背景 http://top500.org/ 2 / 27 705,024コア 数千コア FOCUSスパコン利用料金表 http://www.j-focus.or.jp/spacon/pricelist_spacon.pdf
(Microsoft PowerPoint \211\211\217K3_4\201i\216R\226{_\211\272\215\342\201j.ppt [\214\335\212\267\203\202\201[\203h])
![(Microsoft PowerPoint \211\211\217K3_4\201i\216R\226{_\211\272\215\342\201j.ppt [\214\335\212\267\203\202\201[\203h])](/thumbs/101/148628642.jpg "(Microsoft PowerPoint \211\211\217K3_4\201i\216R\226{_\211\272\215\342\201j.ppt [\214\335\212\267\203\202\201[\203h])") RIKEN AICS Summer School 演習 3 4 MPI による並列計算 2012 年 8 月 8 日 神戸大学大学院システム情報学研究科山本有作理化学研究所計算科学研究機構下坂健則 1 演習の目標 講義 6 並列アルゴリズム基礎 で学んだアルゴリズムのいくつかを,MPI を用いて並列化してみる これを通じて, 基本的な並列化手法と,MPI 通信関数の使い方を身に付ける 2 取り上げる例題と学習項目
RIKEN AICS Summer School 演習 3 4 MPI による並列計算 2012 年 8 月 8 日 神戸大学大学院システム情報学研究科山本有作理化学研究所計算科学研究機構下坂健則 1 演習の目標 講義 6 並列アルゴリズム基礎 で学んだアルゴリズムのいくつかを,MPI を用いて並列化してみる これを通じて, 基本的な並列化手法と,MPI 通信関数の使い方を身に付ける 2 取り上げる例題と学習項目
(速報) Xeon E 系モデル 新プロセッサ性能について
 Xeon E 系モデル 新プロセッサ性能について") ( 速報 ) Xeon E5-2600 系モデル新プロセッサ性能について 2012 年 3 月 16 日 富士通株式会社 2012 年 3 月 7 日 インテル社より最新 CPU インテル Xeon E5 ファミリー の発表がありました この最新 CPU について PC クラスタシステムの観点から性能検証を行いましたので 概要を速報いたします プロセッサインテル Xeon プロセッサ E5-2690
( 速報 ) Xeon E5-2600 系モデル新プロセッサ性能について 2012 年 3 月 16 日 富士通株式会社 2012 年 3 月 7 日 インテル社より最新 CPU インテル Xeon E5 ファミリー の発表がありました この最新 CPU について PC クラスタシステムの観点から性能検証を行いましたので 概要を速報いたします プロセッサインテル Xeon プロセッサ E5-2690
Microsoft PowerPoint - OpenMP入門.pptx
 OpenMP 入門 須田礼仁 2009/10/30 初版 OpenMP 共有メモリ並列処理の標準化 API http://openmp.org/ 最新版は 30 3.0 バージョンによる違いはあまり大きくない サポートしているバージョンはともかく csp で動きます gcc も対応しています やっぱり SPMD Single Program Multiple Data プログラム #pragma omp
OpenMP 入門 須田礼仁 2009/10/30 初版 OpenMP 共有メモリ並列処理の標準化 API http://openmp.org/ 最新版は 30 3.0 バージョンによる違いはあまり大きくない サポートしているバージョンはともかく csp で動きます gcc も対応しています やっぱり SPMD Single Program Multiple Data プログラム #pragma omp
高性能計算研究室の紹介 High Performance Computing Lab.
 高性能計算研究室 (HPC Lab) の紹介 High Performance Computing Lab. 静岡理工科大学総合情報学部コンピュータシステム学科 ( 兼 Web デザイン特別プログラム ) 幸谷智紀 543 研究室 幸谷研究室 @ 静岡 検索 概要 1. 幸谷智紀 個人の研究テーマ 2. 3 年生ゼミ ( 情報セミナー II) 3. 卒研テーマ 4. 過去の卒研 5. 今後について
高性能計算研究室 (HPC Lab) の紹介 High Performance Computing Lab. 静岡理工科大学総合情報学部コンピュータシステム学科 ( 兼 Web デザイン特別プログラム ) 幸谷智紀 543 研究室 幸谷研究室 @ 静岡 検索 概要 1. 幸谷智紀 個人の研究テーマ 2. 3 年生ゼミ ( 情報セミナー II) 3. 卒研テーマ 4. 過去の卒研 5. 今後について
OpenMPプログラミング
 OpenMP 基礎 岩下武史 ( 学術情報メディアセンター ) 1 2013/9/13 並列処理とは 逐次処理 CPU1 並列処理 CPU1 CPU2 CPU3 CPU4 処理 1 処理 1 処理 2 処理 3 処理 4 処理 2 処理 3 処理 4 時間 2 2 種類の並列処理方法 プロセス並列 スレッド並列 並列プログラム 並列プログラム プロセス プロセス 0 プロセス 1 プロセス間通信 スレッド
OpenMP 基礎 岩下武史 ( 学術情報メディアセンター ) 1 2013/9/13 並列処理とは 逐次処理 CPU1 並列処理 CPU1 CPU2 CPU3 CPU4 処理 1 処理 1 処理 2 処理 3 処理 4 処理 2 処理 3 処理 4 時間 2 2 種類の並列処理方法 プロセス並列 スレッド並列 並列プログラム 並列プログラム プロセス プロセス 0 プロセス 1 プロセス間通信 スレッド
熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date Type URL Presentation
 榎本, 昌一 Citation Issue date Type URL Presentation") 熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date 2011-03-17 Type URL Presentation http://hdl.handle.net/2298/23539 Right GPGPU による高速演算について 榎本昌一 東京大学大学院工学系研究科システム創成学専攻
熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date 2011-03-17 Type URL Presentation http://hdl.handle.net/2298/23539 Right GPGPU による高速演算について 榎本昌一 東京大学大学院工学系研究科システム創成学専攻
Microsoft Word - thesis.doc
 剛体の基礎理論 -. 剛体の基礎理論初めに本論文で大域的に使用する記号を定義する. 使用する記号トルク撃力力角運動量角速度姿勢対角化された慣性テンソル慣性テンソル運動量速度位置質量時間 J W f F P p .. 質点の並進運動 質点は位置 と速度 P を用いる. ニュートンの運動方程式 という状態を持つ. 但し ここでは速度ではなく運動量 F P F.... より質点の運動は既に明らかであり 質点の状態ベクトル
剛体の基礎理論 -. 剛体の基礎理論初めに本論文で大域的に使用する記号を定義する. 使用する記号トルク撃力力角運動量角速度姿勢対角化された慣性テンソル慣性テンソル運動量速度位置質量時間 J W f F P p .. 質点の並進運動 質点は位置 と速度 P を用いる. ニュートンの運動方程式 という状態を持つ. 但し ここでは速度ではなく運動量 F P F.... より質点の運動は既に明らかであり 質点の状態ベクトル
PowerPoint プレゼンテーション
 OpenMP 並列解説 1 人が共同作業を行うわけ 田植えの例 重いものを持ち上げる 田おこし 代かき 苗の準備 植付 共同作業する理由 1. 短時間で作業を行うため 2. 一人ではできない作業を行うため 3. 得意分野が異なる人が協力し合うため ポイント 1. 全員が最大限働く 2. タイミングよく 3. 作業順序に注意 4. オーバーヘッドをなくす 2 倍率 効率 並列化率と並列加速率 並列化効率の関係
OpenMP 並列解説 1 人が共同作業を行うわけ 田植えの例 重いものを持ち上げる 田おこし 代かき 苗の準備 植付 共同作業する理由 1. 短時間で作業を行うため 2. 一人ではできない作業を行うため 3. 得意分野が異なる人が協力し合うため ポイント 1. 全員が最大限働く 2. タイミングよく 3. 作業順序に注意 4. オーバーヘッドをなくす 2 倍率 効率 並列化率と並列加速率 並列化効率の関係
PowerPoint プレゼンテーション
 Dell PowerEdge C6320 スケーラブルサーバアプライアンス 仮想化アプライアンスサーバ 最新のプロセッサを搭載したサーバプラットフォーム vsmp Foundation によるサーバ仮想化と統合化の適用 システムはセットアップを完了した状態でご提供 基本構成ではバックプレーン用のスイッチなどが不要 各ノード間を直接接続 冗長性の高いバックプレーン構成 利用するサーバプラットフォームは
Dell PowerEdge C6320 スケーラブルサーバアプライアンス 仮想化アプライアンスサーバ 最新のプロセッサを搭載したサーバプラットフォーム vsmp Foundation によるサーバ仮想化と統合化の適用 システムはセットアップを完了した状態でご提供 基本構成ではバックプレーン用のスイッチなどが不要 各ノード間を直接接続 冗長性の高いバックプレーン構成 利用するサーバプラットフォームは
enshu5_4.key
 http://www.mmsonline.com/articles/parallel-processing-speeds-toolpath-calculations TA : 菅 新 菅沼智史 水曜 新行紗弓 馬淵隼 木曜 情報知能工学演習V (前半第4週) 政田洋平 システム情報学研究科計算科学専攻 演習 V( 前半 ) の内容 第 1 週 : 高性能計算 (High Performance Computing
http://www.mmsonline.com/articles/parallel-processing-speeds-toolpath-calculations TA : 菅 新 菅沼智史 水曜 新行紗弓 馬淵隼 木曜 情報知能工学演習V (前半第4週) 政田洋平 システム情報学研究科計算科学専攻 演習 V( 前半 ) の内容 第 1 週 : 高性能計算 (High Performance Computing
Microsoft PowerPoint - GPGPU実践基礎工学(web).pptx
.pptx") シングルコアとマルチコア 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 前々回の授業の復習 CPUの進化 半導体集積率の向上 CPUの動作周波数の向上 + 複雑な処理を実行する回路を構成 ( 前々回の授業 ) マルチコア CPU への進化 均一 不均一なプロセッサ コプロセッサ, アクセラレータ 210 コンピュータの歴史 世界初のデジタルコンピュータ 1944 年ハーバードMark I
シングルコアとマルチコア 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 前々回の授業の復習 CPUの進化 半導体集積率の向上 CPUの動作周波数の向上 + 複雑な処理を実行する回路を構成 ( 前々回の授業 ) マルチコア CPU への進化 均一 不均一なプロセッサ コプロセッサ, アクセラレータ 210 コンピュータの歴史 世界初のデジタルコンピュータ 1944 年ハーバードMark I
C/C++ FORTRAN FORTRAN MPI MPI MPI UNIX Windows (SIMD Single Instruction Multipule Data) SMP(Symmetric Multi Processor) MPI (thread) OpenMP[5]
![C/C++ FORTRAN FORTRAN MPI MPI MPI UNIX Windows (SIMD Single Instruction Multipule Data) SMP(Symmetric Multi Processor) MPI (thread) OpenMP[5]](/thumbs/73/69613550.jpg "C/C++ FORTRAN FORTRAN MPI MPI MPI UNIX Windows (SIMD Single Instruction Multipule Data) SMP(Symmetric Multi Processor) MPI (thread) OpenMP[5]") MPI ( ) snozawa@env.sci.ibaraki.ac.jp 1 ( ) MPI MPI Message Passing Interface[2] MPI MPICH[3],LAM/MPI[4] (MIMDMultiple Instruction Multipule Data) Message Passing ( ) (MPI (rank) PE(Processing Element)
MPI ( ) snozawa@env.sci.ibaraki.ac.jp 1 ( ) MPI MPI Message Passing Interface[2] MPI MPICH[3],LAM/MPI[4] (MIMDMultiple Instruction Multipule Data) Message Passing ( ) (MPI (rank) PE(Processing Element)
hpc141_shirahata.pdf
 GPU アクセラレータと不揮発性メモリ を考慮した I/O 性能の予備評価 白幡晃一 1,2 佐藤仁 1,2 松岡聡 1 1: 東京工業大学 2: JST CREST 1 GPU と不揮発性メモリを用いた 大規模データ処理 大規模データ処理 センサーネットワーク 遺伝子情報 SNS など ペタ ヨッタバイト級 高速処理が必要 スーパーコンピュータ上での大規模データ処理 GPU 高性能 高バンド幅 例
GPU アクセラレータと不揮発性メモリ を考慮した I/O 性能の予備評価 白幡晃一 1,2 佐藤仁 1,2 松岡聡 1 1: 東京工業大学 2: JST CREST 1 GPU と不揮発性メモリを用いた 大規模データ処理 大規模データ処理 センサーネットワーク 遺伝子情報 SNS など ペタ ヨッタバイト級 高速処理が必要 スーパーコンピュータ上での大規模データ処理 GPU 高性能 高バンド幅 例
<4D F736F F D B B B835E895E97708A4A8E6E82C A98418C6782CC8E6E93AE2E646F63>
 京都大学学術情報メディアセンター 新スーパーコンピュータ運用開始と T2K 連携の始動 アピールポイント 61.2 テラフロップスの京大版 T2K オープンスパコン運用開始 東大 筑波大との T2K 連携による計算科学 工学分野におけるネットワーク型研究推進 人材育成 アプリケーション高度化支援の活動を開始概要国立大学法人京都大学 ( 総長 尾池和夫 ) 学術情報メディアセンター ( センター長 美濃導彦
京都大学学術情報メディアセンター 新スーパーコンピュータ運用開始と T2K 連携の始動 アピールポイント 61.2 テラフロップスの京大版 T2K オープンスパコン運用開始 東大 筑波大との T2K 連携による計算科学 工学分野におけるネットワーク型研究推進 人材育成 アプリケーション高度化支援の活動を開始概要国立大学法人京都大学 ( 総長 尾池和夫 ) 学術情報メディアセンター ( センター長 美濃導彦