PowerPoint Presentation
|
|
|
- れれ めいこ
- 4 years ago
- Views:
Transcription
1 2015 年 4 月 24 日 ( 金 ) 第 18 回 FrontISTR 研究会 FrontISTR の並列計算の基礎 奥田洋司 okuda@k.u-tokyo.ac.jp 東京大学大学院 新領域創成科学研究科 人間環境学専攻
2 目次 導入 計算力学とは 連続体の力学 連立 1 次方程式 FEM 構造解析の概要 なぜ並列化か? 並列アーキテクチャ 並列プログラミング FEM 計算におけるノード間並列 領域分割と MPI FEM 計算におけるノード内並列 ( 単体性能 ) ループ分割と OpenMP 実効性能について
3 連続体の力学 運動の記述 質点系 剛体系 連続体 x f 保存則 質量保存 運動量保存 ( 並進と回転 ) エネルギー保存 境界条件と初期条件 構成則 大きさをもつが変形しない変形しながら運動 これら偏微分方程式により 固体 / 液体 / 気体の物理現象が記述される
4 微分方程式をコンピュータで解くには? 微分方程式 連立 1 次方程式 ( 連続体 ) ( とびとびの点で表現 ) [ K ] { u } = { f } ( 各点での物理量が求まる ) CAD モデル 有限要素モデル要素 (element) と節点 (node) 節点に物理量が定義されている ( 例 ) 節点変位 節点温度
5 連立 1 次方程式を高速に解く 直接解法 ( Direct method ) ガウスの消去法に基づく 決まった演算数で解が求まる 行列の分解の際にフィルインを考慮しなければならないため 多大な記憶容量を必要とする 反復解法 ( Iterative method ) 解の候補を修正しながら反復的に収束解を求める 非ゼロ成分だけを記憶すればよいため大規模問題を扱うことができる 強力な前処理 ( Preconditioning ) が必須
6 直接法 反復法 ( 直接法 + 解の反復修正 ) 直接法が破たんしないような実装 直接法により得られた解を 反復法で修正 ( 強力な前処理 + 反復法 ) 直接法に近い処理 少ない反復回数 結局 上の 2 つは同じこと
7 目次 導入 計算力学とは 連続体の力学 連立 1 次方程式 FEM 構造解析の概要 なぜ並列化か? 並列アーキテクチャ 並列プログラミング FEM 計算におけるノード間並列 領域分割と MPI FEM 計算におけるノード内並列 ( 単体性能 ) ループ分割と OpenMP 実効性能について
8 1K times faster in 10 years 2.3M times faster in 30 years 京 Kei (10 Pflop/s, 2012) 10 PFlop/s
9 並列処理の重要性 計算機ハードウェアの性能向上には 2 つの寄与 < クロック高速化 > 半導体技術と高密度実装技術の高度化 限界 <アーキテクチャにおける並列処理 > ベクトル計算 命令の並列実行 マルチプロセッサ化 マルチコア化など 近年の性能向上にはこの寄与が大きい
10 逐次 (serial) と並列 (parallel) 逐次処理しなければならない例 並列処理できる例 DO J=1, N A(J+1)=A(J)+B(J) END DO DO J=1, N A(J)=B(J)+C(J) END DO 配列 A に関して前のループの演算結果が必要なため インデックス J について並列処理することができない プログラムの中には 並列処理できる部分とできない部分がある
11 最適化 チューニング 並列化は必須 理論性能と実効性能 アナロジー ) 自動車の燃費 理論性能において 並列処理が大きい寄与を占める 実効性能向上のための工夫 並列化プログラミング 並列化支援の通信ライブラリや並列処理 ベクトル処理の指示文を挿入するなど オーダリング 演算順序やデータ配置の並べ替えによる 演算の依存性の排除
12 並列アーキテクチャ (1/3) ベクトル処理 スカラ処理 地球シミュレータ SIMD データレベルでの並列化のひとつ ベクトルデータを同時に処理できるベクトルレジスタとパイプライン ( セグメント ) 化されたベクトル演算器との組み合わせによって高速演算が実現される ベルトコンベアに沿って並べて置かれた装置によって 演算操作はパイプライン上でオーバーラップしてベクトルデータに次々と実行される ( パイプライン実行される ) ため 並んだ装置の数だけ速度が向上する ベクトル型スーパーコンピュータでは 複数個のベクトル演算機を装備してさらに高速化が図られている
13 時間 B(1), C(1) R C S A N W A(1) B(2), C(2) R C S A N W A(2) B(3), C(3) R C S A N W A(3) B(4), C(4) R C S A N W A(4) B(N), C(N) R C S A N W A(N) (a) ベクトル処理 時間 B(1), C(1) R C S A N W B(2), C(2) A(1) R C S A N W A(2) (b) スカラ処理
14 並列アーキテクチャ (2/3) マルチプロセッサ マルチコア 並列 ( パラレル ) 逐次 ( シリアル ) もう一段階上の並列化レベル プロセッサを複数のコアで構成する メモリの割り当て方によって 3 方式 クラスタ計算機 PC クラスタコモディティプロセッサを比較的安価で低速な LAN でネットワーク結合
15 共有メモリ ネットワーク メモリ メモリ メモリ プロセッサプロセッサ プロセッサ プロセッサプロセッサ プロセッサ ノードノードノード (a) 共有メモリ型 (b) 分散メモリ型 ネットワーク 共有メモリ 共有メモリ 共有メモリ プロセッサプロセッサ プロセッサ プロセッサプロセッサ プロセッサ プロセッサプロセッサ プロセッサ ノードノードノード (c) 共有 分散メモリ型 プロセッサはマルチコア化 並列計算機におけるネットワーク メモリ プロセッサの構成


16 Multicore and NUMA (Non-Uniform Memory Access) Today s common architecture in consumer and/or enterprise processors Programming model Distributed memory Shared memory NUMA : MPI : Multi-threads : Hybrid = MPI + Multithreads Intensity Performance of core & memory, vs. Flop/Byte 逆数 BPF

 : MPI Intra-node (core")

17 The K-computer 10 PFLOPS # of CPUs > 80,000 # of cores > 640,000 Total memory > 1PB Parallelism Inter-node (node node) : MPI Intra-node (core core) : OpenMP Flat MPI is NOT recommended Hybrid programming is crucial for K.

18 並列アーキテクチャ (3/3) クラウド データもプログラムも雲 ( クラウド ) の上に置かれている ネットに接続するブラウザがあれば どんな端末からでも雲に届く (Eric Schmidt, Google CEO)
19 計算機を並べただけでは速くならない アムダールの法則 プログラムの並列化率と並列化による実効性能向上の関係 逐次処理部分 並列処理可能部分 逐次計算 Ts (1-α ) Ts α Ts 並列計算 Tp (1-α ) Ts α Ts /n スピードアップ (= Ts / Tp) α: 並列化率 ( 並列処理可能な部分に要した時間の割合 ) n: プロセッサ数
20 スピードアップ スピードアップ =Ts/Tp 理想値は n 32 n= n=16 8 n= 並列化率
21 スピードアップ 1024 n=1, n= 並列化率 n=256 n=128 横軸に注意 (α>0.94 以上を表示 ) 計算全体の演算量 ( 問題規模 ) は一定に固定されていることに注意 実際の並列計算においては 多くの場合 プロセッサ ( あるいはノード ) の数を増やすにつれて計算規模も大きくして実行することが多い
22 目次 導入 計算力学とは 連続体の力学 連立 1 次方程式 FEM 構造解析の概要 なぜ並列化か? 並列アーキテクチャ 並列プログラミング FEM 計算におけるノード間並列 領域分割と MPI FEM 計算におけるノード内並列 ( 単体性能 ) ループ分割と OpenMP 実効性能について
23 アプリケーションレベルにおける 並列化の対象 (1/2) 並列プログラミングとは ワークやデータを どのように分散し どのように同時実行するかをプログラムの中で指示すること ワークシェアリング データシェアリング 複数のプロセッサでループを分担して処理 複数のプロセッサで異なるプログラムを同時に実行 ネットワーク結合されたノードのメモリにデータを分散し ノードごとに異なるデータに対して同じ演算を施す
24 アプリケーションレベルにおける 並列化の対象 (2/2) プログラム中での指示方法 MPI などのメッセージ パッシング ライブラリをアプリとリンクして用いる分散メモリ 共有メモリ アプリの中に並列化指示文 (OpenMPなど) やベクトル化の指示文を挿入する共有メモリ 並列言語 (HPF など ) を用いる
25 微分方程式をコンピュータで解くには? 微分方程式 連立 1 次方程式 ( 連続体 ) ( とびとびの点で表現 ) [ K ] { u } = { f } ( 各点での物理量が求まる ) CAD モデル 有限要素モデル要素 (element) と節点 (node) 節点に物理量が定義されている ( 例 ) 節点変位 節点温度



 precond_33_&")




26 0.56& 0.49& & 0.41& 0.51& & & 1.29& & & Cost%of%hingeS1%8%cores% Cost of hinges1 8 cores (2Kfast,parallel)% (-Kfast,parallel) precond_33_& matvec_33_& m_sta: c_lib_3d.s>_c3._prl_7_& s>_get_block._prl_2_& update_3_r._prl_1_& 50.48& 行節点 precond_33._prl_10_& 番号 precond_33._prl_2_& precond_33._prl_4_& s>_get_block_& GI prin>_fp& (other)& 列節点番号 hecmw_precond_33 と hecmw_matvec_33 が高コストなルーチン ( 全体の 90% 近くを占める )
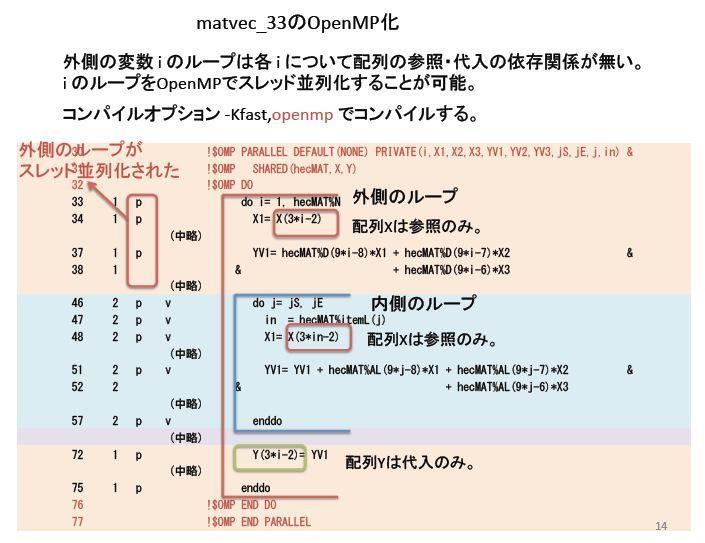
27 program fstr_main +- hecmw_init +- T1 = hecmw_wtime() +- hecmw_get_mesh +- hecmw2fstr_mesh_conv +- fstr_init +- fstr_rcap_initialize +- T2 = hecmw_wtime() +- fstr_linear_static_analysis +- FSTR_SOLVE_LINEAR +- solve_lineq +- hecmw_solve_33 +- ll : Block LU +- hecmw_solve_cg_33 +- T3 = hecmw_wtime() end program CG iter. +- hecmw_solve_cg_33 +- hecmw_precond_33 +- hecmw_matvec_33 +- hecmw_update_3_r +- hecmw_solve_send_recv_33 +- MPI_ISEND +- MPI_IRECV +- MPI_WAITALL +- MPI_WAITALL +- hecmw_innerproduct_r +- hecmw_allreduce_r1 +- hecmw_allreduce_r +- MPI_allREDUCE FrontISTR のプログラム構造 CG iter. 前進 後退代入 行列ベクトル積 高コストルーチン precond_33 と matvec_33 は 剛性方程式の解を求める CG 法においてコールされる 27
28 領域分割 部分領域への分割 部分領域のデータを分散メモリに割り当て 各部分領域の計算を並列に実施する 一般に部分領域ごとの計算は完全には独立ではなく 行列ベクトル積や内積計算において 領域全体の整合性をとるために通信が必要 部分領域間での通信ができるだけ少なくてすむように データが局所化されている必要がある 通信テーブル 隣接する部分領域との間の節点や要素の接続情報 領域分割のツール METIS Scotch
 CAD モデル 有限要素モデル要素 (element) と節点")
29 部分領域ごとに行列ベクトル積を実行する. 全体領域での行列ベクトル積と同じ結果になるように 部分領域間で通信する. メッシュ分割 領域分割 領域分割ツール ( パーティショナ ) CAD モデル 有限要素モデル要素 (element) と節点 (node)
30
31 並列プログラミング方法 (1/3) メッセージ パッシング ライブラリの利用 メッセージ パッシング ライブラリ : 分散 ( 共有 ) メモリ間でネットワークを介して データを送受信 プロセスの起動や同期などの制御 を行うライブラリ群 Fortran や C などの API 逐次プログラムからコールすることで並列計算が可能 MPI MPI は単に規格を指す その実装系である mpich はほとんどのメーカーのプロセッサに対応したものが準備されている 商用の汎用並列計算機にはそれぞれのアーキテクチャに最適化された MPI が実装されている MPI は共有メモリ 分散メモリ 共有 分散メモリのどの形態の計算機システムにおいても用いられる
32 関数名 機能 MPI_INIT MPI_COMM_SIZE MPI_COMM_RANK MPI_FINALIZE MPI_BARRIER MPI_WAITALL MPI_BCAST MPI_ALLREDUCE MPIの起動コミュニケータの立ち上げコミュニケータ内のプロセスの認識 MPIの終了各プロセスの同期各プロセスの同期 1つの送信元から全プロセスにメッセージを送信するすべてのプロセスからメッセージを受信し それらの算術計算結果を全プロセスに送信する MPI_SEND, MPI_RECV 1 対 1 ブロッキング通信 ( 送信 受信 ) MPI_ISEND, MPI_IRECV 1 対 1 非ブロッキング通信 ( 送信 受信 ).MPI_WAIT と共に用いる MPI のサポートする機能の例
33 PE#1 PE# PE# (b) PE#0 が保持する情報 ( 隣接 PE とのオーバーラップあり ) PE#3 PE#2 (a) 4 領域への分割 FrontISTR における有限要素法データの領域分割例
34 Local Data Structure Node-based Partitioning internal nodes - elements - external nodes PE#1 PE#0 PE# PE# PE#3 PE#2 1 2 PE# PE#2
35 Local Data Structure : PE#0 internal nodes - elements - external nodes PE# PE# Partitioned nodes themselves internal nodes Elements which include internal nodes Provide data locality in order to carry out element-by-element operation in each partition Nodes included in the elements external nodes Numbering : internal -> external Internal nodes which are external nodes for other partitions PE#3 PE#2 boundary nodes Communication table provides boundary~external node relationship 1 2
36 場所 FrontISTR_V44/hecmw1/src/solver/solver_33 ファイル名 hecmw_solver_cg_33.f90 サブルーチン名 hecmw_solve_cg_33 ( を使っている限りは 逐次プログラムと同じ) ファイル名 サブルーチン名 hecmw_solver_las_33.f90 hecmw_matvec_33
37 場所 FrontISTR_V44/hecmw1/src/solver/communication ファイル名 サブルーチン名 hecmw_common_f.f90 hecmw_update_3_r ファイル名 サブルーチン名 hecmw_solver_sr_33.f90 hecmw_solve_send_recv_33 ( hecmw_solve_cg_33 より下層 ( アプリ開発者には見せない ) では 部分領域間での通信が行われている )
38 ここで プログラム 4 個 ( 抜粋 ) を参照
39 < 送信部分 > do neib=1,neibpe 隣接 PE 数 istart=index_export(neib-1) inum=index_export(neib)-istart do k=istart+1, istart+inum WS(k)=X(NOD_EXPORT(k)) 送信データのWSへの格納 end do call MPI_ISEND(WS(istart+1), inum, ) 送信 end do < 受信部分 > do neib=1,neibpe 隣接 PE 数 istart=index_import(neib-1) inum=index_import(neib)-istart call MPI_IRECV(WR(istart+1), inum, ) 受信 end do call MPI_WAITALL (NEIBPETOT, ) do neib=1,neibpe 隣接 PE 数 istart=index_import(neib-1) inum=index_import(neib)-istart do k=istart+1, istart+inum X(NOD_IMPORT(k))=WR(k) 受信データのXへの格納 end do end do
40 目次 導入 計算力学とは 連続体の力学 連立 1 次方程式 FEM 構造解析の概要 なぜ並列化か? 並列アーキテクチャ 並列プログラミング FEM 計算におけるノード間並列 領域分割と MPI FEM 計算におけるノード内並列 ( 単体性能 ) ループ分割と OpenMP 実効性能について
41 並列プログラミング方法 (2/3) 並列化指示文 ワークシェアリングやデータシェアリングのための指示文 ( ディレクティブ ) をプログラムの中に挿入する 主に 共有メモリの並列計算機システム 共有 分散メモリのノード内並列化も同様 指示文はプログラム中で見かけ上コメント行のように書かれるが コンパイル時にオプションを指定することによって その指示文が解釈されるようになる ポータビリティ ( 可搬性 移植性 ) を考慮して指示文を統一化した規格が OpenMP, OpenCL, OpenACCn など ベクトルプロセッサの場合 ベクトルベクトル計算に関する指定も指示文の挿入によって行われる
42 SUBROUTINE DAXPY(Z,A,X,Y) INTEGER I DOUBLE PRECISION Z(1000), A, X(1000), Y!$OMP PARALLEL DO SHARED(Z, A, X, Y) PRIVATE(I) DO I=1, 1000 Z(I) = A * X(I) + Y END DO RETURN END OpenMP の記述例!$OMP で始まる文が OpenMP の指示文 DO ループが分割され複数のスレッドによって同時実行される
43 ( 京 でのプログラミング例 )
44 ( 京 でのプログラミング例 )
45 ( FX10 での単体性能 ) ソルバー部分のノード内並列処理性能の比較 (Hinge モデル )
46 並列プログラミング方法 (3/3) 並列言語 HPF Fortran90 にいくつかの指示文を加え Fortran の拡張として定義された言語 分散メモリにおける並列化を対象としている HPF では 指示文によってデータシェアリングを指定すれば 残るワークシェアリングは分散メモリ間の通信を含めてコンパイラが自動的に並列化を行う
47 目次 導入 計算力学とは 連続体の力学 連立 1 次方程式 FEM 構造解析の概要 なぜ並列化か? 並列アーキテクチャ 並列プログラミング FEM 計算におけるノード間並列 領域分割と MPI FEM 計算におけるノード内並列 ( 単体性能 ) ループ分割と OpenMP 実効性能について
48 Flop/Byte SpMV with CSR: Flop/Byte = 1/{6*(1+m/nnz)} = 0.08~0.16 SpMV with BCSR: Flop/Byte = 1/{4*(1+fill/nnz) + 2/c + 2m/nnz*(2+1/r)} = 0.18~0.21 nnz: number of non-zero components m: number of columns, r, c: block size, fill: number of zero s for blocking
49 Sustained Performance Model (1/2) The K-computer s roofline model based on William s model[1]. Sustained performance can be predicted w.r.t. applications Flop/Byte ratio. 実行性能 この辺の Flop/Byte の演算は 演算器性能で実行性能が決まる. マルチコア環境を享受できる. この辺の Flop/Byte の演算は メモリのデータ供給能力で実行性能が決まる [1] S. Williams. Auto-tuning Performance on Multicore Computers. Univ. of California, 演算量とデータ量の比
50 Performance Model (2/2) SpMV with CSR B/F = 6.25~12.5 SpMV with BCSR: B/F = 4.76~5.56 Machine Node performance BW (catalog) BW (STREAM) B/F K 128 Gflops 64 GB/s 46.6 GB/s 0.36 FX Gflops 85 GB/s 64 GB/s 0.27 B/F of FISTR Topeak Measured performance by profiler on FX % SpMV with CSR 2.9~5.8 % SpMV with BCSR: 4.9~7.6 % SpMV with CSR 2.2~4.3 % SpMV with BCSR: 3.7~5.7 %
51 オーダリング (Ordering) ループ依存性 i 番目の結果が i+1 番目以降の計算結果に影響を与えるような場合には 並列処理 ( あるいはベクトル処理 以下も ) してしまうと誤った結果となってしまう オーダリング 配列データの順序を並べ替えるなどの総称 ループ依存性をなくすことができる場合には コンパイラに強制的に並列処理を指示できる オーダリングによって 依存性のない演算部がグループ化され それらに対して並列計算が可能となる 演算が節点や要素についてのループである場合には 依存性の有無は節点や要素の接続関係から判断することができる
52 オーダリング (Ordering) 例えば 次式のような演算を考える x i y i k 1 ここで 添字は節点のインデックスを表す このような演算は 連立一次方程式の解法など多くの行列演算に現れる i 1 L ik x k オーダリング前の節点番号付けの場合 節点 i の演算の際にそれ以前に演算済みの情報が必要であることがわかる 依存性のない節点を 2 色に色分けて ( 黒と白 ) 番号を付け替えた場合 同一色に属する節点に関する演算は互いに依存性がないことがわかる すなわち ノード内並列処理やベクトル処理が可能となる red and black 法 マルチカラー法 演算に依存性のない節点をハイパープレーンと呼ばれるグループに分類し 各ハイパープレーン上の節点についてノード内並列処理やベクトル処理を行うことも多い
53 オーダリング前 Black White Black White オーダリング前 (2 色 ) 節点番号 行列のプロファイル
54 ノード間並列 について詳しく解説した Work Ratio を高くとることで 一般に ノード間並列性能 Weak Scaling は良好な値が得られる ーーー ノード内並列 以降の部分は 時間不足のため後日にあらためて解説予定 対ピーク性能 (= 実効性能 / 理論性能 ) を上げるには ノード内並列 (= スレッド並列 =CPU 単体性能 ) が重要
PowerPoint Presentation
 2016 年 6 月 10 日 ( 金 ) FrontISTR 研究会 FrontISTR の並列計算の基礎 奥田洋司 okuda@k.u-tokyo.ac.jp 東京大学大学院 新領域創成科学研究科 人間環境学専攻 目次 導入 なぜ並列化か? 並列アーキテクチャ 並列プログラミング FrontISTR における並列計算 実効性能について ノード間並列 領域分割と MPI ノード内並列 ( 単体性能
2016 年 6 月 10 日 ( 金 ) FrontISTR 研究会 FrontISTR の並列計算の基礎 奥田洋司 okuda@k.u-tokyo.ac.jp 東京大学大学院 新領域創成科学研究科 人間環境学専攻 目次 導入 なぜ並列化か? 並列アーキテクチャ 並列プログラミング FrontISTR における並列計算 実効性能について ノード間並列 領域分割と MPI ノード内並列 ( 単体性能
PowerPoint Presentation
 FrontISTR の並列計算の基礎 奥田洋司 okuda@k.u-tokyo.ac.jp 東京大学大学院 新領域創成科学研究科 人間環境学専攻 並列有限要素法プログラム FrontISTR ( フロントアイスター ) 並列計算では, メッシュ領域分割によって分散メモリ環境に対応し, 通信ライブラリには MPI を使用 (MPI 並列 ) さらに,CPU 内は OpenMP 並列 ( スレッド並列
FrontISTR の並列計算の基礎 奥田洋司 okuda@k.u-tokyo.ac.jp 東京大学大学院 新領域創成科学研究科 人間環境学専攻 並列有限要素法プログラム FrontISTR ( フロントアイスター ) 並列計算では, メッシュ領域分割によって分散メモリ環境に対応し, 通信ライブラリには MPI を使用 (MPI 並列 ) さらに,CPU 内は OpenMP 並列 ( スレッド並列
GeoFEM開発の経験から
 FrontISTR における並列計算のしくみ < 領域分割に基づく並列 FEM> メッシュ分割 領域分割 領域分割 ( パーティショニングツール ) 全体制御 解析制御 メッシュ hecmw_ctrl.dat 境界条件 材料物性 計算制御パラメータ 可視化パラメータ 領域分割ツール 逐次計算 並列計算 Front ISTR FEM の主な演算 FrontISTR における並列計算のしくみ < 領域分割に基づく並列
FrontISTR における並列計算のしくみ < 領域分割に基づく並列 FEM> メッシュ分割 領域分割 領域分割 ( パーティショニングツール ) 全体制御 解析制御 メッシュ hecmw_ctrl.dat 境界条件 材料物性 計算制御パラメータ 可視化パラメータ 領域分割ツール 逐次計算 並列計算 Front ISTR FEM の主な演算 FrontISTR における並列計算のしくみ < 領域分割に基づく並列
Microsoft PowerPoint - 2_FrontISTRと利用可能なソフトウェア.pptx
 東京大学本郷キャンパス 工学部8号館2階222中会議室 13:30-14:00 FrontISTRと利用可能なソフトウェア 2017年4月28日 第35回FrontISTR研究会 FrontISTRの並列計算ハンズオン 精度検証から並列性能評価まで 観測された物理現象 物理モデル ( 支配方程式 ) 連続体の運動を支配する偏微分方程式 離散化手法 ( 有限要素法, 差分法など ) 代数的な数理モデル
東京大学本郷キャンパス 工学部8号館2階222中会議室 13:30-14:00 FrontISTRと利用可能なソフトウェア 2017年4月28日 第35回FrontISTR研究会 FrontISTRの並列計算ハンズオン 精度検証から並列性能評価まで 観測された物理現象 物理モデル ( 支配方程式 ) 連続体の運動を支配する偏微分方程式 離散化手法 ( 有限要素法, 差分法など ) 代数的な数理モデル
NUMAの構成
 メッセージパッシング プログラミング 天野 共有メモリ対メッセージパッシング 共有メモリモデル 共有変数を用いた単純な記述自動並列化コンパイラ簡単なディレクティブによる並列化 :OpenMP メッセージパッシング 形式検証が可能 ( ブロッキング ) 副作用がない ( 共有変数は副作用そのもの ) コストが小さい メッセージパッシングモデル 共有変数は使わない 共有メモリがないマシンでも実装可能 クラスタ
メッセージパッシング プログラミング 天野 共有メモリ対メッセージパッシング 共有メモリモデル 共有変数を用いた単純な記述自動並列化コンパイラ簡単なディレクティブによる並列化 :OpenMP メッセージパッシング 形式検証が可能 ( ブロッキング ) 副作用がない ( 共有変数は副作用そのもの ) コストが小さい メッセージパッシングモデル 共有変数は使わない 共有メモリがないマシンでも実装可能 クラスタ
最新の並列計算事情とCAE
 1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
Microsoft PowerPoint - 高速化WS富山.pptx
 京 における 高速化ワークショップ 性能分析 チューニングの手順について 登録施設利用促進機関 一般財団法人高度情報科学技術研究機構富山栄治 一般財団法人高度情報科学技術研究機構 2 性能分析 チューニング手順 どの程度の並列数が実現可能か把握する インバランスの懸念があるか把握する タイムステップループ I/O 処理など注目すべき箇所を把握する 並列数 並列化率などの目標を設定し チューニング時の指針とする
京 における 高速化ワークショップ 性能分析 チューニングの手順について 登録施設利用促進機関 一般財団法人高度情報科学技術研究機構富山栄治 一般財団法人高度情報科学技術研究機構 2 性能分析 チューニング手順 どの程度の並列数が実現可能か把握する インバランスの懸念があるか把握する タイムステップループ I/O 処理など注目すべき箇所を把握する 並列数 並列化率などの目標を設定し チューニング時の指針とする
openmp1_Yaguchi_version_170530
 並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
演習準備
 演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
並列計算導入.pptx
 並列計算の基礎 MPI を用いた並列計算 並列計算の環境 並列計算 複数の計算ユニット(PU, ore, Pなど を使用して 一つの問題 計算 を行わせる 近年 並列計算を手軽に使用できる環境が急速に整いつつある >通常のP PU(entral Processing Unit)上に計算装置であるoreが 複数含まれている Intel ore i7 シリーズ: 4つの計算装置(ore) 通常のプログラム
並列計算の基礎 MPI を用いた並列計算 並列計算の環境 並列計算 複数の計算ユニット(PU, ore, Pなど を使用して 一つの問題 計算 を行わせる 近年 並列計算を手軽に使用できる環境が急速に整いつつある >通常のP PU(entral Processing Unit)上に計算装置であるoreが 複数含まれている Intel ore i7 シリーズ: 4つの計算装置(ore) 通常のプログラム
Microsoft PowerPoint - sales2.ppt
 並列化の基礎 ( 言葉の意味 ) 並列実行には 複数のタスク実行主体が必要 共有メモリ型システム (SMP) での並列 プロセスを使用した並列化 スレッドとは? スレッドを使用した並列化 分散メモリ型システムでの並列 メッセージパッシングによる並列化 並列アーキテクチャ関連の言葉を押さえよう 21 プロセスを使用した並列処理 並列処理を行うためには複数のプロセスの生成必要プロセスとは プログラム実行のための能動実態メモリ空間親プロセス子プロセス
並列化の基礎 ( 言葉の意味 ) 並列実行には 複数のタスク実行主体が必要 共有メモリ型システム (SMP) での並列 プロセスを使用した並列化 スレッドとは? スレッドを使用した並列化 分散メモリ型システムでの並列 メッセージパッシングによる並列化 並列アーキテクチャ関連の言葉を押さえよう 21 プロセスを使用した並列処理 並列処理を行うためには複数のプロセスの生成必要プロセスとは プログラム実行のための能動実態メモリ空間親プロセス子プロセス
Microsoft PowerPoint - KHPCSS pptx
 KOBE HPC サマースクール 2018( 初級 ) 9. 1 対 1 通信関数, 集団通信関数 2018/8/8 KOBE HPC サマースクール 2018 1 2018/8/8 KOBE HPC サマースクール 2018 2 MPI プログラム (M-2):1 対 1 通信関数 問題 1 から 100 までの整数の和を 2 並列で求めなさい. プログラムの方針 プロセス0: 1から50までの和を求める.
KOBE HPC サマースクール 2018( 初級 ) 9. 1 対 1 通信関数, 集団通信関数 2018/8/8 KOBE HPC サマースクール 2018 1 2018/8/8 KOBE HPC サマースクール 2018 2 MPI プログラム (M-2):1 対 1 通信関数 問題 1 から 100 までの整数の和を 2 並列で求めなさい. プログラムの方針 プロセス0: 1から50までの和を求める.
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI, MPICH, MVAPICH, MPI.NET プログラミングコストが高いため 生産性が悪い 新しい並
 XcalableMPによる NAS Parallel Benchmarksの実装と評価 中尾 昌広 李 珍泌 朴 泰祐 佐藤 三久 筑波大学 計算科学研究センター 筑波大学大学院 システム情報工学研究科 研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI,
XcalableMPによる NAS Parallel Benchmarksの実装と評価 中尾 昌広 李 珍泌 朴 泰祐 佐藤 三久 筑波大学 計算科学研究センター 筑波大学大学院 システム情報工学研究科 研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI,
Microsoft Word ●IntelクアッドコアCPUでのベンチマーク_吉岡_ _更新__ doc
 2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
Microsoft PowerPoint - 演習1:並列化と評価.pptx
 講義 2& 演習 1 プログラム並列化と性能評価 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 1 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 2 2 次元温度分布の計算
講義 2& 演習 1 プログラム並列化と性能評価 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 1 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 2 2 次元温度分布の計算
TopSE並行システム はじめに
 はじめに 平成 23 年 9 月 1 日 トップエスイープロジェクト 磯部祥尚 ( 産業技術総合研究所 ) 2 本講座の背景と目標 背景 : マルチコア CPU やクラウドコンピューティング等 並列 / 分散処理環境が身近なものになっている 複数のプロセス ( プログラム ) を同時に実行可能 通信等により複数のプロセスが協調可能 並行システムの構築 並行システム 通信 Proc2 プロセス ( プログラム
はじめに 平成 23 年 9 月 1 日 トップエスイープロジェクト 磯部祥尚 ( 産業技術総合研究所 ) 2 本講座の背景と目標 背景 : マルチコア CPU やクラウドコンピューティング等 並列 / 分散処理環境が身近なものになっている 複数のプロセス ( プログラム ) を同時に実行可能 通信等により複数のプロセスが協調可能 並行システムの構築 並行システム 通信 Proc2 プロセス ( プログラム
Microsoft Word - openmp-txt.doc
 ( 付録 A) OpenMP チュートリアル OepnMP は 共有メモリマルチプロセッサ上のマルチスレッドプログラミングのための API です 本稿では OpenMP の簡単な解説とともにプログラム例をつかって説明します 詳しくは OpenMP の規約を決めている OpenMP ARB の http://www.openmp.org/ にある仕様書を参照してください 日本語訳は http://www.hpcc.jp/omni/spec.ja/
( 付録 A) OpenMP チュートリアル OepnMP は 共有メモリマルチプロセッサ上のマルチスレッドプログラミングのための API です 本稿では OpenMP の簡単な解説とともにプログラム例をつかって説明します 詳しくは OpenMP の規約を決めている OpenMP ARB の http://www.openmp.org/ にある仕様書を参照してください 日本語訳は http://www.hpcc.jp/omni/spec.ja/
演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 RIKEN AICS HPC Spring School /3/5
 演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
FEM原理講座 (サンプルテキスト)
") サンプルテキスト FEM 原理講座 サイバネットシステム株式会社 8 年 月 9 日作成 サンプルテキストについて 各講師が 講義の内容が伝わりやすいページ を選びました テキストのページは必ずしも連続していません 一部を抜粋しています 幾何光学講座については 実物のテキストではなくガイダンスを掲載いたします 対象とする構造系 物理モデル 連続体 固体 弾性体 / 弾塑性体 / 粘弾性体 / 固体
サンプルテキスト FEM 原理講座 サイバネットシステム株式会社 8 年 月 9 日作成 サンプルテキストについて 各講師が 講義の内容が伝わりやすいページ を選びました テキストのページは必ずしも連続していません 一部を抜粋しています 幾何光学講座については 実物のテキストではなくガイダンスを掲載いたします 対象とする構造系 物理モデル 連続体 固体 弾性体 / 弾塑性体 / 粘弾性体 / 固体
パソコンシミュレータの現状
 第 2 章微分 偏微分, 写像 豊橋技術科学大学森謙一郎 2. 連続関数と微分 工学において物理現象を支配する方程式は微分方程式で表されていることが多く, 有限要素法も微分方程式を解く数値解析法であり, 定式化においては微分 積分が一般的に用いられており. 数学の基礎知識が必要になる. 図 2. に示すように, 微分は連続な関数 f() の傾きを求めることであり, 微小な に対して傾きを表し, を無限に
第 2 章微分 偏微分, 写像 豊橋技術科学大学森謙一郎 2. 連続関数と微分 工学において物理現象を支配する方程式は微分方程式で表されていることが多く, 有限要素法も微分方程式を解く数値解析法であり, 定式化においては微分 積分が一般的に用いられており. 数学の基礎知識が必要になる. 図 2. に示すように, 微分は連続な関数 f() の傾きを求めることであり, 微小な に対して傾きを表し, を無限に
スライド 1
 本日 (4/25) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
本日 (4/25) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
演習1: 演習準備
 演習 1: 演習準備 2013 年 8 月 6 日神戸大学大学院システム情報学研究科森下浩二 1 演習 1 の内容 神戸大 X10(π-omputer) について システム概要 ログイン方法 コンパイルとジョブ実行方法 OpenMP の演習 ( 入門編 ) 1. parallel 構文 実行時ライブラリ関数 2. ループ構文 3. shared 節 private 節 4. reduction 節
演習 1: 演習準備 2013 年 8 月 6 日神戸大学大学院システム情報学研究科森下浩二 1 演習 1 の内容 神戸大 X10(π-omputer) について システム概要 ログイン方法 コンパイルとジョブ実行方法 OpenMP の演習 ( 入門編 ) 1. parallel 構文 実行時ライブラリ関数 2. ループ構文 3. shared 節 private 節 4. reduction 節
Microsoft Word - HOKUSAI_system_overview_ja.docx
 HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
コードのチューニング
 ハイブリッド並列 八木学 ( 理化学研究所計算科学研究機構 ) 謝辞 松本洋介氏 ( 千葉大学 ) KOBE HPC Spring School 2017 2017 年 3 月 14 日神戸大学計算科学教育センター MPI とは Message Passing Interface 分散メモリのプロセス間の通信規格(API) SPMD(Single Program Multi Data) が基本 -
ハイブリッド並列 八木学 ( 理化学研究所計算科学研究機構 ) 謝辞 松本洋介氏 ( 千葉大学 ) KOBE HPC Spring School 2017 2017 年 3 月 14 日神戸大学計算科学教育センター MPI とは Message Passing Interface 分散メモリのプロセス間の通信規格(API) SPMD(Single Program Multi Data) が基本 -
about MPI
 本日 (4/16) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
本日 (4/16) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
Microsoft PowerPoint - 第10回講義(2015年12月22日)-1 .pptx
-1 .pptx") 非同期通信 東京大学情報基盤センター准教授片桐孝洋 1 2015 年 12 月 22 日 ( 火 )10:25-12:10 講義日程 ( 工学部共通科目 ) 10 月 6 日 : ガイダンス 1. 10 月 13 日 並列数値処理の基本演算 ( 座学 ) 2. 10 月 20 日 : スパコン利用開始 ログイン作業 テストプログラム実行 3. 10 月 27 日 高性能演算技法 1 ( ループアンローリング
非同期通信 東京大学情報基盤センター准教授片桐孝洋 1 2015 年 12 月 22 日 ( 火 )10:25-12:10 講義日程 ( 工学部共通科目 ) 10 月 6 日 : ガイダンス 1. 10 月 13 日 並列数値処理の基本演算 ( 座学 ) 2. 10 月 20 日 : スパコン利用開始 ログイン作業 テストプログラム実行 3. 10 月 27 日 高性能演算技法 1 ( ループアンローリング
コードのチューニング
 OpenMP による並列化実装 八木学 ( 理化学研究所計算科学研究センター ) KOBE HPC Spring School 2019 2019 年 3 月 14 日 スレッド並列とプロセス並列 スレッド並列 OpenMP 自動並列化 プロセス並列 MPI プロセス プロセス プロセス スレッドスレッドスレッドスレッド メモリ メモリ プロセス間通信 Private Private Private
OpenMP による並列化実装 八木学 ( 理化学研究所計算科学研究センター ) KOBE HPC Spring School 2019 2019 年 3 月 14 日 スレッド並列とプロセス並列 スレッド並列 OpenMP 自動並列化 プロセス並列 MPI プロセス プロセス プロセス スレッドスレッドスレッドスレッド メモリ メモリ プロセス間通信 Private Private Private
untitled
 OS 2007/4/27 1 Uni-processor system revisited Memory disk controller frame buffer network interface various devices bus 2 1 Uni-processor system today Intel i850 chipset block diagram Source: intel web
OS 2007/4/27 1 Uni-processor system revisited Memory disk controller frame buffer network interface various devices bus 2 1 Uni-processor system today Intel i850 chipset block diagram Source: intel web
Microsoft PowerPoint _MPI-03.pptx
 計算科学演習 Ⅰ ( 第 11 回 ) MPI を いた並列計算 (III) 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/07/03 計算科学演習 Ⅰ:MPI を用いた並列計算 (III) 1 2014/07/03 計算科学演習 Ⅰ:MPI を用いた並列計算 (III) 2 今週の講義の概要 1. 前回課題の解説 2. 部分配列とローカルインデックス
計算科学演習 Ⅰ ( 第 11 回 ) MPI を いた並列計算 (III) 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/07/03 計算科学演習 Ⅰ:MPI を用いた並列計算 (III) 1 2014/07/03 計算科学演習 Ⅰ:MPI を用いた並列計算 (III) 2 今週の講義の概要 1. 前回課題の解説 2. 部分配列とローカルインデックス
Microsoft PowerPoint - sales2.ppt
 最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
Microsoft Word - thesis.doc
 剛体の基礎理論 -. 剛体の基礎理論初めに本論文で大域的に使用する記号を定義する. 使用する記号トルク撃力力角運動量角速度姿勢対角化された慣性テンソル慣性テンソル運動量速度位置質量時間 J W f F P p .. 質点の並進運動 質点は位置 と速度 P を用いる. ニュートンの運動方程式 という状態を持つ. 但し ここでは速度ではなく運動量 F P F.... より質点の運動は既に明らかであり 質点の状態ベクトル
剛体の基礎理論 -. 剛体の基礎理論初めに本論文で大域的に使用する記号を定義する. 使用する記号トルク撃力力角運動量角速度姿勢対角化された慣性テンソル慣性テンソル運動量速度位置質量時間 J W f F P p .. 質点の並進運動 質点は位置 と速度 P を用いる. ニュートンの運動方程式 という状態を持つ. 但し ここでは速度ではなく運動量 F P F.... より質点の運動は既に明らかであり 質点の状態ベクトル
Microsoft PowerPoint - シミュレーション工学-2010-第1回.ppt
 シミュレーション工学 ( 後半 ) 東京大学人工物工学研究センター 鈴木克幸 CA( Compter Aded geerg ) r. Jaso Lemo (SC, 98) 設計者が解析ツールを使いこなすことにより 設計の評価 設計の質の向上を図る geerg の本質の 計算機による支援 (CA CAM などより広い名前 ) 様々な汎用ソフトの登場 工業製品の設計に不可欠のツール 構造解析 流体解析
シミュレーション工学 ( 後半 ) 東京大学人工物工学研究センター 鈴木克幸 CA( Compter Aded geerg ) r. Jaso Lemo (SC, 98) 設計者が解析ツールを使いこなすことにより 設計の評価 設計の質の向上を図る geerg の本質の 計算機による支援 (CA CAM などより広い名前 ) 様々な汎用ソフトの登場 工業製品の設計に不可欠のツール 構造解析 流体解析
NUMAの構成
 共有メモリを使ったデータ交換と同期 慶應義塾大学理工学部 天野英晴 hunga@am.ics.keio.ac.jp 同期の必要性 あるプロセッサが共有メモリに書いても 別のプロセッサにはそのことが分からない 同時に同じ共有変数に書き込みすると 結果がどうなるか分からない そもそも共有メモリって結構危険な代物 多くのプロセッサが並列に動くには何かの制御機構が要る 不可分命令 同期用メモリ バリア同期機構
共有メモリを使ったデータ交換と同期 慶應義塾大学理工学部 天野英晴 hunga@am.ics.keio.ac.jp 同期の必要性 あるプロセッサが共有メモリに書いても 別のプロセッサにはそのことが分からない 同時に同じ共有変数に書き込みすると 結果がどうなるか分からない そもそも共有メモリって結構危険な代物 多くのプロセッサが並列に動くには何かの制御機構が要る 不可分命令 同期用メモリ バリア同期機構
Microsoft PowerPoint - H21生物計算化学2.ppt
 演算子の行列表現 > L いま 次元ベクトル空間の基底をケットと書くことにする この基底は完全系を成すとすると 空間内の任意のケットベクトルは > > > これより 一度基底を与えてしまえば 任意のベクトルはその基底についての成分で完全に記述することができる これらの成分を列行列の形に書くと M これをベクトル の基底 { >} による行列表現という ところで 行列 A の共役 dont 行列は A
演算子の行列表現 > L いま 次元ベクトル空間の基底をケットと書くことにする この基底は完全系を成すとすると 空間内の任意のケットベクトルは > > > これより 一度基底を与えてしまえば 任意のベクトルはその基底についての成分で完全に記述することができる これらの成分を列行列の形に書くと M これをベクトル の基底 { >} による行列表現という ところで 行列 A の共役 dont 行列は A
Microsoft PowerPoint - 演習2:MPI初歩.pptx
 演習 2:MPI 初歩 - 並列に計算する - 2013 年 8 月 6 日 神戸大学大学院システム情報学研究科計算科学専攻横川三津夫 MPI( メッセージ パッシング インターフェース ) を使おう! [ 演習 2 の内容 ] はじめの一歩課題 1: Hello, world を並列に出力する. 課題 2: プロセス 0 からのメッセージを受け取る (1 対 1 通信 ). 部分に分けて計算しよう課題
演習 2:MPI 初歩 - 並列に計算する - 2013 年 8 月 6 日 神戸大学大学院システム情報学研究科計算科学専攻横川三津夫 MPI( メッセージ パッシング インターフェース ) を使おう! [ 演習 2 の内容 ] はじめの一歩課題 1: Hello, world を並列に出力する. 課題 2: プロセス 0 からのメッセージを受け取る (1 対 1 通信 ). 部分に分けて計算しよう課題
多次元レーザー分光で探る凝縮分子系の超高速動力学
 波動方程式と量子力学 谷村吉隆 京都大学理学研究科化学専攻 http:theochem.kuchem.kyoto-u.ac.jp TA: 岩元佑樹 iwamoto.y@kuchem.kyoto-u.ac.jp ベクトルと行列の作法 A 列ベクトル c = c c 行ベクトル A = [ c c c ] 転置ベクトル T A = [ c c c ] AA 内積 c AA = [ c c c ] c =
波動方程式と量子力学 谷村吉隆 京都大学理学研究科化学専攻 http:theochem.kuchem.kyoto-u.ac.jp TA: 岩元佑樹 iwamoto.y@kuchem.kyoto-u.ac.jp ベクトルと行列の作法 A 列ベクトル c = c c 行ベクトル A = [ c c c ] 転置ベクトル T A = [ c c c ] AA 内積 c AA = [ c c c ] c =
Pervasive PSQL v11 のベンチマーク パフォーマンスの結果
 Pervasive PSQL v11 のベンチマークパフォーマンスの結果 Pervasive PSQL ホワイトペーパー 2010 年 9 月 目次 実施の概要... 3 新しいハードウェアアーキテクチャがアプリケーションに及ぼす影響... 3 Pervasive PSQL v11 の設計... 4 構成... 5 メモリキャッシュ... 6 ベンチマークテスト... 6 アトミックテスト... 7
Pervasive PSQL v11 のベンチマークパフォーマンスの結果 Pervasive PSQL ホワイトペーパー 2010 年 9 月 目次 実施の概要... 3 新しいハードウェアアーキテクチャがアプリケーションに及ぼす影響... 3 Pervasive PSQL v11 の設計... 4 構成... 5 メモリキャッシュ... 6 ベンチマークテスト... 6 アトミックテスト... 7
Microsoft PowerPoint - 講義:コミュニケータ.pptx
 コミュニケータとデータタイプ (Communicator and Datatype) 2019 年 3 月 15 日 神戸大学大学院システム情報学研究科横川三津夫 2019/3/15 Kobe HPC Spring School 2019 1 講義の内容 コミュニケータ (Communicator) データタイプ (Datatype) 演習問題 2019/3/15 Kobe HPC Spring School
コミュニケータとデータタイプ (Communicator and Datatype) 2019 年 3 月 15 日 神戸大学大学院システム情報学研究科横川三津夫 2019/3/15 Kobe HPC Spring School 2019 1 講義の内容 コミュニケータ (Communicator) データタイプ (Datatype) 演習問題 2019/3/15 Kobe HPC Spring School
OpenMP (1) 1, 12 1 UNIX (FUJITSU GP7000F model 900), 13 1 (COMPAQ GS320) FUJITSU VPP5000/64 1 (a) (b) 1: ( 1(a))
 1, 12 1 UNIX (FUJITSU GP7000F model 900), 13 1 (COMPAQ GS320) FUJITSU VPP5000/64 1 (a) (b) 1: ( 1(a))") OpenMP (1) 1, 12 1 UNIX (FUJITSU GP7000F model 900), 13 1 (COMPAQ GS320) FUJITSU VPP5000/64 1 (a) (b) 1: ( 1(a)) E-mail: {nanri,amano}@cc.kyushu-u.ac.jp 1 ( ) 1. VPP Fortran[6] HPF[3] VPP Fortran 2. MPI[5]
OpenMP (1) 1, 12 1 UNIX (FUJITSU GP7000F model 900), 13 1 (COMPAQ GS320) FUJITSU VPP5000/64 1 (a) (b) 1: ( 1(a)) E-mail: {nanri,amano}@cc.kyushu-u.ac.jp 1 ( ) 1. VPP Fortran[6] HPF[3] VPP Fortran 2. MPI[5]
理化学研究所計算科学研究機構研究部門量子系分子科学研究チーム殿 hp170163: 有機半導体 有機分子発光材料の全自動探索シミュレーションシステムの開発 高度化支援作業 2017 年 9 6 ( R405 般財団法 度情報科学技術研究機構利 援部 1
 理化学研究所計算科学研究機構研究部門量子系分子科学研究チーム殿 hp170163: 有機半導体 有機分子発光材料の全自動探索シミュレーションシステムの開発 高度化支援作業 2017 年 9 6 ( )@AICS R405 般財団法 度情報科学技術研究機構利 援部 1 Outline 高度化支援の依頼内容 実行環境と計算条件 PWscf フロー図 各ライブラリを使用した場合のプログラム全体の実行時間の比較
理化学研究所計算科学研究機構研究部門量子系分子科学研究チーム殿 hp170163: 有機半導体 有機分子発光材料の全自動探索シミュレーションシステムの開発 高度化支援作業 2017 年 9 6 ( )@AICS R405 般財団法 度情報科学技術研究機構利 援部 1 Outline 高度化支援の依頼内容 実行環境と計算条件 PWscf フロー図 各ライブラリを使用した場合のプログラム全体の実行時間の比較
スライド 1
 GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
資料3 今後のHPC技術に関する研究開発の方向性について(日立製作所提供資料)
") 今後の HPC 技術に関する 研究開発の方向性について 2012 年 5 月 30 日 ( 株 ) 日立製作所情報 通信システム社 IT プラットフォーム事業本部 Hitachi, Hitachi, Ltd. Ltd. Hitachi 2012. 2012. Ltd. 2012. All rights All rights All rights reserved. reserved. reserved.
今後の HPC 技術に関する 研究開発の方向性について 2012 年 5 月 30 日 ( 株 ) 日立製作所情報 通信システム社 IT プラットフォーム事業本部 Hitachi, Hitachi, Ltd. Ltd. Hitachi 2012. 2012. Ltd. 2012. All rights All rights All rights reserved. reserved. reserved.
Microsoft PowerPoint _MPI-01.pptx
 計算科学演習 Ⅰ MPI を いた並列計算 (I) 神戸大学大学院システム情報学研究科谷口隆晴 yaguchi@pearl.kobe-u.ac.jp この資料は昨年度担当の横川先生の資料を参考にさせて頂いています. 2016/06/23 MPI を用いた並列計算 (I) 1 講義概要 分散メモリ型計算機上のプログラミング メッセージ パシング インターフェイス (Message Passing Interface,MPI)
計算科学演習 Ⅰ MPI を いた並列計算 (I) 神戸大学大学院システム情報学研究科谷口隆晴 yaguchi@pearl.kobe-u.ac.jp この資料は昨年度担当の横川先生の資料を参考にさせて頂いています. 2016/06/23 MPI を用いた並列計算 (I) 1 講義概要 分散メモリ型計算機上のプログラミング メッセージ パシング インターフェイス (Message Passing Interface,MPI)
(Microsoft PowerPoint \215u\213`4\201i\221\272\210\344\201j.pptx)
") AICS 村井均 RIKEN AICS HPC Summer School 2012 8/7/2012 1 背景 OpenMP とは OpenMP の基本 OpenMP プログラミングにおける注意点 やや高度な話題 2 共有メモリマルチプロセッサシステムの普及 共有メモリマルチプロセッサシステムのための並列化指示文を共通化する必要性 各社で仕様が異なり 移植性がない そして いまやマルチコア プロセッサが主流となり
AICS 村井均 RIKEN AICS HPC Summer School 2012 8/7/2012 1 背景 OpenMP とは OpenMP の基本 OpenMP プログラミングにおける注意点 やや高度な話題 2 共有メモリマルチプロセッサシステムの普及 共有メモリマルチプロセッサシステムのための並列化指示文を共通化する必要性 各社で仕様が異なり 移植性がない そして いまやマルチコア プロセッサが主流となり
(Microsoft PowerPoint \211\211\217K3_4\201i\216R\226{_\211\272\215\342\201j.ppt [\214\335\212\267\203\202\201[\203h])
![(Microsoft PowerPoint \211\211\217K3_4\201i\216R\226{_\211\272\215\342\201j.ppt [\214\335\212\267\203\202\201[\203h])](/thumbs/101/148628642.jpg "(Microsoft PowerPoint \211\211\217K3_4\201i\216R\226{_\211\272\215\342\201j.ppt [\214\335\212\267\203\202\201[\203h])") RIKEN AICS Summer School 演習 3 4 MPI による並列計算 2012 年 8 月 8 日 神戸大学大学院システム情報学研究科山本有作理化学研究所計算科学研究機構下坂健則 1 演習の目標 講義 6 並列アルゴリズム基礎 で学んだアルゴリズムのいくつかを,MPI を用いて並列化してみる これを通じて, 基本的な並列化手法と,MPI 通信関数の使い方を身に付ける 2 取り上げる例題と学習項目
RIKEN AICS Summer School 演習 3 4 MPI による並列計算 2012 年 8 月 8 日 神戸大学大学院システム情報学研究科山本有作理化学研究所計算科学研究機構下坂健則 1 演習の目標 講義 6 並列アルゴリズム基礎 で学んだアルゴリズムのいくつかを,MPI を用いて並列化してみる これを通じて, 基本的な並列化手法と,MPI 通信関数の使い方を身に付ける 2 取り上げる例題と学習項目
スライド 1
 計算科学が拓く世界スーパーコンピュータは何故スーパーか 学術情報メディアセンター中島浩 http://www.para.media.kyoto-u.ac.jp/jp/ username=super password=computer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
計算科学が拓く世界スーパーコンピュータは何故スーパーか 学術情報メディアセンター中島浩 http://www.para.media.kyoto-u.ac.jp/jp/ username=super password=computer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司
![4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司](/thumbs/97/131936032.jpg "4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司") 4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
<4D F736F F F696E74202D20906C8D488AC28BAB90DD8C7689F090CD8D488A D91E F1>
 人工環境設計解析工学構造力学と有限要素法 ( 第 回 ) 東京大学新領域創成科学研究科 鈴木克幸 固体力学の基礎方程式 変位 - ひずみの関係 適合条件式 ひずみ - 応力の関係 構成方程式 応力 - 外力の関係 平衡方程式 境界条件 変位規定境界 反力規定境界 境界条件 荷重応力ひずみ変形 場の方程式 Γ t Γ t 平衡方程式構成方程式適合条件式 構造力学の基礎式 ひずみ 一軸 荷重応力ひずみ変形
人工環境設計解析工学構造力学と有限要素法 ( 第 回 ) 東京大学新領域創成科学研究科 鈴木克幸 固体力学の基礎方程式 変位 - ひずみの関係 適合条件式 ひずみ - 応力の関係 構成方程式 応力 - 外力の関係 平衡方程式 境界条件 変位規定境界 反力規定境界 境界条件 荷重応力ひずみ変形 場の方程式 Γ t Γ t 平衡方程式構成方程式適合条件式 構造力学の基礎式 ひずみ 一軸 荷重応力ひずみ変形
C/C++ FORTRAN FORTRAN MPI MPI MPI UNIX Windows (SIMD Single Instruction Multipule Data) SMP(Symmetric Multi Processor) MPI (thread) OpenMP[5]
![C/C++ FORTRAN FORTRAN MPI MPI MPI UNIX Windows (SIMD Single Instruction Multipule Data) SMP(Symmetric Multi Processor) MPI (thread) OpenMP[5]](/thumbs/73/69613550.jpg "C/C++ FORTRAN FORTRAN MPI MPI MPI UNIX Windows (SIMD Single Instruction Multipule Data) SMP(Symmetric Multi Processor) MPI (thread) OpenMP[5]") MPI ( ) snozawa@env.sci.ibaraki.ac.jp 1 ( ) MPI MPI Message Passing Interface[2] MPI MPICH[3],LAM/MPI[4] (MIMDMultiple Instruction Multipule Data) Message Passing ( ) (MPI (rank) PE(Processing Element)
MPI ( ) snozawa@env.sci.ibaraki.ac.jp 1 ( ) MPI MPI Message Passing Interface[2] MPI MPICH[3],LAM/MPI[4] (MIMDMultiple Instruction Multipule Data) Message Passing ( ) (MPI (rank) PE(Processing Element)
行列、ベクトル
 行列 (Mtri) と行列式 (Determinnt). 行列 (Mtri) の演算. 和 差 積.. 行列とは.. 行列の和差 ( 加減算 ).. 行列の積 ( 乗算 ). 転置行列 対称行列 正方行列. 単位行列. 行列式 (Determinnt) と逆行列. 行列式. 逆行列. 多元一次連立方程式のコンピュータによる解法. コンピュータによる逆行列の計算.. 定数項の異なる複数の方程式.. 逆行列の計算
行列 (Mtri) と行列式 (Determinnt). 行列 (Mtri) の演算. 和 差 積.. 行列とは.. 行列の和差 ( 加減算 ).. 行列の積 ( 乗算 ). 転置行列 対称行列 正方行列. 単位行列. 行列式 (Determinnt) と逆行列. 行列式. 逆行列. 多元一次連立方程式のコンピュータによる解法. コンピュータによる逆行列の計算.. 定数項の異なる複数の方程式.. 逆行列の計算
MPI コミュニケータ操作
 コミュニケータとデータタイプ 辻田祐一 (RIKEN AICS) 講義 演習内容 MPI における重要な概念 コミュニケータ データタイプ MPI-IO 集団型 I/O MPI-IO の演習 2 コミュニケータ MPI におけるプロセスの 集団 集団的な操作などにおける操作対象となる MPI における集団的な操作とは? 集団型通信 (Collective Communication) 集団型 I/O(Collective
コミュニケータとデータタイプ 辻田祐一 (RIKEN AICS) 講義 演習内容 MPI における重要な概念 コミュニケータ データタイプ MPI-IO 集団型 I/O MPI-IO の演習 2 コミュニケータ MPI におけるプロセスの 集団 集団的な操作などにおける操作対象となる MPI における集団的な操作とは? 集団型通信 (Collective Communication) 集団型 I/O(Collective
<4D F736F F F696E74202D A A814590DA904796E291E882C991CE82B782E946726F6E CC95C097F190FC8C60835C838B836F815B82C982C282A282C42E >
 東京大学本郷キャンパス 工学部8号館 84講義室 (地下1階) アセンブリ 接触問題に対する FrontISTRの並列線形ソルバー について 2016年11月28日 第32回FrontISTR研究会 FrontISTRによる接触解析における機能拡張と計算事例 本研究開発は, 文部科学省ポスト 京 重点課題 8 近未来型ものづくりを先導する革新的設計 製造プロセスの開発 の一環として実施したものです
東京大学本郷キャンパス 工学部8号館 84講義室 (地下1階) アセンブリ 接触問題に対する FrontISTRの並列線形ソルバー について 2016年11月28日 第32回FrontISTR研究会 FrontISTRによる接触解析における機能拡張と計算事例 本研究開発は, 文部科学省ポスト 京 重点課題 8 近未来型ものづくりを先導する革新的設計 製造プロセスの開発 の一環として実施したものです
スパコンに通じる並列プログラミングの基礎
 2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
スライド 1
 数値解析 平成 30 年度前期第 10 週 [6 月 12 日 ] 静岡大学工学研究科機械工学専攻ロボット 計測情報分野創造科学技術大学院情報科学専攻 三浦憲二郎 講義アウトライン [6 月 12 日 ] 連立 1 次方程式の直接解法 ガウス消去法 ( 復習 ) 部分ピボット選択付きガウス消去法 連立 1 次方程式 連立 1 次方程式の重要性 非線形の問題は基本的には解けない. 非線形問題を線形化して解く.
数値解析 平成 30 年度前期第 10 週 [6 月 12 日 ] 静岡大学工学研究科機械工学専攻ロボット 計測情報分野創造科学技術大学院情報科学専攻 三浦憲二郎 講義アウトライン [6 月 12 日 ] 連立 1 次方程式の直接解法 ガウス消去法 ( 復習 ) 部分ピボット選択付きガウス消去法 連立 1 次方程式 連立 1 次方程式の重要性 非線形の問題は基本的には解けない. 非線形問題を線形化して解く.
PowerPoint プレゼンテーション
 AICS 公開ソフトウェア講習会 15 回 表題通信ライブラリと I/O ライブラリ 場所 AICS R104-2 時間 2016/03/23 ( 水 ) 13:30-17:00 13:30-13:40 全体説明 13:40-14:10 PRDMA 14:10-14:40 MPICH 14:40-15:10 PVAS 15:10-15:30 休憩 15:30-16:00 Carp 16:00-16:30
AICS 公開ソフトウェア講習会 15 回 表題通信ライブラリと I/O ライブラリ 場所 AICS R104-2 時間 2016/03/23 ( 水 ) 13:30-17:00 13:30-13:40 全体説明 13:40-14:10 PRDMA 14:10-14:40 MPICH 14:40-15:10 PVAS 15:10-15:30 休憩 15:30-16:00 Carp 16:00-16:30
数値計算で学ぶ物理学 4 放物運動と惑星運動 地上のように下向きに重力がはたらいているような場においては 物体を投げると放物運動をする 一方 中心星のまわりの重力場中では 惑星は 円 だ円 放物線または双曲線を描きながら運動する ここでは 放物運動と惑星運動を 運動方程式を導出したうえで 数値シミュ
 数値計算で学ぶ物理学 4 放物運動と惑星運動 地上のように下向きに重力がはたらいているような場においては 物体を投げると放物運動をする 一方 中心星のまわりの重力場中では 惑星は 円 だ円 放物線または双曲線を描きながら運動する ここでは 放物運動と惑星運動を 運動方程式を導出したうえで 数値シミュレーションによって計算してみる 4.1 放物運動一様な重力場における放物運動を考える 一般に質量の物体に作用する力をとすると運動方程式は
数値計算で学ぶ物理学 4 放物運動と惑星運動 地上のように下向きに重力がはたらいているような場においては 物体を投げると放物運動をする 一方 中心星のまわりの重力場中では 惑星は 円 だ円 放物線または双曲線を描きながら運動する ここでは 放物運動と惑星運動を 運動方程式を導出したうえで 数値シミュレーションによって計算してみる 4.1 放物運動一様な重力場における放物運動を考える 一般に質量の物体に作用する力をとすると運動方程式は
差分スキーム 物理 化学 生物現象には微分方程式でモデル化される例が多い モデルを使って現実の現象をコンピュータ上で再現することをシミュレーション ( 数値シミュレーション コンピュータシミュレーション ) と呼ぶ そのためには 微分方程式をコンピュータ上で計算できる数値スキームで近似することが必要
 と呼ぶ そのためには 微分方程式をコンピュータ上で計算できる数値スキームで近似することが必要") 差分スキーム 物理 化学 生物現象には微分方程式でモデル化される例が多い モデルを使って現実の現象をコンピュータ上で再現することをシミュレーション ( 数値シミュレーション コンピュータシミュレーション ) と呼ぶ そのためには 微分方程式をコンピュータ上で計算できる数値スキームで近似することが必要になる その一つの方法が微分方程式を差分方程式におき直すことである 微分方程式の差分化 次の 1 次元境界値問題を考える
差分スキーム 物理 化学 生物現象には微分方程式でモデル化される例が多い モデルを使って現実の現象をコンピュータ上で再現することをシミュレーション ( 数値シミュレーション コンピュータシミュレーション ) と呼ぶ そのためには 微分方程式をコンピュータ上で計算できる数値スキームで近似することが必要になる その一つの方法が微分方程式を差分方程式におき直すことである 微分方程式の差分化 次の 1 次元境界値問題を考える
フジタ技術研究報告第 48 号 2012 年 CUDA を用いた並列数値解析手法の一考察 仲沢武志 概 要 従来 大規模な問題や複雑な形状が計算対象の場合では スーパーコンピュータのような高価な計算リソースを使用する必要があった これに対し コンピュータのハード的な進化によって 現在では市販のパーソ
 フジタ技術研究報告第 48 号 2012 年 CUDA を用いた並列数値解析手法の一考察 仲沢武志 概 要 従来 大規模な問題や複雑な形状が計算対象の場合では スーパーコンピュータのような高価な計算リソースを使用する必要があった これに対し コンピュータのハード的な進化によって 現在では市販のパーソナルコンピュータ (PC) でも計算機能は目覚しく向上し 並列演算すらも比較的容易に可能となってきている
フジタ技術研究報告第 48 号 2012 年 CUDA を用いた並列数値解析手法の一考察 仲沢武志 概 要 従来 大規模な問題や複雑な形状が計算対象の場合では スーパーコンピュータのような高価な計算リソースを使用する必要があった これに対し コンピュータのハード的な進化によって 現在では市販のパーソナルコンピュータ (PC) でも計算機能は目覚しく向上し 並列演算すらも比較的容易に可能となってきている
スパコンに通じる並列プログラミングの基礎
 2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
(Microsoft PowerPoint - \221\34613\211\361)
") 計算力学 ~ 第 回弾性問題の有限要素解析 (Ⅱ)~ 修士 年後期 ( 選択科目 ) 担当 : 岩佐貴史 講義の概要 全 5 講義. 計算力学概論, ガイダンス. 自然現象の数理モデル化. 行列 場とその演算. 数値計算法 (Ⅰ) 5. 数値計算法 (Ⅱ) 6. 初期値 境界値問題 (Ⅰ) 7. 初期値 境界値問題 (Ⅱ) 8. マトリックス変位法による構造解析 9. トラス構造の有限要素解析. 重み付き残差法と古典的近似解法.
計算力学 ~ 第 回弾性問題の有限要素解析 (Ⅱ)~ 修士 年後期 ( 選択科目 ) 担当 : 岩佐貴史 講義の概要 全 5 講義. 計算力学概論, ガイダンス. 自然現象の数理モデル化. 行列 場とその演算. 数値計算法 (Ⅰ) 5. 数値計算法 (Ⅱ) 6. 初期値 境界値問題 (Ⅰ) 7. 初期値 境界値問題 (Ⅱ) 8. マトリックス変位法による構造解析 9. トラス構造の有限要素解析. 重み付き残差法と古典的近似解法.
enshu5_4.key
 http://www.mmsonline.com/articles/parallel-processing-speeds-toolpath-calculations TA : 菅 新 菅沼智史 水曜 新行紗弓 馬淵隼 木曜 情報知能工学演習V (前半第4週) 政田洋平 システム情報学研究科計算科学専攻 演習 V( 前半 ) の内容 第 1 週 : 高性能計算 (High Performance Computing
http://www.mmsonline.com/articles/parallel-processing-speeds-toolpath-calculations TA : 菅 新 菅沼智史 水曜 新行紗弓 馬淵隼 木曜 情報知能工学演習V (前半第4週) 政田洋平 システム情報学研究科計算科学専攻 演習 V( 前半 ) の内容 第 1 週 : 高性能計算 (High Performance Computing
Microsoft PowerPoint - compsys2-06.ppt
 情報基盤センター天野浩文 前回のおさらい (1) 並列処理のやり方 何と何を並列に行うのか コントロール並列プログラミング 同時に実行できる多数の処理を, 多数のノードに分配して同時に処理させる しかし, 同時に実行できる多数の処理 を見つけるのは難しい データ並列プログラミング 大量のデータを多数の演算ノードに分配して, それらに同じ演算を同時に適用する コントロール並列よりも, 多数の演算ノードを利用しやすい
情報基盤センター天野浩文 前回のおさらい (1) 並列処理のやり方 何と何を並列に行うのか コントロール並列プログラミング 同時に実行できる多数の処理を, 多数のノードに分配して同時に処理させる しかし, 同時に実行できる多数の処理 を見つけるのは難しい データ並列プログラミング 大量のデータを多数の演算ノードに分配して, それらに同じ演算を同時に適用する コントロール並列よりも, 多数の演算ノードを利用しやすい
多変量解析 ~ 重回帰分析 ~ 2006 年 4 月 21 日 ( 金 ) 南慶典
 南慶典") 多変量解析 ~ 重回帰分析 ~ 2006 年 4 月 21 日 ( 金 ) 南慶典 重回帰分析とは? 重回帰分析とは複数の説明変数から目的変数との関係性を予測 評価説明変数 ( 数量データ ) は目的変数を説明するのに有効であるか得られた関係性より未知のデータの妥当性を判断する これを重回帰分析という つまり どんなことをするのか? 1 最小 2 乗法により重回帰モデルを想定 2 自由度調整済寄与率を求め
多変量解析 ~ 重回帰分析 ~ 2006 年 4 月 21 日 ( 金 ) 南慶典 重回帰分析とは? 重回帰分析とは複数の説明変数から目的変数との関係性を予測 評価説明変数 ( 数量データ ) は目的変数を説明するのに有効であるか得られた関係性より未知のデータの妥当性を判断する これを重回帰分析という つまり どんなことをするのか? 1 最小 2 乗法により重回帰モデルを想定 2 自由度調整済寄与率を求め
<4D F736F F D B B B835E895E97708A4A8E6E82C A98418C6782CC8E6E93AE2E646F63>
 京都大学学術情報メディアセンター 新スーパーコンピュータ運用開始と T2K 連携の始動 アピールポイント 61.2 テラフロップスの京大版 T2K オープンスパコン運用開始 東大 筑波大との T2K 連携による計算科学 工学分野におけるネットワーク型研究推進 人材育成 アプリケーション高度化支援の活動を開始概要国立大学法人京都大学 ( 総長 尾池和夫 ) 学術情報メディアセンター ( センター長 美濃導彦
京都大学学術情報メディアセンター 新スーパーコンピュータ運用開始と T2K 連携の始動 アピールポイント 61.2 テラフロップスの京大版 T2K オープンスパコン運用開始 東大 筑波大との T2K 連携による計算科学 工学分野におけるネットワーク型研究推進 人材育成 アプリケーション高度化支援の活動を開始概要国立大学法人京都大学 ( 総長 尾池和夫 ) 学術情報メディアセンター ( センター長 美濃導彦
Microsoft PowerPoint - OS07.pptx
 この資料は 情報工学レクチャーシリーズ松尾啓志著 ( 森北出版株式会社 ) を用いて授業を行うために 名古屋工業大学松尾啓志 津邑公暁が作成しました 主記憶管理 主記憶管理基礎 パワーポイント 27 で最終版として保存しているため 変更はできませんが 授業でお使いなる場合は松尾 (matsuo@nitech.ac.jp) まで連絡いただければ 編集可能なバージョンをお渡しする事も可能です 復習 OS
この資料は 情報工学レクチャーシリーズ松尾啓志著 ( 森北出版株式会社 ) を用いて授業を行うために 名古屋工業大学松尾啓志 津邑公暁が作成しました 主記憶管理 主記憶管理基礎 パワーポイント 27 で最終版として保存しているため 変更はできませんが 授業でお使いなる場合は松尾 (matsuo@nitech.ac.jp) まで連絡いただければ 編集可能なバージョンをお渡しする事も可能です 復習 OS
PowerPoint プレゼンテーション
 vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
PowerPoint プレゼンテーション
 応用数理概論 準備 端末上で cd ~/ mkdir cppwork cd cppwork wget http://271.jp/gairon/main.cpp wget http://271.jp/gairon/matrix.hpp とコマンドを記入. ls とコマンドをうち,main.cppとmatrix.hppがダウンロードされていることを確認. 1 準備 コンパイル c++ -I. -std=c++0x
応用数理概論 準備 端末上で cd ~/ mkdir cppwork cd cppwork wget http://271.jp/gairon/main.cpp wget http://271.jp/gairon/matrix.hpp とコマンドを記入. ls とコマンドをうち,main.cppとmatrix.hppがダウンロードされていることを確認. 1 準備 コンパイル c++ -I. -std=c++0x
HPC143
 研究背景 GPUクラスタ 高性能 高いエネルギー効率 低価格 様々なHPCアプリケーションで用いられている TCA (Tightly Coupled Accelerators) 密結合並列演算加速機構 筑波大学HA-PACSクラスタ アクセラレータ GPU 間の直接通信 低レイテンシ 今後のHPCアプリは強スケーリングも重要 TCAとアクセラレータを搭載したシステムに おけるプログラミングモデル 例
研究背景 GPUクラスタ 高性能 高いエネルギー効率 低価格 様々なHPCアプリケーションで用いられている TCA (Tightly Coupled Accelerators) 密結合並列演算加速機構 筑波大学HA-PACSクラスタ アクセラレータ GPU 間の直接通信 低レイテンシ 今後のHPCアプリは強スケーリングも重要 TCAとアクセラレータを搭載したシステムに おけるプログラミングモデル 例
次 CAE を取り巻く環境と展望 企業がシミュレーションに抱える痛み :3 つの例 クラウド CAE サービス Cistr Cistr のシステム概要 最新版 Cistr でできること Cistr を利 してみる 2
 クラウド CAE サービス 東京 学 学院新領域創成科学研究科 森 直樹, 井原遊, 野達 1 次 CAE を取り巻く環境と展望 企業がシミュレーションに抱える痛み :3 つの例 クラウド CAE サービス Cistr Cistr のシステム概要 最新版 Cistr でできること Cistr を利 してみる 2 CAE を取り巻く環境と展望 3 国内市場規模は約 3400 億円程度 2015 年度の国内
クラウド CAE サービス 東京 学 学院新領域創成科学研究科 森 直樹, 井原遊, 野達 1 次 CAE を取り巻く環境と展望 企業がシミュレーションに抱える痛み :3 つの例 クラウド CAE サービス Cistr Cistr のシステム概要 最新版 Cistr でできること Cistr を利 してみる 2 CAE を取り巻く環境と展望 3 国内市場規模は約 3400 億円程度 2015 年度の国内
120802_MPI.ppt
 CPU CPU CPU CPU CPU SMP Symmetric MultiProcessing CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CP OpenMP MPI MPI CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU MPI MPI+OpenMP CPU CPU CPU CPU CPU CPU CPU CP
CPU CPU CPU CPU CPU SMP Symmetric MultiProcessing CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CP OpenMP MPI MPI CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU MPI MPI+OpenMP CPU CPU CPU CPU CPU CPU CPU CP
Microsoft PowerPoint - GPGPU実践基礎工学(web).pptx
.pptx") 並列計算の概念 ( プロセスとスレッド ) 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 並列計算の分類 並列アーキテクチャ 並列計算機システム 並列処理 プロセスとスレッド スレッド並列化 OpenMP プロセス並列化 MPI 249 CPU の性能の変化 動作クロックを向上させることで性能を向上 http://pc.watch.impress.co.jp/docs/2003/0227/kaigai01.htm
並列計算の概念 ( プロセスとスレッド ) 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 並列計算の分類 並列アーキテクチャ 並列計算機システム 並列処理 プロセスとスレッド スレッド並列化 OpenMP プロセス並列化 MPI 249 CPU の性能の変化 動作クロックを向上させることで性能を向上 http://pc.watch.impress.co.jp/docs/2003/0227/kaigai01.htm
<4D F736F F F696E74202D D F95C097F D834F E F93FC96E5284D F96E291E85F8DE391E52E >
 SX-ACE 並列プログラミング入門 (MPI) ( 演習補足資料 ) 大阪大学サイバーメディアセンター日本電気株式会社 演習問題の構成 ディレクトリ構成 MPI/ -- practice_1 演習問題 1 -- practice_2 演習問題 2 -- practice_3 演習問題 3 -- practice_4 演習問題 4 -- practice_5 演習問題 5 -- practice_6
SX-ACE 並列プログラミング入門 (MPI) ( 演習補足資料 ) 大阪大学サイバーメディアセンター日本電気株式会社 演習問題の構成 ディレクトリ構成 MPI/ -- practice_1 演習問題 1 -- practice_2 演習問題 2 -- practice_3 演習問題 3 -- practice_4 演習問題 4 -- practice_5 演習問題 5 -- practice_6
Microsoft PowerPoint ppt
 並列アルゴリズム 2005 年後期火曜 2 限 高見利也 ( 青柳睦 ) Aoyagi@cc.kyushu-u.ac.jp http://server-500.cc.kyushu-u.ac.jp/ 12 月 20 日 ( 火 ) 9. PC クラスタによる並列プログラミング ( 演習 ) つづき 1 もくじ 1. 序並列計算機の現状 2. 計算方式およびアーキテクチュアの分類 3. 並列計算の目的と課題
並列アルゴリズム 2005 年後期火曜 2 限 高見利也 ( 青柳睦 ) Aoyagi@cc.kyushu-u.ac.jp http://server-500.cc.kyushu-u.ac.jp/ 12 月 20 日 ( 火 ) 9. PC クラスタによる並列プログラミング ( 演習 ) つづき 1 もくじ 1. 序並列計算機の現状 2. 計算方式およびアーキテクチュアの分類 3. 並列計算の目的と課題
I I / 47
 1 2013.07.18 1 I 2013 3 I 2013.07.18 1 / 47 A Flat MPI B 1 2 C: 2 I 2013.07.18 2 / 47 I 2013.07.18 3 / 47 #PJM -L "rscgrp=small" π-computer small: 12 large: 84 school: 24 84 16 = 1344 small school small
1 2013.07.18 1 I 2013 3 I 2013.07.18 1 / 47 A Flat MPI B 1 2 C: 2 I 2013.07.18 2 / 47 I 2013.07.18 3 / 47 #PJM -L "rscgrp=small" π-computer small: 12 large: 84 school: 24 84 16 = 1344 small school small
PowerPoint プレゼンテーション
 コンピュータアーキテクチャ 第 13 週 割込みアーキテクチャ 2013 年 12 月 18 日 金岡晃 授業計画 第 1 週 (9/25) 第 2 週 (10/2) 第 3 週 (10/9) 第 4 週 (10/16) 第 5 週 (10/23) 第 6 週 (10/30) 第 7 週 (11/6) 授業概要 2 進数表現 論理回路の復習 2 進演算 ( 数の表現 ) 演算アーキテクチャ ( 演算アルゴリズムと回路
コンピュータアーキテクチャ 第 13 週 割込みアーキテクチャ 2013 年 12 月 18 日 金岡晃 授業計画 第 1 週 (9/25) 第 2 週 (10/2) 第 3 週 (10/9) 第 4 週 (10/16) 第 5 週 (10/23) 第 6 週 (10/30) 第 7 週 (11/6) 授業概要 2 進数表現 論理回路の復習 2 進演算 ( 数の表現 ) 演算アーキテクチャ ( 演算アルゴリズムと回路
<4D F736F F F696E74202D F A282BD94BD959C89F A4C E682528D652E707074>
 発表の流れ SSE を用いた反復解法ライブラリ Lis 4 倍精度版の高速化 小武守恒 (JST 東京大学 ) 藤井昭宏 ( 工学院大学 ) 長谷川秀彦 ( 筑波大学 ) 西田晃 ( 中央大学 JST) はじめに 4 倍精度演算について Lisへの実装 SSEによる高速化 性能評価 スピード 収束 まとめ はじめに クリロフ部分空間法たとえば CG 法は, 理論的には高々 n 回 (n は係数行列の次元数
発表の流れ SSE を用いた反復解法ライブラリ Lis 4 倍精度版の高速化 小武守恒 (JST 東京大学 ) 藤井昭宏 ( 工学院大学 ) 長谷川秀彦 ( 筑波大学 ) 西田晃 ( 中央大学 JST) はじめに 4 倍精度演算について Lisへの実装 SSEによる高速化 性能評価 スピード 収束 まとめ はじめに クリロフ部分空間法たとえば CG 法は, 理論的には高々 n 回 (n は係数行列の次元数
スライド 1
 目次 2.MPI プログラミング入門 この資料は, スーパーコン 10 で使用したものである. ごく基本的な内容なので, 現在でも十分利用できると思われるものなので, ここに紹介させて頂く. ただし, 古い情報も含まれているので注意が必要である. 今年度版の解説は, 本選の初日に配布する予定である. 1/20 2.MPI プログラミング入門 (1) 基本 説明 MPI (message passing
目次 2.MPI プログラミング入門 この資料は, スーパーコン 10 で使用したものである. ごく基本的な内容なので, 現在でも十分利用できると思われるものなので, ここに紹介させて頂く. ただし, 古い情報も含まれているので注意が必要である. 今年度版の解説は, 本選の初日に配布する予定である. 1/20 2.MPI プログラミング入門 (1) 基本 説明 MPI (message passing
プログラミング基礎
 C プログラミング Ⅰ 授業ガイダンス C 言語の概要プログラム作成 実行方法 授業内容について 授業目的 C 言語によるプログラミングの基礎を学ぶこと 学習内容 C 言語の基礎的な文法 入出力, 変数, 演算, 条件分岐, 繰り返し, 配列,( 関数 ) C 言語による簡単な計算処理プログラムの開発 到達目標 C 言語の基礎的な文法を理解する 簡単な計算処理プログラムを作成できるようにする 授業ガイダンス
C プログラミング Ⅰ 授業ガイダンス C 言語の概要プログラム作成 実行方法 授業内容について 授業目的 C 言語によるプログラミングの基礎を学ぶこと 学習内容 C 言語の基礎的な文法 入出力, 変数, 演算, 条件分岐, 繰り返し, 配列,( 関数 ) C 言語による簡単な計算処理プログラムの開発 到達目標 C 言語の基礎的な文法を理解する 簡単な計算処理プログラムを作成できるようにする 授業ガイダンス
VXPRO R1400® ご提案資料
 Intel Core i7 プロセッサ 920 Preliminary Performance Report ノード性能評価 ノード性能の評価 NAS Parallel Benchmark Class B OpenMP 版での性能評価 実行スレッド数を 4 で固定 ( デュアルソケットでは各プロセッサに 2 スレッド ) 全て 2.66GHz のコアとなるため コアあたりのピーク性能は同じ 評価システム
Intel Core i7 プロセッサ 920 Preliminary Performance Report ノード性能評価 ノード性能の評価 NAS Parallel Benchmark Class B OpenMP 版での性能評価 実行スレッド数を 4 で固定 ( デュアルソケットでは各プロセッサに 2 スレッド ) 全て 2.66GHz のコアとなるため コアあたりのピーク性能は同じ 評価システム
cp-7. 配列
 cp-7. 配列 (C プログラムの書き方を, パソコン演習で学ぶシリーズ ) https://www.kkaneko.jp/cc/adp/index.html 金子邦彦 1 本日の内容 例題 1. 月の日数配列とは. 配列の宣言. 配列の添え字. 例題 2. ベクトルの内積例題 3. 合計点と平均点例題 4. 棒グラフを描く配列と繰り返し計算の関係例題 5. 行列の和 2 次元配列 2 今日の到達目標
cp-7. 配列 (C プログラムの書き方を, パソコン演習で学ぶシリーズ ) https://www.kkaneko.jp/cc/adp/index.html 金子邦彦 1 本日の内容 例題 1. 月の日数配列とは. 配列の宣言. 配列の添え字. 例題 2. ベクトルの内積例題 3. 合計点と平均点例題 4. 棒グラフを描く配列と繰り返し計算の関係例題 5. 行列の和 2 次元配列 2 今日の到達目標
CPU Levels in the memory hierarchy Level 1 Level 2... Increasing distance from the CPU in access time Level n Size of the memory at each level 1: 2.2
 FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
PowerPoint プレゼンテーション
 Foundation アプライアンス スケーラブルシステムズ株式会社 サーバ クラスタの課題 複数のシステムを一つの だけで容易に管理することは出来ないだろうか? アプリケーションがより多くのメモリを必要とするのだけど ハードウエアの増設なしで対応出来ないだろうか? 現在の利用環境のまま 利用できるコア数やメモリサイズの増強を図ることは出来ないだろうか? 短時間で導入可能で また 必要に応じて 柔軟にシステム構成の変更が可能なソリューションは無いだろうか?...
Foundation アプライアンス スケーラブルシステムズ株式会社 サーバ クラスタの課題 複数のシステムを一つの だけで容易に管理することは出来ないだろうか? アプリケーションがより多くのメモリを必要とするのだけど ハードウエアの増設なしで対応出来ないだろうか? 現在の利用環境のまま 利用できるコア数やメモリサイズの増強を図ることは出来ないだろうか? 短時間で導入可能で また 必要に応じて 柔軟にシステム構成の変更が可能なソリューションは無いだろうか?...
Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]
![Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]](/thumbs/102/156675429.jpg "Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]") 200/0/9 数値流体解析の並列効率とその GPU による高速化の試み 清水建設 ( 株 ) 技術研究所 PHAM VAN PHUC ( ファムバンフック ) 流体計算時間短縮と GPU の活用の試み 現 CPUとの比較によりGPU 活用の可能性 現 CPU の最大利用 ノード内の最大計算資源の利用 すべてCPUコアの利用 適切なアルゴリズムの利用 CPU コア性能の何倍? GPU の利用の試み
200/0/9 数値流体解析の並列効率とその GPU による高速化の試み 清水建設 ( 株 ) 技術研究所 PHAM VAN PHUC ( ファムバンフック ) 流体計算時間短縮と GPU の活用の試み 現 CPUとの比較によりGPU 活用の可能性 現 CPU の最大利用 ノード内の最大計算資源の利用 すべてCPUコアの利用 適切なアルゴリズムの利用 CPU コア性能の何倍? GPU の利用の試み
CSPの紹介
 CSP モデルの優位性 産業技術総合研究所情報技術研究部門磯部祥尚 0:40 第 9 回 CSP 研究会 (2012 年 3 月 17 日 ) 1 講演内容 1. CSPモデルの特徴 CSPモデルとは? 同期型メッセージパッシング通信 イベント駆動 通信相手 ( チャネル ) の自動選択 3. CSPモデルの検証 CSPモデルの記述例 検証ツール 振舞いの等しさ 2. CSPモデルの実装 ライブラリ
CSP モデルの優位性 産業技術総合研究所情報技術研究部門磯部祥尚 0:40 第 9 回 CSP 研究会 (2012 年 3 月 17 日 ) 1 講演内容 1. CSPモデルの特徴 CSPモデルとは? 同期型メッセージパッシング通信 イベント駆動 通信相手 ( チャネル ) の自動選択 3. CSPモデルの検証 CSPモデルの記述例 検証ツール 振舞いの等しさ 2. CSPモデルの実装 ライブラリ
Microsoft PowerPoint MPI.v...O...~...O.e.L.X.g(...Q..)
") MPI プログラミング Information Initiative Center, Hokkaido Univ. MPI ライブラリを利用した分散メモリ型並列プログラミング 分散メモリ型並列処理 : 基礎 分散メモリマルチコンピュータの構成 プロセッサエレメントが専用のメモリ ( ローカルメモリ ) を搭載 スケーラビリティが高い 例 :HITACHI SR8000 Interconnection
MPI プログラミング Information Initiative Center, Hokkaido Univ. MPI ライブラリを利用した分散メモリ型並列プログラミング 分散メモリ型並列処理 : 基礎 分散メモリマルチコンピュータの構成 プロセッサエレメントが専用のメモリ ( ローカルメモリ ) を搭載 スケーラビリティが高い 例 :HITACHI SR8000 Interconnection
バイオプログラミング第 1 榊原康文 佐藤健吾 慶應義塾大学理工学部生命情報学科
 バイオプログラミング第 1 榊原康文 佐藤健吾 慶應義塾大学理工学部生命情報学科 ポインタ変数の扱い方 1 ポインタ変数の宣言 int *p; double *q; 2 ポインタ変数へのアドレスの代入 int *p; と宣言した時,p がポインタ変数 int x; と普通に宣言した変数に対して, p = &x; は x のアドレスのポインタ変数 p への代入 ポインタ変数の扱い方 3 間接参照 (
バイオプログラミング第 1 榊原康文 佐藤健吾 慶應義塾大学理工学部生命情報学科 ポインタ変数の扱い方 1 ポインタ変数の宣言 int *p; double *q; 2 ポインタ変数へのアドレスの代入 int *p; と宣言した時,p がポインタ変数 int x; と普通に宣言した変数に対して, p = &x; は x のアドレスのポインタ変数 p への代入 ポインタ変数の扱い方 3 間接参照 (
並列・高速化を実現するための 高速化サービスの概要と事例紹介
 第 4 回 AVS 可視化フォーラム 2019 並列 高速化を実現するための 高速化サービスの概要と事例紹介 株式会社アーク情報システム営業部仮野亮ソリューション技術部佐々木竜一 2019.08.30 はじめに アーク情報システムの紹介 高速化サービスとは? 事例紹介 コンサルティングサービスについて アーク情報システムの紹介 設立 資本金 :1987 年 10 月 :3 億 600 万円 従業員数
第 4 回 AVS 可視化フォーラム 2019 並列 高速化を実現するための 高速化サービスの概要と事例紹介 株式会社アーク情報システム営業部仮野亮ソリューション技術部佐々木竜一 2019.08.30 はじめに アーク情報システムの紹介 高速化サービスとは? 事例紹介 コンサルティングサービスについて アーク情報システムの紹介 設立 資本金 :1987 年 10 月 :3 億 600 万円 従業員数
修士論文
 AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
Microsoft PowerPoint - OpenMP入門.pptx
 OpenMP 入門 須田礼仁 2009/10/30 初版 OpenMP 共有メモリ並列処理の標準化 API http://openmp.org/ 最新版は 30 3.0 バージョンによる違いはあまり大きくない サポートしているバージョンはともかく csp で動きます gcc も対応しています やっぱり SPMD Single Program Multiple Data プログラム #pragma omp
OpenMP 入門 須田礼仁 2009/10/30 初版 OpenMP 共有メモリ並列処理の標準化 API http://openmp.org/ 最新版は 30 3.0 バージョンによる違いはあまり大きくない サポートしているバージョンはともかく csp で動きます gcc も対応しています やっぱり SPMD Single Program Multiple Data プログラム #pragma omp
Microsoft PowerPoint - 11Web.pptx
 計算機システムの基礎 ( 第 10 回配布 ) 第 7 章 2 節コンピュータの性能の推移 (1) コンピュータの歴史 (2) コンピュータの性能 (3) 集積回路の進歩 (4) アーキテクチャ 第 4 章プロセッサ (1) プロセッサの基本機能 (2) プロセッサの構成回路 (3) コンピュータアーキテクチャ 第 5 章メモリアーキテクチャ 1. コンピュータの世代 計算する機械 解析機関 by
計算機システムの基礎 ( 第 10 回配布 ) 第 7 章 2 節コンピュータの性能の推移 (1) コンピュータの歴史 (2) コンピュータの性能 (3) 集積回路の進歩 (4) アーキテクチャ 第 4 章プロセッサ (1) プロセッサの基本機能 (2) プロセッサの構成回路 (3) コンピュータアーキテクチャ 第 5 章メモリアーキテクチャ 1. コンピュータの世代 計算する機械 解析機関 by
OCW-iダランベールの原理
 講義名連続体力学配布資料 OCW- 第 2 回ダランベールの原理 無機材料工学科准教授安田公一 1 はじめに今回の講義では, まず, 前半でダランベールの原理について説明する これを用いると, 動力学の問題を静力学の問題として解くことができ, さらに, 前回の仮想仕事の原理を適用すると動力学問題も簡単に解くことができるようになる また, 後半では, ダランベールの原理の応用として ラグランジュ方程式の導出を示す
講義名連続体力学配布資料 OCW- 第 2 回ダランベールの原理 無機材料工学科准教授安田公一 1 はじめに今回の講義では, まず, 前半でダランベールの原理について説明する これを用いると, 動力学の問題を静力学の問題として解くことができ, さらに, 前回の仮想仕事の原理を適用すると動力学問題も簡単に解くことができるようになる また, 後半では, ダランベールの原理の応用として ラグランジュ方程式の導出を示す
Microsoft Word _001b_hecmw_PC_cluster_201_howtodevelop.doc
 RSS2108-PJ7- ユーサ マニュアル -001b 文部科学省次世代 IT 基盤構築のための研究開発 革新的シミュレーションソフトウエアの研究開発 RSS21 フリーソフトウエア HEC ミドルウェア (HEC-MW) PC クラスタ用ライブラリ型 HEC-MW (hecmw-pc-cluster) バージョン 2.01 HEC-MW を用いたプログラム作成手法 本ソフトウェアは文部科学省次世代
RSS2108-PJ7- ユーサ マニュアル -001b 文部科学省次世代 IT 基盤構築のための研究開発 革新的シミュレーションソフトウエアの研究開発 RSS21 フリーソフトウエア HEC ミドルウェア (HEC-MW) PC クラスタ用ライブラリ型 HEC-MW (hecmw-pc-cluster) バージョン 2.01 HEC-MW を用いたプログラム作成手法 本ソフトウェアは文部科学省次世代
01_OpenMP_osx.indd
 OpenMP* / 1 1... 2 2... 3 3... 5 4... 7 5... 9 5.1... 9 5.2 OpenMP* API... 13 6... 17 7... 19 / 4 1 2 C/C++ OpenMP* 3 Fortran OpenMP* 4 PC 1 1 9.0 Linux* Windows* Xeon Itanium OS 1 2 2 WEB OS OS OS 1 OS
OpenMP* / 1 1... 2 2... 3 3... 5 4... 7 5... 9 5.1... 9 5.2 OpenMP* API... 13 6... 17 7... 19 / 4 1 2 C/C++ OpenMP* 3 Fortran OpenMP* 4 PC 1 1 9.0 Linux* Windows* Xeon Itanium OS 1 2 2 WEB OS OS OS 1 OS
OpenFOAM(R) ソースコード入門 pt1 熱伝導方程式の解法から有限体積法の実装について考える 前編 : 有限体積法の基礎確認 2013/11/17 オープンCAE 富山富山県立大学中川慎二
 ソースコード入門 pt1 熱伝導方程式の解法から有限体積法の実装について考える 前編 : 有限体積法の基礎確認 2013/11/17 オープンCAE 富山富山県立大学中川慎二") OpenFOAM(R) ソースコード入門 pt1 熱伝導方程式の解法から有限体積法の実装について考える 前編 : 有限体積法の基礎確認 2013/11/17 オープンCAE 勉強会 @ 富山富山県立大学中川慎二 * OpenFOAM のソースコードでは, 基礎式を偏微分方程式の形で記述する.OpenFOAM 内部では, 有限体積法を使ってこの微分方程式を解いている. どのようにして, 有限体積法に基づく離散化が実現されているのか,
OpenFOAM(R) ソースコード入門 pt1 熱伝導方程式の解法から有限体積法の実装について考える 前編 : 有限体積法の基礎確認 2013/11/17 オープンCAE 勉強会 @ 富山富山県立大学中川慎二 * OpenFOAM のソースコードでは, 基礎式を偏微分方程式の形で記述する.OpenFOAM 内部では, 有限体積法を使ってこの微分方程式を解いている. どのようにして, 有限体積法に基づく離散化が実現されているのか,
例 e 指数関数的に減衰する信号を h( a < + a a すると, それらのラプラス変換は, H ( ) { e } e インパルス応答が h( a < ( ただし a >, U( ) { } となるシステムにステップ信号 ( y( のラプラス変換 Y () は, Y ( ) H ( ) X (
 { e } e インパルス応答が h( a < ( ただし a >, U( ) { } となるシステムにステップ信号 ( y( のラプラス変換 Y () は, Y ( ) H ( ) X (") 第 週ラプラス変換 教科書 p.34~ 目標ラプラス変換の定義と意味を理解する フーリエ変換や Z 変換と並ぶ 信号解析やシステム設計における重要なツール ラプラス変換は波動現象や電気回路など様々な分野で 微分方程式を解くために利用されてきた ラプラス変換を用いることで微分方程式は代数方程式に変換される また 工学上使われる主要な関数のラプラス変換は簡単な形の関数で表されるので これを ラプラス変換表
第 週ラプラス変換 教科書 p.34~ 目標ラプラス変換の定義と意味を理解する フーリエ変換や Z 変換と並ぶ 信号解析やシステム設計における重要なツール ラプラス変換は波動現象や電気回路など様々な分野で 微分方程式を解くために利用されてきた ラプラス変換を用いることで微分方程式は代数方程式に変換される また 工学上使われる主要な関数のラプラス変換は簡単な形の関数で表されるので これを ラプラス変換表
Fortran 勉強会 第 5 回 辻野智紀
 Fortran 勉強会 第 5 回 辻野智紀 今回のお品書き サブルーチンの分割コンパイル ライブラリ 静的ライブラリ 動的ライブラリ モジュール その前に 以下の URL から STPK ライブラリをインストールしておいて下さい. http://www.gfd-dennou.org/library/davis/stpk 前回参加された方はインストール済みのはず. サブルーチンの分割コンパイル サブルーチンの独立化
Fortran 勉強会 第 5 回 辻野智紀 今回のお品書き サブルーチンの分割コンパイル ライブラリ 静的ライブラリ 動的ライブラリ モジュール その前に 以下の URL から STPK ライブラリをインストールしておいて下さい. http://www.gfd-dennou.org/library/davis/stpk 前回参加された方はインストール済みのはず. サブルーチンの分割コンパイル サブルーチンの独立化
1.overview
 村井均 ( 理研 ) 2 はじめに 規模シミュレーションなどの計算を うためには クラスタのような分散メモリシステムの利 が 般的 並列プログラミングの現状 半は MPI (Message Passing Interface) を利 MPI はプログラミングコストが きい 標 性能と 産性を兼ね備えた並列プログラミング 語の開発 3 並列プログラミング 語 XcalableMP 次世代並列プログラミング
村井均 ( 理研 ) 2 はじめに 規模シミュレーションなどの計算を うためには クラスタのような分散メモリシステムの利 が 般的 並列プログラミングの現状 半は MPI (Message Passing Interface) を利 MPI はプログラミングコストが きい 標 性能と 産性を兼ね備えた並列プログラミング 語の開発 3 並列プログラミング 語 XcalableMP 次世代並列プログラミング
ex04_2012.ppt
 2012 年度計算機システム演習第 4 回 2012.05.07 第 2 回課題の補足 } TSUBAMEへのログイン } TSUBAMEは学内からのログインはパスワードで可能 } } } } しかし 演習室ではパスワードでログインできない設定 } 公開鍵認証でログイン 公開鍵, 秘密鍵の生成 } ターミナルを開く } $ ssh-keygen } Enter file in which to save
2012 年度計算機システム演習第 4 回 2012.05.07 第 2 回課題の補足 } TSUBAMEへのログイン } TSUBAMEは学内からのログインはパスワードで可能 } } } } しかし 演習室ではパスワードでログインできない設定 } 公開鍵認証でログイン 公開鍵, 秘密鍵の生成 } ターミナルを開く } $ ssh-keygen } Enter file in which to save
次に示す数値の並びを昇順にソートするものとする このソートでは配列の末尾側から操作を行っていく まず 末尾の数値 9 と 8 に着目する 昇順にソートするので この値を交換すると以下の数値の並びになる 次に末尾側から 2 番目と 3 番目の 1
 4. ソート ( 教科書 p.205-p.273) 整列すなわちソートは アプリケーションを作成する際には良く使われる基本的な操作であり 今までに数多くのソートのアルゴリズムが考えられてきた 今回はこれらソートのアルゴリズムについて学習していく ソートとはソートとは与えられたデータの集合をキーとなる項目の値の大小関係に基づき 一定の順序で並べ替える操作である ソートには図 1 に示すように キーの値の小さいデータを先頭に並べる
4. ソート ( 教科書 p.205-p.273) 整列すなわちソートは アプリケーションを作成する際には良く使われる基本的な操作であり 今までに数多くのソートのアルゴリズムが考えられてきた 今回はこれらソートのアルゴリズムについて学習していく ソートとはソートとは与えられたデータの集合をキーとなる項目の値の大小関係に基づき 一定の順序で並べ替える操作である ソートには図 1 に示すように キーの値の小さいデータを先頭に並べる