GPGPUクラスタの性能評価
|
|
|
- えりか ねぎたや
- 7 years ago
- Views:
Transcription
1 2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰
2 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野 BMT 性能 まとめ
3 背景 : GPGPU GPU を汎用計算に 高速化 汎用化が進展 CPU と比べて桁違いの演算性能 メモリ転送性能 プログラム開発環境の整備 CUDA nvidia の統合開発環境 GPU 上のプログラム開発の簡易化 GPGPU 対応の進展 課題 行列演算 N 体問題 FFT CFD GPUはブラックボックス チューニングが困難 GPU 向けプログラム最適化は難しい ノウハウが少ない
4 背景 : GPGPU クラスタ PC クラスタを GPU で加速 GPU 搭載マシンを高速ネットワークで接続 計算は GPU 通信は従来通り CUDA + MPI GPU CPU NIC NIC CPU GPU 課題 通信は CPU を経由 GPUで計算は速くなるが 通信は速くならない GPU-to-GPUで十分な通信性能は出るのか
5 背景 : GPGPU クラスタ 並列処理 時間 計算処理 計算処理 GPU で加速 どれぐらい速くできるか? 通信処理 GPU で加速しない むしろ遅くなる どれぐらい遅くなるか? 姫野 BMT の高速化を題材に 通信処理
6 姫野 BMT 流体アプリのカーネルルーチン Poisson 方程式解法時の性能を測定 メモリアクセス特徴 14 個の 3D 配列 再利用性が低い (1 配列を除く ) キャッシュは効かない メモリバンド幅ネック 14 ストリームで高メモリバンド幅
![姫野 BMT のコア部分 (jacobi) for (i=1; i<imax-1; i++) for (j=1; j<jmax-1; j++) for (k=1; k<kmax-1; k++) { } s0 = a0[i][j][k] * p[i+1][j][k] + a1[i][j][k] * p[i][j+1][k] +](/docs-images/96/127458359/images/7-1.jpg "a2[i][j][k] * p[i][j][k+1] + b0[i][j][k] * (p[i+1][j+1][k] p[i+1][j-1][k] p[i-1][j+1][k] + p[i-1][j-1][k]) + b1[i][j][k] * (p[i][j+1][k+1] p[i][j+1][k-1]")
![p[i][j-1][k+1] + p[i][j-1][k-1]) + b2[i][j][k] * (p[i+1][j][k+1] p[i+1][j][k-1] p[i-1][j][k+1] + p[i-1][j][k-1]) + c0[i][j][k] * p[i-1][j][k] + c1[i][j][k] *](/docs-images/96/127458359/images/7-2.jpg "p[i][j-1][k] + c2[i][j][k] * p[i][j][k-1] + wrk1[i][j][k]; ss = (s0 * a3[i][j][k] p[i][j][k]) * bnd[i][j][k]; wrk2[i][j][k] = p[i][j][k] + omega * ss; 配列 p: ステンシルアクセス")
7 姫野 BMT のコア部分 (jacobi) for (i=1; i<imax-1; i++) for (j=1; j<jmax-1; j++) for (k=1; k<kmax-1; k++) { } s0 = a0[i][j][k] * p[i+1][j][k] + a1[i][j][k] * p[i][j+1][k] + a2[i][j][k] * p[i][j][k+1] + b0[i][j][k] * (p[i+1][j+1][k] p[i+1][j-1][k] p[i-1][j+1][k] + p[i-1][j-1][k]) + b1[i][j][k] * (p[i][j+1][k+1] p[i][j+1][k-1] p[i][j-1][k+1] + p[i][j-1][k-1]) + b2[i][j][k] * (p[i+1][j][k+1] p[i+1][j][k-1] p[i-1][j][k+1] + p[i-1][j][k-1]) + c0[i][j][k] * p[i-1][j][k] + c1[i][j][k] * p[i][j-1][k] + c2[i][j][k] * p[i][j][k-1] + wrk1[i][j][k]; ss = (s0 * a3[i][j][k] p[i][j][k]) * bnd[i][j][k]; wrk2[i][j][k] = p[i][j][k] + omega * ss; 配列 p: ステンシルアクセス 再利用性有り 他 13 配列 : 点アクセス 再利用性無し
8 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野 BMT 性能 まとめ
9 CUDA 概要 : ハードウェア構成 GeForce GTX280 最新世代 CUDA GPU 理論ピークメモリバンド幅 : 141.7GB/s ( = 64bit * 8 * 2.214GHz ) MP 数 : 30 MPの内部構成 SP 数 : 8 ( 全体で240) 共有メモリ : 16KB レジスタ数 : 16K 本 (64KB) MP MP MP Memory Controller 64bit GDDR3 GDDR3 (*) SP = Stream Processor Multi-Processor Register Files (64KB) SP SP SP SP SP SP SP SP Shared Memory (16KB) (x10) X-Bar (x8) MP MP MP Memory Controller 64bit GDDR3 GDDR3 Global Memory
10 CUDA 概要 : プログラミング 2 段階のデータ並列 グリッド 複数のブロックで構成 ブロック 複数のスレッドで構成 スレッド SP 上で実行される MP 内の処理 各ブロックは 1 つの MP に割当 MP が実行可能スレッドを選択 選択単位はワープ (32 スレッド ) Block Warp 0 Warp 1 Warp 7 Grid Block (0,0) Block (0,1) Block (0,15) Thread (0,0) Thread (0,1) Thread (0,7) Block (1,0) Block (1,1) Block (1,15) Block (15,0) Block (15,1) Block (15,15) (*) 256block/grid Thread (1,0) Thread (1,1) Thread (1,7) Thread (31,0) Thread (31,1) Thread (31,7) (*) 256thread/block
11 CUDA 概要 : 実行モデル CUDA の実行モデル : SPMD Single Program Multiple Data 命令列 SIMD Thread0 Thread1 Thread2 Thread3 SPMD Thread0 Thread1 Thread2 Thread3 基本的に スレッド間は非同期 同じワープ内のスレッドだけ同期
12 メモリアクセス特性の調査 高速化の対象 : 姫野 BMT 姫野 BMT はメモリバンド幅ネック 姫野 BMT の高速化 高メモリバンド幅の実現 GPU の実効メモリバンド幅 理論ピークの 8 割超も可能 いつでも高バンド幅を実現できる NO 高バンド幅実現の条件は? GPU のメモリアクセス特性を調査 バンド幅 アクセス遅延
13 メモリバンド幅の調査 メモリコピー時のメモリバンド幅を実測 READ:WRITE 比率 = 1:1 以下の条件を変え 測定を実施 コピー量 (= 転送量 ) 同時コピー数 (= ストリーム数 )
14 メモリコピー ( 基本 ) 普通のメモリコピー for ( i = 0 ; i < num ; i ++ ) { } dst[ i ] = src[ i ]; GPU: データ並列でメモリコピー 各スレッドへのデータ割当 (4 スレッド ): Block (dst) (src) Cyclic (dst) (src) スレッド 1 の担当領域スレッド 2 スレッド 3 スレッド 4
15 メモリコピー ( 基本 ) global void mcopy( float *dst, float *src, int size ) { int id = ( 各スレッド固有の番号 ); int step = ( 総スレッド数 ); int n_total = ( 総コピー回数 ); for ( int i = id ; i < n_total ; i += step ) { dst[ i ] = src[ i ]; } } 配列に対するアクセスパターン スレッド単体で考えるとストライドアクセス スレッド全体で考えると逐次アクセス READ/WRITE 各 1 ストリーム ( 計 2 ストリーム )
16 メモリコピー ( 同時に複数コピー ) 同時に複数のメモリコピー 1-Copy 2-Copy 4-Copy 8-Copy for ( i = 0 ; i < num /; 24 8 i ++ ; i ++ ) { ) { dst[ dst0[ i i i ] ] = = src0[ src[ i ]; i ]; } dst1[ i i ] ] = = src1[ src1[ i ]; i ]; dst2[ i ] = src2[ i ]; } dst2[ i ] = src2[ i ]; dst3[ i ] = src3[ i ]; dst3[ i ] = src3[ i ]; } } dst4[ i ] = src4[ i ]; dst5[ i ] = src5[ i ]; dst6[ i ] = src6[ i ]; dst7[ i ] = src7[ i ];
 (dst) 配列 (src) (dst) 8-copy 同時コピー数の増加 = ストリーム数の増加ストリーム数とメモリバンド幅の関係")
17 メモリコピー ( 同時に複数コピー ) 同時コピー数と配列アクセスパターン 配列 ( メモリ ) 1-copy 2-copy 4-copy 配列 (src) (dst) 配列 (src) (dst) 8-copy 同時コピー数の増加 = ストリーム数の増加ストリーム数とメモリバンド幅の関係
18 メモリコピー ( 同時に複数コピー ) global void mcopy( float *dst, float *src, int size, int n_copy ) { int id = ( 各スレッド固有の番号 ); int step = ( 総スレッド数 ); int n_total = ( 総コピー回数 ); int n_each = n_total / n_copy; for ( int i = id ; i < n_each ; i += step ) { for ( int j = i ; j < n_total ; j += n_each ) { dst[ j ] = src[ j ]; } } } 複数のメモリコピーが同時進行 配列を N 個に分離 ストリーム数 : 2*N
 ブロック数 :60, スレッド数 / ブロック")
19 メモリバンド幅測定結果 バンド幅低下問題 転送量増でバンド幅低下 ストリーム数増でバンド幅低下 cudamemcpy では未発生 (*) ブロック数 :60, スレッド数 / ブロック :256
20 メモリアクセス遅延の調査 遅延は短い方が扱いやすい GPU は遅延が長いと言われている 具体的に どれぐらい長いのか ランダムアクセス時の遅延を測定 int index = ( 各スレッド固有の番号 ); int num = ( アクセス回数 ); while ( num > 0 ) { index = buf[ index ]; num--; }
21 メモリアクセス遅延測定結果 2 つの境界 8MB と 32MB (GTX280) 8MB 境界 : よく分からない.. 32MB 境界 : おそらく TLB ページサイズ : 4MB? エントリ数 : 8? (*) ブロック数 :1 スレッド数 :32 (1 ワープ )
22 調査結果の考察 バンド幅測定 : バンド幅低下問題 転送量増でバンド幅低下 ストリーム数増でバンド幅低下 cudamemcpy 性能に届かない 遅延測定 : TLB の存在 TLB ミスで ~200ns の遅延増 バンド幅低下問題の原因は TLB スラッシング?
23 バンド幅低下のシナリオ CUDA の実行モデルは SPMD 進行の速いスレッド 遅いスレッドが混在 時間が経過 スレッド間の進行差が拡大 メモリアクセス箇所が分散 単位時間あたりアクセスページ数が増加 TLB ミス発生頻度が増加 (TLB スラッシング ) メモリバンド幅低下
 SIMD Thread0 Thread1 Thread2")
 分散 スレッド進行を同期状態に近づける")
24 バンド幅低下のシナリオ CUDA の実行モデルは SPMD メモリコピー時の配列アクセス箇所 配列 ( メモリ ) SIMD Thread0 Thread1 Thread2 Thread3 配列 (src) 局所 SPMD Thread0 Thread1 Thread2 Thread3 配列 (src) 分散 スレッド進行を同期状態に近づける バンド幅低下を回避できる?
25 スレッド進行の同期化 全スレッドの同期 CUDA では出来ない 同じブロック内のスレッド 同期可能 global void mcopy( float *dst, float *src, int size, int n_copy ) { int id = ( 各スレッド固有の番号 ); int step = ( 総スレッド数 ); int n_total = ( 総コピー回数 ); int n_each = n_total / n_copy; for ( int i = id ; i < n_each ; i += step ) { for ( int j = i ; j < n_total ; j += n_each ) { syncthreads() dst[ j ] = src[ j ]; } } }
26 メモリバンド幅測定結果 (*) ブロック数 :60, スレッド数 / ブロック :256
27 メモリバンド幅測定結果 (syncthreads) 転送量増によるバンド幅低下は解消 cudamemcpy 相当の性能 ストリーム数増によるバンド幅低下は改善 でも ストリーム数は少ない方が良い (*) ブロック数 :60, スレッド数 / ブロック :256
28 高メモリバンド幅を実現する方法 スレッド進行の同期化 syncthreads() でブロック内スレッドを同期 同期ペナルティ < 同期メリット アクセスパターンの局所化 アルゴリズム データ構造を見直し ストリーム数減 単位時間あたりアクセスページ数を削減 スレッド数の最適化 レジスタ 共有メモリ使用量を減らし 同時実行可能スレッド数を増加 適切な総スレッド数の選択
29 姫野 BMT on GPU 従来実装 東工大 ) 青木教授の実装 2007 年度理研ベンチマークコンテスト優勝 HPC 研究会で発表 (2008-HPC-115) 姫野 BMT(M サイズ ) の実行ファイルが公開
30 従来実装 128 Array Block z y x ブロック形状 : (16,16,8) ブロック数 : 2,048 各ブロック スレッド数 : 格子点計算 / スレッド 格子点計算開始前に スレッド間で共用する配列値を全て共有メモリにロード 同期回数を減らすため? 共有メモリ使用量 : 12.7KB 4B*(16+2)*(16+2)*(8+2) MP への割当ブロック数 : 1 x 軸と z 軸の入替え マルチ GPU 対応?
31 提案手法に基づく高速化 スレッド進行の同期化 同期処理の多用 ( syncthreads()) アクセスパターンの局所化 配列の次元入替え ブロック形状変更 スレッド数の最適化 同時実行スレッド数の増加 総スレッド数調整 その他 配列間のパディング量調整
32 提案手法適用後 128 z y x 128 Array 4 64 Block 64 ブロック形状 : (64,4,64) ブロック数 : 256 各ブロック スレッド数 : 格子点計算 / スレッド スレッド間で共用する配列値 各格子点計算の開始前に 必要な分だけ共有メモリにロード 同期回数増 問題無し 共有メモリ使用量 : 4.7KB 4B*(64+2)*(4+2)*3 1MP に 3 ブロック割当 256
 1.")
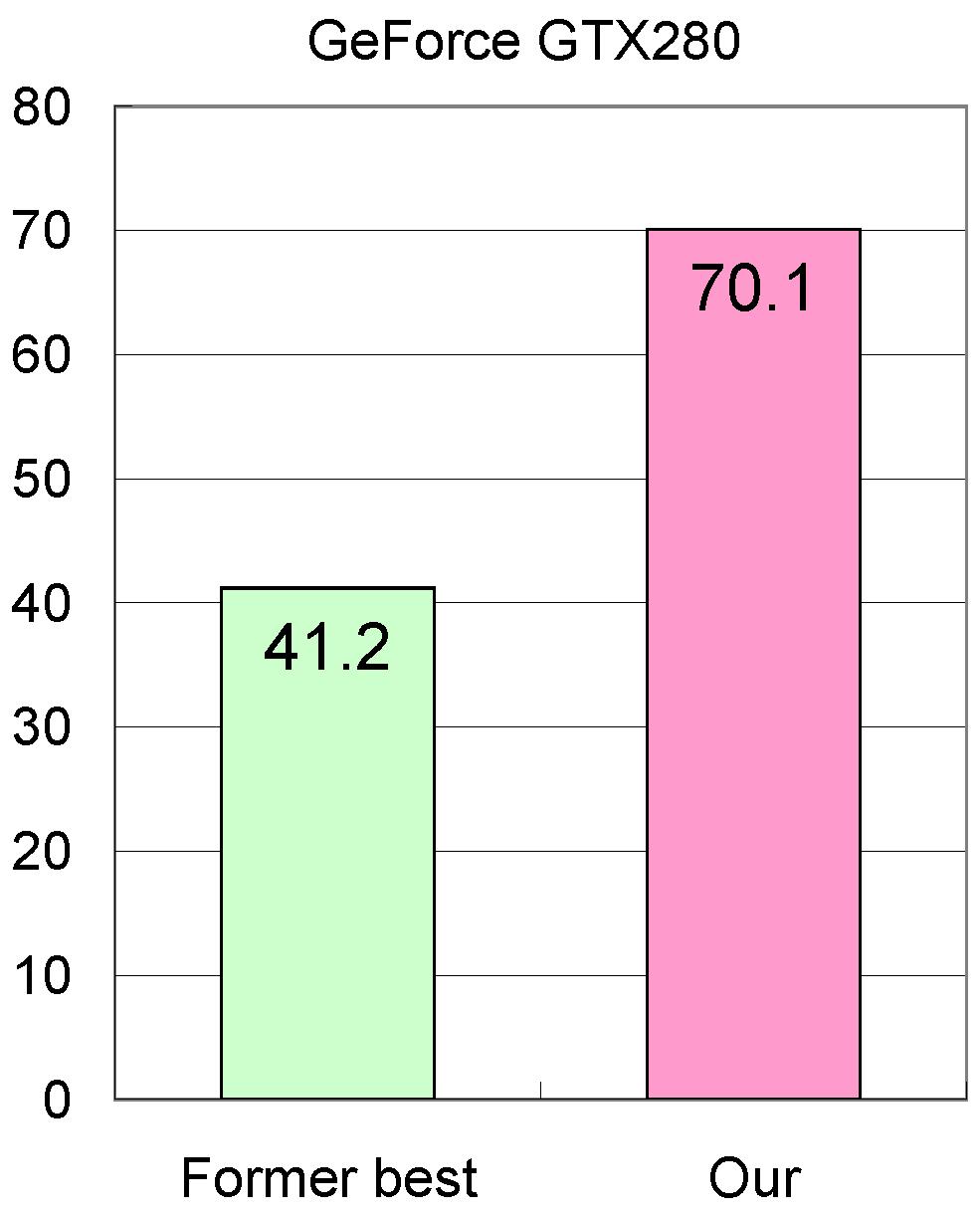
33 姫野 BMT 性能 (GFLOPS) 1.7x 1.7x 従来実装提案手法従来実装提案手法
34 GFLOPS とバンド幅の関係 姫野 BMT のメモリアクセス量 1.65 B/FLOP (*) BF 比は実装依存 1 格子点あたりのメモリアクセス量 : 56 B 1 格子点あたり14 変数のメモリアクセス データ型はfloat (4B) 1 格子点あたりの演算量 : 34 FLOP
")
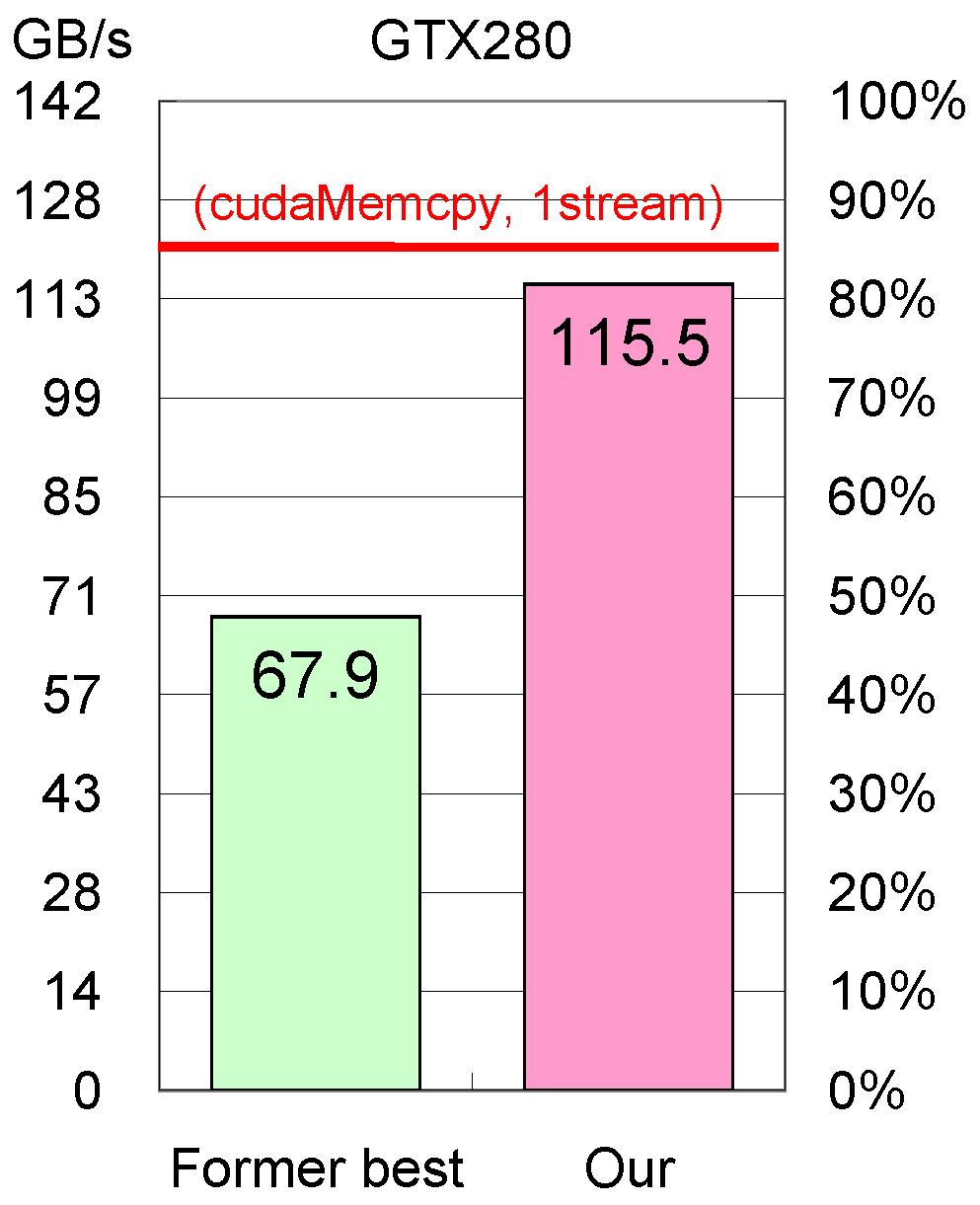


35 姫野 BMT 性能 ( バンド幅 ) 最大実効メモリバンド幅 理論ピークの80% を超えるバンド幅を実現 (GTX280) 従来実装提案手法従来実装提案手法
36 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野 BMT 性能 まとめ
 通信処理 : 配列 p の隣接面を隣のプロセスと送受信 (3) (1)")
37 並列版の姫野 BMT 3 次元配列をプロセス数分割 各プロセスは分割後の配列を担当 (1) 計算処理 : 各プロセスは自分の担当領域を計算 (2) 通信処理 : 配列 p の隣接面を隣のプロセスと送受信 (3) (1) に戻る 3D 配列
38 GPGPU クラスタ試験環境 4 台の GPU 搭載マシンを InfiniBand で接続 マシンスペック GPU: nvidia GTX285 (PCIe2x16) CPU: Intel Core i7 (2.66GHz) NIC: Mellanox ConnectX (DDR-IB, PCIe2x8) M/B: Gigabyte GA-EX58-UD5 (Intel X58) Mem: DDR GB x 3 OS: RHEL 5.3 (64bit) C/C++: GNU CUDA: 2.1 MPI: OpenMPI 1.3
39 姫野 BMT on PC クラスタ PC クラスタの姫野 BMT 性能 ( 実測 L サイズ ) 1 ノード : 4 ノード : 6.5GFLOPS 25.5GFLOPS 1 4 ノードで 3.9 倍性能 UP スケール 4 ノード PC クラスタの処理時間内訳 GPGPU クラスタはスケールするか? 1 ノード : 4 ノード :??? 計算処理 :43 msec 70GFLOPS 程度 通信処理 : 1.0 msec
 GPU Host 間のデータ転送性能が重要 GPGPUクラスタ : GPU-to-GPU 通信 GPUメモリ Hostメモリ (CUDA) Hostメモリ Hostメモリ (MPI) Hostメモリ GPUメモリ")
40 GPU-to-GPU 通信 GPU CPU NIC NIC CPU GPU GPU メモリ Host メモリ Host メモリ GPU メモリ PC クラスタ : CPU-to-CPU 通信 Host メモリ Host メモリ (MPI) GPU Host 間のデータ転送性能が重要 GPGPUクラスタ : GPU-to-GPU 通信 GPUメモリ Hostメモリ (CUDA) Hostメモリ Hostメモリ (MPI) Hostメモリ GPUメモリ (CUDA)
41 GPU Host 間のデータ転送 Pinned メモリと Pageable メモリ Pinned メモリ cudamallochost() DMA 可能 Pageable メモリ malloc() DMA 不可 Host メモリ内でコピーが必要 GPU DMA CPU GPU DMA CPU GPU メモリ Host メモリ Pinned GPU メモリ Host メモリ Pageable COPY

")
42 Core i7 のメモリバンド幅 Core2 Core i7 (1channel)
43 GPU Host 間のデータ転送性能 Pinned Pinned 3ch 2ch 3ch 2ch Pinnedメモリの転送性能が高い 1ch Pageableメモリでもそれなり Pageable Core i7のおかげ 遅延は~10usecと長め 回数を減らし まとめて転送 Pageable 1ch
44 GPU-to-GPU 通信性能 (CPU-to-CPU) 姫野 BMT IB RDMA 域 (Pinned は RDMA NG) Pinned Pageable DDR-IB を GPU-to-GPU で使うと 遅延は GbE 程度 バンド幅は SDR-IB 程度 Pinned メモリ IB RDMA 通信は NG 1 年前から知られている問題
45 GPGPU クラスタの性能予測 処理時間内訳 4 ノード PC クラスタ ( 実測 ) 通信処理 : 1.0 msec 4 ノード GPGPU クラスタ ( 予測 ) 計算時間 : 1/10 倍 通信時間 : 2+ 倍 GPU 使用時の姫野 BMT 性能 1 ノード GPGPU: 計算処理 :43 msec 計算処理 :4.3 msec 70GFLOPS 4 ノード GPGPU クラスタ : 170GFLOPS ( 予測 ) 通信処理 : 2.2 msec
46 姫野 BMT on GPGPU クラスタ
47 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野 BMT 性能 まとめ
48 まとめ GPGPU は使えるか? YES GPU 向けプログラム最適化ノウハウの蓄積 姫野 BMT で メモリバンド幅効率 80% 超 理論ピーク 142GB/s に対して 実効で 115GB/s を実現 GPGPU クラスタは使えるか? 数ノードで通信ネック GPU: 計算にはアクセル 通信にはブレーキ より高速な通信機構が必要 GPU 直接通信 GPU CPU 統合
49
GPU GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1
 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1") GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
Microsoft Word ●IntelクアッドコアCPUでのベンチマーク_吉岡_ _更新__ doc
 2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date Type URL Presentation
 榎本, 昌一 Citation Issue date Type URL Presentation") 熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date 2011-03-17 Type URL Presentation http://hdl.handle.net/2298/23539 Right GPGPU による高速演算について 榎本昌一 東京大学大学院工学系研究科システム創成学専攻
熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date 2011-03-17 Type URL Presentation http://hdl.handle.net/2298/23539 Right GPGPU による高速演算について 榎本昌一 東京大学大学院工学系研究科システム創成学専攻
名称 : 日本 GPU コンピューティングパートナーシップ (G-DEP) 所在 : 東京都文京区本郷 7 丁目 3 番 1 号東京大学アントレプレナープラザ, 他工場 URL アライアンスパートナー コアテクノロジーパートナー NVIDIA JAPAN ソリュ
 所在 : 東京都文京区本郷 7 丁目 3 番 1 号東京大学アントレプレナープラザ, 他工場 URL アライアンスパートナー コアテクノロジーパートナー NVIDIA JAPAN ソリュ") GPUDirect の現状整理 multi-gpu に取組むために G-DEP チーフエンジニア河井博紀 ([email protected]) 名称 : 日本 GPU コンピューティングパートナーシップ (G-DEP) 所在 : 東京都文京区本郷 7 丁目 3 番 1 号東京大学アントレプレナープラザ, 他工場 URL http://www.gdep.jp アライアンスパートナー コアテクノロジーパートナー
GPUDirect の現状整理 multi-gpu に取組むために G-DEP チーフエンジニア河井博紀 ([email protected]) 名称 : 日本 GPU コンピューティングパートナーシップ (G-DEP) 所在 : 東京都文京区本郷 7 丁目 3 番 1 号東京大学アントレプレナープラザ, 他工場 URL http://www.gdep.jp アライアンスパートナー コアテクノロジーパートナー
Microsoft PowerPoint - CCS学際共同boku-08b.ppt
 マルチコア / マルチソケットノードに おけるメモリ性能のインパクト 研究代表者朴泰祐筑波大学システム情報工学研究科 [email protected] アウトライン 近年の高性能 PC クラスタの傾向と問題 multi-core/multi-socket ノードとメモリ性能 メモリバンド幅に着目した性能測定 multi-link network 性能評価 まとめ 近年の高性能 PC
マルチコア / マルチソケットノードに おけるメモリ性能のインパクト 研究代表者朴泰祐筑波大学システム情報工学研究科 [email protected] アウトライン 近年の高性能 PC クラスタの傾向と問題 multi-core/multi-socket ノードとメモリ性能 メモリバンド幅に着目した性能測定 multi-link network 性能評価 まとめ 近年の高性能 PC
ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014
 ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014 コンカレントな処理の実行 システム内部の複数の処理を 平行に実行する CPU GPU メモリ転送 カーネル実行 複数のカーネル間 ストリーム GPU 上の処理キュー カーネル実行 メモリ転送の並列性 実行順序 DEFAULT STREAM Stream : GPU
ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014 コンカレントな処理の実行 システム内部の複数の処理を 平行に実行する CPU GPU メモリ転送 カーネル実行 複数のカーネル間 ストリーム GPU 上の処理キュー カーネル実行 メモリ転送の並列性 実行順序 DEFAULT STREAM Stream : GPU
GPUを用いたN体計算
 単精度 190Tflops GPU クラスタ ( 長崎大 ) の紹介 長崎大学工学部超高速メニーコアコンピューティングセンターテニュアトラック助教濱田剛 1 概要 GPU (Graphics Processing Unit) について簡単に説明します. GPU クラスタが得意とする応用問題を議論し 長崎大学での GPU クラスタによる 取組方針 N 体計算の高速化に関する研究内容 を紹介します. まとめ
単精度 190Tflops GPU クラスタ ( 長崎大 ) の紹介 長崎大学工学部超高速メニーコアコンピューティングセンターテニュアトラック助教濱田剛 1 概要 GPU (Graphics Processing Unit) について簡単に説明します. GPU クラスタが得意とする応用問題を議論し 長崎大学での GPU クラスタによる 取組方針 N 体計算の高速化に関する研究内容 を紹介します. まとめ
23 Fig. 2: hwmodulev2 3. Reconfigurable HPC 3.1 hw/sw hw/sw hw/sw FPGA PC FPGA PC FPGA HPC FPGA FPGA hw/sw hw/sw hw- Module FPGA hwmodule hw/sw FPGA h
 23 FPGA CUDA Performance Comparison of FPGA Array with CUDA on Poisson Equation ([email protected]), ([email protected]), ([email protected]), ([email protected]),
23 FPGA CUDA Performance Comparison of FPGA Array with CUDA on Poisson Equation ([email protected]), ([email protected]), ([email protected]), ([email protected]),
スライド 1
 GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境 Lin
 Windows で始める CUDA 入門 GTC 2013 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境
Windows で始める CUDA 入門 GTC 2013 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境
Microsoft PowerPoint - suda.pptx
 GPU の HWアーキテクチャと高性能化手法 須田礼仁 ( 東京大学 ) 2011/03/22 GPU 高性能プログラミング GPU のハードウェアを理解する CUDA のソフトウェアを理解する CUDA でプログラムを書くのは難しくないが, CUDA で高速なプログラムを書くのは難しい どうすれば遅くなるかを理解する! 効果が大きいものから順に説明します 1 高性能プログラミングの手順 1. 現在のコードの,
GPU の HWアーキテクチャと高性能化手法 須田礼仁 ( 東京大学 ) 2011/03/22 GPU 高性能プログラミング GPU のハードウェアを理解する CUDA のソフトウェアを理解する CUDA でプログラムを書くのは難しくないが, CUDA で高速なプログラムを書くのは難しい どうすれば遅くなるかを理解する! 効果が大きいものから順に説明します 1 高性能プログラミングの手順 1. 現在のコードの,
CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン
 CUDA 画像処理入門 エヌビディアジャパン CUDA エンジニア森野慎也 GTC Japan 2014 CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン RGB Y( 輝度 ) 変換 カラー画像から グレイスケールへの変換 Y = 0.299 R + 0.587
CUDA 画像処理入門 エヌビディアジャパン CUDA エンジニア森野慎也 GTC Japan 2014 CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン RGB Y( 輝度 ) 変換 カラー画像から グレイスケールへの変換 Y = 0.299 R + 0.587
07-二村幸孝・出口大輔.indd
 GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
EnSightのご紹介
 オープン CAE シンポジウム 2014 汎用ポストプロセッサー EnSight の大規模データ対応 CEI ソフトウェア株式会社代表取締役吉川慈人 http://www.ceisoftware.co.jp/ 内容 大規模データで時間のかかる処理 クライアント サーバー機能 マルチスレッドによる並列処理 サーバーの分散処理 クライアントの分散処理 ( 分散レンダリング ) EnSightのOpenFOAMインターフェース
オープン CAE シンポジウム 2014 汎用ポストプロセッサー EnSight の大規模データ対応 CEI ソフトウェア株式会社代表取締役吉川慈人 http://www.ceisoftware.co.jp/ 内容 大規模データで時間のかかる処理 クライアント サーバー機能 マルチスレッドによる並列処理 サーバーの分散処理 クライアントの分散処理 ( 分散レンダリング ) EnSightのOpenFOAMインターフェース
( CUDA CUDA CUDA CUDA ( NVIDIA CUDA I
 GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
3次多項式パラメタ推定計算の CUDAを用いた実装 (CUDAプログラミングの練習として) Implementation of the Estimation of the parameters of 3rd-order-Polynomial with CUDA
 Implementation of the Estimation of the parameters of 3rd-order-Polynomial with CUDA") 3 次多項式パラメタ推定計算の CUDA を用いた実装 (CUDA プログラミングの練習として ) Estimating the Parameters of 3rd-order-Polynomial with CUDA ISS 09/11/12 問題の選択 目的 CUDA プログラミングを経験 ( 試行錯誤と習得 ) 実際に CPU のみの場合と比べて高速化されることを体験 問題 ( インプリメントする内容
3 次多項式パラメタ推定計算の CUDA を用いた実装 (CUDA プログラミングの練習として ) Estimating the Parameters of 3rd-order-Polynomial with CUDA ISS 09/11/12 問題の選択 目的 CUDA プログラミングを経験 ( 試行錯誤と習得 ) 実際に CPU のみの場合と比べて高速化されることを体験 問題 ( インプリメントする内容
システムソリューションのご紹介
 HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
Microsoft PowerPoint - GPGPU実践基礎工学(web).pptx
.pptx") GPU のメモリ階層 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のメモリ階層 グローバルメモリ 共有メモリ モザイク処理への適用 コンスタントメモリ 空間フィルタへの適用 577 GPU の主要部品 基盤 GPU( チップ )+ 冷却部品 画面出力端子 電源入力端子 メモリ 特性の把握が重要 電源入力端子 画面出力端子 メモリ チップ PCI Ex 端子 http://www.geforce.com/whats
GPU のメモリ階層 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のメモリ階層 グローバルメモリ 共有メモリ モザイク処理への適用 コンスタントメモリ 空間フィルタへの適用 577 GPU の主要部品 基盤 GPU( チップ )+ 冷却部品 画面出力端子 電源入力端子 メモリ 特性の把握が重要 電源入力端子 画面出力端子 メモリ チップ PCI Ex 端子 http://www.geforce.com/whats
工学院大学建築系学科近藤研究室2000年度卒業論文梗概
 耐災害性の高い通信システムにおけるサーバ計算機の性能と消費電力に関する考察 耐障害性, 消費電力, 低消費電力サーバ 山口実靖 *. はじめに 性能と表皮電力の関係について調査し, 考察を行う 災害においては, 減災活動が極めて重要である すなわち 災害が発生した後に適切に災害に対処することにより, その被害を大きく軽減できる. 適切な災害対策を行うには災害対策を行う拠点が正常に運営されていることが必要不可欠であり,
耐災害性の高い通信システムにおけるサーバ計算機の性能と消費電力に関する考察 耐障害性, 消費電力, 低消費電力サーバ 山口実靖 *. はじめに 性能と表皮電力の関係について調査し, 考察を行う 災害においては, 減災活動が極めて重要である すなわち 災害が発生した後に適切に災害に対処することにより, その被害を大きく軽減できる. 適切な災害対策を行うには災害対策を行う拠点が正常に運営されていることが必要不可欠であり,
 iphone GPGPU GPU OpenCL Mac OS X Snow LeopardOpenCL iphone OpenCL OpenCL NVIDIA GPU CUDA GPU GPU GPU 15 GPU GPU CPU GPU iii OpenMP MPI CPU OpenCL CUDA OpenCL CPU OpenCL GPU NVIDIA Fermi GPU Fermi GPU GPU
iphone GPGPU GPU OpenCL Mac OS X Snow LeopardOpenCL iphone OpenCL OpenCL NVIDIA GPU CUDA GPU GPU GPU 15 GPU GPU CPU GPU iii OpenMP MPI CPU OpenCL CUDA OpenCL CPU OpenCL GPU NVIDIA Fermi GPU Fermi GPU GPU
Slide 1
 CUDA プログラミングの基本 パート II - カーネル CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パート II カーネルの起動 GPUコードの具体像 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください GPU 上でのコードの実行 カーネルは C 関数 + 多少の制約 ホストメモリはアクセスできない戻り値型は
CUDA プログラミングの基本 パート II - カーネル CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パート II カーネルの起動 GPUコードの具体像 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください GPU 上でのコードの実行 カーネルは C 関数 + 多少の制約 ホストメモリはアクセスできない戻り値型は
Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ 3.7x faster P100 V100 P10
 NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 理化学研究所 共通コードプロジェクト
 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 理化学研究所 共通コードプロジェクト") GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 勉強会 @ 理化学研究所 共通コードプロジェクト Contents Hands On 環境について Introduction to GPU computing Introduction
GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 勉強会 @ 理化学研究所 共通コードプロジェクト Contents Hands On 環境について Introduction to GPU computing Introduction
(速報) Xeon E 系モデル 新プロセッサ性能について
 Xeon E 系モデル 新プロセッサ性能について") ( 速報 ) Xeon E5-2600 系モデル新プロセッサ性能について 2012 年 3 月 16 日 富士通株式会社 2012 年 3 月 7 日 インテル社より最新 CPU インテル Xeon E5 ファミリー の発表がありました この最新 CPU について PC クラスタシステムの観点から性能検証を行いましたので 概要を速報いたします プロセッサインテル Xeon プロセッサ E5-2690
( 速報 ) Xeon E5-2600 系モデル新プロセッサ性能について 2012 年 3 月 16 日 富士通株式会社 2012 年 3 月 7 日 インテル社より最新 CPU インテル Xeon E5 ファミリー の発表がありました この最新 CPU について PC クラスタシステムの観点から性能検証を行いましたので 概要を速報いたします プロセッサインテル Xeon プロセッサ E5-2690
<4D F736F F F696E74202D2091E63489F15F436F6D C982E682E992B48D8291AC92B489B F090CD2888F38DFC E B8CDD8
 Web キャンパス資料 超音波シミュレーションの基礎 ~ 第 4 回 ComWAVEによる超高速超音波解析 ~ 科学システム開発部 Copyright (c)2006 ITOCHU Techno-Solutions Corporation 本日の説明内容 ComWAVEの概要および特徴 GPGPUとは GPGPUによる解析事例 CAE POWER 超音波研究会開催 (10 月 3 日 ) のご紹介
Web キャンパス資料 超音波シミュレーションの基礎 ~ 第 4 回 ComWAVEによる超高速超音波解析 ~ 科学システム開発部 Copyright (c)2006 ITOCHU Techno-Solutions Corporation 本日の説明内容 ComWAVEの概要および特徴 GPGPUとは GPGPUによる解析事例 CAE POWER 超音波研究会開催 (10 月 3 日 ) のご紹介
修士論文
 AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
[4] ACP (Advanced Communication Primitives) [1] ACP ACP [2] ACP Tofu UDP [3] HPC InfiniBand InfiniBand ACP 2 ACP, 3 InfiniBand ACP 4 5 ACP 2. ACP ACP
![[4] ACP (Advanced Communication Primitives) [1] ACP ACP [2] ACP Tofu UDP [3] HPC InfiniBand InfiniBand ACP 2 ACP, 3 InfiniBand ACP 4 5 ACP 2. ACP ACP](/thumbs/88/116107914.jpg "[4] ACP (Advanced Communication Primitives) [1] ACP ACP [2] ACP Tofu UDP [3] HPC InfiniBand InfiniBand ACP 2 ACP, 3 InfiniBand ACP 4 5 ACP 2. ACP ACP") InfiniBand ACP 1,5,a) 1,5,b) 2,5 1,5 4,5 3,5 2,5 ACE (Advanced Communication for Exa) ACP (Advanced Communication Primitives) HPC InfiniBand ACP InfiniBand ACP ACP InfiniBand Open MPI 20% InfiniBand Implementation
InfiniBand ACP 1,5,a) 1,5,b) 2,5 1,5 4,5 3,5 2,5 ACE (Advanced Communication for Exa) ACP (Advanced Communication Primitives) HPC InfiniBand ACP InfiniBand ACP ACP InfiniBand Open MPI 20% InfiniBand Implementation
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日
 TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
GPUコンピューティング講習会パート1
 GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
チューニング講習会 初級編
 GPU のしくみ RICC での使い方 およびベンチマーク 理化学研究所情報基盤センター 2013/6/27 17:00 17:30 中田真秀 RICC の GPU が高速に! ( 旧 C1060 比約 6.6 倍高速 ) RICCのGPUがC2075になりました! C1060 比 6.6 倍高速 倍精度 515GFlops UPCに100 枚導入 : 合計 51.5TFlops うまく行くと5 倍程度高速化
GPU のしくみ RICC での使い方 およびベンチマーク 理化学研究所情報基盤センター 2013/6/27 17:00 17:30 中田真秀 RICC の GPU が高速に! ( 旧 C1060 比約 6.6 倍高速 ) RICCのGPUがC2075になりました! C1060 比 6.6 倍高速 倍精度 515GFlops UPCに100 枚導入 : 合計 51.5TFlops うまく行くと5 倍程度高速化
Microsoft PowerPoint PCクラスタワークショップin京都.ppt
 PC クラスタシステムへの富士通の取り組み 富士通株式会社株式会社富士通研究所久門耕一 29 年度に富士通が提供する ( した ) 大規模クラスタ 今年度はCPUとしてメモリバンド幅がNehalem, QDR- IB( 片方向 4GB/s) などPCクラスタにとって期待できる多くのコモディティコンポーネントが出現 これら魅力ある素材を使ったシステムとして 2つのシステムをご紹介 理化学研究所様 RICC(Riken
PC クラスタシステムへの富士通の取り組み 富士通株式会社株式会社富士通研究所久門耕一 29 年度に富士通が提供する ( した ) 大規模クラスタ 今年度はCPUとしてメモリバンド幅がNehalem, QDR- IB( 片方向 4GB/s) などPCクラスタにとって期待できる多くのコモディティコンポーネントが出現 これら魅力ある素材を使ったシステムとして 2つのシステムをご紹介 理化学研究所様 RICC(Riken
160311_icm2015-muramatsu-v2.pptx
 Linux におけるパケット処理機構の 性能評価に基づいた NFV 導 の 検討 村松真, 川島 太, 中 裕貴, 林經正, 松尾啓志 名古屋 業 学 学院 株式会社ボスコ テクノロジーズ ICM 研究会 2016/03/11 研究 的 VM 仮想 NIC バックエンド機構 仮想化環境 仮想スイッチ パケット処理機構 物理環境 性能要因を考察 汎 IA サーバ NFV 環境に適したサーバ構成を検討
Linux におけるパケット処理機構の 性能評価に基づいた NFV 導 の 検討 村松真, 川島 太, 中 裕貴, 林經正, 松尾啓志 名古屋 業 学 学院 株式会社ボスコ テクノロジーズ ICM 研究会 2016/03/11 研究 的 VM 仮想 NIC バックエンド機構 仮想化環境 仮想スイッチ パケット処理機構 物理環境 性能要因を考察 汎 IA サーバ NFV 環境に適したサーバ構成を検討
― ANSYS Mechanical ―Distributed ANSYS(領域分割法)ベンチマーク測定結果要約
ベンチマーク測定結果要約") ANSYS Mechanical Distributed ANSYS( 領域分割法 ) 2011 年 1 月 17 日 富士通株式会社 ANSYS Mechanical ベンチマーク測定結果 目次 測定条件 1 標準問題モデル 2 総括 3 ベンチマーク測定について 3 留意事項 9 商標について 9 測定条件 測定に使用した環境は下記のとおりです System PRIMERGY BX922 S2
ANSYS Mechanical Distributed ANSYS( 領域分割法 ) 2011 年 1 月 17 日 富士通株式会社 ANSYS Mechanical ベンチマーク測定結果 目次 測定条件 1 標準問題モデル 2 総括 3 ベンチマーク測定について 3 留意事項 9 商標について 9 測定条件 測定に使用した環境は下記のとおりです System PRIMERGY BX922 S2
CCS HPCサマーセミナー 並列数値計算アルゴリズム
 大規模系での高速フーリエ変換 2 高橋大介 [email protected] 筑波大学計算科学研究センター 2016/6/2 計算科学技術特論 B 1 講義内容 並列三次元 FFT における自動チューニング 二次元分割を用いた並列三次元 FFT アルゴリズム GPU クラスタにおける並列三次元 FFT 2016/6/2 計算科学技術特論 B 2 並列三次元 FFT における 自動チューニング
大規模系での高速フーリエ変換 2 高橋大介 [email protected] 筑波大学計算科学研究センター 2016/6/2 計算科学技術特論 B 1 講義内容 並列三次元 FFT における自動チューニング 二次元分割を用いた並列三次元 FFT アルゴリズム GPU クラスタにおける並列三次元 FFT 2016/6/2 計算科学技術特論 B 2 並列三次元 FFT における 自動チューニング
ERDAS IMAGINE における処理速度の向上 株式会社ベストシステムズ PASCO CORPORATION 2015
 ERDAS IMAGINE における処理速度の向上 株式会社ベストシステムズ 本セッションの目的 本セッションでは ERDAS IMAGINEにおける処理速度向上を目的として機器 (SSD 等 ) 及び並列処理の比較 検討を行った 1.SSD 及び RAMDISK を利用した処理速度の検証 2.Condorによる複数 PCを用いた並列処理 2.1 分散並列処理による高速化試験 (ERDAS IMAGINEのCondorを使用した試験
ERDAS IMAGINE における処理速度の向上 株式会社ベストシステムズ 本セッションの目的 本セッションでは ERDAS IMAGINEにおける処理速度向上を目的として機器 (SSD 等 ) 及び並列処理の比較 検討を行った 1.SSD 及び RAMDISK を利用した処理速度の検証 2.Condorによる複数 PCを用いた並列処理 2.1 分散並列処理による高速化試験 (ERDAS IMAGINEのCondorを使用した試験
GPGPU によるアクセラレーション環境について
 GPGPU によるアクセラレーション環境について 長屋貴量 自然科学研究機構分子科学研究所技術課計算科学技術班 概要 GPGPU とは 単純で画一的なデータを一度に大量に処理することに特化したグラフィックカードの演算資源を 画像処理以外の汎用的な目的に応用する技術の一つである 近年 その演算能力は CPU で通常言われるムーアの法則に則った場合とは異なり 飛躍的に向上しており その演算性能に魅力を感じた各分野での応用が広がってきている
GPGPU によるアクセラレーション環境について 長屋貴量 自然科学研究機構分子科学研究所技術課計算科学技術班 概要 GPGPU とは 単純で画一的なデータを一度に大量に処理することに特化したグラフィックカードの演算資源を 画像処理以外の汎用的な目的に応用する技術の一つである 近年 その演算能力は CPU で通常言われるムーアの法則に則った場合とは異なり 飛躍的に向上しており その演算性能に魅力を感じた各分野での応用が広がってきている
資料3 今後のHPC技術に関する研究開発の方向性について(日立製作所提供資料)
") 今後の HPC 技術に関する 研究開発の方向性について 2012 年 5 月 30 日 ( 株 ) 日立製作所情報 通信システム社 IT プラットフォーム事業本部 Hitachi, Hitachi, Ltd. Ltd. Hitachi 2012. 2012. Ltd. 2012. All rights All rights All rights reserved. reserved. reserved.
今後の HPC 技術に関する 研究開発の方向性について 2012 年 5 月 30 日 ( 株 ) 日立製作所情報 通信システム社 IT プラットフォーム事業本部 Hitachi, Hitachi, Ltd. Ltd. Hitachi 2012. 2012. Ltd. 2012. All rights All rights All rights reserved. reserved. reserved.
1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU
![1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU](/thumbs/89/99132402.jpg "1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU") GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
PowerPoint プレゼンテーション
 vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
Microsoft PowerPoint - GPU_computing_2013_01.pptx
 GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格
GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格
ポスト「京」でのコデザイン 活動報告
 重点課題 9 でのポスト 京 に対す るコデザイン活動報告 広島大学理学研究科 石川健一 1 目次 1. コデザイン活動 2. ポスト京関連公開情報 3. 重点課題 9 に関するコデザイン活動 2 1. コデザイン活動 RIKEN,R-CCS と FUJITSU によるポスト京計算機開発 コデザイン活動 重点課題からのターゲットアプリケーションの開発とシステムやソフトウェア開発を連携して開発 9 個のターゲットアプリケーション
重点課題 9 でのポスト 京 に対す るコデザイン活動報告 広島大学理学研究科 石川健一 1 目次 1. コデザイン活動 2. ポスト京関連公開情報 3. 重点課題 9 に関するコデザイン活動 2 1. コデザイン活動 RIKEN,R-CCS と FUJITSU によるポスト京計算機開発 コデザイン活動 重点課題からのターゲットアプリケーションの開発とシステムやソフトウェア開発を連携して開発 9 個のターゲットアプリケーション
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司
![4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司](/thumbs/97/131936032.jpg "4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司") 4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
TopSE並行システム はじめに
 はじめに 平成 23 年 9 月 1 日 トップエスイープロジェクト 磯部祥尚 ( 産業技術総合研究所 ) 2 本講座の背景と目標 背景 : マルチコア CPU やクラウドコンピューティング等 並列 / 分散処理環境が身近なものになっている 複数のプロセス ( プログラム ) を同時に実行可能 通信等により複数のプロセスが協調可能 並行システムの構築 並行システム 通信 Proc2 プロセス ( プログラム
はじめに 平成 23 年 9 月 1 日 トップエスイープロジェクト 磯部祥尚 ( 産業技術総合研究所 ) 2 本講座の背景と目標 背景 : マルチコア CPU やクラウドコンピューティング等 並列 / 分散処理環境が身近なものになっている 複数のプロセス ( プログラム ) を同時に実行可能 通信等により複数のプロセスが協調可能 並行システムの構築 並行システム 通信 Proc2 プロセス ( プログラム
Microsoft Word - Dolphin Expressによる10Gbpソケット通信.docx
 Dolphin Express による 10Gbps ソケット通信 Dolphin Express は 標準的な低価格のサーバを用いて 強力なクラスタリングシステムが構築できる ハードウェアとソフトウェアによる通信用アーキテクチャです 本資料では Dolphin Express 製品の概要と 実際にどの程度の性能が出るのか市販 PC での実験結果をご紹介します Dolphin Express 製品体系
Dolphin Express による 10Gbps ソケット通信 Dolphin Express は 標準的な低価格のサーバを用いて 強力なクラスタリングシステムが構築できる ハードウェアとソフトウェアによる通信用アーキテクチャです 本資料では Dolphin Express 製品の概要と 実際にどの程度の性能が出るのか市販 PC での実験結果をご紹介します Dolphin Express 製品体系
研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI, MPICH, MVAPICH, MPI.NET プログラミングコストが高いため 生産性が悪い 新しい並
 XcalableMPによる NAS Parallel Benchmarksの実装と評価 中尾 昌広 李 珍泌 朴 泰祐 佐藤 三久 筑波大学 計算科学研究センター 筑波大学大学院 システム情報工学研究科 研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI,
XcalableMPによる NAS Parallel Benchmarksの実装と評価 中尾 昌広 李 珍泌 朴 泰祐 佐藤 三久 筑波大学 計算科学研究センター 筑波大学大学院 システム情報工学研究科 研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI,
最新の並列計算事情とCAE
 1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
Insert your Title here
 マルチコア マルチスレッド環境での静的解析ツールの応用 米 GrammaTech 社 CodeSonar によるスレッド間のデータ競合の検出 2013 GrammaTech, Inc. All rights reserved Agenda 並列実行に起因する不具合の摘出 なぜ 並列実行されるプログラミングは難しいのか データの競合 デッドロック どのようにして静的解析ツールで並列実行の問題を見つけるのか?
マルチコア マルチスレッド環境での静的解析ツールの応用 米 GrammaTech 社 CodeSonar によるスレッド間のデータ競合の検出 2013 GrammaTech, Inc. All rights reserved Agenda 並列実行に起因する不具合の摘出 なぜ 並列実行されるプログラミングは難しいのか データの競合 デッドロック どのようにして静的解析ツールで並列実行の問題を見つけるのか?
untitled
 A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU.....
 CPU GPU N Q07-065 2011 2 17 1 1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU...........................................
CPU GPU N Q07-065 2011 2 17 1 1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU...........................................
Microsoft PowerPoint - GPGPU実践基礎工学(web).pptx
.pptx") GPU のプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU プログラミング環境 (CUDA) GPU プログラムの実行の流れ CUDA によるプログラムの記述 カーネル (GPU で処理する関数 ) の構造 記述方法とその理由 GPU 固有のパラメータの確認 405 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ
GPU のプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU プログラミング環境 (CUDA) GPU プログラムの実行の流れ CUDA によるプログラムの記述 カーネル (GPU で処理する関数 ) の構造 記述方法とその理由 GPU 固有のパラメータの確認 405 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ
GPGPU
 GPGPU 2013 1008 2015 1 23 Abstract In recent years, with the advance of microscope technology, the alive cells have been able to observe. On the other hand, from the standpoint of image processing, the
GPGPU 2013 1008 2015 1 23 Abstract In recent years, with the advance of microscope technology, the alive cells have been able to observe. On the other hand, from the standpoint of image processing, the
ためのオーバーヘッドが課題となりつつある しかしこのオーバーヘッドに関する数値はほとんど公開されていない この論文ではこの cache coherency の時間を Linux カーネルで提供されている atomic_inc 関数を用いて測定する方法を新たに考案し 実測プログラムを作成した 実測はプ
 Intel Xeon プロセッサにおける Cache Coherency 時間の測定方法と大規模システムにおける実測結果 Performance Measurement Method of Cache Coherency Effects on a large Intel Xeon Processor System 河辺峻 1 古谷英祐 2 KAWABE Shun, FURUYA Eisuke 要旨現在のプロセッサの構成は,
Intel Xeon プロセッサにおける Cache Coherency 時間の測定方法と大規模システムにおける実測結果 Performance Measurement Method of Cache Coherency Effects on a large Intel Xeon Processor System 河辺峻 1 古谷英祐 2 KAWABE Shun, FURUYA Eisuke 要旨現在のプロセッサの構成は,
GPUコンピューティング講習会パート1
 GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
Microsoft PowerPoint - sales2.ppt
 最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2
![! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2](/thumbs/88/115445009.jpg "! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2") ! OpenCL [Open Computing Language] 言 [OpenCL C 言 ] CPU, GPU, Cell/B.E.,DSP 言 行行 [OpenCL Runtime] OpenCL C 言 API Khronos OpenCL Working Group AMD Broadcom Blizzard Apple ARM Codeplay Electronic Arts Freescale
! OpenCL [Open Computing Language] 言 [OpenCL C 言 ] CPU, GPU, Cell/B.E.,DSP 言 行行 [OpenCL Runtime] OpenCL C 言 API Khronos OpenCL Working Group AMD Broadcom Blizzard Apple ARM Codeplay Electronic Arts Freescale
Microsoft Word - nvsi_050110jp_netvault_vtl_on_dothill_sannetII.doc
 Article ID: NVSI-050110JP Created: 2005/10/19 Revised: - NetVault 仮想テープ ライブラリのパフォーマンス検証 : dothill SANnetⅡSATA 編 1. 検証の目的 ドットヒルシステムズ株式会社の SANnetll SATA は 安価な SATA ドライブを使用した大容量ストレージで ディスクへのバックアップを行う際の対象デバイスとして最適と言えます
Article ID: NVSI-050110JP Created: 2005/10/19 Revised: - NetVault 仮想テープ ライブラリのパフォーマンス検証 : dothill SANnetⅡSATA 編 1. 検証の目的 ドットヒルシステムズ株式会社の SANnetll SATA は 安価な SATA ドライブを使用した大容量ストレージで ディスクへのバックアップを行う際の対象デバイスとして最適と言えます
Agenda GRAPE-MPの紹介と性能評価 GRAPE-MPの概要 OpenCLによる四倍精度演算 (preliminary) 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops
 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops") Agenda GRAPE-MPの紹介と性能評価 GRAPE-MPの概要 OpenCLによる四倍精度演算 (preliminary) 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops ボードの概要 Control processor (FPGA by Altera) GRAPE-MP chip[nextreme
Agenda GRAPE-MPの紹介と性能評価 GRAPE-MPの概要 OpenCLによる四倍精度演算 (preliminary) 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops ボードの概要 Control processor (FPGA by Altera) GRAPE-MP chip[nextreme