Microsoft PowerPoint - GPU_computing_2013_01.pptx
|
|
|
- えの やすこ
- 8 years ago
- Views:
Transcription




1 GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2
2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格 : ハイエンドでもコンシューマタイプは数万円 プログラミング開発 : 無償の開発環境 CPU と比較して単一 GPU は高消費電力 低消費電力 : FlOPS/W 3 講義を受ける目的 既存のコードを GPU 化して高速に実行したい 新たに GPU プログラムを開発し 研究を促進したい これから主流となるであろう GPU のプログラミングをマスターしたい 超並列計算を習得したい 単位が欲しい その きっかけを得る 4







 5")
3 ショッキングな GPU の計算性能 レーリーテーラー不安定性成長 u Q v e Q t E x u 2 u p E uv eu pu F y 0 v uv F 2 v p ev pv Core2 duo 1 core Video captured demonstration GeForce GTX 260M X 50 Speed Up Y. Imai, T. Aoki and K. Takizawa, J. Comp. Phys., Vol. 227, Issue 4, (2008) 5 Supercomputer in the world 2010 November
")

 1442 nodes:")



")
4 TSUBAME 2.0 Rack (30 nodes) Performance: 51.0 TFLOPS Memory: 2.03 TB System (58 racks) 1442 nodes: 2952 CPU sockets, 4264 GPUs Performance: TFLOPS (CPU) Turbo boost 2196 TFLOPS (GPU) Total: 2420 TFLOPS Memory: TB Compute Node (2 CPUs, 3 GPUs) Performance: 1.7 TFLOPS Memory: 58.0GB(CPU) +9.7GB(GPU) GPU M2050 8




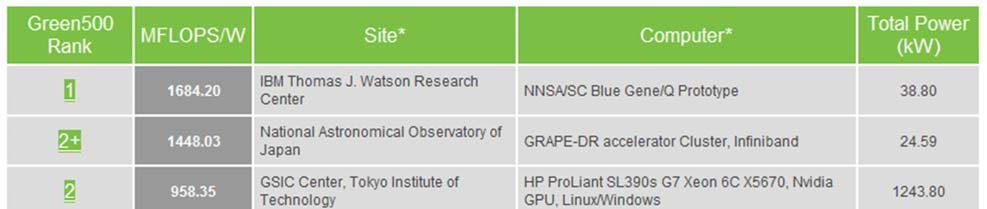

5 ORNL Jaguar vs Tsubame 2.0 Similar Peak Performance, 1/4 the Size and Power Supercomputer in the world The Green500 list -- November 2010

![GeForce GTX Titan Peak Performance [GFlops] 76.](/docs-images/63/50031166/images/6-3.jpg "8*,153.6 515*,1030 1.3T*,4.")
![5T Number of Processor 6 448 2688 Core Clock [GHz]](/docs-images/63/50031166/images/6-4.jpg "2930 1150 837 Bandwidth[GB/s] 32.0 148.8 288.")
![4 Memory Interface [bit] 64 384 384 Memory Memory](/docs-images/63/50031166/images/6-6.jpg "Clock [GHz] 1.333 (DDR3) 1.50 (GDDR5) 1.")
![50 (GDDR5) Capacity [GB] ----- 3.0 1.](/docs-images/63/50031166/images/6-7.jpg "536 Bpeak/Fpeak Bandwidth/Performance 0.416 0.")
6 Supercomputer in the world 2012 November CPU/GPU Spec Sheet GPU Intel Xeon X5670 Tesla C2050 /M2050 GeForce GTX Titan Peak Performance [GFlops] 76.8*, *, T*,4.5T Number of Processor Core Clock [GHz] Bandwidth[GB/s] Memory Interface [bit] Memory Memory Clock [GHz] (DDR3) 1.50 (GDDR5) 1.50 (GDDR5) Capacity [GB] Bpeak/Fpeak Bandwidth/Performance Tesla M2050 Peak Power : 225W Peak Power : 244W 12






 言語 (HLSL 似")
7 GPU アーキテクチャーの変更 Graphics Pipeline Unified Shader Vertex Rasterize Pixel Test & Blend Framebuffer 13 Shader 言語 Unified Shader: プログラマブル シェーダー OpenGL や DirectX などの API に専用のプログラマブルなシェーディング機能 Open GL では version 1.5, DirectX では version 8 から Shader プログラミング言語 OpenGL: DLSL 言語 DirectX: HLSL 言語 NVIDIA 独自の Cg (C for Graphics) 言語 (HLSL 似 ) 汎用計算を Graphics の機能に置き換えてプログラミング 14
8 TSUBAME に login Windows 端末の Bash Shell から $ ssh user_account@login t2.g.gsic.titech.ac.jp user_account@login t2.g.gsic.titech.ac.jp s password: インストールされている CUDA のバージョンの確認 /opt/cuda/ が置いてある 現在の TSUBAME には最新の CUDA 5.0 がインストールされている 15 CUDA 5.0 $ cd /opt/cuda/5.0 $ sh cuda.sh // 環境設定 CUDA コンパイラ nvcc のバージョンの確認 user_account@t2a006169:~> nvcc version nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) NVIDIA Corporation Built on Fri_Sep_21_17:28:58_PDT_2012 Cuda compilation tools, release 5.0, V
9 DeviceQuery $ cd /opt/cuda/5.0/samples/1_utilities/devicequery> $./devicequery./devicequery Starting... CUDA Device Query (Runtime API) version (CUDART static linking) Detected 3 CUDA Capable device(s) Device 0: "Tesla M2050" CUDA Driver Version / Runtime Version 5.0 / 5.0 CUDA Capability Major/Minor version number: 2.0 Total amount of global memory: 2687 MBytes ( bytes) (14) Multiprocessors x ( 32) CUDA Cores/MP: 448 CUDA Cores GPU Clock rate: 1147 MHz (1.15 GHz) Memory Clock rate: 1566 Mhz Memory Bus Width: 384-bit L2 Cache Size: Max Texture Dimension Size (x,y,z) bytes 1D=(65536), 2D=(65536,65535), 3D=(2048,2048,2048) Max Layered Texture Size (dim) x layers 1D=(16384) x 2048, 2D=(16384,16384) x 2048 Total amount of constant memory: bytes 17 DeviceQuery Total amount of shared memory per block: bytes Total number of registers available per block: Warp size: 32 Maximum number of threads per multiprocessor: 1536 Maximum number of threads per block: 1024 Maximum sizes of each dimension of a block: 1024 x 1024 x 64 Maximum sizes of each dimension of a grid: x x Maximum memory pitch: bytes Texture alignment: 512 bytes Concurrent copy and kernel execution: Yes with 2 copy engine(s) Run time limit on kernels: No Integrated GPU sharing Host Memory: No Support host page-locked memory mapping: Yes Alignment requirement for Surfaces: Yes Device has ECC support: Enabled Device supports Unified Addressing (UVA): Yes Device PCI Bus ID / PCI location ID: 6 / 0 18
07-二村幸孝・出口大輔.indd
 GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
Microsoft PowerPoint - suda.pptx
 GPU の HWアーキテクチャと高性能化手法 須田礼仁 ( 東京大学 ) 2011/03/22 GPU 高性能プログラミング GPU のハードウェアを理解する CUDA のソフトウェアを理解する CUDA でプログラムを書くのは難しくないが, CUDA で高速なプログラムを書くのは難しい どうすれば遅くなるかを理解する! 効果が大きいものから順に説明します 1 高性能プログラミングの手順 1. 現在のコードの,
GPU の HWアーキテクチャと高性能化手法 須田礼仁 ( 東京大学 ) 2011/03/22 GPU 高性能プログラミング GPU のハードウェアを理解する CUDA のソフトウェアを理解する CUDA でプログラムを書くのは難しくないが, CUDA で高速なプログラムを書くのは難しい どうすれば遅くなるかを理解する! 効果が大きいものから順に説明します 1 高性能プログラミングの手順 1. 現在のコードの,
1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU
![1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU](/thumbs/89/99132402.jpg "1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU") GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
GPGPU
 GPGPU 2013 1008 2015 1 23 Abstract In recent years, with the advance of microscope technology, the alive cells have been able to observe. On the other hand, from the standpoint of image processing, the
GPGPU 2013 1008 2015 1 23 Abstract In recent years, with the advance of microscope technology, the alive cells have been able to observe. On the other hand, from the standpoint of image processing, the
GPU n Graphics Processing Unit CG CAD
 GPU 2016/06/27 第 20 回 GPU コンピューティング講習会 ( 東京工業大学 ) 1 GPU n Graphics Processing Unit CG CAD www.nvidia.co.jp www.autodesk.co.jp www.pixar.com GPU n GPU ü n NVIDIA CUDA ü NVIDIA GPU ü OS Linux, Windows, Mac
GPU 2016/06/27 第 20 回 GPU コンピューティング講習会 ( 東京工業大学 ) 1 GPU n Graphics Processing Unit CG CAD www.nvidia.co.jp www.autodesk.co.jp www.pixar.com GPU n GPU ü n NVIDIA CUDA ü NVIDIA GPU ü OS Linux, Windows, Mac
PGIコンパイラ導入手順
 1 注意この資料は PGI compiler 18.10 が最新であるときに作成した資料を元にしています PGI compiler 19.4 がリリースされましたが インストール手順や利用手順は 18.10 と変わりません 資料中の 1810 を 194 に 18.10 を 19.4 に読み替えてください 2019 年 6 月版 2 大きく分けて以下の 3 つの方法が利用可能 1. 手元のウェブブラウザでダウンロードして
1 注意この資料は PGI compiler 18.10 が最新であるときに作成した資料を元にしています PGI compiler 19.4 がリリースされましたが インストール手順や利用手順は 18.10 と変わりません 資料中の 1810 を 194 に 18.10 を 19.4 に読み替えてください 2019 年 6 月版 2 大きく分けて以下の 3 つの方法が利用可能 1. 手元のウェブブラウザでダウンロードして
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
GPU GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1
 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1") GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
GPUコンピューティング講習会パート1
 GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
Microsoft PowerPoint - GPGPU実践基礎工学(web).pptx
.pptx") GPU のプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU プログラミング環境 (CUDA) GPU プログラムの実行の流れ CUDA によるプログラムの記述 カーネル (GPU で処理する関数 ) の構造 記述方法とその理由 GPU 固有のパラメータの確認 405 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ
GPU のプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU プログラミング環境 (CUDA) GPU プログラムの実行の流れ CUDA によるプログラムの記述 カーネル (GPU で処理する関数 ) の構造 記述方法とその理由 GPU 固有のパラメータの確認 405 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ
23 Fig. 2: hwmodulev2 3. Reconfigurable HPC 3.1 hw/sw hw/sw hw/sw FPGA PC FPGA PC FPGA HPC FPGA FPGA hw/sw hw/sw hw- Module FPGA hwmodule hw/sw FPGA h
 23 FPGA CUDA Performance Comparison of FPGA Array with CUDA on Poisson Equation ([email protected]), ([email protected]), ([email protected]), ([email protected]),
23 FPGA CUDA Performance Comparison of FPGA Array with CUDA on Poisson Equation ([email protected]), ([email protected]), ([email protected]), ([email protected]),
GPUコンピューティング講習会パート1
 GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2
![! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2](/thumbs/88/115445009.jpg "! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2") ! OpenCL [Open Computing Language] 言 [OpenCL C 言 ] CPU, GPU, Cell/B.E.,DSP 言 行行 [OpenCL Runtime] OpenCL C 言 API Khronos OpenCL Working Group AMD Broadcom Blizzard Apple ARM Codeplay Electronic Arts Freescale
! OpenCL [Open Computing Language] 言 [OpenCL C 言 ] CPU, GPU, Cell/B.E.,DSP 言 行行 [OpenCL Runtime] OpenCL C 言 API Khronos OpenCL Working Group AMD Broadcom Blizzard Apple ARM Codeplay Electronic Arts Freescale
 iphone GPGPU GPU OpenCL Mac OS X Snow LeopardOpenCL iphone OpenCL OpenCL NVIDIA GPU CUDA GPU GPU GPU 15 GPU GPU CPU GPU iii OpenMP MPI CPU OpenCL CUDA OpenCL CPU OpenCL GPU NVIDIA Fermi GPU Fermi GPU GPU
iphone GPGPU GPU OpenCL Mac OS X Snow LeopardOpenCL iphone OpenCL OpenCL NVIDIA GPU CUDA GPU GPU GPU 15 GPU GPU CPU GPU iii OpenMP MPI CPU OpenCL CUDA OpenCL CPU OpenCL GPU NVIDIA Fermi GPU Fermi GPU GPU
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日
 TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
HPEハイパフォーマンスコンピューティング ソリューション
 HPE HPC / AI Page 2 No.1 * 24.8% No.1 * HPE HPC / AI HPC AI SGIHPE HPC / AI GPU TOP500 50th edition Nov. 2017 HPE No.1 124 www.top500.org HPE HPC / AI TSUBAME 3.0 2017 7 AI TSUBAME 3.0 HPE SGI 8600 System
HPE HPC / AI Page 2 No.1 * 24.8% No.1 * HPE HPC / AI HPC AI SGIHPE HPC / AI GPU TOP500 50th edition Nov. 2017 HPE No.1 124 www.top500.org HPE HPC / AI TSUBAME 3.0 2017 7 AI TSUBAME 3.0 HPE SGI 8600 System
main.dvi
 PC 1 1 [1][2] [3][4] ( ) GPU(Graphics Processing Unit) GPU PC GPU PC ( 2 GPU ) GPU Harris Corner Detector[5] CPU ( ) ( ) CPU GPU 2 3 GPU 4 5 6 7 1 [email protected] 45 2 ( ) CPU ( ) ( ) () 2.1
PC 1 1 [1][2] [3][4] ( ) GPU(Graphics Processing Unit) GPU PC GPU PC ( 2 GPU ) GPU Harris Corner Detector[5] CPU ( ) ( ) CPU GPU 2 3 GPU 4 5 6 7 1 [email protected] 45 2 ( ) CPU ( ) ( ) () 2.1
AMD/ATI Radeon HD 5870 GPU DEGIMA LINPACK HD 5870 GPU DEGIMA LINPACK GFlops/Watt GFlops/Watt Abstract GPU Computing has lately attracted
 DEGIMA LINPACK Energy Performance for LINPACK Benchmark on DEGIMA 1 AMD/ATI Radeon HD 5870 GPU DEGIMA LINPACK HD 5870 GPU DEGIMA LINPACK 1.4698 GFlops/Watt 1.9658 GFlops/Watt Abstract GPU Computing has
DEGIMA LINPACK Energy Performance for LINPACK Benchmark on DEGIMA 1 AMD/ATI Radeon HD 5870 GPU DEGIMA LINPACK HD 5870 GPU DEGIMA LINPACK 1.4698 GFlops/Watt 1.9658 GFlops/Watt Abstract GPU Computing has
スライド 1
 GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
IPSJ SIG Technical Report Vol.2013-ARC-203 No /2/1 SMYLE OpenCL (NEDO) IT FPGA SMYLEref SMYLE OpenCL SMYLE OpenCL FPGA 1
 IT FPGA SMYLEref SMYLE OpenCL SMYLE OpenCL FPGA 1") SMYLE OpenCL 128 1 1 1 1 1 2 2 3 3 3 (NEDO) IT FPGA SMYLEref SMYLE OpenCL SMYLE OpenCL FPGA 128 SMYLEref SMYLE OpenCL SMYLE OpenCL Implementation and Evaluations on 128 Cores Takuji Hieda 1 Noriko Etani
SMYLE OpenCL 128 1 1 1 1 1 2 2 3 3 3 (NEDO) IT FPGA SMYLEref SMYLE OpenCL SMYLE OpenCL FPGA 128 SMYLEref SMYLE OpenCL SMYLE OpenCL Implementation and Evaluations on 128 Cores Takuji Hieda 1 Noriko Etani
untitled
 A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
GPUを用いたN体計算
 単精度 190Tflops GPU クラスタ ( 長崎大 ) の紹介 長崎大学工学部超高速メニーコアコンピューティングセンターテニュアトラック助教濱田剛 1 概要 GPU (Graphics Processing Unit) について簡単に説明します. GPU クラスタが得意とする応用問題を議論し 長崎大学での GPU クラスタによる 取組方針 N 体計算の高速化に関する研究内容 を紹介します. まとめ
単精度 190Tflops GPU クラスタ ( 長崎大 ) の紹介 長崎大学工学部超高速メニーコアコンピューティングセンターテニュアトラック助教濱田剛 1 概要 GPU (Graphics Processing Unit) について簡単に説明します. GPU クラスタが得意とする応用問題を議論し 長崎大学での GPU クラスタによる 取組方針 N 体計算の高速化に関する研究内容 を紹介します. まとめ
DO 時間積分 START 反変速度の計算 contravariant_velocity 移流項の計算 advection_adams_bashforth_2nd DO implicit loop( 陰解法 ) 速度勾配, 温度勾配の計算 gradient_cell_center_surface 速
 速度勾配, 温度勾配の計算 gradient_cell_center_surface 速") 1 1, 2 1, 2 3 2, 3 4 GP LES ASUCA LES NVIDIA CUDA LES 1. Graphics Processing Unit GP General-Purpose SIMT Single Instruction Multiple Threads 1 2 3 4 1),2) LES Large Eddy Simulation 3) ASUCA 4) LES LES
1 1, 2 1, 2 3 2, 3 4 GP LES ASUCA LES NVIDIA CUDA LES 1. Graphics Processing Unit GP General-Purpose SIMT Single Instruction Multiple Threads 1 2 3 4 1),2) LES Large Eddy Simulation 3) ASUCA 4) LES LES
1 3DCG [2] 3DCG CG 3DCG [3] 3DCG 3 3 API 2 3DCG 3 (1) Saito [4] (a) 1920x1080 (b) 1280x720 (c) 640x360 (d) 320x G-Buffer Decaudin[5] G-Buffer D
![1 3DCG [2] 3DCG CG 3DCG [3] 3DCG 3 3 API 2 3DCG 3 (1) Saito [4] (a) 1920x1080 (b) 1280x720 (c) 640x360 (d) 320x G-Buffer Decaudin[5] G-Buffer D](/thumbs/91/105248386.jpg "1 3DCG [2] 3DCG CG 3DCG [3] 3DCG 3 3 API 2 3DCG 3 (1) Saito [4] (a) 1920x1080 (b) 1280x720 (c) 640x360 (d) 320x G-Buffer Decaudin[5] G-Buffer D") 3DCG 1) ( ) 2) 2) 1) 2) Real-Time Line Drawing Using Image Processing and Deforming Process Together in 3DCG Takeshi Okuya 1) Katsuaki Tanaka 2) Shigekazu Sakai 2) 1) Department of Intermedia Art and Science,
3DCG 1) ( ) 2) 2) 1) 2) Real-Time Line Drawing Using Image Processing and Deforming Process Together in 3DCG Takeshi Okuya 1) Katsuaki Tanaka 2) Shigekazu Sakai 2) 1) Department of Intermedia Art and Science,
HP Workstation 総合カタログ
 HP Workstation Z HP 6 Z HP HP Z840 Workstation P.9 HP Z640 Workstation & CPU P.10 HP Z440 Workstation P.11 17.3in WIDE HP ZBook 17 G2 Mobile Workstation P.15 15.6in WIDE HP ZBook 15 G2 Mobile Workstation
HP Workstation Z HP 6 Z HP HP Z840 Workstation P.9 HP Z640 Workstation & CPU P.10 HP Z440 Workstation P.11 17.3in WIDE HP ZBook 17 G2 Mobile Workstation P.15 15.6in WIDE HP ZBook 15 G2 Mobile Workstation
EGunGPU
 Super Computing in Accelerator simulations - Electron Gun simulation using GPGPU - K. Ohmi, KEK-Accel Accelerator Physics seminar 2009.11.19 Super computers in KEK HITACHI SR11000 POWER5 16 24GB 16 134GFlops,
Super Computing in Accelerator simulations - Electron Gun simulation using GPGPU - K. Ohmi, KEK-Accel Accelerator Physics seminar 2009.11.19 Super computers in KEK HITACHI SR11000 POWER5 16 24GB 16 134GFlops,
WebGL OpenGL GLSL Kageyama (Kobe Univ.) Visualization / 57
 Visualization / 57") WebGL 2014.04.15 X021 2014 3 1F Kageyama (Kobe Univ.) Visualization 2014.04.15 1 / 57 WebGL OpenGL GLSL Kageyama (Kobe Univ.) Visualization 2014.04.15 2 / 57 WebGL Kageyama (Kobe Univ.) Visualization 2014.04.15
WebGL 2014.04.15 X021 2014 3 1F Kageyama (Kobe Univ.) Visualization 2014.04.15 1 / 57 WebGL OpenGL GLSL Kageyama (Kobe Univ.) Visualization 2014.04.15 2 / 57 WebGL Kageyama (Kobe Univ.) Visualization 2014.04.15
( CUDA CUDA CUDA CUDA ( NVIDIA CUDA I
 GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
untitled
 PC [email protected] muscle server blade server PC PC + EHPC/Eric (Embedded HPC with Eric) 1216 Compact PCI Compact PCIPC Compact PCISH-4 Compact PCISH-4 Eric Eric EHPC/Eric EHPC/Eric Gigabit
PC [email protected] muscle server blade server PC PC + EHPC/Eric (Embedded HPC with Eric) 1216 Compact PCI Compact PCIPC Compact PCISH-4 Compact PCISH-4 Eric Eric EHPC/Eric EHPC/Eric Gigabit
Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ 3.7x faster P100 V100 P10
 NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
HP xw9400 Workstation
 HP xw9400 Workstation HP xw9400 Workstation AMD Opteron TM PCI Express x16 64 PCI Express x16 2 USB2.0 8 IEEE1394 2 8DIMM HP HP xw9400 Workstation HP CPU HP CPU 240W CPU HP xw9400 HP CPU CPU CPU CPU Sound
HP xw9400 Workstation HP xw9400 Workstation AMD Opteron TM PCI Express x16 64 PCI Express x16 2 USB2.0 8 IEEE1394 2 8DIMM HP HP xw9400 Workstation HP CPU HP CPU 240W CPU HP xw9400 HP CPU CPU CPU CPU Sound
mate10„”„õŒì4
 2002.10 1 2 3 4 2 LINE UP 31w 79w 3 4 LINE UP Windows XP Windows 98 Pentium 1.70GHz Pentium 1.80GHz Pentium 2A GHz Pentium 2.40GHz Pentium 2.53GHz 0 50 100 150 200 250 Processor:Pentium 4 processor 1.50
2002.10 1 2 3 4 2 LINE UP 31w 79w 3 4 LINE UP Windows XP Windows 98 Pentium 1.70GHz Pentium 1.80GHz Pentium 2A GHz Pentium 2.40GHz Pentium 2.53GHz 0 50 100 150 200 250 Processor:Pentium 4 processor 1.50
 26102 (1/2) LSISoC: (1) (*) (*) GPU SIMD MIMD FPGA DES, AES (2/2) (2) FPGA(8bit) (ISS: Instruction Set Simulator) (3) (4) LSI ECU110100ECU1 ECU ECU ECU ECU FPGA ECU main() { int i, j, k for { } 1 GP-GPU
26102 (1/2) LSISoC: (1) (*) (*) GPU SIMD MIMD FPGA DES, AES (2/2) (2) FPGA(8bit) (ISS: Instruction Set Simulator) (3) (4) LSI ECU110100ECU1 ECU ECU ECU ECU FPGA ECU main() { int i, j, k for { } 1 GP-GPU
HP Workstation Xeon 5600
 HP Workstation Xeon 5600 HP 2 No.1 HP 5 3 Z 2No.1 HP :IDC's Worldwide Quarterly Workstation Tracker, 2009 Q4 14.0in Wide HP EliteBook 8440w/CT Mobile Workstation 15.6in Wide HP EliteBook 8540w Mobile Workstation
HP Workstation Xeon 5600 HP 2 No.1 HP 5 3 Z 2No.1 HP :IDC's Worldwide Quarterly Workstation Tracker, 2009 Q4 14.0in Wide HP EliteBook 8440w/CT Mobile Workstation 15.6in Wide HP EliteBook 8540w Mobile Workstation
GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 理化学研究所 共通コードプロジェクト
 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 理化学研究所 共通コードプロジェクト") GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 勉強会 @ 理化学研究所 共通コードプロジェクト Contents Hands On 環境について Introduction to GPU computing Introduction
GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 勉強会 @ 理化学研究所 共通コードプロジェクト Contents Hands On 環境について Introduction to GPU computing Introduction
GPGPU によるアクセラレーション環境について
 GPGPU によるアクセラレーション環境について 長屋貴量 自然科学研究機構分子科学研究所技術課計算科学技術班 概要 GPGPU とは 単純で画一的なデータを一度に大量に処理することに特化したグラフィックカードの演算資源を 画像処理以外の汎用的な目的に応用する技術の一つである 近年 その演算能力は CPU で通常言われるムーアの法則に則った場合とは異なり 飛躍的に向上しており その演算性能に魅力を感じた各分野での応用が広がってきている
GPGPU によるアクセラレーション環境について 長屋貴量 自然科学研究機構分子科学研究所技術課計算科学技術班 概要 GPGPU とは 単純で画一的なデータを一度に大量に処理することに特化したグラフィックカードの演算資源を 画像処理以外の汎用的な目的に応用する技術の一つである 近年 その演算能力は CPU で通常言われるムーアの法則に則った場合とは異なり 飛躍的に向上しており その演算性能に魅力を感じた各分野での応用が広がってきている
HPE Moonshot System ~ビッグデータ分析&モバイルワークプレイスを新たなステージへ~
 Brochure HPE Moonshot System HPE Moonshot System 4.3U 45 HPE Moonshot System Xeon & HPE Moonshot System HPE Moonshot System HPE HPE Moonshot System &IoT & SoC Xeon D-1500 Broadwell-DE HPE ProLiant m510
Brochure HPE Moonshot System HPE Moonshot System 4.3U 45 HPE Moonshot System Xeon & HPE Moonshot System HPE Moonshot System HPE HPE Moonshot System &IoT & SoC Xeon D-1500 Broadwell-DE HPE ProLiant m510
1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU.....
 CPU GPU N Q07-065 2011 2 17 1 1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU...........................................
CPU GPU N Q07-065 2011 2 17 1 1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU...........................................
Express5800/320Fc-MR
 7 7 Phoenix BIOS 4.0 Release 6.0.XXXX : CPU=Pentium III Processor XXX MHz 0640K System RAM Passed 0127M Extended RAM Passed WARNING 0212: Keybord Controller Failed. : Press to resume, to setup
7 7 Phoenix BIOS 4.0 Release 6.0.XXXX : CPU=Pentium III Processor XXX MHz 0640K System RAM Passed 0127M Extended RAM Passed WARNING 0212: Keybord Controller Failed. : Press to resume, to setup
HBase Phoenix API Mars GPU MapReduce GPU Hadoop Hadoop Hadoop MapReduce : (1) MapReduce (2)JobTracker 1 Hadoop CPU GPU Fig. 1 The overview of CPU-GPU
 MapReduce (2)JobTracker 1 Hadoop CPU GPU Fig. 1 The overview of CPU-GPU") GPU MapReduce 1 1 1, 2, 3 MapReduce GPGPU GPU GPU MapReduce CPU GPU GPU CPU GPU CPU GPU Map K-Means CPU 2GPU CPU 1.02-1.93 Improving MapReduce Task Scheduling for CPU-GPU Heterogeneous Environments Koichi
GPU MapReduce 1 1 1, 2, 3 MapReduce GPGPU GPU GPU MapReduce CPU GPU GPU CPU GPU CPU GPU Map K-Means CPU 2GPU CPU 1.02-1.93 Improving MapReduce Task Scheduling for CPU-GPU Heterogeneous Environments Koichi
2ndD3.eps
 CUDA GPGPU 2012 UDX 12/5/24 p. 1 FDTD GPU FDTD GPU FDTD FDTD FDTD PGI Acceralator CUDA OpenMP Fermi GPU (Tesla C2075/C2070, GTX 580) GT200 GPU (Tesla C1060, GTX 285) PC GPGPU 2012 UDX 12/5/24 p. 2 FDTD
CUDA GPGPU 2012 UDX 12/5/24 p. 1 FDTD GPU FDTD GPU FDTD FDTD FDTD PGI Acceralator CUDA OpenMP Fermi GPU (Tesla C2075/C2070, GTX 580) GT200 GPU (Tesla C1060, GTX 285) PC GPGPU 2012 UDX 12/5/24 p. 2 FDTD
チューニング講習会 初級編
 GPU のしくみ RICC での使い方 およびベンチマーク 理化学研究所情報基盤センター 2013/6/27 17:00 17:30 中田真秀 RICC の GPU が高速に! ( 旧 C1060 比約 6.6 倍高速 ) RICCのGPUがC2075になりました! C1060 比 6.6 倍高速 倍精度 515GFlops UPCに100 枚導入 : 合計 51.5TFlops うまく行くと5 倍程度高速化
GPU のしくみ RICC での使い方 およびベンチマーク 理化学研究所情報基盤センター 2013/6/27 17:00 17:30 中田真秀 RICC の GPU が高速に! ( 旧 C1060 比約 6.6 倍高速 ) RICCのGPUがC2075になりました! C1060 比 6.6 倍高速 倍精度 515GFlops UPCに100 枚導入 : 合計 51.5TFlops うまく行くと5 倍程度高速化
スパコンに通じる並列プログラミングの基礎
 2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
Express5800/R320a-E4/Express5800/R320b-M4ユーザーズガイド
 7 7 障害箇所の切り分け 万一 障害が発生した場合は ESMPRO/ServerManagerを使って障害の発生箇所を確認し 障害がハー ドウェアによるものかソフトウェアによるものかを判断します 障害発生個所や内容の確認ができたら 故障した部品の交換やシステム復旧などの処置を行います 障害がハードウェア要因によるものかソフトウェア要因によるものかを判断するには E S M P R O / ServerManagerが便利です
7 7 障害箇所の切り分け 万一 障害が発生した場合は ESMPRO/ServerManagerを使って障害の発生箇所を確認し 障害がハー ドウェアによるものかソフトウェアによるものかを判断します 障害発生個所や内容の確認ができたら 故障した部品の交換やシステム復旧などの処置を行います 障害がハードウェア要因によるものかソフトウェア要因によるものかを判断するには E S M P R O / ServerManagerが便利です
システムソリューションのご紹介
 HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
Microsoft Word - 0_0_表紙.doc
 2km Local Forecast Model; LFM Local Analysis; LA 2010 11 2.1.1 2010a LFM 2.1.1 2011 3 11 2.1.1 2011 5 2010 6 1 8 3 1 LFM LFM MSM LFM FT=2 2009; 2010 MSM RMSE RMSE MSM RMSE 2010 1 8 3 2010 6 2010 6 8 2010
2km Local Forecast Model; LFM Local Analysis; LA 2010 11 2.1.1 2010a LFM 2.1.1 2011 3 11 2.1.1 2011 5 2010 6 1 8 3 1 LFM LFM MSM LFM FT=2 2009; 2010 MSM RMSE RMSE MSM RMSE 2010 1 8 3 2010 6 2010 6 8 2010
Vol.214-HPC-145 No /7/3 C #pragma acc directive-name [clause [[,] clause] ] new-line structured block Fortran!$acc directive-name [clause [[,] c
![Vol.214-HPC-145 No /7/3 C #pragma acc directive-name [clause [[,] clause] ] new-line structured block Fortran!$acc directive-name [clause [[,] c](/thumbs/83/88091581.jpg "Vol.214-HPC-145 No /7/3 C #pragma acc directive-name [clause [[,] clause] ] new-line structured block Fortran!$acc directive-name [clause [[,] c") Vol.214-HPC-145 No.45 214/7/3 OpenACC 1 3,1,2 1,2 GPU CUDA OpenCL OpenACC OpenACC High-level OpenACC CPU Intex Xeon Phi K2X GPU Intel Xeon Phi 27% K2X GPU 24% 1. TSUBAME2.5 CPU GPU CUDA OpenCL CPU OpenMP
Vol.214-HPC-145 No.45 214/7/3 OpenACC 1 3,1,2 1,2 GPU CUDA OpenCL OpenACC OpenACC High-level OpenACC CPU Intex Xeon Phi K2X GPU Intel Xeon Phi 27% K2X GPU 24% 1. TSUBAME2.5 CPU GPU CUDA OpenCL CPU OpenMP
FIT2013( 第 12 回情報科学技術フォーラム ) I-032 Acceleration of Adaptive Bilateral Filter base on Spatial Decomposition and Symmetry of Weights 1. Taiki Makishi Ch
 I-032 Acceleration of Adaptive Bilateral Filter base on Spatial Decomposition and Symmetry of Weights 1. Taiki Makishi Ch") I-032 Acceleration of Adaptive Bilateral Filter base on Spatial Decomposition and Symmetry of Weights 1. Taiki Makishi Chikatoshi Yamada Shuichi Ichikawa Gaussian Filter GF GF Bilateral Filter BF CG [1]
I-032 Acceleration of Adaptive Bilateral Filter base on Spatial Decomposition and Symmetry of Weights 1. Taiki Makishi Chikatoshi Yamada Shuichi Ichikawa Gaussian Filter GF GF Bilateral Filter BF CG [1]
1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境 Lin
 Windows で始める CUDA 入門 GTC 2013 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境
Windows で始める CUDA 入門 GTC 2013 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境
スパコンに通じる並列プログラミングの基礎
 2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
strtok-count.eps
 IoT FPGA 2016/12/1 IoT FPGA 200MHz 32 ASCII PCI Express FPGA OpenCL (Volvox) Volvox CPU 10 1 IoT (Internet of Things) 2020 208 [1] IoT IoT HTTP JSON ( Python Ruby) IoT IoT IoT (Hadoop [2] ) AI (Artificial
IoT FPGA 2016/12/1 IoT FPGA 200MHz 32 ASCII PCI Express FPGA OpenCL (Volvox) Volvox CPU 10 1 IoT (Internet of Things) 2020 208 [1] IoT IoT HTTP JSON ( Python Ruby) IoT IoT IoT (Hadoop [2] ) AI (Artificial
BIOS 設定書 BIOS 出荷時設定 BIOS 設定を工場出荷状態に戻す必要がある場合は 本書の手順に従って作業をおこなってください BIOS 設定を変更されていない場合は 本書の作業は必要ありません BIOS 出荷時設定は以下の手順でおこないます スタート A) BIOS の Setup Uti
 BIOS の Setup Uti") BIOS 出荷時設定 BIOS 設定を工場出荷状態に戻す必要がある場合は 本書の手順に従って作業をおこなってください BIOS 設定を変更されていない場合は 本書の作業は必要ありません BIOS 出荷時設定は以下の手順でおこないます スタート A) BIOS の Setup Utility を起動 B) BIOS 設定をデフォルトに戻す C) 工場出荷時状態に再設定 D) 設定状態をセーブして終了
BIOS 出荷時設定 BIOS 設定を工場出荷状態に戻す必要がある場合は 本書の手順に従って作業をおこなってください BIOS 設定を変更されていない場合は 本書の作業は必要ありません BIOS 出荷時設定は以下の手順でおこないます スタート A) BIOS の Setup Utility を起動 B) BIOS 設定をデフォルトに戻す C) 工場出荷時状態に再設定 D) 設定状態をセーブして終了
Source: Intel.Config: Pentium III Processor-Intel Seattle SE440BX-2, 128MB PC100 CL2 SDRAM Intel 440BX-2 Chipset Platform- Diamond Viper 550 /
 2002.1 4 1 2 3 Source: Intel.Config: Pentium III Processor-Intel Seattle SE440BX-2, 128MB PC100 CL2 SDRAM Intel 440BX-2 Chipset Platform- Diamond Viper 550 / nvidia TNT 2x AGP with 16MB memory, nvidia
2002.1 4 1 2 3 Source: Intel.Config: Pentium III Processor-Intel Seattle SE440BX-2, 128MB PC100 CL2 SDRAM Intel 440BX-2 Chipset Platform- Diamond Viper 550 / nvidia TNT 2x AGP with 16MB memory, nvidia
MATLAB® における並列・分散コンピューティング ~ Parallel Computing Toolbox™ & MATLAB Distributed Computing Server™ ~
 MATLAB における並列 分散コンピューティング ~ Parallel Computing Toolbox & MATLAB Distributed Computing Server ~ MathWorks Japan Application Engineering Group Takashi Yoshida 2016 The MathWorks, Inc. 1 System Configuration
MATLAB における並列 分散コンピューティング ~ Parallel Computing Toolbox & MATLAB Distributed Computing Server ~ MathWorks Japan Application Engineering Group Takashi Yoshida 2016 The MathWorks, Inc. 1 System Configuration
HP High Performance Computing(HPC)
") ACCELERATE HP High Performance Computing HPC HPC HPC HPC HPC 1000 HPHPC HPC HP HPC HPC HPC HP HPCHP HP HPC 1 HPC HP 2 HPC HPC HP ITIDC HP HPC 1HPC HPC No.1 HPC TOP500 2010 11 HP 159 32% HP HPCHP 2010 Q1-Q4
ACCELERATE HP High Performance Computing HPC HPC HPC HPC HPC 1000 HPHPC HPC HP HPC HPC HPC HP HPCHP HP HPC 1 HPC HP 2 HPC HPC HP ITIDC HP HPC 1HPC HPC No.1 HPC TOP500 2010 11 HP 159 32% HP HPCHP 2010 Q1-Q4
<4D F736F F F696E74202D2091E63489F15F436F6D C982E682E992B48D8291AC92B489B F090CD2888F38DFC E B8CDD8
 Web キャンパス資料 超音波シミュレーションの基礎 ~ 第 4 回 ComWAVEによる超高速超音波解析 ~ 科学システム開発部 Copyright (c)2006 ITOCHU Techno-Solutions Corporation 本日の説明内容 ComWAVEの概要および特徴 GPGPUとは GPGPUによる解析事例 CAE POWER 超音波研究会開催 (10 月 3 日 ) のご紹介
Web キャンパス資料 超音波シミュレーションの基礎 ~ 第 4 回 ComWAVEによる超高速超音波解析 ~ 科学システム開発部 Copyright (c)2006 ITOCHU Techno-Solutions Corporation 本日の説明内容 ComWAVEの概要および特徴 GPGPUとは GPGPUによる解析事例 CAE POWER 超音波研究会開催 (10 月 3 日 ) のご紹介
HA8000xH ハードウェア アーキテクチャーガイド
 Microsoft Windows Corp. Pentium,Xeon,Celeron Intel Corporation. ( ) 2008 4 ( 1 ) HA8000/TS10 AH,BH,CH,DH Intel 3200 1way Xeon X3360(2.83GHz) Xeon E3110(3GHz) Pentium E2180(2GHz) FSB1,333/800MHz SDRAM ECC
Microsoft Windows Corp. Pentium,Xeon,Celeron Intel Corporation. ( ) 2008 4 ( 1 ) HA8000/TS10 AH,BH,CH,DH Intel 3200 1way Xeon X3360(2.83GHz) Xeon E3110(3GHz) Pentium E2180(2GHz) FSB1,333/800MHz SDRAM ECC
B 2 Thin Q=3 0 0 P= N ( )P Q = 2 3 ( )6 N N TSUB- Hub PCI-Express (PCIe) Gen 2 x8 AME1 5) 3 GPU Socket 0 High-performance Linpack 1
P Q = 2 3 ( )6 N N TSUB- Hub PCI-Express (PCIe) Gen 2 x8 AME1 5) 3 GPU Socket 0 High-performance Linpack 1") TSUBAME 2.0 Linpack 1,,,, Intel NVIDIA GPU 2010 11 TSUBAME 2.0 Linpack 2CPU 3GPU 1400 Dual-Rail QDR InfiniBand TSUBAME 1.0 30 2.4PFlops TSUBAME 1.0 Linpack GPU 1.192PFlops PFlops Top500 4 Achievement of
TSUBAME 2.0 Linpack 1,,,, Intel NVIDIA GPU 2010 11 TSUBAME 2.0 Linpack 2CPU 3GPU 1400 Dual-Rail QDR InfiniBand TSUBAME 1.0 30 2.4PFlops TSUBAME 1.0 Linpack GPU 1.192PFlops PFlops Top500 4 Achievement of
HP Personal Workstations
 HP Personal Workstations HP Personal Workstations Engineered for innovators HPPersonal Workstations HP Personal Workstations HPWindows Vista TM Business HP Personal Workstation HP xw900 Workstation HP
HP Personal Workstations HP Personal Workstations Engineered for innovators HPPersonal Workstations HP Personal Workstations HPWindows Vista TM Business HP Personal Workstation HP xw900 Workstation HP
N Express5800/R320a-E4 N Express5800/R320a-M4 ユーザーズガイド
 7 7 Phoenix BIOS 4.0 Release 6.0.XXXX : CPU=Pentium III Processor XXX MHz 0640K System RAM Passed 0127M Extended RAM Passed WARNING 0212: Keybord Controller Failed. : Press to resume, to setup
7 7 Phoenix BIOS 4.0 Release 6.0.XXXX : CPU=Pentium III Processor XXX MHz 0640K System RAM Passed 0127M Extended RAM Passed WARNING 0212: Keybord Controller Failed. : Press to resume, to setup
Express5800/R320a-E4, Express5800/R320b-M4ユーザーズガイド
 7 7 Phoenix BIOS 4.0 Release 6.0.XXXX : CPU=Pentium III Processor XXX MHz 0640K System RAM Passed 0127M Extended RAM Passed WARNING 0212: Keybord Controller Failed. : Press to resume, to setup
7 7 Phoenix BIOS 4.0 Release 6.0.XXXX : CPU=Pentium III Processor XXX MHz 0640K System RAM Passed 0127M Extended RAM Passed WARNING 0212: Keybord Controller Failed. : Press to resume, to setup
Microsoft PowerPoint - ★13_日立_清水.ppt
 PC クラスタワークショップ in 京都 日立テクニカルコンピューティングクラスタ 2008/7/25 清水正明 日立製作所中央研究所 1 目次 1 2 3 4 日立テクニカルサーバラインナップ SR16000 シリーズ HA8000-tc/RS425 日立自動並列化コンパイラ 2 1 1-1 日立テクニカルサーバの歴史 最大性能 100TF 10TF 30 年間で百万倍以上の向上 (5 年で 10
PC クラスタワークショップ in 京都 日立テクニカルコンピューティングクラスタ 2008/7/25 清水正明 日立製作所中央研究所 1 目次 1 2 3 4 日立テクニカルサーバラインナップ SR16000 シリーズ HA8000-tc/RS425 日立自動並列化コンパイラ 2 1 1-1 日立テクニカルサーバの歴史 最大性能 100TF 10TF 30 年間で百万倍以上の向上 (5 年で 10
ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014
 ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014 コンカレントな処理の実行 システム内部の複数の処理を 平行に実行する CPU GPU メモリ転送 カーネル実行 複数のカーネル間 ストリーム GPU 上の処理キュー カーネル実行 メモリ転送の並列性 実行順序 DEFAULT STREAM Stream : GPU
ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014 コンカレントな処理の実行 システム内部の複数の処理を 平行に実行する CPU GPU メモリ転送 カーネル実行 複数のカーネル間 ストリーム GPU 上の処理キュー カーネル実行 メモリ転送の並列性 実行順序 DEFAULT STREAM Stream : GPU
スパコンに通じる並列プログラミングの基礎
 2018.09.10 [email protected] ( ) 2018.09.10 1 / 59 [email protected] ( ) 2018.09.10 2 / 59 Windows, Mac Unix 0444-J [email protected] ( ) 2018.09.10 3 / 59 Part I Unix GUI CUI:
2018.09.10 [email protected] ( ) 2018.09.10 1 / 59 [email protected] ( ) 2018.09.10 2 / 59 Windows, Mac Unix 0444-J [email protected] ( ) 2018.09.10 3 / 59 Part I Unix GUI CUI:
1 2
 1 1 2 3 1 2 3 4 5 2 3 4 4 1 2 3 4 5 5 5 6 1 1 2 3 1 8 1 3 1 9 2 10 2 3 1 11 2 12 13 3 1 2 2 14 2 3 1 15 2 16 2 3 1 17 2 18 2 3 1 19 3 20 3 3 1 21 3 22 3 3 1 23 3 24 3 3 1 25 3 26 3 3 1 27 3 28 3 3 1 29
1 1 2 3 1 2 3 4 5 2 3 4 4 1 2 3 4 5 5 5 6 1 1 2 3 1 8 1 3 1 9 2 10 2 3 1 11 2 12 13 3 1 2 2 14 2 3 1 15 2 16 2 3 1 17 2 18 2 3 1 19 3 20 3 3 1 21 3 22 3 3 1 23 3 24 3 3 1 25 3 26 3 3 1 27 3 28 3 3 1 29
211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS /1/18 a a 1 a 2 a 3 a a GPU Graphics Processing Unit GPU CPU GPU GPGPU G
 211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS211 211/1/18 GPU 4 8 BLAS 4 8 BLAS Basic Linear Algebra Subprograms GPU Graphics Processing Unit 4 8 double 2 4 double-double DD 4 4 8 quad-double
211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS211 211/1/18 GPU 4 8 BLAS 4 8 BLAS Basic Linear Algebra Subprograms GPU Graphics Processing Unit 4 8 double 2 4 double-double DD 4 4 8 quad-double
CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン
 CUDA 画像処理入門 エヌビディアジャパン CUDA エンジニア森野慎也 GTC Japan 2014 CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン RGB Y( 輝度 ) 変換 カラー画像から グレイスケールへの変換 Y = 0.299 R + 0.587
CUDA 画像処理入門 エヌビディアジャパン CUDA エンジニア森野慎也 GTC Japan 2014 CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン RGB Y( 輝度 ) 変換 カラー画像から グレイスケールへの変換 Y = 0.299 R + 0.587
GPGPUクラスタの性能評価
 2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
12 PowerEdge PowerEdge Xeon E PowerEdge 11 PowerEdge DIMM Xeon E PowerEdge DIMM DIMM 756GB 12 PowerEdge Xeon E5-
 12ways-12th Generation PowerEdge Servers improve your IT experience 12 PowerEdge 12 1 6 2 GPU 8 4 PERC RAID I/O Cachecade I/O 5 Dell Express Flash PCIe SSD 6 7 OS 8 85.5% 9 Dell OpenManage PowerCenter
12ways-12th Generation PowerEdge Servers improve your IT experience 12 PowerEdge 12 1 6 2 GPU 8 4 PERC RAID I/O Cachecade I/O 5 Dell Express Flash PCIe SSD 6 7 OS 8 85.5% 9 Dell OpenManage PowerCenter
Express5800/320Fa-L/320Fa-LR
 7 7 Phoenix BIOS 4.0 Release 6.0.XXXX : CPU=Pentium III Processor XXX MHz 0640K System RAM Passed 0127M Extended RAM Passed WARNING 0212: Keybord Controller Failed. : Press to resume, to setup
7 7 Phoenix BIOS 4.0 Release 6.0.XXXX : CPU=Pentium III Processor XXX MHz 0640K System RAM Passed 0127M Extended RAM Passed WARNING 0212: Keybord Controller Failed. : Press to resume, to setup