GPUコンピューティングの現状と未来
|
|
|
- ゆめじ わかはら
- 7 years ago
- Views:
Transcription


1 GPU コンピューティングの現状と未来 成瀬彰, HPC Developer Technology, NVIDIA
2 Summary 我々のゴールと方向性 ゴール実現に向けて進めている技術開発 Unified Memory, OpenACC Libraries, GPU Direct Kepler の機能紹介 Warp shuffle, Memory system Hyper-Q, Dynamic Parallelism



3 Our Goals 電力効率 プログラミング簡易化ポータビリティ 多数アプリをカバー

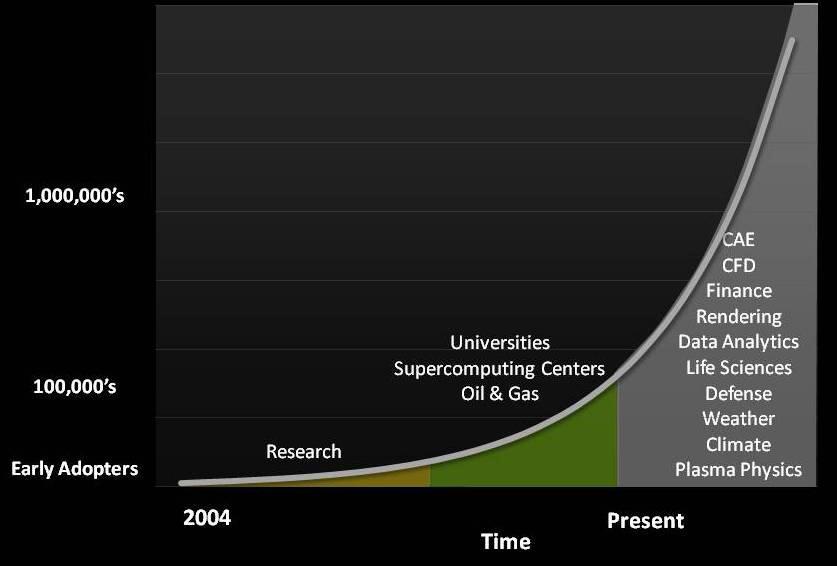
4 様々な分野で使われる GPU コンピューティング

5 CUDA パラレル コンピューティング プラットフォーム

6 CUDA パラレル コンピューティング プラットフォーム

7 CUDA パラレル コンピューティング プラットフォーム

8 GPU プログラミング言語

9 GPU プログラム実行環境

10 DP GFLOPS per Watt GPU ロードマップ 32 Now Kepler Dynamic Parallelism Maxwell Unified Memory 2 Fermi FP Tesla CUDA

11 Tesla K40 メモリ容量より多くのアプリ CPU クロック電力状況により適切なクロックを選択 6GB 流体解析 地震波解析 レンダリング GPU Boost 12GB

12 Unified Memory 現在 将来
13 Unified Memory void sortfile(file *fp, int N) { char *data = (char*)malloc(n); char *sorted = (char*)malloc(n); fread(data, 1, N, fp); } CPU code cpu_sort(sorted, data, N); use_data(sorted); free(data); free(sorted) GPU code void sortfile(file *fp, int N) { char *data = (char*)malloc(n); char *sorted = (char*)malloc(n); fread(data, 1, N, fp); char *d_data, *d_sorted; cudamalloc(&d_data, N); cudamalloc(&d_sorted, N); cudamemcpy(d_data, data, N, ); gpu_sort<<< >>>(d_sorted, d_data, N); cudamemcpy(sorted, d_sorted, N, ); cudafree(d_data); cudafree(d_sorted); use_data(sorted); free(data); free(sorted) }
14 Unified Memory CPU code void sortfile(file *fp, int N) { char *data = (char*)malloc(n); char *sorted = (char*)malloc(n); fread(data, 1, N, fp); GPU code (UVM) void sortfile(file *fp, int N) { char *data = (char*)malloc(n); char *sorted = (char*)malloc(n); fread(data, 1, N, fp); cpu_sort(sorted, data, N); gpu_sort<<< >>>(sorted, data, N); } use_data(sorted); free(data); free(sorted) } use_data(sorted); free(data); free(sorted)




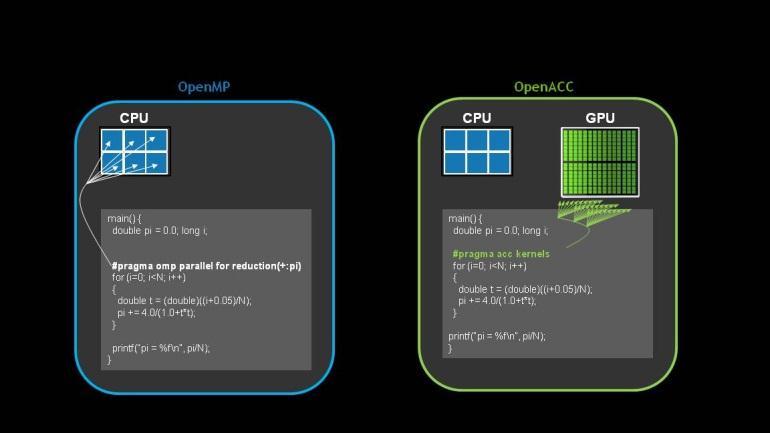
15 OpenACC: ディレクティブ CPU GPU Program myscience... serial code...!$acc kernels do k = 1,n1 do i = 1,n2... parallel code... enddo enddo!$acc end kernels... End Program myscience オリジナル Fotrran/C コード OpenACC Compiler Hint シンプル : ディレクティブ挿入 パワフル : 少ない労力 コンパイラが並列化 オープン : 多数のベンダのアクセラレータをサポート NVIDIA, AMD, (soon) Intel


16 OpenACC の特徴 親しみやすいプログラミングモデル 多分野への応用 ヘテロジニアスアーキテクチャ オープンスタンダード X86 and ARM AMD, Intel, NVIDIA



17 プログラマは並列化に注力 ( アーキテクチャ向け最適化はコンパイラが実施 ) OpenACC によるアプリ高速化事例事例 (ORNL and Tokyo Tech) (dual-cpu nods vs. CPU+GPU) S3D Combustion NICAM Weather/Climate Tuned top 3 kernels for GPUs (90% of runtime) End result: 2.2X faster with K20X vs. dual AMD node Kepler is 6X faster than Fermi Improved performance of CPU-only version by 50% Tuned top kernels using CUDA, then OpenACC CUDA result: 3.1x faster on GPU vs. CPU node OpenACC result (preliminary ) = 69-77% of CUDA More portable, more maintainable Full OpenACC port in progress Results from Cray/ORNL and Tokyo Tech
18 OpenACC 対応状況 Geology Weather/Climate/ Ocean Plasma & Combustion Fluid Dynamics / Cosmology Quantum Chemistry AWP-ODC CAM-SE Cloverleaf CHIMERA CASTEP EMGS ELAN COSMO Physics GENE PMH bv DELPASS GAMESS CCSD(T) *Seismic CPML* FIM GTC DNS GAUSSIAN SPECFM3D GEOS-5 LULESH MiniGHOST MiniMD Harmonie S3D RAMSES ONETEP HBM UPACS Quantum Espresso ICON NICAM NEMO GYRE NIM PALM-GPU ROMS WRF X-ECHO
19 Speed-up CUBLAS: 逆行列計算 LAPACK 準拠 API cublas<t>getrfbatched() LU 分解 cublas<t>getribatched() 逆行列計算 多数の小サイズ行列用 (*) 行列サイズ :64, 行列数 :1000 CPU-1core (2.8GHz,MKL) GPU (K20,naïve) GPU (K20,cublas)
20 NVIDIA GPUDirect データ移動を最適化する技術ファミリー GPUDirect Shared GPU and System memory ノード内のメモリコピー負荷を削減 GPUDirect Peer-to-Peer ノード内の別 GPUのメモリを直接アクセスノード内のGPU-to-GPUメモリ転送を加速 GPUDirect RDMA ノード間で GPU-to-GPU RDMA 通信
21 1 2 1 GPUDirect Shared GPU and System Memory Without GPUDirect GPU writes to pinned main memory 1 CPU copies main memory 1 to main memory 2 Network driver reads main memory 2 With GPUDirect GPU writes to pinned main memory Network driver reads from main memory CPU Main Mem CPU Main Mem Chip set GPU Chip set GPU Network GPU Memory Network GPU Memory
")
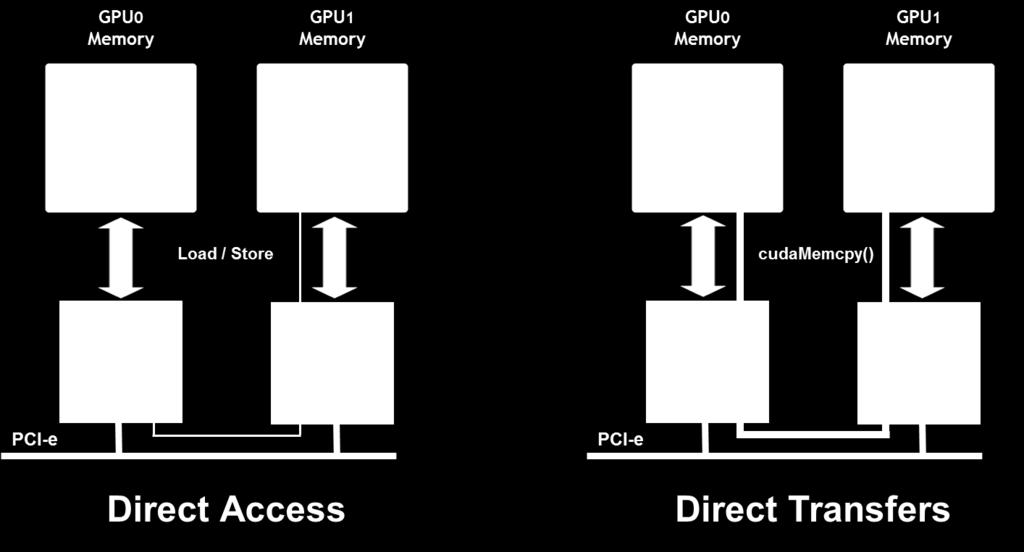
22 GPUDirect (Peer-to-Peer) ホストメモリを仲介せずにデータ移動 ( ノード内 ) Fermi 以上
 Kepler 以上 System Memory GDDR5")


23 GPUDirect RDMA ホストメモリを仲介せずにデータ移動 ( ノード間 ) Kepler 以上 System Memory GDDR5 Memory GDDR5 Memory GDDR5 Memory GDDR5 Memory System Memory CPU GPU1 GPU2 GPU2 GPU1 CPU Server 1 PCI-e Network Card Network Network Card PCI-e Server 2
24 GPU-aware MPI MPI 関数だけで GPU-to-GPU 通信を可能に MPI_Send(), MPI_Recv() にデバイスメモリを指定を可能に通信処理の最適化からプログラマを解放 パイプライン転送 (Device Host, Host Host, Host Device) 送信 : Without GPU-aware MPI cudamemcpy( s_buf, s_device, size, ); MPI_Send( s_buf, size, ); 受信 : MPI_Recv( r_buf, size, ); cudamemcpy( r_device, r_buf, size, ); With GPU-aware MPI 送信 : MPI_Send( s_device, size, ); 受信 : MPI_Recv( r_device, size, );


25 GPU-aware MPI Libraries GPU メモリからの送信 受信 多くの集合通信に対応 利用可能な最も良い転送方式を選択 MVAPICH Open MPI IBM Platform Computing Computing IBM Platform MPI Versions: MVAPICH2 1.9 OpenMPI IBM Platform MPI V9.1.2 (Free Community Edition) Reference NVIDIA GPUDirect Technology Overview
26 DP GFLOPS per Watt Kepler Kepler Dynamic Parallelism Maxwell Unified Memory 2 Fermi FP Tesla CUDA
27 性能と電力 : Fermi Kepler Fermi (M2090) Kepler (K20X) ピーク演算性能 (DP) TFLOPS 1.31 TFLOPS ピーク演算性能 (SP) 1.33 TFLOPS 3.95 TFLOPS 最大メモリバンド幅 177 GB/s 250 GB/s TDP 225 Watt 235 Watt x2 x3 x1.4 x1 27




28 Fermi から Kepler へ Kepler Fermi 最大 3 倍の電力あたり性能 28
29 SM(Fermi) SMX(Kepler) Fermi (M2090) Kepler (K20X) CUDA コア コア周波数 1.3GHz 0.73GHz 最大スレッド数 最大スレッドブロック数 ビットレジスタ数 32 K 64 K L2 容量 0.75 MB 1.5 MB x6 x0.6 x1.3 x2 x2 x2 29
30 Kepler で強化された機能 Warp Shuffle Memory System Atomics Operations Read-only Cache Hyper-Q Concurrency Overlapping Dynamic Parallelism 30
31 Warp Shuffle 他スレッドのレジスタの読み出しを可能に 対象 : 同一ワープ内のスレッド (32 スレッド ) 共有メモリ不要のスレッド間データ交換 syncthreads() も不要に Kepler 世代 (CC 3.0 以上 ) から利用可能 31
32 4 種類の関数 idx, up, down, xor a b c d e f g h shfl() shfl_up() shfl_down() shfl_xor() h d f e a c c b a b a b c d e f c d e f g h g h c d a b g h e f Indexed any-to-any Shift right/up to n th neighbour Shift left/down to n th neighbour Butterfly (XOR) exchange
33 Shuffle の効果 (scan) スレッドブロック内 scan(prefix sum) 入力 出力 SMEM (Shared Memory) for (ofst = 1; ofst < BLOCK_SIZE; ofst *= 2) { if (idx >= ofst) smem[idx] += smem[idx - ofst]; syncthreads(); } 4 11 SHFL (Shuffle) for (ofst = 1; ofst < WARP_SIZE; ofst *= 2) { if (idx >= ofst) val += shfl_up(val,ofst,warp_size); } if (idx % WARP_SIZE == WARP_SIZE - 1) smem[idx/warp_size] = val; syncthreads(); if (idx < NUM_WARP) { sum = smem[idx]; for (ofst = 1; ofst < NUM_WARP; ofst *= 2) { if (idx >= ofst) sum += shfl_up(sum,ofst,num_warp); } smem[idx] = sum; } syncthreads(); if (idx/warp_size > 0) val += smem[idx/warp_size - 1]; 33
34 Parallel scan
35 Parallel scan Warp scan Warp scan Warp scan Warp scan Warp scan
36 Time (ms) Shuffle の効果事例 (scan) SMEM Scan (fp32) x3.0 SHFL 3 倍の性能 UP Tesla K20 グリッド形状 (26, 1, 1) ブロック形状 (1024, 1, 1) 1000 回実行 4,096B smem per block 128B 36
37 Shuffle の効果 (reduction) スレッドブロック内 reduction reduction コード例 ( ワープ内 ) SMEM (Shared Memory) SHFL (Shuffle) idx = threadidx.x; for (mask = WARP_SIZE/2 ; mask > 0 ; mask >>= 1) { if (idx < mask) smem[idx] += smem[idx ^ mask]; syncthreads(); } for (mask = WARP_SIZE/2 ; mask > 0 ; mask >>= 1) { var = shfl_xor( var, mask, WARP_SIZE ); } 37
38 Time (ms) Shuffle の効果事例 (reduction) Reduction within TB (fp32) x 倍の性能 UP SMEM SHFL Tesla K20 ブロック形状 (1024, 1, 1) グリッド形状 (26, 1, 1) 1000 回実行 4,096B smem per block 128B 38
39 Atomic Operations サポートタイプ データ型の拡張 グローバルメモリ上の Atomic 操作を高速化 複数カーネルに分離していた処理を単一カーネルで 効果確認 16M 要素 reduction データ型は float smem[idx] = input[g_idx]; for (mask = BLOCK_SIZE/2; mask > 0; mask /= 2) { if (idx < mask) { smem[idx] += smem[idx ^ mask]; } syncthreads(); } if (idx == 0) { atomicadd( output, smem[idx] ); } 39
40 Time (ms) Atomic Operations 効果事例 Reduction (Sum, SP, 16M elements) x2.1 x3.7 Fermi(C2075) Kepler(K20) Kepler(K20) with SHFL Fermi から Kepler で 2.1 倍の性能 UP Shuffle 命令併用で 3.7 倍の性能 UP ブロック形状 (1024, 1, 1) ECC off 40
41 Read-Only(RO) Cache SM SMEM Threads L1 Read TEX only TEX Texture API CUDA Arrays 一般的な Read-Only キャッシュとして使用可能 L2 cache Kepler 以降 コンパイラに指示 DRAM 41
42 2 つの使い方 組み込み関数 : ldg() global kernel( int* output, int* input ) {... output[idx] =... + input[idx ldg( &input[idx + delta] + + delta]...; ) +...;... } 型修飾子 : const restrict global kernel( int* output, int* const input int* ) restrict input ) {... output[idx] =... + input[idx + delta] +...;... } 42
43 RO Cache の効果 Himeno BMT 19 ポイント ステンシル テストコード 共有メモリを使用せずに CUDA 化 jacobi_kernel(..., float* p,... ); jacobi_kernel(..., const float* strict p,... ); 43
44 GFLOPS RO Cache の効果事例 (Himeno BMT) Without RO cache (Fermi: C2075) GFLOPS (Himeno BMT) Without RO cache (Kepler: K20) 25% With RO cache (Kepler: K20) 25% 性能 UP Himeno BMT 問題サイズ : L ブロック形状 (128, 2, 1) ECC off 44
45 Hyper-Q Stream Queue Mgmt より多くのカーネルを同時実行可能に Stream Queue Mgmt C R B Q A P Z Y X C B A R Q P Z Y X CUDA Generated Work Grid Management Unit Pending & Suspended Grids 1000s of pending grids Work Distributor Work Distributor 16 active grids 32 active grids SM SM SM SM SMX SMX SMX SMX Fermi Kepler 45
46 Without Hyper-Q (Fermi) Stream 1 Kernel A, B, C A B C P Q R X Y Z Single Hardware Work Queue Stream 2 Stream 3 Kernel P, Q, R Kernel X, Y, Z 最多 16 同時実行 制限 : 同時実行できるのはストリーム端のカーネル 46
47 With Hyper-Q (Kepler) A B C P Q R X Y Z Stream 1 Stream 2 Stream 3 Kernel A, B, C Kernel P, Q, R Kernel X, Y, Z Multiple Hardware Work Queue 最多 32 同時実行 ( 偽の ) ストリーム依存性から開放 47
48 小カーネル同時実行テストコード cudastream_t stream[nstreams]; for (i = 0 ; i < nstreams ; ++i) { // ストリーム生成 cudacreatestream( &stream[i] ); } dim3 gdim( 1, 1, 1 ); dim3 bdim( 1024, 1, 1 ); for (i = 0 ; i < nstreams ; ++i) { // カーネル 1 を投入 kernel_1<<<gdim, bdim, 0, stream[i]>>>(... ); // カーネル 2 を投入 kernel_2<<<gdim, bdim, 0, stream[i]>>>(... ); } // カーネル 3 を投入 kernel_3<<<gdim, bdim, 0, stream[i]>>>(... ); 48

49 小カーネル同時実行テスト (Fermi) 部分的に同時実行 シングルハードウェアキューの制約 Tesla C
 を同時実行")
50 小カーネル同時実行テスト (Kepler) Tesla K20 全カーネル ( ストリーム ) を同時実行 これまでより簡単に同時実行が可能に 50
51 データ転送とカーネル実行のオーバーラップ 3つの処理をオーバーラップ可能 データ転送 (Host to Device) カーネル実行データ転送 (Device to Host) cudamemcpy( a_dev, a_host, all, cudamemcpyhosttodevice ); kernel_1<<<gdim, bdim>>>( c_dev, a_dev, all ); cudamemcpy( b_dev, b_host, all, cudamemcpyhosttodevice ); kernel_2<<<gdim, bdim>>>( c_dev, b_dev, all ); cudamemcpy( c_host, c_dev, all, cudamemcpydevicetohost ); 51
52 データ転送とカーネル実行のオーバーラップ パイプライン化 cudastream_t stream[nstreams]; for (s = 0 ; s < nstreams ; ++s) { cudacreatestream( &stream[s] ); } s = 0; for (p = 0 ; p < npipeline; ++p) { cudamemcpyasync( a_dev[p], a_host[p], part, cudamemcpyhosttodevice, stream[s] ); kernel_1<<<gdim, bdim, 0, stream[s]>>>( c_dev[p], a_dev[p], part ); cudamemcpyasync( b_dev[p], b_host[p], part, cudamemcpyhosttodevice, stream[s] ); kernel_2<<<gdim, bdim, 0, stream[s]>>>( c_dev[p], b_dev[p], part ); cudamemcpyasync( c_host[p], c_dev[p], part, cudamemcpydevicetohost, stream[s] ); s = (s+1) % nstreams; } パイプラインコードも Hyper-Q で効率化 52
53 オーバーラップ実行テスト (Fermi) パイプライン化前 データ転送とカーネル実行のオーバーラップ無し Tesla C

54 オーバーラップ実行テスト (Fermi) パイプライン後 Tesla C2075 データ転送とカーネル実行 相応の時間でオーバーラップ カーネル実行の間に隙間 54

55 オーバーラップ実行テスト (Kepler) 完全にオーバーラップ Tesla K20 カーネル実行の間に空き無し Hyper-Q の効果 55
56 Dynamic Parallelism とは? GPU からカーネルを起動する仕組み Dynamically 実行時のデータ値に基づくカーネル起動 Simultaneously 複数スレッドから同時に起動 Independently スレッド毎に独自グリッドで起動 CPU GPU CPU GPU Fermi Kepler

57 Dynamic Parallelism の動作イメージ CPU GPU CPU GPU CPU がきめ細かく制御 GPU が自律的にに動作
58 Dynamic Parallelism コードサンプル void rec_func(... ) { }... rec_func(... ); rec_func(... );... global void rec_func(... ) {... if ( blockidx.x == 0 ) { cudastreamcreate( &st0 ); cudastreamcreate( &st1 ); rec_func<<<..., st0 >>>(... ); rec_func<<<..., st1 >>>(... ); cudadevicesynchronize(); cudastreamdestroy( st0 ); cudastreamdestroy( st1 ); } syncthreads();... }
59 まとめ 我々のゴール 電力効率, プログラミング簡易化, 多数アプリその達成のために開発している技術 Unified Memory, OpenACC Libraries, GPU Direct, GPU-aware MPI Kepler の機能 Warp shuffle, Memory system Hyper-Q, Dynamic Parallelism
1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境 Lin
 Windows で始める CUDA 入門 GTC 2013 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境
Windows で始める CUDA 入門 GTC 2013 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
07-二村幸孝・出口大輔.indd
 GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014
 ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014 コンカレントな処理の実行 システム内部の複数の処理を 平行に実行する CPU GPU メモリ転送 カーネル実行 複数のカーネル間 ストリーム GPU 上の処理キュー カーネル実行 メモリ転送の並列性 実行順序 DEFAULT STREAM Stream : GPU
ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014 コンカレントな処理の実行 システム内部の複数の処理を 平行に実行する CPU GPU メモリ転送 カーネル実行 複数のカーネル間 ストリーム GPU 上の処理キュー カーネル実行 メモリ転送の並列性 実行順序 DEFAULT STREAM Stream : GPU
GPGPUクラスタの性能評価
 2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
Slide 1
 CUDA プログラミングの基本 パート II - カーネル CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パート II カーネルの起動 GPUコードの具体像 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください GPU 上でのコードの実行 カーネルは C 関数 + 多少の制約 ホストメモリはアクセスできない戻り値型は
CUDA プログラミングの基本 パート II - カーネル CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パート II カーネルの起動 GPUコードの具体像 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください GPU 上でのコードの実行 カーネルは C 関数 + 多少の制約 ホストメモリはアクセスできない戻り値型は
Microsoft PowerPoint - GPU_computing_2013_01.pptx
 GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格
GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格
名称 : 日本 GPU コンピューティングパートナーシップ (G-DEP) 所在 : 東京都文京区本郷 7 丁目 3 番 1 号東京大学アントレプレナープラザ, 他工場 URL アライアンスパートナー コアテクノロジーパートナー NVIDIA JAPAN ソリュ
 所在 : 東京都文京区本郷 7 丁目 3 番 1 号東京大学アントレプレナープラザ, 他工場 URL アライアンスパートナー コアテクノロジーパートナー NVIDIA JAPAN ソリュ") GPUDirect の現状整理 multi-gpu に取組むために G-DEP チーフエンジニア河井博紀 ([email protected]) 名称 : 日本 GPU コンピューティングパートナーシップ (G-DEP) 所在 : 東京都文京区本郷 7 丁目 3 番 1 号東京大学アントレプレナープラザ, 他工場 URL http://www.gdep.jp アライアンスパートナー コアテクノロジーパートナー
GPUDirect の現状整理 multi-gpu に取組むために G-DEP チーフエンジニア河井博紀 ([email protected]) 名称 : 日本 GPU コンピューティングパートナーシップ (G-DEP) 所在 : 東京都文京区本郷 7 丁目 3 番 1 号東京大学アントレプレナープラザ, 他工場 URL http://www.gdep.jp アライアンスパートナー コアテクノロジーパートナー
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日
 TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date Type URL Presentation
 榎本, 昌一 Citation Issue date Type URL Presentation") 熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date 2011-03-17 Type URL Presentation http://hdl.handle.net/2298/23539 Right GPGPU による高速演算について 榎本昌一 東京大学大学院工学系研究科システム創成学専攻
熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date 2011-03-17 Type URL Presentation http://hdl.handle.net/2298/23539 Right GPGPU による高速演算について 榎本昌一 東京大学大学院工学系研究科システム創成学専攻
Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ 3.7x faster P100 V100 P10
 NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
GPGPU
 GPGPU 2013 1008 2015 1 23 Abstract In recent years, with the advance of microscope technology, the alive cells have been able to observe. On the other hand, from the standpoint of image processing, the
GPGPU 2013 1008 2015 1 23 Abstract In recent years, with the advance of microscope technology, the alive cells have been able to observe. On the other hand, from the standpoint of image processing, the
GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 理化学研究所 共通コードプロジェクト
 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 理化学研究所 共通コードプロジェクト") GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 勉強会 @ 理化学研究所 共通コードプロジェクト Contents Hands On 環境について Introduction to GPU computing Introduction
GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 勉強会 @ 理化学研究所 共通コードプロジェクト Contents Hands On 環境について Introduction to GPU computing Introduction
CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン
 CUDA 画像処理入門 エヌビディアジャパン CUDA エンジニア森野慎也 GTC Japan 2014 CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン RGB Y( 輝度 ) 変換 カラー画像から グレイスケールへの変換 Y = 0.299 R + 0.587
CUDA 画像処理入門 エヌビディアジャパン CUDA エンジニア森野慎也 GTC Japan 2014 CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン RGB Y( 輝度 ) 変換 カラー画像から グレイスケールへの変換 Y = 0.299 R + 0.587
GPU GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1
 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1") GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
Microsoft PowerPoint - GPGPU実践基礎工学(web).pptx
.pptx") GPU のプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU プログラミング環境 (CUDA) GPU プログラムの実行の流れ CUDA によるプログラムの記述 カーネル (GPU で処理する関数 ) の構造 記述方法とその理由 GPU 固有のパラメータの確認 405 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ
GPU のプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU プログラミング環境 (CUDA) GPU プログラムの実行の流れ CUDA によるプログラムの記述 カーネル (GPU で処理する関数 ) の構造 記述方法とその理由 GPU 固有のパラメータの確認 405 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ
スライド 1
 GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
IPSJ SIG Technical Report Vol.2013-HPC-138 No /2/21 GPU CRS 1,a) 2,b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla
 2,b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla") GPU CRS 1,a),b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla K0 CUDA5.0 cusparse CRS SpMV 00 1.86 177 1. SpMV SpMV CRS Compressed Row Storage *1 SpMV GPU GPU NVIDIA Kepler
GPU CRS 1,a),b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla K0 CUDA5.0 cusparse CRS SpMV 00 1.86 177 1. SpMV SpMV CRS Compressed Row Storage *1 SpMV GPU GPU NVIDIA Kepler
GPU n Graphics Processing Unit CG CAD
 GPU 2016/06/27 第 20 回 GPU コンピューティング講習会 ( 東京工業大学 ) 1 GPU n Graphics Processing Unit CG CAD www.nvidia.co.jp www.autodesk.co.jp www.pixar.com GPU n GPU ü n NVIDIA CUDA ü NVIDIA GPU ü OS Linux, Windows, Mac
GPU 2016/06/27 第 20 回 GPU コンピューティング講習会 ( 東京工業大学 ) 1 GPU n Graphics Processing Unit CG CAD www.nvidia.co.jp www.autodesk.co.jp www.pixar.com GPU n GPU ü n NVIDIA CUDA ü NVIDIA GPU ü OS Linux, Windows, Mac
PowerPoint Presentation
 ヘテロジニアスな環境におけるソフトウェア開発 Agenda 今日の概要 ヘテロジニアスな環境の登場 ホモジニアスからヘテロジニアスへ ヘテロジニアスなアーキテクチャ GPU CUDA OpenACC, XeonPhi 自分のプログラムを理解するために デバッガ 共通の操作体験 TotalView 続きはブースで より速く ホモジーニアスな並列 HPC 銀河生成 金融のリスク計算 車の衝突解析 製薬
ヘテロジニアスな環境におけるソフトウェア開発 Agenda 今日の概要 ヘテロジニアスな環境の登場 ホモジニアスからヘテロジニアスへ ヘテロジニアスなアーキテクチャ GPU CUDA OpenACC, XeonPhi 自分のプログラムを理解するために デバッガ 共通の操作体験 TotalView 続きはブースで より速く ホモジーニアスな並列 HPC 銀河生成 金融のリスク計算 車の衝突解析 製薬
( CUDA CUDA CUDA CUDA ( NVIDIA CUDA I
 GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
CUDA 連携とライブラリの活用 2
 1 09:30-10:00 受付 10:00-12:00 Reedbush-H ログイン GPU 入門 13:30-15:00 OpenACC 入門 15:15-16:45 OpenACC 最適化入門と演習 17:00-18:00 OpenACC の活用 (CUDA 連携とライブラリの活用 ) CUDA 連携とライブラリの活用 2 3 OpenACC 簡単にGPUプログラムが作成できる それなりの性能が得られる
1 09:30-10:00 受付 10:00-12:00 Reedbush-H ログイン GPU 入門 13:30-15:00 OpenACC 入門 15:15-16:45 OpenACC 最適化入門と演習 17:00-18:00 OpenACC の活用 (CUDA 連携とライブラリの活用 ) CUDA 連携とライブラリの活用 2 3 OpenACC 簡単にGPUプログラムが作成できる それなりの性能が得られる
1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU
![1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU](/thumbs/89/99132402.jpg "1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU") GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
Microsoft PowerPoint - suda.pptx
 GPU の HWアーキテクチャと高性能化手法 須田礼仁 ( 東京大学 ) 2011/03/22 GPU 高性能プログラミング GPU のハードウェアを理解する CUDA のソフトウェアを理解する CUDA でプログラムを書くのは難しくないが, CUDA で高速なプログラムを書くのは難しい どうすれば遅くなるかを理解する! 効果が大きいものから順に説明します 1 高性能プログラミングの手順 1. 現在のコードの,
GPU の HWアーキテクチャと高性能化手法 須田礼仁 ( 東京大学 ) 2011/03/22 GPU 高性能プログラミング GPU のハードウェアを理解する CUDA のソフトウェアを理解する CUDA でプログラムを書くのは難しくないが, CUDA で高速なプログラムを書くのは難しい どうすれば遅くなるかを理解する! 効果が大きいものから順に説明します 1 高性能プログラミングの手順 1. 現在のコードの,
! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2
![! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2](/thumbs/88/115445009.jpg "! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2") ! OpenCL [Open Computing Language] 言 [OpenCL C 言 ] CPU, GPU, Cell/B.E.,DSP 言 行行 [OpenCL Runtime] OpenCL C 言 API Khronos OpenCL Working Group AMD Broadcom Blizzard Apple ARM Codeplay Electronic Arts Freescale
! OpenCL [Open Computing Language] 言 [OpenCL C 言 ] CPU, GPU, Cell/B.E.,DSP 言 行行 [OpenCL Runtime] OpenCL C 言 API Khronos OpenCL Working Group AMD Broadcom Blizzard Apple ARM Codeplay Electronic Arts Freescale
システムソリューションのご紹介
 HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
MATLAB® における並列・分散コンピューティング ~ Parallel Computing Toolbox™ & MATLAB Distributed Computing Server™ ~
 MATLAB における並列 分散コンピューティング ~ Parallel Computing Toolbox & MATLAB Distributed Computing Server ~ MathWorks Japan Application Engineering Group Takashi Yoshida 2016 The MathWorks, Inc. 1 System Configuration
MATLAB における並列 分散コンピューティング ~ Parallel Computing Toolbox & MATLAB Distributed Computing Server ~ MathWorks Japan Application Engineering Group Takashi Yoshida 2016 The MathWorks, Inc. 1 System Configuration
KBLAS[7] *1., CUBLAS.,,, Byte/flop., [13] 1 2. (AT). GPU AT,, GPU SYMV., SYMV CUDABLAS., (double, float) (cu- FloatComplex, cudoublecomplex).,, DD(dou
![KBLAS[7] *1., CUBLAS.,,, Byte/flop., [13] 1 2. (AT). GPU AT,, GPU SYMV., SYMV CUDABLAS., (double, float) (cu- FloatComplex, cudoublecomplex).,, DD(dou](/thumbs/71/64446865.jpg "KBLAS[7] *1., CUBLAS.,,, Byte/flop., [13] 1 2. (AT). GPU AT,, GPU SYMV., SYMV CUDABLAS., (double, float) (cu- FloatComplex, cudoublecomplex).,, DD(dou") Vol.214-HPC-146 No.14 214/1/3 CUDA-xSYMV 1,3,a) 1 2,3 2,3 (SYMV)., (GEMV) 2.,, mutex., CUBLAS., 1 2,. (AT). 2, SYMV GPU., SSYMV( SYMV), GeForce GTXTitan Black 211GFLOPS( 62.8%)., ( ) (, ) DD(double-double),
Vol.214-HPC-146 No.14 214/1/3 CUDA-xSYMV 1,3,a) 1 2,3 2,3 (SYMV)., (GEMV) 2.,, mutex., CUBLAS., 1 2,. (AT). 2, SYMV GPU., SSYMV( SYMV), GeForce GTXTitan Black 211GFLOPS( 62.8%)., ( ) (, ) DD(double-double),
Microsoft PowerPoint - GPGPU実践基礎工学(web).pptx
.pptx") GPU のメモリ階層 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のメモリ階層 グローバルメモリ 共有メモリ モザイク処理への適用 コンスタントメモリ 空間フィルタへの適用 577 GPU の主要部品 基盤 GPU( チップ )+ 冷却部品 画面出力端子 電源入力端子 メモリ 特性の把握が重要 電源入力端子 画面出力端子 メモリ チップ PCI Ex 端子 http://www.geforce.com/whats
GPU のメモリ階層 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のメモリ階層 グローバルメモリ 共有メモリ モザイク処理への適用 コンスタントメモリ 空間フィルタへの適用 577 GPU の主要部品 基盤 GPU( チップ )+ 冷却部品 画面出力端子 電源入力端子 メモリ 特性の把握が重要 電源入力端子 画面出力端子 メモリ チップ PCI Ex 端子 http://www.geforce.com/whats
CCS HPCサマーセミナー 並列数値計算アルゴリズム
 大規模系での高速フーリエ変換 2 高橋大介 [email protected] 筑波大学計算科学研究センター 2016/6/2 計算科学技術特論 B 1 講義内容 並列三次元 FFT における自動チューニング 二次元分割を用いた並列三次元 FFT アルゴリズム GPU クラスタにおける並列三次元 FFT 2016/6/2 計算科学技術特論 B 2 並列三次元 FFT における 自動チューニング
大規模系での高速フーリエ変換 2 高橋大介 [email protected] 筑波大学計算科学研究センター 2016/6/2 計算科学技術特論 B 1 講義内容 並列三次元 FFT における自動チューニング 二次元分割を用いた並列三次元 FFT アルゴリズム GPU クラスタにおける並列三次元 FFT 2016/6/2 計算科学技術特論 B 2 並列三次元 FFT における 自動チューニング
GPUコンピューティング講習会パート1
 GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
概要 目的 CUDA Fortran の利用に関する基本的なノウハウを提供する 本チュートリアル受講後は Web 上で公開されている資料等を参照しながら独力で CUDA Fortran が利用できることが目標 対象 CUDA Fortran の利用に興味を抱いている方 前提とする知識 Fortran
 CUDA Fortran チュートリアル 2010 年 9 月 29 日 NEC 概要 目的 CUDA Fortran の利用に関する基本的なノウハウを提供する 本チュートリアル受講後は Web 上で公開されている資料等を参照しながら独力で CUDA Fortran が利用できることが目標 対象 CUDA Fortran の利用に興味を抱いている方 前提とする知識 Fortran を用いた Linux
CUDA Fortran チュートリアル 2010 年 9 月 29 日 NEC 概要 目的 CUDA Fortran の利用に関する基本的なノウハウを提供する 本チュートリアル受講後は Web 上で公開されている資料等を参照しながら独力で CUDA Fortran が利用できることが目標 対象 CUDA Fortran の利用に興味を抱いている方 前提とする知識 Fortran を用いた Linux
スパコンに通じる並列プログラミングの基礎
 2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
スパコンに通じる並列プログラミングの基礎
 2018.09.10 [email protected] ( ) 2018.09.10 1 / 59 [email protected] ( ) 2018.09.10 2 / 59 Windows, Mac Unix 0444-J [email protected] ( ) 2018.09.10 3 / 59 Part I Unix GUI CUI:
2018.09.10 [email protected] ( ) 2018.09.10 1 / 59 [email protected] ( ) 2018.09.10 2 / 59 Windows, Mac Unix 0444-J [email protected] ( ) 2018.09.10 3 / 59 Part I Unix GUI CUI:
スパコンに通じる並列プログラミングの基礎
 2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
GPUを用いたN体計算
 単精度 190Tflops GPU クラスタ ( 長崎大 ) の紹介 長崎大学工学部超高速メニーコアコンピューティングセンターテニュアトラック助教濱田剛 1 概要 GPU (Graphics Processing Unit) について簡単に説明します. GPU クラスタが得意とする応用問題を議論し 長崎大学での GPU クラスタによる 取組方針 N 体計算の高速化に関する研究内容 を紹介します. まとめ
単精度 190Tflops GPU クラスタ ( 長崎大 ) の紹介 長崎大学工学部超高速メニーコアコンピューティングセンターテニュアトラック助教濱田剛 1 概要 GPU (Graphics Processing Unit) について簡単に説明します. GPU クラスタが得意とする応用問題を議論し 長崎大学での GPU クラスタによる 取組方針 N 体計算の高速化に関する研究内容 を紹介します. まとめ
VOLTA ARCHITECTURE DEEP DIVE 成瀬彰, シニアデベロッパーテクノロジーエンジニア, 2017/12/12
 VOLTA ARCHITECTURE DEEP DIVE 成瀬彰, シニアデベロッパーテクノロジーエンジニア, 2017/12/12 TESLA V100 の概要 Volta Architecture Improved NVLink & HBM2 Volta MPS Improved SIMT Model Tensor Core Most Productive GPU Efficient Bandwidth
VOLTA ARCHITECTURE DEEP DIVE 成瀬彰, シニアデベロッパーテクノロジーエンジニア, 2017/12/12 TESLA V100 の概要 Volta Architecture Improved NVLink & HBM2 Volta MPS Improved SIMT Model Tensor Core Most Productive GPU Efficient Bandwidth
23 Fig. 2: hwmodulev2 3. Reconfigurable HPC 3.1 hw/sw hw/sw hw/sw FPGA PC FPGA PC FPGA HPC FPGA FPGA hw/sw hw/sw hw- Module FPGA hwmodule hw/sw FPGA h
 23 FPGA CUDA Performance Comparison of FPGA Array with CUDA on Poisson Equation ([email protected]), ([email protected]), ([email protected]), ([email protected]),
23 FPGA CUDA Performance Comparison of FPGA Array with CUDA on Poisson Equation ([email protected]), ([email protected]), ([email protected]), ([email protected]),
Slide 1
 OPENACC の現状 Akira Naruse NVIDAI Developer Technologies アプリを GPU で加速する方法 Application CUDA OpenACC Library 主要処理を CUDA で記述高い自由度 既存コードにディレクティブを挿入簡単に加速 GPU 対応ライブラリにチェンジ簡単に開始 OPENACC CPU GPU Program myscience...
OPENACC の現状 Akira Naruse NVIDAI Developer Technologies アプリを GPU で加速する方法 Application CUDA OpenACC Library 主要処理を CUDA で記述高い自由度 既存コードにディレクティブを挿入簡単に加速 GPU 対応ライブラリにチェンジ簡単に開始 OPENACC CPU GPU Program myscience...
VOLTA AND TURING: ARCHITECTURE Akira Naruse, Developer Technology, 2018/9/14
 VOLTA AND TURING: ARCHITECTURE AND PERFORMANCE OPTIMIZATION Akira Naruse, Developer Technology, 2018/9/14 VOLTA AND TURING: ARCHITECTURE Akira Naruse, Developer Technology, 2018/9/14 For HPC and Deep Learning
VOLTA AND TURING: ARCHITECTURE AND PERFORMANCE OPTIMIZATION Akira Naruse, Developer Technology, 2018/9/14 VOLTA AND TURING: ARCHITECTURE Akira Naruse, Developer Technology, 2018/9/14 For HPC and Deep Learning
Microsoft PowerPoint - CCS学際共同boku-08b.ppt
 マルチコア / マルチソケットノードに おけるメモリ性能のインパクト 研究代表者朴泰祐筑波大学システム情報工学研究科 [email protected] アウトライン 近年の高性能 PC クラスタの傾向と問題 multi-core/multi-socket ノードとメモリ性能 メモリバンド幅に着目した性能測定 multi-link network 性能評価 まとめ 近年の高性能 PC
マルチコア / マルチソケットノードに おけるメモリ性能のインパクト 研究代表者朴泰祐筑波大学システム情報工学研究科 [email protected] アウトライン 近年の高性能 PC クラスタの傾向と問題 multi-core/multi-socket ノードとメモリ性能 メモリバンド幅に着目した性能測定 multi-link network 性能評価 まとめ 近年の高性能 PC
NVIDIA Tesla K20/K20X GPU アクセラレータ アプリケーション パフォーマンス テクニカル ブリーフ
 NVIDIA Tesla K20/K20X GPU アクセラレータ アプリケーション パフォーマンス テクニカル ブリーフ K20 GPU2 個に対するスピードアップ NVIDIA は Fermi アーキテクチャ GPU の発表により パフォーマンス エネルギー効率の両面で飛躍的な性能向上を実現し ハイパフォーマンスコンピューティング (HPC) の世界に変革をもたらしました また 実際に GPU
NVIDIA Tesla K20/K20X GPU アクセラレータ アプリケーション パフォーマンス テクニカル ブリーフ K20 GPU2 個に対するスピードアップ NVIDIA は Fermi アーキテクチャ GPU の発表により パフォーマンス エネルギー効率の両面で飛躍的な性能向上を実現し ハイパフォーマンスコンピューティング (HPC) の世界に変革をもたらしました また 実際に GPU
12 PowerEdge PowerEdge Xeon E PowerEdge 11 PowerEdge DIMM Xeon E PowerEdge DIMM DIMM 756GB 12 PowerEdge Xeon E5-
 12ways-12th Generation PowerEdge Servers improve your IT experience 12 PowerEdge 12 1 6 2 GPU 8 4 PERC RAID I/O Cachecade I/O 5 Dell Express Flash PCIe SSD 6 7 OS 8 85.5% 9 Dell OpenManage PowerCenter
12ways-12th Generation PowerEdge Servers improve your IT experience 12 PowerEdge 12 1 6 2 GPU 8 4 PERC RAID I/O Cachecade I/O 5 Dell Express Flash PCIe SSD 6 7 OS 8 85.5% 9 Dell OpenManage PowerCenter
GPU のアーキテクチャとプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓
 GPU のアーキテクチャとプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のアーキテクチャ CUDA CUDA によるプログラミング 58 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ チップ単体では販売されていない PCI Ex カードで販売 ( チップ単体と区別せずに GPU と呼ぶことも多い
GPU のアーキテクチャとプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のアーキテクチャ CUDA CUDA によるプログラミング 58 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ チップ単体では販売されていない PCI Ex カードで販売 ( チップ単体と区別せずに GPU と呼ぶことも多い
main.dvi
 PC 1 1 [1][2] [3][4] ( ) GPU(Graphics Processing Unit) GPU PC GPU PC ( 2 GPU ) GPU Harris Corner Detector[5] CPU ( ) ( ) CPU GPU 2 3 GPU 4 5 6 7 1 [email protected] 45 2 ( ) CPU ( ) ( ) () 2.1
PC 1 1 [1][2] [3][4] ( ) GPU(Graphics Processing Unit) GPU PC GPU PC ( 2 GPU ) GPU Harris Corner Detector[5] CPU ( ) ( ) CPU GPU 2 3 GPU 4 5 6 7 1 [email protected] 45 2 ( ) CPU ( ) ( ) () 2.1
untitled
 A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
openmp1_Yaguchi_version_170530
 並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
Slide 1
 GPUコンピューティング入門 2015.08.26 エヌビディア合同会社 CUDAエンジニア 村上真奈 エヌビディアのGPUについて (20 分 ) GPUコンピューティングとは?(10 分 ) OpenACC 入門 (90 分 ) CUDA 入門 (90 分 ) Agenda 2 エヌビディアのGPUについて (20 分 ) GPUコンピューティングとは?(10 分 ) OpenACC 入門 (90
GPUコンピューティング入門 2015.08.26 エヌビディア合同会社 CUDAエンジニア 村上真奈 エヌビディアのGPUについて (20 分 ) GPUコンピューティングとは?(10 分 ) OpenACC 入門 (90 分 ) CUDA 入門 (90 分 ) Agenda 2 エヌビディアのGPUについて (20 分 ) GPUコンピューティングとは?(10 分 ) OpenACC 入門 (90
1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU.....
 CPU GPU N Q07-065 2011 2 17 1 1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU...........................................
CPU GPU N Q07-065 2011 2 17 1 1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU...........................................
211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS /1/18 a a 1 a 2 a 3 a a GPU Graphics Processing Unit GPU CPU GPU GPGPU G
 211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS211 211/1/18 GPU 4 8 BLAS 4 8 BLAS Basic Linear Algebra Subprograms GPU Graphics Processing Unit 4 8 double 2 4 double-double DD 4 4 8 quad-double
211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS211 211/1/18 GPU 4 8 BLAS 4 8 BLAS Basic Linear Algebra Subprograms GPU Graphics Processing Unit 4 8 double 2 4 double-double DD 4 4 8 quad-double
<4D F736F F F696E74202D2091E63489F15F436F6D C982E682E992B48D8291AC92B489B F090CD2888F38DFC E B8CDD8
 Web キャンパス資料 超音波シミュレーションの基礎 ~ 第 4 回 ComWAVEによる超高速超音波解析 ~ 科学システム開発部 Copyright (c)2006 ITOCHU Techno-Solutions Corporation 本日の説明内容 ComWAVEの概要および特徴 GPGPUとは GPGPUによる解析事例 CAE POWER 超音波研究会開催 (10 月 3 日 ) のご紹介
Web キャンパス資料 超音波シミュレーションの基礎 ~ 第 4 回 ComWAVEによる超高速超音波解析 ~ 科学システム開発部 Copyright (c)2006 ITOCHU Techno-Solutions Corporation 本日の説明内容 ComWAVEの概要および特徴 GPGPUとは GPGPUによる解析事例 CAE POWER 超音波研究会開催 (10 月 3 日 ) のご紹介
HPEハイパフォーマンスコンピューティング ソリューション
 HPE HPC / AI Page 2 No.1 * 24.8% No.1 * HPE HPC / AI HPC AI SGIHPE HPC / AI GPU TOP500 50th edition Nov. 2017 HPE No.1 124 www.top500.org HPE HPC / AI TSUBAME 3.0 2017 7 AI TSUBAME 3.0 HPE SGI 8600 System
HPE HPC / AI Page 2 No.1 * 24.8% No.1 * HPE HPC / AI HPC AI SGIHPE HPC / AI GPU TOP500 50th edition Nov. 2017 HPE No.1 124 www.top500.org HPE HPC / AI TSUBAME 3.0 2017 7 AI TSUBAME 3.0 HPE SGI 8600 System
(速報) Xeon E 系モデル 新プロセッサ性能について
 Xeon E 系モデル 新プロセッサ性能について") ( 速報 ) Xeon E5-2600 系モデル新プロセッサ性能について 2012 年 3 月 16 日 富士通株式会社 2012 年 3 月 7 日 インテル社より最新 CPU インテル Xeon E5 ファミリー の発表がありました この最新 CPU について PC クラスタシステムの観点から性能検証を行いましたので 概要を速報いたします プロセッサインテル Xeon プロセッサ E5-2690
( 速報 ) Xeon E5-2600 系モデル新プロセッサ性能について 2012 年 3 月 16 日 富士通株式会社 2012 年 3 月 7 日 インテル社より最新 CPU インテル Xeon E5 ファミリー の発表がありました この最新 CPU について PC クラスタシステムの観点から性能検証を行いましたので 概要を速報いたします プロセッサインテル Xeon プロセッサ E5-2690
GPGPU によるアクセラレーション環境について
 GPGPU によるアクセラレーション環境について 長屋貴量 自然科学研究機構分子科学研究所技術課計算科学技術班 概要 GPGPU とは 単純で画一的なデータを一度に大量に処理することに特化したグラフィックカードの演算資源を 画像処理以外の汎用的な目的に応用する技術の一つである 近年 その演算能力は CPU で通常言われるムーアの法則に則った場合とは異なり 飛躍的に向上しており その演算性能に魅力を感じた各分野での応用が広がってきている
GPGPU によるアクセラレーション環境について 長屋貴量 自然科学研究機構分子科学研究所技術課計算科学技術班 概要 GPGPU とは 単純で画一的なデータを一度に大量に処理することに特化したグラフィックカードの演算資源を 画像処理以外の汎用的な目的に応用する技術の一つである 近年 その演算能力は CPU で通常言われるムーアの法則に則った場合とは異なり 飛躍的に向上しており その演算性能に魅力を感じた各分野での応用が広がってきている
チューニング講習会 初級編
 GPU のしくみ RICC での使い方 およびベンチマーク 理化学研究所情報基盤センター 2013/6/27 17:00 17:30 中田真秀 RICC の GPU が高速に! ( 旧 C1060 比約 6.6 倍高速 ) RICCのGPUがC2075になりました! C1060 比 6.6 倍高速 倍精度 515GFlops UPCに100 枚導入 : 合計 51.5TFlops うまく行くと5 倍程度高速化
GPU のしくみ RICC での使い方 およびベンチマーク 理化学研究所情報基盤センター 2013/6/27 17:00 17:30 中田真秀 RICC の GPU が高速に! ( 旧 C1060 比約 6.6 倍高速 ) RICCのGPUがC2075になりました! C1060 比 6.6 倍高速 倍精度 515GFlops UPCに100 枚導入 : 合計 51.5TFlops うまく行くと5 倍程度高速化
Agenda GRAPE-MPの紹介と性能評価 GRAPE-MPの概要 OpenCLによる四倍精度演算 (preliminary) 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops
 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops") Agenda GRAPE-MPの紹介と性能評価 GRAPE-MPの概要 OpenCLによる四倍精度演算 (preliminary) 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops ボードの概要 Control processor (FPGA by Altera) GRAPE-MP chip[nextreme
Agenda GRAPE-MPの紹介と性能評価 GRAPE-MPの概要 OpenCLによる四倍精度演算 (preliminary) 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops ボードの概要 Control processor (FPGA by Altera) GRAPE-MP chip[nextreme
DO 時間積分 START 反変速度の計算 contravariant_velocity 移流項の計算 advection_adams_bashforth_2nd DO implicit loop( 陰解法 ) 速度勾配, 温度勾配の計算 gradient_cell_center_surface 速
 速度勾配, 温度勾配の計算 gradient_cell_center_surface 速") 1 1, 2 1, 2 3 2, 3 4 GP LES ASUCA LES NVIDIA CUDA LES 1. Graphics Processing Unit GP General-Purpose SIMT Single Instruction Multiple Threads 1 2 3 4 1),2) LES Large Eddy Simulation 3) ASUCA 4) LES LES
1 1, 2 1, 2 3 2, 3 4 GP LES ASUCA LES NVIDIA CUDA LES 1. Graphics Processing Unit GP General-Purpose SIMT Single Instruction Multiple Threads 1 2 3 4 1),2) LES Large Eddy Simulation 3) ASUCA 4) LES LES
3次多項式パラメタ推定計算の CUDAを用いた実装 (CUDAプログラミングの練習として) Implementation of the Estimation of the parameters of 3rd-order-Polynomial with CUDA
 Implementation of the Estimation of the parameters of 3rd-order-Polynomial with CUDA") 3 次多項式パラメタ推定計算の CUDA を用いた実装 (CUDA プログラミングの練習として ) Estimating the Parameters of 3rd-order-Polynomial with CUDA ISS 09/11/12 問題の選択 目的 CUDA プログラミングを経験 ( 試行錯誤と習得 ) 実際に CPU のみの場合と比べて高速化されることを体験 問題 ( インプリメントする内容
3 次多項式パラメタ推定計算の CUDA を用いた実装 (CUDA プログラミングの練習として ) Estimating the Parameters of 3rd-order-Polynomial with CUDA ISS 09/11/12 問題の選択 目的 CUDA プログラミングを経験 ( 試行錯誤と習得 ) 実際に CPU のみの場合と比べて高速化されることを体験 問題 ( インプリメントする内容
rank ”«‘‚“™z‡Ì GPU ‡É‡æ‡éŁÀŠñ›»
 rank GPU ERATO 2011 11 1 1 / 26 GPU rank/select wavelet tree balanced parenthesis GPU rank 2 / 26 GPU rank/select wavelet tree balanced parenthesis GPU rank 2 / 26 GPU rank/select wavelet tree balanced
rank GPU ERATO 2011 11 1 1 / 26 GPU rank/select wavelet tree balanced parenthesis GPU rank 2 / 26 GPU rank/select wavelet tree balanced parenthesis GPU rank 2 / 26 GPU rank/select wavelet tree balanced
IPSJ SIG Technical Report Vol.2013-ARC-203 No /2/1 SMYLE OpenCL (NEDO) IT FPGA SMYLEref SMYLE OpenCL SMYLE OpenCL FPGA 1
 IT FPGA SMYLEref SMYLE OpenCL SMYLE OpenCL FPGA 1") SMYLE OpenCL 128 1 1 1 1 1 2 2 3 3 3 (NEDO) IT FPGA SMYLEref SMYLE OpenCL SMYLE OpenCL FPGA 128 SMYLEref SMYLE OpenCL SMYLE OpenCL Implementation and Evaluations on 128 Cores Takuji Hieda 1 Noriko Etani
SMYLE OpenCL 128 1 1 1 1 1 2 2 3 3 3 (NEDO) IT FPGA SMYLEref SMYLE OpenCL SMYLE OpenCL FPGA 128 SMYLEref SMYLE OpenCL SMYLE OpenCL Implementation and Evaluations on 128 Cores Takuji Hieda 1 Noriko Etani
工学院大学建築系学科近藤研究室2000年度卒業論文梗概
 耐災害性の高い通信システムにおけるサーバ計算機の性能と消費電力に関する考察 耐障害性, 消費電力, 低消費電力サーバ 山口実靖 *. はじめに 性能と表皮電力の関係について調査し, 考察を行う 災害においては, 減災活動が極めて重要である すなわち 災害が発生した後に適切に災害に対処することにより, その被害を大きく軽減できる. 適切な災害対策を行うには災害対策を行う拠点が正常に運営されていることが必要不可欠であり,
耐災害性の高い通信システムにおけるサーバ計算機の性能と消費電力に関する考察 耐障害性, 消費電力, 低消費電力サーバ 山口実靖 *. はじめに 性能と表皮電力の関係について調査し, 考察を行う 災害においては, 減災活動が極めて重要である すなわち 災害が発生した後に適切に災害に対処することにより, その被害を大きく軽減できる. 適切な災害対策を行うには災害対策を行う拠点が正常に運営されていることが必要不可欠であり,
Ver. 3.8 Ver NOTE E v3 2.4GHz, 20M cache, 8.00GT/s QPI,, HT, 8C/16T 85W E v3 1.6GHz, 15M cache, 6.40GT/s QPI,
 PowerEdge T630 Contents RAID /RAID & PCIe GPU OS v3.8 Apr. 2017 P3-5 P6 P7 P8-9 P10-11 P12-16 P17-79 P80-85 P86-87 P88-90 P90 P91-92 P93-96 P97-100 P101-107 P107-108 P109-110 2017 4 28 2016 4 22 Ver. 3.8
PowerEdge T630 Contents RAID /RAID & PCIe GPU OS v3.8 Apr. 2017 P3-5 P6 P7 P8-9 P10-11 P12-16 P17-79 P80-85 P86-87 P88-90 P90 P91-92 P93-96 P97-100 P101-107 P107-108 P109-110 2017 4 28 2016 4 22 Ver. 3.8
GPUコンピューティング講習会パート1
 GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
AMD/ATI Radeon HD 5870 GPU DEGIMA LINPACK HD 5870 GPU DEGIMA LINPACK GFlops/Watt GFlops/Watt Abstract GPU Computing has lately attracted
 DEGIMA LINPACK Energy Performance for LINPACK Benchmark on DEGIMA 1 AMD/ATI Radeon HD 5870 GPU DEGIMA LINPACK HD 5870 GPU DEGIMA LINPACK 1.4698 GFlops/Watt 1.9658 GFlops/Watt Abstract GPU Computing has
DEGIMA LINPACK Energy Performance for LINPACK Benchmark on DEGIMA 1 AMD/ATI Radeon HD 5870 GPU DEGIMA LINPACK HD 5870 GPU DEGIMA LINPACK 1.4698 GFlops/Watt 1.9658 GFlops/Watt Abstract GPU Computing has
hotspot の特定と最適化
 1 1? 1 1 2 1. hotspot : hotspot hotspot Parallel Amplifier 1? 2. hotspot : (1 ) Parallel Composer 1 Microsoft* Ticker Tape Smoke 1.0 PiSolver 66 / 64 / 2.76 ** 84 / 27% ** 75 / 17% ** 1.46 89% Microsoft*
1 1? 1 1 2 1. hotspot : hotspot hotspot Parallel Amplifier 1? 2. hotspot : (1 ) Parallel Composer 1 Microsoft* Ticker Tape Smoke 1.0 PiSolver 66 / 64 / 2.76 ** 84 / 27% ** 75 / 17% ** 1.46 89% Microsoft*
Microsoft PowerPoint - sales2.ppt
 最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
Ver Ver NOTE E v3 2.4GHz, 20M cache, 8.00GT/s QPI,, HT, 8C/16T 85W E v3 1.6GHz, 15M cache, 6.40GT/s QPI
 PowerEdge T630 Contents RAID /RAID & PCIe GPU OS V4.10 Mar.2018 P3-5 P6 P7 P8-9 P10-11 P12-16 P17-84 P85-90 P91-92 P93-95 P95 P96-97 P98-101 P102-105 P106-110 P110-111 P112-113 2018 3 30 2016 4 22 Ver.
PowerEdge T630 Contents RAID /RAID & PCIe GPU OS V4.10 Mar.2018 P3-5 P6 P7 P8-9 P10-11 P12-16 P17-84 P85-90 P91-92 P93-95 P95 P96-97 P98-101 P102-105 P106-110 P110-111 P112-113 2018 3 30 2016 4 22 Ver.
Ver. 3.8 Ver NOTE E v3 2.4GHz, 20M cache, 8.00GT/s QPI,, HT, 8C/16T 85W E v3 1.6GHz, 15M cache, 6.40GT/s QPI,,
 PowerEdge R730 Contents RAID /RAID & PCIe GPU OS P3-5 P6 P7 P8 P9-10 P11-16 P17-55 P56 P57-66 P67-69 P70-72 P72 P73 P74-77 P78-81 P82-88 P88-89 P90-91 V3.8 Apr. 2017 2017 4 28 2016 4 22 Ver. 3.8 Ver. 1.0
PowerEdge R730 Contents RAID /RAID & PCIe GPU OS P3-5 P6 P7 P8 P9-10 P11-16 P17-55 P56 P57-66 P67-69 P70-72 P72 P73 P74-77 P78-81 P82-88 P88-89 P90-91 V3.8 Apr. 2017 2017 4 28 2016 4 22 Ver. 3.8 Ver. 1.0