PowerPoint Presentation
|
|
|
- よしじろう さかど
- 6 years ago
- Views:
Transcription
1 OpenFOAM の性能強化と 1 千億格子規模データのポスト処理の試み 清水建設株式会社 PHAM VAN PHUC 内山学
2 京 における OpenFOAM に関する取組み 第 1 回 OpenFOAM ワークショップ (2013) 京 への移植 10 億格子計算の壁 解決策 (Int32, プリ ポスト ) 第 2 回 OpenFOAM ワークショップ (2014) 1 万並列計算の壁 解決策 (MPI プラットフォーム ) 第 3 回 OpenFOAM ワークショップ (2015) 超並列 超大規模解析の性能評価 (10 5 並列 1 千億格子 ) 第 4 回 OpenFOAM ワークショップ ( 本日 ) OpenFOAM 性能強化, 超大規模ポスト処理 (1 千億格子 ) 2
3 内容 OpenFOAM の性能強化 ( 内山 ) 1 千億格子規模データのポスト処理の試み ( フック ) 3
4 OpenFOAM の性能強化ー thread 並列化 ( 非構造格子対応 ) - 清水建設株式会社 内山学 4
5 1. 目的と背景 目的 : 流体解析やFEM 解析をHybrid 並列化する ( 本報告ではthread 並列化まで ) 背景 Flat MPIによる超並列計算では通信の負担が大 流体コードで, 直交格子については文献 [3] で検討したが 実用面では非構造格子に適用できる方法が必要 格子単位のマルチカラー法では PCG 法の収斂性が悪い 色数を増やせば収斂性は改善されるが, 並列性は悪化 係数行列の行単位の並列化は性能が悪い( 演算量小 ) 使用コード :OpenFOAM-v1606+(pisoFOAM) [3] 内山, 他, OpenFOAM による流体コードの Hybrid 並列化の評価, 第 151 回ハイパフォーマンスコンピューティング報告発表会,

6 2. 格子のオーダリングと行列格納方法 格子のグループ分け Figure 格子のグループ分け 6

7 2. 格子のオーダリングと行列格納方法 モデル :motorbike グループ数 :(32, 4, 2) Figure 2 係数行列の非零項の分布イメージ 格子の 99% 以上が level=0 と level=1 に含まれる 7
8 2. 格子のオーダリングと行列格納方法 対角ブロックのオーダリング U[*][4] の形に格納 (m1=4 の場合 ) Figure 3 対角ブロック内のオーダリング 8
9 3. 計算方法 対角ブロックの A 部分 (m1=3): 前進代入 A 部分の行数 対角ブロックの A 部分 (m1=3): 後退代入と行列ベクトル積 9



10 4. 数値実験 : 高層ビル 風速 10m/s 1 Δt= s 最初の 2 step の圧力方程式を解く ICCG 法を計測 計算機 :Xeon E v2 (2.70GHz, 12 cores, 30 MB Cache) 2 10
11 4. 数値実験 : 高層ビル 2 (6 色 ) CM: Cuthill-Mckey ordering S: profile reduction by Sloan EGMC: multi-color b128_s0: level0 が 128 ブロックブロック内が Sloan b128_s2: b128_s0 に対してブロック内を部分的に U[*][m1] と保持 number of iterations CM0 EGMC b128_cm0/1 b128_s0/2 b256_s

12 4. 数値実験 : 高層ビル 収斂計算回数の増加以上に遅い 計算の制御が増加並列時に逆転 16 threads での高速化率が良くない 対角ブロック内 Sloan で悪化 対角ブロック内提案方法で高速化 Figure 6 Elapsed Time of ICCG Figure 7 高速化率 12



13 4. 数値実験 :motorbike 風速 10m/s 3 Δt= s 最初の 10 step の圧力方程式を解く ICCG 法を計測 13

14 4. 数値実験 :motorbike 4 CM: Cuthill-Mckey ordering S: profile reduction by Sloan b128_s0: level0 が 128 ブロックブロック内が Sloan b128_s2: b128_s0 に対してブロック内を部分的に U[*][m1] と保持 16 threads での高速化率が良くない Figure 9 Elapsed Time of ICCG Figure 10 高速化率 14
15 4. 数値実験 EGMC ICCG 法の収斂性は著しく悪化し, 高速化率も余り良くない b128_s2 CM0と比べてICCG 法の収斂性を殆ど悪化させない Thread 並列化しない状態で計算時間を約 5% 短縮 8 threads 時で高速化率が5.3であり 良い結果と言える 16 threadsでは高速化率の伸びが良くない 15
16 他の部分の高速化の例 surfacescalarfield phihbya ("phihbya", (fvc::interpolate(hbya) & mesh.sf()) + fvc::ddtphicorr(rau, U, phi)); コードを展開 : 多次元配列化 作業配列削除 #pragma omp parallel if(nths>1) { #pragma omp for for (register idata i=0; i<ncells; i++) { irauu[i][0] = irau[i]*(c0*iu0[i][0]-c00*iu00[i][0]); irauu[i][1] = irau[i]*(c0*iu0[i][1]-c00*iu00[i][1]); irauu[i][2] = irau[i]*(c0*iu0[i][2]-c00*iu00[i][2]); } #pragma omp for nowait for (register idata fi=0; fi<nfaces; fi++) { idata i=p[fi], j=n[fi]; rdata s1 = isf[fi][0]*( iweights[fi]*(iu0[i][0]-iu0[j][0]) +iu0[j][0] ) +isf[fi][1]*( iweights[fi]*(iu0[i][1]-iu0[j][1]) +iu0[j][1] ) +isf[fi][2]*( iweights[fi]*(iu0[i][2]-iu0[j][2]) +iu0[j][2] ); rdata ddtcouplingcoeff = 1.0 -min( fabs(iphi0[fi]-s1)/(fabs(iphi0[fi])+vsmall), 1.0 ); 当該箇所の計算時間 : 高層ビル (9,973,802 格子 ) 2.21 sec 0.66 sec ( コードを展開 ) 0.35 sec (8 threads) 未展開部分があり十分に並列化されていない こういう部分はたくさんある C++ の良さはなくなるが速くなる } 以下略. rdata gamma_ra = iweights[fi]*(irau[i] -irau[j]) + irau[j]; rdata s2 = isf[fi][0]*( iweights[fi]*(irauu[i][0]-irauu[j][0]) +irauu[j][0] ) +isf[fi][1]*( iweights[fi]*(irauu[i][1]-irauu[j][1]) +irauu[j][1] ) +isf[fi][2]*( iweights[fi]*(irauu[i][2]-irauu[j][2]) +irauu[j][2] ); rdata ddtphicorr = rdt *ddtcouplingcoeff *( gamma_ra*(c0*iphi0[fi]-c00*iphi00[fi]) -s2 ); rdata s3 = isf[fi][0]*( iweights[fi]*(ihbya[i][0]-ihbya[j][0]) +ihbya[j][0] ) +isf[fi][1]*( iweights[fi]*(ihbya[i][1]-ihbya[j][1]) +ihbya[j][1] ) +isf[fi][2]*( iweights[fi]*(ihbya[i][2]-ihbya[j][2]) +ihbya[j][2] ); iphihbya[fi] = s3 + ddtphicorr; 計算機 :Xeon E v3 (3.50GHz, 4 cores) 2 16
17 1 千億格子規模データのポスト処理の試み 清水建設株式会社 PHAM VAN PHUC
, 千葉修一 ( 富士通 ) : 京 コンピュータでの C++ 型流体コードにおける MPI の評価, 第 151 回ハイパフォーマンスコンピューティング研究発表会論文集 (2015.")
18 超並列 超大規模解析の性能 第 3 回 OpenFOAM ワークショップ (2015) Weak Scaling ( 単相流解析ソルバ pisofoam) PHAM VAN PHUC 内山学 ( 清水建設 ), 井上義昭 浅見暁 (RIST), 千葉修一 ( 富士通 ) : 京 コンピュータでの C++ 型流体コードにおける MPI の評価, 第 151 回ハイパフォーマンスコンピューティング研究発表会論文集 (2015.9)
 1,000")
19 超並列 超大規模解析の性能 第 3 回 OpenFOAM ワークショップ (2015) Weak Scaling ( 単相流解析ソルバ pisofoam) 1,000 億格子規模の計算は可能である

20 最新 OpenFOAM の並列性能 Weak Scaling ( 二相流解析ソルバ interfoam) 清水建設 理研 富士通との共同研究 計算コア部分の大きな技術課題はほぼクリア プリ ポストの課題 32 億格子 256 億格子 PHAM VAN PHUC( 清水建設 ): Large Scale Transient CFD Simulations for Buildings using OpenFOAM on a World s Top-class Supercomputer, The 4th Annual OpenFOAM User Conference 2016/ 2016 North American OpenFOAM User Conference, Keynote 講演, 2016
")

21 プリ ポスト処理の課題 シリアル処理の限界 ( データハンドリング メモリ不足 ) データの分割 結合が非常にかかる 10 億格子の壁 10 億格子データ 1TB メモリの利用 京のプリ ポスト処理 PC: 1TB モデル作成 ( プリ処理 ) 初期化領域分割 シミュレーション データ結合ポスト処理 出力 可視化 Computational domain in a single processor Computational domain, results in a single processor
22 プリ ポスト処理プロセスの提案 第 1 回 OpenFOAM ワークショップ (2013) 分散処理による解決 OpenFOAMの既存ツールの改良モデルの作成 ( プリ ) 初期化ロードバランス シミュレーション ポスト処理 データ出力 可視化 画像処理 データ処理等

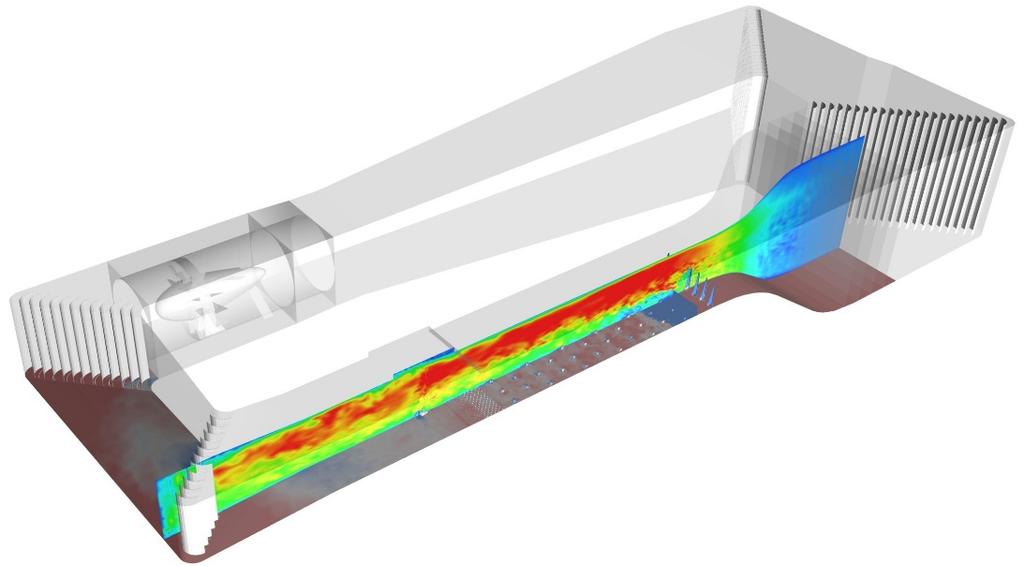




23 京 における可視化プロセスの実装 風洞実験の再現 (64 億格子 ) 広域市街地の再現 (20 億格子 ) 1,000 億格子規模データ可視化のトライ
 PHAM VAN PHUC と渡辺宏一 ( 清水建設 ): 建築環境の超高速計算可視化システム, 招待講演, 2012 http://www.")
24 大規模 超高速の可視化システムの開発取組み TSUBAME2.0 スパコンでの実施検討 (2012) PHAM VAN PHUC と渡辺宏一 ( 清水建設 ): 建築環境の超高速計算可視化システム, 招待講演,
25 シミュレーション技術のコンセプト 精緻なデータの利用 ( プリ ) 3 次元データの利用 高解像度計算モデルの作成 プロ 素人とは関係なく 自動作成 高速 大規模計算の実施 ( 解析 ) 最新ハード 分散処理 超高速 超並列計算の実施 高精度予測 リアルタイム性処理 どこでも活用できる ( ポスト ) リモート クラウド技術の活用 客先と対話可能

26 シミュレーション技術のフレームワーク Database (3D データ ) どこでも活用できる ユーザー Platform 画像レンダリング 流体解析 構造解析 IT Services 京 : 解析の高精度化 CPUs GPUs CPU GPU クラウド ユーザー
27 数値流体解析データ容量の次元 2K 4K 8K 1KB~100MB 1GB~1TB 1TB~100TB 画像レンダリング データ合体 Screen pixels Image pixels 必要な可視化データ 計算領域物理情報 可視化エンジン Paraview Ensight FieldView
28 戦略的な可視化方法の概要 2K 4K 8K 1KB~100MB 1GB~1TB 1TB~100TB 画像レンダリング 低解像度化データ伝送 Screen pixels 画像伝送 Image pixels 必要な可視化データ データ合体 画像処理 計算領域物理情報 Multi-Screen pixels 多並列の画像レンダリング LOCAL (PC) REMOTE ( 京 コンピュータ等 )
29 京 での可視化エンジンの移植 対応ソフト ParaView ParaView ParaView コードの一部修正 移植 画像処理ソフトは独自コード
 京 利用課題の")


30 対象とする解析モデル (1,000 千億 ) 京 利用課題の 竜巻シミュレーション 2m 竜巻のコア 建物 16m processors: =98,304 総格子数 : 25,856 2,424 1,616 1 千億 3m
31 データ容量 ハンドリング 計算格子 : 3.19TB *) 物理量 (U, p) : 0.56TB/ ステップ *) データファイルのハンドリング Processor 数 : 98,304 ステージングイン時間 : 約 10 分 (proc=98,304) *) tgz 圧縮フォーマット
32 画像の概要 Resolution 解像度 X Y Pixels per Frame ( 画素数 ) Full HD(2K) 1,920 1,080 2,073,600 4K 3,840 2,160 8,294,400 8K 7,680 4,320 33,177,600 16K 15,360 8, ,710,400(1 億 ) 32K 30,720 17, ,841,600(5 億 ) 48K 46,080 25,920 1,194,393,600(11 億 ) 64K 61,400 34,560 2,123,366,400(21 億 ) 世界最高画素数カメラ : 5,060 万画素 ( キャノン EOS 5Ds) 超高精細ディスプレイ : ~8K 世界最大画像サイズ : 3,650 億画素 ( 画像処理 )


33 可視化の画素数 ( 投影面 ) 1pixel/ 格子 4pixels/ 格子 9pixels/ 格子 十分な画素数を用いる必要がある


34 全メッシュ図の可視化 9pixels/ 格子 フォト表示サイズ :722.5KB Pixel サイズ :91,648 17,184 ~ 16 億画素数 ~ 64K 34


35 建物周辺のメッシュ図 9pixels/格子 サイズ:2.21MB Pixelサイズ 8,000 8,000 ~ 6400万画素数 8K 35

36 風速コンター図の可視化 9pixels/ 格子 フォト表示サイズ :16.3MB Pixel サイズ :91,648 17,184 ~ 16 億画素数 ~ 64K 1,000 億のデータを技術的に可視化できることを確認! 36

37 計算格子の低解像度化による変化 1,000 億格子 データマッピング 2 億格子 画像はやや劣化しているが 現象の観察について十分
38 まとめ 1,000 億格子規模データのハンドリングや可視化は分散処理により行うことが可能である 現象の把握を目的とした場合 部分可視化やデータの低解像度化を行うことは有効な方法である 可視化レベルによってそれを限らない
PowerPoint Presentation
 OpenFOAM を用いた 超大規模計算モデル作成とその性能の評価 清水建設株式会社 PHAM VAN PHUC 内山学 京 での OpenFOAM に関する取組み 第 1 回 OpenFOAM ワークショップ (2013) コード移植 10 億格子計算の壁 解決策 ( プリ ポスト ) 第 2 回 OpenFOAM ワークショップ (2014) 1 万並列計算の壁 解決策 (MPI プラットフォーム
OpenFOAM を用いた 超大規模計算モデル作成とその性能の評価 清水建設株式会社 PHAM VAN PHUC 内山学 京 での OpenFOAM に関する取組み 第 1 回 OpenFOAM ワークショップ (2013) コード移植 10 億格子計算の壁 解決策 ( プリ ポスト ) 第 2 回 OpenFOAM ワークショップ (2014) 1 万並列計算の壁 解決策 (MPI プラットフォーム
Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]
![Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]](/thumbs/102/156675429.jpg "Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]") 200/0/9 数値流体解析の並列効率とその GPU による高速化の試み 清水建設 ( 株 ) 技術研究所 PHAM VAN PHUC ( ファムバンフック ) 流体計算時間短縮と GPU の活用の試み 現 CPUとの比較によりGPU 活用の可能性 現 CPU の最大利用 ノード内の最大計算資源の利用 すべてCPUコアの利用 適切なアルゴリズムの利用 CPU コア性能の何倍? GPU の利用の試み
200/0/9 数値流体解析の並列効率とその GPU による高速化の試み 清水建設 ( 株 ) 技術研究所 PHAM VAN PHUC ( ファムバンフック ) 流体計算時間短縮と GPU の活用の試み 現 CPUとの比較によりGPU 活用の可能性 現 CPU の最大利用 ノード内の最大計算資源の利用 すべてCPUコアの利用 適切なアルゴリズムの利用 CPU コア性能の何倍? GPU の利用の試み
EnSightのご紹介
 オープン CAE シンポジウム 2014 汎用ポストプロセッサー EnSight の大規模データ対応 CEI ソフトウェア株式会社代表取締役吉川慈人 http://www.ceisoftware.co.jp/ 内容 大規模データで時間のかかる処理 クライアント サーバー機能 マルチスレッドによる並列処理 サーバーの分散処理 クライアントの分散処理 ( 分散レンダリング ) EnSightのOpenFOAMインターフェース
オープン CAE シンポジウム 2014 汎用ポストプロセッサー EnSight の大規模データ対応 CEI ソフトウェア株式会社代表取締役吉川慈人 http://www.ceisoftware.co.jp/ 内容 大規模データで時間のかかる処理 クライアント サーバー機能 マルチスレッドによる並列処理 サーバーの分散処理 クライアントの分散処理 ( 分散レンダリング ) EnSightのOpenFOAMインターフェース
ParallelCalculationSeminar_imano.key
 1 OPENFOAM(R) is a registered trade mark of OpenCFD Limited, the producer of the OpenFOAM software and owner of the OPENFOAM(R) and OpenCFD(R) trade marks. 2 3 Open FOAM の歴史 1989年ー2000年 研究室のハウスコード 開発元
1 OPENFOAM(R) is a registered trade mark of OpenCFD Limited, the producer of the OpenFOAM software and owner of the OPENFOAM(R) and OpenCFD(R) trade marks. 2 3 Open FOAM の歴史 1989年ー2000年 研究室のハウスコード 開発元
<4D F736F F F696E74202D2091E63489F15F436F6D C982E682E992B48D8291AC92B489B F090CD2888F38DFC E B8CDD8
 Web キャンパス資料 超音波シミュレーションの基礎 ~ 第 4 回 ComWAVEによる超高速超音波解析 ~ 科学システム開発部 Copyright (c)2006 ITOCHU Techno-Solutions Corporation 本日の説明内容 ComWAVEの概要および特徴 GPGPUとは GPGPUによる解析事例 CAE POWER 超音波研究会開催 (10 月 3 日 ) のご紹介
Web キャンパス資料 超音波シミュレーションの基礎 ~ 第 4 回 ComWAVEによる超高速超音波解析 ~ 科学システム開発部 Copyright (c)2006 ITOCHU Techno-Solutions Corporation 本日の説明内容 ComWAVEの概要および特徴 GPGPUとは GPGPUによる解析事例 CAE POWER 超音波研究会開催 (10 月 3 日 ) のご紹介
スライド 1
 計算科学が拓く世界スーパーコンピュータは何故スーパーか 学術情報メディアセンター中島浩 http://www.para.media.kyoto-u.ac.jp/jp/ username=super password=computer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
計算科学が拓く世界スーパーコンピュータは何故スーパーか 学術情報メディアセンター中島浩 http://www.para.media.kyoto-u.ac.jp/jp/ username=super password=computer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
HPC (pay-as-you-go) HPC Web 2
 HPC Web 2") ,, 1 HPC (pay-as-you-go) HPC Web 2 HPC Amazon EC2 OpenFOAM GPU EC2 3 HPC MPI MPI Courant 1 GPGPU MPI 4 AMAZON EC2 GPU CLUSTER COMPUTE INSTANCE EC2 GPU (cg1.4xlarge) ( N. Virgina ) Quadcore Intel Xeon 5570
,, 1 HPC (pay-as-you-go) HPC Web 2 HPC Amazon EC2 OpenFOAM GPU EC2 3 HPC MPI MPI Courant 1 GPGPU MPI 4 AMAZON EC2 GPU CLUSTER COMPUTE INSTANCE EC2 GPU (cg1.4xlarge) ( N. Virgina ) Quadcore Intel Xeon 5570
密集市街地における換気・通風性能簡易評価ツールの開発 (その2 流体計算部分の開発)」
」") OpenCAE ワークショップ 2013 2013.6.21 密集市街地における換気 通風性能簡易評価ツールの開発その 2 : 流体計算部分の開発 福本雅彦 ( 株式会社森村設計 ) 小縣信也 ( 株式会社森村設計 ) 勝又済 ( 国土交通省国土技術政策総合研究所 ) 西澤繁毅 ( 国土交通省国土技術政策総合研究所 ) 岩見達也 ( 国土交通省国土技術政策総合研究所 ) 概要 換気 通風性能簡易評価ツール
OpenCAE ワークショップ 2013 2013.6.21 密集市街地における換気 通風性能簡易評価ツールの開発その 2 : 流体計算部分の開発 福本雅彦 ( 株式会社森村設計 ) 小縣信也 ( 株式会社森村設計 ) 勝又済 ( 国土交通省国土技術政策総合研究所 ) 西澤繁毅 ( 国土交通省国土技術政策総合研究所 ) 岩見達也 ( 国土交通省国土技術政策総合研究所 ) 概要 換気 通風性能簡易評価ツール
Microsoft Word ●IntelクアッドコアCPUでのベンチマーク_吉岡_ _更新__ doc
 2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
PowerPoint プレゼンテーション
 総務省 ICTスキル総合習得教材 概要版 eラーニング用 [ コース2] データ蓄積 2-5: 多様化が進展するクラウドサービス [ コース1] データ収集 [ コース2] データ蓄積 [ コース3] データ分析 [ コース4] データ利活用 1 2 3 4 5 座学本講座の学習内容 (2-5: 多様化が進展するクラウドサービス ) 講座概要 近年 注目されているクラウドの関連技術を紹介します PCやサーバを構成するパーツを紹介後
総務省 ICTスキル総合習得教材 概要版 eラーニング用 [ コース2] データ蓄積 2-5: 多様化が進展するクラウドサービス [ コース1] データ収集 [ コース2] データ蓄積 [ コース3] データ分析 [ コース4] データ利活用 1 2 3 4 5 座学本講座の学習内容 (2-5: 多様化が進展するクラウドサービス ) 講座概要 近年 注目されているクラウドの関連技術を紹介します PCやサーバを構成するパーツを紹介後
MATLAB® における並列・分散コンピューティング ~ Parallel Computing Toolbox™ & MATLAB Distributed Computing Server™ ~
 MATLAB における並列 分散コンピューティング ~ Parallel Computing Toolbox & MATLAB Distributed Computing Server ~ MathWorks Japan Application Engineering Group Takashi Yoshida 2016 The MathWorks, Inc. 1 System Configuration
MATLAB における並列 分散コンピューティング ~ Parallel Computing Toolbox & MATLAB Distributed Computing Server ~ MathWorks Japan Application Engineering Group Takashi Yoshida 2016 The MathWorks, Inc. 1 System Configuration
ERDAS IMAGINE における処理速度の向上 株式会社ベストシステムズ PASCO CORPORATION 2015
 ERDAS IMAGINE における処理速度の向上 株式会社ベストシステムズ 本セッションの目的 本セッションでは ERDAS IMAGINEにおける処理速度向上を目的として機器 (SSD 等 ) 及び並列処理の比較 検討を行った 1.SSD 及び RAMDISK を利用した処理速度の検証 2.Condorによる複数 PCを用いた並列処理 2.1 分散並列処理による高速化試験 (ERDAS IMAGINEのCondorを使用した試験
ERDAS IMAGINE における処理速度の向上 株式会社ベストシステムズ 本セッションの目的 本セッションでは ERDAS IMAGINEにおける処理速度向上を目的として機器 (SSD 等 ) 及び並列処理の比較 検討を行った 1.SSD 及び RAMDISK を利用した処理速度の検証 2.Condorによる複数 PCを用いた並列処理 2.1 分散並列処理による高速化試験 (ERDAS IMAGINEのCondorを使用した試験
Microsoft PowerPoint - 演習1:並列化と評価.pptx
 講義 2& 演習 1 プログラム並列化と性能評価 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 1 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 2 2 次元温度分布の計算
講義 2& 演習 1 プログラム並列化と性能評価 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 1 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 2 2 次元温度分布の計算
技術資料 JARI Research Journal OpenFOAM を用いた沿道大気質モデルの開発 Development of a Roadside Air Quality Model with OpenFOAM 木村真 *1 Shin KIMURA 伊藤晃佳 *2 Akiy
 技術資料 176 OpenFOAM を用いた沿道大気質モデルの開発 Development of a Roadside Air Quality Model with OpenFOAM 木村真 *1 Shin KIMURA 伊藤晃佳 *2 Akiyoshi ITO 1. はじめに自動車排出ガスの環境影響は, 道路沿道で大きく, 建物など構造物が複雑な気流を形成するため, 沿道大気中の自動車排出ガス濃度分布も複雑になる.
技術資料 176 OpenFOAM を用いた沿道大気質モデルの開発 Development of a Roadside Air Quality Model with OpenFOAM 木村真 *1 Shin KIMURA 伊藤晃佳 *2 Akiyoshi ITO 1. はじめに自動車排出ガスの環境影響は, 道路沿道で大きく, 建物など構造物が複雑な気流を形成するため, 沿道大気中の自動車排出ガス濃度分布も複雑になる.
PowerPoint プレゼンテーション
 2011/12/2 オープンCAEシンポジウム2011 オープンCAEを活用した 大規模高速演算及び 大規模モデルの取扱 株式会社デンソー 技術管理部 CAE開発設計 促進室 野村悦治 今川洋造 背景 http://top500.org/ 2 / 27 705,024コア 数千コア FOCUSスパコン利用料金表 http://www.j-focus.or.jp/spacon/pricelist_spacon.pdf
2011/12/2 オープンCAEシンポジウム2011 オープンCAEを活用した 大規模高速演算及び 大規模モデルの取扱 株式会社デンソー 技術管理部 CAE開発設計 促進室 野村悦治 今川洋造 背景 http://top500.org/ 2 / 27 705,024コア 数千コア FOCUSスパコン利用料金表 http://www.j-focus.or.jp/spacon/pricelist_spacon.pdf
PowerPoint Presentation
 Embedded CFD 1D-3D 連成によるエンジンコンパートメント熱収支解析手法の提案 June 9, 2017 . アジェンダ Embedded CFD 概要 エンコパ内風流れデモモデル 他用途への適用可能性, まとめ V サイクルにおける,1D-3D シミュレーションの使い分け ( 現状 ) 1D 機能的表現 企画 & 初期設計 詳細 3D 形状情報の無い段階 1D 1D 空気流れ計算精度に限度
Embedded CFD 1D-3D 連成によるエンジンコンパートメント熱収支解析手法の提案 June 9, 2017 . アジェンダ Embedded CFD 概要 エンコパ内風流れデモモデル 他用途への適用可能性, まとめ V サイクルにおける,1D-3D シミュレーションの使い分け ( 現状 ) 1D 機能的表現 企画 & 初期設計 詳細 3D 形状情報の無い段階 1D 1D 空気流れ計算精度に限度
<4D F736F F D20332E322E332E819C97AC91CC89F090CD82A982E78CA982E9466F E393082CC8D5C91A291CC90AB945C955D89BF5F8D8296D85F F8D F5F E646F63>
 3.2.3. 流体解析から見る Fortran90 の構造体性能評価 宇宙航空研究開発機構 高木亮治 1. はじめに Fortran90 では 構造体 動的配列 ポインターなど様々な便利な機能が追加され ユーザーがプログラムを作成する際に選択の幅が広がりより便利になった 一方で 実際のアプリケーションプログラムを開発する際には 解析対象となる物理現象を記述する数学モデルやそれらを解析するための計算手法が内包する階層構造を反映したプログラムを作成できるかどうかは一つの重要な観点であると考えられる
3.2.3. 流体解析から見る Fortran90 の構造体性能評価 宇宙航空研究開発機構 高木亮治 1. はじめに Fortran90 では 構造体 動的配列 ポインターなど様々な便利な機能が追加され ユーザーがプログラムを作成する際に選択の幅が広がりより便利になった 一方で 実際のアプリケーションプログラムを開発する際には 解析対象となる物理現象を記述する数学モデルやそれらを解析するための計算手法が内包する階層構造を反映したプログラムを作成できるかどうかは一つの重要な観点であると考えられる
次 CAE を取り巻く環境と展望 企業がシミュレーションに抱える痛み :3 つの例 クラウド CAE サービス Cistr Cistr のシステム概要 最新版 Cistr でできること Cistr を利 してみる 2
 クラウド CAE サービス 東京 学 学院新領域創成科学研究科 森 直樹, 井原遊, 野達 1 次 CAE を取り巻く環境と展望 企業がシミュレーションに抱える痛み :3 つの例 クラウド CAE サービス Cistr Cistr のシステム概要 最新版 Cistr でできること Cistr を利 してみる 2 CAE を取り巻く環境と展望 3 国内市場規模は約 3400 億円程度 2015 年度の国内
クラウド CAE サービス 東京 学 学院新領域創成科学研究科 森 直樹, 井原遊, 野達 1 次 CAE を取り巻く環境と展望 企業がシミュレーションに抱える痛み :3 つの例 クラウド CAE サービス Cistr Cistr のシステム概要 最新版 Cistr でできること Cistr を利 してみる 2 CAE を取り巻く環境と展望 3 国内市場規模は約 3400 億円程度 2015 年度の国内
Microsoft Word - HOKUSAI_system_overview_ja.docx
 HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司
![4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司](/thumbs/97/131936032.jpg "4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司") 4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
cp-7. 配列
 cp-7. 配列 (C プログラムの書き方を, パソコン演習で学ぶシリーズ ) https://www.kkaneko.jp/cc/adp/index.html 金子邦彦 1 本日の内容 例題 1. 月の日数配列とは. 配列の宣言. 配列の添え字. 例題 2. ベクトルの内積例題 3. 合計点と平均点例題 4. 棒グラフを描く配列と繰り返し計算の関係例題 5. 行列の和 2 次元配列 2 今日の到達目標
cp-7. 配列 (C プログラムの書き方を, パソコン演習で学ぶシリーズ ) https://www.kkaneko.jp/cc/adp/index.html 金子邦彦 1 本日の内容 例題 1. 月の日数配列とは. 配列の宣言. 配列の添え字. 例題 2. ベクトルの内積例題 3. 合計点と平均点例題 4. 棒グラフを描く配列と繰り返し計算の関係例題 5. 行列の和 2 次元配列 2 今日の到達目標
粒子画像流速測定法を用いた室内流速測定法に関する研究
 可視化手法を用いた室内気流分布の測定法に関する研究 -PIV を用いた通風時及び空調吹出気流の測定 - T08K729D 大久保肇 指導教員 赤林伸一教授 流れの可視化は古来より流れの特性を直感的に把握する手法として様々な測定法が試みられている 近年の画像処理技術の発展及び PC の性能向上により粒子画像流速測定法 (PIV ) が実用化されている Particle Image Velocimetry
可視化手法を用いた室内気流分布の測定法に関する研究 -PIV を用いた通風時及び空調吹出気流の測定 - T08K729D 大久保肇 指導教員 赤林伸一教授 流れの可視化は古来より流れの特性を直感的に把握する手法として様々な測定法が試みられている 近年の画像処理技術の発展及び PC の性能向上により粒子画像流速測定法 (PIV ) が実用化されている Particle Image Velocimetry
CCS HPCサマーセミナー 並列数値計算アルゴリズム
 大規模系での高速フーリエ変換 2 高橋大介 daisuke@cs.tsukuba.ac.jp 筑波大学計算科学研究センター 2016/6/2 計算科学技術特論 B 1 講義内容 並列三次元 FFT における自動チューニング 二次元分割を用いた並列三次元 FFT アルゴリズム GPU クラスタにおける並列三次元 FFT 2016/6/2 計算科学技術特論 B 2 並列三次元 FFT における 自動チューニング
大規模系での高速フーリエ変換 2 高橋大介 daisuke@cs.tsukuba.ac.jp 筑波大学計算科学研究センター 2016/6/2 計算科学技術特論 B 1 講義内容 並列三次元 FFT における自動チューニング 二次元分割を用いた並列三次元 FFT アルゴリズム GPU クラスタにおける並列三次元 FFT 2016/6/2 計算科学技術特論 B 2 並列三次元 FFT における 自動チューニング
並列・高速化を実現するための 高速化サービスの概要と事例紹介
 第 4 回 AVS 可視化フォーラム 2019 並列 高速化を実現するための 高速化サービスの概要と事例紹介 株式会社アーク情報システム営業部仮野亮ソリューション技術部佐々木竜一 2019.08.30 はじめに アーク情報システムの紹介 高速化サービスとは? 事例紹介 コンサルティングサービスについて アーク情報システムの紹介 設立 資本金 :1987 年 10 月 :3 億 600 万円 従業員数
第 4 回 AVS 可視化フォーラム 2019 並列 高速化を実現するための 高速化サービスの概要と事例紹介 株式会社アーク情報システム営業部仮野亮ソリューション技術部佐々木竜一 2019.08.30 はじめに アーク情報システムの紹介 高速化サービスとは? 事例紹介 コンサルティングサービスについて アーク情報システムの紹介 設立 資本金 :1987 年 10 月 :3 億 600 万円 従業員数
CAE/CFD Revolution2007セミナー社長挨拶
 Ver19 ~ さらなる軽量化を実現するための具体的ノウハウを紹介 ~ 主催株式会社ヴァイナス 2009 年 7 月 代表取締役社長藤川泰彦 fujikawa@vinas.com 1 事業近況 設立 1996 年 3 月 事業所 ( 営業サポート拠点 ) 本社大阪 東京営業所 名古屋営業所 資本金 : 1 億 60 百万円 売上高 : 8 億 25 百万円 社員数 : 48 名 本社 ( 大阪北区京阪堂島ビル
Ver19 ~ さらなる軽量化を実現するための具体的ノウハウを紹介 ~ 主催株式会社ヴァイナス 2009 年 7 月 代表取締役社長藤川泰彦 fujikawa@vinas.com 1 事業近況 設立 1996 年 3 月 事業所 ( 営業サポート拠点 ) 本社大阪 東京営業所 名古屋営業所 資本金 : 1 億 60 百万円 売上高 : 8 億 25 百万円 社員数 : 48 名 本社 ( 大阪北区京阪堂島ビル
NUMAの構成
 共有メモリを使ったデータ交換と同期 慶應義塾大学理工学部 天野英晴 hunga@am.ics.keio.ac.jp 同期の必要性 あるプロセッサが共有メモリに書いても 別のプロセッサにはそのことが分からない 同時に同じ共有変数に書き込みすると 結果がどうなるか分からない そもそも共有メモリって結構危険な代物 多くのプロセッサが並列に動くには何かの制御機構が要る 不可分命令 同期用メモリ バリア同期機構
共有メモリを使ったデータ交換と同期 慶應義塾大学理工学部 天野英晴 hunga@am.ics.keio.ac.jp 同期の必要性 あるプロセッサが共有メモリに書いても 別のプロセッサにはそのことが分からない 同時に同じ共有変数に書き込みすると 結果がどうなるか分からない そもそも共有メモリって結構危険な代物 多くのプロセッサが並列に動くには何かの制御機構が要る 不可分命令 同期用メモリ バリア同期機構
平成 22 年度 革新的な三次元映像技術による超臨場感コミュニケーション技術研究開発 の開発成果について 1. 施策の目標 人体を収容できる大きさの 3 次元音響空間についてリアルタイムに音響レンダリングできるシステム ( シリコンコンサートホール ) を 2013 年までに開発する 具体的には,
 を 2013 年までに開発する 具体的には,") 平成 22 年度 革新的な三次元映像技術による超臨場感コミュニケーション技術研究開発 の開発成果について 1. 施策の目標 人体を収容できる大きさの 3 次元音響空間についてリアルタイムに音響レンダリングできるシステム ( シリコンコンサートホール ) を 2013 年までに開発する 具体的には, 直方体領域 (2m 2m 4m 程度 ) の室内音場を想定し, 音声周波数帯域 (3kHz まで )
平成 22 年度 革新的な三次元映像技術による超臨場感コミュニケーション技術研究開発 の開発成果について 1. 施策の目標 人体を収容できる大きさの 3 次元音響空間についてリアルタイムに音響レンダリングできるシステム ( シリコンコンサートホール ) を 2013 年までに開発する 具体的には, 直方体領域 (2m 2m 4m 程度 ) の室内音場を想定し, 音声周波数帯域 (3kHz まで )
PowerPoint プレゼンテーション
 各種計算機アプリケーション性能比較 目次. はじめに. 行列積計算.QDR 積計算 4.N 体問題計算 5. 多次元積分計算 5. 次元積分計算 5. 次元積分計算 5. 4 次元積分計算 5.4 5 次元積分計算 5.5 6 次元積分計算 平成 6 年度第 四半期 . はじめに 今までと少し性質の異なるグラフィックボードが使用できる様になったので従来のアプリケーションで性能比較を実施しました 主に使用した計算機は以下のものです
各種計算機アプリケーション性能比較 目次. はじめに. 行列積計算.QDR 積計算 4.N 体問題計算 5. 多次元積分計算 5. 次元積分計算 5. 次元積分計算 5. 4 次元積分計算 5.4 5 次元積分計算 5.5 6 次元積分計算 平成 6 年度第 四半期 . はじめに 今までと少し性質の異なるグラフィックボードが使用できる様になったので従来のアプリケーションで性能比較を実施しました 主に使用した計算機は以下のものです
hpc141_shirahata.pdf
 GPU アクセラレータと不揮発性メモリ を考慮した I/O 性能の予備評価 白幡晃一 1,2 佐藤仁 1,2 松岡聡 1 1: 東京工業大学 2: JST CREST 1 GPU と不揮発性メモリを用いた 大規模データ処理 大規模データ処理 センサーネットワーク 遺伝子情報 SNS など ペタ ヨッタバイト級 高速処理が必要 スーパーコンピュータ上での大規模データ処理 GPU 高性能 高バンド幅 例
GPU アクセラレータと不揮発性メモリ を考慮した I/O 性能の予備評価 白幡晃一 1,2 佐藤仁 1,2 松岡聡 1 1: 東京工業大学 2: JST CREST 1 GPU と不揮発性メモリを用いた 大規模データ処理 大規模データ処理 センサーネットワーク 遺伝子情報 SNS など ペタ ヨッタバイト級 高速処理が必要 スーパーコンピュータ上での大規模データ処理 GPU 高性能 高バンド幅 例
Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ 3.7x faster P100 V100 P10
 NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
組込み Linux の起動高速化 株式会社富士通コンピュータテクノロジーズ 亀山英司 1218ka01 Copyright 2013 FUJITSU COMPUTER TECHNOLOGIES LIMITED
 組込み Linux の起動高速化 株式会社富士通コンピュータテクノロジーズ 亀山英司 1218ka01 組込み Linux における起動高速化 組込み Linux の起動時間短縮について依頼あり スペック CPU : Cortex-A9 ( 800MB - single) RAM: 500MB 程度 要件 起動時間 画出し 5 秒 音出し 3 秒 終了時間 数 ms で電源断 1 課題と対策 問題点
組込み Linux の起動高速化 株式会社富士通コンピュータテクノロジーズ 亀山英司 1218ka01 組込み Linux における起動高速化 組込み Linux の起動時間短縮について依頼あり スペック CPU : Cortex-A9 ( 800MB - single) RAM: 500MB 程度 要件 起動時間 画出し 5 秒 音出し 3 秒 終了時間 数 ms で電源断 1 課題と対策 問題点
STAR-CCM+ の大規模並列化仕様とクラウドライセンス (PoD) ソリューション 株式会社 CD-adapco 吉田稔彦
 ソリューション 株式会社 CD-adapco 吉田稔彦") STAR-CCM+ の大規模並列化仕様とクラウドライセンス (PoD) ソリューション 株式会社 CD-adapco 吉田稔彦 大規模モデルと STAR-CCM+ ソフトウエア側の対応機能 クライアント サーバアーキテクチャ ( リリース当初からの設計仕様 ) 区分化 (Partitioning) 機能の実装 (V8.04) パフォーマンス改善 (V8.02, V8.04) パラレルトリマーの実装
STAR-CCM+ の大規模並列化仕様とクラウドライセンス (PoD) ソリューション 株式会社 CD-adapco 吉田稔彦 大規模モデルと STAR-CCM+ ソフトウエア側の対応機能 クライアント サーバアーキテクチャ ( リリース当初からの設計仕様 ) 区分化 (Partitioning) 機能の実装 (V8.04) パフォーマンス改善 (V8.02, V8.04) パラレルトリマーの実装
1
 1 2 OpenFOAMの特徴 @T +r T @t r ( T ) = ST solve(fvm::ddt(t) + fvm::div(phi,t) - fvm::laplacian(dt,t) == fvoptions(t)); ポリヘドラル 境界適合Hex メッシャー C++ マルチフィジックス 乱流モデル: RAS, LES, DES, 線型ソルバー : AMG, PCG, PBiCG, 離散化スキーム:
1 2 OpenFOAMの特徴 @T +r T @t r ( T ) = ST solve(fvm::ddt(t) + fvm::div(phi,t) - fvm::laplacian(dt,t) == fvoptions(t)); ポリヘドラル 境界適合Hex メッシャー C++ マルチフィジックス 乱流モデル: RAS, LES, DES, 線型ソルバー : AMG, PCG, PBiCG, 離散化スキーム:
Coding theorems for correlated sources with cooperative information
 MCMC-based particle filter を用いた人間の映像注視行動の実時間推定 2009 年 7 月 21 日 宮里洸司 (2) 木村昭悟 (1) 高木茂 (2) 大和淳司 (1) 柏野邦夫 (1) (1) 日本電信電話 ( 株 )NTT コミュニケーション科学基礎研究所メディア情報研究部メディア認識研究グループ (2) 国立沖縄工業高等専門学校情報通信システム工学科 背景 ヒトはどのようにして
MCMC-based particle filter を用いた人間の映像注視行動の実時間推定 2009 年 7 月 21 日 宮里洸司 (2) 木村昭悟 (1) 高木茂 (2) 大和淳司 (1) 柏野邦夫 (1) (1) 日本電信電話 ( 株 )NTT コミュニケーション科学基礎研究所メディア情報研究部メディア認識研究グループ (2) 国立沖縄工業高等専門学校情報通信システム工学科 背景 ヒトはどのようにして
データセンターの効率的な資源活用のためのデータ収集・照会システムの設計
 データセンターの効率的な 資源活用のためのデータ収集 照会システムの設計 株式会社ネットワーク応用通信研究所前田修吾 2014 年 11 月 20 日 本日のテーマ データセンターの効率的な資源活用のためのデータ収集 照会システムの設計 時系列データを効率的に扱うための設計 1 システムの目的 データセンター内の機器のセンサーなどからデータを取集し その情報を元に機器の制御を行うことで 電力消費量を抑制する
データセンターの効率的な 資源活用のためのデータ収集 照会システムの設計 株式会社ネットワーク応用通信研究所前田修吾 2014 年 11 月 20 日 本日のテーマ データセンターの効率的な資源活用のためのデータ収集 照会システムの設計 時系列データを効率的に扱うための設計 1 システムの目的 データセンター内の機器のセンサーなどからデータを取集し その情報を元に機器の制御を行うことで 電力消費量を抑制する
スライド 0
 2012/7/11 OpeMP を用いた Fortra コードの並列化基礎セミナー 株式会社計算力学研究センター 技術 1 部三又秀行 mimata@rccm.co.jp 目次 高速化 並列化事例 PARDISO について (XLsoft 黒澤様 ) 並列化 並列化について 並列化作業の流れ 並列化の手段 OpeMP デモ OpeMP で並列計算する 円周率 p の計算 (private reductio)
2012/7/11 OpeMP を用いた Fortra コードの並列化基礎セミナー 株式会社計算力学研究センター 技術 1 部三又秀行 mimata@rccm.co.jp 目次 高速化 並列化事例 PARDISO について (XLsoft 黒澤様 ) 並列化 並列化について 並列化作業の流れ 並列化の手段 OpeMP デモ OpeMP で並列計算する 円周率 p の計算 (private reductio)
地図情報の差分更新・自動図化 概要版
 戦略的イノベーション創造プログラム (SIP) 自動走行システム / / 大規模実証実験 / ダイナミックマップ / 地図情報の差分更新 自動図化 報告書 平成 29 年度報告 平成 30 年 3 月 31 日 三菱電機株式会社 目次 1. 研究開発の目的 2. 静的高精度 3D 地図データの自動図化 / 差分抽出技術の実用性検証 (2) 自動図化 / 差分抽出技術適用による改善効果検証 3. リアルタイム自動図化
戦略的イノベーション創造プログラム (SIP) 自動走行システム / / 大規模実証実験 / ダイナミックマップ / 地図情報の差分更新 自動図化 報告書 平成 29 年度報告 平成 30 年 3 月 31 日 三菱電機株式会社 目次 1. 研究開発の目的 2. 静的高精度 3D 地図データの自動図化 / 差分抽出技術の実用性検証 (2) 自動図化 / 差分抽出技術適用による改善効果検証 3. リアルタイム自動図化
Microsoft PowerPoint - 高速化WS富山.pptx
 京 における 高速化ワークショップ 性能分析 チューニングの手順について 登録施設利用促進機関 一般財団法人高度情報科学技術研究機構富山栄治 一般財団法人高度情報科学技術研究機構 2 性能分析 チューニング手順 どの程度の並列数が実現可能か把握する インバランスの懸念があるか把握する タイムステップループ I/O 処理など注目すべき箇所を把握する 並列数 並列化率などの目標を設定し チューニング時の指針とする
京 における 高速化ワークショップ 性能分析 チューニングの手順について 登録施設利用促進機関 一般財団法人高度情報科学技術研究機構富山栄治 一般財団法人高度情報科学技術研究機構 2 性能分析 チューニング手順 どの程度の並列数が実現可能か把握する インバランスの懸念があるか把握する タイムステップループ I/O 処理など注目すべき箇所を把握する 並列数 並列化率などの目標を設定し チューニング時の指針とする
【資料3】エクサスケール時代に向けたソフトウェアベンダの産業利用に対する考え方・将来展望
 資料 3 市販ソフトウェアの産業利用に対する将来展望についてヒアリング エクサスケール時代に向けたソフトウェアベンダの産業利用に対する考え方 将来展望 産業利用アプリケーション検討サブワーキンググループ ( 第 3 回 ) 2013 年 9 月 17 日 株式会社ソフトウェアクレイドル技術部黒石浩之 1 目次 ソフトウェアクレイドルについて 現状について エクサスケール時代における実用的な使われ方のビジョン
資料 3 市販ソフトウェアの産業利用に対する将来展望についてヒアリング エクサスケール時代に向けたソフトウェアベンダの産業利用に対する考え方 将来展望 産業利用アプリケーション検討サブワーキンググループ ( 第 3 回 ) 2013 年 9 月 17 日 株式会社ソフトウェアクレイドル技術部黒石浩之 1 目次 ソフトウェアクレイドルについて 現状について エクサスケール時代における実用的な使われ方のビジョン
スパコンに通じる並列プログラミングの基礎
 2018.09.10 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 1 / 59 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 2 / 59 Windows, Mac Unix 0444-J furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 3 / 59 Part I Unix GUI CUI:
2018.09.10 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 1 / 59 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 2 / 59 Windows, Mac Unix 0444-J furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 3 / 59 Part I Unix GUI CUI:
スパコンに通じる並列プログラミングの基礎
 2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
本文ALL.indd
 Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法河辺峻田口成美古谷英祐 Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法 Performance Measurement Method of Cache Coherency Effects on an Intel Xeon Processor System 河辺峻田口成美古谷英祐
Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法河辺峻田口成美古谷英祐 Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法 Performance Measurement Method of Cache Coherency Effects on an Intel Xeon Processor System 河辺峻田口成美古谷英祐
コンピュータグラフィックス第8回
 コンピュータグラフィックス 第 8 回 レンダリング技法 1 ~ 基礎と概要, 隠面消去 ~ 理工学部 兼任講師藤堂英樹 レポート提出状況 課題 1 の選択が多い (STAND BY ME ドラえもん ) 体験演習型 ( 課題 3, 課題 4) の選択も多い 内訳 課題 1 課題 2 課題 3 課題 4 課題 5 2014/11/24 コンピュータグラフィックス 2 次回レポートの体験演習型 メタセコイア,
コンピュータグラフィックス 第 8 回 レンダリング技法 1 ~ 基礎と概要, 隠面消去 ~ 理工学部 兼任講師藤堂英樹 レポート提出状況 課題 1 の選択が多い (STAND BY ME ドラえもん ) 体験演習型 ( 課題 3, 課題 4) の選択も多い 内訳 課題 1 課題 2 課題 3 課題 4 課題 5 2014/11/24 コンピュータグラフィックス 2 次回レポートの体験演習型 メタセコイア,
スライド 1
 知能制御システム学 画像処理の高速化 OpenCV による基礎的な例 東北大学大学院情報科学研究科鏡慎吾 swk(at)ic.is.tohoku.ac.jp 2007.07.03 リアルタイム処理と高速化 リアルタイム = 高速 ではない 目標となる時間制約が定められているのがリアルタイム処理である.34 ms かかった処理が 33 ms に縮んだだけでも, それによって与えられた時間制約が満たされるのであれば,
知能制御システム学 画像処理の高速化 OpenCV による基礎的な例 東北大学大学院情報科学研究科鏡慎吾 swk(at)ic.is.tohoku.ac.jp 2007.07.03 リアルタイム処理と高速化 リアルタイム = 高速 ではない 目標となる時間制約が定められているのがリアルタイム処理である.34 ms かかった処理が 33 ms に縮んだだけでも, それによって与えられた時間制約が満たされるのであれば,
Microsoft PowerPoint - OpenMP入門.pptx
 OpenMP 入門 須田礼仁 2009/10/30 初版 OpenMP 共有メモリ並列処理の標準化 API http://openmp.org/ 最新版は 30 3.0 バージョンによる違いはあまり大きくない サポートしているバージョンはともかく csp で動きます gcc も対応しています やっぱり SPMD Single Program Multiple Data プログラム #pragma omp
OpenMP 入門 須田礼仁 2009/10/30 初版 OpenMP 共有メモリ並列処理の標準化 API http://openmp.org/ 最新版は 30 3.0 バージョンによる違いはあまり大きくない サポートしているバージョンはともかく csp で動きます gcc も対応しています やっぱり SPMD Single Program Multiple Data プログラム #pragma omp
修士論文
 AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
差分スキーム 物理 化学 生物現象には微分方程式でモデル化される例が多い モデルを使って現実の現象をコンピュータ上で再現することをシミュレーション ( 数値シミュレーション コンピュータシミュレーション ) と呼ぶ そのためには 微分方程式をコンピュータ上で計算できる数値スキームで近似することが必要
 と呼ぶ そのためには 微分方程式をコンピュータ上で計算できる数値スキームで近似することが必要") 差分スキーム 物理 化学 生物現象には微分方程式でモデル化される例が多い モデルを使って現実の現象をコンピュータ上で再現することをシミュレーション ( 数値シミュレーション コンピュータシミュレーション ) と呼ぶ そのためには 微分方程式をコンピュータ上で計算できる数値スキームで近似することが必要になる その一つの方法が微分方程式を差分方程式におき直すことである 微分方程式の差分化 次の 1 次元境界値問題を考える
差分スキーム 物理 化学 生物現象には微分方程式でモデル化される例が多い モデルを使って現実の現象をコンピュータ上で再現することをシミュレーション ( 数値シミュレーション コンピュータシミュレーション ) と呼ぶ そのためには 微分方程式をコンピュータ上で計算できる数値スキームで近似することが必要になる その一つの方法が微分方程式を差分方程式におき直すことである 微分方程式の差分化 次の 1 次元境界値問題を考える
製品開発の現場では 各種のセンサーや測定環境を利用したデータ解析が行われ シミュレーションや動作検証等に役立てられています しかし 日々収集されるデータ量は増加し 解析も複雑化しており データ解析の負荷は徐々に重くなっています 例えば自動車の車両計測データを解析する場合 取得したデータをそのまま解析
 ホワイトペーパー Excel と MATLAB の連携がデータ解析の課題を解決 製品開発の現場では 各種のセンサーや測定環境を利用したデータ解析が行われ シミュレーションや動作検証等に役立てられています しかし 日々収集されるデータ量は増加し 解析も複雑化しており データ解析の負荷は徐々に重くなっています 例えば自動車の車両計測データを解析する場合 取得したデータをそのまま解析に使用することはできず
ホワイトペーパー Excel と MATLAB の連携がデータ解析の課題を解決 製品開発の現場では 各種のセンサーや測定環境を利用したデータ解析が行われ シミュレーションや動作検証等に役立てられています しかし 日々収集されるデータ量は増加し 解析も複雑化しており データ解析の負荷は徐々に重くなっています 例えば自動車の車両計測データを解析する場合 取得したデータをそのまま解析に使用することはできず
Microsoft PowerPoint - stream.ppt [互換モード]
![Microsoft PowerPoint - stream.ppt [互換モード]](/thumbs/94/118945109.jpg "Microsoft PowerPoint - stream.ppt [互換モード]") STREAM 1 Quad Opteron: ccnuma Arch. AMD Quad Opteron 2.3GHz Quad のソケット 4 1 ノード (16コア ) 各ソケットがローカルにメモリを持っている NUMA:Non-Uniform Access ローカルのメモリをアクセスして計算するようなプログラミング, データ配置, 実行時制御 (numactl) が必要 cc: cache-coherent
STREAM 1 Quad Opteron: ccnuma Arch. AMD Quad Opteron 2.3GHz Quad のソケット 4 1 ノード (16コア ) 各ソケットがローカルにメモリを持っている NUMA:Non-Uniform Access ローカルのメモリをアクセスして計算するようなプログラミング, データ配置, 実行時制御 (numactl) が必要 cc: cache-coherent
Microsoft PowerPoint - ARC-SWoPP2011OkaSlides.pptx
 データ値の局所性を利用した ライン共有キャッシュの提案 九州大学大学院 岡慶太郎 福本尚人 井上弘士 村上和彰 1 キャッシュメモリの大容量化 マルチコア プロセッサが主流 メモリウォール問題の深刻化 メモリアクセス要求増加 IOピンの制限 大容量の LL(Last Level) キャッシュを搭載 8MB の L3 キャッシュを搭載 Core i7 のチップ写真 * * http://www.atmarkit.co.jp/fsys/zunouhoudan/102zunou/corei7.html
データ値の局所性を利用した ライン共有キャッシュの提案 九州大学大学院 岡慶太郎 福本尚人 井上弘士 村上和彰 1 キャッシュメモリの大容量化 マルチコア プロセッサが主流 メモリウォール問題の深刻化 メモリアクセス要求増加 IOピンの制限 大容量の LL(Last Level) キャッシュを搭載 8MB の L3 キャッシュを搭載 Core i7 のチップ写真 * * http://www.atmarkit.co.jp/fsys/zunouhoudan/102zunou/corei7.html
研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI, MPICH, MVAPICH, MPI.NET プログラミングコストが高いため 生産性が悪い 新しい並
 XcalableMPによる NAS Parallel Benchmarksの実装と評価 中尾 昌広 李 珍泌 朴 泰祐 佐藤 三久 筑波大学 計算科学研究センター 筑波大学大学院 システム情報工学研究科 研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI,
XcalableMPによる NAS Parallel Benchmarksの実装と評価 中尾 昌広 李 珍泌 朴 泰祐 佐藤 三久 筑波大学 計算科学研究センター 筑波大学大学院 システム情報工学研究科 研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI,
enshu5_6.key
 情報知能工学演習V (前半第6週) 政田洋平 システム情報学研究科計算科学専攻 TA : 菅 新 菅沼智史 水曜 新行紗弓 馬淵隼 木曜 演習 V( 前半 ) の内容 第 1 週 : 高性能計算 (High Performance Computing = HPC) 向けプログラミングの基礎 第 2 週 : シミュレーションの基礎 第 3 週 : 波の移流方程式のシミュレーション 第 4,5 週 :
情報知能工学演習V (前半第6週) 政田洋平 システム情報学研究科計算科学専攻 TA : 菅 新 菅沼智史 水曜 新行紗弓 馬淵隼 木曜 演習 V( 前半 ) の内容 第 1 週 : 高性能計算 (High Performance Computing = HPC) 向けプログラミングの基礎 第 2 週 : シミュレーションの基礎 第 3 週 : 波の移流方程式のシミュレーション 第 4,5 週 :
<4D F736F F F696E74202D A A814590DA904796E291E882C991CE82B782E946726F6E CC95C097F190FC8C60835C838B836F815B82C982C282A282C42E >
 東京大学本郷キャンパス 工学部8号館 84講義室 (地下1階) アセンブリ 接触問題に対する FrontISTRの並列線形ソルバー について 2016年11月28日 第32回FrontISTR研究会 FrontISTRによる接触解析における機能拡張と計算事例 本研究開発は, 文部科学省ポスト 京 重点課題 8 近未来型ものづくりを先導する革新的設計 製造プロセスの開発 の一環として実施したものです
東京大学本郷キャンパス 工学部8号館 84講義室 (地下1階) アセンブリ 接触問題に対する FrontISTRの並列線形ソルバー について 2016年11月28日 第32回FrontISTR研究会 FrontISTRによる接触解析における機能拡張と計算事例 本研究開発は, 文部科学省ポスト 京 重点課題 8 近未来型ものづくりを先導する革新的設計 製造プロセスの開発 の一環として実施したものです
メモリ階層構造を考慮した大規模グラフ処理の高速化
 , CREST ERATO 0.. (, CREST) ERATO / 8 Outline NETAL (NETwork Analysis Library) NUMA BFS raph500, reenraph500 Kronecker raph Level Synchronized parallel BFS Hybrid Algorithm for Parallel BFS NUMA Hybrid
, CREST ERATO 0.. (, CREST) ERATO / 8 Outline NETAL (NETwork Analysis Library) NUMA BFS raph500, reenraph500 Kronecker raph Level Synchronized parallel BFS Hybrid Algorithm for Parallel BFS NUMA Hybrid
Microsoft PowerPoint _QSG AIR PRO WiFi_iphone.ppt
 P - [ ion アプリ ] iphone と WiFi 接続 STEP WiFi PODZ の電源をいれてください ランプが青く光ります ウォームアップに 5 秒ほどかかり 通信が可能になると点滅し始めます バッテリー残量が少なくなると WiFi 接続が不安定になることがあります その場合には フル充電後に再度お試しください! 注意! WiFi PODZ のファームウェアが最新でない場合 ion
P - [ ion アプリ ] iphone と WiFi 接続 STEP WiFi PODZ の電源をいれてください ランプが青く光ります ウォームアップに 5 秒ほどかかり 通信が可能になると点滅し始めます バッテリー残量が少なくなると WiFi 接続が不安定になることがあります その場合には フル充電後に再度お試しください! 注意! WiFi PODZ のファームウェアが最新でない場合 ion
슬라이드 1
 SoilWorks for FLIP 主な機能特徴 1 / 13 SoilWorks for FLIP Pre-Processing 1. CADのような形状作成 修正機能 AutoCAD感覚の使いやすいモデリングや修正機能 1 CADで形状をレイヤー整理したりDXFに変換しなくても Ctrl+C でコピーしてSoilWorks上で Ctrl+V で読込む 2. AutoCAD同様のコマンドキー入力による形状作成
SoilWorks for FLIP 主な機能特徴 1 / 13 SoilWorks for FLIP Pre-Processing 1. CADのような形状作成 修正機能 AutoCAD感覚の使いやすいモデリングや修正機能 1 CADで形状をレイヤー整理したりDXFに変換しなくても Ctrl+C でコピーしてSoilWorks上で Ctrl+V で読込む 2. AutoCAD同様のコマンドキー入力による形状作成
int main(int argc, char *argv[]) #include "setrootcase.h" #include "createtime.h" #include "createmesh.h" #include "createfields.h" #include "initcont
![int main(int argc, char *argv[]) #include setrootcase.h #include createtime.h #include createmesh.h #include createfields.h #include initcont](/thumbs/85/92072318.jpg "int main(int argc, char *argv[]) #include setrootcase.h #include createtime.h #include createmesh.h #include createfields.h #include initcont") 京 コンピュータでの C++ 型流体コードにおける MPI の評価 ファムバンフック 1 2 井上義昭 2 浅見暁 1 内山学 3 千葉修一 本研究では C++ オープンソース OpenFOAM を対象として, 利用しているデータ交換形態,C++ テンプレートおよび MPI プラットフォームの特徴とその課題を述べた. また, 京 コンピュータの Tofu 高機能バリア通信機能を活用して, データ型に合わせたテンプレートの追加による全体実行時間の軽減を確認した.
京 コンピュータでの C++ 型流体コードにおける MPI の評価 ファムバンフック 1 2 井上義昭 2 浅見暁 1 内山学 3 千葉修一 本研究では C++ オープンソース OpenFOAM を対象として, 利用しているデータ交換形態,C++ テンプレートおよび MPI プラットフォームの特徴とその課題を述べた. また, 京 コンピュータの Tofu 高機能バリア通信機能を活用して, データ型に合わせたテンプレートの追加による全体実行時間の軽減を確認した.
ソフト活用事例③自動Rawデータ管理システム
 ソフト活用事例 3 自動 Raw データ管理システム ACD/Labs NMR 無料講習会 & セミナー 2014 於 )2014.7.29 東京 /2014.7.31 大阪 富士通株式会社テクニカルコンピューティング ソリューション事業本部 HPC アプリケーション統括部 ACD/Spectrus をご選択頂いた理由 (NMR 領域 ) パワフルな解 析機能 ベンダーニュートラルな解析環境 直感的なインターフェース
ソフト活用事例 3 自動 Raw データ管理システム ACD/Labs NMR 無料講習会 & セミナー 2014 於 )2014.7.29 東京 /2014.7.31 大阪 富士通株式会社テクニカルコンピューティング ソリューション事業本部 HPC アプリケーション統括部 ACD/Spectrus をご選択頂いた理由 (NMR 領域 ) パワフルな解 析機能 ベンダーニュートラルな解析環境 直感的なインターフェース
Microsoft PowerPoint - GPU_computing_2013_01.pptx
 GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格
GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格
最新の並列計算事情とCAE
 1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
Microsoft PowerPoint - スライド_河村.pptx
 粒子ベースボリュームレンダリングを用いた大規模複雑流体データの遠隔可視化 河村拓馬日本原子力研究開発機構システム計算科学センター 粒子ベースボリュームレンダリングを用いた大規模複雑流体データの遠隔可視化 河村拓馬 井戸村泰宏 宮村 ( 中村 ) 浩子 武宮博 日本原子力研究開発機構 システム計算科学センター 277-0871 千葉県柏市若柴 178-4 柏の葉キャンパス 148 街区 4 東京大学柏の葉キャンパス駅前サテライト
粒子ベースボリュームレンダリングを用いた大規模複雑流体データの遠隔可視化 河村拓馬日本原子力研究開発機構システム計算科学センター 粒子ベースボリュームレンダリングを用いた大規模複雑流体データの遠隔可視化 河村拓馬 井戸村泰宏 宮村 ( 中村 ) 浩子 武宮博 日本原子力研究開発機構 システム計算科学センター 277-0871 千葉県柏市若柴 178-4 柏の葉キャンパス 148 街区 4 東京大学柏の葉キャンパス駅前サテライト
Presentation Title
 コード生成製品の普及と最新の技術動向 MathWorks Japan パイロットエンジニアリング部 東達也 2014 The MathWorks, Inc. 1 MBD 概要 MATLABおよびSimulinkを使用したモデルベース デザイン ( モデルベース開発 ) 紹介ビデオ 2 MBD による制御開発フローとコード生成製品の活用 制御設計の最適化で性能改善 設計図ですぐに挙動確認 MILS:
コード生成製品の普及と最新の技術動向 MathWorks Japan パイロットエンジニアリング部 東達也 2014 The MathWorks, Inc. 1 MBD 概要 MATLABおよびSimulinkを使用したモデルベース デザイン ( モデルベース開発 ) 紹介ビデオ 2 MBD による制御開発フローとコード生成製品の活用 制御設計の最適化で性能改善 設計図ですぐに挙動確認 MILS:
第 1 回ディープラーニング分散学習ハッカソン <ChainerMN 紹介 + スパコンでの実 法 > チューター福 圭祐 (PFN) 鈴 脩司 (PFN)
 鈴 脩司 (PFN)") 第 1 回ディープラーニング分散学習ハッカソン チューター福 圭祐 (PFN) 鈴 脩司 (PFN) https://chainer.org/ 2 Chainer: A Flexible Deep Learning Framework Define-and-Run Define-by-Run Define Define by Run Model
第 1 回ディープラーニング分散学習ハッカソン チューター福 圭祐 (PFN) 鈴 脩司 (PFN) https://chainer.org/ 2 Chainer: A Flexible Deep Learning Framework Define-and-Run Define-by-Run Define Define by Run Model
GPGPUクラスタの性能評価
 2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
Microsoft PowerPoint - H24全国大会_発表資料.ppt [互換モード]
![Microsoft PowerPoint - H24全国大会_発表資料.ppt [互換モード]](/thumbs/94/118755799.jpg "Microsoft PowerPoint - H24全国大会_発表資料.ppt [互換モード]") 第 47 回地盤工学研究発表会 モアレを利用した変位計測システムの開発 ( 計測原理と画像解析 ) 平成 24 年 7 月 15 日 山形設計 ( 株 ) 技術部長堀内宏信 1. はじめに ひびわれ計測の必要性 高度成長期に建設された社会基盤の多くが老朽化を迎え, また近年多発している地震などの災害により, 何らかの損傷を有する構造物は膨大な数に上ると想定される 老朽化による劣化や外的要因による損傷などが生じた構造物の適切な維持管理による健全性の確保と長寿命化のためには,
第 47 回地盤工学研究発表会 モアレを利用した変位計測システムの開発 ( 計測原理と画像解析 ) 平成 24 年 7 月 15 日 山形設計 ( 株 ) 技術部長堀内宏信 1. はじめに ひびわれ計測の必要性 高度成長期に建設された社会基盤の多くが老朽化を迎え, また近年多発している地震などの災害により, 何らかの損傷を有する構造物は膨大な数に上ると想定される 老朽化による劣化や外的要因による損傷などが生じた構造物の適切な維持管理による健全性の確保と長寿命化のためには,
HPC可視化_小野2.pptx
 大 小 二 生 高 方 目 大 方 方 方 Rank Site Processors RMax Processor System Model 1 DOE/NNSA/LANL 122400 1026000 PowerXCell 8i BladeCenter QS22 Cluster 2 DOE/NNSA/LLNL 212992 478200 PowerPC 440 BlueGene/L 3 Argonne
大 小 二 生 高 方 目 大 方 方 方 Rank Site Processors RMax Processor System Model 1 DOE/NNSA/LANL 122400 1026000 PowerXCell 8i BladeCenter QS22 Cluster 2 DOE/NNSA/LLNL 212992 478200 PowerPC 440 BlueGene/L 3 Argonne
目次 第 1 章はじめに 本ソフトの概要... 2 第 2 章インストール編 ソフトの動作環境を確認しましょう ソフトをコンピュータにセットアップしましょう 動作を確認しましょう コンピュータからアンインストー
 JS 管理ファイル作成支援ソフト 工事用 Ver.4.0 インストールマニュアル 操作マニュアル 日本下水道事業団 目次 第 1 章はじめに... 1 1-1 本ソフトの概要... 2 第 2 章インストール編... 3 2-1 ソフトの動作環境を確認しましょう... 4 2-2 ソフトをコンピュータにセットアップしましょう... 5 2-3 動作を確認しましょう... 8 2-4 コンピュータからアンインストールする方法...
JS 管理ファイル作成支援ソフト 工事用 Ver.4.0 インストールマニュアル 操作マニュアル 日本下水道事業団 目次 第 1 章はじめに... 1 1-1 本ソフトの概要... 2 第 2 章インストール編... 3 2-1 ソフトの動作環境を確認しましょう... 4 2-2 ソフトをコンピュータにセットアップしましょう... 5 2-3 動作を確認しましょう... 8 2-4 コンピュータからアンインストールする方法...
Microsoft PowerPoint - CAEworkshop_ _01.ver1.3
 GPU メニーコアにおける OpenFOAM の高度化支援紹介 第 1 回 CAE ワークショップ 流体 構造解析アプリケーションを中心に 2017 年 12 月 6 日秋葉原 UDX Gallery NEXT 山岸孝輝井上義昭青柳哲雄浅見曉 ( 高度情報科学技術研究機構 ) ver 1.3 1 outline RISTの高度化支援について GPU メニーコアについて OpenFOAMとGPU GPU
GPU メニーコアにおける OpenFOAM の高度化支援紹介 第 1 回 CAE ワークショップ 流体 構造解析アプリケーションを中心に 2017 年 12 月 6 日秋葉原 UDX Gallery NEXT 山岸孝輝井上義昭青柳哲雄浅見曉 ( 高度情報科学技術研究機構 ) ver 1.3 1 outline RISTの高度化支援について GPU メニーコアについて OpenFOAMとGPU GPU
板バネの元は固定にします x[0] は常に0です : > x[0]:=t->0; (1.2) 初期値の設定をします 以降 for 文処理のため 空集合を生成しておきます : > init:={}: 30 番目 ( 端 ) 以外については 初期高さおよび初速は全て 0 にします 初期高さを x[j]
![板バネの元は固定にします x[0] は常に0です : > x[0]:=t->0; (1.2) 初期値の設定をします 以降 for 文処理のため 空集合を生成しておきます : > init:={}: 30 番目 ( 端 ) 以外については 初期高さおよび初速は全て 0 にします 初期高さを x[j]](/thumbs/93/112208237.jpg "板バネの元は固定にします x[0] は常に0です : > x[0]:=t->0; (1.2) 初期値の設定をします 以降 for 文処理のため 空集合を生成しておきます : > init:={}: 30 番目 ( 端 ) 以外については 初期高さおよび初速は全て 0 にします 初期高さを x[j]") 機械振動論固有振動と振動モード 本事例では 板バネを解析対象として 数値計算 ( シミュレーション ) と固有値問題を解くことにより振動解析を行っています 実際の振動は振動モードと呼ばれる特定パターンが複数組み合わされますが 各振動モードによる振動に分けて解析を行うことでその現象を捉え易くすることが出来ます そこで 本事例では アニメーションを活用した解析結果の可視化も取り入れています 板バネの振動
機械振動論固有振動と振動モード 本事例では 板バネを解析対象として 数値計算 ( シミュレーション ) と固有値問題を解くことにより振動解析を行っています 実際の振動は振動モードと呼ばれる特定パターンが複数組み合わされますが 各振動モードによる振動に分けて解析を行うことでその現象を捉え易くすることが出来ます そこで 本事例では アニメーションを活用した解析結果の可視化も取り入れています 板バネの振動
PowerPoint プレゼンテーション
 音響解析プログラム WAON 最新開発動向と適用例のご紹介 サイバネットシステム株式会社 メカニカル CAE 事業部 WAON 推進室 アジェンダ 1. 会社紹介 2. WAON とは? 3. なぜ WAON なのか? 4. 各種適用例のご紹介 5. 最新開発動向 2 1. 会社紹介サイバネットシステム ( 株 ) メカニカル CAE 事業部 音響 構造 熱 電磁場 熱流体 衝突 板成形 樹脂流動などの各種解析
音響解析プログラム WAON 最新開発動向と適用例のご紹介 サイバネットシステム株式会社 メカニカル CAE 事業部 WAON 推進室 アジェンダ 1. 会社紹介 2. WAON とは? 3. なぜ WAON なのか? 4. 各種適用例のご紹介 5. 最新開発動向 2 1. 会社紹介サイバネットシステム ( 株 ) メカニカル CAE 事業部 音響 構造 熱 電磁場 熱流体 衝突 板成形 樹脂流動などの各種解析
<4D F736F F F696E74202D208C7997CA89BB8E9E8AD491AA92E B2E B8CDD8AB B83685D>
 NXPowerLite 5 ファイルサーバーエディションについて 株式会社オーシャンブリッジ FSE521-140121 測定環境 検証マシンスペック OS : Windows Sever 2008 R2, Standard Edition SP1 CPU : Intel Xeon X3430 2.4GHz (4コア ) メモリ :8.0 GB アプリケーション : NXPowerLite 5 ファイルサーバエディション
NXPowerLite 5 ファイルサーバーエディションについて 株式会社オーシャンブリッジ FSE521-140121 測定環境 検証マシンスペック OS : Windows Sever 2008 R2, Standard Edition SP1 CPU : Intel Xeon X3430 2.4GHz (4コア ) メモリ :8.0 GB アプリケーション : NXPowerLite 5 ファイルサーバエディション
スライド 1
 超解像技術とは? 動画や静止画連写などで得られる複数の低解像度 (= 小さな ) 画像を組み合わせ 演算により高解像度の (= 大きな ) 画像を作り出す技術の事を一般に 超解像 技術と呼びます 超解像処理 高解像処理 (1 枚超解像 ) 超解像 のように複数の画像を用いるのではなく 1 枚の画像が持つ情報を深く解析する事で 高解像度の画像を得る最新技術です では 最新の画像処理技術により この高解像処理を実現しました
超解像技術とは? 動画や静止画連写などで得られる複数の低解像度 (= 小さな ) 画像を組み合わせ 演算により高解像度の (= 大きな ) 画像を作り出す技術の事を一般に 超解像 技術と呼びます 超解像処理 高解像処理 (1 枚超解像 ) 超解像 のように複数の画像を用いるのではなく 1 枚の画像が持つ情報を深く解析する事で 高解像度の画像を得る最新技術です では 最新の画像処理技術により この高解像処理を実現しました
スライド 1
 swk(at)ic.is.tohoku.ac.jp 2 Outline 3 ? 4 S/N CCD 5 Q Q V 6 CMOS 1 7 1 2 N 1 2 N 8 CCD: CMOS: 9 : / 10 A-D A D C A D C A D C A D C A D C A D C ADC 11 A-D ADC ADC ADC ADC ADC ADC ADC ADC ADC A-D 12 ADC
swk(at)ic.is.tohoku.ac.jp 2 Outline 3 ? 4 S/N CCD 5 Q Q V 6 CMOS 1 7 1 2 N 1 2 N 8 CCD: CMOS: 9 : / 10 A-D A D C A D C A D C A D C A D C A D C ADC 11 A-D ADC ADC ADC ADC ADC ADC ADC ADC ADC A-D 12 ADC
Microsoft PowerPoint - sales2.ppt
 最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
行列、ベクトル
 行列 (Mtri) と行列式 (Determinnt). 行列 (Mtri) の演算. 和 差 積.. 行列とは.. 行列の和差 ( 加減算 ).. 行列の積 ( 乗算 ). 転置行列 対称行列 正方行列. 単位行列. 行列式 (Determinnt) と逆行列. 行列式. 逆行列. 多元一次連立方程式のコンピュータによる解法. コンピュータによる逆行列の計算.. 定数項の異なる複数の方程式.. 逆行列の計算
行列 (Mtri) と行列式 (Determinnt). 行列 (Mtri) の演算. 和 差 積.. 行列とは.. 行列の和差 ( 加減算 ).. 行列の積 ( 乗算 ). 転置行列 対称行列 正方行列. 単位行列. 行列式 (Determinnt) と逆行列. 行列式. 逆行列. 多元一次連立方程式のコンピュータによる解法. コンピュータによる逆行列の計算.. 定数項の異なる複数の方程式.. 逆行列の計算
目次 第 1 章はじめに 本ソフトの概要... 2 第 2 章インストール編 ソフトの動作環境を確認しましょう ソフトをコンピュータにセットアップしましょう 動作を確認しましょう コンピュータからアンインストー
 JS 管理ファイル作成支援ソフト 設計用 Ver.4.0 インストールマニュアル 操作マニュアル 日本下水道事業団 目次 第 1 章はじめに... 1 1-1 本ソフトの概要... 2 第 2 章インストール編... 3 2-1 ソフトの動作環境を確認しましょう... 4 2-2 ソフトをコンピュータにセットアップしましょう... 5 2-3 動作を確認しましょう... 9 2-4 コンピュータからアンインストールする方法...
JS 管理ファイル作成支援ソフト 設計用 Ver.4.0 インストールマニュアル 操作マニュアル 日本下水道事業団 目次 第 1 章はじめに... 1 1-1 本ソフトの概要... 2 第 2 章インストール編... 3 2-1 ソフトの動作環境を確認しましょう... 4 2-2 ソフトをコンピュータにセットアップしましょう... 5 2-3 動作を確認しましょう... 9 2-4 コンピュータからアンインストールする方法...
小型移動ロボット
 小型移動ロボット 千葉工業大学 未来ロボット技術研究センター 吉田智章 背景 過去に開発した災害対応ロボット Hibiscus (2006) Kenaf (2007-2009) Quince (2009-2010) 4 大都市大震災軽減化特別プロジェクト ( 文科省 ) 戦略的先端ロボット要素技術開発プロジェクト (NEDO) 2006-2010 2002 2006 2011 2012 Kenaf
小型移動ロボット 千葉工業大学 未来ロボット技術研究センター 吉田智章 背景 過去に開発した災害対応ロボット Hibiscus (2006) Kenaf (2007-2009) Quince (2009-2010) 4 大都市大震災軽減化特別プロジェクト ( 文科省 ) 戦略的先端ロボット要素技術開発プロジェクト (NEDO) 2006-2010 2002 2006 2011 2012 Kenaf
目次 1. CAD インターフェイス (3D_Analyzer&3D_Evolution) ユーザーインターフェイス機能強化 (3D_Analyzer&3D_Evolution)... 3 レポート... 3 クリッピング機能... 4 言語... 4 表示オプション
 ユーザーインターフェイス機能強化 (3D_Analyzer&3D_Evolution)... 3 レポート... 3 クリッピング機能... 4 言語... 4 表示オプション") 2016 年 6 月 22 日 3D_Analyzer & 3D_Evolution リリースノート 1/8 目次 1. CAD インターフェイス (3D_Analyzer&3D_Evolution)... 3 2. ユーザーインターフェイス機能強化 (3D_Analyzer&3D_Evolution)... 3 レポート... 3 クリッピング機能... 4 言語... 4 表示オプション...
2016 年 6 月 22 日 3D_Analyzer & 3D_Evolution リリースノート 1/8 目次 1. CAD インターフェイス (3D_Analyzer&3D_Evolution)... 3 2. ユーザーインターフェイス機能強化 (3D_Analyzer&3D_Evolution)... 3 レポート... 3 クリッピング機能... 4 言語... 4 表示オプション...
PowerPoint プレゼンテーション
 Foundation アプライアンス スケーラブルシステムズ株式会社 サーバ クラスタの課題 複数のシステムを一つの だけで容易に管理することは出来ないだろうか? アプリケーションがより多くのメモリを必要とするのだけど ハードウエアの増設なしで対応出来ないだろうか? 現在の利用環境のまま 利用できるコア数やメモリサイズの増強を図ることは出来ないだろうか? 短時間で導入可能で また 必要に応じて 柔軟にシステム構成の変更が可能なソリューションは無いだろうか?...
Foundation アプライアンス スケーラブルシステムズ株式会社 サーバ クラスタの課題 複数のシステムを一つの だけで容易に管理することは出来ないだろうか? アプリケーションがより多くのメモリを必要とするのだけど ハードウエアの増設なしで対応出来ないだろうか? 現在の利用環境のまま 利用できるコア数やメモリサイズの増強を図ることは出来ないだろうか? 短時間で導入可能で また 必要に応じて 柔軟にシステム構成の変更が可能なソリューションは無いだろうか?...
Microsoft PowerPoint - 2_FrontISTRと利用可能なソフトウェア.pptx
 東京大学本郷キャンパス 工学部8号館2階222中会議室 13:30-14:00 FrontISTRと利用可能なソフトウェア 2017年4月28日 第35回FrontISTR研究会 FrontISTRの並列計算ハンズオン 精度検証から並列性能評価まで 観測された物理現象 物理モデル ( 支配方程式 ) 連続体の運動を支配する偏微分方程式 離散化手法 ( 有限要素法, 差分法など ) 代数的な数理モデル
東京大学本郷キャンパス 工学部8号館2階222中会議室 13:30-14:00 FrontISTRと利用可能なソフトウェア 2017年4月28日 第35回FrontISTR研究会 FrontISTRの並列計算ハンズオン 精度検証から並列性能評価まで 観測された物理現象 物理モデル ( 支配方程式 ) 連続体の運動を支配する偏微分方程式 離散化手法 ( 有限要素法, 差分法など ) 代数的な数理モデル
2007年度 計算機システム演習 第3回
 2014 年度 実践的並列コンピューティング 第 10 回 MPI による分散メモリ並列プログラミング (3) 遠藤敏夫 endo@is.titech.ac.jp 1 MPI プログラムの性能を考える 前回までは MPI プログラムの挙動の正しさを議論 今回は速度性能に注目 MPIプログラムの実行時間 = プロセス内計算時間 + プロセス間通信時間 計算量 ( プロセス内 ) ボトルネック有無メモリアクセス量
2014 年度 実践的並列コンピューティング 第 10 回 MPI による分散メモリ並列プログラミング (3) 遠藤敏夫 endo@is.titech.ac.jp 1 MPI プログラムの性能を考える 前回までは MPI プログラムの挙動の正しさを議論 今回は速度性能に注目 MPIプログラムの実行時間 = プロセス内計算時間 + プロセス間通信時間 計算量 ( プロセス内 ) ボトルネック有無メモリアクセス量
Microsoft PowerPoint ppt
 並列アルゴリズム 2005 年後期火曜 2 限 高見利也 ( 青柳睦 ) Aoyagi@cc.kyushu-u.ac.jp http://server-500.cc.kyushu-u.ac.jp/ 12 月 20 日 ( 火 ) 9. PC クラスタによる並列プログラミング ( 演習 ) つづき 1 もくじ 1. 序並列計算機の現状 2. 計算方式およびアーキテクチュアの分類 3. 並列計算の目的と課題
並列アルゴリズム 2005 年後期火曜 2 限 高見利也 ( 青柳睦 ) Aoyagi@cc.kyushu-u.ac.jp http://server-500.cc.kyushu-u.ac.jp/ 12 月 20 日 ( 火 ) 9. PC クラスタによる並列プログラミング ( 演習 ) つづき 1 もくじ 1. 序並列計算機の現状 2. 計算方式およびアーキテクチュアの分類 3. 並列計算の目的と課題
平成 24 年度 革新的な三次元映像技術による超臨場感コミュニケーション技術研究開発 の研究開発目標 成果と今後の研究計画 1. 実施機関 研究開発期間 研究開発費 実施機関同志社大学 ( 幹事者 ), 北陸先端科学技術大学院大学, 東北大学 研究開発期間平成 21 年度から平成 24 年度 (4
, 北陸先端科学技術大学院大学, 東北大学 研究開発期間平成 21 年度から平成 24 年度 (4") 平成 24 年度 革新的な三次元映像技術による超臨場感コミュニケーション技術研究開発 の研究開発目標 成果と今後の研究計画 1. 実施機関 研究開発期間 研究開発費 実施機関同志社大学 ( 幹事者 ), 北陸先端科学技術大学院大学, 東北大学 研究開発期間平成 21 年度から平成 24 年度 (4 年間 ) 研究開発費総額 54.9 百万円 ( 平成 24 年度 12.5 百万円 ) 2. 研究開発の目標
平成 24 年度 革新的な三次元映像技術による超臨場感コミュニケーション技術研究開発 の研究開発目標 成果と今後の研究計画 1. 実施機関 研究開発期間 研究開発費 実施機関同志社大学 ( 幹事者 ), 北陸先端科学技術大学院大学, 東北大学 研究開発期間平成 21 年度から平成 24 年度 (4 年間 ) 研究開発費総額 54.9 百万円 ( 平成 24 年度 12.5 百万円 ) 2. 研究開発の目標
 招待論文 フルスペック 8K スーパーハイビジョン圧縮記録装置の開発 3.3 記録制御機能と記録媒体 144 Gbps の映像信号を 1/8 に圧縮した場合 18 Gbps 程度 の転送速度が要求される さらに音声データやその他のメ タデータを同時に記録すると 記録再生には 20 Gbps 程度 の転送性能が必要となる また 記録媒体は記録装置から 着脱して持ち運ぶため 不慮の落下などにも耐性のあるこ
招待論文 フルスペック 8K スーパーハイビジョン圧縮記録装置の開発 3.3 記録制御機能と記録媒体 144 Gbps の映像信号を 1/8 に圧縮した場合 18 Gbps 程度 の転送速度が要求される さらに音声データやその他のメ タデータを同時に記録すると 記録再生には 20 Gbps 程度 の転送性能が必要となる また 記録媒体は記録装置から 着脱して持ち運ぶため 不慮の落下などにも耐性のあるこ
並列計算導入.pptx
 並列計算の基礎 MPI を用いた並列計算 並列計算の環境 並列計算 複数の計算ユニット(PU, ore, Pなど を使用して 一つの問題 計算 を行わせる 近年 並列計算を手軽に使用できる環境が急速に整いつつある >通常のP PU(entral Processing Unit)上に計算装置であるoreが 複数含まれている Intel ore i7 シリーズ: 4つの計算装置(ore) 通常のプログラム
並列計算の基礎 MPI を用いた並列計算 並列計算の環境 並列計算 複数の計算ユニット(PU, ore, Pなど を使用して 一つの問題 計算 を行わせる 近年 並列計算を手軽に使用できる環境が急速に整いつつある >通常のP PU(entral Processing Unit)上に計算装置であるoreが 複数含まれている Intel ore i7 シリーズ: 4つの計算装置(ore) 通常のプログラム
JavaプログラミングⅠ
 Java プログラミング Ⅰ 11 回目多次元配列 今日の講義で学ぶ内容 2 次元配列とその使い方 不規則な 2 次元配列.length 修飾子 2 次元配列 1 次元配列配列要素が直線的に並ぶ配列です次のように考えると分かりやすいでしょう 2 次元配列配列要素が平面的に並ぶ配列です次のように考えると分かりやすいでしょう 2 次元以上の配列のことを多次元配列といいます 2 次元配列の利用 2 次元配列の利用手順配列変数の宣言
Java プログラミング Ⅰ 11 回目多次元配列 今日の講義で学ぶ内容 2 次元配列とその使い方 不規則な 2 次元配列.length 修飾子 2 次元配列 1 次元配列配列要素が直線的に並ぶ配列です次のように考えると分かりやすいでしょう 2 次元配列配列要素が平面的に並ぶ配列です次のように考えると分かりやすいでしょう 2 次元以上の配列のことを多次元配列といいます 2 次元配列の利用 2 次元配列の利用手順配列変数の宣言
Microsoft Word - nvsi_050110jp_netvault_vtl_on_dothill_sannetII.doc
 Article ID: NVSI-050110JP Created: 2005/10/19 Revised: - NetVault 仮想テープ ライブラリのパフォーマンス検証 : dothill SANnetⅡSATA 編 1. 検証の目的 ドットヒルシステムズ株式会社の SANnetll SATA は 安価な SATA ドライブを使用した大容量ストレージで ディスクへのバックアップを行う際の対象デバイスとして最適と言えます
Article ID: NVSI-050110JP Created: 2005/10/19 Revised: - NetVault 仮想テープ ライブラリのパフォーマンス検証 : dothill SANnetⅡSATA 編 1. 検証の目的 ドットヒルシステムズ株式会社の SANnetll SATA は 安価な SATA ドライブを使用した大容量ストレージで ディスクへのバックアップを行う際の対象デバイスとして最適と言えます
PowerPoint プレゼンテーション
 20150528 信号処理システム特論 本日の内容 適応フィルタ ( 時間領域 ) 適応アルゴリズム (LMS,NLMS,RLS) 適応フィルタの応用例 適応処理 非適応処理 : 状況によらずいつでも同じ処理 適応処理 : 状況に応じた適切な処理 高度な適応処理の例 雑音抑圧, 音響エコーキャンセラ, 騒音制御など 時間領域の適応フィルタ 誤差信号 与えられた手順に従ってフィルタ係数を更新し 自動的に所望の信号を得るフィルタ
20150528 信号処理システム特論 本日の内容 適応フィルタ ( 時間領域 ) 適応アルゴリズム (LMS,NLMS,RLS) 適応フィルタの応用例 適応処理 非適応処理 : 状況によらずいつでも同じ処理 適応処理 : 状況に応じた適切な処理 高度な適応処理の例 雑音抑圧, 音響エコーキャンセラ, 騒音制御など 時間領域の適応フィルタ 誤差信号 与えられた手順に従ってフィルタ係数を更新し 自動的に所望の信号を得るフィルタ
平成 28 年 6 月 3 日 報道機関各位 東京工業大学広報センター長 岡田 清 カラー画像と近赤外線画像を同時に撮影可能なイメージングシステムを開発 - 次世代画像センシングに向けオリンパスと共同開発 - 要点 可視光と近赤外光を同時に撮像可能な撮像素子の開発 撮像データをリアルタイムで処理する
 平成 28 年 6 月 3 日 報道機関各位 東京工業大学広報センター長 岡田 清 カラー画像と近赤外線画像を同時に撮影可能なイメージングシステムを開発 - 次世代画像センシングに向けオリンパスと共同開発 - 要点 可視光と近赤外光を同時に撮像可能な撮像素子の開発 撮像データをリアルタイムで処理する画像処理システムの開発 カラー画像と近赤外線画像を同時に撮影可能なプロトタイプシステムの開発 概要 国立大学法人東京工業大学工学院システム制御系の奥富正敏教授らと
平成 28 年 6 月 3 日 報道機関各位 東京工業大学広報センター長 岡田 清 カラー画像と近赤外線画像を同時に撮影可能なイメージングシステムを開発 - 次世代画像センシングに向けオリンパスと共同開発 - 要点 可視光と近赤外光を同時に撮像可能な撮像素子の開発 撮像データをリアルタイムで処理する画像処理システムの開発 カラー画像と近赤外線画像を同時に撮影可能なプロトタイプシステムの開発 概要 国立大学法人東京工業大学工学院システム制御系の奥富正敏教授らと
PowerPoint プレゼンテーション
 Dell PowerEdge C6320 スケーラブルサーバアプライアンス 仮想化アプライアンスサーバ 最新のプロセッサを搭載したサーバプラットフォーム vsmp Foundation によるサーバ仮想化と統合化の適用 システムはセットアップを完了した状態でご提供 基本構成ではバックプレーン用のスイッチなどが不要 各ノード間を直接接続 冗長性の高いバックプレーン構成 利用するサーバプラットフォームは
Dell PowerEdge C6320 スケーラブルサーバアプライアンス 仮想化アプライアンスサーバ 最新のプロセッサを搭載したサーバプラットフォーム vsmp Foundation によるサーバ仮想化と統合化の適用 システムはセットアップを完了した状態でご提供 基本構成ではバックプレーン用のスイッチなどが不要 各ノード間を直接接続 冗長性の高いバックプレーン構成 利用するサーバプラットフォームは
3次多項式パラメタ推定計算の CUDAを用いた実装 (CUDAプログラミングの練習として) Implementation of the Estimation of the parameters of 3rd-order-Polynomial with CUDA
 Implementation of the Estimation of the parameters of 3rd-order-Polynomial with CUDA") 3 次多項式パラメタ推定計算の CUDA を用いた実装 (CUDA プログラミングの練習として ) Estimating the Parameters of 3rd-order-Polynomial with CUDA ISS 09/11/12 問題の選択 目的 CUDA プログラミングを経験 ( 試行錯誤と習得 ) 実際に CPU のみの場合と比べて高速化されることを体験 問題 ( インプリメントする内容
3 次多項式パラメタ推定計算の CUDA を用いた実装 (CUDA プログラミングの練習として ) Estimating the Parameters of 3rd-order-Polynomial with CUDA ISS 09/11/12 問題の選択 目的 CUDA プログラミングを経験 ( 試行錯誤と習得 ) 実際に CPU のみの場合と比べて高速化されることを体験 問題 ( インプリメントする内容
Microsoft Word - 卒業論文.doc
 006 年度卒業研究 画像補間法を用いた拡大画像の比較 岡山理科大学総合情報学部情報科学科 澤見研究室 I03I04 兼安俊治 I03I050 境永 目次 はじめに ラスタ画像 3 画像補間法 3. ニアレストネイバー法 3. バイリニア法 3.3 バイキュービック法 4 DCT を用いた拡大画像手法 5 FIR 法 6 評価 6. SNR 6. PSNR 7 実験 7. 主観評価 7. 客観評価
006 年度卒業研究 画像補間法を用いた拡大画像の比較 岡山理科大学総合情報学部情報科学科 澤見研究室 I03I04 兼安俊治 I03I050 境永 目次 はじめに ラスタ画像 3 画像補間法 3. ニアレストネイバー法 3. バイリニア法 3.3 バイキュービック法 4 DCT を用いた拡大画像手法 5 FIR 法 6 評価 6. SNR 6. PSNR 7 実験 7. 主観評価 7. 客観評価
スライド 1
 本日 (4/25) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
本日 (4/25) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
研究報告用MS-Wordテンプレートファイル
 マルチコアおよび GPGPU 環境における画像処理最適化 矢野勝久 高山征大 境隆二出宮健彦 スケーラを題材として, マルチコアおよび GPGPU 各々の HW 特性に適した画像処理の最適化を図る. マルチコア環境では, 数値演算処理の削減,SIMD 化など直列性能の最適化を行った後,OpenMP を利用して並列化を図る.GPGPU(CUDA) では, スレッド並列を優先して並列処理の設計を行いブロックサイズを決める.
マルチコアおよび GPGPU 環境における画像処理最適化 矢野勝久 高山征大 境隆二出宮健彦 スケーラを題材として, マルチコアおよび GPGPU 各々の HW 特性に適した画像処理の最適化を図る. マルチコア環境では, 数値演算処理の削減,SIMD 化など直列性能の最適化を行った後,OpenMP を利用して並列化を図る.GPGPU(CUDA) では, スレッド並列を優先して並列処理の設計を行いブロックサイズを決める.
Microsoft PowerPoint - OS07.pptx
 この資料は 情報工学レクチャーシリーズ松尾啓志著 ( 森北出版株式会社 ) を用いて授業を行うために 名古屋工業大学松尾啓志 津邑公暁が作成しました 主記憶管理 主記憶管理基礎 パワーポイント 27 で最終版として保存しているため 変更はできませんが 授業でお使いなる場合は松尾 (matsuo@nitech.ac.jp) まで連絡いただければ 編集可能なバージョンをお渡しする事も可能です 復習 OS
この資料は 情報工学レクチャーシリーズ松尾啓志著 ( 森北出版株式会社 ) を用いて授業を行うために 名古屋工業大学松尾啓志 津邑公暁が作成しました 主記憶管理 主記憶管理基礎 パワーポイント 27 で最終版として保存しているため 変更はできませんが 授業でお使いなる場合は松尾 (matsuo@nitech.ac.jp) まで連絡いただければ 編集可能なバージョンをお渡しする事も可能です 復習 OS
今後の予定 6/29 パターン形成第 11 回 7/6 データ解析第 12 回 7/13 群れ行動 ( 久保先生 ) 第 13 回 7/17 ( 金 ) 休講 7/20 まとめ第 14 回 7/27 休講?
 第 13 回 7/17 ( 金 ) 休講 7/20 まとめ第 14 回 7/27 休講?") 今後の予定 6/29 パターン形成第 11 回 7/6 データ解析第 12 回 7/13 群れ行動 ( 久保先生 ) 第 13 回 7/17 ( 金 ) 休講 7/20 まとめ第 14 回 7/27 休講? 数理生物学演習 第 11 回パターン形成 本日の目標 2 次元配列 分子の拡散 反応拡散モデル チューリングパタン 拡散方程式 拡散方程式 u t = D 2 u 拡散が生じる分子などの挙動を記述する.
今後の予定 6/29 パターン形成第 11 回 7/6 データ解析第 12 回 7/13 群れ行動 ( 久保先生 ) 第 13 回 7/17 ( 金 ) 休講 7/20 まとめ第 14 回 7/27 休講? 数理生物学演習 第 11 回パターン形成 本日の目標 2 次元配列 分子の拡散 反応拡散モデル チューリングパタン 拡散方程式 拡散方程式 u t = D 2 u 拡散が生じる分子などの挙動を記述する.
単位、情報量、デジタルデータ、CPUと高速化 ~ICT用語集~
 CPU ICT mizutani@ic.daito.ac.jp 2014 SI: Systèm International d Unités SI SI 10 1 da 10 1 d 10 2 h 10 2 c 10 3 k 10 3 m 10 6 M 10 6 µ 10 9 G 10 9 n 10 12 T 10 12 p 10 15 P 10 15 f 10 18 E 10 18 a 10 21
CPU ICT mizutani@ic.daito.ac.jp 2014 SI: Systèm International d Unités SI SI 10 1 da 10 1 d 10 2 h 10 2 c 10 3 k 10 3 m 10 6 M 10 6 µ 10 9 G 10 9 n 10 12 T 10 12 p 10 15 P 10 15 f 10 18 E 10 18 a 10 21
RICCについて
 RICC 1 RICC 2 RICC 3 RICC GPU 1039Nodes 8312core) 93.0GFLOPS, 12GB(mem), 500GB (hdd) DDR IB!1 PC100Nodes(800core) 9.3 GPGPU 93.3TFLOPS HPSS (4PB) (550TB) 0.24 512GB 1500GB MDGRAPE33TFLOPS MDGRAPE-3 64
RICC 1 RICC 2 RICC 3 RICC GPU 1039Nodes 8312core) 93.0GFLOPS, 12GB(mem), 500GB (hdd) DDR IB!1 PC100Nodes(800core) 9.3 GPGPU 93.3TFLOPS HPSS (4PB) (550TB) 0.24 512GB 1500GB MDGRAPE33TFLOPS MDGRAPE-3 64