2 09:00-09:30 受付 09:30-12:00 GPU 入門,CUDA 入門 13:00-14:30 OpenACC 入門 + HA-PACS ログイン 14:45-16:15 OpenACC 最適化入門と演習 16:30-18:00 CUDA 最適化入門と演習
|
|
|
- ゆき やなぎしま
- 8 years ago
- Views:
Transcription
 hoshino@cc.u-tokyo.ac.")

1 担当 大島聡史 ( 助教 ) [email protected] 星野哲也 ( 助教 ) [email protected] 質問やサンプルプログラムの提供についてはメールでお問い合わせください 年 6 月 8 日 ( 水 ) 東京大学情報基盤センター

2 2 09:00-09:30 受付 09:30-12:00 GPU 入門,CUDA 入門 13:00-14:30 OpenACC 入門 + HA-PACS ログイン 14:45-16:15 OpenACC 最適化入門と演習 16:30-18:00 CUDA 最適化入門と演習
3 3 GPUについて GPUスパコン事情 Reedbushシステムの紹介
4 4 現在の HPC 計算機科学 計算科学分野では様々な並列計算ハードウェアが利用されている マルチコア CPU: 複数の計算コアを 1 つのチップにまとめた CPU 代表例 :Intel Xeon / Core, AMD Opteron/FX, IBM POWER, FUJITSU SPARC64, ARM Cortex サーバ向けでは1999 年 POWER4 PC 向けでは2005 用 Dual-Core Opteron/AthlonX2が初出と言われている メニーコアプロセッサ : マルチコアCPUよりも多数の計算コアを搭載 代表例 :Intel Xeon Phi, Sun Niagara, PEZY PEZY-1/SC 明確に何コア以上がメニーコアという定義が有るわけではない GPU: 画像処理用 HWに端を発するメニーコアプロセッサ 代表例 :NVIDIA Tesla/GeForce, AMD FirePro/Radeon FPGA: プログラミングにより回路構成を変更可能なプロセッサ 代表例 :Xilinx Virtex, Altera Stratix

5 5 ムーアの法則に支えられた CPU の性能向上が終わりつつある 微細化によるチップあたりトランジスタ数の向上 クロック周波数の向上 消費電力や発熱が問題となり頭打ち マルチコア化 メニーコア化による並列演算性能の向上へ 出展 : The chips are down for Moore s law : Nature News & Comment
 参考 3 次元画像描画の手順 1 (2, 2) 2 (8, 3) 3 (5, 7) オブジェクト単位 頂点単位 ピクセル単位で並列処理が可能")
6 6 画像処理用のハードウェア 高速 高解像度描画 3D 描画処理 ( 透視変換 陰影 照明 ) 画面出力 CPU やマザーボードに組み込まれたチップとして また拡張スロットに搭載するビデオカードとして広く利用される GPU に求められる処理が並列計算に適した処理であったため CPU に先んじて並列化による高性能化が進んだ 性能 機能の向上に伴い2000 年代後半から汎用演算への活用が進み GPGPUやGPUコンピューティングと呼ばれる General-Purpose computation on GPUs) 参考 3 次元画像描画の手順 1 (2, 2) 2 (8, 3) 3 (5, 7) オブジェクト単位 頂点単位 ピクセル単位で並列処理が可能 並列化により高速化しやすい









7 7 ハードウェアの構成バランスの違い ( イメージ ) 限られたトランジスタを主に何に用いるか 計算ユニット メモリキャッシュなど マルチコア CPU メニーコアプロセッサ GPU 制御部など 多数の計算ユニットを搭載し全体として高性能を得ることを重視 ( この図ではわからないが ) 総メモリ転送性能も重視している
8 8 CPU とは異なる特徴を持つ 非常に多くの (1000 以上 ) の計算ユニットを搭載 計算ユニット単体の性能は低い 動作周波数 キャッシュ 分岐 計算コアが完全に個別には動けない 32 個などの単位でスケジューリング SIMD 演算器が大量に搭載されたイメージ 浅めのキャッシュ階層 複数階層のメモリ 特定のアプリケーションでは非常に高い性能 ビッグデータや機械学習の分野で有用なため 最近特に注目されている CPU とは異なるプログラミング 最適化の知識と技術が必要 本講習会がその手助け 入り口となることを期待します
9 9 GPU 等の アクセラレータ を搭載したスパコンの普及 TOP500 ( ) TOP20 中 8, TOP500 中 100 以上が GPU スパコン

10 10 Oakleaf-FX ( 通常ジョブ用 ) (Fujitsu PRIMEHPC FX10) Oakbridge-FX ( 長時間ジョブ用 ) (Fujitsu PRIMEHPC FX10 ) Yayoi (Hitachi SR16000/M1) Total Peak performance : 1.13 PFLOPS Total number of nodes : 4800 Total memory : 150 TB Peak performance / node : GFLOPS Main memory per node : 32 GB Disk capacity : 1.1 PB PB SPARC64 Ixfx 1.84GHz Total Peak performance : TFLOPS Total number of nodes : 576 Total memory : 18 TB Peak performance / node : GFLOPS Main memory per node : 32 GB Disk capacity : 147TB + 295TB SPARC64 Ixfx 1.84GHz Total Peak performance : 54.9 TFLOPS Total number of nodes : 56 Total memory : GB Peak performance / node : GFLOPS Main memory per node : 200 GB Disk capacity : 556 TB IBM POWER GHz Total Users > 2,000
 により導入 JCAHPC は東大 - 筑波大の共同組織 ピーク性能 :25PFFLOPS 8,208 Intel Xeon Phi (KNL) 日本最速になる予定 2016/12/1")
11 11 Reedbush ( データ解析 シミュレーション融合スーパーコンピュータシステム ) Reedbush-U (CPU only) と Reedbush-H (with GPU) からなる Reedbush-U TFlops 2016/7/1 試験運用開始 Reedbush-H TFlops 2017/3/1 試験運用開始 Oakforest-PACS 最先端共同 HPC 基盤施設 (JCAHPC) により導入 JCAHPC は東大 - 筑波大の共同組織 ピーク性能 :25PFFLOPS 8,208 Intel Xeon Phi (KNL) 日本最速になる予定 2016/12/1 試験運用開始
 CPU メモリ :Reedbush-U と同様 NVIDIA Tesla P100 (Pascal 世代 GPU) (4.8-5.3TF, 720GB/sec, 16GiB) x 2 / ノード InfiniBand FDR x 2ch, Full bisection BW Fat-tree 120 ノード, 145.2 TF(CPU)+ 1.")
12 12 システム構成 運用 :SGI Reedbush-U (CPU only) Intel Xeon E5-2695v4 (Broadwell-EP, 2.1GHz 18core,) x 2 ソケット (1.210 TF), 256 GiB (153.6GB/sec) InfiniBand EDR, Full bisection BW Fat-tree システム全系 : 420 ノード, TF Reedbush-H (with GPU) CPU メモリ :Reedbush-U と同様 NVIDIA Tesla P100 (Pascal 世代 GPU) ( TF, 720GB/sec, 16GiB) x 2 / ノード InfiniBand FDR x 2ch, Full bisection BW Fat-tree 120 ノード, TF(CPU)+ 1.15~1.27 PF(GPU)= 1.30~1.42 PF




13 13 L'homme est un roseau pensant. Man is a thinking reed. 人間は考える葦である Pensées (Blaise Pascal) Blaise Pascal ( )
 < 90 m 2 データ解析 ディープラーニング向けソフトウェア ツールキット OpenCV, Theano, Anaconda, ROOT, TensorFlow, Torch, Caffe, Chainer, GEANT4 利用申込み受付中 詳しくは Web")
14 14 ストレージ / ファイルシステム 並列ファイルシステム (Lustre) 5.04 PB, GB/sec 高速ファイルキャッシュシステム : Burst Buffer (DDN IME (Infinite Memory Engine)) SSD: TB, 450 GB/sec 電力, 冷却, 設置面積 空冷, 378 kva( 冷却除く ) < 90 m 2 データ解析 ディープラーニング向けソフトウェア ツールキット OpenCV, Theano, Anaconda, ROOT, TensorFlow, Torch, Caffe, Chainer, GEANT4 利用申込み受付中 詳しくは Web をご参照ください
15 15 計算ノード : PFlops Reedbush-U (CPU only) TFlops CPU: Intel Xeon E v4 x 2 socket (Broadwell-EP 2.1 GHz 18 core, 45 MB L3-cache) Mem: 256GB (DDR4-2400, GB/sec) SGI Rackable C2112-4GP3 InfiniBand EDR 4x 100 Gbps /node 420 Reedbush-H (w/accelerators) TFlops CPU: Intel Xeon E v4 x 2 socket Mem: 256 GB (DDR4-2400, GB/sec) GPU: NVIDIA Tesla P100 x 2 (Pascal, SXM2, TF, Mem: 16 GB, 720 GB/sec, PCIe Gen3 x16, NVLink (for GPU) 20 GB/sec x 2 brick ) SGI Rackable C1102-PL1 Dual-port InfiniBand FDR 4x 56 Gbps x2 /node 120 InfiniBand EDR 4x, Full-bisection Fat-tree GB/s 並列ファイルシステム 5.04 PB Lustre Filesystem DDN SFA14KE x GB/s 高速ファイルキャッシュシステム 209 TB DDN IME14K x6 管理サーバー群 Login node UTnet ユーザ ログインノード x6 Mellanox CS port + SB7800/ port x 14





16 16 メモリ 128GB DDR4 DDR4 DDR4 DDR4 76.8GB/s Intel Xeon E v4 (Broadwell- EP) G3 x GB/s QPI QPI 76.8GB/s 15.7 GB/s 15.7 GB/s Intel Xeon E v4 (Broadwell- EP) G3 x16 DDR4 DDR4 DDR4 DDR4 76.8GB/s メモリ 128GB PCIe sw PCIe sw IB FDR HCA G3 x16 NVIDIA Pascal 20 GB/s NVLinK NVLinK 20 GB/s G3 x16 NVIDIA Pascal IB FDR HCA EDR switch EDR
GPU に対応したライブラリやフレームワークを使う GPU 上で行われる計算自体は実装しない 基本的にGPUの知識は不要 対象分野における共通のAPIが存在しGPU 化されていれば恩恵は大 BLASなどの数値計算ライブラリ ビッグデータ 機械学習系のライブラリ フレームワークなど 3.")
17 17 1. GPU に対応したソフトウェア ( アプリケーション ) を使う GPU 上で行われる計算自体は実装しない 基本的に GPU の知識は不要 存在するものしか使えない 手持ちのプログラムには適用不能 2. (GPU に対応していないプログラムから )GPU に対応したライブラリやフレームワークを使う GPU 上で行われる計算自体は実装しない 基本的にGPUの知識は不要 対象分野における共通のAPIが存在しGPU 化されていれば恩恵は大 BLASなどの数値計算ライブラリ ビッグデータ 機械学習系のライブラリ フレームワークなど 3. GPU 上で行われる計算そのものを実装する 1や2で用いるソフトウェア ライブラリ等そのものを作る GPUに関する知識が必要本講習会の対象 手持ちのプログラム 独自のプログラムをGPU 化できる
18 18 主な開発環境 ( プログラミング言語など 特に並列化に用いるもの ) CPU/MIC MPI, OpenMP (pthread, Cilk+, TBB, ) GPU CUDA, DirectCompute FPGA Verilog HDL OpenACC OpenCL 従来は個別のものが使われていたが 近年では共通化も進みつつある 習得が大変 移植が大変という利用者の声が反映されている
19 19 対象とする GPU:NVIDIA Tesla M2090 Tesla:NVIDIA 社が開発している GPU シリーズの 1 つ HPC 向け コンシューマ向けの GeForce シリーズと比べて 倍精度演算が高速 ECC 対応メモリを搭載 などの違いがある M2090 は 2011 年に発売された GPU であり アーキテクチャ名は Fermi 現行の GPU と比べると古いが GPU を用いた最適化プログラミングの基礎を学ぶには十分なもの 対象とする GPU プログラミング開発環境 :CUDA と OpenACC CUDA (Compute Unified Device Architecture):NVIDIAのGPU 向け開発環境 C 言語版はCUDA CとしてNVIDIAから Fortran 版はCUDA FortranとしてPGI( 現在はNVIDIAの子会社 ) から提供されている OpenACC: 指示文を用いて並列化を行うプログラミング環境 C 言語と Fortranの両方の仕様が定められている PGIコンパイラなど幾つかのコンパイラが対応 (GPUが主なターゲットだが)GPU 専用言語ではない
 により高機能化 制限の撤廃 2011 年頃 :OpenACC が提案される CUDAより容易で汎用性のある (NVIDIA GPUに縛られない ) プログラミング環境に対する要求の高まり 最新仕様は2.5 実装されているのは2.")
20 年頃 :GPU 上である程度プログラミングが可能となった プログラマブルシェーダ が登場 それ以前は機能の切替程度しかできなかった 主に画像処理のためのプログラミングであり 様々なアルゴリズムを実装するのに十分なものとは言えなかった 2006 年頃 :CUDA が登場 様々な制限はありつつも 普通のプログラム が利用可能に 様々なアルゴリズムが実装された 科学技術計算への応用も活発化 GPUスパコンの誕生 バージョンアップ ( 最新は7.5) により高機能化 制限の撤廃 2011 年頃 :OpenACC が提案される CUDAより容易で汎用性のある (NVIDIA GPUに縛られない ) プログラミング環境に対する要求の高まり 最新仕様は2.5 実装されているのは2.1 程度まで
21 21 GeForce コンシューマ向けグラフィックスカード 主にゲーミング PC で使われる (+ 最近は機械学習 VR?) 単精度演算性能を重視 ( 倍精度演算用の HW をあまり搭載していない ) クロック周波数が高めの傾向 安価 Quadro ワークステーション用グラフィックスカード (GeForce や Tesla と比べると注目されていない?) Tesla HPC( 科学技術計算 スパコン ) 向け 画面出力できないモデルも多い ( Graphics Processing Unit?) 倍精度演算性能も重視 クロック周波数が低めの傾向 ECC メモリ対応 安価とは言えない
 シャッフル命令 読み込み専用データキャッシュ Unified メモリ PCI-Express 3.0 Maxwell: コンシューマ向け GPU 電力あたり性能の向上 Tesla としての製品は存在しない Pascal: まだ販売されていない GPU Reedbush に搭載 HBM2( 高速メモリ ) NVLink( 高速バス )")
22 22 アーキテクチャ ( 世代 ) と特徴 新機能 Tesla: 最初の HPC 向け GPU Fermi: 本講習会で用いる GPU ECC メモリ対応 FMA 演算 atomic 演算 Kepler: 現行の HPC 向け GPU コア群を構成するコア数の増加 動的な並列処理 (GPU カーネルから GPU カーネルの起動 ) Hyper-Q( 複数 CPU コアによる GPU 共有 ) シャッフル命令 読み込み専用データキャッシュ Unified メモリ PCI-Express 3.0 Maxwell: コンシューマ向け GPU 電力あたり性能の向上 Tesla としての製品は存在しない Pascal: まだ販売されていない GPU Reedbush に搭載 HBM2( 高速メモリ ) NVLink( 高速バス )
23 23 現行 GPU ではできるが 講習会で使う GPU ではできないこと もあるが 最適化を行ううえで基本となる点は共通している Reedbush でも活用できる そもそも HPC 向けのプログラミングには不要に近い機能も多い 世代毎に色々な制限等に違いがあるため 細かい最適化パラメタについては都度考える必要がある 最大並列度 レジスタ数 共有メモリ容量 命令実行サイクル数 etc.
 CPU OS")

 GPU を使う為には 1.2.3.")
24 24 ストレージなど 1. 計算したいデータを送る 何らかのバス ネットワーク ~20GB/s (IB) CPU OS が動いている ~32GB/s (PCI-Express) 3. 計算結果を返す GPU OS は存在しない 2. 計算を行う ~200GB/s ~1,000GB/s メインメモリ (DDR など ) デバイスメモリ (GDDR など 今後は HBM など ) GPU を使う為には を考える ( 実装する ) 必要がある デバイス内外のデータ転送速度差が大きいことから 対象とするプロセッサ内で計算が完結していることが望ましいことがわかる


25 25 GPU の構造と CUDA を用いたプログラミングの方法を学ぶ 最適化を行ううえで考えるべきこと ( 概要 ) を学ぶ
26 26 SPARC64 IXfx Xeon E (Sandy Bridge-EP) HA-PACS ホスト CPU Tesla M2090 (Fermi) HA-PACS GPU Tesla K40 (Kepler) コア数 16 8 (HT 16) 512 (32*16) 2880 (192*15) クロック周波数 GHz 2.60 GHz 1.3 GHz 745 MHz 搭載メモリ種別 DDR3 32GB DDR3 最大 384GB (HA-PACS 64GB/socket) GDDR5 6GB GDDR5 12GB Peak FLOPS [GFLOPS] (SP/DP) / / /1430 Peak B/W [GB/s] (ECC off) 288 TDP [W]
")







27 27 ホスト (CPU) とデバイス (GPU) はPCI-Expressなどで接続されている GPU 上にはいくつかのコア群とデバイスメモリが搭載されている コア群にはいくつかの計算コアと局所的な共有メモリが搭載されている 局所的な共有メモリはデバイスメモリと比べて高速だが小容量 GPU コア群 PCIe など デバイスメモリ 計算コア計算コア ( 演算器 レジス計算コア ( 演算器 レジス計算コア ( 演算器 レジスタ キャッシュタ キャッシュ ( 演算器 レジス ) タ キャッシュ ) ) タ キャッシュ ) 局所的な共有メモリ
 ( より細かく")
28 28 CUDA C (RuntimeAPI) GPU が処理を行う単位は関数 CPUがGPUに関数を実行させるための記述が用意されている gpufuncname<<< 並列実行形状の指定 >>>( 引数 ); 並列実行形状に 接頭辞を用いて関数の実行方法とメモリ配置を指定ついては後述 実行対象指定 ( 組み合わせ可能 ) global CPU から呼び出し GPU 上で実行 device GPU から呼び出し GPU 上で実行 host CPU から呼び出し CPU 上で実行 配置指定 device GlobalMemory:GPU 全体で共有するデバイスメモリ shared SharedMemory: 局所的な高速共有メモリ constant ConstantMemory: 読み出し専用に使う特殊なメモリ ( 専用のクラスを用いて扱う TextureMemory) ( より細かく CUDA を制御可能な DriverAPI もあるが あまり使う必要は無いため割愛 )
29 29 主な API 関数 cudamalloc GPU 上のメモリを確保する GPU 版 malloc cudafree cudamallocで確保したメモリを解放する GPU 版 free cudamemcpy CPU-GPU 間のデータ転送を行う データ転送方向は引数で指定する Fortran 版ではどうか? 概念 考えるべきことは同様 言語仕様の違いがあるため具体的な記述の仕方には違いがある 配列等の宣言時にメモリ配置等を指定することで 専用の API を使わずに GPU を利用可能
30 30 CPU からの指示に従って GPU が動作する CPU GPU main 関数実行開始 cudamalloc cudamemcpy: データ送信 gpufunc<<<>>>() カーネル起動 GPU が計算を行っている間に CPU は他の処理をしても良い cudamemcpy : データ取得リクエスト cudafree メモリ確保データ受信計算開始 結果返送 メモリ解放
 #define N 100000 device float d_a[n], d_c[n]; global void gpukernel() { for(int i=0; i<n; i++){ d_c[i] = d_a[i]; } } 単純な配列のコピー GPU 上のメモリ ( 配列 ) GPU 上で行われる処理 (GPU カーネル ) float A[N], C[N]; ホスト上のメモリ")
31 31 目標 : どのような情報を書く必要があるのかを把握する simple1.cu(cuda C プログラムの拡張子は.cu) #define N device float d_a[n], d_c[n]; global void gpukernel() { for(int i=0; i<n; i++){ d_c[i] = d_a[i]; } } 単純な配列のコピー GPU 上のメモリ ( 配列 ) GPU 上で行われる処理 (GPU カーネル ) float A[N], C[N]; ホスト上のメモリ ( 配列 ) int main(int argc, char **argv){ cudamemcpy CPU-GPU 間のコピー cudamemcpy(d_a, A, sizeof(float)*n, cudamemcpyhosttodevice); CPU 上で行われる処理 } gpukernel<<<1,1>>>(); <<<>>> GPUカーネルの実行 1,1なので逐次実行 cudamemcpy(c, d_c, sizeof(float)*n, cudamemcpydevicetohost); return 0; 各種 API 関数の細かい説明は後述 ( 午後 ) 配列 A,C の値は適当に初期化されていると仮定
{ for(int i=0; i<n; i++){ C[i] = A[i]; } } サイズや配列を引数として受け取る GPU 上で行われる処理 (GPU カーネル ) int main(int argc, char **argv){ cudamalloc GPU 上のメモリを確保する int")
32 32 simple1a.cu global void gpukernel (int N, float* C, float* A){ for(int i=0; i<n; i++){ C[i] = A[i]; } } サイズや配列を引数として受け取る GPU 上で行われる処理 (GPU カーネル ) int main(int argc, char **argv){ cudamalloc GPU 上のメモリを確保する int N = ; cudafree GPU 上のメモリを解放する float *A, *C; float *d_a, *d_c; A = (float*)malloc(sizeof(float)*n); cudamalloc((void**)&d_a, sizeof(float)*n); cudamemcpy(d_a, A, sizeof(float)*n, cudamemcpyhosttodevice); cudamemcpy(d_c, C, sizeof(float)*n, cudamemcpyhosttodevice); gpukernel<<<1,1>>>(n, d_c, d_a); cudamemcpy(c, d_c, sizeof(float)*n, cudamemcpydevicetohost); cudafree(d_a); return 0; } 残りのメモリ解放はスペースの都合で省略 C, d_c のメモリ確保も必要だが スペースの都合で省略 CPU 上で行われる処理
33 33 simple1b.cu global void gpukernel (int N, float* C, float* A){ int tid = blockidx.x*blockdim.x + threadidx.x; int nt = griddimd.x * blockdim.x; for(int i=tid; i<n; i+=nt){ C[i] = A[i]; } } CUDA における並列計算の基本 GPU カーネル内で自分の ID を取得し 計算するべき範囲を特定する GPU カーネル関数が 16 個同時に起動すると思えば良い GPU 上で行われる処理 (GPU カーネル ) int main(int argc, char **argv){ // simple1a.cu とほぼ同様 CPU 上で行われる処理 } gpukernel<<<4,4>>>(n, d_c, d_a); return 0; 並列実行形状を与える ここでは 4*4=16 並列での実行 ( のようなものだと思えば良い )
34 34 通常の C プログラムと同様にコンパイル 実行が可能 nvcc を使う nvcc simple.cu./a.out nvcc が GPU カーネルを分離し CPU 部と GPU 部をそれぞれコンパイルし 単一の実行ファイルを生成する CPU 部または GPU 部のみをコンパイルしたり 中間表現ファイル (PTX アセンブラ ) を出力して解析することも可能
 subroutine gpukernel(n, C, A) integer, value :: N real, device :: C(N), A(N) C = A end subroutine gpukernel end module cudamod program")
35 35 配列に属性を付加しておけば 確保や代入などの処理が GPU に対して行われる device, global など CUDA Cよりも簡単 コンパイル例 pgf90 Mcuda arraytest.cuf module cudamod use cudafor contains attributes(global) subroutine gpukernel(n, C, A) integer, value :: N real, device :: C(N), A(N) C = A end subroutine gpukernel end module cudamod program arraytest use cudafor CUDA Fortranを使う為に必要 use cudamod GPUカーネルを含むモジュール integer, parameter :: N=10 integer i real, allocatable, dimension(:) :: A, C real, device, allocatable, dimension(:) :: d_a, d_c allocate(a(n)) allocate(c(n)) A = C = allocate(d_a(n)) GPUに対して行われる allocate(d_c(n)) d_a = A d_c = C call gpukernel<<<1,1>>>(n, d_c, d_a) C = d_c deallocate(d_a) deallocate(d_c) deallocate(a) deallocate(c) end program arraytest CPU-GPU 間でコピーされる GPU 側 CPU 側 GPU カーネル内で配列のコピーを行う例









36 36 物理的な構成の概要 SM/SMXはGPUあたり1~30(GPUのグレードに依存 ) CUDAコアはSM/SMXあたり8~192(GPU 世代に依存 ) 以下 SM/SMX を SMx と表記する HOST GPU Streaming Multiprocessor (SM/SMX) MainMemory PCI-Express DeviceMemory TextureCache ConstantCache CUDA コア Register 数グループスケジューラ SharedMemory ( 数グループ )
37 37 階層性のあるハードウェア構成 演算器の構成 階層性のある演算器配置 (CUDA コア *m SMx*n) 幾つかの計算コアがグループを構成 同一グループ内のコアは同時に同じ演算のみ可能 (SIMD 的な構成 ) CPUのコアのように独立して動作できず 分岐方向が違う場合にはマスク処理される NVIDIAはSIMTと呼んでいる メモリの構成 階層性と局所性のあるメモリ配置 全体的な共有メモリ + 部分的な共有メモリ + ローカルメモリ GPU 上に搭載された大容量でグローバルなメモリ :DeviceMemory 局所的に共有される小容量高速共有メモリ :SharedMemory コア毎に持つレジスタ
38 38 実行モデルとメモリ構成の概要 SMx に対応 Host (CPU, MainMemory) Grid (DeviceMemory) GlobalMemory ConstantMemory TextureMemory Block n 個 Register Thread m 個 CUDA コアに対応 SharedMemory CPU のプロセスやスレッド同様に Block Thread は物理的な数以上に生成可能 GPU カーネル起動時に <<<,>>> で指定するのはこの値 特に Thread は物理的な数を超えて作成した方が良い ( 後述 )
39 39 特徴の異なる複数種類のメモリ 必ずしも全てのメモリを使う必要はない 名称 Lifetime 共有範囲速度容量 GlobalMemory プログラム GPU 全体高速 高レイテンシ ~GB ConstantMemory プログラム GPU 全体 高速 高レイテンシ +キャッシュ 64KB TextureMemory プログラム GPU 全体 高速 高レイテンシ +キャッシュ GlobalMemory と共用 SharedMemory Grid SMx 単位超高速 低レイテンシ ~112KB/SMx * Register Grid 非共有超高速 低レイテンシ ~64KB/SMx * LocalMemory ** Grid 非共有高速 高レイテンシ - * GPU の世代により異なる ** 実体は GlobalMemory レジスタを使いすぎると LocalMemory に配置されてしまう
")
")


40 40 計算時のデータの流れ Grid (DeviceMemory) Block n 個 Host (CPU, MainMemory) TextureMemory 1 5 ConstantMemory GlobalMemory 2 4 Register Thread 3 m 個 SharedMemory
















41 41 もう少し詳しい実行モデル解説 CPUによるGPU制御 GPU上のコアの一斉動作 Host GPU MainMemory ① Send CPU ② Exec ③ Recv ① ③ GlobalMemory 一斉に 動作 ② コア コア コア SharedMemory コア コア コア SharedMemory








42 42 もう少し詳しい実行モデルのイメージ 各コアが流れてくる命令を処理していくようなイメージで考える GPU 上のコア群は同時に同じ命令を実行している ( 全体で ではない ) マルチコアCPU CUDA 命令 H 命令 G 命令 F 命令 E 命令 D コア 0 命令 C 命令 B 命令 A 命令 h 命令 g 命令 f 命令 e 命令 d コア 1 命令 c 命令 b 命令 a 命令 H 命令 G 命令 F 命令 E 命令 D コア 0 コア 1 コア 2 コア 3 命令 C 命令 B 命令 A
43 43 実際のスケジューリングは32スレッド単位 (=WARP 単位 ) で実行される 異なるデータに対して同時に同じ演算を行う 実行時に取得できるスレッド ID を用いて各自の計算対象 ( 配列インデックス ) を算出すれば良い WARP 内のスレッド毎に分岐方向が異なるプログラムを実行する場合は 分岐方向の異なるスレッドは待たされる divergent warp 重要な性能低下要因 スレッドIDが連続する32 個のスレッド毎に分岐方向が揃うようなプログラムを作成すれば divergent warpによるペナルティが発生しない
44 44 どのようなプログラムに対して高性能が得られるか 大量のスレッドを生成する 理想的な Block あたりスレッド数は 64~256 程度 GPU の世代やプログラムの複雑度などにも影響を受ける GlobalMemory のコアレスアクセスを行う メモリアクセスをまとめる機能がある SharedMemory のバンクコンフリクトを回避する SharedMemory を利用する際に同じメモリバンクにアクセスすると性能が低下する ループアンローリング 分岐回数を減らす GPU は分岐処理に弱いので重要 以下 各手法の概要について説明する 実例や対策は後述 (CUDA OpenACC の最適化の中で扱う ) 最適化の際には各手法が衝突することもあるので注意が必要
45 45 スレッドのコンテキスト切り替えがとても速いため メモリアクセスを待つよりコンテキストを切り替えて別のスレッドを処理した方が速い 逆に言えば大量のスレッドでGlobalMemoryに対するメモリアクセスのレイテンシを隠蔽しないと高い性能が得られない ただし レジスタや共有メモリの使用量が多すぎると多数のスレッドを実行できない 同時に実行できるスレッドやブロックの数は色々な資源の使用量によって決まる 並列度の高いシンプルな GPU カーネルが望ましい



46 46 CPU CUDA 計算命令 メモリアクセス命令 メモリアクセス待ちの際に実行スレッドを切り替える メモリアクセス待ち メモリアクセス待ち time time


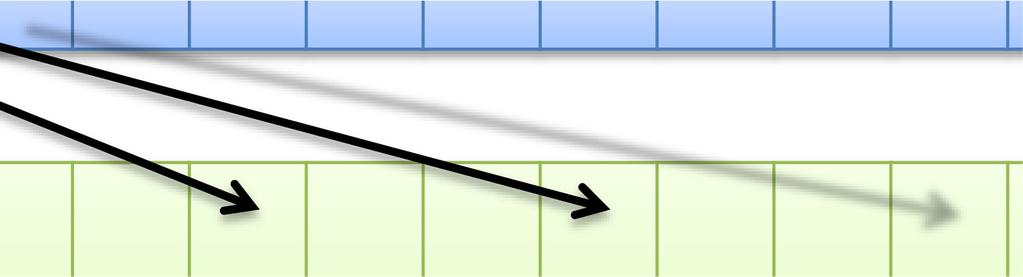
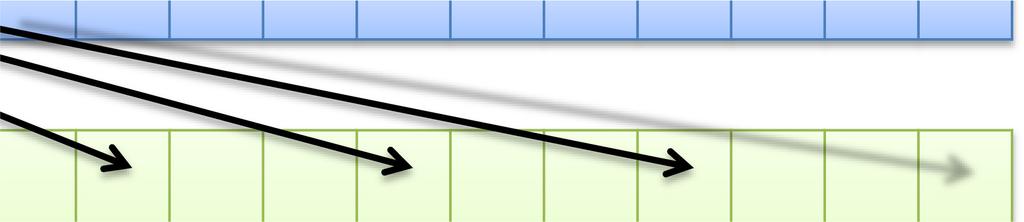
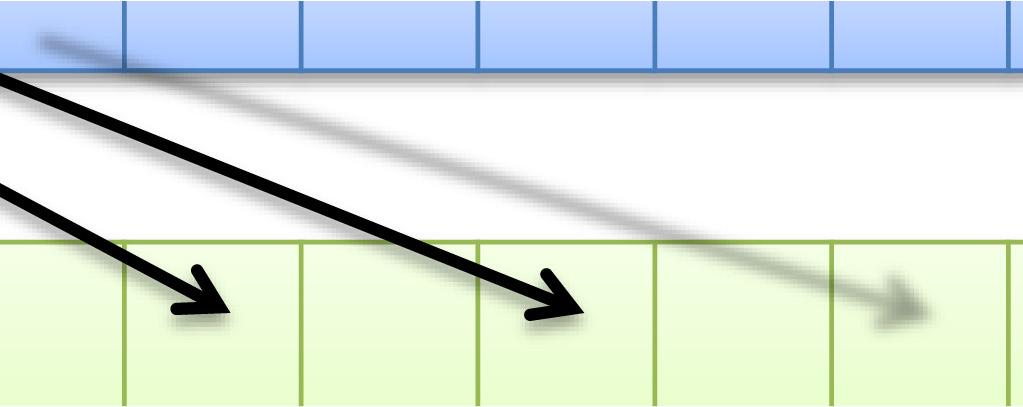
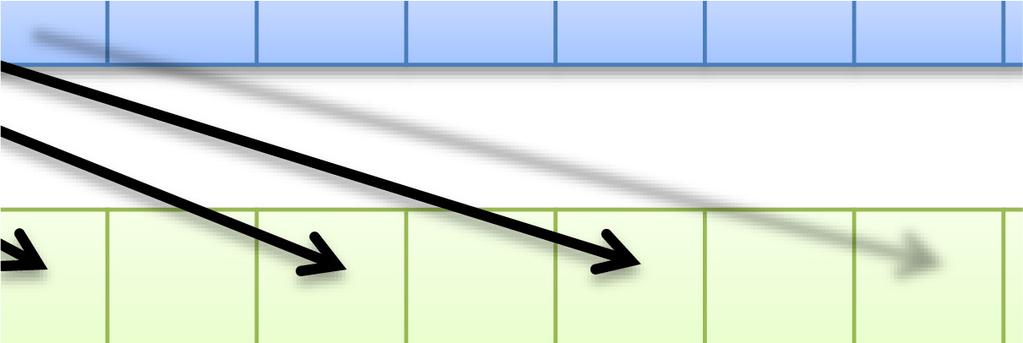
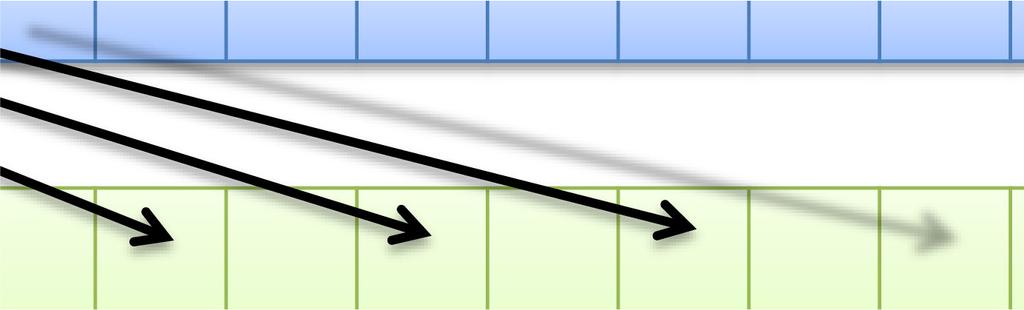
47 47 同一 SMx 内の複数 CUDA コアによるメモリアクセスが近い場合にまとめてアクセスできる 詳細な条件は GPU の世代によって異なる 最新世代ほど条件が緩い アクセスがバラバラな ( 遠い ) 場合 コア 0 コア 1 コア 2 コア 3 4 回のメモリアクセスが行われる GlobalMemory アクセスが揃っている ( 近い ) 場合 コア 0 コア 1 コア 2 コア 3 1 回のメモリアクセスに纏められる GlobalMemory


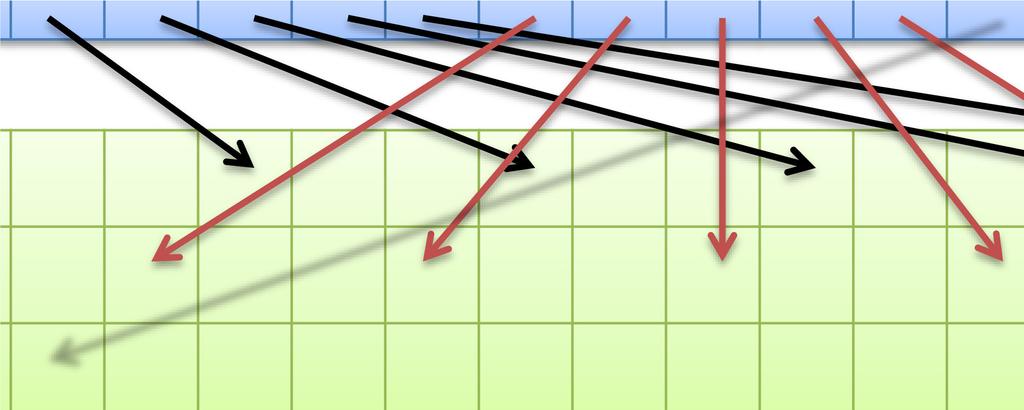
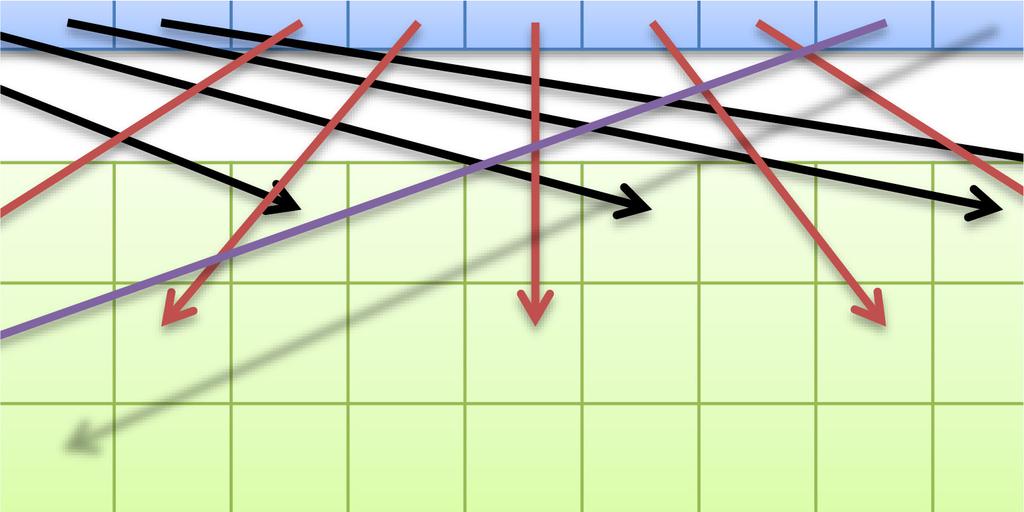
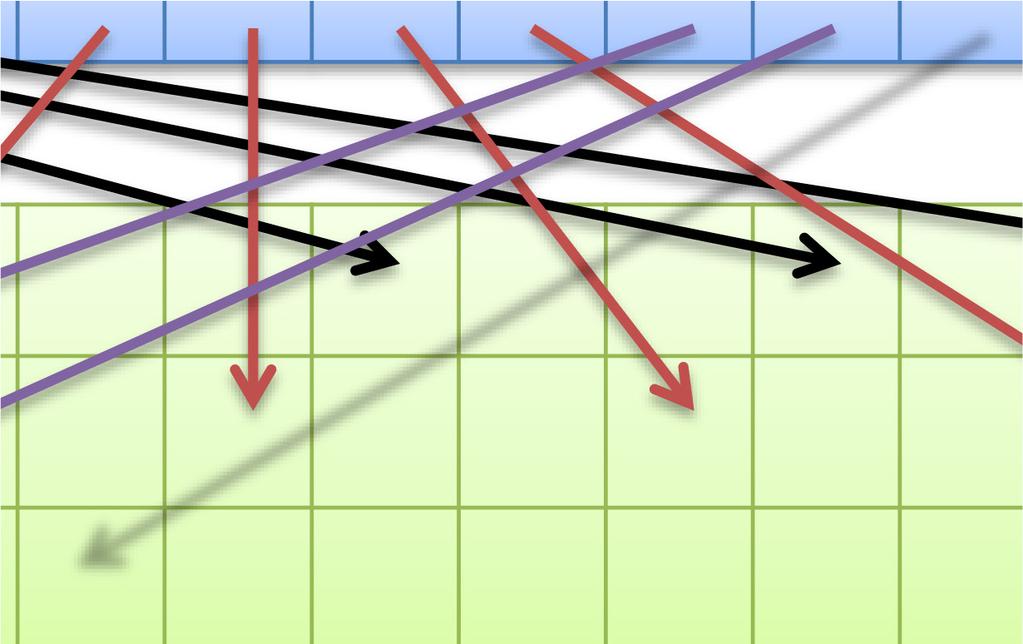
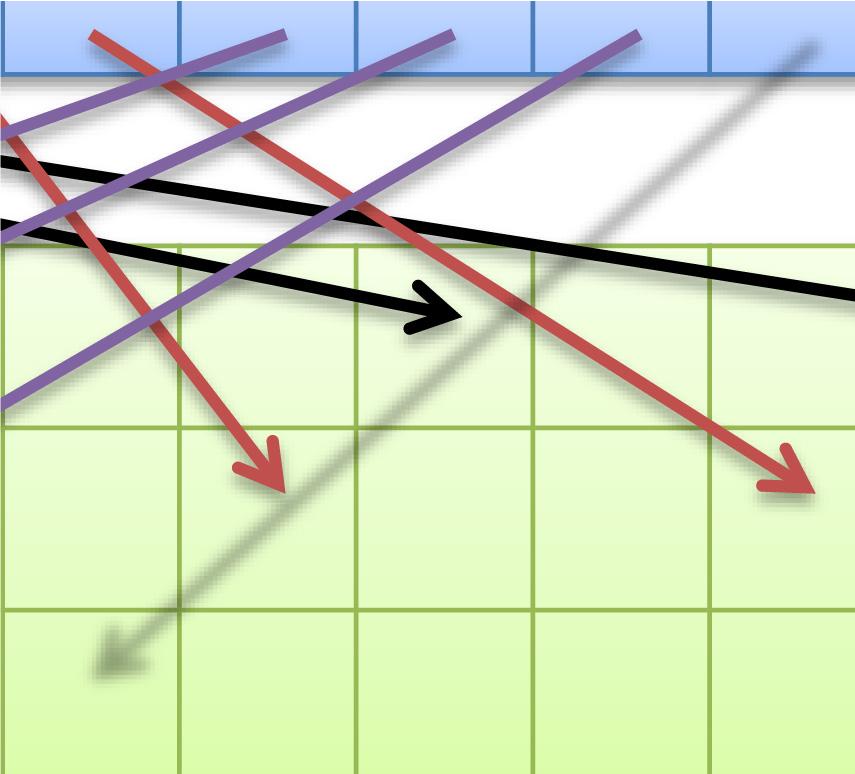
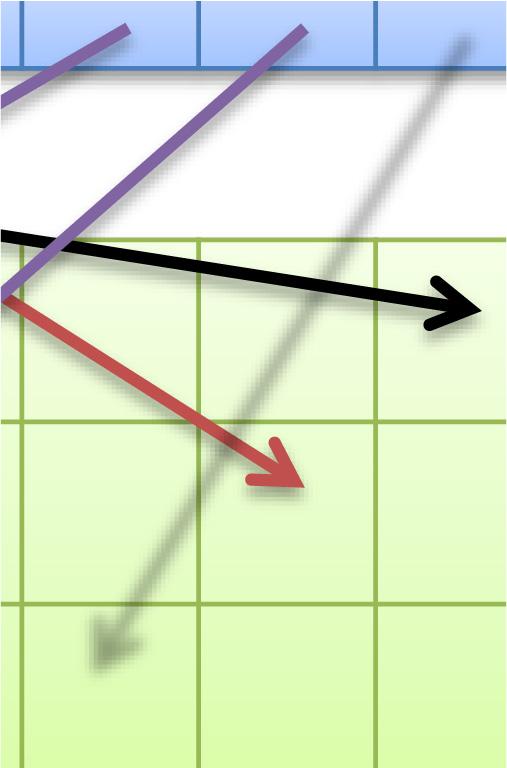


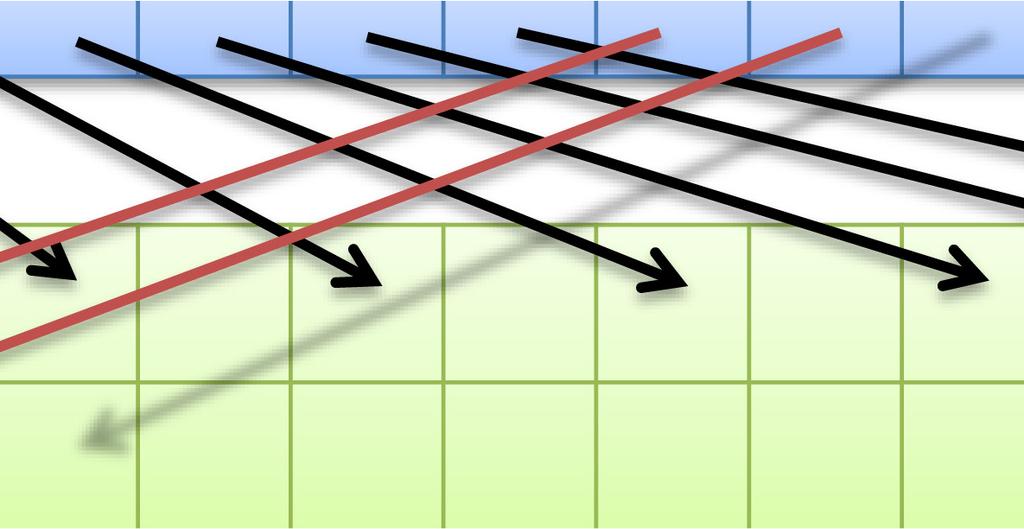
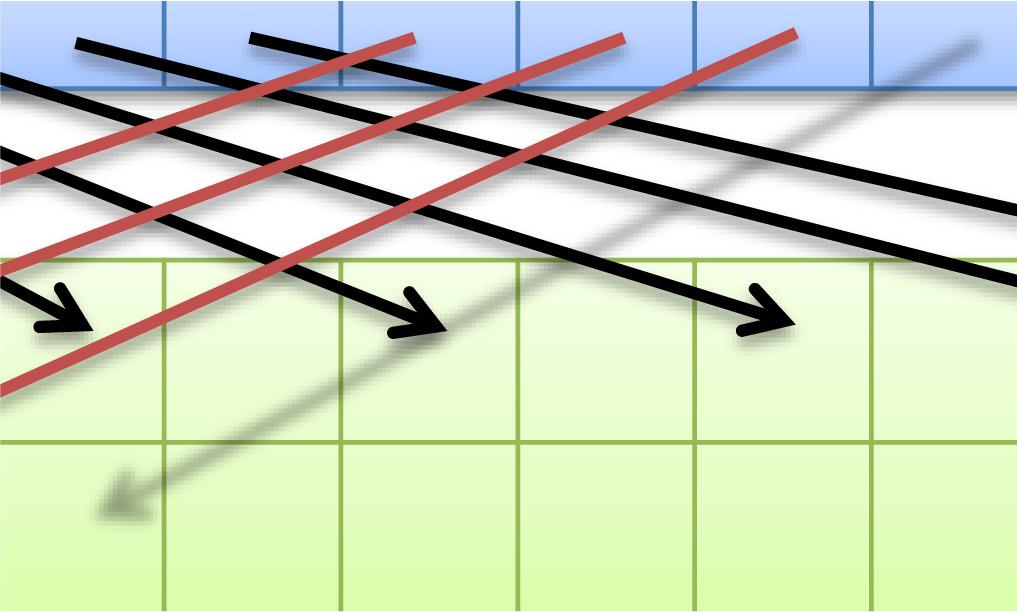

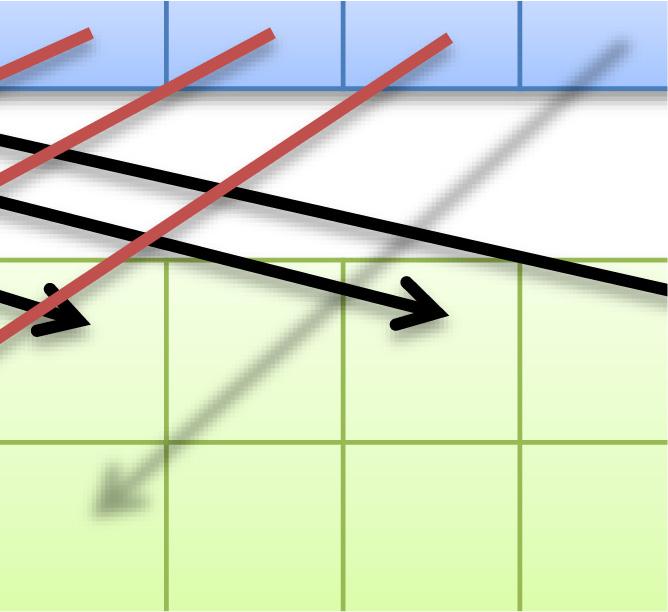
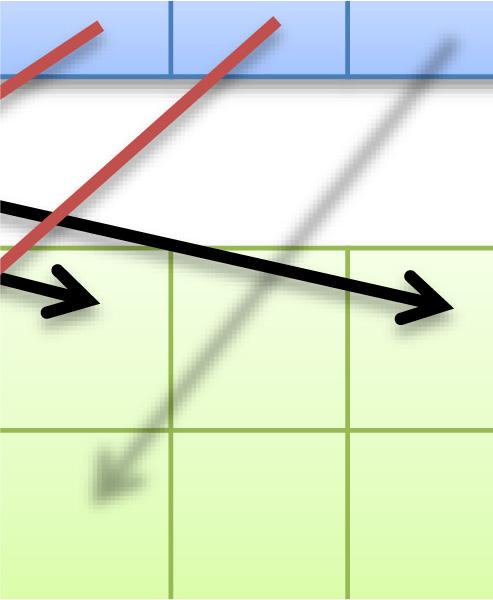
48 48 高速共有メモリは16個or32個ずつのバンクにより構成 同一バンクへのアクセスが集中すると性能低下 均等なアクセス 性能低下しない SharedMemory アクセスが集中 性能低下する 2-way バンクコンフリクトの例 SharedMemory
49 簡単な数値計算プログラム ( 行列積 行列ベクトル積 ) の最適化を題材に CUDA プログラムの最適化の基本について学ぶ 1

50 2 問題設定 行列積 C=A B データ型 : 単精度浮動小数点型 CUDA C : float 型 CUDA Fortran : real 型 倍精度浮動小数点型でも特に考え方は変わりません 話を簡単にするため N N サイズの正方行列を対象として 主に行列 A の参照を並列高速化することについて考える N N N N C = N A N B
51 3 まずは一次元配列を処理する簡単なプログラムを作成し CUDAプログラムの作成方法を理解する 用意するもの :CUDAプログラム arraytest.cu/arraytest.cuf プログラム内で行うこと 書かねばならないこと CPU 側 ( ホスト側処理 ) 配列を確保する :CPU 用 GPU 用 CPUからGPUへデータを送る GPUカーネルを起動する GPUからCPUへデータを書き戻す GPU 側 ( カーネル関数 ) 引数として問題サイズと計算対象配列を受け取る 配列を処理 ( コピー or 加算 ) する
52 4 配列 A と配列 C を用意し 配列 C に配列 A の内容をコピーする main 関数内 const int N = 1000; float *A, *C; A = (float*)malloc(sizeof(float)*n); C = (float*)malloc(sizeof(float)*n); for(i=0; i<n; i++){a[i]=(float)i; C[i] = 0.0f;} float *d_a, *d_c; cudamalloc((void**) &d_a, sizeof(float)*n); cudamalloc((void**) &d_c, sizeof(float)*n); cudamemcpy(d_a, A, sizeof(float)*n, cudamemcpyhosttodevice); cudamemcpy(d_c, C, sizeof(float)*n, cudamemcpyhosttodevice); dim3 blocks(1, 1, 1); dim3 threads(1, 1, 1); gpukernel<<< blocks, threads >>>(N, d_c, d_a); CPU メモリ確保 初期化 GPU メモリ確保 CPU から GPU へのデータ転送 並列度の指定 (1: 逐次 ) GPUカーネル実行開始 cudamemcpy(c, d_c, sizeof(float)*n, cudamemcpydevicetohost); 演算終了待ち 結果取得 cudafree(d_a); cudafree(d_c); GPUメモリ破棄 free(a); free(c); CPUメモリ破棄
 第四引数 : 転送方向 cudamemcpydevicetohost cudamemcpyhosttodevice 第五引数 : ストリーム ( 省略可能")
53 5 配列の確保 :cudamalloc 第一引数 : 確保対象 第二引数 : サイズ ( バイト数 ) 配列の破棄 :cudafree 引数 : 破棄対象 プログラム終了時に破棄されていなくても特にペナルティは無い CPU-GPU 間のデータ転送 :cudamemcpy 第一引数 : 転送先 第二引数 : 転送元 第三引数 : 転送サイズ ( バイト数 ) 第四引数 : 転送方向 cudamemcpydevicetohost cudamemcpyhosttodevice 第五引数 : ストリーム ( 省略可能 今回は扱わない )
54 6 GPU カーネル関数 global void gpukernel (int N, float *C, float *A) { int i; for(i=0; i<n; i++){ C[i] = A[i]; } } 配列と変数の扱い コンパイル $ nvcc arraytest.cu 引数として与えられた配列は GlobalMemory 上に配置される 引数として与えられた変数はレジスタ上に配置される カーネル内で宣言された変数や配列はレジスタ上に配置される 容量が大きすぎると LocalMemory 扱いにされる (GlobalMemory に配置される ) ので注意
) A =! 適当に配列の C =! 初期化を行う allocate(d_a(n))! GPU 上での allocate(d_c(n))! メモリ確保 d_a = A! CPUからGPUへの d_c = C! データ転送 call gpukernel<<<1,1>>>(n, d_c, d_a) C = d_c!")
55 7 program arraytest use cudafor use cudamod integer, parameter :: N=10 integer i real, allocatable, dimension(:) :: A, C real, device, allocatable, dimension(:) :: d_a, d_c allocate(a(n)) allocate(c(n)) A =! 適当に配列の C =! 初期化を行う allocate(d_a(n))! GPU 上での allocate(d_c(n))! メモリ確保 d_a = A! CPUからGPUへの d_c = C! データ転送 call gpukernel<<<1,1>>>(n, d_c, d_a) C = d_c! 結果の取得 deallocate(d_a) deallocate(d_c) deallocate(a) deallocate(c) end program arraytest CUDA Fortan を使うには use cudafor が必要 GPU 上に置かれるデータには device 属性を付加 device 属性を持つ配列に対して allocate や配列コピーをすると GPU 用の処理が行われる GPU カーネルの起動は CUDA C と同様に <<< >>> を使って行う
56 8 GPU カーネル関数 module cudamod use cudafor contains attributes(global) subroutine gpukernel(n, C, A) integer, value :: N real, device :: C(N), A(N) C = A end subroutine gpukernel end module cudamod コンパイル $ pgf90 Mcuda arraytest.cuf さらに -Minfo を追加指定すると様々な情報が表示される ( ことがある ) 注意この資料は基本的に CUDA C を使う前提で書いているが CUDA Fortran でも GPU カーネルの中身はほとんど同じである 適宜読み替えること
57 9 arraytest.cu/arraytest.cuf を完成させ 計算後の配列 C を表示して正しく動作していることを確認する 問題サイズや初期データは自由に決めて良い GlobalMemory 上のデータは次に GPU カーネルを実行するときも引き継がれる GPU カーネルを複数回実行したり 送受信する配列を増やしたりして動作を確認してみよう
58 10 多くの API 関数は返値を見れば関数の成否が確認できる 成功時は cudasuccess という値が得られる 問題があった場合はその内容を専用の関数で取得できる cudagetlasterror 関数と cudageterrorstring を使う cudaerror ret = cudamalloc( ); if(ret!=cudasuccess){ cudaerror _err = cudagetlasterror(); if(cudasuccess!=_err){ printf("%s n, cudageterrorstring(_err)); } }
59 11 行列積 GPU カーネルを実装し性能を確認する 段階的に最適化を適用して性能の差を確認する
60 12 CPU 側は共通のプログラムを使用 並列度は必要に応じ変更する cudamalloc((void**) &d_a, sizeof(float)*n*n); cudamalloc((void**) &d_b, sizeof(float)*n*n); cudamalloc((void**) &d_c, sizeof(float)*n*n); cudamemcpy(d_a, A, sizeof(float)*n*n, cudamemcpyhosttodevice); cudamemcpy(d_b, B, sizeof(float)*n*n, cudamemcpyhosttodevice); cudamemcpy(d_c, C, sizeof(float)*n*n, cudamemcpyhosttodevice); dim3 threads(tx, TY, 1); dim3 grid(gx, GY, 1); gpukernel<<< grid, threads >>>(N, d_c, d_a, d_b); cudamemcpy(c, d_c, sizeof(float)*n*n, cudamemcpydevicetohost); cudafree(d_a); cudafree(d_b); cudafree(d_c); GPU メモリ確保 データ転送 並列度の指定 ( 必要に応じて変更する ) 演算開始演算終了待ちと結果の取得
61 13 CUDA C では多次元配列は扱いにくい cudamalloc, cudamemcpy は一次元配列のみを対象としている 解決策はいくつかあるが 多次元配列を扱うための関数を使う 専用の関数 手順が必要 めんどくさい device 接頭辞をつけた固定長の配列を確保する 簡単だが扱いにくい ( 問題サイズの変更などがしにくい ) 一次元配列に置き換えて考える プログラムが若干複雑になるが使い方自体は簡単で汎用的 本資料では CPU 上でも GPU 上でも全て一次元配列を用いる 問題サイズを可変にするため ポインタを宣言しておいて動的に確保する float *d_a, *d_b, *d_c; // GPU float *A, *B, *C; // CPU CUDA Fortran でも一次元配列を使う 同様の GPU カーネル
62 14 特に最適化を行っていない逐次実行カーネル global void gpukernel ( int N, float *C, float *A, float *B ){ int i, j, k; for(k=0; k<n; k++){ for(j=0; j<n; j++){ for(i=0; i<n; i++){ C[k*N+j] += A[k*N+i] * B[i*N+j]; } } } } 単純な 3 重ループ 遅い 並列演算していない 計算コア単体の性能は同世代の CPU 未満 GlobalMemory アクセスばかりしている mm1
63 15 GlobalMemory 上の配列を毎回書き換えるのをやめるだけでもそれなりに影響がある global void gpukernel ( int N, float *C, float *A, float *B ){ int i, j, k; float tmp; for(k=0; k<n; k++){ for(j=0; j<n; j++){ tmp = 0.0f; for(i=0; i<n; i++){ tmp += A[k*N+i] * B[i*N+j]; } C[k*N+j] = tmp; } } 演習 } 実装し 実行して比較してみる 実行時間はどのように測定するべきか? mm2
64 汎用のタイマー関数 OpenMP や MPI の提供する測定関数 gettimeofday, omp_get_wtime, MPI_Wtime もちろん これらを使っても良い 非同期関数には注意 ( 次頁 ) CUDA に用意されているもの :cudaevent プロファイラ cudaevent float elapsedtime; cudaevent_t start, stop; cudaeventcreate(&start); cudaeventcreate(&stop); cudaeventrecord(start, 0); ここに測定対象の処理を入れる cudaeventrecord(stop, 0); cudaeventsynchronize(stop); cudaeventelapsedtime(&elapsedtime, start, stop); cudaeventdestroy(start); cudaeventdestroy(stop);
65 17 CUDA の提供する関数 (API) には非同期な関数が多い (CUDA における ) 非同期な関数とは? GPU に対して処理内容を伝えた時点で CPU に制御が返ってくる関数 CPU からは処理が終わっているかのように見えるが GPU は動作している 状態がありえる 単純に API 関数の実行時間を測定すると 正しい実行時間にならない 大きな行列に対する行列積を逐次実行するとわかりやすい 正しく測定する方法 GPU が処理を終えるのを待つ関数を実行し 終了を保証する cudathreadsynchronize( 引数無し ); プロファイラを使う ( 次頁 )
66 18 環境変数 COMPUTE_PROFILE に 1 をセットして CUDA プログラムを実行すれば実行情報を取得できる COMPUTE_PROFILE=1./a.out もしくは export COMPUTE_PROFILE=1 してから./a.out ジョブスクリプトに書き足す cuda_profile_0.log のようなファイルが作られる gputime の項を見ると時間がわかる method=[ memcpyhtod ] gputime=[ ] cputime=[ ] method=[ _Z9gpukerneliPfS_ ] gputime=[ ] cputime=[ ] occupancy=[ ] method=[ memcpydtoh ] gputime=[ ] cputime=[ ] さらに色々な情報を得たい場合には設定を追加する COMPUTE_PROFILE_CONFIGなどの設定を利用する が いずれ廃止される予定であり 現在はnvprofの使用が推奨されている模様
67 19 実行ファイルを与えるだけで良い :nvprof./a.out ==203057== NVPROF is profiling process , command:./mm.out ==203057== Profiling application:./mm.out ==203057== Profiling result: Time(%) Time Calls Avg Min Max Name 96.56% us us us us gpukernel(int, float*, float*, float*) 2.12% us 3 842ns 768ns 992ns [CUDA memcpy HtoD] 1.32% us us us us [CUDA memcpy DtoH] ==203057== API calls: Time(%) Time Calls Avg Min Max Name 99.76% ms ms us ms cudamalloc 0.16% ms us 120ns us cudevicegetattribute 0.02% us us us us cudamemcpy 0.02% us us us us cudevicetotalmem 0.02% us us us us cudafree 0.02% us us us us cudevicegetname 0.00% us us us us cudalaunch 0.00% us us 180ns us cudevicegetcount 0.00% us us 148ns us cudasetupargument 0.00% us us us us cudaconfigurecall 0.00% us 8 225ns 123ns 785ns cudeviceget 各演習において測定してみよう
68 20 GPU カーネルを起動する際にブロック (Block) とスレッド (Thread) の数を指定する <<< グリッドあたりブロックサイズ, ブロックあたりスレッドサイズ >>> 各値の乗算分のスレッドがGPU 上で動作する それぞれ三次元の値を指定可能 dim3 block; block.x = 32; block.y = 4; block.z = 2; dim3 thread(32,16,2); のように宣言時に指定しても良い <<<32,2>>> のようにスカラー値を直接与えても良い :(32,1,1), (2,1,1) 扱い 最大並列度 グリッドあたりブロックサイズ 公式ドキュメントにおけるMaximum ~ of a grid of thread blocks x 次元 :Fermiでは65535, Kepler 以降では y,z 次元 :65535 ブロックあたりスレッドサイズ 公式ドキュメントにおけるMaximum ~ of a block x,y 次元 :1024 z 次元 :64

 Grid")





")
69 午前の資料の再掲 21 実行モデルとメモリ構成の概要 SMx に対応 Host (CPU, MainMemory) Grid (DeviceMemory) GlobalMemory ConstantMemory TextureMemory Block n 個 Register Thread m 個 CUDA コアに対応 SharedMemory GPU カーネルは 1 つのグリッド (Grid) として GPU 上で実行される スレッドの集合がブロック (Block) ブロックの集合がグリッド (Grid) ブロックとスレッドは物理的な数以上に生成可能 ( 時分割実行される ) 生成する数量は GPU カーネル起動時に <<<,>>> で指定する
70 22 メモリアクセスパターンとの対応づけ 同一ブロック内の近いIDを持つスレッド群はコアレスなメモリアクセスが行える 同一ブロック内のスレッド群は高速共有メモリ (SharedMemory) を共有する データの使い回しを考える必要がある いくつくらいの値を与えるのが妥当なのか? 不足するとGPUに仕事が行き渡らない 多すぎる方がマシ ブロックあたりスレッドサイズ ( 細かい話を省くと )128~256 程度 32の倍数で試すのが良い グリッドあたりブロックサイズ GPUに搭載されているSMxの数に応じて指定 Tesla M2090は16ユニット搭載のため 16またはその倍数が妥当? ( 実際にはそれほどこだわらなくても良い )
71 23 GPU 内部での命令割り当ては32スレッド単位 (WARP 単位 ) で行われている 分岐処理の単位もWARP (Fermiでは使えないが)WARP 内でデータをやりとりする命令 ( シャッフル命令 ) も存在する 常に32スレッド単位での動作を意識しておくと良い
{ tmp = 0.")
72 24 Thread0 global void gpukernel Thread1 (int N, float *C, float *A, float *B){ Block0 Thread2 Thread3 int i, j, k; Thread4 float tmp; k = blockidx.x*blockdim.x + threadidx.x; Block1 for(j=0; j<n; j++){ tmp = 0.0f; for(i=0; i<n; i++){ tmp += A[k*N+i] * B[i*N+j]; } C[k*N+j] = tmp; } Block2 Block3 N/4 } 最外ループを並列化 5Thread*4Blockの場合の担当範囲例 blockidx, blockdim, threadidxを使ってidを得る この例ではブロック スレッドともに一次元を想定している ~IdxでID ~Dimで総数を取得できる 各スレッドが行列の1 行を担当するため スレッド数 ブロック数 =Nである必要がある 並列化により性能が向上するはず? mm3


{")


![A[k*N+i] *](/docs-images/63/49412511/images/73-11.jpg "B[i*N+j]; }")
![C[k*N+j] =](/docs-images/63/49412511/images/73-12.jpg "tmp; } Thread")

73 25 k = blockidx.x*blockdim.x + threadidx.x; for(j=0; j<n; j++){ tmp = 0.0f; for(i=0; i<n; i++){ tmp += A[k*N+i] * B[i*N+j]; } C[k*N+j] = tmp; } Thread 0 メモリの連続方向 Thread 1 B Thread 2 Thread n 同時にアクセスしている方向 A Block0 担当領域 C

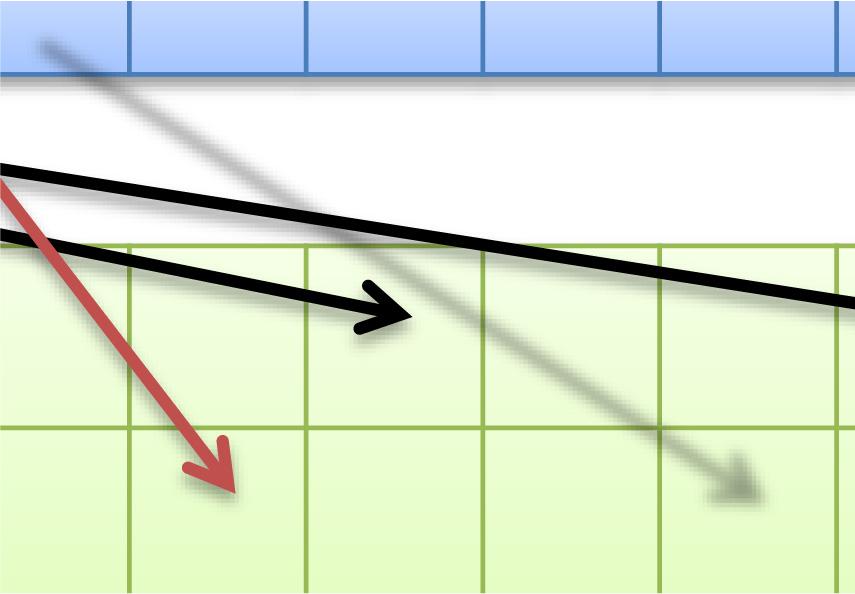
74 26 理想的なメモリアクセス メモリの連続方向 現在のメモリアクセス メモリの連続方向 Thread0,1,2,3 が同時に行うメモリアクセス 行列 A コアレスなメモリアクセス が行われるため高速 行列 A コアレスなメモリアクセス が行われないため低速 並列化自体はできているため性能は向上する 不連続なメモリに一度にアクセスしているのを修正 解消すれば もっと性能が向上するはず
75 27 global void gpukernel (int N, float *C, float *A, float *B){ int i, j, k; float tmp; k = blockidx.x; j = threadidx.x; tmp = 0.0f; for(i=0; i<n; i++){ tmp += A[k*N+i] * B[i*N+j]; } C[k*N+j] = tmp; } N Block N Thread 各スレッドが計算結果行列の 1 要素ずつを担当するイメージ ( 要素が多すぎる場合には複数要素を担当する などの改善も可能 ) 同一 Block 内の Thread はメモリアクセス方向に並ぶ : メモリアクセスが不連続にならないため性能改善する? mm4

76 28 Thread 0 Thread 1 Thread 2 Thread n B メモリの連続方向 同時にアクセスしている方向 A Block0 担当領域 C

77 29 現在のメモリアクセス メモリの連続方向 Thread0,1,2,3 が同時に行うメモリアクセス 行列 A ちがう そうじゃない 別のスレッドが GlobalMemory から取得済の行列 A のデータを共有したい
78 30 共有範囲 同一ブロック内のスレッド群 利点 高速 ( レジスタ並 ) 注意点 小容量 :Fermi では SMx あたり 48KB バンクコンフリクト : メモリアクセスパターンによっては性能が低下 使い方 記述 : shared 接頭辞 よくある使い方 :GlobalMemory からコアレスなメモリアクセスでデータを取得し 計算に使う SharedeMemory 内ではランダムなメモリアクセスでも高速
79 31 #define MAX_SM 1024 global void gpukernel (int N, float *C, float *A, float *B){ int i, j, k, ntx; float tmp; shared float sa[max_sm]; k = blockidx.x; j = threadidx.x; ntx = blockdim.x; tmp = 0.0f; } for(i=j; i<n; i+=ntx){ sa[i] = A[k*N+i]; } syncthreads(); for(i=0; i<n; i++){ tmp += sa[i] * B[i*N+j]; } C[k*N+j] = tmp; GlobalMemory に連続読み込みアクセスして SharedMemory へデータを格納 SharedMemory 格納済みのデータを用いて計算 Register へ syncthreads は N>32 の場合のみ必要 SharedMemory を用いて Block 内でデータを再利用 共通してアクセスするデータを SharedMemory に格納しておいて再利用する 説明を簡単にするため固定長の SharedMemory を用意したが 動的な確保も可能 サイズを未指定 ([]) にしてお き <<< >>> の第 3 引数で指定 総命令実行回数自体は増加 問題サイズが大きくないとペイしない? CUDA Fortran の場合は real, shared :: sa(max_sm) のように指定 mm5
80 32 同一 WARP 内のスレッド群は常に同期して動作している 乱すことは不可能 メモリアクセスの待ち時間が均一でないときは遅いスレッドが足を引っ張る 同一ブロック内のスレッド群 ( 異なる WARP のスレッド同士 ) は同期を取ることができる syncthreads(); 異なるブロックをまたいだ同期は不可能 ( 後述の atomic 関数を使えば同期のようなこともできなくはないが 非推奨 )

81 33 Thread 0 Thread 1 Thread 2 Thread n B 連続領域をアクセス SharedMemory へ格納して共有 メモリの連続方向 同時にアクセスしている方向 A Block0 担当領域 C
82 34 メモリの連続方向 Thread0,1,2,3 が同時に行うメモリアクセス 一時的に格納 行列 A コアレスなメモリアクセス が行われるため高速 共有メモリ GlobalMemory の代わりに SharedMemory を用いて計算 ( その後 結果をコアレスなメモリアクセスで行列 C に書き戻す )
83 35 texture<float, 1>texA; global void gpukernel (int N, float *C, float *B){ int i, j, k; float tmp; k = blockidx.x; j = threadidx.x; tmp = 0.0f; for(i=0; i<n; i++){ tmp += tex1dfetch(texa,k*n+i) * B[i*N+j]; } } C[k*N+j] = tmp; CPU 側コード size_t offset = size_t(-1); cudamemcpy( d_a, A, sizeof(float)*n*n, cudamemcpyhosttodevice ); cudabindtexture(&offset, texa, d_a); TextureMemory でメモリアクセスを高速化 キャッシュ効果があるため SharedMemory を使うのに似た効果が期待される Kepler 以降では ReadOnlyDataCache を使うと良い 本当は二次元空間的な補間が使えるときなどに有効な方法 mm6
84 36 行列 B に関する最適化 行列 A に関する最適化しか考えていない 行列 B についてはどうか? ヒント : 行列 A( 横方向 ) と行列 B( 縦方向 ) の両方で SharedMemory を活用するにはどうすれば良いだろうか? 様々な数の最適化 スレッド数 ブロック数 SharedMemory に格納する単位 ベストな数を選ぶことで高い性能が得られるはずである

85 37 可視化機能を持つプロファイラを用いて性能の差を視覚的に理解する デモ ( 実演 ) による紹介 準備 :HA-PACSにSSHログインする際に-Yオプションをつけておく インタラクティブジョブを実行する qsub_gpu -I -X -A GPUSEMINAR -q gpuseminar nvvpコマンドを実行して起動



86 38 行列ベクトル積の場合はどうだろうか? ブロックごとに1 行の計算を担当することを考える 行列データの再利用性がないため 行列積のような最適化の余地がない コアレスなメモリアクセスは必須 連続するスレッドが配列を順番にアクセスすれば良い 簡単 ブロック内での足しあわせ ( リダクション ) はどうする? 1 N 1 N C = N A N B
87 39 int tid = threadidx.x; int ntx = blockdim.x; int bid = blockidx.x; float tmp = 0.0f; for(j=tid; j<n; j+=ntx){ tmp += A[bid*N + j] * B[j]; } ブロック ID = 行番号 行内のスレッド群が全体で一行を計算 // この時点で各スレッドは結果の一部を持った状態 result = ; // どうにかしてスレッド間で足しあわせたい if(tid==0){ // スレッドID=0のスレッドが計算結果を書き戻して終了 C[bid] = result; }

88 40 OpenMP や OpenACC では指示文を一行入れるだけ CUDA ではどのように行えば良いだろうか? 何も考えずに GlobalMemory に足し合わせると タイミングによって値が変わってしまう あるスレッドが値を読み込んで足して書き戻す間に 他のスレッドが割り込む可能性がある GlobalMemory 上の配列の値 1 スレッド 0 のレジスタの値 スレッド 1 のレジスタの値 時間経過 2 2 読み込み 書き戻し 読み込み 書き戻し +1 を 2 回行ったはずなのに 1 しか増えていない
89 41 他のスレッドに割り込まれずに GlobalMemory 上の値を更新するための関数群が提供されている atomicadd, atomicsub, atomicexch, atomicmin, atomicmax, atomicinc, atomicdec, atomiccas, atomicand, atomicor, atomicxor atomicadd(&hoge, 1.0f); atomicsub(&hoge, -1); メリット : 割り込まれる心配が不要になる デメリット : 性能低下要因 多用しすぎには注意 新しい世代のGPUほどatomic 演算も高性能 様々なデータ型に対応 GPU 全体でのリダクション演算も不可能ではない が 数千スレッドが同一の変数に対してリダクション演算を行うのは推奨できない 同一ブロック内でのリダクション演算は別の方法で行い ブロック間のリダクションにatomic 演算を使うのが妥当



90 色々な方法が考えられるが 42
? g_idata[i] : 0; syncthreads(); for (unsigned int s=1; s < blockdim.x; s *= 2) { int index = 2 * s * tid; } if (index < blockdim.")
91 43 CUDA サンプルの 6_Advanced/reduction/reduction_kernel.cu より template <class T> T *sdata = SharedMemory<T>(); unsigned int tid = threadidx.x; unsigned int i = blockidx.x*blockdim.x + threadidx.x; sdata[tid] = (i < n)? g_idata[i] : 0; syncthreads(); for (unsigned int s=1; s < blockdim.x; s *= 2) { int index = 2 * s * tid; } if (index < blockdim.x) { sdata[index] += sdata[index + s]; } syncthreads(); Divergent WARP だらけになり良い性能は得られない ( 足し合わせる順序よりむしろ実装の仕方が悪い )
; unsigned")
?")
![g_idata[i] : 0; if (i + blocksize < n)mysum += g_idata[i+blocksize]; sdata[tid] = mysum;](/docs-images/63/49412511/images/92-7.jpg "syncthreads(); if((blocksize >= 512)&&(tid < 256)){ sdata[tid] = mysum = mysum +")
![sdata[tid + 256];} syncthreads(); if((blocksize >= 256)&&(tid < 128)){ sdata[tid] = mysum](/docs-images/63/49412511/images/92-8.jpg "= mysum + sdata[tid + 128];} syncthreads(); if((blocksize >= 128)&&(tid < 64)){")
![sdata[tid] = mysum = mysum + sdata[tid + 64];} syncthreads(); if((blocksize >= 64)&&(tid](/docs-images/63/49412511/images/92-9.jpg "< 32)){ sdata[tid] = mysum = mysum + sdata[tid + 32];} syncthreads(); if((blocksize >=")
![32)&&(tid < 16)){ sdata[tid] = mysum = mysum + sdata[tid + 16];} syncthreads();](/docs-images/63/49412511/images/92-11.jpg "if((blocksize >= 16)&&(tid < 8)){ sdata[tid] = mysum = mysum + sdata[tid + 8];}")
![syncthreads(); if((blocksize >= 8)&&(tid < 4)){ sdata[tid] = mysum = mysum + sdata[tid +](/docs-images/63/49412511/images/92-12.jpg "4];} syncthreads(); if((blocksize >= 4)&&(tid < 2)){ sdata[tid] = mysum = mysum +")
92 44 CUDA サンプルの 6_Advanced/reduction/reduction_kernel.cu より template <class T, unsigned int blocksize> T *sdata = SharedMemory<T>(); unsigned int tid = threadidx.x; unsigned int i = blockidx.x*(blocksize*2) + threadidx.x; T mysum = (i < n)? g_idata[i] : 0; if (i + blocksize < n)mysum += g_idata[i+blocksize]; sdata[tid] = mysum; syncthreads(); if((blocksize >= 512)&&(tid < 256)){ sdata[tid] = mysum = mysum + sdata[tid + 256];} syncthreads(); if((blocksize >= 256)&&(tid < 128)){ sdata[tid] = mysum = mysum + sdata[tid + 128];} syncthreads(); if((blocksize >= 128)&&(tid < 64)){ sdata[tid] = mysum = mysum + sdata[tid + 64];} syncthreads(); if((blocksize >= 64)&&(tid < 32)){ sdata[tid] = mysum = mysum + sdata[tid + 32];} syncthreads(); if((blocksize >= 32)&&(tid < 16)){ sdata[tid] = mysum = mysum + sdata[tid + 16];} syncthreads(); if((blocksize >= 16)&&(tid < 8)){ sdata[tid] = mysum = mysum + sdata[tid + 8];} syncthreads(); if((blocksize >= 8)&&(tid < 4)){ sdata[tid] = mysum = mysum + sdata[tid + 4];} syncthreads(); if((blocksize >= 4)&&(tid < 2)){ sdata[tid] = mysum = mysum + sdata[tid + 2];} syncthreads(); if((blocksize >= 2)&&(tid < 1)){ sdata[tid] = mysum = mysum + sdata[tid + 1];} Divergent WARP が発生しない実装の工夫のおかげで高速一見すると分岐だらけだが テンプレート展開によって消滅する
93 45 行列ベクトル積を作成する リダクション方法を変えて性能を比較する 並列化方法を変えて性能を比較する 1ブロックあたり1 行 をやめる (WARPあたり1 行など ) 行列サイズ 並列度 性能の関係を調べる CUDA を用いた並列リダクションについては以下の資料に詳細に書かれているので参考にしてください その他にも各種資料がオンラインで公開されています (CUDA Toolkit をインストールする際に入手することもできます )
94 46 この時間に扱ったこと CUDA(CUDA C, CUDA Fortran) の基本的な使い方 CUDA プログラムの最適化方法のほんの一部 スレッドとブロックを使った並列化 コアレスなメモリアクセス SharedMemory TextureMemory atomic 演算 リダクション処理 扱っていないこと Kepler 以降の新機能 CPU-GPU 間データ転送を考慮した最適化 ( ストリームなど ) 複数 GPU の活用 入門 であり いずれも触った程度 GPU の持つ性能を引きだすにはさらなる経験が必要
CUDA 連携とライブラリの活用 2
 1 09:30-10:00 受付 10:00-12:00 Reedbush-H ログイン GPU 入門 13:30-15:00 OpenACC 入門 15:15-16:45 OpenACC 最適化入門と演習 17:00-18:00 OpenACC の活用 (CUDA 連携とライブラリの活用 ) CUDA 連携とライブラリの活用 2 3 OpenACC 簡単にGPUプログラムが作成できる それなりの性能が得られる
1 09:30-10:00 受付 10:00-12:00 Reedbush-H ログイン GPU 入門 13:30-15:00 OpenACC 入門 15:15-16:45 OpenACC 最適化入門と演習 17:00-18:00 OpenACC の活用 (CUDA 連携とライブラリの活用 ) CUDA 連携とライブラリの活用 2 3 OpenACC 簡単にGPUプログラムが作成できる それなりの性能が得られる
1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境 Lin
 Windows で始める CUDA 入門 GTC 2013 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境
Windows で始める CUDA 入門 GTC 2013 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境
Microsoft PowerPoint - RBU-introduction-J.pptx
 Reedbush-U の概要 ログイン方法 東京大学情報基盤センタースーパーコンピューティング研究部門 http://www.cc.u-tokyo.ac.jp/ 東大センターのスパコン 2 基の大型システム,6 年サイクル (?) FY 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 Hitachi SR11K/J2 IBM Power 5+ 18.8TFLOPS,
Reedbush-U の概要 ログイン方法 東京大学情報基盤センタースーパーコンピューティング研究部門 http://www.cc.u-tokyo.ac.jp/ 東大センターのスパコン 2 基の大型システム,6 年サイクル (?) FY 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 Hitachi SR11K/J2 IBM Power 5+ 18.8TFLOPS,
担当 大島聡史 ( 助教 ) 星野哲也 ( 助教 ) 質問やサンプルプログラムの提供についてはメールでお問い合わせください 年 03 月 14 日 ( 火 )
 星野哲也 ( 助教 ) 質問やサンプルプログラムの提供についてはメールでお問い合わせください 年 03 月 14 日 ( 火 )") 担当 大島聡史 ( 助教 ) [email protected] 星野哲也 ( 助教 ) [email protected] 質問やサンプルプログラムの提供についてはメールでお問い合わせください 1 2017 年 03 月 14 日 ( 火 ) 2 09:30-10:00 受付 10:00-12:00 Reedbush-H ログイン GPU 入門 13:30-15:00
担当 大島聡史 ( 助教 ) [email protected] 星野哲也 ( 助教 ) [email protected] 質問やサンプルプログラムの提供についてはメールでお問い合わせください 1 2017 年 03 月 14 日 ( 火 ) 2 09:30-10:00 受付 10:00-12:00 Reedbush-H ログイン GPU 入門 13:30-15:00
CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン
 CUDA 画像処理入門 エヌビディアジャパン CUDA エンジニア森野慎也 GTC Japan 2014 CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン RGB Y( 輝度 ) 変換 カラー画像から グレイスケールへの変換 Y = 0.299 R + 0.587
CUDA 画像処理入門 エヌビディアジャパン CUDA エンジニア森野慎也 GTC Japan 2014 CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン RGB Y( 輝度 ) 変換 カラー画像から グレイスケールへの変換 Y = 0.299 R + 0.587
Slide 1
 CUDA プログラミングの基本 パート II - カーネル CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パート II カーネルの起動 GPUコードの具体像 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください GPU 上でのコードの実行 カーネルは C 関数 + 多少の制約 ホストメモリはアクセスできない戻り値型は
CUDA プログラミングの基本 パート II - カーネル CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パート II カーネルの起動 GPUコードの具体像 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください GPU 上でのコードの実行 カーネルは C 関数 + 多少の制約 ホストメモリはアクセスできない戻り値型は
( CUDA CUDA CUDA CUDA ( NVIDIA CUDA I
 GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
07-二村幸孝・出口大輔.indd
 GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
概要 目的 CUDA Fortran の利用に関する基本的なノウハウを提供する 本チュートリアル受講後は Web 上で公開されている資料等を参照しながら独力で CUDA Fortran が利用できることが目標 対象 CUDA Fortran の利用に興味を抱いている方 前提とする知識 Fortran
 CUDA Fortran チュートリアル 2010 年 9 月 29 日 NEC 概要 目的 CUDA Fortran の利用に関する基本的なノウハウを提供する 本チュートリアル受講後は Web 上で公開されている資料等を参照しながら独力で CUDA Fortran が利用できることが目標 対象 CUDA Fortran の利用に興味を抱いている方 前提とする知識 Fortran を用いた Linux
CUDA Fortran チュートリアル 2010 年 9 月 29 日 NEC 概要 目的 CUDA Fortran の利用に関する基本的なノウハウを提供する 本チュートリアル受講後は Web 上で公開されている資料等を参照しながら独力で CUDA Fortran が利用できることが目標 対象 CUDA Fortran の利用に興味を抱いている方 前提とする知識 Fortran を用いた Linux
資料2-1 計算科学・データ科学融合へ向けた東大情報基盤センターの取り組み(中村委員 資料)
") 資料 2-1 計算科学 データ科学融合へ向けた 東大情報基盤センターの取り組み 東京大学情報基盤センター中村宏 東大情報基盤センターのスパコン FY 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 Hitachi SR11K/J2 IBM Power-5+ 18.8TFLOPS, 16.4TB Hitachi HA8000 (T2K) AMD Opteron
資料 2-1 計算科学 データ科学融合へ向けた 東大情報基盤センターの取り組み 東京大学情報基盤センター中村宏 東大情報基盤センターのスパコン FY 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 Hitachi SR11K/J2 IBM Power-5+ 18.8TFLOPS, 16.4TB Hitachi HA8000 (T2K) AMD Opteron
熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date Type URL Presentation
 榎本, 昌一 Citation Issue date Type URL Presentation") 熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date 2011-03-17 Type URL Presentation http://hdl.handle.net/2298/23539 Right GPGPU による高速演算について 榎本昌一 東京大学大学院工学系研究科システム創成学専攻
熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date 2011-03-17 Type URL Presentation http://hdl.handle.net/2298/23539 Right GPGPU による高速演算について 榎本昌一 東京大学大学院工学系研究科システム創成学専攻
Reedbush-U の概要 ログイン方法 東京大学情報基盤センタースーパーコンピューティング研究部門
 Reedbush-U の概要 ログイン方法 東京大学情報基盤センタースーパーコンピューティング研究部門 http://www.cc.u-tokyo.ac.jp/ 東大センターのスパコン 2 基の大型システム,6 年サイクル ( だった ) FY 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 2 Yayoi: Hitachi SR16000/M1 IBM Power-7
Reedbush-U の概要 ログイン方法 東京大学情報基盤センタースーパーコンピューティング研究部門 http://www.cc.u-tokyo.ac.jp/ 東大センターのスパコン 2 基の大型システム,6 年サイクル ( だった ) FY 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 2 Yayoi: Hitachi SR16000/M1 IBM Power-7
Microsoft PowerPoint - suda.pptx
 GPU の HWアーキテクチャと高性能化手法 須田礼仁 ( 東京大学 ) 2011/03/22 GPU 高性能プログラミング GPU のハードウェアを理解する CUDA のソフトウェアを理解する CUDA でプログラムを書くのは難しくないが, CUDA で高速なプログラムを書くのは難しい どうすれば遅くなるかを理解する! 効果が大きいものから順に説明します 1 高性能プログラミングの手順 1. 現在のコードの,
GPU の HWアーキテクチャと高性能化手法 須田礼仁 ( 東京大学 ) 2011/03/22 GPU 高性能プログラミング GPU のハードウェアを理解する CUDA のソフトウェアを理解する CUDA でプログラムを書くのは難しくないが, CUDA で高速なプログラムを書くのは難しい どうすれば遅くなるかを理解する! 効果が大きいものから順に説明します 1 高性能プログラミングの手順 1. 現在のコードの,
Microsoft PowerPoint - GPGPU実践基礎工学(web).pptx
.pptx") GPU のプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU プログラミング環境 (CUDA) GPU プログラムの実行の流れ CUDA によるプログラムの記述 カーネル (GPU で処理する関数 ) の構造 記述方法とその理由 GPU 固有のパラメータの確認 405 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ
GPU のプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU プログラミング環境 (CUDA) GPU プログラムの実行の流れ CUDA によるプログラムの記述 カーネル (GPU で処理する関数 ) の構造 記述方法とその理由 GPU 固有のパラメータの確認 405 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ
Microsoft PowerPoint - GPGPU実践基礎工学(web).pptx
.pptx") GPU のメモリ階層 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のメモリ階層 グローバルメモリ 共有メモリ モザイク処理への適用 コンスタントメモリ 空間フィルタへの適用 577 GPU の主要部品 基盤 GPU( チップ )+ 冷却部品 画面出力端子 電源入力端子 メモリ 特性の把握が重要 電源入力端子 画面出力端子 メモリ チップ PCI Ex 端子 http://www.geforce.com/whats
GPU のメモリ階層 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のメモリ階層 グローバルメモリ 共有メモリ モザイク処理への適用 コンスタントメモリ 空間フィルタへの適用 577 GPU の主要部品 基盤 GPU( チップ )+ 冷却部品 画面出力端子 電源入力端子 メモリ 特性の把握が重要 電源入力端子 画面出力端子 メモリ チップ PCI Ex 端子 http://www.geforce.com/whats
GPU のアーキテクチャとプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓
 GPU のアーキテクチャとプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のアーキテクチャ CUDA CUDA によるプログラミング 58 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ チップ単体では販売されていない PCI Ex カードで販売 ( チップ単体と区別せずに GPU と呼ぶことも多い
GPU のアーキテクチャとプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のアーキテクチャ CUDA CUDA によるプログラミング 58 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ チップ単体では販売されていない PCI Ex カードで販売 ( チップ単体と区別せずに GPU と呼ぶことも多い
システムソリューションのご紹介
 HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日
 TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 理化学研究所 共通コードプロジェクト
 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 理化学研究所 共通コードプロジェクト") GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 勉強会 @ 理化学研究所 共通コードプロジェクト Contents Hands On 環境について Introduction to GPU computing Introduction
GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 勉強会 @ 理化学研究所 共通コードプロジェクト Contents Hands On 環境について Introduction to GPU computing Introduction
1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU.....
 CPU GPU N Q07-065 2011 2 17 1 1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU...........................................
CPU GPU N Q07-065 2011 2 17 1 1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU...........................................
GPGPUクラスタの性能評価
 2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
3次多項式パラメタ推定計算の CUDAを用いた実装 (CUDAプログラミングの練習として) Implementation of the Estimation of the parameters of 3rd-order-Polynomial with CUDA
 Implementation of the Estimation of the parameters of 3rd-order-Polynomial with CUDA") 3 次多項式パラメタ推定計算の CUDA を用いた実装 (CUDA プログラミングの練習として ) Estimating the Parameters of 3rd-order-Polynomial with CUDA ISS 09/11/12 問題の選択 目的 CUDA プログラミングを経験 ( 試行錯誤と習得 ) 実際に CPU のみの場合と比べて高速化されることを体験 問題 ( インプリメントする内容
3 次多項式パラメタ推定計算の CUDA を用いた実装 (CUDA プログラミングの練習として ) Estimating the Parameters of 3rd-order-Polynomial with CUDA ISS 09/11/12 問題の選択 目的 CUDA プログラミングを経験 ( 試行錯誤と習得 ) 実際に CPU のみの場合と比べて高速化されることを体験 問題 ( インプリメントする内容
ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014
 ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014 コンカレントな処理の実行 システム内部の複数の処理を 平行に実行する CPU GPU メモリ転送 カーネル実行 複数のカーネル間 ストリーム GPU 上の処理キュー カーネル実行 メモリ転送の並列性 実行順序 DEFAULT STREAM Stream : GPU
ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014 コンカレントな処理の実行 システム内部の複数の処理を 平行に実行する CPU GPU メモリ転送 カーネル実行 複数のカーネル間 ストリーム GPU 上の処理キュー カーネル実行 メモリ転送の並列性 実行順序 DEFAULT STREAM Stream : GPU
GPU GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1
 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1") GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
Microsoft PowerPoint - 09.pptx
 情報処理 Ⅱ 第 9 回 2014 年 12 月 22 日 ( 月 ) 関数とは なぜ関数 関数の分類 自作関数 : 自分で定義する. ユーザ関数 ユーザ定義関数 などともいう. 本日のテーマ ライブラリ関数 : 出来合いのもの.printf など. なぜ関数を定義するのか? 処理を共通化 ( 一般化 ) する プログラムの見通しをよくする 機能分割 ( モジュール化, 再利用 ) 責任 ( あるいは不具合の発生源
情報処理 Ⅱ 第 9 回 2014 年 12 月 22 日 ( 月 ) 関数とは なぜ関数 関数の分類 自作関数 : 自分で定義する. ユーザ関数 ユーザ定義関数 などともいう. 本日のテーマ ライブラリ関数 : 出来合いのもの.printf など. なぜ関数を定義するのか? 処理を共通化 ( 一般化 ) する プログラムの見通しをよくする 機能分割 ( モジュール化, 再利用 ) 責任 ( あるいは不具合の発生源
演習1: 演習準備
 演習 1: 演習準備 2013 年 8 月 6 日神戸大学大学院システム情報学研究科森下浩二 1 演習 1 の内容 神戸大 X10(π-omputer) について システム概要 ログイン方法 コンパイルとジョブ実行方法 OpenMP の演習 ( 入門編 ) 1. parallel 構文 実行時ライブラリ関数 2. ループ構文 3. shared 節 private 節 4. reduction 節
演習 1: 演習準備 2013 年 8 月 6 日神戸大学大学院システム情報学研究科森下浩二 1 演習 1 の内容 神戸大 X10(π-omputer) について システム概要 ログイン方法 コンパイルとジョブ実行方法 OpenMP の演習 ( 入門編 ) 1. parallel 構文 実行時ライブラリ関数 2. ループ構文 3. shared 節 private 節 4. reduction 節
Microsoft PowerPoint - GPU_computing_2013_01.pptx
 GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格
GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格
PowerPoint プレゼンテーション
 vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
GPU n Graphics Processing Unit CG CAD
 GPU 2016/06/27 第 20 回 GPU コンピューティング講習会 ( 東京工業大学 ) 1 GPU n Graphics Processing Unit CG CAD www.nvidia.co.jp www.autodesk.co.jp www.pixar.com GPU n GPU ü n NVIDIA CUDA ü NVIDIA GPU ü OS Linux, Windows, Mac
GPU 2016/06/27 第 20 回 GPU コンピューティング講習会 ( 東京工業大学 ) 1 GPU n Graphics Processing Unit CG CAD www.nvidia.co.jp www.autodesk.co.jp www.pixar.com GPU n GPU ü n NVIDIA CUDA ü NVIDIA GPU ü OS Linux, Windows, Mac
スライド 1
 GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
openmp1_Yaguchi_version_170530
 並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
C プログラミング演習 1( 再 ) 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ
 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ") C プログラミング演習 1( 再 ) 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ 今回のプログラミングの課題 次のステップによって 徐々に難易度の高いプログラムを作成する ( 参照用の番号は よくわかる C 言語 のページ番号 ) 1. キーボード入力された整数 10 個の中から最大のものを答える 2. 整数を要素とする配列 (p.57-59) に初期値を与えておき
C プログラミング演習 1( 再 ) 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ 今回のプログラミングの課題 次のステップによって 徐々に難易度の高いプログラムを作成する ( 参照用の番号は よくわかる C 言語 のページ番号 ) 1. キーボード入力された整数 10 個の中から最大のものを答える 2. 整数を要素とする配列 (p.57-59) に初期値を与えておき
CCS HPCサマーセミナー 並列数値計算アルゴリズム
 大規模系での高速フーリエ変換 2 高橋大介 [email protected] 筑波大学計算科学研究センター 2016/6/2 計算科学技術特論 B 1 講義内容 並列三次元 FFT における自動チューニング 二次元分割を用いた並列三次元 FFT アルゴリズム GPU クラスタにおける並列三次元 FFT 2016/6/2 計算科学技術特論 B 2 並列三次元 FFT における 自動チューニング
大規模系での高速フーリエ変換 2 高橋大介 [email protected] 筑波大学計算科学研究センター 2016/6/2 計算科学技術特論 B 1 講義内容 並列三次元 FFT における自動チューニング 二次元分割を用いた並列三次元 FFT アルゴリズム GPU クラスタにおける並列三次元 FFT 2016/6/2 計算科学技術特論 B 2 並列三次元 FFT における 自動チューニング
GPUコンピューティング講習会パート1
 GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
並列計算導入.pptx
 並列計算の基礎 MPI を用いた並列計算 並列計算の環境 並列計算 複数の計算ユニット(PU, ore, Pなど を使用して 一つの問題 計算 を行わせる 近年 並列計算を手軽に使用できる環境が急速に整いつつある >通常のP PU(entral Processing Unit)上に計算装置であるoreが 複数含まれている Intel ore i7 シリーズ: 4つの計算装置(ore) 通常のプログラム
並列計算の基礎 MPI を用いた並列計算 並列計算の環境 並列計算 複数の計算ユニット(PU, ore, Pなど を使用して 一つの問題 計算 を行わせる 近年 並列計算を手軽に使用できる環境が急速に整いつつある >通常のP PU(entral Processing Unit)上に計算装置であるoreが 複数含まれている Intel ore i7 シリーズ: 4つの計算装置(ore) 通常のプログラム
GPGPU によるアクセラレーション環境について
 GPGPU によるアクセラレーション環境について 長屋貴量 自然科学研究機構分子科学研究所技術課計算科学技術班 概要 GPGPU とは 単純で画一的なデータを一度に大量に処理することに特化したグラフィックカードの演算資源を 画像処理以外の汎用的な目的に応用する技術の一つである 近年 その演算能力は CPU で通常言われるムーアの法則に則った場合とは異なり 飛躍的に向上しており その演算性能に魅力を感じた各分野での応用が広がってきている
GPGPU によるアクセラレーション環境について 長屋貴量 自然科学研究機構分子科学研究所技術課計算科学技術班 概要 GPGPU とは 単純で画一的なデータを一度に大量に処理することに特化したグラフィックカードの演算資源を 画像処理以外の汎用的な目的に応用する技術の一つである 近年 その演算能力は CPU で通常言われるムーアの法則に則った場合とは異なり 飛躍的に向上しており その演算性能に魅力を感じた各分野での応用が広がってきている
PowerPoint プレゼンテーション
 講座準備 講座資料は次の URL から DL 可能 https://goo.gl/jnrfth 1 ポインタ講座 2017/01/06,09 fumi 2 はじめに ポインタはC 言語において理解が難しいとされる そのポインタを理解することを目的とする 講座は1 日で行うので 詳しいことは調べること 3 はじめに みなさん復習はしましたか? 4 & 演算子 & 演算子を使うと 変数のアドレスが得られる
講座準備 講座資料は次の URL から DL 可能 https://goo.gl/jnrfth 1 ポインタ講座 2017/01/06,09 fumi 2 はじめに ポインタはC 言語において理解が難しいとされる そのポインタを理解することを目的とする 講座は1 日で行うので 詳しいことは調べること 3 はじめに みなさん復習はしましたか? 4 & 演算子 & 演算子を使うと 変数のアドレスが得られる
Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ 3.7x faster P100 V100 P10
 NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
HPEハイパフォーマンスコンピューティング ソリューション
 HPE HPC / AI Page 2 No.1 * 24.8% No.1 * HPE HPC / AI HPC AI SGIHPE HPC / AI GPU TOP500 50th edition Nov. 2017 HPE No.1 124 www.top500.org HPE HPC / AI TSUBAME 3.0 2017 7 AI TSUBAME 3.0 HPE SGI 8600 System
HPE HPC / AI Page 2 No.1 * 24.8% No.1 * HPE HPC / AI HPC AI SGIHPE HPC / AI GPU TOP500 50th edition Nov. 2017 HPE No.1 124 www.top500.org HPE HPC / AI TSUBAME 3.0 2017 7 AI TSUBAME 3.0 HPE SGI 8600 System
1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU
![1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU](/thumbs/89/99132402.jpg "1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU") GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
演習準備
 演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
情報処理概論(第二日目)
") 情報処理概論 工学部物質科学工学科応用化学コース機能物質化学クラス 第 8 回 2005 年 6 月 9 日 前回の演習の解答例 多項式の計算 ( 前半 ): program poly implicit none integer, parameter :: number = 5 real(8), dimension(0:number) :: a real(8) :: x, total integer
情報処理概論 工学部物質科学工学科応用化学コース機能物質化学クラス 第 8 回 2005 年 6 月 9 日 前回の演習の解答例 多項式の計算 ( 前半 ): program poly implicit none integer, parameter :: number = 5 real(8), dimension(0:number) :: a real(8) :: x, total integer
プログラミング実習I
 プログラミング実習 I 05 関数 (1) 人間システム工学科井村誠孝 [email protected] 関数とは p.162 数学的には入力に対して出力が決まるもの C 言語では入出力が定まったひとまとまりの処理 入力や出力はあるときもないときもある main() も関数の一種 何かの仕事をこなしてくれる魔法のブラックボックス 例 : printf() 関数中で行われている処理の詳細を使う側は知らないが,
プログラミング実習 I 05 関数 (1) 人間システム工学科井村誠孝 [email protected] 関数とは p.162 数学的には入力に対して出力が決まるもの C 言語では入出力が定まったひとまとまりの処理 入力や出力はあるときもないときもある main() も関数の一種 何かの仕事をこなしてくれる魔法のブラックボックス 例 : printf() 関数中で行われている処理の詳細を使う側は知らないが,
書式に示すように表示したい文字列をダブルクォーテーション (") の間に書けば良い ダブルクォーテーションで囲まれた文字列は 文字列リテラル と呼ばれる プログラム中では以下のように用いる プログラム例 1 printf(" 情報処理基礎 "); printf("c 言語の練習 "); printf
 の間に書けば良い ダブルクォーテーションで囲まれた文字列は 文字列リテラル と呼ばれる プログラム中では以下のように用いる プログラム例 1 printf( 情報処理基礎 ); printf(c 言語の練習 ); printf") 情報処理基礎 C 言語についてプログラミング言語は 1950 年以前の機械語 アセンブリ言語 ( アセンブラ ) の開発を始めとして 現在までに非常に多くの言語が開発 発表された 情報処理基礎で習う C 言語は 1972 年にアメリカの AT&T ベル研究所でオペレーションシステムである UNIX を作成するために開発された C 言語は現在使われている多数のプログラミング言語に大きな影響を与えている
情報処理基礎 C 言語についてプログラミング言語は 1950 年以前の機械語 アセンブリ言語 ( アセンブラ ) の開発を始めとして 現在までに非常に多くの言語が開発 発表された 情報処理基礎で習う C 言語は 1972 年にアメリカの AT&T ベル研究所でオペレーションシステムである UNIX を作成するために開発された C 言語は現在使われている多数のプログラミング言語に大きな影響を与えている
チューニング講習会 初級編
 GPU のしくみ RICC での使い方 およびベンチマーク 理化学研究所情報基盤センター 2013/6/27 17:00 17:30 中田真秀 RICC の GPU が高速に! ( 旧 C1060 比約 6.6 倍高速 ) RICCのGPUがC2075になりました! C1060 比 6.6 倍高速 倍精度 515GFlops UPCに100 枚導入 : 合計 51.5TFlops うまく行くと5 倍程度高速化
GPU のしくみ RICC での使い方 およびベンチマーク 理化学研究所情報基盤センター 2013/6/27 17:00 17:30 中田真秀 RICC の GPU が高速に! ( 旧 C1060 比約 6.6 倍高速 ) RICCのGPUがC2075になりました! C1060 比 6.6 倍高速 倍精度 515GFlops UPCに100 枚導入 : 合計 51.5TFlops うまく行くと5 倍程度高速化
TopSE並行システム はじめに
 はじめに 平成 23 年 9 月 1 日 トップエスイープロジェクト 磯部祥尚 ( 産業技術総合研究所 ) 2 本講座の背景と目標 背景 : マルチコア CPU やクラウドコンピューティング等 並列 / 分散処理環境が身近なものになっている 複数のプロセス ( プログラム ) を同時に実行可能 通信等により複数のプロセスが協調可能 並行システムの構築 並行システム 通信 Proc2 プロセス ( プログラム
はじめに 平成 23 年 9 月 1 日 トップエスイープロジェクト 磯部祥尚 ( 産業技術総合研究所 ) 2 本講座の背景と目標 背景 : マルチコア CPU やクラウドコンピューティング等 並列 / 分散処理環境が身近なものになっている 複数のプロセス ( プログラム ) を同時に実行可能 通信等により複数のプロセスが協調可能 並行システムの構築 並行システム 通信 Proc2 プロセス ( プログラム
最新の並列計算事情とCAE
 1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
Fortran 勉強会 第 5 回 辻野智紀
 Fortran 勉強会 第 5 回 辻野智紀 今回のお品書き サブルーチンの分割コンパイル ライブラリ 静的ライブラリ 動的ライブラリ モジュール その前に 以下の URL から STPK ライブラリをインストールしておいて下さい. http://www.gfd-dennou.org/library/davis/stpk 前回参加された方はインストール済みのはず. サブルーチンの分割コンパイル サブルーチンの独立化
Fortran 勉強会 第 5 回 辻野智紀 今回のお品書き サブルーチンの分割コンパイル ライブラリ 静的ライブラリ 動的ライブラリ モジュール その前に 以下の URL から STPK ライブラリをインストールしておいて下さい. http://www.gfd-dennou.org/library/davis/stpk 前回参加された方はインストール済みのはず. サブルーチンの分割コンパイル サブルーチンの独立化
PowerPoint Presentation
 ヘテロジニアスな環境におけるソフトウェア開発 Agenda 今日の概要 ヘテロジニアスな環境の登場 ホモジニアスからヘテロジニアスへ ヘテロジニアスなアーキテクチャ GPU CUDA OpenACC, XeonPhi 自分のプログラムを理解するために デバッガ 共通の操作体験 TotalView 続きはブースで より速く ホモジーニアスな並列 HPC 銀河生成 金融のリスク計算 車の衝突解析 製薬
ヘテロジニアスな環境におけるソフトウェア開発 Agenda 今日の概要 ヘテロジニアスな環境の登場 ホモジニアスからヘテロジニアスへ ヘテロジニアスなアーキテクチャ GPU CUDA OpenACC, XeonPhi 自分のプログラムを理解するために デバッガ 共通の操作体験 TotalView 続きはブースで より速く ホモジーニアスな並列 HPC 銀河生成 金融のリスク計算 車の衝突解析 製薬
Microsoft PowerPoint - CCS学際共同boku-08b.ppt
 マルチコア / マルチソケットノードに おけるメモリ性能のインパクト 研究代表者朴泰祐筑波大学システム情報工学研究科 [email protected] アウトライン 近年の高性能 PC クラスタの傾向と問題 multi-core/multi-socket ノードとメモリ性能 メモリバンド幅に着目した性能測定 multi-link network 性能評価 まとめ 近年の高性能 PC
マルチコア / マルチソケットノードに おけるメモリ性能のインパクト 研究代表者朴泰祐筑波大学システム情報工学研究科 [email protected] アウトライン 近年の高性能 PC クラスタの傾向と問題 multi-core/multi-socket ノードとメモリ性能 メモリバンド幅に着目した性能測定 multi-link network 性能評価 まとめ 近年の高性能 PC
修士論文
 AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
memo
 数理情報工学演習第一 C プログラミング演習 ( 第 5 回 ) 2015/05/11 DEPARTMENT OF MATHEMATICAL INFORMATICS 1 今日の内容 : プロトタイプ宣言 ヘッダーファイル, プログラムの分割 課題 : 疎行列 2 プロトタイプ宣言 3 C 言語では, 関数や変数は使用する前 ( ソースの上のほう ) に定義されている必要がある. double sub(int
数理情報工学演習第一 C プログラミング演習 ( 第 5 回 ) 2015/05/11 DEPARTMENT OF MATHEMATICAL INFORMATICS 1 今日の内容 : プロトタイプ宣言 ヘッダーファイル, プログラムの分割 課題 : 疎行列 2 プロトタイプ宣言 3 C 言語では, 関数や変数は使用する前 ( ソースの上のほう ) に定義されている必要がある. double sub(int
Microsoft Word ●IntelクアッドコアCPUでのベンチマーク_吉岡_ _更新__ doc
 2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
資料3 今後のHPC技術に関する研究開発の方向性について(日立製作所提供資料)
") 今後の HPC 技術に関する 研究開発の方向性について 2012 年 5 月 30 日 ( 株 ) 日立製作所情報 通信システム社 IT プラットフォーム事業本部 Hitachi, Hitachi, Ltd. Ltd. Hitachi 2012. 2012. Ltd. 2012. All rights All rights All rights reserved. reserved. reserved.
今後の HPC 技術に関する 研究開発の方向性について 2012 年 5 月 30 日 ( 株 ) 日立製作所情報 通信システム社 IT プラットフォーム事業本部 Hitachi, Hitachi, Ltd. Ltd. Hitachi 2012. 2012. Ltd. 2012. All rights All rights All rights reserved. reserved. reserved.
第1回 プログラミング演習3 センサーアプリケーション
 C プログラミング - ポインタなんて恐くない! - 藤田悟 [email protected] 目標 C 言語プログラムとメモリ ポインタの関係を深く理解する C 言語プログラムは メモリを素のまま利用できます これが原因のエラーが多く発生します メモリマップをよく頭にいれて ポインタの動きを理解できれば C 言語もこわくありません 1. ポインタ入門編 ディレクトリの作成と移動 mkdir
C プログラミング - ポインタなんて恐くない! - 藤田悟 [email protected] 目標 C 言語プログラムとメモリ ポインタの関係を深く理解する C 言語プログラムは メモリを素のまま利用できます これが原因のエラーが多く発生します メモリマップをよく頭にいれて ポインタの動きを理解できれば C 言語もこわくありません 1. ポインタ入門編 ディレクトリの作成と移動 mkdir
第 1 回ディープラーニング分散学習ハッカソン <ChainerMN 紹介 + スパコンでの実 法 > チューター福 圭祐 (PFN) 鈴 脩司 (PFN)
 鈴 脩司 (PFN)") 第 1 回ディープラーニング分散学習ハッカソン チューター福 圭祐 (PFN) 鈴 脩司 (PFN) https://chainer.org/ 2 Chainer: A Flexible Deep Learning Framework Define-and-Run Define-by-Run Define Define by Run Model
第 1 回ディープラーニング分散学習ハッカソン チューター福 圭祐 (PFN) 鈴 脩司 (PFN) https://chainer.org/ 2 Chainer: A Flexible Deep Learning Framework Define-and-Run Define-by-Run Define Define by Run Model
RX ファミリ用 C/C++ コンパイラ V.1.00 Release 02 ご使用上のお願い RX ファミリ用 C/C++ コンパイラの使用上の注意事項 4 件を連絡します #pragma option 使用時の 1 または 2 バイトの整数型の関数戻り値に関する注意事項 (RXC#012) 共用
 共用") RX ファミリ用 C/C++ コンパイラ V.1.00 Release 02 ご使用上のお願い RX ファミリ用 C/C++ コンパイラの使用上の注意事項 4 件を連絡します #pragma option 使用時の 1 または 2 バイトの整数型の関数戻り値に関する注意事項 (RXC#012) 共用体型のローカル変数を文字列操作関数で操作する場合の注意事項 (RXC#013) 配列型構造体または共用体の配列型メンバから読み出した値を動的初期化に用いる場合の注意事項
RX ファミリ用 C/C++ コンパイラ V.1.00 Release 02 ご使用上のお願い RX ファミリ用 C/C++ コンパイラの使用上の注意事項 4 件を連絡します #pragma option 使用時の 1 または 2 バイトの整数型の関数戻り値に関する注意事項 (RXC#012) 共用体型のローカル変数を文字列操作関数で操作する場合の注意事項 (RXC#013) 配列型構造体または共用体の配列型メンバから読み出した値を動的初期化に用いる場合の注意事項
計算機アーキテクチャ
 計算機アーキテクチャ 第 11 回命令実行の流れ 2014 年 6 月 20 日 電気情報工学科 田島孝治 1 授業スケジュール ( 前期 ) 2 回日付タイトル 1 4/7 コンピュータ技術の歴史と コンピュータアーキテクチャ 2 4/14 ノイマン型コンピュータ 3 4/21 コンピュータのハードウェア 4 4/28 数と文字の表現 5 5/12 固定小数点数と浮動小数点表現 6 5/19 計算アーキテクチャ
計算機アーキテクチャ 第 11 回命令実行の流れ 2014 年 6 月 20 日 電気情報工学科 田島孝治 1 授業スケジュール ( 前期 ) 2 回日付タイトル 1 4/7 コンピュータ技術の歴史と コンピュータアーキテクチャ 2 4/14 ノイマン型コンピュータ 3 4/21 コンピュータのハードウェア 4 4/28 数と文字の表現 5 5/12 固定小数点数と浮動小数点表現 6 5/19 計算アーキテクチャ
GPUコンピューティング講習会パート1
 GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の