理研スーパーコンピュータ・システム
|
|
|
- つねとき じゅふく
- 5 years ago
- Views:
Transcription
1 線形代数演算ライブラリ BLAS と LAPACK の基礎と実践 2 理化学研究所情報基盤センター 2013/5/30 13:00- 大阪大学基礎工学部 中田真秀
2 この授業の目的 対象者 - 研究用プログラムを高速化したい人 - LAPACK についてよく知らない人 この講習会の目的 - コンピュータの簡単な仕組みについて - 今後 どうやってプログラムを高速化するか - BLAS, LAPACK を高速なものに変えられるようにすること
3 コンピュータの簡単な仕組みについて
4 コンピュータの簡単な仕組み コンピュータを最も簡単にあらわすと右図のようになる ( ノイマン型コンピュータ ) CPU が高速というのは この図では論理演算装置が高速ということ フォン ノイマンボトルネック - バスのスピードが (CPU- メモリの転送速度など ) がスピードのボトルネックになることがある - CPU, メモリ, 入出力が高速 = 必ずしもコンピュータが高速ではない - プログラムの高速化にはボトルネックがどこかを見極める必要あり CPU メモリ コントロールバスアドレスバスデータバス 入力と出力

5 CPU のスピードについて コンピュータは年々高速になってきている ただ コア一個単位処理能力は落ちてきており 2000 年からマルチコア化をしてきている - 様々な物理的な限界 マルチコアとは - 下図のように コアの処理能力を上げるのではなく いくつもコアを用意することで 処理能力をあげている マルチコア化
6 メモリ ( 記憶装置 ) のスピードについて メモリ ( 記憶装置 ) にも幾つか種類がある アクセススピードが速い = コスト高 容量小アクセススピードが遅い = コスト安 容量大一桁容量が大きくなると 一桁遅くなる一桁容量が小さくなると 一桁速くなるレイテンシ : アクセスする時間データを取ってくる命令を出してから 帰ってくるまでのことをレイテンシ (latency) データを一個だけ取ってくる これは時間がかかる 高速化するには : アクセススピードを意識しよう データの移動を少なくしよう 一度にデータを転送し 転送している間に計算をしよう (= レイテンシを隠す ) メモリバンド幅が大きい 小さいと表現


7 CPU とメモリのスピード比の変化 CPU とメモリのパフォーマンス (= スピード ) を年によってプロットしてみる 1990 年くらいまでは メモリーのスピードのほうが速く CPU が遅かった - なるべく CPU に計算させないプログラムが高速だった 1990 年以降 メモリより CPU が高速 - メモリの転送を抑えて 無駄でも計算させた方が高速 - このトレンドは変わらないと言われている
8 GPU についての紹介
9 GPU とは?GPGPU とは? GPU とは? - Graphics Processing Unit ( グラフィックス処理器 ) のこと - 本来 画像処理を担当する主要な部品 - 例 :3D ゲーム ムービー GUI などの処理を高速に行える 年からは科学計算にも使われるようになってきた GPGPU とは? - General-Purpose computing on Graphics Processing Units - GPU による 汎用目的計算 - 画像処理でなくて科学技術計算することは - GPGPU といえる 現在は PCI express につなげる形で存在 - バスがボトルネック - 将来は CPU/GPU が共有される?
10 GPU の使い方 CPU からデータを送り GPU で計算させて 計算結果を回収 - なるべくデータ転送を少なくした方が良い - メモリは共有されない 1. データを送る 3. 計算結果を返す 2. 計算をする ( ゲームの場合は 3D 画像処理など )


11 GPU はどうして高速か? Part I CPU と比べると 1 コ 1 コの処理能力は低いが ものすごい数のコアがあって 似たような処理を同時に沢山行えるので高速 CPU GPU 画像処理だと沢山独立した点に対して似たような処理をする CPU みたいには複雑な処理はできないが 工夫次第で色々可能
12 GPU はどうして高速か? Part II メモリバンド幅が GPU のほうが大きい 40G 32GB/s 150GB/s
13 プログラムを速くするには?
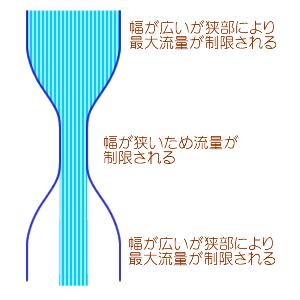
14 プログラムを高速化する一般的な手法 ボトルネックを見極めよう
15 プログラムを高速化する一般的な手法 ノイマン型のコンピュータのボトルネック - 演算量? バス? データ転送量 < 演算量の場合 - データの使い回しを行なうことで基本的には高速化する - また CPU が高速であればあるほど 高速化する - 例 : 行列 - 行列積 - 高速化はしやすい データ転送量 >= 演算量の場合 - メモリー CPU の転送が高速であればあるほど 高速化する - 例 : 行列 - ベクトル積 - データの使い回しができないため 高速化は面倒 - メモリと CPU を比較して高速化の度合いがメモリは小さく 差も広がっている - 高速なメモリを搭載しているマシンが少ない
16 今後 並列化プログラミングは必須になる CPU のコア周波数は 2002 年には 3GHz を超えた それ以降は横ばい CPU はスピードを上げるため SIMD やマルチコア化した - SIMD:1 個の命令で多数の処理を行うこと - マルチコア :CPU を 2 8 個程度一つのパッケージに詰める - 1 個のコアのスピード上げるのはもう限界 並列処理が必須に
17 高速な BLAS LAPACK を使うには
18 高速な BLAS LAPACK を使う コンピュータのパフォーマンスの計り方 - ボトルネック DGEMM ( 行列 - 行列積 ), DGEMV ( 行列 - ベクトル積 ) - 二つの典型的な例 CPU 演算 メモリバンド幅がボトルネック 高速な BLAS, LAPACK: GotoBLAS2 Octave で試してみる どうして高速なのか? GPU で cublas を使う
19 FLOPS : マシンの性能の計り方のひとつ FLOPS : マシンの性能の計り方のひとつ Floating point operations per second 一秒間に何回浮動小数点演算ができるか カタログ値ではこのピーク性能を FLOPS で出すことが多い - ただし その通りの値は実際の計算では出ない 中田は多分 Flops 程度 - 倍精度の計算は間違うかも - そろばんやってる人は 0.1Flops くらいあるかもしれない GPU は 1TFlops = 1,000,000,000,000Flpps 京コンピュータは 10PFlops - 10,000,000,000,000,000 Flops
20 Bytes per FLOPS Bytes per FLOPS: - 一回の浮動小数点演算を行う際に必要なメモリアクセス量を Byte/Flop で定義する - ( 違う定義 :1 回の浮動小数点計算に何 bytes メモリにアクセスできるか ) たとえば daxpy を例にとる x[i], y[i] はベクトル a はスカラー y[i] y[i] + a x[i] 2n 回の浮動小数点演算 3n 回のデータの読み書きが必要 - x[i], y[i] を読んで y[i] に書く 倍精度一つで 8bytes なので 24bytes / 2 Flops = 12 bytes/ flops. 小さければ小さいほど高速に処理できる
21 DGEMM 行列 - 行列積 マシンのパワーをみるには DGEMM ( 行列 - 行列積 ) と DGEMV ( 行列ベクトル積 ) をみればよい DGEMM ( 行列 - 行列積 ) - CPU のパワーがどの程度あるかの良い目安 - C αab+βc = + * - データの量は O(n^2) - 演算量は O(n^3) - 大きなサイズの DGEMM は演算スピードが律速となる - Bytes / flop は O(1/n) なので 大きな次元でほぼゼロとなる
22 DGEMV : 行列ベクトル積 DGEMV ( 行列ベクトル積 ) - メモリバンド幅がどの程度あるかの良い目安 - y αax + βy = + - データの量は O(n^2) - 演算量は O(n^2) - Bytes / flop は O(1) - 大きなサイズの DGEMV はメモリバンド幅が律速となる - メモリバンド幅が大きいと高速になる - CPU だけが高速でも DGEMV は高速にならない *
23 高速な BLAS LAPACK の力を知る 行列 - 行列積 DGEMM, DGEMV を試し 違いを見る - Reference BLAS - をそのままコンパイルしたもの - Ubuntu 標準 ATLAS, - 自分でビルドした ATLAS バージョン GotoBLAS2 Octave - Matlab のフリーのクローン - かなり使える - 内部で BLAS, LAPACK を呼ぶ 使ったマシン - Intel Core i7 920 (2.66GHz, 理論性能値 42.56GFlops)
24 環境を整える Ubuntu x86(lucid Lynx) を使ってお試し - 開発環境設定 - 端末から - $ sudo apt-get install patch gfortran g++ libblas-dev octave3.2 GotoBLAS2 のインストール $ cd ; cp <somewhere>/gotoblas2-1.13_bsd.tar.gz. - $ tar xvfz GotoBLAS2-1.13_bsd.tar.gz - $ cd GotoBLAS2 - $./quickbuild.64bit - ln -fs libgoto2_nehalemp-r1.13.so libgoto2.so - - GotoBLAS build complete.
25 Reference BLAS の DGEMM Reference BLAS の場合の設定 $ LD_PRELOAD=/usr/lib/libblas.so:/usr/lib/liblapack.so; export LD_PRELOAD Octave で行列 - 行列積 4000x4000 の正方行列の積 値はランダム -$ octave... 途中略... octave:1> n=4000; A=rand(n); B=rand(n); octave:2> tic(); C=A*B; t=toc(); GFLOPS=2*nˆ3/t*1e-9 GFLOPS = GFLops => 理論性能値のたった 4%
26 Ubuntu 標準 ATLAS の行列 - 行列積 Ubuntu 付属 ATLAS の場合の設定 $ LD_PRELOAD=/usr/lib/atlas/libblas.so; export LD_PRELOAD Octave で行列 - 行列積 4000x4000 の正方行列の積 値はランダム $ octave... 途中略... octave:1> n=4000; A=rand(n); B=rand(n); octave:2> tic(); C=A*B; t=toc(); GFLOPS=2*nˆ3/t*1e-9 GFLOPS = GFLops => 理論性能値のたった 16.5% - 違うマシンで最適化 ( 多くのマシンで使えるように ) - マルチコアは使わない - 使ったとすると 66% 程度とソコソコでるはず
27 ATLAS の行列 - 行列積 自分でビルドしなおした ATLAS の場合の設定例 $ LD_PRELOAD=/home/maho/atlas/libblas.so; export LD_PRELOAD Octave で行列 - 行列積 Octave1:> n=4000; A=rand(n); B=rand(n); octave:2> tic(); C=A*B; t=toc(); GFLOPS=2*nˆ3/t*1e-9 GFLOPS = GFLops => 理論性能値の 77.1%!! - オートチューニングは大変使える - 開発コストは低い - 但し マシン毎にビルドし直さなくてはならない - そもそもそういうもの - Linux のディストリビューションとは相性が悪い
28 GotoBLAS2 の行列 - 行列積 GotoBLAS2 の場合の設定例 $ LD_PRELOAD=/home/maho/GotoBLAS2/libgoto2.so ; export LD_PRELOAD $ octave Octave で行列 - 行列積 Octave1:> n=4000; A=rand(n); B=rand(n); octave:2> tic(); C=A*B; t=toc(); GFLOPS=2*nˆ3/t*1e-9 GFLOPS = GFLops => 理論性能値の 91.2% - 一番高速 ただし 開発コストが非常に高い - 開発は終了 (OpenBLAS に引き継がれた ) - 標準になるまでには時間がかかる - オープンソースになって日が浅いため

29 高速なBLAS LAPACKの力を知る : Core i7 920の理論性能値は 4 FLOPS/Clock 2.66GHz 4コア=42.56GFlops reference BLAS 付属 ATLAS ATLAS GotoBLAS2 Corei7 920 理 論性能
30 DGEMV を使う : メモリバンド幅理論性能値 Core i7 920マシンメモリバンド幅の理論性能値 -という言い方は変だが -DDR3-1066(PC3-8500) -メモリ帯域は25.6GB/s ( トリプルチャネル ) MHz x 4 ( 外部クロック ) x 8 (I/O buffer 読み込み ) x 2 (8bit per ½ clock) / 8 (1bytes=8bit) * 8 (I/F data 幅 ) = 8.53GB/sec (=1066 Mbps) x 3 (triple channel)= 25.6GB/s - 理論性能値 / 8 (bytes/1 倍精度 )= 3.19GFlops -これはCPUの速度に比べて10 倍以上遅い -メモリバンド幅は今後上がる見込みが少ない
31 DGEMV を使う :GotoBLAS2 の例 GotoBLAS2 の場合の設定例 $ LD_PRELOAD=/home/maho/GotoBLAS2/libgoto2.so ; export LD_PRELOAD Octaveで行列-ベクトル積 $ octave Octave1:> n=10000; A=rand(n); y = rand(n,1) ; x = rand(n,1) ; tic(); y=a*x; t=toc(); GFLOPS=2*n^2/t*1e-9 GFLOPS = GFlops : ピーク性能に近い値
32 DGEMV を使う : 付属 ATLAS の例 Ubuntu 付属 ATLAS の場合の設定例 $ LD_PRELOAD=/usr/lib/atlas-base/libatlas.so ; export LD_PRELOAD Octaveで行列-ベクトル積 octave:1> n=10000; A=rand(n); y = rand(n,1) ; x = rand(n,1) ; tic(); y=a*x; t=toc(); GFLOPS=2*n^2/t*1e-9 GFLOPS = だいたい半分くらいでた
33 DGEMV を使う :ATLAS の例 ATLAS の場合の設定例 $ LD_PRELOAD=/home/maho/atlas/libatlas.so ; export LD_PRELOAD Octaveで行列-ベクトル積 octave:1> n=10000; A=rand(n); y = rand(n,1) ; x = rand(n,1) ; tic(); y=a*x; t=toc(); GFLOPS=2*n^2/t*1e-9 GFLOPS = ほぼ標準のものと同じ
34 DGEMV を使う :Reference BLAS の例 Reference BLAS の場合の設定例 $ LD_PRELOAD=/usr/lib/libblas/libblas.so.3gf.0 ; export LD_PRELOAD Octaveで行列-ベクトル積 octave:1> n=10000; A=rand(n); y = rand(n,1) ; x = rand(n,1) ; tic(); y=a*x; t=toc(); GFLOPS=2*n^2/t*1e-9 GFLOPS = ATLAS よりよい?

35 DGEMV を使う : 表 reference BLAS 付属 ATLAS ATLAS GotoBLAS2 DDR3-1060x3 理論性能
36 ここまでのまとめ コンピュータの仕組みを述べた -フォンノイマン図 高速化するにはどうしたらよいか -ボトルネックを探す - 言葉 : flops, byte per flops -メモリバンド幅 CPU 性能値が重要なボトルネック 最適化されたBLAS (GotoBLAS2) を使ったベンチマークを行った DGEMM ( 行列 - 行列積 ) で CPUの理論性能と比較 DGEMV ( 行列 -ベクトル積) で メモリバンド幅の理論性能と比較 大きな次元での結果であることに注意
37 高速化の手法
38 レジスタとアンローリング 8x8 行列の積 c=a*b を考える i,j ループの 2 段のアンローリングを行う a[i][k],a[i+1][k],b[k][j],b[k][j+1] が 2 回づつ現われるので レジスタの再利用が可能になり メモリからのロードを減らせる for(i=0;i<8;i++){ for(i=0;i<8;i+=2){ for(j=0;j<8;j++){ for(j=0;j<8;j+=2){ for(k=0;k<8;k++){ for(k=0;k<8;k++){ c[i][j]+=a[i][k]*b[k][j] c[i][j] += a[i][k]*b[k][j] }}} c[i+1][j] += a[i+1][k]*b[k][j] 通常の行列積の演算 c の要素 1 つの計算に a と b の要素が 1 つずつ必要 }}} c[i][j+1] += a[i][k]*b[k][j+1] c[i+1][j+1] += a[i+1][k]*b[k][j+1] 2 段アンローリングを行った行列積の演算 c の要素 4 つの計算に a と b の要素が 2 つずつ必要
39 キャッシュ キャッシュメモリではキャッシュラインの単位でデータを管理 キャッシュラインのデータ置き換えは Least Recently Used(LRU) 方式が多い ダイレクトマッピング方式であるとすると キャッシュラインを 4 とすると メインメモリのデータは 4 毎に同じキャッシュラインに乗る 配列が 2 のベキ乗の場合は キャッシュライン衝突 バンクコンフリクトの可能性 パティングにより回避 隣り合ったキャッシュラインに 隣り合ったメインメモリのデータを持ってくるメモリインタリービング機能
40 ブロック行列化 キャッシュラインが 4 つあり 各キャッシュラインに 4 変数格納出来るとする キャッシュラインの置き換えアルゴリズムは LRU とする 2 行 2 列のブロック行列に分けて計算する for(i=0;i<8;i++){ for(j=0;j<8;j++){ for(k=0;k<8;k++){ c[i][j]+=a[i][k]*b[k][j] }}} for(ib=0;ib<8;ib+=2){ for(jb=0;jb<8;jb+=2){ for(kb=0;kb<8;kb+=2){ for(i=ib;i<ib+2;i++){ for(j=jb;j<jb+2;j++){ for(k=kb;k<kb+2;k++){ c[i][j]+=a[i][k]*b[k][j] }}}}}}
41 c[0][0] += a[0][0] * b[0][0] + a[0][1] * b[1][0] + a[0][2] * b[2][0] + a[0][3] * b[3][0] + a[0][4] * b[4][0] + a[0][5] * b[5][0] + a[0][6] * b[6][0] + a[0][7] * b[7][0] ブロック行列化 2 c[0][0],c[0][1],c[1][0],c[1][1] の計算の際のキャッシュミス回数を数える 下線を引いた所でキャッシュミス c[0][0] の計算で 11 回のキャッシュミス 4 要素の計算で 11x4=44 回のキャッシュミス c[0][0] += a[0][0] * b[0][0] + a[0][1] * b[1][0] c[0][1] += a[0][0] * b[0][1] + a[0][1] * b[1][1] c[1][0] += a[1][0] * b[0][0] + a[1][1] * b[1][0] c[1][1] += a[1][0] * b[0][1] + a[1][1] * b[1][1] c[0][0] += a[0][2] * b[2][0] + a[0][3] * b[3][0]... c[1][1] += a[1][6] + b[6][1] + a[1][7] + b[7][1] 4 要素の計算で 20 回のキャッシュミス


42 cublas+ 行列 - 行列積編 詳しいことは抜きにして ライブラリを叩くのみ cublas を用いて行列 - 行列積を実行してみよう - A,B,C を n x n の行列として C=AB を計算してみよう 走らせ方のイメージは下図のようになる 1. 行列 A,B のデータを送る 3. 結果の行列 C を返す 2. 行列積の 計算をする
43 GPU での BLAS (cublas)

44 GPU の使い方 :GPU の弱点 PCIe というバスでつながっているが この転送速度が遅い - GPU は PC は別のコンピュータ - それをつないでいるのが PCIe バス これが遅い! 30GB/ 秒 :DDR3 フォン ノイマンボトルネックの一種他にもさまざまな制限がある - メモリのアクセスパターン - スレッドの使い方
45 cublas とはなにか? ( まずは BLAS) そのまえに BLAS の復習 BLAS (Basic Linear Algebra Subprograms) とは 基本的なベクトルや行列演算をおこなうとき基本となる ビルディングブロック ルーチンをあつめたもの Level 1, 2, 3 とあり - Level1 はスカラー ベクトル およびベクトル - ベクトル演算を行う - Level2 は行列 - ベクトル演算を行う - Level3 は行列 - 行列演算を行う - 効率よく演算できるようになっていて 広く入手可能であるため LAPACK など高性能な線形代数演算ライブラリの構築に利用される - 高速な実装がある - Intel MKL (math kernel library) - GotoBLAS2 - OpenBLAS - ATLAS - IBM ESSL
46 cublas とは何か cublas とは? - CUDA で書かれた GPU 向けに加速された BLAS - ソースコードには少し変更が必要 ただし CUDA は CPU とはアーキテクチャ ( 設計 ) かなり違うため 効率的に使うには そのまま ではなくソースコードの変更が必要 - 行列やベクトルを GPU に転送し GPU が計算し 回収する のような仕組みをとる.
47 cublas での行列 - 行列積 (I) cublas の dgemm を行なってみる - 行列 - 行列積を行うルーチン - 具体的には - A, B, C を行列とし α, β をスカラーとして - C αab+βc - を行う - 他にも A,B をそれぞれ転置するかしないかを選択できる ( が今回はやらない ) - 今回試して見ること : 3x3 の行列 A,B,C を下のようにして - スカラは α=3.0, β=-2.0 とした

48 cublas での行列 - 行列積 (II)
49

50 cublas での行列 - 行列積 (V)
51 cublas での行列 - 行列積 (VI) 注意点 - コンパイルには accel に入る必要がある (ssh accel) - ジョブのサブミットには ricc に入る必要がある (ssh ricc) - インタラクティブノードはない - 従って accel でコンパイルし ジョブを ricc に入ってサブミットしなければならない... - A, B, C の行列の値の並びは FORTRAN のように column major になっている column major row major
52 cublas での行列 - 行列積 (VIII) 行列 - 行列積の計算 dgemm を呼んだ場合の結果 - 正方行列 A, B, C およびスカラー α, β について - C αab+βc - 行列のサイズ n を まで変えた場合 - 縦軸は FLOPS (Floating-point Operations Per Second) 先のグラフ 赤い線は GPU のみのパフォーマンス - 理論性能値 515GFlops 中 300Glops 程度出ている 緑の線は CPU-GPU を含んだ場合のパフォーマンス - GPU をアクセラレータとしてみた場合 - PCIe バスでのデータ ( 行列の ) 転送速度が遅い 青の線は Intel Xeon 5680 (Nehalem 3.3GHz) 6 core x 2 のパフォーマンス - 理論性能値 158.4GFlops/ ノード - RICC は理論性能値 93.76GFlops/ ノード
53 cublas での行列 - 行列積 (VII) どの程度パフォーマンスが出るか見てみよう
54 難しい問題 サイズの大きな問題は比較的簡単に性能評価できる サイズの小さな問題を多数解きたい場合は性能が下がる傾向にある - これはメモリバンド幅の問題となる
チューニング講習会 初級編
 GPU のしくみ RICC での使い方 およびベンチマーク 理化学研究所情報基盤センター 2013/6/27 17:00 17:30 中田真秀 RICC の GPU が高速に! ( 旧 C1060 比約 6.6 倍高速 ) RICCのGPUがC2075になりました! C1060 比 6.6 倍高速 倍精度 515GFlops UPCに100 枚導入 : 合計 51.5TFlops うまく行くと5 倍程度高速化
GPU のしくみ RICC での使い方 およびベンチマーク 理化学研究所情報基盤センター 2013/6/27 17:00 17:30 中田真秀 RICC の GPU が高速に! ( 旧 C1060 比約 6.6 倍高速 ) RICCのGPUがC2075になりました! C1060 比 6.6 倍高速 倍精度 515GFlops UPCに100 枚導入 : 合計 51.5TFlops うまく行くと5 倍程度高速化
untitled
 A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
untitled
 A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
0530cmsi教育計算科学技術特論a_中田真秀 (nakata maho's conflicted copy) (6)
 (6)") 線形代数演算ライブラリBLAS とLAPACKの基礎と実践 (II) BLAS, LAPACK実践編 中田 真秀 理化学研究所 情報システム本部 2019/5/30 計算科学技術特論A 13:00 BLAS, LAPACK実践編 講義内容 コンピュータの簡単な仕組みとボトルネック フォン ノイマン型コンピュータ フォン ノイマンボトルネック 演算バンド幅のトレンド メモリバンド幅のトレンド 演算バンド幅の理論性能
線形代数演算ライブラリBLAS とLAPACKの基礎と実践 (II) BLAS, LAPACK実践編 中田 真秀 理化学研究所 情報システム本部 2019/5/30 計算科学技術特論A 13:00 BLAS, LAPACK実践編 講義内容 コンピュータの簡単な仕組みとボトルネック フォン ノイマン型コンピュータ フォン ノイマンボトルネック 演算バンド幅のトレンド メモリバンド幅のトレンド 演算バンド幅の理論性能
PowerPoint プレゼンテーション
 応用数理概論 準備 端末上で cd ~/ mkdir cppwork cd cppwork wget http://271.jp/gairon/main.cpp wget http://271.jp/gairon/matrix.hpp とコマンドを記入. ls とコマンドをうち,main.cppとmatrix.hppがダウンロードされていることを確認. 1 準備 コンパイル c++ -I. -std=c++0x
応用数理概論 準備 端末上で cd ~/ mkdir cppwork cd cppwork wget http://271.jp/gairon/main.cpp wget http://271.jp/gairon/matrix.hpp とコマンドを記入. ls とコマンドをうち,main.cppとmatrix.hppがダウンロードされていることを確認. 1 準備 コンパイル c++ -I. -std=c++0x
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司
![4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司](/thumbs/97/131936032.jpg "4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司") 4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
Microsoft Word - HOKUSAI_system_overview_ja.docx
 HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
Microsoft PowerPoint - sales2.ppt
 最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
Microsoft Word ●IntelクアッドコアCPUでのベンチマーク_吉岡_ _更新__ doc
 2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS /1/18 a a 1 a 2 a 3 a a GPU Graphics Processing Unit GPU CPU GPU GPGPU G
 211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS211 211/1/18 GPU 4 8 BLAS 4 8 BLAS Basic Linear Algebra Subprograms GPU Graphics Processing Unit 4 8 double 2 4 double-double DD 4 4 8 quad-double
211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS211 211/1/18 GPU 4 8 BLAS 4 8 BLAS Basic Linear Algebra Subprograms GPU Graphics Processing Unit 4 8 double 2 4 double-double DD 4 4 8 quad-double
GPGPU によるアクセラレーション環境について
 GPGPU によるアクセラレーション環境について 長屋貴量 自然科学研究機構分子科学研究所技術課計算科学技術班 概要 GPGPU とは 単純で画一的なデータを一度に大量に処理することに特化したグラフィックカードの演算資源を 画像処理以外の汎用的な目的に応用する技術の一つである 近年 その演算能力は CPU で通常言われるムーアの法則に則った場合とは異なり 飛躍的に向上しており その演算性能に魅力を感じた各分野での応用が広がってきている
GPGPU によるアクセラレーション環境について 長屋貴量 自然科学研究機構分子科学研究所技術課計算科学技術班 概要 GPGPU とは 単純で画一的なデータを一度に大量に処理することに特化したグラフィックカードの演算資源を 画像処理以外の汎用的な目的に応用する技術の一つである 近年 その演算能力は CPU で通常言われるムーアの法則に則った場合とは異なり 飛躍的に向上しており その演算性能に魅力を感じた各分野での応用が広がってきている
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
PowerPoint プレゼンテーション
 各種計算機アプリケーション性能比較 目次. はじめに. 行列積計算.QDR 積計算 4.N 体問題計算 5. 多次元積分計算 5. 次元積分計算 5. 次元積分計算 5. 4 次元積分計算 5.4 5 次元積分計算 5.5 6 次元積分計算 平成 6 年度第 四半期 . はじめに 今までと少し性質の異なるグラフィックボードが使用できる様になったので従来のアプリケーションで性能比較を実施しました 主に使用した計算機は以下のものです
各種計算機アプリケーション性能比較 目次. はじめに. 行列積計算.QDR 積計算 4.N 体問題計算 5. 多次元積分計算 5. 次元積分計算 5. 次元積分計算 5. 4 次元積分計算 5.4 5 次元積分計算 5.5 6 次元積分計算 平成 6 年度第 四半期 . はじめに 今までと少し性質の異なるグラフィックボードが使用できる様になったので従来のアプリケーションで性能比較を実施しました 主に使用した計算機は以下のものです
スライド 1
 知能制御システム学 画像処理の高速化 OpenCV による基礎的な例 東北大学大学院情報科学研究科鏡慎吾 swk(at)ic.is.tohoku.ac.jp 2007.07.03 リアルタイム処理と高速化 リアルタイム = 高速 ではない 目標となる時間制約が定められているのがリアルタイム処理である.34 ms かかった処理が 33 ms に縮んだだけでも, それによって与えられた時間制約が満たされるのであれば,
知能制御システム学 画像処理の高速化 OpenCV による基礎的な例 東北大学大学院情報科学研究科鏡慎吾 swk(at)ic.is.tohoku.ac.jp 2007.07.03 リアルタイム処理と高速化 リアルタイム = 高速 ではない 目標となる時間制約が定められているのがリアルタイム処理である.34 ms かかった処理が 33 ms に縮んだだけでも, それによって与えられた時間制約が満たされるのであれば,
11020070-0_Vol16No2.indd
 2552 チュートリアル BLAS, LAPACK 2 1 BLAS, LAPACKチュートリアル パート1 ( 簡 単 な 使 い 方 とプログラミング) 中 田 真 秀 1 読 者 の 想 定 BLAS [1], LAPACK [2] 2 線 形 代 数 の 重 要 性 について Google Page Rank 3D CPU 筆 者 紹 介 BLAS LAPACK http://accc.riken.jp/maho/
2552 チュートリアル BLAS, LAPACK 2 1 BLAS, LAPACKチュートリアル パート1 ( 簡 単 な 使 い 方 とプログラミング) 中 田 真 秀 1 読 者 の 想 定 BLAS [1], LAPACK [2] 2 線 形 代 数 の 重 要 性 について Google Page Rank 3D CPU 筆 者 紹 介 BLAS LAPACK http://accc.riken.jp/maho/
tabaicho3mukunoki.pptx
 1 2 はじめに n 目的 4倍精度演算より高速な3倍精度演算を実現する l 倍精度では足りないが4倍精度は必要ないケースに欲しい l 4倍精度に比べてデータサイズが小さい Ø 少なくともメモリ律速な計算では4倍精度よりデータ 転送時間を減らすことが可能 Ø PCIeやノード間通信がボトルネックとなりやすい GPUクラスタ環境に有効か n 研究概要 l DD型4倍精度演算 DD演算 に基づく3倍精度演算
1 2 はじめに n 目的 4倍精度演算より高速な3倍精度演算を実現する l 倍精度では足りないが4倍精度は必要ないケースに欲しい l 4倍精度に比べてデータサイズが小さい Ø 少なくともメモリ律速な計算では4倍精度よりデータ 転送時間を減らすことが可能 Ø PCIeやノード間通信がボトルネックとなりやすい GPUクラスタ環境に有効か n 研究概要 l DD型4倍精度演算 DD演算 に基づく3倍精度演算
RICCについて
 RICC 1 RICC 2 RICC 3 RICC GPU 1039Nodes 8312core) 93.0GFLOPS, 12GB(mem), 500GB (hdd) DDR IB!1 PC100Nodes(800core) 9.3 GPGPU 93.3TFLOPS HPSS (4PB) (550TB) 0.24 512GB 1500GB MDGRAPE33TFLOPS MDGRAPE-3 64
RICC 1 RICC 2 RICC 3 RICC GPU 1039Nodes 8312core) 93.0GFLOPS, 12GB(mem), 500GB (hdd) DDR IB!1 PC100Nodes(800core) 9.3 GPGPU 93.3TFLOPS HPSS (4PB) (550TB) 0.24 512GB 1500GB MDGRAPE33TFLOPS MDGRAPE-3 64
資料3 今後のHPC技術に関する研究開発の方向性について(日立製作所提供資料)
") 今後の HPC 技術に関する 研究開発の方向性について 2012 年 5 月 30 日 ( 株 ) 日立製作所情報 通信システム社 IT プラットフォーム事業本部 Hitachi, Hitachi, Ltd. Ltd. Hitachi 2012. 2012. Ltd. 2012. All rights All rights All rights reserved. reserved. reserved.
今後の HPC 技術に関する 研究開発の方向性について 2012 年 5 月 30 日 ( 株 ) 日立製作所情報 通信システム社 IT プラットフォーム事業本部 Hitachi, Hitachi, Ltd. Ltd. Hitachi 2012. 2012. Ltd. 2012. All rights All rights All rights reserved. reserved. reserved.
修士論文
 AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
BLAS の概要
 GotoBLAS チュートリアル 後藤和茂 ( テキサス州立大学 ) 26/12/9 Kazushige Goto (TACC) 1 自己紹介 お題目 数値計算と最適化の基本事項の確認 BLAS とは? GotoBLAS の特徴 Level 1 ~Level 3 ルーチンの構造と特徴 BLAS による最適化の限界 26/12/9 Kazushige Goto (TACC) 2 自己紹介 早稲田大学電気工学修士課程卒
GotoBLAS チュートリアル 後藤和茂 ( テキサス州立大学 ) 26/12/9 Kazushige Goto (TACC) 1 自己紹介 お題目 数値計算と最適化の基本事項の確認 BLAS とは? GotoBLAS の特徴 Level 1 ~Level 3 ルーチンの構造と特徴 BLAS による最適化の限界 26/12/9 Kazushige Goto (TACC) 2 自己紹介 早稲田大学電気工学修士課程卒
N08
 CPU のキモチ C.John 自己紹介 英語きらい 絵かけない 人の話を素直に信じない CPUにキモチなんてない お詫び 予告ではCとC# とありましたがやる気と時間の都合上 C++のみを対象とします 今日のネタ元 MSDN マガジン 2010 年 10 月号 http://msdn.microsoft.com/ja-jp/magazine/cc850829.aspx Windows と C++
CPU のキモチ C.John 自己紹介 英語きらい 絵かけない 人の話を素直に信じない CPUにキモチなんてない お詫び 予告ではCとC# とありましたがやる気と時間の都合上 C++のみを対象とします 今日のネタ元 MSDN マガジン 2010 年 10 月号 http://msdn.microsoft.com/ja-jp/magazine/cc850829.aspx Windows と C++
ComputerArchitecture.ppt
 1 人間とコンピュータの違い コンピュータ 複雑な科学計算や膨大な量のデータの処理, さまざまな装置の制御, 通信などを定められた手順に従って間違いなく高速に実行する 人間 誰かに命令されなくても自発的に処理したり, 条件が変化しても臨機応変に対処できる 多くの問題解決を経験することで, より高度な問題解決法を考え出す 数値では表しにくい情報の処理ができる 2 コンピュータの構成要素 構成要素 ハードウェア
1 人間とコンピュータの違い コンピュータ 複雑な科学計算や膨大な量のデータの処理, さまざまな装置の制御, 通信などを定められた手順に従って間違いなく高速に実行する 人間 誰かに命令されなくても自発的に処理したり, 条件が変化しても臨機応変に対処できる 多くの問題解決を経験することで, より高度な問題解決法を考え出す 数値では表しにくい情報の処理ができる 2 コンピュータの構成要素 構成要素 ハードウェア
Microsoft PowerPoint - GPGPU実践基礎工学(web).pptx
.pptx") シングルコアとマルチコア 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 前々回の授業の復習 CPUの進化 半導体集積率の向上 CPUの動作周波数の向上 + 複雑な処理を実行する回路を構成 ( 前々回の授業 ) マルチコア CPU への進化 均一 不均一なプロセッサ コプロセッサ, アクセラレータ 210 コンピュータの歴史 世界初のデジタルコンピュータ 1944 年ハーバードMark I
シングルコアとマルチコア 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 前々回の授業の復習 CPUの進化 半導体集積率の向上 CPUの動作周波数の向上 + 複雑な処理を実行する回路を構成 ( 前々回の授業 ) マルチコア CPU への進化 均一 不均一なプロセッサ コプロセッサ, アクセラレータ 210 コンピュータの歴史 世界初のデジタルコンピュータ 1944 年ハーバードMark I
PowerPoint プレゼンテーション
 コンピュータアーキテクチャ 第 13 週 割込みアーキテクチャ 2013 年 12 月 18 日 金岡晃 授業計画 第 1 週 (9/25) 第 2 週 (10/2) 第 3 週 (10/9) 第 4 週 (10/16) 第 5 週 (10/23) 第 6 週 (10/30) 第 7 週 (11/6) 授業概要 2 進数表現 論理回路の復習 2 進演算 ( 数の表現 ) 演算アーキテクチャ ( 演算アルゴリズムと回路
コンピュータアーキテクチャ 第 13 週 割込みアーキテクチャ 2013 年 12 月 18 日 金岡晃 授業計画 第 1 週 (9/25) 第 2 週 (10/2) 第 3 週 (10/9) 第 4 週 (10/16) 第 5 週 (10/23) 第 6 週 (10/30) 第 7 週 (11/6) 授業概要 2 進数表現 論理回路の復習 2 進演算 ( 数の表現 ) 演算アーキテクチャ ( 演算アルゴリズムと回路
Microsoft PowerPoint - CCS学際共同boku-08b.ppt
 マルチコア / マルチソケットノードに おけるメモリ性能のインパクト 研究代表者朴泰祐筑波大学システム情報工学研究科 taisuke@cs.tsukuba.ac.jp アウトライン 近年の高性能 PC クラスタの傾向と問題 multi-core/multi-socket ノードとメモリ性能 メモリバンド幅に着目した性能測定 multi-link network 性能評価 まとめ 近年の高性能 PC
マルチコア / マルチソケットノードに おけるメモリ性能のインパクト 研究代表者朴泰祐筑波大学システム情報工学研究科 taisuke@cs.tsukuba.ac.jp アウトライン 近年の高性能 PC クラスタの傾向と問題 multi-core/multi-socket ノードとメモリ性能 メモリバンド幅に着目した性能測定 multi-link network 性能評価 まとめ 近年の高性能 PC
PowerPoint プレゼンテーション
 みんなの ベクトル計算 たけおか @takeoka PC クラスタ コンソーシアム理事でもある 2011/FEB/20 ベクトル計算が新しい と 2008 年末に言いました Intelに入ってる! (2008 年から見た 近未来? ) GPU 計算が新しい (2008 年当時 ) Intel AVX (Advanced Vector Extension) SIMD 命令を進めて ベクトル機構をつける
みんなの ベクトル計算 たけおか @takeoka PC クラスタ コンソーシアム理事でもある 2011/FEB/20 ベクトル計算が新しい と 2008 年末に言いました Intelに入ってる! (2008 年から見た 近未来? ) GPU 計算が新しい (2008 年当時 ) Intel AVX (Advanced Vector Extension) SIMD 命令を進めて ベクトル機構をつける
スライド 1
 計算科学が拓く世界スーパーコンピュータは何故スーパーか 学術情報メディアセンター中島浩 http://www.para.media.kyoto-u.ac.jp/jp/ username=super password=computer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
計算科学が拓く世界スーパーコンピュータは何故スーパーか 学術情報メディアセンター中島浩 http://www.para.media.kyoto-u.ac.jp/jp/ username=super password=computer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日
 TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date Type URL Presentation
 榎本, 昌一 Citation Issue date Type URL Presentation") 熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date 2011-03-17 Type URL Presentation http://hdl.handle.net/2298/23539 Right GPGPU による高速演算について 榎本昌一 東京大学大学院工学系研究科システム創成学専攻
熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date 2011-03-17 Type URL Presentation http://hdl.handle.net/2298/23539 Right GPGPU による高速演算について 榎本昌一 東京大学大学院工学系研究科システム創成学専攻
計算機アーキテクチャ
 計算機アーキテクチャ 第 11 回命令実行の流れ 2014 年 6 月 20 日 電気情報工学科 田島孝治 1 授業スケジュール ( 前期 ) 2 回日付タイトル 1 4/7 コンピュータ技術の歴史と コンピュータアーキテクチャ 2 4/14 ノイマン型コンピュータ 3 4/21 コンピュータのハードウェア 4 4/28 数と文字の表現 5 5/12 固定小数点数と浮動小数点表現 6 5/19 計算アーキテクチャ
計算機アーキテクチャ 第 11 回命令実行の流れ 2014 年 6 月 20 日 電気情報工学科 田島孝治 1 授業スケジュール ( 前期 ) 2 回日付タイトル 1 4/7 コンピュータ技術の歴史と コンピュータアーキテクチャ 2 4/14 ノイマン型コンピュータ 3 4/21 コンピュータのハードウェア 4 4/28 数と文字の表現 5 5/12 固定小数点数と浮動小数点表現 6 5/19 計算アーキテクチャ
C プログラミング演習 1( 再 ) 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ
 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ") C プログラミング演習 1( 再 ) 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ 今回のプログラミングの課題 次のステップによって 徐々に難易度の高いプログラムを作成する ( 参照用の番号は よくわかる C 言語 のページ番号 ) 1. キーボード入力された整数 10 個の中から最大のものを答える 2. 整数を要素とする配列 (p.57-59) に初期値を与えておき
C プログラミング演習 1( 再 ) 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ 今回のプログラミングの課題 次のステップによって 徐々に難易度の高いプログラムを作成する ( 参照用の番号は よくわかる C 言語 のページ番号 ) 1. キーボード入力された整数 10 個の中から最大のものを答える 2. 整数を要素とする配列 (p.57-59) に初期値を与えておき
高性能計算研究室の紹介 High Performance Computing Lab.
 高性能計算研究室 (HPC Lab) の紹介 High Performance Computing Lab. 静岡理工科大学総合情報学部コンピュータシステム学科 ( 兼 Web デザイン特別プログラム ) 幸谷智紀 543 研究室 幸谷研究室 @ 静岡 検索 概要 1. 幸谷智紀 個人の研究テーマ 2. 3 年生ゼミ ( 情報セミナー II) 3. 卒研テーマ 4. 過去の卒研 5. 今後について
高性能計算研究室 (HPC Lab) の紹介 High Performance Computing Lab. 静岡理工科大学総合情報学部コンピュータシステム学科 ( 兼 Web デザイン特別プログラム ) 幸谷智紀 543 研究室 幸谷研究室 @ 静岡 検索 概要 1. 幸谷智紀 個人の研究テーマ 2. 3 年生ゼミ ( 情報セミナー II) 3. 卒研テーマ 4. 過去の卒研 5. 今後について
<4D F736F F F696E74202D F A282BD94BD959C89F A4C E682528D652E707074>
 発表の流れ SSE を用いた反復解法ライブラリ Lis 4 倍精度版の高速化 小武守恒 (JST 東京大学 ) 藤井昭宏 ( 工学院大学 ) 長谷川秀彦 ( 筑波大学 ) 西田晃 ( 中央大学 JST) はじめに 4 倍精度演算について Lisへの実装 SSEによる高速化 性能評価 スピード 収束 まとめ はじめに クリロフ部分空間法たとえば CG 法は, 理論的には高々 n 回 (n は係数行列の次元数
発表の流れ SSE を用いた反復解法ライブラリ Lis 4 倍精度版の高速化 小武守恒 (JST 東京大学 ) 藤井昭宏 ( 工学院大学 ) 長谷川秀彦 ( 筑波大学 ) 西田晃 ( 中央大学 JST) はじめに 4 倍精度演算について Lisへの実装 SSEによる高速化 性能評価 スピード 収束 まとめ はじめに クリロフ部分空間法たとえば CG 法は, 理論的には高々 n 回 (n は係数行列の次元数
この方法では, 複数のアドレスが同じインデックスに対応づけられる可能性があるため, キャッシュラインのコピーと書き戻しが交互に起きる性のミスが発生する可能性がある. これを回避するために考案されたのが, 連想メモリアクセスができる形キャッシュである. この方式は, キャッシュに余裕がある限り主記憶の
 計算機システム Ⅱ 演習問題学科学籍番号氏名 1. 以下の分の空白を埋めなさい. CPUは, 命令フェッチ (F), 命令デコード (D), 実行 (E), 計算結果の書き戻し (W), の異なるステージの処理を反復実行するが, ある命令の計算結果の書き戻しをするまで, 次の命令のフェッチをしない場合, ( 単位時間当たりに実行できる命令数 ) が低くなる. これを解決するために考案されたのがパイプライン処理である.
計算機システム Ⅱ 演習問題学科学籍番号氏名 1. 以下の分の空白を埋めなさい. CPUは, 命令フェッチ (F), 命令デコード (D), 実行 (E), 計算結果の書き戻し (W), の異なるステージの処理を反復実行するが, ある命令の計算結果の書き戻しをするまで, 次の命令のフェッチをしない場合, ( 単位時間当たりに実行できる命令数 ) が低くなる. これを解決するために考案されたのがパイプライン処理である.
処理効率
 処理効率 処理効率の改善 : 基本関数複数メモリ領域線形代数の並列処理並列ガベージコレクタ多項式演算疎な行列とベクトル Maplesoft は 新しいリリースのたびに数学計算の効率と速度の改善を追求してきました これには 頻繁にコールされるルーチンやアルゴリズムの改善だけでなく ローレベルの基礎構造の改善も含まれます Maple では 複素数を含む数値計算を高速化する新しいアル 17 ゴリズムおよび疎な行列とベクトルをより実用的に結合するためのローレベルルーチンが導入されました
処理効率 処理効率の改善 : 基本関数複数メモリ領域線形代数の並列処理並列ガベージコレクタ多項式演算疎な行列とベクトル Maplesoft は 新しいリリースのたびに数学計算の効率と速度の改善を追求してきました これには 頻繁にコールされるルーチンやアルゴリズムの改善だけでなく ローレベルの基礎構造の改善も含まれます Maple では 複素数を含む数値計算を高速化する新しいアル 17 ゴリズムおよび疎な行列とベクトルをより実用的に結合するためのローレベルルーチンが導入されました
コンピュータ工学Ⅰ
 コンピュータ工学 Ⅰ Rev. 2018.01.20 コンピュータの基本構成と CPU 内容 ➊ CPUの構成要素 ➋ 命令サイクル ➌ アセンブリ言語 ➍ アドレッシング方式 ➎ CPUの高速化 ➏ CPUの性能評価 コンピュータの構成装置 中央処理装置 (CPU) 主記憶装置から命令を読み込み 実行を行う 主記憶装置 CPU で実行するプログラム ( 命令の集合 ) やデータを記憶する 補助記憶装置
コンピュータ工学 Ⅰ Rev. 2018.01.20 コンピュータの基本構成と CPU 内容 ➊ CPUの構成要素 ➋ 命令サイクル ➌ アセンブリ言語 ➍ アドレッシング方式 ➎ CPUの高速化 ➏ CPUの性能評価 コンピュータの構成装置 中央処理装置 (CPU) 主記憶装置から命令を読み込み 実行を行う 主記憶装置 CPU で実行するプログラム ( 命令の集合 ) やデータを記憶する 補助記憶装置
最新の並列計算事情とCAE
 1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
hpc141_shirahata.pdf
 GPU アクセラレータと不揮発性メモリ を考慮した I/O 性能の予備評価 白幡晃一 1,2 佐藤仁 1,2 松岡聡 1 1: 東京工業大学 2: JST CREST 1 GPU と不揮発性メモリを用いた 大規模データ処理 大規模データ処理 センサーネットワーク 遺伝子情報 SNS など ペタ ヨッタバイト級 高速処理が必要 スーパーコンピュータ上での大規模データ処理 GPU 高性能 高バンド幅 例
GPU アクセラレータと不揮発性メモリ を考慮した I/O 性能の予備評価 白幡晃一 1,2 佐藤仁 1,2 松岡聡 1 1: 東京工業大学 2: JST CREST 1 GPU と不揮発性メモリを用いた 大規模データ処理 大規模データ処理 センサーネットワーク 遺伝子情報 SNS など ペタ ヨッタバイト級 高速処理が必要 スーパーコンピュータ上での大規模データ処理 GPU 高性能 高バンド幅 例
CCS HPCサマーセミナー 並列数値計算アルゴリズム
 大規模系での高速フーリエ変換 2 高橋大介 daisuke@cs.tsukuba.ac.jp 筑波大学計算科学研究センター 2016/6/2 計算科学技術特論 B 1 講義内容 並列三次元 FFT における自動チューニング 二次元分割を用いた並列三次元 FFT アルゴリズム GPU クラスタにおける並列三次元 FFT 2016/6/2 計算科学技術特論 B 2 並列三次元 FFT における 自動チューニング
大規模系での高速フーリエ変換 2 高橋大介 daisuke@cs.tsukuba.ac.jp 筑波大学計算科学研究センター 2016/6/2 計算科学技術特論 B 1 講義内容 並列三次元 FFT における自動チューニング 二次元分割を用いた並列三次元 FFT アルゴリズム GPU クラスタにおける並列三次元 FFT 2016/6/2 計算科学技術特論 B 2 並列三次元 FFT における 自動チューニング
Microsoft PowerPoint ppt
 並列アルゴリズム 2005 年後期火曜 2 限 高見利也 ( 青柳睦 ) Aoyagi@cc.kyushu-u.ac.jp http://server-500.cc.kyushu-u.ac.jp/ 12 月 20 日 ( 火 ) 9. PC クラスタによる並列プログラミング ( 演習 ) つづき 1 もくじ 1. 序並列計算機の現状 2. 計算方式およびアーキテクチュアの分類 3. 並列計算の目的と課題
並列アルゴリズム 2005 年後期火曜 2 限 高見利也 ( 青柳睦 ) Aoyagi@cc.kyushu-u.ac.jp http://server-500.cc.kyushu-u.ac.jp/ 12 月 20 日 ( 火 ) 9. PC クラスタによる並列プログラミング ( 演習 ) つづき 1 もくじ 1. 序並列計算機の現状 2. 計算方式およびアーキテクチュアの分類 3. 並列計算の目的と課題
スライド 1
 GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
COMET II のプログラミング ここでは機械語レベルプログラミングを学びます 1
 COMET II のプログラミング ここでは機械語レベルプログラミングを学びます 1 ここでは機械命令レベルプログラミングを学びます 機械命令の形式は学びましたね機械命令を並べたプログラムを作ります 2 その前に プログラミング言語について 4 プログラミング言語について 高級言語 (Java とか C とか ) と機械命令レベルの言語 ( アセンブリ言語 ) があります 5 プログラミング言語について
COMET II のプログラミング ここでは機械語レベルプログラミングを学びます 1 ここでは機械命令レベルプログラミングを学びます 機械命令の形式は学びましたね機械命令を並べたプログラムを作ります 2 その前に プログラミング言語について 4 プログラミング言語について 高級言語 (Java とか C とか ) と機械命令レベルの言語 ( アセンブリ言語 ) があります 5 プログラミング言語について
about MPI
 本日 (4/16) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
本日 (4/16) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
コンピュータ工学Ⅰ
 コンピュータ工学 Ⅰ 中央処理装置 Rev. 2019.01.16 コンピュータの基本構成と CPU 内容 ➊ CPUの構成要素 ➋ 命令サイクル ➌ アセンブリ言語 ➍ アドレッシング方式 ➎ CPUの高速化 ➏ CPUの性能評価 コンピュータの構成装置 中央処理装置 (CPU) 主記憶装置から命令を読み込み 実行を行う 主記憶装置 CPU で実行するプログラム ( 命令の集合 ) やデータを記憶する
コンピュータ工学 Ⅰ 中央処理装置 Rev. 2019.01.16 コンピュータの基本構成と CPU 内容 ➊ CPUの構成要素 ➋ 命令サイクル ➌ アセンブリ言語 ➍ アドレッシング方式 ➎ CPUの高速化 ➏ CPUの性能評価 コンピュータの構成装置 中央処理装置 (CPU) 主記憶装置から命令を読み込み 実行を行う 主記憶装置 CPU で実行するプログラム ( 命令の集合 ) やデータを記憶する
高性能計算研究室の紹介 High Performance Computing Lab.
 高性能計算研究室 (HPC Lab) の紹介 High Performance Computing Lab. 静岡理工科大学総合情報学部コンピュータシステム学科 ( 兼 Web デザイン特別プログラム ) 幸谷智紀 http://na-inet.jp/ 概要 1. 幸谷智紀 個人の研究テーマ 2. 3 年生ゼミ ( 情報セミナー II) 3. 卒研テーマ 4. Webデザイン特別プログラム 5. 今後について
高性能計算研究室 (HPC Lab) の紹介 High Performance Computing Lab. 静岡理工科大学総合情報学部コンピュータシステム学科 ( 兼 Web デザイン特別プログラム ) 幸谷智紀 http://na-inet.jp/ 概要 1. 幸谷智紀 個人の研究テーマ 2. 3 年生ゼミ ( 情報セミナー II) 3. 卒研テーマ 4. Webデザイン特別プログラム 5. 今後について
製品開発の現場では 各種のセンサーや測定環境を利用したデータ解析が行われ シミュレーションや動作検証等に役立てられています しかし 日々収集されるデータ量は増加し 解析も複雑化しており データ解析の負荷は徐々に重くなっています 例えば自動車の車両計測データを解析する場合 取得したデータをそのまま解析
 ホワイトペーパー Excel と MATLAB の連携がデータ解析の課題を解決 製品開発の現場では 各種のセンサーや測定環境を利用したデータ解析が行われ シミュレーションや動作検証等に役立てられています しかし 日々収集されるデータ量は増加し 解析も複雑化しており データ解析の負荷は徐々に重くなっています 例えば自動車の車両計測データを解析する場合 取得したデータをそのまま解析に使用することはできず
ホワイトペーパー Excel と MATLAB の連携がデータ解析の課題を解決 製品開発の現場では 各種のセンサーや測定環境を利用したデータ解析が行われ シミュレーションや動作検証等に役立てられています しかし 日々収集されるデータ量は増加し 解析も複雑化しており データ解析の負荷は徐々に重くなっています 例えば自動車の車両計測データを解析する場合 取得したデータをそのまま解析に使用することはできず
<4D F736F F F696E74202D2091E63489F15F436F6D C982E682E992B48D8291AC92B489B F090CD2888F38DFC E B8CDD8
 Web キャンパス資料 超音波シミュレーションの基礎 ~ 第 4 回 ComWAVEによる超高速超音波解析 ~ 科学システム開発部 Copyright (c)2006 ITOCHU Techno-Solutions Corporation 本日の説明内容 ComWAVEの概要および特徴 GPGPUとは GPGPUによる解析事例 CAE POWER 超音波研究会開催 (10 月 3 日 ) のご紹介
Web キャンパス資料 超音波シミュレーションの基礎 ~ 第 4 回 ComWAVEによる超高速超音波解析 ~ 科学システム開発部 Copyright (c)2006 ITOCHU Techno-Solutions Corporation 本日の説明内容 ComWAVEの概要および特徴 GPGPUとは GPGPUによる解析事例 CAE POWER 超音波研究会開催 (10 月 3 日 ) のご紹介
Microsoft Word - Quadro Mシリーズ_テクニカルガイド_R1-2.doc
 (2016/01/28) グラフィックス アクセラレータ Quadro M シリーズ - 1 - 1. 機能仕様 Quadro M5000/M4000 型名 N8005-FS61/122 N8005- FS60/121 製品名 Quadro M5000 Quadro M4000 GPU NVIDIA Quadro M5000 NVIDIA Quadro M4000 メモリ 8GB 256bit GDDR5
(2016/01/28) グラフィックス アクセラレータ Quadro M シリーズ - 1 - 1. 機能仕様 Quadro M5000/M4000 型名 N8005-FS61/122 N8005- FS60/121 製品名 Quadro M5000 Quadro M4000 GPU NVIDIA Quadro M5000 NVIDIA Quadro M4000 メモリ 8GB 256bit GDDR5
Hphi実行環境導入マニュアル_v1.1.1
 HΦ の計算環境構築方法マニュアル 2016 年 7 月 25 日 東大物性研ソフトウェア高度化推進チーム 目次 VirtualBox を利用した HΦ の導入... 2 VirtualBox を利用した MateriAppsLive! の導入... 3 MateriAppsLive! への HΦ のインストール... 6 ISSP スパコンシステム B での HΦ の利用方法... 8 各種ファイルの置き場所...
HΦ の計算環境構築方法マニュアル 2016 年 7 月 25 日 東大物性研ソフトウェア高度化推進チーム 目次 VirtualBox を利用した HΦ の導入... 2 VirtualBox を利用した MateriAppsLive! の導入... 3 MateriAppsLive! への HΦ のインストール... 6 ISSP スパコンシステム B での HΦ の利用方法... 8 各種ファイルの置き場所...
VXPRO R1400® ご提案資料
 Intel Core i7 プロセッサ 920 Preliminary Performance Report ノード性能評価 ノード性能の評価 NAS Parallel Benchmark Class B OpenMP 版での性能評価 実行スレッド数を 4 で固定 ( デュアルソケットでは各プロセッサに 2 スレッド ) 全て 2.66GHz のコアとなるため コアあたりのピーク性能は同じ 評価システム
Intel Core i7 プロセッサ 920 Preliminary Performance Report ノード性能評価 ノード性能の評価 NAS Parallel Benchmark Class B OpenMP 版での性能評価 実行スレッド数を 4 で固定 ( デュアルソケットでは各プロセッサに 2 スレッド ) 全て 2.66GHz のコアとなるため コアあたりのピーク性能は同じ 評価システム
ERDAS IMAGINE における処理速度の向上 株式会社ベストシステムズ PASCO CORPORATION 2015
 ERDAS IMAGINE における処理速度の向上 株式会社ベストシステムズ 本セッションの目的 本セッションでは ERDAS IMAGINEにおける処理速度向上を目的として機器 (SSD 等 ) 及び並列処理の比較 検討を行った 1.SSD 及び RAMDISK を利用した処理速度の検証 2.Condorによる複数 PCを用いた並列処理 2.1 分散並列処理による高速化試験 (ERDAS IMAGINEのCondorを使用した試験
ERDAS IMAGINE における処理速度の向上 株式会社ベストシステムズ 本セッションの目的 本セッションでは ERDAS IMAGINEにおける処理速度向上を目的として機器 (SSD 等 ) 及び並列処理の比較 検討を行った 1.SSD 及び RAMDISK を利用した処理速度の検証 2.Condorによる複数 PCを用いた並列処理 2.1 分散並列処理による高速化試験 (ERDAS IMAGINEのCondorを使用した試験
Microsoft PowerPoint - OS12.pptx
 # # この資料は 情報工学レクチャーシリーズ松尾啓志著 ( 森北出版株式会社 ) を用いて授業を行うために 名古屋工業大学松尾啓志 津邑公暁が作成しました パワーポイント 7 で最終版として保存しているため 変更はできませんが 授業でお使いなる場合は松尾 (matsuo@nitech.ac.jp) まで連絡いただければ 編集可能なバージョンをお渡しする事も可能です # 主記憶管理 : ページ置き換え方式
# # この資料は 情報工学レクチャーシリーズ松尾啓志著 ( 森北出版株式会社 ) を用いて授業を行うために 名古屋工業大学松尾啓志 津邑公暁が作成しました パワーポイント 7 で最終版として保存しているため 変更はできませんが 授業でお使いなる場合は松尾 (matsuo@nitech.ac.jp) まで連絡いただければ 編集可能なバージョンをお渡しする事も可能です # 主記憶管理 : ページ置き換え方式
本文ALL.indd
 Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法河辺峻田口成美古谷英祐 Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法 Performance Measurement Method of Cache Coherency Effects on an Intel Xeon Processor System 河辺峻田口成美古谷英祐
Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法河辺峻田口成美古谷英祐 Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法 Performance Measurement Method of Cache Coherency Effects on an Intel Xeon Processor System 河辺峻田口成美古谷英祐
openmp1_Yaguchi_version_170530
 並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
システムソリューションのご紹介
 HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
GPGPUクラスタの性能評価
 2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
(速報) Xeon E 系モデル 新プロセッサ性能について
 Xeon E 系モデル 新プロセッサ性能について") ( 速報 ) Xeon E5-2600 系モデル新プロセッサ性能について 2012 年 3 月 16 日 富士通株式会社 2012 年 3 月 7 日 インテル社より最新 CPU インテル Xeon E5 ファミリー の発表がありました この最新 CPU について PC クラスタシステムの観点から性能検証を行いましたので 概要を速報いたします プロセッサインテル Xeon プロセッサ E5-2690
( 速報 ) Xeon E5-2600 系モデル新プロセッサ性能について 2012 年 3 月 16 日 富士通株式会社 2012 年 3 月 7 日 インテル社より最新 CPU インテル Xeon E5 ファミリー の発表がありました この最新 CPU について PC クラスタシステムの観点から性能検証を行いましたので 概要を速報いたします プロセッサインテル Xeon プロセッサ E5-2690
並列計算の数理とアルゴリズム サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. このサンプルページの内容は, 初版 1 刷発行時のものです.
 並列計算の数理とアルゴリズム サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. http://www.morikita.co.jp/books/mid/080711 このサンプルページの内容は, 初版 1 刷発行時のものです. Calcul scientifique parallèle by Frédéric Magoulès and François-Xavier
並列計算の数理とアルゴリズム サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. http://www.morikita.co.jp/books/mid/080711 このサンプルページの内容は, 初版 1 刷発行時のものです. Calcul scientifique parallèle by Frédéric Magoulès and François-Xavier
九州大学がスーパーコンピュータ「高性能アプリケーションサーバシステム」の本格稼働を開始
 2014 年 1 月 31 日 国立大学法人九州大学 株式会社日立製作所 九州大学がスーパーコンピュータ 高性能アプリケーションサーバシステム の本格稼働を開始 日立のテクニカルサーバ HA8000-tc/HT210 などを採用 従来システム比で 約 28 倍の性能を実現し 1TFLOPS あたりの消費電力は約 17 分の 1 に低減 九州大学情報基盤研究開発センター ( センター長 : 青柳睦 /
2014 年 1 月 31 日 国立大学法人九州大学 株式会社日立製作所 九州大学がスーパーコンピュータ 高性能アプリケーションサーバシステム の本格稼働を開始 日立のテクニカルサーバ HA8000-tc/HT210 などを採用 従来システム比で 約 28 倍の性能を実現し 1TFLOPS あたりの消費電力は約 17 分の 1 に低減 九州大学情報基盤研究開発センター ( センター長 : 青柳睦 /
TFTP serverの実装
 TFTP サーバーの実装 デジタルビジョンソリューション 佐藤史明 1 1 プレゼンのテーマ組み込みソフトのファイル転送を容易に 2 3 4 5 基礎知識 TFTP とは 実践 1 実際に作ってみよう 実践 2 組み込みソフトでの実装案 最後におさらい 2 プレゼンのテーマ 組み込みソフトのファイル転送を容易に テーマ選択の理由 現在従事しているプロジェクトで お客様からファームウェアなどのファイル転送を独自方式からTFTPに変更したいと要望があった
TFTP サーバーの実装 デジタルビジョンソリューション 佐藤史明 1 1 プレゼンのテーマ組み込みソフトのファイル転送を容易に 2 3 4 5 基礎知識 TFTP とは 実践 1 実際に作ってみよう 実践 2 組み込みソフトでの実装案 最後におさらい 2 プレゼンのテーマ 組み込みソフトのファイル転送を容易に テーマ選択の理由 現在従事しているプロジェクトで お客様からファームウェアなどのファイル転送を独自方式からTFTPに変更したいと要望があった
スライド 1
 ATI Stream SDK による 天文 物理計算の高速化 会津大学中里直人 計算事例 : 重力 N 体計算 No.2 プログラム :N 体の重力計算 (1) No.3 既存のアルゴリズムやアプリケーションを CAL で実装するには 前提として 並列計算可能な問題でなくては 利用する意味がない GPU のアーキテクチャにあわせて アルゴリズムを変更する必要あり GPU のメモリに合わせた 効率のよいデータ構造を考える必要あり
ATI Stream SDK による 天文 物理計算の高速化 会津大学中里直人 計算事例 : 重力 N 体計算 No.2 プログラム :N 体の重力計算 (1) No.3 既存のアルゴリズムやアプリケーションを CAL で実装するには 前提として 並列計算可能な問題でなくては 利用する意味がない GPU のアーキテクチャにあわせて アルゴリズムを変更する必要あり GPU のメモリに合わせた 効率のよいデータ構造を考える必要あり
NVIDIA Tesla K20/K20X GPU アクセラレータ アプリケーション パフォーマンス テクニカル ブリーフ
 NVIDIA Tesla K20/K20X GPU アクセラレータ アプリケーション パフォーマンス テクニカル ブリーフ K20 GPU2 個に対するスピードアップ NVIDIA は Fermi アーキテクチャ GPU の発表により パフォーマンス エネルギー効率の両面で飛躍的な性能向上を実現し ハイパフォーマンスコンピューティング (HPC) の世界に変革をもたらしました また 実際に GPU
NVIDIA Tesla K20/K20X GPU アクセラレータ アプリケーション パフォーマンス テクニカル ブリーフ K20 GPU2 個に対するスピードアップ NVIDIA は Fermi アーキテクチャ GPU の発表により パフォーマンス エネルギー効率の両面で飛躍的な性能向上を実現し ハイパフォーマンスコンピューティング (HPC) の世界に変革をもたらしました また 実際に GPU
Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]
![Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]](/thumbs/102/156675429.jpg "Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]") 200/0/9 数値流体解析の並列効率とその GPU による高速化の試み 清水建設 ( 株 ) 技術研究所 PHAM VAN PHUC ( ファムバンフック ) 流体計算時間短縮と GPU の活用の試み 現 CPUとの比較によりGPU 活用の可能性 現 CPU の最大利用 ノード内の最大計算資源の利用 すべてCPUコアの利用 適切なアルゴリズムの利用 CPU コア性能の何倍? GPU の利用の試み
200/0/9 数値流体解析の並列効率とその GPU による高速化の試み 清水建設 ( 株 ) 技術研究所 PHAM VAN PHUC ( ファムバンフック ) 流体計算時間短縮と GPU の活用の試み 現 CPUとの比較によりGPU 活用の可能性 現 CPU の最大利用 ノード内の最大計算資源の利用 すべてCPUコアの利用 適切なアルゴリズムの利用 CPU コア性能の何倍? GPU の利用の試み
倍々精度RgemmのnVidia C2050上への実装と応用
 .. maho@riken.jp http://accc.riken.jp/maho/,,, 2011/2/16 1 - : GPU : SDPA-DD 10 1 - Rgemm : 4 (32 ) nvidia C2050, GPU CPU 150, 24GFlops 25 20 GFLOPS 15 10 QuadAdd Cray, QuadMul Sloppy Kernel QuadAdd Cray,
.. maho@riken.jp http://accc.riken.jp/maho/,,, 2011/2/16 1 - : GPU : SDPA-DD 10 1 - Rgemm : 4 (32 ) nvidia C2050, GPU CPU 150, 24GFlops 25 20 GFLOPS 15 10 QuadAdd Cray, QuadMul Sloppy Kernel QuadAdd Cray,
CPU Levels in the memory hierarchy Level 1 Level 2... Increasing distance from the CPU in access time Level n Size of the memory at each level 1: 2.2
 FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
スパコンに通じる並列プログラミングの基礎
 2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
supercomputer2010.ppt
 nanri@cc.kyushu-u.ac.jp 1 !! : 11 12! : nanri@cc.kyushu-u.ac.jp! : Word 2 ! PC GPU) 1997 7 http://wiredvision.jp/news/200806/2008062322.html 3 !! (Cell, GPU )! 4 ! etc...! 5 !! etc. 6 !! 20km 40 km ) 340km
nanri@cc.kyushu-u.ac.jp 1 !! : 11 12! : nanri@cc.kyushu-u.ac.jp! : Word 2 ! PC GPU) 1997 7 http://wiredvision.jp/news/200806/2008062322.html 3 !! (Cell, GPU )! 4 ! etc...! 5 !! etc. 6 !! 20km 40 km ) 340km
スパコンに通じる並列プログラミングの基礎
 2018.09.10 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 1 / 59 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 2 / 59 Windows, Mac Unix 0444-J furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 3 / 59 Part I Unix GUI CUI:
2018.09.10 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 1 / 59 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 2 / 59 Windows, Mac Unix 0444-J furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 3 / 59 Part I Unix GUI CUI:
27_02.indd
 GPGPU を用いたソフトウェア高速化手法 Technique to Speedup of the software by GPGPU 大田弘樹 馬場明子 下田雄一 安田隆洋 山本啓二 Hiroki Ota, Akiko Baba, Shimoda Yuichi, Takahiro Yasuta, Keiji Yamamoto PCやワークステーションにおいて画像処理に特化して使用されてきたGPUを
GPGPU を用いたソフトウェア高速化手法 Technique to Speedup of the software by GPGPU 大田弘樹 馬場明子 下田雄一 安田隆洋 山本啓二 Hiroki Ota, Akiko Baba, Shimoda Yuichi, Takahiro Yasuta, Keiji Yamamoto PCやワークステーションにおいて画像処理に特化して使用されてきたGPUを
基盤研究(B) 「マルチコア複合環境を指向した適応型自動チューニング技術」
 「マルチコア複合環境を指向した適応型自動チューニング技術」") 複合マルチコア環境のため の自動チューニング技術 第 2 回自動チューニング技術の現状と応用に関するシンポジウム Second symposium on Automatic Tuning Technology and its Application 基盤研究 (B) 21300013 マルチコア複合環境を指向した適応型自動チューニング技術 今村俊幸 電気通信大学情報理工学研究科 2010/11/04
複合マルチコア環境のため の自動チューニング技術 第 2 回自動チューニング技術の現状と応用に関するシンポジウム Second symposium on Automatic Tuning Technology and its Application 基盤研究 (B) 21300013 マルチコア複合環境を指向した適応型自動チューニング技術 今村俊幸 電気通信大学情報理工学研究科 2010/11/04
スパコンに通じる並列プログラミングの基礎
 2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
スライド 1
 本日 (4/25) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
本日 (4/25) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
Microsoft PowerPoint PCクラスタワークショップin京都.ppt
 PC クラスタシステムへの富士通の取り組み 富士通株式会社株式会社富士通研究所久門耕一 29 年度に富士通が提供する ( した ) 大規模クラスタ 今年度はCPUとしてメモリバンド幅がNehalem, QDR- IB( 片方向 4GB/s) などPCクラスタにとって期待できる多くのコモディティコンポーネントが出現 これら魅力ある素材を使ったシステムとして 2つのシステムをご紹介 理化学研究所様 RICC(Riken
PC クラスタシステムへの富士通の取り組み 富士通株式会社株式会社富士通研究所久門耕一 29 年度に富士通が提供する ( した ) 大規模クラスタ 今年度はCPUとしてメモリバンド幅がNehalem, QDR- IB( 片方向 4GB/s) などPCクラスタにとって期待できる多くのコモディティコンポーネントが出現 これら魅力ある素材を使ったシステムとして 2つのシステムをご紹介 理化学研究所様 RICC(Riken
並列・高速化を実現するための 高速化サービスの概要と事例紹介
 第 4 回 AVS 可視化フォーラム 2019 並列 高速化を実現するための 高速化サービスの概要と事例紹介 株式会社アーク情報システム営業部仮野亮ソリューション技術部佐々木竜一 2019.08.30 はじめに アーク情報システムの紹介 高速化サービスとは? 事例紹介 コンサルティングサービスについて アーク情報システムの紹介 設立 資本金 :1987 年 10 月 :3 億 600 万円 従業員数
第 4 回 AVS 可視化フォーラム 2019 並列 高速化を実現するための 高速化サービスの概要と事例紹介 株式会社アーク情報システム営業部仮野亮ソリューション技術部佐々木竜一 2019.08.30 はじめに アーク情報システムの紹介 高速化サービスとは? 事例紹介 コンサルティングサービスについて アーク情報システムの紹介 設立 資本金 :1987 年 10 月 :3 億 600 万円 従業員数
EnSightのご紹介
 オープン CAE シンポジウム 2014 汎用ポストプロセッサー EnSight の大規模データ対応 CEI ソフトウェア株式会社代表取締役吉川慈人 http://www.ceisoftware.co.jp/ 内容 大規模データで時間のかかる処理 クライアント サーバー機能 マルチスレッドによる並列処理 サーバーの分散処理 クライアントの分散処理 ( 分散レンダリング ) EnSightのOpenFOAMインターフェース
オープン CAE シンポジウム 2014 汎用ポストプロセッサー EnSight の大規模データ対応 CEI ソフトウェア株式会社代表取締役吉川慈人 http://www.ceisoftware.co.jp/ 内容 大規模データで時間のかかる処理 クライアント サーバー機能 マルチスレッドによる並列処理 サーバーの分散処理 クライアントの分散処理 ( 分散レンダリング ) EnSightのOpenFOAMインターフェース
Microsoft Word - nvsi_050110jp_netvault_vtl_on_dothill_sannetII.doc
 Article ID: NVSI-050110JP Created: 2005/10/19 Revised: - NetVault 仮想テープ ライブラリのパフォーマンス検証 : dothill SANnetⅡSATA 編 1. 検証の目的 ドットヒルシステムズ株式会社の SANnetll SATA は 安価な SATA ドライブを使用した大容量ストレージで ディスクへのバックアップを行う際の対象デバイスとして最適と言えます
Article ID: NVSI-050110JP Created: 2005/10/19 Revised: - NetVault 仮想テープ ライブラリのパフォーマンス検証 : dothill SANnetⅡSATA 編 1. 検証の目的 ドットヒルシステムズ株式会社の SANnetll SATA は 安価な SATA ドライブを使用した大容量ストレージで ディスクへのバックアップを行う際の対象デバイスとして最適と言えます
Microsoft Word - CygwinでPython.docx
 Cygwin でプログラミング 2018/4/9 千葉 数値計算は計算プログラムを書いて行うわけですが プログラムには様々な 言語 があるので そのうちどれかを選択する必要があります プログラム言語には 人間が書いたプログラムを一度計算機用に翻訳したのち計算を実行するものと 人間が書いたプログラムを計算機が読んでそのまま実行するものとがあります ( 若干不正確な説明ですが ) 前者を システム言語
Cygwin でプログラミング 2018/4/9 千葉 数値計算は計算プログラムを書いて行うわけですが プログラムには様々な 言語 があるので そのうちどれかを選択する必要があります プログラム言語には 人間が書いたプログラムを一度計算機用に翻訳したのち計算を実行するものと 人間が書いたプログラムを計算機が読んでそのまま実行するものとがあります ( 若干不正確な説明ですが ) 前者を システム言語
PowerPoint プレゼンテーション
 総務省 ICTスキル総合習得教材 概要版 eラーニング用 [ コース2] データ蓄積 2-5: 多様化が進展するクラウドサービス [ コース1] データ収集 [ コース2] データ蓄積 [ コース3] データ分析 [ コース4] データ利活用 1 2 3 4 5 座学本講座の学習内容 (2-5: 多様化が進展するクラウドサービス ) 講座概要 近年 注目されているクラウドの関連技術を紹介します PCやサーバを構成するパーツを紹介後
総務省 ICTスキル総合習得教材 概要版 eラーニング用 [ コース2] データ蓄積 2-5: 多様化が進展するクラウドサービス [ コース1] データ収集 [ コース2] データ蓄積 [ コース3] データ分析 [ コース4] データ利活用 1 2 3 4 5 座学本講座の学習内容 (2-5: 多様化が進展するクラウドサービス ) 講座概要 近年 注目されているクラウドの関連技術を紹介します PCやサーバを構成するパーツを紹介後
Microsoft Word - VBA基礎(6).docx
.docx") あるクラスの算数の平均点と理科の平均点を読み込み 総点を計算するプログラムを考えてみましょう 一クラスだけ読み込む場合は test50 のようなプログラムになります プログラムの流れとしては非常に簡単です Sub test50() a = InputBox(" バナナ組の算数の平均点を入力してください ") b = InputBox(" バナナ組の理科の平均点を入力してください ") MsgBox
あるクラスの算数の平均点と理科の平均点を読み込み 総点を計算するプログラムを考えてみましょう 一クラスだけ読み込む場合は test50 のようなプログラムになります プログラムの流れとしては非常に簡単です Sub test50() a = InputBox(" バナナ組の算数の平均点を入力してください ") b = InputBox(" バナナ組の理科の平均点を入力してください ") MsgBox
計算機アーキテクチャ
 計算機アーキテクチャ 第 3 回コンピュータのハードウェア 2014 年 4 月 21 日 電気情報工学科 田島孝治 1 授業スケジュール ( 前期 ) 2 回 日付タイトル 回日付タイトル 1 4/7 コンピュータ技術の歴史と コンピュータアーキテクチャ 2 4/14 ノイマン型コンピュータ 3 4/21 コンピュータのハードウェア 4 4/28 数と文字の表現 5 5/12 固定小数点数と浮動小数点表現
計算機アーキテクチャ 第 3 回コンピュータのハードウェア 2014 年 4 月 21 日 電気情報工学科 田島孝治 1 授業スケジュール ( 前期 ) 2 回 日付タイトル 回日付タイトル 1 4/7 コンピュータ技術の歴史と コンピュータアーキテクチャ 2 4/14 ノイマン型コンピュータ 3 4/21 コンピュータのハードウェア 4 4/28 数と文字の表現 5 5/12 固定小数点数と浮動小数点表現
Agenda GRAPE-MPの紹介と性能評価 GRAPE-MPの概要 OpenCLによる四倍精度演算 (preliminary) 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops
 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops") Agenda GRAPE-MPの紹介と性能評価 GRAPE-MPの概要 OpenCLによる四倍精度演算 (preliminary) 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops ボードの概要 Control processor (FPGA by Altera) GRAPE-MP chip[nextreme
Agenda GRAPE-MPの紹介と性能評価 GRAPE-MPの概要 OpenCLによる四倍精度演算 (preliminary) 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops ボードの概要 Control processor (FPGA by Altera) GRAPE-MP chip[nextreme
cp-7. 配列
 cp-7. 配列 (C プログラムの書き方を, パソコン演習で学ぶシリーズ ) https://www.kkaneko.jp/cc/adp/index.html 金子邦彦 1 本日の内容 例題 1. 月の日数配列とは. 配列の宣言. 配列の添え字. 例題 2. ベクトルの内積例題 3. 合計点と平均点例題 4. 棒グラフを描く配列と繰り返し計算の関係例題 5. 行列の和 2 次元配列 2 今日の到達目標
cp-7. 配列 (C プログラムの書き方を, パソコン演習で学ぶシリーズ ) https://www.kkaneko.jp/cc/adp/index.html 金子邦彦 1 本日の内容 例題 1. 月の日数配列とは. 配列の宣言. 配列の添え字. 例題 2. ベクトルの内積例題 3. 合計点と平均点例題 4. 棒グラフを描く配列と繰り返し計算の関係例題 5. 行列の和 2 次元配列 2 今日の到達目標
Microsoft PowerPoint - qcomp.ppt [互換モード]
![Microsoft PowerPoint - qcomp.ppt [互換モード]](/thumbs/85/91243661.jpg "Microsoft PowerPoint - qcomp.ppt [互換モード]") 量子計算基礎 東京工業大学 河内亮周 概要 計算って何? 数理科学的に 計算 を扱うには 量子力学を計算に使おう! 量子情報とは? 量子情報に対する演算 = 量子計算 一般的な量子回路の構成方法 計算って何? 計算とは? 計算 = 入力情報から出力情報への変換 入力 計算機構 ( デジタルコンピュータ,etc ) 出力 計算とは? 計算 = 入力情報から出力情報への変換 この関数はどれくらい計算が大変か??
量子計算基礎 東京工業大学 河内亮周 概要 計算って何? 数理科学的に 計算 を扱うには 量子力学を計算に使おう! 量子情報とは? 量子情報に対する演算 = 量子計算 一般的な量子回路の構成方法 計算って何? 計算とは? 計算 = 入力情報から出力情報への変換 入力 計算機構 ( デジタルコンピュータ,etc ) 出力 計算とは? 計算 = 入力情報から出力情報への変換 この関数はどれくらい計算が大変か??
memcached 方式 (No Replication) 認証情報は ログインした tomcat と設定された各 memcached サーバーに認証情報を分割し振り分けて保管する memcached の方系がダウンした場合は ログインしたことのあるサーバーへのアクセスでは tomcat に認証情報
 認証情報は ログインした tomcat と設定された各 memcached サーバーに認証情報を分割し振り分けて保管する memcached の方系がダウンした場合は ログインしたことのあるサーバーへのアクセスでは tomcat に認証情報") IdPClusteringPerformance Shibboleth-IdP 冗長化パフォーマンス比較試験報告書 2012 年 1 月 17 日国立情報学研究所 Stateless Clustering 方式は SAML2 を想定しているため CryptoTransientID は不使用 使用するとパフォーマンスが悪くなる可能性あり Terracotta による冗長化について EventingMapBasedStorageService
IdPClusteringPerformance Shibboleth-IdP 冗長化パフォーマンス比較試験報告書 2012 年 1 月 17 日国立情報学研究所 Stateless Clustering 方式は SAML2 を想定しているため CryptoTransientID は不使用 使用するとパフォーマンスが悪くなる可能性あり Terracotta による冗長化について EventingMapBasedStorageService
GPUコンピューティング講習会パート1
 GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
memo
 数理情報工学演習第一 C プログラミング演習 ( 第 5 回 ) 2015/05/11 DEPARTMENT OF MATHEMATICAL INFORMATICS 1 今日の内容 : プロトタイプ宣言 ヘッダーファイル, プログラムの分割 課題 : 疎行列 2 プロトタイプ宣言 3 C 言語では, 関数や変数は使用する前 ( ソースの上のほう ) に定義されている必要がある. double sub(int
数理情報工学演習第一 C プログラミング演習 ( 第 5 回 ) 2015/05/11 DEPARTMENT OF MATHEMATICAL INFORMATICS 1 今日の内容 : プロトタイプ宣言 ヘッダーファイル, プログラムの分割 課題 : 疎行列 2 プロトタイプ宣言 3 C 言語では, 関数や変数は使用する前 ( ソースの上のほう ) に定義されている必要がある. double sub(int
HPCマシンの変遷と 今後の情報基盤センターの役割
 筑波大学計算科学センターシンポジウム 計算機アーキテクトが考える 次世代スパコン 2006 年 4 月 5 日 村上和彰 九州大学 murakami@cc.kyushu-u.ac.jp 次世代スパコン ~ 達成目標と制約条件の整理 ~ 達成目標 性能目標 (2011 年 ) LINPACK (HPL):10PFlop/s 実アプリケーション :1PFlop/s 成果目標 ( 私見 ) 科学技術計算能力の国際競争力の向上ならびに維持による我が国の科学技術力
筑波大学計算科学センターシンポジウム 計算機アーキテクトが考える 次世代スパコン 2006 年 4 月 5 日 村上和彰 九州大学 murakami@cc.kyushu-u.ac.jp 次世代スパコン ~ 達成目標と制約条件の整理 ~ 達成目標 性能目標 (2011 年 ) LINPACK (HPL):10PFlop/s 実アプリケーション :1PFlop/s 成果目標 ( 私見 ) 科学技術計算能力の国際競争力の向上ならびに維持による我が国の科学技術力
プログラミング実習I
 プログラミング実習 I 05 関数 (1) 人間システム工学科井村誠孝 m.imura@kwansei.ac.jp 関数とは p.162 数学的には入力に対して出力が決まるもの C 言語では入出力が定まったひとまとまりの処理 入力や出力はあるときもないときもある main() も関数の一種 何かの仕事をこなしてくれる魔法のブラックボックス 例 : printf() 関数中で行われている処理の詳細を使う側は知らないが,
プログラミング実習 I 05 関数 (1) 人間システム工学科井村誠孝 m.imura@kwansei.ac.jp 関数とは p.162 数学的には入力に対して出力が決まるもの C 言語では入出力が定まったひとまとまりの処理 入力や出力はあるときもないときもある main() も関数の一種 何かの仕事をこなしてくれる魔法のブラックボックス 例 : printf() 関数中で行われている処理の詳細を使う側は知らないが,
C に必要なコンピュータ知識 C はコンピュータの力を引き出せるように設計 コンピュータの知識が必要
 C プログラミング 1( 再 ) 第 5 回 講義では C プログラミングの基本を学び演習では やや実践的なプログラミングを通して学ぶ C に必要なコンピュータ知識 C はコンピュータの力を引き出せるように設計 コンピュータの知識が必要 1 コンピュータの構造 1.1 パーソナルコンピュータの構造 自分の ( 目の前にある ) コンピュータの仕様を調べてみよう パソコン本体 = CPU( 中央処理装置
C プログラミング 1( 再 ) 第 5 回 講義では C プログラミングの基本を学び演習では やや実践的なプログラミングを通して学ぶ C に必要なコンピュータ知識 C はコンピュータの力を引き出せるように設計 コンピュータの知識が必要 1 コンピュータの構造 1.1 パーソナルコンピュータの構造 自分の ( 目の前にある ) コンピュータの仕様を調べてみよう パソコン本体 = CPU( 中央処理装置
1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU
![1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU](/thumbs/89/99132402.jpg "1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU") GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
Microsoft PowerPoint - 11Web.pptx
 計算機システムの基礎 ( 第 10 回配布 ) 第 7 章 2 節コンピュータの性能の推移 (1) コンピュータの歴史 (2) コンピュータの性能 (3) 集積回路の進歩 (4) アーキテクチャ 第 4 章プロセッサ (1) プロセッサの基本機能 (2) プロセッサの構成回路 (3) コンピュータアーキテクチャ 第 5 章メモリアーキテクチャ 1. コンピュータの世代 計算する機械 解析機関 by
計算機システムの基礎 ( 第 10 回配布 ) 第 7 章 2 節コンピュータの性能の推移 (1) コンピュータの歴史 (2) コンピュータの性能 (3) 集積回路の進歩 (4) アーキテクチャ 第 4 章プロセッサ (1) プロセッサの基本機能 (2) プロセッサの構成回路 (3) コンピュータアーキテクチャ 第 5 章メモリアーキテクチャ 1. コンピュータの世代 計算する機械 解析機関 by
Pervasive PSQL v11 のベンチマーク パフォーマンスの結果
 Pervasive PSQL v11 のベンチマークパフォーマンスの結果 Pervasive PSQL ホワイトペーパー 2010 年 9 月 目次 実施の概要... 3 新しいハードウェアアーキテクチャがアプリケーションに及ぼす影響... 3 Pervasive PSQL v11 の設計... 4 構成... 5 メモリキャッシュ... 6 ベンチマークテスト... 6 アトミックテスト... 7
Pervasive PSQL v11 のベンチマークパフォーマンスの結果 Pervasive PSQL ホワイトペーパー 2010 年 9 月 目次 実施の概要... 3 新しいハードウェアアーキテクチャがアプリケーションに及ぼす影響... 3 Pervasive PSQL v11 の設計... 4 構成... 5 メモリキャッシュ... 6 ベンチマークテスト... 6 アトミックテスト... 7
線形代数演算ライブラリBLASとLAPACKの 基礎と実践1
 1 / 50 BLAS LAPACK 1, 2015/05/21 CMSI A 2 / 50 BLAS LAPACK (I) BLAS, LAPACK BLAS : - LAPACK : 3 / 50 ( ) 1000 ( ; 1 2 ) :... 3 / 50 ( ) 1000 ( ; 1 2 ) :... 3 / 50 ( ) 1000 ( ; 1 2 ) :... 3 / 50 ( ) 1000
1 / 50 BLAS LAPACK 1, 2015/05/21 CMSI A 2 / 50 BLAS LAPACK (I) BLAS, LAPACK BLAS : - LAPACK : 3 / 50 ( ) 1000 ( ; 1 2 ) :... 3 / 50 ( ) 1000 ( ; 1 2 ) :... 3 / 50 ( ) 1000 ( ; 1 2 ) :... 3 / 50 ( ) 1000
08 年 月一般財団法人高度情報科学技術研究機構 本資料を教育目的等で利用いただいて構いません 利用に際しては以下の点に留意いただくとともに 下記のヘルプデスクにお問い合わせ下さい 本資料は 構成 文章 画像などの全てにおいて著作権法上の保護を受けています 本資料の一部あるいは全部について いかなる
 チューニング技法入門 : キャッシュチューニング太田幸宏 ( 高度情報科学技術研究機構 ) E-mail: yota@rist.or.jp 教科書青山幸也 チューニング技法虎の巻 ( 平成 8 年 8 月 日版 ) 質問について ( 主に ) 休憩時間に受け付けます E-mail もご利用ください ( 後日, 回答します ) HPC プログラミングセミナー チューニング技法入門 : キャッシュチューニング
チューニング技法入門 : キャッシュチューニング太田幸宏 ( 高度情報科学技術研究機構 ) E-mail: yota@rist.or.jp 教科書青山幸也 チューニング技法虎の巻 ( 平成 8 年 8 月 日版 ) 質問について ( 主に ) 休憩時間に受け付けます E-mail もご利用ください ( 後日, 回答します ) HPC プログラミングセミナー チューニング技法入門 : キャッシュチューニング
演習1: 演習準備
 演習 1: 演習準備 2013 年 8 月 6 日神戸大学大学院システム情報学研究科森下浩二 1 演習 1 の内容 神戸大 X10(π-omputer) について システム概要 ログイン方法 コンパイルとジョブ実行方法 OpenMP の演習 ( 入門編 ) 1. parallel 構文 実行時ライブラリ関数 2. ループ構文 3. shared 節 private 節 4. reduction 節
演習 1: 演習準備 2013 年 8 月 6 日神戸大学大学院システム情報学研究科森下浩二 1 演習 1 の内容 神戸大 X10(π-omputer) について システム概要 ログイン方法 コンパイルとジョブ実行方法 OpenMP の演習 ( 入門編 ) 1. parallel 構文 実行時ライブラリ関数 2. ループ構文 3. shared 節 private 節 4. reduction 節
memo
 計数工学プログラミング演習 ( 第 3 回 ) 2017/04/25 DEPARTMENT OF MATHEMATICAL INFORMATICS 1 内容 ポインタの続き 引数の値渡しと参照渡し 構造体 2 ポインタで指されるメモリへのアクセス double **R; 型 R[i] と *(R+i) は同じ意味 意味 R double ** ポインタの配列 ( の先頭 ) へのポインタ R[i]
計数工学プログラミング演習 ( 第 3 回 ) 2017/04/25 DEPARTMENT OF MATHEMATICAL INFORMATICS 1 内容 ポインタの続き 引数の値渡しと参照渡し 構造体 2 ポインタで指されるメモリへのアクセス double **R; 型 R[i] と *(R+i) は同じ意味 意味 R double ** ポインタの配列 ( の先頭 ) へのポインタ R[i]
TopSE並行システム はじめに
 はじめに 平成 23 年 9 月 1 日 トップエスイープロジェクト 磯部祥尚 ( 産業技術総合研究所 ) 2 本講座の背景と目標 背景 : マルチコア CPU やクラウドコンピューティング等 並列 / 分散処理環境が身近なものになっている 複数のプロセス ( プログラム ) を同時に実行可能 通信等により複数のプロセスが協調可能 並行システムの構築 並行システム 通信 Proc2 プロセス ( プログラム
はじめに 平成 23 年 9 月 1 日 トップエスイープロジェクト 磯部祥尚 ( 産業技術総合研究所 ) 2 本講座の背景と目標 背景 : マルチコア CPU やクラウドコンピューティング等 並列 / 分散処理環境が身近なものになっている 複数のプロセス ( プログラム ) を同時に実行可能 通信等により複数のプロセスが協調可能 並行システムの構築 並行システム 通信 Proc2 プロセス ( プログラム
スライド 1
 東北大学工学部機械知能 航空工学科 2016 年度 5 セメスター クラス C3 D1 D2 D3 計算機工学 13. メモリシステム ( 教科書 8 章 ) 大学院情報科学研究科 鏡慎吾 http://www.ic.is.tohoku.ac.jp/~swk/lecture/ レジスタ選択( 復習 ) MIPS の構造 PC 命令デコーダ 次 PC 計算 mux 32x32 ビットレジスタファイル
東北大学工学部機械知能 航空工学科 2016 年度 5 セメスター クラス C3 D1 D2 D3 計算機工学 13. メモリシステム ( 教科書 8 章 ) 大学院情報科学研究科 鏡慎吾 http://www.ic.is.tohoku.ac.jp/~swk/lecture/ レジスタ選択( 復習 ) MIPS の構造 PC 命令デコーダ 次 PC 計算 mux 32x32 ビットレジスタファイル
3次多項式パラメタ推定計算の CUDAを用いた実装 (CUDAプログラミングの練習として) Implementation of the Estimation of the parameters of 3rd-order-Polynomial with CUDA
 Implementation of the Estimation of the parameters of 3rd-order-Polynomial with CUDA") 3 次多項式パラメタ推定計算の CUDA を用いた実装 (CUDA プログラミングの練習として ) Estimating the Parameters of 3rd-order-Polynomial with CUDA ISS 09/11/12 問題の選択 目的 CUDA プログラミングを経験 ( 試行錯誤と習得 ) 実際に CPU のみの場合と比べて高速化されることを体験 問題 ( インプリメントする内容
3 次多項式パラメタ推定計算の CUDA を用いた実装 (CUDA プログラミングの練習として ) Estimating the Parameters of 3rd-order-Polynomial with CUDA ISS 09/11/12 問題の選択 目的 CUDA プログラミングを経験 ( 試行錯誤と習得 ) 実際に CPU のみの場合と比べて高速化されることを体験 問題 ( インプリメントする内容
研究報告用MS-Wordテンプレートファイル
 マルチコアおよび GPGPU 環境における画像処理最適化 矢野勝久 高山征大 境隆二出宮健彦 スケーラを題材として, マルチコアおよび GPGPU 各々の HW 特性に適した画像処理の最適化を図る. マルチコア環境では, 数値演算処理の削減,SIMD 化など直列性能の最適化を行った後,OpenMP を利用して並列化を図る.GPGPU(CUDA) では, スレッド並列を優先して並列処理の設計を行いブロックサイズを決める.
マルチコアおよび GPGPU 環境における画像処理最適化 矢野勝久 高山征大 境隆二出宮健彦 スケーラを題材として, マルチコアおよび GPGPU 各々の HW 特性に適した画像処理の最適化を図る. マルチコア環境では, 数値演算処理の削減,SIMD 化など直列性能の最適化を行った後,OpenMP を利用して並列化を図る.GPGPU(CUDA) では, スレッド並列を優先して並列処理の設計を行いブロックサイズを決める.