Microsoft PowerPoint - 09-pFEM3D-VIS.pptx
|
|
|
- のぶみつ わたぬき
- 4 years ago
- Views:
Transcription
1 並列有限要素法による 三次元定常熱伝導解析プログラム 並列可視化 中島研吾東京大学情報基盤センター
2 自動チューニング機構を有する アプリケーション開発 実行環境 ppopen HPC 中島研吾 東京大学情報基盤センター 佐藤正樹 ( 東大 大気海洋研究所 ), 奥田洋司 ( 東大 新領域創成科学研究科 ), 古村孝志 ( 東大 情報学環 / 地震研 ), 岩下武史 ( 京大 学術情報メディアセンター ), 阪口秀 ( 海洋研究開発機構 )
3 3 背景 (1/2) 大規模化, 複雑化, 多様化するハイエンド計算機環境の能力を充分に引き出し, 効率的なアプリケーションプログラムを開発することは困難 有限要素法等の科学技術計算手法 : プリ ポスト処理, 行列生成, 線形方程式求解等の一連の共通プロセスから構成される これら共通プロセスを抽出し, ハードウェアに応じた最適化を施したライブラリとして整備することで, アプリケーション開発者から共通プロセスに関わるプログラミング作業, 並列化も含むチューニング作業を隠蔽できる アプリケーションMW,HPC MW, フレームワーク

4 4 背景 (2/2) A.D.2000 年前後 GeoFEM,HPC MW 地球シミュレータ,Flat MPI,FEM 現在 : より多様, 複雑な環境 マルチコア,GPU ハイブリッド並列 MPIまでは何とかたどり着いたが 京 でも重要 CUDA,OpenCL,OpenACC ポストペタスケールからエクサスケールへ より一層の複雑化 FEM code developed on PC I/F for I/O I/F for Mat.Ass. I/F for Solvers I/F for Vis. I/O Matrix Assemble Linear Solver Vis. HPC-MW for T2K I/O Matrix Assemble Linear Solver Vis. HPC-MW for Earth Simulator I/O Matrix Assemble Linear Solver Vis. HPC-MW for Next Generation Supercomputer
5 5 HPC ミドルウェア : 何がうれしいか アプリケーション開発者のチューニング ( 並列, 単体 ) からの解放 SMASH の探求に専念 一生 SMASH と付き合うのはきつい SMASH をカバー コーディングの量が減る 教育にも適している 問題点 ハードウェア, 環境が変わるたびに最適化が必要となる Science Modeling Algorithm Software Hardware 5

 (Hitachi HA8000-tc/RS425 ) Total Peak performance : 140 TFLOPS Total number of nodes : 952 Total memory : 32000 GB")
 Total Peak performance : 54.")
6 東大情報基盤センターのスパコン 1 システム ~6 年,3 年周期でリプレース Oakleaf-FX (Fujitsu PRIMEHPC FX10) Total Peak performance : 1.13 PFLOPS Total number of nodes : 4800 Total memory : 150 TB Peak performance / node : GFLOPS Main memory per node : 32 GB Disk capacity : 1.1 PB PB SPARC64 Ixfx 1.84GHz T2K-Todai(2014 年 3 月退役 ) (Hitachi HA8000-tc/RS425 ) Total Peak performance : 140 TFLOPS Total number of nodes : 952 Total memory : GB Peak performance / node : GFLOPS Main memory per node : 32 GB, 128 GB Disk capacity : 1 PB AMD Quad Core Opteron 2.3GHz Yayoi (Hitachi SR16000/M1) Total Peak performance : 54.9 TFLOPS Total number of nodes : 56 Total memory : GB Peak performance / node : GFLOPS Main memory per node : 200 GB Disk capacity : 556 TB IBM POWER GHz Oakbridge fx with 576 nodes installed in April 2014 (separated) (136TF) Total Users > 2,000 6
7 7 FY Hitachi SR11000/J2 18.8TFLOPS, 16.4TB 大容量メモリを使って自動並列化 Hitachi SR16000/M1 based on IBM Power TFLOPS, 11.2 TB Our Last SMP,MPP へ移行サポート HOP Hitachi HA8000 (T2K) 140TFLOPS, 31.3TB MPI による並列化, メモリは遅いが通信は良い STEP Fujitsu PRIMEHPC FX10 based on SPARC64 IXfx 1.13 PFLOPS, 150 TB Hybrid への転回点,Flat MPI でも高い性能 JUMP Post T2K O( )PFLOPS Peta 京 Exa
 筑波大学計算科学研究センター, 東京大学情報基盤センター Programming is still difficult, although Intel compiler works. (MPI + OpenMP) Tuning for performance (e.g. prefetching) is essential Some framework for helping users needed")
8 8 Post T2K System PFLOPS, FY.2015 Many core based (e.g. (only) Intel MIC/Xeon Phi) Joint Center for Advanced High Performance Computing ( 最先端共同 HPC 基盤施設,JCAHPC, 筑波大学計算科学研究センター, 東京大学情報基盤センター Programming is still difficult, although Intel compiler works. (MPI + OpenMP) Tuning for performance (e.g. prefetching) is essential Some framework for helping users needed
9 ppopen HPC 9 東京大学情報基盤センターでは, メニィコアに基づく計算ノードを有するポストペタスケールシステムの処理能力を充分に引き出す科学技術アプリケーションの効率的な開発, 安定な実行に資する 自動チューニング機構を有するアプリケーション開発 実行環境 :ppopen HPC を開発中 科学技術振興機構戦略的創造研究推進事業 (CREST) 研究領域 ポストペタスケール高性能計算に資するシステムソフトウェア技術の創出 (Post Peta CREST) (2011~2015 年度 )( 領域統括 : 米澤明憲教授 ( 理化学研究所計算科学研究機構 )) PI: 中島研吾 ( 東京大学情報基盤センター ) 東大 ( 情報基盤センター, 大気海洋研究所, 地震研究所, 大学院新領域創成科学研究科 ), 京都大学術情報メディアセンター, 北海道大学情報基盤センター, 海洋研究開発機構 様々な分野の専門家によるCo Design
10 2013 OCT 10 概要 (1/3) メニーコアクラスタによるポストペタスケールシステム上での科学技術アプリケーションの効率的開発, 安定な実行に資する ppopen HPC の研究開発を計算科学, 計算機科学, 数理科学各分野の緊密な協力のもとに実施している 6 Issues in Post Peta/Exascale Computing を考慮 pp : Post Peta 東大情報基盤センターに平成 27 年度導入予定の O(10)PFLOPS 級システム ( ポスト T2K,Intel MIC/Xeon Phi ベース ) をターゲット : スパコンユーザーの円滑な移行支援 大規模シミュレーションに適した 5 種の離散化手法に限定し, 各手法の特性に基づいたアプリケーション開発用ライブラリ群, 耐故障機能を含む実行環境を実現する ppopen APPL: 各手法に対応した並列プログラム開発のためのライブラリ群 ppopen MATH: 各離散化手法に共通の数値演算ライブラリ群 ppopen AT: 科学技術計算のための自動チューニング (AT) 機構 ppopen SYS: ノード間通信, 耐故障機能に関連するライブラリ群

11 11

12 12 対象とする離散化手法 局所的 隣接通信中心 疎行列
13 13 概要 (2/3) 先行研究において各メンバーが開発した大規模アプリケーションに基づき ppopen APPL の各機能を開発, 実装 各離散化手法の特性に基づき開発 最適化 共通データ入出力インタフェース, 領域間通信, 係数マトリクス生成 離散化手法の特性を考慮した前処理付き反復法 適応格子, 動的負荷分散 実際に動いているアプリケーションから機能を切り出す 各メンバー開発による既存ソフトウェア資産の効率的利用 GeoFEM,HEC MW,HPC MW,DEMIGLACE,ABCLibScript ppopen AT は ppopen APPL の原型コードを対象として研究開発を実施し, その知見を各 ppopen APPL の開発, 最適化に適用 自動チューニング技術により, 様々な環境下における最適化ライブラリ アプリケーション自動生成を目指す
14 14 概要 (3/3) 平成 24 年 11 月にマルチコアクラスタ向けに各グループの開発した ppopen APPL,ppOpen AT, ppopen MATH の各機能を公開 (Ver.0.1.0) tokyo.ac.jp/ 平成 25 年 11 月に Ver 公開 現在は各機能の最適化, 機能追加,ppOpen APPL によるアプリケーション開発とともに,Intel Xeon/Phi 等メニーコア向けバージョンを開発中

15 15
16 16 ppopen-appl A set of libraries corresponding to each of the five methods noted above (FEM, FDM, FVM, BEM, DEM), providing: I/O netcdf-based Interface Domain-to-Domain Communications Optimized Linear Solvers (Preconditioned Iterative Solvers) Optimized for each discretization method H-Matrix Solvers in ppopen-appl/bem Matrix Assembling AMR and Dynamic Load Balancing Most of components are extracted from existing codes developed by members
17 FEM Code on ppopen HPC Optimization/parallelization could be hidden from application developers Program My_pFEM use ppopenfem_util use ppopenfem_solver call ppopenfem_init call ppopenfem_cntl call ppopenfem_mesh call ppopenfem_mat_init do call Users_FEM_mat_ass call Users_FEM_mat_bc call ppopenfem_solve call ppopenfem_vis Time= Time + DT enddo call ppopenfem_finalize stop end 17
18 Target Applications 18 Our goal is not development of applications, but we need some target appl. for evaluation of ppopen HPC. ppopen APPL/FEM Incompressible Navier Stokes Heat Transfer, Solid Mechanics (Static, Dynamic) ppopen APPL/FDM Incompressible Navier Stokes Transient Heat Transfer, Solid Mechanics (Dynamic) ppopen APPL/FVM Compressible Navier Stokes, Heat Transfer ppopen APPL/BEM Electromagnetics, Solid Mechanics (Quasi Static) (Earthquake Generation Cycle) ppopen APPL/DEM Incompressible Navier Stokes, Solid Mechanics (Dynamic)








19 19
 : A test of a coupling simulation of FDM (regular grid) and FEM")

 FEM: Building Response Model size: 400x400x200 m Time: 60 s Resolution (space): 1 m")
20 Large-Scale Coupled Simulations in FY Challenge (FY2013) : A test of a coupling simulation of FDM (regular grid) and FEM (unconstructed grid) using newly developed ppopen MATH/MP Coupler c/o T.Furumura FDM: Seismic Wave Propagation Model size: 80x80x400 km Time: 240 s Resolution (space): 0.1 km (regular) Resolution (time) : 5 ms (effective freq.<1hz) FEM: Building Response Model size: 400x400x200 m Time: 60 s Resolution (space): 1 m Resolution (time) : 1 ms ppopen MATH/MP: Space temporal interpolation, Mapping between FDM and FEM mesh, etc.
21 Schedule of Public Release (with English Documents, MIT License) We are now focusing on MIC/Xeon Phi 21 4Q 2012 (Ver.0.1.0) ppopen-hpc for Multicore Cluster (Cray, K etc.) Preliminary version of ppopen-at/static 4Q 2013 (Ver.0.2.0) ppopen-hpc for Multicore Cluster & Xeon Phi (& GPU) available in SC 13 4Q 2014 Prototype of ppopen-hpc for Post-Peta Scale System 4Q 2015 Final version of ppopen-hpc for Post-Peta Scale System Further optimization on the target system
22 ppopen-hpc Ver Released at SC12 (or can be downloaded) Multicore cluster version (Flat MPI, OpenMP/MPI Hybrid) with documents in English Collaborations with scientists Component Archive Flat MPI OpenMP/MPI C F ppopen APPL/FDM ppohfdm_0.1.0 ppopen APPL/FVM ppohfvm_0.1.0 ppopen APPL/FEM ppohfem_0.1.0 ppopen APPL/BEM ppohbem_0.1.0 ppopen APPL/DEM ppohdem_0.1.0 ppopen MATH/VIS ppohvis_fdm3d_0.1.0 ppopen AT/STATIC ppohat_
23 What is new in Ver.0.2.0? Available in SC13 (or can be downloaded) Component New Development ppopen APPL/FDM OpenMP/MPI Hybrid Parallel Programming Model Intel Xeon/Phi Version Interface for ppopen MATH/VIS FDM3D ppopen APPL/FVM Optimized Communication ppopen APPL/FEM ppopen MATH/MP PP Sample Implementations for Dynamic Solid Mechanics API for Linear Solver in Fortran Tool for Generation of Remapping Table in ppopen MATH/MP ppopen MATH/VIS Optimized ppopen MATH/VIS FDM3D ppopen AT/STATIC Sequence of Statements, Loop Splitting (Optimized) ppopen APPL/FVM ppopen APPL/FDM BEM 23
24 24 ppopen AT 関連共同研究 工学院大学田中研究室 普及活動 (1/2) 田中研究室開発の AT 方式 (d spline 方式 ) の適用対象として ppopen AT の AT 機能を拡張 東京大学須田研究室 電力最適化のため, 須田研究室で開発中の AT 方式と電力測定の共通 API を利用し,ppOpen AT を用いた電力最適化方式を提案 JHPCN 共同研究課題 高精度行列 行列積アルゴリズムにおける並列化手法の開発 ( 東大, 早稲田大 )(H24 年度 )( 研究としては継続 ) 高精度行列 行列積演算における行列 行列積の実装方式選択に利用 粉体解析アルゴリズムの並列化に関する研究 ( 東大, 法政大 ) (H25 年度 ) 粉体シミュレーションのための高速化手法で現れる性能パラメタの AT で利用を検討
25 25 JHPCN 共同研究課題 ( 続き ) 普及活動 (2/2) 巨大地震発生サイクルシミュレーションの高度化 ( 京大, 東大他 )(H24 25 年度 ) H マトリクス, 領域細分化 ポストペタスケールシステムを目指した二酸化炭素地中貯留シミュレーション技術の研究開発 ( 大成建設, 東大 )(H25 年度 ) 疎行列ソルバー, 並列可視化 太陽磁気活動の大規模シミュレーション ( 東大 ( 地球惑星, 情報基盤センター ))(H25 年度 ) 疎行列ソルバー, 並列可視化 講習会, 講義 ppopen HPCの講習会を2014 年 3 月から実施 講義, 講習会 ( 並列有限要素法 ) でppOpen MATH/VISを使用して可視化を実施する予定



26 3D MHD Simulations of Black Hole 26 [Prof. Ryoji Matsumoto, Chiba U.]


27 CO 2 地下貯留シミュレーション 27 画像提供 : 山本肇博士 ( 大成建設 )


28 CO 2 が地下水に溶けていく様子正確な予測のためには細かいメッシュが必要 大規模な計算モデル, 連立一次方程式 粗いメッシュ 細かいメッシュ 画像提供 : 山本肇博士 ( 大成建設 )

29 可視化の意義 シミュレーションや計測から得られた大規模数値データを視覚表現に変換し対象の直感的理解 効果的解析を支援 Controllable pictures are worth more than a thousand of words! Data file 29
30 Seeing is Believing 人間にとって画像や映像は, さまざまな情報の交換 保存 伝達等における最も重要なメディアとなっている 複雑な現象や実験結果等の各種の情報を, コンピュータグラフィックス (CG) を用いて人間に理解しやすい形で視覚化し, 画像や映像として表現する技術がコンピュータービジュアリゼーション (Computer Visualization)( ビジュアリゼーション または 可視化 ) である 中嶋正之, 藤代一成編著 コンピュータビジュアリゼーション, 共立出版,2000. 可視化とは CG のことではない CG に至るまでの様々な処理を 可視化 という 30
31 可視化の重要性 中島が社会人になったころ (1985 年 ) は, シミュレーションは二次元が中心で,FEM( 有限要素法 ) のモデルを使っても 1,000 メッシュ程度であった リストを出力し, それを 読む ことによって結果を評価していた ( モデルのチェックも含む ) 三次元, 並列 ( 分散 ) 処理によるシミュレーションが主流になりつつある現在, 可視化技術の重要性は 30 年前とは比較にならないくらい大きい 効率的に特徴をつかむ方法 立体視 ができるにしても, あくまでも二次元画面への投影が中心 31
 を処理して, 一枚の画像で見ることができるようにすること 結果データは非常に大規模 単一データは不可能 分散結果データ")
32 並列 可視化 並列シミュレーションの結果を, 並列計算機を使用して可視化すること ここでは, 並列シミュレーションによって得られた分散データ ( ファイルまたはメモリイメージ ) を処理して, 一枚の画像で見ることができるようにすること 結果データは非常に大規模 単一データは不可能 分散結果データ 並列可視化処理 32
33 Data-Flow Paradigm for Parallel Visualization (Fujishiro et al.) models Simulation data Filtering data Mapping patches Rendering images Presentation Computational Efficiency PB (parallel backend) Supercomputer VF (visualization front end) Interactivity 33
34 GeoFEM,HPC-MWにおける並列可視化機能の特徴 (20 世紀末 ~ 今世紀初頭 ) 様々な可視化手法, メッシュ体系をサポート 特殊なハードウェア, ライブラリは不要 高い並列性能 複雑形状への適用性 様々なハードウェアに対する最適化 使用法 ファイル渡し, または, メモリ渡し Patch File(AVS) またはImage File(BMP) メモリ渡しは結果ファイルを残さない 34
35 並列可視化フレームワーク 1 ファイル渡しバージョン Mesh Files Analysis Result Files Visualization Visualization Result Files mesh #0 FEM-#0 I/O Solver I/O result #0 VIS-#0 mesh #1 FEM-#1 I/O Solver I/O result #1 VIS-#1 UCD etc. Images VIEWER AVS etc. on Client mesh #n-1 FEM-#n-1 I/O Solver I/O result #n-1 VIS-#n-1 Input Output Communication /
36 並列可視化フレームワーク 2 メモリ渡しバージョン Mesh Files Analysis+Visualization on GeoFEM Platform Visualization Result Files mesh #0 FEM-#0 I/O Solver I/O VIS-#0 mesh #1 FEM-#1 I/O Solver I/O VIS-#1 UCD etc. Images VIEWER AVS etc. on Client mesh #n-1 FEM-#n-1 I/O Solver I/O VIS-#n-1 Input Output Communication /
37 Data-Flow Paradigm for Parallel Visualization (Fujishiro et al.) models Simulation data Filtering data Mapping patches Rendering images Presentation GeoFEM via-file PB VF GeoFEM via-memory PB VF 37
38 AVS/Express PCE Parallel Cluster Edition AVS/Express PCEでは, クラスタ化された複数の Linuxマシンで, 各計算ノードが持つ部分領域のみを可視化し, 最終的な可視化結果のみ制御ノード上で表示するという構成になっている 並列計算の結果, 出力される大規模データを可視化する場合でも, 高い精度を保ったまま, 可視化処理を実現することが可能 並列計算機上で対話処理可能 Windowsより制御可能 T2K 東大に導入 (~4 ノードまで使用可能 ): バッチ環境 38
KGT 社 HP")
39 AVS/Express PCE Parallel Cluster Edition ( 旧 )KGT 社 HP より 39
40 Data-Flow Paradigm for Parallel Visualization (Fujishiro et al.) models Simulation data Filtering data Mapping patches Rendering GeoFEM via-file PB VF GeoFEM via-memory PB images Presentation VF AVS/PCE PB=VF 40
41 AVS/Express PCE Parallel Cluster Edition(cont.) ノード数が増えた場合, 部分領域を集めるプロセスがボトルネックとなる MPI_Gather アルゴリズムの改良が必要 小野謙二博士 ( 理研 AICS) らの研究 京コンピュータ上での並列可視化システム 41
42 ppopen HPC における 42 並列可視化の考え方 models Simulation data Filtering data Mapping patches Rendering images Presentation GeoFEM via File PB VF 自己完結的なファイルを生成して PC で見る (e.g. ParaView,MicroAVS) GeoFEM の場合は Patch 抽出型で, 例えば視点を変えることはできたが, 可視化する変数, 切り出す面等を変更することはできなかった ピーク ( 最大, 最小 ), 分布を抑えることが大事, 形状もある程度再現できていてほしい /
43 ppopen HPC における 43 並列可視化の考え方 自己完結的なファイルを生成して PC で見る GeoFEMの場合はPatch 抽出型で, 例えば視点を変えることはできたが, 可視化する変数, 切り出す面等を変更することはできなかった ピーク ( 最大, 最小 ), 分布を抑えることが大事, 形状もある程度再現できていてほしい 見る ためにスパコンは使わない 絵を出すために計算をやり直す という考え方も採らない 自己完結的ファイルができたら後はParaView,MicroAVS に任せる 大型計算機センターとしては, つぎ込めるだけの予算を計算エンジンにつぎ込みたい
, not available in this version.")
44 44 ppopen MATH/VIS ボクセル型背景格子を使用した大規模並列可視化手法 Nakajima & Chen 2006 に基づく 差分格子用バージョン公開 :ppopen MATH/VIS FDM3D UCD single file プラットフォーム T2K,Cray FX10 Flat MPI Hybrid, 非構造格子 : 開発中 [Refine] AvailableMemory = 2.0 Available memory size (GB), not available in this version. MaxVoxelCount = 500 Maximum number of voxels MaxRefineLevel = 20 Maximum number of refinement levels
45 Simplified Parallel Visualization 45 using Background Voxels [KN, Chen 2006] Octree-based AMR AMR applied to the region where gradient of field values are large stress concentration, shock wave, separation etc. If the number of voxels are controled, a single file with 10 5 meshes is possible, even though entire problem size is 10 9 with distributed data sets.
46 46 Procedure Background Voxel s with AMR Original Meshes Delaunay Meshes (2D: triangle, 3D: tetrahedra) Surface Nodes after Simplification



47 Voxel Mesh (adapted) 47

48 Flow around a sphere 48
 95% reduction (594) 98% reduction")
49 49 Example of Surface Simplification Initial (11,884 tri s) 50% reduction (5,942 ) 95% reduction (594) 98% reduction (238)

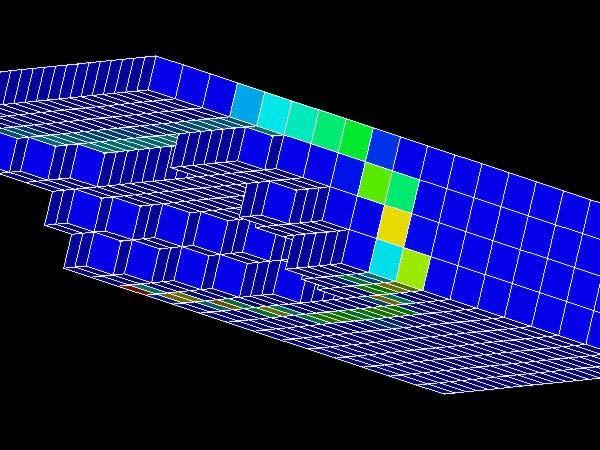
50 FEM Mesh (SW Japan Model) 50
51 pfem VIS 51 pfem3d + ppopen MATH/VIS コピー >$ cd ~/pfem >$ cp /home/ss/aics60/2014summer/pvis.tar. >$ tar xvf pvis.tar FORTRAN ユーザー >$ cd ~/pfem/pvis/f/src >$ make >$ cd../run >$ pjsub go.sh C ユーザー >$ cd ~/pfem/pvis/c/src >$ make >$ cd../run >$ pjsub go.sh
52 pfem VIS 52 Makefile CFLAGSL = -I/home/ss/aics60/ppohFVM-tutorial/ppohFILES/include LDFLAGSL = -L/home/ss/aics60/ppohFVM-tutorial/ppohFILES/lib LIBSL = -lppohvispfem3d.suffixes:.suffixes:.o.c.c.o: $(CC) -c $(CFLAGS) $(CFLAGSL) $< -o $@ TARGET =../run/pfem3d_test OBJS = test1.o... all: $(TARGET) $(TARGET): $(OBJS) $(CC) -o $(TARGET) $(CFLAGS) $(CFLAGSL) $(OBJS) $(LDFLAGSL) $(LIBS) $(LIBSL) rm -f *.o *.mod
53 pfem VIS ~/pfem/pvis/f(c)/run 53 cube_20x20x20_4pe_kmetis.0 cube_20x20x20_4pe_kmetis.1 cube_20x20x20_4pe_kmetis.2 cube_20x20x20_4pe_kmetis.3 cube_20x20x20_4pe.out go.sh INPUT.DAT vis.cnt vis_temp.1.inp cube_20x20x20_4pe_kmetis e-08 #!/bin/sh #PJM -L "rscgrp=school" #PJM -L "node=4" #PJM --mpi "proc=4" #PJM -L "elapse=00:10:00" #PJM -j #PJM -o "cube_20x20x20_4pe.out" mpiexec./pfem3d_test
54 pfem VIS 54 pfem3d + ppopen MATH/VIS INPUT.DAT <HEADER>.* pfem3d_test vis.cnt 局所分散メッシュファイル test.inp vis_temp.1.inp ParaView 出力 : 名称固定
55 pfem VIS 55 use solver11 use pfem_util use ppohvis_pfem3d_util Fortran/main (1/2) implicit REAL*8(A-H,O-Z) type(ppohvis_base_stcontrol) :: pcontrol type(ppohvis_base_stresultcollection) :: pnoderesult type(ppohvis_base_stresultcollection) :: pelemresult character(len=ppohvis_base_file_name_len) :: CtrlName character(len=ppohvis_base_file_name_len) :: VisName character(len=ppohvis_base_label_len) :: ValLabel integer(kind=4) :: ierr CtrlName = "" CtrlName = "vis.cnt" VisName = "" VisName = "vis" ValLabel = "" ValLabel = "temp" call PFEM_INIT call ppohvis_pfem3d_init(mpi_comm_world, ierr) call ppohvis_pfem3d_getcontrol(ctrlname, pcontrol, ierr); call INPUT_CNTL call INPUT_GRID call ppohvis_pfem3d_setmeshex( & & NP, N, NODE_ID, XYZ, & & ICELTOT, ICELTOT_INT, ELEM_ID, ICELNOD, & & NEIBPETOT, NEIBPE, IMPORT_INDEX, IMPORT_ITEM, & & EXPORT_INDEX, EXPORT_ITEM, ierr)
56 pfem VIS 56 call MAT_ASS_MAIN call MAT_ASS_BC call SOLVE11 call OUTPUT_UCD Fortran/main (2/2) pnoderesult%listcount = 1 pelemresult%listcount = 0 allocate(pnoderesult%results(1)) call ppohvis_pfem3d_convresultnodeitem1n( & & NP, ValLabel, X, pnoderesult%results(1), ierr) call ppohvis_pfem3d_visualize(pnoderesult, pelemresult, pcontrol, & & VisName, 1, ierr) call PFEM_FINALIZE end program heat3dp
57 pfem VIS C/main (1/2) 57 #include <stdio.h> #include <stdlib.h> FILE* fp_log; #define GLOBAL_VALUE_DEFINE #include "pfem_util.h" #include "ppohvis_pfem3d_util.h" extern void PFEM_INIT(int,char**); extern void INPUT_CNTL(); extern void INPUT_GRID(); extern void MAT_CON0(); extern void MAT_CON1(); extern void MAT_ASS_MAIN(); extern void MAT_ASS_BC(); extern void SOLVE11(); extern void OUTPUT_UCD(); extern void PFEM_FINALIZE(); int main(int argc,char* argv[]) { double START_TIME,END_TIME; struct ppohvis_fdm3d_stcontrol *pcontrol = NULL; struct ppohvis_fdm3d_stresultcollection *pnoderesult = NULL; PFEM_INIT(argc,argv); ppohvis_pfem3d_init(mpi_comm_world); pcontrol = ppohvis_fdm3d_getcontrol("vis.cnt"); INPUT_CNTL(); INPUT_GRID(); if(ppohvis_pfem3d_setmeshex( NP,N,NODE_ID,XYZ, ICELTOT,ICELTOT_INT,ELEM_ID,ICELNOD, NEIBPETOT,NEIBPE,IMPORT_INDEX,IMPORT_ITEM,EXPORT_INDEX,EXPORT_ITEM)) { ppohvis_base_printerror(stderr); MPI_Abort(MPI_COMM_WORLD,errno); };
58 pfem VIS MAT_CON0(); MAT_CON1(); MAT_ASS_MAIN(); MAT_ASS_BC() ; SOLVE11(); OUTPUT_UCD(); C/main (2/2) 58 pnoderesult=ppohvis_base_allocateresultcollection(); if(pnoderesult == NULL) { ppohvis_base_printerror(stderr); MPI_Abort(MPI_COMM_WORLD,errno); }; if(ppohvis_base_initresultcollection(pnoderesult, 1)) { ppohvis_base_printerror(stderr); MPI_Abort(MPI_COMM_WORLD,errno); }; pnoderesult->results[0] = ppohvis_pfem3d_convresultnodeitempart(np,1,0,"temp",x); START_TIME= MPI_Wtime(); if(ppohvis_pfem3d_visualize(pnoderesult,null,pcontrol,"vis",1)) { ppohvis_base_printerror(stderr); MPI_Abort(MPI_COMM_WORLD,errno); }; ppohvis_pfem3d_finalize(); } PFEM_FINALIZE() ;
![pfem VIS vis.cnt 59 [Refine] 細分化制御情報セクション AvailableMemory = 2.](/docs-images/100/144786200/images/59-0.jpg "0 利用可能メモリ容量 (GB)not in use MaxVoxelCount = 1000 Max Voxel #")
![MaxRefineLevel = 20 Max Voxel Refinement Level [Simple]](/docs-images/100/144786200/images/59-1.jpg "簡素化制御情報セクション ReductionRate = 0.0 表面パッチ削減率 1.52 MB 8,000 elements.")
59 pfem VIS vis.cnt 59 [Refine] 細分化制御情報セクション AvailableMemory = 2.0 利用可能メモリ容量 (GB)not in use MaxVoxelCount = 1000 Max Voxel # MaxRefineLevel = 20 Max Voxel Refinement Level [Simple] 簡素化制御情報セクション ReductionRate = 0.0 表面パッチ削減率 1.52 MB 8,000 elements.385 MB, 813 elements
60 60 現状 実はまだ, 最適化が進んでおらず, ノード数が増えると時間がかかる
61 pfem3d-2 61 簡易可視化方法 各領域が規則正しい直方体構造となっていることを仮定 一様形状である必要はない pmeshで生成されるようなメッシュ 最終的に出力するParaView 用出力ファイルの全体のメッシュ数を規定 各部分領域 (MPIプロセス) の従属変数分布から, 各領域に割り当てる 可視化用 メッシュ数の決定 八分木で領域ごとに可視化用メッシュ生成 値の変化の多い領域にメッシュ数を多く割当 ルールは色々と検討する必要がある NZ 各領域で生成した可視化用メッシュを集める NY NX
62 pfem VIS 62 代替法 ( プログラムは Fortran のみ ) FORTRAN ユーザー >$ cd ~/pfem/pfem3dv/src >$ make >$ cd../run >$ pjsub go.sh C ユーザー >$ cd ~/pfem/pfem3dv/src >$ make >$ cd../run >$ pjsub go.sh
63 pfem VIS 63 Fortran/main program heat3dp use solver11 use pfem_util implicit REAL*8(A-H,O-Z) call PFEM_INIT call INPUT_CNTL call INPUT_GRID call MAT_CON0 call MAT_CON1 call MAT_ASS_MAIN call MAT_ASS_BC call SOLVE11 call OUTPUT_UCD_REGULAR call PFEM_FINALIZE end program heat3dp
64 pfem3d-2 64 制御ファイル :INPUT.DAT../pmesh/pcube HEADER 2000 ITER COND, QVOL 1.0e-08 RESID 1000 N_MESH_VIS HEADER: 局所分散ファイルヘッダ名, <HEADER>.my_rank ITER: 反復回数上限 COND: 熱伝導率 QVOL: 体積当たり発熱量係数 RESID: 反復法の収束判定値 N_MESH_VIS: 簡易可視化機能における表示メッシュ数の目安 x T x Q y T y z x, y, z QVOL x C yc T z Q x, y, z 0
65 pfem3d-2 65 計算例 節点 (=16,777,216 節点,16,581,375 要素 ) 128コア 可視化 2,970 節点,834 要素 Movie 各 MPI プロセスで可視化データを生成してマージするので, MPI プロセス数が増えると重複する節点の数が増えてしまう 修正中
ppopen-hpc の概要自動チューニング機構を有するアプリケーション開発 実行環境 松本正晴, 片桐孝洋, 中島研吾 東京大学情報基盤センター 第 39 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用 : 高性能プログラミング初級入門 2014 年 9 月 10 日 ~11 日
 ppopen-hpc の概要自動チューニング機構を有するアプリケーション開発 実行環境 松本正晴, 片桐孝洋, 中島研吾 東京大学情報基盤センター 第 39 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用 : 高性能プログラミング初級入門 2014 年 9 月 10 日 ~11 日 2 背景 (1/2) 大規模化, 複雑化, 多様化するハイエンド計算機環境の能力を充分に引き出し, 効率的なアプリケーションプログラムを開発することは困難
ppopen-hpc の概要自動チューニング機構を有するアプリケーション開発 実行環境 松本正晴, 片桐孝洋, 中島研吾 東京大学情報基盤センター 第 39 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用 : 高性能プログラミング初級入門 2014 年 9 月 10 日 ~11 日 2 背景 (1/2) 大規模化, 複雑化, 多様化するハイエンド計算機環境の能力を充分に引き出し, 効率的なアプリケーションプログラムを開発することは困難
2 背景 (1/2) 大規模化, 複雑化, 多様化するハイエンド計算機環境の能力を充分に引き出し, 効率的なアプリケーションプログラムを開発することは困難 有限要素法等の科学技術計算手法 : プリ ポスト処理, 行列生成, 線形方程式求解等の一連の共通プロセスから構成される これら共通プロセスを抽出
 大規模化, 複雑化, 多様化するハイエンド計算機環境の能力を充分に引き出し, 効率的なアプリケーションプログラムを開発することは困難 有限要素法等の科学技術計算手法 : プリ ポスト処理, 行列生成, 線形方程式求解等の一連の共通プロセスから構成される これら共通プロセスを抽出") ppopen-hpc の概要自動チューニング機構を有するアプリケーション開発 実行環境 松本正晴, 片桐孝洋, 中島研吾 東京大学情報基盤センター 第 52 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用 : 高性能プログラミング初級入門 2016 年 2 月 3 日 ~4 日 2 背景 (1/2) 大規模化, 複雑化, 多様化するハイエンド計算機環境の能力を充分に引き出し, 効率的なアプリケーションプログラムを開発することは困難
ppopen-hpc の概要自動チューニング機構を有するアプリケーション開発 実行環境 松本正晴, 片桐孝洋, 中島研吾 東京大学情報基盤センター 第 52 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用 : 高性能プログラミング初級入門 2016 年 2 月 3 日 ~4 日 2 背景 (1/2) 大規模化, 複雑化, 多様化するハイエンド計算機環境の能力を充分に引き出し, 効率的なアプリケーションプログラムを開発することは困難
ppopen-hpc の概要自動チューニング機構を有するアプリケーション開発 実行環境 松本正晴, 片桐孝洋, 中島研吾 東京大学情報基盤センター 第 48 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用 : 高性能プログラミング初級入門 2015 年 9 月 1 日 ~2 日
 ppopen-hpc の概要自動チューニング機構を有するアプリケーション開発 実行環境 松本正晴, 片桐孝洋, 中島研吾 東京大学情報基盤センター 第 48 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用 : 高性能プログラミング初級入門 2015 年 9 月 1 日 ~2 日 2 背景 (1/2) 大規模化, 複雑化, 多様化するハイエンド計算機環境の能力を充分に引き出し, 効率的なアプリケーションプログラムを開発することは困難
ppopen-hpc の概要自動チューニング機構を有するアプリケーション開発 実行環境 松本正晴, 片桐孝洋, 中島研吾 東京大学情報基盤センター 第 48 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用 : 高性能プログラミング初級入門 2015 年 9 月 1 日 ~2 日 2 背景 (1/2) 大規模化, 複雑化, 多様化するハイエンド計算機環境の能力を充分に引き出し, 効率的なアプリケーションプログラムを開発することは困難
_ _2013_中島_YR
 ポストペタ - スケール高性能計算に資するシステムソフトウェア技術の創出 平成 22 年度採択研究代表者 H25 年度 実績報告 中島研吾 東京大学情報基盤センター 教授 自動チューニング機構を有するアプリケーション開発 実行環境 1. 研究実施体制 (1) 中島グループ 1 研究代表者 : 中島研吾 ( 東京大学情報基盤センター 教授 ) 2 研究項目 : 自動チューニング機構を有するポストペタスケールアプリケーション開発
ポストペタ - スケール高性能計算に資するシステムソフトウェア技術の創出 平成 22 年度採択研究代表者 H25 年度 実績報告 中島研吾 東京大学情報基盤センター 教授 自動チューニング機構を有するアプリケーション開発 実行環境 1. 研究実施体制 (1) 中島グループ 1 研究代表者 : 中島研吾 ( 東京大学情報基盤センター 教授 ) 2 研究項目 : 自動チューニング機構を有するポストペタスケールアプリケーション開発
GeoFEM開発の経験から
 FrontISTR における並列計算のしくみ < 領域分割に基づく並列 FEM> メッシュ分割 領域分割 領域分割 ( パーティショニングツール ) 全体制御 解析制御 メッシュ hecmw_ctrl.dat 境界条件 材料物性 計算制御パラメータ 可視化パラメータ 領域分割ツール 逐次計算 並列計算 Front ISTR FEM の主な演算 FrontISTR における並列計算のしくみ < 領域分割に基づく並列
FrontISTR における並列計算のしくみ < 領域分割に基づく並列 FEM> メッシュ分割 領域分割 領域分割 ( パーティショニングツール ) 全体制御 解析制御 メッシュ hecmw_ctrl.dat 境界条件 材料物性 計算制御パラメータ 可視化パラメータ 領域分割ツール 逐次計算 並列計算 Front ISTR FEM の主な演算 FrontISTR における並列計算のしくみ < 領域分割に基づく並列
ppopen-hpc の概要とシミュレーション基本的流れ体験 松本正晴 東京大学大学院情報理工学系研究科コンピュータ科学専攻 第 71 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用: 科学技術計算の効率化入門 2017 年 2 月 28 日 ( 火 )~3 月 1 日 ( 水 )
~3 月 1 日 ( 水 )") ppopen-hpc の概要とシミュレーション基本的流れ体験 松本正晴 東京大学大学院情報理工学系研究科コンピュータ科学専攻 第 71 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用: 科学技術計算の効率化入門 2017 年 2 月 28 日 ( 火 )~3 月 1 日 ( 水 ) 本日の内容 1. 近年のスーパーコンピュータのトレンドと ppopen-hpc の概要 ( 座学 )
ppopen-hpc の概要とシミュレーション基本的流れ体験 松本正晴 東京大学大学院情報理工学系研究科コンピュータ科学専攻 第 71 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用: 科学技術計算の効率化入門 2017 年 2 月 28 日 ( 火 )~3 月 1 日 ( 水 ) 本日の内容 1. 近年のスーパーコンピュータのトレンドと ppopen-hpc の概要 ( 座学 )
200708_LesHouches_02.ppt
 Numerical Methods for Geodynamo Simulation Akira Kageyama Earth Simulator Center, JAMSTEC, Japan Part 2 Geodynamo Simulations in a Sphere or a Spherical Shell Outline 1. Various numerical methods used
Numerical Methods for Geodynamo Simulation Akira Kageyama Earth Simulator Center, JAMSTEC, Japan Part 2 Geodynamo Simulations in a Sphere or a Spherical Shell Outline 1. Various numerical methods used
MATLAB® における並列・分散コンピューティング ~ Parallel Computing Toolbox™ & MATLAB Distributed Computing Server™ ~
 MATLAB における並列 分散コンピューティング ~ Parallel Computing Toolbox & MATLAB Distributed Computing Server ~ MathWorks Japan Application Engineering Group Takashi Yoshida 2016 The MathWorks, Inc. 1 System Configuration
MATLAB における並列 分散コンピューティング ~ Parallel Computing Toolbox & MATLAB Distributed Computing Server ~ MathWorks Japan Application Engineering Group Takashi Yoshida 2016 The MathWorks, Inc. 1 System Configuration
GPGPU
 GPGPU 2013 1008 2015 1 23 Abstract In recent years, with the advance of microscope technology, the alive cells have been able to observe. On the other hand, from the standpoint of image processing, the
GPGPU 2013 1008 2015 1 23 Abstract In recent years, with the advance of microscope technology, the alive cells have been able to observe. On the other hand, from the standpoint of image processing, the
Stage 並列プログラミングを習得するためには : 1 計算機リテラシ, プログラミング言語 2 基本的な数値解析 3 実アプリケーション ( 例えば有限要素法, 分子動力学 ) のプログラミング 4 その並列化 という 4 つの段階 (stage) が必要である 本人材育成プログラムでは1~4を
 のプログラミング 4 その並列化 という 4 つの段階 (stage) が必要である 本人材育成プログラムでは1~4を") コンピュータ科学特別講義 科学技術計算プログラミング I ( 有限要素法 ) 中島研吾 東京大学情報基盤センター 1. はじめに本稿では,2008 年度冬学期に実施した, コンピュータ科学特別講義 I 科学技術計算プログラミング ( 有限要素法 ) について紹介する 計算科学 工学, ハードウェアの急速な進歩, 発達を背景に, 第 3 の科学 としての大規模並列シミュレーションへの期待は, 産学において一層高まっている
コンピュータ科学特別講義 科学技術計算プログラミング I ( 有限要素法 ) 中島研吾 東京大学情報基盤センター 1. はじめに本稿では,2008 年度冬学期に実施した, コンピュータ科学特別講義 I 科学技術計算プログラミング ( 有限要素法 ) について紹介する 計算科学 工学, ハードウェアの急速な進歩, 発達を背景に, 第 3 の科学 としての大規模並列シミュレーションへの期待は, 産学において一層高まっている
ppopen-hpc の概要とシミュレーション基本的流れ体験 松本正晴 東京大学大学院情報理工学系研究科コンピュータ科学専攻 第 95 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用: 科学技術計算の効率化入門 2018 年 3 月 13 日 ( 火 )~3 月 14 日 ( 水 )
~3 月 14 日 ( 水 )") ppopen-hpc の概要とシミュレーション基本的流れ体験 松本正晴 東京大学大学院情報理工学系研究科コンピュータ科学専攻 第 95 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用: 科学技術計算の効率化入門 2018 年 3 月 13 日 ( 火 )~3 月 14 日 ( 水 ) 本日の内容 1. 近年のスーパーコンピュータのトレンドと ppopen-hpc の概要 ( 座学 )
ppopen-hpc の概要とシミュレーション基本的流れ体験 松本正晴 東京大学大学院情報理工学系研究科コンピュータ科学専攻 第 95 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用: 科学技術計算の効率化入門 2018 年 3 月 13 日 ( 火 )~3 月 14 日 ( 水 ) 本日の内容 1. 近年のスーパーコンピュータのトレンドと ppopen-hpc の概要 ( 座学 )
1重谷.PDF
 RSCC RSCC RSCC BMT 1 6 3 3000 3000 200310 1994 19942 VPP500/32PE 19992 VPP700E/128PE 160PE 20043 2 2 PC Linux 2048 CPU Intel Xeon 3.06GHzDual) 12.5 TFLOPS SX-7 32CPU/256GB 282.5 GFLOPS Linux 3 PC 1999
RSCC RSCC RSCC BMT 1 6 3 3000 3000 200310 1994 19942 VPP500/32PE 19992 VPP700E/128PE 160PE 20043 2 2 PC Linux 2048 CPU Intel Xeon 3.06GHzDual) 12.5 TFLOPS SX-7 32CPU/256GB 282.5 GFLOPS Linux 3 PC 1999
HPC可視化_小野2.pptx
 大 小 二 生 高 方 目 大 方 方 方 Rank Site Processors RMax Processor System Model 1 DOE/NNSA/LANL 122400 1026000 PowerXCell 8i BladeCenter QS22 Cluster 2 DOE/NNSA/LLNL 212992 478200 PowerPC 440 BlueGene/L 3 Argonne
大 小 二 生 高 方 目 大 方 方 方 Rank Site Processors RMax Processor System Model 1 DOE/NNSA/LANL 122400 1026000 PowerXCell 8i BladeCenter QS22 Cluster 2 DOE/NNSA/LLNL 212992 478200 PowerPC 440 BlueGene/L 3 Argonne
ppopen-hpc の概要とシミュレーション基本的流れ体験 松本正晴 東京大学情報基盤センター 第 62 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用: 科学技術計算の効率化入門 2016 年 9 月 6 日 ( 火 )~7 日 ( 水 )
~7 日 ( 水 )") ppopen-hpc の概要とシミュレーション基本的流れ体験 松本正晴 東京大学情報基盤センター 第 62 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用: 科学技術計算の効率化入門 2016 年 9 月 6 日 ( 火 )~7 日 ( 水 ) 本日の内容 1. 近年のスーパーコンピュータのトレンドと ppopen-hpc の概要 ( 座学 ) 2. 3D 熱伝導解析による並列化シミュレーションの基本的
ppopen-hpc の概要とシミュレーション基本的流れ体験 松本正晴 東京大学情報基盤センター 第 62 回お試しアカウント付き並列プログラミング講習会 ライブラリ利用: 科学技術計算の効率化入門 2016 年 9 月 6 日 ( 火 )~7 日 ( 水 ) 本日の内容 1. 近年のスーパーコンピュータのトレンドと ppopen-hpc の概要 ( 座学 ) 2. 3D 熱伝導解析による並列化シミュレーションの基本的
Microsoft Word - HOKUSAI_system_overview_ja.docx
 HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
スパコンに通じる並列プログラミングの基礎
 2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
スパコンに通じる並列プログラミングの基礎
 2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
情報処理学会研究報告 IPSJ SIG Technical Report Vol.2013-HPC-139 No /5/29 Gfarm/Pwrake NICT NICT 10TB 100TB CPU I/O HPC I/O NICT Gf
 Gfarm/Pwrake NICT 1 1 1 1 2 2 3 4 5 5 5 6 NICT 10TB 100TB CPU I/O HPC I/O NICT Gfarm Gfarm Pwrake A Parallel Processing Technique on the NICT Science Cloud via Gfarm/Pwrake KEN T. MURATA 1 HIDENOBU WATANABE
Gfarm/Pwrake NICT 1 1 1 1 2 2 3 4 5 5 5 6 NICT 10TB 100TB CPU I/O HPC I/O NICT Gfarm Gfarm Pwrake A Parallel Processing Technique on the NICT Science Cloud via Gfarm/Pwrake KEN T. MURATA 1 HIDENOBU WATANABE
スパコンに通じる並列プログラミングの基礎
 2018.09.10 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 1 / 59 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 2 / 59 Windows, Mac Unix 0444-J furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 3 / 59 Part I Unix GUI CUI:
2018.09.10 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 1 / 59 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 2 / 59 Windows, Mac Unix 0444-J furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 3 / 59 Part I Unix GUI CUI:
CPU Levels in the memory hierarchy Level 1 Level 2... Increasing distance from the CPU in access time Level n Size of the memory at each level 1: 2.2
 FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
Microsoft PowerPoint - 07-pFEM3D-1.ppt [互換モード]
![Microsoft PowerPoint - 07-pFEM3D-1.ppt [互換モード]](/thumbs/93/111421614.jpg "Microsoft PowerPoint - 07-pFEM3D-1.ppt [互換モード]") 並列有限要素法による 三次元定常熱伝導解析プログラム (1/2) 中島研吾東京大学情報基盤センター RIKEN AICS HPC Spring School 201 pfem3d-1 2 fem3dの並列版 MPIによる並列化 扱うプログラム pfem3d-1 3 プログラムのインストール 実行 並列有限要素法の手順 領域分割とは? 本当の実行 データ構造 pfem3d-1 ファイルコピー on FX10
並列有限要素法による 三次元定常熱伝導解析プログラム (1/2) 中島研吾東京大学情報基盤センター RIKEN AICS HPC Spring School 201 pfem3d-1 2 fem3dの並列版 MPIによる並列化 扱うプログラム pfem3d-1 3 プログラムのインストール 実行 並列有限要素法の手順 領域分割とは? 本当の実行 データ構造 pfem3d-1 ファイルコピー on FX10
A Feasibility Study of Direct-Mapping-Type Parallel Processing Method to Solve Linear Equations in Load Flow Calculations Hiroaki Inayoshi, Non-member
 A Feasibility Study of Direct-Mapping-Type Parallel Processing Method to Solve Linear Equations in Load Flow Calculations Hiroaki Inayoshi, Non-member (University of Tsukuba), Yasuharu Ohsawa, Member (Kobe
A Feasibility Study of Direct-Mapping-Type Parallel Processing Method to Solve Linear Equations in Load Flow Calculations Hiroaki Inayoshi, Non-member (University of Tsukuba), Yasuharu Ohsawa, Member (Kobe
,,,,., C Java,,.,,.,., ,,.,, i
 24 Development of the programming s learning tool for children be derived from maze 1130353 2013 3 1 ,,,,., C Java,,.,,.,., 1 6 1 2.,,.,, i Abstract Development of the programming s learning tool for children
24 Development of the programming s learning tool for children be derived from maze 1130353 2013 3 1 ,,,,., C Java,,.,,.,., 1 6 1 2.,,.,, i Abstract Development of the programming s learning tool for children
I I / 47
 1 2013.07.18 1 I 2013 3 I 2013.07.18 1 / 47 A Flat MPI B 1 2 C: 2 I 2013.07.18 2 / 47 I 2013.07.18 3 / 47 #PJM -L "rscgrp=small" π-computer small: 12 large: 84 school: 24 84 16 = 1344 small school small
1 2013.07.18 1 I 2013 3 I 2013.07.18 1 / 47 A Flat MPI B 1 2 C: 2 I 2013.07.18 2 / 47 I 2013.07.18 3 / 47 #PJM -L "rscgrp=small" π-computer small: 12 large: 84 school: 24 84 16 = 1344 small school small
,4) 1 P% P%P=2.5 5%!%! (1) = (2) l l Figure 1 A compilation flow of the proposing sampling based architecture simulation
 1 P% P%P=2.5 5%!%! (1) = (2) l l Figure 1 A compilation flow of the proposing sampling based architecture simulation") 1 1 1 1 SPEC CPU 2000 EQUAKE 1.6 50 500 A Parallelizing Compiler Cooperative Multicore Architecture Simulator with Changeover Mechanism of Simulation Modes GAKUHO TAGUCHI 1 YOUICHI ABE 1 KEIJI KIMURA 1
1 1 1 1 SPEC CPU 2000 EQUAKE 1.6 50 500 A Parallelizing Compiler Cooperative Multicore Architecture Simulator with Changeover Mechanism of Simulation Modes GAKUHO TAGUCHI 1 YOUICHI ABE 1 KEIJI KIMURA 1
VXPRO R1400® ご提案資料
 Intel Core i7 プロセッサ 920 Preliminary Performance Report ノード性能評価 ノード性能の評価 NAS Parallel Benchmark Class B OpenMP 版での性能評価 実行スレッド数を 4 で固定 ( デュアルソケットでは各プロセッサに 2 スレッド ) 全て 2.66GHz のコアとなるため コアあたりのピーク性能は同じ 評価システム
Intel Core i7 プロセッサ 920 Preliminary Performance Report ノード性能評価 ノード性能の評価 NAS Parallel Benchmark Class B OpenMP 版での性能評価 実行スレッド数を 4 で固定 ( デュアルソケットでは各プロセッサに 2 スレッド ) 全て 2.66GHz のコアとなるため コアあたりのピーク性能は同じ 評価システム
<4D F736F F F696E74202D D F95C097F D834F E F93FC96E5284D F96E291E85F8DE391E52E >
 SX-ACE 並列プログラミング入門 (MPI) ( 演習補足資料 ) 大阪大学サイバーメディアセンター日本電気株式会社 演習問題の構成 ディレクトリ構成 MPI/ -- practice_1 演習問題 1 -- practice_2 演習問題 2 -- practice_3 演習問題 3 -- practice_4 演習問題 4 -- practice_5 演習問題 5 -- practice_6
SX-ACE 並列プログラミング入門 (MPI) ( 演習補足資料 ) 大阪大学サイバーメディアセンター日本電気株式会社 演習問題の構成 ディレクトリ構成 MPI/ -- practice_1 演習問題 1 -- practice_2 演習問題 2 -- practice_3 演習問題 3 -- practice_4 演習問題 4 -- practice_5 演習問題 5 -- practice_6
Microsoft Word _001b_hecmw_PC_cluster_201_howtodevelop.doc
 RSS2108-PJ7- ユーサ マニュアル -001b 文部科学省次世代 IT 基盤構築のための研究開発 革新的シミュレーションソフトウエアの研究開発 RSS21 フリーソフトウエア HEC ミドルウェア (HEC-MW) PC クラスタ用ライブラリ型 HEC-MW (hecmw-pc-cluster) バージョン 2.01 HEC-MW を用いたプログラム作成手法 本ソフトウェアは文部科学省次世代
RSS2108-PJ7- ユーサ マニュアル -001b 文部科学省次世代 IT 基盤構築のための研究開発 革新的シミュレーションソフトウエアの研究開発 RSS21 フリーソフトウエア HEC ミドルウェア (HEC-MW) PC クラスタ用ライブラリ型 HEC-MW (hecmw-pc-cluster) バージョン 2.01 HEC-MW を用いたプログラム作成手法 本ソフトウェアは文部科学省次世代
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司
![4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司](/thumbs/97/131936032.jpg "4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司") 4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
Microsoft PowerPoint - 07-pFEM3D-1.ppt [互換モード]
![Microsoft PowerPoint - 07-pFEM3D-1.ppt [互換モード]](/thumbs/93/111421663.jpg "Microsoft PowerPoint - 07-pFEM3D-1.ppt [互換モード]") 並列有限要素法による 三次元定常熱伝導解析プログラム (1/2) 中島研吾東京大学情報基盤センター pfem3d-1 2 fem3dの並列版 MPIによる並列化 扱うプログラム pfem3d-1 3 プログラムのインストール 実行 並列有限要素法の手順 領域分割とは? 本当の実行 データ構造 pfem3d-1 4 ファイルコピー on FX10 FORTRAN ユーザー >$ cd ~/pfem >$
並列有限要素法による 三次元定常熱伝導解析プログラム (1/2) 中島研吾東京大学情報基盤センター pfem3d-1 2 fem3dの並列版 MPIによる並列化 扱うプログラム pfem3d-1 3 プログラムのインストール 実行 並列有限要素法の手順 領域分割とは? 本当の実行 データ構造 pfem3d-1 4 ファイルコピー on FX10 FORTRAN ユーザー >$ cd ~/pfem >$
Microsoft Word - appli_SMASH_tutorial_2.docx
 チュートリアル SMASH version 2.2.0 (Linux 64 ビット版 ) 本チュートリアルでは 量子化学計算ソフトウェア SMASH バージョン 2.2.0 について ソフトウェアの入手 / 実行モジュール作成 / 計算実行 / 可視化処理までを例示します 1. ソフトウェアの入手以下の URL よりダウンロードします https://sourceforge.net/projects/smash-qc/files/smash-2.2.0.tgz/download
チュートリアル SMASH version 2.2.0 (Linux 64 ビット版 ) 本チュートリアルでは 量子化学計算ソフトウェア SMASH バージョン 2.2.0 について ソフトウェアの入手 / 実行モジュール作成 / 計算実行 / 可視化処理までを例示します 1. ソフトウェアの入手以下の URL よりダウンロードします https://sourceforge.net/projects/smash-qc/files/smash-2.2.0.tgz/download
1 OpenCL OpenCL 1 OpenCL GPU ( ) 1 OpenCL Compute Units Elements OpenCL OpenCL SPMD (Single-Program, Multiple-Data) SPMD OpenCL work-item work-group N
 1 OpenCL Compute Units Elements OpenCL OpenCL SPMD (Single-Program, Multiple-Data) SPMD OpenCL work-item work-group N") GPU 1 1 2 1, 3 2, 3 (Graphics Unit: GPU) GPU GPU GPU Evaluation of GPU Computing Based on An Automatic Program Generation Technology Makoto Sugawara, 1 Katsuto Sato, 1 Kazuhiko Komatsu, 2 Hiroyuki Takizawa
GPU 1 1 2 1, 3 2, 3 (Graphics Unit: GPU) GPU GPU GPU Evaluation of GPU Computing Based on An Automatic Program Generation Technology Makoto Sugawara, 1 Katsuto Sato, 1 Kazuhiko Komatsu, 2 Hiroyuki Takizawa
PowerPoint プレゼンテーション
 PC クラスタシンポジウム 日立のテクニカルコンピューティングへの取り組み 2010/12/10 株式会社日立製作所中央研究所清水正明 1 目次 1 2 3 日立テクニカルサーバラインナップ 日立サーバラインナップ GPU コンピューティングへの取り組み 4 SC10 日立展示 2 1-1 日立テクニカルサーバ : History & Future Almost 30 Years of Super
PC クラスタシンポジウム 日立のテクニカルコンピューティングへの取り組み 2010/12/10 株式会社日立製作所中央研究所清水正明 1 目次 1 2 3 日立テクニカルサーバラインナップ 日立サーバラインナップ GPU コンピューティングへの取り組み 4 SC10 日立展示 2 1-1 日立テクニカルサーバ : History & Future Almost 30 Years of Super
workshop Eclipse TAU AICS.key
 11 AICS 2016/02/10 1 Bryzgalov Peter @ HPC Usability Research Team RIKEN AICS Copyright 2016 RIKEN AICS 2 3 OS X, Linux www.eclipse.org/downloads/packages/eclipse-parallel-application-developers/lunasr2
11 AICS 2016/02/10 1 Bryzgalov Peter @ HPC Usability Research Team RIKEN AICS Copyright 2016 RIKEN AICS 2 3 OS X, Linux www.eclipse.org/downloads/packages/eclipse-parallel-application-developers/lunasr2
IPSJ SIG Technical Report Vol.2015-HPC-150 No /8/6 I/O Jianwei Liao 1 Gerofi Balazs 1 1 Guo-Yuan Lien Prototyping F
 I/O Jianwei Liao 1 Gerofi Balazs 1 1 Guo-Yuan Lien 1 1 1 1 1 30 30 100 30 30 2 Prototyping File I/O Arbitrator Middleware for Real-Time Severe Weather Prediction System Jianwei Liao 1 Gerofi Balazs 1 Yutaka
I/O Jianwei Liao 1 Gerofi Balazs 1 1 Guo-Yuan Lien 1 1 1 1 1 30 30 100 30 30 2 Prototyping File I/O Arbitrator Middleware for Real-Time Severe Weather Prediction System Jianwei Liao 1 Gerofi Balazs 1 Yutaka
23 Fig. 2: hwmodulev2 3. Reconfigurable HPC 3.1 hw/sw hw/sw hw/sw FPGA PC FPGA PC FPGA HPC FPGA FPGA hw/sw hw/sw hw- Module FPGA hwmodule hw/sw FPGA h
 23 FPGA CUDA Performance Comparison of FPGA Array with CUDA on Poisson Equation (lijiang@sekine-lab.ei.tuat.ac.jp), (kazuki@sekine-lab.ei.tuat.ac.jp), (takahashi@sekine-lab.ei.tuat.ac.jp), (tamukoh@cc.tuat.ac.jp),
23 FPGA CUDA Performance Comparison of FPGA Array with CUDA on Poisson Equation (lijiang@sekine-lab.ei.tuat.ac.jp), (kazuki@sekine-lab.ei.tuat.ac.jp), (takahashi@sekine-lab.ei.tuat.ac.jp), (tamukoh@cc.tuat.ac.jp),
演習1: 演習準備
 演習 1: 演習準備 2013 年 8 月 6 日神戸大学大学院システム情報学研究科森下浩二 1 演習 1 の内容 神戸大 X10(π-omputer) について システム概要 ログイン方法 コンパイルとジョブ実行方法 OpenMP の演習 ( 入門編 ) 1. parallel 構文 実行時ライブラリ関数 2. ループ構文 3. shared 節 private 節 4. reduction 節
演習 1: 演習準備 2013 年 8 月 6 日神戸大学大学院システム情報学研究科森下浩二 1 演習 1 の内容 神戸大 X10(π-omputer) について システム概要 ログイン方法 コンパイルとジョブ実行方法 OpenMP の演習 ( 入門編 ) 1. parallel 構文 実行時ライブラリ関数 2. ループ構文 3. shared 節 private 節 4. reduction 節
Microsoft Word ●IntelクアッドコアCPUでのベンチマーク_吉岡_ _更新__ doc
 2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI, MPICH, MVAPICH, MPI.NET プログラミングコストが高いため 生産性が悪い 新しい並
 XcalableMPによる NAS Parallel Benchmarksの実装と評価 中尾 昌広 李 珍泌 朴 泰祐 佐藤 三久 筑波大学 計算科学研究センター 筑波大学大学院 システム情報工学研究科 研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI,
XcalableMPによる NAS Parallel Benchmarksの実装と評価 中尾 昌広 李 珍泌 朴 泰祐 佐藤 三久 筑波大学 計算科学研究センター 筑波大学大学院 システム情報工学研究科 研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI,
258 5) GPS 1 GPS 6) GPS DP 7) 8) 10) GPS GPS 2 3 4 5 2. 2.1 3 1) GPS Global Positioning System
 GPS 1 GPS 6) GPS DP 7) 8) 10) GPS GPS 2 3 4 5 2. 2.1 3 1) GPS Global Positioning System") Vol. 52 No. 1 257 268 (Jan. 2011) 1 2, 1 1 measurement. In this paper, a dynamic road map making system is proposed. The proposition system uses probe-cars which has an in-vehicle camera and a GPS receiver.
Vol. 52 No. 1 257 268 (Jan. 2011) 1 2, 1 1 measurement. In this paper, a dynamic road map making system is proposed. The proposition system uses probe-cars which has an in-vehicle camera and a GPS receiver.
資料3 今後のHPC技術に関する研究開発の方向性について(日立製作所提供資料)
") 今後の HPC 技術に関する 研究開発の方向性について 2012 年 5 月 30 日 ( 株 ) 日立製作所情報 通信システム社 IT プラットフォーム事業本部 Hitachi, Hitachi, Ltd. Ltd. Hitachi 2012. 2012. Ltd. 2012. All rights All rights All rights reserved. reserved. reserved.
今後の HPC 技術に関する 研究開発の方向性について 2012 年 5 月 30 日 ( 株 ) 日立製作所情報 通信システム社 IT プラットフォーム事業本部 Hitachi, Hitachi, Ltd. Ltd. Hitachi 2012. 2012. Ltd. 2012. All rights All rights All rights reserved. reserved. reserved.
2. CABAC CABAC CABAC 1 1 CABAC Figure 1 Overview of CABAC 2 DCT 2 0/ /1 CABAC [3] 3. 2 値化部 コンテキスト計算部 2 値算術符号化部 CABAC CABAC
![2. CABAC CABAC CABAC 1 1 CABAC Figure 1 Overview of CABAC 2 DCT 2 0/ /1 CABAC [3] 3. 2 値化部 コンテキスト計算部 2 値算術符号化部 CABAC CABAC](/thumbs/92/108208872.jpg "2. CABAC CABAC CABAC 1 1 CABAC Figure 1 Overview of CABAC 2 DCT 2 0/ /1 CABAC [3] 3. 2 値化部 コンテキスト計算部 2 値算術符号化部 CABAC CABAC") H.264 CABAC 1 1 1 1 1 2, CABAC(Context-based Adaptive Binary Arithmetic Coding) H.264, CABAC, A Parallelization Technology of H.264 CABAC For Real Time Encoder of Moving Picture YUSUKE YATABE 1 HIRONORI
H.264 CABAC 1 1 1 1 1 2, CABAC(Context-based Adaptive Binary Arithmetic Coding) H.264, CABAC, A Parallelization Technology of H.264 CABAC For Real Time Encoder of Moving Picture YUSUKE YATABE 1 HIRONORI
Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]
![Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]](/thumbs/102/156675429.jpg "Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]") 200/0/9 数値流体解析の並列効率とその GPU による高速化の試み 清水建設 ( 株 ) 技術研究所 PHAM VAN PHUC ( ファムバンフック ) 流体計算時間短縮と GPU の活用の試み 現 CPUとの比較によりGPU 活用の可能性 現 CPU の最大利用 ノード内の最大計算資源の利用 すべてCPUコアの利用 適切なアルゴリズムの利用 CPU コア性能の何倍? GPU の利用の試み
200/0/9 数値流体解析の並列効率とその GPU による高速化の試み 清水建設 ( 株 ) 技術研究所 PHAM VAN PHUC ( ファムバンフック ) 流体計算時間短縮と GPU の活用の試み 現 CPUとの比較によりGPU 活用の可能性 現 CPU の最大利用 ノード内の最大計算資源の利用 すべてCPUコアの利用 適切なアルゴリズムの利用 CPU コア性能の何倍? GPU の利用の試み
スライド 1
 GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
Microsoft PowerPoint - 2_FrontISTRと利用可能なソフトウェア.pptx
 東京大学本郷キャンパス 工学部8号館2階222中会議室 13:30-14:00 FrontISTRと利用可能なソフトウェア 2017年4月28日 第35回FrontISTR研究会 FrontISTRの並列計算ハンズオン 精度検証から並列性能評価まで 観測された物理現象 物理モデル ( 支配方程式 ) 連続体の運動を支配する偏微分方程式 離散化手法 ( 有限要素法, 差分法など ) 代数的な数理モデル
東京大学本郷キャンパス 工学部8号館2階222中会議室 13:30-14:00 FrontISTRと利用可能なソフトウェア 2017年4月28日 第35回FrontISTR研究会 FrontISTRの並列計算ハンズオン 精度検証から並列性能評価まで 観測された物理現象 物理モデル ( 支配方程式 ) 連続体の運動を支配する偏微分方程式 離散化手法 ( 有限要素法, 差分法など ) 代数的な数理モデル
07-二村幸孝・出口大輔.indd
 GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
スライド 1
 計算科学が拓く世界スーパーコンピュータは何故スーパーか 学術情報メディアセンター中島浩 http://www.para.media.kyoto-u.ac.jp/jp/ username=super password=computer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
計算科学が拓く世界スーパーコンピュータは何故スーパーか 学術情報メディアセンター中島浩 http://www.para.media.kyoto-u.ac.jp/jp/ username=super password=computer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
1 Table 1: Identification by color of voxel Voxel Mode of expression Nothing Other 1 Orange 2 Blue 3 Yellow 4 SSL Humanoid SSL-Vision 3 3 [, 21] 8 325
![1 Table 1: Identification by color of voxel Voxel Mode of expression Nothing Other 1 Orange 2 Blue 3 Yellow 4 SSL Humanoid SSL-Vision 3 3 [, 21] 8 325](/thumbs/91/105378470.jpg "1 Table 1: Identification by color of voxel Voxel Mode of expression Nothing Other 1 Orange 2 Blue 3 Yellow 4 SSL Humanoid SSL-Vision 3 3 [, 21] 8 325") 社団法人人工知能学会 Japanese Society for Artificial Intelligence 人工知能学会研究会資料 JSAI Technical Report SIG-Challenge-B3 (5/5) RoboCup SSL Humanoid A Proposal and its Application of Color Voxel Server for RoboCup SSL
社団法人人工知能学会 Japanese Society for Artificial Intelligence 人工知能学会研究会資料 JSAI Technical Report SIG-Challenge-B3 (5/5) RoboCup SSL Humanoid A Proposal and its Application of Color Voxel Server for RoboCup SSL
新しい価値創出に貢献する大規模CAEシミュレーション
 CAE Large-scale CAE Simulation Supporting New Value-creation あらまし CAE Computer Aided Engineering LS-DYNA CAE CAE afjrls-dyna CAE Abstract In the manufacturing industry, numerical simulation assisted by
CAE Large-scale CAE Simulation Supporting New Value-creation あらまし CAE Computer Aided Engineering LS-DYNA CAE CAE afjrls-dyna CAE Abstract In the manufacturing industry, numerical simulation assisted by
hpc141_shirahata.pdf
 GPU アクセラレータと不揮発性メモリ を考慮した I/O 性能の予備評価 白幡晃一 1,2 佐藤仁 1,2 松岡聡 1 1: 東京工業大学 2: JST CREST 1 GPU と不揮発性メモリを用いた 大規模データ処理 大規模データ処理 センサーネットワーク 遺伝子情報 SNS など ペタ ヨッタバイト級 高速処理が必要 スーパーコンピュータ上での大規模データ処理 GPU 高性能 高バンド幅 例
GPU アクセラレータと不揮発性メモリ を考慮した I/O 性能の予備評価 白幡晃一 1,2 佐藤仁 1,2 松岡聡 1 1: 東京工業大学 2: JST CREST 1 GPU と不揮発性メモリを用いた 大規模データ処理 大規模データ処理 センサーネットワーク 遺伝子情報 SNS など ペタ ヨッタバイト級 高速処理が必要 スーパーコンピュータ上での大規模データ処理 GPU 高性能 高バンド幅 例
TOOLS for UR44 Release Notes for Windows
 TOOLS for UR44 V2.1.2 for Windows Release Notes TOOLS for UR44 V2.1.2 for Windows consists of the following programs. - V1.9.9 - Steinberg UR44 Applications V2.1.1 - Basic FX Suite V1.0.1 Steinberg UR44
TOOLS for UR44 V2.1.2 for Windows Release Notes TOOLS for UR44 V2.1.2 for Windows consists of the following programs. - V1.9.9 - Steinberg UR44 Applications V2.1.1 - Basic FX Suite V1.0.1 Steinberg UR44
次 CAE を取り巻く環境と展望 企業がシミュレーションに抱える痛み :3 つの例 クラウド CAE サービス Cistr Cistr のシステム概要 最新版 Cistr でできること Cistr を利 してみる 2
 クラウド CAE サービス 東京 学 学院新領域創成科学研究科 森 直樹, 井原遊, 野達 1 次 CAE を取り巻く環境と展望 企業がシミュレーションに抱える痛み :3 つの例 クラウド CAE サービス Cistr Cistr のシステム概要 最新版 Cistr でできること Cistr を利 してみる 2 CAE を取り巻く環境と展望 3 国内市場規模は約 3400 億円程度 2015 年度の国内
クラウド CAE サービス 東京 学 学院新領域創成科学研究科 森 直樹, 井原遊, 野達 1 次 CAE を取り巻く環境と展望 企業がシミュレーションに抱える痛み :3 つの例 クラウド CAE サービス Cistr Cistr のシステム概要 最新版 Cistr でできること Cistr を利 してみる 2 CAE を取り巻く環境と展望 3 国内市場規模は約 3400 億円程度 2015 年度の国内
地質調査総合センター研究資料集, no. 586 日本列島の地殻温度構造と粘弾性構造の 3 次元モデルおよび地殻活動シミュレーションに関する数値データ Digital data of three-dimensional models of thermal and viscoelastic crust
 地質調査総合センター研究資料集, no. 586 日本列島の地殻温度構造と粘弾性構造の 3 次元モデルおよび地殻活動シミュレーションに関する数値データ Digital data of three-dimensional models of thermal and viscoelastic crustal structures of the Japanese Islands and related data
地質調査総合センター研究資料集, no. 586 日本列島の地殻温度構造と粘弾性構造の 3 次元モデルおよび地殻活動シミュレーションに関する数値データ Digital data of three-dimensional models of thermal and viscoelastic crustal structures of the Japanese Islands and related data
EnSightのご紹介
 オープン CAE シンポジウム 2014 汎用ポストプロセッサー EnSight の大規模データ対応 CEI ソフトウェア株式会社代表取締役吉川慈人 http://www.ceisoftware.co.jp/ 内容 大規模データで時間のかかる処理 クライアント サーバー機能 マルチスレッドによる並列処理 サーバーの分散処理 クライアントの分散処理 ( 分散レンダリング ) EnSightのOpenFOAMインターフェース
オープン CAE シンポジウム 2014 汎用ポストプロセッサー EnSight の大規模データ対応 CEI ソフトウェア株式会社代表取締役吉川慈人 http://www.ceisoftware.co.jp/ 内容 大規模データで時間のかかる処理 クライアント サーバー機能 マルチスレッドによる並列処理 サーバーの分散処理 クライアントの分散処理 ( 分散レンダリング ) EnSightのOpenFOAMインターフェース
Introduction Purpose This training course describes the configuration and session features of the High-performance Embedded Workshop (HEW), a key tool
, a key tool") Introduction Purpose This training course describes the configuration and session features of the High-performance Embedded Workshop (HEW), a key tool for developing software for embedded systems that
Introduction Purpose This training course describes the configuration and session features of the High-performance Embedded Workshop (HEW), a key tool for developing software for embedded systems that
演習準備
 演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
演習準備 2014 年 3 月 5 日神戸大学大学院システム情報学研究科森下浩二 1 演習準備の内容 神戸大 FX10(π-Computer) 利用準備 システム概要 ログイン方法 コンパイルとジョブ実行方法 MPI 復習 1. MPIプログラムの基本構成 2. 並列実行 3. 1 対 1 通信 集団通信 4. データ 処理分割 5. 計算時間計測 2 神戸大 FX10(π-Computer) 利用準備
FFT
 ACTRAN for NASTRAN Product Overview Copyright Free Field Technologies ACTRAN Modules ACTRAN for NASTRAN ACTRAN DGM ACTRAN Vibro-Acoustics ACTRAN Aero-Acoustics ACTRAN TM ACTRAN Acoustics ACTRAN VI 2 Copyright
ACTRAN for NASTRAN Product Overview Copyright Free Field Technologies ACTRAN Modules ACTRAN for NASTRAN ACTRAN DGM ACTRAN Vibro-Acoustics ACTRAN Aero-Acoustics ACTRAN TM ACTRAN Acoustics ACTRAN VI 2 Copyright
fx-9860G Manager PLUS_J
 fx-9860g J fx-9860g Manager PLUS http://edu.casio.jp k 1 k III 2 3 1. 2. 4 3. 4. 5 1. 2. 3. 4. 5. 1. 6 7 k 8 k 9 k 10 k 11 k k k 12 k k k 1 2 3 4 5 6 1 2 3 4 5 6 13 k 1 2 3 1 2 3 1 2 3 1 2 3 14 k a j.+-(),m1
fx-9860g J fx-9860g Manager PLUS http://edu.casio.jp k 1 k III 2 3 1. 2. 4 3. 4. 5 1. 2. 3. 4. 5. 1. 6 7 k 8 k 9 k 10 k 11 k k k 12 k k k 1 2 3 4 5 6 1 2 3 4 5 6 13 k 1 2 3 1 2 3 1 2 3 1 2 3 14 k a j.+-(),m1
Microsoft PowerPoint - RBU-introduction-J.pptx
 Reedbush-U の概要 ログイン方法 東京大学情報基盤センタースーパーコンピューティング研究部門 http://www.cc.u-tokyo.ac.jp/ 東大センターのスパコン 2 基の大型システム,6 年サイクル (?) FY 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 Hitachi SR11K/J2 IBM Power 5+ 18.8TFLOPS,
Reedbush-U の概要 ログイン方法 東京大学情報基盤センタースーパーコンピューティング研究部門 http://www.cc.u-tokyo.ac.jp/ 東大センターのスパコン 2 基の大型システム,6 年サイクル (?) FY 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 Hitachi SR11K/J2 IBM Power 5+ 18.8TFLOPS,
1
 5-3 Photonic Antennas and its Application to Radio-over-Fiber Wireless Communication Systems LI Keren, MATSUI Toshiaki, and IZUTSU Masayuki In this paper, we presented our recent works on development of
5-3 Photonic Antennas and its Application to Radio-over-Fiber Wireless Communication Systems LI Keren, MATSUI Toshiaki, and IZUTSU Masayuki In this paper, we presented our recent works on development of
資料2-1 計算科学・データ科学融合へ向けた東大情報基盤センターの取り組み(中村委員 資料)
") 資料 2-1 計算科学 データ科学融合へ向けた 東大情報基盤センターの取り組み 東京大学情報基盤センター中村宏 東大情報基盤センターのスパコン FY 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 Hitachi SR11K/J2 IBM Power-5+ 18.8TFLOPS, 16.4TB Hitachi HA8000 (T2K) AMD Opteron
資料 2-1 計算科学 データ科学融合へ向けた 東大情報基盤センターの取り組み 東京大学情報基盤センター中村宏 東大情報基盤センターのスパコン FY 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 Hitachi SR11K/J2 IBM Power-5+ 18.8TFLOPS, 16.4TB Hitachi HA8000 (T2K) AMD Opteron
09中西
 PC NEC Linux (1) (2) (1) (2) 1 Linux Linux 2002.11.22) LLNL Linux Intel Xeon 2300 ASCIWhite1/7 / HPC (IDC) 2002 800 2005 2004 HPC 80%Linux) Linux ASCI Purple (ASCI 100TFlops Blue Gene/L 1PFlops (2005)
PC NEC Linux (1) (2) (1) (2) 1 Linux Linux 2002.11.22) LLNL Linux Intel Xeon 2300 ASCIWhite1/7 / HPC (IDC) 2002 800 2005 2004 HPC 80%Linux) Linux ASCI Purple (ASCI 100TFlops Blue Gene/L 1PFlops (2005)
第62巻 第1号 平成24年4月/石こうを用いた木材ペレット
 Bulletin of Japan Association for Fire Science and Engineering Vol. 62. No. 1 (2012) Development of Two-Dimensional Simple Simulation Model and Evaluation of Discharge Ability for Water Discharge of Firefighting
Bulletin of Japan Association for Fire Science and Engineering Vol. 62. No. 1 (2012) Development of Two-Dimensional Simple Simulation Model and Evaluation of Discharge Ability for Water Discharge of Firefighting
EQUIVALENT TRANSFORMATION TECHNIQUE FOR ISLANDING DETECTION METHODS OF SYNCHRONOUS GENERATOR -REACTIVE POWER PERTURBATION METHODS USING AVR OR SVC- Ju
 EQUIVALENT TRANSFORMATION TECHNIQUE FOR ISLANDING DETECTION METHODS OF SYNCHRONOUS GENERATOR -REACTIVE POWER PERTURBATION METHODS USING AVR OR SVC- Jun Motohashi, Member, Takashi Ichinose, Member (Tokyo
EQUIVALENT TRANSFORMATION TECHNIQUE FOR ISLANDING DETECTION METHODS OF SYNCHRONOUS GENERATOR -REACTIVE POWER PERTURBATION METHODS USING AVR OR SVC- Jun Motohashi, Member, Takashi Ichinose, Member (Tokyo
マルチコアPCクラスタ環境におけるBDD法のハイブリッド並列実装
 2010 GPGPU 2010 9 29 MPI/Pthread (DDM) DDM CPU CPU CPU CPU FEM GPU FEM CPU Mult - NUMA Multprocessng Cell GPU Accelerator, GPU CPU Heterogeneous computng L3 cache L3 cache CPU CPU + GPU GPU L3 cache 4
2010 GPGPU 2010 9 29 MPI/Pthread (DDM) DDM CPU CPU CPU CPU FEM GPU FEM CPU Mult - NUMA Multprocessng Cell GPU Accelerator, GPU CPU Heterogeneous computng L3 cache L3 cache CPU CPU + GPU GPU L3 cache 4
ParallelCalculationSeminar_imano.key
 1 OPENFOAM(R) is a registered trade mark of OpenCFD Limited, the producer of the OpenFOAM software and owner of the OPENFOAM(R) and OpenCFD(R) trade marks. 2 3 Open FOAM の歴史 1989年ー2000年 研究室のハウスコード 開発元
1 OPENFOAM(R) is a registered trade mark of OpenCFD Limited, the producer of the OpenFOAM software and owner of the OPENFOAM(R) and OpenCFD(R) trade marks. 2 3 Open FOAM の歴史 1989年ー2000年 研究室のハウスコード 開発元
untitled
 taisuke@cs.tsukuba.ac.jp http://www.hpcs.is.tsukuba.ac.jp/~taisuke/ CP-PACS HPC PC post CP-PACS CP-PACS II 1990 HPC RWCP, HPC かつての世界最高速計算機も 1996年11月のTOP500 第一位 ピーク性能 614 GFLOPS Linpack性能 368 GFLOPS (地球シミュレータの前
taisuke@cs.tsukuba.ac.jp http://www.hpcs.is.tsukuba.ac.jp/~taisuke/ CP-PACS HPC PC post CP-PACS CP-PACS II 1990 HPC RWCP, HPC かつての世界最高速計算機も 1996年11月のTOP500 第一位 ピーク性能 614 GFLOPS Linpack性能 368 GFLOPS (地球シミュレータの前
IEEE HDD RAID MPI MPU/CPU GPGPU GPU cm I m cm /g I I n/ cm 2 s X n/ cm s cm g/cm
 Neutron Visual Sensing Techniques Making Good Use of Computer Science J-PARC CT CT-PET TB IEEE HDD RAID MPI MPU/CPU GPGPU GPU cm I m cm /g I I n/ cm 2 s X n/ cm s cm g/cm cm cm barn cm thn/ cm s n/ cm
Neutron Visual Sensing Techniques Making Good Use of Computer Science J-PARC CT CT-PET TB IEEE HDD RAID MPI MPU/CPU GPGPU GPU cm I m cm /g I I n/ cm 2 s X n/ cm s cm g/cm cm cm barn cm thn/ cm s n/ cm
NUMAの構成
 メッセージパッシング プログラミング 天野 共有メモリ対メッセージパッシング 共有メモリモデル 共有変数を用いた単純な記述自動並列化コンパイラ簡単なディレクティブによる並列化 :OpenMP メッセージパッシング 形式検証が可能 ( ブロッキング ) 副作用がない ( 共有変数は副作用そのもの ) コストが小さい メッセージパッシングモデル 共有変数は使わない 共有メモリがないマシンでも実装可能 クラスタ
メッセージパッシング プログラミング 天野 共有メモリ対メッセージパッシング 共有メモリモデル 共有変数を用いた単純な記述自動並列化コンパイラ簡単なディレクティブによる並列化 :OpenMP メッセージパッシング 形式検証が可能 ( ブロッキング ) 副作用がない ( 共有変数は副作用そのもの ) コストが小さい メッセージパッシングモデル 共有変数は使わない 共有メモリがないマシンでも実装可能 クラスタ
[4] ACP (Advanced Communication Primitives) [1] ACP ACP [2] ACP Tofu UDP [3] HPC InfiniBand InfiniBand ACP 2 ACP, 3 InfiniBand ACP 4 5 ACP 2. ACP ACP
![[4] ACP (Advanced Communication Primitives) [1] ACP ACP [2] ACP Tofu UDP [3] HPC InfiniBand InfiniBand ACP 2 ACP, 3 InfiniBand ACP 4 5 ACP 2. ACP ACP](/thumbs/88/116107914.jpg "[4] ACP (Advanced Communication Primitives) [1] ACP ACP [2] ACP Tofu UDP [3] HPC InfiniBand InfiniBand ACP 2 ACP, 3 InfiniBand ACP 4 5 ACP 2. ACP ACP") InfiniBand ACP 1,5,a) 1,5,b) 2,5 1,5 4,5 3,5 2,5 ACE (Advanced Communication for Exa) ACP (Advanced Communication Primitives) HPC InfiniBand ACP InfiniBand ACP ACP InfiniBand Open MPI 20% InfiniBand Implementation
InfiniBand ACP 1,5,a) 1,5,b) 2,5 1,5 4,5 3,5 2,5 ACE (Advanced Communication for Exa) ACP (Advanced Communication Primitives) HPC InfiniBand ACP InfiniBand ACP ACP InfiniBand Open MPI 20% InfiniBand Implementation
XcalableMP入門
 XcalableMP 1 HPC-Phys@, 2018 8 22 XcalableMP XMP XMP Lattice QCD!2 XMP MPI MPI!3 XMP 1/2 PCXMP MPI Fortran CCoarray C++ MPIMPI XMP OpenMP http://xcalablemp.org!4 XMP 2/2 SPMD (Single Program Multiple Data)
XcalableMP 1 HPC-Phys@, 2018 8 22 XcalableMP XMP XMP Lattice QCD!2 XMP MPI MPI!3 XMP 1/2 PCXMP MPI Fortran CCoarray C++ MPIMPI XMP OpenMP http://xcalablemp.org!4 XMP 2/2 SPMD (Single Program Multiple Data)
IPSJ SIG Technical Report Vol.2014-CG-155 No /6/28 1,a) 1,2,3 1 3,4 CG An Interpolation Method of Different Flow Fields using Polar Inter
 1,2,3 1 3,4 CG An Interpolation Method of Different Flow Fields using Polar Inter") ,a),2,3 3,4 CG 2 2 2 An Interpolation Method of Different Flow Fields using Polar Interpolation Syuhei Sato,a) Yoshinori Dobashi,2,3 Tsuyoshi Yamamoto Tomoyuki Nishita 3,4 Abstract: Recently, realistic
,a),2,3 3,4 CG 2 2 2 An Interpolation Method of Different Flow Fields using Polar Interpolation Syuhei Sato,a) Yoshinori Dobashi,2,3 Tsuyoshi Yamamoto Tomoyuki Nishita 3,4 Abstract: Recently, realistic
HPC143
 研究背景 GPUクラスタ 高性能 高いエネルギー効率 低価格 様々なHPCアプリケーションで用いられている TCA (Tightly Coupled Accelerators) 密結合並列演算加速機構 筑波大学HA-PACSクラスタ アクセラレータ GPU 間の直接通信 低レイテンシ 今後のHPCアプリは強スケーリングも重要 TCAとアクセラレータを搭載したシステムに おけるプログラミングモデル 例
研究背景 GPUクラスタ 高性能 高いエネルギー効率 低価格 様々なHPCアプリケーションで用いられている TCA (Tightly Coupled Accelerators) 密結合並列演算加速機構 筑波大学HA-PACSクラスタ アクセラレータ GPU 間の直接通信 低レイテンシ 今後のHPCアプリは強スケーリングも重要 TCAとアクセラレータを搭載したシステムに おけるプログラミングモデル 例
RICCについて
 RICC 1 RICC 2 RICC 3 RICC GPU 1039Nodes 8312core) 93.0GFLOPS, 12GB(mem), 500GB (hdd) DDR IB!1 PC100Nodes(800core) 9.3 GPGPU 93.3TFLOPS HPSS (4PB) (550TB) 0.24 512GB 1500GB MDGRAPE33TFLOPS MDGRAPE-3 64
RICC 1 RICC 2 RICC 3 RICC GPU 1039Nodes 8312core) 93.0GFLOPS, 12GB(mem), 500GB (hdd) DDR IB!1 PC100Nodes(800core) 9.3 GPGPU 93.3TFLOPS HPSS (4PB) (550TB) 0.24 512GB 1500GB MDGRAPE33TFLOPS MDGRAPE-3 64
01_OpenMP_osx.indd
 OpenMP* / 1 1... 2 2... 3 3... 5 4... 7 5... 9 5.1... 9 5.2 OpenMP* API... 13 6... 17 7... 19 / 4 1 2 C/C++ OpenMP* 3 Fortran OpenMP* 4 PC 1 1 9.0 Linux* Windows* Xeon Itanium OS 1 2 2 WEB OS OS OS 1 OS
OpenMP* / 1 1... 2 2... 3 3... 5 4... 7 5... 9 5.1... 9 5.2 OpenMP* API... 13 6... 17 7... 19 / 4 1 2 C/C++ OpenMP* 3 Fortran OpenMP* 4 PC 1 1 9.0 Linux* Windows* Xeon Itanium OS 1 2 2 WEB OS OS OS 1 OS
28 Docker Design and Implementation of Program Evaluation System Using Docker Virtualized Environment
 28 Docker Design and Implementation of Program Evaluation System Using Docker Virtualized Environment 1170288 2017 2 28 Docker,.,,.,,.,,.,. Docker.,..,., Web, Web.,.,.,, CPU,,. i ., OS..,, OS, VirtualBox,.,
28 Docker Design and Implementation of Program Evaluation System Using Docker Virtualized Environment 1170288 2017 2 28 Docker,.,,.,,.,,.,. Docker.,..,., Web, Web.,.,.,, CPU,,. i ., OS..,, OS, VirtualBox,.,
Microsoft Word - koubo-H26.doc
 平成 26 年度学際共同利用プログラム 計算基礎科学プロジェクト 公募要項 - 計算基礎科学連携拠点 ( 筑波大学 高エネルギー加速器研究機構 国立天文台 ) では スーパーコンピュータの学際共同利用プログラム 計算基礎科学プロジェクト を平成 22 年度から実施しております 平成 23 年度からは HPCI 戦略プログラム 分野 5 物質と宇宙の起源と構造 の協力機関である京都大学基礎物理学研究所
平成 26 年度学際共同利用プログラム 計算基礎科学プロジェクト 公募要項 - 計算基礎科学連携拠点 ( 筑波大学 高エネルギー加速器研究機構 国立天文台 ) では スーパーコンピュータの学際共同利用プログラム 計算基礎科学プロジェクト を平成 22 年度から実施しております 平成 23 年度からは HPCI 戦略プログラム 分野 5 物質と宇宙の起源と構造 の協力機関である京都大学基礎物理学研究所
Fujitsu Standard Tool
 低レベル通信ライブラリ ACP の PGAS ランタイム向け機能 2014 年 10 月 24 日富士通株式会社 JST CREST 安島雄一郎 Copyright 2014 FUJITSU LIMITED 本発表の構成 概要 インタフェース チャネル ベクタ リスト メモリアロケータ アドレス変換 グローバルメモリ参照 モジュール構成 メモリ消費量と性能評価 利用例 今後の課題 まとめ 1 Copyright
低レベル通信ライブラリ ACP の PGAS ランタイム向け機能 2014 年 10 月 24 日富士通株式会社 JST CREST 安島雄一郎 Copyright 2014 FUJITSU LIMITED 本発表の構成 概要 インタフェース チャネル ベクタ リスト メモリアロケータ アドレス変換 グローバルメモリ参照 モジュール構成 メモリ消費量と性能評価 利用例 今後の課題 まとめ 1 Copyright
2012年度HPCサマーセミナー_多田野.pptx
 ! CCS HPC! I " tadano@cs.tsukuba.ac.jp" " 1 " " " " " " " 2 3 " " Ax = b" " " 4 Ax = b" A = a 11 a 12... a 1n a 21 a 22... a 2n...... a n1 a n2... a nn, x = x 1 x 2. x n, b = b 1 b 2. b n " " 5 Gauss LU
! CCS HPC! I " tadano@cs.tsukuba.ac.jp" " 1 " " " " " " " 2 3 " " Ax = b" " " 4 Ax = b" A = a 11 a 12... a 1n a 21 a 22... a 2n...... a n1 a n2... a nn, x = x 1 x 2. x n, b = b 1 b 2. b n " " 5 Gauss LU
IPSJ SIG Technical Report Vol.2013-ARC-207 No.23 Vol.2013-HPC-142 No /12/17 1,a) 1,b) 1,c) 1,d) OpenFOAM OpenFOAM A Bottleneck and Cooperation
 1,b) 1,c) 1,d) OpenFOAM OpenFOAM A Bottleneck and Cooperation") 1,a) 1,b) 1,c) 1,d) OpenFOAM OpenFOAM A Bottleneck and Cooperation with the Post Processes in Numerical Calculation of Transient Phenomena Taizo Kobayashi 1,a) Yoshiyuki Morie 1,b) Toshiya Takami 1,c)
1,a) 1,b) 1,c) 1,d) OpenFOAM OpenFOAM A Bottleneck and Cooperation with the Post Processes in Numerical Calculation of Transient Phenomena Taizo Kobayashi 1,a) Yoshiyuki Morie 1,b) Toshiya Takami 1,c)
Microsoft PowerPoint - 演習1:並列化と評価.pptx
 講義 2& 演習 1 プログラム並列化と性能評価 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 1 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 2 2 次元温度分布の計算
講義 2& 演習 1 プログラム並列化と性能評価 神戸大学大学院システム情報学研究科横川三津夫 yokokawa@port.kobe-u.ac.jp 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 1 2014/3/5 RIKEN AICS HPC Spring School 2014: プログラム並列化と性能評価 2 2 次元温度分布の計算
AMD/ATI Radeon HD 5870 GPU DEGIMA LINPACK HD 5870 GPU DEGIMA LINPACK GFlops/Watt GFlops/Watt Abstract GPU Computing has lately attracted
 DEGIMA LINPACK Energy Performance for LINPACK Benchmark on DEGIMA 1 AMD/ATI Radeon HD 5870 GPU DEGIMA LINPACK HD 5870 GPU DEGIMA LINPACK 1.4698 GFlops/Watt 1.9658 GFlops/Watt Abstract GPU Computing has
DEGIMA LINPACK Energy Performance for LINPACK Benchmark on DEGIMA 1 AMD/ATI Radeon HD 5870 GPU DEGIMA LINPACK HD 5870 GPU DEGIMA LINPACK 1.4698 GFlops/Watt 1.9658 GFlops/Watt Abstract GPU Computing has
4.1 % 7.5 %
 2018 (412837) 4.1 % 7.5 % Abstract Recently, various methods for improving computial performance have been proposed. One of these various methods is Multi-core. Multi-core can execute processes in parallel
2018 (412837) 4.1 % 7.5 % Abstract Recently, various methods for improving computial performance have been proposed. One of these various methods is Multi-core. Multi-core can execute processes in parallel
openmp1_Yaguchi_version_170530
 並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
Vol. 48 No. 4 Apr LAN TCP/IP LAN TCP/IP 1 PC TCP/IP 1 PC User-mode Linux 12 Development of a System to Visualize Computer Network Behavior for L
 Vol. 48 No. 4 Apr. 2007 LAN TCP/IP LAN TCP/IP 1 PC TCP/IP 1 PC User-mode Linux 12 Development of a System to Visualize Computer Network Behavior for Learning to Associate LAN Construction Skills with TCP/IP
Vol. 48 No. 4 Apr. 2007 LAN TCP/IP LAN TCP/IP 1 PC TCP/IP 1 PC User-mode Linux 12 Development of a System to Visualize Computer Network Behavior for Learning to Associate LAN Construction Skills with TCP/IP
PowerPoint プレゼンテーション
 vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
Microsoft Word ●MPI性能検証_志田_ _更新__ doc
 2.2.2. MPI 性能検証 富士通株式会社 志田直之 ここでは,Open MPI および富士通 MPI を用いて,MPI 性能の評価結果について報告する 1. 性能評価のポイント MPI の性能評価は, 大きく 3 つに分けて評価を行った プロセス数増加に向けた検証 ノード内通信とノード間通信の検証 性能検証 - 連続データ転送 - ストライド転送 2. プロセス数増加に向けた検証 評価に用いたシステムを以下に示す
2.2.2. MPI 性能検証 富士通株式会社 志田直之 ここでは,Open MPI および富士通 MPI を用いて,MPI 性能の評価結果について報告する 1. 性能評価のポイント MPI の性能評価は, 大きく 3 つに分けて評価を行った プロセス数増加に向けた検証 ノード内通信とノード間通信の検証 性能検証 - 連続データ転送 - ストライド転送 2. プロセス数増加に向けた検証 評価に用いたシステムを以下に示す
P2P P2P peer peer P2P peer P2P peer P2P i
 26 P2P Proposed a system for the purpose of idle resource utilization of the computer using the P2P 1150373 2015 2 27 P2P P2P peer peer P2P peer P2P peer P2P i Abstract Proposed a system for the purpose
26 P2P Proposed a system for the purpose of idle resource utilization of the computer using the P2P 1150373 2015 2 27 P2P P2P peer peer P2P peer P2P peer P2P i Abstract Proposed a system for the purpose
Microsoft PowerPoint - ★13_日立_清水.ppt
 PC クラスタワークショップ in 京都 日立テクニカルコンピューティングクラスタ 2008/7/25 清水正明 日立製作所中央研究所 1 目次 1 2 3 4 日立テクニカルサーバラインナップ SR16000 シリーズ HA8000-tc/RS425 日立自動並列化コンパイラ 2 1 1-1 日立テクニカルサーバの歴史 最大性能 100TF 10TF 30 年間で百万倍以上の向上 (5 年で 10
PC クラスタワークショップ in 京都 日立テクニカルコンピューティングクラスタ 2008/7/25 清水正明 日立製作所中央研究所 1 目次 1 2 3 4 日立テクニカルサーバラインナップ SR16000 シリーズ HA8000-tc/RS425 日立自動並列化コンパイラ 2 1 1-1 日立テクニカルサーバの歴史 最大性能 100TF 10TF 30 年間で百万倍以上の向上 (5 年で 10
東京大学情報基盤センターFX10スパコンシステム(Oakleaf-FX)活用事例
活用事例") FX10 Oakleaf-FX Practical use of FX10 Supercomputer System (Oakleaf-FX) of Information Technology Center, The University of Tokyo 坂口吉生 小倉崇浩 あらまし FUJITSU Supercomputer PRIMEHPC FX10 Oakleaf-FX 2012 4 Oakleaf-FX
FX10 Oakleaf-FX Practical use of FX10 Supercomputer System (Oakleaf-FX) of Information Technology Center, The University of Tokyo 坂口吉生 小倉崇浩 あらまし FUJITSU Supercomputer PRIMEHPC FX10 Oakleaf-FX 2012 4 Oakleaf-FX
Microsoft Word - nvsi_050110jp_netvault_vtl_on_dothill_sannetII.doc
 Article ID: NVSI-050110JP Created: 2005/10/19 Revised: - NetVault 仮想テープ ライブラリのパフォーマンス検証 : dothill SANnetⅡSATA 編 1. 検証の目的 ドットヒルシステムズ株式会社の SANnetll SATA は 安価な SATA ドライブを使用した大容量ストレージで ディスクへのバックアップを行う際の対象デバイスとして最適と言えます
Article ID: NVSI-050110JP Created: 2005/10/19 Revised: - NetVault 仮想テープ ライブラリのパフォーマンス検証 : dothill SANnetⅡSATA 編 1. 検証の目的 ドットヒルシステムズ株式会社の SANnetll SATA は 安価な SATA ドライブを使用した大容量ストレージで ディスクへのバックアップを行う際の対象デバイスとして最適と言えます
最新の並列計算事情とCAE
 1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
040312研究会HPC2500.ppt
 2004312 e-mail : m-aoki@jp.fujitsu.com 1 2 PRIMEPOWER VX/VPP300 VPP700 GP7000 AP3000 VPP5000 PRIMEPOWER 2000 PRIMEPOWER HPC2500 1998 1999 2000 2001 2002 2003 3 VPP5000 PRIMEPOWER ( 1 VU 9.6 GF 16GB 1 VU
2004312 e-mail : m-aoki@jp.fujitsu.com 1 2 PRIMEPOWER VX/VPP300 VPP700 GP7000 AP3000 VPP5000 PRIMEPOWER 2000 PRIMEPOWER HPC2500 1998 1999 2000 2001 2002 2003 3 VPP5000 PRIMEPOWER ( 1 VU 9.6 GF 16GB 1 VU
修士論文
 AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
PowerPoint プレゼンテーション
 Foundation アプライアンス スケーラブルシステムズ株式会社 サーバ クラスタの課題 複数のシステムを一つの だけで容易に管理することは出来ないだろうか? アプリケーションがより多くのメモリを必要とするのだけど ハードウエアの増設なしで対応出来ないだろうか? 現在の利用環境のまま 利用できるコア数やメモリサイズの増強を図ることは出来ないだろうか? 短時間で導入可能で また 必要に応じて 柔軟にシステム構成の変更が可能なソリューションは無いだろうか?...
Foundation アプライアンス スケーラブルシステムズ株式会社 サーバ クラスタの課題 複数のシステムを一つの だけで容易に管理することは出来ないだろうか? アプリケーションがより多くのメモリを必要とするのだけど ハードウエアの増設なしで対応出来ないだろうか? 現在の利用環境のまま 利用できるコア数やメモリサイズの増強を図ることは出来ないだろうか? 短時間で導入可能で また 必要に応じて 柔軟にシステム構成の変更が可能なソリューションは無いだろうか?...
九州大学がスーパーコンピュータ「高性能アプリケーションサーバシステム」の本格稼働を開始
 2014 年 1 月 31 日 国立大学法人九州大学 株式会社日立製作所 九州大学がスーパーコンピュータ 高性能アプリケーションサーバシステム の本格稼働を開始 日立のテクニカルサーバ HA8000-tc/HT210 などを採用 従来システム比で 約 28 倍の性能を実現し 1TFLOPS あたりの消費電力は約 17 分の 1 に低減 九州大学情報基盤研究開発センター ( センター長 : 青柳睦 /
2014 年 1 月 31 日 国立大学法人九州大学 株式会社日立製作所 九州大学がスーパーコンピュータ 高性能アプリケーションサーバシステム の本格稼働を開始 日立のテクニカルサーバ HA8000-tc/HT210 などを採用 従来システム比で 約 28 倍の性能を実現し 1TFLOPS あたりの消費電力は約 17 分の 1 に低減 九州大学情報基盤研究開発センター ( センター長 : 青柳睦 /
GPU n Graphics Processing Unit CG CAD
 GPU 2016/06/27 第 20 回 GPU コンピューティング講習会 ( 東京工業大学 ) 1 GPU n Graphics Processing Unit CG CAD www.nvidia.co.jp www.autodesk.co.jp www.pixar.com GPU n GPU ü n NVIDIA CUDA ü NVIDIA GPU ü OS Linux, Windows, Mac
GPU 2016/06/27 第 20 回 GPU コンピューティング講習会 ( 東京工業大学 ) 1 GPU n Graphics Processing Unit CG CAD www.nvidia.co.jp www.autodesk.co.jp www.pixar.com GPU n GPU ü n NVIDIA CUDA ü NVIDIA GPU ü OS Linux, Windows, Mac
Microsoft Word - JP FEA Post Text Neutral File Format.doc
 FEA Post Text File Format 1. 共通事項 (1) ファイル拡張子 *.fpt (FEA Post Text File Format) () 脚注 脚注記号 : セミコロン (;) 脚注記号の後に来るテキストは変換されない (3) データ区分 データ区分記号 :, (4) コマンド表示 コマンドの前は * 記号を付けてデータと区分する Example. 単位のコマンド *UNIT
FEA Post Text File Format 1. 共通事項 (1) ファイル拡張子 *.fpt (FEA Post Text File Format) () 脚注 脚注記号 : セミコロン (;) 脚注記号の後に来るテキストは変換されない (3) データ区分 データ区分記号 :, (4) コマンド表示 コマンドの前は * 記号を付けてデータと区分する Example. 単位のコマンド *UNIT
IPSJ SIG Technical Report Vol.2014-EIP-63 No /2/21 1,a) Wi-Fi Probe Request MAC MAC Probe Request MAC A dynamic ads control based on tra
 Wi-Fi Probe Request MAC MAC Probe Request MAC A dynamic ads control based on tra") 1,a) 1 1 2 1 Wi-Fi Probe Request MAC MAC Probe Request MAC A dynamic ads control based on traffic Abstract: The equipment with Wi-Fi communication function such as a smart phone which are send on a regular
1,a) 1 1 2 1 Wi-Fi Probe Request MAC MAC Probe Request MAC A dynamic ads control based on traffic Abstract: The equipment with Wi-Fi communication function such as a smart phone which are send on a regular