Microsoft PowerPoint - CW-intro01.ppt [互換モード]
|
|
|
- えみ かみこ
- 5 years ago
- Views:
Transcription
1 はじめに, 並列有限要素法とは 2011 年度冬学期 中島研吾 科学技術計算 Ⅱ( ) コンピュータ科学特別講義 ( ) 1205) ( 並列有限要素法 )
2 CW-Intro01 2 概要 はじめに MPI とは 並列有限要素法とは?
3 CW-Intro01 3 本講義の目的 (1/3) 科学技術計算 Ⅱ( ) 情報理工学系数理情報学専攻 コンピュータ科学特別講義 Ⅱ( ) 情報理工学系コンピュータ科学専攻 科学技術計算 Ⅰ コンピュータ科学特別講義 Ⅰ ( 有限要素法 ) ( 夏学期 ) に引き続き以下の講義, 実習を実施 : MPIによる並列計算プログラミング入門 並列有限要素法のためのデータ構造 並列プログラムの作成法 T2K オープンスパコンによるプログラミング実習 夏学期に扱った三次元弾性静解析プログラム fem3d の並列 夏学期に扱った三次元弾性静解析プログラム fem3d の並列化を MPI によって実施する
4 4 並列計算の意義 たくさんの計算機を使って より速く より大規模に より複雑に 連成, 連結シミュレーション


5 2003 年十勝沖地震長周期地震波動 ( 表面波 ) のために苫小牧の石油タンクがスロッシングを起こし火災発生 5
6 6 地盤 石油タンク振動連成シミュレーション (Engineering) Basement ( 工学基盤 ): Vs~ 400~700 m/sec. + 表層 ( 更に遅い ) Sedimentary Layers ( 堆積層 ): Vs 1,000~2,000 m/sec. Wave Propagation Earthquake Bedrock ( 地震基盤 ): Vs~ 3,000 m/sec.
7 7 対象とするアプリケーション 地盤 石油タンク振動 地盤 タンクへの 一方向 連成 地盤表層の変位 タンク底面の強制変位として与える このアプリケーションに対して, 連成シミュレーションのためシのフレームワークを開発, 実装 1 タンク=1PE: シリアル計算 eformation of surface will be given as boundary conditions at bottom of tanks.

, 三次元弾性動解析 後退オイラー陰解法, スカイライン法")


8 8 地盤モデル :ORTRAN 並列 EM, 三次元弾性動解析 前進オイラー陽解法,EBE 各要素は一辺 2m の立方体 240m 240m 100m タンクモデル :C 地盤, タンクモデル シリアル EM(EP), 三次元弾性動解析 後退オイラー陰解法, スカイライン法 シェル要素 +ポテンシャル流 ( 非粘性 ) 直径 :42.7m, 高さ :24.9m, 厚さ :20mm, 液面 :12.45m, スロッシング周期 :7.6sec. 周方向 80 分割, 高さ方向 :0.6m 幅 60 間隔で 4 4 に配置 60m 間隔で 4 4 に配置 合計自由度数 :2,918,169





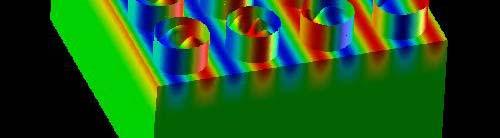


9 計算結果 9




10 10
11 Intro 本講義の歴史 2008 年度 : コンピュータ科学専攻 冬学期 : コンピュータ科学特別講義 Ⅰ 現在の Ⅰ,Ⅱ を一学期にまとめた内容,EM+ 並列 EM 2009 年度 : コンピュータ科学専攻 夏学期 : コンピュータ科学特別講義 Ⅰ 冬学期 : コンピュータ科学特別講義 Ⅱ 2010 年度 : 数理情報学専攻 夏学期 : 科学技術計算 Ⅰ 冬学期 : 科学技術計算 Ⅱ 2011 年度 : 数理情報学 コンピュータ科学専攻 夏学期 : 科学技術計算 Ⅰ,, コンピュータ科学特別講義 Ⅰ 冬学期 : 科学技術計算 Ⅱ, コンピュータ科学特別講義 Ⅱ
12 CW-Intro01 12 計算機ハードウェアの歴史 プロセッサは 年に 2 倍の割合で処理速度が増加している Moore s Law: 集積度が 18 ヶ月から 24 ヶ月で 2 倍 並列計算機の発達 1983 年 :1 GLOPS,1996 年 :1 TLOPS,2002 年 :36 TLOPS,2005 年 :280TLOPS,2008 年 :1,000TLOPS MLOPS: Millions of Loating Point OPerations per Second.(1 秒間に 10 6 回の浮動小数点処理 ) GLOPS: 10 9 回, TLOPS: 回, PLOPS: 回
13 CW-Intro01 13 計算機ハードウェア発達の歴史
14 CW-Intro01 14 年 2 回更新 TOP 500 List LINPACK と言われるベンチマークテストを実施する 密行列を係数とする連立一次方程式を解く ベクトル機でもスカラー機でも性能が出やすい 実際のアプリケーションではこれほどの性能は出ない 差分法, スペクトル法系の手法 : ピーク性能の 60% 程度 AES on the Earth Simulator(Old): 26 TLOPS( ピーク性能の 65%) 有限要素法 GeoEM on the Earth Simulator (512ノード)(Old):10 TLOPS(30%) スカラー機ではこれほど出ない :5%~10% 最近は消費電力も考慮した Green500 というランキングもある
15 CW-Intro01 15 Site Computer/Year Vendor Cores R max R peak Power 1 RIKEN Advanced Institute for K computer, SPARC64 VIIIfx 2.0GHz, Tofu Computational Science (AICS) interconnect t / 2011 ujitsu Japan National Supercomputing Tianhe-1A - NUT TH MPP, Ghz 6C, Center in Tianjin NVIIA GPU, T C / 2010 NUT China OE/SC/Oak Ridge National Jaguar - Cray T5-HE Opteron 6-core 2.6 GHz / 2009 Laboratory Cray Inc. United States National Supercomputing Nebulae - awning TC3600 Blade, Intel 5650, Centre in Shenzhen (NSCS) NVidia Tesla C2050 GPU / 2010 awning China GSIC Center, Tokyo Institute of Technology Japan TSUBAME HP ProLiant SL390s G7 eon 6C 5670, Nvidia GPU, Linux/Windows / 2010 NEC/HP OE/NNSA/LANL/SNL Cielo - Cray E6 8-core 2.4 GHz / United States 2011 Cray Inc NASA/Ames Research Center/NAS United States Pleiades - SGI Altix ICE 8200E/8400E, eon HT QC 3.0/eon 5570/ Ghz, Infiniband / 2011 SGI OE/SC/LBNL/NERSC Hopper - Cray E6 12-core 2.1 GHz / 2010 United States Cray Inc Commissariat a l'energie Atomique (CEA) rance OE/NNSA/LANL United States Tera Bull bullx super-node S6010/S6030 / 2010 Bull SA Roadrunner - BladeCenter QS22/LS21 Cluster, PowerCell 8i 3.2 Ghz / Opteron C 1.8 GHz, Voltaire Infiniband / 2009 IBM R max : 実効性能 (GLOPS),R peak : ピーク性能 (GLOPS)
16 Introduction 16 PLOPS: Peta (=10 15 ) loating OPerations per Sec. Exa-LOPS (=10 18 ) will be attained in
 http://www.aics.")

17 Introduction 17 次世代スーパーコンピュータ 京 理化学研究所計算科学研究機構 ( 神戸 ) 京速計算機 京 = 兆 の 10,000 倍 = = 10 Peta LOPS 2011 年 6 月現在世界最速 ( 未完成 )



18 Introduction 18 T2Kオープンスパコン ( 筑波, 東大, 京都 ) Socket #0: Memory Socket #1: Memory L3 L2 L2 L2 L2 L1 L1 L1 L1 Core Core Core Core L3 L2 L2 L2 L2 L1 L1 L1 L1 Core Core Core Core Bridge Myrinet Myrinet Core Core Core Core Core Core Core Core L1 L1 L1 L1 L2 L2 L2 L2 L3 Socket #2: Memory L1 L1 L1 L1 L2 L2 L2 L2 L3 Socket #3: Memory Bridge Myrinet Myrinet GbE RAI
19 Introduction 19 専用計算機 GRAPE(GRAvity ( PipE ) 宇宙物理学における N 対 N 問題用専用ハードウェア :M, 境界要素法等 コストパフォーマンス MGRAPE M(Molecular ( ynamics) ) 専用のGRAPE MGRAPE を通常のクラスタの Accelerator のように使用することもできる
20 Introduction 20 様々な技術的課題 コアの性能 今後 10 年間でそれほど変化無し 電力消費量 Exascale(2019 年頃 ) だと 2GW( 電気代 ,000 億円 / 年 ) これを 100MW 未満に抑えるための技術革新必要 マルチコア化, メニーコア化 メモリー性能の低下 GPGPU: 高いメモリバンド幅 設置場所 故障 用途は限られる, プログラミングの困難さ Exaslcale: 億 規模のコア数
21 マイクロプロセッサの動向 CPU 性能, メモリバンド幅のギャップ 21
22 Introduction 22 疎行列ソルバーの性能 : 三次元弾性問題 ICCG 法,T2K SR ノード : メモリバンド幅が効く Hitachi SR11000/J2 T2K/Tokyo Power GHz x 16 Opteron 2.3GHz x GLOPS/node GLOPS/node 100 GB/s for STREAM/Triad 20 GB/s for STREAM/Triad L3 cache: 18MB/core L3 cache: 0.5MB/core Perform mance Rat tio (%) lat MPI. HB 4x4 HB 8x2 HB 16x E+04 1.E+05 1.E+06 1.E+07 O tio (%) Perform mance Ra lat MPI. HB 4x4 HB 8x2 HB 16x E+04 1.E+05 1.E+06 1.E+07 O
23 CW-Intro
24 マイクロプロセッサの動向 CPU 性能, メモリバンド幅のギャップ 24
25 スカラープロセッサ メモリへ直接アクセスするのは実際的でない CPU Register SLOW Main Memory
26 スカラープロセッサ CPU- キャッシュ - メモリの階層構造 AST CPU Register Cache 小容量 (MB): 一時置き場高価大きい (1 億以上のトランジスタ ) SLOW Main Memory 大容量 (GB) 廉価 26
27 ベクトルプロセッサベクトルレジスタと高速メモリ Vector Processor 単純構造のOループの並列処理 単純, 大規模な演算に適している Vector Register do i= 1, N A(i)= B(i) + C(i) enddo Very AST Main Memory
28 典型的な挙動 :ICCG 法 E % of peak LOPS G % of peak GL LOPS 1.0E E E E E E+07 IBM-SP3: O: Problem Size 問題サイズが小さい場合はキャッシュの影響のため性能が良い 1.0E E E E E+07 Earth Simulator: O: Problem Size 大規模な問題ほどベクトル長が長くなり, 性能が高い 28
29 専用計算機 GRAPE(GRAvity PipE ) 宇宙物理学におけるN 対 N 問題用専用ハードウェア :M, 境界要素法等 コストパフォーマンス MGRAPE M(Molecular ynamics) 専用のGRAPE MGRAPEを通常のクラスタのAcceleratorのように使用することもできる
 だと 2GW( 電気代 2000 2,000 億円 / 年")

30 様々な技術的課題 コアの性能 今後 10 年間でそれほど変化無し 電力消費量 Exascale(2018 年頃 ) だと 2GW( 電気代 ,000 億円 / 年 ) これを 20MW くらいまでに抑えるための技術革新必要 マルチコア化, メニーコア化 メモリー性能の低下 GPGPU: 高いメモリバンド幅 設置場所 故障 用途は限られる Exaslcale: 億 規模のコア数




31 CW-Intro01 31 The T2K Open Supercomputer Alliance Tsukuba: Appro-Cray Tokyo: Hitachi Kyoyo: ujitsu
32 CW-Intro01 32 The T2K Open Supercomputer Alliance 各ノード :Quad-core Opteron(Barcelona) 4 Socket #0: Memory Socket #1: Memory L3 L2 L2 L2 L2 L1 L1 L1 L1 Core Core Core Core L3 L2 L2 L2 L2 L1 L1 L1 L1 Core Core Core Core Bridge Myrinet Myrinet Core Core Core Core Core Core Core Core L1 L1 L1 L1 L2 L2 L2 L2 L3 Socket #2: Memory L1 L1 L1 L1 L2 L2 L2 L2 L3 Socket #3: Memory Bridge Myrinet Myrinet GbE RAI
33 CW-Intro01 33 本講義の目的 (2/3) 本講義 実習は 東京大学学際計算科学 工学人材育成プログラム の一環として実施され, 科学技術計算プログラミングに必須の項目である SMASH(Science- Modeling-Algorithm-Software- Hardware) を, できるだけ幅広くカバーし, 広い視野を持った人材を育成することを目標とするものです Science i Modeling A lgorithm Software Hardware
34 CW-Intro01 34 本講義の目的 (3/3) 並列計算機を使用した大規模シミュレーションの実施のためには, 科学 工学と計算機科学, 数値アルゴリズム ( 数理科学 ) の専門家の密接な協力が必要となります そのためには, 数理科学, 計算機科学の専門家もある程度アプリケーションに関する知識と経験が要求されます 本講義は, 情報理工学系研究科の学生がアプリケーションに関する知識を効率的に得るのにも適しています
35 CW-Intro01 35 中島研吾 担当教員 情報基盤センタースーパーコンピューティング研究部門 大学院情報理工学系研究科数理情報学専攻兼担 工学部航空学科 ( 現航空宇宙工学科 ) 卒 (Y.2004~2007) 理学系研究科地球惑星科学専攻 専門 計算力学, 数値流体力学 数値線形代数 並列プログラミングモデル, 並列アルゴリズム 情報基盤センター別館 3, 内線 :22719 nakajima@cc.u-tokyo.ac.jp 質問等は随時, 電話で所在確認
36 CW-Intro01 36 受講に必要な知識等 UNI の操作 準備等 ORTRAN または C による基礎的なプログラミングの経験 基礎的な数値解析に関する知識 情報基盤センター教育用計算機システムのアカウント 科学技術計算 Ⅰ ( 有限要素法 ) を履修していること, または同等の知識を有すること その他, 連絡事項については随時 HP に掲載する u-tokyo.ac.jp/11w/
37 CW-Intro01 3 分でわかる有限要素法 inite-element Method (EM) 37 偏微分方程式の解法として広く知られている elements (meshes, 要素 ) & nodes (vertices, 節点 ) 以下の二次元熱伝導問題を考える : T λ 2 x T 2 y + Q = 0 16 節点,9 要素 ( 四角形 ) 一様な熱伝導率 (λ=1) 一様な体積発熱 (Q=1) 節点 1 で温度固定 :T= 周囲断熱
38 CW-Intro01 Galerkin EM procedures 3 分でわかる有限要素法 38 各要素にガラーキン法を適用 : V + x y 2 2 T T = 2 2 [ N ] T λ + Q dv 0 各要素で : T = [ N ]{φ } [N] : 形状関数 ( 内挿関数 ) 偏微分方程式に対して, ガウ ス グリーンの定理を適用し, 以下の 弱形式 を導く λ V T T [ N ] [ N ] [ N ] [ N ] ] x x + y y dv { φ} T 1 [ N ] = 0 + Q dv V
39 CW-Intro01 Element Matrix 要素マトリクス 3 分でわかる有限要素法 39 Element Matrix: 要素マトリクス各要素において積分を実行し要素マトリクスを得る 各要素において積分を実行し, 要素マトリクスを得る e C [ ] [ ] [ ] [ ] { } + dv N N N N T T φ λ B A { } [ ] 0 = + + dv N Q dv y y x x T V φ λ = ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( } { } ]{ [ e e e e e e e e e f k k k k f k φ φ [ ] 0 + dv N Q V = ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( e e B A e e B A e e e e e B e BC e BB e BA A AC AB AA f f f k k k k k k k k k k k k φ φ φ ) ( ) ( ) ( ) ( ) ( ) ( e C e C e e C e B e A C CC CB CA f f k k k k k k k k φ φ
40 CW-Intro01 Global/overall Matrix: 全体マトリクス 3 分でわかる有限要素法 40 Global/overall Matrix: 全体マトリクス各要素マトリクスを全体マトリクスに足しこむ = 1 1 } { } ]{ [ K =
41 CW-Intro01 Global/overall Matrix: 全体マトリクス 3 分でわかる有限要素法 41 Global/overall Matrix: 全体マトリクス各要素マトリクスを全体マトリクスに足しこむ = 1 1 } { } ]{ [ K =
42 CW-Intro01 得られた大規模連立一次方程式を解く 3 分でわかる有限要素法 42 得られた大規模連立一次方程式を解くある適切な境界条件 ( ここでは 1 =0) を適用 疎 ( ゼロが多い ) な行列 疎 ( ゼロが多い ) な行列 =
43 CW-Intro01 3 分でわかる有限要素法 43 計算結果 λ x 2 2 T T + + Q = 2 2 y
44 CW-Intro01 44 年月日内容 2010 年 10 月 04 日 ( 火 ) はじめに 10 月 11 日 ( 火 ) 復習, 並列データ構造 10 月 18 日 ( 火 ) 並列データ構造 ( 続き ),T2Kオープンスパコン 10 月 25 日 ( 火 ) ( 休講 ) 11 月 01 日 ( 火 ) MPIによる並列プログラミング (1) 11 月 08 日 ( 火 ) MPI による並列プログラミング (2) 11 月 15 日 ( 火 ) ( 休講 ) 11 月 22 日 ( 火 ) チューニング入門 11 月 29 日 ( 火 ) MPIによる並列プログラミング (3) 12 月 06 日 ( 火 ) MPIによる並列プログラミング (4) 12 月 13 日 ( 火 ) 課題 S1 解説 12 月 20 日 ( 火 ) 課題 S2 解説 2011 年 01 月 17 日 ( 火 ) 三次元並列有限要素法 (1) 01 月 24 日 ( 火 ) ( 休講 ) 01 月 31 日 ( 火 ) 三次元並列有限要素法 (2) 02 月 07 日 ( 火 ) 三次元並列有限要素法 (3) 02 月 14 日 ( 火 ) 最近の話題
45 CW-Intro01 45 講義の進め方 夏学期の復習は随時実施する MPI の既習者? 講義資料 月曜正午までに WEB にアップ 各自印刷のこと ( 配布はしない : 今日は特別 ) 評価 レポート
46 CW-Intro01 46 はじめに MPI とは 並列有限要素法とは?
47 CW-Intro01 47 MPI とは (1/2) Message Passing Interface 分散メモリ間のメッセージ通信 API の 規格 プログラム, ライブラリ, そのものではない h h / h / j/ i j t t l 歴史 1992 MPI フォーラム 1994 MPI-1 規格 1997 MPI-2 規格 ( 拡張版 ), 現在は MPI-3 が検討されている 実装 mpich アルゴンヌ国立研究所 LAM 各ベンダー C/C++,OTRAN,Java ; Unix,Linux,Windows,Mac OS
48 CW-Intro01 48 MPI とは (2/2) 現状では,mpich( p フリー ) が広く使用されている 部分的に MPI-2 規格をサポート 2005 年 11 月から MPICH2 に移行 MPI が普及した理由 MPI フォーラムによる規格統一 どんな計算機でも動く ORTRAN,C からサブルーチン, 関数として呼び出すことが可能 mpich の存在 フリー, あらゆるアーキテクチュアをサポート 同様の試みとして PVM(Parallel Virtual Machine) があっ同様試 ( ) あたが, こちらはそれほど広がらず
49 CW-Intro01 49 参考文献 P.Pacheco MPI 並列プログラミング, 培風館,2001( 原著 1997) W.Gropp 他 Using MPI second edition,mit Press, M.J.Quinn Parallel Programming in C with MPI and OpenMP, McGrawhill, W.Gropp 他 MPI:The Complete Reference Vol.I, II,MIT Press, API(Application ( Interface) ) の説明
50 CW-Intro01 50 文法 MPI を学ぶにあたって MPI-1 の基本的な機能 (10 程度 ) について習熟する MPI-2 では色々と便利な機能があるが あとは自分に必要な機能について調べる, あるいは知っている人, 知っていそうな人に尋ねる 実習の重要性 プログラミング その前にまず実行してみること SPM/SIM のオペレーションに慣れること つかむ こと Single Program/Instruction Multiple ata 基本的に各プロセスは 同じことをやる が データが違う 大規模なデータを分割し, 各部分について各プロセス ( プロセッサ ) が計算する 全体データと局所データ, 全体番号と局所番号
51 CW-Intro01 51 PE: Processing Element プロセッサ, 領域, プロセス SPM/SIM mpirun -np M <Program> この絵が理解できればMPIは 9 割方理解できたことになる コンピュータサイエンスの学科でもこれを上手に教えるのは難しいらしい PE #0 PE #1 PE #2 PE #M-1 Program Program Program Program ata #0 ata #1 ata #2 ata #M-1 各プロセスは 同じことをやる が データが違う 大規模なデータを分割し, 各部分について各プロセス ( プロセッサ ) が計算する
52 CW-Intro01 52 T2K オープンスパコン ( 東大 ) 1 コア =1 領域 Socket #0: Memory Socket #1: Memory L3 L2 L2 L2 L2 L1 L1 L1 L1 Core Core Core Core L3 L2 L2 L2 L2 L1 L1 L1 L1 Core Core Core Core Bridge Myrinet Myrinet Core Core Core Core Core Core Core Core L1 L1 L1 L1 L2 L2 L2 L2 L3 Socket #2: Memory L1 L1 L1 L1 L2 L2 L2 L2 L3 Socket #3: Memory Bridge Myrinet Myrinet GbE RAI
53 CW-Intro01 53 はじめに MPI とは 並列有限要素法とは? 基本的な考え方 局所データ構造
54 CW-Intro01 54 高速, 大規模 並列計算の目的 大規模 の方が 新しい科学 という観点からのウェイトとしては高い しかし, 高速 ももちろん重要である + 複雑 細かいメッシュ 理想 :Scalable N 倍の規模の計算をN 倍のCPUを使って, 同じ時間で 解く ( 大規模性の追求 :Weak Scaling) 実際はそうは行かない 例 : 共役勾配法 問題規模が大きくなると反復回数が増加 同じ問題をN 倍のCPUを使って 1/Nの時間で 解く という場合もある ( 高速性の追求 :Strong Scaling) これも余り簡単な話では無い
55 CW-Intro01 55 並列計算とは?(1/2) より大規模で複雑な問題を高速に解きたい Homogeneous/Heterogeneous Porous Media Lawrence Livermore National Laboratory Homogeneous Heterogeneous このように不均質な場を模擬するには非常に細かいメッシュが必要となる
56 CW-Intro01 56 並列計算とは?(2/2) 1GB 程度の PC <10 6 メッシュが限界 :EM 1000km 1000km 100km の領域 ( 西南日本 ) を 1km メッシュで切ると 10 8 メッシュになる 大規模データ 領域分割, 局所データ並列処理 全体系計算 領域間の通信が必要 大規模データ 領域分割 局所データ 局所データ 局所データ 局所データ 通信 局所局所データデータ 局所 局所 データ データ
57 CW-Intro01 57 通信とは? 並列計算とはデータと処理をできるだけ 局所的 (local) に実施すること 要素マトリクスの計算 有限要素法の計算は本来並列計算向けである 大域的(global) な情報を必要とする場合に通信が生じる ( 必要となる ) 全体マトリクスを線形ソルバーで解く
58 CW-Intro01 58 並列有限要素法の処理 :SPM 巨大な解析対象 局所分散データ, 領域分割 (Partitioning) 有限要素コードは領域ごとに係数マトリクスを生成 : 要素単位の処理によって可能 : シリアルコードと変わらない処理 グローバル処理, 通信は線形ソルバーのみで生じる内積, 行列ベクトル積, 前処理 局所データ EM コード線形ソルバー MPI 局所データ EM コード線形ソルバー MPI 局所データ EM コード線形ソルバー MPI 局所データ EM コード線形ソルバー
59 CW-Intro01 59 並列有限要素法プログラムの開発 前頁のようなオペレーションを実現するためのデータ構造が重要 アプリケーションの 並列化 にあたって重要なのは, 適切な局所分散データ構造の設計である 前処理付反復法 マトリクス生成 : ローカルに処理
60 CW-Intro01 60 はじめに MPI とは 並列有限要素法とは? 基本的な考え方 局所データ構造
61 四角形要素 節点ベース( 領域ごとの節点数がバランスする ) の分割自由度 : 節点上で定義 これではマトリクス生成に必要な情報は不十分 マトリクス生成のためには, オーバーラップ部分の要素と節点の情報が必要 CW-Intro01 61
62 並列有限要素法の局所データ構造 節点ベース :Node-based N d b d partitioning i 局所データに含まれるもの : その領域に本来含まれる節点 それらの節点を含む要素 本来領域外であるが, それらの要素に含まれる節点 節点は以下の 3 種類に分類 内点 :Internal nodes その領域に本来含まれる節点 外点 :External nodes 本来領域外であるがマトリクス生成に必要な節点 境界点 :Boundary nodes 他の領域の 外点 となっている節点 領域間の通信テーブル 領域間の接続をのぞくと, 大域的な情報は不要 有限要素法の特性 : 要素で閉じた計算 CW-Intro01 62
63 Node-based Partitioning internal nodes - elements - external nodes PE#1 PE#0 PE# PE# PE#3 PE# CW-Intro01 63 PE# PE#2
64 Node-based Partitioning internal nodes - elements - external nodes Partitioned nodes themselves (Internal Nodes) 内点 Elements which include Internal Nodes 内点を含む要素 External Nodes included in the Elements 外点 in overlapped region among partitions. Info of External Nodes are required for completely local element based operations on each processor CW-Intro01 64











65 Node-based Partitioning マトリクス生成時の通信は不要 internal nodes - elements - external nodes Partitioned nodes themselves (Internal Nodes) 内点 Elements which include Internal Nodes 内点を含む要素 External Nodes included in the Elements 外点 in overlapped region among partitions. Info of External Nodes are required for completely local element based operations on each processor CW-Intro01 65
66 Parallel Computing in EM SPM: Single-Program Multiple-ata Local ata EM code Linear Solvers MPI Local ata EM code Linear Solvers MPI Local ata EM code Linear Solvers MPI Local ata EM code Linear Solvers CW-Intro01 66
67 Parallel Computing in EM SPM: Single-Program Multiple-ata Local ata EM code Linear Solvers MPI Local ata EM code Linear Solvers MPI Local ata EM code Linear Solvers MPI Local ata EM code Linear Solvers CW-Intro01 67
68 Parallel Computing in EM SPM: Single-Program Multiple-ata Local ata EM code Linear Solvers MPI Local ata EM code Linear Solvers MPI Local ata EM code Linear Solvers MPI Local ata EM code Linear Solvers CW-Intro
69 Parallel Computing in EM SPM: Single-Program Multiple-ata Local ata EM code Linear Solvers MPI 8 Local ata 6 EM code Linear Solvers MPI 1 Local 2 ata 3 11 EM code Linear Solvers MPI 5 6 Local 3 ata EM code Linear Solvers CW-Intro
70 Parallel Computing in EM SPM: Single-Program Multiple-ata Local ata EM code Linear Solvers MPI Local ata EM code Linear Solvers MPI Local ata EM code Linear Solvers MPI Local ata EM code Linear Solvers CW-Intro01 70
71 通信とは何か? 外点 の情報を外部の領域からもらってくること 通信テーブル にその情報が含まれている CW-Intro01 71
Stage 並列プログラミングを習得するためには : 1 計算機リテラシ, プログラミング言語 2 基本的な数値解析 3 実アプリケーション ( 例えば有限要素法, 分子動力学 ) のプログラミング 4 その並列化 という 4 つの段階 (stage) が必要である 本人材育成プログラムでは1~4を
 のプログラミング 4 その並列化 という 4 つの段階 (stage) が必要である 本人材育成プログラムでは1~4を") コンピュータ科学特別講義 科学技術計算プログラミング I ( 有限要素法 ) 中島研吾 東京大学情報基盤センター 1. はじめに本稿では,2008 年度冬学期に実施した, コンピュータ科学特別講義 I 科学技術計算プログラミング ( 有限要素法 ) について紹介する 計算科学 工学, ハードウェアの急速な進歩, 発達を背景に, 第 3 の科学 としての大規模並列シミュレーションへの期待は, 産学において一層高まっている
コンピュータ科学特別講義 科学技術計算プログラミング I ( 有限要素法 ) 中島研吾 東京大学情報基盤センター 1. はじめに本稿では,2008 年度冬学期に実施した, コンピュータ科学特別講義 I 科学技術計算プログラミング ( 有限要素法 ) について紹介する 計算科学 工学, ハードウェアの急速な進歩, 発達を背景に, 第 3 の科学 としての大規模並列シミュレーションへの期待は, 産学において一層高まっている
SC SC10 (International Conference for High Performance Computing, Networking, Storage and Analysis) (HPC) Ernest N.
 (HPC) Ernest N.") SC10 2010 11 13 19 SC10 (International Conference for High Performance Computing, Networking, Storage and Analysis) (HPC) 1 2005 8 8 2010 4 Ernest N. Morial Convention Center (ENMCC) Climate Simulation(
SC10 2010 11 13 19 SC10 (International Conference for High Performance Computing, Networking, Storage and Analysis) (HPC) 1 2005 8 8 2010 4 Ernest N. Morial Convention Center (ENMCC) Climate Simulation(
GPU n Graphics Processing Unit CG CAD
 GPU 2016/06/27 第 20 回 GPU コンピューティング講習会 ( 東京工業大学 ) 1 GPU n Graphics Processing Unit CG CAD www.nvidia.co.jp www.autodesk.co.jp www.pixar.com GPU n GPU ü n NVIDIA CUDA ü NVIDIA GPU ü OS Linux, Windows, Mac
GPU 2016/06/27 第 20 回 GPU コンピューティング講習会 ( 東京工業大学 ) 1 GPU n Graphics Processing Unit CG CAD www.nvidia.co.jp www.autodesk.co.jp www.pixar.com GPU n GPU ü n NVIDIA CUDA ü NVIDIA GPU ü OS Linux, Windows, Mac
Microsoft PowerPoint - stream.ppt [互換モード]
![Microsoft PowerPoint - stream.ppt [互換モード]](/thumbs/94/118945109.jpg "Microsoft PowerPoint - stream.ppt [互換モード]") STREAM 1 Quad Opteron: ccnuma Arch. AMD Quad Opteron 2.3GHz Quad のソケット 4 1 ノード (16コア ) 各ソケットがローカルにメモリを持っている NUMA:Non-Uniform Access ローカルのメモリをアクセスして計算するようなプログラミング, データ配置, 実行時制御 (numactl) が必要 cc: cache-coherent
STREAM 1 Quad Opteron: ccnuma Arch. AMD Quad Opteron 2.3GHz Quad のソケット 4 1 ノード (16コア ) 各ソケットがローカルにメモリを持っている NUMA:Non-Uniform Access ローカルのメモリをアクセスして計算するようなプログラミング, データ配置, 実行時制御 (numactl) が必要 cc: cache-coherent
0..Campus の利用.Campusに登録確認木曜 4 限にPCリテラシーがあるか確認ショートコード : Campusをお気に入りに追加.Campusから講義ファイル取得.Campusにレポート提出 2
 PC リテラシー NO.2 情報処理入門 2012 年 4 月 19 日 後保範 1 0..Campus の利用.Campusに登録確認木曜 4 限にPCリテラシーがあるか確認ショートコード : 86311.Campusをお気に入りに追加.Campusから講義ファイル取得.Campusにレポート提出 2 1. 講義で使用するもの (1) オペレーションシステム Windows XP,Vista 使用しない
PC リテラシー NO.2 情報処理入門 2012 年 4 月 19 日 後保範 1 0..Campus の利用.Campusに登録確認木曜 4 限にPCリテラシーがあるか確認ショートコード : 86311.Campusをお気に入りに追加.Campusから講義ファイル取得.Campusにレポート提出 2 1. 講義で使用するもの (1) オペレーションシステム Windows XP,Vista 使用しない
GeoFEM開発の経験から
 FrontISTR における並列計算のしくみ < 領域分割に基づく並列 FEM> メッシュ分割 領域分割 領域分割 ( パーティショニングツール ) 全体制御 解析制御 メッシュ hecmw_ctrl.dat 境界条件 材料物性 計算制御パラメータ 可視化パラメータ 領域分割ツール 逐次計算 並列計算 Front ISTR FEM の主な演算 FrontISTR における並列計算のしくみ < 領域分割に基づく並列
FrontISTR における並列計算のしくみ < 領域分割に基づく並列 FEM> メッシュ分割 領域分割 領域分割 ( パーティショニングツール ) 全体制御 解析制御 メッシュ hecmw_ctrl.dat 境界条件 材料物性 計算制御パラメータ 可視化パラメータ 領域分割ツール 逐次計算 並列計算 Front ISTR FEM の主な演算 FrontISTR における並列計算のしくみ < 領域分割に基づく並列
スライド 1
 計算科学が拓く世界スーパーコンピュータは何故スーパーか 学術情報メディアセンター中島浩 http://www.para.media.kyoto-u.ac.jp/jp/ username=super password=computer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
計算科学が拓く世界スーパーコンピュータは何故スーパーか 学術情報メディアセンター中島浩 http://www.para.media.kyoto-u.ac.jp/jp/ username=super password=computer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
HPC可視化_小野2.pptx
 大 小 二 生 高 方 目 大 方 方 方 Rank Site Processors RMax Processor System Model 1 DOE/NNSA/LANL 122400 1026000 PowerXCell 8i BladeCenter QS22 Cluster 2 DOE/NNSA/LLNL 212992 478200 PowerPC 440 BlueGene/L 3 Argonne
大 小 二 生 高 方 目 大 方 方 方 Rank Site Processors RMax Processor System Model 1 DOE/NNSA/LANL 122400 1026000 PowerXCell 8i BladeCenter QS22 Cluster 2 DOE/NNSA/LLNL 212992 478200 PowerPC 440 BlueGene/L 3 Argonne
09中西
 PC NEC Linux (1) (2) (1) (2) 1 Linux Linux 2002.11.22) LLNL Linux Intel Xeon 2300 ASCIWhite1/7 / HPC (IDC) 2002 800 2005 2004 HPC 80%Linux) Linux ASCI Purple (ASCI 100TFlops Blue Gene/L 1PFlops (2005)
PC NEC Linux (1) (2) (1) (2) 1 Linux Linux 2002.11.22) LLNL Linux Intel Xeon 2300 ASCIWhite1/7 / HPC (IDC) 2002 800 2005 2004 HPC 80%Linux) Linux ASCI Purple (ASCI 100TFlops Blue Gene/L 1PFlops (2005)
Microsoft Word ●IntelクアッドコアCPUでのベンチマーク_吉岡_ _更新__ doc
 2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
2.3. アプリ性能 2.3.1. Intel クアッドコア CPU でのベンチマーク 東京海洋大学吉岡諭 1. はじめにこの数年でマルチコア CPU の普及が進んできた x86 系の CPU でも Intel と AD がデュアルコア クアッドコアの CPU を次々と市場に送り出していて それらが PC クラスタの CPU として採用され HPC に活用されている ここでは Intel クアッドコア
Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]
![Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]](/thumbs/102/156675429.jpg "Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]") 200/0/9 数値流体解析の並列効率とその GPU による高速化の試み 清水建設 ( 株 ) 技術研究所 PHAM VAN PHUC ( ファムバンフック ) 流体計算時間短縮と GPU の活用の試み 現 CPUとの比較によりGPU 活用の可能性 現 CPU の最大利用 ノード内の最大計算資源の利用 すべてCPUコアの利用 適切なアルゴリズムの利用 CPU コア性能の何倍? GPU の利用の試み
200/0/9 数値流体解析の並列効率とその GPU による高速化の試み 清水建設 ( 株 ) 技術研究所 PHAM VAN PHUC ( ファムバンフック ) 流体計算時間短縮と GPU の活用の試み 現 CPUとの比較によりGPU 活用の可能性 現 CPU の最大利用 ノード内の最大計算資源の利用 すべてCPUコアの利用 適切なアルゴリズムの利用 CPU コア性能の何倍? GPU の利用の試み
最新の並列計算事情とCAE
 1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
Microsoft PowerPoint - introduction [互換モード]
![Microsoft PowerPoint - introduction [互換モード]](/thumbs/95/125448795.jpg "Microsoft PowerPoint - introduction [互換モード]") イントロダクション 本講義の概要 2012 年夏季集中講義中島研吾 並列計算プログラミング (616-2057) 先端計算機演習 (616-4009) 略歴 工学部航空学科出身, 博士 ( 工学 ) 株式会社三菱総合研究所等 2004 年 ~: 地球惑星科学専攻 ( 多圏 COE 特任教員 ) 2008 年 ~: 情報基盤センター 専門 数値流体力学 並列プログラミングモデル, 大規模数値解法 地球惑星科学とのかかわり
イントロダクション 本講義の概要 2012 年夏季集中講義中島研吾 並列計算プログラミング (616-2057) 先端計算機演習 (616-4009) 略歴 工学部航空学科出身, 博士 ( 工学 ) 株式会社三菱総合研究所等 2004 年 ~: 地球惑星科学専攻 ( 多圏 COE 特任教員 ) 2008 年 ~: 情報基盤センター 専門 数値流体力学 並列プログラミングモデル, 大規模数値解法 地球惑星科学とのかかわり
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
有限要素法入門 中島研吾 東京大学情報基盤センター
 有限要素法入門 中島研吾 東京大学情報基盤センター EM-ntro 有限要素法入門 偏微分方程式の数値解法 重み付き残差法 偏微分方程式の数値解法 変分法 EM-ntro 差分法と有限要素法 偏微分方程式の近似解法 全領域を小領域 メッシュ 要素 に分割する 差分法 微分係数を直接近似 Tylor 展開 nte fference Method M Tylor Seres Epnson -!!!! nd
有限要素法入門 中島研吾 東京大学情報基盤センター EM-ntro 有限要素法入門 偏微分方程式の数値解法 重み付き残差法 偏微分方程式の数値解法 変分法 EM-ntro 差分法と有限要素法 偏微分方程式の近似解法 全領域を小領域 メッシュ 要素 に分割する 差分法 微分係数を直接近似 Tylor 展開 nte fference Method M Tylor Seres Epnson -!!!! nd
スライド 1
 GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
OpenFOAM(R) ソースコード入門 pt1 熱伝導方程式の解法から有限体積法の実装について考える 前編 : 有限体積法の基礎確認 2013/11/17 オープンCAE 富山富山県立大学中川慎二
 ソースコード入門 pt1 熱伝導方程式の解法から有限体積法の実装について考える 前編 : 有限体積法の基礎確認 2013/11/17 オープンCAE 富山富山県立大学中川慎二") OpenFOAM(R) ソースコード入門 pt1 熱伝導方程式の解法から有限体積法の実装について考える 前編 : 有限体積法の基礎確認 2013/11/17 オープンCAE 勉強会 @ 富山富山県立大学中川慎二 * OpenFOAM のソースコードでは, 基礎式を偏微分方程式の形で記述する.OpenFOAM 内部では, 有限体積法を使ってこの微分方程式を解いている. どのようにして, 有限体積法に基づく離散化が実現されているのか,
OpenFOAM(R) ソースコード入門 pt1 熱伝導方程式の解法から有限体積法の実装について考える 前編 : 有限体積法の基礎確認 2013/11/17 オープンCAE 勉強会 @ 富山富山県立大学中川慎二 * OpenFOAM のソースコードでは, 基礎式を偏微分方程式の形で記述する.OpenFOAM 内部では, 有限体積法を使ってこの微分方程式を解いている. どのようにして, 有限体積法に基づく離散化が実現されているのか,
openmp1_Yaguchi_version_170530
 並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
GPUコンピューティング講習会パート1
 GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
<4D F736F F D B B B835E895E97708A4A8E6E82C A98418C6782CC8E6E93AE2E646F63>
 京都大学学術情報メディアセンター 新スーパーコンピュータ運用開始と T2K 連携の始動 アピールポイント 61.2 テラフロップスの京大版 T2K オープンスパコン運用開始 東大 筑波大との T2K 連携による計算科学 工学分野におけるネットワーク型研究推進 人材育成 アプリケーション高度化支援の活動を開始概要国立大学法人京都大学 ( 総長 尾池和夫 ) 学術情報メディアセンター ( センター長 美濃導彦
京都大学学術情報メディアセンター 新スーパーコンピュータ運用開始と T2K 連携の始動 アピールポイント 61.2 テラフロップスの京大版 T2K オープンスパコン運用開始 東大 筑波大との T2K 連携による計算科学 工学分野におけるネットワーク型研究推進 人材育成 アプリケーション高度化支援の活動を開始概要国立大学法人京都大学 ( 総長 尾池和夫 ) 学術情報メディアセンター ( センター長 美濃導彦
Microsoft Word - HOKUSAI_system_overview_ja.docx
 HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
hpc141_shirahata.pdf
 GPU アクセラレータと不揮発性メモリ を考慮した I/O 性能の予備評価 白幡晃一 1,2 佐藤仁 1,2 松岡聡 1 1: 東京工業大学 2: JST CREST 1 GPU と不揮発性メモリを用いた 大規模データ処理 大規模データ処理 センサーネットワーク 遺伝子情報 SNS など ペタ ヨッタバイト級 高速処理が必要 スーパーコンピュータ上での大規模データ処理 GPU 高性能 高バンド幅 例
GPU アクセラレータと不揮発性メモリ を考慮した I/O 性能の予備評価 白幡晃一 1,2 佐藤仁 1,2 松岡聡 1 1: 東京工業大学 2: JST CREST 1 GPU と不揮発性メモリを用いた 大規模データ処理 大規模データ処理 センサーネットワーク 遺伝子情報 SNS など ペタ ヨッタバイト級 高速処理が必要 スーパーコンピュータ上での大規模データ処理 GPU 高性能 高バンド幅 例
情報1(化学科)NO.1 コンピュータシステムの基礎と データの表現方法
NO.1 コンピュータシステムの基礎と データの表現方法") PC リテラシー NO.2 情報処理入門 2017 年 9 月 28 日 後保範 1 0. dotcampus の利用 dotcampusに登録確認木曜 4 限にPCリテラシーがあるか確認ショートコード : 221136 dotcampusをお気に入りに追加 dotcampusから講義ファイル取得 dotcampusにレポート提出 2 1. 講義で使用するもの (1) オペレーションシステム Windows
PC リテラシー NO.2 情報処理入門 2017 年 9 月 28 日 後保範 1 0. dotcampus の利用 dotcampusに登録確認木曜 4 限にPCリテラシーがあるか確認ショートコード : 221136 dotcampusをお気に入りに追加 dotcampusから講義ファイル取得 dotcampusにレポート提出 2 1. 講義で使用するもの (1) オペレーションシステム Windows
研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI, MPICH, MVAPICH, MPI.NET プログラミングコストが高いため 生産性が悪い 新しい並
 XcalableMPによる NAS Parallel Benchmarksの実装と評価 中尾 昌広 李 珍泌 朴 泰祐 佐藤 三久 筑波大学 計算科学研究センター 筑波大学大学院 システム情報工学研究科 研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI,
XcalableMPによる NAS Parallel Benchmarksの実装と評価 中尾 昌広 李 珍泌 朴 泰祐 佐藤 三久 筑波大学 計算科学研究センター 筑波大学大学院 システム情報工学研究科 研究背景 大規模な演算を行うためには 分散メモリ型システムの利用が必須 Message Passing Interface MPI 並列プログラムの大半はMPIを利用 様々な実装 OpenMPI,
(Microsoft PowerPoint - \221\34613\211\361)
") 計算力学 ~ 第 回弾性問題の有限要素解析 (Ⅱ)~ 修士 年後期 ( 選択科目 ) 担当 : 岩佐貴史 講義の概要 全 5 講義. 計算力学概論, ガイダンス. 自然現象の数理モデル化. 行列 場とその演算. 数値計算法 (Ⅰ) 5. 数値計算法 (Ⅱ) 6. 初期値 境界値問題 (Ⅰ) 7. 初期値 境界値問題 (Ⅱ) 8. マトリックス変位法による構造解析 9. トラス構造の有限要素解析. 重み付き残差法と古典的近似解法.
計算力学 ~ 第 回弾性問題の有限要素解析 (Ⅱ)~ 修士 年後期 ( 選択科目 ) 担当 : 岩佐貴史 講義の概要 全 5 講義. 計算力学概論, ガイダンス. 自然現象の数理モデル化. 行列 場とその演算. 数値計算法 (Ⅰ) 5. 数値計算法 (Ⅱ) 6. 初期値 境界値問題 (Ⅰ) 7. 初期値 境界値問題 (Ⅱ) 8. マトリックス変位法による構造解析 9. トラス構造の有限要素解析. 重み付き残差法と古典的近似解法.
VXPRO R1400® ご提案資料
 Intel Core i7 プロセッサ 920 Preliminary Performance Report ノード性能評価 ノード性能の評価 NAS Parallel Benchmark Class B OpenMP 版での性能評価 実行スレッド数を 4 で固定 ( デュアルソケットでは各プロセッサに 2 スレッド ) 全て 2.66GHz のコアとなるため コアあたりのピーク性能は同じ 評価システム
Intel Core i7 プロセッサ 920 Preliminary Performance Report ノード性能評価 ノード性能の評価 NAS Parallel Benchmark Class B OpenMP 版での性能評価 実行スレッド数を 4 で固定 ( デュアルソケットでは各プロセッサに 2 スレッド ) 全て 2.66GHz のコアとなるため コアあたりのピーク性能は同じ 評価システム
smpp_resume.dvi
 6 mmiki@mail.doshisha.ac.jp Parallel Processing Parallel Pseudo-parallel Concurrent 1) 1/60 1) 1997 5 11 IBM Deep Blue Deep Blue 2) PC 2000 167 Rank Manufacturer Computer Rmax Installation Site Country
6 mmiki@mail.doshisha.ac.jp Parallel Processing Parallel Pseudo-parallel Concurrent 1) 1/60 1) 1997 5 11 IBM Deep Blue Deep Blue 2) PC 2000 167 Rank Manufacturer Computer Rmax Installation Site Country
FEM原理講座 (サンプルテキスト)
") サンプルテキスト FEM 原理講座 サイバネットシステム株式会社 8 年 月 9 日作成 サンプルテキストについて 各講師が 講義の内容が伝わりやすいページ を選びました テキストのページは必ずしも連続していません 一部を抜粋しています 幾何光学講座については 実物のテキストではなくガイダンスを掲載いたします 対象とする構造系 物理モデル 連続体 固体 弾性体 / 弾塑性体 / 粘弾性体 / 固体
サンプルテキスト FEM 原理講座 サイバネットシステム株式会社 8 年 月 9 日作成 サンプルテキストについて 各講師が 講義の内容が伝わりやすいページ を選びました テキストのページは必ずしも連続していません 一部を抜粋しています 幾何光学講座については 実物のテキストではなくガイダンスを掲載いたします 対象とする構造系 物理モデル 連続体 固体 弾性体 / 弾塑性体 / 粘弾性体 / 固体
情報1(化学科)NO.1 コンピュータシステムの基礎と データの表現方法
NO.1 コンピュータシステムの基礎と データの表現方法") PC リテラシー NO.2 情報処理入門 2017 年 4 月 20 日後保範 0. dotcampus の利用 dotcampus に登録確認木曜 4 限に PC リテラシーがあるか確認ショートコード : 179047 dotcampus をお気に入りに追加 dotcampus から講義ファイル取得 dotcampus にレポート提出 1 2 1. 講義で使用するもの 1.1 の構成 (1) オペレーションシステム
PC リテラシー NO.2 情報処理入門 2017 年 4 月 20 日後保範 0. dotcampus の利用 dotcampus に登録確認木曜 4 限に PC リテラシーがあるか確認ショートコード : 179047 dotcampus をお気に入りに追加 dotcampus から講義ファイル取得 dotcampus にレポート提出 1 2 1. 講義で使用するもの 1.1 の構成 (1) オペレーションシステム
<4D F736F F F696E74202D2091E63489F15F436F6D C982E682E992B48D8291AC92B489B F090CD2888F38DFC E B8CDD8
 Web キャンパス資料 超音波シミュレーションの基礎 ~ 第 4 回 ComWAVEによる超高速超音波解析 ~ 科学システム開発部 Copyright (c)2006 ITOCHU Techno-Solutions Corporation 本日の説明内容 ComWAVEの概要および特徴 GPGPUとは GPGPUによる解析事例 CAE POWER 超音波研究会開催 (10 月 3 日 ) のご紹介
Web キャンパス資料 超音波シミュレーションの基礎 ~ 第 4 回 ComWAVEによる超高速超音波解析 ~ 科学システム開発部 Copyright (c)2006 ITOCHU Techno-Solutions Corporation 本日の説明内容 ComWAVEの概要および特徴 GPGPUとは GPGPUによる解析事例 CAE POWER 超音波研究会開催 (10 月 3 日 ) のご紹介
supercomputer2010.ppt
 nanri@cc.kyushu-u.ac.jp 1 !! : 11 12! : nanri@cc.kyushu-u.ac.jp! : Word 2 ! PC GPU) 1997 7 http://wiredvision.jp/news/200806/2008062322.html 3 !! (Cell, GPU )! 4 ! etc...! 5 !! etc. 6 !! 20km 40 km ) 340km
nanri@cc.kyushu-u.ac.jp 1 !! : 11 12! : nanri@cc.kyushu-u.ac.jp! : Word 2 ! PC GPU) 1997 7 http://wiredvision.jp/news/200806/2008062322.html 3 !! (Cell, GPU )! 4 ! etc...! 5 !! etc. 6 !! 20km 40 km ) 340km
卒業論文
 PC OpenMP SCore PC OpenMP PC PC PC Myrinet PC PC 1 OpenMP 2 1 3 3 PC 8 OpenMP 11 15 15 16 16 18 19 19 19 20 20 21 21 23 26 29 30 31 32 33 4 5 6 7 SCore 9 PC 10 OpenMP 14 16 17 10 17 11 19 12 19 13 20 1421
PC OpenMP SCore PC OpenMP PC PC PC Myrinet PC PC 1 OpenMP 2 1 3 3 PC 8 OpenMP 11 15 15 16 16 18 19 19 19 20 20 21 21 23 26 29 30 31 32 33 4 5 6 7 SCore 9 PC 10 OpenMP 14 16 17 10 17 11 19 12 19 13 20 1421
Microsoft PowerPoint - 2_FrontISTRと利用可能なソフトウェア.pptx
 東京大学本郷キャンパス 工学部8号館2階222中会議室 13:30-14:00 FrontISTRと利用可能なソフトウェア 2017年4月28日 第35回FrontISTR研究会 FrontISTRの並列計算ハンズオン 精度検証から並列性能評価まで 観測された物理現象 物理モデル ( 支配方程式 ) 連続体の運動を支配する偏微分方程式 離散化手法 ( 有限要素法, 差分法など ) 代数的な数理モデル
東京大学本郷キャンパス 工学部8号館2階222中会議室 13:30-14:00 FrontISTRと利用可能なソフトウェア 2017年4月28日 第35回FrontISTR研究会 FrontISTRの並列計算ハンズオン 精度検証から並列性能評価まで 観測された物理現象 物理モデル ( 支配方程式 ) 連続体の運動を支配する偏微分方程式 離散化手法 ( 有限要素法, 差分法など ) 代数的な数理モデル
untitled
 taisuke@cs.tsukuba.ac.jp http://www.hpcs.is.tsukuba.ac.jp/~taisuke/ CP-PACS HPC PC post CP-PACS CP-PACS II 1990 HPC RWCP, HPC かつての世界最高速計算機も 1996年11月のTOP500 第一位 ピーク性能 614 GFLOPS Linpack性能 368 GFLOPS (地球シミュレータの前
taisuke@cs.tsukuba.ac.jp http://www.hpcs.is.tsukuba.ac.jp/~taisuke/ CP-PACS HPC PC post CP-PACS CP-PACS II 1990 HPC RWCP, HPC かつての世界最高速計算機も 1996年11月のTOP500 第一位 ピーク性能 614 GFLOPS Linpack性能 368 GFLOPS (地球シミュレータの前
Microsoft PowerPoint - シミュレーション工学-2010-第1回.ppt
 シミュレーション工学 ( 後半 ) 東京大学人工物工学研究センター 鈴木克幸 CA( Compter Aded geerg ) r. Jaso Lemo (SC, 98) 設計者が解析ツールを使いこなすことにより 設計の評価 設計の質の向上を図る geerg の本質の 計算機による支援 (CA CAM などより広い名前 ) 様々な汎用ソフトの登場 工業製品の設計に不可欠のツール 構造解析 流体解析
シミュレーション工学 ( 後半 ) 東京大学人工物工学研究センター 鈴木克幸 CA( Compter Aded geerg ) r. Jaso Lemo (SC, 98) 設計者が解析ツールを使いこなすことにより 設計の評価 設計の質の向上を図る geerg の本質の 計算機による支援 (CA CAM などより広い名前 ) 様々な汎用ソフトの登場 工業製品の設計に不可欠のツール 構造解析 流体解析
Microsoft PowerPoint - ITC [互換モード]
![Microsoft PowerPoint - ITC [互換モード]](/thumbs/82/86903656.jpg "Microsoft PowerPoint - ITC [互換モード]") 情報基盤センターの スパコン 東京大学情報基盤センター 人間の全ての行動において 情報 と無縁なものは無い 学問, 研究もその例外では無い 東京大学における様々な 情報 に関わる活動を支援する 学術情報メディア 図書館電子化, 学術情報 ネットワーク スーパーコンピューティング 大量で多様な情報 : コンピュータ + ネットワーク CSE 2 スーパーコンピューティング部門 (1/2) http://www.cc.u-tokyo.ac.jp/
情報基盤センターの スパコン 東京大学情報基盤センター 人間の全ての行動において 情報 と無縁なものは無い 学問, 研究もその例外では無い 東京大学における様々な 情報 に関わる活動を支援する 学術情報メディア 図書館電子化, 学術情報 ネットワーク スーパーコンピューティング 大量で多様な情報 : コンピュータ + ネットワーク CSE 2 スーパーコンピューティング部門 (1/2) http://www.cc.u-tokyo.ac.jp/
パソコンシミュレータの現状
 第 2 章微分 偏微分, 写像 豊橋技術科学大学森謙一郎 2. 連続関数と微分 工学において物理現象を支配する方程式は微分方程式で表されていることが多く, 有限要素法も微分方程式を解く数値解析法であり, 定式化においては微分 積分が一般的に用いられており. 数学の基礎知識が必要になる. 図 2. に示すように, 微分は連続な関数 f() の傾きを求めることであり, 微小な に対して傾きを表し, を無限に
第 2 章微分 偏微分, 写像 豊橋技術科学大学森謙一郎 2. 連続関数と微分 工学において物理現象を支配する方程式は微分方程式で表されていることが多く, 有限要素法も微分方程式を解く数値解析法であり, 定式化においては微分 積分が一般的に用いられており. 数学の基礎知識が必要になる. 図 2. に示すように, 微分は連続な関数 f() の傾きを求めることであり, 微小な に対して傾きを表し, を無限に
<4D6963726F736F667420506F776572506F696E74202D20834B8343835F83938358815C8FEE95F183568358836583808A7793C195CA8D758B608252816932303134944E348C8E3893FA816A202D2048502E70707478>
 ガイダンス 東 京 大 学 情 報 基 盤 センター 准 教 授 片 桐 孝 洋 204 年 4 月 8 日 ( 火 )4:40-6:0 ガイダンスの 流 れ. 講 義 の 目 的 2. 講 師 紹 介 3. 講 義 日 程 の 確 認 4. 成 績 の 評 価 方 法 5. イントロダクション(30 分 ) 2 本 講 義 の 目 的 近 年 京 コンピュータに 代 表 される 世 界 トップクラスのスーパーコンピュータが
ガイダンス 東 京 大 学 情 報 基 盤 センター 准 教 授 片 桐 孝 洋 204 年 4 月 8 日 ( 火 )4:40-6:0 ガイダンスの 流 れ. 講 義 の 目 的 2. 講 師 紹 介 3. 講 義 日 程 の 確 認 4. 成 績 の 評 価 方 法 5. イントロダクション(30 分 ) 2 本 講 義 の 目 的 近 年 京 コンピュータに 代 表 される 世 界 トップクラスのスーパーコンピュータが
Microsoft Word - koubo-H26.doc
 平成 26 年度学際共同利用プログラム 計算基礎科学プロジェクト 公募要項 - 計算基礎科学連携拠点 ( 筑波大学 高エネルギー加速器研究機構 国立天文台 ) では スーパーコンピュータの学際共同利用プログラム 計算基礎科学プロジェクト を平成 22 年度から実施しております 平成 23 年度からは HPCI 戦略プログラム 分野 5 物質と宇宙の起源と構造 の協力機関である京都大学基礎物理学研究所
平成 26 年度学際共同利用プログラム 計算基礎科学プロジェクト 公募要項 - 計算基礎科学連携拠点 ( 筑波大学 高エネルギー加速器研究機構 国立天文台 ) では スーパーコンピュータの学際共同利用プログラム 計算基礎科学プロジェクト を平成 22 年度から実施しております 平成 23 年度からは HPCI 戦略プログラム 分野 5 物質と宇宙の起源と構造 の協力機関である京都大学基礎物理学研究所
システムソリューションのご紹介
 HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
PowerPoint プレゼンテーション
 Dell PowerEdge C6320 スケーラブルサーバアプライアンス 仮想化アプライアンスサーバ 最新のプロセッサを搭載したサーバプラットフォーム vsmp Foundation によるサーバ仮想化と統合化の適用 システムはセットアップを完了した状態でご提供 基本構成ではバックプレーン用のスイッチなどが不要 各ノード間を直接接続 冗長性の高いバックプレーン構成 利用するサーバプラットフォームは
Dell PowerEdge C6320 スケーラブルサーバアプライアンス 仮想化アプライアンスサーバ 最新のプロセッサを搭載したサーバプラットフォーム vsmp Foundation によるサーバ仮想化と統合化の適用 システムはセットアップを完了した状態でご提供 基本構成ではバックプレーン用のスイッチなどが不要 各ノード間を直接接続 冗長性の高いバックプレーン構成 利用するサーバプラットフォームは
九州大学がスーパーコンピュータ「高性能アプリケーションサーバシステム」の本格稼働を開始
 2014 年 1 月 31 日 国立大学法人九州大学 株式会社日立製作所 九州大学がスーパーコンピュータ 高性能アプリケーションサーバシステム の本格稼働を開始 日立のテクニカルサーバ HA8000-tc/HT210 などを採用 従来システム比で 約 28 倍の性能を実現し 1TFLOPS あたりの消費電力は約 17 分の 1 に低減 九州大学情報基盤研究開発センター ( センター長 : 青柳睦 /
2014 年 1 月 31 日 国立大学法人九州大学 株式会社日立製作所 九州大学がスーパーコンピュータ 高性能アプリケーションサーバシステム の本格稼働を開始 日立のテクニカルサーバ HA8000-tc/HT210 などを採用 従来システム比で 約 28 倍の性能を実現し 1TFLOPS あたりの消費電力は約 17 分の 1 に低減 九州大学情報基盤研究開発センター ( センター長 : 青柳睦 /
PowerPoint プレゼンテーション
 みんなの ベクトル計算 たけおか @takeoka PC クラスタ コンソーシアム理事でもある 2011/FEB/20 ベクトル計算が新しい と 2008 年末に言いました Intelに入ってる! (2008 年から見た 近未来? ) GPU 計算が新しい (2008 年当時 ) Intel AVX (Advanced Vector Extension) SIMD 命令を進めて ベクトル機構をつける
みんなの ベクトル計算 たけおか @takeoka PC クラスタ コンソーシアム理事でもある 2011/FEB/20 ベクトル計算が新しい と 2008 年末に言いました Intelに入ってる! (2008 年から見た 近未来? ) GPU 計算が新しい (2008 年当時 ) Intel AVX (Advanced Vector Extension) SIMD 命令を進めて ベクトル機構をつける
ÊÂÎó·×»»¤È¤Ï/OpenMP¤Î½éÊâ¡Ê£±¡Ë
 2015 5 21 OpenMP Hello World Do (omp do) Fortran (omp workshare) CPU Richardson s Forecast Factory 64,000 L.F. Richardson, Weather Prediction by Numerical Process, Cambridge, University Press (1922) Drawing
2015 5 21 OpenMP Hello World Do (omp do) Fortran (omp workshare) CPU Richardson s Forecast Factory 64,000 L.F. Richardson, Weather Prediction by Numerical Process, Cambridge, University Press (1922) Drawing
PowerPoint Presentation
 2015 年 4 月 24 日 ( 金 ) 第 18 回 FrontISTR 研究会 FrontISTR の並列計算の基礎 奥田洋司 okuda@k.u-tokyo.ac.jp 東京大学大学院 新領域創成科学研究科 人間環境学専攻 目次 導入 計算力学とは 連続体の力学 連立 1 次方程式 FEM 構造解析の概要 なぜ並列化か? 並列アーキテクチャ 並列プログラミング FEM 計算におけるノード間並列
2015 年 4 月 24 日 ( 金 ) 第 18 回 FrontISTR 研究会 FrontISTR の並列計算の基礎 奥田洋司 okuda@k.u-tokyo.ac.jp 東京大学大学院 新領域創成科学研究科 人間環境学専攻 目次 導入 計算力学とは 連続体の力学 連立 1 次方程式 FEM 構造解析の概要 なぜ並列化か? 並列アーキテクチャ 並列プログラミング FEM 計算におけるノード間並列
GPUコンピューティング講習会パート1
 GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
CPU Levels in the memory hierarchy Level 1 Level 2... Increasing distance from the CPU in access time Level n Size of the memory at each level 1: 2.2
 FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
マルチコアPCクラスタ環境におけるBDD法のハイブリッド並列実装
 2010 GPGPU 2010 9 29 MPI/Pthread (DDM) DDM CPU CPU CPU CPU FEM GPU FEM CPU Mult - NUMA Multprocessng Cell GPU Accelerator, GPU CPU Heterogeneous computng L3 cache L3 cache CPU CPU + GPU GPU L3 cache 4
2010 GPGPU 2010 9 29 MPI/Pthread (DDM) DDM CPU CPU CPU CPU FEM GPU FEM CPU Mult - NUMA Multprocessng Cell GPU Accelerator, GPU CPU Heterogeneous computng L3 cache L3 cache CPU CPU + GPU GPU L3 cache 4
PowerPoint Presentation
 2016 年 6 月 10 日 ( 金 ) FrontISTR 研究会 FrontISTR の並列計算の基礎 奥田洋司 okuda@k.u-tokyo.ac.jp 東京大学大学院 新領域創成科学研究科 人間環境学専攻 目次 導入 なぜ並列化か? 並列アーキテクチャ 並列プログラミング FrontISTR における並列計算 実効性能について ノード間並列 領域分割と MPI ノード内並列 ( 単体性能
2016 年 6 月 10 日 ( 金 ) FrontISTR 研究会 FrontISTR の並列計算の基礎 奥田洋司 okuda@k.u-tokyo.ac.jp 東京大学大学院 新領域創成科学研究科 人間環境学専攻 目次 導入 なぜ並列化か? 並列アーキテクチャ 並列プログラミング FrontISTR における並列計算 実効性能について ノード間並列 領域分割と MPI ノード内並列 ( 単体性能
RICCについて
 RICC 1 RICC 2 RICC 3 RICC GPU 1039Nodes 8312core) 93.0GFLOPS, 12GB(mem), 500GB (hdd) DDR IB!1 PC100Nodes(800core) 9.3 GPGPU 93.3TFLOPS HPSS (4PB) (550TB) 0.24 512GB 1500GB MDGRAPE33TFLOPS MDGRAPE-3 64
RICC 1 RICC 2 RICC 3 RICC GPU 1039Nodes 8312core) 93.0GFLOPS, 12GB(mem), 500GB (hdd) DDR IB!1 PC100Nodes(800core) 9.3 GPGPU 93.3TFLOPS HPSS (4PB) (550TB) 0.24 512GB 1500GB MDGRAPE33TFLOPS MDGRAPE-3 64
Microsoft PowerPoint - 11Web.pptx
 計算機システムの基礎 ( 第 10 回配布 ) 第 7 章 2 節コンピュータの性能の推移 (1) コンピュータの歴史 (2) コンピュータの性能 (3) 集積回路の進歩 (4) アーキテクチャ 第 4 章プロセッサ (1) プロセッサの基本機能 (2) プロセッサの構成回路 (3) コンピュータアーキテクチャ 第 5 章メモリアーキテクチャ 1. コンピュータの世代 計算する機械 解析機関 by
計算機システムの基礎 ( 第 10 回配布 ) 第 7 章 2 節コンピュータの性能の推移 (1) コンピュータの歴史 (2) コンピュータの性能 (3) 集積回路の進歩 (4) アーキテクチャ 第 4 章プロセッサ (1) プロセッサの基本機能 (2) プロセッサの構成回路 (3) コンピュータアーキテクチャ 第 5 章メモリアーキテクチャ 1. コンピュータの世代 計算する機械 解析機関 by
1重谷.PDF
 RSCC RSCC RSCC BMT 1 6 3 3000 3000 200310 1994 19942 VPP500/32PE 19992 VPP700E/128PE 160PE 20043 2 2 PC Linux 2048 CPU Intel Xeon 3.06GHzDual) 12.5 TFLOPS SX-7 32CPU/256GB 282.5 GFLOPS Linux 3 PC 1999
RSCC RSCC RSCC BMT 1 6 3 3000 3000 200310 1994 19942 VPP500/32PE 19992 VPP700E/128PE 160PE 20043 2 2 PC Linux 2048 CPU Intel Xeon 3.06GHzDual) 12.5 TFLOPS SX-7 32CPU/256GB 282.5 GFLOPS Linux 3 PC 1999
Microsoft Word - UT_SCnews教育報告(200905_ver3.doc
 東京大学のスーパーコンピュータを用いた並列プログラミング教育 (3) 工学部 工学系研究科共通科目 スパコンプログラミング1およびⅠ (2008 年度夏 冬学期 ) および 全学ゼミ スパコンプログラミング研究ゼミ ( 夏学期 ) を通じて 1 片桐孝洋東京大学情報基盤センター特任准教授 1. はじめに東京大学情報基盤センター ( 以降 センター ) では スーパーコンピュータ ( 以降 スパコン
東京大学のスーパーコンピュータを用いた並列プログラミング教育 (3) 工学部 工学系研究科共通科目 スパコンプログラミング1およびⅠ (2008 年度夏 冬学期 ) および 全学ゼミ スパコンプログラミング研究ゼミ ( 夏学期 ) を通じて 1 片桐孝洋東京大学情報基盤センター特任准教授 1. はじめに東京大学情報基盤センター ( 以降 センター ) では スーパーコンピュータ ( 以降 スパコン
Microsoft PowerPoint ppt
 並列アルゴリズム 2005 年後期火曜 2 限 高見利也 ( 青柳睦 ) Aoyagi@cc.kyushu-u.ac.jp http://server-500.cc.kyushu-u.ac.jp/ 12 月 20 日 ( 火 ) 9. PC クラスタによる並列プログラミング ( 演習 ) つづき 1 もくじ 1. 序並列計算機の現状 2. 計算方式およびアーキテクチュアの分類 3. 並列計算の目的と課題
並列アルゴリズム 2005 年後期火曜 2 限 高見利也 ( 青柳睦 ) Aoyagi@cc.kyushu-u.ac.jp http://server-500.cc.kyushu-u.ac.jp/ 12 月 20 日 ( 火 ) 9. PC クラスタによる並列プログラミング ( 演習 ) つづき 1 もくじ 1. 序並列計算機の現状 2. 計算方式およびアーキテクチュアの分類 3. 並列計算の目的と課題
1 OpenCL OpenCL 1 OpenCL GPU ( ) 1 OpenCL Compute Units Elements OpenCL OpenCL SPMD (Single-Program, Multiple-Data) SPMD OpenCL work-item work-group N
 1 OpenCL Compute Units Elements OpenCL OpenCL SPMD (Single-Program, Multiple-Data) SPMD OpenCL work-item work-group N") GPU 1 1 2 1, 3 2, 3 (Graphics Unit: GPU) GPU GPU GPU Evaluation of GPU Computing Based on An Automatic Program Generation Technology Makoto Sugawara, 1 Katsuto Sato, 1 Kazuhiko Komatsu, 2 Hiroyuki Takizawa
GPU 1 1 2 1, 3 2, 3 (Graphics Unit: GPU) GPU GPU GPU Evaluation of GPU Computing Based on An Automatic Program Generation Technology Makoto Sugawara, 1 Katsuto Sato, 1 Kazuhiko Komatsu, 2 Hiroyuki Takizawa
PowerPoint プレゼンテーション
 vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
vsmp Foundation スケーラブル SMP システム スケーラブル SMP システム 製品コンセプト 2U サイズの 8 ソケット SMP サーバ コンパクトな筐体に多くのコアとメモリを実装し SMP システムとして利用可能 スイッチなし構成でのシステム構築によりラックスペースを無駄にしない構成 将来的な拡張性を保証 8 ソケット以上への拡張も可能 2 システム構成例 ベースシステム 2U
高性能計算研究室の紹介 High Performance Computing Lab.
 高性能計算研究室 (HPC Lab) の紹介 High Performance Computing Lab. 静岡理工科大学総合情報学部コンピュータシステム学科 ( 兼 Web デザイン特別プログラム ) 幸谷智紀 543 研究室 幸谷研究室 @ 静岡 検索 概要 1. 幸谷智紀 個人の研究テーマ 2. 3 年生ゼミ ( 情報セミナー II) 3. 卒研テーマ 4. 過去の卒研 5. 今後について
高性能計算研究室 (HPC Lab) の紹介 High Performance Computing Lab. 静岡理工科大学総合情報学部コンピュータシステム学科 ( 兼 Web デザイン特別プログラム ) 幸谷智紀 543 研究室 幸谷研究室 @ 静岡 検索 概要 1. 幸谷智紀 個人の研究テーマ 2. 3 年生ゼミ ( 情報セミナー II) 3. 卒研テーマ 4. 過去の卒研 5. 今後について
Microsoft PowerPoint - ★13_日立_清水.ppt
 PC クラスタワークショップ in 京都 日立テクニカルコンピューティングクラスタ 2008/7/25 清水正明 日立製作所中央研究所 1 目次 1 2 3 4 日立テクニカルサーバラインナップ SR16000 シリーズ HA8000-tc/RS425 日立自動並列化コンパイラ 2 1 1-1 日立テクニカルサーバの歴史 最大性能 100TF 10TF 30 年間で百万倍以上の向上 (5 年で 10
PC クラスタワークショップ in 京都 日立テクニカルコンピューティングクラスタ 2008/7/25 清水正明 日立製作所中央研究所 1 目次 1 2 3 4 日立テクニカルサーバラインナップ SR16000 シリーズ HA8000-tc/RS425 日立自動並列化コンパイラ 2 1 1-1 日立テクニカルサーバの歴史 最大性能 100TF 10TF 30 年間で百万倍以上の向上 (5 年で 10
高性能計算研究室の紹介 High Performance Computing Lab.
 高性能計算研究室 (HPC Lab) の紹介 High Performance Computing Lab. 静岡理工科大学総合情報学部コンピュータシステム学科 ( 兼 Web デザイン特別プログラム ) 幸谷智紀 http://na-inet.jp/ 概要 1. 幸谷智紀 個人の研究テーマ 2. 3 年生ゼミ ( 情報セミナー II) 3. 卒研テーマ 4. Webデザイン特別プログラム 5. 今後について
高性能計算研究室 (HPC Lab) の紹介 High Performance Computing Lab. 静岡理工科大学総合情報学部コンピュータシステム学科 ( 兼 Web デザイン特別プログラム ) 幸谷智紀 http://na-inet.jp/ 概要 1. 幸谷智紀 個人の研究テーマ 2. 3 年生ゼミ ( 情報セミナー II) 3. 卒研テーマ 4. Webデザイン特別プログラム 5. 今後について
Microsoft PowerPoint - FEMintro [互換モード]
![Microsoft PowerPoint - FEMintro [互換モード]](/thumbs/93/113568989.jpg "Microsoft PowerPoint - FEMintro [互換モード]") 有限要素法入門 年夏季集中講義中島研吾 並列計算プログラミング 66-57 先端計算機演習 66-49 EM-ntro 有限要素法入門 偏微分方程式の数値解法 重み付き残差法 ガウス グリーンの定理 偏微分方程式の数値解法 変分法 EM-ntro 差分法と有限要素法 偏微分方程式の近似解法 全領域を小領域 メッシュ 要素 に分割する 差分法 微分係数を直接近似 Tylor 展開 EM-ntro 差分法
有限要素法入門 年夏季集中講義中島研吾 並列計算プログラミング 66-57 先端計算機演習 66-49 EM-ntro 有限要素法入門 偏微分方程式の数値解法 重み付き残差法 ガウス グリーンの定理 偏微分方程式の数値解法 変分法 EM-ntro 差分法と有限要素法 偏微分方程式の近似解法 全領域を小領域 メッシュ 要素 に分割する 差分法 微分係数を直接近似 Tylor 展開 EM-ntro 差分法
MATLAB® における並列・分散コンピューティング ~ Parallel Computing Toolbox™ & MATLAB Distributed Computing Server™ ~
 MATLAB における並列 分散コンピューティング ~ Parallel Computing Toolbox & MATLAB Distributed Computing Server ~ MathWorks Japan Application Engineering Group Takashi Yoshida 2016 The MathWorks, Inc. 1 System Configuration
MATLAB における並列 分散コンピューティング ~ Parallel Computing Toolbox & MATLAB Distributed Computing Server ~ MathWorks Japan Application Engineering Group Takashi Yoshida 2016 The MathWorks, Inc. 1 System Configuration
HPC (pay-as-you-go) HPC Web 2
 HPC Web 2") ,, 1 HPC (pay-as-you-go) HPC Web 2 HPC Amazon EC2 OpenFOAM GPU EC2 3 HPC MPI MPI Courant 1 GPGPU MPI 4 AMAZON EC2 GPU CLUSTER COMPUTE INSTANCE EC2 GPU (cg1.4xlarge) ( N. Virgina ) Quadcore Intel Xeon 5570
,, 1 HPC (pay-as-you-go) HPC Web 2 HPC Amazon EC2 OpenFOAM GPU EC2 3 HPC MPI MPI Courant 1 GPGPU MPI 4 AMAZON EC2 GPU CLUSTER COMPUTE INSTANCE EC2 GPU (cg1.4xlarge) ( N. Virgina ) Quadcore Intel Xeon 5570
EGunGPU
 Super Computing in Accelerator simulations - Electron Gun simulation using GPGPU - K. Ohmi, KEK-Accel Accelerator Physics seminar 2009.11.19 Super computers in KEK HITACHI SR11000 POWER5 16 24GB 16 134GFlops,
Super Computing in Accelerator simulations - Electron Gun simulation using GPGPU - K. Ohmi, KEK-Accel Accelerator Physics seminar 2009.11.19 Super computers in KEK HITACHI SR11000 POWER5 16 24GB 16 134GFlops,
Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ 3.7x faster P100 V100 P10
 NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
ペタスケール計算環境に向けたFFTライブラリ
 A01 高橋班 大規模並列環境における 数値計算アルゴリズム 研究代表者 : 高橋大介 筑波大学大学院システム情報工学研究科 研究組織 研究代表者 高橋大介 ( 筑波大学 ): 研究統括および高速アルゴリズム 研究分担者 今村俊幸 ( 電気通信大学 ): 性能チューニング 多田野寛人 ( 筑波大学 ): 大規模線形計算 連携研究者 佐藤三久 ( 筑波大学 ): 並列システムの性能評価 朴泰祐 ( 筑波大学
A01 高橋班 大規模並列環境における 数値計算アルゴリズム 研究代表者 : 高橋大介 筑波大学大学院システム情報工学研究科 研究組織 研究代表者 高橋大介 ( 筑波大学 ): 研究統括および高速アルゴリズム 研究分担者 今村俊幸 ( 電気通信大学 ): 性能チューニング 多田野寛人 ( 筑波大学 ): 大規模線形計算 連携研究者 佐藤三久 ( 筑波大学 ): 並列システムの性能評価 朴泰祐 ( 筑波大学
ガイダンス(2016年4月19日)-HP
-HP") スパコンプログラミング(), (I) ガイダンス 東 京 大 学 情 報 基 盤 センター 准 教 授 塙 敏 博 206 年 4 月 9 日 ( 火 )0:25-2:0 206/4/9 スパコンプログラミング (), (I) 2 ガイダンスの 流 れ. 講 義 の 目 的 2. 講 師 紹 介 3. 講 義 日 程 の 確 認 4. 成 績 の 評 価 方 法 5. 計 算 機 利 用 申 請 6.
スパコンプログラミング(), (I) ガイダンス 東 京 大 学 情 報 基 盤 センター 准 教 授 塙 敏 博 206 年 4 月 9 日 ( 火 )0:25-2:0 206/4/9 スパコンプログラミング (), (I) 2 ガイダンスの 流 れ. 講 義 の 目 的 2. 講 師 紹 介 3. 講 義 日 程 の 確 認 4. 成 績 の 評 価 方 法 5. 計 算 機 利 用 申 請 6.
PowerPoint Presentation
 FrontISTR の並列計算の基礎 奥田洋司 okuda@k.u-tokyo.ac.jp 東京大学大学院 新領域創成科学研究科 人間環境学専攻 並列有限要素法プログラム FrontISTR ( フロントアイスター ) 並列計算では, メッシュ領域分割によって分散メモリ環境に対応し, 通信ライブラリには MPI を使用 (MPI 並列 ) さらに,CPU 内は OpenMP 並列 ( スレッド並列
FrontISTR の並列計算の基礎 奥田洋司 okuda@k.u-tokyo.ac.jp 東京大学大学院 新領域創成科学研究科 人間環境学専攻 並列有限要素法プログラム FrontISTR ( フロントアイスター ) 並列計算では, メッシュ領域分割によって分散メモリ環境に対応し, 通信ライブラリには MPI を使用 (MPI 並列 ) さらに,CPU 内は OpenMP 並列 ( スレッド並列
PC Development of Distributed PC Grid System,,,, Junji Umemoto, Hiroyuki Ebara, Katsumi Onishi, Hiroaki Morikawa, and Bunryu U PC WAN PC PC WAN PC 1 P
 PC Development of Distributed PC Grid System,,,, Junji Umemoto, Hiroyuki Ebara, Katsumi Onishi, Hiroaki Morikawa, and Bunryu U PC WAN PC PC WAN PC 1 PC PC PC PC PC Key Words:Grid, PC Cluster, Distributed
PC Development of Distributed PC Grid System,,,, Junji Umemoto, Hiroyuki Ebara, Katsumi Onishi, Hiroaki Morikawa, and Bunryu U PC WAN PC PC WAN PC 1 PC PC PC PC PC Key Words:Grid, PC Cluster, Distributed
フジタ技術研究報告第 48 号 2012 年 CUDA を用いた並列数値解析手法の一考察 仲沢武志 概 要 従来 大規模な問題や複雑な形状が計算対象の場合では スーパーコンピュータのような高価な計算リソースを使用する必要があった これに対し コンピュータのハード的な進化によって 現在では市販のパーソ
 フジタ技術研究報告第 48 号 2012 年 CUDA を用いた並列数値解析手法の一考察 仲沢武志 概 要 従来 大規模な問題や複雑な形状が計算対象の場合では スーパーコンピュータのような高価な計算リソースを使用する必要があった これに対し コンピュータのハード的な進化によって 現在では市販のパーソナルコンピュータ (PC) でも計算機能は目覚しく向上し 並列演算すらも比較的容易に可能となってきている
フジタ技術研究報告第 48 号 2012 年 CUDA を用いた並列数値解析手法の一考察 仲沢武志 概 要 従来 大規模な問題や複雑な形状が計算対象の場合では スーパーコンピュータのような高価な計算リソースを使用する必要があった これに対し コンピュータのハード的な進化によって 現在では市販のパーソナルコンピュータ (PC) でも計算機能は目覚しく向上し 並列演算すらも比較的容易に可能となってきている
スライド 0
 2012/7/11 OpeMP を用いた Fortra コードの並列化基礎セミナー 株式会社計算力学研究センター 技術 1 部三又秀行 mimata@rccm.co.jp 目次 高速化 並列化事例 PARDISO について (XLsoft 黒澤様 ) 並列化 並列化について 並列化作業の流れ 並列化の手段 OpeMP デモ OpeMP で並列計算する 円周率 p の計算 (private reductio)
2012/7/11 OpeMP を用いた Fortra コードの並列化基礎セミナー 株式会社計算力学研究センター 技術 1 部三又秀行 mimata@rccm.co.jp 目次 高速化 並列化事例 PARDISO について (XLsoft 黒澤様 ) 並列化 並列化について 並列化作業の流れ 並列化の手段 OpeMP デモ OpeMP で並列計算する 円周率 p の計算 (private reductio)
PowerPoint プレゼンテーション
 各種計算機アプリケーション性能比較 目次. はじめに. 行列積計算.QDR 積計算 4.N 体問題計算 5. 多次元積分計算 5. 次元積分計算 5. 次元積分計算 5. 4 次元積分計算 5.4 5 次元積分計算 5.5 6 次元積分計算 平成 6 年度第 四半期 . はじめに 今までと少し性質の異なるグラフィックボードが使用できる様になったので従来のアプリケーションで性能比較を実施しました 主に使用した計算機は以下のものです
各種計算機アプリケーション性能比較 目次. はじめに. 行列積計算.QDR 積計算 4.N 体問題計算 5. 多次元積分計算 5. 次元積分計算 5. 次元積分計算 5. 4 次元積分計算 5.4 5 次元積分計算 5.5 6 次元積分計算 平成 6 年度第 四半期 . はじめに 今までと少し性質の異なるグラフィックボードが使用できる様になったので従来のアプリケーションで性能比較を実施しました 主に使用した計算機は以下のものです
Microsoft PowerPoint - 発表II-3原稿r02.ppt [互換モード]
![Microsoft PowerPoint - 発表II-3原稿r02.ppt [互換モード]](/thumbs/91/105561911.jpg "Microsoft PowerPoint - 発表II-3原稿r02.ppt [互換モード]") 地震時の原子力発電所燃料プールからの溢水量解析プログラム 地球工学研究所田中伸和豊田幸宏 Central Research Institute of Electric Power Industry 1 1. はじめに ( その 1) 2003 年十勝沖地震では 震源から離れた苫小牧地区の石油タンクに スロッシング ( 液面揺動 ) による火災被害が生じた 2007 年中越沖地震では 原子力発電所内の燃料プールからの溢水があり
地震時の原子力発電所燃料プールからの溢水量解析プログラム 地球工学研究所田中伸和豊田幸宏 Central Research Institute of Electric Power Industry 1 1. はじめに ( その 1) 2003 年十勝沖地震では 震源から離れた苫小牧地区の石油タンクに スロッシング ( 液面揺動 ) による火災被害が生じた 2007 年中越沖地震では 原子力発電所内の燃料プールからの溢水があり
[4] ACP (Advanced Communication Primitives) [1] ACP ACP [2] ACP Tofu UDP [3] HPC InfiniBand InfiniBand ACP 2 ACP, 3 InfiniBand ACP 4 5 ACP 2. ACP ACP
![[4] ACP (Advanced Communication Primitives) [1] ACP ACP [2] ACP Tofu UDP [3] HPC InfiniBand InfiniBand ACP 2 ACP, 3 InfiniBand ACP 4 5 ACP 2. ACP ACP](/thumbs/88/116107914.jpg "[4] ACP (Advanced Communication Primitives) [1] ACP ACP [2] ACP Tofu UDP [3] HPC InfiniBand InfiniBand ACP 2 ACP, 3 InfiniBand ACP 4 5 ACP 2. ACP ACP") InfiniBand ACP 1,5,a) 1,5,b) 2,5 1,5 4,5 3,5 2,5 ACE (Advanced Communication for Exa) ACP (Advanced Communication Primitives) HPC InfiniBand ACP InfiniBand ACP ACP InfiniBand Open MPI 20% InfiniBand Implementation
InfiniBand ACP 1,5,a) 1,5,b) 2,5 1,5 4,5 3,5 2,5 ACE (Advanced Communication for Exa) ACP (Advanced Communication Primitives) HPC InfiniBand ACP InfiniBand ACP ACP InfiniBand Open MPI 20% InfiniBand Implementation
Microsoft Word ●MPI性能検証_志田_ _更新__ doc
 2.2.2. MPI 性能検証 富士通株式会社 志田直之 ここでは,Open MPI および富士通 MPI を用いて,MPI 性能の評価結果について報告する 1. 性能評価のポイント MPI の性能評価は, 大きく 3 つに分けて評価を行った プロセス数増加に向けた検証 ノード内通信とノード間通信の検証 性能検証 - 連続データ転送 - ストライド転送 2. プロセス数増加に向けた検証 評価に用いたシステムを以下に示す
2.2.2. MPI 性能検証 富士通株式会社 志田直之 ここでは,Open MPI および富士通 MPI を用いて,MPI 性能の評価結果について報告する 1. 性能評価のポイント MPI の性能評価は, 大きく 3 つに分けて評価を行った プロセス数増加に向けた検証 ノード内通信とノード間通信の検証 性能検証 - 連続データ転送 - ストライド転送 2. プロセス数増加に向けた検証 評価に用いたシステムを以下に示す
Microsoft PowerPoint - sales2.ppt
 最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
Microsoft PowerPoint - CCS学際共同boku-08b.ppt
 マルチコア / マルチソケットノードに おけるメモリ性能のインパクト 研究代表者朴泰祐筑波大学システム情報工学研究科 taisuke@cs.tsukuba.ac.jp アウトライン 近年の高性能 PC クラスタの傾向と問題 multi-core/multi-socket ノードとメモリ性能 メモリバンド幅に着目した性能測定 multi-link network 性能評価 まとめ 近年の高性能 PC
マルチコア / マルチソケットノードに おけるメモリ性能のインパクト 研究代表者朴泰祐筑波大学システム情報工学研究科 taisuke@cs.tsukuba.ac.jp アウトライン 近年の高性能 PC クラスタの傾向と問題 multi-core/multi-socket ノードとメモリ性能 メモリバンド幅に着目した性能測定 multi-link network 性能評価 まとめ 近年の高性能 PC
<4D F736F F F696E74202D20906C8D488AC28BAB90DD8C7689F090CD8D488A D91E F1>
 人工環境設計解析工学構造力学と有限要素法 ( 第 回 ) 東京大学新領域創成科学研究科 鈴木克幸 固体力学の基礎方程式 変位 - ひずみの関係 適合条件式 ひずみ - 応力の関係 構成方程式 応力 - 外力の関係 平衡方程式 境界条件 変位規定境界 反力規定境界 境界条件 荷重応力ひずみ変形 場の方程式 Γ t Γ t 平衡方程式構成方程式適合条件式 構造力学の基礎式 ひずみ 一軸 荷重応力ひずみ変形
人工環境設計解析工学構造力学と有限要素法 ( 第 回 ) 東京大学新領域創成科学研究科 鈴木克幸 固体力学の基礎方程式 変位 - ひずみの関係 適合条件式 ひずみ - 応力の関係 構成方程式 応力 - 外力の関係 平衡方程式 境界条件 変位規定境界 反力規定境界 境界条件 荷重応力ひずみ変形 場の方程式 Γ t Γ t 平衡方程式構成方程式適合条件式 構造力学の基礎式 ひずみ 一軸 荷重応力ひずみ変形
NS NS Scalar turbulence 5 6 FEM NS Mesh (A )
") 22 3 2 1 2 2 2 3 3 4 NS 4 4.1 NS............ 5 5 Scalar turbulence 5 6 FEM 5 6.1 NS.................................... 6 6.2 Mes A )................................... 6 6.3.....................................
22 3 2 1 2 2 2 3 3 4 NS 4 4.1 NS............ 5 5 Scalar turbulence 5 6 FEM 5 6.1 NS.................................... 6 6.2 Mes A )................................... 6 6.3.....................................
PowerPoint プレゼンテーション
 応用数理概論 準備 端末上で cd ~/ mkdir cppwork cd cppwork wget http://271.jp/gairon/main.cpp wget http://271.jp/gairon/matrix.hpp とコマンドを記入. ls とコマンドをうち,main.cppとmatrix.hppがダウンロードされていることを確認. 1 準備 コンパイル c++ -I. -std=c++0x
応用数理概論 準備 端末上で cd ~/ mkdir cppwork cd cppwork wget http://271.jp/gairon/main.cpp wget http://271.jp/gairon/matrix.hpp とコマンドを記入. ls とコマンドをうち,main.cppとmatrix.hppがダウンロードされていることを確認. 1 準備 コンパイル c++ -I. -std=c++0x
PowerPoint Presentation
 GF(2) 上疎行列線形解法の 現状と評価 中央大学 21 世紀 COE プログラム JST CREST 西田晃 July 8, 2006 JSIAM JANT Conference 1 背景 情報システムの安全性 公開鍵暗号システムに依存 最新の計算機環境による素因数分解のコストを常に正確に評価する必要 July 8, 2006 JSIAM JANT Conference 2 関連研究 公開鍵暗号
GF(2) 上疎行列線形解法の 現状と評価 中央大学 21 世紀 COE プログラム JST CREST 西田晃 July 8, 2006 JSIAM JANT Conference 1 背景 情報システムの安全性 公開鍵暗号システムに依存 最新の計算機環境による素因数分解のコストを常に正確に評価する必要 July 8, 2006 JSIAM JANT Conference 2 関連研究 公開鍵暗号
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司
![4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司](/thumbs/97/131936032.jpg "4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司") 4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
about MPI
 本日 (4/16) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
本日 (4/16) の内容 1 並列計算の概要 並列化計算の目的 並列コンピュータ環境 並列プログラミングの方法 MPI を用いた並列プログラミング 並列化効率 2 並列計算の実行方法 Hello world モンテカルロ法による円周率計算 並列計算のはじまり 並列計算の最初の構想を イギリスの科学者リチャードソンが 1922 年に発表 < リチャードソンの夢 > 64000 人を円形の劇場に集めて
PowerPoint プレゼンテーション
 PC クラスタシンポジウム 日立のテクニカルコンピューティングへの取り組み 2010/12/10 株式会社日立製作所中央研究所清水正明 1 目次 1 2 3 日立テクニカルサーバラインナップ 日立サーバラインナップ GPU コンピューティングへの取り組み 4 SC10 日立展示 2 1-1 日立テクニカルサーバ : History & Future Almost 30 Years of Super
PC クラスタシンポジウム 日立のテクニカルコンピューティングへの取り組み 2010/12/10 株式会社日立製作所中央研究所清水正明 1 目次 1 2 3 日立テクニカルサーバラインナップ 日立サーバラインナップ GPU コンピューティングへの取り組み 4 SC10 日立展示 2 1-1 日立テクニカルサーバ : History & Future Almost 30 Years of Super
 iphone GPGPU GPU OpenCL Mac OS X Snow LeopardOpenCL iphone OpenCL OpenCL NVIDIA GPU CUDA GPU GPU GPU 15 GPU GPU CPU GPU iii OpenMP MPI CPU OpenCL CUDA OpenCL CPU OpenCL GPU NVIDIA Fermi GPU Fermi GPU GPU
iphone GPGPU GPU OpenCL Mac OS X Snow LeopardOpenCL iphone OpenCL OpenCL NVIDIA GPU CUDA GPU GPU GPU 15 GPU GPU CPU GPU iii OpenMP MPI CPU OpenCL CUDA OpenCL CPU OpenCL GPU NVIDIA Fermi GPU Fermi GPU GPU
PowerPoint プレゼンテーション
 スーパーコンピュータのネットワーク 情報ネットワーク特論 南里豪志 ( 九州大学情報基盤研究開発センター ) 1 今日の講義内容 スーパーコンピュータとは どうやって計算機を速くするか スーパーコンピュータのネットワーク 2 スーパーコンピュータとは? " スーパー " な計算機 = その時点で 一般的な計算機の性能をはるかに超える性能を持つ計算機 スーパーコンピュータの用途 主に科学技術分野 創薬
スーパーコンピュータのネットワーク 情報ネットワーク特論 南里豪志 ( 九州大学情報基盤研究開発センター ) 1 今日の講義内容 スーパーコンピュータとは どうやって計算機を速くするか スーパーコンピュータのネットワーク 2 スーパーコンピュータとは? " スーパー " な計算機 = その時点で 一般的な計算機の性能をはるかに超える性能を持つ計算機 スーパーコンピュータの用途 主に科学技術分野 創薬
Autodesk Inventor Skill Builders Autodesk Inventor 2010 構造解析の精度改良 メッシュリファインメントによる収束計算 予想作業時間:15 分 対象のバージョン:Inventor 2010 もしくはそれ以降のバージョン シミュレーションを設定する際
 Autodesk Inventor Skill Builders Autodesk Inventor 2010 構造解析の精度改良 メッシュリファインメントによる収束計算 予想作業時間:15 分 対象のバージョン:Inventor 2010 もしくはそれ以降のバージョン シミュレーションを設定する際に 収束判定に関するデフォルトの設定をそのまま使うか 修正をします 応力解析ソルバーでは計算の終了を判断するときにこの設定を使います
Autodesk Inventor Skill Builders Autodesk Inventor 2010 構造解析の精度改良 メッシュリファインメントによる収束計算 予想作業時間:15 分 対象のバージョン:Inventor 2010 もしくはそれ以降のバージョン シミュレーションを設定する際に 収束判定に関するデフォルトの設定をそのまま使うか 修正をします 応力解析ソルバーでは計算の終了を判断するときにこの設定を使います
NUMAの構成
 共有メモリを使ったデータ交換と同期 慶應義塾大学理工学部 天野英晴 hunga@am.ics.keio.ac.jp 同期の必要性 あるプロセッサが共有メモリに書いても 別のプロセッサにはそのことが分からない 同時に同じ共有変数に書き込みすると 結果がどうなるか分からない そもそも共有メモリって結構危険な代物 多くのプロセッサが並列に動くには何かの制御機構が要る 不可分命令 同期用メモリ バリア同期機構
共有メモリを使ったデータ交換と同期 慶應義塾大学理工学部 天野英晴 hunga@am.ics.keio.ac.jp 同期の必要性 あるプロセッサが共有メモリに書いても 別のプロセッサにはそのことが分からない 同時に同じ共有変数に書き込みすると 結果がどうなるか分からない そもそも共有メモリって結構危険な代物 多くのプロセッサが並列に動くには何かの制御機構が要る 不可分命令 同期用メモリ バリア同期機構
今後の予定 6/29 パターン形成第 11 回 7/6 データ解析第 12 回 7/13 群れ行動 ( 久保先生 ) 第 13 回 7/17 ( 金 ) 休講 7/20 まとめ第 14 回 7/27 休講?
 第 13 回 7/17 ( 金 ) 休講 7/20 まとめ第 14 回 7/27 休講?") 今後の予定 6/29 パターン形成第 11 回 7/6 データ解析第 12 回 7/13 群れ行動 ( 久保先生 ) 第 13 回 7/17 ( 金 ) 休講 7/20 まとめ第 14 回 7/27 休講? 数理生物学演習 第 11 回パターン形成 本日の目標 2 次元配列 分子の拡散 反応拡散モデル チューリングパタン 拡散方程式 拡散方程式 u t = D 2 u 拡散が生じる分子などの挙動を記述する.
今後の予定 6/29 パターン形成第 11 回 7/6 データ解析第 12 回 7/13 群れ行動 ( 久保先生 ) 第 13 回 7/17 ( 金 ) 休講 7/20 まとめ第 14 回 7/27 休講? 数理生物学演習 第 11 回パターン形成 本日の目標 2 次元配列 分子の拡散 反応拡散モデル チューリングパタン 拡散方程式 拡散方程式 u t = D 2 u 拡散が生じる分子などの挙動を記述する.
スライド 1
 大規模連立一次方程式に対する 高並列前処理技術について 今倉暁筑波大学計算科学研究センター 共同研究者櫻井鉄也 ( 筑波大学 ), 住吉光介 ( 沼津高専 ), 松古栄夫 (KEK) 1 /49 本日のトピック 大規模連立一次方程式 のための ( 前処理付き )Krylov 部分空間法の概略について紹介する. 高並列性を考慮した前処理として, 反復法を用いた重み付き定常反復型前処理を導入し, そのパラメータを最適化手法を提案
大規模連立一次方程式に対する 高並列前処理技術について 今倉暁筑波大学計算科学研究センター 共同研究者櫻井鉄也 ( 筑波大学 ), 住吉光介 ( 沼津高専 ), 松古栄夫 (KEK) 1 /49 本日のトピック 大規模連立一次方程式 のための ( 前処理付き )Krylov 部分空間法の概略について紹介する. 高並列性を考慮した前処理として, 反復法を用いた重み付き定常反復型前処理を導入し, そのパラメータを最適化手法を提案
untitled
 AMD HPC GP-GPU Opteron HPC 2 1 AMD Opteron 85 FLOPS 10,480 TOP500 16 T2K 95 FLOPS 10,800 140 FLOPS 15,200 61 FLOPS 7,200 3 Barcelona 4 2 AMD Opteron CPU!! ( ) L1 5 2003 2004 2005 2006 2007 2008 2009 2010
AMD HPC GP-GPU Opteron HPC 2 1 AMD Opteron 85 FLOPS 10,480 TOP500 16 T2K 95 FLOPS 10,800 140 FLOPS 15,200 61 FLOPS 7,200 3 Barcelona 4 2 AMD Opteron CPU!! ( ) L1 5 2003 2004 2005 2006 2007 2008 2009 2010
修士論文
 AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
Microsoft PowerPoint rev.pptx
 研究室紹介 卒業研究テーマ紹介 木村拓馬 佐賀大学理工学部知能情報システム学科第 2 研究グループ 第 2 研究グループ -- 木村拓馬 : 卒業研究テーマ紹介 (2016/2/16) 1/15 木村の専門分野 応用数学 ( 数値解析 最適化 ) 内容 : 数学 + 計算機 数学の理論に裏付けされた 良い 計算方法 良さ を計算機で検証する方法について研究 目標は でかい 速い 正確 第 2 研究グループ
研究室紹介 卒業研究テーマ紹介 木村拓馬 佐賀大学理工学部知能情報システム学科第 2 研究グループ 第 2 研究グループ -- 木村拓馬 : 卒業研究テーマ紹介 (2016/2/16) 1/15 木村の専門分野 応用数学 ( 数値解析 最適化 ) 内容 : 数学 + 計算機 数学の理論に裏付けされた 良い 計算方法 良さ を計算機で検証する方法について研究 目標は でかい 速い 正確 第 2 研究グループ
main.dvi
 PC 1 1 [1][2] [3][4] ( ) GPU(Graphics Processing Unit) GPU PC GPU PC ( 2 GPU ) GPU Harris Corner Detector[5] CPU ( ) ( ) CPU GPU 2 3 GPU 4 5 6 7 1 toyohiro@isc.kyutech.ac.jp 45 2 ( ) CPU ( ) ( ) () 2.1
PC 1 1 [1][2] [3][4] ( ) GPU(Graphics Processing Unit) GPU PC GPU PC ( 2 GPU ) GPU Harris Corner Detector[5] CPU ( ) ( ) CPU GPU 2 3 GPU 4 5 6 7 1 toyohiro@isc.kyutech.ac.jp 45 2 ( ) CPU ( ) ( ) () 2.1
目次 LS-DYNA 利用の手引き 1 1. はじめに 利用できるバージョン 概要 1 2. TSUBAME での利用方法 使用可能な LS-DYNA の実行 4 (1) TSUBAMEにログイン 4 (2) バージョンの切り替え 4 (3) インタラ
 TSUBAMEにログイン 4 (2) バージョンの切り替え 4 (3) インタラ") LS-DYNA 利用の手引 東京工業大学学術国際情報センター 2016.04 version 1.10 目次 LS-DYNA 利用の手引き 1 1. はじめに 1 1.1 利用できるバージョン 1 1.2 概要 1 2. TSUBAME での利用方法 1 2.1 使用可能な 1 2.2 LS-DYNA の実行 4 (1) TSUBAMEにログイン 4 (2) バージョンの切り替え 4 (3) インタラクティブ実行
LS-DYNA 利用の手引 東京工業大学学術国際情報センター 2016.04 version 1.10 目次 LS-DYNA 利用の手引き 1 1. はじめに 1 1.1 利用できるバージョン 1 1.2 概要 1 2. TSUBAME での利用方法 1 2.1 使用可能な 1 2.2 LS-DYNA の実行 4 (1) TSUBAMEにログイン 4 (2) バージョンの切り替え 4 (3) インタラクティブ実行
_計算科学が拓く世界.key
 11 3 @takeshi_enomoto enomoto.takeshi.3n@kyoto-u.ac.jp 2017 12 13 5 bbc.com pakistantoday.com.pk 1 V. Bjerknes (1904) L. F. Richardson (1922)... 145 hpa/6h J. Charney, R. Fjørtoft and J. von Neuman
11 3 @takeshi_enomoto enomoto.takeshi.3n@kyoto-u.ac.jp 2017 12 13 5 bbc.com pakistantoday.com.pk 1 V. Bjerknes (1904) L. F. Richardson (1922)... 145 hpa/6h J. Charney, R. Fjørtoft and J. von Neuman
GPGPU
 GPGPU 2013 1008 2015 1 23 Abstract In recent years, with the advance of microscope technology, the alive cells have been able to observe. On the other hand, from the standpoint of image processing, the
GPGPU 2013 1008 2015 1 23 Abstract In recent years, with the advance of microscope technology, the alive cells have been able to observe. On the other hand, from the standpoint of image processing, the
スパコンに通じる並列プログラミングの基礎
 2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
並列計算導入.pptx
 並列計算の基礎 MPI を用いた並列計算 並列計算の環境 並列計算 複数の計算ユニット(PU, ore, Pなど を使用して 一つの問題 計算 を行わせる 近年 並列計算を手軽に使用できる環境が急速に整いつつある >通常のP PU(entral Processing Unit)上に計算装置であるoreが 複数含まれている Intel ore i7 シリーズ: 4つの計算装置(ore) 通常のプログラム
並列計算の基礎 MPI を用いた並列計算 並列計算の環境 並列計算 複数の計算ユニット(PU, ore, Pなど を使用して 一つの問題 計算 を行わせる 近年 並列計算を手軽に使用できる環境が急速に整いつつある >通常のP PU(entral Processing Unit)上に計算装置であるoreが 複数含まれている Intel ore i7 シリーズ: 4つの計算装置(ore) 通常のプログラム
FFT
 ACTRAN for NASTRAN Product Overview Copyright Free Field Technologies ACTRAN Modules ACTRAN for NASTRAN ACTRAN DGM ACTRAN Vibro-Acoustics ACTRAN Aero-Acoustics ACTRAN TM ACTRAN Acoustics ACTRAN VI 2 Copyright
ACTRAN for NASTRAN Product Overview Copyright Free Field Technologies ACTRAN Modules ACTRAN for NASTRAN ACTRAN DGM ACTRAN Vibro-Acoustics ACTRAN Aero-Acoustics ACTRAN TM ACTRAN Acoustics ACTRAN VI 2 Copyright