GPU 画像 動画処理用ハードウェア 低性能なプロセッサがたくさん詰まっている ピーク性能が非常に高い GPUを数値計算に用いるのがGPGPU Graphics Processing Unit General Purpose GPU TSUBAME2.0: GPUスパコン 本演習ではNVIDIA社の
|
|
|
- さや こしの
- 5 years ago
- Views:
Transcription
1 演習II (連続系アルゴリズム) 第2回: GPGPU 須田研究室 M1 本谷 徹 2012/10/19
2 GPU 画像 動画処理用ハードウェア 低性能なプロセッサがたくさん詰まっている ピーク性能が非常に高い GPUを数値計算に用いるのがGPGPU Graphics Processing Unit General Purpose GPU TSUBAME2.0: GPUスパコン 本演習ではNVIDIA社のGPUを用いる CUDA プログラミングをしてもらいます
3 性能指標 (1) FLOPS Floating point operations per second 1秒あたりに何回浮動小数点数演算ができるか TOP500 ( ) にスパコンのLINPACK 性能, ピーク性能が載っている ピーク性能 (理論性能): 物理的な性能の限界 性能を測る際の目標 Xeon X 数十GFLOPS Tesla M 倍精度: 515 Gflops 単精度: 1.03 Tflops GPU はピーク性能に近づけるのが難しい
4 性能指標 (2) バンド幅 通信帯域 1秒あたりにどれだけデータが送れるか Tesla M2050 の理論値は 148 GB/sec GPU内のプロセッサ メモリ間のバンド幅

5


6 GPU アーキテクチャ SP: SM: Cuda core Multiprocessor
7 GPU の情報を調べるには? devicequery コマンドを使う csc ではログインノードで実行してもGPUが無い ジョブに書いて投げてください 計算ノードに入ればGPUが見えます GPUの情報がたくさん返ってくる コア数 メモリ量 メインメモリ キャッシュ 共有メモリ Warp cudagetdevcieproperties を呼ぶ
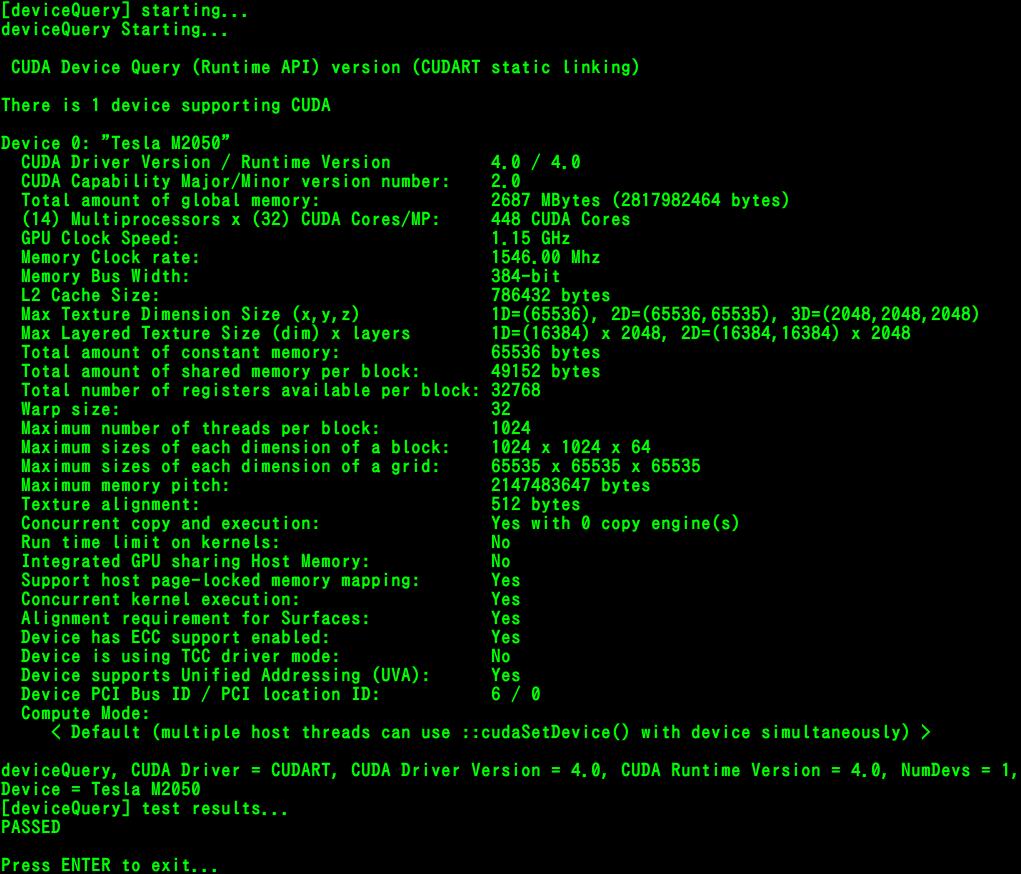
8
9 CUDAプログラミング Compute Unified Device Architecture プログラミングモデルはSPMD CPUからGPUを呼び出す GPUでの命令処理はSIMD CPUをホスト GPUをデバイスと呼んで区別 Single Instruction Multiple Data C, C++ の拡張として実装されている 拡張子は *.cu コンパイラはnvcc #include<cuda.h>, #include<cuda_runtime.h> csc では Torque を通して実行してください ノード は 1つ
 ブロック処理はSMに割り当てられる ブロックの中にはスレッドが3次元的に配置される 1つのブロックの最大スレッド数は512 各辺の最大は512 x 512 x 64 スレッドは平行に処理される")
10 CUDAのスレッド管理 実際のSP数よりはるかに多いスレッドを走らせることができる スレッドは階層的になっている グリッドにスレッドを詰め込んで その中にあるスレッドをまとめて実行 グリッドの中にはブロックが2次元的に配置される 1辺の長さは最大で65535 各辺の最大は65535 x (x1) ブロック処理はSMに割り当てられる ブロックの中にはスレッドが3次元的に配置される 1つのブロックの最大スレッド数は512 各辺の最大は512 x 512 x 64 スレッドは平行に処理される スレッド処理はSPに割り当てられる
11 ベクトル型 dim3 宣言 3次元ベクトル整数型 x,y,z の要素を持つ構造体のようなもの 要素は全て1で初期化されている dim3 hoge(8, 9, 10); dim3 hoge; hoge.x = 8; hoge.y = 9; hoge.z = 10; dim3 hoge = {8, 9, 10}; dim3 に似たものに uint3 (符号無整数ベクトル型)がある uint3 は構造体と同じ扱いをする unit3 と同様のものとしてshort3, float3, float4 などが用意されている float4 のメンバは x,y,z,w
12 カーネル関数 (1) CPUから直接呼び出され GPUで計算する関数をカーネル関数と呼ぶ 普通の関数呼び出しに <<<>>> をかませるだけ cf. function<<<dg, Db>>>(a, b, c); Dg, Db はdim3 変数 Dg にはグリッドに詰めるブロックの数を渡す Db には1つのブロックに詰めるスレッドの数を渡す 個々のスレッドの処理をカーネル関数に記述する uint3 blockidx, uint3 threadidx, dim3 griddim, dim3 blockdim の4つが それぞれ予め用意されていてカーネル関数内からアクセスできる blockidx の値を読み出して自分のブロック番号を知る threadidx の値を読み出して自分のブロックにおける自分のスレッド番号を知る griddim には上記Dg の値がそのまま入る blockdim には上記Gb の値がそのまま入る
13 カーネル関数 (2) GPU(カーネル関数) とCPUは非同期に実行 cudathreadsynchronize() で同期を取る カーネル関数どうしは基本的には同期的 時間の測り方 struct timeval t0,t1; gettimeofday(&t0, NULL); KernelFunction<<<Grid, Thread>>>(Args); cudathreadsynchronize(); gettimeofday(&t1, NULL); printf( Elapsed time = %lf\n, (double)(t1.tv_sec t0.tv_sec) + (double)(t1.tv_usec t0.tv_usec) /(1000*1000)); float f; cudaevent_t event[2]; For (i=0; i<2; i++) cudaeventcreate(&event[i], 0); cudaeventrecord(event[0], stream_1); KernelFunction<<<G,T,0,stream_1>>>(Args); cudaeventrecord(event[1],stream_1); cudaeventsynchronize(event[1]); cudaeventelapsedtime(&f, event[0], event[1]); printf( Elapsed time = %lf\n, f*1000)
14 関数修飾詞 global device カーネル関数に付く修飾詞 ちなみにカーネル関数の返り値は voidである カーネル関数以外でデバイスのみで実行される関数に付く 同じく void型の関数に付く host ホストで実行される関数の修飾詞 省略可
15 GPU のメモリ階層 名称 アクセス 速度 レジスタ 自分のスレッドのみ 4 cycle 共有メモリ 同じMultiprocessor内にあるスレッド syncthreads() で同期 デバイスメモリ 同じGPU内にある全てのスレッド 500 cycle 同期にカーネル関数再呼び出しが必要 キャッシュされる 定数メモリ 全てのスレッド キャッシュされる ローカルメモリ レジスタが溢れると使われる デバイスメモリ上に置かれる 12 cycle hit: 20 cycle miss: 500 cycle 500 cycle
16 メモリ操作関数 cudaerror_t cudasuccess cudaerror_t cudamalloc(void **devptr, size_t count) GPUのデバイスメモリに配列を確保する関数 cudaerror_t cudafree(void *devptr) CUDA関数が成功したときに返る値 確保したデバイスメモリの配列を開放する関数 cudaerror_t cudamemcpy(void *dst, const void *src, size_t count, enum cudamemcpukind kind) src からdstにメモリ転送する関数 kind には 以下の3種類を指定 cudamemcpyhosttodevice cudamemcpydevicetohost cudamemcpydevicetodevice (CPUからGPU) (GPUからCPU) (GPUからGPU) CPU から直接デバイスメモリをいじることはできない
17 メモリ修飾詞 device constant 定数メモリを修飾する 関数外に宣言する 初期化するかcudaMemcpyToSymbol()で転送する shared デバイスメモリを静的に宣言する場合に修飾させる 関数外に宣言する cudamemcpytosymbol()で転送する 共有メモリを修飾する カーネル関数内に宣言する cudaerror_t cudamemcpytosymbol(const char *symbol, const void *src, sizt_t count, size_t offset, enum cudamemcpykind kind) offset = 0, kind = cudamemcpyhosttodevice
18 デバイス操作関数 cudaerror_t cudagetdevicecount(int *count) cudaerror_t cudagetdevcieproperties( struct cudadeviceprop *prop, int device) デバイスのプロパティがpropに入って返ってくる関数 cudaerror_t cudasetdevice(int device) 使用可能なデバイスの数がcount に入って返ってくる関数 使用するデバイスを指定する関数 使用できるデバイスはCPU 1スレッドにつき 1個まで cudaerror_t cudagetdevice(int *device) 現在使用しているデバイス番号がdevice に入って返ってくる関数
19 サンプルコード ベクトルの和計算 global void AddVector_GPU(float *a, float *b, float *c, int size){ int index = blockidx.x * blockdim.x + threadidx.x; if(index<size) c[index] = a[index] + b[index]; } float *dev_a, *dev_b, *dev_c; cudamalloc((void**)&dev_a, sizeof(float)*n); cudamalloc((void**)&dev_b, sizeof(float)*n); cudamalloc((void**)&dev_c, sizeof(float)*n); dim3 Grid, Block; Block.x = 196; Grid.x = N/ ; cudamemcpy(dev_a, a, sizeof(float)*n, cudamemcpyhosttodevice); cudamemcpy(dev_b, b, sizeof(float)*n, cudamemcpyhosttodevice); AddVector_GPU<<<Grid, Block>>>(dev_a, dev_b, dev_c, N); cudathreadsynchronize(); cudamemcpy(c, dev_c, sizeof(float)*n, cudamemcpydevicetohost); cudafree(dev_a); cudafree(dev_b); cudafree(dev_c);
20 Warp (1) GPUはSIMD型の命令実行を行う 同じ命令を32個のスレッドが同時に実行する Warp はout-of-order 実行 8つのSPが4cycle かけて実行する 同時実行する32個のスレッド単位をWarp(縦糸)と呼ぶ 準備のできたWarpから実行していく int 型の組み込み変数warpSize がカーネル関数 に用意されている もちろん 32
 B; else")
21 Warp (2) GPUでは条件分岐の分岐先が全て 実行される 有効なスレッドの結果のみが反映 不必要な命令実行が発生する このことをWarp divergence と呼ぶ なるべくWarp divergence は避ける if(a) B; else C;
22 デバイスメモリの coalescing メモリアクセスは16スレッドが同時に行う グローバルメモリのアクセス及び転送は以下の3つ (Compute capability 1.2 以上) Warp の半分 32バイト境界でアラインメントされた32バイト 64バイト境界でアラインメントされた64バイト 128バイト境界でアラインメントされた128バイト 同時に行われるメモリアクセスはなるべく少なく済ます 同時に発生するメモリアクセスの場所をできるだけ固まらせ かつでき るだけ同じアラインメント内に納めることを coalescing と呼ぶ
23 共有メモリ (1) GPUでのソフトウェアキャッシュ グローバルメモリより非常に高速 プログラムに明示的に記述する 同じブロック内のスレッドがアクセスできる カーネル関数に shared 修飾詞を付けて宣言 syncthreads() を用いて同期を取る必要がある
24 共有メモリ (2) 共有メモリも16 スレッドが同時にアクセスする 32個のバンクで構成されている 各バンクに対して1回につき1つのアドレスにアクセス 16スレッドがそれぞれ別のバンクにアクセスしたい 1つでもバンクが被ることをバンクコンフリクトと呼ぶ バンクコンフリクトはなるべく避ける
25 初級CUDA (6) 共有メモリ (3) Bank conflict が発生しているケース shared float s[n]; s[threadidx.x*2] = f(x);

26 初級CUDA (7) 共有メモリ (4) Bank conflict が発生していないケース shared float s[n]; s[threadidx.x] = f(x);
27 ループアンローリング for ループは展開したい 回数が定数なら nvccが展開してくれる #pragma unroll をforループの直前に書くことで 明示的に展開できる #pragma unroll n とすることで n回分展開される #pragma unroll 1 で展開されなくなる #pragma unroll 4 for(i=0; i<n; i++){ y[i] = f(x[i]); } for(i=0;i<n-4;i+=4){ y[i] = f(x[i]); y[i+1] = f(x[i+1]); y[i+2] = f(x[i+2]); y[i+3] = f(x[i+3]); } for(;i<n;i++){ y[i] = f(x[i]); }
28 第2回課題 差分法で偏微分方程式の数値シミュレーションをせよ 陽解法を使って2次元拡散方程式を解いてください 初期条件: 境界以外全て 1.0 境界条件: 境界において常に0 0 < r < 0.25 計算領域は任意 上限反復回数は100回 まずはCPUで実装してください GPUを用いて高速化をしてください CPU, GPU ともに FLOPS, GB/s をそれぞれ測定してください 上記方程式1回当たり6FLOPSとしてください
29 補足 (1) 偏微分方程式 偏導関数を含む等式 2種類以上の変数で偏微分されている 空間方向 時間方向など 常微分方程式は特殊な偏微分方程式 境界条件 初期条件が解を決定づける 解析的に解くのは困難もしくは不可能 計算機を用いて数値解を求める 空間 時間それぞれに関して離散化して数値計算する
30 補足 (2) 偏微分方程式と有限差分法 連続な偏微分方程式を離散化して解く手法 有限差分法は最も簡易かつ明解な方法の1つ 偏微分されている方向に向かって格子を生成する それぞれの格子の点に対して微分を差分に置き換 えて値を求める

31 補足 (2) 偏微分方程式と有限差分法 連続な偏微分方程式を離散化して解く手法 有限差分法は最も簡易かつ明解な方法の1つ 偏微分されている方向に向かって格子を生成する それぞれの格子の点に対して微分を差分に置き換 えて値を求める
32 補足 (3) 偏導関数と離散化誤差 例としてx軸方向の2階偏導関数 Taylor 展開を使う 離散化誤差
 時間発展型の偏微分方程式")
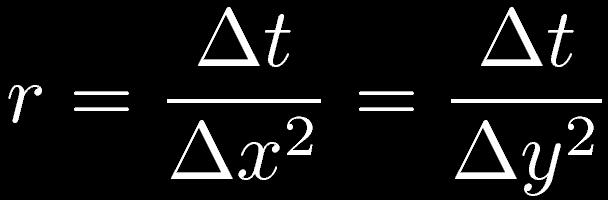
33 補足 (4) 2次元拡散方程式とその離散化 (1) 時間発展型の偏微分方程式 熱や流体中のインクの濃度が拡散していく様子を表す これを離散化する とし 未知数を左辺にもってくる
")
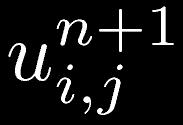
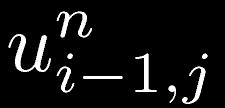
34 補足 (5) 2次元拡散方程式とその離散化 (2) 今回の課題では陽解法を使ってもらいます 前の時刻の値を用いて次の時刻の値を求めていく方法 今回の2次元拡散方程式の離散化スキームでは自分を 含めて周りの5つの点から次の自分の値を求めている 赤が現在 青が未来
35 補足 (6) ダブルバッファリング 時間発展型の偏微分方程式を解く過程において 全ての時間の値を保存していくと容量が足りない 時間を更新していくには最低で2つの領域が必要 片方の領域の数値を計算に使い もう片方の領域 に次の時間の値を埋めていく
36 課題について に提出 氏名 学籍番号 出題日を明記 レポートを pdf にした上でメールで提出 演習IIであることも明記 Subject は 演習2第 回レポート 提出者氏名 プログラム+レポート 課題の半分以上の提出が単位の取得条件 全8回を予定 締切は各課題出題日から2週間後
1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境 Lin
 Windows で始める CUDA 入門 GTC 2013 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境
Windows で始める CUDA 入門 GTC 2013 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境
Slide 1
 CUDA プログラミングの基本 パート II - カーネル CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パート II カーネルの起動 GPUコードの具体像 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください GPU 上でのコードの実行 カーネルは C 関数 + 多少の制約 ホストメモリはアクセスできない戻り値型は
CUDA プログラミングの基本 パート II - カーネル CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パート II カーネルの起動 GPUコードの具体像 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください GPU 上でのコードの実行 カーネルは C 関数 + 多少の制約 ホストメモリはアクセスできない戻り値型は
CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン
 CUDA 画像処理入門 エヌビディアジャパン CUDA エンジニア森野慎也 GTC Japan 2014 CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン RGB Y( 輝度 ) 変換 カラー画像から グレイスケールへの変換 Y = 0.299 R + 0.587
CUDA 画像処理入門 エヌビディアジャパン CUDA エンジニア森野慎也 GTC Japan 2014 CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン RGB Y( 輝度 ) 変換 カラー画像から グレイスケールへの変換 Y = 0.299 R + 0.587
TSUBAME2.0におけるGPUの 活用方法
 GPU プログラミング 基礎編 東京工業大学学術国際情報センター 1. GPU コンピューティングと TSUBAME2.0 スーパーコンピュータ GPU コンピューティングとは グラフィックプロセッサ (GPU) は グラフィック ゲームの画像計算のために 進化を続けてきた 現在 CPU のコア数は 2~12 個に対し GPU 中には数百コア その GPU を一般アプリケーションの高速化に利用! GPGPU
GPU プログラミング 基礎編 東京工業大学学術国際情報センター 1. GPU コンピューティングと TSUBAME2.0 スーパーコンピュータ GPU コンピューティングとは グラフィックプロセッサ (GPU) は グラフィック ゲームの画像計算のために 進化を続けてきた 現在 CPU のコア数は 2~12 個に対し GPU 中には数百コア その GPU を一般アプリケーションの高速化に利用! GPGPU
07-二村幸孝・出口大輔.indd
 GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
Microsoft PowerPoint - GPGPU実践基礎工学(web).pptx
.pptx") GPU のプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU プログラミング環境 (CUDA) GPU プログラムの実行の流れ CUDA によるプログラムの記述 カーネル (GPU で処理する関数 ) の構造 記述方法とその理由 GPU 固有のパラメータの確認 405 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ
GPU のプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU プログラミング環境 (CUDA) GPU プログラムの実行の流れ CUDA によるプログラムの記述 カーネル (GPU で処理する関数 ) の構造 記述方法とその理由 GPU 固有のパラメータの確認 405 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ
Slide 1
 CUDA プログラミングの基本 パート I - ソフトウェアスタックとメモリ管理 CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パートII カーネルの起動 GPUコードの具体項目 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください CUDA インストレーション CUDA インストレーションの構成
CUDA プログラミングの基本 パート I - ソフトウェアスタックとメモリ管理 CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パートII カーネルの起動 GPUコードの具体項目 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください CUDA インストレーション CUDA インストレーションの構成
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
untitled
 GPGPU NVIDACUDA Learn More about CUDA - NVIDIA http://www.nvidia.co.jp/object/cuda_education_jp.html NVIDIA CUDA programming Guide CUDA http://www.sintef.no/upload/ikt/9011/simoslo/evita/2008/seland.pdf
GPGPU NVIDACUDA Learn More about CUDA - NVIDIA http://www.nvidia.co.jp/object/cuda_education_jp.html NVIDIA CUDA programming Guide CUDA http://www.sintef.no/upload/ikt/9011/simoslo/evita/2008/seland.pdf
熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date Type URL Presentation
 榎本, 昌一 Citation Issue date Type URL Presentation") 熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date 2011-03-17 Type URL Presentation http://hdl.handle.net/2298/23539 Right GPGPU による高速演算について 榎本昌一 東京大学大学院工学系研究科システム創成学専攻
熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date 2011-03-17 Type URL Presentation http://hdl.handle.net/2298/23539 Right GPGPU による高速演算について 榎本昌一 東京大学大学院工学系研究科システム創成学専攻
NUMAの構成
 GPU のプログラム 天野 アクセラレータとは? 特定の性質のプログラムを高速化するプロセッサ 典型的なアクセラレータ GPU(Graphic Processing Unit) Xeon Phi FPGA(Field Programmable Gate Array) 最近出て来た Deep Learning 用ニューロチップなど Domain Specific Architecture 1GPGPU:General
GPU のプログラム 天野 アクセラレータとは? 特定の性質のプログラムを高速化するプロセッサ 典型的なアクセラレータ GPU(Graphic Processing Unit) Xeon Phi FPGA(Field Programmable Gate Array) 最近出て来た Deep Learning 用ニューロチップなど Domain Specific Architecture 1GPGPU:General
Microsoft PowerPoint - GPGPU実践基礎工学(web).pptx
.pptx") GPU のメモリ階層 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のメモリ階層 グローバルメモリ 共有メモリ モザイク処理への適用 コンスタントメモリ 空間フィルタへの適用 577 GPU の主要部品 基盤 GPU( チップ )+ 冷却部品 画面出力端子 電源入力端子 メモリ 特性の把握が重要 電源入力端子 画面出力端子 メモリ チップ PCI Ex 端子 http://www.geforce.com/whats
GPU のメモリ階層 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のメモリ階層 グローバルメモリ 共有メモリ モザイク処理への適用 コンスタントメモリ 空間フィルタへの適用 577 GPU の主要部品 基盤 GPU( チップ )+ 冷却部品 画面出力端子 電源入力端子 メモリ 特性の把握が重要 電源入力端子 画面出力端子 メモリ チップ PCI Ex 端子 http://www.geforce.com/whats
1. マシンビジョンにおける GPU の活用
 CUDA 画像処理入門 GTC 213 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. マシンビジョンにおける GPU の活用 1. 医用画像処理における GPU の活用 CT や MRI から画像を受信して三次元画像の構築をするシステム 2 次元スキャンデータから 3 次元 4 次元イメージの高速生成 CUDA 化により画像処理速度を約 2 倍に高速化 1. CUDA で画像処理
CUDA 画像処理入門 GTC 213 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. マシンビジョンにおける GPU の活用 1. 医用画像処理における GPU の活用 CT や MRI から画像を受信して三次元画像の構築をするシステム 2 次元スキャンデータから 3 次元 4 次元イメージの高速生成 CUDA 化により画像処理速度を約 2 倍に高速化 1. CUDA で画像処理
GPU のアーキテクチャとプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓
 GPU のアーキテクチャとプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のアーキテクチャ CUDA CUDA によるプログラミング 58 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ チップ単体では販売されていない PCI Ex カードで販売 ( チップ単体と区別せずに GPU と呼ぶことも多い
GPU のアーキテクチャとプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のアーキテクチャ CUDA CUDA によるプログラミング 58 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ チップ単体では販売されていない PCI Ex カードで販売 ( チップ単体と区別せずに GPU と呼ぶことも多い
CUDA基礎1
 CUDA 基礎 1 東京工業大学 学術国際情報センター 黄遠雄 2016/6/27 第 20 回 GPU コンピューティング講習会 1 ヘテロジニアス コンピューティング ヘテロジニアス コンピューティング (CPU + GPU) は広く使われている Financial Analysis Scientific Simulation Engineering Simulation Data Intensive
CUDA 基礎 1 東京工業大学 学術国際情報センター 黄遠雄 2016/6/27 第 20 回 GPU コンピューティング講習会 1 ヘテロジニアス コンピューティング ヘテロジニアス コンピューティング (CPU + GPU) は広く使われている Financial Analysis Scientific Simulation Engineering Simulation Data Intensive
Microsoft PowerPoint - suda.pptx
 GPU の HWアーキテクチャと高性能化手法 須田礼仁 ( 東京大学 ) 2011/03/22 GPU 高性能プログラミング GPU のハードウェアを理解する CUDA のソフトウェアを理解する CUDA でプログラムを書くのは難しくないが, CUDA で高速なプログラムを書くのは難しい どうすれば遅くなるかを理解する! 効果が大きいものから順に説明します 1 高性能プログラミングの手順 1. 現在のコードの,
GPU の HWアーキテクチャと高性能化手法 須田礼仁 ( 東京大学 ) 2011/03/22 GPU 高性能プログラミング GPU のハードウェアを理解する CUDA のソフトウェアを理解する CUDA でプログラムを書くのは難しくないが, CUDA で高速なプログラムを書くのは難しい どうすれば遅くなるかを理解する! 効果が大きいものから順に説明します 1 高性能プログラミングの手順 1. 現在のコードの,
GPGPUクラスタの性能評価
 2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
GPU GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1
 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1") GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
スライド 1
 知能制御システム学 画像処理の高速化 OpenCV による基礎的な例 東北大学大学院情報科学研究科鏡慎吾 swk(at)ic.is.tohoku.ac.jp 2007.07.03 リアルタイム処理と高速化 リアルタイム = 高速 ではない 目標となる時間制約が定められているのがリアルタイム処理である.34 ms かかった処理が 33 ms に縮んだだけでも, それによって与えられた時間制約が満たされるのであれば,
知能制御システム学 画像処理の高速化 OpenCV による基礎的な例 東北大学大学院情報科学研究科鏡慎吾 swk(at)ic.is.tohoku.ac.jp 2007.07.03 リアルタイム処理と高速化 リアルタイム = 高速 ではない 目標となる時間制約が定められているのがリアルタイム処理である.34 ms かかった処理が 33 ms に縮んだだけでも, それによって与えられた時間制約が満たされるのであれば,
Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]
![Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]](/thumbs/102/156675429.jpg "Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]") 200/0/9 数値流体解析の並列効率とその GPU による高速化の試み 清水建設 ( 株 ) 技術研究所 PHAM VAN PHUC ( ファムバンフック ) 流体計算時間短縮と GPU の活用の試み 現 CPUとの比較によりGPU 活用の可能性 現 CPU の最大利用 ノード内の最大計算資源の利用 すべてCPUコアの利用 適切なアルゴリズムの利用 CPU コア性能の何倍? GPU の利用の試み
200/0/9 数値流体解析の並列効率とその GPU による高速化の試み 清水建設 ( 株 ) 技術研究所 PHAM VAN PHUC ( ファムバンフック ) 流体計算時間短縮と GPU の活用の試み 現 CPUとの比較によりGPU 活用の可能性 現 CPU の最大利用 ノード内の最大計算資源の利用 すべてCPUコアの利用 適切なアルゴリズムの利用 CPU コア性能の何倍? GPU の利用の試み
( CUDA CUDA CUDA CUDA ( NVIDIA CUDA I
 GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
2011 年 3 月 3 日 GPGPU ハンズオンプログラミング演習 株式会社クロスアビリティ ability.jp 3 Mar 2011 Copyright (C) 2011 X-Ability Co.,Ltd. All rights reserved.
 2011 X-Ability Co.,Ltd. All rights reserved.") 2011 年 3 月 3 日 GPGPU ハンズオンプログラミング演習 株式会社クロスアビリティ rkoga@x ability.jp 講師 : 古賀良太 / 古川祐貴 取締役計算化学ソルバー XA CHEM SUITE の開発 コンサルティングパートナー 並列ソフトウェアの開発 ビルド サーバ販売 ソフトウェア代理店 会社紹介 社名株式会社クロスアビリティ (X Ability Co.,Ltd)
2011 年 3 月 3 日 GPGPU ハンズオンプログラミング演習 株式会社クロスアビリティ rkoga@x ability.jp 講師 : 古賀良太 / 古川祐貴 取締役計算化学ソルバー XA CHEM SUITE の開発 コンサルティングパートナー 並列ソフトウェアの開発 ビルド サーバ販売 ソフトウェア代理店 会社紹介 社名株式会社クロスアビリティ (X Ability Co.,Ltd)
CUDA 連携とライブラリの活用 2
 1 09:30-10:00 受付 10:00-12:00 Reedbush-H ログイン GPU 入門 13:30-15:00 OpenACC 入門 15:15-16:45 OpenACC 最適化入門と演習 17:00-18:00 OpenACC の活用 (CUDA 連携とライブラリの活用 ) CUDA 連携とライブラリの活用 2 3 OpenACC 簡単にGPUプログラムが作成できる それなりの性能が得られる
1 09:30-10:00 受付 10:00-12:00 Reedbush-H ログイン GPU 入門 13:30-15:00 OpenACC 入門 15:15-16:45 OpenACC 最適化入門と演習 17:00-18:00 OpenACC の活用 (CUDA 連携とライブラリの活用 ) CUDA 連携とライブラリの活用 2 3 OpenACC 簡単にGPUプログラムが作成できる それなりの性能が得られる
PowerPoint プレゼンテーション
 講座準備 講座資料は次の URL から DL 可能 https://goo.gl/jnrfth 1 ポインタ講座 2017/01/06,09 fumi 2 はじめに ポインタはC 言語において理解が難しいとされる そのポインタを理解することを目的とする 講座は1 日で行うので 詳しいことは調べること 3 はじめに みなさん復習はしましたか? 4 & 演算子 & 演算子を使うと 変数のアドレスが得られる
講座準備 講座資料は次の URL から DL 可能 https://goo.gl/jnrfth 1 ポインタ講座 2017/01/06,09 fumi 2 はじめに ポインタはC 言語において理解が難しいとされる そのポインタを理解することを目的とする 講座は1 日で行うので 詳しいことは調べること 3 はじめに みなさん復習はしましたか? 4 & 演算子 & 演算子を使うと 変数のアドレスが得られる
3次多項式パラメタ推定計算の CUDAを用いた実装 (CUDAプログラミングの練習として) Implementation of the Estimation of the parameters of 3rd-order-Polynomial with CUDA
 Implementation of the Estimation of the parameters of 3rd-order-Polynomial with CUDA") 3 次多項式パラメタ推定計算の CUDA を用いた実装 (CUDA プログラミングの練習として ) Estimating the Parameters of 3rd-order-Polynomial with CUDA ISS 09/11/12 問題の選択 目的 CUDA プログラミングを経験 ( 試行錯誤と習得 ) 実際に CPU のみの場合と比べて高速化されることを体験 問題 ( インプリメントする内容
3 次多項式パラメタ推定計算の CUDA を用いた実装 (CUDA プログラミングの練習として ) Estimating the Parameters of 3rd-order-Polynomial with CUDA ISS 09/11/12 問題の選択 目的 CUDA プログラミングを経験 ( 試行錯誤と習得 ) 実際に CPU のみの場合と比べて高速化されることを体験 問題 ( インプリメントする内容
1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU.....
 CPU GPU N Q07-065 2011 2 17 1 1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU...........................................
CPU GPU N Q07-065 2011 2 17 1 1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU...........................................
N 体問題 長岡技術科学大学電気電子情報工学専攻出川智啓
 N 体問題 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 天体の運動方程式 天体運動の GPU 実装 最適化による性能変化 #pragma unroll 855 計算の種類 画像処理, 差分法 空間に固定された観測点を配置 観測点 ( 固定 ) 観測点上で物理量がどのように変化するかを追跡 Euler 型 多粒子の運動 観測点を配置せず, 観測点が粒子と共に移動 Lagrange 型 観測点
N 体問題 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 天体の運動方程式 天体運動の GPU 実装 最適化による性能変化 #pragma unroll 855 計算の種類 画像処理, 差分法 空間に固定された観測点を配置 観測点 ( 固定 ) 観測点上で物理量がどのように変化するかを追跡 Euler 型 多粒子の運動 観測点を配置せず, 観測点が粒子と共に移動 Lagrange 型 観測点
Microsoft PowerPoint - 11.pptx
 ポインタと配列 ポインタと配列 配列を関数に渡す 法 課題 : 配列によるスタックの実現 ポインタと配列 (1/2) a が配列であるとき, 変数の場合と同様に, &a[0] [] の値は配列要素 a[0] のアドレス. C 言語では, 配列は主記憶上の連続領域に割り当てられるようになっていて, 配列名 a はその配列に割り当てられた領域の先頭番地となる. したがって,&a[0] と a は同じ値.
ポインタと配列 ポインタと配列 配列を関数に渡す 法 課題 : 配列によるスタックの実現 ポインタと配列 (1/2) a が配列であるとき, 変数の場合と同様に, &a[0] [] の値は配列要素 a[0] のアドレス. C 言語では, 配列は主記憶上の連続領域に割り当てられるようになっていて, 配列名 a はその配列に割り当てられた領域の先頭番地となる. したがって,&a[0] と a は同じ値.
演算増幅器
 構造体 ここまでに char int doulbe などの基本的なデータ型に加えて 同じデータ型が連続している 配列についてのデータ構造について習った これ以外にも もっと複雑なデータ型をユーザが定義 することが可能である それが構造体と呼ばれるもので 異なる型のデータをひとかたまりのデー タとして扱うことができる 異なるデータをまとめて扱いたい時とはどんな場合だろうか 例えば 住民データを管理したい
構造体 ここまでに char int doulbe などの基本的なデータ型に加えて 同じデータ型が連続している 配列についてのデータ構造について習った これ以外にも もっと複雑なデータ型をユーザが定義 することが可能である それが構造体と呼ばれるもので 異なる型のデータをひとかたまりのデー タとして扱うことができる 異なるデータをまとめて扱いたい時とはどんな場合だろうか 例えば 住民データを管理したい
GPU CUDA CUDA 2010/06/28 1
 GPU CUDA CUDA 2010/06/28 1 GPU NVIDIA Mark Harris, Optimizing Parallel Reduction in CUDA http://developer.download.nvidia.com/ compute/cuda/1_1/website/data- Parallel_Algorithms.html#reduction CUDA SDK
GPU CUDA CUDA 2010/06/28 1 GPU NVIDIA Mark Harris, Optimizing Parallel Reduction in CUDA http://developer.download.nvidia.com/ compute/cuda/1_1/website/data- Parallel_Algorithms.html#reduction CUDA SDK
概要 プログラミング論 変数のスコープ, 記憶クラス. メモリ動的確保. 変数のスコープ 重要. おそらく簡単. 記憶クラス 自動変数 (auto) と静的変数 (static). スコープほどではないが重要.
 と静的変数 (static). スコープほどではないが重要.") 概要 プログラミング論 変数のスコープ, 記憶クラス. メモリ動的確保. 変数のスコープ 重要. おそらく簡単. 記憶クラス 自動変数 (auto) と静的変数 (static). スコープほどではないが重要. http://www.ns.kogakuin.ac.jp/~ct13140/progc/ C-2 ブロック 変数のスコープ C 言語では, から をブロックという. for( ) if( )
概要 プログラミング論 変数のスコープ, 記憶クラス. メモリ動的確保. 変数のスコープ 重要. おそらく簡単. 記憶クラス 自動変数 (auto) と静的変数 (static). スコープほどではないが重要. http://www.ns.kogakuin.ac.jp/~ct13140/progc/ C-2 ブロック 変数のスコープ C 言語では, から をブロックという. for( ) if( )
GPGPUイントロダクション
 大島聡史 ( 並列計算分科会主査 東京大学情報基盤センター助教 ) GPGPU イントロダクション 1 目的 昨今注目を集めている GPGPU(GPU コンピューティング ) について紹介する GPGPU とは何か? 成り立ち 特徴 用途 ( ソフトウェアや研究例の紹介 ) 使い方 ( ライブラリ 言語 ) CUDA GPGPU における課題 2 GPGPU とは何か? GPGPU General-Purpose
大島聡史 ( 並列計算分科会主査 東京大学情報基盤センター助教 ) GPGPU イントロダクション 1 目的 昨今注目を集めている GPGPU(GPU コンピューティング ) について紹介する GPGPU とは何か? 成り立ち 特徴 用途 ( ソフトウェアや研究例の紹介 ) 使い方 ( ライブラリ 言語 ) CUDA GPGPU における課題 2 GPGPU とは何か? GPGPU General-Purpose
Microsoft PowerPoint - GPU_computing_2013_01.pptx
 GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格
GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格
tabaicho3mukunoki.pptx
 1 2 はじめに n 目的 4倍精度演算より高速な3倍精度演算を実現する l 倍精度では足りないが4倍精度は必要ないケースに欲しい l 4倍精度に比べてデータサイズが小さい Ø 少なくともメモリ律速な計算では4倍精度よりデータ 転送時間を減らすことが可能 Ø PCIeやノード間通信がボトルネックとなりやすい GPUクラスタ環境に有効か n 研究概要 l DD型4倍精度演算 DD演算 に基づく3倍精度演算
1 2 はじめに n 目的 4倍精度演算より高速な3倍精度演算を実現する l 倍精度では足りないが4倍精度は必要ないケースに欲しい l 4倍精度に比べてデータサイズが小さい Ø 少なくともメモリ律速な計算では4倍精度よりデータ 転送時間を減らすことが可能 Ø PCIeやノード間通信がボトルネックとなりやすい GPUクラスタ環境に有効か n 研究概要 l DD型4倍精度演算 DD演算 に基づく3倍精度演算
スライド 1
 計算科学が拓く世界スーパーコンピュータは何故スーパーか 学術情報メディアセンター中島浩 http://www.para.media.kyoto-u.ac.jp/jp/ username=super password=computer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
計算科学が拓く世界スーパーコンピュータは何故スーパーか 学術情報メディアセンター中島浩 http://www.para.media.kyoto-u.ac.jp/jp/ username=super password=computer 講義の概要 目的 計算科学に不可欠の道具スーパーコンピュータが どういうものか なぜスーパーなのか どう使うとスーパーなのかについて雰囲気をつかむ 内容 スーパーコンピュータの歴史を概観しつつ
Microsoft PowerPoint - kougi7.ppt
 C プログラミング演習 第 7 回メモリ内でのデータの配置 例題 1. 棒グラフを描く 整数の配列から, その棒グラフを表示する ループの入れ子で, 棒グラフの表示を行う ( 参考 : 第 6 回授業の例題 3) 棒グラフの1 本の棒を画面に表示する機能を持った関数を補助関数として作る #include "stdafx.h" #include void draw_bar( int
C プログラミング演習 第 7 回メモリ内でのデータの配置 例題 1. 棒グラフを描く 整数の配列から, その棒グラフを表示する ループの入れ子で, 棒グラフの表示を行う ( 参考 : 第 6 回授業の例題 3) 棒グラフの1 本の棒を画面に表示する機能を持った関数を補助関数として作る #include "stdafx.h" #include void draw_bar( int
PowerPoint プレゼンテーション
 各種計算機アプリケーション性能比較 目次. はじめに. 行列積計算.QDR 積計算 4.N 体問題計算 5. 多次元積分計算 5. 次元積分計算 5. 次元積分計算 5. 4 次元積分計算 5.4 5 次元積分計算 5.5 6 次元積分計算 平成 6 年度第 四半期 . はじめに 今までと少し性質の異なるグラフィックボードが使用できる様になったので従来のアプリケーションで性能比較を実施しました 主に使用した計算機は以下のものです
各種計算機アプリケーション性能比較 目次. はじめに. 行列積計算.QDR 積計算 4.N 体問題計算 5. 多次元積分計算 5. 次元積分計算 5. 次元積分計算 5. 4 次元積分計算 5.4 5 次元積分計算 5.5 6 次元積分計算 平成 6 年度第 四半期 . はじめに 今までと少し性質の異なるグラフィックボードが使用できる様になったので従来のアプリケーションで性能比較を実施しました 主に使用した計算機は以下のものです
演習 II 2 つの講義の演習 奇数回 : 連続系アルゴリズム 部分 偶数回 : 計算量理論 部分 連続系アルゴリズム部分は全 8 回を予定 前半 2 回 高性能計算 後半 6 回 数値計算 4 回以上の課題提出 ( プログラム + 考察レポート ) で単位
 で単位") 演習 II ( 連続系アルゴリズム ) 第 1 回 : MPI 須田研究室 M2 本谷徹 motoya@is.s.u-tokyo.ac.jp 2012/10/05 2012/10/18 補足 訂正 演習 II 2 つの講義の演習 奇数回 : 連続系アルゴリズム 部分 偶数回 : 計算量理論 部分 連続系アルゴリズム部分は全 8 回を予定 前半 2 回 高性能計算 後半 6 回 数値計算 4 回以上の課題提出
演習 II ( 連続系アルゴリズム ) 第 1 回 : MPI 須田研究室 M2 本谷徹 motoya@is.s.u-tokyo.ac.jp 2012/10/05 2012/10/18 補足 訂正 演習 II 2 つの講義の演習 奇数回 : 連続系アルゴリズム 部分 偶数回 : 計算量理論 部分 連続系アルゴリズム部分は全 8 回を予定 前半 2 回 高性能計算 後半 6 回 数値計算 4 回以上の課題提出
program7app.ppt
 プログラム理論と言語第 7 回 ポインタと配列, 高階関数, まとめ 有村博紀 吉岡真治 公開スライド PDF( 情報知識ネットワーク研 HP/ 授業 ) http://www-ikn.ist.hokudai.ac.jp/~arim/pub/proriron/ 本スライドは,2015 北海道大学吉岡真治 プログラム理論と言語, に基づいて, 現著者の承諾のもとに, 改訂者 ( 有村 ) が加筆修正しています.
プログラム理論と言語第 7 回 ポインタと配列, 高階関数, まとめ 有村博紀 吉岡真治 公開スライド PDF( 情報知識ネットワーク研 HP/ 授業 ) http://www-ikn.ist.hokudai.ac.jp/~arim/pub/proriron/ 本スライドは,2015 北海道大学吉岡真治 プログラム理論と言語, に基づいて, 現著者の承諾のもとに, 改訂者 ( 有村 ) が加筆修正しています.
パソコンシミュレータの現状
 第 2 章微分 偏微分, 写像 豊橋技術科学大学森謙一郎 2. 連続関数と微分 工学において物理現象を支配する方程式は微分方程式で表されていることが多く, 有限要素法も微分方程式を解く数値解析法であり, 定式化においては微分 積分が一般的に用いられており. 数学の基礎知識が必要になる. 図 2. に示すように, 微分は連続な関数 f() の傾きを求めることであり, 微小な に対して傾きを表し, を無限に
第 2 章微分 偏微分, 写像 豊橋技術科学大学森謙一郎 2. 連続関数と微分 工学において物理現象を支配する方程式は微分方程式で表されていることが多く, 有限要素法も微分方程式を解く数値解析法であり, 定式化においては微分 積分が一般的に用いられており. 数学の基礎知識が必要になる. 図 2. に示すように, 微分は連続な関数 f() の傾きを求めることであり, 微小な に対して傾きを表し, を無限に
OpenFOAM(R) ソースコード入門 pt1 熱伝導方程式の解法から有限体積法の実装について考える 前編 : 有限体積法の基礎確認 2013/11/17 オープンCAE 富山富山県立大学中川慎二
 ソースコード入門 pt1 熱伝導方程式の解法から有限体積法の実装について考える 前編 : 有限体積法の基礎確認 2013/11/17 オープンCAE 富山富山県立大学中川慎二") OpenFOAM(R) ソースコード入門 pt1 熱伝導方程式の解法から有限体積法の実装について考える 前編 : 有限体積法の基礎確認 2013/11/17 オープンCAE 勉強会 @ 富山富山県立大学中川慎二 * OpenFOAM のソースコードでは, 基礎式を偏微分方程式の形で記述する.OpenFOAM 内部では, 有限体積法を使ってこの微分方程式を解いている. どのようにして, 有限体積法に基づく離散化が実現されているのか,
OpenFOAM(R) ソースコード入門 pt1 熱伝導方程式の解法から有限体積法の実装について考える 前編 : 有限体積法の基礎確認 2013/11/17 オープンCAE 勉強会 @ 富山富山県立大学中川慎二 * OpenFOAM のソースコードでは, 基礎式を偏微分方程式の形で記述する.OpenFOAM 内部では, 有限体積法を使ってこの微分方程式を解いている. どのようにして, 有限体積法に基づく離散化が実現されているのか,
Microsoft PowerPoint - handout07.ppt [互換モード]
![Microsoft PowerPoint - handout07.ppt [互換モード]](/thumbs/101/148831116.jpg "Microsoft PowerPoint - handout07.ppt [互換モード]") Outline プログラミング演習第 7 回構造体 on 2012.12.06 電気通信大学情報理工学部知能機械工学科長井隆行 今日の主眼 構造体 構造体の配列 構造体とポインタ 演習課題 2 今日の主眼 配列を使うと 複数の ( 異なる型を含む ) データを扱いたい 例えば 成績データの管理 複数のデータを扱う 配列を使う! 名前学籍番号点数 ( 英語 ) 点数 ( 数学 ) Aomori 1 59.4
Outline プログラミング演習第 7 回構造体 on 2012.12.06 電気通信大学情報理工学部知能機械工学科長井隆行 今日の主眼 構造体 構造体の配列 構造体とポインタ 演習課題 2 今日の主眼 配列を使うと 複数の ( 異なる型を含む ) データを扱いたい 例えば 成績データの管理 複数のデータを扱う 配列を使う! 名前学籍番号点数 ( 英語 ) 点数 ( 数学 ) Aomori 1 59.4
Microsoft PowerPoint - 先端GPGPUシミュレーション工学特論(web).pptx
.pptx") 偏微分方程式の差分計算 拡散方程式 ) 長岡技術科学大学電気電子情報工学専攻出川智啓 今日の内容 シミュレーションの歴史と進歩 差分法 1 階微分 階微分に対する差分法 1 次関数の差分 次元拡散方程式 付録 共有メモリの典型的な使い方 49 先端 GPGPUシミュレーション工学特論 数値計算 計算機を利用して数学 物理学的問題の解を計算 微積分を計算機で扱える形に変換 処理自体はあまり複雑ではない
偏微分方程式の差分計算 拡散方程式 ) 長岡技術科学大学電気電子情報工学専攻出川智啓 今日の内容 シミュレーションの歴史と進歩 差分法 1 階微分 階微分に対する差分法 1 次関数の差分 次元拡散方程式 付録 共有メモリの典型的な使い方 49 先端 GPGPUシミュレーション工学特論 数値計算 計算機を利用して数学 物理学的問題の解を計算 微積分を計算機で扱える形に変換 処理自体はあまり複雑ではない
PowerPoint Presentation
 ヘテロジニアスな環境におけるソフトウェア開発 Agenda 今日の概要 ヘテロジニアスな環境の登場 ホモジニアスからヘテロジニアスへ ヘテロジニアスなアーキテクチャ GPU CUDA OpenACC, XeonPhi 自分のプログラムを理解するために デバッガ 共通の操作体験 TotalView 続きはブースで より速く ホモジーニアスな並列 HPC 銀河生成 金融のリスク計算 車の衝突解析 製薬
ヘテロジニアスな環境におけるソフトウェア開発 Agenda 今日の概要 ヘテロジニアスな環境の登場 ホモジニアスからヘテロジニアスへ ヘテロジニアスなアーキテクチャ GPU CUDA OpenACC, XeonPhi 自分のプログラムを理解するために デバッガ 共通の操作体験 TotalView 続きはブースで より速く ホモジーニアスな並列 HPC 銀河生成 金融のリスク計算 車の衝突解析 製薬
1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU
![1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU](/thumbs/89/99132402.jpg "1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU") GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
Microsoft PowerPoint _OpenCAE並列計算分科会.pptx
 地球流体力学に関する GPGPU を用いた数値計算 神戸大学惑星科学研究センター西澤誠也 地球流体力学とは 地球 惑星に関連がある流体の力学 回転, 重力の影響 e.g. 大気, 海洋, マントル 数値計算は天気予報 & 弾道軌道予測から始まった ベクトル計算機 地球流体の計算はベクトル長が長いものが多い ベクトル計算機の凋落 某社の次世代スパコンからの撤退 個人的スパコンの将来予想 個々の演算器はシンプルに
地球流体力学に関する GPGPU を用いた数値計算 神戸大学惑星科学研究センター西澤誠也 地球流体力学とは 地球 惑星に関連がある流体の力学 回転, 重力の影響 e.g. 大気, 海洋, マントル 数値計算は天気予報 & 弾道軌道予測から始まった ベクトル計算機 地球流体の計算はベクトル長が長いものが多い ベクトル計算機の凋落 某社の次世代スパコンからの撤退 個人的スパコンの将来予想 個々の演算器はシンプルに
ex04_2012.ppt
 2012 年度計算機システム演習第 4 回 2012.05.07 第 2 回課題の補足 } TSUBAMEへのログイン } TSUBAMEは学内からのログインはパスワードで可能 } } } } しかし 演習室ではパスワードでログインできない設定 } 公開鍵認証でログイン 公開鍵, 秘密鍵の生成 } ターミナルを開く } $ ssh-keygen } Enter file in which to save
2012 年度計算機システム演習第 4 回 2012.05.07 第 2 回課題の補足 } TSUBAMEへのログイン } TSUBAMEは学内からのログインはパスワードで可能 } } } } しかし 演習室ではパスワードでログインできない設定 } 公開鍵認証でログイン 公開鍵, 秘密鍵の生成 } ターミナルを開く } $ ssh-keygen } Enter file in which to save
Microsoft PowerPoint - 計算機言語 第7回.ppt
 計算機言語第 7 回 長宗高樹 目的 関数について理解する. 入力 X 関数 f 出力 Y Y=f(X) 関数の例 関数の型 #include int tasu(int a, int b); main(void) int x1, x2, y; x1 = 2; x2 = 3; y = tasu(x1,x2); 実引数 printf( %d + %d = %d, x1, x2, y);
計算機言語第 7 回 長宗高樹 目的 関数について理解する. 入力 X 関数 f 出力 Y Y=f(X) 関数の例 関数の型 #include int tasu(int a, int b); main(void) int x1, x2, y; x1 = 2; x2 = 3; y = tasu(x1,x2); 実引数 printf( %d + %d = %d, x1, x2, y);
微分方程式 モデリングとシミュレーション
 1 微分方程式モデリングとシミュレーション 2018 年度 2 質点の運動のモデル化 粒子と粒子に働く力 粒子の運動 粒子の位置の時間変化 粒子の位置の変化の割合 速度 速度の変化の割合 加速度 力と加速度の結び付け Newtonの運動方程式 : 微分方程式 解は 時間の関数としての位置 3 Newton の運動方程式 質点の運動は Newton の運動方程式で記述される 加速度は力に比例する 2
1 微分方程式モデリングとシミュレーション 2018 年度 2 質点の運動のモデル化 粒子と粒子に働く力 粒子の運動 粒子の位置の時間変化 粒子の位置の変化の割合 速度 速度の変化の割合 加速度 力と加速度の結び付け Newtonの運動方程式 : 微分方程式 解は 時間の関数としての位置 3 Newton の運動方程式 質点の運動は Newton の運動方程式で記述される 加速度は力に比例する 2
Microsoft PowerPoint - kougi9.ppt
 C プログラミング演習 第 9 回ポインタとリンクドリストデータ構造 1 今まで説明してきた変数 #include "stdafx.h" #include int _tmain(int argc, _TCHAR* argv[]) { double x; double y; char buf[256]; int i; double start_x; double step_x; FILE*
C プログラミング演習 第 9 回ポインタとリンクドリストデータ構造 1 今まで説明してきた変数 #include "stdafx.h" #include int _tmain(int argc, _TCHAR* argv[]) { double x; double y; char buf[256]; int i; double start_x; double step_x; FILE*
DO 時間積分 START 反変速度の計算 contravariant_velocity 移流項の計算 advection_adams_bashforth_2nd DO implicit loop( 陰解法 ) 速度勾配, 温度勾配の計算 gradient_cell_center_surface 速
 速度勾配, 温度勾配の計算 gradient_cell_center_surface 速") 1 1, 2 1, 2 3 2, 3 4 GP LES ASUCA LES NVIDIA CUDA LES 1. Graphics Processing Unit GP General-Purpose SIMT Single Instruction Multiple Threads 1 2 3 4 1),2) LES Large Eddy Simulation 3) ASUCA 4) LES LES
1 1, 2 1, 2 3 2, 3 4 GP LES ASUCA LES NVIDIA CUDA LES 1. Graphics Processing Unit GP General-Purpose SIMT Single Instruction Multiple Threads 1 2 3 4 1),2) LES Large Eddy Simulation 3) ASUCA 4) LES LES
GPUを用いたN体計算
 単精度 190Tflops GPU クラスタ ( 長崎大 ) の紹介 長崎大学工学部超高速メニーコアコンピューティングセンターテニュアトラック助教濱田剛 1 概要 GPU (Graphics Processing Unit) について簡単に説明します. GPU クラスタが得意とする応用問題を議論し 長崎大学での GPU クラスタによる 取組方針 N 体計算の高速化に関する研究内容 を紹介します. まとめ
単精度 190Tflops GPU クラスタ ( 長崎大 ) の紹介 長崎大学工学部超高速メニーコアコンピューティングセンターテニュアトラック助教濱田剛 1 概要 GPU (Graphics Processing Unit) について簡単に説明します. GPU クラスタが得意とする応用問題を議論し 長崎大学での GPU クラスタによる 取組方針 N 体計算の高速化に関する研究内容 を紹介します. まとめ
PowerPoint プレゼンテーション
 みんなの ベクトル計算 たけおか @takeoka PC クラスタ コンソーシアム理事でもある 2011/FEB/20 ベクトル計算が新しい と 2008 年末に言いました Intelに入ってる! (2008 年から見た 近未来? ) GPU 計算が新しい (2008 年当時 ) Intel AVX (Advanced Vector Extension) SIMD 命令を進めて ベクトル機構をつける
みんなの ベクトル計算 たけおか @takeoka PC クラスタ コンソーシアム理事でもある 2011/FEB/20 ベクトル計算が新しい と 2008 年末に言いました Intelに入ってる! (2008 年から見た 近未来? ) GPU 計算が新しい (2008 年当時 ) Intel AVX (Advanced Vector Extension) SIMD 命令を進めて ベクトル機構をつける
概要 目的 CUDA Fortran の利用に関する基本的なノウハウを提供する 本チュートリアル受講後は Web 上で公開されている資料等を参照しながら独力で CUDA Fortran が利用できることが目標 対象 CUDA Fortran の利用に興味を抱いている方 前提とする知識 Fortran
 CUDA Fortran チュートリアル 2010 年 9 月 29 日 NEC 概要 目的 CUDA Fortran の利用に関する基本的なノウハウを提供する 本チュートリアル受講後は Web 上で公開されている資料等を参照しながら独力で CUDA Fortran が利用できることが目標 対象 CUDA Fortran の利用に興味を抱いている方 前提とする知識 Fortran を用いた Linux
CUDA Fortran チュートリアル 2010 年 9 月 29 日 NEC 概要 目的 CUDA Fortran の利用に関する基本的なノウハウを提供する 本チュートリアル受講後は Web 上で公開されている資料等を参照しながら独力で CUDA Fortran が利用できることが目標 対象 CUDA Fortran の利用に興味を抱いている方 前提とする知識 Fortran を用いた Linux
Microsoft Word - 3new.doc
 プログラミング演習 II 講義資料 3 ポインタ I - ポインタの基礎 1 ポインタとは ポインタとはポインタは, アドレス ( データが格納されている場所 ) を扱うデータ型です つまり, アドレスを通してデータを間接的に処理します ポインタを使用する場合の, 処理の手順は以下のようになります 1 ポインタ変数を宣言する 2 ポインタ変数へアドレスを割り当てる 3 ポインタ変数を用いて処理 (
プログラミング演習 II 講義資料 3 ポインタ I - ポインタの基礎 1 ポインタとは ポインタとはポインタは, アドレス ( データが格納されている場所 ) を扱うデータ型です つまり, アドレスを通してデータを間接的に処理します ポインタを使用する場合の, 処理の手順は以下のようになります 1 ポインタ変数を宣言する 2 ポインタ変数へアドレスを割り当てる 3 ポインタ変数を用いて処理 (
RX ファミリ用 C/C++ コンパイラ V.1.00 Release 02 ご使用上のお願い RX ファミリ用 C/C++ コンパイラの使用上の注意事項 4 件を連絡します #pragma option 使用時の 1 または 2 バイトの整数型の関数戻り値に関する注意事項 (RXC#012) 共用
 共用") RX ファミリ用 C/C++ コンパイラ V.1.00 Release 02 ご使用上のお願い RX ファミリ用 C/C++ コンパイラの使用上の注意事項 4 件を連絡します #pragma option 使用時の 1 または 2 バイトの整数型の関数戻り値に関する注意事項 (RXC#012) 共用体型のローカル変数を文字列操作関数で操作する場合の注意事項 (RXC#013) 配列型構造体または共用体の配列型メンバから読み出した値を動的初期化に用いる場合の注意事項
RX ファミリ用 C/C++ コンパイラ V.1.00 Release 02 ご使用上のお願い RX ファミリ用 C/C++ コンパイラの使用上の注意事項 4 件を連絡します #pragma option 使用時の 1 または 2 バイトの整数型の関数戻り値に関する注意事項 (RXC#012) 共用体型のローカル変数を文字列操作関数で操作する場合の注意事項 (RXC#013) 配列型構造体または共用体の配列型メンバから読み出した値を動的初期化に用いる場合の注意事項
修士論文
 AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014
 ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014 コンカレントな処理の実行 システム内部の複数の処理を 平行に実行する CPU GPU メモリ転送 カーネル実行 複数のカーネル間 ストリーム GPU 上の処理キュー カーネル実行 メモリ転送の並列性 実行順序 DEFAULT STREAM Stream : GPU
ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014 コンカレントな処理の実行 システム内部の複数の処理を 平行に実行する CPU GPU メモリ転送 カーネル実行 複数のカーネル間 ストリーム GPU 上の処理キュー カーネル実行 メモリ転送の並列性 実行順序 DEFAULT STREAM Stream : GPU
GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 理化学研究所 共通コードプロジェクト
 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 理化学研究所 共通コードプロジェクト") GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 勉強会 @ 理化学研究所 共通コードプロジェクト Contents Hands On 環境について Introduction to GPU computing Introduction
GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 勉強会 @ 理化学研究所 共通コードプロジェクト Contents Hands On 環境について Introduction to GPU computing Introduction
Microsoft PowerPoint - 先端GPGPUシミュレーション工学特論(web).pptx
.pptx") 複数 GPU の利用 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 並列アーキテクチャと並列処理の分類 OpenMP 複数 GPU の利用 GPU Direct によるデータ通信 939 複数の GPU を利用する目的 Grouse の 1 ノードには 4 台の GPU を搭載 Tesla M2050 1T FLOPS/ 台 3 GB/ 台 4 台全てを使う事で期待できる性能 GPU を
複数 GPU の利用 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 並列アーキテクチャと並列処理の分類 OpenMP 複数 GPU の利用 GPU Direct によるデータ通信 939 複数の GPU を利用する目的 Grouse の 1 ノードには 4 台の GPU を搭載 Tesla M2050 1T FLOPS/ 台 3 GB/ 台 4 台全てを使う事で期待できる性能 GPU を
<4D F736F F F696E74202D2091E63489F15F436F6D C982E682E992B48D8291AC92B489B F090CD2888F38DFC E B8CDD8
 Web キャンパス資料 超音波シミュレーションの基礎 ~ 第 4 回 ComWAVEによる超高速超音波解析 ~ 科学システム開発部 Copyright (c)2006 ITOCHU Techno-Solutions Corporation 本日の説明内容 ComWAVEの概要および特徴 GPGPUとは GPGPUによる解析事例 CAE POWER 超音波研究会開催 (10 月 3 日 ) のご紹介
Web キャンパス資料 超音波シミュレーションの基礎 ~ 第 4 回 ComWAVEによる超高速超音波解析 ~ 科学システム開発部 Copyright (c)2006 ITOCHU Techno-Solutions Corporation 本日の説明内容 ComWAVEの概要および特徴 GPGPUとは GPGPUによる解析事例 CAE POWER 超音波研究会開催 (10 月 3 日 ) のご紹介
スライド 1
 東北大学工学部機械知能 航空工学科 2019 年度クラス C D 情報科学基礎 I 14. さらに勉強するために 大学院情報科学研究科 鏡慎吾 http://www.ic.is.tohoku.ac.jp/~swk/lecture/ 0 と 1 の世界 これまで何を学んだか 2 進数, 算術演算, 論理演算 計算機はどのように動くのか プロセッサとメモリ 演算命令, ロード ストア命令, 分岐命令 計算機はどのように構成されているのか
東北大学工学部機械知能 航空工学科 2019 年度クラス C D 情報科学基礎 I 14. さらに勉強するために 大学院情報科学研究科 鏡慎吾 http://www.ic.is.tohoku.ac.jp/~swk/lecture/ 0 と 1 の世界 これまで何を学んだか 2 進数, 算術演算, 論理演算 計算機はどのように動くのか プロセッサとメモリ 演算命令, ロード ストア命令, 分岐命令 計算機はどのように構成されているのか
7 ポインタ (P.61) ポインタを使うと, メモリ上のデータを直接操作することができる. 例えばデータの変更 やコピーなどが簡単にできる. また処理が高速になる. 7.1 ポインタの概念 変数を次のように宣言すると, int num; メモリにその領域が確保される. 仮にその開始のアドレスを 1
 ポインタを使うと, メモリ上のデータを直接操作することができる. 例えばデータの変更 やコピーなどが簡単にできる. また処理が高速になる. 7.1 ポインタの概念 変数を次のように宣言すると, int num; メモリにその領域が確保される. 仮にその開始のアドレスを 1") 7 ポインタ (P.61) ポインタを使うと, メモリ上のデータを直接操作することができる. 例えばデータの変更 やコピーなどが簡単にできる. また処理が高速になる. 7.1 ポインタの概念 変数を次のように宣言すると, int num; メモリにその領域が確保される. 仮にその開始のアドレスを 10001 番地とすると, そこから int 型のサイズ, つまり 4 バイト分の領域が確保される.1
7 ポインタ (P.61) ポインタを使うと, メモリ上のデータを直接操作することができる. 例えばデータの変更 やコピーなどが簡単にできる. また処理が高速になる. 7.1 ポインタの概念 変数を次のように宣言すると, int num; メモリにその領域が確保される. 仮にその開始のアドレスを 10001 番地とすると, そこから int 型のサイズ, つまり 4 バイト分の領域が確保される.1
偏微分方程式の差分計算 長岡技術科学大学電気電子情報工学専攻出川智啓
 偏微分方程式の差分計算 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 差分法 階微分 階微分に対する差分法 次元拡散方程式 guplot による結果の表示 分岐の書き方による実行時間の変化 高速化に利用できるいくつかのテクニック 7 前回授業 ビットマップを使った画像処理 配列の 要素が物理的な配置に対応 配列の 要素に物理的なデータが定義 B G R 7 数値計算 ( 差分法 ) 計算機を利用して数学
偏微分方程式の差分計算 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 差分法 階微分 階微分に対する差分法 次元拡散方程式 guplot による結果の表示 分岐の書き方による実行時間の変化 高速化に利用できるいくつかのテクニック 7 前回授業 ビットマップを使った画像処理 配列の 要素が物理的な配置に対応 配列の 要素に物理的なデータが定義 B G R 7 数値計算 ( 差分法 ) 計算機を利用して数学
Microsoft Word - no12.doc
 7.5 ポインタと構造体 構造体もメモリのどこかに値が格納されているのですから 構造体へのポインタ も存在します また ポインタも変数ですから 構造体のメンバに含めることができます まずは 構造体へのポインタをあつかってみます ex53.c /* 成績表 */ #define IDLENGTH 7 /* 学籍番号の長さ */ #define MAX 100 /* 最大人数 */ /* 成績管理用の構造体の定義
7.5 ポインタと構造体 構造体もメモリのどこかに値が格納されているのですから 構造体へのポインタ も存在します また ポインタも変数ですから 構造体のメンバに含めることができます まずは 構造体へのポインタをあつかってみます ex53.c /* 成績表 */ #define IDLENGTH 7 /* 学籍番号の長さ */ #define MAX 100 /* 最大人数 */ /* 成績管理用の構造体の定義
cp-7. 配列
 cp-7. 配列 (C プログラムの書き方を, パソコン演習で学ぶシリーズ ) https://www.kkaneko.jp/cc/adp/index.html 金子邦彦 1 本日の内容 例題 1. 月の日数配列とは. 配列の宣言. 配列の添え字. 例題 2. ベクトルの内積例題 3. 合計点と平均点例題 4. 棒グラフを描く配列と繰り返し計算の関係例題 5. 行列の和 2 次元配列 2 今日の到達目標
cp-7. 配列 (C プログラムの書き方を, パソコン演習で学ぶシリーズ ) https://www.kkaneko.jp/cc/adp/index.html 金子邦彦 1 本日の内容 例題 1. 月の日数配列とは. 配列の宣言. 配列の添え字. 例題 2. ベクトルの内積例題 3. 合計点と平均点例題 4. 棒グラフを描く配列と繰り返し計算の関係例題 5. 行列の和 2 次元配列 2 今日の到達目標
Microsoft PowerPoint - 09.pptx
 情報処理 Ⅱ 第 9 回 2014 年 12 月 22 日 ( 月 ) 関数とは なぜ関数 関数の分類 自作関数 : 自分で定義する. ユーザ関数 ユーザ定義関数 などともいう. 本日のテーマ ライブラリ関数 : 出来合いのもの.printf など. なぜ関数を定義するのか? 処理を共通化 ( 一般化 ) する プログラムの見通しをよくする 機能分割 ( モジュール化, 再利用 ) 責任 ( あるいは不具合の発生源
情報処理 Ⅱ 第 9 回 2014 年 12 月 22 日 ( 月 ) 関数とは なぜ関数 関数の分類 自作関数 : 自分で定義する. ユーザ関数 ユーザ定義関数 などともいう. 本日のテーマ ライブラリ関数 : 出来合いのもの.printf など. なぜ関数を定義するのか? 処理を共通化 ( 一般化 ) する プログラムの見通しをよくする 機能分割 ( モジュール化, 再利用 ) 責任 ( あるいは不具合の発生源
工学院大学建築系学科近藤研究室2000年度卒業論文梗概
 耐災害性の高い通信システムにおけるサーバ計算機の性能と消費電力に関する考察 耐障害性, 消費電力, 低消費電力サーバ 山口実靖 *. はじめに 性能と表皮電力の関係について調査し, 考察を行う 災害においては, 減災活動が極めて重要である すなわち 災害が発生した後に適切に災害に対処することにより, その被害を大きく軽減できる. 適切な災害対策を行うには災害対策を行う拠点が正常に運営されていることが必要不可欠であり,
耐災害性の高い通信システムにおけるサーバ計算機の性能と消費電力に関する考察 耐障害性, 消費電力, 低消費電力サーバ 山口実靖 *. はじめに 性能と表皮電力の関係について調査し, 考察を行う 災害においては, 減災活動が極めて重要である すなわち 災害が発生した後に適切に災害に対処することにより, その被害を大きく軽減できる. 適切な災害対策を行うには災害対策を行う拠点が正常に運営されていることが必要不可欠であり,
Microsoft PowerPoint - OpenMP入門.pptx
 OpenMP 入門 須田礼仁 2009/10/30 初版 OpenMP 共有メモリ並列処理の標準化 API http://openmp.org/ 最新版は 30 3.0 バージョンによる違いはあまり大きくない サポートしているバージョンはともかく csp で動きます gcc も対応しています やっぱり SPMD Single Program Multiple Data プログラム #pragma omp
OpenMP 入門 須田礼仁 2009/10/30 初版 OpenMP 共有メモリ並列処理の標準化 API http://openmp.org/ 最新版は 30 3.0 バージョンによる違いはあまり大きくない サポートしているバージョンはともかく csp で動きます gcc も対応しています やっぱり SPMD Single Program Multiple Data プログラム #pragma omp
N08
 CPU のキモチ C.John 自己紹介 英語きらい 絵かけない 人の話を素直に信じない CPUにキモチなんてない お詫び 予告ではCとC# とありましたがやる気と時間の都合上 C++のみを対象とします 今日のネタ元 MSDN マガジン 2010 年 10 月号 http://msdn.microsoft.com/ja-jp/magazine/cc850829.aspx Windows と C++
CPU のキモチ C.John 自己紹介 英語きらい 絵かけない 人の話を素直に信じない CPUにキモチなんてない お詫び 予告ではCとC# とありましたがやる気と時間の都合上 C++のみを対象とします 今日のネタ元 MSDN マガジン 2010 年 10 月号 http://msdn.microsoft.com/ja-jp/magazine/cc850829.aspx Windows と C++
スライド 1
 東北大学工学部機械知能 航空工学科 2016 年度 5 セメスター クラス C3 D1 D2 D3 計算機工学 14. さらに勉強するために 大学院情報科学研究科 鏡慎吾 http://www.ic.is.tohoku.ac.jp/~swk/lecture/ 0 と 1 の世界 これまで何を学んだか 2 進数, 算術演算, 論理演算 計算機はどのように動くのか プロセッサとメモリ 演算命令, ロード
東北大学工学部機械知能 航空工学科 2016 年度 5 セメスター クラス C3 D1 D2 D3 計算機工学 14. さらに勉強するために 大学院情報科学研究科 鏡慎吾 http://www.ic.is.tohoku.ac.jp/~swk/lecture/ 0 と 1 の世界 これまで何を学んだか 2 進数, 算術演算, 論理演算 計算機はどのように動くのか プロセッサとメモリ 演算命令, ロード
Microsoft PowerPoint - 13th.ppt [互換モード]
![Microsoft PowerPoint - 13th.ppt [互換モード]](/thumbs/99/142206290.jpg "Microsoft PowerPoint - 13th.ppt [互換モード]") 工学部 6 7 8 9 10 組 ( 奇数学籍番号 ) 担当 : 長谷川英之 情報処理演習 第 13 回 2011 年 1 月 13 日 1 本日の講義の内容 1. 配列データを main 以外の関数とやりとりする方法 2. データの型構造体, 共用体という新しいデータ型を学習します. 2 2 次元ベクトルのノルム ( 長さ ) を計算するプログラム 2 次元ベクトル a(x, y) のノルム (
工学部 6 7 8 9 10 組 ( 奇数学籍番号 ) 担当 : 長谷川英之 情報処理演習 第 13 回 2011 年 1 月 13 日 1 本日の講義の内容 1. 配列データを main 以外の関数とやりとりする方法 2. データの型構造体, 共用体という新しいデータ型を学習します. 2 2 次元ベクトルのノルム ( 長さ ) を計算するプログラム 2 次元ベクトル a(x, y) のノルム (
スライド 1
 東北大学工学部機械知能 航空工学科 2015 年度 5 セメスター クラス D 計算機工学 6. MIPS の命令と動作 演算 ロード ストア ( 教科書 6.3 節,6.4 節 ) 大学院情報科学研究科鏡慎吾 http://www.ic.is.tohoku.ac.jp/~swk/lecture/ レジスタ間の演算命令 (C 言語 ) c = a + b; ( 疑似的な MIPS アセンブリ言語 )
東北大学工学部機械知能 航空工学科 2015 年度 5 セメスター クラス D 計算機工学 6. MIPS の命令と動作 演算 ロード ストア ( 教科書 6.3 節,6.4 節 ) 大学院情報科学研究科鏡慎吾 http://www.ic.is.tohoku.ac.jp/~swk/lecture/ レジスタ間の演算命令 (C 言語 ) c = a + b; ( 疑似的な MIPS アセンブリ言語 )
コンピュータ工学講義プリント (7 月 17 日 ) 今回の講義では フローチャートについて学ぶ フローチャートとはフローチャートは コンピュータプログラムの処理の流れを視覚的に表し 処理の全体像を把握しやすくするために書く図である 日本語では流れ図という 図 1 は ユーザーに 0 以上の整数 n
 今回の講義では フローチャートについて学ぶ フローチャートとはフローチャートは コンピュータプログラムの処理の流れを視覚的に表し 処理の全体像を把握しやすくするために書く図である 日本語では流れ図という 図 1 は ユーザーに 0 以上の整数 n") コンピュータ工学講義プリント (7 月 17 日 ) 今回の講義では フローチャートについて学ぶ フローチャートとはフローチャートは コンピュータプログラムの処理の流れを視覚的に表し 処理の全体像を把握しやすくするために書く図である 日本語では流れ図という 図 1 は ユーザーに 0 以上の整数 n を入力してもらい その後 1 から n までの全ての整数の合計 sum を計算し 最後にその sum
コンピュータ工学講義プリント (7 月 17 日 ) 今回の講義では フローチャートについて学ぶ フローチャートとはフローチャートは コンピュータプログラムの処理の流れを視覚的に表し 処理の全体像を把握しやすくするために書く図である 日本語では流れ図という 図 1 は ユーザーに 0 以上の整数 n を入力してもらい その後 1 から n までの全ての整数の合計 sum を計算し 最後にその sum
MPI または CUDA を用いた将棋評価関数学習プログラムの並列化 2009/06/30
 MPI または CUDA を用いた将棋評価関数学習プログラムの並列化 2009/06/30 目次 1. まえがき 3 2. 計算方法 4 3. MPI を用いた並列化 6 4. CUDA を用いた並列化 11 5. 計算結果 20 6. まとめ 24 2 1. まえがき 目的将棋の評価関数を棋譜から学習するボナンザメソッドの簡易版を作成し それを MPI または CUDA を用いて並列化し 計算時間を短縮することを目的とする
MPI または CUDA を用いた将棋評価関数学習プログラムの並列化 2009/06/30 目次 1. まえがき 3 2. 計算方法 4 3. MPI を用いた並列化 6 4. CUDA を用いた並列化 11 5. 計算結果 20 6. まとめ 24 2 1. まえがき 目的将棋の評価関数を棋譜から学習するボナンザメソッドの簡易版を作成し それを MPI または CUDA を用いて並列化し 計算時間を短縮することを目的とする
27_02.indd
 GPGPU を用いたソフトウェア高速化手法 Technique to Speedup of the software by GPGPU 大田弘樹 馬場明子 下田雄一 安田隆洋 山本啓二 Hiroki Ota, Akiko Baba, Shimoda Yuichi, Takahiro Yasuta, Keiji Yamamoto PCやワークステーションにおいて画像処理に特化して使用されてきたGPUを
GPGPU を用いたソフトウェア高速化手法 Technique to Speedup of the software by GPGPU 大田弘樹 馬場明子 下田雄一 安田隆洋 山本啓二 Hiroki Ota, Akiko Baba, Shimoda Yuichi, Takahiro Yasuta, Keiji Yamamoto PCやワークステーションにおいて画像処理に特化して使用されてきたGPUを
Microsoft PowerPoint - OS07.pptx
 この資料は 情報工学レクチャーシリーズ松尾啓志著 ( 森北出版株式会社 ) を用いて授業を行うために 名古屋工業大学松尾啓志 津邑公暁が作成しました 主記憶管理 主記憶管理基礎 パワーポイント 27 で最終版として保存しているため 変更はできませんが 授業でお使いなる場合は松尾 (matsuo@nitech.ac.jp) まで連絡いただければ 編集可能なバージョンをお渡しする事も可能です 復習 OS
この資料は 情報工学レクチャーシリーズ松尾啓志著 ( 森北出版株式会社 ) を用いて授業を行うために 名古屋工業大学松尾啓志 津邑公暁が作成しました 主記憶管理 主記憶管理基礎 パワーポイント 27 で最終版として保存しているため 変更はできませんが 授業でお使いなる場合は松尾 (matsuo@nitech.ac.jp) まで連絡いただければ 編集可能なバージョンをお渡しする事も可能です 復習 OS
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日
 TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
Fujitsu Standard Tool
 低レベル通信ライブラリ ACP の PGAS ランタイム向け機能 2014 年 10 月 24 日富士通株式会社 JST CREST 安島雄一郎 Copyright 2014 FUJITSU LIMITED 本発表の構成 概要 インタフェース チャネル ベクタ リスト メモリアロケータ アドレス変換 グローバルメモリ参照 モジュール構成 メモリ消費量と性能評価 利用例 今後の課題 まとめ 1 Copyright
低レベル通信ライブラリ ACP の PGAS ランタイム向け機能 2014 年 10 月 24 日富士通株式会社 JST CREST 安島雄一郎 Copyright 2014 FUJITSU LIMITED 本発表の構成 概要 インタフェース チャネル ベクタ リスト メモリアロケータ アドレス変換 グローバルメモリ参照 モジュール構成 メモリ消費量と性能評価 利用例 今後の課題 まとめ 1 Copyright
C プログラミング演習 1( 再 ) 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ
 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ") C プログラミング演習 1( 再 ) 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ 今回のプログラミングの課題 次のステップによって 徐々に難易度の高いプログラムを作成する ( 参照用の番号は よくわかる C 言語 のページ番号 ) 1. キーボード入力された整数 10 個の中から最大のものを答える 2. 整数を要素とする配列 (p.57-59) に初期値を与えておき
C プログラミング演習 1( 再 ) 2 講義では C プログラミングの基本を学び 演習では やや実践的なプログラミングを通して学ぶ 今回のプログラミングの課題 次のステップによって 徐々に難易度の高いプログラムを作成する ( 参照用の番号は よくわかる C 言語 のページ番号 ) 1. キーボード入力された整数 10 個の中から最大のものを答える 2. 整数を要素とする配列 (p.57-59) に初期値を与えておき
PowerPoint プレゼンテーション
 プログラミング初級 第 7 回 2017 年 5 月 29 日 配列 ( 復習 )~ 文字列 1 配列とは 2 配列 : 複数の変数をグループとしてまとめて扱うもの 配列 変数 int data[10]; 整数型の配列 同種のデータ型を連続して確保したものを配列とよぶ = 整数がそれぞれにひとつずつ入る箱を 10 個用意したようなもの int data; 整数型の変数 = 整数がひとつ入る dataという名前の箱を用意したようなもの
プログラミング初級 第 7 回 2017 年 5 月 29 日 配列 ( 復習 )~ 文字列 1 配列とは 2 配列 : 複数の変数をグループとしてまとめて扱うもの 配列 変数 int data[10]; 整数型の配列 同種のデータ型を連続して確保したものを配列とよぶ = 整数がそれぞれにひとつずつ入る箱を 10 個用意したようなもの int data; 整数型の変数 = 整数がひとつ入る dataという名前の箱を用意したようなもの
プログラム言語及び演習Ⅲ
 平成 28 年度後期データ構造とアルゴリズム期末テスト 各問題中のアルゴリズムを表すプログラムは, 変数の宣言が省略されているなど, 完全なものではありませんが, 適宜, 常識的な解釈をしてください. 疑問があれば, 挙手をして質問してください. 時間計算量をオーダ記法で表せという問題では, 入力サイズ n を無限大に近づけた場合の漸近的な時間計算量を表せということだと考えてください. 問題 1 入力サイズが
平成 28 年度後期データ構造とアルゴリズム期末テスト 各問題中のアルゴリズムを表すプログラムは, 変数の宣言が省略されているなど, 完全なものではありませんが, 適宜, 常識的な解釈をしてください. 疑問があれば, 挙手をして質問してください. 時間計算量をオーダ記法で表せという問題では, 入力サイズ n を無限大に近づけた場合の漸近的な時間計算量を表せということだと考えてください. 問題 1 入力サイズが
memo
 計数工学プログラミング演習 ( 第 3 回 ) 2016/04/26 DEPARTMENT OF MATHEMATICAL INFORMATICS 1 内容 ポインタ malloc 構造体 2 ポインタ あるメモリ領域 ( アドレス ) を代入できる変数 型は一致している必要がある 定義時には値は不定 ( 何も指していない ) 実際にはどこかのメモリを指しているので, #include
計数工学プログラミング演習 ( 第 3 回 ) 2016/04/26 DEPARTMENT OF MATHEMATICAL INFORMATICS 1 内容 ポインタ malloc 構造体 2 ポインタ あるメモリ領域 ( アドレス ) を代入できる変数 型は一致している必要がある 定義時には値は不定 ( 何も指していない ) 実際にはどこかのメモリを指しているので, #include
この方法では, 複数のアドレスが同じインデックスに対応づけられる可能性があるため, キャッシュラインのコピーと書き戻しが交互に起きる性のミスが発生する可能性がある. これを回避するために考案されたのが, 連想メモリアクセスができる形キャッシュである. この方式は, キャッシュに余裕がある限り主記憶の
 計算機システム Ⅱ 演習問題学科学籍番号氏名 1. 以下の分の空白を埋めなさい. CPUは, 命令フェッチ (F), 命令デコード (D), 実行 (E), 計算結果の書き戻し (W), の異なるステージの処理を反復実行するが, ある命令の計算結果の書き戻しをするまで, 次の命令のフェッチをしない場合, ( 単位時間当たりに実行できる命令数 ) が低くなる. これを解決するために考案されたのがパイプライン処理である.
計算機システム Ⅱ 演習問題学科学籍番号氏名 1. 以下の分の空白を埋めなさい. CPUは, 命令フェッチ (F), 命令デコード (D), 実行 (E), 計算結果の書き戻し (W), の異なるステージの処理を反復実行するが, ある命令の計算結果の書き戻しをするまで, 次の命令のフェッチをしない場合, ( 単位時間当たりに実行できる命令数 ) が低くなる. これを解決するために考案されたのがパイプライン処理である.
Microsoft PowerPoint - exp2-02_intro.ppt [互換モード]
![Microsoft PowerPoint - exp2-02_intro.ppt [互換モード]](/thumbs/96/128100373.jpg "Microsoft PowerPoint - exp2-02_intro.ppt [互換モード]") 情報工学実験 II 実験 2 アルゴリズム ( リスト構造とハッシュ ) 実験を始める前に... C 言語を復習しよう 0. プログラム書ける? 1. アドレスとポインタ 2. 構造体 3. 構造体とポインタ 0. プログラム書ける? 講義を聴いているだけで OK? 言語の要素技術を覚えれば OK? 目的のプログラム? 要素技術 データ型 配列 文字列 関数 オブジェクト クラス ポインタ 2 0.
情報工学実験 II 実験 2 アルゴリズム ( リスト構造とハッシュ ) 実験を始める前に... C 言語を復習しよう 0. プログラム書ける? 1. アドレスとポインタ 2. 構造体 3. 構造体とポインタ 0. プログラム書ける? 講義を聴いているだけで OK? 言語の要素技術を覚えれば OK? 目的のプログラム? 要素技術 データ型 配列 文字列 関数 オブジェクト クラス ポインタ 2 0.
型名 RF007 ラジオコミュニケーションテスタ Radio Communication Tester ソフトウェア開発キット マニュアル アールエフネットワーク株式会社 RFnetworks Corporation RF007SDK-M001 RF007SDK-M001 参考資料 1
 型名 RF007 ラジオコミュニケーションテスタ Radio Communication Tester ソフトウェア開発キット マニュアル アールエフネットワーク株式会社 RFnetworks Corporation RF007SDK-M001 RF007SDK-M001 参考資料 1 第 1 章製品概要本開発キットは RF007 ラジオコミュニケーションテスタ ( 本器 ) を使用したソフトウェアを開発するためのライブラリソフトウェアです
型名 RF007 ラジオコミュニケーションテスタ Radio Communication Tester ソフトウェア開発キット マニュアル アールエフネットワーク株式会社 RFnetworks Corporation RF007SDK-M001 RF007SDK-M001 参考資料 1 第 1 章製品概要本開発キットは RF007 ラジオコミュニケーションテスタ ( 本器 ) を使用したソフトウェアを開発するためのライブラリソフトウェアです
02: 変数と標準入出力
 C プログラミング入門 基幹 7 ( 水 5) 12: コマンドライン引数 Linux にログインし 以下の講義ページを開いておくこと http://www-it.sci.waseda.ac.jp/ teachers/w483692/cpr1/ 2016-06-29 1 まとめ : ポインタを使った処理 内容呼び出し元の変数を書き換える文字列を渡す 配列を渡すファイルポインタ複数の値を返す大きな領域を確保する
C プログラミング入門 基幹 7 ( 水 5) 12: コマンドライン引数 Linux にログインし 以下の講義ページを開いておくこと http://www-it.sci.waseda.ac.jp/ teachers/w483692/cpr1/ 2016-06-29 1 まとめ : ポインタを使った処理 内容呼び出し元の変数を書き換える文字列を渡す 配列を渡すファイルポインタ複数の値を返す大きな領域を確保する
Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ 3.7x faster P100 V100 P10
 NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
スライド 1
 GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
Prog1_10th
 2012 年 6 月 20 日 ( 木 ) 実施ポインタ変数と文字列前回は, ポインタ演算が用いられる典型的な例として, ポインタ変数が 1 次元配列を指す場合を挙げたが, 特に,char 型の配列に格納された文字列に対し, ポインタ変数に配列の 0 番の要素の先頭アドレスを代入して文字列を指すことで, 配列そのものを操作するよりも便利な利用法が存在する なお, 文字列リテラルは, その文字列が格納されている領域の先頭アドレスを表すので,
2012 年 6 月 20 日 ( 木 ) 実施ポインタ変数と文字列前回は, ポインタ演算が用いられる典型的な例として, ポインタ変数が 1 次元配列を指す場合を挙げたが, 特に,char 型の配列に格納された文字列に対し, ポインタ変数に配列の 0 番の要素の先頭アドレスを代入して文字列を指すことで, 配列そのものを操作するよりも便利な利用法が存在する なお, 文字列リテラルは, その文字列が格納されている領域の先頭アドレスを表すので,
Microsoft Word - HOKUSAI_system_overview_ja.docx
 HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
02: 変数と標準入出力
 C プログラミング入門 基幹 2 ( 月 4) 11: 動的メモリ確保 Linux にログインし 以下の講義ページを開いておくこと http://www-it.sci.waseda.ac.jp/ teachers/w483692/cpr1/ 2014-06-22 1 まとめ : ポインタを使った処理 内容 説明 呼び出し元の変数を書き換える第 9 回 文字列を渡す 配列を渡す 第 10 回 ファイルポインタ
C プログラミング入門 基幹 2 ( 月 4) 11: 動的メモリ確保 Linux にログインし 以下の講義ページを開いておくこと http://www-it.sci.waseda.ac.jp/ teachers/w483692/cpr1/ 2014-06-22 1 まとめ : ポインタを使った処理 内容 説明 呼び出し元の変数を書き換える第 9 回 文字列を渡す 配列を渡す 第 10 回 ファイルポインタ
GPUによる樹枝状凝固成長のフェーズフィールド計算 青木尊之 * 小川慧 ** 山中晃徳 ** * 東京工業大学学術国際情報センター, ** 東京工業大学理工学研究科 溶融金属の冷却過程において形成される凝固組織の形態によって材料の機械的特性が決定することは良く知られている このようなミクロな組織の
 1 創刊号 TSUBAME 2.0 の全貌 GPU による樹枝状凝固成長のフェーズフィールド計算 TSUBAME を用いたフラーレン ナノチューブ グラフェンの構造変化と新物質研究 GPUによる樹枝状凝固成長のフェーズフィールド計算 青木尊之 * 小川慧 ** 山中晃徳 ** * 東京工業大学学術国際情報センター, ** 東京工業大学理工学研究科 溶融金属の冷却過程において形成される凝固組織の形態によって材料の機械的特性が決定することは良く知られている
1 創刊号 TSUBAME 2.0 の全貌 GPU による樹枝状凝固成長のフェーズフィールド計算 TSUBAME を用いたフラーレン ナノチューブ グラフェンの構造変化と新物質研究 GPUによる樹枝状凝固成長のフェーズフィールド計算 青木尊之 * 小川慧 ** 山中晃徳 ** * 東京工業大学学術国際情報センター, ** 東京工業大学理工学研究科 溶融金属の冷却過程において形成される凝固組織の形態によって材料の機械的特性が決定することは良く知られている
バイオプログラミング第 1 榊原康文 佐藤健吾 慶應義塾大学理工学部生命情報学科
 バイオプログラミング第 1 榊原康文 佐藤健吾 慶應義塾大学理工学部生命情報学科 ポインタ変数の扱い方 1 ポインタ変数の宣言 int *p; double *q; 2 ポインタ変数へのアドレスの代入 int *p; と宣言した時,p がポインタ変数 int x; と普通に宣言した変数に対して, p = &x; は x のアドレスのポインタ変数 p への代入 ポインタ変数の扱い方 3 間接参照 (
バイオプログラミング第 1 榊原康文 佐藤健吾 慶應義塾大学理工学部生命情報学科 ポインタ変数の扱い方 1 ポインタ変数の宣言 int *p; double *q; 2 ポインタ変数へのアドレスの代入 int *p; と宣言した時,p がポインタ変数 int x; と普通に宣言した変数に対して, p = &x; は x のアドレスのポインタ変数 p への代入 ポインタ変数の扱い方 3 間接参照 (
最新の並列計算事情とCAE
 1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
1 大島聡史 ( 東京大学情報基盤センター助教 / 並列計算分科会主査 ) 最新の並列計算事情と CAE アウトライン 最新の並列計算機事情と CAE 世界一の性能を達成した 京 について マルチコア メニーコア GPU クラスタ 最新の並列計算事情と CAE MPI OpenMP CUDA OpenCL etc. 京 については 仕分けやら予算やら計画やらの面で問題視する意見もあるかと思いますが
PowerPoint Template
 プログラミング演習 Ⅲ Linked List P. Ravindra S. De Silva e-mail: ravi@cs.tut.ac.jp, Room F-413 URL: www.icd.cs.tut.ac.jp/~ravi/prog3/index_j.html 連結リストとは? 一つひとつの要素がその前後の要素との参照関係をもつデータ構造 A B C D 連結リストを使用する利点 - 通常の配列はサイズが固定されている
プログラミング演習 Ⅲ Linked List P. Ravindra S. De Silva e-mail: ravi@cs.tut.ac.jp, Room F-413 URL: www.icd.cs.tut.ac.jp/~ravi/prog3/index_j.html 連結リストとは? 一つひとつの要素がその前後の要素との参照関係をもつデータ構造 A B C D 連結リストを使用する利点 - 通常の配列はサイズが固定されている
数値計算
 プログラム作成から実行まで 数値計算 垣谷公徳 17 号館 3 階電子メール : kimi@ee.ous.ac.jp Source program hello.c printf("hello\n"); コンパイラ Library libc.a 0011_printf000101001 1101_getc00011100011 1011_scanf1110010100 コンパイル Object module
プログラム作成から実行まで 数値計算 垣谷公徳 17 号館 3 階電子メール : kimi@ee.ous.ac.jp Source program hello.c printf("hello\n"); コンパイラ Library libc.a 0011_printf000101001 1101_getc00011100011 1011_scanf1110010100 コンパイル Object module
<4D F736F F D20438CBE8CEA8D758DC F0939A82C282AB2E646F63>
 C 言語講座第 2 回 作成 : ハルト 前回の復習基本的に main () の中カッコの中にプログラムを書く また 変数 ( int, float ) はC 言語では main() の中カッコの先頭で宣言する 1 画面へ出力 printf() 2 キーボードから入力 scanf() printf / scanf で整数を表示 / 入力 %d 小数を表示 / 入力 %f 3 整数を扱う int 型を使う
C 言語講座第 2 回 作成 : ハルト 前回の復習基本的に main () の中カッコの中にプログラムを書く また 変数 ( int, float ) はC 言語では main() の中カッコの先頭で宣言する 1 画面へ出力 printf() 2 キーボードから入力 scanf() printf / scanf で整数を表示 / 入力 %d 小数を表示 / 入力 %f 3 整数を扱う int 型を使う
memo
 計数工学プログラミング演習 ( 第 3 回 ) 2017/04/25 DEPARTMENT OF MATHEMATICAL INFORMATICS 1 内容 ポインタの続き 引数の値渡しと参照渡し 構造体 2 ポインタで指されるメモリへのアクセス double **R; 型 R[i] と *(R+i) は同じ意味 意味 R double ** ポインタの配列 ( の先頭 ) へのポインタ R[i]
計数工学プログラミング演習 ( 第 3 回 ) 2017/04/25 DEPARTMENT OF MATHEMATICAL INFORMATICS 1 内容 ポインタの続き 引数の値渡しと参照渡し 構造体 2 ポインタで指されるメモリへのアクセス double **R; 型 R[i] と *(R+i) は同じ意味 意味 R double ** ポインタの配列 ( の先頭 ) へのポインタ R[i]