PowerPoint Presentation
|
|
|
- がんま しろみず
- 4 years ago
- Views:
Transcription
1 CLC Genomics Workbench ハンズオントレーニング変異解析編 株式会社キアゲングローバルイフォマティクスソリューション & サポートアプライドアドバンストゲノミクス 1

2 Genomics Workbench で可能な解析 新規生物種変異解析 ChIP-seq RNA-seq small RNA インポート インポート インポート インポート インポート Quality check Quality check Quality check Quality check タグの抽出 De Novo アッセンブリ マッピング マッピング RNA-seq mirbase ダウンロード BLAST 検索 変異検出 ピーク検出 RPKM 計算 アノテーション付け フィルタリング ピーク精査 群間比較 既知の mirna とそれ以外の分類 2

3 データ管理 データロケーション Genomics Workbench ではデータ保存の階層のトップを Location と呼びます Location デフォルトの Location は CLC_Data が作成されていますが 左の図のように Location は追加可能です Folder Location の新規追加は Navigation Area 左上のアイコンから作成可能です シークエンスデータはサイズが大きいため 容量が大きいディスクへ Location を作成することをお勧めします Location 作成 Folder 作成 また解析が一通り終了し バックアップや外付けのディスクへ移動する場合は この Location 単位での移動をお願いします 3

4 今日のデータ データインポート 今日は 変異解析用データと 発現差解析用データを使います それぞれ zip 形式で圧縮されていますが 圧縮された状態のまま 以下の Import > Standard Import よりインポートしてください 4
5 変異解析フロー 全体の流れ インポート QC トリミングマッピングマッピング補正変異解析アノテーションフィルタリング Title, Location, Date 5
6 CLC Genomics Workbench データインポート 6
7 データインポート リードデータインポート 次世代シークエンサー以外のファイル アノテーションファイルのインポート SAM/BAM インポート * シークエンサーデータインポート SAM/BAM ファイルは マッピング後のデータにおいて利用される一般的なフォーマットです 7
 Paired options: ペアのオプション Paired-end: ペアエンドかどうか Mate-pair: メイトペアかどうか ペアを選んだ場合はリード長を含めた距離を入力 古いバージョンの Illumina のソフトウェアで処理されたデータの場合は")
8 データインポート リードデータインポート : イルミナ リードファイルの選択 General options: 共通のオプション Paired reads: ペアかどうか Discard reads names: リード名を捨てるかどうか ( 捨てないことをお勧め ) Discard quality scores: クオリティスコアを捨てるかどうか ( 捨てないことをお勧め ) Paired options: ペアのオプション Paired-end: ペアエンドかどうか Mate-pair: メイトペアかどうか ペアを選んだ場合はリード長を含めた距離を入力 古いバージョンの Illumina のソフトウェアで処理されたデータの場合は バージョンを指定 8
9 データインポート リードデータインポート : イルミナ Result handling: 結果の扱い方 Open: インポート後開く Save: インポートして保存 Into separate folders: データごとにフォルダを作成するかどうか 複数ファイルをインポートする場合は チェックを入れておくことで データごとにフォルダが作成され 管理が容易になります 9
 Fastq か sff を選択可能 Ion Torrent オプション :.")
10 データインポート リードデータインポート :Ion Torrent リードファイルの選択 General options: 共通のオプション Paired reads: ペアかどうか Discard reads names: リード名を捨てるかどうか ( 捨てないことをお勧め ) Discard quality scores: クオリティスコアを捨てるかどうか ( 捨てないことをお勧め ) Fastq か sff を選択可能 Ion Torrent オプション :.sff ファイルでのインポートの場合 Clipping された情報を使うかどうか 選択できる Paired options: ペアのオプション Paired-end: ペアエンドかどうか Mate-pair: メイトペアかどうか ペアを選んだ場合はリード長を含めた距離を入力 10

11 データインポート リードデータインポート :Ion Torrent Result handling: 結果の扱い方 Open: インポート後開く Save: インポートして保存 Into separate folders: データごとにフォルダを作成するかどうか 複数ファイルをインポートする場合は チェックを入れておくことで データごとにフォルダが作成され 管理が容易になります 11
12 データインポート リードデータインポート :Ion Torrent (Unmapped BAM ファイル ) 注意 Ion Torrent のシークエンサーデータを処理する Torrent Suit では バージョン 3.0 以降 デフォルトでは fastq ファイルや sff ファイルが作成されず Unmapped BAM ファイルが作成されます Unmapped BAM ファイルは Import > Standard Import よりインポートいただくことで fastq ファイルをインポートした場合と同じようにインポートが可能です リードデータとしてインポートされます マッピングデータとしてインポートされます 12

13 データインポート ゲノムインポート ゲノムデータは よく知られているモデル動物についてはの Download Genome よりインポートできます 13

14 データインポート ゲノム配列の入手方法 Download 機能を用いる または Download サイトからダウンロードしたファイルをインポートする 14


15 データインポート ゲノムインポート Download genome sequence: 新規にゲノムをダウンロードする場合 Use exsting genome sequence track: すでにダウンロードしたゲノムにアノテーションを追加する場合 以下のようにトラックのフォーマットになっているゲノムを選択 ドロップダウンリストから生物種を選択 15

16 データインポート ゲノムインポート 希望するアノテーションにチェックを入れる ゲノム配列をダウンロードするときは Sequences にもチェックを入れる 選択した生物種により 表示されるアノテーションの種類は異なります 16


17 データインポート NCBI で検索してインポート または NCBI のサイトに検索をかけて 直接ゲノム配列をダウンロードすることができます 17

18 データインポート Search for Sequences at NCBI 検索のキーワードを入れて Start search をクリックします 目的の配列を選択して Download and Save で配列をダウンロードできます 18
19 データインポート アノテーションインポート Download Genome 以外にも アノテーションファイルをインポート可能です アノテーションとして取り込めるファイルは以下のフォーマットです アノテーションファイルをインポートする際には 対象となるゲノム配列がすでにインポートされ Track のフォーマットになっていることが前提です VCF GFF/GTF/GVF BED Wiggle Complete Genomics Var file UCSC Variation table damp COSMIC variation database 変異のデータについても アノテーションとして自分の変異へアノテーションとして情報の追加や比較ができるため アノテーションのインポート可能フォーマットに含めています 19

20 データインポート アノテーションインポート アノテーションのインポートは Import > Tracks より行います 20
 を選択")
21 データインポート トラックインポート インポートするファイルのタイプを選択 インポートするファイルを選択 対象とする参照配列 ( ゲノム配列 ) を選択 あらかじめインポートされている必要があります 21
22 データフォーマット編スタンドアロンフォーマットとトラックフォーマット 22

23 スタンドアロンフォーマット スタンドアロンフォーマットでは 1 つのデータに配列情報 アノテーションがセットになっています 23

24 トラックフォーマット トラックフォーマットでは リードやゲノム配列 アノテーションがばらばらのファイルになっており 好きに組み合わせて表示が可能です 24

25 トラックリスト 複数のトラックを組み合わせて Track list を作ることで好きなビューを作成できます 25
Track 解析によって必要とするフォーマットが異なります スタンドアロン トラックの変換は自由に行えます")
26 フォーマットとアイコン表示 スタンドアロンフォーマット 染色体のセットやリード配列など配列のセット 染色体 1 本など 1 つの配列 リードマッピング トラックフォーマット 青いヒストグラムが目印 ゲノム Track アノテーション Track 変異 Track リード ( マッピング )Track 解析によって必要とするフォーマットが異なります スタンドアロン トラックの変換は自由に行えます 26
27 フォーマットの変換 トラックフォーマットからスタンドアロンフォーマット またスタンドアロンフォーマットからトラックフォーマットへは Toolbox > Track tools の中のツールを使って変換可能です スタンドアロンフォーマットからトラックへの変換 トラックからスタンドアロンフォーマットへの変換 27

28 フォーマットの変換 トラックフォーマットからスタンドアロンフォーマット またスタンドアロンフォーマットからトラックフォーマットへは Toolbox > Track tools の中のツールを使って変換可能です スタンドアロンフォーマットからトラックへの変換 トラックからスタンドアロンフォーマットへの変換 スタンドアロンフォーマットへ変換する場合 スタンドアロン内に含めるアノテーショントラックを含めて変換するようにしてください 28


29 フォーマットの変換 スタンドアロンフォーマットへ変換する場合 スタンドアロン内に含めるアノテーショントラックを含めて変換するようにしてください スタンドアロンフォーマットでは Setting Panel の Annotation Type からどういったアノテーションが付属しているか確認できます 29
30 クオリティチェックとトリミング 30
31 クオリティチェックとトリミング Quality Report 作成 : Create Sequencing QC Report インポートしたリードのクオリティがどのぐらいか その後のトリミングや PCR Duplicate の状況などを確認するためにレポートを作成 トリミング : Trim Sequences アダプターの除去 クオリティスコアによる除去 長さを指定した除去などを選択 組み合わせてトリミング 上記処理の後に再度 Quality Report を作成すると処理前と処理後でのリードのクオリティを比較でき 便利です 31
32 クオリティトリミング : 原理 クオリティスコア シークエンサーから出てきたリードは 各塩基ごとにエラーの確率の値を持っている Genomics Workbench へインポートされた時点で Phred Score に変換されるようになっています Pred Score は 塩基のエラー確率の Log を取り -10 をかけてスコア化したものです 値が大きくなるほど精度が高いことをあらわしています Phred Score Error の確率 Base call の精度 10 1/10 90% 20 1/100 99% 30 1/1, % 40 1/10, % 50 1/100, % 60 1/1,000, % 32


33 QC レポート作成 :Create Sequencing QC Report Navigation Area から使用するリードデータを選択 Toolbox から NGS Core Tools > Create Sequencing QC Report を選択 ダブルクリック ウィザードが起動し 選択したデータが選ばれていることを確認 33

34 QC レポート作成 :Create Sequencing QC Report Quality analysis: クオリティスコアに関する解析 Over-representations analysis: 過度に現れているような塩基配列などの解析 Create graphical report: グラフィカルなレポート作成 Create supplementary report: 数値のレポート作成 Create duplicated sequence list: 重複のあった配列のリスト作成 34

35 QC レポート作成 :Create Sequencing QC Report 35
36 トリミング原理 3 種類のトリミング アダプター除去 あらかじめ登録されているアダプターの除去 新規で独自の配列を登録することも可能 クオリティトリミング Quality Score を使い Quality の低い配列が連続するようになる箇所からカット 正確に読めていない塩基をいくつ許容するか 長さによる除去 塩基数を指定して 5 末端 3 末端をカット Quality Score でカット後 短くなりすぎた配列をカット 36
37 クオリティトリミング : 原理 クオリティスコア Trimming では Quality Score を使い 累積の Quality Score がある一定の値より大きいものが続いた場合に その箇所を取り除く という処理を行います 具体的には以下 : 1. Phred Score を p 値へ変換 2. Trimming 中に設定するパラメータ (Limit) とp 値の差を計算 3. 差の累積和を計算 このとき 0 以下の値は0とする 4. Trimming 後のリード開始点は累積和がはじめて0 以上になった点 Trimming 後のリー ド終了点は累積和が最大の点 37
38 クオリティトリミング : 原理 原理 リード配列 G C C C A T G T T C G A T G C Phred score p 値 Limit - p 値 (D) (D) の累積和 Limit = 0.05 の場合 Phred score の棒グラフ スタート点 : 累積和が 0 より大きくなった塩基 終了点 : 累積和が最大を示す塩基 グラフより ある程度クオリティが高くなった場所からリードを使い クオリティが連続して悪くなっている箇所からリードをトリムしていることがわかる 途中 1 塩基のみクオリティが低いような場合は 必ずしもトリムされない これはできるだけリードを長く保とうとするため 38


39 トリミング Navigation Area から使用するデータを選択 Toolbox から Trim Sequences を選択 ダブルクリック ウィザードが起動し 選択したデータが選ばれていることを確認 39

40 トリミング クオリティトリミング Trim using quality scores : トリミングに使用するLimitパラメータを決定 Trim ambiguous nucleotides:n 表示される塩基について 最大何塩基まで保持させるか 今回はアダプターは設定なし 40

41 トリミング 長さによるトリミング 5 末 3 末の塩基数を指定してカットする Quality Score によるトリミングであまりに短いリードの除去など長さによるトリミング 41

42 トリミング結果 結果 トリミング後は トリムされたリードと レポートを作成した場合は そのレポートが作成されます トリミング結果のデータはファイル名の後に trimmed という名前が付いています ファイル内容はインポート後のデータ同様に 配列と クオリティスコアを含んだファイルとなっています 42

43 トリミングレポート 結果 43
44 QC レポート再作成による比較 エクササイズ トリミング後のデータでレポートを作成してみましょう! Before After 44


45 アダプタートリミング : アダプターの指定 File > New > Trim Adapter List Name: アダプターの名前 Sequcence: アダプターの配列 Strand アダプターが見つかった場合のアクションの指定 Alignment scores costs: ミスマッチとギャップに対するペナルティのコスト Match thresholds: internal または end のマッチに対する criteria 45 45
46 マッピング 46
47 マッピング原理 2 つのステップ 1. ローカルアライメント 参照配列と似ている場所を探す 2. フィルタリング どの程度参照配列と一致しているリードをその後の解析に残すか 47
48 マッピング原理 マッピング原理 スコアリング 最適なマップ場所を Local Alignment で探索 Match = 1, Mismatch cost = 2 リード配列 (20bp) が全て一致した場合 CGTATCAATCGATTACGCTATGAATG ATCAATCGATTACGCTATGA アライメントスコア = 20 48
49 マッピング原理 マッピング原理 スコアリング CGTATCAATCGATTACGCTATGAATG TTCAATCGATTACGCTATGA アライメントスコア = 19 CGTATCAATCGATTACGCTATGAATG TTCAATCAATTACGCTATGA アライメントスコア = 16 CGTATCAATCGATTACGCTATGAATG TTCAATCAATTGCGCTATGC アライメントスコア = 10 49
50 マッピング原理 フィルタリング 最も高いアライメントスコアにマップされたリードのうち どの程度参照配列と類似しているリードをその後の解析に残すのかを決定します 50
51 マッピング原理 Linear gap と Affine gap Linear gap cost の場合 (Deletion コストが 3 の場合 ) A Genome Read AATTCGCGCGGCATTCGCGCC AAATCG----GCATTCGCGCC 50 match x (-3) + 11 = 55 B Affine Gap cost を使った場合 (Gap open = 6, Gap extend = 1) C AATTCGCGCGGCATTCGCGCC AAATCG----GCATTCGCGCC = 56 AATTCGCGCGGCATTCGCGCC AAATCG----GCATTCGCGCC (-6) + 4 x (-1) + 11 = 57 これまでのマッピングでは A のように本来マッピングすべきような場合でも リードの末端部分をアライメントしない (B のブルーの箇所 ) 場合のほうが アライメントスコアが高くなるため 大きな挿入や欠失がうまくマップできていないことがありました アフィン Gap コストの場合 このような問題を防ぐことができます また Gap を開くときのコスト (Open) と延長するときのコスト (Extend) が別に設定できることで より細かくコントロールが可能になる場合があります 51
52 マッピング原理 フィルタリング原理 Length Fraction と Similarity パラメータを使って どの程度アライメントされたリードを マッピングされたものとして保持するか 決定します Length Fraction と Similarity は 2 つのパラメータの組み合わせで使用されます Length fraction: フィルターをかける際に 考慮する長さ Similarity: Length Fraction で指定した長さのうち どの程度類似しているものを残すか リード長 :100 bp デフォルトのLength Fraction, bp x 0.5 = 50 bp, デフォルトのSimilarity bp x 0.8 = 塩基中 40 塩基が完全一致していることがフィルタリングの条件となる Reference 52
53 マッピング原理 2 つのパラメータを使う理由 Reference リードの一部は似ているけれども 大きな挿入や 欠失によりリードの一部が参照配列と一致しない可能性がある場合 トリミングが完全にできなかったクオリティの低い配列が末端部にある場合 (Length Fraction を小さくすることで リードの一部に限定してアライメントの類似度を設定できる ) Reference 参照配列とほぼ一致するが 所々 1 塩基の変異があると想定される場合 53



54 マッピング Navigation Area から使用するデータを選択 Toolbox から NGS Core Tools > Map Reads to Reference を選択 ダブルクリック ウィザードが起動し 選択したデータが選ばれていることを確認 54


55 マッピング Reference: 使用する参照配列を選択 Reference masking Exclude annotated: あるアノテーションを除外したい場合 Include annotated only: あるアノテーションのみ含みたい場合 Reference に使用するデータを選択 55
56 Mapping parameters: Linear Gap cost Mismatch の penalty Insertion/deletion の penalty (Linear) Filter の parameter 56
 と Insertion, Deletion が 1 塩基長くなる際に増えるコスト (Insertion/Deletion extended cost) 57")
57 Mapping parameters: Affine gap cost Insertion/deletion の penalty (Affine) Insertion, Deletion 開始時点でカウントされるコスト (Insertion/Deletion open cost) と Insertion, Deletion が 1 塩基長くなる際に増えるコスト (Insertion/Deletion extended cost) 57
58 マッピング Mismatch cost: アライメントにマッチしないものがあった場合のコスト Insertion cost: アライメントに挿入がある場合のコスト Deletion cost: アライメントに欠失がある場合のコスト Insertion open cost: 挿入を開始する場合のコスト Insertion extend cost: 挿入を延長する場合のコスト Deletion open cost: 欠失を開始する場合のコスト Deletion extend cost: 欠失を延長する場合のコスト Length fraction: リードの長さのどの程度がマッピングされているべきか Similarity : どの程度類似しているべきか Global alignment: Global alignment を行うかどうか チェックが外れている場合は Local alignment を実行 Color space alignment: カラースペースのデータかどうか その場合にカラーによるエラー補正を行うかどうか Auto-detect paired distances: 自動でペアの距離を決めるかどうか Non-specific match handling: 同一スコアでマップされる箇所がある場合の対処 58
 で作成するか Create report: マッピング結果のレポート作成 Collect un-mapped reads: マップされなかったリードをリストとして作成するかどうか ( リスト化することにより De Novo")
59 マッピング Create reads track: 結果をトラックとして作成する場合 Create stand-alone read mappings: 結果を stand-alone フォーマット ( 参照配列 リードマッピング アノテーションが一つになったファイル ) で作成するか Create report: マッピング結果のレポート作成 Collect un-mapped reads: マップされなかったリードをリストとして作成するかどうか ( リスト化することにより De Novo など 別の解析へ利用可能 ) 59
60 マッピング : 結果 結果のトラック トラック 選択ツール 拡大ツール 縮小して全体表示ボタン スライドズーム Tool バー 60

61 マッピング : 結果 背景に色が付いている箇所は 参照配列と異なる箇所です 緑色のリードは センス鎖にマップされたリード 赤色のリードはアンチセンス鎖へマップされたリードになります 青色のリードは ペアとして認識されているリードです 色がうすくなっている箇所はマッピングされていません カバレッジの計算にも考慮されていません 61


62 マッピング : レポート 基本の Report は Summary Report という名前で保存されています 62

63 マッピング :Track list の作成 参照配列の追加 リードマッピングの結果に参照配列を追加しましょう 63

 のアイコンがのような場合 Track")

64 マッピング :Track list の作成 追加されたゲノムトラックと遺伝子トラック マッピングに使用したゲノムを選択 ゲノム ( 参照配列 ) のアイコンがのような場合 Track Tools > Convert to Track を使って 変換を行ってください ドラッグアンドドロップで簡単に位置を変更できます 64
65 Local Realignment 65

66 Local Realignment 原理 マッピングのプロセスでは 各リードがもっとも高いアライメントスコア ( 参照配列との一致度を示すスコア ) を示す場所にマッピングをしています しかしながら 時には近傍のリードのマッピングの状況から 最も高いアライメントスコアではなくとも もっともらしいマッピング結果が考えられる場合があります たとえば上記例では GCCG は左横にずれることで 他のリードのマッピングとも一致しもっともらしいマッピングになると考えられます マッピングの段階では 各々のリードのアライメントスコアのみを考えているため このような状況が発生します さらにこの状況で変異やInsertion Deletionの検出を行うと 正しく検出できないものも発生します 特にInsertionやDeletionが影響をうけると考えられています 66

67 Local Realignment 原理 Local Realignment では このような状況を修正するため マッピングを部分的にやり直します この際 通常のマッピングの段階とは異なり 他のリードのマッピング状況を考慮するため 先ほどのマッピングは以下のように変化します 先ほどのマッピングよりも こちらの方がもっともらしい結果であることが直感的に分かります 67


68 Local Realignment Toolbox > NGS Core Tools > Local Realignment 2 種類の Local Realignments があります さらに Guided に No force と Force の 2 種類があります Non guided Guided No force Force 68

69 Local Realignment Guided Local Realignment ガイドとなるような変異 (Insertion や Deletion) の情報をあらかじめ与えておくことで その領域の Insertion Deletion を考慮してリアライメントを行う ガイドとなる変異情報がない場合 Local Realignment では 少なくとも 1 本のリードが Insertion や Deletion を支持している必要がある このような場合 ガイドとなる変異情報を与えることで Insertion や Deletion を効率的に検出できるようになる Guided Local Realignment が有効な例 69



70 Local Realignment 実行方法 Navigation Area から使用するマッピングデータを選択 Toolbox から NGS Core Tools > Local Realignment を選択 ダブルクリック ウィザードが起動し 選択したデータが選ばれていることを確認 70

71 Local Realignment 実行方法 Realign unaligned ends: マッピングの際にマップされなかった末端 (soft clipping) を Local Realignment の際に利用するかどうか アダプターの一部のようなものが残っていない限り ここはチェックを入れる Guidance-variant settings: ガイダンスあり なしの設定 Guidance-variant track: ガイダンスに使用するトラックを選択 Force realignment to guidance-variants: ここにチェックを入れることで より積極的に Realignment を行える 71
72 Local Realignment 実行方法 Output options アウトプットの選択 Create reads track: トラックフォーマットでの作成 Create stand-alone read mappings: スタンドアロンフォーマットでの作成 Output track of realigned regions: Realignment された個所をトラックとして保存するかどうか 確認に便利 Result handling Open: 実行後すぐに開く Save: 実行後一旦保存 Log handling Make log: ログを作成するかどうか 72
73 Local Realignment: 結果 結果はマッピングのファイルとして作成され 名前の最後に locally realigned として作成されます スタンドアロンフォーマットで作成した場合 トラックフォーマットで作成した場合 この後 通常と同じ方法で変異や Insertion, Deletion の検出を行います 73
74 変異検出 74
75 SNV 検出 3 種類の variant detection tools Basic Variant Detection : クオリティと バリアントの見られる頻度からバリアントのサイトを検出 (version 7.5 以前の Quality-Based Variant Detection) Fixed Ploidy Variant Detection: 確率モデルを使い バリアントのサイトを検出 (version 7.5 以前の Probabilistic Variant Detection) Low Frequency Variant Detection: 低頻度で見られるバリアントの検出ツール 倍数性を指定しないでバリアントの検出が行える 使い分け : バリアントの見られる頻度が その領域において 15% 以下のような場合は Basic Variant Detection, それよりも多い場合は Fixed Ploidy Variant Detection をご利用ください バリアントの見られる頻度が低い場合や 倍数性を指定できない場合などは Low Frequency Variant Detection をご利用ください 75
76 フィルター :General Filter 共通フィルター Reference masking Ignore positions with coverage above: カバレッジが指定した数字以上のバリアントについてリストに含めない Restrict calling to target regions: バリアントを検出したい領域の指定 ( アノテーショントラックで指定 ) Read filters Ignore broken pairs: ペアエンドのリードでペアと認識されなかったリードをバリアント検出の計算に含めるかどうか Ignore non-specific matches: Reads を選択すると non-specific なマッチのリードを計算に含めなくなり Regions を選択すると 1 本でも non-specific なリードが含まれる場合 その領域のバリアントを検出しません Minimum read length:ignore broken pair と Ignore non-specific regions が指定された場合 このフィルターの対象となる最小のリードの長さの設定が必要です これは非常に短いリードは その短さから non-specific になる可能性があるためです 76
: 最小頻度")
77 フィルター :General Filter 共通フィルター Coverage and count filters Minimum coverage: 最小カバレッジ Minimum count: バリアントを支持するリードの最低カウント数 Minimum frequency (%): 最小頻度 77
 Minimum central quality: 縦方向の数 ( リード数 ) Minimum neighborhood quality:neighborhood radius で指定した範囲の最低クオリティ (Phred score) 78 78")
78 フィルター :Noise Filters 共通フィルター Quality filter Base quality filter: 塩基のクオリティに関するフィルター Neighborhood radius: クオリティフィルターの対象とする横方向の塩基数 ( 奇数 ) Minimum central quality: 縦方向の数 ( リード数 ) Minimum neighborhood quality:neighborhood radius で指定した範囲の最低クオリティ (Phred score) 78 78
79 フィルター :Noise Filters 共通フィルター Direction and position filters: リードの方向 (Forward と Reverse) とポジションを使ったフィルター Read direction filter: どちらか一方の方向のリードが多数見られる場合にそれを排除 ( ただし アンプリコンには適していません ) Relative read direction filter: リードの方向が一方のみに偏りすぎていないか 全体の Forward と Reverse のバランスを見て統計検定を行う Significance で閾値を入力 Read position filter: システマティックなエラーを取り除くために用いるツールでハイブリダイゼーションを行った場合のデータに有効 リードを 5 つのセグメントに分割し バリアントの見られるポジションの 5 つのセグメントに分割されたリードの分布が全体のそれと似ているかどうか検定を行う Significance で閾値を入力 * 詳細は後述 79 79
80 フィルター :Noise Filters 共通フィルター Technology specific filters Remove pyro-error variants: ホモポリマー領域に対するエラーの除去 In homopolymer regions with minimum length: 指定した長さのホモポリマー領域の InDel を取り除く With frequency below: 指定した頻度以下のものについてのみフィルターを適用 80 80

81 Base quality filter フィルター例 Base quality filter 適用例 : マッピングしたリードをクオリティで表示 クオリティの低いリードがマップされている箇所がバリアントのリストからはずされます 81
 を示しており 緑のリードが大部分のバリアントをサポートしていることがわかる こういったアンバランスな箇所で検出されたバリアントが取り除かれる")
82 Read direction フィルター例 Read direction filter 適用例 : リードの色は緑 (Forward) 赤 (Reverse) 黄色 (nonspecific) を示しており 緑のリードが大部分のバリアントをサポートしていることがわかる こういったアンバランスな箇所で検出されたバリアントが取り除かれる 82
83 Read position filter 原理 もしリードが理想的な均一なカバレッジであれば 検出されるバリアントをサポートする塩基のリード中の位置は さまざまになるはずです これを使い リードを Forward Reverse の向きを考慮して それぞれ 5 分割 計 10 個の領域に分断し 変異が見つかった箇所がリードのどの領域に属するか それらの分布が全体と大きく差がないかを検定しています 83

84 Read position filter フィルター例 Read position filter 適用例 : バリアントをサポートしているリードがリードの同じ位置で検出されているため このバリアントは Read position filter により除去されます 84
85 Basic Variant Detection 変異検出ツールでは フィルターの条件をクリアした場合に variant をコールします 85

86 Basic Variant Detection Navigation Area からマッピングデータを選択 Toolbox から Resequencing Analysis > Variant Detectors > Basic Variant Detection を選択 ダブルクリック ウィザードが起動し 選択したデータが選ばれていることを確認 86
87 Basic Variant Detection Ploidy: 参照配列の倍数性 87
88 Basic Variant Detection Reference masking Ignore positions with coverage above: カバレッジが指定した数字以上のバリアントについてリストに含めない Restrict calling to target regions: バリアントを検出したい領域の指定 ( アノテーショントラックで指定 ) 88
89 Basic Variant Detection Read filters Ignore broken pairs: ペアエンドのリードでペアと認識されなかったリードをバリアント検出の計算に含めるかどうか Ignore non-specific matches: Reads を選択すると non-specific なマッチのリードを計算に含めなくなり Regions を選択すると 1 本でも non-specific なリードが含まれる場合 その領域のバリアントを検出しません Minimum read length:ignore broken pair と Ignore non-specific regions が指定された場合 このフィルターの対象となる最小のリードの長さの設定が必要です これは非常に短いリードは その短さから non-specific になる可能性があるためです 89
:")
90 Basic Variant Detection Coverage and count filters Minimum coverage: 最小カバレッジ Minimum count: バリアントを支持するリードの最低カウント数 Minimum frequency (%): 最小頻度 90
91 Basic Variant Detection Quality filter Base quality filter: 塩基のクオリティに関するフィルター Neighborhood radius: クオリティフィルターの対象とする横方向の塩基数 ( 奇数 ) Minimum central quality: 縦方向の数 ( リード数 ) Minimum neighborhood quality: Neighborhood radius で指定した範囲の最低クオリティ (Phred score) 91 91
92 Basic Variant Detection Direction and position filters: Read direction filter: どちらか一方の方向のリードが多数見られる場合にそれを排除 ( ただし アンプリコンには適していません ) Relative read direction filter: リードの方向が一方のみに偏りすぎていないか 全体の Forward と Reverse のバランスを見て統計検定を行う Significance で閾値を入力 Read position filter: システマティックなエラーを取り除くために用いるツールでハイブリダイゼーションを行った場合のデータに有効 リードを 5 つのセグメントに分割し バリアントの見られるポジションの 5 つのセグメントに分割されたリードの分布が全体のそれと似ているかどうか検定を行う Significance で閾値を入力 92 92

93 Basic Variant Detection Technology specific filters Remove pyro-error variants: ホモポリマー領域に対するエラーの除去 In homopolymer regions with minimum length: 指定した長さのホモポリマー領域の InDel を取り除く With frequency below: 指定した頻度以下のものについてのみフィルターを適用 93 93

94 Basic Variant Detection Create track: トラックの作成 Create annotated table: アノテーション付のテーブルの作成 94



95 Basic Variant Detection 結果 結果はデフォルトではトラックフォーマットになっています 左下のテーブルアイコンをクリックするとテーブルに代わります 95
96 Basic Variant Detection: 結果 Count: クオリティのフィルターをパスしたリードの数 Coverage: クオリティのフィルターをパスしたリードの数 Frequency: バリアントが見られた頻度 Probability: バリアントのアレルの事後確率 ( そのアレルが尤もであるとする確率 高い方がより確度が高いという事 ) Forward reads: その領域に見られた Forward リードの数 Reverse reads: その領域に見られた Reverse リードの数 Forward/reverse: Forward/Total reads または Reverse/Total reads のうち小さい方の値 Forward と Reverse が同じなら 0.5 となる Average quality: 該当する領域の平均リードクオリティ # unique start positions: バリアントコールに使われたリードのうちスタートポジションにあるリードの数 # unique end positions: バリアントコールに使われたリードのうち最後の箇所にあるリードの数 BaseQRankSum: クオリティスコアについて 参照配列と同じアレルとバアリアントのアレルについてマンホイットニー U 検定を行い計算された Z スコア これが高いほど参照配列の塩基とバリアントの塩基に差がある Hyper-alleic: 想定されるアレルよりも頻度が高いかどうか Homopolymer: ホモポリマー領域かどうか 96

97 Basic Variant Detection トラックリストの作成 97



98 Basic Variant Detection トラックリスト作成 Navigation Area からマッピングデータとバリアントの結果を選択 Toolbox から ResequTrack Tools > Create Track List を選択 ダブルクリック ウィザードが起動し 選択したデータが選ばれていることを確認 98


99 Basic Variant Detection トラックリストの作成 バリアントのトラックの名前のところでダブルクリック テーブルが現れます テーブルの行と マッピングのビューアは対応しているので テーブルで指定したポジションに自動的にビューアが移動します 99
 A/A, A/T, A/C...? 与えられるリードから そのポジションの Site Type を推定 Reference と推定した Site type が異なる場合 バリアントとして結果返す 100")
100 Fixed Ploidy Variant Detection Probabilistic Variant Detection 確率モデル (Bayes model) を使ったバリアント検出 Reference A? A A T T C? : Site type (ex) A/A, A/T, A/C...? 与えられるリードから そのポジションの Site Type を推定 Reference と推定した Site type が異なる場合 バリアントとして結果返す 100
 ( ) ( ) ( ) ( A P B P B A P A B P = ベイズの定理事後確率 Posterior 事前確率 Prior 尤度")
101 Fixed Ploidy Variant Detection 101 A B A B P(A) P(B ) P(A B) ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( B P B A P A P A B P B P B A P B A P A P A B P B A P = = = ) ( ) ( ) ( ) ( A P B P B A P A B P = ベイズの定理事後確率 Posterior 事前確率 Prior 尤度 Likelihood
102 Fixed Ploidy Variant Detection Reference A? A A T T C? : Site type (ex) A/A, A/T, A/C...? P ( S R) = P( R S) P( S) P( R) S :Site type R : Reads P( R S) P(S) : Error Model を使って推定 : Genome Model を使って推定 102
103 Fixed Ploidy Variant Detection Genome Model Reference が A のとき Read の大部分は A になると仮定し 初期の確率を以下のように設定し EM アルゴリズムを使ってそれぞれの確率を推定する EM アルゴリズム (Expectation Maximization algorithm) は 得られたデータから推定したい現象が観察できない場合に その確率を推定する 一般的な統計の手法 Site Type Initial Probability A/A A/C A/G A/T T/C T/G T/T G/C C/C G/G G/ A/ C/ T/
104 Fixed Ploidy Variant Detection Error Model リードに含まれるエラーを考慮するため 尤度のところにエラーを考慮した確率を推定する 初期値を以下のように設定し EM アルゴリズムにて確率を推定する Reference Reads A C G T - A C G T



105 Fixed Ploidy Variant Detection Navigation Area からマッピングデータを選択 Toolbox から Resequencing Analysis > Variant Detectors > Fixed Ploidy Variant Detection を選択 ダブルクリック ウィザードが起動し 選択したデータが選ばれていることを確認 105
 この値を低くすると 検出されるバリアントが多くなります")
106 Fixed Ploidy Variant Detection Ploidy: 参照配列の倍数性 Required variant probability: バリアントが参照配列と異なる確率 ( 想定で入力 ) この値を低くすると 検出されるバリアントが多くなります 106
107 Fixed Ploidy Variant Detection Reference masking Ignore positions with coverage above: カバレッジが指定した数字以上のバリアントについてリストに含めない Restrict calling to target regions: バリアントを検出したい領域の指定 ( アノテーショントラックで指定 ) 107
108 Fixed Ploidy Variant Detection Read filters Ignore broken pairs: ペアエンドのリードでペアと認識されなかったリードをバリアント検出の計算に含めるかどうか Ignore non-specific matches: Reads を選択すると non-specific なマッチのリードを計算に含めなくなり Regions を選択すると 1 本でも non-specific なリードが含まれる場合 その領域のバリアントを検出しません Minimum read length:ignore broken pair と Ignore non-specific regions が指定された場合 このフィルターの対象となる最小のリードの長さの設定が必要です これは非常に短いリードは その短さから non-specific になる可能性があるためです 108
109 Fixed Ploidy Variant Detection Coverage and count filters Minimum coverage: 最小カバレッジ Minimum count: バリアントを支持するリードの最低カウント数 Minimum frequency (%): 最小頻度 109
110 Fixed Ploidy Variant Detection Quality filter Base quality filter: 塩基のクオリティに関するフィルター Neighborhood radius: クオリティフィルターの対象とする横方向の塩基数 ( 奇数 ) Minimum central quality: 縦方向の数 ( リード数 ) Minimum neighborhood quality: Neighborhood radius で指定した範囲の最低クオリティ (Phred score)
111 Fixed Ploidy Variant Detection Direction and position filters: Read direction filter: どちらか一方の方向のリードが多数見られる場合にそれを排除 ( ただし アンプリコンには適していません ) Relative read direction filter: リードの方向が一方のみに偏りすぎていないか 全体の Forward と Reverse のバランスを見て統計検定を行う Significance で閾値を入力 Read position filter: システマティックなエラーを取り除くために用いるツールでハイブリダイゼーションを行った場合のデータに有効 リードを 5 つのセグメントに分割し バリアントの見られるポジションの 5 つのセグメントに分割されたリードの分布が全体のそれと似ているかどうか検定を行う Significance で閾値を入力

112 Fixed Ploidy Variant Detection Technology specific filters Remove pyro-error variants: ホモポリマー領域に対するエラーの除去 In homopolymer regions with minimum length: 指定した長さのホモポリマー領域の InDel を取り除く With frequency below: 指定した頻度以下のものについてのみフィルターを適用 112

113 Fixed Ploidy Variant Detection Create track: トラックの作成 Create annotated table: アノテーション付のテーブルの作成 113

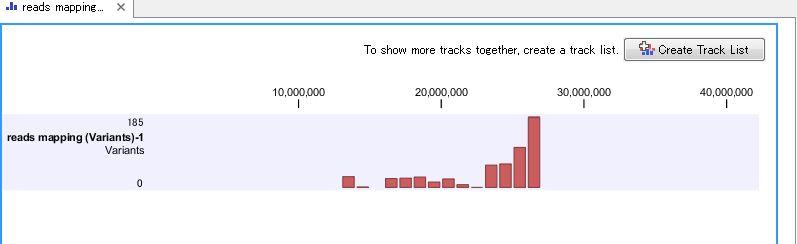

114 Fixed Ploidy Variant Detection: ビューの見方 114
115 Fixed Ploidy Variant Detection: 結果 Count: クオリティのフィルターをパスしたリードの数 Coverage: クオリティのフィルターをパスしたリードの数 Frequency: バリアントが見られた頻度 Probability: バリアントのアレルの事後確率 ( そのアレルが尤もであるとする確率 高い方がより確度が高いという事 ) Forward reads: その領域に見られた Forward リードの数 Reverse reads: その領域に見られた Reverse リードの数 Forward/reverse: Forward/Total reads または Reverse/Total reads のうち小さい方の値 Forward と Reverse が同じなら 0.5 となる Average quality: 該当する領域の平均リードクオリティ # unique start positions: バリアントコールに使われたリードのうちスタートポジションにあるリードの数 # unique end positions: バリアントコールに使われたリードのうち最後の箇所にあるリードの数 BaseQRankSum: クオリティスコアについて 参照配列と同じアレルとバアリアントのアレルについてマンホイットニー U 検定を行い計算された Z スコア これが高いほど参照配列の塩基とバリアントの塩基に差がある Hyper-alleic: 想定されるアレルよりも頻度が高いかどうか Homopolymer: ホモポリマー領域かどうか 115
116 Low Frequency Variant Detection Low frequency Variant Detection では 倍数性を仮定せず 対象となる領域が シーケンスエラーなのか そうではない (= バリアント ) なのかを検定しています Error モデルについては Fixed Ploidy Variant Detection にて採用したエラーモデルを使い 計算し 尤度比検定を行っています 116
117 Low Frequency Variant Detection Navigation Area からマッピングデータを選択 Toolbox から Resequencing Analysis > Variant Detectors > Low Frequency Variant Detection を選択 ダブルクリック ウィザードが起動し 選択したデータが選ばれていることを確認 117

118 Low Frequency Variant Detection Required significance : シーケンスエラーかどうか 検定の際の閾値 118
119 Low Frequency Variant Detection Reference masking Ignore positions with coverage above: カバレッジが指定した数字以上のバリアントについてリストに含めない Restrict calling to target regions: バリアントを検出したい領域の指定 ( アノテーショントラックで指定 ) 119
120 Low Frequency Variant Detection Read filters Ignore broken pairs: ペアエンドのリードでペアと認識されなかったリードをバリアント検出の計算に含めるかどうか Ignore non-specific matches: Reads を選択すると non-specific なマッチのリードを計算に含めなくなり Regions を選択すると 1 本でも non-specific なリードが含まれる場合 その領域のバリアントを検出しません Minimum read length:ignore broken pair と Ignore non-specific regions が指定された場合 このフィルターの対象となる最小のリードの長さの設定が必要です これは非常に短いリードは その短さから non-specific になる可能性があるためです 120
121 Low Frequency Variant Detection Coverage and count filters Minimum coverage: 最小カバレッジ Minimum count: バリアントを支持するリードの最低カウント数 Minimum frequency (%): 最小頻度 121
122 Low Frequency Variant Detection Quality filter Base quality filter: 塩基のクオリティに関するフィルター Neighborhood radius: クオリティフィルターの対象とする横方向の塩基数 ( 奇数 ) Minimum central quality: 縦方向の数 ( リード数 ) Minimum neighborhood quality: Neighborhood radius で指定した範囲の最低クオリティ (Phred score)
123 Low Frequency Variant Detection Direction and position filters: Read direction filter: どちらか一方の方向のリードが多数見られる場合にそれを排除 ( ただし アンプリコンには適していません ) Relative read direction filter: リードの方向が一方のみに偏りすぎていないか 全体の Forward と Reverse のバランスを見て統計検定を行う Significance で閾値を入力 Read position filter: システマティックなエラーを取り除くために用いるツールでハイブリダイゼーションを行った場合のデータに有効 リードを 5 つのセグメントに分割し バリアントの見られるポジションの 5 つのセグメントに分割されたリードの分布が全体のそれと似ているかどうか検定を行う Significance で閾値を入力

124 Low Frequency Variant Detection Technology specific filters Remove pyro-error variants: ホモポリマー領域に対するエラーの除去 In homopolymer regions with minimum length: 指定した長さのホモポリマー領域の InDel を取り除く With frequency below: 指定した頻度以下のものについてのみフィルターを適用
125 Low Frequency Variant Detection Create track: トラックの作成 Create annotated table: アノテーション付のテーブルの作成 125
 Forward reads: その領域に見られた Forward リードの数 Reverse reads: その領域に見られた Reverse リードの数 Forward/reverse: Forward/Total reads または Reverse/Total reads のうち小さい方の値")

126 Low Frequency Variant Detection: 結果 Count: クオリティのフィルターをパスしたリードの数 Coverage: クオリティのフィルターをパスしたリードの数 Frequency: バリアントが見られた頻度 Probability: バリアントのアレルの事後確率 ( そのアレルが尤もであるとする確率 高い方がより確度が高いという事 ) Forward reads: その領域に見られた Forward リードの数 Reverse reads: その領域に見られた Reverse リードの数 Forward/reverse: Forward/Total reads または Reverse/Total reads のうち小さい方の値 Forward と Reverse が同じなら 0.5 となる Average quality: 該当する領域の平均リードクオリティ # unique start positions: バリアントコールに使われたリードのうちスタートポジションにあるリードの数 # unique end positions: バリアントコールに使われたリードのうち最後の箇所にあるリードの数 BaseQRankSum: クオリティスコアについて 参照配列と同じアレルとバアリアントのアレルについてマンホイットニー U 検定を行い計算された Z スコア これが高いほど参照配列の塩基とバリアントの塩基に差がある Hyper-alleic: 想定されるアレルよりも頻度が高いかどうか Homopolymer: ホモポリマー領域かどうか 126
127 挿入 欠失と構造変異解析 127
128 InDels and Structural Variants Quality Based Variant Detection や Probabilistic Variant Detection では変異や InDel を検出できました しかしながら大きな InDel の検出や構造変異については 上記ツールでの検出は難しい場合があります < アルゴリズムにとっては 大きな Insertion や Deletion を受け入れるよりは Unaligned end とするほうがスコアを大きくできるからです InDel and Structural Variants ツールでは この Unaligned end に着目して 大きな InDel や構造変異を見つけます Unaligned end が別の領域に十分な量マップすることができれば そこまでの距離の Insertion や Deletion 構造変異と考えられます 注意 : このツールでは 同一染色体内の構造変異のみが検出可能です 128


129 InDels and Structural Variants Navigation Area からマップするデータを選択 Toolbox から InDels and Structural Variants を選択 ダブルクリック ウィザードが起動し 選択したデータが選ばれていることを確認 129
130 InDels and Structural Variants P-value threshold: 得られた coverage 数において 生じた unaligned end の数が得られる確率がこの p-value より少ない場合 break point を生成する Maximum number of mismatches: align された部分の mismatch がこの数以下のもののみカウントする Filter variants: ここで指定した数より少ないリードにしかサポートされていない break point は除く 130
131 InDels and Structural Variants Output について設定する 131

132 InDels and Structural Variants 132

133 リシーケンシング解析 : その他の機能 Annotate from Known Variants : known variants とオーバーラップする variants にアノテーション付けする Filter against Known variants : known variants と比較してフィルタリングする Annotate with Exon Numbers : exon の番号をアノテーションに追加する Annotate with Flanking Sequences : reference の隣接する塩基とともにアノテーション付けする Filter Marginal Variant Calls : Variant frequency, Forward/reverse balance, Average base quality などの条件でフィルタリングする Filter Reference Variants : reference allele variants をフィルタリングする 133
 Compare Variants within Group : グループの中で common variants を検索する Frequency を % で指定できる Fisher Exact Test : Case-control study で case に有意に存在する variants を検出する Trio Analysis : 子供と両親のデータを用いて trio")
134 リシーケンシング解析 : その他の機能 Compare Sample Variant Tracks: 2 つの variant track を比較して 共通する または 異なる variant を出力する (Ver6.5 で追加 ) Compare Variants within Group : グループの中で common variants を検索する Frequency を % で指定できる Fisher Exact Test : Case-control study で case に有意に存在する variants を検出する Trio Analysis : 子供と両親のデータを用いて trio 解析を行う Variants が親に由来するのか de novo なのかをレポートする Filter against Control Reads : Control に存在する variant をフィルタリングする 134

135 リシーケンシング解析 : その他の機能 GO Enrichment Analysis : 検出された variants が含まれる遺伝子にどのような Gene Ontology と関連するものが多いのかを解析する Amino Acid Changes : variants に アミノ酸置換に関するアノテーション付けを行う Annotate with Conservation Score : 異なる種におけるアミノ酸の保存の程度に関する情報をアノテーション付けする 保存の度合いが高いほど 機能的に重要であると期待される Predict Splice Site Effect : variants の splice site に対する影響を予測する 135
136 アミノ酸置換の解析 136

137 アミノ酸置換の解析 Resequencing Analysis Amino Acid Changes を選択 Variant データを選択 137

138 アミノ酸置換の解析 CDS の track を選択 mrna の track を選択 ゲノム配列の track を選択 Filter synonymous: アミノ酸が変化する variant のみをアノテーション付けするときにチェックする Filter CDS regions with no variants: variant が無い領域をフィルターする Genetic code: 解析しているゲノムで該当するものを選択する 138



139 アミノ酸置換の解析 Variant Track 139


140 アミノ酸置換の解析 アミノ酸置換に関する情報がテーブルに追加されました 140

141 アミノ酸置換の解析 Amino Acid Track 141
142 変異のフィルタリング 142
 を選択 Toolbox から")

143 既知の variants の filter:filter against Known Variants Navigation Area から変異トラック ( アミノ酸置換を調べたもの ) を選択 Toolbox から Resequencing Analysis > Annotate and Filter Variants > Filter against Known Variants を選択 ダブルクリック ウィザードが起動し 選択したデータが選ばれていることを確認 143


144 既知の variants の filter:filter against Known Variants Known variants track: 比較したい変異トラックを選択 Auto join: 隣り合わせの変異について フィルターをかける際に一つの変異として扱うかどうか Filter Option Match を残す : アレルまで完全に一致しているものを残す Overlap を残す : オーバーラップがあるものを残す Not match を残す : 完全に一致しなかったものを残す SNP のトラックを選択 144

145 既知の variants の filter:filter against Known Variants 145

146 既知の variants の filter:filter against Known Variants トラックで表示 dbsnp 共通しなかったもの 146
147 遺伝子のアノテーション 147



148 アノテーション付け :Annotate with Overlap Information Navigation Area から変異トラック ( フィルタリングしたもの ) を選択 Toolbox から Track tools > Annotate and Filter > Annotate with Overlap Information を選択 ダブルクリック ウィザードが起動し 選択したデータが選ばれていることを確認 148
149 アノテーション付け :Annotate with Overlap Information Gene の track を選択 149





150 アノテーション付け :Annotate with Overlap Information 150
151 3D 構造解析 151
152 3D 構造解析 :Link variants to 3D Protein Structure Download 3D Protin Structure Database: Resequencing Analysis > Functional Consequences の中に含まれるこのツールでは PDB に登録されているアミノ酸配列のデータベースをダウンロードします この後の Link Variant to 3D Protein Structure で必要となります Link Variants to 3D Protein Structure: ダウンロードしたアミノ酸配列に対して 変異の検出からアミノ酸置換させた配列を使い BLAST 検索をかけます 152


153 3D 構造解析 :Link variants to 3D Protein Structure 153

154 3D 構造解析 :Link variants to 3D Protein Structure 154

155 お疲れ様でした 155
リード・ゲノム・アノテーションインポート
 リード ゲノム アノテーションインポート 1 Location と Folder ロケーション フォルダ Genomics Workbenchではデータを以下のような階層構造で保存可能です フォルダの一番上位の階層を Location と呼び その下の階層を Folder と呼びます データの保存場所はロケーション毎に設定可能です たとえばあるデータは C ドライブに保存し あるデータは D ドライブに保存するといった事が可能です
リード ゲノム アノテーションインポート 1 Location と Folder ロケーション フォルダ Genomics Workbenchではデータを以下のような階層構造で保存可能です フォルダの一番上位の階層を Location と呼び その下の階層を Folder と呼びます データの保存場所はロケーション毎に設定可能です たとえばあるデータは C ドライブに保存し あるデータは D ドライブに保存するといった事が可能です
CLC Genomics Workbench ウェブトレーニングセミナー: 変異解析編
 CLC Genomics Workbench ウェブトレーニングセミナー : 変異解析編 22 nd Dec., 2015 フィルジェン株式会社バイオサイエンス部 biosupport@filgen.jp Dec., 2015_V1 1 本日の内容 データのインポート 3 リファレンスデータの取得 10 データフォーマット 21 解析ワークフロー 22 変異のフィルタリング 77 変異データのエクスポート
CLC Genomics Workbench ウェブトレーニングセミナー : 変異解析編 22 nd Dec., 2015 フィルジェン株式会社バイオサイエンス部 biosupport@filgen.jp Dec., 2015_V1 1 本日の内容 データのインポート 3 リファレンスデータの取得 10 データフォーマット 21 解析ワークフロー 22 変異のフィルタリング 77 変異データのエクスポート
GWB
 NGS データ解析入門 Web セミナー : 変異解析編 1 NGS 変異データ解析の手順 シークエンス 変異検出 マッピング データの精査 解釈 2 CLC Genomics Workbench 使用ツール シークエンスデータのインポート NGS data import クオリティチェック QC for Sequencing Reads Trim Reads 参照ゲノム配列へのマッピング 再アライメント
NGS データ解析入門 Web セミナー : 変異解析編 1 NGS 変異データ解析の手順 シークエンス 変異検出 マッピング データの精査 解釈 2 CLC Genomics Workbench 使用ツール シークエンスデータのインポート NGS data import クオリティチェック QC for Sequencing Reads Trim Reads 参照ゲノム配列へのマッピング 再アライメント
RNA-seq
 CLC Genomics Workbench ハンズオントレーニング RNA-seq 株式会社 CLCバイオジャパンシニアフィールドバイオインフォマティクスサイエンティスト宮本真理 Ph.D. mmiyamoto@clcbio.co.jp 1 support@clcbio.co.jp 2 アジェンダ Genomics Workbench 概要 今日のデータ RNA-seq 解析 データインポート QC
CLC Genomics Workbench ハンズオントレーニング RNA-seq 株式会社 CLCバイオジャパンシニアフィールドバイオインフォマティクスサイエンティスト宮本真理 Ph.D. mmiyamoto@clcbio.co.jp 1 support@clcbio.co.jp 2 アジェンダ Genomics Workbench 概要 今日のデータ RNA-seq 解析 データインポート QC
GWB
 NGS データ解析入門 Web セミナー : 変異解析編 1 NGS 変異データ解析の手順 シークエンス 変異検出 マッピング データの精査 解釈 2 解析ワークフローと使用ソフトウェア シークエンスデータのインポート クオリティチェック 参照ゲノム配列へのマッピング 再アライメント 変異検出 CLC Genomics Workbench または Biomedical Genomics Workbench
NGS データ解析入門 Web セミナー : 変異解析編 1 NGS 変異データ解析の手順 シークエンス 変異検出 マッピング データの精査 解釈 2 解析ワークフローと使用ソフトウェア シークエンスデータのインポート クオリティチェック 参照ゲノム配列へのマッピング 再アライメント 変異検出 CLC Genomics Workbench または Biomedical Genomics Workbench
NGSデータ解析入門Webセミナー
 NGS データ解析入門 Web セミナー : RNA-Seq 解析編 1 RNA-Seq データ解析の手順 遺伝子発現量測定 シークエンス マッピング サンプル間比較 機能解析など 2 CLC Genomics Workbench 使用ツール シークエンスデータ メタデータのインポート NGS data import Import Metadata クオリティチェック Create Sequencing
NGS データ解析入門 Web セミナー : RNA-Seq 解析編 1 RNA-Seq データ解析の手順 遺伝子発現量測定 シークエンス マッピング サンプル間比較 機能解析など 2 CLC Genomics Workbench 使用ツール シークエンスデータ メタデータのインポート NGS data import Import Metadata クオリティチェック Create Sequencing
使いこなそう!CLC Genomics Workbench パート1 QCからトリミング
 解析の詳細 宮本真理 Ph.D. シニアフィールドバイオインフォマティクスサイエンティスト CLCバイオジャパン mmiyamoto@clcbio.co.jp 1 はじめに 今日のセミナーでお話しすること データ解析の流れ 内部でのデータ処理の流れとその原理 今日のセミナーでお話ししないこと 詳細な使い方はお話ししませんが デモにてどのように実行可能かお話しします パラメータについては 必要な個所はスライドに含めています
解析の詳細 宮本真理 Ph.D. シニアフィールドバイオインフォマティクスサイエンティスト CLCバイオジャパン mmiyamoto@clcbio.co.jp 1 はじめに 今日のセミナーでお話しすること データ解析の流れ 内部でのデータ処理の流れとその原理 今日のセミナーでお話ししないこと 詳細な使い方はお話ししませんが デモにてどのように実行可能かお話しします パラメータについては 必要な個所はスライドに含めています
RNA-seq
 RNA-seq 1 RNA-seq 解析フロー RNA-seq インポート クオリティチェック RNA-seq 発現差解析 この資料では RNA-seq からの説明となりますが インポート クオリティチェックについては サポート資料のページより内容をご確認いただけます 2 データ 発現解析用デモデータは 以下よりダウンロードいただけます ES 細胞 (ESC) と神経前駆細胞 (NPC) の発現解析を小さなデモデータで行えます
RNA-seq 1 RNA-seq 解析フロー RNA-seq インポート クオリティチェック RNA-seq 発現差解析 この資料では RNA-seq からの説明となりますが インポート クオリティチェックについては サポート資料のページより内容をご確認いただけます 2 データ 発現解析用デモデータは 以下よりダウンロードいただけます ES 細胞 (ESC) と神経前駆細胞 (NPC) の発現解析を小さなデモデータで行えます
GWB
 NGS データ解析入門 Web セミナー : De Novo シークエンス解析編 1 NGS 新規ゲノム配列解析の手順 シークエンス 遺伝子領域の検出 アセンブル データベース検索 2 解析ワークフローと使用ソフトウェア シークエンスデータのインポート クオリティチェック 前処理 コンティグ配列の作成 CLC Genomics Workbench 遺伝子領域の検出 Blast2GO PRO データベース検索
NGS データ解析入門 Web セミナー : De Novo シークエンス解析編 1 NGS 新規ゲノム配列解析の手順 シークエンス 遺伝子領域の検出 アセンブル データベース検索 2 解析ワークフローと使用ソフトウェア シークエンスデータのインポート クオリティチェック 前処理 コンティグ配列の作成 CLC Genomics Workbench 遺伝子領域の検出 Blast2GO PRO データベース検索
CLC Genomics Workbench ウェブトレーニングセミナー: 変異解析編
 CLC Genomics Workbench ウェブトレーニングセミナー : 遺伝子発現解析編 12 th Feb., 2016 フィルジェン株式会社バイオサイエンス部 biosupport@filgen.jp Feb., 2016_V2 1 遺伝子発現解析概要 本日のセミナーにおける解析の流れ及び使用するツール名 ( 図中赤枠部分 ) Case Control インポート インポート インポート
CLC Genomics Workbench ウェブトレーニングセミナー : 遺伝子発現解析編 12 th Feb., 2016 フィルジェン株式会社バイオサイエンス部 biosupport@filgen.jp Feb., 2016_V2 1 遺伝子発現解析概要 本日のセミナーにおける解析の流れ及び使用するツール名 ( 図中赤枠部分 ) Case Control インポート インポート インポート
ChIP-seq
 ChIP-seq 1 ChIP-seq 解析原理 ChIP サンプルのフラグメントでは タンパク質結合部位付近にそれぞれ Forward と Reverse のリードがマップされることが予想される ChIP のサンプルでは Forward と Reverse のリードを 3 側へシフトさせ ChIP のピークを算出する コントロールサンプルでは ChIP のサンプルとは異なり 特定の場所に多くマップされないため
ChIP-seq 1 ChIP-seq 解析原理 ChIP サンプルのフラグメントでは タンパク質結合部位付近にそれぞれ Forward と Reverse のリードがマップされることが予想される ChIP のサンプルでは Forward と Reverse のリードを 3 側へシフトさせ ChIP のピークを算出する コントロールサンプルでは ChIP のサンプルとは異なり 特定の場所に多くマップされないため
PowerPoint Presentation
 エピジェノミクス解析編 2016/08/10 Filgen ChIP-seq (Transfactor & Histone), Bisulfite webex seminar 株式会社キアゲンアプライドアドバンストゲノミクス宮本真理, PhD 1 アジェンダ ChIP-seq 解析 Transcription Factor ChIP-seq Histone ChIP-seq Bisulfite-seq
エピジェノミクス解析編 2016/08/10 Filgen ChIP-seq (Transfactor & Histone), Bisulfite webex seminar 株式会社キアゲンアプライドアドバンストゲノミクス宮本真理, PhD 1 アジェンダ ChIP-seq 解析 Transcription Factor ChIP-seq Histone ChIP-seq Bisulfite-seq
GWB_RNA-Seq_
 CLC Genomics Workbench ウェブトレーニングセミナー : RNA-Seq 編 フィルジェン株式会社バイオサイエンス部 (biosupport@filgen.jp) 1 Advanced RNA-Seq プラグイン CLC Genomics Workbench 9.0 / Biomedical Genomics Workbench 3.0 以降で使用可能な無償プラグイン RNA-Seq
CLC Genomics Workbench ウェブトレーニングセミナー : RNA-Seq 編 フィルジェン株式会社バイオサイエンス部 (biosupport@filgen.jp) 1 Advanced RNA-Seq プラグイン CLC Genomics Workbench 9.0 / Biomedical Genomics Workbench 3.0 以降で使用可能な無償プラグイン RNA-Seq
PowerPoint プレゼンテーション
 CLC Genomics Workbench ~ アプリケーションおよびバージョン 8 新機能の紹介 ~ フィルジェン株式会社バイオサイエンス部 (biosupport@filgen.jp) 1 本日の内容 1. CLC Genomics Workbench 概要 2. 基本機能 3. 解析アプリケーション 4. バージョン 8 新機能 : デモンストレーション ( 一部 ) 5. その他機能 6.
CLC Genomics Workbench ~ アプリケーションおよびバージョン 8 新機能の紹介 ~ フィルジェン株式会社バイオサイエンス部 (biosupport@filgen.jp) 1 本日の内容 1. CLC Genomics Workbench 概要 2. 基本機能 3. 解析アプリケーション 4. バージョン 8 新機能 : デモンストレーション ( 一部 ) 5. その他機能 6.
nagasaki_GMT2015_key09
 Workflow Variant Calling 03 長崎は遺伝研 大量遺伝情報研究室の所属です 国立遺伝学研究所 生命情報研究センター 3F 2F 欧州EBIと米国NCBIと密接に協力しながら DDBJ/EMBL/GenBank国際塩基配列データ ベースを構築しています 私たちは 塩基配列登録を支援するシステムづくり 登録データを活用するシステムづくり 高速シーケンス配列の情報解析 を行なっています
Workflow Variant Calling 03 長崎は遺伝研 大量遺伝情報研究室の所属です 国立遺伝学研究所 生命情報研究センター 3F 2F 欧州EBIと米国NCBIと密接に協力しながら DDBJ/EMBL/GenBank国際塩基配列データ ベースを構築しています 私たちは 塩基配列登録を支援するシステムづくり 登録データを活用するシステムづくり 高速シーケンス配列の情報解析 を行なっています
次世代シークエンサーを用いたがんクリニカルシークエンス解析
 次世代シークエンサーを用いた がんクリニカルシークエンス解析 フィルジェン株式会社バイオサイエンス部 (biosupport@filgen.jp) 1 がん遺伝子パネル がん関連遺伝子のターゲットシークエンス用のアッセイキット コストの低減や 研究プログラムの簡素化に有用 網羅的シークエンス解析の場合に比べて 1 遺伝子あたりのシークエンス量が増えるため より高感度な変異の検出が可能 2 変異データ解析パイプライン
次世代シークエンサーを用いた がんクリニカルシークエンス解析 フィルジェン株式会社バイオサイエンス部 (biosupport@filgen.jp) 1 がん遺伝子パネル がん関連遺伝子のターゲットシークエンス用のアッセイキット コストの低減や 研究プログラムの簡素化に有用 網羅的シークエンス解析の場合に比べて 1 遺伝子あたりのシークエンス量が増えるため より高感度な変異の検出が可能 2 変異データ解析パイプライン
Easy Sep
 utype v7.1 簡易マニュアル 注 : この説明書は 英文添付文書の簡易訳です 製品に添付されている英文マニュアルも必ずご確認ください 1. システム要件 ソフトウェアをインストールするドライブは最低 1GB の空き容量が必要です Windows XP 及び Windows 7 で動作が確認されております 2. シークエンスファイル utype ではシークエンスの際に下記のルールでサンプル名を入力する必要があります
utype v7.1 簡易マニュアル 注 : この説明書は 英文添付文書の簡易訳です 製品に添付されている英文マニュアルも必ずご確認ください 1. システム要件 ソフトウェアをインストールするドライブは最低 1GB の空き容量が必要です Windows XP 及び Windows 7 で動作が確認されております 2. シークエンスファイル utype ではシークエンスの際に下記のルールでサンプル名を入力する必要があります
シーケンサー利用技術講習会 第10回 サンプルQC、RNAseqライブラリー作製/データ解析実習講習会
 シーケンサー利用技術講習会 第 10 回サンプル QC RNAseq ライブ ラリー作製 / データ解析実習講習会 理化学研究所ライフサイエンス技術基盤研究センターゲノムネットワーク解析支援施設田上道平 次世代シーケンサー Sequencer File Format Output(Max) Read length Illumina Hiseq2500 Fastq 600 Gb 100 bp Life
シーケンサー利用技術講習会 第 10 回サンプル QC RNAseq ライブ ラリー作製 / データ解析実習講習会 理化学研究所ライフサイエンス技術基盤研究センターゲノムネットワーク解析支援施設田上道平 次世代シーケンサー Sequencer File Format Output(Max) Read length Illumina Hiseq2500 Fastq 600 Gb 100 bp Life
IonTorrent RNA-Seq 解析概要 サーモフィッシャーサイエンティフィックライフテクノロジーズジャパンテクニカルサポート The world leader in serving science
 IonTorrent RNA-Seq 解析概要 2017-03 サーモフィッシャーサイエンティフィックライフテクノロジーズジャパンテクニカルサポート The world leader in serving science 資料概要 この資料は IonTorrent シーケンサーで RNA-Seq (WholeTranscriptome mrna ampliseqrna mirna) 解析を実施されるユーザー様向けの内容となっています
IonTorrent RNA-Seq 解析概要 2017-03 サーモフィッシャーサイエンティフィックライフテクノロジーズジャパンテクニカルサポート The world leader in serving science 資料概要 この資料は IonTorrent シーケンサーで RNA-Seq (WholeTranscriptome mrna ampliseqrna mirna) 解析を実施されるユーザー様向けの内容となっています
AJACS18_ ppt
 1, 1, 1, 1, 1, 1,2, 1,2, 1 1 DDBJ 2 AJACS3 2010 6 414:20-15:20 2231 DDBJ DDBJ DDBJ DDBJ NCBI (GenBank) DDBJ EBI (EMBL-Bank) GEO DDBJ Omics ARchive(DOR) ArrayExpress DTA (DDBJ Trace Archive) DRA (DDBJ
1, 1, 1, 1, 1, 1,2, 1,2, 1 1 DDBJ 2 AJACS3 2010 6 414:20-15:20 2231 DDBJ DDBJ DDBJ DDBJ NCBI (GenBank) DDBJ EBI (EMBL-Bank) GEO DDBJ Omics ARchive(DOR) ArrayExpress DTA (DDBJ Trace Archive) DRA (DDBJ
Microsoft PowerPoint - Ion Reporter?ソフトウェアを用いた変異解析4.6.pptx
 Ion Reporter ソフトウェアデモンストレーション Ion AmpliSeq Comprehensive Cancer Panel を用いたがん部および非がん部の体細胞変異比較解析 1 Ion Torrent システムを用いた実験例 Ion AmpliSeq Comprehensive Cancer Panel を 2 サンプル実施 ランレポート ランレポート サンプル 1 サンプル 2 2
Ion Reporter ソフトウェアデモンストレーション Ion AmpliSeq Comprehensive Cancer Panel を用いたがん部および非がん部の体細胞変異比較解析 1 Ion Torrent システムを用いた実験例 Ion AmpliSeq Comprehensive Cancer Panel を 2 サンプル実施 ランレポート ランレポート サンプル 1 サンプル 2 2
PowerPoint プレゼンテーション
 V1 次世代シークエンサ実習 II 本講義の内容 Reseq 解析 RNA-seq 解析 公開データ取得 クオリティコントロール マッピング 変異検出 公開データ取得 クオリティコントロール マッピング 発現定量 FPKM を算出します 2 R N A - s e q とは メッセンジャー RNA(mRNA) をキャプチャして次世代シーケンサーでシーケンシングする手法 リファレンスがある生物種の場合
V1 次世代シークエンサ実習 II 本講義の内容 Reseq 解析 RNA-seq 解析 公開データ取得 クオリティコントロール マッピング 変異検出 公開データ取得 クオリティコントロール マッピング 発現定量 FPKM を算出します 2 R N A - s e q とは メッセンジャー RNA(mRNA) をキャプチャして次世代シーケンサーでシーケンシングする手法 リファレンスがある生物種の場合
1. MEGA 5 をインストールする 1.1 ダウンロード手順 MEGA のホームページ (http://www.megasoftware.net/index.php) から MEGA 5 software をコンピュータにインストールする 2. 塩基配列を決定する 2.1 Alignment E
 から MEGA 5 software をコンピュータにインストールする 2. 塩基配列を決定する 2.1 Alignment E") MEGA 5 を用いた塩基配列解析法および分子系統樹作成法 Ver.1 Update: 2012.04.01 ウイルス 疫学研究領域井関博 < 内容 > 1. MEGA 5 をインストールする 1.1 ダウンロード手順 2. 塩基配列を決定する 2.1 Alignment Explorer の起動 2.2 シークエンスデータの入力 2.2.1 テキストファイルから読み込む場合 2.2.2 波形データから読み込む場合
MEGA 5 を用いた塩基配列解析法および分子系統樹作成法 Ver.1 Update: 2012.04.01 ウイルス 疫学研究領域井関博 < 内容 > 1. MEGA 5 をインストールする 1.1 ダウンロード手順 2. 塩基配列を決定する 2.1 Alignment Explorer の起動 2.2 シークエンスデータの入力 2.2.1 テキストファイルから読み込む場合 2.2.2 波形データから読み込む場合
スライド 1
 デザイン ID の確認法 SureDesign version 3.0 2015/4/15 予告無くソフトウェアのアップデートを行う場合があります そのため 本資料とソフトウェア画面が異なる場合があります ご了承ください 最新資料ダウンロードサイト ;http://www.chem-agilent.com/contents.php?id=1002474 Page1 目次 ファイルダウンロード方法 1
デザイン ID の確認法 SureDesign version 3.0 2015/4/15 予告無くソフトウェアのアップデートを行う場合があります そのため 本資料とソフトウェア画面が異なる場合があります ご了承ください 最新資料ダウンロードサイト ;http://www.chem-agilent.com/contents.php?id=1002474 Page1 目次 ファイルダウンロード方法 1
PowerPoint プレゼンテーション
 バイオインフォマティクス 講習会 V 事前準備 が完了されている方は コンテナの起動 ファイルのコピー (Windows) まで 進めておいてください メニュー 1. 環境構築の確認 2. 基本的なLinuxコマンド 3. ツールのインストール 4. NGSデータの基礎知識と前処理 5. トランスクリプトのアッセンブル 6. RNA-seqのリファレンスcDNAマッピングとFPKM 算出 7. RNA-seqのリファレンスゲノムマッピングとFPKM
バイオインフォマティクス 講習会 V 事前準備 が完了されている方は コンテナの起動 ファイルのコピー (Windows) まで 進めておいてください メニュー 1. 環境構築の確認 2. 基本的なLinuxコマンド 3. ツールのインストール 4. NGSデータの基礎知識と前処理 5. トランスクリプトのアッセンブル 6. RNA-seqのリファレンスcDNAマッピングとFPKM 算出 7. RNA-seqのリファレンスゲノムマッピングとFPKM
PowerPoint プレゼンテーション
 V1 次世代シークエンサ実習 II 本講義にあたって 代表的な解析の流れを紹介します 論文でよく使用されているツールを使用します コマンドを沢山実行します スペルミスが心配な方は コマンド例がありますのでコピーして実行してください /home/admin1409/amelieff/ngs/reseq_command.txt マークのコマンドは実行してください 実行が遅れてもあせらずに 応用や課題の間に追い付いてください
V1 次世代シークエンサ実習 II 本講義にあたって 代表的な解析の流れを紹介します 論文でよく使用されているツールを使用します コマンドを沢山実行します スペルミスが心配な方は コマンド例がありますのでコピーして実行してください /home/admin1409/amelieff/ngs/reseq_command.txt マークのコマンドは実行してください 実行が遅れてもあせらずに 応用や課題の間に追い付いてください
アノテーション・フィルタリング用パイプラインとクリニカルレポートの作成
 アノテーション フィルタリング用パイプラインと クリニカルレポートの作成 フィルジェン株式会社バイオサイエンス部 (biosupport@filgen.jp) 1 クリニカルシーケンス解析パイプライン 1. リファレンスゲノム配列へのアライメント / マッピング 2. 変異の検出 3. アノテーション付けとフィルタリング 4. レポートの作成 2 臨床現場で活用する場合は シンプルな操作性で 高度な専門知識がなくても使用できる
アノテーション フィルタリング用パイプラインと クリニカルレポートの作成 フィルジェン株式会社バイオサイエンス部 (biosupport@filgen.jp) 1 クリニカルシーケンス解析パイプライン 1. リファレンスゲノム配列へのアライメント / マッピング 2. 変異の検出 3. アノテーション付けとフィルタリング 4. レポートの作成 2 臨床現場で活用する場合は シンプルな操作性で 高度な専門知識がなくても使用できる
生命情報学
 生命情報学 5 隠れマルコフモデル 阿久津達也 京都大学化学研究所 バイオインフォマティクスセンター 内容 配列モチーフ 最尤推定 ベイズ推定 M 推定 隠れマルコフモデル HMM Verアルゴリズム EMアルゴリズム Baum-Welchアルゴリズム 前向きアルゴリズム 後向きアルゴリズム プロファイル HMM 配列モチーフ モチーフ発見 配列モチーフ : 同じ機能を持つ遺伝子配列などに見られる共通の文字列パターン
生命情報学 5 隠れマルコフモデル 阿久津達也 京都大学化学研究所 バイオインフォマティクスセンター 内容 配列モチーフ 最尤推定 ベイズ推定 M 推定 隠れマルコフモデル HMM Verアルゴリズム EMアルゴリズム Baum-Welchアルゴリズム 前向きアルゴリズム 後向きアルゴリズム プロファイル HMM 配列モチーフ モチーフ発見 配列モチーフ : 同じ機能を持つ遺伝子配列などに見られる共通の文字列パターン
レポートでのデータのフィルタ
 フィルタのタイプ, 1 ページ 日付の範囲フィルタの設定, 2 ページ 値リストまたはコレクション フィルタの設定, 3 ページ 詳細フィルタの設定, 5 ページ フィルタのタイプ フィルタのタイプは [基本フィルタ Basic Filters ] と [詳細フィルタ Advanced Filters ] の 2 種類から選択できます [基本フィルタ Basic Filters ] [基本フィルタ
フィルタのタイプ, 1 ページ 日付の範囲フィルタの設定, 2 ページ 値リストまたはコレクション フィルタの設定, 3 ページ 詳細フィルタの設定, 5 ページ フィルタのタイプ フィルタのタイプは [基本フィルタ Basic Filters ] と [詳細フィルタ Advanced Filters ] の 2 種類から選択できます [基本フィルタ Basic Filters ] [基本フィルタ
V1 ゲノム R e s e q 変異解析 Copyright Amelieff Corporation All Rights Reserved.
 V1 ゲノム R e s e q 変異解析 本講義にあたって 代表的な解析の流れを紹介します 論文でよく使用されているツールを使用します コマンドを沢山実行します スペルミスが心配な方は コマンド例がありますのでコピーし て実行してください マークのコマンドは実行してください 実行が遅れてもあせらずに 応用や課題の間に追い付いてくだ さい 2 本講義の内容 Reseq解析 RNA-seq解析 公開データ取得
V1 ゲノム R e s e q 変異解析 本講義にあたって 代表的な解析の流れを紹介します 論文でよく使用されているツールを使用します コマンドを沢山実行します スペルミスが心配な方は コマンド例がありますのでコピーし て実行してください マークのコマンドは実行してください 実行が遅れてもあせらずに 応用や課題の間に追い付いてくだ さい 2 本講義の内容 Reseq解析 RNA-seq解析 公開データ取得
ThermoFisher
 Thermo Fisher Connect Relative Quantification 操作簡易資料 http://www.thermofisher.com/cloud 使用には事前登録が必要になります 画面は予告なく変わることがあります The world leader in serving science Thermo Fisher Connect とは? キャピラリシーケンサ リアルタイム
Thermo Fisher Connect Relative Quantification 操作簡易資料 http://www.thermofisher.com/cloud 使用には事前登録が必要になります 画面は予告なく変わることがあります The world leader in serving science Thermo Fisher Connect とは? キャピラリシーケンサ リアルタイム
PowerPoint Presentation
 CLC Microbial Genomics Module 株式会社キアゲングローバルインフォマティクスソリューションズ & サポートアプライドアドバンストゲノミクス宮本真理 Ph.D. Filgen WebEx seminar, 2015/07/16 (2015/07/30) 1 Agenda メタゲノミクス解析 製品概要 機能紹介 デモ Filgen WebEx seminar, 2015/07/16
CLC Microbial Genomics Module 株式会社キアゲングローバルインフォマティクスソリューションズ & サポートアプライドアドバンストゲノミクス宮本真理 Ph.D. Filgen WebEx seminar, 2015/07/16 (2015/07/30) 1 Agenda メタゲノミクス解析 製品概要 機能紹介 デモ Filgen WebEx seminar, 2015/07/16
AmpliSeqDataAnalysis
 Ion AmpliSeq TM データ解析基礎 ~ 次世代シーケンサによる変異検出 ~ ライフテクノロジーズジャパンテクニカルサポート Oct 2013 アジェンダ Ion Torrent データ解析概略 Torrent Variant Caller - 変異の検出 - 実行手順 -パラメータの設定 - 実行結果 リファレンスとターゲット領域の登録 Ion Reporter - 変異の絞り込みとアノテーション
Ion AmpliSeq TM データ解析基礎 ~ 次世代シーケンサによる変異検出 ~ ライフテクノロジーズジャパンテクニカルサポート Oct 2013 アジェンダ Ion Torrent データ解析概略 Torrent Variant Caller - 変異の検出 - 実行手順 -パラメータの設定 - 実行結果 リファレンスとターゲット領域の登録 Ion Reporter - 変異の絞り込みとアノテーション
Microsoft Word - CBSNet-It連携ガイドver8.2.doc
 (Net-It Central 8.2) 本ガイドでは ConceptBase Search Lite.1.1 と Net-It Central 8.2 の連携手順について説明します 目次 1 はじめに...2 1.1 本書について...2 1.2 前提条件...2 1.3 システム構成...2 2 ConceptBase のインストール...3 2.1 インストールと初期設定...3 2.2 動作確認...3
(Net-It Central 8.2) 本ガイドでは ConceptBase Search Lite.1.1 と Net-It Central 8.2 の連携手順について説明します 目次 1 はじめに...2 1.1 本書について...2 1.2 前提条件...2 1.3 システム構成...2 2 ConceptBase のインストール...3 2.1 インストールと初期設定...3 2.2 動作確認...3
PowerPoint Presentation
 パターン認識入門 パターン認識 音や画像に中に隠れたパターンを認識する 音素 音節 単語 文 基本図形 文字 指紋 物体 人物 顔 パターン は唯一のデータではなく 似通ったデータの集まりを表している 多様性 ノイズ 等しい から 似ている へ ~ だ から ~ らしい へ 等しい から 似ている へ 完全に等しいかどうかではなく 似ているか どうかを判定する パターンを代表する模範的データとどのくらい似ているか
パターン認識入門 パターン認識 音や画像に中に隠れたパターンを認識する 音素 音節 単語 文 基本図形 文字 指紋 物体 人物 顔 パターン は唯一のデータではなく 似通ったデータの集まりを表している 多様性 ノイズ 等しい から 似ている へ ~ だ から ~ らしい へ 等しい から 似ている へ 完全に等しいかどうかではなく 似ているか どうかを判定する パターンを代表する模範的データとどのくらい似ているか
1. はじめに 1. はじめに 1-1. KaPPA-Average とは KaPPA-Average は KaPPA-View( でマイクロアレイデータを解析する際に便利なデータ変換ソフトウェアです 一般のマイクロアレイでは 一つのプロー
 KaPPA-Average 1.0 マニュアル 第 1.0 版 制作者 : かずさ DNA 研究所櫻井望 制作日 : 2010 年 1 月 12 日 目次 1. はじめに 2 1-1. KaPPA-Average とは 2 1-2. 動作環境 3 1-3. インストールと起動 3 2. 操作説明 4 2-1. メイン機能 - Calc. Average 4 2-1-1. データの準備 4 2-1-2.
KaPPA-Average 1.0 マニュアル 第 1.0 版 制作者 : かずさ DNA 研究所櫻井望 制作日 : 2010 年 1 月 12 日 目次 1. はじめに 2 1-1. KaPPA-Average とは 2 1-2. 動作環境 3 1-3. インストールと起動 3 2. 操作説明 4 2-1. メイン機能 - Calc. Average 4 2-1-1. データの準備 4 2-1-2.
バクテリアゲノム解析
 GCCGTAGCTACCTTTACAATA GCCGTAGCT AGCTACC GCTACCTTT CCTTTAC CTTTACAATA GCCG CCGT CGTA GTAG TAGC AGCT AGCT GCTA CTAC TACC GCTA CTAC TACC ACCT CCTT CTTT CCTT CTTT TTTA TTAC CTTT TTTA TTAC TACA ACAA CAAT AATA
GCCGTAGCTACCTTTACAATA GCCGTAGCT AGCTACC GCTACCTTT CCTTTAC CTTTACAATA GCCG CCGT CGTA GTAG TAGC AGCT AGCT GCTA CTAC TACC GCTA CTAC TACC ACCT CCTT CTTT CCTT CTTT TTTA TTAC CTTT TTTA TTAC TACA ACAA CAAT AATA
目次 ページ 1. 本マニュアルについて 3 2. 動作環境 4 3. ( 前準備 ) ライブラリの解凍と保存 5 4. モデルのインポート 6 5. インポートしたモデルのインピーダンス計算例 8 6. 補足 単シリーズ 単モデルのインポート お問い合わせ先 21 2
 ライブラリの解凍と保存 5 4. モデルのインポート 6 5. インポートしたモデルのインピーダンス計算例 8 6. 補足 単シリーズ 単モデルのインポート お問い合わせ先 21 2") SIMetrix/SIMPLIS ライブラリ ユーザーマニュアル 2018 年 8 月 株式会社村田製作所 Ver1.0 1 22 August 2018 目次 ページ 1. 本マニュアルについて 3 2. 動作環境 4 3. ( 前準備 ) ライブラリの解凍と保存 5 4. モデルのインポート 6 5. インポートしたモデルのインピーダンス計算例 8 6. 補足 単シリーズ 単モデルのインポート
SIMetrix/SIMPLIS ライブラリ ユーザーマニュアル 2018 年 8 月 株式会社村田製作所 Ver1.0 1 22 August 2018 目次 ページ 1. 本マニュアルについて 3 2. 動作環境 4 3. ( 前準備 ) ライブラリの解凍と保存 5 4. モデルのインポート 6 5. インポートしたモデルのインピーダンス計算例 8 6. 補足 単シリーズ 単モデルのインポート
Agilent 1色法 2条件比較 繰り返し実験なし
 GeneSpring GX11.0.2 ビギナーズガイド Agilent 1 色法 2 条件の比較繰り返し実験あり 適用 薬剤非投与と投与の解析 Wild type と Knock out の解析 正常細胞と病態細胞の解析 など ビギナーズガイドは 様々なマイクロアレイの実験デザインがあるなかで 実験デザインの種類ごとに適切なデータ解析の流れを 実例とともに紹介するガイドブックです ご自分の実験デザインに適合したガイドをお使いください
GeneSpring GX11.0.2 ビギナーズガイド Agilent 1 色法 2 条件の比較繰り返し実験あり 適用 薬剤非投与と投与の解析 Wild type と Knock out の解析 正常細胞と病態細胞の解析 など ビギナーズガイドは 様々なマイクロアレイの実験デザインがあるなかで 実験デザインの種類ごとに適切なデータ解析の流れを 実例とともに紹介するガイドブックです ご自分の実験デザインに適合したガイドをお使いください
Slide 1
 イルミナテクニカルセミナー session3 Illumina Experiment Manager の使い方 サービス サポート部テクニカルサポートサイエンティスト渡辺真子 2011 Illumina, Inc. All rights reserved. Illumina, illuminadx, BeadArray, BeadXpress, cbot, CSPro, DASL, Eco, Genetic
イルミナテクニカルセミナー session3 Illumina Experiment Manager の使い方 サービス サポート部テクニカルサポートサイエンティスト渡辺真子 2011 Illumina, Inc. All rights reserved. Illumina, illuminadx, BeadArray, BeadXpress, cbot, CSPro, DASL, Eco, Genetic
カスタムアレイ作成の流れ Probe x Probe D Probes Probe Groups Microarray Designs Probe 4 Probe 1 Probe C Probe A Probe w Probe 2 アップロード Probe 3 Probe y Probe B プロー
 カスタムアレイ作成の流れ Probe x Probe D Probes Probe Groups Microarray Designs Probe 4 Probe 1 Probe C Probe A Probe w Probe 2 アップロード Probe 3 Probe y Probe B プローブ設計 プローブの検索 選択 プローブ設計あるいはプローブのアップロードを行います Step1 Probe
カスタムアレイ作成の流れ Probe x Probe D Probes Probe Groups Microarray Designs Probe 4 Probe 1 Probe C Probe A Probe w Probe 2 アップロード Probe 3 Probe y Probe B プローブ設計 プローブの検索 選択 プローブ設計あるいはプローブのアップロードを行います Step1 Probe
Oracle ESB - レッスン02: CustomerDataバッチCSVファイル・アダプタ
 Oracle ESB レッスン 02: CustomerData バッチ CSV ファイル アダプタ Oracle 統合製品管理 Page 1 シナリオの概要 機能 複数レコードを含む CSV ファイルを 1 レコードずつ処理する CustomerData にインバウンド ファイル アダプタを追加する 顧客データと同期する CSV ファイル Features - JDeveloper ESB ダイアグラマ
Oracle ESB レッスン 02: CustomerData バッチ CSV ファイル アダプタ Oracle 統合製品管理 Page 1 シナリオの概要 機能 複数レコードを含む CSV ファイルを 1 レコードずつ処理する CustomerData にインバウンド ファイル アダプタを追加する 顧客データと同期する CSV ファイル Features - JDeveloper ESB ダイアグラマ
PrimerArray® Analysis Tool Ver.2.2
 研究用 PrimerArray Analysis Tool Ver.2.2 説明書 v201801 PrimerArray Analysis Tool Ver.2.2 は PrimerArray( 製品コード PH001 ~ PH007 PH009 ~ PH015 PN001 ~ PN015) で得られたデータを解析するためのツールで コントロールサンプルと 1 種類の未知サンプル間の比較が可能です
研究用 PrimerArray Analysis Tool Ver.2.2 説明書 v201801 PrimerArray Analysis Tool Ver.2.2 は PrimerArray( 製品コード PH001 ~ PH007 PH009 ~ PH015 PN001 ~ PN015) で得られたデータを解析するためのツールで コントロールサンプルと 1 種類の未知サンプル間の比較が可能です
Microsoft Word - CBESNet-It連携ガイドver8.1.doc
 (Net-It Central 8.1) 本ガイドでは ConceptBase Enterprise Search 1.3 と Net-It Central 8.1 の連携手順について説明します 目次 1 はじめに... 2 1.1 本書について... 2 1.2 前提条件... 2 1.3 システム構成... 2 2 ConceptBase Enterprise Search のインストール...
(Net-It Central 8.1) 本ガイドでは ConceptBase Enterprise Search 1.3 と Net-It Central 8.1 の連携手順について説明します 目次 1 はじめに... 2 1.1 本書について... 2 1.2 前提条件... 2 1.3 システム構成... 2 2 ConceptBase Enterprise Search のインストール...
<4D F736F F F696E74202D D D E C815B836A F B83582E >
 2012.03.22 マッピングデータの基本フォーマットと基本ツール 次世代シーケンサーに良く用いられるファイル形式 Samtools Integrative Genomics Viewer(IGV) 基礎生物学研究所 生物機能解析センター 山口勝司 NIBB CORE RESEARCH FACILITIES FUNCTIONAL GENOMICS FACILITY NIBB CORE RESEARCH
2012.03.22 マッピングデータの基本フォーマットと基本ツール 次世代シーケンサーに良く用いられるファイル形式 Samtools Integrative Genomics Viewer(IGV) 基礎生物学研究所 生物機能解析センター 山口勝司 NIBB CORE RESEARCH FACILITIES FUNCTIONAL GENOMICS FACILITY NIBB CORE RESEARCH
障害およびログの表示
 この章の内容は 次のとおりです 障害サマリー, 1 ページ 障害履歴, 4 ページ Cisco IMC ログ, 7 ページ システム イベント ログ, 9 ページ ロギング制御, 12 ページ 障害サマリー 障害サマリーの表示 手順 ステップ 1 [ナビゲーション Navigation ] ペインの [シャーシ Chassis ] メニューをクリックします ステップ 2 [シャーシ Chassis
この章の内容は 次のとおりです 障害サマリー, 1 ページ 障害履歴, 4 ページ Cisco IMC ログ, 7 ページ システム イベント ログ, 9 ページ ロギング制御, 12 ページ 障害サマリー 障害サマリーの表示 手順 ステップ 1 [ナビゲーション Navigation ] ペインの [シャーシ Chassis ] メニューをクリックします ステップ 2 [シャーシ Chassis
スライド 1
 EndNote X2 セミナー < 初級 > 平成 20 年 8 月 1 日 1 目次 PubMedからの文献の取り込み 医中誌 Webからの文献の取り込み Web of Scienceからの文献の取り込み E-Journalサイトからの文献の取り込み EndNoteを利用した文献の取り込み 参考文献リストの作成 < 便利な機能の一例 > PDF Fileやその他ファイルの貼り付け 省略形式を表示させる方法
EndNote X2 セミナー < 初級 > 平成 20 年 8 月 1 日 1 目次 PubMedからの文献の取り込み 医中誌 Webからの文献の取り込み Web of Scienceからの文献の取り込み E-Journalサイトからの文献の取り込み EndNoteを利用した文献の取り込み 参考文献リストの作成 < 便利な機能の一例 > PDF Fileやその他ファイルの貼り付け 省略形式を表示させる方法
 GenBank クイックスタート GenBank は NLM/NCBI にて維持管理されている核酸配列データベースです また GenBank は EMBL, DDBJ と三極間で連携しながら国際核酸配列データベースを共同で構築しています これら三機関はデータを日々交換し続けており その規模は 160000 種にも及ぶ生物種の塩基配列から成り立つまでになっています この GenBank クイックスタートでは
GenBank クイックスタート GenBank は NLM/NCBI にて維持管理されている核酸配列データベースです また GenBank は EMBL, DDBJ と三極間で連携しながら国際核酸配列データベースを共同で構築しています これら三機関はデータを日々交換し続けており その規模は 160000 種にも及ぶ生物種の塩基配列から成り立つまでになっています この GenBank クイックスタートでは
 UCSC ゲノムブラウザチュートリアル UCSC ゲノムブラウザはゲノム解読がなされている真核生物を対象として自動アノテーションを行い その結果をデータベースとして公開している UCSC が進めているプロジェクトです NCBI MapViewer のようにゲノムベースでその上にアノテーションされている遺伝子などの情報を閲覧すると共に ホモロジー検索や必要なデータのダウンロードなどの機能を提供しています
UCSC ゲノムブラウザチュートリアル UCSC ゲノムブラウザはゲノム解読がなされている真核生物を対象として自動アノテーションを行い その結果をデータベースとして公開している UCSC が進めているプロジェクトです NCBI MapViewer のようにゲノムベースでその上にアノテーションされている遺伝子などの情報を閲覧すると共に ホモロジー検索や必要なデータのダウンロードなどの機能を提供しています
ACD/1D NMR Processor:基本トレーニング
 Quick Start Guide ACD/1D NMR Processor: 基本トレーニング Version 12 富士通株式会社 TC ソリューション事業本部 計算科学ソリューション統括部 目次 はじめに... 2 Raw データのインポート... 2 スペクトルデータをインポートするには... 2 フーリエ変換, ベースライン補正, フェーズ補正... 3 フーリエ変換 ベースライン補正 フェーズ補正を自動実行するには...
Quick Start Guide ACD/1D NMR Processor: 基本トレーニング Version 12 富士通株式会社 TC ソリューション事業本部 計算科学ソリューション統括部 目次 はじめに... 2 Raw データのインポート... 2 スペクトルデータをインポートするには... 2 フーリエ変換, ベースライン補正, フェーズ補正... 3 フーリエ変換 ベースライン補正 フェーズ補正を自動実行するには...
2. 設定画面から 下記の項目について入力を行って下さい Report Type - 閲覧したい利用統計の種類を選択 Database Usage Report: ご契約データベース毎の利用統計 Interface Usage Report: 使用しているインターフェイス * 毎の利用統計 * 専用
 EBSCOadmin 利用統計設定方法 EBSCOadmin 内の Report & Statistics 機能をご利用頂くことで セッション別 発信元の IP アドレス別 デー タベース別 最も多く検索された雑誌タイトルなどに限定して ユーザーのデータベース利用頻度を把握すること ができます ここでは 基本的なデータベースの利用統計レポートの作成方法をご説明します 利用統計を設定する (=Standard
EBSCOadmin 利用統計設定方法 EBSCOadmin 内の Report & Statistics 機能をご利用頂くことで セッション別 発信元の IP アドレス別 デー タベース別 最も多く検索された雑誌タイトルなどに限定して ユーザーのデータベース利用頻度を把握すること ができます ここでは 基本的なデータベースの利用統計レポートの作成方法をご説明します 利用統計を設定する (=Standard
基本的な利用法
 (R で ) 塩基配列解析 基本的な利用法 Macintosh 版 到達目標 : このスライドに書かれている程度のことは自在にできるようにしてエラーへの対処法を身につける 1. 必要なパッケージのインストールが正しくできているかどうかの自力での判定 および個別のパッケージのインストール 2. 作業ディレクトリの変更 3. テキストエディタで自在に入出力ファイル名の変更 ( どんなファイル名のものがどこに生成されるかという全体像の把握
(R で ) 塩基配列解析 基本的な利用法 Macintosh 版 到達目標 : このスライドに書かれている程度のことは自在にできるようにしてエラーへの対処法を身につける 1. 必要なパッケージのインストールが正しくできているかどうかの自力での判定 および個別のパッケージのインストール 2. 作業ディレクトリの変更 3. テキストエディタで自在に入出力ファイル名の変更 ( どんなファイル名のものがどこに生成されるかという全体像の把握
Microsoft Word - SSI_Smart-Trading_QA_ja_ doc
 サイゴン証券会社 (SSI) SSI Smarttrading の設定に関する Q&A 06-2009 Q&A リスト 1. Q1 http://smarttrading.ssi.com.vn へアクセスしましたが 黒い画面になり X のマークが左上に出ている A1 原因はまだ設定していない アドミニストレータで設定しない あるいは自動設定プログラムがお客様の PC に適合しないと考えられます 解決方法アドミニストレータの権限のユーザーでログインし
サイゴン証券会社 (SSI) SSI Smarttrading の設定に関する Q&A 06-2009 Q&A リスト 1. Q1 http://smarttrading.ssi.com.vn へアクセスしましたが 黒い画面になり X のマークが左上に出ている A1 原因はまだ設定していない アドミニストレータで設定しない あるいは自動設定プログラムがお客様の PC に適合しないと考えられます 解決方法アドミニストレータの権限のユーザーでログインし
Microsoft PowerPoint - SNGS_Ana講習会5月29日.pptx
 NGS analyzer: 次世代シークエンス解析プログラム 独立行政法人理化学研究所情報基盤センター HPCI 計算生命科学推進プログラム須永泰弘 2013/5/29 次世代シークエンス解析ソフト講習会 1 NGS analyzer とは? 次世代シークエンサー (NGS) からの塩基配列データを用いて マッピング PCR の除去 SNP タイピング 欠失挿入の検出を行う 一連の作業はパイプライン化してある
NGS analyzer: 次世代シークエンス解析プログラム 独立行政法人理化学研究所情報基盤センター HPCI 計算生命科学推進プログラム須永泰弘 2013/5/29 次世代シークエンス解析ソフト講習会 1 NGS analyzer とは? 次世代シークエンサー (NGS) からの塩基配列データを用いて マッピング PCR の除去 SNP タイピング 欠失挿入の検出を行う 一連の作業はパイプライン化してある
 BLAST クイックスタート このミニコースでは 配列相同性検索プログラムである BLAST ファミリについて実用的な紹介をしていきます その課題は単純な探索から ある特別な目的の探索を BLAST の創造的な使い方で実現するといった幅の広いものになっています 課題.1 blastn の利用 課題.1-1 プライマーでの増幅領域の特定 下に示したプライマーを用いることで増幅できる GenBank に登録されているヒトゲノムの配列を
BLAST クイックスタート このミニコースでは 配列相同性検索プログラムである BLAST ファミリについて実用的な紹介をしていきます その課題は単純な探索から ある特別な目的の探索を BLAST の創造的な使い方で実現するといった幅の広いものになっています 課題.1 blastn の利用 課題.1-1 プライマーでの増幅領域の特定 下に示したプライマーを用いることで増幅できる GenBank に登録されているヒトゲノムの配列を
Maser - User Operation Manual
 Maser 3 Cell Innovation User Operation Manual 2013.4.1 1 目次 1. はじめに... 3 1.1. 推奨動作環境... 3 2. データの登録... 4 2.1. プロジェクトの作成... 4 2.2. Projectへのデータのアップロード... 8 2.2.1. HTTPSでのアップロード... 8 2.2.2. SFTPでのアップロード...
Maser 3 Cell Innovation User Operation Manual 2013.4.1 1 目次 1. はじめに... 3 1.1. 推奨動作環境... 3 2. データの登録... 4 2.1. プロジェクトの作成... 4 2.2. Projectへのデータのアップロード... 8 2.2.1. HTTPSでのアップロード... 8 2.2.2. SFTPでのアップロード...
リアルタイムPCR実験のためのガイドライン
 リアルタイム PCR 実践編 - プライマー設計ガイドライン - 効率的なリアルタイム PCR を行うためには 最適なプライマーを設計することがもっとも重要であり 増幅効率が良く 非特異的増幅が起こらないプライマーが設計できれば リアルタイム PCR は ほぼ確実に成功する ここでは プライマーを設計する際に考慮すべきパラメータについて個々に解説し 最後に 専用のソフトウェアを使用してプライマー設計をする方法について簡単に説明する
リアルタイム PCR 実践編 - プライマー設計ガイドライン - 効率的なリアルタイム PCR を行うためには 最適なプライマーを設計することがもっとも重要であり 増幅効率が良く 非特異的増幅が起こらないプライマーが設計できれば リアルタイム PCR は ほぼ確実に成功する ここでは プライマーを設計する際に考慮すべきパラメータについて個々に解説し 最後に 専用のソフトウェアを使用してプライマー設計をする方法について簡単に説明する
国際塩基配列データベース n DNA のデータベース GenBank ( アメリカ :Na,onal Center for Biotechnology Informa,on, NCBI が運営 ) EMBL ( ヨーロッパ : 欧州生命情報学研究所が運営 ) DDBJ ( 日本 : 国立遺伝研内の日
 EMBL ( ヨーロッパ : 欧州生命情報学研究所が運営 ) DDBJ ( 日本 : 国立遺伝研内の日") 生物情報工学 BioInforma*cs 3 遺伝子データベース 16/06/09 1 国際塩基配列データベース n DNA のデータベース GenBank ( アメリカ :Na,onal Center for Biotechnology Informa,on, NCBI が運営 ) EMBL ( ヨーロッパ : 欧州生命情報学研究所が運営 ) DDBJ ( 日本 : 国立遺伝研内の日本 DNA データバンクが運営
生物情報工学 BioInforma*cs 3 遺伝子データベース 16/06/09 1 国際塩基配列データベース n DNA のデータベース GenBank ( アメリカ :Na,onal Center for Biotechnology Informa,on, NCBI が運営 ) EMBL ( ヨーロッパ : 欧州生命情報学研究所が運営 ) DDBJ ( 日本 : 国立遺伝研内の日本 DNA データバンクが運営
Qlucore_seminar_slide_180604
 シングルセル RNA-Seq のための 情報解析 フィルジェン株式会社バイオサイエンス部 (biosupport@filgen.jp) 1 シングルセル RNA-Seq シングルセル RNA-Seq のデータ解析では 通常の RNA-Seq データの解析手法に加え データセット内の各細胞の遺伝子発現プロファイルの違いを俯瞰できるような 強力な情報解析アルゴリズムと データのビジュアライズ機能を利用する必要がある
シングルセル RNA-Seq のための 情報解析 フィルジェン株式会社バイオサイエンス部 (biosupport@filgen.jp) 1 シングルセル RNA-Seq シングルセル RNA-Seq のデータ解析では 通常の RNA-Seq データの解析手法に加え データセット内の各細胞の遺伝子発現プロファイルの違いを俯瞰できるような 強力な情報解析アルゴリズムと データのビジュアライズ機能を利用する必要がある
A Constructive Approach to Gene Expression Dynamics
 配列アラインメント (I): 大域アラインメント http://www.lab.tohou.ac.jp/sci/is/nacher/eaching/bioinformatics/ week.pdf 08/4/0 08/4/0 基本的な考え方 バイオインフォマティクスにはさまざまなアルゴリズムがありますが その多くにおいて基本的な考え方は 配列が類似していれば 機能も類似している というものである 例えば
配列アラインメント (I): 大域アラインメント http://www.lab.tohou.ac.jp/sci/is/nacher/eaching/bioinformatics/ week.pdf 08/4/0 08/4/0 基本的な考え方 バイオインフォマティクスにはさまざまなアルゴリズムがありますが その多くにおいて基本的な考え方は 配列が類似していれば 機能も類似している というものである 例えば
サンプルシート作成ツール: Illumina Experimental Manager(IEM)の使用方法 -最新バージョンIEMv1.15のご紹介-
の使用方法 -最新バージョンIEMv1.15のご紹介-") サンプルシート作成ツール : Illumina Experimental Manager (IEM) の使用方法 - 最新バージョン v1.15.1 のご紹介 - 上利佳弘フィールドアプリケーションスーパーバイザー 25-Jul-2018 2017 Illumina, Inc. All rights reserved. For Research Use Only. Not for use in diagnostic
サンプルシート作成ツール : Illumina Experimental Manager (IEM) の使用方法 - 最新バージョン v1.15.1 のご紹介 - 上利佳弘フィールドアプリケーションスーパーバイザー 25-Jul-2018 2017 Illumina, Inc. All rights reserved. For Research Use Only. Not for use in diagnostic
Microsoft PowerPoint - 8_TS-0894(TaqMan_SNPGenotypingAssays_製品情報及び検索方法再修正.pptx
 Applied Biosystems TaqMan SNP Genotyping Assays インターネット検索方法 2010/04/23 目次 TaqMan SNP Genotyping Assays の概要 --------------- 3 検索方法の流れ --------------- 4 TaqMan SNP Genotyping Assays 検索方法 ---------------
Applied Biosystems TaqMan SNP Genotyping Assays インターネット検索方法 2010/04/23 目次 TaqMan SNP Genotyping Assays の概要 --------------- 3 検索方法の流れ --------------- 4 TaqMan SNP Genotyping Assays 検索方法 ---------------
講義内容 ファイル形式 データの可視化 データのクオリティチェック マッピング アセンブル 資料の見方 $ pwd 実際に入力するコマンドを黄色い四角の中に示します 2
 N G S 解析基礎 講義内容 ファイル形式 データの可視化 データのクオリティチェック マッピング アセンブル 資料の見方 $ pwd 実際に入力するコマンドを黄色い四角の中に示します 2 ファイル形式 NGS 解析でよく使われるファイル形式 ファイル形式 fastq bam/sam vcf bed fasta サンプルデータの場所 /home/ ユーザ名 /Desktop/amelieff/1K_ERR038793_1.fastq
N G S 解析基礎 講義内容 ファイル形式 データの可視化 データのクオリティチェック マッピング アセンブル 資料の見方 $ pwd 実際に入力するコマンドを黄色い四角の中に示します 2 ファイル形式 NGS 解析でよく使われるファイル形式 ファイル形式 fastq bam/sam vcf bed fasta サンプルデータの場所 /home/ ユーザ名 /Desktop/amelieff/1K_ERR038793_1.fastq
分子系統解析における様々な問題について 田辺晶史
 分子系統解析における様々な問題について 田辺晶史 そもそもどこの配列を使うべき? そもそもどこの配列を使うべき? 置換が早すぎず遅すぎない (= 多すぎず少なすぎない ) そもそもどこの配列を使うべき? 置換が早すぎず遅すぎない (= 多すぎず少なすぎない ) 連続長は長い方が良い そもそもどこの配列を使うべき? 置換が早すぎず遅すぎない (= 多すぎず少なすぎない ) 連続長は長い方が良い 遺伝子重複が起きていない
分子系統解析における様々な問題について 田辺晶史 そもそもどこの配列を使うべき? そもそもどこの配列を使うべき? 置換が早すぎず遅すぎない (= 多すぎず少なすぎない ) そもそもどこの配列を使うべき? 置換が早すぎず遅すぎない (= 多すぎず少なすぎない ) 連続長は長い方が良い そもそもどこの配列を使うべき? 置換が早すぎず遅すぎない (= 多すぎず少なすぎない ) 連続長は長い方が良い 遺伝子重複が起きていない
SILAND.JP テンプレート集
 試金石 Ver29.00 ダウンロードから操作方法までの解説 第 1 版 作成者勝時研究会 作成日 2017 年 6 月 18 日 最終更新日 2017 年 6 月 18 日 1 / 29 ダウンロードはこちら http://shikinseki.info/ 目次 試金石 Ver29.00... 1 目次... 2 はじめに... 4 パソコンの基本 OS の確認... 4 Access 2010
試金石 Ver29.00 ダウンロードから操作方法までの解説 第 1 版 作成者勝時研究会 作成日 2017 年 6 月 18 日 最終更新日 2017 年 6 月 18 日 1 / 29 ダウンロードはこちら http://shikinseki.info/ 目次 試金石 Ver29.00... 1 目次... 2 はじめに... 4 パソコンの基本 OS の確認... 4 Access 2010
Data Explorerの使い方|国立教育政策研究所 National Institute for Educational Policy Research
 Data Explorer の使い方 Data Explorer は 国際成人力調査 (Programme for the International Assessment of Adult Competencies=PIAAC) のコンソーシアムが提供する 2011 年に実施された PIAAC の調査結果のデータ集計及び集計結果の出力用ツールです Data Explorer は現在 英語のみで提供されています
Data Explorer の使い方 Data Explorer は 国際成人力調査 (Programme for the International Assessment of Adult Competencies=PIAAC) のコンソーシアムが提供する 2011 年に実施された PIAAC の調査結果のデータ集計及び集計結果の出力用ツールです Data Explorer は現在 英語のみで提供されています
電話機のファイル形式
 この章では テキスト エディタを使用して作成する CSV データ ファイルのファイル形式を設定 する方法について説明します 電話機 CSV データ ファイルを作成するためのテキスト エディタ, 1 ページ の検索, 2 ページ CSV データ ファイルの電話機ファイル形式の設定, 3 ページ テキストベースのファイル形式と CSV データ ファイルの関連付け, 7 ページ 電話機 CSV データ ファイルを作成するためのテキスト
この章では テキスト エディタを使用して作成する CSV データ ファイルのファイル形式を設定 する方法について説明します 電話機 CSV データ ファイルを作成するためのテキスト エディタ, 1 ページ の検索, 2 ページ CSV データ ファイルの電話機ファイル形式の設定, 3 ページ テキストベースのファイル形式と CSV データ ファイルの関連付け, 7 ページ 電話機 CSV データ ファイルを作成するためのテキスト
eService
 eservice ご利用の手引き ソフトウェア エー ジー株式会社グローバルサポート Page 1 eservice eservice は弊社サポート WEB サイト EMPOWER のサービスです お客様は eservice にて サポートインシデントの発行と管理を行うことができます eservice では お客様に以下のサービスをご提供致します - サポートインシデントの検索と閲覧 - サポートインシデントの新規作成と更新
eservice ご利用の手引き ソフトウェア エー ジー株式会社グローバルサポート Page 1 eservice eservice は弊社サポート WEB サイト EMPOWER のサービスです お客様は eservice にて サポートインシデントの発行と管理を行うことができます eservice では お客様に以下のサービスをご提供致します - サポートインシデントの検索と閲覧 - サポートインシデントの新規作成と更新
メールアーカイブASP ご利用マニュアル
 メールアーカイブ ASP ご利用マニュアル (Ver.1.5) 富士通クラウドテクノロジーズ株式会社 2010/11/10 メールアーカイブ ASP ご利用マニュアル 目 次 管理者用マニュアル 1. 利用開始 / 終了 3 2. ホームについて 4 3. パスワード変更 4 4. 検索 / 表示 6 4.1 検索結果一覧表示 7 4.2 メール表示 7 5. サブアカウント管理 9 6. 表示設定
メールアーカイブ ASP ご利用マニュアル (Ver.1.5) 富士通クラウドテクノロジーズ株式会社 2010/11/10 メールアーカイブ ASP ご利用マニュアル 目 次 管理者用マニュアル 1. 利用開始 / 終了 3 2. ホームについて 4 3. パスワード変更 4 4. 検索 / 表示 6 4.1 検索結果一覧表示 7 4.2 メール表示 7 5. サブアカウント管理 9 6. 表示設定
2015 年 5 月 15 日イルミナサポートウェビナー Nextera Rapid Capture Exome キットを用いたエクソームシーケンス - ドライ編 BaseSpace で行うかんたん NGS データ解析 < Enrichment アプリ > イルミナ株式会社バイオインフォマティクスサ
 2015 年 5 月 15 日イルミナサポートウェビナー Nextera Rapid Capture Exome キットを用いたエクソームシーケンス - ドライ編 BaseSpace で行うかんたん NGS データ解析 < アプリ > イルミナ株式会社バイオインフォマティクスサポートサイエンティスト癸生川絵里 (Eri Kibukawa) 2014 Illumina, Inc. All rights
2015 年 5 月 15 日イルミナサポートウェビナー Nextera Rapid Capture Exome キットを用いたエクソームシーケンス - ドライ編 BaseSpace で行うかんたん NGS データ解析 < アプリ > イルミナ株式会社バイオインフォマティクスサポートサイエンティスト癸生川絵里 (Eri Kibukawa) 2014 Illumina, Inc. All rights
動作環境 対応 LAN DISK ( 設定復元に対応 ) HDL-H シリーズ HDL-X シリーズ HDL-AA シリーズ HDL-XV シリーズ (HDL-XVLP シリーズを含む ) HDL-XV/2D シリーズ HDL-XR シリーズ HDL-XR/2D シリーズ HDL-XR2U シリーズ
 HDL-H シリーズ HDL-X シリーズ HDL-AA シリーズ HDL-XV シリーズ (HDL-XVLP シリーズを含む ) HDL-XV/2D シリーズ HDL-XR シリーズ HDL-XR/2D シリーズ HDL-XR2U シリーズ") 複数台導入時の初期設定を省力化 設定復元ツール LAN DISK Restore LAN DISK Restore は 対応機器の各種設定情報を設定ファイルとして保存し 保存した設定ファイルから LAN DISK シリーズに対して設定の移行をおこなうことができます 複数の LAN DISK シリーズ導入時や大容量モデルへの移行の際の初期設定を簡単にします LAN DISK Restore インストール時に
複数台導入時の初期設定を省力化 設定復元ツール LAN DISK Restore LAN DISK Restore は 対応機器の各種設定情報を設定ファイルとして保存し 保存した設定ファイルから LAN DISK シリーズに対して設定の移行をおこなうことができます 複数の LAN DISK シリーズ導入時や大容量モデルへの移行の際の初期設定を簡単にします LAN DISK Restore インストール時に
Microsoft Word - KML変換操作方法_fujii改.doc
 KML 変換操作方法 ご利用前の準備 ご利用前に下記のものをご用意ください ナビ本機対象機種をよくご確認のうえ ご用意ください パソコン Google Earth のインストールが必要ですので Google Earth のホームページをご確認の上 動作要件を満たすものをご使用ください SD カードナビ本機の取扱説明書に推奨品の一覧が記載されていますので そちらをご参照ください Google Earth
KML 変換操作方法 ご利用前の準備 ご利用前に下記のものをご用意ください ナビ本機対象機種をよくご確認のうえ ご用意ください パソコン Google Earth のインストールが必要ですので Google Earth のホームページをご確認の上 動作要件を満たすものをご使用ください SD カードナビ本機の取扱説明書に推奨品の一覧が記載されていますので そちらをご参照ください Google Earth
機能ゲノム学(第6回)
") トランスクリプトーム解析の今昔 なぜマイクロアレイ? なぜRNA-Seq? 東京大学大学院農学生命科学研究科アグリバイオインフォマティクス教育研究ユニット門田幸二 ( かどたこうじ ) http://www.iu.a.u-tokyo.ac.jp/~kadota/ kadota@iu.a.u-tokyo.ac.jp 1 Contents トランスクリプトーム解析の概要 各手法の長所 短所 マイクロアレイ
トランスクリプトーム解析の今昔 なぜマイクロアレイ? なぜRNA-Seq? 東京大学大学院農学生命科学研究科アグリバイオインフォマティクス教育研究ユニット門田幸二 ( かどたこうじ ) http://www.iu.a.u-tokyo.ac.jp/~kadota/ kadota@iu.a.u-tokyo.ac.jp 1 Contents トランスクリプトーム解析の概要 各手法の長所 短所 マイクロアレイ
1:.anchors Menubar Sequence Navigation order Plot & Color options Left sidebar ON/OFF Right sidebar ON/OFF History / Bookmark Apply sequence order / p
 GMV 2009 2 1 GMV GMV 1.1 GMV Murasaki GMV (GTK+ based Murasaki Viewer) 1.1.1 GMV GMV Murasaki (http://murasaki.dna.bio.keio.ac.jp/gmv.html) 1.1.2 gmv Open Anchors File ( 1) murasaki 1.1.3 GMV 2 GMV on/off
GMV 2009 2 1 GMV GMV 1.1 GMV Murasaki GMV (GTK+ based Murasaki Viewer) 1.1.1 GMV GMV Murasaki (http://murasaki.dna.bio.keio.ac.jp/gmv.html) 1.1.2 gmv Open Anchors File ( 1) murasaki 1.1.3 GMV 2 GMV on/off
DragonDisk
 オブジェクトストレージサービス S3 Browser ご利用ガイド サービスマニュアル Ver.1.10 2017 年 8 月 21 日 株式会社 IDC フロンティア S3 Browser の利用方法 S3 Browser は Windows で動作するエクスプローラ形式のストレージ操作 GUI です S3 Browser(http://s3browser.com) S3 Browser は有償のソフトウェアです
オブジェクトストレージサービス S3 Browser ご利用ガイド サービスマニュアル Ver.1.10 2017 年 8 月 21 日 株式会社 IDC フロンティア S3 Browser の利用方法 S3 Browser は Windows で動作するエクスプローラ形式のストレージ操作 GUI です S3 Browser(http://s3browser.com) S3 Browser は有償のソフトウェアです
認証システムのパスワード変更方法
 AL-Mail32 から Thunderbird への移行方法 在学生が利用しているメーラーは AL-Mail32 と呼ばれるソフトウェアを利用しています 在学生が今後 Thunderbird Portable を利用したい場合には 1. 現在利用している AL-Mail32 は過去のメールを確認する場合に利用し 新規で受信するメールは Thunderbird Portable を利用する 2. 現在使用している
AL-Mail32 から Thunderbird への移行方法 在学生が利用しているメーラーは AL-Mail32 と呼ばれるソフトウェアを利用しています 在学生が今後 Thunderbird Portable を利用したい場合には 1. 現在利用している AL-Mail32 は過去のメールを確認する場合に利用し 新規で受信するメールは Thunderbird Portable を利用する 2. 現在使用している
目次 1. Azure Storage をインストールする Azure Storage のインストール Azure Storage のアンインストール Azure Storage を使う ストレージアカウントの登録... 7
 QNAP Azure Storage ユーザーガイド 発行 : 株式会社フォースメディア 2014/6/2 Rev. 1.00 2014 Force Media, Inc. 目次 1. Azure Storage をインストールする... 3 1.1. Azure Storage のインストール... 3 1.2. Azure Storage のアンインストール... 5 2. Azure Storage
QNAP Azure Storage ユーザーガイド 発行 : 株式会社フォースメディア 2014/6/2 Rev. 1.00 2014 Force Media, Inc. 目次 1. Azure Storage をインストールする... 3 1.1. Azure Storage のインストール... 3 1.2. Azure Storage のアンインストール... 5 2. Azure Storage
HDC-EDI Manager Ver レベルアップ詳細情報 < 製品一覧 > 製品名バージョン HDC-EDI Manager < 対応 JavaVM> Java 2 Software Development Kit, Standard Edition 1.4 Java 2
 レベルアップ詳細情報 < 製品一覧 > 製品名バージョン HDC-EDI Manager 2.2.0 < 対応 JavaVM> Java 2 Software Development Kit, Standard Edition 1.4 Java 2 Platform Standard Edition Development Kit 5.0 Java SE Development Kit 6 < 追加機能一覧
レベルアップ詳細情報 < 製品一覧 > 製品名バージョン HDC-EDI Manager 2.2.0 < 対応 JavaVM> Java 2 Software Development Kit, Standard Edition 1.4 Java 2 Platform Standard Edition Development Kit 5.0 Java SE Development Kit 6 < 追加機能一覧
独立行政法人産業技術総合研究所 PMID-Extractor ユーザ利用マニュアル バイオメディシナル情報研究センター 2009/03/09 第 1.0 版
 独立行政法人産業技術総合研究所 PMID-Extractor ユーザ利用マニュアル バイオメディシナル情報研究センター 2009/03/09 第 1.0 版 目次 1. はじめに... 3 2. インストール方法... 4 3. プログラムの実行... 5 4. プログラムの終了... 5 5. 操作方法... 6 6. 画面の説明... 8 付録 A:Java のインストール方法について... 11
独立行政法人産業技術総合研究所 PMID-Extractor ユーザ利用マニュアル バイオメディシナル情報研究センター 2009/03/09 第 1.0 版 目次 1. はじめに... 3 2. インストール方法... 4 3. プログラムの実行... 5 4. プログラムの終了... 5 5. 操作方法... 6 6. 画面の説明... 8 付録 A:Java のインストール方法について... 11
PowerPoint Presentation
 Library for Keysight ADS (for 2011 and later) ユーザーマニュアル 1 28 September 2018 0. 目次 1. 本マニュアルについて 2. 動作環境 3. インストール方法 4. 使用法 5. お問い合わせ先 2 1. 本マニュアルについて 本マニュアルは 株式会社村田製作所 ( 以下 当社 ) 製品のパラメータを Keysight 社 ADS2011
Library for Keysight ADS (for 2011 and later) ユーザーマニュアル 1 28 September 2018 0. 目次 1. 本マニュアルについて 2. 動作環境 3. インストール方法 4. 使用法 5. お問い合わせ先 2 1. 本マニュアルについて 本マニュアルは 株式会社村田製作所 ( 以下 当社 ) 製品のパラメータを Keysight 社 ADS2011
プレゼンテーション2.ppt
 ryamasi@hgc.jp BLAST Genome browser InterProScan PSORT DBTSS Seqlogo JASPAR Melina II Panther Babelomics +@ >cdna_test CCCCTGCCCTCAACAAGATGTTTTGCCAACTGGCCAAGACCTGCCCTGTGCAGCTGTGGGTTGATTCCAC ACCCCCGCCCGGCACCCGCGTCCGCGCCATGGCCATCTACAAGCAGTCACAGCACATGACGGAGGTTGTG
ryamasi@hgc.jp BLAST Genome browser InterProScan PSORT DBTSS Seqlogo JASPAR Melina II Panther Babelomics +@ >cdna_test CCCCTGCCCTCAACAAGATGTTTTGCCAACTGGCCAAGACCTGCCCTGTGCAGCTGTGGGTTGATTCCAC ACCCCCGCCCGGCACCCGCGTCCGCGCCATGGCCATCTACAAGCAGTCACAGCACATGACGGAGGTTGTG
1. 画面説明 ここでは普通にアプリケーションを開いた場合に表示される対話型画面の説明をしています パスワード ( 再入力 ) パスワード登録 パスワード消去 事前チェックの処理の際に必要になるパスワ
 パスワード登録 パスワード消去 事前チェックの処理の際に必要になるパスワ") 使い方ガイド 1. 画面説明... 2 2. 使用方法 ( 対話型画面編 )... 5 3. 使用方法 ( 右クリックメニュー編 )... 10 4. 使用方法 ( フォルダ単位編 )... 12 5. 注意事項... 15 1 1. 画面説明 ここでは普通にアプリケーションを開いた場合に表示される対話型画面の説明をしています 1 2 3 4 5 6 7 8 9 10 11 14 12 13 15
使い方ガイド 1. 画面説明... 2 2. 使用方法 ( 対話型画面編 )... 5 3. 使用方法 ( 右クリックメニュー編 )... 10 4. 使用方法 ( フォルダ単位編 )... 12 5. 注意事項... 15 1 1. 画面説明 ここでは普通にアプリケーションを開いた場合に表示される対話型画面の説明をしています 1 2 3 4 5 6 7 8 9 10 11 14 12 13 15
Bioinformatics2
 バイオインフォマティクス配列データ解析 2 藤 博幸 データベース検索 (1) ブラウザで NCBI を検索 (2)NCBI で配列データの取得 (3)NCBI で BLAST 検索 ブラウザで NCBI を検索 ブラウザで NCBI を検索 クリック ブラウザで NCBI を検索 NCBI トップページ National Center for Biotechnology Information 分
バイオインフォマティクス配列データ解析 2 藤 博幸 データベース検索 (1) ブラウザで NCBI を検索 (2)NCBI で配列データの取得 (3)NCBI で BLAST 検索 ブラウザで NCBI を検索 ブラウザで NCBI を検索 クリック ブラウザで NCBI を検索 NCBI トップページ National Center for Biotechnology Information 分
第 10 回シーケンス講習会 RNA-seq library 調製法の特徴と選び方 理化学研究所 (RIKEN) ライフサイエンス技術基盤研究センター (CLST) 機能性ゲノム解析部門 (DGT) ゲノムネットワーク解析支援施設 (GeNAS) 野間将平
 ライフサイエンス技術基盤研究センター (CLST) 機能性ゲノム解析部門 (DGT) ゲノムネットワーク解析支援施設 (GeNAS) 野間将平") 第 10 回シーケンス講習会 RNA-seq library 調製法の特徴と選び方 理化学研究所 (RIKEN) ライフサイエンス技術基盤研究センター (CLST) 機能性ゲノム解析部門 (DGT) ゲノムネットワーク解析支援施設 (GeNAS) 野間将平 l シーケンスをする目的は? 概略 l よいシーケンスライブラリーとは? RNA-seq ライブラリーのムリ ムダ ムラ l いろいろな RNA-seq
第 10 回シーケンス講習会 RNA-seq library 調製法の特徴と選び方 理化学研究所 (RIKEN) ライフサイエンス技術基盤研究センター (CLST) 機能性ゲノム解析部門 (DGT) ゲノムネットワーク解析支援施設 (GeNAS) 野間将平 l シーケンスをする目的は? 概略 l よいシーケンスライブラリーとは? RNA-seq ライブラリーのムリ ムダ ムラ l いろいろな RNA-seq
ProVisionaire Control V3.0セットアップガイド
 ProVisionaire Control V3 1 Manual Development Group 2018 Yamaha Corporation JA 2 3 4 5 NOTE 6 7 8 9 q w e r t r t y u y q w u e 10 3. NOTE 1. 2. 11 4. NOTE 5. Tips 12 2. 1. 13 3. 4. Tips 14 5. 1. 2. 3.
ProVisionaire Control V3 1 Manual Development Group 2018 Yamaha Corporation JA 2 3 4 5 NOTE 6 7 8 9 q w e r t r t y u y q w u e 10 3. NOTE 1. 2. 11 4. NOTE 5. Tips 12 2. 1. 13 3. 4. Tips 14 5. 1. 2. 3.
アーカイブ機能インストールマニュアル
 Microsoft SQL Server 2008 SQL Server Management Studio データベースバックアップ設定マニュアル 1. 注意事項... 1 2. データベースのバックアッププラン作成方法... 2 3. データベースのバックアップ... 8 4. データベースの復元方法について... 11 5. データベースのログの圧縮... 13 Copyright(c)
Microsoft SQL Server 2008 SQL Server Management Studio データベースバックアップ設定マニュアル 1. 注意事項... 1 2. データベースのバックアッププラン作成方法... 2 3. データベースのバックアップ... 8 4. データベースの復元方法について... 11 5. データベースのログの圧縮... 13 Copyright(c)
レポートのデータへのフィルタの適用
 レポート内のフィルタ, 1 ページ フィルタのタイプ, 2 ページ 日時範囲フィルタの設定, 2 ページ キー基準フィールドの設定, 3 ページ フィールド フィルタの設定, 3 ページ レポート内のフィルタ Unified Intelligence Center のレポート フィルタを使用して 表示するデータを選択します [フィ ルタ Filter ] ページを使用してフィルタを定義し レポートに表示するデータをフィルタ処理
レポート内のフィルタ, 1 ページ フィルタのタイプ, 2 ページ 日時範囲フィルタの設定, 2 ページ キー基準フィールドの設定, 3 ページ フィールド フィルタの設定, 3 ページ レポート内のフィルタ Unified Intelligence Center のレポート フィルタを使用して 表示するデータを選択します [フィ ルタ Filter ] ページを使用してフィルタを定義し レポートに表示するデータをフィルタ処理
RADIUS サーバを使用して NT のパスワード期限切れ機能をサポートするための Cisco VPN 3000 シリーズ コンセントレータの設定
 RADIUS サーバを使用して NT のパスワード期限切れ機能をサポートするための Cisco VPN 3000 シリーズコンセントレータの設定 目次 概要前提条件要件使用するコンポーネントネットワーク図 VPN 3000 コンセントレータの設定グループの設定 RADIUS の設定 Cisco Secure NT RADIUS サーバの設定 VPN 3000 コンセントレータ用のエントリの設定 NT
RADIUS サーバを使用して NT のパスワード期限切れ機能をサポートするための Cisco VPN 3000 シリーズコンセントレータの設定 目次 概要前提条件要件使用するコンポーネントネットワーク図 VPN 3000 コンセントレータの設定グループの設定 RADIUS の設定 Cisco Secure NT RADIUS サーバの設定 VPN 3000 コンセントレータ用のエントリの設定 NT
Microsoft Word - BMDS_guidance pdf_final
 BMDS を用いたベンチマークドース法適用ガイダンス (BMDS は 米国 EPA のホームページ (http://www.epa.gov/ncea/bmds/) より無償でダウンロードで きる ) 最初に データ入力フォームにデータを入力する 病理所見の発現頻度等の非連続データの場合は モデルタイプとしてDichotomousを選択し 体重 血液 / 血液生化学検査値や器官重量等の連続データの場合は
BMDS を用いたベンチマークドース法適用ガイダンス (BMDS は 米国 EPA のホームページ (http://www.epa.gov/ncea/bmds/) より無償でダウンロードで きる ) 最初に データ入力フォームにデータを入力する 病理所見の発現頻度等の非連続データの場合は モデルタイプとしてDichotomousを選択し 体重 血液 / 血液生化学検査値や器官重量等の連続データの場合は
メニューの Programmer をクリックしますと下記の画面になります Search of programmers をクリックしますとそこで使用するプログラマーを選択することが出来ます 選択の後 下記のボタンでプログラマーの接続を行って下さい Connect programmers - 全ての選択
 PG4UWMC マルチルチ プログラプログラミング コンング コントロール パネル Pg4uwMC プログラムは 1 台のコンピュータの USB ポートに接続された BeeProg, Beeprog+, BeeProg2C, 又は BeeProg2 を 4~8 台まで 又は BeeHive4+ 又は BeeHive204 を 2 台接続して 8 サイトでのマルチプログラミングを行うことが出来ます n
PG4UWMC マルチルチ プログラプログラミング コンング コントロール パネル Pg4uwMC プログラムは 1 台のコンピュータの USB ポートに接続された BeeProg, Beeprog+, BeeProg2C, 又は BeeProg2 を 4~8 台まで 又は BeeHive4+ 又は BeeHive204 を 2 台接続して 8 サイトでのマルチプログラミングを行うことが出来ます n
OECD QSAR Toolbox活用マニュアルv1.0
 OECD QSAR Toolbox 活用マニュアル ~ データのインポートと構造検索 ~ Ver.1.0 平成 26 年 9 月 独立行政法人製品評価技術基盤機構 免責事項 本マニュアルを使用したことにより 直接的 間接的に発生した損害 損失につい ては いかなる責任も負いかねます 改訂履歴 Version 日付改訂内容 Ver.1.0 平成 26 年 9 月初版 このマニュアルは OECD QSAR
OECD QSAR Toolbox 活用マニュアル ~ データのインポートと構造検索 ~ Ver.1.0 平成 26 年 9 月 独立行政法人製品評価技術基盤機構 免責事項 本マニュアルを使用したことにより 直接的 間接的に発生した損害 損失につい ては いかなる責任も負いかねます 改訂履歴 Version 日付改訂内容 Ver.1.0 平成 26 年 9 月初版 このマニュアルは OECD QSAR
2.Picasa3 の実行 デスクトップの をダブルククリック 一番最初の起動の時だけ下記画 面が立ち上がります マイドキュメント マイピクチャ デスクトップのみスキャン にチェックを入れ続行 これはパソコン内部の全画像を検索して Picasa で使用する基本データを作成するものですが 完全スキャン
 Picasa3 を使った写真の整理 写真の整理はエクスプローラーを開いてフォルダの作成から写真の移動やコピーを行うことが望ましいのですが エクスプローラーの操作を覚えられずに写真の整理が進んでいない人のために画像管理ソフト Picasa3 を使った整理方法を説明します なお このソフトは画像に関する多くの機能を持ったものですが 画像整理だけの利用では容量も大きいですからエクスプローラーの使い方をマスターしている人はこのソフトを使う必要はありません
Picasa3 を使った写真の整理 写真の整理はエクスプローラーを開いてフォルダの作成から写真の移動やコピーを行うことが望ましいのですが エクスプローラーの操作を覚えられずに写真の整理が進んでいない人のために画像管理ソフト Picasa3 を使った整理方法を説明します なお このソフトは画像に関する多くの機能を持ったものですが 画像整理だけの利用では容量も大きいですからエクスプローラーの使い方をマスターしている人はこのソフトを使う必要はありません
スライド 1
 Hos-CanR 2.5 3.0 クライアント サーバー (CS) 版データ移行マニュアル Hos-CanR クライアント サーバー (CS) 版 Ver. 2.5 Ver. 3.0 データ移行マニュアル システム管理者用 Ver. 2 バージョン改訂日付改訂内容 Ver. 1 2010/3/15 初版 Ver. 2 2010/12/10 作業対象コンピュータのアイコン追加 Hos-CanR 2.5
Hos-CanR 2.5 3.0 クライアント サーバー (CS) 版データ移行マニュアル Hos-CanR クライアント サーバー (CS) 版 Ver. 2.5 Ver. 3.0 データ移行マニュアル システム管理者用 Ver. 2 バージョン改訂日付改訂内容 Ver. 1 2010/3/15 初版 Ver. 2 2010/12/10 作業対象コンピュータのアイコン追加 Hos-CanR 2.5
 NCBI BLAST チュートリアル このチュートリアルでは NCBI サイトでの BLAST による相同性検索の方法について 一般的な使い方を紹介しています はじめに. BLAST とは まずはじめに 簡単に BLAST について紹介することにしましょう BLAST は Basic Local Alignment Search Tool の略で ペアワイズの局所的なアライメント / 相同性検索 (
NCBI BLAST チュートリアル このチュートリアルでは NCBI サイトでの BLAST による相同性検索の方法について 一般的な使い方を紹介しています はじめに. BLAST とは まずはじめに 簡単に BLAST について紹介することにしましょう BLAST は Basic Local Alignment Search Tool の略で ペアワイズの局所的なアライメント / 相同性検索 (
untitled
 6 野生株と変異株に対するプライマー設計 PrimerExplorer Ver.4 ではターゲット配列に変異を導入してプライマーを設計することが可能です しかしながら変異が多すぎると設計条件が厳しくなるため プライマーが生成されないか バラエティーに欠けることがあります その場合 変異の導入箇所数を減らす 或は変異を導入せずにマニュアルで設計し ターゲット配列の変異の位置がプライマー領域のどこに相当するかを確認しながら
6 野生株と変異株に対するプライマー設計 PrimerExplorer Ver.4 ではターゲット配列に変異を導入してプライマーを設計することが可能です しかしながら変異が多すぎると設計条件が厳しくなるため プライマーが生成されないか バラエティーに欠けることがあります その場合 変異の導入箇所数を減らす 或は変異を導入せずにマニュアルで設計し ターゲット配列の変異の位置がプライマー領域のどこに相当するかを確認しながら
機能ゲノム学(第6回)
") RNA-Seqデータ解析における正規化法の選択 :RPKM 値でサンプル間比較は危険?! 東京大学大学院農学生命科学研究科アグリバイオインフォマティクス教育研究ユニット門田幸二 ( かどたこうじ ) http://www.iu.a.u-tokyo.ac.jp/~kadota/ kadota@iu.a.u-tokyo.ac.jp 1 よりよい正規化法とは? その正規化法によって得られたデータを用いて発現変動の度合いでランキングしたときに
RNA-Seqデータ解析における正規化法の選択 :RPKM 値でサンプル間比較は危険?! 東京大学大学院農学生命科学研究科アグリバイオインフォマティクス教育研究ユニット門田幸二 ( かどたこうじ ) http://www.iu.a.u-tokyo.ac.jp/~kadota/ kadota@iu.a.u-tokyo.ac.jp 1 よりよい正規化法とは? その正規化法によって得られたデータを用いて発現変動の度合いでランキングしたときに
Introduction Purpose This training course demonstrates the use of the High-performance Embedded Workshop (HEW), a key tool for developing software for
, a key tool for developing software for") Introduction Purpose This training course demonstrates the use of the High-performance Embedded Workshop (HEW), a key tool for developing software for embedded systems that use microcontrollers (MCUs)
Introduction Purpose This training course demonstrates the use of the High-performance Embedded Workshop (HEW), a key tool for developing software for embedded systems that use microcontrollers (MCUs)
141025mishima
 NGS (RNAseq) »NGS Now Generation Sequencer»NGS»» 4 NGS(Next Generation Sequencer) Now Generation Sequencer http://www.youtube.com/watch?v=womkfikwlxm http://www.youtube.com/watch?v=mxkya9xcvbq http://www.youtube.com/watch?v=nhcj8ptycfc
NGS (RNAseq) »NGS Now Generation Sequencer»NGS»» 4 NGS(Next Generation Sequencer) Now Generation Sequencer http://www.youtube.com/watch?v=womkfikwlxm http://www.youtube.com/watch?v=mxkya9xcvbq http://www.youtube.com/watch?v=nhcj8ptycfc
ver
 MacVector 基本操作 ( マルチプルアラインメント ) MacVector でマルチプルアラインメントをするために必要な操作の一部を紹介いたしす マルチプルアラインメントに関しての主要な操作は下記のものです A. 配列情報のファイルの入手 B. 配列情報ファイルの作成 ( 新規 ) C. マルチプルアラインメント D. 系統樹の作成 まず MacVector を起動してください ( 注意!MacVector
MacVector 基本操作 ( マルチプルアラインメント ) MacVector でマルチプルアラインメントをするために必要な操作の一部を紹介いたしす マルチプルアラインメントに関しての主要な操作は下記のものです A. 配列情報のファイルの入手 B. 配列情報ファイルの作成 ( 新規 ) C. マルチプルアラインメント D. 系統樹の作成 まず MacVector を起動してください ( 注意!MacVector
配付資料 自習用テキスト 解析サンプル配布ページ 2
 分子系統樹推定法 理論と応用 2009年11月6日 筑波大 院 生命環境 田辺晶史 配付資料 自習用テキスト 解析サンプル配布ページ http://www.fifthdimension.jp/documents/molphytextbook/ 2 参考書籍 分子系統学 3 参考書籍 統計的モデル選択とベイジアンMCMC 4 祖先的な形質 問題 OTU左の の色は表現型形質の状態を表している 赤と青
分子系統樹推定法 理論と応用 2009年11月6日 筑波大 院 生命環境 田辺晶史 配付資料 自習用テキスト 解析サンプル配布ページ http://www.fifthdimension.jp/documents/molphytextbook/ 2 参考書籍 分子系統学 3 参考書籍 統計的モデル選択とベイジアンMCMC 4 祖先的な形質 問題 OTU左の の色は表現型形質の状態を表している 赤と青