|
|
|
- みりあ やたけ
- 7 years ago
- Views:
Transcription
1 ( )
2
3
4 MPFR/GMP BNCpack (cf., Vol, 21, pp , 2011) Runge-Kutta (cf. arxiv preprint arxiv: , Vol.19, No.3, pp , 2009) Strassen (cf. JSIAM Letters, Vol.6, pp.81-84, 2014)
5
6 + - ケチ表現 (1bit) 小数点 Precision _mpfr_prec 符号部 (1bit) 指数部仮数部 in bits + 8bits 1 23 bits ( + 1bit) _mpfr_sign Sign - 単精度 (single) 32 bits _mpfr_exp Exponent Practical multiple + Pointer to 11 bitsieee754(r) 1 standard 52 bits ( + 1bit) *_mpfr_d World record of π Mantissa - precision mantissa 倍精度 (double) 64 bits 1,030,700,000,000 in hex bits =4,122,800,000, bits ~65536 single double extented quadruple octuple double IEEE (CPU, GPU) Length of mantissa in bits (mpfr t ) IEEE754(r) standard 実用的な多倍長精度 ~65536 π の世界記録 ( 高橋, 2009) dec. digits = bits single double extented double quadruple octuple 仮数部の bit 数 1
7 IEEE754 ( ) vs. DD(4 ) QD(8 ) exflib MPFR/GMP, mpf(gmp), ARPREC(?) IEEE745 vs. DD QD, ARPREC (by Baily) exflib, MPFR/GMP, mpf(gmp) (GMP ) cf. MPACK (by ( )) = LAPACK / (DD QD + MPFR)
8 Year Category Integrated Computer Algebra Software Maple Mathematica Maxima Linear Computation LINPACK EISPACK LAPACK BLAS ScaLAPACK XBLAS ATLAS exflib CLN MPFR Over-quadruple Precision Floating-point Arithmetic Library GMP ARPREC Double-double QD/DD MP Floating-point Format and Arithmetic (Single and Double Precision) Binary Floating-point Arithmetic in Microsoft BASIC Hexadecimal Floating-point Arithmetic (IBM format) IEEE754 Binary Floating-point Arithmetic
9 MPFR/GMP GMP (GNU MP) (mpn) (mpz) (mpq) (mpf) Version 6.0.0a MPFR (GNU MPFR) GMP mpn IEEE754 Version mpz (integer) GNU MP(GMP) mpq (rational) mpf (real) GNU MPFR mpn(mp Natural number arithmetic) kernel generic (pure C codes) x86 x86_64 sparc arm Assembler codes
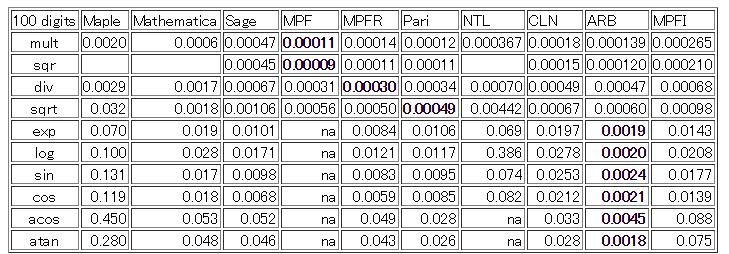
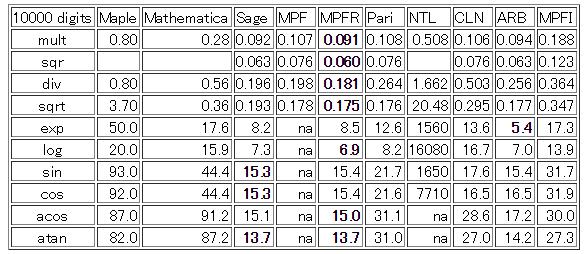
10 ( ) MPFR/GMP
11 MPFR/GMP GMP mpn basecase Karatsuba Toom-Cook FFT CPU SIMD milli-sec/mul 1.E+01 1.E #bits E-01 1.E-02 1.E-03 1.E-04 1.E-05 Mul of MPFR N^1.5 N^1.6 PentiumD Pentium4 Pentium4 Add milli-sec/div 1.E+02 1.E+01 1.E #bits E-01 N^1.4 1.E-02 N^1.5 PentiumD 1.E-03 Pentium4 1.E-04 Div of MPFR O(N 1.4 ) O(N 1.6 )
12 BNCpack BNCpack Basic Numerical Computation PACKage 2001 GMP mpf t MPFR/GMP mpfr t C (C++ ) MPI ( ) ( ( ) ) 3. ( ) 4. ( QR ) 5. (Newton Newton, Regula-Falsi ) 6. (DKA ) 7. ( Romberg ) 8. ( ) 9. ( )
13 A = [a ij ], B = [b ij ] C := AB a ij = 5 (i + j 1), b ij = 3 (n i + 1). l c ij := a ik b kj A = [A ik ], B = [B kj ] (1 i M, 1 k L, 1 j N) A, B C = [C ij ] L C ij := A ik B kj k=1 k=1
14 ( ): 128bits vs. Intel Math Kernel( ) H/W Intel Core i (3.6 GHz), 64 GB RAM S/W Scientific Linux 6.3 x86 64, Intel C Compiler Ver , BNCpack ver. 0.8, MPFR 3.1.2, GMP m n Simple Block(16) Block(32) Block(64) Double
15 : 1024bits m n Simple Block(16) Block(32) Block(64) bits alloc, free )
16
17 CPU 12 mpfrbench:100 decimal digits 25 mpfrbench: decimal digits Speedup Ratio digits ION digits PentiumIII 100digits PentiumIV 100digits PentiumD 100digits Corei7 100digits Athlon64X2 100digits Core2Quad 100digits CeleronE digits PhenomII Speedup Ratio digits Corei digits ION digits PentiumIII 10000digits PentiumIV 10000digits PentiumD 10000digits Corei digits Athlon64X digits Core2Quad 10000digits CeleronE digits PhenomII 10000digits Corei CPU(1 core) MPI MPIBNCpack OpenMP( CPU) + BNCpack, CUDA(NVIDIA GPU) CUMP
18 MPIBNCpack MPFR/GMP or GMP (MPIGMP) _mpfr_size _mpfr_prec _mpfr_exp *_mpfr_d 符号部 指数部 仮数部 mpfr_t data type PE0 0 1 N (_mpfr_prec) パッキング処理 void * _mpfr_size _mpfr_prec _mpfr_exp 0 1 送受信 Tutorial
19 OpenMP( CPU) GPU CUMP ( GMP mpf t mpn generic C basecase ) (H/W) Intel Xeon E v2(2.10ghz) 2 = 12 cores, NVIDIA Tesla K20 (S/W) CentOS 6.5 x86 64, gcc-4.4.7, Intel C compiler , GMP 6.0.0a, MPFR 3.1.2, CUDA 6.5 CPU:12 threads, GPU: 8 8 = 64 threads
20 12 cores CPU vs. Tesla K20 GPU CPU / GPU CPU/GPU bits CPU GPU GPU
21
22 [ ] Ax = b A R n n, b, x i nr n E(Ã), E( b) E( x) [ ] à x = b à = A + E(Ã), b = b + E( b), x = x + E( x) κ(a) = A A 1 ( ) E( x) κ(a) x 1 E(Ã) E(Ã) + E( b) A b A Strassen LU
23 1967 Moler n f(x) = 0, f : R n R n (1) Newton (1) f(x) = Ax b Jacobi A (L >> S) [L ] r k := b Ax k (2) [S ] Solve Az k = r k for z k (3) [L ] x k+1 := x k + z k (4) r k x k
24 (2) (4) A [S], b [L] S L A [L] := A, A [S] := A [L], b [L] := b, b [S] := b [L] A [S] := P [S] L [S] U [S] Solve (P [S] L [S] U [S] )x [S] 0 = b [S] for x [S] 0 x [L] 0 := x [S] 0 For k = 0, 1, 2,... r [L] k r [S] k := b [L] Ax [L] k := r [L] k Solve (P [S] L [S] U [S] )z [S] k z [L] k x [L] k+1 := z [S] k := x[l] k Exit if r [L] k + z[l] k = r [S] k for z [S] k 2 n ε R A F x [L] 2 + ε A k
25 ρ F (n)κ(a)ε S 1 ψ F (n)κ(a)ε S < 1 α F < 1 (5) lim x x k k β F 1 α F x (6) β F /(1 α F ) (cf. A.Buttari, J.Dogarra, Julie Langou, Julien Langou, P.Luszczek, and J.Karzak, Mixed precision iterative refinement techniques for the solution of dense linear system, The International Journal of High Performance Computing Applications, Vol. 21, No. 4, pp , 2007.) S-L κ(a)ε S << 1 (7) ε S, ε L S,L
26 Computational Time L digits Direct Method LU Decomposition Forward & Backward Substitions S digits Direct Method LU F&B Subst S-L Iterative Refinement LU Matrix-Vector Multiplication F&B Subst Matrix-Vector Multiplication F&B Subst Iteration 3 1. κ(a) < 10 7 = (S = 7)- (L = 15): SP-DP ( ) 2. κ(a) < = (S = 15)-4 or (L > 30): DP-MP 3. κ(a) > = 4 or - 8 or : MP-MP
27 DP-MP H/W AMD Athlon64X , 4GB S/W CentOS 5.2 x86 64, GCC 4.1.2, MPFR 2.3.2/GMP BNCpack 0.7b, LAPACK 3.2, ATLAS ^ Z DW DW W DW dd ^ Z / Z DW DW W DW dd dd dd dd dd ldde ldde lddd ldddd d d E >W< d>^ E >W< d>^ E >W< d>^ >ldd >lddd >lddd
28 (1/6): n n (ODE) { dy dt = f(t, y) Rn y(t 0 ) = y 0 :[t 0, α] (8) m IRK c 1,..., c m, a 11,..., a mm, b 1,..., b m m 2m Gauss c 1 a 11 a 1m... c m a m1 a mm b 1 b m = c A b T (9)
29 (2/6): m Runge-Kutta t 0, t 1 := t 0 + h 0,..., t k+1 := t k + h k... t k t k+1 y k+1 y(t k+1 ) 2 (A) Y = [Y 1... Y m ] T R mn Y 1 = y k + h m k j=1 a 1jf(t k + c j h k, Y j ). Y m = y k + h m k j=1 a mjf(t k + c j h k, Y j ) F(Y) = 0 (10) (B) Y y k+1 y k+1 := y k + h k m j=1 b j f(t k + c j h k, Y j )
30 (3/6):SPARK3 (1/2) W (Hairer & Wanner) (Gauss ) 1/2 ζ 1. X = W T ζ BAW = ζm 2 ζ m 2 0 ζ m 1 ζ m 1 0 W = [w ij ] = [ P j 1 (c i )] (i, j = 1, 2,..., m) ( P s (x) : s-th shifted Legendre polynomial) ( ζ i = 2 1 4i 2 1) (i = 1, 2,..., m 1) B = diag(b), I m = W T BW = diag(1 1 1)
31 (4/6):SPARK3 (2/4) Newton (W T B I n )(I m I n h k A J)(W I n ) E 1 F 1 G 1 E 2 F 2 = I m I n h k X J = G m 2 E m 1 F m 1 G m 1 E m E 1 = I n 1 2 h kj, E 2 = = E s = I n F i = h k ζ i J, G i = h k ζ i J (i = 1, 2,..., m 1)
32 (5/6):SPARK3 + Newton + 1. Y 1 := [y k y k... y k ] T R mn 2. For l = 0, 1, 2,... Newton Y l := [Y (l) 1 Y (l) 2... Y m (l) ] T Y (l) i = y 0 + h mj=1 k a ij f(t k + c i h k, Y (l 1) i ) C := I m I n h k X J, d := (W T B I n )( F(Y l )) (S) Solve Cx 0 = d for x 0 For ν = 0, 1, 2,... r ν := d Cx ν (S) r ν := r ν / r ν (S) Solve Cz = r ν for z x ν+1 := x ν + r ν z Check convergence x νstop Y l+1 := Y l + (W I n )x νstop Check convergence Y lstop 3. Y := Y lstop = [Y 1 Y 2... Y m ] T 4. y k+1 := y k + h k m j=1 b jf(t k + c j h k, Y j )
33 (6/6) Runge-Kutta (Gauss ) 128 ODE (10 50 ) Intel Core i7 920, 8GB RAM, CentOS 5.6 x86 64, gcc MPFR 3.1.1/GMP Comp.Time (s) m Relative Error 1.E+14 1.E+10 1.E+06 1.E+02 1.E-02 1.E-06 1.E-10 1.E-14 1.E-18 1.E-22 1.E-26 1.E-30 1.E-34 1.E-38 Iter.Ref-DM W-Trans. W-Iter.Ref-MM W-Iter.Ref-DM Max.Rel.Err SPARK3 + DP-MP
34 Strassen LU LU (A = LU) 1. A A 11 R K K A 12 R K (n K), A 21 R (n K) K, and A 22 R (n K) (n K) 2. A 11 L 11 U 11 (= A 11 ) LU, A 12 U 12 A 21 L A (1) 22 := A 22 L 21 U A := A (1) 22 n K 0
35 Winograd s variant (1/2) C := AB = [c ij ] C R m n, A = [a ij ] R m l B = [b ij ] R l n [ ] [ ] A11 A A = 12 B11 B, B = 12. (11) A 21 A 22 B 21 B 22 S 1 := A 21 + A 22, S 2 := S 1 A 11, S 3 := A 11 A 21, S 4 := A 12 S 2, S 5 := B 12 B 11, S 6 := B 22 S 5, S 7 := B 22 B 12, S 8 := S 6 B 21, (12) M 1 := S 2 S 6, M 2 := A 11 B 11, M 3 := A 12 B 21, M 4 := S 3 S 7, M 5 := S 1 S 5, M 6 := S 4 B 22, M 7 := A 22 S 8, (13)
36 Winograd s variant (2/2) T 1 := M 1 + M 2, T 2 := T 1 + M 4. (14) Through (12) (13) (14), we can obtain C as follows: [ ] M2 + M C := 3 T 1 + M 5 + M 6 T 2 M 7 T 2 + M 5 Winograd s variant involves the following arithmetical operations: Mul(m, l, n) = 7Mul(m/2, l/2, n/2), Addsub(m, l, n) = 4Addsub(m/2, l/2) + 4Addsub(l/2, n/2) + 7Addsub(m/2, n/2).
37 Table: Computation time: Strassen s and Winograd s algorithms (128 bits) m n min(simple, Block) Strassen Winograd
38 Table: Computation time: Strassen s and Winograd s algorithms (1024 bits) n n min(simple, Block) Strassen Winograd
39 Lotkin a ij = { 1 (i = 1) 1/(i + j 1) (i 2) A 1 A (n = 1024) x = [ n 1] T α K := 32α
40 Lotkin (n = 1024 ) 8650bits (458bits ) Comp.Time (s) Winograd 8192bits vs. 8650bits: Lotkin matrix, Normal LU: s min: s Normal LU: 3.3E log10(max.relative Error) α Winograd(8192 bits) Comp.Time Winograd(8650 bits) Comp.Time Winograd(8192 bits) Max.Rel.Err Winograd(8650 bits) Max.Rel.Err 32 %
41
42 1CPU
43 1. GPU 2. 3.
1 (bit ) ( ) PC WS CPU IEEE754 standard ( 24bit) ( 53bit)
 ( ) PC WS CPU IEEE754 standard ( 24bit) ( 53bit)") GNU MP BNCpack [email protected] 2002 9 20 ( ) Linux Conference 2002 1 1 (bit ) ( ) PC WS CPU IEEE754 standard ( 24bit) ( 53bit) 10 2 2 3 4 5768:9:; = %? @BADCEGFH-I:JLKNMNOQP R )TSVU!" # %$ & " #
GNU MP BNCpack [email protected] 2002 9 20 ( ) Linux Conference 2002 1 1 (bit ) ( ) PC WS CPU IEEE754 standard ( 24bit) ( 53bit) 10 2 2 3 4 5768:9:; = %? @BADCEGFH-I:JLKNMNOQP R )TSVU!" # %$ & " #
211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS /1/18 a a 1 a 2 a 3 a a GPU Graphics Processing Unit GPU CPU GPU GPGPU G
 211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS211 211/1/18 GPU 4 8 BLAS 4 8 BLAS Basic Linear Algebra Subprograms GPU Graphics Processing Unit 4 8 double 2 4 double-double DD 4 4 8 quad-double
211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS211 211/1/18 GPU 4 8 BLAS 4 8 BLAS Basic Linear Algebra Subprograms GPU Graphics Processing Unit 4 8 double 2 4 double-double DD 4 4 8 quad-double
untitled
 A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
倍々精度RgemmのnVidia C2050上への実装と応用
 .. [email protected] http://accc.riken.jp/maho/,,, 2011/2/16 1 - : GPU : SDPA-DD 10 1 - Rgemm : 4 (32 ) nvidia C2050, GPU CPU 150, 24GFlops 25 20 GFLOPS 15 10 QuadAdd Cray, QuadMul Sloppy Kernel QuadAdd Cray,
.. [email protected] http://accc.riken.jp/maho/,,, 2011/2/16 1 - : GPU : SDPA-DD 10 1 - Rgemm : 4 (32 ) nvidia C2050, GPU CPU 150, 24GFlops 25 20 GFLOPS 15 10 QuadAdd Cray, QuadMul Sloppy Kernel QuadAdd Cray,
Krylov (b) x k+1 := x k + α k p k (c) r k+1 := r k α k Ap k ( := b Ax k+1 ) (d) β k := r k r k 2 2 (e) : r k 2 / r 0 2 < ε R (f) p k+1 :=
 x k+1 := x k + α k p k (c) r k+1 := r k α k Ap k ( := b Ax k+1 ) (d) β k := r k r k 2 2 (e) : r k 2 / r 0 2 < ε R (f) p k+1 :=") 127 10 Krylov Krylov (Conjugate-Gradient (CG ), Krylov ) MPIBNCpack 10.1 CG (Conjugate-Gradient CG ) A R n n a 11 a 12 a 1n a 21 a 22 a 2n A T = =... a n1 a n2 a nn n a 11 a 21 a n1 a 12 a 22 a n2 = A...
127 10 Krylov Krylov (Conjugate-Gradient (CG ), Krylov ) MPIBNCpack 10.1 CG (Conjugate-Gradient CG ) A R n n a 11 a 12 a 1n a 21 a 22 a 2n A T = =... a n1 a n2 a nn n a 11 a 21 a n1 a 12 a 22 a n2 = A...
86 6 r (6) y y d y = y 3 (64) y r y r y r ϕ(x, y, y,, y r ) n dy = f(x, y) (6) 6 Lipschitz 6 dy = y x c R y(x) y(x) = c exp(x) x x = x y(x ) = y (init
 y y d y = y 3 (64) y r y r y r ϕ(x, y, y,, y r ) n dy = f(x, y) (6) 6 Lipschitz 6 dy = y x c R y(x) y(x) = c exp(x) x x = x y(x ) = y (init") 8 6 ( ) ( ) 6 ( ϕ x, y, dy ), d y,, dr y r = (x R, y R n ) (6) n r y(x) (explicit) d r ( y r = ϕ x, y, dy ), d y,, dr y r y y y r (6) dy = f (x, y) (63) = y dy/ d r y/ r 86 6 r (6) y y d y = y 3 (64) y
8 6 ( ) ( ) 6 ( ϕ x, y, dy ), d y,, dr y r = (x R, y R n ) (6) n r y(x) (explicit) d r ( y r = ϕ x, y, dy ), d y,, dr y r y y y r (6) dy = f (x, y) (63) = y dy/ d r y/ r 86 6 r (6) y y d y = y 3 (64) y
Agenda GRAPE-MPの紹介と性能評価 GRAPE-MPの概要 OpenCLによる四倍精度演算 (preliminary) 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops
 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops") Agenda GRAPE-MPの紹介と性能評価 GRAPE-MPの概要 OpenCLによる四倍精度演算 (preliminary) 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops ボードの概要 Control processor (FPGA by Altera) GRAPE-MP chip[nextreme
Agenda GRAPE-MPの紹介と性能評価 GRAPE-MPの概要 OpenCLによる四倍精度演算 (preliminary) 4倍精度演算用SIM 加速ボード 6 processor elem with 128 bit logic Peak: 1.2Gflops ボードの概要 Control processor (FPGA by Altera) GRAPE-MP chip[nextreme
Second-semi.PDF
 PC 2000 2 18 2 HPC Agenda PC Linux OS UNIX OS Linux Linux OS HPC 1 1CPU CPU Beowulf PC (PC) PC CPU(Pentium ) Beowulf: NASA Tomas Sterling Donald Becker 2 (PC ) Beowulf PC!! Linux Cluster (1) Level 1:
PC 2000 2 18 2 HPC Agenda PC Linux OS UNIX OS Linux Linux OS HPC 1 1CPU CPU Beowulf PC (PC) PC CPU(Pentium ) Beowulf: NASA Tomas Sterling Donald Becker 2 (PC ) Beowulf PC!! Linux Cluster (1) Level 1:
23 Fig. 2: hwmodulev2 3. Reconfigurable HPC 3.1 hw/sw hw/sw hw/sw FPGA PC FPGA PC FPGA HPC FPGA FPGA hw/sw hw/sw hw- Module FPGA hwmodule hw/sw FPGA h
 23 FPGA CUDA Performance Comparison of FPGA Array with CUDA on Poisson Equation ([email protected]), ([email protected]), ([email protected]), ([email protected]),
23 FPGA CUDA Performance Comparison of FPGA Array with CUDA on Poisson Equation ([email protected]), ([email protected]), ([email protected]), ([email protected]),
FFTSS Library Version 3.0 User's Guide
 : 19 10 31 FFTSS 3.0 Copyright (C) 2002-2007 The Scalable Software Infrastructure Project, (CREST),,. http://www.ssisc.org/ Contents 1 4 2 (DFT) 4 3 4 3.1 UNIX............................................
: 19 10 31 FFTSS 3.0 Copyright (C) 2002-2007 The Scalable Software Infrastructure Project, (CREST),,. http://www.ssisc.org/ Contents 1 4 2 (DFT) 4 3 4 3.1 UNIX............................................
インテル(R) Visual Fortran Composer XE
 Visual Fortran Composer XE") Visual Fortran Composer XE 1. 2. 3. 4. 5. Visual Studio 6. Visual Studio 7. 8. Compaq Visual Fortran 9. Visual Studio 10. 2 https://registrationcenter.intel.com/regcenter/ w_fcompxe_all_jp_2013_sp1.1.139.exe
Visual Fortran Composer XE 1. 2. 3. 4. 5. Visual Studio 6. Visual Studio 7. 8. Compaq Visual Fortran 9. Visual Studio 10. 2 https://registrationcenter.intel.com/regcenter/ w_fcompxe_all_jp_2013_sp1.1.139.exe
A11 (1993,1994) 29 A12 (1994) 29 A13 Trefethen and Bau Numerical Linear Algebra (1997) 29 A14 (1999) 30 A15 (2003) 30 A16 (2004) 30 A17 (2007) 30 A18
 29 A12 (1994) 29 A13 Trefethen and Bau Numerical Linear Algebra (1997) 29 A14 (1999) 30 A15 (2003) 30 A16 (2004) 30 A17 (2007) 30 A18") 2013 8 29y, 2016 10 29 1 2 2 Jordan 3 21 3 3 Jordan (1) 3 31 Jordan 4 32 Jordan 4 33 Jordan 6 34 Jordan 8 35 9 4 Jordan (2) 10 41 x 11 42 x 12 43 16 44 19 441 19 442 20 443 25 45 25 5 Jordan 26 A 26 A1
2013 8 29y, 2016 10 29 1 2 2 Jordan 3 21 3 3 Jordan (1) 3 31 Jordan 4 32 Jordan 4 33 Jordan 6 34 Jordan 8 35 9 4 Jordan (2) 10 41 x 11 42 x 12 43 16 44 19 441 19 442 20 443 25 45 25 5 Jordan 26 A 26 A1
rank ”«‘‚“™z‡Ì GPU ‡É‡æ‡éŁÀŠñ›»
 rank GPU ERATO 2011 11 1 1 / 26 GPU rank/select wavelet tree balanced parenthesis GPU rank 2 / 26 GPU rank/select wavelet tree balanced parenthesis GPU rank 2 / 26 GPU rank/select wavelet tree balanced
rank GPU ERATO 2011 11 1 1 / 26 GPU rank/select wavelet tree balanced parenthesis GPU rank 2 / 26 GPU rank/select wavelet tree balanced parenthesis GPU rank 2 / 26 GPU rank/select wavelet tree balanced
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司
![4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司](/thumbs/97/131936032.jpg "4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司") 4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
07-二村幸孝・出口大輔.indd
 GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
44 6 MPI 4 : #LIB=-lmpich -lm 5 : LIB=-lmpi -lm 7 : mpi1: mpi1.c 8 : $(CC) -o mpi1 mpi1.c $(LIB) 9 : 10 : clean: 11 : -$(DEL) mpi1 make mpi1 1 % mpiru
 -o mpi1 mpi1.c $(LIB) 9 : 10 : clean: 11 : -$(DEL) mpi1 make mpi1 1 % mpiru") 43 6 MPI MPI(Message Passing Interface) MPI 1CPU/1 PC Cluster MPICH[5] 6.1 MPI MPI MPI 1 : #include 2 : #include 3 : #include 4 : 5 : #include "mpi.h" 7 : int main(int argc,
43 6 MPI MPI(Message Passing Interface) MPI 1CPU/1 PC Cluster MPICH[5] 6.1 MPI MPI MPI 1 : #include 2 : #include 3 : #include 4 : 5 : #include "mpi.h" 7 : int main(int argc,
Microsoft PowerPoint - sales2.ppt
 最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
最新耐震構造解析 ( 第 3 版 ) サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. このサンプルページの内容は, 第 3 版 1 刷発行時のものです.
 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. このサンプルページの内容は, 第 3 版 1 刷発行時のものです.") 最新耐震構造解析 ( 第 3 版 ) サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. http://www.morikita.co.jp/books/mid/052093 このサンプルページの内容は, 第 3 版 1 刷発行時のものです. i 3 10 3 2000 2007 26 8 2 SI SI 20 1996 2000 SI 15 3 ii 1 56 6
最新耐震構造解析 ( 第 3 版 ) サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. http://www.morikita.co.jp/books/mid/052093 このサンプルページの内容は, 第 3 版 1 刷発行時のものです. i 3 10 3 2000 2007 26 8 2 SI SI 20 1996 2000 SI 15 3 ii 1 56 6
main.dvi
 y () 5 C Fortran () Fortran 32bit 64bit 2 0 1 2 1 1bit bit 3 0 0 2 1 3 0 1 2 1 bit bit byte 8bit 1byte 3 0 10010011 2 1 3 0 01001011 2 1 byte Fortran A A 8byte double presicion y ( REAL*8) A 64bit 4byte
y () 5 C Fortran () Fortran 32bit 64bit 2 0 1 2 1 1bit bit 3 0 0 2 1 3 0 1 2 1 bit bit byte 8bit 1byte 3 0 10010011 2 1 3 0 01001011 2 1 byte Fortran A A 8byte double presicion y ( REAL*8) A 64bit 4byte
(Basic Theory of Information Processing) 1
 1") (Basic Theory of Information Processing) 1 10 (p.178) Java a[0] = 1; 1 a[4] = 7; i = 2; j = 8; a[i] = j; b[0][0] = 1; 2 b[2][3] = 10; b[i][j] = a[2] * 3; x = a[2]; a[2] = b[i][3] * x; 2 public class Array0
(Basic Theory of Information Processing) 1 10 (p.178) Java a[0] = 1; 1 a[4] = 7; i = 2; j = 8; a[i] = j; b[0][0] = 1; 2 b[2][3] = 10; b[i][j] = a[2] * 3; x = a[2]; a[2] = b[i][3] * x; 2 public class Array0
(1) 1 y = 2 = = b (2) 2 y = 2 = 2 = 2 + h B h h h< h 2 h
 1 y = 2 = = b (2) 2 y = 2 = 2 = 2 + h B h h h< h 2 h") 6 6.1 6.1.1 O y A y y = f() y = f() b f(b) B y f(b) f() = b f(b) f() f() = = b A f() b AB O b 6.1 2 y = 2 = 1 = 1 + h (1 + h) 2 1 2 (1 + h) 1 2h + h2 = h h(2 + h) = h = 2 + h y (1 + h) 2 1 2 O y = 2 1
6 6.1 6.1.1 O y A y y = f() y = f() b f(b) B y f(b) f() = b f(b) f() f() = = b A f() b AB O b 6.1 2 y = 2 = 1 = 1 + h (1 + h) 2 1 2 (1 + h) 1 2h + h2 = h h(2 + h) = h = 2 + h y (1 + h) 2 1 2 O y = 2 1
2ndD3.eps
 CUDA GPGPU 2012 UDX 12/5/24 p. 1 FDTD GPU FDTD GPU FDTD FDTD FDTD PGI Acceralator CUDA OpenMP Fermi GPU (Tesla C2075/C2070, GTX 580) GT200 GPU (Tesla C1060, GTX 285) PC GPGPU 2012 UDX 12/5/24 p. 2 FDTD
CUDA GPGPU 2012 UDX 12/5/24 p. 1 FDTD GPU FDTD GPU FDTD FDTD FDTD PGI Acceralator CUDA OpenMP Fermi GPU (Tesla C2075/C2070, GTX 580) GT200 GPU (Tesla C1060, GTX 285) PC GPGPU 2012 UDX 12/5/24 p. 2 FDTD
 2005 2006.2.22-1 - 1 Fig. 1 2005 2006.2.22-2 - Element-Free Galerkin Method (EFGM) Meshless Local Petrov-Galerkin Method (MLPGM) 2005 2006.2.22-3 - 2 MLS u h (x) 1 p T (x) = [1, x, y]. (1) φ(x) 0.5 φ(x)
2005 2006.2.22-1 - 1 Fig. 1 2005 2006.2.22-2 - Element-Free Galerkin Method (EFGM) Meshless Local Petrov-Galerkin Method (MLPGM) 2005 2006.2.22-3 - 2 MLS u h (x) 1 p T (x) = [1, x, y]. (1) φ(x) 0.5 φ(x)
d dt A B C = A B C d dt x = Ax, A 0 B 0 C 0 = mm 0 mm 0 mm AP = PΛ P AP = Λ P A = ΛP P d dt x = P Ax d dt (P x) = Λ(P x) d dt P x =
 = Λ(P x) d dt P x =") 3 MATLAB Runge-Kutta Butcher 3. Taylor Taylor y(x 0 + h) = y(x 0 ) + h y (x 0 ) + h! y (x 0 ) + Taylor 3. Euler, Runge-Kutta Adams Implicit Euler, Implicit Runge-Kutta Gear y n+ y n (n+ ) y n+ y n+ y n+
3 MATLAB Runge-Kutta Butcher 3. Taylor Taylor y(x 0 + h) = y(x 0 ) + h y (x 0 ) + h! y (x 0 ) + Taylor 3. Euler, Runge-Kutta Adams Implicit Euler, Implicit Runge-Kutta Gear y n+ y n (n+ ) y n+ y n+ y n+
EGunGPU
 Super Computing in Accelerator simulations - Electron Gun simulation using GPGPU - K. Ohmi, KEK-Accel Accelerator Physics seminar 2009.11.19 Super computers in KEK HITACHI SR11000 POWER5 16 24GB 16 134GFlops,
Super Computing in Accelerator simulations - Electron Gun simulation using GPGPU - K. Ohmi, KEK-Accel Accelerator Physics seminar 2009.11.19 Super computers in KEK HITACHI SR11000 POWER5 16 24GB 16 134GFlops,
Part () () Γ Part ,
 () Γ Part ,") Contents a 6 6 6 6 6 6 6 7 7. 8.. 8.. 8.3. 8 Part. 9. 9.. 9.. 3. 3.. 3.. 3 4. 5 4.. 5 4.. 9 4.3. 3 Part. 6 5. () 6 5.. () 7 5.. 9 5.3. Γ 3 6. 3 6.. 3 6.. 3 6.3. 33 Part 3. 34 7. 34 7.. 34 7.. 34 8. 35
Contents a 6 6 6 6 6 6 6 7 7. 8.. 8.. 8.3. 8 Part. 9. 9.. 9.. 3. 3.. 3.. 3 4. 5 4.. 5 4.. 9 4.3. 3 Part. 6 5. () 6 5.. () 7 5.. 9 5.3. Γ 3 6. 3 6.. 3 6.. 3 6.3. 33 Part 3. 34 7. 34 7.. 34 7.. 34 8. 35
64bit SSE2 SSE2 FPU Visual C++ 64bit Inline Assembler 4 FPU SSE2 4.1 FPU Control Word FPU 16bit R R R IC RC(2) PC(2) R R PM UM OM ZM DM IM R: reserved
 PC(2) R R PM UM OM ZM DM IM R: reserved") (Version: 2013/5/16) Intel CPU ([email protected]) 1 Intel CPU( AMD CPU) 64bit SIMD Inline Assemler Windows Visual C++ Linux gcc 2 FPU SSE2 Intel CPU double 8087 FPU (floating point number processing unit)
(Version: 2013/5/16) Intel CPU ([email protected]) 1 Intel CPU( AMD CPU) 64bit SIMD Inline Assemler Windows Visual C++ Linux gcc 2 FPU SSE2 Intel CPU double 8087 FPU (floating point number processing unit)
医系の統計入門第 2 版 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. このサンプルページの内容は, 第 2 版 1 刷発行時のものです.
 医系の統計入門第 2 版 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. http://www.morikita.co.jp/books/mid/009192 このサンプルページの内容は, 第 2 版 1 刷発行時のものです. i 2 t 1. 2. 3 2 3. 6 4. 7 5. n 2 ν 6. 2 7. 2003 ii 2 2013 10 iii 1987
医系の統計入門第 2 版 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. http://www.morikita.co.jp/books/mid/009192 このサンプルページの内容は, 第 2 版 1 刷発行時のものです. i 2 t 1. 2. 3 2 3. 6 4. 7 5. n 2 ν 6. 2 7. 2003 ii 2 2013 10 iii 1987
IPSJ SIG Technical Report Vol.2013-HPC-138 No /2/21 GPU CRS 1,a) 2,b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla
 2,b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla") GPU CRS 1,a),b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla K0 CUDA5.0 cusparse CRS SpMV 00 1.86 177 1. SpMV SpMV CRS Compressed Row Storage *1 SpMV GPU GPU NVIDIA Kepler
GPU CRS 1,a),b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla K0 CUDA5.0 cusparse CRS SpMV 00 1.86 177 1. SpMV SpMV CRS Compressed Row Storage *1 SpMV GPU GPU NVIDIA Kepler
1 = = = (set) (element) a A a A a A a A a A {2, 5, (0, 1)}, [ 1, 1] = {x; 1 x 1}. (proposition) A = {x; P (x)} P (x) x x a A a A Remark. (i) {2, 0, 0,
![1 = = = (set) (element) a A a A a A a A a A {2, 5, (0, 1)}, [ 1, 1] = {x; 1 x 1}. (proposition) A = {x; P (x)} P (x) x x a A a A Remark. (i) {2, 0, 0,](/thumbs/91/105754557.jpg "1 = = = (set) (element) a A a A a A a A a A {2, 5, (0, 1)}, [ 1, 1] = {x; 1 x 1}. (proposition) A = {x; P (x)} P (x) x x a A a A Remark. (i) {2, 0, 0,") 2005 4 1 1 2 2 6 3 8 4 11 5 14 6 18 7 20 8 22 9 24 10 26 11 27 http://matcmadison.edu/alehnen/weblogic/logset.htm 1 1 = = = (set) (element) a A a A a A a A a A {2, 5, (0, 1)}, [ 1, 1] = {x; 1 x 1}. (proposition)
2005 4 1 1 2 2 6 3 8 4 11 5 14 6 18 7 20 8 22 9 24 10 26 11 27 http://matcmadison.edu/alehnen/weblogic/logset.htm 1 1 = = = (set) (element) a A a A a A a A a A {2, 5, (0, 1)}, [ 1, 1] = {x; 1 x 1}. (proposition)
JFE.dvi
 ,, Department of Civil Engineering, Chuo University Kasuga 1-13-27, Bunkyo-ku, Tokyo 112 8551, JAPAN E-mail : [email protected] E-mail : [email protected] SATO KOGYO CO., LTD. 12-20, Nihonbashi-Honcho
,, Department of Civil Engineering, Chuo University Kasuga 1-13-27, Bunkyo-ku, Tokyo 112 8551, JAPAN E-mail : [email protected] E-mail : [email protected] SATO KOGYO CO., LTD. 12-20, Nihonbashi-Honcho
2012年度HPCサマーセミナー_多田野.pptx
 ! CCS HPC! I " [email protected]" " 1 " " " " " " " 2 3 " " Ax = b" " " 4 Ax = b" A = a 11 a 12... a 1n a 21 a 22... a 2n...... a n1 a n2... a nn, x = x 1 x 2. x n, b = b 1 b 2. b n " " 5 Gauss LU
! CCS HPC! I " [email protected]" " 1 " " " " " " " 2 3 " " Ax = b" " " 4 Ax = b" A = a 11 a 12... a 1n a 21 a 22... a 2n...... a n1 a n2... a nn, x = x 1 x 2. x n, b = b 1 b 2. b n " " 5 Gauss LU
1 Abstract 2 3 n a ax 2 + bx + c = 0 (a 0) (1) ( x + b ) 2 = b2 4ac 2a 4a 2 D = b 2 4ac > 0 (1) 2 D = 0 D < 0 x + b 2a = ± b2 4ac 2a b ± b 2
 (1) ( x + b ) 2 = b2 4ac 2a 4a 2 D = b 2 4ac > 0 (1) 2 D = 0 D < 0 x + b 2a = ± b2 4ac 2a b ± b 2") 1 Abstract n 1 1.1 a ax + bx + c = 0 (a 0) (1) ( x + b ) = b 4ac a 4a D = b 4ac > 0 (1) D = 0 D < 0 x + b a = ± b 4ac a b ± b 4ac a b a b ± 4ac b i a D (1) ax + bx + c D 0 () () (015 8 1 ) 1. D = b 4ac
1 Abstract n 1 1.1 a ax + bx + c = 0 (a 0) (1) ( x + b ) = b 4ac a 4a D = b 4ac > 0 (1) D = 0 D < 0 x + b a = ± b 4ac a b ± b 4ac a b a b ± 4ac b i a D (1) ax + bx + c D 0 () () (015 8 1 ) 1. D = b 4ac
1 8, : 8.1 1, 2 z = ax + by + c ax by + z c = a b +1 x y z c = 0, (0, 0, c), n = ( a, b, 1). f = n i=1 a ii x 2 i + i<j 2a ij x i x j = ( x, A x), f =
, n = ( a, b, 1). f = n i=1 a ii x 2 i + i<j 2a ij x i x j = ( x, A x), f =") 1 8, : 8.1 1, z = ax + by + c ax by + z c = a b +1 x y z c = 0, (0, 0, c), n = ( a, b, 1). f = a ii x i + i
1 8, : 8.1 1, z = ax + by + c ax by + z c = a b +1 x y z c = 0, (0, 0, c), n = ( a, b, 1). f = a ii x i + i
修士論文
 AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
AVX を用いた倍々精度疎行列ベクトル積の高速化 菱沼利彰 1 藤井昭宏 1 田中輝雄 1 長谷川秀彦 2 1 工学院大学 2 筑波大学 1 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算 - 4. 実験 - 倍々精度疎行列ベクトル積 - 5. まとめ 多倍長精度計算フォーラム 2 目次 1. 研究背景 目的 2. 実装, 実験環境 3. 実験 - 倍々精度ベクトル演算
微分積分 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. このサンプルページの内容は, 初版 1 刷発行時のものです.
 微分積分 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. ttp://www.morikita.co.jp/books/mid/00571 このサンプルページの内容は, 初版 1 刷発行時のものです. i ii 014 10 iii [note] 1 3 iv 4 5 3 6 4 x 0 sin x x 1 5 6 z = f(x, y) 1 y = f(x)
微分積分 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. ttp://www.morikita.co.jp/books/mid/00571 このサンプルページの内容は, 初版 1 刷発行時のものです. i ii 014 10 iii [note] 1 3 iv 4 5 3 6 4 x 0 sin x x 1 5 6 z = f(x, y) 1 y = f(x)
106 4 4.1 1 25.1 25.4 20.4 17.9 21.2 23.1 26.2 1 24 12 14 18 36 42 24 10 5 15 120 30 15 20 10 25 35 20 18 30 12 4.1 7 min. z = 602.5x 1 + 305.0x 2 + 2
 105 4 0 1? 1 LP 0 1 4.1 4.1.1 (intger programming problem) 1 0.5 x 1 = 447.7 448 / / 2 1.1.2 1. 2. 1000 3. 40 4. 20 106 4 4.1 1 25.1 25.4 20.4 17.9 21.2 23.1 26.2 1 24 12 14 18 36 42 24 10 5 15 120 30
105 4 0 1? 1 LP 0 1 4.1 4.1.1 (intger programming problem) 1 0.5 x 1 = 447.7 448 / / 2 1.1.2 1. 2. 1000 3. 40 4. 20 106 4 4.1 1 25.1 25.4 20.4 17.9 21.2 23.1 26.2 1 24 12 14 18 36 42 24 10 5 15 120 30
p12.dvi
 301 12 (2) : 1 (1) dx dt = f(x,t) ( (t 0,t 1,...,t N ) ) h k = t k+1 t k. h k k h. x(t k ) x k. : 2 (2) :1. step. 1 : explicit( ) : ξ k+1 = ξ k +h k Ψ(t k,ξ k,h k ) implicit( ) : ξ k+1 = ξ k +h k Ψ(t k,t
301 12 (2) : 1 (1) dx dt = f(x,t) ( (t 0,t 1,...,t N ) ) h k = t k+1 t k. h k k h. x(t k ) x k. : 2 (2) :1. step. 1 : explicit( ) : ξ k+1 = ξ k +h k Ψ(t k,ξ k,h k ) implicit( ) : ξ k+1 = ξ k +h k Ψ(t k,t
GPU GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1
 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1") GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
 2 2 MATHEMATICS.PDF 200-2-0 3 2 (p n ), ( ) 7 3 4 6 5 20 6 GL 2 (Z) SL 2 (Z) 27 7 29 8 SL 2 (Z) 35 9 2 40 0 2 46 48 2 2 5 3 2 2 58 4 2 6 5 2 65 6 2 67 7 2 69 2 , a 0 + a + a 2 +... b b 2 b 3 () + b n a
2 2 MATHEMATICS.PDF 200-2-0 3 2 (p n ), ( ) 7 3 4 6 5 20 6 GL 2 (Z) SL 2 (Z) 27 7 29 8 SL 2 (Z) 35 9 2 40 0 2 46 48 2 2 5 3 2 2 58 4 2 6 5 2 65 6 2 67 7 2 69 2 , a 0 + a + a 2 +... b b 2 b 3 () + b n a
ストリーミング SIMD 拡張命令2 (SSE2) を使用した SAXPY/DAXPY
 を使用した SAXPY/DAXPY") SIMD 2(SSE2) SAXPY/DAXPY 2.0 2000 7 : 248600J-001 01/12/06 1 305-8603 115 Fax: 0120-47-8832 * Copyright Intel Corporation 1999, 2000 01/12/06 2 1...5 2 SAXPY DAXPY...5 2.1 SAXPY DAXPY...6 2.1.1 SIMD C++...6
SIMD 2(SSE2) SAXPY/DAXPY 2.0 2000 7 : 248600J-001 01/12/06 1 305-8603 115 Fax: 0120-47-8832 * Copyright Intel Corporation 1999, 2000 01/12/06 2 1...5 2 SAXPY DAXPY...5 2.1 SAXPY DAXPY...6 2.1.1 SIMD C++...6
main.dvi
 3 Signicant discrepancies (between the computed and the true result) are very rare, too rare to worry about all the time, yet not rare enough to ignore. by W.M.Kahan supercomputer 1 supercomputer supercomputer
3 Signicant discrepancies (between the computed and the true result) are very rare, too rare to worry about all the time, yet not rare enough to ignore. by W.M.Kahan supercomputer 1 supercomputer supercomputer
_0212_68<5A66><4EBA><79D1>_<6821><4E86><FF08><30C8><30F3><30DC><306A><3057><FF09>.pdf

スライド 1
 GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
HP High Performance Computing(HPC)
") ACCELERATE HP High Performance Computing HPC HPC HPC HPC HPC 1000 HPHPC HPC HP HPC HPC HPC HP HPCHP HP HPC 1 HPC HP 2 HPC HPC HP ITIDC HP HPC 1HPC HPC No.1 HPC TOP500 2010 11 HP 159 32% HP HPCHP 2010 Q1-Q4
ACCELERATE HP High Performance Computing HPC HPC HPC HPC HPC 1000 HPHPC HPC HP HPC HPC HPC HP HPCHP HP HPC 1 HPC HP 2 HPC HPC HP ITIDC HP HPC 1HPC HPC No.1 HPC TOP500 2010 11 HP 159 32% HP HPCHP 2010 Q1-Q4
A Feasibility Study of Direct-Mapping-Type Parallel Processing Method to Solve Linear Equations in Load Flow Calculations Hiroaki Inayoshi, Non-member
 A Feasibility Study of Direct-Mapping-Type Parallel Processing Method to Solve Linear Equations in Load Flow Calculations Hiroaki Inayoshi, Non-member (University of Tsukuba), Yasuharu Ohsawa, Member (Kobe
A Feasibility Study of Direct-Mapping-Type Parallel Processing Method to Solve Linear Equations in Load Flow Calculations Hiroaki Inayoshi, Non-member (University of Tsukuba), Yasuharu Ohsawa, Member (Kobe
. a, b, c, d b a ± d bc ± ad = c ac b a d c = bd ac b a d c = bc ad n m nm [2][3] BASIC [4] B BASIC [5] BASIC Intel x * IEEE a e d
![. a, b, c, d b a ± d bc ± ad = c ac b a d c = bd ac b a d c = bc ad n m nm [2][3] BASIC [4] B BASIC [5] BASIC Intel x * IEEE a e d](/thumbs/84/90471282.jpg ". a, b, c, d b a ± d bc ± ad = c ac b a d c = bd ac b a d c = bc ad n m nm [2][3] BASIC [4] B BASIC [5] BASIC Intel x * IEEE a e d") 3 3 BASIC C++ 8 Tflop/s 8TB [] High precision symmetric eigenvalue computation through exact tridiagonalization by using rational number arithmetic Hikaru Samukawa Abstract: Since rational number arithmetic,
3 3 BASIC C++ 8 Tflop/s 8TB [] High precision symmetric eigenvalue computation through exact tridiagonalization by using rational number arithmetic Hikaru Samukawa Abstract: Since rational number arithmetic,
simx simxdx, cosxdx, sixdx 6.3 px m m + pxfxdx = pxf x p xf xdx = pxf x p xf x + p xf xdx 7.4 a m.5 fx simxdx 8 fx fx simxdx = πb m 9 a fxdx = πa a =
 II 6 [email protected] 6.. 5.4.. f Rx = f Lx = fx fx + lim = lim x x + x x f c = f x + x < c < x x x + lim x x fx fx x x = lim x x f c = f x x < c < x cosmx cosxdx = {cosm x + cosm + x} dx = [
II 6 [email protected] 6.. 5.4.. f Rx = f Lx = fx fx + lim = lim x x + x x f c = f x + x < c < x x x + lim x x fx fx x x = lim x x f c = f x x < c < x cosmx cosxdx = {cosm x + cosm + x} dx = [
kokyuroku.dvi
 On Applications of Rigorous Computing to Dynamical Systems (Zin ARAI) Department of Mathematics, Kyoto University email: [email protected] 1 [12, 13] Lorenz 2 Lorenz 3 4 2 Lorenz 2.1 Lorenz E. Lorenz
On Applications of Rigorous Computing to Dynamical Systems (Zin ARAI) Department of Mathematics, Kyoto University email: [email protected] 1 [12, 13] Lorenz 2 Lorenz 3 4 2 Lorenz 2.1 Lorenz E. Lorenz
D = [a, b] [c, d] D ij P ij (ξ ij, η ij ) f S(f,, {P ij }) S(f,, {P ij }) = = k m i=1 j=1 m n f(ξ ij, η ij )(x i x i 1 )(y j y j 1 ) = i=1 j
![D = [a, b] [c, d] D ij P ij (ξ ij, η ij ) f S(f,, {P ij }) S(f,, {P ij }) = = k m i=1 j=1 m n f(ξ ij, η ij )(x i x i 1 )(y j y j 1 ) = i=1 j](/thumbs/103/158001152.jpg "D = [a, b] [c, d] D ij P ij (ξ ij, η ij ) f S(f,, {P ij }) S(f,, {P ij }) = = k m i=1 j=1 m n f(ξ ij, η ij )(x i x i 1 )(y j y j 1 ) = i=1 j") 6 6.. [, b] [, d] ij P ij ξ ij, η ij f Sf,, {P ij } Sf,, {P ij } k m i j m fξ ij, η ij i i j j i j i m i j k i i j j m i i j j k i i j j kb d {P ij } lim Sf,, {P ij} kb d f, k [, b] [, d] f, d kb d 6..
6 6.. [, b] [, d] ij P ij ξ ij, η ij f Sf,, {P ij } Sf,, {P ij } k m i j m fξ ij, η ij i i j j i j i m i j k i i j j m i i j j k i i j j kb d {P ij } lim Sf,, {P ij} kb d f, k [, b] [, d] f, d kb d 6..
! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2
![! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2](/thumbs/88/115445009.jpg "! 行行 CPUDSP PPESPECell/B.E. CPUGPU 行行 SIMD [SSE, AltiVec] 用 HPC CPUDSP PPESPE (Cell/B.E.) SPE CPUGPU GPU CPU DSP DSP PPE SPE SPE CPU DSP SPE 2") ! OpenCL [Open Computing Language] 言 [OpenCL C 言 ] CPU, GPU, Cell/B.E.,DSP 言 行行 [OpenCL Runtime] OpenCL C 言 API Khronos OpenCL Working Group AMD Broadcom Blizzard Apple ARM Codeplay Electronic Arts Freescale
! OpenCL [Open Computing Language] 言 [OpenCL C 言 ] CPU, GPU, Cell/B.E.,DSP 言 行行 [OpenCL Runtime] OpenCL C 言 API Khronos OpenCL Working Group AMD Broadcom Blizzard Apple ARM Codeplay Electronic Arts Freescale
DO 時間積分 START 反変速度の計算 contravariant_velocity 移流項の計算 advection_adams_bashforth_2nd DO implicit loop( 陰解法 ) 速度勾配, 温度勾配の計算 gradient_cell_center_surface 速
 速度勾配, 温度勾配の計算 gradient_cell_center_surface 速") 1 1, 2 1, 2 3 2, 3 4 GP LES ASUCA LES NVIDIA CUDA LES 1. Graphics Processing Unit GP General-Purpose SIMT Single Instruction Multiple Threads 1 2 3 4 1),2) LES Large Eddy Simulation 3) ASUCA 4) LES LES
1 1, 2 1, 2 3 2, 3 4 GP LES ASUCA LES NVIDIA CUDA LES 1. Graphics Processing Unit GP General-Purpose SIMT Single Instruction Multiple Threads 1 2 3 4 1),2) LES Large Eddy Simulation 3) ASUCA 4) LES LES
I A A441 : April 21, 2014 Version : Kawahira, Tomoki TA (Kondo, Hirotaka ) Google
 Google") I4 - : April, 4 Version :. Kwhir, Tomoki TA (Kondo, Hirotk) Google http://www.mth.ngoy-u.c.jp/~kwhir/courses/4s-biseki.html pdf 4 4 4 4 8 e 5 5 9 etc. 5 6 6 6 9 n etc. 6 6 6 3 6 3 7 7 etc 7 4 7 7 8 5 59
I4 - : April, 4 Version :. Kwhir, Tomoki TA (Kondo, Hirotk) Google http://www.mth.ngoy-u.c.jp/~kwhir/courses/4s-biseki.html pdf 4 4 4 4 8 e 5 5 9 etc. 5 6 6 6 9 n etc. 6 6 6 3 6 3 7 7 etc 7 4 7 7 8 5 59
IA 2013 : :10722 : 2 : :2 :761 :1 (23-27) : : ( / ) (1 /, ) / e.g. (Taylar ) e x = 1 + x + x xn n! +... sin x = x x3 6 + x5 x2n+1 + (
 : : ( / ) (1 /, ) / e.g. (Taylar ) e x = 1 + x + x xn n! +... sin x = x x3 6 + x5 x2n+1 + (") IA 2013 : :10722 : 2 : :2 :761 :1 23-27) : : 1 1.1 / ) 1 /, ) / e.g. Taylar ) e x = 1 + x + x2 2 +... + xn n! +... sin x = x x3 6 + x5 x2n+1 + 1)n 5! 2n + 1)! 2 2.1 = 1 e.g. 0 = 0.00..., π = 3.14..., 1
IA 2013 : :10722 : 2 : :2 :761 :1 23-27) : : 1 1.1 / ) 1 /, ) / e.g. Taylar ) e x = 1 + x + x2 2 +... + xn n! +... sin x = x x3 6 + x5 x2n+1 + 1)n 5! 2n + 1)! 2 2.1 = 1 e.g. 0 = 0.00..., π = 3.14..., 1
スパコンに通じる並列プログラミングの基礎
 2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
n (1.6) i j=1 1 n a ij x j = b i (1.7) (1.7) (1.4) (1.5) (1.4) (1.7) u, v, w ε x, ε y, ε x, γ yz, γ zx, γ xy (1.8) ε x = u x ε y = v y ε z = w z γ yz
 i j=1 1 n a ij x j = b i (1.7) (1.7) (1.4) (1.5) (1.4) (1.7) u, v, w ε x, ε y, ε x, γ yz, γ zx, γ xy (1.8) ε x = u x ε y = v y ε z = w z γ yz") 1 2 (a 1, a 2, a n ) (b 1, b 2, b n ) A (1.1) A = a 1 b 1 + a 2 b 2 + + a n b n (1.1) n A = a i b i (1.2) i=1 n i 1 n i=1 a i b i n i=1 A = a i b i (1.3) (1.3) (1.3) (1.1) (ummation convention) a 11 x
1 2 (a 1, a 2, a n ) (b 1, b 2, b n ) A (1.1) A = a 1 b 1 + a 2 b 2 + + a n b n (1.1) n A = a i b i (1.2) i=1 n i 1 n i=1 a i b i n i=1 A = a i b i (1.3) (1.3) (1.3) (1.1) (ummation convention) a 11 x
13 Student Software TI-Nspire CX CAS TI Web TI-Nspire CX CAS Student Software ( ) 1 Student Software 37 Student Software Nspire Nspire Nspir
 1 Student Software 37 Student Software Nspire Nspire Nspir") 13 Student Software TI-Nspire CX CAS TI Web TI-Nspire CX CAS Student Software ( ) 1 Student Software 37 Student Software 37.1 37.1 Nspire Nspire Nspire 37.1: Student Software 13 2 13 Student Software esc
13 Student Software TI-Nspire CX CAS TI Web TI-Nspire CX CAS Student Software ( ) 1 Student Software 37 Student Software 37.1 37.1 Nspire Nspire Nspire 37.1: Student Software 13 2 13 Student Software esc
main.dvi
 PC 1 1 [1][2] [3][4] ( ) GPU(Graphics Processing Unit) GPU PC GPU PC ( 2 GPU ) GPU Harris Corner Detector[5] CPU ( ) ( ) CPU GPU 2 3 GPU 4 5 6 7 1 [email protected] 45 2 ( ) CPU ( ) ( ) () 2.1
PC 1 1 [1][2] [3][4] ( ) GPU(Graphics Processing Unit) GPU PC GPU PC ( 2 GPU ) GPU Harris Corner Detector[5] CPU ( ) ( ) CPU GPU 2 3 GPU 4 5 6 7 1 [email protected] 45 2 ( ) CPU ( ) ( ) () 2.1
II No.01 [n/2] [1]H n (x) H n (x) = ( 1) r n! r!(n 2r)! (2x)n 2r. r=0 [2]H n (x) n,, H n ( x) = ( 1) n H n (x). [3] H n (x) = ( 1) n dn x2 e dx n e x2
![II No.01 [n/2] [1]H n (x) H n (x) = ( 1) r n! r!(n 2r)! (2x)n 2r. r=0 [2]H n (x) n,, H n ( x) = ( 1) n H n (x). [3] H n (x) = ( 1) n dn x2 e dx n e x2](/thumbs/101/149159646.jpg "II No.01 [n/2] [1]H n (x) H n (x) = ( 1) r n! r!(n 2r)! (2x)n 2r. r=0 [2]H n (x) n,, H n ( x) = ( 1) n H n (x). [3] H n (x) = ( 1) n dn x2 e dx n e x2") II No.1 [n/] [1]H n x) H n x) = 1) r n! r!n r)! x)n r r= []H n x) n,, H n x) = 1) n H n x) [3] H n x) = 1) n dn x e dx n e x [4] H n+1 x) = xh n x) nh n 1 x) ) d dx x H n x) = H n+1 x) d dx H nx) = nh
II No.1 [n/] [1]H n x) H n x) = 1) r n! r!n r)! x)n r r= []H n x) n,, H n x) = 1) n H n x) [3] H n x) = 1) n dn x e dx n e x [4] H n+1 x) = xh n x) nh n 1 x) ) d dx x H n x) = H n+1 x) d dx H nx) = nh
ÊÂÎó·×»»¤È¤Ï/OpenMP¤Î½éÊâ¡Ê£±¡Ë
 2015 5 21 OpenMP Hello World Do (omp do) Fortran (omp workshare) CPU Richardson s Forecast Factory 64,000 L.F. Richardson, Weather Prediction by Numerical Process, Cambridge, University Press (1922) Drawing
2015 5 21 OpenMP Hello World Do (omp do) Fortran (omp workshare) CPU Richardson s Forecast Factory 64,000 L.F. Richardson, Weather Prediction by Numerical Process, Cambridge, University Press (1922) Drawing
(I) GotoBALS, http://www-is.amp.i.kyoto-u.ac.jp/ kkimur/charpoly.html 2
 GotoBALS, http://www-is.amp.i.kyoto-u.ac.jp/ kkimur/charpoly.html 2") sdmp Maple - (Ver.2) ( ) September 27, 2011 1 (I) GotoBALS, http://www-is.amp.i.kyoto-u.ac.jp/ kkimur/charpoly.html 2 (II) Nehalem CPU GotoBLAS Intel CPU Nehalem CPU, GotoBLAS, Hyper-Thread technology
sdmp Maple - (Ver.2) ( ) September 27, 2011 1 (I) GotoBALS, http://www-is.amp.i.kyoto-u.ac.jp/ kkimur/charpoly.html 2 (II) Nehalem CPU GotoBLAS Intel CPU Nehalem CPU, GotoBLAS, Hyper-Thread technology