Slide 1
|
|
|
- ありかつ もてぎ
- 5 years ago
- Views:
Transcription

1 GPUコンピューティング入門 エヌビディア合同会社 CUDAエンジニア 村上真奈
2 エヌビディアのGPUについて (20 分 ) GPUコンピューティングとは?(10 分 ) OpenACC 入門 (90 分 ) CUDA 入門 (90 分 ) Agenda 2
3 エヌビディアのGPUについて (20 分 ) GPUコンピューティングとは?(10 分 ) OpenACC 入門 (90 分 ) CUDA 入門 (90 分 ) Agenda 3

4 年創立 共同創業者 社長兼 CEO : ジェンスン フアン 1999 年 銘柄コード NVDA で NASDAQ に株式上場 1999 年に GPU を発明し 現在までに10 億点以上を出荷 2015 年会計年度の収益 : 46.8 億ドル世界中に 9,300 名の従業員 7,300 件の特許取得済み資産本社 : カリフォルニア州サンタクララ 4






5 3 ゲーミング オートモーティブ エンタープライズ HPC クラウド 当社は ビジュアル コンピューティングが必要不可欠で重要な価値を持つ大規模な市場に特化し プロセッサのプラット フォーム ソフトウェア システム サービスを提供しています 当社はPCテクノロジ データセンター テクノロジ モバイル テ クノロジの革新に取り組んでいます そして 当社の発明は さまざまな業界のOEM製品の原動力となっています 5

6 6

7 東京工業大学 TSUBAME 2.5 4,224 枚の Tesla K20X 単精度理論性能値で日本 No.1 スパコン 17PFLOPS SP 7
 - TH-IVB-FEP Cluster, Intel Xeon E5-2692 12C 2.")
8 NVIDIA GPU OFFERS TOP LEVEL COMPUTATIONAL PERFORMANCE WITH HIGH ENERGY EFFICIENVY From SC TOP500 Nov., 2014 Rank Country Site System Cores Rmax 1 China National Super Computer Center in Guangzhou Tianhe-2 (MilkyWay-2) - TH-IVB-FEP Cluster, Intel Xeon E C 2.200GHz, TH Express-2, Intel Xeon Phi 31S1P (TFlop/s) Rpeak (TFlop/s) Power (kw) 3,120,000 33, , ,808 2 US DOE/SC/Oak Ridge National laboratory Titan-Cray XK7, Opt C 2.2GHz, NVIDIA K20x 560,640 17, , ,209 3 US DOE/NNSA/LLNL Sequoia - BlueGene/Q, Power BQC 16C 1.60 GHz, Custom 1,572,864 17, , ,890 4 Japan RIKEN Advanced Institute for Computational Science (AICS) 5 US DOE/SC/Argonne National Laboratory K computer, SPARC64 VIIIfx 2.0GHz, Tofu interconnect Mira - BlueGene/Q, Power BQC 16C 1.60GHz, Custom 705,024 10, , , ,432 8, , ,945 In GREEN500 the most energy efficient super computers, NVIDIA GPU drives 8 systems out of TOP 10. 8

9 REAL WORLD EXAMPLE Rendering 30-second Animation at Renault 9



10 Deep Learning における GPU の活用 Deep Learning に GPU を活用 Input Result % 26% 60 16% 12% 7% person dog chair GPU 対応した Deep Learning 用ツール Caffe Torch Theano Cuda-convnet cudnn cublas 10
11 SGEMM / W GPU ロードマップ Volta Pascal 24 Maxwell 12 0 Tesla Fermi Kepler
 4.29 TF (3.22TF) 2.91TF (1.87TF) 1.43 TF (1.")
 1.32 TF (1.22 TF) 1.17 TF (1.10 TF) 6 GB 250 GB/s Gen 2 Server only 5 GB 208 GB/s Gen 2 Server + Workstation Image, Signal, Video, Seismic K10 4.58 TF 0.")
12 TESLA KEPLER FAMILY WORLD S FASTEST AND MOST EFFICIENT HPC ACCELERATORS GPUs Single Precision Peak (SGEMM) Double Precision Peak (DGEMM) Memory Size Memory Bandwidth (ECC off) PCIe Gen System Solution CFD, BioChemistry, Neural Networks, High Energy Physiscs, Graph analytics, Material Science, BioInformatics, M&E K80 K TF (5.6TF) 4.29 TF (3.22TF) 2.91TF (1.87TF) 1.43 TF (1.33 TF) 24 GB 480GB/s (240GB/s x2) 12 GB 288 GB/s Gen 3 Gen 3 Server + Workstation Server + Workstation Weather & Climate, Physics, BioChemistry, CAE, Material Science K20X K TF (2.90 TF) 3.52 TF (2.61 TF) 1.32 TF (1.22 TF) 1.17 TF (1.10 TF) 6 GB 250 GB/s Gen 2 Server only 5 GB 208 GB/s Gen 2 Server + Workstation Image, Signal, Video, Seismic K TF 0.19 TF 8 GB 320 GB/s Gen 3 Server only 12

13 M6000 K6000 K5200 K4200 K2200 K620 K420 # CUDA Cores Single Precision 5.2 TFLOPs 3.1 TFLOPs 2.1 TFLOPs 1.3 TFLOPs 0.8 TFLOPs 0.3 TFLOPs PCIe Gen Memory Size 12GB 12 GB 8 GB 4 GB 4 GB 2 GB 1 GB Memory BW 317 GB/s 288 GB/s 192 GB/s 173 GB/s 80 GB/s 29 GB/s 29 GB/s Slots + Display Connectors THE NEW QUADRO FAMILY 2x DP * + 2x DVI 2x DP * + 2x DVI 2x DP * + 2x DVI 2x DP * + DVI * * 2x DP + DVI DP + DVI * DP + DVI Max Resolution 4096 x x 2160 Max Displays Pro Features SDI, SYNC, STEREO, MOSAIC, NVIEW MOSAIC, NVIEW Board Power 250W 225 W 150 W 108 W 68 W 45 W 41 W * DisplayPort 1.2 multi-streaming can be used to drive multiple displays from a single DP connector 13

14 TFLOPS TFLOPS 前世代比 3 倍の性能 Double Precision FLOPS (DGEMM) 1.33 TFLOPS 0.40 TFLOPS Tesla M2090 Tesla K40 Single Precision FLOPS (SGEMM) 3.22 TFLOPS 0.89 TFLOPS Tesla M2090 Tesla K40 Tesla M2090 Tesla K40 CUDA コア数 倍精度演算性能 DGEMM 単精度演算性能 SGEMM 665 G 400 GF 1.33 TF 0.89 TF 1.43 TF 1.33 TF 4.29 TF 3.22 TF メモリバンド幅 178 GB/s 288 GB/s メモリサイズ 6 GB 12 GB 消費電力 225W 235W 14




15 NVIDIA GPU SCALABLE ARCHITECTURE FROM SUPER COMPUTER TO MOBILE Tegra Tesla In Super Computers Quadro In Work Stations GeForce In PCs Mobile GPU In Tegra 17

16 2015 TEGRA X1 MOBILE SUPERCHIP 256-core Maxwell GPU 8-core 64-bit CPU 4Kp60 10-bit H.265/VP9 19

17 CPU: Quad ARM Cortex A57/A53 64/32b CPU that delivers Performance and Power Efficiency GPU: Next Generation 256- Core Maxwell GPU that deliver Class-Leading Performance and Power Efficiency End-to-End 4k 60fps Pipeline that delivers Premium 4K Experience Built on 20nm Process Technology TEGRA X1 OVERVIEW 20

18 Advancements BRIDGING THE GAP Maxwell Tesla Fermi Kepler Tegra K1 Tegra X1 GEFORCE ARCHITECTURE Tegra 4 Tegra 3 MOBILE ARCHITECTURE 21

19 GFLOPS WORLD S 1 ST TERAFLOPS MOBILE PROCESSOR 1200 Tegra X1 (FP16) Tegra X Core i7 GPU GPU CPU 800 CPU FP16/INT Tegra K1 200 Tegra 2 Tegra 3 Tegra 4 0 TIME Note: 4790K Core i7, 4GHz, GPU 350 MHz
20 エヌビディアのGPUについて (20 分 ) GPUコンピューティングとは?(10 分 ) OpenACC 入門 (90 分 ) CUDA 入門 (90 分 ) Agenda 24






21 NVIDIA GPU の歴史 2010 Fermi 3 Billion Transistors 2012 Kepler 7 Billion Transistors GPU 統合シェーダ + CUDA 25
22 PCI Express GPU の構造 GPU Giga Thread Engine SM SM SM SM L2 Cache DRAM 26
23 GPU アーキテクチャ概要 PCI I/F SM SM SM SM SM SM SM SM ホスト接続インタフェース Giga Thread Engine SM に処理を割り振るスケジューラ DRAM (384-bit, GDDR5) SM SM SM SM SM SM SM 全 SM PCI I/F からアクセス可能なメモリ ( デバイスメモリ, フレームバッファ ) Kepler GK110 L2 cache (1.5MB) 全 SM からアクセス可能な R/W キャッシュ SM (Streaming Multiprocessor) 並列 プロセッサ 27
24 SM (STREAMING MULTIPROCESSOR) CUDA core GPU スレッドはこの上で動作 Kepler: 192 個 Other units DP, LD/ST, SFU Register File (65,536 x 32bit) Shared Memory/L1 Cache (64KB) Kepler GK110 Read-Only Cache(48KB) 28
25 COMPUTE CAPABILITY GPU コアアーキテクチャのバージョン CUDA GPUs : アーキテクチャは進化する 高効率の命令実行 省消費電力 29






26 SM ARCHITECTURE VS COMPUTE CAPABILITY Instruction Cache Scheduler Scheduler Dispatch Dispatch Register File Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Load/Store Units x 16 Special Func Units x 4 Interconnect Network 64K Configurable Cache/Shared Mem Uniform Cache Fermi CC 2.0 : 32 cores / SM Kepler CC 3.5 : 192 cores / SMX Maxwell CC 5.0 : 128 cores / SMM 30

27 GPU コンピューティングとは? GPUは何の略? Graphics Processing Unit 3DCG 等 画像データ処理の為のデバイス GPUによる汎用コンピューティングのこと 計算科学など様々な用途でGPUを利用する 31






28 ヘテロジニアス コンピューティング CPU 逐次処理に最適化 GPU Accelerator 並列処理に最適化 32







29 GPU アプリケーションの例 画像処理コンピュータビジョン医療画像防衛計算化学 気象金融工学バイオ数値解析 33




30 GPU アクセラレーションの実現方法 アプリケーション GPU ライブラリ OpenACC ディレクティブ CUDA ライブラリを呼び出すだけ簡単に高速化を実現 既存コードにディレクティブを挿入して高速化 重要なコードを CUDA で記述最も自由度が高い 34
31 簡単 GPU アクセラレーションの実現方法 ライブラリ ライブラリを呼び出すだけで 高速化が可能ライブラリとして提供されている機能のみ高速化が可能 OpenACC 既存の C 言語や Fortran のコードにディレクティブを挿入するだけで簡単に高速化 最適化はコンパイラが行う為 細かいチューニングを行う事は出来ない 高速化 CUDA 自由度が最も高く 細かいチューニングが可能 CUDA でのプログラミングを学ぶ必要がある 35
32 エヌビディアのGPUについて (20 分 ) GPUコンピューティングとは?(10 分 ) OpenACC 入門 (90 分 ) CUDA 入門 (90 分 ) Agenda 36
33 GPU アクセラレーションの実現方法 アプリケーション GPU ライブラリ OpenACC ディレクティブ CUDA ライブラリを呼び出すだけ簡単に高速化を実現 既存コードにディレクティブを挿入して高速化 重要なコードを CUDA で記述最も自由度が高い 37
34 OPENACC 標準的な GPU ディレクティブ シンプル : ディレクティブを挿入するのみ コードを変更する事なく高速化 オープン : OpenACC はマルチコアプロセッサで並列化を行う為のオープン標準 柔軟 : GPU ディレクティブは 高い並列性を保ちつつ同一コードで複数のアーキテクチャに対応可能 38













35 OpenACC メンバーとパートナー 39


")


36 コンパイラとツール 2013 年 12 月 ~ 2014 年 1 月 ~ 2015 年 ( 予定 ) コンパイラ OpenACC 2.0 対応 デバッグツール 40
37 簡単に高速 自動車金融生命科学 Real-Time Object Detection Global Manufacturer of Navigation Systems Valuation of Stock Portfolios using Monte Carlo Global Technology Consulting Company Interaction of Solvents and Biomolecules University of Texas at San Antonio 40 時間で 5 倍 4 時間で 2 倍 8 時間で 5 倍 41




38 大学関係者の方は無償で使用可能に 簡単に始められる 下記のサイトから OpenACC toolkit をダウンロード PGI コンパイラ /MPI/CUDA など一式が簡単にインストール可能 42


39 実行モデル アプリケーション コード $acc parallel GPU CPU 逐次部分は CPU コードを生成 $acc end parallel 計算の重い部分 並列部分は GPU コードを生成 43





40 OpenACC ディレクティブ CPU GPU コンパイラへシンプルなヒント Program myscience... serial code...!$acc kernels do k = 1,n1 do i = 1,n2... parallel code... enddo enddo!$acc end kernels... End Program myscience コンパイラがコードを並列化 コンパイラへの OpenACC ヒント 並列部はGPUで 逐次処理はCPUで動作 Fortran または C言語 のオリジナルコード 44
41 OpenMP と OpenACC の比較 OpenMP OpenACC CPU CPU GPU main() { double pi = 0.0; long i; main() { double pi = 0.0; long i; CPUコアに計算処理を分散 #pragma omp parallel for reduction(+:pi) for (i=0; i<n; i++) { double t = (double)((i+0.05)/n); pi += 4.0/(1.0+t*t); printf( pi = %f\n, pi/n); #pragma acc kernels for (i=0; i<n; i++) { double t = (double)((i+0.05)/n); pi += 4.0/(1.0+t*t); printf( pi = %f\n, pi/n); GPU コアに計算処理を分散 45
42 OpenACC ディレクティブ構文 C/C++ #pragma acc 指示行 [ 節 [,] 節 ] ] { structured block Fortran!$acc 指示行 [ 節 [,] 節 ] ] { structured block!$acc end directive 46
43 OpenACC構文: parallel 指示行 parallel : 並列に実行される領域を指示行で指定 #pragma acc parallel for(int i=0;i<n;i++){ a[i] = 0.0; b[i] = 1.0; c[i] = 2.0; kernel 1 Kernel(カーネル): GPU上で実行される 関数 47
![OpenACC 構文 : kernels 指示行 kernels : 複数のカーネルを作成 #pragma acc kernels for(int i=0;i<n;i++){ a[i] = 0.0; b[i] = 1.](/docs-images/81/82552234/images/44-4.jpg "0; c[i] = 2.")
44 OpenACC 構文 : kernels 指示行 kernels : 複数のカーネルを作成 #pragma acc kernels for(int i=0;i<n;i++){ a[i] = 0.0; b[i] = 1.0; c[i] = 2.0; #pragma acc kernels for(int i=0;i<n;i++){ a[i] = b[i] + c[i]; kernel 1 kernel 2 Kernel( カーネル ): GPU 上で実行される関数 48
45 [C tips]: restrict 修飾子 コンパイラに対して明示的に restrict 修飾子を指定 ポインタのエイリアシングを制限 例 ) float *restrict ptr OpenACC コンパイラに restrict 修飾子をつけ変数の独立性を伝える 独立性の保障がないとコンパイラは並列化を行う事が出来ない 49
 N = atoi(argv[1]); #include <stdlib.")
![h> void saxpy(int n, float a, float *x, float *restrict y) { #pragma acc kernels for (int i = 0; i < n; ++i) y[i] = a * x[i] + y[i];](/docs-images/81/82552234/images/46-3.jpg "*restrict: y は x のエイリアスでない と明示的に指定 float *x = (float*)malloc(n * sizeof(float)); float *y = (float*)malloc(n * sizeof(float)); for (int i =")
46 例 :SAXPY (Y=A*X+Y) Trivial first example Apply a loop directive Learn compiler commands int main(int argc, char **argv) { int N = 1<<20; // 1 million floats if (argc > 1) N = atoi(argv[1]); #include <stdlib.h> void saxpy(int n, float a, float *x, float *restrict y) { #pragma acc kernels for (int i = 0; i < n; ++i) y[i] = a * x[i] + y[i]; *restrict: y は x のエイリアスでない と明示的に指定 float *x = (float*)malloc(n * sizeof(float)); float *y = (float*)malloc(n * sizeof(float)); for (int i = 0; i < N; ++i) { x[i] = 2.0f; y[i] = 1.0f; saxpy(n, 3.0f, x, y); return 0; 50
 y[i] += a*x[i];... saxpy(n, 3.0, x, y);.")
![.. void saxpy(int n, float a, float *x, float *restrict y) { #pragma acc parallel copy(y[:n])](/docs-images/81/82552234/images/47-4.jpg "copyin(x[:n]) for (int i = 0; i < n; ++i) y[i] += a*x[i];... saxpy(n, 3.0, x, y);.")
47 C 言語 :SAXPY (Y=A*X+Y) OpenMP void saxpy(int n, float a, float *x, float *restrict y) { #pragma omp parallel for for (int i = 0; i < n; ++i) y[i] += a*x[i];... saxpy(n, 3.0, x, y);... void saxpy(int n, float a, float *x, float *restrict y) { #pragma acc parallel copy(y[:n]) copyin(x[:n]) for (int i = 0; i < n; ++i) y[i] += a*x[i];... saxpy(n, 3.0, x, y);... OpenACC omp acc データの移動 51
 = a*x(i)+y(i) enddo!")
) copyin(x(:)) do i=1,n Y(i) = a*x(i)+y(i) enddo!")
48 Fortran: SAXPY (Y=A*X+Y) OpenMP subroutine saxpy(n, a, X, Y) real :: a, X(:), Y(:) integer :: n, i!$omp parallel do do i=1,n Y(i) = a*x(i)+y(i) enddo!$omp end parallel do end subroutine saxpy OpenACC subroutine saxpy(n, a, X, Y) real :: a, Y(:), Y(:) integer :: n, i!$acc parallel copy(y(:)) copyin(x(:)) do i=1,n Y(i) = a*x(i)+y(i) enddo!$acc end parallel end subroutine saxpy... call saxpy(n, 3.0, x, y) call saxpy(n, 3.0, x, y)... 52
49 コンパイルオプション C: pgcc acc -ta=nvidia -Minfo=accel o saxpy_acc saxpy.c Fortran: pgf90 acc -ta=nvidia -Minfo=accel o saxpy_acc saxpy.f90 ターゲットに nvidia を指定 コンパイラが GPU 用のコードを生成する際の情報を表示する 53
 copyin(x[:n]) 16, Generating #pragma present_or_copy(y[:n]) omp parallel for")
![Generating for present_or_copyin(x[:n]) (int i = 0; i < n; ++i) Generating y[i] Tesla += code a*x[i]; 19, Loop is](/docs-images/81/82552234/images/50-5.jpg "parallelizable Accelerator kernel generated 19, #pragma... acc loop gang, vector(128) /* blockidx.x threadidx.")
50 簡単にコンパイル OpenMP / OpenACC void saxpy(int n, float a, float *x, float *restrict y) $ pgcc acc { ta=nvidia Minfo=accel saxpy.c saxpy: #pragma acc parallel copy(y[:n]) copyin(x[:n]) 16, Generating #pragma present_or_copy(y[:n]) omp parallel for Generating for present_or_copyin(x[:n]) (int i = 0; i < n; ++i) Generating y[i] Tesla += code a*x[i]; 19, Loop is parallelizable Accelerator kernel generated 19, #pragma... acc loop gang, vector(128) /* blockidx.x threadidx.x */ saxpy(n, 3.0, x, y);... 54
 copyin(x[:n]) ==10302== 16, Generating NVPROF #pragma is present_or_copy(y[:n]) profiling omp parallel process for 10302, command:./a.")
![out ==10302== Generating Profiling for present_or_copyin(x[:n]) (int application: i = 0; i./a.](/docs-images/81/82552234/images/51-6.jpg "out < n; ++i) ==10302== Generating Profiling y[i] Tesla result: += code a*x[i]; Time(%) 19, Loop Time is parallelizable Calls Avg Min Max Name 62.95% Accelerator 3.0358ms kernel 2 generated 1.")
51 簡単に実行 OpenMP / OpenACC void saxpy(int n, float a, float *x, float *restrict y) $ pgcc -Minfo -acc { saxpy.c saxpy: $ nvprof./a.out #pragma acc kernels copy(y[:n]) copyin(x[:n]) ==10302== 16, Generating NVPROF #pragma is present_or_copy(y[:n]) profiling omp parallel process for 10302, command:./a.out ==10302== Generating Profiling for present_or_copyin(x[:n]) (int application: i = 0; i./a.out < n; ++i) ==10302== Generating Profiling y[i] Tesla result: += code a*x[i]; Time(%) 19, Loop Time is parallelizable Calls Avg Min Max Name 62.95% Accelerator ms kernel 2 generated ms ms ms [CUDA memcpy HtoD] 31.48% 19, ms #pragma... acc loop ms gang, vector(128) ms /* ms blockidx.x [CUDA threadidx.x memcpy DtoH] */ 5.56% us saxpy(n, 3.0, 1 x, us y); us us saxpy_19_gpu... 55
52 例 : ヤコビ反復法 正しい値になるように反復計算を行う 隣接点の平均値で値を更新 連立一次方程式を解く為のオーソドックスな手法 例 : 2 次元ラプラス方程式 : 2 f(x, y) = 0 A(i,j+1) A(i-1,j) A(i,j) A(i+1,j) A k+1 i, j = A k(i 1, j) + A k i + 1, j + A k i, j 1 + A k i, j A(i,j-1) 56
 { for (int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.")
53 ヤコビ反復法 ( アルゴリズム ) while ( error > tol ) { error = 0.0; for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.25; error = max(error, abs(anew[j][i] - A[j][i])); A(i-1,j) A(i,j+1) A(i,j) A(i+1,j) A(i,j-1) for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { A[j][i] = Anew[j][i]; 57
 for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.")
54 並列領域 (OpenMP) while ( error > tol ) { error = 0.0; #pragma omp parallel for shared(m, n, Anew, A) for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.25; error = max(error, abs(anew[j][i] - A[j][i]); #pragma omp parallel for shared(m, n, Anew, A) for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { A[j][i] = Anew[j][i]; 58
 { for (int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.")
55 並列領域 (OpenACC) while ( error > tol ) { error = 0.0; #pragma acc kernels for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.25; error = max(error, abs(anew[j][i] - A[j][i]); #pragma acc kernels for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { A[j][i] = Anew[j][i]; Parallels と Kernels 並列領域を指示 Parallels 並列実行スタート Kernels 複数のカーネル 59
56 [PGI tips] コンパイラメッセージ $ pgcc acc ta=nvidia Minfo=accel jacobi.c jacobi: 44, Generating copyout(anew[1:4094][1:4094]) Generating copyin(a[:][:]) Generating Tesla code 45, Loop is parallelizable 46, Loop is parallelizable Accelerator kernel generated 45, #pragma acc loop gang /* blockidx.y */ 46, #pragma acc loop gang, vector(128) /* blockidx.x threadidx.x */ 49, Max reduction generated for error 60
 { for (int i = 1; i < M-1; i++) { Anew[j][i] =")
![(A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.](/docs-images/81/82552234/images/57-4.jpg "25; 並列走行の開始 $ pgcc acc ta=nvidia error = max(error, -Minfo=accel abs(anew[j][i] -jacobi.")
![c A[j][i]); jacobi: 59, Generating present_or_copyout(anew[1:4094][1:4094]) Parallels Kernels 複数のGPUカーネル Generating](/docs-images/81/82552234/images/57-5.jpg "present_or_copyin(a[:][:]) #pragma acc kernels Generating code{ for (int j = 1; j <Tesla N-1; j++) for (int = 1; i < M-1; i++) { 61, Loop")
57 並列領域 (KERNELS CONSTRUCT) while ( error > tol ) { error = 0.0; Parallels と Kernels 並列領域を指示 #pragma acc kernels for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.25; 並列走行の開始 $ pgcc acc ta=nvidia error = max(error, -Minfo=accel abs(anew[j][i] -jacobi.c A[j][i]); jacobi: 59, Generating present_or_copyout(anew[1:4094][1:4094]) Parallels Kernels 複数のGPUカーネル Generating present_or_copyin(a[:][:]) #pragma acc kernels Generating code{ for (int j = 1; j <Tesla N-1; j++) for (int = 1; i < M-1; i++) { 61, Loop iis parallelizable A[j][i] = Anew[j][i]; 63, Loop is parallelizable Accelerator kernel generated 61, #pragma acc loop gang /* blockidx.y */ 63, #pragma acc loop gang, vector(128) /* blockidx.x threadidx.x */ Max reduction generated for error 61
58 データ転送 (DATA CLAUSE) while ( error > tol ) { error = 0.0; #pragma acc kernels for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + $ pgcc acc ta=nvidia A[j-1][i] -Minfo=acc + A[j+1][i]) jacobi.c * 0.25; jacobi: error = max(error, abs(anew[j][i] - A[j][i]); 59, Generating present_or_copyout(anew[1:4094][1:4094]) Generating present_or_copyin(a[:][:]) #pragma Generating acc kernels Tesla code for 61, (int Loop j = is 1; parallelizable j < N-1; j++) { for (int i = 1; i < M-1; i++) { 63, Loop is parallelizable A[j][i] = Anew[j][i]; Accelerator kernel generated 61, #pragma acc loop gang /* blockidx.y */ 63, #pragma acc loop gang, vector(128) /* blockidx.x threadidx.x */ Max reduction generated for error 62
59 コードの解析 実行状況を確認 ボトルネックはどの部分か? 実行時間の内訳を調べる 63
60 -ta=nvidia,time コンパイルオプションに -ta=nvidia,time を追加して コンパイル 実行 /home/openacc/c/jacobi.c jacobi NVIDIA devicenum=0 Kernel 実行 :196ms time(us): 4,595,922 44: compute region reached 200 times 46: kernel launched 200 times grid: [32x4094] block: [128] device time(us): total=196,036 max=1,053 min=931 avg=980 データコピー (H->D):1087ms elapsed time(us): total=201,618 max=1,084 min=958 avg=1,008 46: reduction kernel launched 200 times grid: [1] block: [256] device time(us): total=39,356 max=206 min=187 avg=196 elapsed time(us): total=42,155 max=227 min=200 avg=210 44: data region reached 200 times 44: data copyin transfers: 800 device time(us): total=1,087,027 max=1,374 min=1,354 データコピーがボトルネック avg=1,358 53: compute region reached 200 times 55: kernel launched 200 times 64 grid: [32x4094] block: [128]
61 NVIDIA Visual Profiler (NVVP) を使用 65

62 NVVP による解析 : データ転送がボトルネック 1 cycle 利用率 : 低い GPU kernel GPU kernel 66



63 計算処理とデータ転送 CPU Memory データ転送 GPU Memory PCI 計算オフロード 計算オフロード データ転送 両方を考慮する必要がある 67
64 OpenACC 構文 : データ指示行 copy ( X ) copyin(list) + copyout(list) copyin ( X ) アクセラレータ領域に入る際に GPU 上に X 用のメモリを確保し ホストから GPU( デバイス ) へ X を転送する copyout ( X ) アクセラレータ領域に入る際に GPU 上に X 用のメモリを確保し アクセラレータ領域から出る時に GPU( デバイス ) からホストへ X を転送する create ( X ) アクセラレータ領域に入る時に GPU 上に X 用のメモリが確保される ( 転送はされない ) present ( X ) アクセラレータ領域に入る時に X が既にデバイス上に存在することを示す 68
65 OpenACC 構文 : データ指示行 pcopy ( X ) present (X) + copy(x) pcopyin ( X ) present (X) + copyin(x) pcopyout ( X ) present (X) + copyout(x) pcreate ( X ) present (X) + create(x) 69
 pcopyin(a[0:n][0:m]) for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i])")
66 データ転送 (DATA CLAUSE) while ( error > tol ) { error = 0.0; #pragma acc kernels \ pcopyout(anew[1:n-2][1:m-2]) pcopyin(a[0:n][0:m]) for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.25; error = max(error, abs(anew[j][i] - A[j][i]); #pragma acc kernels \ pcopyout(a[1:n-2][1:m-2]) pcopyin(anew[1:n-2][1:m-2]) for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { A[j][i] = Anew[j][i]; copyin (Host GPU) copyout (Host GPU) copy create present pcopyin pcopyout pcopy pcreate 70
67 データ転送 (DATA CLAUSE) while ( error > tol ) { error = 0.0; #pragma acc kernels \ pcopy(anew[:][:]) pcopyin(a[:][:]) for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.25; error = max(error, abs(anew[j][i] - A[j][i]); #pragma acc kernels \ pcopy(a[:][:]) pcopyin(anew[:][:]) for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { A[j][i] = Anew[j][i]; copyin (Host GPU) copyout (Host GPU) copy create present pcopyin pcopyout pcopy pcreate 71
 pcopyin(a[:][:]) for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.")
68 過剰なデータ転送 while ( error > tol ) { error = 0.0; #pragma acc kernels \ pcopy(anew[:][:]) pcopyin(a[:][:]) for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.25; error = max(error, abs(anew[j][i] - A[j][i]); #pragma acc kernels \ pcopy(a[:][:]) pcopyin(anew[:][:]) for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { A[j][i] = Anew[j][i]; 72
 \ pcopyin(a[:][:]) { #pragma acc kernels \ pcopy(a[:][:]) \")
![pcopyin(anew[:][:]) { copyin copyout copyin copyout #pragma acc loop reduction(max:error) for (int j = 1; j < N-1; j++) { for](/docs-images/81/82552234/images/69-5.jpg "(int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.")
69 Host while ( error > tol ) { error = 0.0; 過剰なデータ転送 GPU #pragma acc kernels \ pcopy(anew[:][:]) \ pcopyin(a[:][:]) { #pragma acc kernels \ pcopy(a[:][:]) \ pcopyin(anew[:][:]) { copyin copyout copyin copyout #pragma acc loop reduction(max:error) for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.25; error = max(error, abs(anew[j][i] - A[j][i]); for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { A[j][i] = Anew[j][i]; 73
70 データ領域 (data construct) #pragma acc data pcopy(a, Anew) while ( error > tol ) { error = 0.0; #pragma acc kernels pcopy(anew[:][:]) pcopyin(a[:][:]) for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.25; error = max(error, abs(anew[j][i] - A[j][i]); #pragma acc kernels pcopy(a[:][:]) pcopyin(anew[:][:]) for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { A[j][i] = Anew[j][i]; copyin (CPU GPU) copyout (CPU GPU) copy create present pcopyin pcopyout pcopy pcreate 74
 pcopyin(a[:][:]) for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.")
71 データ領域 (data CONSTRUCT) #pragma acc data pcopy(a) create(anew) while ( error > tol ) { error = 0.0; #pragma acc kernels pcopy(anew[:][:]) pcopyin(a[:][:]) for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.25; error = max(error, abs(anew[j][i] - A[j][i]); #pragma acc kernels pcopy(a[:][:]) pcopyin(anew[:][:]) for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { A[j][i] = Anew[j][i]; copyin (CPU GPU) copyout (CPU GPU) copy create present pcopyin pcopyout pcopy pcreate 75
 \ pcopyin(a[:][:]) { for (int j = 1; j < N-1; j++) { for (int")
![i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.](/docs-images/81/82552234/images/72-5.jpg "25; error = max(error, abs(anew[j][i] - A[j][i]); #pragma acc kernels \ pcopy(a[:][:]) \ pcopyin(anew[:][:]) { copyout for")
72 Host #pragma acc data \ pcopy(a) create(anew) while ( error > tol ) { error = 0.0; 適正なデータ転送 copyin GPU #pragma acc kernels \ pcopy(anew[:][:]) \ pcopyin(a[:][:]) { for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { Anew[j][i] = (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]) * 0.25; error = max(error, abs(anew[j][i] - A[j][i]); #pragma acc kernels \ pcopy(a[:][:]) \ pcopyin(anew[:][:]) { copyout for (int j = 1; j < N-1; j++) { for (int i = 1; i < M-1; i++) { A[j][i] = Anew[j][i]; 76

73 データ転送の削減 (NVVP) 1 cycle 稼働率 : 高い 77
74 GPU アクセラレーションの実現方法 アプリケーション GPU ライブラリ OpenACC ディレクティブ CUDA ライブラリを呼び出すだけ簡単に高速化を実現 既存コードにディレクティブを挿入して高速化 重要なコードを CUDA で記述最も自由度が高い 78
75 CUDA とは? Compute Unified Device Architectureの略 NVIDIA GPU 上の汎用並列計算プラットフォーム Linux Windows MacOS X(+Android) で動作 現在 7.0が最新 7.5RCも公開中 79
76 CUDA 開発 実行環境 ライブラリ ミドルウェア 開発環境 cufft cublas cusparse cudnn cusolver curand Thrust NPP NVRTC MATLAB Mathematica etc.. NVCC (CUDA compiler) プログラミング言語 CUDA-GDB C C++ C++11 Fortran Java Python etc.. Profiler NVIDIA-GPUs( ハードウェア ) Nsight IDE HyperQ Dynamic Parallelism GPU Direct 82
77 CUDA 開発 実行環境 ライブラリ ミドルウェア 開発環境 cufft cublas cusparse cudnn cusolver curand Thrust NPP NVRTC MATLAB Mathematica etc.. NVCC (CUDA compiler) プログラミング言語 CUDA-GDB C C++ C++11 Fortran Java Python etc.. Profiler NVIDIA-GPUs( ハードウェア ) Nsight IDE HyperQ Dynamic Parallelism GPU Direct 83

78 進化するハードウェア NVIDIA-GPUS 84


79 進化するハードウェア NVIDIA-GPUS Hyper-Q Dynamic Parallelism GPU Direct 85
80 CUDA 開発 実行環境 ライブラリ ミドルウェア 開発環境 cufft cublas cusparse cudnn cusolver curand Thrust NPP NVRTC MATLAB Mathematica etc.. NVCC (CUDA compiler) プログラミング言語 CUDA-GDB C C++ C++11 Fortran Java Python etc.. Profiler NVIDIA-GPUs( ハードウェア ) Nsight IDE HyperQ Dynamic Parallelism GPU Direct 87
81 プログラミング言語 C C++ Python Fortran その他 CUDA C CUDA C++(C++11),Thrust PyCUDA CUDA Fortran F#, MATLAB, Mathematica, 88
82 CUDA 開発 実行環境 ライブラリ ミドルウェア 開発環境 cufft cublas cusparse cudnn cusolver curand Thrust NPP NVRTC MATLAB Mathematica etc.. NVCC (CUDA compiler) プログラミング言語 CUDA-GDB C C++ C++11 Fortran Java Python etc.. Profiler NVIDIA-GPUs( ハードウェア ) Nsight IDE HyperQ Dynamic Parallelism GPU Direct 90








83 CUDA ライブラリ cudnn ディープニューラルネットワーク計算用ライブラリ cusolver 線形代数演算 LAPACK 用ライブラリ curand 乱数生成ライブラリ cusparse 疎行列計算用ライブラリ cufft 高速フーリエ変換ライブラリ cublas 線形代数計算用ライブラリ NPP 動画像処理 信号処理用ライブラリ Thrust C++ テンプレートライブラリ 91






84 CUDA を使用したソフトウェア MATLAB Mathematica ArrayFire OpenCV etc Caffe torch theano 92
85 CUDA 開発 実行環境 ライブラリ ミドルウェア 開発環境 cufft cublas cusparse cudnn cusolver curand Thrust NPP NVRTC MATLAB Mathematica etc.. NVCC (CUDA compiler) プログラミング言語 CUDA-GDB C C++ C++11 Fortran Java Python etc.. Profiler NVIDIA-GPUs( ハードウェア ) Nsight IDE HyperQ Dynamic Parallelism GPU Direct 94
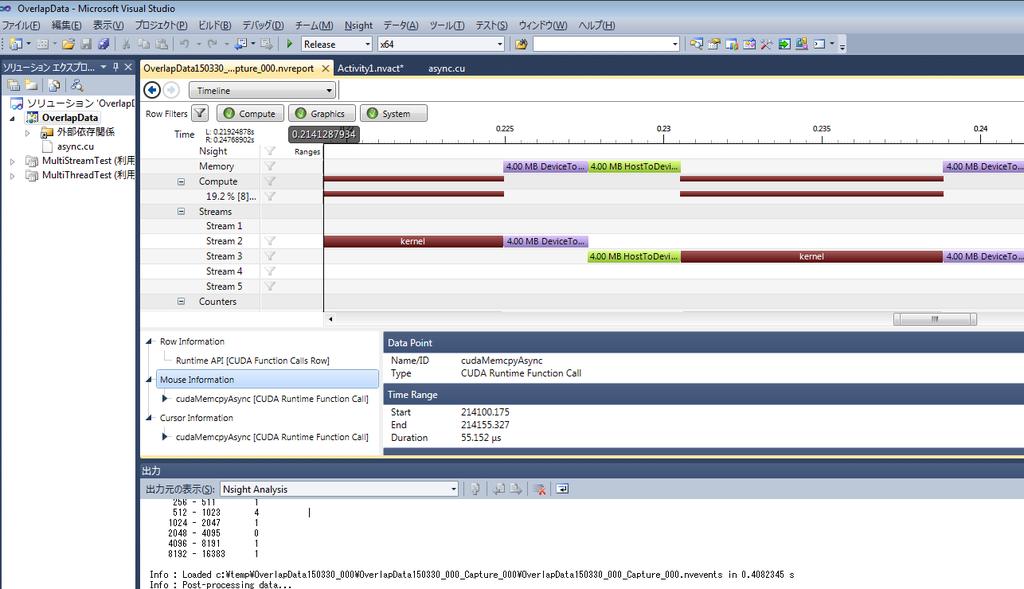
86 開発環境 DEBUG & ANALYSIS NVCC CUDA-GDB CUDA-MEMCHECK Nsight IDE Profiler CUDA 用コンパイラ CUDA 用デバッガ (Linux,Mac) GPUメモリエラーチェックツール CUDA 統合開発環境 (Linux,Windows) CUDA 解析ツール 95



87 NSIGHT VISUAL STUDIO EDITION 96
88 ここまでの復習 CUDAでは 様々なプログラミング言語やライブラリを使う事が可能 ケースによって最適なものを選択すれば良い 既存のライブラリやミドルウェアを有効活用する CUDAはロードマップが存在し 進化し続けている よりプログラミングしやすく パフォーマンスが出やすいように 97
89 CUDA C/C++ アプリケーション入門 今回は CUDA C/C++ で説明します 98
90 典型的な装置構成 PC GPU CPU につながった外部演算装置 CPU ( 数コア ) 制御 PCIe Giga Thread Engine SM SM SM SM L2 Cache ホスト側 DRAM 転送 DRAM 99
91 典型的な実行例 CPU プログラム開始 GPU は CPU からの制御で動作する データ転送 CUDA カーネル実行 完了待ち データ転送 入力データは CPU GPU へと転送 GPU 結果は GPU CPU と転送 GPU での演算 GPU 上に常駐するプログラムはない 100
92 CUDA C/C++ 用語 GPU で実行される関数をカーネル (kernel) と呼ぶ CPU で実行されるコードをホストコード GPU で実行されるコードをデバイスコードと呼ぶ データ並列を表現する為に以下の概念を用いる グリッド (grid) ブロック (block) スレッド (thread) 101
93 グリッド ブロック スレッド グリッド (grid) ブロックをまとめた物 ブロック (block) スレッドをまとめた物 1ブロックあたり最大 1024スレッド スレッド (thread) カーネルを動作させる最小単位 Block0 Thread Block1 Thread Grid Block2 Thread Block Thread n 103
94 グリッド ブロック スレッド CUDA GPU Block0 Thread SM GPU SM Block1 Thread core Grid Block2 Thread SM SM Block n Thread 105
95 カーネル実行の流れ Giga Thread Engine がブロックを SM に割り当てる Grid Block0 Giga Thread Engine Block1 Block2 Block3 Block4 BlockN Block4 107
96 カーネル実行の流れ SM の中のスケジューラがコアにスレッドを投入する Grid Block 0 Thread ワープを投入 32スレッド単位で投入 Thread Thread Thread BlockN 108
97 Block 1 SM BLOCK は SM 上で実行 複数の SM にまたがらない (SM 中では 複数 Block が実行される場合もある ) Block 内部では SMX のリソースを活用可能 各々の Block は 独立に 非同期に処理を実行する 実行順序の保証はない Block 間の通信 同期は行わない 109
98 例 : 一次元配列の加算 配列 A と配列 B の加算結果を配列 C に書き込む [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] A B = = = = = = = = = = = = = = = = C
99 CPU 例 : 一次元配列の加算 (CPU) 配列の 0 番から逐次加算していく C[0] = A[0] + B[0]; C[1] = A[1] + B[1]; C[2] = A[2] + B[2]; for(int i=0 C[3] ; = i<nmatrixsize A[3] + B[3]; ; i++) { C[i] C[4] = = A[i] A[4] + B[i]; + B[4]; C[5] = A[5] + B[5]; 111
100 例 : 一次元配列の加算 (GPU) [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] A B = = = = = = = = = = = = = = = = C T0 T1 T2 T3 T4 T5 T6 T7 T8 T9 T10 T11 T12 T13 Block0 Block1 Block2 BlockN 112

101 ブロック ID とスレッド ID ブロック ID とスレッド ID から インデックス ( グローバル ID) を生成する インデックスを用いて各スレッドから グローバルメモリへアクセスする index = blockdim.x * blockidx.x + threadidx.x; Thread Block
102 例 : 一次元配列の加算 (GPU) ホスト側 (CPU) int main(int argc,char** argv){ MatrixAdd<<<N, M>>>(C,A,B); デバイス側 (GPU) global void MatrixAdd(float* C,const float* A,const float* B){ int i = blockdim.x * blockidx.x + threadidx.x; C[i] = A[i] + B[i]; 114
103 GPU 側メモリの確保 復習 : 典型的な実行例 CPU GPU は CPU からの制御で動作する データ転送 CUDA カーネル実行 完了待ち データ転送 入力データは CPU GPU へと転送 GPU 結果は GPU CPU と転送 GPU での演算 GPU 上に常駐するプログラムはない 115
104 ホスト側から呼び出す API cudamalloc GPU 上の DRAM( グローバルメモリ ) にメモリの確保を行う cudafree cudamalloc で取得したメモリの解放を行う cudamemcpy CPU->GPU GPU->GPU GPU->CPU のメモリ転送を行う cudadevicesynchronize CUDA カーネルが終了するまで待つ 116
105 cudamemcpy() メモリは ホスト デバイス の二種類 enum cudamemcpykind cudamemcpyhosttodevice cudamemcpydevicetohost cudamemcpydevicetodevice cudamemcpyhosttohost (cudamemcpydefault : UVA) 117
106 int main() { 略 サンプルコード ( ホスト ) int matrixsize= 256 * 100; float *A, *B, *C; cudamalloc(&a,sizeof(float)*matrixsize); cudamalloc(&b,sizeof(float)*matrixsize); cudamalloc(&c,sizeof(float)*matrixsize); cudamemcpy(a,ha, sizeof(float)*matrixsize, cudamemcpyhosttodevice); cudamemcpy(b,hb, sizeof(float)*matrixsize, cudamemcpyhosttodevice); MatrixAdd<<<matrixSize/256, 256>>>(C, A, B, matrixsize); cudadevicesynchronize(); cudamemcpy(hc, C, sizeof(float)*matrixsize, cudamemcpydevicetohost); cudafree(a); cudafree(b); cudafree(c); 略 118
107 サンプルコード ( デバイス ) global void MatrixAdd(float* C,const float* A,const float* B,const int size){ int i = blockdim.x * blockidx.x + threadidx.x; if( i < size){ C[i] = A[i] + B[i]; 119
108 例 :RGB->YUV 変換を考える Y U V = R G B 121
109 1. GPU のメモリ構造 最適化の為に理解する事 2. スレッド (thread) 構成と占有率 (Occupancy) 122
110 1. GPU のメモリ構造 最適化の為に理解する事 2. スレッド (thread) 構成と占有率 (Occupancy) 123
111 GPU のメモリ階層 SM Threads アクセスが速い SMEM L1 Read TEX only L2 cache DRAM アクセスが遅い 124
112 Global Memory Local Memory GPU 上のメモリ キャッシュ レジスタ GPU 内部の記憶域 GPU 上の DRAM すべての SM からアクセス可能 Thread スコープのメモリ GPU 上の DRAM スレッド内部の配列 レジスタスピル時の記憶域 L2 Cache L1(Kepler のみ ) L2 Shared Memory SM 内部のメモリ Blockスコープでアクセス なし 手動管理のキャッ低レイテンシのRead/Write シュとして用いる場合あスレッド間のデータ共有り Texture Memory テクスチャユニット経由でアクセスするメモリ L1(Texture) L2 Read-only Data Cache Read Only でアクセスできる Global Memory L1(Texture) L2 Constant Memory 定数を収めるメモリ ブロードキャストアクセスに特化 Registers SM 内部のレジスタ 演算可能 なし SM 内部のキャッシュ 125
113 READ-ONLY(RO) CACHE SM Threads TEX Texture API SMEM L1 Read TEX only CUDA Arrays 一般的な Read-Only キャッシュとして使用可能 L2 cache Kepler 以降 コンパイラに指示 DRAM
114 RO DATA CACHE 使い方 型修飾子 : const restrict を付ける global kernel( int* output, const int* restrict input ) input ) {... output[idx] =... + input[idx + delta] +...;
115 GLOBAL MEMORY SM SMEM Threads L1 Read TEX only GPU 上のメモリの中で最もポピュラーなメモリ メモリサイズは大きく アクセスコストは高い L2 cache Global DRAM Memory 128

116 コアレスアクセス 連続するスレッドは連続するメモリアクセスになるようにデバイスメモリは32byte,64byte,128byteの単位でロード ストア CUDA7.0 現在 thread0 thread1 thread2 thread3 thread4 thread Device Memory 129
117 コアレスアクセス 連続するスレッドは連続するメモリアクセスになるようにデバイスメモリは32byte,64byte,128byteの単位でロード ストア CUDA7.0 現在 thread0 thread1 thread2 thread3 thread4 thread Device Memory 130
118 コアレスアクセス 連続するスレッドは連続するメモリアクセスになるようにデバイスメモリは32byte,64byte,128byteの単位でロード ストア CUDA7.0 現在 thread0 thread1 thread2 thread3 thread4 thread Device Memory 131
119 height パディングを考慮したメモリの確保 x 方向の先頭アドレスが 32byte の倍数になるようにパディング 例 : RGB 24byte padding = 32 (3*width%32) width padding 132
120 2 次元メモリ確保 転送 API cudamallocpitch width バイトのメモリを height 行分 取得する 行は パディングを考慮した pitch バイトで整列する cudamemcpy2d cudamallocpitch で取得したパディングを考慮したメモリ (Dst) に Src のメモリ ( パディングなし ) をコピーする 133
121 サンプルコード uchar4 *src, *dimage; size_t spitch, dpitch, dpitchinpixel; // ピッチつきで メモリをアロケート cudamallocpitch(&dimage, &dpitch, width * sizeof(uchar4), height); dpitchinpixel = dpitch / sizeof(uchar4); // ピッチを変換しつつ ホスト デバイスへと メモリ転送 cudamemcpy2d(dimage, dpitch, src, spitch, width * sizeof(uchar4), height,cudamemcpyhosttodevice); 134
122 1. GPU のメモリ構造 最適化の為に理解する事 2. スレッド (thread) 構成と占有率 (Occupancy) 135
123 復習 : 一次元配列の加算 global void MatrixAdd(float *A, const float *B,const float *C) { グローバルID int i = threadidx.x + blodkdim.x * blockidx.x; if ( i >= N j >=N ) return; C[i][i] = A[i][j] + B[i][j]; 総スレッド数 1ブロックあたりのスレッド数... MatrixAdd<<< N/128, 128>>>(A, B, C);
124 復習 : ブロック ID とスレッド ID ブロック ID とスレッド ID から インデックス ( グローバル ID) を生成する インデックスを用いて各スレッドから グローバルメモリへアクセスする index = blockdim.x * blockidx.x + threadidx.x; Thread Block
125 ブロック ID とスレッド ID( 二次元 ) BLOCK (M,0) BLOCK (M,N-2) BLOCK (M,N-1) BLOCK (M,N) index_x = blockdim.x * blockidx.x + threadidx.x; Index_y = blockdim.y * blockidx.y + threadidx.y; thread BLOCK (15,0) (M-1,N) thread (15,15) BLOCK (1,0) BLOCK (1,1) thread (1,0) thread (1,1) BLOCK (0,0) BLOCK (0,1) BLOCK (0,2) thread (0,0) BLOCK thread (0,1) (0,N) thread (0,15) 138
126 二次元配列の加算 global void MatrixAdd(float A[N][N], float *B[N][N], float *C[N][N]) { int i = threadidx.x + blodkdim.x * blockidx.x; int j = threadidx.y + blodkdim.y * blockidy.y; if ( i >= N j >=N ) return; C[i][i] = A[i][j] + B[i][j]; 1ブロックあたり16*16=256スレッド... dim3 sizeblock( 16, 16 ); dim3 numblocks( N/sizeBlock.x, N/sizeBlock.y ); MatrixAdd<<< numblocks, sizeblock >>>(A, B, C);
127 例 :RGB->YUV 変換を考える 1スレッドで1pixelぶんの処理を行うピクセルの数だけスレッドを作成例 ) 1920*1080 = 2,073,600 スレッド 3840*2160 = 8,294,400 スレッド 140
128 例 :RGB->YUV 変換を考える thread7 thread6 thread5 thread4 thread3 thread2 thread1 int x = blockdim.x * blockidx.x + threadidx.x; int y = blockdim.y * blockidx.y + threadidx.y; if ((x < w) && (y < h)) { //Global Memory(Src) から 4byte ロード uchar4 urgb = gsrc[index]; //Global Memory(Dst) へ変換後の値を 4byte ストア gdst[idx] = RGB2YUV(uRGB.x, urgb.y, urgb.z); Height thread0 Width 141
129 ブロックサイズの決定 x = BlockDim.x * BlockIdx.x + threadidx.x (0<= x < width) y = BlockDim.x * BlockIdx.x + threadidx.x (0<= y < height) グリッド ブロックサイズの例 ) 960 threads / block 128 threads / block 32 threads / block? height width 142
130 ブロックサイズの決定 占有率を 100% にする ブロックサイズ ( ブロック辺りのスレッドの数 ) は少ない方が良い ブロックは横長の方が良い 143
131 占有率 (OCCUPANCY) とは? マルチプロセッサで同時に実行されるワープの数を同時に実行できるワープの最大数で除算したもの 144
132 BLOCKDIM の決定 ( 占有率から ) 項目 値 最大のBlock 数 / SMX 16 最大のThread 数 / SMX 2048 最大のThread 数 / Block 1024 SMX あたり 2048 Thread 走らせたい Occupancy ( 占有率 ) = 100 % Occupancy = 100 % を満たす Block あたりのスレッド数は 2048 Thread / 16 Block = 128 Thread / Block 2048 Thread / 8 Block = 256 Thread / Block 2048 Thread / 4 Block = 512 Thread / Block 2048 Thread / 2 Block = 1024 Thread / Block 145
133 BLOCKDIM の決め方 (BLOCK の粒度から ) Grid = 4096 Thread の実行例を考えてみる Block : 256 Thread 1024 Thread で比較 3 SMX / GPU 1 SMX あたり 1 Block が実行可能とする SMX 0 SMX 1 SMX 2 Block Block Block Block Block Block Block Block Block Block Block Block 256 Thread / Block Block Block Block Block t SMX 0 SMX 1 SMX 2 Block Block Block 1024 Thread / Block Block Block サイズは小さいほうが得 128 Threads / Block 146 t
134 復習 : カーネル実行の流れ Giga Thread Engine がブロックを SM に割り当てる Grid Block0 Giga Thread Engine Block1 Block2 Block3 Block4 BlockN Block4 148

135 復習 : カーネル実行の流れ SM の中のスケジューラがコアにスレッドを投入する Grid Block 0 Thread 32スレッド単位でワープを投入投入 Thread Thread Thread BlockN 149
136 Block Warp 32 GPU Thread CUDA cores Warp ワープ (WARP) : 並列実行の最少単位 - ワープ (Warp) : 32 GPU スレッド 1 命令を Warp (32 スレッド ) が 並列に処理 SIMT (Single Instruction Multiple Thread) SW SMX Warp Thread Thread Thread Thread Thread Thread Core Core Core Core Core 1 命令を 32 並列実行 150
137 BLOCKDIM の決め方 (SMX の構造から ) Warp Scheduler x 4 : 1 clock あたり 4 Warp に対する命令発行 Block のサイズは 128 Thread の倍数が望ましい (128 Thread = 32 Thread/Warp x 4 Warp) 152
138 タイルは横長がよい タイルの横幅は 32(Warp の幅 ) の倍数がよい 32 より小さい場合 16 もしくは 8 を使う Thread : Memory : threadidx.x 153
139 blockdim.y RGB Y 変換時のバンド幅 : TESLA K20C blockdim.x Occupancy < 100 % blockdim.x < 8 値 : バンド幅 (GB/sec) Tesla K20c (ECC off) 154
140 RGB->YUV 変換 ( ホスト ) /* value radix で割って 切り上げる */ int divroundup(int value, int radix) { return (value + radix 1) / radix; /* griddim, blockdim を 2 次元 (x, y 方向 ) に初期化 */ dim3 blockdim(128, 1); /* divroundup() は 切り上げの割り算 */ dim3 griddim(divroundup(width, blockdim.x),divroundup(height, blockdim.y)); RGB2YUV<<<gridDim, blockdim>>>(ddst, dsrc, ); 155
141 RGB->YUV 変換 ( デバイス ) device inline uchar4 rgb_2_yuv(unsigned char R, unsigned char G, unsigned char B){ float fy,fu,fy; unsigned char uy,uu,uv; fy = 0.299f * value.x f * value.y f * value.z; uy = (unsigned char)min(255, (int)y); U と Y の処理は省略 make_uchar4(uy, uu, uv, 0); global void RGB2YUV (uchar4 *gdst, const uchar4 *gsrc, int w, int h){ int x = blockdim.x * blockidx.x + threadidx.x; int y = blockdim.y * blockidx.y + threadidx.y; if ((x < w) && (y < h)) { int index = y * width + x; //Global Memory(Src) から 4byte ロード uchar4 urgb = gsrc[index]; //Global Memory(Dst) へ変換後の値を 4byte ストア gdst[idx] = rgb_2_yuv(urgb.x, urgb.y, urgb.z); 156
142 まとめ グローバルメモリはコアレスアクセスする 二次元の場合は cudamallocpitch を使う事でメモリアライメントを考慮したメモリ確保が可能 メモリの Load のみの場合は Read Only Data Cache を活用 占有率 (Occupancy) と Block 内のスレッド構成を意識 Block サイズは 128 が適当 ( 単純なカーネルの場合 ) Block の横幅は 32 の倍数 無理な場合 16, 8 を選択 (4 byte / pixel の場合 ) 157

143 158

144 159

145 160
146 Appendix. CUDA ダウンロードサイト OpenACC toolkit OpenACC オンライン講座 Landing-Page.html GPU コンピューティング Facebook ページ 161
147 Thankyou 162

148 Thank you 173
CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン
 CUDA 画像処理入門 エヌビディアジャパン CUDA エンジニア森野慎也 GTC Japan 2014 CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン RGB Y( 輝度 ) 変換 カラー画像から グレイスケールへの変換 Y = 0.299 R + 0.587
CUDA 画像処理入門 エヌビディアジャパン CUDA エンジニア森野慎也 GTC Japan 2014 CUDA を用いた画像処理 画像処理を CUDA で並列化 基本的な並列化の考え方 目標 : 妥当な Naïve コードが書ける 最適化の初歩がわかる ブロックサイズ メモリアクセスパターン RGB Y( 輝度 ) 変換 カラー画像から グレイスケールへの変換 Y = 0.299 R + 0.587
1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境 Lin
 Windows で始める CUDA 入門 GTC 2013 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境
Windows で始める CUDA 入門 GTC 2013 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. GPU コンピューティング GPU コンピューティング GPUによる 汎用コンピューティング GPU = Graphics Processing Unit CUDA Compute Unified Device Architecture NVIDIA の GPU コンピューティング環境
GPU n Graphics Processing Unit CG CAD
 GPU 2016/06/27 第 20 回 GPU コンピューティング講習会 ( 東京工業大学 ) 1 GPU n Graphics Processing Unit CG CAD www.nvidia.co.jp www.autodesk.co.jp www.pixar.com GPU n GPU ü n NVIDIA CUDA ü NVIDIA GPU ü OS Linux, Windows, Mac
GPU 2016/06/27 第 20 回 GPU コンピューティング講習会 ( 東京工業大学 ) 1 GPU n Graphics Processing Unit CG CAD www.nvidia.co.jp www.autodesk.co.jp www.pixar.com GPU n GPU ü n NVIDIA CUDA ü NVIDIA GPU ü OS Linux, Windows, Mac
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日
 TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
Slides: TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
 計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
計算機アーキテクチャ第 11 回 マルチプロセッサ 本資料は授業用です 無断で転載することを禁じます 名古屋大学 大学院情報科学研究科 准教授加藤真平 デスクトップ ジョブレベル並列性 スーパーコンピュータ 並列処理プログラム プログラムの並列化 for (i = 0; i < N; i++) { x[i] = a[i] + b[i]; } プログラムの並列化 x[0] = a[0] + b[0];
07-二村幸孝・出口大輔.indd
 GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 理化学研究所 共通コードプロジェクト
 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 理化学研究所 共通コードプロジェクト") GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 勉強会 @ 理化学研究所 共通コードプロジェクト Contents Hands On 環境について Introduction to GPU computing Introduction
GPU チュートリアル :OpenACC 篇 Himeno benchmark を例題として 高エネルギー加速器研究機構 (KEK) 松古栄夫 (Hideo Matsufuru) 1 December 2018 HPC-Phys 勉強会 @ 理化学研究所 共通コードプロジェクト Contents Hands On 環境について Introduction to GPU computing Introduction
Slide 1
 OpenACC CUDA による GPU コンピューティング Akira Naruse, 19 th Jul. 2018 成瀬彰 (Naruse, Akira) 自己紹介 2013 年 ~: NVIDIA シニア デベローパーテクノロジー エンジニア 1996~2013 年 : 富士通研究所 研究員など 専門 興味 : 並列処理 性能最適化 スパコン HPC GPU コンピューティング DeepLearning
OpenACC CUDA による GPU コンピューティング Akira Naruse, 19 th Jul. 2018 成瀬彰 (Naruse, Akira) 自己紹介 2013 年 ~: NVIDIA シニア デベローパーテクノロジー エンジニア 1996~2013 年 : 富士通研究所 研究員など 専門 興味 : 並列処理 性能最適化 スパコン HPC GPU コンピューティング DeepLearning
CUDA 連携とライブラリの活用 2
 1 09:30-10:00 受付 10:00-12:00 Reedbush-H ログイン GPU 入門 13:30-15:00 OpenACC 入門 15:15-16:45 OpenACC 最適化入門と演習 17:00-18:00 OpenACC の活用 (CUDA 連携とライブラリの活用 ) CUDA 連携とライブラリの活用 2 3 OpenACC 簡単にGPUプログラムが作成できる それなりの性能が得られる
1 09:30-10:00 受付 10:00-12:00 Reedbush-H ログイン GPU 入門 13:30-15:00 OpenACC 入門 15:15-16:45 OpenACC 最適化入門と演習 17:00-18:00 OpenACC の活用 (CUDA 連携とライブラリの活用 ) CUDA 連携とライブラリの活用 2 3 OpenACC 簡単にGPUプログラムが作成できる それなりの性能が得られる
1. マシンビジョンにおける GPU の活用
 CUDA 画像処理入門 GTC 213 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. マシンビジョンにおける GPU の活用 1. 医用画像処理における GPU の活用 CT や MRI から画像を受信して三次元画像の構築をするシステム 2 次元スキャンデータから 3 次元 4 次元イメージの高速生成 CUDA 化により画像処理速度を約 2 倍に高速化 1. CUDA で画像処理
CUDA 画像処理入門 GTC 213 チュートリアル エヌビディアジャパン CUDA エンジニア森野慎也 1. マシンビジョンにおける GPU の活用 1. 医用画像処理における GPU の活用 CT や MRI から画像を受信して三次元画像の構築をするシステム 2 次元スキャンデータから 3 次元 4 次元イメージの高速生成 CUDA 化により画像処理速度を約 2 倍に高速化 1. CUDA で画像処理
NUMAの構成
 GPU のプログラム 天野 アクセラレータとは? 特定の性質のプログラムを高速化するプロセッサ 典型的なアクセラレータ GPU(Graphic Processing Unit) Xeon Phi FPGA(Field Programmable Gate Array) 最近出て来た Deep Learning 用ニューロチップなど Domain Specific Architecture 1GPGPU:General
GPU のプログラム 天野 アクセラレータとは? 特定の性質のプログラムを高速化するプロセッサ 典型的なアクセラレータ GPU(Graphic Processing Unit) Xeon Phi FPGA(Field Programmable Gate Array) 最近出て来た Deep Learning 用ニューロチップなど Domain Specific Architecture 1GPGPU:General
Slide 1
 OPENACC の現状 Akira Naruse NVIDAI Developer Technologies アプリを GPU で加速する方法 Application CUDA OpenACC Library 主要処理を CUDA で記述高い自由度 既存コードにディレクティブを挿入簡単に加速 GPU 対応ライブラリにチェンジ簡単に開始 OPENACC CPU GPU Program myscience...
OPENACC の現状 Akira Naruse NVIDAI Developer Technologies アプリを GPU で加速する方法 Application CUDA OpenACC Library 主要処理を CUDA で記述高い自由度 既存コードにディレクティブを挿入簡単に加速 GPU 対応ライブラリにチェンジ簡単に開始 OPENACC CPU GPU Program myscience...
Slide 1
 CUDA プログラミングの基本 パート I - ソフトウェアスタックとメモリ管理 CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パートII カーネルの起動 GPUコードの具体項目 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください CUDA インストレーション CUDA インストレーションの構成
CUDA プログラミングの基本 パート I - ソフトウェアスタックとメモリ管理 CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パートII カーネルの起動 GPUコードの具体項目 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください CUDA インストレーション CUDA インストレーションの構成
Microsoft PowerPoint - GPGPU実践基礎工学(web).pptx
.pptx") GPU のプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU プログラミング環境 (CUDA) GPU プログラムの実行の流れ CUDA によるプログラムの記述 カーネル (GPU で処理する関数 ) の構造 記述方法とその理由 GPU 固有のパラメータの確認 405 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ
GPU のプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU プログラミング環境 (CUDA) GPU プログラムの実行の流れ CUDA によるプログラムの記述 カーネル (GPU で処理する関数 ) の構造 記述方法とその理由 GPU 固有のパラメータの確認 405 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ
Microsoft PowerPoint - GPU_computing_2013_01.pptx
 GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格
GPU コンピューティン No.1 導入 東京工業大学 学術国際情報センター 青木尊之 1 GPU とは 2 GPGPU (General-purpose computing on graphics processing units) GPU を画像処理以外の一般的計算に使う GPU の魅力 高性能 : ハイエンド GPU はピーク 4 TFLOPS 超 手軽さ : 普通の PC にも装着できる 低価格
Slide 1
 CUDA プログラミングの基本 パート II - カーネル CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パート II カーネルの起動 GPUコードの具体像 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください GPU 上でのコードの実行 カーネルは C 関数 + 多少の制約 ホストメモリはアクセスできない戻り値型は
CUDA プログラミングの基本 パート II - カーネル CUDA の基本の概要 パート I CUDAのソフトウェアスタックとコンパイル GPUのメモリ管理 パート II カーネルの起動 GPUコードの具体像 注 : 取り上げているのは基本事項のみです そのほか多数の API 関数についてはプログラミングガイドを ご覧ください GPU 上でのコードの実行 カーネルは C 関数 + 多少の制約 ホストメモリはアクセスできない戻り値型は
ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014
 ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014 コンカレントな処理の実行 システム内部の複数の処理を 平行に実行する CPU GPU メモリ転送 カーネル実行 複数のカーネル間 ストリーム GPU 上の処理キュー カーネル実行 メモリ転送の並列性 実行順序 DEFAULT STREAM Stream : GPU
ストリームを用いたコンカレントカーネルプログラミングと最適化 エヌビディアジャパン CUDAエンジニア森野慎也 GTC Japan 2014 コンカレントな処理の実行 システム内部の複数の処理を 平行に実行する CPU GPU メモリ転送 カーネル実行 複数のカーネル間 ストリーム GPU 上の処理キュー カーネル実行 メモリ転送の並列性 実行順序 DEFAULT STREAM Stream : GPU
TSUBAME2.0におけるGPUの 活用方法
 GPU プログラミング 基礎編 東京工業大学学術国際情報センター 1. GPU コンピューティングと TSUBAME2.0 スーパーコンピュータ GPU コンピューティングとは グラフィックプロセッサ (GPU) は グラフィック ゲームの画像計算のために 進化を続けてきた 現在 CPU のコア数は 2~12 個に対し GPU 中には数百コア その GPU を一般アプリケーションの高速化に利用! GPGPU
GPU プログラミング 基礎編 東京工業大学学術国際情報センター 1. GPU コンピューティングと TSUBAME2.0 スーパーコンピュータ GPU コンピューティングとは グラフィックプロセッサ (GPU) は グラフィック ゲームの画像計算のために 進化を続けてきた 現在 CPU のコア数は 2~12 個に対し GPU 中には数百コア その GPU を一般アプリケーションの高速化に利用! GPGPU
熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date Type URL Presentation
 榎本, 昌一 Citation Issue date Type URL Presentation") 熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date 2011-03-17 Type URL Presentation http://hdl.handle.net/2298/23539 Right GPGPU による高速演算について 榎本昌一 東京大学大学院工学系研究科システム創成学専攻
熊本大学学術リポジトリ Kumamoto University Repositor Title GPGPU による高速演算について Author(s) 榎本, 昌一 Citation Issue date 2011-03-17 Type URL Presentation http://hdl.handle.net/2298/23539 Right GPGPU による高速演算について 榎本昌一 東京大学大学院工学系研究科システム創成学専攻
GPU GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1
 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1") GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
( CUDA CUDA CUDA CUDA ( NVIDIA CUDA I
 GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
DO 時間積分 START 反変速度の計算 contravariant_velocity 移流項の計算 advection_adams_bashforth_2nd DO implicit loop( 陰解法 ) 速度勾配, 温度勾配の計算 gradient_cell_center_surface 速
 速度勾配, 温度勾配の計算 gradient_cell_center_surface 速") 1 1, 2 1, 2 3 2, 3 4 GP LES ASUCA LES NVIDIA CUDA LES 1. Graphics Processing Unit GP General-Purpose SIMT Single Instruction Multiple Threads 1 2 3 4 1),2) LES Large Eddy Simulation 3) ASUCA 4) LES LES
1 1, 2 1, 2 3 2, 3 4 GP LES ASUCA LES NVIDIA CUDA LES 1. Graphics Processing Unit GP General-Purpose SIMT Single Instruction Multiple Threads 1 2 3 4 1),2) LES Large Eddy Simulation 3) ASUCA 4) LES LES
PowerPoint Presentation
 ヘテロジニアスな環境におけるソフトウェア開発 Agenda 今日の概要 ヘテロジニアスな環境の登場 ホモジニアスからヘテロジニアスへ ヘテロジニアスなアーキテクチャ GPU CUDA OpenACC, XeonPhi 自分のプログラムを理解するために デバッガ 共通の操作体験 TotalView 続きはブースで より速く ホモジーニアスな並列 HPC 銀河生成 金融のリスク計算 車の衝突解析 製薬
ヘテロジニアスな環境におけるソフトウェア開発 Agenda 今日の概要 ヘテロジニアスな環境の登場 ホモジニアスからヘテロジニアスへ ヘテロジニアスなアーキテクチャ GPU CUDA OpenACC, XeonPhi 自分のプログラムを理解するために デバッガ 共通の操作体験 TotalView 続きはブースで より速く ホモジーニアスな並列 HPC 銀河生成 金融のリスク計算 車の衝突解析 製薬
Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]
![Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]](/thumbs/102/156675429.jpg "Microsoft PowerPoint - GPUシンポジウム _d公開版.ppt [互換モード]") 200/0/9 数値流体解析の並列効率とその GPU による高速化の試み 清水建設 ( 株 ) 技術研究所 PHAM VAN PHUC ( ファムバンフック ) 流体計算時間短縮と GPU の活用の試み 現 CPUとの比較によりGPU 活用の可能性 現 CPU の最大利用 ノード内の最大計算資源の利用 すべてCPUコアの利用 適切なアルゴリズムの利用 CPU コア性能の何倍? GPU の利用の試み
200/0/9 数値流体解析の並列効率とその GPU による高速化の試み 清水建設 ( 株 ) 技術研究所 PHAM VAN PHUC ( ファムバンフック ) 流体計算時間短縮と GPU の活用の試み 現 CPUとの比較によりGPU 活用の可能性 現 CPU の最大利用 ノード内の最大計算資源の利用 すべてCPUコアの利用 適切なアルゴリズムの利用 CPU コア性能の何倍? GPU の利用の試み
1 OpenCL OpenCL 1 OpenCL GPU ( ) 1 OpenCL Compute Units Elements OpenCL OpenCL SPMD (Single-Program, Multiple-Data) SPMD OpenCL work-item work-group N
 1 OpenCL Compute Units Elements OpenCL OpenCL SPMD (Single-Program, Multiple-Data) SPMD OpenCL work-item work-group N") GPU 1 1 2 1, 3 2, 3 (Graphics Unit: GPU) GPU GPU GPU Evaluation of GPU Computing Based on An Automatic Program Generation Technology Makoto Sugawara, 1 Katsuto Sato, 1 Kazuhiko Komatsu, 2 Hiroyuki Takizawa
GPU 1 1 2 1, 3 2, 3 (Graphics Unit: GPU) GPU GPU GPU Evaluation of GPU Computing Based on An Automatic Program Generation Technology Makoto Sugawara, 1 Katsuto Sato, 1 Kazuhiko Komatsu, 2 Hiroyuki Takizawa
ÊÂÎó·×»»¤È¤Ï/OpenMP¤Î½éÊâ¡Ê£±¡Ë
 2015 5 21 OpenMP Hello World Do (omp do) Fortran (omp workshare) CPU Richardson s Forecast Factory 64,000 L.F. Richardson, Weather Prediction by Numerical Process, Cambridge, University Press (1922) Drawing
2015 5 21 OpenMP Hello World Do (omp do) Fortran (omp workshare) CPU Richardson s Forecast Factory 64,000 L.F. Richardson, Weather Prediction by Numerical Process, Cambridge, University Press (1922) Drawing
GPU のアーキテクチャとプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓
 GPU のアーキテクチャとプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のアーキテクチャ CUDA CUDA によるプログラミング 58 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ チップ単体では販売されていない PCI Ex カードで販売 ( チップ単体と区別せずに GPU と呼ぶことも多い
GPU のアーキテクチャとプログラム構造 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のアーキテクチャ CUDA CUDA によるプログラミング 58 GPU(Graphics Processing Unit) とは 画像処理専用のハードウェア 具体的には画像処理用のチップ チップ単体では販売されていない PCI Ex カードで販売 ( チップ単体と区別せずに GPU と呼ぶことも多い
MATLAB® における並列・分散コンピューティング ~ Parallel Computing Toolbox™ & MATLAB Distributed Computing Server™ ~
 MATLAB における並列 分散コンピューティング ~ Parallel Computing Toolbox & MATLAB Distributed Computing Server ~ MathWorks Japan Application Engineering Group Takashi Yoshida 2016 The MathWorks, Inc. 1 System Configuration
MATLAB における並列 分散コンピューティング ~ Parallel Computing Toolbox & MATLAB Distributed Computing Server ~ MathWorks Japan Application Engineering Group Takashi Yoshida 2016 The MathWorks, Inc. 1 System Configuration
XACCの概要
 2 global void kernel(int a[max], int llimit, int ulimit) {... } : int main(int argc, char *argv[]){ MPI_Int(&argc, &argc); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); dx
2 global void kernel(int a[max], int llimit, int ulimit) {... } : int main(int argc, char *argv[]){ MPI_Int(&argc, &argc); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); dx
GPGPU
 GPGPU 2013 1008 2015 1 23 Abstract In recent years, with the advance of microscope technology, the alive cells have been able to observe. On the other hand, from the standpoint of image processing, the
GPGPU 2013 1008 2015 1 23 Abstract In recent years, with the advance of microscope technology, the alive cells have been able to observe. On the other hand, from the standpoint of image processing, the
Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ 3.7x faster P100 V100 P10
 NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
NVIDIA TESLA V100 CUDA 9 のご紹介 森野慎也, シニアソリューションアーキテクト (GPU-Computing) NVIDIA Images per Second Images per Second VOLTA: ディープラーニングにおける大きな飛躍 ResNet-50 トレーニング 2.4x faster ResNet-50 推論 TensorRT - 7ms レイテンシ
1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU.....
 CPU GPU N Q07-065 2011 2 17 1 1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU...........................................
CPU GPU N Q07-065 2011 2 17 1 1 4 1.1........................................... 4 1.2.................................. 4 1.3................................... 4 2 5 2.1 GPU...........................................
スライド 1
 GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
GPU クラスタによる格子 QCD 計算 広大理尾崎裕介 石川健一 1.1 Introduction Graphic Processing Units 1 チップに数百個の演算器 多数の演算器による並列計算 ~TFLOPS ( 単精度 ) CPU 数十 GFLOPS バンド幅 ~100GB/s コストパフォーマンス ~$400 GPU の開発環境 NVIDIA CUDA http://www.nvidia.co.jp/object/cuda_home_new_jp.html
概要 OpenACC とは OpenACC について OpenMP, CUDA との違い OpenACC の指示文 並列化領域指定指示文 (kernels/parallel) データ移動指示文 ループ指示文 OpenACC の実用例 実習 コンパイラメッセージの見方 OpenACC プログラムの実装
 データ移動指示文 ループ指示文 OpenACC の実用例 実習 コンパイラメッセージの見方 OpenACC プログラムの実装") 第 74 回お試しアカウント付き 並列プログラミング講習会 GPU プログラミング入門 in 名古屋 星野哲也 ( 助教 ) hoshino@cc.u-tokyo.ac.jp 大島聡史 ( 助教 ) ohshima@cc.u-tokyo.ac.jp 2016 年 3 月 14 日 ( 火 ) 東京大学情報基盤センター 概要 OpenACC とは OpenACC について OpenMP, CUDA との違い
第 74 回お試しアカウント付き 並列プログラミング講習会 GPU プログラミング入門 in 名古屋 星野哲也 ( 助教 ) hoshino@cc.u-tokyo.ac.jp 大島聡史 ( 助教 ) ohshima@cc.u-tokyo.ac.jp 2016 年 3 月 14 日 ( 火 ) 東京大学情報基盤センター 概要 OpenACC とは OpenACC について OpenMP, CUDA との違い
untitled
 GPGPU NVIDACUDA Learn More about CUDA - NVIDIA http://www.nvidia.co.jp/object/cuda_education_jp.html NVIDIA CUDA programming Guide CUDA http://www.sintef.no/upload/ikt/9011/simoslo/evita/2008/seland.pdf
GPGPU NVIDACUDA Learn More about CUDA - NVIDIA http://www.nvidia.co.jp/object/cuda_education_jp.html NVIDIA CUDA programming Guide CUDA http://www.sintef.no/upload/ikt/9011/simoslo/evita/2008/seland.pdf
Vol.214-HPC-145 No /7/3 C #pragma acc directive-name [clause [[,] clause] ] new-line structured block Fortran!$acc directive-name [clause [[,] c
![Vol.214-HPC-145 No /7/3 C #pragma acc directive-name [clause [[,] clause] ] new-line structured block Fortran!$acc directive-name [clause [[,] c](/thumbs/83/88091581.jpg "Vol.214-HPC-145 No /7/3 C #pragma acc directive-name [clause [[,] clause] ] new-line structured block Fortran!$acc directive-name [clause [[,] c") Vol.214-HPC-145 No.45 214/7/3 OpenACC 1 3,1,2 1,2 GPU CUDA OpenCL OpenACC OpenACC High-level OpenACC CPU Intex Xeon Phi K2X GPU Intel Xeon Phi 27% K2X GPU 24% 1. TSUBAME2.5 CPU GPU CUDA OpenCL CPU OpenMP
Vol.214-HPC-145 No.45 214/7/3 OpenACC 1 3,1,2 1,2 GPU CUDA OpenCL OpenACC OpenACC High-level OpenACC CPU Intex Xeon Phi K2X GPU Intel Xeon Phi 27% K2X GPU 24% 1. TSUBAME2.5 CPU GPU CUDA OpenCL CPU OpenMP
GPGPUイントロダクション
 大島聡史 ( 並列計算分科会主査 東京大学情報基盤センター助教 ) GPGPU イントロダクション 1 目的 昨今注目を集めている GPGPU(GPU コンピューティング ) について紹介する GPGPU とは何か? 成り立ち 特徴 用途 ( ソフトウェアや研究例の紹介 ) 使い方 ( ライブラリ 言語 ) CUDA GPGPU における課題 2 GPGPU とは何か? GPGPU General-Purpose
大島聡史 ( 並列計算分科会主査 東京大学情報基盤センター助教 ) GPGPU イントロダクション 1 目的 昨今注目を集めている GPGPU(GPU コンピューティング ) について紹介する GPGPU とは何か? 成り立ち 特徴 用途 ( ソフトウェアや研究例の紹介 ) 使い方 ( ライブラリ 言語 ) CUDA GPGPU における課題 2 GPGPU とは何か? GPGPU General-Purpose
1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU
![1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU](/thumbs/89/99132402.jpg "1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU") GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
Microsoft PowerPoint - GTC2012-SofTek.pptx
 GTC Japan 2012 PGI Accelerator Compiler 実践! PGI OpenACC ディレクティブを使用したポーティング 2012 年 7 月 加藤努株式会社ソフテック 本日の話 OpenACC によるポーティングの実際 OpenACC ディレクティブ概略説明 Accelerator Programming Model Fortran プログラムによるポーティング ステップ三つのディレクティブの利用性能チューニング
GTC Japan 2012 PGI Accelerator Compiler 実践! PGI OpenACC ディレクティブを使用したポーティング 2012 年 7 月 加藤努株式会社ソフテック 本日の話 OpenACC によるポーティングの実際 OpenACC ディレクティブ概略説明 Accelerator Programming Model Fortran プログラムによるポーティング ステップ三つのディレクティブの利用性能チューニング
概要 目的 CUDA Fortran の利用に関する基本的なノウハウを提供する 本チュートリアル受講後は Web 上で公開されている資料等を参照しながら独力で CUDA Fortran が利用できることが目標 対象 CUDA Fortran の利用に興味を抱いている方 前提とする知識 Fortran
 CUDA Fortran チュートリアル 2010 年 9 月 29 日 NEC 概要 目的 CUDA Fortran の利用に関する基本的なノウハウを提供する 本チュートリアル受講後は Web 上で公開されている資料等を参照しながら独力で CUDA Fortran が利用できることが目標 対象 CUDA Fortran の利用に興味を抱いている方 前提とする知識 Fortran を用いた Linux
CUDA Fortran チュートリアル 2010 年 9 月 29 日 NEC 概要 目的 CUDA Fortran の利用に関する基本的なノウハウを提供する 本チュートリアル受講後は Web 上で公開されている資料等を参照しながら独力で CUDA Fortran が利用できることが目標 対象 CUDA Fortran の利用に興味を抱いている方 前提とする知識 Fortran を用いた Linux
N08
 CPU のキモチ C.John 自己紹介 英語きらい 絵かけない 人の話を素直に信じない CPUにキモチなんてない お詫び 予告ではCとC# とありましたがやる気と時間の都合上 C++のみを対象とします 今日のネタ元 MSDN マガジン 2010 年 10 月号 http://msdn.microsoft.com/ja-jp/magazine/cc850829.aspx Windows と C++
CPU のキモチ C.John 自己紹介 英語きらい 絵かけない 人の話を素直に信じない CPUにキモチなんてない お詫び 予告ではCとC# とありましたがやる気と時間の都合上 C++のみを対象とします 今日のネタ元 MSDN マガジン 2010 年 10 月号 http://msdn.microsoft.com/ja-jp/magazine/cc850829.aspx Windows と C++
Microsoft PowerPoint - suda.pptx
 GPU の HWアーキテクチャと高性能化手法 須田礼仁 ( 東京大学 ) 2011/03/22 GPU 高性能プログラミング GPU のハードウェアを理解する CUDA のソフトウェアを理解する CUDA でプログラムを書くのは難しくないが, CUDA で高速なプログラムを書くのは難しい どうすれば遅くなるかを理解する! 効果が大きいものから順に説明します 1 高性能プログラミングの手順 1. 現在のコードの,
GPU の HWアーキテクチャと高性能化手法 須田礼仁 ( 東京大学 ) 2011/03/22 GPU 高性能プログラミング GPU のハードウェアを理解する CUDA のソフトウェアを理解する CUDA でプログラムを書くのは難しくないが, CUDA で高速なプログラムを書くのは難しい どうすれば遅くなるかを理解する! 効果が大きいものから順に説明します 1 高性能プログラミングの手順 1. 現在のコードの,
HPC143
 研究背景 GPUクラスタ 高性能 高いエネルギー効率 低価格 様々なHPCアプリケーションで用いられている TCA (Tightly Coupled Accelerators) 密結合並列演算加速機構 筑波大学HA-PACSクラスタ アクセラレータ GPU 間の直接通信 低レイテンシ 今後のHPCアプリは強スケーリングも重要 TCAとアクセラレータを搭載したシステムに おけるプログラミングモデル 例
研究背景 GPUクラスタ 高性能 高いエネルギー効率 低価格 様々なHPCアプリケーションで用いられている TCA (Tightly Coupled Accelerators) 密結合並列演算加速機構 筑波大学HA-PACSクラスタ アクセラレータ GPU 間の直接通信 低レイテンシ 今後のHPCアプリは強スケーリングも重要 TCAとアクセラレータを搭載したシステムに おけるプログラミングモデル 例
Microsoft PowerPoint - GPGPU実践基礎工学(web).pptx
.pptx") GPU のメモリ階層 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のメモリ階層 グローバルメモリ 共有メモリ モザイク処理への適用 コンスタントメモリ 空間フィルタへの適用 577 GPU の主要部品 基盤 GPU( チップ )+ 冷却部品 画面出力端子 電源入力端子 メモリ 特性の把握が重要 電源入力端子 画面出力端子 メモリ チップ PCI Ex 端子 http://www.geforce.com/whats
GPU のメモリ階層 長岡技術科学大学電気電子情報工学専攻出川智啓 今回の内容 GPU のメモリ階層 グローバルメモリ 共有メモリ モザイク処理への適用 コンスタントメモリ 空間フィルタへの適用 577 GPU の主要部品 基盤 GPU( チップ )+ 冷却部品 画面出力端子 電源入力端子 メモリ 特性の把握が重要 電源入力端子 画面出力端子 メモリ チップ PCI Ex 端子 http://www.geforce.com/whats
スライド 1
 GTC Japan 2013 PGI Accelerator Compiler 新 OpenACC 2.0 の機能と PGI アクセラレータコンパイラ 2013 年 7 月 加藤努株式会社ソフテック 本日の話 OpenACC ディレクティブで出来ることを改めて知ろう! OpenACC 1.0 の復習 ディレクティブ操作で出来ることを再確認 OpenACC 2.0 の新機能 プログラミングの自由度の向上へ
GTC Japan 2013 PGI Accelerator Compiler 新 OpenACC 2.0 の機能と PGI アクセラレータコンパイラ 2013 年 7 月 加藤努株式会社ソフテック 本日の話 OpenACC ディレクティブで出来ることを改めて知ろう! OpenACC 1.0 の復習 ディレクティブ操作で出来ることを再確認 OpenACC 2.0 の新機能 プログラミングの自由度の向上へ
23 Fig. 2: hwmodulev2 3. Reconfigurable HPC 3.1 hw/sw hw/sw hw/sw FPGA PC FPGA PC FPGA HPC FPGA FPGA hw/sw hw/sw hw- Module FPGA hwmodule hw/sw FPGA h
 23 FPGA CUDA Performance Comparison of FPGA Array with CUDA on Poisson Equation (lijiang@sekine-lab.ei.tuat.ac.jp), (kazuki@sekine-lab.ei.tuat.ac.jp), (takahashi@sekine-lab.ei.tuat.ac.jp), (tamukoh@cc.tuat.ac.jp),
23 FPGA CUDA Performance Comparison of FPGA Array with CUDA on Poisson Equation (lijiang@sekine-lab.ei.tuat.ac.jp), (kazuki@sekine-lab.ei.tuat.ac.jp), (takahashi@sekine-lab.ei.tuat.ac.jp), (tamukoh@cc.tuat.ac.jp),
01_OpenMP_osx.indd
 OpenMP* / 1 1... 2 2... 3 3... 5 4... 7 5... 9 5.1... 9 5.2 OpenMP* API... 13 6... 17 7... 19 / 4 1 2 C/C++ OpenMP* 3 Fortran OpenMP* 4 PC 1 1 9.0 Linux* Windows* Xeon Itanium OS 1 2 2 WEB OS OS OS 1 OS
OpenMP* / 1 1... 2 2... 3 3... 5 4... 7 5... 9 5.1... 9 5.2 OpenMP* API... 13 6... 17 7... 19 / 4 1 2 C/C++ OpenMP* 3 Fortran OpenMP* 4 PC 1 1 9.0 Linux* Windows* Xeon Itanium OS 1 2 2 WEB OS OS OS 1 OS
Microsoft Word - HOKUSAI_system_overview_ja.docx
 HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
GPGPUクラスタの性能評価
 2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
2008 年度理研 HPC シンポジウム第 3 世代 PC クラスタ GPGPU クラスタの性能評価 2009 年 3 月 12 日 富士通研究所成瀬彰 発表の概要 背景 GPGPU による高速化 CUDA の概要 GPU のメモリアクセス特性調査 姫野 BMT の高速化 GPGPU クラスタによる高速化 GPU Host 間のデータ転送 GPU-to-GPU の通信性能 GPGPU クラスタ上での姫野
3次多項式パラメタ推定計算の CUDAを用いた実装 (CUDAプログラミングの練習として) Implementation of the Estimation of the parameters of 3rd-order-Polynomial with CUDA
 Implementation of the Estimation of the parameters of 3rd-order-Polynomial with CUDA") 3 次多項式パラメタ推定計算の CUDA を用いた実装 (CUDA プログラミングの練習として ) Estimating the Parameters of 3rd-order-Polynomial with CUDA ISS 09/11/12 問題の選択 目的 CUDA プログラミングを経験 ( 試行錯誤と習得 ) 実際に CPU のみの場合と比べて高速化されることを体験 問題 ( インプリメントする内容
3 次多項式パラメタ推定計算の CUDA を用いた実装 (CUDA プログラミングの練習として ) Estimating the Parameters of 3rd-order-Polynomial with CUDA ISS 09/11/12 問題の選択 目的 CUDA プログラミングを経験 ( 試行錯誤と習得 ) 実際に CPU のみの場合と比べて高速化されることを体験 問題 ( インプリメントする内容
Slide 1
 電子情報通信学会研究会組込みシステム研究会 (IPSJ-EMB) 2010 年 1 月 28 日 超並列マルチコア GPU を用いた高速演算処理の実用化 NVIDIA Solution Architect 馬路徹 目次 なぜ今 GPU コンピューティングか? CPUの性能向上速度が減速 性能向上 = 並列処理 にGPUコンピューティングが応える CUDAシステムアーキテクチャによる超並列処理の実現
電子情報通信学会研究会組込みシステム研究会 (IPSJ-EMB) 2010 年 1 月 28 日 超並列マルチコア GPU を用いた高速演算処理の実用化 NVIDIA Solution Architect 馬路徹 目次 なぜ今 GPU コンピューティングか? CPUの性能向上速度が減速 性能向上 = 並列処理 にGPUコンピューティングが応える CUDAシステムアーキテクチャによる超並列処理の実現
CCS HPCサマーセミナー 並列数値計算アルゴリズム
 大規模系での高速フーリエ変換 2 高橋大介 daisuke@cs.tsukuba.ac.jp 筑波大学計算科学研究センター 2016/6/2 計算科学技術特論 B 1 講義内容 並列三次元 FFT における自動チューニング 二次元分割を用いた並列三次元 FFT アルゴリズム GPU クラスタにおける並列三次元 FFT 2016/6/2 計算科学技術特論 B 2 並列三次元 FFT における 自動チューニング
大規模系での高速フーリエ変換 2 高橋大介 daisuke@cs.tsukuba.ac.jp 筑波大学計算科学研究センター 2016/6/2 計算科学技術特論 B 1 講義内容 並列三次元 FFT における自動チューニング 二次元分割を用いた並列三次元 FFT アルゴリズム GPU クラスタにおける並列三次元 FFT 2016/6/2 計算科学技術特論 B 2 並列三次元 FFT における 自動チューニング
IPSJ SIG Technical Report Vol.2013-HPC-138 No /2/21 GPU CRS 1,a) 2,b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla
 2,b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla") GPU CRS 1,a),b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla K0 CUDA5.0 cusparse CRS SpMV 00 1.86 177 1. SpMV SpMV CRS Compressed Row Storage *1 SpMV GPU GPU NVIDIA Kepler
GPU CRS 1,a),b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla K0 CUDA5.0 cusparse CRS SpMV 00 1.86 177 1. SpMV SpMV CRS Compressed Row Storage *1 SpMV GPU GPU NVIDIA Kepler
OpenACCによる並列化
 実習 OpenACC による ICCG ソルバーの並列化 1 ログイン Reedbush へのログイン $ ssh reedbush.cc.u-tokyo.ac.jp l txxxxx Module のロード $ module load pgi/17.3 cuda ログインするたびに必要です! ワークディレクトリに移動 $ cdw ターゲットプログラム /srcx OpenACC 用のディレクトリの作成
実習 OpenACC による ICCG ソルバーの並列化 1 ログイン Reedbush へのログイン $ ssh reedbush.cc.u-tokyo.ac.jp l txxxxx Module のロード $ module load pgi/17.3 cuda ログインするたびに必要です! ワークディレクトリに移動 $ cdw ターゲットプログラム /srcx OpenACC 用のディレクトリの作成
main.dvi
 PC 1 1 [1][2] [3][4] ( ) GPU(Graphics Processing Unit) GPU PC GPU PC ( 2 GPU ) GPU Harris Corner Detector[5] CPU ( ) ( ) CPU GPU 2 3 GPU 4 5 6 7 1 toyohiro@isc.kyutech.ac.jp 45 2 ( ) CPU ( ) ( ) () 2.1
PC 1 1 [1][2] [3][4] ( ) GPU(Graphics Processing Unit) GPU PC GPU PC ( 2 GPU ) GPU Harris Corner Detector[5] CPU ( ) ( ) CPU GPU 2 3 GPU 4 5 6 7 1 toyohiro@isc.kyutech.ac.jp 45 2 ( ) CPU ( ) ( ) () 2.1
スパコンに通じる並列プログラミングの基礎
 2018.09.10 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 1 / 59 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 2 / 59 Windows, Mac Unix 0444-J furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 3 / 59 Part I Unix GUI CUI:
2018.09.10 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 1 / 59 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 2 / 59 Windows, Mac Unix 0444-J furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 3 / 59 Part I Unix GUI CUI:
スパコンに通じる並列プログラミングの基礎
 2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
openmp1_Yaguchi_version_170530
 並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
並列計算とは /OpenMP の初歩 (1) 今 の内容 なぜ並列計算が必要か? スーパーコンピュータの性能動向 1ExaFLOPS 次世代スハ コン 京 1PFLOPS 性能 1TFLOPS 1GFLOPS スカラー機ベクトル機ベクトル並列機並列機 X-MP ncube2 CRAY-1 S-810 SR8000 VPP500 CM-5 ASCI-5 ASCI-4 S3800 T3E-900 SR2201
チューニング講習会 初級編
 GPU のしくみ RICC での使い方 およびベンチマーク 理化学研究所情報基盤センター 2013/6/27 17:00 17:30 中田真秀 RICC の GPU が高速に! ( 旧 C1060 比約 6.6 倍高速 ) RICCのGPUがC2075になりました! C1060 比 6.6 倍高速 倍精度 515GFlops UPCに100 枚導入 : 合計 51.5TFlops うまく行くと5 倍程度高速化
GPU のしくみ RICC での使い方 およびベンチマーク 理化学研究所情報基盤センター 2013/6/27 17:00 17:30 中田真秀 RICC の GPU が高速に! ( 旧 C1060 比約 6.6 倍高速 ) RICCのGPUがC2075になりました! C1060 比 6.6 倍高速 倍精度 515GFlops UPCに100 枚導入 : 合計 51.5TFlops うまく行くと5 倍程度高速化
Microsoft PowerPoint - sales2.ppt
 最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
最適化とは何? CPU アーキテクチャに沿った形で最適な性能を抽出できるようにする技法 ( 性能向上技法 ) コンパイラによるプログラム最適化 コンパイラメーカの技量 経験量に依存 最適化ツールによるプログラム最適化 KAP (Kuck & Associates, Inc. ) 人によるプログラム最適化 アーキテクチャのボトルネックを知ること 3 使用コンパイラによる性能の違い MFLOPS 90
演習1: 演習準備
 演習 1: 演習準備 2013 年 8 月 6 日神戸大学大学院システム情報学研究科森下浩二 1 演習 1 の内容 神戸大 X10(π-omputer) について システム概要 ログイン方法 コンパイルとジョブ実行方法 OpenMP の演習 ( 入門編 ) 1. parallel 構文 実行時ライブラリ関数 2. ループ構文 3. shared 節 private 節 4. reduction 節
演習 1: 演習準備 2013 年 8 月 6 日神戸大学大学院システム情報学研究科森下浩二 1 演習 1 の内容 神戸大 X10(π-omputer) について システム概要 ログイン方法 コンパイルとジョブ実行方法 OpenMP の演習 ( 入門編 ) 1. parallel 構文 実行時ライブラリ関数 2. ループ構文 3. shared 節 private 節 4. reduction 節
XcalableMP入門
 XcalableMP 1 HPC-Phys@, 2018 8 22 XcalableMP XMP XMP Lattice QCD!2 XMP MPI MPI!3 XMP 1/2 PCXMP MPI Fortran CCoarray C++ MPIMPI XMP OpenMP http://xcalablemp.org!4 XMP 2/2 SPMD (Single Program Multiple Data)
XcalableMP 1 HPC-Phys@, 2018 8 22 XcalableMP XMP XMP Lattice QCD!2 XMP MPI MPI!3 XMP 1/2 PCXMP MPI Fortran CCoarray C++ MPIMPI XMP OpenMP http://xcalablemp.org!4 XMP 2/2 SPMD (Single Program Multiple Data)
VXPRO R1400® ご提案資料
 Intel Core i7 プロセッサ 920 Preliminary Performance Report ノード性能評価 ノード性能の評価 NAS Parallel Benchmark Class B OpenMP 版での性能評価 実行スレッド数を 4 で固定 ( デュアルソケットでは各プロセッサに 2 スレッド ) 全て 2.66GHz のコアとなるため コアあたりのピーク性能は同じ 評価システム
Intel Core i7 プロセッサ 920 Preliminary Performance Report ノード性能評価 ノード性能の評価 NAS Parallel Benchmark Class B OpenMP 版での性能評価 実行スレッド数を 4 で固定 ( デュアルソケットでは各プロセッサに 2 スレッド ) 全て 2.66GHz のコアとなるため コアあたりのピーク性能は同じ 評価システム
GPUコンピューティング講習会パート1
 GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
CPU Levels in the memory hierarchy Level 1 Level 2... Increasing distance from the CPU in access time Level n Size of the memory at each level 1: 2.2
 FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
GPUコンピューティングの現状と未来
 GPU コンピューティングの現状と未来 成瀬彰, HPC Developer Technology, NVIDIA Summary 我々のゴールと方向性 ゴール実現に向けて進めている技術開発 Unified Memory, OpenACC Libraries, GPU Direct Kepler の機能紹介 Warp shuffle, Memory system Hyper-Q, Dynamic Parallelism
GPU コンピューティングの現状と未来 成瀬彰, HPC Developer Technology, NVIDIA Summary 我々のゴールと方向性 ゴール実現に向けて進めている技術開発 Unified Memory, OpenACC Libraries, GPU Direct Kepler の機能紹介 Warp shuffle, Memory system Hyper-Q, Dynamic Parallelism
untitled
 A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
スパコンに通じる並列プログラミングの基礎
 2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
スライド 1
 知能制御システム学 画像処理の高速化 OpenCV による基礎的な例 東北大学大学院情報科学研究科鏡慎吾 swk(at)ic.is.tohoku.ac.jp 2007.07.03 リアルタイム処理と高速化 リアルタイム = 高速 ではない 目標となる時間制約が定められているのがリアルタイム処理である.34 ms かかった処理が 33 ms に縮んだだけでも, それによって与えられた時間制約が満たされるのであれば,
知能制御システム学 画像処理の高速化 OpenCV による基礎的な例 東北大学大学院情報科学研究科鏡慎吾 swk(at)ic.is.tohoku.ac.jp 2007.07.03 リアルタイム処理と高速化 リアルタイム = 高速 ではない 目標となる時間制約が定められているのがリアルタイム処理である.34 ms かかった処理が 33 ms に縮んだだけでも, それによって与えられた時間制約が満たされるのであれば,
hpc141_shirahata.pdf
 GPU アクセラレータと不揮発性メモリ を考慮した I/O 性能の予備評価 白幡晃一 1,2 佐藤仁 1,2 松岡聡 1 1: 東京工業大学 2: JST CREST 1 GPU と不揮発性メモリを用いた 大規模データ処理 大規模データ処理 センサーネットワーク 遺伝子情報 SNS など ペタ ヨッタバイト級 高速処理が必要 スーパーコンピュータ上での大規模データ処理 GPU 高性能 高バンド幅 例
GPU アクセラレータと不揮発性メモリ を考慮した I/O 性能の予備評価 白幡晃一 1,2 佐藤仁 1,2 松岡聡 1 1: 東京工業大学 2: JST CREST 1 GPU と不揮発性メモリを用いた 大規模データ処理 大規模データ処理 センサーネットワーク 遺伝子情報 SNS など ペタ ヨッタバイト級 高速処理が必要 スーパーコンピュータ上での大規模データ処理 GPU 高性能 高バンド幅 例
NVIDIA Tesla K20/K20X GPU アクセラレータ アプリケーション パフォーマンス テクニカル ブリーフ
 NVIDIA Tesla K20/K20X GPU アクセラレータ アプリケーション パフォーマンス テクニカル ブリーフ K20 GPU2 個に対するスピードアップ NVIDIA は Fermi アーキテクチャ GPU の発表により パフォーマンス エネルギー効率の両面で飛躍的な性能向上を実現し ハイパフォーマンスコンピューティング (HPC) の世界に変革をもたらしました また 実際に GPU
NVIDIA Tesla K20/K20X GPU アクセラレータ アプリケーション パフォーマンス テクニカル ブリーフ K20 GPU2 個に対するスピードアップ NVIDIA は Fermi アーキテクチャ GPU の発表により パフォーマンス エネルギー効率の両面で飛躍的な性能向上を実現し ハイパフォーマンスコンピューティング (HPC) の世界に変革をもたらしました また 実際に GPU
CUDA基礎1
 CUDA 基礎 1 東京工業大学 学術国際情報センター 黄遠雄 2016/6/27 第 20 回 GPU コンピューティング講習会 1 ヘテロジニアス コンピューティング ヘテロジニアス コンピューティング (CPU + GPU) は広く使われている Financial Analysis Scientific Simulation Engineering Simulation Data Intensive
CUDA 基礎 1 東京工業大学 学術国際情報センター 黄遠雄 2016/6/27 第 20 回 GPU コンピューティング講習会 1 ヘテロジニアス コンピューティング ヘテロジニアス コンピューティング (CPU + GPU) は広く使われている Financial Analysis Scientific Simulation Engineering Simulation Data Intensive
本文ALL.indd
 Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法河辺峻田口成美古谷英祐 Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法 Performance Measurement Method of Cache Coherency Effects on an Intel Xeon Processor System 河辺峻田口成美古谷英祐
Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法河辺峻田口成美古谷英祐 Intel Xeon プロセッサにおける Cache Coherency 時間の性能測定方法 Performance Measurement Method of Cache Coherency Effects on an Intel Xeon Processor System 河辺峻田口成美古谷英祐
GPU 画像 動画処理用ハードウェア 低性能なプロセッサがたくさん詰まっている ピーク性能が非常に高い GPUを数値計算に用いるのがGPGPU Graphics Processing Unit General Purpose GPU TSUBAME2.0: GPUスパコン 本演習ではNVIDIA社の
 演習II (連続系アルゴリズム) 第2回: GPGPU 須田研究室 M1 本谷 徹 motoya@is.s.u-tokyo.ac.jp 2012/10/19 GPU 画像 動画処理用ハードウェア 低性能なプロセッサがたくさん詰まっている ピーク性能が非常に高い GPUを数値計算に用いるのがGPGPU Graphics Processing Unit General Purpose GPU TSUBAME2.0:
演習II (連続系アルゴリズム) 第2回: GPGPU 須田研究室 M1 本谷 徹 motoya@is.s.u-tokyo.ac.jp 2012/10/19 GPU 画像 動画処理用ハードウェア 低性能なプロセッサがたくさん詰まっている ピーク性能が非常に高い GPUを数値計算に用いるのがGPGPU Graphics Processing Unit General Purpose GPU TSUBAME2.0:
並列・高速化を実現するための 高速化サービスの概要と事例紹介
 第 4 回 AVS 可視化フォーラム 2019 並列 高速化を実現するための 高速化サービスの概要と事例紹介 株式会社アーク情報システム営業部仮野亮ソリューション技術部佐々木竜一 2019.08.30 はじめに アーク情報システムの紹介 高速化サービスとは? 事例紹介 コンサルティングサービスについて アーク情報システムの紹介 設立 資本金 :1987 年 10 月 :3 億 600 万円 従業員数
第 4 回 AVS 可視化フォーラム 2019 並列 高速化を実現するための 高速化サービスの概要と事例紹介 株式会社アーク情報システム営業部仮野亮ソリューション技術部佐々木竜一 2019.08.30 はじめに アーク情報システムの紹介 高速化サービスとは? 事例紹介 コンサルティングサービスについて アーク情報システムの紹介 設立 資本金 :1987 年 10 月 :3 億 600 万円 従業員数
HP Workstation 総合カタログ
 HP Workstation Z HP 6 Z HP HP Z840 Workstation P.9 HP Z640 Workstation & CPU P.10 HP Z440 Workstation P.11 17.3in WIDE HP ZBook 17 G2 Mobile Workstation P.15 15.6in WIDE HP ZBook 15 G2 Mobile Workstation
HP Workstation Z HP 6 Z HP HP Z840 Workstation P.9 HP Z640 Workstation & CPU P.10 HP Z440 Workstation P.11 17.3in WIDE HP ZBook 17 G2 Mobile Workstation P.15 15.6in WIDE HP ZBook 15 G2 Mobile Workstation
HPEハイパフォーマンスコンピューティング ソリューション
 HPE HPC / AI Page 2 No.1 * 24.8% No.1 * HPE HPC / AI HPC AI SGIHPE HPC / AI GPU TOP500 50th edition Nov. 2017 HPE No.1 124 www.top500.org HPE HPC / AI TSUBAME 3.0 2017 7 AI TSUBAME 3.0 HPE SGI 8600 System
HPE HPC / AI Page 2 No.1 * 24.8% No.1 * HPE HPC / AI HPC AI SGIHPE HPC / AI GPU TOP500 50th edition Nov. 2017 HPE No.1 124 www.top500.org HPE HPC / AI TSUBAME 3.0 2017 7 AI TSUBAME 3.0 HPE SGI 8600 System
GPU CUDA CUDA 2010/06/28 1
 GPU CUDA CUDA 2010/06/28 1 GPU NVIDIA Mark Harris, Optimizing Parallel Reduction in CUDA http://developer.download.nvidia.com/ compute/cuda/1_1/website/data- Parallel_Algorithms.html#reduction CUDA SDK
GPU CUDA CUDA 2010/06/28 1 GPU NVIDIA Mark Harris, Optimizing Parallel Reduction in CUDA http://developer.download.nvidia.com/ compute/cuda/1_1/website/data- Parallel_Algorithms.html#reduction CUDA SDK
2 09:30-10:00 受付 10:00-12:00 HA-PACS ログイン GPU 入門 13:30-15:00 OpenACC 入門 15:15-16:45 OpenACC 最適化入門と演習 17:00-18:00 OpenACC の活用 (CUDA 連携とライブラリの活用 )
") 担当 大島聡史 ( 助教 ) ohshima@cc.u-tokyo.ac.jp 星野哲也 ( 助教 ) hoshino@cc.u-tokyo.ac.jp 質問やサンプルプログラムの提供についてはメールでお問い合わせください 1 2016 年 10 月 17 日 ( 月 ) 東京大学情報基盤センター 2 09:30-10:00 受付 10:00-12:00 HA-PACS ログイン GPU 入門 13:30-15:00
担当 大島聡史 ( 助教 ) ohshima@cc.u-tokyo.ac.jp 星野哲也 ( 助教 ) hoshino@cc.u-tokyo.ac.jp 質問やサンプルプログラムの提供についてはメールでお問い合わせください 1 2016 年 10 月 17 日 ( 月 ) 東京大学情報基盤センター 2 09:30-10:00 受付 10:00-12:00 HA-PACS ログイン GPU 入門 13:30-15:00
AMD/ATI Radeon HD 5870 GPU DEGIMA LINPACK HD 5870 GPU DEGIMA LINPACK GFlops/Watt GFlops/Watt Abstract GPU Computing has lately attracted
 DEGIMA LINPACK Energy Performance for LINPACK Benchmark on DEGIMA 1 AMD/ATI Radeon HD 5870 GPU DEGIMA LINPACK HD 5870 GPU DEGIMA LINPACK 1.4698 GFlops/Watt 1.9658 GFlops/Watt Abstract GPU Computing has
DEGIMA LINPACK Energy Performance for LINPACK Benchmark on DEGIMA 1 AMD/ATI Radeon HD 5870 GPU DEGIMA LINPACK HD 5870 GPU DEGIMA LINPACK 1.4698 GFlops/Watt 1.9658 GFlops/Watt Abstract GPU Computing has
いまからはじめる組み込みGPU実装
 いまからはじめる組み込み GPU 実装 ~ コンピュータービジョン ディープラーニング編 ~ MathWorks Japan アプリケーションエンジニアリング部シニアアプリケーションエンジニア大塚慶太郎 2017 The MathWorks, Inc. 1 コンピュータービジョン ディープラーニングによる 様々な可能性 自動運転 ロボティクス 予知保全 ( 製造設備 ) セキュリティ 2 転移学習を使った画像分類
いまからはじめる組み込み GPU 実装 ~ コンピュータービジョン ディープラーニング編 ~ MathWorks Japan アプリケーションエンジニアリング部シニアアプリケーションエンジニア大塚慶太郎 2017 The MathWorks, Inc. 1 コンピュータービジョン ディープラーニングによる 様々な可能性 自動運転 ロボティクス 予知保全 ( 製造設備 ) セキュリティ 2 転移学習を使った画像分類
RX ファミリ用 C/C++ コンパイラ V.1.00 Release 02 ご使用上のお願い RX ファミリ用 C/C++ コンパイラの使用上の注意事項 4 件を連絡します #pragma option 使用時の 1 または 2 バイトの整数型の関数戻り値に関する注意事項 (RXC#012) 共用
 共用") RX ファミリ用 C/C++ コンパイラ V.1.00 Release 02 ご使用上のお願い RX ファミリ用 C/C++ コンパイラの使用上の注意事項 4 件を連絡します #pragma option 使用時の 1 または 2 バイトの整数型の関数戻り値に関する注意事項 (RXC#012) 共用体型のローカル変数を文字列操作関数で操作する場合の注意事項 (RXC#013) 配列型構造体または共用体の配列型メンバから読み出した値を動的初期化に用いる場合の注意事項
RX ファミリ用 C/C++ コンパイラ V.1.00 Release 02 ご使用上のお願い RX ファミリ用 C/C++ コンパイラの使用上の注意事項 4 件を連絡します #pragma option 使用時の 1 または 2 バイトの整数型の関数戻り値に関する注意事項 (RXC#012) 共用体型のローカル変数を文字列操作関数で操作する場合の注意事項 (RXC#013) 配列型構造体または共用体の配列型メンバから読み出した値を動的初期化に用いる場合の注意事項
システムソリューションのご紹介
 HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
HP 2 C 製品 :VXPRO/VXSMP サーバ 製品アップデート 製品アップデート VXPRO と VXSMP での製品オプションの追加 8 ポート InfiniBand スイッチ Netlist HyperCloud メモリ VXPRO R2284 GPU サーバ 製品アップデート 8 ポート InfiniBand スイッチ IS5022 8 ポート 40G InfiniBand スイッチ
WebGL OpenGL GLSL Kageyama (Kobe Univ.) Visualization / 57
 Visualization / 57") WebGL 2014.04.15 X021 2014 3 1F Kageyama (Kobe Univ.) Visualization 2014.04.15 1 / 57 WebGL OpenGL GLSL Kageyama (Kobe Univ.) Visualization 2014.04.15 2 / 57 WebGL Kageyama (Kobe Univ.) Visualization 2014.04.15
WebGL 2014.04.15 X021 2014 3 1F Kageyama (Kobe Univ.) Visualization 2014.04.15 1 / 57 WebGL OpenGL GLSL Kageyama (Kobe Univ.) Visualization 2014.04.15 2 / 57 WebGL Kageyama (Kobe Univ.) Visualization 2014.04.15
HP_PPT_Standard_16x9_JP
 Autodesk Simulation に最適 HP Z Workstation 最新情報 日本ヒューレット パッカード株式会社ワークステーション市場開発大橋秀樹 HP Workstation 軌跡 新 Z シリーズ初のモバイル製品 2008 年から日本でマーケットシェア No.1 Unix WS や独自グラフィックスなど開発実績
Autodesk Simulation に最適 HP Z Workstation 最新情報 日本ヒューレット パッカード株式会社ワークステーション市場開発大橋秀樹 HP Workstation 軌跡 新 Z シリーズ初のモバイル製品 2008 年から日本でマーケットシェア No.1 Unix WS や独自グラフィックスなど開発実績
GPUコンピューティング講習会パート1
 GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
GPU コンピューティング (CUDA) 講習会 GPU と GPU を用いた計算の概要 丸山直也 スケジュール 13:20-13:50 GPU を用いた計算の概要 担当丸山 13:50-14:30 GPU コンピューティングによる HPC アプリケーションの高速化の事例紹介 担当青木 14:30-14:40 休憩 14:40-17:00 CUDA プログラミングの基礎 担当丸山 TSUBAME の
表面RTX入稿
 Quadro 2019.04 NVIDIA Quadro NVIDIA Quadro NVIDIA NVIDIA QUADRO BREAKTHROUGH IN EVERY FORM. RTX NVIDIA QUADRO RTX QUADRO RTX FAMILY QUADRO RTX 6000 24 GB 10 Giga Rays/sec QUADRO RTX 4000 8 GB 6 Giga Rays/sec
Quadro 2019.04 NVIDIA Quadro NVIDIA Quadro NVIDIA NVIDIA QUADRO BREAKTHROUGH IN EVERY FORM. RTX NVIDIA QUADRO RTX QUADRO RTX FAMILY QUADRO RTX 6000 24 GB 10 Giga Rays/sec QUADRO RTX 4000 8 GB 6 Giga Rays/sec
OpenCV IS Report No Report Medical Information System Labratry
 OpenCV 2014 8 25 IS Report No. 2014090201 Report Medical Information System Labratry Abstract OpenCV OpenCV 1............................ 2 1.1 OpenCV.......................... 2 1.2......................
OpenCV 2014 8 25 IS Report No. 2014090201 Report Medical Information System Labratry Abstract OpenCV OpenCV 1............................ 2 1.1 OpenCV.......................... 2 1.2......................
名称 : 日本 GPU コンピューティングパートナーシップ (G-DEP) 所在 : 東京都文京区本郷 7 丁目 3 番 1 号東京大学アントレプレナープラザ, 他工場 URL アライアンスパートナー コアテクノロジーパートナー NVIDIA JAPAN ソリュ
 所在 : 東京都文京区本郷 7 丁目 3 番 1 号東京大学アントレプレナープラザ, 他工場 URL アライアンスパートナー コアテクノロジーパートナー NVIDIA JAPAN ソリュ") GPUDirect の現状整理 multi-gpu に取組むために G-DEP チーフエンジニア河井博紀 (kawai@gdep.jp) 名称 : 日本 GPU コンピューティングパートナーシップ (G-DEP) 所在 : 東京都文京区本郷 7 丁目 3 番 1 号東京大学アントレプレナープラザ, 他工場 URL http://www.gdep.jp アライアンスパートナー コアテクノロジーパートナー
GPUDirect の現状整理 multi-gpu に取組むために G-DEP チーフエンジニア河井博紀 (kawai@gdep.jp) 名称 : 日本 GPU コンピューティングパートナーシップ (G-DEP) 所在 : 東京都文京区本郷 7 丁目 3 番 1 号東京大学アントレプレナープラザ, 他工場 URL http://www.gdep.jp アライアンスパートナー コアテクノロジーパートナー
untitled
 A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS /1/18 a a 1 a 2 a 3 a a GPU Graphics Processing Unit GPU CPU GPU GPGPU G
 211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS211 211/1/18 GPU 4 8 BLAS 4 8 BLAS Basic Linear Algebra Subprograms GPU Graphics Processing Unit 4 8 double 2 4 double-double DD 4 4 8 quad-double
211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS211 211/1/18 GPU 4 8 BLAS 4 8 BLAS Basic Linear Algebra Subprograms GPU Graphics Processing Unit 4 8 double 2 4 double-double DD 4 4 8 quad-double
HPC可視化_小野2.pptx
 大 小 二 生 高 方 目 大 方 方 方 Rank Site Processors RMax Processor System Model 1 DOE/NNSA/LANL 122400 1026000 PowerXCell 8i BladeCenter QS22 Cluster 2 DOE/NNSA/LLNL 212992 478200 PowerPC 440 BlueGene/L 3 Argonne
大 小 二 生 高 方 目 大 方 方 方 Rank Site Processors RMax Processor System Model 1 DOE/NNSA/LANL 122400 1026000 PowerXCell 8i BladeCenter QS22 Cluster 2 DOE/NNSA/LLNL 212992 478200 PowerPC 440 BlueGene/L 3 Argonne
Microsoft PowerPoint - OpenMP入門.pptx
 OpenMP 入門 須田礼仁 2009/10/30 初版 OpenMP 共有メモリ並列処理の標準化 API http://openmp.org/ 最新版は 30 3.0 バージョンによる違いはあまり大きくない サポートしているバージョンはともかく csp で動きます gcc も対応しています やっぱり SPMD Single Program Multiple Data プログラム #pragma omp
OpenMP 入門 須田礼仁 2009/10/30 初版 OpenMP 共有メモリ並列処理の標準化 API http://openmp.org/ 最新版は 30 3.0 バージョンによる違いはあまり大きくない サポートしているバージョンはともかく csp で動きます gcc も対応しています やっぱり SPMD Single Program Multiple Data プログラム #pragma omp
b4-deeplearning-embedded-c-mw
 ディープラーニングアプリケーション の組み込み GPU/CPU 実装 アプリケーションエンジニアリング部町田和也 2015 The MathWorks, Inc. 1 アジェンダ MATLAB Coder/GPU Coder の概要 ディープニューラルネットワークの組み込み実装ワークフロー パフォーマンスに関して まとめ 2 ディープラーニングワークフローのおさらい Application logic
ディープラーニングアプリケーション の組み込み GPU/CPU 実装 アプリケーションエンジニアリング部町田和也 2015 The MathWorks, Inc. 1 アジェンダ MATLAB Coder/GPU Coder の概要 ディープニューラルネットワークの組み込み実装ワークフロー パフォーマンスに関して まとめ 2 ディープラーニングワークフローのおさらい Application logic
02_C-C++_osx.indd
 C/C++ OpenMP* / 2 C/C++ OpenMP* OpenMP* 9.0 1... 2 2... 3 3OpenMP*... 5 3.1... 5 3.2 OpenMP*... 6 3.3 OpenMP*... 8 4OpenMP*... 9 4.1... 9 4.2 OpenMP*... 9 4.3 OpenMP*... 10 4.4... 10 5OpenMP*... 11 5.1
C/C++ OpenMP* / 2 C/C++ OpenMP* OpenMP* 9.0 1... 2 2... 3 3OpenMP*... 5 3.1... 5 3.2 OpenMP*... 6 3.3 OpenMP*... 8 4OpenMP*... 9 4.1... 9 4.2 OpenMP*... 9 4.3 OpenMP*... 10 4.4... 10 5OpenMP*... 11 5.1
Microsoft PowerPoint - GDEP-GPG_softek_May24-2.pptx
 G-DEP 第 3 回セミナー PGI OpenACC Compiler PGIコンパイラ使用の実際 新しい OpenACC によるプログラミング 2012 年 5 月 加藤努株式会社ソフテック OpenACC によるプログラミング GPU / Accelerator Computing Model のデファクト スタンダードへ OpenACC Standard 概略説明 Accelerator Programming
G-DEP 第 3 回セミナー PGI OpenACC Compiler PGIコンパイラ使用の実際 新しい OpenACC によるプログラミング 2012 年 5 月 加藤努株式会社ソフテック OpenACC によるプログラミング GPU / Accelerator Computing Model のデファクト スタンダードへ OpenACC Standard 概略説明 Accelerator Programming
Catalog_Quadro_Series_ のコピー2
 NVIDIA Quadro Series NVIDIA Quadro Design, Built, and Tested by NVIDIA NVIDIA QUADRO シリーズ 総合カタログ BREAKTHROUGH IN EVERY FORM. 比類なきパワー 比類なき創造的自由 NVIDIA のこ れ ま で で 最 も 強 力 な GPU アー キ テ クチャであ る NVIDIA Pascal
NVIDIA Quadro Series NVIDIA Quadro Design, Built, and Tested by NVIDIA NVIDIA QUADRO シリーズ 総合カタログ BREAKTHROUGH IN EVERY FORM. 比類なきパワー 比類なき創造的自由 NVIDIA のこ れ ま で で 最 も 強 力 な GPU アー キ テ クチャであ る NVIDIA Pascal
OpenGL GLSL References Kageyama (Kobe Univ.) Visualization / 58
 Visualization / 58") WebGL *1 2013.04.23 *1 X021 2013 LR301 Kageyama (Kobe Univ.) Visualization 2013.04.23 1 / 58 OpenGL GLSL References Kageyama (Kobe Univ.) Visualization 2013.04.23 2 / 58 Kageyama (Kobe Univ.) Visualization
WebGL *1 2013.04.23 *1 X021 2013 LR301 Kageyama (Kobe Univ.) Visualization 2013.04.23 1 / 58 OpenGL GLSL References Kageyama (Kobe Univ.) Visualization 2013.04.23 2 / 58 Kageyama (Kobe Univ.) Visualization