MCMCについて
|
|
|
- ひとお よどぎみ
- 8 years ago
- Views:
Transcription
1 MCMC について 水産資源学におけるベイズ統計の応用ワークショップ 2007 年 8 月 2-3 日, 中央水研 遠洋水産研究所外洋資源部 鯨類管理研究室 岡村寛
2 事後分布からサンプルする Pr(θ 1, θ 2, θ 3, ) θ 1 は重要. あとは必要だけど直接的じゃないというようなとき, P(θ 1 x)= P(θ 1,, θ n x)dθ 2 dθ n を計算したい. モンテカルロ近似 E π (f(x)) = f(x)π(x)dx を計算したい (1/N)Σf(x (i) ) E π (f(x)), x (1),, x (N) ~ π(x) π(x) からデータを取り出せれば良い. しかし, ある確率分布からランダムにデータを取り出すのは一般に難しい
3 MCMC でない方法
4 逆関数法 まず分布関数 F(x) = Pr(X x) の逆関数を求める. 一様分布 U[0,1] から乱数 u を発生.F -1 (u) は分布関数 F(x) の確率分布からとったランダムサンプルとなる. なぜなら, Pr(F -1 (U) x) = Pr(U F(x)) = F(x) だから,F -1 (U) は X に対応している. 例 : 指数分布密度関数 f(x) = 1/2 exp(-x/2) 分布関数 F(x) = Pr(X x) = 1-exp(-x/2) U = F(v) v = - 2log(1-U)
,ylim=c(0,0.5),xlab=\"\",yla b=\"density\",main=\"exponential distribution\",cex.lab=2,cex.main=2) x1 <- seq(0,30,by=0.")
5 逆関数法の例 R プログラム : u1 <- runif(100000,0,1) par(mfrow=c(1,1),mar=c(5,5,5,5)) plot(density(- 2*log(u1)),type="l",lty=1,lwd=3,col=2, xlim=c(0,25),ylim=c(0,0.5),xlab="",yla b="density",main="exponential distribution",cex.lab=2,cex.main=2) x1 <- seq(0,30,by=0.01) lines(x1,dgamma(x1,1,1/2),lty=2,lwd =2,col=1)
6 グリッド法 ( 復習 ) 1 つ 2 つのパラメータ, 細かい分析をする必要がなければ有効 ( 楽チン ) 1. パラメータのグリッドを用意する 2. 各値に事前確率を割り当てる ( 一様分布なら必要なし ) 3. 事後確率 ( 尤度 事前確率 ) を計算. 4. 事後確率に従ってグリッドの値を抽出する 事後サンプル
 にしたがって y を B 個サンプルする 3.")
7 2 変数の場合 上の事後確率行列を M とする. 1. まず x の周辺事後分布から x を B 個サンプルする 2. 次に上でサンプルした x の条件付確率 p(y x) にしたがって y を B 個サンプルする 3. 得られた (x, y) は上の事後確率を持つ分布からのサンプルである
8 R プログラム x <- c(1,2,3); y <- c(1,2,3,4); B < M <- matrix(c(0.017,0.067,0.017,0.083,0.2,0.03 3,0.083,0.117,0.150,0.1,0.133,0),nrow=3,n col=4) nx <- sample(nrow(m),b,replace=t,prob=rowsu ms(m)) x1 <- x[nx] f1 <- function(x) sample(ncol(m),1,replace=t,prob=m[x,]) ny <- apply(as.matrix(nx), 1, f1) y1 <- y[ny] x2 <- x1+rnorm(length(x1),0,0.05) y2 <- y1+rnorm(length(y1),0,0.05) par(mfrow=c(1,1),mar=c(5,5,5,5)) plot(y2,-x2,xlab="y",ylab="x",cex.lab=2)
9 シミュレーションによる資源管理方式 の頑健性評価 さまざまな不確実性 t-1 年末の個体数プロダクションモデル t 年はじめの個体数管理方式によって漁獲 t 年末の個体数 加入 自然死亡の変動自然災害による大量死個体群動態モデルの不確実性資源評価の誤り混獲 投棄 密漁 虚偽報告 100 年後の個体群の減少率, 平均漁獲数などから, 管理方式の違いによる影響を評価
10 シミュレーションを用いる利点 様々な不確実性を取り込んだ上で影響評価が可能 これまでの水産資源評価 管理は, 不確実性の大きさのため, 意思決定が不可能であった. 分からないから何もしない から 分からない中でどうするか へ
11 シミュレーションモデル N t+1 = [N t + r N t {1-(N t /K) z }]exp(u t ), u t ~N(0,s 2 ) 今後 5 年ごとに調査を行って新しい個体数推定値を得る 翌年から最新の個体数推定値に従って捕獲枠を決定.5 年ごとに見直しをする ( 前年に新しい個体数推定値が得られることを想定 ) 捕獲の方法として, 個体数推定値の 2% をとる場合,PBR でとる場合を考える
12 PBR Potential Biological Removal PBR = 1/2R max N min F R N min : 最小個体数推定値 ( 下限 20% 点 ) N min = Nexp(-0.84CV) R max : 純増加率 ( 鯨類 0.04, 鰭脚類 0.12) F R : 回復係数 (0.1 for endangered, 0.5 for depleted)

13 有効なデータ 捕獲統計 個体数推定値
14 コンディショニング 実際のデータに合うような環境収容力のサンプルを取り出す ( ここでグリッド法を使う ) それから将来に対するシミュレーションを行う 環境収容力 K のサンプルの取り出し方 K にある範囲のグリッドデータを割り当てるそれぞれの K に対して, 既存の個体数推定値に基づく尤度を計算尤度の大きさに従って K をサンプルプログラムを配布するので詳細はそれを見てください
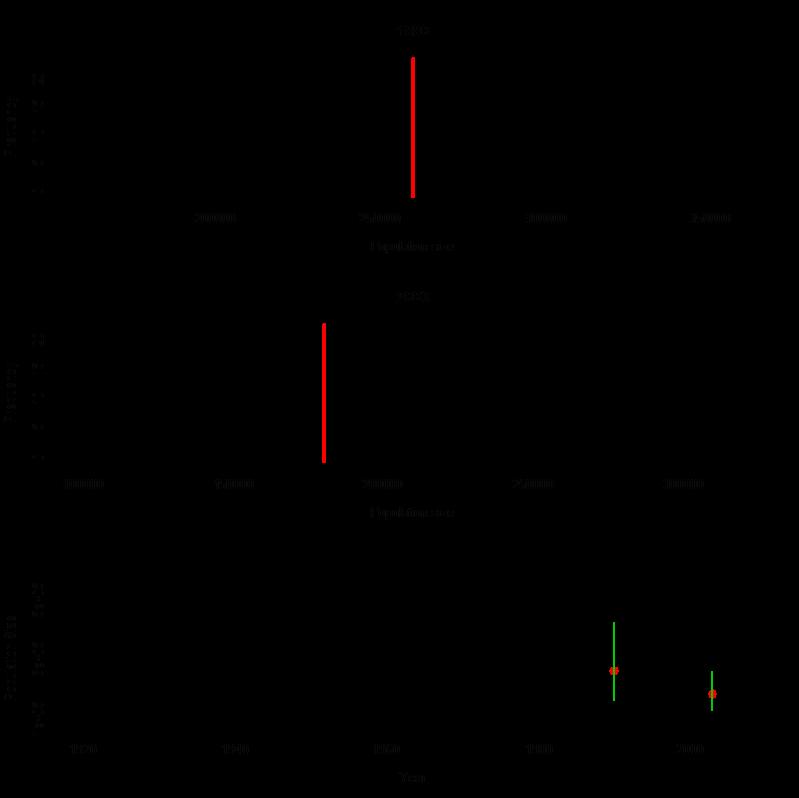
15 コンディショニング結果

16 管理方式の評価 2% 捕獲 PBR(FR=1)
17 頑健性テスト PBR(FR=1) PBR(FR=0.5) 追加分散 = プロセスエラーがある場合の結果
18 Rejection サンプリング ある確率分布 f(x) から乱数を発生させるのが難しいとき, まず発生させやすい確率分布 g(x) から乱数 x* を発生させて, さらに一様分布 U[0,1] から値 u をとり, u < f(x*)/{cg(x*)} ならば,x* をとっておき, u f(x*)/{cg(x*)} ならば x* を捨てる. 結果, 残った x* は f(x) からのランダムサンプル.
19 正規分布からのサンプリング cg(x) = 10/60 f(x * ) N(x 1,3) からサンプルすることを考える. x=1 のとき, 高さ なので, 一様分布 U[-30,30] からデータ x * を発生させてやると,c = 10 とすれば,10/60 = となり, 一様分布 u ~ U[0,1] と N(x * 1,3)/(10/60) を比較することになる. x * ~ U[-30,30]
20 R プログラム x1 <- runif(100000,-30,30) u <- runif(100000) ac1 <- which(u < dnorm(x1,1,3)/(10/60)) x1 <- x1[ac1] plot(density(x1),col=2,lty=1,lwd=4, xlim=c(-15,15),ylim=c(0,0.15), main="n(1,3)",xlab="x",ylab=" Density") x2 <- seq(-15,15,by=0.1) lines(x2,dnorm(x2,1,3),col=1,lty= 2,lwd=3)
21 インポータンスサンプリング Q. 対数正規分布 LN(1.1, 0.6) の平均を求めよ. f(x) からのサンプルが難しいとき, サンプルしやすい g(x) からサンプルして, E(x) = (1/n)Σ{f(x*)/g(x*)}x* と計算する. アルゴリズム : この重みをインポータンス比と呼ぶ x1 <- runif(100000,0,60) mean(dlnorm(x1,1.1,0.6)*x1*60) = 真の平均 exp( /2) = 3.597
22 SIR 法 Sampling-Importance Resampling 法 f(x) からのサンプルは困難,g(x) からは容易 1. g(x) からM 個のサンプルx 1*,, x M* を発生 2. w * = f(x*)/g(x*) を計算 3. x 1*,, x M* からw 1*,, w M* に比例する確率でサン プルをm 個とってくる 4. 得られたm 個のサンプルはf(x) からの事後サンプル
) x2 <- x1[n2] par(mfrow=c(1,1),mar=c(5,5,5,5)) plot(density(x2),lty=1,lwd=3,col=2,xla b=\"x\",ylab=\"density\",main=\"lognormal distribution LN(1.1,0.6)\",xlim=c(0,20),ylim=c(0,0.3 ),cex.")
23 R プログラム x1 <- runif(100000,0,60) n2 <- sample(length(x1), 1000, replace=t, prob=dlnorm(x1,1.1,0.6)) x2 <- x1[n2] par(mfrow=c(1,1),mar=c(5,5,5,5)) plot(density(x2),lty=1,lwd=3,col=2,xla b="x",ylab="density",main="lognormal distribution LN(1.1,0.6)",xlim=c(0,20),ylim=c(0,0.3 ),cex.lab=2,cex.main=1.5) x3 <- seq(0,20,by=0.01) lines(x3,dlnorm(x3,1.1,0.6),lty=2,lwd= 2,col=1)
24 MCMC
25 マルコフ連鎖とは Pr(x t+1 x t,x t-1,x t-2, ) = Pr(x t+1 x t ) 良い性質を持つマルコフ連鎖は定常分布に収束する ( 生態学の例では,Leslie 行列モデルが安定齢分布を持つ, というのを想像せよ ). この性質を使って, 定常分布が ( サンプルしたいけどしにくい )f(x) になるようにデータを生成するのがマルコフ連鎖モンテカルロ法 (MCMC) である. マルコフ性により得られるサンプルは独立でないことに注意 ( これまでと違うとこ ).
26 なぜ MCMC? Rejection サンプリング,SIR 法では, 効率良いサンプリングのために, サンプラー g(x) を上手に選んでやる必要がある 非常に複雑な分布 ( 非線形モデル ), たくさんのパラメータがあるとき, 適当な g(x) を見つけるのは難しい ( ときに不可能 ) マルコフ連鎖を使うのは, 暗闇でいきなり動くとタンスに頭をぶつけるが, 手探りで ( 危ない時にはそろそろ, 行ける時には大胆に ) 動けばより安全というイメージ ( 手探りで動くという部分がマルコフ連鎖 )
27 メトロポリス法 f(x) からサンプルしたい. 1. q(y x)=q(x y) となる分布 ( 対称サンプラーという ) を用意する. たとえば,N(y x,σ 2 ) は対称サンプラー. 2. 初期値 x 0 を決める. 3. q(y x 0 ) からサンプル y を取り出す. 4. 一様分布 U[0,1] から乱数 u を発生. 5. u < f(y)/f(x 0 ) なら,x 1 =y, そうでなければ x 1 =x この操作を繰り返して得た x 1,, x n は f(x) からのサンプルである. x n+1 x n x n+1
28 N(0,1) のサンプリング B < x0 <- -2 e1 <- runif(b,-5,5) u1 <- runif(b,0,1) x1 <- rep(na,b+1) x1[1] <- x0 for (i in 1:B){ xs <- x1[i]+e1[i] x1[i+1] <- ifelse(u1[i] < dnorm(xs)/dnorm(x1[i]), xs, x1[i]) } plot 部分は省略
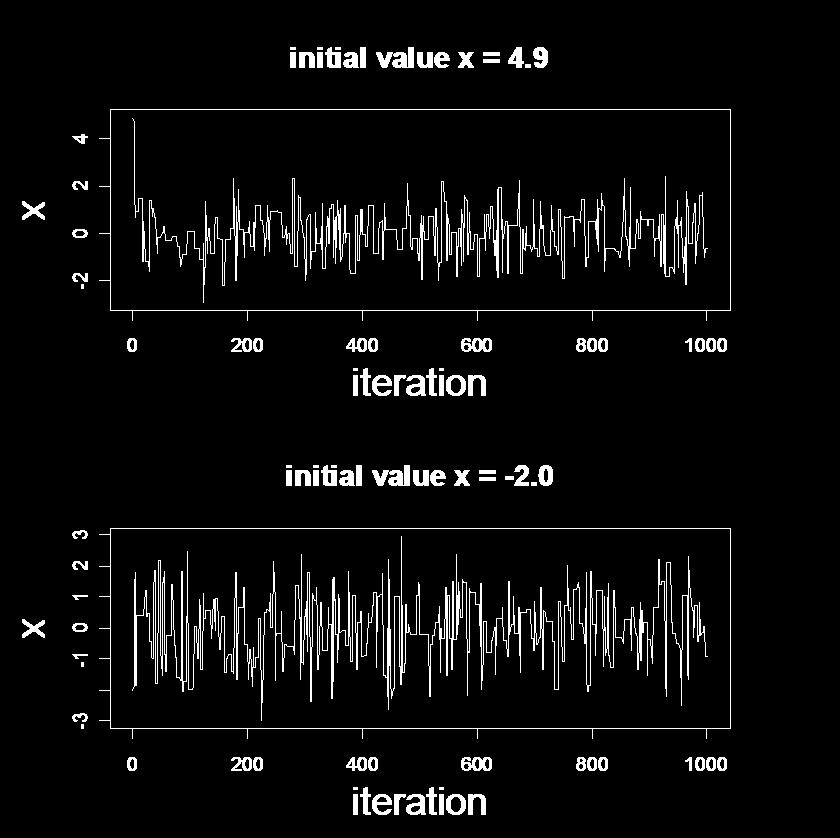

29 初期値の影響
 q(y x) y もし q(x y) > q(y x) ならば,x は y")

30 メトロポリス ヘイスティングス (MH) 法 対称サンプラーでない場合を考えてみる. x q(x y) q(y x) y もし q(x y) > q(y x) ならば,x は y よりもずっとサンプルされやすくなる. これでは正しい f(x) からのサンプルにならない. インポータンスサンプリングと同様に重み付き分布の考え方を使って, 事後分布をインポータンス比で置き換えてやる. つまり,f(x)/q(x y) である.
31 MH 法のアルゴリズム f(x) からサンプルしたい. 1. ある条件付分布 q(y x) を用意する. 2. 初期値 x 0 を決める. 3. q(y x 0 ) からサンプル y を取り出す. 4. 一様分布 U[0,1] から乱数 u を発生. 5. u < {f(y)/q(y x 0 )}/{f(x 0 )/q(x 0 y)} = {f(y)q(x 0 y)}/{f(x 0 )q(y x 0 )} なら,x 1 = y, そうでなければ x 1 =x この操作を繰り返して得た x 1,, x n は f(x) からのサンプルである.
) x1[1] <- x0 y <- rnorm(b,0,s1) u1 <- runif(b) for (i in 1:B){ a1 <-")
32 t(15) のサンプリング 独立サンプラー N(0,1.5 2 ) を使って,t 分布 t(15) からサンプルする. x0 <- -1 s1 <- 1.5 B < x1 <- rep(na,(b+1)) x1[1] <- x0 y <- rnorm(b,0,s1) u1 <- runif(b) for (i in 1:B){ a1 <- min(1,dt(y[i],15)*dnorm(x1[i],0,s1)/(dt(x1[i], 15)*dnorm(y[i],0,s1))) x1[i+1] <- ifelse(u1[i] < a1, y[i], x1[i]) }
33 Single-component MH 法 多変量 f(x 1,x 2, ) の場合 ひとつの変数に対して順番にMH 法を繰り返す 1. x (0), y (0) を決定 2. f(x y (0) ) からのサンプルをMH 法で,x (1) =x * or x (0) 3. f(y x (1) ) からのサンプルをMH 法で,y (1) =y * or y (0) 4. この操作を繰り返す ここで,f(x y) = f(x,y)/ f(x,y)dx ( フル条件付分布 )
")


34 なぜうまくいくか ( 直感的に ) y x 4 y x 7 x y 1 x y 2 x y 6 禁ななめ移動
35 例題 データ x = (1,2,3) を得たとき, 正規分布 N(m,s 2 ) の事後分布は, 事前分布をP(m,s) 1/sとして, P(m,s x) (1/s 4 )exp{-{s 2 +3(m-mx) 2 }/(2s 2 )} となる ( ここで,mx = (1+2+3)/3,S 2 =Σ(x i -mx) 2 ). この P(m,s (1,2,3)) からサンプリングせよ
36 R プログラム x0 <- -1; y0 <- 1; B < e1 <- runif(b,-7,7); u1 <- runif(b,0,1) ys <- rgamma(b,1,1); u2 <- runif(b,0,1) x1 <- y1 <- rep(na,b+1); x1[1] <- x0; y1[1] <- y0 xobs <- c(1,2,3) mx <- mean(xobs); S2 <- sum((xobs-mx)^2) n <- length(xobs); nu <- n-1 MH 法の場合, 分母の積分値がいらないのに注意 post1 <- function(m,s1) (1/s1^(n+1))*exp(-(S2+n*(m-mx)^2)/(2*s1^2)) for (i in 1:B){ xs <- x1[i]+e1[i] x1[i+1] <- ifelse(u1[i] < post1(xs,y1[i])/post1(x1[i],y1[i]), xs, x1[i]) y1[i+1] <- ifelse(u2[i] < post1(x1[i+1],ys[i])*dgamma(y1[i],2,0.5)/(post1(x1[i+1],y1[i])*dgamm a(ys[i],2,0.5)), ys[i], y1[i]) }
 (tは一般化 t 分布 )")
 (IGは逆ガンマ分布)")
37 事後分布 実は, muの周辺事後分布は, t(mx, S 2 /n, n-1) (tは一般化 t 分布 ) s 2 の周辺事後分布は, IG(n/2, S 2 /2) (IGは逆ガンマ分布) に従うことが分かっている.
38 ギブスサンプリング Single-component MH 法でサンプラーをフル条件付分布にする. MH 法の採択確率は,f(x)q(y x)/f(y)q(x y) であるから, サンプルしたい目的の関数 f(x) とサンプルしやすい関数 q(x y) をどちらも同じフル条件付分布にすることになる. よって, 採択確率 =1 効率が良い
39 ギブスサンプリング 多変量関数 f(x 1,x 2,x 3, ) からサンプルひとつの変数に対して順番にフル条件付分布からサンプルする 1. x (0) 1, x (0) 2,x (0) 3, を決定 2. f(x 1 x (0) 2,x (0), 3 ) からサンプルx (1) 1 を得る. 3. f(x 2 x (1) 1,x (0), 3 ) からサンプルx (1) 2 を得る. 4. この操作を繰り返す
40 ギブスサンプリング フル条件付分布からのサンプリングが簡単な場合とても魅力的 フル条件付分布からのサンプリングが簡単ではない場合,Rejection サンプリングや MH 法と組み合わせる (MH 法と組み合わせたとき, MH within Gibbs と呼んだりする ) 明日使う WinBUGS は基本的に Gibbs Sampler を用いて事後分布からサンプルするソフトである
41 例題 2 変量正規分布 x x ~ N, からデータをサンプルする. この場合, x 1 x 2 ~ N(1+0.7(x 2-2), ) x 2 x 1 ~ N(2+0.7(x 1-1), ) となることが分かっている. フル条件付分布からのサンプルは通常の正規分布からのサンプル
{")
![x1[i+1] <- rnorm(1,1+0.7*(x2[i]- 2),sqrt(1-0.](/docs-images/77/75537660/images/42-1.jpg "7^2)) x2[i+1] <- rnorm(1,2+0.")
42 R プログラム B < x1 <- x2 <- rep(na,b+1) x1[1] <- -2; x2[1] <- 1 for (i in 1:B){ x1[i+1] <- rnorm(1,1+0.7*(x2[i]- 2),sqrt(1-0.7^2)) x2[i+1] <- rnorm(1,2+0.7*(x1[i+1]- 1),sqrt(1-0.7^2)) }
43 スライスサンプリング X~f(x) (X,V)~U[(x,v):0 v f(x)] これを使って, 1. u (0), x (0) を決めてやる 2. u (1) ~ U[0, f(x (0) )] 3. x (1) ~ U[x: f(x) u (1) ] 4. この操作を繰り返す (f(x) の代わりにf 1 (x)=cf(x) を用いてもOK)
 からのサンプリングを考えても同じことである.")
44 N(0,1) からのサンプリング u (t+1) N(0,1) からのサンプリングを考える. これは exp(-x 2 /2) からのサンプリングを考えても同じことである. この場合, exp(-x 2 /2) u は,x 2-2log(u) となる. これが slice x (t) x (t+1)
45 R プログラム B < x1 <- u1 <- rep(na,b+1) x1[1] <- 0.5 u1[1] <- 0.5 for (i in 1:B){ u1[i+1] <- runif(1,0,dnorm(x1[i],0,1)*sqrt(2*pi)) x1[i+1] <- runif(1,-sqrt(- 2*log(u1[i+1])),sqrt(-2*log(u1[i+1]))) }
46 Burn-in と Thinning Burn-in: 初期値が目的とする分布のはじっこの方にあるとき, 最初の方のサンプルはまだ定常分布に収束していないので捨ててやる必要がある Thinning: MCMC の結果得られたサンプルは互いに相関しており, 独立なサンプルとなっていない. 独立サンプルを得るためのひとつの (ad hoc) 方法として, ある間隔ごとにデータをとる. コンピュータメモリの節約にも.
47 初期値の影響 自己相関 初期値の影響が大きい 自己相関している
48 収束診断 MCMC 時系列が目的とする分布に収束している必要がある. 収束したかどうかの判定にはいくつかの方法が考えられている. よく使われるのは, 数本のMCMCを走らせて, それらがどれも同じようなところに分布するかどうかを見る方法である ( 詳細は明日のWinBUGSの話で見る ).MCMCではとにかく色々とプロットしてみることが重要である ( そんなときRが便利 ).
49 MCMC 注意 何でも OK な万能薬ではない パラメータが多いと計算時間がかかる パラメータ間の相関が大きいと計算時間がかかる log をとったりすると計算時間がかかる 初期値を変えて同じ結果になるか確かめろ, 計算時間がかかるけど うまくプログラムしないと計算時間がやたらとかかる
50 参考文献 平松一彦 MCMC 入門. 水産資源管理談話会報 34: 大森裕浩 マルコフ連鎖モンテカルロ法の最近の展開. 日本統計学会誌 31: 伊庭幸人 マルコフ連鎖モンテカルロ法の基礎. 統計科学のフロンティア計算統計 II :
Probit , Mixed logit
 Probit, Mixed logit 2016/5/16 スタートアップゼミ #5 B4 後藤祥孝 1 0. 目次 Probit モデルについて 1. モデル概要 2. 定式化と理解 3. 推定 Mixed logit モデルについて 4. モデル概要 5. 定式化と理解 6. 推定 2 1.Probit 概要 プロビットモデルとは. 効用関数の誤差項に多変量正規分布を仮定したもの. 誤差項には様々な要因が存在するため,
Probit, Mixed logit 2016/5/16 スタートアップゼミ #5 B4 後藤祥孝 1 0. 目次 Probit モデルについて 1. モデル概要 2. 定式化と理解 3. 推定 Mixed logit モデルについて 4. モデル概要 5. 定式化と理解 6. 推定 2 1.Probit 概要 プロビットモデルとは. 効用関数の誤差項に多変量正規分布を仮定したもの. 誤差項には様々な要因が存在するため,
スライド 1
 WinBUGS 入門 水産資源学におけるベイズ統計の応用ワークショップ 2007 年 8 月 2-3 日, 中央水研 遠洋水産研究所外洋資源部 鯨類管理研究室 岡村寛 WinBUGS とは BUGS (Bayesian Inference Using Gibbs Sampling) の Windows バージョン フリーのソフトウェア Gibbs samplingを利用した事後確率からのサンプリングを行う
WinBUGS 入門 水産資源学におけるベイズ統計の応用ワークショップ 2007 年 8 月 2-3 日, 中央水研 遠洋水産研究所外洋資源部 鯨類管理研究室 岡村寛 WinBUGS とは BUGS (Bayesian Inference Using Gibbs Sampling) の Windows バージョン フリーのソフトウェア Gibbs samplingを利用した事後確率からのサンプリングを行う
ベイズ統計入門
 ベイズ統計入門 条件付確率 事象 F が起こったことが既知であるという条件の下で E が起こる確率を条件付確率 (codtoal probablt) という P ( E F ) P ( E F ) P( F ) 定義式を変形すると 確率の乗法公式となる ( E F ) P( F ) P( E F ) P( E) P( F E) P 事象の独立 ある事象の生起する確率が 他のある事象が生起するかどうかによって変化しないとき
ベイズ統計入門 条件付確率 事象 F が起こったことが既知であるという条件の下で E が起こる確率を条件付確率 (codtoal probablt) という P ( E F ) P ( E F ) P( F ) 定義式を変形すると 確率の乗法公式となる ( E F ) P( F ) P( E F ) P( E) P( F E) P 事象の独立 ある事象の生起する確率が 他のある事象が生起するかどうかによって変化しないとき
Microsoft Word - 補論3.2
 補論 3. 多変量 GARC モデル 07//6 新谷元嗣 藪友良 対数尤度関数 3 章 7 節では 変量の対数尤度を求めた ここでは多変量の場合 とくに 変量について対数尤度を求める 誤差項 は平均 0 で 次元の正規分布に従うとする 単純化のため 分散と共分散は時間を通じて一定としよう ( この仮定は後で変更される ) したがって ij から添え字 を除くことができる このとき と の尤度関数は
補論 3. 多変量 GARC モデル 07//6 新谷元嗣 藪友良 対数尤度関数 3 章 7 節では 変量の対数尤度を求めた ここでは多変量の場合 とくに 変量について対数尤度を求める 誤差項 は平均 0 で 次元の正規分布に従うとする 単純化のため 分散と共分散は時間を通じて一定としよう ( この仮定は後で変更される ) したがって ij から添え字 を除くことができる このとき と の尤度関数は
講義「○○○○」
 講義 信頼度の推定と立証 内容. 点推定と区間推定. 指数分布の点推定 区間推定 3. 指数分布 正規分布の信頼度推定 担当 : 倉敷哲生 ( ビジネスエンジニアリング専攻 ) 統計的推測 標本から得られる情報を基に 母集団に関する結論の導出が目的 測定値 x x x 3 : x 母集団 (populaio) 母集団の特性値 統計的推測 標本 (sample) 標本の特性値 分布のパラメータ ( 母数
講義 信頼度の推定と立証 内容. 点推定と区間推定. 指数分布の点推定 区間推定 3. 指数分布 正規分布の信頼度推定 担当 : 倉敷哲生 ( ビジネスエンジニアリング専攻 ) 統計的推測 標本から得られる情報を基に 母集団に関する結論の導出が目的 測定値 x x x 3 : x 母集団 (populaio) 母集団の特性値 統計的推測 標本 (sample) 標本の特性値 分布のパラメータ ( 母数
Microsoft PowerPoint - 14回パラメータ推定配布用.pptx
 パラメータ推定の理論と実践 BEhavior Study for Transportation Graduate school, Univ. of Yamanashi 山梨大学佐々木邦明 最尤推定法 点推定量を求める最もポピュラーな方法 L n x n i1 f x i 右上の式を θ の関数とみなしたものが尤度関数 データ (a,b) が得られたとき, 全体の平均がいくつとするのがよいか 平均がいくつだったら
パラメータ推定の理論と実践 BEhavior Study for Transportation Graduate school, Univ. of Yamanashi 山梨大学佐々木邦明 最尤推定法 点推定量を求める最もポピュラーな方法 L n x n i1 f x i 右上の式を θ の関数とみなしたものが尤度関数 データ (a,b) が得られたとき, 全体の平均がいくつとするのがよいか 平均がいくつだったら
様々なミクロ計量モデル†
 担当 : 長倉大輔 ( ながくらだいすけ ) この資料は私の講義において使用するために作成した資料です WEB ページ上で公開しており 自由に参照して頂いて構いません ただし 内容について 一応検証してありますが もし間違いがあった場合でもそれによって生じるいかなる損害 不利益について責任を負いかねますのでご了承ください 間違いは発見次第 継続的に直していますが まだ存在する可能性があります 1 カウントデータモデル
担当 : 長倉大輔 ( ながくらだいすけ ) この資料は私の講義において使用するために作成した資料です WEB ページ上で公開しており 自由に参照して頂いて構いません ただし 内容について 一応検証してありますが もし間違いがあった場合でもそれによって生じるいかなる損害 不利益について責任を負いかねますのでご了承ください 間違いは発見次第 継続的に直していますが まだ存在する可能性があります 1 カウントデータモデル
Microsoft Word - å“Ÿåłžå¸°173.docx
 回帰分析 ( その 3) 経済情報処理 価格弾力性の推定ある商品について その購入量を w 単価を p とし それぞれの変化量を w p で表 w w すことにする この時 この商品の価格弾力性 は により定義される これ p p は p が 1 パーセント変化した場合に w が何パーセント変化するかを示したものである ここで p を 0 に近づけていった極限を考えると d ln w 1 dw dw
回帰分析 ( その 3) 経済情報処理 価格弾力性の推定ある商品について その購入量を w 単価を p とし それぞれの変化量を w p で表 w w すことにする この時 この商品の価格弾力性 は により定義される これ p p は p が 1 パーセント変化した場合に w が何パーセント変化するかを示したものである ここで p を 0 に近づけていった極限を考えると d ln w 1 dw dw
kubo2015ngt6 p.2 ( ( (MLE 8 y i L(q q log L(q q 0 ˆq log L(q / q = 0 q ˆq = = = * ˆq = 0.46 ( 8 y 0.46 y y y i kubo (ht
 kubo2015ngt6 p.1 2015 (6 MCMC [email protected], @KuboBook http://goo.gl/m8hsbm 1 ( 2 3 4 5 JAGS : 2015 05 18 16:48 kubo (http://goo.gl/m8hsbm 2015 (6 1 / 70 kubo (http://goo.gl/m8hsbm 2015 (6 2 /
kubo2015ngt6 p.1 2015 (6 MCMC [email protected], @KuboBook http://goo.gl/m8hsbm 1 ( 2 3 4 5 JAGS : 2015 05 18 16:48 kubo (http://goo.gl/m8hsbm 2015 (6 1 / 70 kubo (http://goo.gl/m8hsbm 2015 (6 2 /
ii 3.,. 4. F. (), ,,. 8.,. 1. (75% ) (25% ) =9 7, =9 8 (. ). 1.,, (). 3.,. 1. ( ).,.,.,.,.,. ( ) (1 2 )., ( ), 0. 2., 1., 0,.
, ,,. 8.,. 1. (75% ) (25% ) =9 7, =9 8 (. ). 1.,, (). 3.,. 1. ( ).,.,.,.,.,. ( ) (1 2 )., ( ), 0. 2., 1., 0,.") 23(2011) (1 C104) 5 11 (2 C206) 5 12 http://www.math.is.tohoku.ac.jp/~obata,.,,,.. 1. 2. 3. 4. 5. 6. 7.,,. 1., 2007 ( ). 2. P. G. Hoel, 1995. 3... 1... 2.,,. ii 3.,. 4. F. (),.. 5.. 6.. 7.,,. 8.,. 1. (75%
23(2011) (1 C104) 5 11 (2 C206) 5 12 http://www.math.is.tohoku.ac.jp/~obata,.,,,.. 1. 2. 3. 4. 5. 6. 7.,,. 1., 2007 ( ). 2. P. G. Hoel, 1995. 3... 1... 2.,,. ii 3.,. 4. F. (),.. 5.. 6.. 7.,,. 8.,. 1. (75%
スライド 1
 データ解析特論第 10 回 ( 全 15 回 ) 2012 年 12 月 11 日 ( 火 ) 情報エレクトロニクス専攻横田孝義 1 終了 11/13 11/20 重回帰分析をしばらくやります 12/4 12/11 12/18 2 前回から回帰分析について学習しています 3 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える
データ解析特論第 10 回 ( 全 15 回 ) 2012 年 12 月 11 日 ( 火 ) 情報エレクトロニクス専攻横田孝義 1 終了 11/13 11/20 重回帰分析をしばらくやります 12/4 12/11 12/18 2 前回から回帰分析について学習しています 3 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える
ファイナンスのための数学基礎 第1回 オリエンテーション、ベクトル
 時系列分析 変量時系列モデルとその性質 担当 : 長倉大輔 ( ながくらだいすけ 時系列モデル 時系列モデルとは時系列データを生み出すメカニズムとなるものである これは実際には未知である 私たちにできるのは観測された時系列データからその背後にある時系列モデルを推測 推定するだけである 以下ではいくつかの代表的な時系列モデルを考察する 自己回帰モデル (Auoregressive Model もっとも頻繁に使われる時系列モデルは自己回帰モデル
時系列分析 変量時系列モデルとその性質 担当 : 長倉大輔 ( ながくらだいすけ 時系列モデル 時系列モデルとは時系列データを生み出すメカニズムとなるものである これは実際には未知である 私たちにできるのは観測された時系列データからその背後にある時系列モデルを推測 推定するだけである 以下ではいくつかの代表的な時系列モデルを考察する 自己回帰モデル (Auoregressive Model もっとも頻繁に使われる時系列モデルは自己回帰モデル
NLMIXED プロシジャを用いた生存時間解析 伊藤要二アストラゼネカ株式会社臨床統計 プログラミング グループグルプ Survival analysis using PROC NLMIXED Yohji Itoh Clinical Statistics & Programming Group, A
 NLMIXED プロシジャを用いた生存時間解析 伊藤要二アストラゼネカ株式会社臨床統計 プログラミング グループグルプ Survival analysis using PROC NLMIXED Yohji Itoh Clinical Statistics & Programming Group, AstraZeneca KK 要旨 : NLMIXEDプロシジャの最尤推定の機能を用いて 指数分布 Weibull
NLMIXED プロシジャを用いた生存時間解析 伊藤要二アストラゼネカ株式会社臨床統計 プログラミング グループグルプ Survival analysis using PROC NLMIXED Yohji Itoh Clinical Statistics & Programming Group, AstraZeneca KK 要旨 : NLMIXEDプロシジャの最尤推定の機能を用いて 指数分布 Weibull
PowerPoint プレゼンテーション
 1/X Chapter 9: Linear correlation Cohen, B. H. (2007). In B. H. Cohen (Ed.), Explaining Psychological Statistics (3rd ed.) (pp. 255-285). NJ: Wiley. 概要 2/X 相関係数とは何か 相関係数の数式 検定 注意点 フィッシャーのZ 変換 信頼区間 相関係数の差の検定
1/X Chapter 9: Linear correlation Cohen, B. H. (2007). In B. H. Cohen (Ed.), Explaining Psychological Statistics (3rd ed.) (pp. 255-285). NJ: Wiley. 概要 2/X 相関係数とは何か 相関係数の数式 検定 注意点 フィッシャーのZ 変換 信頼区間 相関係数の差の検定
14 化学実験法 II( 吉村 ( 洋 mmol/l の半分だったから さんの測定値は くんの測定値の 4 倍の重みがあり 推定値 としては 0.68 mmol/l その標準偏差は mmol/l 程度ということになる 測定値を 特徴づけるパラメータ t を推定するこの手
 14 化学実験法 II( 吉村 ( 洋 014.6.1. 最小 乗法のはなし 014.6.1. 内容 最小 乗法のはなし...1 最小 乗法の考え方...1 最小 乗法によるパラメータの決定... パラメータの信頼区間...3 重みの異なるデータの取扱い...4 相関係数 決定係数 ( 最小 乗法を語るもう一つの立場...5 実験条件の誤差の影響...5 問題...6 最小 乗法の考え方 飲料水中のカルシウム濃度を
14 化学実験法 II( 吉村 ( 洋 014.6.1. 最小 乗法のはなし 014.6.1. 内容 最小 乗法のはなし...1 最小 乗法の考え方...1 最小 乗法によるパラメータの決定... パラメータの信頼区間...3 重みの異なるデータの取扱い...4 相関係数 決定係数 ( 最小 乗法を語るもう一つの立場...5 実験条件の誤差の影響...5 問題...6 最小 乗法の考え方 飲料水中のカルシウム濃度を
第 3 回講義の項目と概要 統計的手法入門 : 品質のばらつきを解析する 平均と標準偏差 (P30) a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均
 a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均") 第 3 回講義の項目と概要 016.8.9 1.3 統計的手法入門 : 品質のばらつきを解析する 1.3.1 平均と標準偏差 (P30) a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均 :AVERAGE 関数, 標準偏差 :STDEVP 関数とSTDEVという関数 1 取得したデータそのものの標準偏差
第 3 回講義の項目と概要 016.8.9 1.3 統計的手法入門 : 品質のばらつきを解析する 1.3.1 平均と標準偏差 (P30) a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均 :AVERAGE 関数, 標準偏差 :STDEVP 関数とSTDEVという関数 1 取得したデータそのものの標準偏差
() Remrk I = [0, ] [x i, x i ]. (x : ) f(x) = 0 (x : ) ξ i, (f) = f(ξ i )(x i x i ) = (x i x i ) = ξ i, (f) = f(ξ i )(x i x i ) = 0 (f) 0.
![() Remrk I = [0, ] [x i, x i ]. (x : ) f(x) = 0 (x : ) ξ i, (f) = f(ξ i )(x i x i ) = (x i x i ) = ξ i, (f) = f(ξ i )(x i x i ) = 0 (f) 0.](/thumbs/89/98384840.jpg "() Remrk I = [0, ] [x i, x i ]. (x : ) f(x) = 0 (x : ) ξ i, (f) = f(ξ i )(x i x i ) = (x i x i ) = ξ i, (f) = f(ξ i )(x i x i ) = 0 (f) 0.") () 6 f(x) [, b] 6. Riemnn [, b] f(x) S f(x) [, b] (Riemnn) = x 0 < x < x < < x n = b. I = [, b] = {x,, x n } mx(x i x i ) =. i [x i, x i ] ξ i n (f) = f(ξ i )(x i x i ) i=. (ξ i ) (f) 0( ), ξ i, S, ε >
() 6 f(x) [, b] 6. Riemnn [, b] f(x) S f(x) [, b] (Riemnn) = x 0 < x < x < < x n = b. I = [, b] = {x,, x n } mx(x i x i ) =. i [x i, x i ] ξ i n (f) = f(ξ i )(x i x i ) i=. (ξ i ) (f) 0( ), ξ i, S, ε >
基礎統計
 基礎統計 第 11 回講義資料 6.4.2 標本平均の差の標本分布 母平均の差 標本平均の差をみれば良い ただし, 母分散に依存するため場合分けをする 1 2 3 分散が既知分散が未知であるが等しい分散が未知であり等しいとは限らない 1 母分散が既知のとき が既知 標準化変量 2 母分散が未知であり, 等しいとき 分散が未知であるが, 等しいということは分かっているとき 標準化変量 自由度 の t
基礎統計 第 11 回講義資料 6.4.2 標本平均の差の標本分布 母平均の差 標本平均の差をみれば良い ただし, 母分散に依存するため場合分けをする 1 2 3 分散が既知分散が未知であるが等しい分散が未知であり等しいとは限らない 1 母分散が既知のとき が既知 標準化変量 2 母分散が未知であり, 等しいとき 分散が未知であるが, 等しいということは分かっているとき 標準化変量 自由度 の t
Kumamoto University Center for Multimedia and Information Technologies Lab. 熊本大学アプリケーション実験 ~ 実環境における無線 LAN 受信電波強度を用いた位置推定手法の検討 ~ InKIAI 宮崎県美郷
 熊本大学アプリケーション実験 ~ 実環境における無線 LAN 受信電波強度を用いた位置推定手法の検討 ~ InKIAI プロジェクト @ 宮崎県美郷町 熊本大学副島慶人川村諒 1 実験の目的 従来 信号の受信電波強度 (RSSI:RecevedSgnal StrengthIndcator) により 対象の位置を推定する手法として 無線 LAN の AP(AccessPont) から受信する信号の減衰量をもとに位置を推定する手法が多く検討されている
熊本大学アプリケーション実験 ~ 実環境における無線 LAN 受信電波強度を用いた位置推定手法の検討 ~ InKIAI プロジェクト @ 宮崎県美郷町 熊本大学副島慶人川村諒 1 実験の目的 従来 信号の受信電波強度 (RSSI:RecevedSgnal StrengthIndcator) により 対象の位置を推定する手法として 無線 LAN の AP(AccessPont) から受信する信号の減衰量をもとに位置を推定する手法が多く検討されている
Microsoft PowerPoint - H17-5時限(パターン認識).ppt
.ppt") パターン認識早稲田大学講義 平成 7 年度 独 産業技術総合研究所栗田多喜夫 赤穂昭太郎 統計的特徴抽出 パターン認識過程 特徴抽出 認識対象から何らかの特徴量を計測 抽出 する必要がある 認識に有効な情報 特徴 を抽出し 次元を縮小した効率の良い空間を構成する過程 文字認識 : スキャナ等で取り込んだ画像から文字の識別に必要な本質的な特徴のみを抽出 例 文字線の傾き 曲率 面積など 識別 与えられた未知の対象を
パターン認識早稲田大学講義 平成 7 年度 独 産業技術総合研究所栗田多喜夫 赤穂昭太郎 統計的特徴抽出 パターン認識過程 特徴抽出 認識対象から何らかの特徴量を計測 抽出 する必要がある 認識に有効な情報 特徴 を抽出し 次元を縮小した効率の良い空間を構成する過程 文字認識 : スキャナ等で取り込んだ画像から文字の識別に必要な本質的な特徴のみを抽出 例 文字線の傾き 曲率 面積など 識別 与えられた未知の対象を
memo
 数理情報工学特論第一 機械学習とデータマイニング 4 章 : 教師なし学習 3 かしまひさし 鹿島久嗣 ( 数理 6 研 ) [email protected].~ DEPARTMENT OF MATHEMATICAL INFORMATICS 1 グラフィカルモデルについて学びます グラフィカルモデル グラフィカルラッソ グラフィカルラッソの推定アルゴリズム 2 グラフィカルモデル 3 教師なし学習の主要タスクは
数理情報工学特論第一 機械学習とデータマイニング 4 章 : 教師なし学習 3 かしまひさし 鹿島久嗣 ( 数理 6 研 ) [email protected].~ DEPARTMENT OF MATHEMATICAL INFORMATICS 1 グラフィカルモデルについて学びます グラフィカルモデル グラフィカルラッソ グラフィカルラッソの推定アルゴリズム 2 グラフィカルモデル 3 教師なし学習の主要タスクは
統計学 - 社会統計の基礎 - 正規分布 標準正規分布累積分布関数の逆関数 t 分布正規分布に従うサンプルの平均の信頼区間 担当 : 岸 康人 資料ページ :
 統計学 - 社会統計の基礎 - 正規分布 標準正規分布累積分布関数の逆関数 t 分布正規分布に従うサンプルの平均の信頼区間 担当 : 岸 康人 資料ページ : https://goo.gl/qw1djw 正規分布 ( 復習 ) 正規分布 (Normal Distribution)N (μ, σ 2 ) 別名 : ガウス分布 (Gaussian Distribution) 密度関数 Excel:= NORM.DIST
統計学 - 社会統計の基礎 - 正規分布 標準正規分布累積分布関数の逆関数 t 分布正規分布に従うサンプルの平均の信頼区間 担当 : 岸 康人 資料ページ : https://goo.gl/qw1djw 正規分布 ( 復習 ) 正規分布 (Normal Distribution)N (μ, σ 2 ) 別名 : ガウス分布 (Gaussian Distribution) 密度関数 Excel:= NORM.DIST
Microsoft Word - 微分入門.doc
 基本公式 例題 0 定義式 f( ) 数 Ⅲ 微分入門 = の導関数を定義式にもとづいて計算しなさい 基本事項 ( f( ), g( ) が微分可能ならば ) y= f( ) g( ) のとき, y = y= f( ) g( ) h( ) のとき, y = ( f( ), g( ) が微分可能で, g( ) 0 ならば ) f( ) y = のとき, y = g ( ) とくに, y = のとき,
基本公式 例題 0 定義式 f( ) 数 Ⅲ 微分入門 = の導関数を定義式にもとづいて計算しなさい 基本事項 ( f( ), g( ) が微分可能ならば ) y= f( ) g( ) のとき, y = y= f( ) g( ) h( ) のとき, y = ( f( ), g( ) が微分可能で, g( ) 0 ならば ) f( ) y = のとき, y = g ( ) とくに, y = のとき,
Microsoft PowerPoint - 基礎・経済統計6.ppt
 . 確率変数 基礎 経済統計 6 確率分布 事象を数値化したもの ( 事象ー > 数値 の関数 自然に数値されている場合 さいころの目 量的尺度 数値化が必要な場合 質的尺度, 順序的尺度 それらの尺度に数値を割り当てる 例えば, コインの表が出たら, 裏なら 0. 離散確率変数と連続確率変数 確率変数の値 連続値をとるもの 身長, 体重, 実質 GDP など とびとびの値 離散値をとるもの 新生児の性別
. 確率変数 基礎 経済統計 6 確率分布 事象を数値化したもの ( 事象ー > 数値 の関数 自然に数値されている場合 さいころの目 量的尺度 数値化が必要な場合 質的尺度, 順序的尺度 それらの尺度に数値を割り当てる 例えば, コインの表が出たら, 裏なら 0. 離散確率変数と連続確率変数 確率変数の値 連続値をとるもの 身長, 体重, 実質 GDP など とびとびの値 離散値をとるもの 新生児の性別
統計的データ解析
 統計的データ解析 011 011.11.9 林田清 ( 大阪大学大学院理学研究科 ) 連続確率分布の平均値 分散 比較のため P(c ) c 分布 自由度 の ( カイ c 平均値 0, 標準偏差 1の正規分布 に従う変数 xの自乗和 c x =1 が従う分布を自由度 の分布と呼ぶ 一般に自由度の分布は f /1 c / / ( c ) {( c ) e }/ ( / ) 期待値 二乗 ) 分布 c
統計的データ解析 011 011.11.9 林田清 ( 大阪大学大学院理学研究科 ) 連続確率分布の平均値 分散 比較のため P(c ) c 分布 自由度 の ( カイ c 平均値 0, 標準偏差 1の正規分布 に従う変数 xの自乗和 c x =1 が従う分布を自由度 の分布と呼ぶ 一般に自由度の分布は f /1 c / / ( c ) {( c ) e }/ ( / ) 期待値 二乗 ) 分布 c
CAEシミュレーションツールを用いた統計の基礎教育 | (株)日科技研
日科技研") CAE シミュレーションツール を用いた統計の基礎教育 ( 株 ) 日本科学技術研修所数理事業部 1 現在の統計教育の課題 2009 年から統計教育が中等 高等教育の必須科目となり, 大学でも問題解決ができるような人材 ( 学生 ) を育てたい. 大学ではコンピューター ( 統計ソフトの利用 ) を重視した教育をより積極的におこなうのと同時に, 理論面もきちんと教育すべきである. ( 報告 数理科学分野における統計科学教育
CAE シミュレーションツール を用いた統計の基礎教育 ( 株 ) 日本科学技術研修所数理事業部 1 現在の統計教育の課題 2009 年から統計教育が中等 高等教育の必須科目となり, 大学でも問題解決ができるような人材 ( 学生 ) を育てたい. 大学ではコンピューター ( 統計ソフトの利用 ) を重視した教育をより積極的におこなうのと同時に, 理論面もきちんと教育すべきである. ( 報告 数理科学分野における統計科学教育
OpRisk VaR3.2 Presentation
 オペレーショナル リスク VaR 計量の実施例 2009 年 5 月 SAS Institute Japan 株式会社 RI ビジネス開発部羽柴利明 オペレーショナル リスク計量の枠組み SAS OpRisk VaR の例 損失情報スケーリング計量単位の設定分布推定各種調整 VaR 計量 内部損失データ スケーリング 頻度分布 規模分布 分布の補正相関調整外部データによる分布の補正 損失シナリオ 分布の統合モンテカルロシミュレーション
オペレーショナル リスク VaR 計量の実施例 2009 年 5 月 SAS Institute Japan 株式会社 RI ビジネス開発部羽柴利明 オペレーショナル リスク計量の枠組み SAS OpRisk VaR の例 損失情報スケーリング計量単位の設定分布推定各種調整 VaR 計量 内部損失データ スケーリング 頻度分布 規模分布 分布の補正相関調整外部データによる分布の補正 損失シナリオ 分布の統合モンテカルロシミュレーション
Microsoft PowerPoint - 統計科学研究所_R_重回帰分析_変数選択_2.ppt
 重回帰分析 残差分析 変数選択 1 内容 重回帰分析 残差分析 歯の咬耗度データの分析 R で変数選択 ~ step 関数 ~ 2 重回帰分析と単回帰分析 体重を予測する問題 分析 1 身長 のみから体重を予測 分析 2 身長 と ウエスト の両方を用いて体重を予測 分析 1 と比べて大きな改善 体重 に関する推測では 身長 だけでは不十分 重回帰分析における問題 ~ モデルの構築 ~ 適切なモデルで分析しているか?
重回帰分析 残差分析 変数選択 1 内容 重回帰分析 残差分析 歯の咬耗度データの分析 R で変数選択 ~ step 関数 ~ 2 重回帰分析と単回帰分析 体重を予測する問題 分析 1 身長 のみから体重を予測 分析 2 身長 と ウエスト の両方を用いて体重を予測 分析 1 と比べて大きな改善 体重 に関する推測では 身長 だけでは不十分 重回帰分析における問題 ~ モデルの構築 ~ 適切なモデルで分析しているか?
EBNと疫学
 推定と検定 57 ( 復習 ) 記述統計と推測統計 統計解析は大きく 2 つに分けられる 記述統計 推測統計 記述統計 観察集団の特性を示すもの 代表値 ( 平均値や中央値 ) や ばらつきの指標 ( 標準偏差など ) 図表を効果的に使う 推測統計 観察集団のデータから母集団の特性を 推定 する 平均 / 分散 / 係数値などの推定 ( 点推定 ) 点推定値のばらつきを調べる ( 区間推定 ) 検定統計量を用いた検定
推定と検定 57 ( 復習 ) 記述統計と推測統計 統計解析は大きく 2 つに分けられる 記述統計 推測統計 記述統計 観察集団の特性を示すもの 代表値 ( 平均値や中央値 ) や ばらつきの指標 ( 標準偏差など ) 図表を効果的に使う 推測統計 観察集団のデータから母集団の特性を 推定 する 平均 / 分散 / 係数値などの推定 ( 点推定 ) 点推定値のばらつきを調べる ( 区間推定 ) 検定統計量を用いた検定
PowerPoint プレゼンテーション
 第 6 回基礎ゼミ資料 Practice NL&MXL from R 平成 30 年 5 月 18 日 ( 金 ) 朝倉研究室修士 1 年小池卓武 使用データ 1 ~ 横浜プローブパーソンデータ ~ 主なデータの中身 トリップ ID 目的 出発, 到着時刻 総所要時間 移動距離 交通機関別の時間, 距離 アクセス, イグレス時間, 距離 費用 代表交通手段 代替手段生成可否 性別, 年齢等の個人属性
第 6 回基礎ゼミ資料 Practice NL&MXL from R 平成 30 年 5 月 18 日 ( 金 ) 朝倉研究室修士 1 年小池卓武 使用データ 1 ~ 横浜プローブパーソンデータ ~ 主なデータの中身 トリップ ID 目的 出発, 到着時刻 総所要時間 移動距離 交通機関別の時間, 距離 アクセス, イグレス時間, 距離 費用 代表交通手段 代替手段生成可否 性別, 年齢等の個人属性
ii 3.,. 4. F. (), ,,. 8.,. 1. (75%) (25%) =7 20, =7 21 (. ). 1.,, (). 3.,. 1. ().,.,.,.,.,. () (12 )., (), 0. 2., 1., 0,.
, ,,. 8.,. 1. (75%) (25%) =7 20, =7 21 (. ). 1.,, (). 3.,. 1. ().,.,.,.,.,. () (12 )., (), 0. 2., 1., 0,.") 24(2012) (1 C106) 4 11 (2 C206) 4 12 http://www.math.is.tohoku.ac.jp/~obata,.,,,.. 1. 2. 3. 4. 5. 6. 7.,,. 1., 2007 (). 2. P. G. Hoel, 1995. 3... 1... 2.,,. ii 3.,. 4. F. (),.. 5... 6.. 7.,,. 8.,. 1. (75%)
24(2012) (1 C106) 4 11 (2 C206) 4 12 http://www.math.is.tohoku.ac.jp/~obata,.,,,.. 1. 2. 3. 4. 5. 6. 7.,,. 1., 2007 (). 2. P. G. Hoel, 1995. 3... 1... 2.,,. ii 3.,. 4. F. (),.. 5... 6.. 7.,,. 8.,. 1. (75%)
Stanによるハミルトニアンモンテカルロ法を用いたサンプリングについて
 Stan によるハミルトニアンモンテカルロ法を用いたサンプリングについて 10 月 22 日中村文士 1 目次 1.STANについて 2.RでSTANをするためのインストール 3.STANのコード記述方法 4.STANによるサンプリングの例 2 1.STAN について ハミルトニアンモンテカルロ法に基づいた事後分布からのサンプリングなどができる STAN の HP: mc-stan.org 3 由来
Stan によるハミルトニアンモンテカルロ法を用いたサンプリングについて 10 月 22 日中村文士 1 目次 1.STANについて 2.RでSTANをするためのインストール 3.STANのコード記述方法 4.STANによるサンプリングの例 2 1.STAN について ハミルトニアンモンテカルロ法に基づいた事後分布からのサンプリングなどができる STAN の HP: mc-stan.org 3 由来
x = a 1 f (a r, a + r) f(a) r a f f(a) 2 2. (a, b) 2 f (a, b) r f(a, b) r (a, b) f f(a, b)
 f(a) r a f f(a) 2 2. (a, b) 2 f (a, b) r f(a, b) r (a, b) f f(a, b)") 2011 I 2 II III 17, 18, 19 7 7 1 2 2 2 1 2 1 1 1.1.............................. 2 1.2 : 1.................... 4 1.2.1 2............................... 5 1.3 : 2.................... 5 1.3.1 2.....................................
2011 I 2 II III 17, 18, 19 7 7 1 2 2 2 1 2 1 1 1.1.............................. 2 1.2 : 1.................... 4 1.2.1 2............................... 5 1.3 : 2.................... 5 1.3.1 2.....................................
ボルツマンマシンの高速化
 1. はじめに ボルツマン学習と平均場近似 山梨大学工学部宗久研究室 G04MK016 鳥居圭太 ボルツマンマシンは学習可能な相互結合型ネットワー クの代表的なものである. ボルツマンマシンには, 学習のための統計平均を取る必要があり, 結果を求めるまでに長い時間がかかってしまうという欠点がある. そこで, 学習の高速化のために, 統計を取る2つのステップについて, 以下のことを行う. まず1つ目のステップでは,
1. はじめに ボルツマン学習と平均場近似 山梨大学工学部宗久研究室 G04MK016 鳥居圭太 ボルツマンマシンは学習可能な相互結合型ネットワー クの代表的なものである. ボルツマンマシンには, 学習のための統計平均を取る必要があり, 結果を求めるまでに長い時間がかかってしまうという欠点がある. そこで, 学習の高速化のために, 統計を取る2つのステップについて, 以下のことを行う. まず1つ目のステップでは,
1. はじめにこれまで 我々は社会システム分析ソフトウェア College Analysis において 統計分析 数学 経営科学 意思決定手法などを中心にプログラムを作成してきたが 今回は シミュレーションや統計的な母数推定に利用される乱数の生成と検定の問題について考える 乱数は一様分布を元にして
 社会システム分析のための統合化プログラム 21 - 乱数生成と検定 - 福井正康 * 孟紅燕 * 呉夢 * 崔永杰 福山平成大学経営学部経営学科 * 福山平成大学大学院経営学研究科経営情報学専攻 概要 我々は教育分野での利用を目的に社会システム分析に用いられる様々な手法を統合化したプログラム College Analysis を作成してきた 今回は 様々なシミュレーションや統計的な母数推定などに用いられる乱数生成とその検定についてプログラムを作成した
社会システム分析のための統合化プログラム 21 - 乱数生成と検定 - 福井正康 * 孟紅燕 * 呉夢 * 崔永杰 福山平成大学経営学部経営学科 * 福山平成大学大学院経営学研究科経営情報学専攻 概要 我々は教育分野での利用を目的に社会システム分析に用いられる様々な手法を統合化したプログラム College Analysis を作成してきた 今回は 様々なシミュレーションや統計的な母数推定などに用いられる乱数生成とその検定についてプログラムを作成した
Microsoft PowerPoint - 測量学.ppt [互換モード]
![Microsoft PowerPoint - 測量学.ppt [互換モード]](/thumbs/92/109082022.jpg "Microsoft PowerPoint - 測量学.ppt [互換モード]") 8/5/ 誤差理論 測定の分類 性格による分類 独立 ( な ) 測定 : 測定値がある条件を満たさなければならないなどの拘束や制約を持たないで独立して行う測定 条件 ( 付き ) 測定 : 三角形の 3 つの内角の和のように, 個々の測定値間に満たすべき条件式が存在する場合の測定 方法による分類 直接測定 : 距離や角度などを機器を用いて直接行う測定 間接測定 : 求めるべき量を直接測定するのではなく,
8/5/ 誤差理論 測定の分類 性格による分類 独立 ( な ) 測定 : 測定値がある条件を満たさなければならないなどの拘束や制約を持たないで独立して行う測定 条件 ( 付き ) 測定 : 三角形の 3 つの内角の和のように, 個々の測定値間に満たすべき条件式が存在する場合の測定 方法による分類 直接測定 : 距離や角度などを機器を用いて直接行う測定 間接測定 : 求めるべき量を直接測定するのではなく,
Microsoft Word - lec_student-chp3_1-representative
 1. はじめに この節でのテーマ データ分布の中心位置を数値で表す 可視化でとらえた分布の中心位置を数量化する 平均値とメジアン, 幾何平均 この節での到達目標 1 平均値 メジアン 幾何平均の定義を書ける 2 平均値とメジアン, 幾何平均の特徴と使える状況を説明できる. 3 平均値 メジアン 幾何平均を計算できる 2. 特性値 集めたデータを度数分布表やヒストグラムに整理する ( 可視化する )
1. はじめに この節でのテーマ データ分布の中心位置を数値で表す 可視化でとらえた分布の中心位置を数量化する 平均値とメジアン, 幾何平均 この節での到達目標 1 平均値 メジアン 幾何平均の定義を書ける 2 平均値とメジアン, 幾何平均の特徴と使える状況を説明できる. 3 平均値 メジアン 幾何平均を計算できる 2. 特性値 集めたデータを度数分布表やヒストグラムに整理する ( 可視化する )
森林水文 水資源学 2 2. 水文統計 豪雨があった時, 新聞やテレビのニュースで 50 年に一度の大雨だった などと報告されることがある. 今争点となっている川辺川ダムは,80 年に 1 回の洪水を想定して治水計画が立てられている. 畑地かんがいでは,10 年に 1 回の渇水を対象として計画が立て
 . 水文統計 豪雨があった時, 新聞やテレビのニュースで 50 年に一度の大雨だった などと報告されることがある. 今争点となっている川辺川ダムは,80 年に 回の洪水を想定して治水計画が立てられている. 畑地かんがいでは,0 年に 回の渇水を対象として計画が立てられる. このように, 水利構造物の設計や, 治水や利水の計画などでは, 年に 回起こるような降雨事象 ( 最大降雨強度, 最大連続干天日数など
. 水文統計 豪雨があった時, 新聞やテレビのニュースで 50 年に一度の大雨だった などと報告されることがある. 今争点となっている川辺川ダムは,80 年に 回の洪水を想定して治水計画が立てられている. 畑地かんがいでは,0 年に 回の渇水を対象として計画が立てられる. このように, 水利構造物の設計や, 治水や利水の計画などでは, 年に 回起こるような降雨事象 ( 最大降雨強度, 最大連続干天日数など
ii 2. F. ( ), ,,. 5. G., L., D. ( ) ( ), 2005.,. 6.,,. 7.,. 8. ( ), , (20 ). 1. (75% ) (25% ). 60.,. 2. =8 5, =8 4 (. 1.) 1.,,
, ,,. 5. G., L., D. ( ) ( ), 2005.,. 6.,,. 7.,. 8. ( ), , (20 ). 1. (75% ) (25% ). 60.,. 2. =8 5, =8 4 (. 1.) 1.,,") (1 C205) 4 8 27(2015) http://www.math.is.tohoku.ac.jp/~obata,.,,,..,,. 1. 2. 3. 4. 5. 6. 7.... 1., 2014... 2. P. G., 1995.,. 3.,. 4.. 5., 1996... 1., 2007,. ii 2. F. ( ),.. 3... 4.,,. 5. G., L., D. ( )
(1 C205) 4 8 27(2015) http://www.math.is.tohoku.ac.jp/~obata,.,,,..,,. 1. 2. 3. 4. 5. 6. 7.... 1., 2014... 2. P. G., 1995.,. 3.,. 4.. 5., 1996... 1., 2007,. ii 2. F. ( ),.. 3... 4.,,. 5. G., L., D. ( )
ビジネス統計 統計基礎とエクセル分析 正誤表
 ビジネス統計統計基礎とエクセル分析 ビジネス統計スペシャリスト エクセル分析スペシャリスト 公式テキスト正誤表と学習用データ更新履歴 平成 30 年 5 月 14 日現在 公式テキスト正誤表 頁場所誤正修正 6 知識編第 章 -3-3 最頻値の解説内容 たとえば, 表.1 のデータであれば, 最頻値は 167.5cm というたとえば, 表.1 のデータであれば, 最頻値は 165.0cm ということになります
ビジネス統計統計基礎とエクセル分析 ビジネス統計スペシャリスト エクセル分析スペシャリスト 公式テキスト正誤表と学習用データ更新履歴 平成 30 年 5 月 14 日現在 公式テキスト正誤表 頁場所誤正修正 6 知識編第 章 -3-3 最頻値の解説内容 たとえば, 表.1 のデータであれば, 最頻値は 167.5cm というたとえば, 表.1 のデータであれば, 最頻値は 165.0cm ということになります
kubostat1g p. MCMC binomial distribution q MCMC : i N i y i p(y i q = ( Ni y i q y i (1 q N i y i, q {y i } q likelihood q L(q {y i } = i=1 p(y i q 1
 kubostat1g p.1 1 (g Hierarchical Bayesian Model [email protected] http://goo.gl/7ci The development of linear models Hierarchical Bayesian Model Be more flexible Generalized Linear Mixed Model (GLMM
kubostat1g p.1 1 (g Hierarchical Bayesian Model [email protected] http://goo.gl/7ci The development of linear models Hierarchical Bayesian Model Be more flexible Generalized Linear Mixed Model (GLMM
多変量解析 ~ 重回帰分析 ~ 2006 年 4 月 21 日 ( 金 ) 南慶典
 南慶典") 多変量解析 ~ 重回帰分析 ~ 2006 年 4 月 21 日 ( 金 ) 南慶典 重回帰分析とは? 重回帰分析とは複数の説明変数から目的変数との関係性を予測 評価説明変数 ( 数量データ ) は目的変数を説明するのに有効であるか得られた関係性より未知のデータの妥当性を判断する これを重回帰分析という つまり どんなことをするのか? 1 最小 2 乗法により重回帰モデルを想定 2 自由度調整済寄与率を求め
多変量解析 ~ 重回帰分析 ~ 2006 年 4 月 21 日 ( 金 ) 南慶典 重回帰分析とは? 重回帰分析とは複数の説明変数から目的変数との関係性を予測 評価説明変数 ( 数量データ ) は目的変数を説明するのに有効であるか得られた関係性より未知のデータの妥当性を判断する これを重回帰分析という つまり どんなことをするのか? 1 最小 2 乗法により重回帰モデルを想定 2 自由度調整済寄与率を求め
Microsoft PowerPoint - Econometrics pptx
 計量経済学講義 第 4 回回帰モデルの診断と選択 Part 07 年 ( ) 限 担当教員 : 唐渡 広志 研究室 : 経済学研究棟 4 階 43 号室 emal: [email protected] webste: http://www3.u-toyama.ac.p/kkarato/ 講義の目的 誤差項の分散が不均 である場合や, 系列相関を持つ場合についての検定 法と修正 法を学びます
計量経済学講義 第 4 回回帰モデルの診断と選択 Part 07 年 ( ) 限 担当教員 : 唐渡 広志 研究室 : 経済学研究棟 4 階 43 号室 emal: [email protected] webste: http://www3.u-toyama.ac.p/kkarato/ 講義の目的 誤差項の分散が不均 である場合や, 系列相関を持つ場合についての検定 法と修正 法を学びます
PowerPoint プレゼンテーション
 復習 ) 時系列のモデリング ~a. 離散時間モデル ~ y k + a 1 z 1 y k + + a na z n ay k = b 0 u k + b 1 z 1 u k + + b nb z n bu k y k = G z 1 u k = B(z 1 ) A(z 1 u k ) ARMA モデル A z 1 B z 1 = 1 + a 1 z 1 + + a na z n a = b 0
復習 ) 時系列のモデリング ~a. 離散時間モデル ~ y k + a 1 z 1 y k + + a na z n ay k = b 0 u k + b 1 z 1 u k + + b nb z n bu k y k = G z 1 u k = B(z 1 ) A(z 1 u k ) ARMA モデル A z 1 B z 1 = 1 + a 1 z 1 + + a na z n a = b 0
PowerPoint プレゼンテーション
 非線形カルマンフィルタ ~a. 問題設定 ~ 離散時間非線形状態空間表現 x k + 1 = f x k y k = h x k + bv k + w k f : ベクトル値をとるx k の非線形関数 h : スカラ値をとるx k の非線形関数 v k システム雑音 ( 平均値 0, 分散 σ v 2 k ) x k + 1 = f x k,v k w k 観測雑音 ( 平均値 0, 分散 σ w
非線形カルマンフィルタ ~a. 問題設定 ~ 離散時間非線形状態空間表現 x k + 1 = f x k y k = h x k + bv k + w k f : ベクトル値をとるx k の非線形関数 h : スカラ値をとるx k の非線形関数 v k システム雑音 ( 平均値 0, 分散 σ v 2 k ) x k + 1 = f x k,v k w k 観測雑音 ( 平均値 0, 分散 σ w
(Microsoft Word - 10ta320a_\220U\223\256\212w\223\301\230__6\217\315\221O\224\274\203\214\203W\203\201.docx)
") 6 章スペクトルの平滑化 スペクトルの平滑化とはフーリエスペクトルやパワ スペクトルのギザギザを取り除き 滑らかにする操作のことをいう ただし 波のもっている本質的なものをゆがめてはいけない 図 6-7 パワ スペクトルの平滑化 6. 合積のフーリエ変換スペクトルの平滑化を学ぶ前に 合積とそのフーリエ変換について説明する 6. データ ウィンドウデータ ウィンドウの定義と特徴について説明する 6.3
6 章スペクトルの平滑化 スペクトルの平滑化とはフーリエスペクトルやパワ スペクトルのギザギザを取り除き 滑らかにする操作のことをいう ただし 波のもっている本質的なものをゆがめてはいけない 図 6-7 パワ スペクトルの平滑化 6. 合積のフーリエ変換スペクトルの平滑化を学ぶ前に 合積とそのフーリエ変換について説明する 6. データ ウィンドウデータ ウィンドウの定義と特徴について説明する 6.3
68 A mm 1/10 A. (a) (b) A.: (a) A.3 A.4 1 1
 (b) A.: (a) A.3 A.4 1 1") 67 A Section A.1 0 1 0 1 Balmer 7 9 1 0.1 0.01 1 9 3 10:09 6 A.1: A.1 1 10 9 68 A 10 9 10 9 1 10 9 10 1 mm 1/10 A. (a) (b) A.: (a) A.3 A.4 1 1 A.1. 69 5 1 10 15 3 40 0 0 ¾ ¾ É f Á ½ j 30 A.3: A.4: 1/10
67 A Section A.1 0 1 0 1 Balmer 7 9 1 0.1 0.01 1 9 3 10:09 6 A.1: A.1 1 10 9 68 A 10 9 10 9 1 10 9 10 1 mm 1/10 A. (a) (b) A.: (a) A.3 A.4 1 1 A.1. 69 5 1 10 15 3 40 0 0 ¾ ¾ É f Á ½ j 30 A.3: A.4: 1/10
スライド 1
 データ解析特論重回帰分析編 2017 年 7 月 10 日 ( 月 )~ 情報エレクトロニクスコース横田孝義 1 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える 具体的には y = a + bx という回帰直線 ( モデル ) でデータを代表させる このためにデータからこの回帰直線の切片 (a) と傾き (b) を最小
データ解析特論重回帰分析編 2017 年 7 月 10 日 ( 月 )~ 情報エレクトロニクスコース横田孝義 1 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える 具体的には y = a + bx という回帰直線 ( モデル ) でデータを代表させる このためにデータからこの回帰直線の切片 (a) と傾き (b) を最小
Microsoft PowerPoint - stat-2014-[9] pptx
![Microsoft PowerPoint - stat-2014-[9] pptx](/thumbs/49/25555771.jpg "Microsoft PowerPoint - stat-2014-[9] pptx") 統計学 第 17 回 講義 母平均の区間推定 Part-1 014 年 6 17 ( )6-7 限 担当教員 : 唐渡 広志 ( からと こうじ ) 研究室 : 経済学研究棟 4 階 43 号室 email: [email protected] website: htt://www3.u-toyama.ac.j/kkarato/ 1 講義の目的 標本平均は正規分布に従うという性質を
統計学 第 17 回 講義 母平均の区間推定 Part-1 014 年 6 17 ( )6-7 限 担当教員 : 唐渡 広志 ( からと こうじ ) 研究室 : 経済学研究棟 4 階 43 号室 email: [email protected] website: htt://www3.u-toyama.ac.j/kkarato/ 1 講義の目的 標本平均は正規分布に従うという性質を
Microsoft PowerPoint - 資料04 重回帰分析.ppt
 04. 重回帰分析 京都大学 加納学 Division of Process Control & Process Sstems Engineering Department of Chemical Engineering, Koto Universit [email protected] http://www-pse.cheme.koto-u.ac.jp/~kano/ Outline
04. 重回帰分析 京都大学 加納学 Division of Process Control & Process Sstems Engineering Department of Chemical Engineering, Koto Universit [email protected] http://www-pse.cheme.koto-u.ac.jp/~kano/ Outline
PowerPoint Presentation
 付録 2 2 次元アフィン変換 直交変換 たたみ込み 1.2 次元のアフィン変換 座標 (x,y ) を (x,y) に移すことを 2 次元での変換. 特に, 変換が と書けるとき, アフィン変換, アフィン変換は, その 1 次の項による変換 と 0 次の項による変換 アフィン変換 0 次の項は平行移動 1 次の項は座標 (x, y ) をベクトルと考えて とすれば このようなもの 2 次元ベクトルの線形写像
付録 2 2 次元アフィン変換 直交変換 たたみ込み 1.2 次元のアフィン変換 座標 (x,y ) を (x,y) に移すことを 2 次元での変換. 特に, 変換が と書けるとき, アフィン変換, アフィン変換は, その 1 次の項による変換 と 0 次の項による変換 アフィン変換 0 次の項は平行移動 1 次の項は座標 (x, y ) をベクトルと考えて とすれば このようなもの 2 次元ベクトルの線形写像
スライド 1
 計測工学第 12 回以降 測定値の誤差と精度編 2014 年 7 月 2 日 ( 水 )~7 月 16 日 ( 水 ) 知能情報工学科 横田孝義 1 授業計画 4/9 4/16 4/23 5/7 5/14 5/21 5/28 6/4 6/11 6/18 6/25 7/2 7/9 7/16 7/23 2 誤差とその取扱い 3 誤差 = 測定値 真の値 相対誤差 = 誤差 / 真の値 4 誤差 (error)
計測工学第 12 回以降 測定値の誤差と精度編 2014 年 7 月 2 日 ( 水 )~7 月 16 日 ( 水 ) 知能情報工学科 横田孝義 1 授業計画 4/9 4/16 4/23 5/7 5/14 5/21 5/28 6/4 6/11 6/18 6/25 7/2 7/9 7/16 7/23 2 誤差とその取扱い 3 誤差 = 測定値 真の値 相対誤差 = 誤差 / 真の値 4 誤差 (error)
統計学的画像再構成法である
 OSEM アルゴリズムの基礎論 第 1 章 確率 統計の基礎 1.13 最尤推定 やっと本命の最尤推定という言葉が出てきました. お待たせしました. この節はいままでの中で最も長く, 少し難しい内容も出てきます. がんばってください. これが終わるといよいよ本命の MLEM,OSEM の章です. ところで 尤 なる字はあまり見かけませんね. ゆう と読みます. いぬ ではありません!! この意味は
OSEM アルゴリズムの基礎論 第 1 章 確率 統計の基礎 1.13 最尤推定 やっと本命の最尤推定という言葉が出てきました. お待たせしました. この節はいままでの中で最も長く, 少し難しい内容も出てきます. がんばってください. これが終わるといよいよ本命の MLEM,OSEM の章です. ところで 尤 なる字はあまり見かけませんね. ゆう と読みます. いぬ ではありません!! この意味は
Statistical inference for one-sample proportion
 RAND 関数による擬似乱数の生成 魚住龍史 * 浜田知久馬東京理科大学大学院工学研究科経営工学専攻 Generating pseudo-random numbers using RAND function Ryuji Uozumi * and Chikuma Hamada Department of Management Science, Graduate School of Engineering,
RAND 関数による擬似乱数の生成 魚住龍史 * 浜田知久馬東京理科大学大学院工学研究科経営工学専攻 Generating pseudo-random numbers using RAND function Ryuji Uozumi * and Chikuma Hamada Department of Management Science, Graduate School of Engineering,
<4D F736F F D208EC08CB18C7689E68A E F AA957A82C682948C9F92E82E646F63>
 第 7 回 t 分布と t 検定 実験計画学 A.t 分布 ( 小標本に関する平均の推定と検定 ) 前々回と前回の授業では, 標本が十分に大きいあるいは母分散が既知であることを条件に正規分布を用いて推定 検定した. しかし, 母集団が正規分布し, 標本が小さい場合には, 標本分散から母分散を推定するときの不確実さを加味したt 分布を用いて推定 検定しなければならない. t 分布は標本分散の自由度 f(
第 7 回 t 分布と t 検定 実験計画学 A.t 分布 ( 小標本に関する平均の推定と検定 ) 前々回と前回の授業では, 標本が十分に大きいあるいは母分散が既知であることを条件に正規分布を用いて推定 検定した. しかし, 母集団が正規分布し, 標本が小さい場合には, 標本分散から母分散を推定するときの不確実さを加味したt 分布を用いて推定 検定しなければならない. t 分布は標本分散の自由度 f(
Microsoft PowerPoint - kyoto
 研究集会 代数系アルゴリズムと言語および計算理論 知識の証明と暗号技術 情報セキュリティ大学大学院学院 有田正剛 1 はじめに 暗号技術の面白さとむずかしさ システムには攻撃者が存在する 条件が整ったときのベストパフォーマンスより 条件が整わないときの安全性 攻撃者は約束事 ( プロトコル ) には従わない 表面上は従っているふり 放置すると 正直者が損をする それを防ぐには 知識の証明 が基本手段
研究集会 代数系アルゴリズムと言語および計算理論 知識の証明と暗号技術 情報セキュリティ大学大学院学院 有田正剛 1 はじめに 暗号技術の面白さとむずかしさ システムには攻撃者が存在する 条件が整ったときのベストパフォーマンスより 条件が整わないときの安全性 攻撃者は約束事 ( プロトコル ) には従わない 表面上は従っているふり 放置すると 正直者が損をする それを防ぐには 知識の証明 が基本手段
今日の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか
 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか") 時系列データ解析でよく見る あぶない モデリング 久保拓弥 (北海道大 環境科学) 1/56 今日の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか (危 1) 時系列データを GLM で (危 2) 時系列Yt 時系列 Xt 相関は因果関係ではない 問題の一部
時系列データ解析でよく見る あぶない モデリング 久保拓弥 (北海道大 環境科学) 1/56 今日の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか (危 1) 時系列データを GLM で (危 2) 時系列Yt 時系列 Xt 相関は因果関係ではない 問題の一部
「統 計 数 学 3」
 関数の使い方 1 関数と引数 関数の構造 関数名 ( 引数 1, 引数 2, 引数 3, ) 例 : マハラノビス距離を求める関数 mahalanobis(data,m,v) 引数名を指定して記述する場合 mahalanobis(x=data, center=m, cov=v) 2 関数についてのヘルプ 基本的な関数のヘルプの呼び出し? 関数名 例 :?mean 例 :?mahalanobis 指定できる引数を確認する関数
関数の使い方 1 関数と引数 関数の構造 関数名 ( 引数 1, 引数 2, 引数 3, ) 例 : マハラノビス距離を求める関数 mahalanobis(data,m,v) 引数名を指定して記述する場合 mahalanobis(x=data, center=m, cov=v) 2 関数についてのヘルプ 基本的な関数のヘルプの呼び出し? 関数名 例 :?mean 例 :?mahalanobis 指定できる引数を確認する関数
データ科学2.pptx
 データ科学 多重検定 2 mul%ple test False Discovery Rate 藤博幸 前回の復習 1 多くの検定を繰り返す時には 単純に個々の検定を繰り返すだけでは不十分 5% 有意水準ということは, 1000 回検定を繰り返すと, 50 回くらいは帰無仮説が正しいのに 間違って棄却されてすまうじちがあるということ ex) 1 万個の遺伝子について 正常細胞とガン細胞で それぞれの遺伝子の発現に差があるかどうかを検定
データ科学 多重検定 2 mul%ple test False Discovery Rate 藤博幸 前回の復習 1 多くの検定を繰り返す時には 単純に個々の検定を繰り返すだけでは不十分 5% 有意水準ということは, 1000 回検定を繰り返すと, 50 回くらいは帰無仮説が正しいのに 間違って棄却されてすまうじちがあるということ ex) 1 万個の遺伝子について 正常細胞とガン細胞で それぞれの遺伝子の発現に差があるかどうかを検定