スライド 1
|
|
|
- えの みょうだに
- 7 years ago
- Views:
Transcription
1 WinBUGS 入門 水産資源学におけるベイズ統計の応用ワークショップ 2007 年 8 月 2-3 日, 中央水研 遠洋水産研究所外洋資源部 鯨類管理研究室 岡村寛
2 WinBUGS とは BUGS (Bayesian Inference Using Gibbs Sampling) の Windows バージョン フリーのソフトウェア Gibbs samplingを利用した事後確率からのサンプリングを行う
3 WinBUGS プログラムコードは R とよく似ている それゆえ,Rでプログラムが書けると理解が早いし, 何かと便利 R2WinBUGSというRからWinBUGSを呼び出して実行するプログラムも開発されている 様々な状況に自動で対応して適当なサンプリング法を選んでくれる 例. log-concave adaptive rejection sampling 範囲を制限したとき スライスサンプラー範囲制約がないとき Metropolis 法

4 WinBUGS 画面
5 WinBUGS プログラム 基本的に,model.odc,data.dat,inits.inの3つのファイルからなる. model.odc の中身の例 model{ for (i in 1:N){ Y[i] ~ dnorm(mu[i],tau) mu[i] <- a + b*x[i] # a + b*(x[i]-mean(x)) is better. } }
6 WinBUGS プログラミングの注意 1 変数を2 度定義できない x <- 1 x <- 3 ベクトルや行列で対応 if 文は使えない X = (3, NA, 2) X=cbind(c(1,3),c(3,2)) X[t,2]~dpois(N[X[t,1]]) ( ただし, この場合はNAのままでもOK) Y ~ dnorm(log(n), sigma) Y ~ dnorm(ln, sigma) LN <- log(n)
7 WinBUGS プログラミングの注意 2 最初に少ないパラメータからスタートして ( いくつかのパラメータをfix), 段々複雑にする R2WinBUGSを使うとデータの扱いなど便利 bugs(data, inits,, debug=true, ) Trapというエラーメッセージが出ることがある 初期値がおかしい事前分布を少し狭く ~ 徐々に広げる
8 WinBUGS プログラミングの注意 3 まず最尤法を用いた簡単なプログラムであたりをつける プロット! プロット! プロット! あまり洗練されたプログラムを書こうとしないこと よく使う人と友達になる 仲間を増やす
.")
9 例題 1( 検定 ) 池 A, 池 B の中のある場所をランダムに選んで毎回同じ時間調査し, その中にいるメダカの数を数えた結果, 下のようなデータが得られた ( 池 B は行きにくいので 3 回しか調査できなかった ). 池 A と池 B のメダカの数は違うであろうか?
10 検定仮説 検定したい仮説 : 池 Aの平均メダカ数 = 池 Bの平均メダカ数 池 Aと池 Bの平均メダカ数は, 池 A: 平均 1.5, 分散 1.7 池 B: 平均 0.0, 分散 0.0
11 t 検定 池 B はメダカのサンプルなしなので, 池 A の平均 が 0 と有意に違うかどうかを見る t 検定を行う > x <- c(1,1,0,4,2,2,0,2) > t.test(x) t = , df = 7, p-value = 有意
12 通常の検定の何が問題か? 池 Bはすべて0の観測値であるが,3 回 0が続いただけである. これは10 回 0が続いたのとは証拠の大きさが異なるはずである. 先の検定は, そこのとこを考慮していない. 3 回とも0だったので分散は0となり,0 確実である. しかし,3 回しかやってないので, たまたま0が続いたということもあるのでは? > rpois(3,1.5) [1] なんていこうともありうる.
13 GLM してみる カウントデータであるし, 池 A の平均と分散はおよそ等しいのでポアソン分布を仮定して GLM してみる a <- factor(c(rep("a",8),rep("b",3))) x1 <- data.frame(area=a, med=c(x,rep(0,3))) res <- glm(med~area,family=poisson,data=x1)
14 GLM 結果 > summary(res) Coefficients: Estimate Std. Error z value Pr(> z ) (Intercept) areab 収束していない. これは池 B が全部 0 だからである
15 こんなふうに考えてみる 池 Aから3 回続けてサンプルしたとき, すべて0となる確率はどうなるか? これがすごく小さかったら, 池 Bは池 Aよりメダカが少ないと考えてもおかしくないであろう. 確率が大きければ, 池 Aと池 Bが違うと考える根拠は希薄であることになる.
16 事後予測分布 ベイズ推定で考えると, 池 A のデータが与えられたとき, 新たな調査を行って 3 回続けて 0 となる確率を推定す れば良い y = { 新たに調査したら3 回続けて0} とするとき, 事後予測分布 P(y x) = P(y θ)p(θ x)dθを推定する ポアソン分布を仮定すると3 回続けて0 = {exp(-θ)} 3 = exp(-3θ)
17 WinBUGS コード model{ Jm ~ dunif(0,100) mu <- pow(jm,-2) for (i in 1:N){ x[i] ~ dpois(mu) # likelihood } Prob <- exp(-3*mu) } list(x = c(1,1,0,4,2,2,0,2), N=8) # data
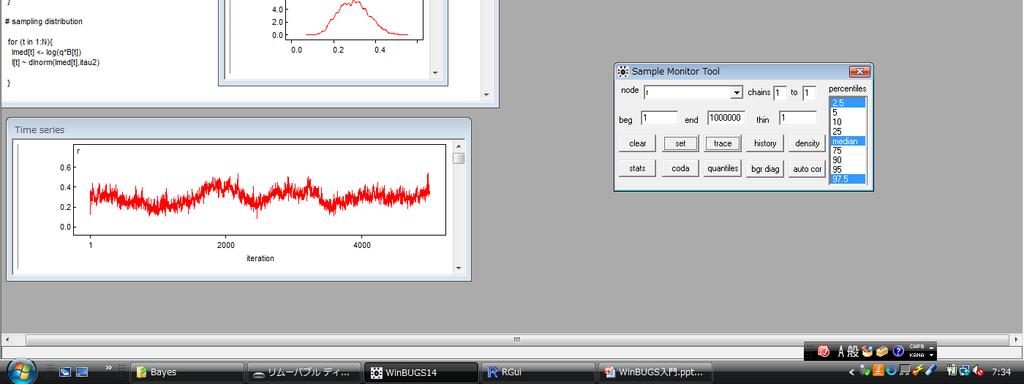
18 WinBUGS 実行 1. プログラムを WinBUGS 上で開く 2. ツールバーの Model の Specification を選択 3. プログラムの model 部分を選んで, Specification Tool の check model をクリック 4. データ先頭の list を選んで,Specification Tool の load data をクリック 5. compile をクリック
19 WinBUGS 実行 6. 初期値を自動生成するため, 今回は gen inits をクリック 7. ツールバー Inference をクリックして, Samples を選択 8. Sample Monitor Tool の node に mu と入れて, set をクリック 9. Sample Monitor Tool の node に Prob と入れて,set をクリック
20 WinBUGS 実行 10. 再びツールバーの Model をクリックし, 今度は Update を選択 11. Update Tool の update ボタンをクリック 12. Sample Monitor Tool に行って,node に mu と入れる. 下のボタンが active になる 13. density や stats ボタンを押して結果を見る 14. node に Prob を入れて同じことをする
21 WinBUGS 実行 と文章や口で言っても分かりにくいので, 実際にやってみる 実演 WinBUGS the movie! というページもある. 動画で紹介.
22 事後分布 平均 %CI[0.72, 2.38] 平均 %CI[0.001, 0.11]
23 まとめ ベイズ推定によって, うまいこと問題 ( 池 Bのサンプルサイズを考慮, 観測したどのデータも0, など ) を回避していることに注意 池 Bの結果を, 池 Aの結果が与えられたという条件のもとで, 池 A= 池 Bとしたとき, 池 Bの結果と同じようになる確率で評価した. 他にどんなモデリングが考えられるか?( 例. 池 Bの方も池 Aと同じようにモデル化して, 二つの平均を比較するとか )
24 例題 2( 階層ベイズ ) 大西洋ビンナガマグロの漁獲量と CPUEのデータにプロダクションモデルをフィットし, そのパラメータの推定結果を用いて,MSYを計算せよ. 最近の漁獲量は適切な水準にあると言えるか?
25 CPUE (Catch Per Unit Effort) CPUE = 漁獲量 / 努力量 CPUE = qp q: 漁獲効率,P: 資源量 ( 個体数 or 個体重量 ) CPUE を使って個体群の増減が分かる 年トレンドの推定 CPUE の標準化 (GLM 等 ) CPUE = qp x (Hilborn & Walters 1992)
26 MSY の考え方 個体群の増加率 ( ロジスティック曲線 ) dp/dt = rp(1-p/k) P: 資源量,r: 内的自然増加率, K: 環境収容量 MSY(Maximum Sustainable Yield): dp/dt が最大になるのは,P=K/2 のとき 0 K P P=K/2 になるように魚を獲っていたら, 最大の収穫を得ながら, 個体群を健全に維持できる!
27 状態空間モデル State-Space Model X t-1 X t X t+1 Y t-1 Y t Y t+1 プロセス方程式 : X t = G(X t-1, w t ) 観測方程式 : Y t = F(X t, v t )
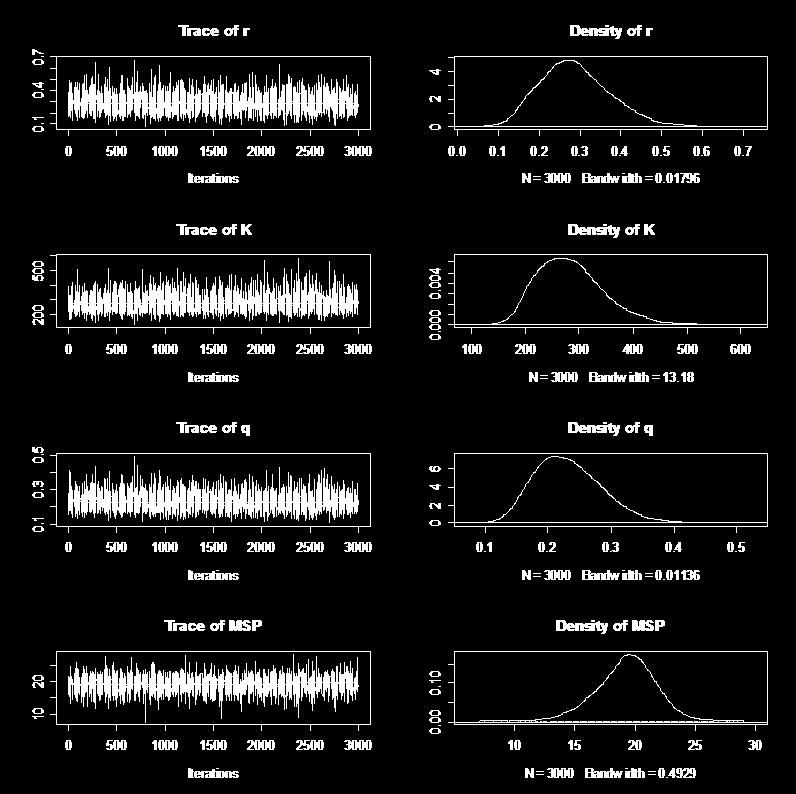
28 個体群動態モデルのパラメータ推定 ロジスティックモデル B t+1 = {B t + rb t (1-B t /K)-C t }exp(u t ) I t = qb t exp(w t ) MSY = rk/4 B MSY = K/2 E MSY = r/(2q) u t ~ N(0,s A2 ), w t ~ N(0,s O2 ) プログラム中では,r と K の相関を弱めるため,P t = B t /K を使う
29 状態空間モデルの特徴 観測誤差とプロセス誤差を同時に推定することが可能 計算機集約的な方法と組み合わせることにより, 柔軟なモデリング 推定が可能 カルマン フィルタは状態空間モデルの特殊な場合と考えられる 一般に計算大変


30 データ : 漁獲量と CPUE 南大西洋ビン ナガマグロの データ
31 WinBUGS 実行 実演
32 事後分布 110,000 万回計算して, 最初の 10,000 回を burn-in として取り除いた
33 R と K の相関 K 相関係数 = r
34 自己相関 thinning なし thinning=50 thinning=100 thinning=200
35 2 本の chain でやってみる V R W R = V/W V = pool した chain の変動 W = 個々の chain の平均変動
36 2 本の chain でやってみる
37 R2WinBUGS RからWinBUGSを呼び出して解析を実行し,Rの中でoutputを操作 データや初期値の作成が楽ちん 即 codaを使える 最初は少ない繰り返し数で

38 R2WinBUGS でやってみる

39 coda
40 まとめ 個体群動態モデルでは, 従来観測誤差かプロセス誤差のどちらか一方だけを仮定することが多かったが, ベイズ型状態空間モデルを使うことによってどちらの誤差も考慮した分析が比較的容易に行える いろいろプロットして, うまくいっているか確認することが大事 R2WinBUGSを使うといろいろ便利なことが
41 参考文献 Meyer, R., and Millar, R. B BUGS in Bayesian stock assessments. CJFAS 56: Plummer, M CODA: convergence diagnosis and output analysis for MCMC. R News 6(1): Spiegelhalter et al WinBUGS user manual version 1.4.
kubo2015ngt6 p.2 ( ( (MLE 8 y i L(q q log L(q q 0 ˆq log L(q / q = 0 q ˆq = = = * ˆq = 0.46 ( 8 y 0.46 y y y i kubo (ht
 kubo2015ngt6 p.1 2015 (6 MCMC [email protected], @KuboBook http://goo.gl/m8hsbm 1 ( 2 3 4 5 JAGS : 2015 05 18 16:48 kubo (http://goo.gl/m8hsbm 2015 (6 1 / 70 kubo (http://goo.gl/m8hsbm 2015 (6 2 /
kubo2015ngt6 p.1 2015 (6 MCMC [email protected], @KuboBook http://goo.gl/m8hsbm 1 ( 2 3 4 5 JAGS : 2015 05 18 16:48 kubo (http://goo.gl/m8hsbm 2015 (6 1 / 70 kubo (http://goo.gl/m8hsbm 2015 (6 2 /
/22 R MCMC R R MCMC? 3. Gibbs sampler : kubo/
 2006-12-09 1/22 R MCMC R 1. 2. R MCMC? 3. Gibbs sampler : [email protected] http://hosho.ees.hokudai.ac.jp/ kubo/ 2006-12-09 2/22 : ( ) : : ( ) : (?) community ( ) 2006-12-09 3/22 :? 1. ( ) 2. ( )
2006-12-09 1/22 R MCMC R 1. 2. R MCMC? 3. Gibbs sampler : [email protected] http://hosho.ees.hokudai.ac.jp/ kubo/ 2006-12-09 2/22 : ( ) : : ( ) : (?) community ( ) 2006-12-09 3/22 :? 1. ( ) 2. ( )
/ *1 *1 c Mike Gonzalez, October 14, Wikimedia Commons.
 2010 05 22 1/ 35 2010 2010 05 22 *1 [email protected] *1 c Mike Gonzalez, October 14, 2007. Wikimedia Commons. 2010 05 22 2/ 35 1. 2. 3. 2010 05 22 3/ 35 : 1.? 2. 2010 05 22 4/ 35 1. 2010 05 22 5/
2010 05 22 1/ 35 2010 2010 05 22 *1 [email protected] *1 c Mike Gonzalez, October 14, 2007. Wikimedia Commons. 2010 05 22 2/ 35 1. 2. 3. 2010 05 22 3/ 35 : 1.? 2. 2010 05 22 4/ 35 1. 2010 05 22 5/
今日の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか
 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか") 時系列データ解析でよく見る あぶない モデリング 久保拓弥 (北海道大 環境科学) 1/56 今日の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか (危 1) 時系列データを GLM で (危 2) 時系列Yt 時系列 Xt 相関は因果関係ではない 問題の一部
時系列データ解析でよく見る あぶない モデリング 久保拓弥 (北海道大 環境科学) 1/56 今日の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか (危 1) 時系列データを GLM で (危 2) 時系列Yt 時系列 Xt 相関は因果関係ではない 問題の一部
この 2 つの式に基づきシェーファーが考えたのがシェーファーのプロダクションモデル 式 (3) です (Schaefer 1957) db/dt = rb (1 B/K) qxb (3) ここで q は漁具能率 X は漁獲努力量 Y は漁獲量で Y = qxb と仮定されています ロジスティック式を
 です (Schaefer 1957) db/dt = rb (1 B/K) qxb (3) ここで q は漁具能率 X は漁獲努力量 Y は漁獲量で Y = qxb と仮定されています ロジスティック式を") 10. プロダクションモデル - 漁獲量と努力量から- 10.1 概要これまで紹介した成長生残モデルに基づく資源解析の方法は多くのデータを必要とします 一方 ここで紹介するプロダクションモデルは漁獲量や努力量などのデータだけで資源解析ができる方法です また 直接 漁獲量や単位努力量当たり漁獲量などに合わせる方法なので 予測値に関しては実績値から外れた値が出にくいと考えられています プロダクションモデルを使用する際に
10. プロダクションモデル - 漁獲量と努力量から- 10.1 概要これまで紹介した成長生残モデルに基づく資源解析の方法は多くのデータを必要とします 一方 ここで紹介するプロダクションモデルは漁獲量や努力量などのデータだけで資源解析ができる方法です また 直接 漁獲量や単位努力量当たり漁獲量などに合わせる方法なので 予測値に関しては実績値から外れた値が出にくいと考えられています プロダクションモデルを使用する際に
今回 次回の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ Danger!! (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか これは次回)
 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか これは次回)") 生態学の時系列データ解析でよく見る あぶない モデリング 久保拓弥 mailto:[email protected] statistical model for time-series data 2017-07-03 kubostat2017 (h) 1/59 今回 次回の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ Danger!! (危 1) 時系列データの
生態学の時系列データ解析でよく見る あぶない モデリング 久保拓弥 mailto:[email protected] statistical model for time-series data 2017-07-03 kubostat2017 (h) 1/59 今回 次回の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ Danger!! (危 1) 時系列データの
kubostat2017j p.2 CSV CSV (!) d2.csv d2.csv,, 286,0,A 85,0,B 378,1,A 148,1,B ( :27 ) 10/ 51 kubostat2017j (http://goo.gl/76c4i
 d2.csv d2.csv,, 286,0,A 85,0,B 378,1,A 148,1,B ( :27 ) 10/ 51 kubostat2017j (http://goo.gl/76c4i") kubostat2017j p.1 2017 (j) Categorical Data Analsis [email protected] http://goo.gl/76c4i 2017 11 15 : 2017 11 08 17:11 kubostat2017j (http://goo.gl/76c4i) 2017 (j) 2017 11 15 1 / 63 A B C D E F G
kubostat2017j p.1 2017 (j) Categorical Data Analsis [email protected] http://goo.gl/76c4i 2017 11 15 : 2017 11 08 17:11 kubostat2017j (http://goo.gl/76c4i) 2017 (j) 2017 11 15 1 / 63 A B C D E F G
MCMCについて
 MCMC について 水産資源学におけるベイズ統計の応用ワークショップ 2007 年 8 月 2-3 日, 中央水研 遠洋水産研究所外洋資源部 鯨類管理研究室 岡村寛 事後分布からサンプルする Pr(θ 1, θ 2, θ 3, ) θ 1 は重要. あとは必要だけど直接的じゃないというようなとき, P(θ 1 x)= P(θ 1,, θ n x)dθ 2 dθ n を計算したい. モンテカルロ近似
MCMC について 水産資源学におけるベイズ統計の応用ワークショップ 2007 年 8 月 2-3 日, 中央水研 遠洋水産研究所外洋資源部 鯨類管理研究室 岡村寛 事後分布からサンプルする Pr(θ 1, θ 2, θ 3, ) θ 1 は重要. あとは必要だけど直接的じゃないというようなとき, P(θ 1 x)= P(θ 1,, θ n x)dθ 2 dθ n を計算したい. モンテカルロ近似
kubostat1g p. MCMC binomial distribution q MCMC : i N i y i p(y i q = ( Ni y i q y i (1 q N i y i, q {y i } q likelihood q L(q {y i } = i=1 p(y i q 1
 kubostat1g p.1 1 (g Hierarchical Bayesian Model [email protected] http://goo.gl/7ci The development of linear models Hierarchical Bayesian Model Be more flexible Generalized Linear Mixed Model (GLMM
kubostat1g p.1 1 (g Hierarchical Bayesian Model [email protected] http://goo.gl/7ci The development of linear models Hierarchical Bayesian Model Be more flexible Generalized Linear Mixed Model (GLMM
12/1 ( ) GLM, R MCMC, WinBUGS 12/2 ( ) WinBUGS WinBUGS 12/2 ( ) : 12/3 ( ) :? ( :51 ) 2/ 71
 GLM, R MCMC, WinBUGS 12/2 ( ) WinBUGS WinBUGS 12/2 ( ) : 12/3 ( ) :? ( :51 ) 2/ 71") 2010-12-02 (2010 12 02 10 :51 ) 1/ 71 GCOE 2010-12-02 WinBUGS [email protected] http://goo.gl/bukrb 12/1 ( ) GLM, R MCMC, WinBUGS 12/2 ( ) WinBUGS WinBUGS 12/2 ( ) : 12/3 ( ) :? 2010-12-02 (2010 12
2010-12-02 (2010 12 02 10 :51 ) 1/ 71 GCOE 2010-12-02 WinBUGS [email protected] http://goo.gl/bukrb 12/1 ( ) GLM, R MCMC, WinBUGS 12/2 ( ) WinBUGS WinBUGS 12/2 ( ) : 12/3 ( ) :? 2010-12-02 (2010 12
統計的データ解析
 統計的データ解析 011 011.11.9 林田清 ( 大阪大学大学院理学研究科 ) 連続確率分布の平均値 分散 比較のため P(c ) c 分布 自由度 の ( カイ c 平均値 0, 標準偏差 1の正規分布 に従う変数 xの自乗和 c x =1 が従う分布を自由度 の分布と呼ぶ 一般に自由度の分布は f /1 c / / ( c ) {( c ) e }/ ( / ) 期待値 二乗 ) 分布 c
統計的データ解析 011 011.11.9 林田清 ( 大阪大学大学院理学研究科 ) 連続確率分布の平均値 分散 比較のため P(c ) c 分布 自由度 の ( カイ c 平均値 0, 標準偏差 1の正規分布 に従う変数 xの自乗和 c x =1 が従う分布を自由度 の分布と呼ぶ 一般に自由度の分布は f /1 c / / ( c ) {( c ) e }/ ( / ) 期待値 二乗 ) 分布 c
EBNと疫学
 推定と検定 57 ( 復習 ) 記述統計と推測統計 統計解析は大きく 2 つに分けられる 記述統計 推測統計 記述統計 観察集団の特性を示すもの 代表値 ( 平均値や中央値 ) や ばらつきの指標 ( 標準偏差など ) 図表を効果的に使う 推測統計 観察集団のデータから母集団の特性を 推定 する 平均 / 分散 / 係数値などの推定 ( 点推定 ) 点推定値のばらつきを調べる ( 区間推定 ) 検定統計量を用いた検定
推定と検定 57 ( 復習 ) 記述統計と推測統計 統計解析は大きく 2 つに分けられる 記述統計 推測統計 記述統計 観察集団の特性を示すもの 代表値 ( 平均値や中央値 ) や ばらつきの指標 ( 標準偏差など ) 図表を効果的に使う 推測統計 観察集団のデータから母集団の特性を 推定 する 平均 / 分散 / 係数値などの推定 ( 点推定 ) 点推定値のばらつきを調べる ( 区間推定 ) 検定統計量を用いた検定
講義「○○○○」
 講義 信頼度の推定と立証 内容. 点推定と区間推定. 指数分布の点推定 区間推定 3. 指数分布 正規分布の信頼度推定 担当 : 倉敷哲生 ( ビジネスエンジニアリング専攻 ) 統計的推測 標本から得られる情報を基に 母集団に関する結論の導出が目的 測定値 x x x 3 : x 母集団 (populaio) 母集団の特性値 統計的推測 標本 (sample) 標本の特性値 分布のパラメータ ( 母数
講義 信頼度の推定と立証 内容. 点推定と区間推定. 指数分布の点推定 区間推定 3. 指数分布 正規分布の信頼度推定 担当 : 倉敷哲生 ( ビジネスエンジニアリング専攻 ) 統計的推測 標本から得られる情報を基に 母集団に関する結論の導出が目的 測定値 x x x 3 : x 母集団 (populaio) 母集団の特性値 統計的推測 標本 (sample) 標本の特性値 分布のパラメータ ( 母数
PowerPoint プレゼンテーション
 1/X Chapter 9: Linear correlation Cohen, B. H. (2007). In B. H. Cohen (Ed.), Explaining Psychological Statistics (3rd ed.) (pp. 255-285). NJ: Wiley. 概要 2/X 相関係数とは何か 相関係数の数式 検定 注意点 フィッシャーのZ 変換 信頼区間 相関係数の差の検定
1/X Chapter 9: Linear correlation Cohen, B. H. (2007). In B. H. Cohen (Ed.), Explaining Psychological Statistics (3rd ed.) (pp. 255-285). NJ: Wiley. 概要 2/X 相関係数とは何か 相関係数の数式 検定 注意点 フィッシャーのZ 変換 信頼区間 相関係数の差の検定
kubo2017sep16a p.1 ( 1 ) : : :55 kubo ( ( 1 ) / 10
 : : :55 kubo ( ( 1 ) / 10") kubo2017sep16a p.1 ( 1 ) [email protected] 2017 09 16 : http://goo.gl/8je5wh : 2017 09 13 16:55 kubo (http://goo.gl/ufq2) ( 1 ) 2017 09 16 1 / 106 kubo (http://goo.gl/ufq2) ( 1 ) 2017 09 16 2 / 106
kubo2017sep16a p.1 ( 1 ) [email protected] 2017 09 16 : http://goo.gl/8je5wh : 2017 09 13 16:55 kubo (http://goo.gl/ufq2) ( 1 ) 2017 09 16 1 / 106 kubo (http://goo.gl/ufq2) ( 1 ) 2017 09 16 2 / 106
Kumamoto University Center for Multimedia and Information Technologies Lab. 熊本大学アプリケーション実験 ~ 実環境における無線 LAN 受信電波強度を用いた位置推定手法の検討 ~ InKIAI 宮崎県美郷
 熊本大学アプリケーション実験 ~ 実環境における無線 LAN 受信電波強度を用いた位置推定手法の検討 ~ InKIAI プロジェクト @ 宮崎県美郷町 熊本大学副島慶人川村諒 1 実験の目的 従来 信号の受信電波強度 (RSSI:RecevedSgnal StrengthIndcator) により 対象の位置を推定する手法として 無線 LAN の AP(AccessPont) から受信する信号の減衰量をもとに位置を推定する手法が多く検討されている
熊本大学アプリケーション実験 ~ 実環境における無線 LAN 受信電波強度を用いた位置推定手法の検討 ~ InKIAI プロジェクト @ 宮崎県美郷町 熊本大学副島慶人川村諒 1 実験の目的 従来 信号の受信電波強度 (RSSI:RecevedSgnal StrengthIndcator) により 対象の位置を推定する手法として 無線 LAN の AP(AccessPont) から受信する信号の減衰量をもとに位置を推定する手法が多く検討されている
(3) 検定統計量の有意確率にもとづく仮説の採否データから有意確率 (significant probability, p 値 ) を求め 有意水準と照合する 有意確率とは データの分析によって得られた統計値が偶然おこる確率のこと あらかじめ設定した有意確率より低い場合は 帰無仮説を棄却して対立仮説
 検定統計量の有意確率にもとづく仮説の採否データから有意確率 (significant probability, p 値 ) を求め 有意水準と照合する 有意確率とは データの分析によって得られた統計値が偶然おこる確率のこと あらかじめ設定した有意確率より低い場合は 帰無仮説を棄却して対立仮説") 第 3 章 t 検定 (pp. 33-42) 3-1 統計的検定 統計的検定とは 設定した仮説を検証する場合に 仮説に基づいて集めた標本を 確率論の観点から分析 検証すること 使用する標本は 母集団から無作為抽出されたものでなければならない パラメトリック検定とノンパラメトリック検定 パラメトリック検定は母集団が正規分布に従う間隔尺度あるいは比率尺度の連続データを対象とする ノンパラメトリック検定は母集団に特定の分布を仮定しない
第 3 章 t 検定 (pp. 33-42) 3-1 統計的検定 統計的検定とは 設定した仮説を検証する場合に 仮説に基づいて集めた標本を 確率論の観点から分析 検証すること 使用する標本は 母集団から無作為抽出されたものでなければならない パラメトリック検定とノンパラメトリック検定 パラメトリック検定は母集団が正規分布に従う間隔尺度あるいは比率尺度の連続データを対象とする ノンパラメトリック検定は母集団に特定の分布を仮定しない
様々なミクロ計量モデル†
 担当 : 長倉大輔 ( ながくらだいすけ ) この資料は私の講義において使用するために作成した資料です WEB ページ上で公開しており 自由に参照して頂いて構いません ただし 内容について 一応検証してありますが もし間違いがあった場合でもそれによって生じるいかなる損害 不利益について責任を負いかねますのでご了承ください 間違いは発見次第 継続的に直していますが まだ存在する可能性があります 1 カウントデータモデル
担当 : 長倉大輔 ( ながくらだいすけ ) この資料は私の講義において使用するために作成した資料です WEB ページ上で公開しており 自由に参照して頂いて構いません ただし 内容について 一応検証してありますが もし間違いがあった場合でもそれによって生じるいかなる損害 不利益について責任を負いかねますのでご了承ください 間違いは発見次第 継続的に直していますが まだ存在する可能性があります 1 カウントデータモデル
kubostat2017c p (c) Poisson regression, a generalized linear model (GLM) : :
 Poisson regression, a generalized linear model (GLM) : :") kubostat2017c p.1 2017 (c), a generalized linear model (GLM) : [email protected] http://goo.gl/76c4i 2017 11 14 : 2017 11 07 15:43 kubostat2017c (http://goo.gl/76c4i) 2017 (c) 2017 11 14 1 / 47 agenda
kubostat2017c p.1 2017 (c), a generalized linear model (GLM) : [email protected] http://goo.gl/76c4i 2017 11 14 : 2017 11 07 15:43 kubostat2017c (http://goo.gl/76c4i) 2017 (c) 2017 11 14 1 / 47 agenda
Microsoft PowerPoint - 14回パラメータ推定配布用.pptx
 パラメータ推定の理論と実践 BEhavior Study for Transportation Graduate school, Univ. of Yamanashi 山梨大学佐々木邦明 最尤推定法 点推定量を求める最もポピュラーな方法 L n x n i1 f x i 右上の式を θ の関数とみなしたものが尤度関数 データ (a,b) が得られたとき, 全体の平均がいくつとするのがよいか 平均がいくつだったら
パラメータ推定の理論と実践 BEhavior Study for Transportation Graduate school, Univ. of Yamanashi 山梨大学佐々木邦明 最尤推定法 点推定量を求める最もポピュラーな方法 L n x n i1 f x i 右上の式を θ の関数とみなしたものが尤度関数 データ (a,b) が得られたとき, 全体の平均がいくつとするのがよいか 平均がいくつだったら
解析センターを知っていただく キャンペーン
 005..5 SAS 問題設定 目的 PKパラメータ (AUC,Cmax,Tmaxなど) の推定 PKパラメータの群間比較 PKパラメータのバラツキの評価! データの特徴 非反復測定値 個体につき 個の測定値しか得られない plasma concentration 非反復測定値のイメージ図 測定時点間で個体の対応がない 着目する状況 plasma concentration 経時反復測定値のイメージ図
005..5 SAS 問題設定 目的 PKパラメータ (AUC,Cmax,Tmaxなど) の推定 PKパラメータの群間比較 PKパラメータのバラツキの評価! データの特徴 非反復測定値 個体につき 個の測定値しか得られない plasma concentration 非反復測定値のイメージ図 測定時点間で個体の対応がない 着目する状況 plasma concentration 経時反復測定値のイメージ図
kubostat2018a p.1 統計モデリング入門 2018 (a) The main language of this class is 生物多様性学特論 Japanese Sorry An overview: Statistical Modeling 観測されたパターンを説明する統計モデル
 The main language of this class is 生物多様性学特論 Japanese Sorry An overview: Statistical Modeling 観測されたパターンを説明する統計モデル") p.1 統計モデリング入門 2018 (a) The main language of this class is 生物多様性学特論 Japanese Sorry An overview: Statistical Modeling 観測されたパターンを説明する統計モデル 久保拓弥 (北海道大 環境科学) Why in Japanese? because even in Japanese, statistics
p.1 統計モデリング入門 2018 (a) The main language of this class is 生物多様性学特論 Japanese Sorry An overview: Statistical Modeling 観測されたパターンを説明する統計モデル 久保拓弥 (北海道大 環境科学) Why in Japanese? because even in Japanese, statistics
統計モデリング入門 2018 (a) 生物多様性学特論 An overview: Statistical Modeling 観測されたパターンを説明する統計モデル 久保拓弥 (北海道大 環境科学) 統計モデリング入門 2018a 1
 生物多様性学特論 An overview: Statistical Modeling 観測されたパターンを説明する統計モデル 久保拓弥 (北海道大 環境科学) 統計モデリング入門 2018a 1") 統計モデリング入門 2018 (a) 生物多様性学特論 An overview: Statistical Modeling 観測されたパターンを説明する統計モデル 久保拓弥 (北海道大 環境科学) [email protected] 1/56 The main language of this class is Japanese Sorry Why in Japanese? because
統計モデリング入門 2018 (a) 生物多様性学特論 An overview: Statistical Modeling 観測されたパターンを説明する統計モデル 久保拓弥 (北海道大 環境科学) [email protected] 1/56 The main language of this class is Japanese Sorry Why in Japanese? because
kubostat2018d p.2 :? bod size x and fertilization f change seed number? : a statistical model for this example? i response variable seed number : { i
 kubostat2018d p.1 I 2018 (d) model selection and [email protected] http://goo.gl/76c4i 2018 06 25 : 2018 06 21 17:45 1 2 3 4 :? AIC : deviance model selection misunderstanding kubostat2018d (http://goo.gl/76c4i)
kubostat2018d p.1 I 2018 (d) model selection and [email protected] http://goo.gl/76c4i 2018 06 25 : 2018 06 21 17:45 1 2 3 4 :? AIC : deviance model selection misunderstanding kubostat2018d (http://goo.gl/76c4i)
Microsoft PowerPoint - GLMMexample_ver pptx
 Linear Mixed Model ( 以下 混合モデル ) の短い解説 この解説のPDFは http://www.lowtem.hokudai.ac.jp/plantecol/akihiro/sumida-index.html の お勉強 のページにあります. ver 20121121 と との間に次のような関係が見つかったとしよう 全体的な傾向に対する回帰直線を点線で示した ところが これらのデータは実は異なる
Linear Mixed Model ( 以下 混合モデル ) の短い解説 この解説のPDFは http://www.lowtem.hokudai.ac.jp/plantecol/akihiro/sumida-index.html の お勉強 のページにあります. ver 20121121 と との間に次のような関係が見つかったとしよう 全体的な傾向に対する回帰直線を点線で示した ところが これらのデータは実は異なる
第 3 回講義の項目と概要 統計的手法入門 : 品質のばらつきを解析する 平均と標準偏差 (P30) a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均
 a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均") 第 3 回講義の項目と概要 016.8.9 1.3 統計的手法入門 : 品質のばらつきを解析する 1.3.1 平均と標準偏差 (P30) a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均 :AVERAGE 関数, 標準偏差 :STDEVP 関数とSTDEVという関数 1 取得したデータそのものの標準偏差
第 3 回講義の項目と概要 016.8.9 1.3 統計的手法入門 : 品質のばらつきを解析する 1.3.1 平均と標準偏差 (P30) a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均 :AVERAGE 関数, 標準偏差 :STDEVP 関数とSTDEVという関数 1 取得したデータそのものの標準偏差
Microsoft Word - VB.doc
 第 1 章 初めてのプログラミング 本章では カウントアップというボタンを押すと表示されている値が1ずつ増加し カウントダウンというボタンを押すと表示されている値が1ずつ減少する簡単な機能のプログラムを作り これを通して Visual Basic.NET によるプログラム開発の概要を学んでいきます 1.1 起動とプロジェクトの新規作成 Visual Studio.NET の起動とプロジェクトの新規作成の方法を
第 1 章 初めてのプログラミング 本章では カウントアップというボタンを押すと表示されている値が1ずつ増加し カウントダウンというボタンを押すと表示されている値が1ずつ減少する簡単な機能のプログラムを作り これを通して Visual Basic.NET によるプログラム開発の概要を学んでいきます 1.1 起動とプロジェクトの新規作成 Visual Studio.NET の起動とプロジェクトの新規作成の方法を
PowerPoint プレゼンテーション
 非線形カルマンフィルタ ~a. 問題設定 ~ 離散時間非線形状態空間表現 x k + 1 = f x k y k = h x k + bv k + w k f : ベクトル値をとるx k の非線形関数 h : スカラ値をとるx k の非線形関数 v k システム雑音 ( 平均値 0, 分散 σ v 2 k ) x k + 1 = f x k,v k w k 観測雑音 ( 平均値 0, 分散 σ w
非線形カルマンフィルタ ~a. 問題設定 ~ 離散時間非線形状態空間表現 x k + 1 = f x k y k = h x k + bv k + w k f : ベクトル値をとるx k の非線形関数 h : スカラ値をとるx k の非線形関数 v k システム雑音 ( 平均値 0, 分散 σ v 2 k ) x k + 1 = f x k,v k w k 観測雑音 ( 平均値 0, 分散 σ w
スライド 1
 ベイジアンモデルによる地域人口予測モデルの可能性について 片桐智志 1 山下諭史 1 ( 1 ネイチャーインサイト株式会社 ) The possibility of regional population forecasting model by Bayesian model KATAGIRI, Satoshi 1 YAMASHITA, Satoshi 1 1 Nature Insight Co.,
ベイジアンモデルによる地域人口予測モデルの可能性について 片桐智志 1 山下諭史 1 ( 1 ネイチャーインサイト株式会社 ) The possibility of regional population forecasting model by Bayesian model KATAGIRI, Satoshi 1 YAMASHITA, Satoshi 1 1 Nature Insight Co.,
C#の基本
 C# の基本 ~ 開発環境の使い方 ~ C# とは プログラミング言語のひとつであり C C++ Java 等に並ぶ代表的な言語の一つである 容易に GUI( グラフィックやボタンとの連携ができる ) プログラミングが可能である メモリ管理等の煩雑な操作が必要なく 比較的初心者向きの言語である C# の利点 C C++ に比べて メモリ管理が必要ない GUIが作りやすい Javaに比べて コードの制限が少ない
C# の基本 ~ 開発環境の使い方 ~ C# とは プログラミング言語のひとつであり C C++ Java 等に並ぶ代表的な言語の一つである 容易に GUI( グラフィックやボタンとの連携ができる ) プログラミングが可能である メモリ管理等の煩雑な操作が必要なく 比較的初心者向きの言語である C# の利点 C C++ に比べて メモリ管理が必要ない GUIが作りやすい Javaに比べて コードの制限が少ない
スライド 1
 データ解析特論第 10 回 ( 全 15 回 ) 2012 年 12 月 11 日 ( 火 ) 情報エレクトロニクス専攻横田孝義 1 終了 11/13 11/20 重回帰分析をしばらくやります 12/4 12/11 12/18 2 前回から回帰分析について学習しています 3 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える
データ解析特論第 10 回 ( 全 15 回 ) 2012 年 12 月 11 日 ( 火 ) 情報エレクトロニクス専攻横田孝義 1 終了 11/13 11/20 重回帰分析をしばらくやります 12/4 12/11 12/18 2 前回から回帰分析について学習しています 3 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える
カイ二乗フィット検定、パラメータの誤差
 統計的データ解析 008 008.. 林田清 ( 大阪大学大学院理学研究科 ) 問題 C (, ) ( x xˆ) ( y yˆ) σ x πσ σ y y Pabx (, ;,,, ) ˆ y σx σ y = dx exp exp πσx ただし xy ˆ ˆ はyˆ = axˆ+ bであらわされる直線モデル上の点 ( ˆ) ( ˆ ) ( ) x x y ax b y ax b Pabx (,
統計的データ解析 008 008.. 林田清 ( 大阪大学大学院理学研究科 ) 問題 C (, ) ( x xˆ) ( y yˆ) σ x πσ σ y y Pabx (, ;,,, ) ˆ y σx σ y = dx exp exp πσx ただし xy ˆ ˆ はyˆ = axˆ+ bであらわされる直線モデル上の点 ( ˆ) ( ˆ ) ( ) x x y ax b y ax b Pabx (,
多変量解析 ~ 重回帰分析 ~ 2006 年 4 月 21 日 ( 金 ) 南慶典
 南慶典") 多変量解析 ~ 重回帰分析 ~ 2006 年 4 月 21 日 ( 金 ) 南慶典 重回帰分析とは? 重回帰分析とは複数の説明変数から目的変数との関係性を予測 評価説明変数 ( 数量データ ) は目的変数を説明するのに有効であるか得られた関係性より未知のデータの妥当性を判断する これを重回帰分析という つまり どんなことをするのか? 1 最小 2 乗法により重回帰モデルを想定 2 自由度調整済寄与率を求め
多変量解析 ~ 重回帰分析 ~ 2006 年 4 月 21 日 ( 金 ) 南慶典 重回帰分析とは? 重回帰分析とは複数の説明変数から目的変数との関係性を予測 評価説明変数 ( 数量データ ) は目的変数を説明するのに有効であるか得られた関係性より未知のデータの妥当性を判断する これを重回帰分析という つまり どんなことをするのか? 1 最小 2 乗法により重回帰モデルを想定 2 自由度調整済寄与率を求め
 2009 5 1...1 2...3 2.1...3 2.2...3 3...10 3.1...10 3.1.1...10 3.1.2... 11 3.2...14 3.2.1...14 3.2.2...16 3.3...18 3.4...19 3.4.1...19 3.4.2...20 3.4.3...21 4...24 4.1...24 4.2...24 4.3 WinBUGS...25 4.4...28
2009 5 1...1 2...3 2.1...3 2.2...3 3...10 3.1...10 3.1.1...10 3.1.2... 11 3.2...14 3.2.1...14 3.2.2...16 3.3...18 3.4...19 3.4.1...19 3.4.2...20 3.4.3...21 4...24 4.1...24 4.2...24 4.3 WinBUGS...25 4.4...28
Microsoft PowerPoint - 時系列解析(11)_講義用.pptx
_講義用.pptx") 時系列解析 () ボラティリティ 時変係数 AR モデル 東京 学数理 情報教育研究センター 北川源四郎 概要. 分散 定常モデル : 線形化 正規近似. 共分散 定常モデル : 時変係数モデル 3. 線形 ガウス型状態空間モデル 分散 共分散 定常 3 地震波 経 5 定常時系列のモデル 4. 平均 定常 トレンド, 季節調整. 分散 定常 線形 ガウスモデル ( カルマンフィルタ ) で推定するためには
時系列解析 () ボラティリティ 時変係数 AR モデル 東京 学数理 情報教育研究センター 北川源四郎 概要. 分散 定常モデル : 線形化 正規近似. 共分散 定常モデル : 時変係数モデル 3. 線形 ガウス型状態空間モデル 分散 共分散 定常 3 地震波 経 5 定常時系列のモデル 4. 平均 定常 トレンド, 季節調整. 分散 定常 線形 ガウスモデル ( カルマンフィルタ ) で推定するためには
一般化線形 (混合) モデル (2) - ロジスティック回帰と GLMM
 モデル (2) - ロジスティック回帰と GLMM") .. ( ) (2) GLMM [email protected] I http://goo.gl/rrhzey 2013 08 27 : 2013 08 27 08:29 kubostat2013ou2 (http://goo.gl/rrhzey) ( ) (2) 2013 08 27 1 / 74 I.1 N k.2 binomial distribution logit link function.3.4!
.. ( ) (2) GLMM [email protected] I http://goo.gl/rrhzey 2013 08 27 : 2013 08 27 08:29 kubostat2013ou2 (http://goo.gl/rrhzey) ( ) (2) 2013 08 27 1 / 74 I.1 N k.2 binomial distribution logit link function.3.4!
ベイズ統計入門
 ベイズ統計入門 条件付確率 事象 F が起こったことが既知であるという条件の下で E が起こる確率を条件付確率 (codtoal probablt) という P ( E F ) P ( E F ) P( F ) 定義式を変形すると 確率の乗法公式となる ( E F ) P( F ) P( E F ) P( E) P( F E) P 事象の独立 ある事象の生起する確率が 他のある事象が生起するかどうかによって変化しないとき
ベイズ統計入門 条件付確率 事象 F が起こったことが既知であるという条件の下で E が起こる確率を条件付確率 (codtoal probablt) という P ( E F ) P ( E F ) P( F ) 定義式を変形すると 確率の乗法公式となる ( E F ) P( F ) P( E F ) P( E) P( F E) P 事象の独立 ある事象の生起する確率が 他のある事象が生起するかどうかによって変化しないとき
Dependent Variable: LOG(GDP00/(E*HOUR)) Date: 02/27/06 Time: 16:39 Sample (adjusted): 1994Q1 2005Q3 Included observations: 47 after adjustments C -1.5
) Date: 02/27/06 Time: 16:39 Sample (adjusted): 1994Q1 2005Q3 Included observations: 47 after adjustments C -1.5") 第 4 章 この章では 最小二乗法をベースにして 推計上のさまざまなテクニックを検討する 変数のバリエーション 係数の制約係数にあらかじめ制約がある場合がある たとえばマクロの生産関数は 次のように表すことができる 生産要素は資本と労働である 稼動資本は資本ストックに稼働率をかけることで計算でき 労働投入量は 就業者数に総労働時間をかけることで計算できる 制約を掛けずに 推計すると次の結果が得られる
第 4 章 この章では 最小二乗法をベースにして 推計上のさまざまなテクニックを検討する 変数のバリエーション 係数の制約係数にあらかじめ制約がある場合がある たとえばマクロの生産関数は 次のように表すことができる 生産要素は資本と労働である 稼動資本は資本ストックに稼働率をかけることで計算でき 労働投入量は 就業者数に総労働時間をかけることで計算できる 制約を掛けずに 推計すると次の結果が得られる
Medical3
 Chapter 1 1.4.1 1 元配置分散分析と多重比較の実行 3つの治療法による測定値に有意な差が認められるかどうかを分散分析で調べます この例では 因子が1つだけ含まれるため1 元配置分散分析 one-way ANOVA の適用になります また 多重比較法 multiple comparison procedure を用いて 具体的のどの治療法の間に有意差が認められるかを検定します 1. 分析メニュー
Chapter 1 1.4.1 1 元配置分散分析と多重比較の実行 3つの治療法による測定値に有意な差が認められるかどうかを分散分析で調べます この例では 因子が1つだけ含まれるため1 元配置分散分析 one-way ANOVA の適用になります また 多重比較法 multiple comparison procedure を用いて 具体的のどの治療法の間に有意差が認められるかを検定します 1. 分析メニュー
みっちりGLM
 2015/3/27 12:00-13:00 日本草地学会若手 R 統計企画 ( 信州大学農学部 ) R と一般化線形モデル入門 山梨県富士山科学研究所 安田泰輔 謝辞 : 日本草地学会若手の会の皆様 発表の機会を頂き たいへんありがとうございます! 茨城大学 学生時代 自己紹介 ベータ二項分布を用いた種の空間分布の解析 所属 : 山梨県富士山科学研究所 最近の研究テーマ 近接リモートセンシングによる半自然草地のモニタリング手法開発
2015/3/27 12:00-13:00 日本草地学会若手 R 統計企画 ( 信州大学農学部 ) R と一般化線形モデル入門 山梨県富士山科学研究所 安田泰輔 謝辞 : 日本草地学会若手の会の皆様 発表の機会を頂き たいへんありがとうございます! 茨城大学 学生時代 自己紹介 ベータ二項分布を用いた種の空間分布の解析 所属 : 山梨県富士山科学研究所 最近の研究テーマ 近接リモートセンシングによる半自然草地のモニタリング手法開発
スライド 1
 データ解析特論重回帰分析編 2017 年 7 月 10 日 ( 月 )~ 情報エレクトロニクスコース横田孝義 1 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える 具体的には y = a + bx という回帰直線 ( モデル ) でデータを代表させる このためにデータからこの回帰直線の切片 (a) と傾き (b) を最小
データ解析特論重回帰分析編 2017 年 7 月 10 日 ( 月 )~ 情報エレクトロニクスコース横田孝義 1 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える 具体的には y = a + bx という回帰直線 ( モデル ) でデータを代表させる このためにデータからこの回帰直線の切片 (a) と傾き (b) を最小
Microsoft PowerPoint - e-stat(OLS).pptx
.pptx") 経済統計学 ( 補足 ) 最小二乗法について 担当 : 小塚匡文 2015 年 11 月 19 日 ( 改訂版 ) 神戸大学経済学部 2015 年度後期開講授業 補足 : 最小二乗法 ( 単回帰分析 ) 1.( 単純 ) 回帰分析とは? 標本サイズTの2 変数 ( ここではXとY) のデータが存在 YをXで説明する回帰方程式を推定するための方法 Y: 被説明変数 ( または従属変数 ) X: 説明変数
経済統計学 ( 補足 ) 最小二乗法について 担当 : 小塚匡文 2015 年 11 月 19 日 ( 改訂版 ) 神戸大学経済学部 2015 年度後期開講授業 補足 : 最小二乗法 ( 単回帰分析 ) 1.( 単純 ) 回帰分析とは? 標本サイズTの2 変数 ( ここではXとY) のデータが存在 YをXで説明する回帰方程式を推定するための方法 Y: 被説明変数 ( または従属変数 ) X: 説明変数
Microsoft Word - apstattext04.docx
 4 章母集団と指定値との量的データの検定 4.1 検定手順今までは質的データの検定の方法を学んで来ましたが これからは量的データについてよく利用される方法を説明します 量的データでは データの分布が正規分布か否かで検定の方法が著しく異なります この章ではまずデータの分布の正規性を調べる方法を述べ 次にデータの平均値または中央値がある指定された値と違うかどうかの検定方法を説明します 以下の図 4.1.1
4 章母集団と指定値との量的データの検定 4.1 検定手順今までは質的データの検定の方法を学んで来ましたが これからは量的データについてよく利用される方法を説明します 量的データでは データの分布が正規分布か否かで検定の方法が著しく異なります この章ではまずデータの分布の正規性を調べる方法を述べ 次にデータの平均値または中央値がある指定された値と違うかどうかの検定方法を説明します 以下の図 4.1.1
PrimerArray® Analysis Tool Ver.2.2
 研究用 PrimerArray Analysis Tool Ver.2.2 説明書 v201801 PrimerArray Analysis Tool Ver.2.2 は PrimerArray( 製品コード PH001 ~ PH007 PH009 ~ PH015 PN001 ~ PN015) で得られたデータを解析するためのツールで コントロールサンプルと 1 種類の未知サンプル間の比較が可能です
研究用 PrimerArray Analysis Tool Ver.2.2 説明書 v201801 PrimerArray Analysis Tool Ver.2.2 は PrimerArray( 製品コード PH001 ~ PH007 PH009 ~ PH015 PN001 ~ PN015) で得られたデータを解析するためのツールで コントロールサンプルと 1 種類の未知サンプル間の比較が可能です
Probit , Mixed logit
 Probit, Mixed logit 2016/5/16 スタートアップゼミ #5 B4 後藤祥孝 1 0. 目次 Probit モデルについて 1. モデル概要 2. 定式化と理解 3. 推定 Mixed logit モデルについて 4. モデル概要 5. 定式化と理解 6. 推定 2 1.Probit 概要 プロビットモデルとは. 効用関数の誤差項に多変量正規分布を仮定したもの. 誤差項には様々な要因が存在するため,
Probit, Mixed logit 2016/5/16 スタートアップゼミ #5 B4 後藤祥孝 1 0. 目次 Probit モデルについて 1. モデル概要 2. 定式化と理解 3. 推定 Mixed logit モデルについて 4. モデル概要 5. 定式化と理解 6. 推定 2 1.Probit 概要 プロビットモデルとは. 効用関数の誤差項に多変量正規分布を仮定したもの. 誤差項には様々な要因が存在するため,
Stanによるハミルトニアンモンテカルロ法を用いたサンプリングについて
 Stan によるハミルトニアンモンテカルロ法を用いたサンプリングについて 10 月 22 日中村文士 1 目次 1.STANについて 2.RでSTANをするためのインストール 3.STANのコード記述方法 4.STANによるサンプリングの例 2 1.STAN について ハミルトニアンモンテカルロ法に基づいた事後分布からのサンプリングなどができる STAN の HP: mc-stan.org 3 由来
Stan によるハミルトニアンモンテカルロ法を用いたサンプリングについて 10 月 22 日中村文士 1 目次 1.STANについて 2.RでSTANをするためのインストール 3.STANのコード記述方法 4.STANによるサンプリングの例 2 1.STAN について ハミルトニアンモンテカルロ法に基づいた事後分布からのサンプリングなどができる STAN の HP: mc-stan.org 3 由来
Microsoft Word - mstattext02.docx
 章重回帰分析 複数の変数で 1つの変数を予測するような手法を 重回帰分析 といいます 前の巻でところで述べた回帰分析は 1つの説明変数で目的変数を予測 ( 説明 ) する手法でしたが この説明変数が複数個になったと考えればよいでしょう 重回帰分析はこの予測式を与える分析手法です 以下の例を見て下さい 例 以下のデータ (Samples 重回帰分析 1.txt) をもとに体重を身長と胸囲の1 次関数で
章重回帰分析 複数の変数で 1つの変数を予測するような手法を 重回帰分析 といいます 前の巻でところで述べた回帰分析は 1つの説明変数で目的変数を予測 ( 説明 ) する手法でしたが この説明変数が複数個になったと考えればよいでしょう 重回帰分析はこの予測式を与える分析手法です 以下の例を見て下さい 例 以下のデータ (Samples 重回帰分析 1.txt) をもとに体重を身長と胸囲の1 次関数で
Microsoft Word - å“Ÿåłžå¸°173.docx
 回帰分析 ( その 3) 経済情報処理 価格弾力性の推定ある商品について その購入量を w 単価を p とし それぞれの変化量を w p で表 w w すことにする この時 この商品の価格弾力性 は により定義される これ p p は p が 1 パーセント変化した場合に w が何パーセント変化するかを示したものである ここで p を 0 に近づけていった極限を考えると d ln w 1 dw dw
回帰分析 ( その 3) 経済情報処理 価格弾力性の推定ある商品について その購入量を w 単価を p とし それぞれの変化量を w p で表 w w すことにする この時 この商品の価格弾力性 は により定義される これ p p は p が 1 パーセント変化した場合に w が何パーセント変化するかを示したものである ここで p を 0 に近づけていった極限を考えると d ln w 1 dw dw
JMP による 2 群間の比較 SAS Institute Japan 株式会社 JMP ジャパン事業部 2008 年 3 月 JMP で t 検定や Wilcoxon 検定はどのメニューで実行できるのか または検定を行う際の前提条件の評価 ( 正規性 等分散性 ) はどのメニューで実行できるのかと
 はどのメニューで実行できるのかと") JMP による 2 群間の比較 SAS Institute Japan 株式会社 JMP ジャパン事業部 2008 年 3 月 JMP で t 検定や Wilcoxon 検定はどのメニューで実行できるのか または検定を行う際の前提条件の評価 ( 正規性 等分散性 ) はどのメニューで実行できるのかというお問い合わせがよくあります そこで本文書では これらについて の回答を 例題を用いて説明します 1.
JMP による 2 群間の比較 SAS Institute Japan 株式会社 JMP ジャパン事業部 2008 年 3 月 JMP で t 検定や Wilcoxon 検定はどのメニューで実行できるのか または検定を行う際の前提条件の評価 ( 正規性 等分散性 ) はどのメニューで実行できるのかというお問い合わせがよくあります そこで本文書では これらについて の回答を 例題を用いて説明します 1.
Microsoft Word doc
 . 正規線形モデルのベイズ推定翠川 大竹距離減衰式 (PGA(Midorikawa, S., and Ohtake, Y. (, Attenuation relationships of peak ground acceleration and velocity considering attenuation characteristics for shallow and deeper earthquakes,
. 正規線形モデルのベイズ推定翠川 大竹距離減衰式 (PGA(Midorikawa, S., and Ohtake, Y. (, Attenuation relationships of peak ground acceleration and velocity considering attenuation characteristics for shallow and deeper earthquakes,
Excelにおける回帰分析(最小二乗法)の手順と出力
の手順と出力") Microsoft Excel Excel 1 1 x y x y y = a + bx a b a x 1 3 x 0 1 30 31 y b log x α x α x β 4 version.01 008 3 30 Website:http://keijisaito.info, E-mail:[email protected] 1 Excel Excel.1 Excel Excel
Microsoft Excel Excel 1 1 x y x y y = a + bx a b a x 1 3 x 0 1 30 31 y b log x α x α x β 4 version.01 008 3 30 Website:http://keijisaito.info, E-mail:[email protected] 1 Excel Excel.1 Excel Excel
まず y t を定数項だけに回帰する > levelmod = lm(topixrate~1) 次にこの出力を使って先ほどのレジームスイッチングモデルを推定する 以下のように入力する > levelswmod = msmfit(levelmod,k=,p=0,sw=c(t,t)) ここで k はレジ
 次にこの出力を使って先ほどのレジームスイッチングモデルを推定する 以下のように入力する > levelswmod = msmfit(levelmod,k=,p=0,sw=c(t,t)) ここで k はレジ") マルコフレジームスイッチングモデルの推定 1. マルコフレジームスイッチング (MS) モデルを推定する 1.1 パッケージ MSwM インスツールする MS モデルを推定するために R のパッケージ MSwM をインスツールする パッケージとは通常の R には含まれていない 追加的な R のコマンドの集まりのようなものである R には追加的に 600 以上のパッケージが用意されており それぞれ分析の目的に応じて標準の
マルコフレジームスイッチングモデルの推定 1. マルコフレジームスイッチング (MS) モデルを推定する 1.1 パッケージ MSwM インスツールする MS モデルを推定するために R のパッケージ MSwM をインスツールする パッケージとは通常の R には含まれていない 追加的な R のコマンドの集まりのようなものである R には追加的に 600 以上のパッケージが用意されており それぞれ分析の目的に応じて標準の
kubostat2017b p.1 agenda I 2017 (b) probability distribution and maximum likelihood estimation :
 probability distribution and maximum likelihood estimation :") kubostat2017b p.1 agenda I 2017 (b) probabilit distribution and maimum likelihood estimation [email protected] http://goo.gl/76c4i 2017 11 14 : 2017 11 07 15:43 1 : 2 3? 4 kubostat2017b (http://goo.gl/76c4i)
kubostat2017b p.1 agenda I 2017 (b) probabilit distribution and maimum likelihood estimation [email protected] http://goo.gl/76c4i 2017 11 14 : 2017 11 07 15:43 1 : 2 3? 4 kubostat2017b (http://goo.gl/76c4i)
C3 データ可視化とツール
 < 第 3 回 > データ可視化とツール 統計数理研究所 中野純司 [email protected] データ可視化とツール 概要 データサイエンティスト育成クラッシュコース データサイエンティストとしてデータ分析を行う際に必要な可視化の考え方と それを実行するためのフリーソフトウェアを紹介する 1. はじめに 2. 静的なグラフィックス 3. 動的なグラフィックス 4. 対話的なグラフィックス 1.
< 第 3 回 > データ可視化とツール 統計数理研究所 中野純司 [email protected] データ可視化とツール 概要 データサイエンティスト育成クラッシュコース データサイエンティストとしてデータ分析を行う際に必要な可視化の考え方と それを実行するためのフリーソフトウェアを紹介する 1. はじめに 2. 静的なグラフィックス 3. 動的なグラフィックス 4. 対話的なグラフィックス 1.
3. みせかけの相関単位根系列が注目されるのは これを持つ変数同士の回帰には意味がないためだ 単位根系列で代表的なドリフト付きランダムウォークを発生させてそれを確かめてみよう yと xという変数名の系列をを作成する yt=0.5+yt-1+et xt=0.1+xt-1+et 初期値を y は 10
 第 10 章 くさりのない犬 はじめにこの章では 単位根検定や 共和分検定を説明する データが単位根を持つ系列の場合 見せかけの相関をする場合があり 推計結果が信用できなくなる 経済分析の手順として 系列が定常系列か単位根を持つ非定常系列かを見極め 定常系列であればそのまま推計し 非定常系列であれば階差をとって推計するのが一般的である 1. ランダムウオーク 最も簡単な単位根を持つ系列としてランダムウオークがある
第 10 章 くさりのない犬 はじめにこの章では 単位根検定や 共和分検定を説明する データが単位根を持つ系列の場合 見せかけの相関をする場合があり 推計結果が信用できなくなる 経済分析の手順として 系列が定常系列か単位根を持つ非定常系列かを見極め 定常系列であればそのまま推計し 非定常系列であれば階差をとって推計するのが一般的である 1. ランダムウオーク 最も簡単な単位根を持つ系列としてランダムウオークがある
講義のーと : データ解析のための統計モデリング. 第2回
 Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
数量的アプローチ 年 6 月 11 日 イントロダクション データ分析をマスターする 12 のレッスン ウェブサポートページ ( 有斐閣 ) 水落研究室 R http:
 水落研究室 R http:") イントロダクション データ分析をマスターする 12 のレッスン ウェブサポートページ ( 有斐閣 ) http://yuhikaku-nibu.txt-nifty.com/blog/2017/09/22103.html 水落研究室 R http://depts.nanzan-u.ac.jp/ugrad/ps/mizuochi/r.html 1 この授業では統計ソフト R を使って分析を行います データを扱うソフトとして
イントロダクション データ分析をマスターする 12 のレッスン ウェブサポートページ ( 有斐閣 ) http://yuhikaku-nibu.txt-nifty.com/blog/2017/09/22103.html 水落研究室 R http://depts.nanzan-u.ac.jp/ugrad/ps/mizuochi/r.html 1 この授業では統計ソフト R を使って分析を行います データを扱うソフトとして
Microsoft PowerPoint - 資料04 重回帰分析.ppt
 04. 重回帰分析 京都大学 加納学 Division of Process Control & Process Sstems Engineering Department of Chemical Engineering, Koto Universit [email protected] http://www-pse.cheme.koto-u.ac.jp/~kano/ Outline
04. 重回帰分析 京都大学 加納学 Division of Process Control & Process Sstems Engineering Department of Chemical Engineering, Koto Universit [email protected] http://www-pse.cheme.koto-u.ac.jp/~kano/ Outline
NLMIXED プロシジャを用いた生存時間解析 伊藤要二アストラゼネカ株式会社臨床統計 プログラミング グループグルプ Survival analysis using PROC NLMIXED Yohji Itoh Clinical Statistics & Programming Group, A
 NLMIXED プロシジャを用いた生存時間解析 伊藤要二アストラゼネカ株式会社臨床統計 プログラミング グループグルプ Survival analysis using PROC NLMIXED Yohji Itoh Clinical Statistics & Programming Group, AstraZeneca KK 要旨 : NLMIXEDプロシジャの最尤推定の機能を用いて 指数分布 Weibull
NLMIXED プロシジャを用いた生存時間解析 伊藤要二アストラゼネカ株式会社臨床統計 プログラミング グループグルプ Survival analysis using PROC NLMIXED Yohji Itoh Clinical Statistics & Programming Group, AstraZeneca KK 要旨 : NLMIXEDプロシジャの最尤推定の機能を用いて 指数分布 Weibull
Microsoft PowerPoint - S11_1 2010Econometrics [互換モード]
![Microsoft PowerPoint - S11_1 2010Econometrics [互換モード]](/thumbs/79/79771572.jpg "Microsoft PowerPoint - S11_1 2010Econometrics [互換モード]") S11_1 計量経済学 一般化古典的回帰モデル -3 1 図 7-3 不均一分散の検定と想定の誤り 想定の誤りと不均一分散均一分散を棄却 3つの可能性 1. 不均一分散がある. 不均一分散はないがモデルの想定に誤り 3. 両者が同時に起きている 想定に誤り不均一分散を 検出 したら散布図に戻り関数形の想定や説明変数の選択を再検討 残差 残差 Y 真の関係 e e 線形回帰 X X 1 実行可能な一般化最小二乗法
S11_1 計量経済学 一般化古典的回帰モデル -3 1 図 7-3 不均一分散の検定と想定の誤り 想定の誤りと不均一分散均一分散を棄却 3つの可能性 1. 不均一分散がある. 不均一分散はないがモデルの想定に誤り 3. 両者が同時に起きている 想定に誤り不均一分散を 検出 したら散布図に戻り関数形の想定や説明変数の選択を再検討 残差 残差 Y 真の関係 e e 線形回帰 X X 1 実行可能な一般化最小二乗法
2. 時系列分析 プラットフォームの使用法 JMP の 時系列分析 プラットフォームでは 一変量の時系列に対する分析を行うことができます この章では JMP のサンプルデ ータを用いて このプラットフォームの使用法をご説明します JMP のメニューバーより [ ヘルプ ] > [ サンプルデータ ]
![2. 時系列分析 プラットフォームの使用法 JMP の 時系列分析 プラットフォームでは 一変量の時系列に対する分析を行うことができます この章では JMP のサンプルデ ータを用いて このプラットフォームの使用法をご説明します JMP のメニューバーより [ ヘルプ ] > [ サンプルデータ ]](/thumbs/49/25514951.jpg "2. 時系列分析 プラットフォームの使用法 JMP の 時系列分析 プラットフォームでは 一変量の時系列に対する分析を行うことができます この章では JMP のサンプルデ ータを用いて このプラットフォームの使用法をご説明します JMP のメニューバーより [ ヘルプ ] > [ サンプルデータ ]") JMP を用いた ARIMA モデルのあてはめ SAS Institute Japan 株式会社 JMP ジャパン事業部 2013 年 2 月作成 1. はじめに JMP の時系列分析では 一変量の時系列データに対する分析や予測を行うことができ 時系列データに対するグラフ表示 時系列モデルのあてはめ モデルの評価 予測まで 対話的に分析を実行することができます 時系列データにあてはめるモデルとしては
JMP を用いた ARIMA モデルのあてはめ SAS Institute Japan 株式会社 JMP ジャパン事業部 2013 年 2 月作成 1. はじめに JMP の時系列分析では 一変量の時系列データに対する分析や予測を行うことができ 時系列データに対するグラフ表示 時系列モデルのあてはめ モデルの評価 予測まで 対話的に分析を実行することができます 時系列データにあてはめるモデルとしては
講義のーと : データ解析のための統計モデリング. 第5回
 Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20

Microsoft PowerPoint - 統計科学研究所_R_重回帰分析_変数選択_2.ppt
 重回帰分析 残差分析 変数選択 1 内容 重回帰分析 残差分析 歯の咬耗度データの分析 R で変数選択 ~ step 関数 ~ 2 重回帰分析と単回帰分析 体重を予測する問題 分析 1 身長 のみから体重を予測 分析 2 身長 と ウエスト の両方を用いて体重を予測 分析 1 と比べて大きな改善 体重 に関する推測では 身長 だけでは不十分 重回帰分析における問題 ~ モデルの構築 ~ 適切なモデルで分析しているか?
重回帰分析 残差分析 変数選択 1 内容 重回帰分析 残差分析 歯の咬耗度データの分析 R で変数選択 ~ step 関数 ~ 2 重回帰分析と単回帰分析 体重を予測する問題 分析 1 身長 のみから体重を予測 分析 2 身長 と ウエスト の両方を用いて体重を予測 分析 1 と比べて大きな改善 体重 に関する推測では 身長 だけでは不十分 重回帰分析における問題 ~ モデルの構築 ~ 適切なモデルで分析しているか?
Microsoft Word - 補論3.2
 補論 3. 多変量 GARC モデル 07//6 新谷元嗣 藪友良 対数尤度関数 3 章 7 節では 変量の対数尤度を求めた ここでは多変量の場合 とくに 変量について対数尤度を求める 誤差項 は平均 0 で 次元の正規分布に従うとする 単純化のため 分散と共分散は時間を通じて一定としよう ( この仮定は後で変更される ) したがって ij から添え字 を除くことができる このとき と の尤度関数は
補論 3. 多変量 GARC モデル 07//6 新谷元嗣 藪友良 対数尤度関数 3 章 7 節では 変量の対数尤度を求めた ここでは多変量の場合 とくに 変量について対数尤度を求める 誤差項 は平均 0 で 次元の正規分布に従うとする 単純化のため 分散と共分散は時間を通じて一定としよう ( この仮定は後で変更される ) したがって ij から添え字 を除くことができる このとき と の尤度関数は
Microsoft PowerPoint - stat-2014-[9] pptx
![Microsoft PowerPoint - stat-2014-[9] pptx](/thumbs/49/25555771.jpg "Microsoft PowerPoint - stat-2014-[9] pptx") 統計学 第 17 回 講義 母平均の区間推定 Part-1 014 年 6 17 ( )6-7 限 担当教員 : 唐渡 広志 ( からと こうじ ) 研究室 : 経済学研究棟 4 階 43 号室 email: [email protected] website: htt://www3.u-toyama.ac.j/kkarato/ 1 講義の目的 標本平均は正規分布に従うという性質を
統計学 第 17 回 講義 母平均の区間推定 Part-1 014 年 6 17 ( )6-7 限 担当教員 : 唐渡 広志 ( からと こうじ ) 研究室 : 経済学研究棟 4 階 43 号室 email: [email protected] website: htt://www3.u-toyama.ac.j/kkarato/ 1 講義の目的 標本平均は正規分布に従うという性質を
dae opixrae 1 Feb Mar Apr May Jun と表示される 今 必要なのは opixrae のデータだけなので > opixrae=opixdaa$opi
 R による時系列分析 4 1. GARCH モデルを推定する 1.1 パッケージ rugarch をインスツールする パッケージとは通常の R には含まれていない 追加的な R のコマンドの集まりのようなものである R には追加的に 600 以上のパッケージが用意されており それぞれ分析の目的に応じて標準の R にパッケージを追加していくことになる インターネットに接続してあるパソコンで R を起動させ
R による時系列分析 4 1. GARCH モデルを推定する 1.1 パッケージ rugarch をインスツールする パッケージとは通常の R には含まれていない 追加的な R のコマンドの集まりのようなものである R には追加的に 600 以上のパッケージが用意されており それぞれ分析の目的に応じて標準の R にパッケージを追加していくことになる インターネットに接続してあるパソコンで R を起動させ
統計学 - 社会統計の基礎 - 正規分布 標準正規分布累積分布関数の逆関数 t 分布正規分布に従うサンプルの平均の信頼区間 担当 : 岸 康人 資料ページ :
 統計学 - 社会統計の基礎 - 正規分布 標準正規分布累積分布関数の逆関数 t 分布正規分布に従うサンプルの平均の信頼区間 担当 : 岸 康人 資料ページ : https://goo.gl/qw1djw 正規分布 ( 復習 ) 正規分布 (Normal Distribution)N (μ, σ 2 ) 別名 : ガウス分布 (Gaussian Distribution) 密度関数 Excel:= NORM.DIST
統計学 - 社会統計の基礎 - 正規分布 標準正規分布累積分布関数の逆関数 t 分布正規分布に従うサンプルの平均の信頼区間 担当 : 岸 康人 資料ページ : https://goo.gl/qw1djw 正規分布 ( 復習 ) 正規分布 (Normal Distribution)N (μ, σ 2 ) 別名 : ガウス分布 (Gaussian Distribution) 密度関数 Excel:= NORM.DIST
データ科学2.pptx
 データ科学 多重検定 2 mul%ple test False Discovery Rate 藤博幸 前回の復習 1 多くの検定を繰り返す時には 単純に個々の検定を繰り返すだけでは不十分 5% 有意水準ということは, 1000 回検定を繰り返すと, 50 回くらいは帰無仮説が正しいのに 間違って棄却されてすまうじちがあるということ ex) 1 万個の遺伝子について 正常細胞とガン細胞で それぞれの遺伝子の発現に差があるかどうかを検定
データ科学 多重検定 2 mul%ple test False Discovery Rate 藤博幸 前回の復習 1 多くの検定を繰り返す時には 単純に個々の検定を繰り返すだけでは不十分 5% 有意水準ということは, 1000 回検定を繰り返すと, 50 回くらいは帰無仮説が正しいのに 間違って棄却されてすまうじちがあるということ ex) 1 万個の遺伝子について 正常細胞とガン細胞で それぞれの遺伝子の発現に差があるかどうかを検定
角度統計配布_final.pptx
 01/1/7 1, 1 JST GFP {x 1,x,,,x n } Credit: Elowitz lab {θ 1, θ, θ 3,,, θ n } (+) EB3-GFP π π π θ+π = θ movie Shindo et al., PLoS one, 008 (+) beating Shindo et al., PLoS one, 008 Guirao et al., NCB, 010
01/1/7 1, 1 JST GFP {x 1,x,,,x n } Credit: Elowitz lab {θ 1, θ, θ 3,,, θ n } (+) EB3-GFP π π π θ+π = θ movie Shindo et al., PLoS one, 008 (+) beating Shindo et al., PLoS one, 008 Guirao et al., NCB, 010
Microsoft PowerPoint - Econometrics pptx
 計量経済学講義 第 4 回回帰モデルの診断と選択 Part 07 年 ( ) 限 担当教員 : 唐渡 広志 研究室 : 経済学研究棟 4 階 43 号室 emal: [email protected] webste: http://www3.u-toyama.ac.p/kkarato/ 講義の目的 誤差項の分散が不均 である場合や, 系列相関を持つ場合についての検定 法と修正 法を学びます
計量経済学講義 第 4 回回帰モデルの診断と選択 Part 07 年 ( ) 限 担当教員 : 唐渡 広志 研究室 : 経済学研究棟 4 階 43 号室 emal: [email protected] webste: http://www3.u-toyama.ac.p/kkarato/ 講義の目的 誤差項の分散が不均 である場合や, 系列相関を持つ場合についての検定 法と修正 法を学びます
計量経済学の第一歩 田中隆一 ( 著 ) gretl で例題と実証分析問題を 再現する方法 発行所株式会社有斐閣 2015 年 12 月 20 日初版第 1 刷発行 ISBN , Ryuichi Tanaka, Printed in Japan
 gretl で例題と実証分析問題を 再現する方法 発行所株式会社有斐閣 2015 年 12 月 20 日初版第 1 刷発行 ISBN , Ryuichi Tanaka, Printed in Japan") 計量経済学の第一歩 田中隆一 ( 著 ) gretl で例題と実証分析問題を 再現する方法 発行所株式会社有斐閣 2015 年 12 月 20 日初版第 1 刷発行 ISBN 978-4-641-15028-7, Printed in Japan 第 5 章単回帰分析 本文例例 5. 1: 学歴と年収の関係 まず 5_income.csv を読み込み, メニューの モデル (M) 最小 2 乗法 (O)
計量経済学の第一歩 田中隆一 ( 著 ) gretl で例題と実証分析問題を 再現する方法 発行所株式会社有斐閣 2015 年 12 月 20 日初版第 1 刷発行 ISBN 978-4-641-15028-7, Printed in Japan 第 5 章単回帰分析 本文例例 5. 1: 学歴と年収の関係 まず 5_income.csv を読み込み, メニューの モデル (M) 最小 2 乗法 (O)
このうち ツールバーが表示されていないときは メニューバーから [ 表示 (V)] [ ツールバー (T)] の [ 標準のボタン (S)] [ アドレスバー (A)] と [ ツールバーを固定する (B)] をクリックしてチェックを付けておくとよい また ツールバーはユーザ ( 利用者 ) が変更
![このうち ツールバーが表示されていないときは メニューバーから [ 表示 (V)] [ ツールバー (T)] の [ 標準のボタン (S)] [ アドレスバー (A)] と [ ツールバーを固定する (B)] をクリックしてチェックを付けておくとよい また ツールバーはユーザ ( 利用者 ) が変更](/thumbs/93/112077293.jpg "このうち ツールバーが表示されていないときは メニューバーから [ 表示 (V)] [ ツールバー (T)] の [ 標準のボタン (S)] [ アドレスバー (A)] と [ ツールバーを固定する (B)] をクリックしてチェックを付けておくとよい また ツールバーはユーザ ( 利用者 ) が変更") ファイル操作 アプリケーションソフトウェアなどで作成したデータはディスクにファイルとして保存される そのファイルに関してコピーや削除などの基本的な操作について実習する また ファイルを整理するためのフォルダの作成などの実習をする (A) ファイル名 ファイル名はデータなどのファイルをディスクに保存しておくときに付ける名前である データファイルはどんどん増えていくので 何のデータであるのかわかりやすいファイル名を付けるようにする
ファイル操作 アプリケーションソフトウェアなどで作成したデータはディスクにファイルとして保存される そのファイルに関してコピーや削除などの基本的な操作について実習する また ファイルを整理するためのフォルダの作成などの実習をする (A) ファイル名 ファイル名はデータなどのファイルをディスクに保存しておくときに付ける名前である データファイルはどんどん増えていくので 何のデータであるのかわかりやすいファイル名を付けるようにする
201711grade2.pdf
 2017 11 26 1 2 28 3 90 4 5 A 1 2 3 4 Web Web 6 B 10 3 10 3 7 34 8 23 9 10 1 2 3 1 (A) 3 32.14 0.65 2.82 0.93 7.48 (B) 4 6 61.30 54.68 34.86 5.25 19.07 (C) 7 13 5.89 42.18 56.51 35.80 50.28 (D) 14 20 0.35
2017 11 26 1 2 28 3 90 4 5 A 1 2 3 4 Web Web 6 B 10 3 10 3 7 34 8 23 9 10 1 2 3 1 (A) 3 32.14 0.65 2.82 0.93 7.48 (B) 4 6 61.30 54.68 34.86 5.25 19.07 (C) 7 13 5.89 42.18 56.51 35.80 50.28 (D) 14 20 0.35
Microsoft PowerPoint - H17-5時限(パターン認識).ppt
.ppt") パターン認識早稲田大学講義 平成 7 年度 独 産業技術総合研究所栗田多喜夫 赤穂昭太郎 統計的特徴抽出 パターン認識過程 特徴抽出 認識対象から何らかの特徴量を計測 抽出 する必要がある 認識に有効な情報 特徴 を抽出し 次元を縮小した効率の良い空間を構成する過程 文字認識 : スキャナ等で取り込んだ画像から文字の識別に必要な本質的な特徴のみを抽出 例 文字線の傾き 曲率 面積など 識別 与えられた未知の対象を
パターン認識早稲田大学講義 平成 7 年度 独 産業技術総合研究所栗田多喜夫 赤穂昭太郎 統計的特徴抽出 パターン認識過程 特徴抽出 認識対象から何らかの特徴量を計測 抽出 する必要がある 認識に有効な情報 特徴 を抽出し 次元を縮小した効率の良い空間を構成する過程 文字認識 : スキャナ等で取り込んだ画像から文字の識別に必要な本質的な特徴のみを抽出 例 文字線の傾き 曲率 面積など 識別 与えられた未知の対象を
1 環境統計学ぷらす 第 5 回 一般 ( 化 ) 線形混合モデル 高木俊 2013/11/21
 線形混合モデル 高木俊 2013/11/21") 1 環境統計学ぷらす 第 5 回 一般 ( 化 ) 線形混合モデル 高木俊 [email protected] 2013/11/21 2 予定 第 1 回 : Rの基礎と仮説検定 第 2 回 : 分散分析と回帰 第 3 回 : 一般線形モデル 交互作用 第 4.1 回 : 一般化線形モデル 第 4.2 回 : モデル選択 (11/29?) 第 5 回 : 一般化線形混合モデル
1 環境統計学ぷらす 第 5 回 一般 ( 化 ) 線形混合モデル 高木俊 [email protected] 2013/11/21 2 予定 第 1 回 : Rの基礎と仮説検定 第 2 回 : 分散分析と回帰 第 3 回 : 一般線形モデル 交互作用 第 4.1 回 : 一般化線形モデル 第 4.2 回 : モデル選択 (11/29?) 第 5 回 : 一般化線形混合モデル
③ 水産資源解析の概要 さまざまな資源量推定手法 どの資源評価モデルが良いのか 資源量推定のさいに重要な3つのこと 1
 ③ 水産資源解析の概要 さまざまな資源量推定手法 どの資源評価モデルが良いのか 資源量推定のさいに重要な3つのこと 1 適切な資源管理へむけて 適切な資源管理 減っていたら漁獲を減らす 増えていたら増やしても良い 妥当な資源評価 減っているか 増えているか MSYはどのあたりか データ収集 漁獲量 漁獲物のサイズ組成 生物的知見 2 さまざまな資源評価手法 初級 水産資源解析マニュアル 水研ホームページ
③ 水産資源解析の概要 さまざまな資源量推定手法 どの資源評価モデルが良いのか 資源量推定のさいに重要な3つのこと 1 適切な資源管理へむけて 適切な資源管理 減っていたら漁獲を減らす 増えていたら増やしても良い 妥当な資源評価 減っているか 増えているか MSYはどのあたりか データ収集 漁獲量 漁獲物のサイズ組成 生物的知見 2 さまざまな資源評価手法 初級 水産資源解析マニュアル 水研ホームページ
最小二乗法とロバスト推定
 はじめに 最小二乗法とロバスト推定 (M 推定 ) Maplesoft / サイバネットシステム ( 株 ) 最小二乗法は データフィッティングをはじめとしてデータ解析ではもっともよく用いられる手法のひとつです Maple では CurveFitting パッケージの LeastSquares コマンドや Statistics パッケージの Fit コマンド NonlinearFit コマンドなどを用いてデータに適合する数式モデルを求めることが可能です
はじめに 最小二乗法とロバスト推定 (M 推定 ) Maplesoft / サイバネットシステム ( 株 ) 最小二乗法は データフィッティングをはじめとしてデータ解析ではもっともよく用いられる手法のひとつです Maple では CurveFitting パッケージの LeastSquares コマンドや Statistics パッケージの Fit コマンド NonlinearFit コマンドなどを用いてデータに適合する数式モデルを求めることが可能です