一元配置分散分析法 F 検定と Welch 検定 一元配置分散分析で一般的に使用される F 検定は すべてのグループが共通だが未知の標準偏差 (σ) を共有するという仮定に基づきます 実際には この仮定が当てはまることはまれで その結果 タイプ I 過誤率の制御が難しくなります タイプ I の誤りと
|
|
|
- しほこ おとべ
- 7 years ago
- Views:
Transcription
1 MINITAB アシスタントホワイトペーパー本書は Minitab 統計ソフトウェアのアシスタントで使用される方法およびデータチェックを開発するため Minitab の統計専門家によって行われた調査に関する一連の文書群を構成する文書の 1 つです 一元配置分散分析 (ANOVA) 概要 一元配置分散分析は 3 つ以上のグループの平均を比較し 互いに有意に異なるかどうかを判断するために使用されます もう 1 つ重要な機能は 特定のグループ間の差を推定することです 一元配置分散分析でグループ間の差を検出する最も一般的な方法は F 検定です これは すべてのサンプルの母集団が共通だが未知の標準偏差を共有するという仮定に基づきます 実際には サンプルの標準偏差が異なる場合が多いことは認識しています したがって F 検定の代替法として 等しくない標準偏差に対応できる Welch 法について調べる必要がありました また 標準偏差が等しくないサンプルを考慮する多重比較を計算するための方法を開発する必要がありました この方法を使用すると 個別区間をグラフ化でき 互いに異なるグループを簡単に特定できます 本書では 次について Minitab アシスタントの一元配置分散分析手順で使用される方法をどのように開発したのかについて説明します Welch 検定 多重比較区間 さらに 異常なデータの有無 検定のサンプルサイズおよび検出力 データの正規性など 一元配置分散分析の結果の妥当性に影響する可能性がある条件について調べます これらの条件に基づき アシスタントでは データに対して次のチェックが自動的に実行され レポートカードで結果が報告されます 異常なデータ サンプルサイズ データの正規性 本書では これらの条件が一元配置分散分析に実際どのように関連するのかを調べ アシスタントでこれらの条件をチェックするためのガイドラインをどのように確立したのかについて説明します
2 一元配置分散分析法 F 検定と Welch 検定 一元配置分散分析で一般的に使用される F 検定は すべてのグループが共通だが未知の標準偏差 (σ) を共有するという仮定に基づきます 実際には この仮定が当てはまることはまれで その結果 タイプ I 過誤率の制御が難しくなります タイプ I の誤りとは 帰無仮説を誤って棄却する ( サンプルが有意に異ならないのに 異なると結論付ける ) 確率を指します サンプルの標準偏差が異なる場合 検定で誤った結論に達する可能性がより高くなります この問題に対処するために F 検定の代替法として Welch 検定が開発されました (Welch 1951) 目的 アシスタントの一元配置分散分析手順に F 検定と Welch 検定のどちらを使用するかを判断する必要がありました そのために F 検定と Welch 検定の実際の検定結果が 検定の目標有意水準 (α すなわちタイプ I 過誤率 ) とどれくらい厳密に一致するのか つまり所与のさまざまなサンプルサイズとサンプル標準偏差を使用した場合に 検定で帰無仮説が誤って棄却される回数が目的より多かったか または少なかったかを評価する必要がありました 方法 F 検定と Welch 検定を比較するために さまざまなサンプル数 サンプルサイズ およびサンプル標準偏差を使用して 複数のシミュレーションを行いました 各条件で F 検定と Welch 法の両方を使用して分散分析検定を 10,000 回実行しました サンプルの平均が同じになるように したがって各検定で帰無仮説が真となるように ランダムデータを生成しました 次に と の目標有意水準を使用して検定を実行しました 10,000 回の検定のうち F 検定と Welch 検定で実際に帰無仮説が棄却された回数を数え この比率と目標有意水準を比較しました 検定が正しく行われれば 推定されるタイプ I 過誤率は目標有意水準にかなり近くなります 結果 検定したすべての条件において Welch 法は F 検定と同等以上の性能を示しました たとえば Welch 検定を使用して 5 つのサンプルを比較したとき タイプ I 過誤率は ~ 40 で 目標有意水準の にかなり近くなりました これは サンプルサイズと標準偏差が全サンプルで異なる場合でも Welch 法のタイプ I 過誤率は目標値に一致することを示しています 一方 F 検定のタイプ I 過誤率は ~ でした 特に次の条件のとき F 検定は正しく行われませんでした 最大サンプルの標準偏差もまた最大だった場合 タイプ I 過誤率は を下回りました この条件では検定がより保守的になり サンプルの標準偏差が等しくない場合は単純にサンプルサイズを増加しても 有効な解決策にはならないことを示しています サンプルサイズが等しいけれども 標準偏差が異なる場合 タイプ I 過誤率は を上回りました 標準偏差がより大きいサンプルのサイズが他のサンプルより小さ 一元配置分散分析 (ANOVA) 2
3 い場合でも 過誤率は より大きくなりました 特に より小さいサンプルにより大きい標準偏差があると この検定で帰無仮説が誤って棄却される危険性が大幅に増加します シミュレーションの手法と結果についての詳細は 付録 A を参照してください Welch 法は標準偏差とサンプルのサイズが等しくない場合に正しく行われたため アシスタントの一元配置分散分析手順では Welch 法を使用します 比較区間 分散分析検定が統計的に有意で 少なくとも 1 つのサンプル平均が他と異なることを示す場合 分析の次のステップは どのサンプルが統計的に異なるのかを判断することです この比較を行う直観的な方法は 信頼区間をグラフ化し 区間が重なり合っていないサンプルを特定することです ただし 個別信頼区間は比較するためのものではないため グラフから引き出す結論が検定結果と一致しない場合があります 標準偏差が等しいサンプルに使用する多重比較方法が発表されていますが 標準偏差が等しくないサンプルを考慮するために この方法を拡張する必要がありました 目的 サンプル全体を比較するために使用でき また検定結果にできるだけ厳密に一致する個別比較区間を計算する方法を開発する必要がありました また 他のサンプルと統計的に異なるサンプルを判断する視覚的方法を提供する必要もありました 方法 標準の多重比較の方法 (Hsu 1996) は 多重比較で生じる誤差の増加を制御しながら 平均の各ペア間の差に区間を提供します サンプルサイズが等しい特別なケースで 標準偏差が等しいと仮定する場合 すべてのペアの差の区間に正確に対応するように各平均の個別区間を表示することができます Hochberg, Weiss, and Hart(1982) は サンプルサイズが等しくないケースで 標準偏差が等しいと仮定し Tukey-Kramer の多重比較の方法に基づいて ペア間の差の区間にほぼ等しくなる個別区間を開発しました アシスタントでは 標準偏差が等しいと仮定しない Games-Howell の多重比較の方法に同じ手法を応用しました Minitab リリース 16 のアシスタントで使用される手法は 概念的に似ていますが Games- Howell の手法に直接基づくものではありませんでした 詳細は 付録 B を参照してください 結果 アシスタントの一元配置分散分析要約レポートの平均比較管理チャートに比較区間が表示されます 分散分析検定が統計的に有意である場合 少なくとも他の 1 つの区間と重なり合っていない区間はすべて赤でマークされます 帰無仮説が真のときに棄却される確率は両方の検定で同じなので そのような結果が出ることはまれですが 検定と比較区間が一致しないことがあります 分散分析検定が有意であるのに 区間のすべてが重なり合っている場合 重なりの量が最小のペアが赤でマークされます 分散分析検定が統計的に有意でない場合 重なり合っていない区間があっても 赤でマークされる区間は 1 つもありません 一元配置分散分析 (ANOVA) 3
4 データチェック 異常なデータ 異常なデータとは 極端に大きいまたは小さいデータ値を指し 外れ値とも呼ばれています 異常なデータは 分析の結果に強い影響を与える可能性があり 特にサンプルが小さい場合には 統計的に有意な結果を検出する確率に影響することがあります 異常なデータは データ収集での問題を示している可能性や 分析している工程の異常な動作に起因する場合があります したがって これらのデータ点は調べる価値があり 可能な場合には修正する必要があります 目的 分析の結果に影響する可能性がある 全体のサンプルに比べて非常に大きい または非常に小さいデータ値をチェックする方法を開発する必要がありました 方法 箱ひげ図の外れ値を特定するために Hoaglin, Iglewicz, and Tukey(1986) によって説明された方法に基づいて 異常データをチェックする方法を開発しました 結果 アシスタントでは 分布の下位四分位数を下回る幅または上位四分位数を上回る幅が四分位間範囲の 1.5 倍より大きいデータ点は異常と識別されます 下位四分位数および上位四分位数とは データの 25 番目および 75 番目の百分位数を指します 四分位間範囲とは 2 つの四分位数間の差を指します この方法は 特定の各外れ値を検出することが可能なため 複数の外れ値がある場合でも有効に機能します 異常なデータをチェックするときに レポートカードに次のステータスインジケータが表示されます ステータス 状態 異常なデータ点はありません 少なくとも 1 つのデータ点が異常です 結果に強い影響を与える可能性があります 一元配置分散分析 (ANOVA) 4
5 サンプルサイズ 検出力は有意な効果または差が真に存在する場合にそれを識別する尤度を示すため すべての仮説検定で重要な特性です 検出力は 対立仮説を支持し 帰無仮説を棄却する確率です 多くの場合 検定の検出力を高める最も簡単な方法は サンプルサイズを大きくすることです アシスタントでは 検定の検出力が低いと ユーザーが指定した差を検出するために必要なサンプルの大きさが示されます 差が指定されていない場合は 適度な検出力で検出できる差が表示されます アシスタントでは Welch 法が使用され この方法には検出力の厳密式がないため この情報を提供するためには検出力を計算する方法を開発する必要がありました 目的 検出力を計算する手法を開発するため 2 つの問題に取り組む必要がありました 1 つ目は アシスタントではユーザーはすべての平均セットを入力する必要がないということです 入力が必須なのは 実用的な意味を持つ平均間の差のみです どのような差を求める場合でも その差が生じる可能性のある平均の配置は無数にあります したがって 可能なすべての平均の配置の検出力を計算することはできないので 検出力を計算するときにどの平均を使用するのかを判断する妥当な手法を開発する必要がありました 2 つ目に アシスタントでは サンプルサイズまたは標準偏差が等しいことを必要としない Welch 法が使用されるため 検出力を計算する方法を開発する必要がありました 方法 無数にある可能な平均の配置に対処するために Minitab の標準の一元配置分散分析手順 ([ 統計 ] > [ 分散分析 ] > [ 一元配置 ]) で使用される手法に基づく方法を開発しました 規定量の差がある平均が 2 つのみで その他の平均は等しくなるケースに焦点を当てました ( 平均の加重平均に設定 ) 全体平均と異なる平均は 2 つのみ (2 つ以下 ) と仮定するため 推定される検出力は保守的になります ただし サンプルのサイズまたは標準偏差が異なる場合があるので 検出力の計算は どの 2 つの平均が異なると仮定されるのかに依存します この問題を解決するために 最良ケースと最悪ケースを表す 2 つの平均ペアを特定します 最悪のケースは サンプルサイズがサンプル分散に対して比較的小さいときに発生し 検出力は最小化されます 最良ケースは サンプルサイズがサンプル分散に対して比較的大きいときに発生し 検出力は最大化されます すべての検出力の計算で ちょうど 2 つの平均が平均の全体加重平均と異なるという仮定のもとで 検出力が最小化および最大化される 2 つの極端なケースが検討されます 検出力の計算を開発するために Kulinskaya et al.(2003) で示された方法を使用しました シミュレーション 平均の配置に対処するために開発した方法 および Kulinskaya et al.(2003) が示した方法の それぞれの検出力の計算を比較しました また 検出力がどのように平均の配置に依存するのかをより明確に示す 別の検出力の近似も調べました 検出力の計算についての詳細は 付録 C を参照してください 一元配置分散分析 (ANOVA) 5
6 結果 これらの方法の比較から 検出力の近似が良好なのは Kulinskaya の方法で 平均の配置を処理する方法は適切だということが示されました データから帰無仮説に反する十分な証拠が得られない場合 アシスタントでは与えられたサンプルサイズで 80% および 90% の確率で検出できる実質的な差が計算されます さらに ユーザーが実質的な差を指定すると この差の最小および最大検出力が計算されます 検出力が 90% 未満の場合 アシスタントでは指定された差と観測されたサンプル標準偏差に基づいて サンプルサイズが計算されます このサンプルサイズで 最小および最大検出力の両方が確実に 90% 以上となるように 指定された差は 最も大きな変動性を持つ 2 つの平均の間にあると仮定します ユーザーが差を指定しない場合 アシスタントでは 検出力範囲の最大が 60% となる最大の差が検出されます この値は 検出力レポートで 60% の検出力に対応する 赤いバーと黄色のバーの境界にラベル表示されます また 検出力範囲の最小が 90% となる最小の差も検出します この値は 検出力レポートで 90% の検出力に対応する 黄色のバーと緑のバーの境界にラベル表示されます 検出力とサンプルサイズを調べる場合 レポートカードには次のステータスインジケータが表示されます ステータス 状態 データから平均間に差があると結論付けるのに十分な証拠が得られません 差が指定されていませんでした 検定で平均間の差が検出されます 検出力に問題はありません または 検出力は十分です 検定で平均間の差は検出されませんでしたが サンプルは少なくとも 90% の確率で差を検出するのに十分な大きさです 検出力は十分な可能性があります 検定で平均間の差は検出されませんでしたが サンプルは少なくとも 80~90% の確率で差を検出するのに十分な大きさです 90% の検出力を達成するのに必要なサンプルサイズが報告されます 検出力は十分でない可能性があります 検定で平均間の差は検出されませんでしたが サンプルは少なくとも 60~80% の確率で差を検出するのに十分な大きさです 80% および 90% の検出力を達成するのに必要なサンプルサイズが報告されます 検出力は十分ではありません 検定で平均間の差は検出されませんでした サンプルは少なくとも 60% の確率で差を検出するのに十分な大きさではありません 80% および 90% の検出力を達成するのに必要なサンプルサイズが報告されます 正規性 多くの統計手法に共通する仮定は データが正規分布に従っているということです データが正規分布に従っていない場合でも 正規性の仮定に基づく方法は正しく行われることがあります これは すべてのサンプル平均の分布は近似の正規分布に従い 近似はサンプルサイズが大きくなるにつれ ほぼ正規になるという 中心極限定理である程度説明されます 一元配置分散分析 (ANOVA) 6
7 目的 目的は 正規分布の適度に良好な近似を得るために必要なサンプルの大きさを判断することでした さまざまな非正規分布で小規模から中規模のサイズのサンプルを使用して Welch 検定と比較区間を調べる必要がありました Welch 法の実際の検定結果と比較区間が 検定の選択された有意水準 (α すなわちタイプ I 過誤率 ) にどれくらい厳密に一致するのか つまり所与のさまざまなサンプルサイズ 水準数 非正規分布を使用した場合に 検定で帰無仮説が誤って棄却される回数が期待より多かったか または少なかったかを判断する必要がありました 方法 タイプ I 過誤率を推定するために さまざまなサンプル数 サンプルサイズ およびデータ分布を使用して 複数のシミュレーションを行いました シミュレーションには 正規分布から大幅に逸脱する歪んだ裾の重い分布が含まれました サイズおよび標準偏差は 各検定内の全サンプルで一定でした 各条件で Welch 法と比較区間を使用して分散分析検定を 10,000 回実行しました サンプルの平均が同じになるように したがって各検定で帰無仮説が真となるように ランダムデータを生成しました 次に の目標有意水準を使用して検定を実行しました 10,000 回のうち 検定で実際に帰無仮説が棄却された回数を数え この比率と目標有意水準を比較しました 比較区間の場合は 10,000 回のうち 区間が差を示した回数を数えました 検定が正しく行われれば タイプ I 過誤率は目標有意水準に非常に近くなります 結果 全体として 検定および比較区間は 10 または 15 の小さいサンプルサイズを使用したすべての条件で正しく行われました 水準数が 9 以下の検定の場合 ほとんどすべてのケースで サンプルサイズ 10 は目標有意水準の 3 パーセントポイント以内 サンプルサイズ 15 は 2 パーセントポイント以内という結果になります 水準数が 10 以上の検定の場合 ほとんどのケースで サンプルサイズ 15 は目標有意水準の 3 パーセントポイント以内 サンプルサイズ 20 は 2 パーセントポイント以内という結果になります 詳細は 付録 D を参照してください 比較的小さなサンプルで検定が正しく行われるため アシスタントではデータの正規性は検定されません 代わりに サンプルのサイズをチェックし サンプルが水準数 2~9 で 15 未満のとき 水準数 10~12 で 20 未満のときに表示されます これらの結果に基づき レポートカードには次のステータスインジケータが表示されます ステータス 状態 サンプルサイズが 15 または 20 未満です 正規性に問題はありません 一部のサンプルサイズが 15 または 20 未満です 正規性に問題がある可能性があります 一元配置分散分析 (ANOVA) 7
8 参考文献 Dunnet, C. W. (1980). Pairwise Multiple Comparisons in the Unequal Variance Case. Journal of the American Statistical Association, 75, Hoaglin, D.Hoaglin, D. C., Iglewicz, B., and Tukey, J. W. (1986). Performance of some resistant rules for outlier labeling. Journal of the American Statistical Association, 81, Hochberg, Y., Weiss G., and Hart, S. (1982). On graphical procedures for multiple comparisons. Journal of the American Statistical Association, 77, Hsu, J. (1996). Multiple comparisons: Theory and methods. Boca Raton, FL: Chapman & Hall. Kulinskaya, E., Staudte, R. G., and Gao, H. (2003). Power approximations in testing for unequal means in a One-Way ANOVA weighted for unequal variances, Communication in Statistics, 32 (12), Welch, B.L. (1947). The generalization of Student s problem when several different population variances are involved. Biometrika, 34, Welch, B.L. (1951). On the comparison of several mean values: An alternative approach. Biometrika 38, 一元配置分散分析 (ANOVA) 8
9 付録 A: F 検定と Welch 検定 F 検定では 同等標準偏差の仮定に違反すると タイプ I 過誤率が上昇する可能性があります Welch 検定はこの問題を回避するために設計されています Welch 検定 k 母集団から得たサイズ n 1 n k のランダムサンプルが観測されます μ 1 μ k は母集団平均を表し σ 1 2,, σ k 2 は母集団分散を表すとします x 1,, x k はサンプル平均を表し s 1 2,, s k 2 はサンプル分散を表すとします 次の仮説を検定します H 0: μ 1 = μ 2 = = μ k H 1: ある i j の μ i μ j k 平均の同等性を検定する Welch 検定では 統計量 W = k w j (x j μ ) 2 j=1 (k 1) 1+[2(k 2) (k 2 1) ] k j=1 h j と F(k 1, f) 分布を比較します ここで w j = n j s j 2 W = μ = k j=1 w j k j=1 w j x j W h j = (1 w j W f = n j 1 k k j =1 h j ) 2 および となります Welch 検定は W F k 1,f,1 α ( 確率 α で超過される F 分布の百分位 ) の場合 帰無仮説を 棄却します 等しくない標準偏差 このセクションでは 同等標準偏差の仮定の違反に対する F 検定の感度を実証し Welch 検定と比較します 次に N(0, σ2) の 5 つのサンプルを使用した 一元配置分散分析検定の結果を示します 各行は F 検定と Welch 検定を使用した 10,000 回のシミュレーションに基づいています 5 番目のサンプルの標準偏差を他のサンプルの 2 倍と 4 倍に増加し 標準偏差について 2 つの条件を検定しました サンプルサイズについては サンプルサイズが等しい 5 番目のサンプルが他より大きい 5 番目のサンプルが他より小さい という 3 つの条件を検定しました 一元配置分散分析 (ANOVA) 9
10 表 1 5 つのサンプルと目標有意水準 α = でシミュレートした F 検定と Welch 検定のタイプ I 過誤率 標準偏差 (σ1 σ2 σ3 σ4 σ5) サンプルサイズ (n1 n2 n3 n4 n5) F 検定 Welch 検定 サンプルサイズが等しい場合 ( 行 2 と行 5) F 検定で帰無仮説が誤って棄却される確率は目標の より大きくなり 標準偏差間の非同等性が大きくなると確率が増加します この問題は 標準偏差が最も大きいサンプルのサイズが減少するとさらに悪化します 一方 標準偏差が最も大きいサンプルのサイズが増加すると 棄却の確率は低下します ただし サンプルサイズが増加しすぎると 棄却の確率が低くなりすぎ 帰無仮説での検定が必要以上に保守的になるだけではなく 対立仮説での検定の検出力にも悪影響を及ぼします すべてのケースで目標有意水準の によく一致する Welch 検定でのこれらの結果を比較します 次に k = 7 サンプルを使用するケースのシミュレーションを行いました 表の各行は 10,000 回シミュレートした F 検定を要約しています 標準偏差とサンプルサイズはさまざまに変化を持たせました 目標有意水準は α = と α = です 上記では 目標値からの偏差がかなり大きくなる場合があることがわかります 変動性がより高いときに より小さいサンプルサイズを使用すると タイプ I 過誤率の確率が非常に高くなるのに対し より大きいサンプルを使用すると 検定が極端に保守的になる可能性があります 次の表 2 に結果を示します 表 2 7 つのサンプルでシミュレートした F 検定のタイプ I 過誤率 標準偏差 (σ1 σ2 σ3 σ4 σ5 σ6 σ7) サンプルサイズ (n1 n2 n3 n4 n5 n6 n7) 目標 α = 目標 α = 一元配置分散分析 (ANOVA) 10
11 標準偏差 (σ1 σ2 σ3 σ4 σ5 σ6 σ7) サンプルサイズ (n1 n2 n3 n4 n5 n6 n7) 目標 α = 目標 α = 一元配置分散分析 (ANOVA) 11
12 標準偏差 (σ1 σ2 σ3 σ4 σ5 σ6 σ7) サンプルサイズ (n1 n2 n3 n4 n5 n6 n7) 目標 α = 目標 α = 一元配置分散分析 (ANOVA) 12
13 標準偏差 (σ1 σ2 σ3 σ4 σ5 σ6 σ7) サンプルサイズ (n1 n2 n3 n4 n5 n6 n7) 目標 α = 目標 α = 一元配置分散分析 (ANOVA) 13
")
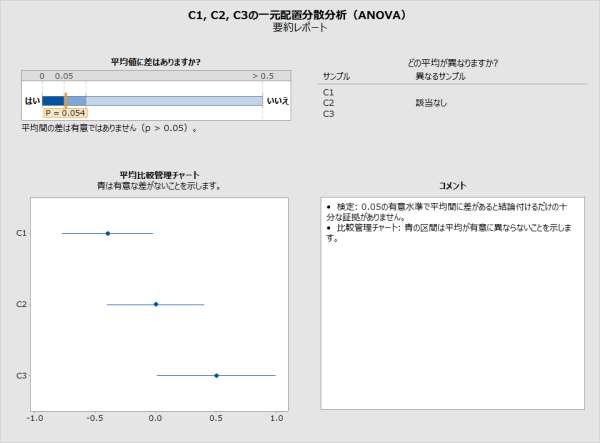
14 付録 B: 比較区間 平均比較管理チャートを使用して 母集団平均間の差の統計的有意性を評価できます 図 1 アシスタントの一元配置分散分析要約レポートの平均比較管理チャート 一元配置分散分析 (ANOVA) 14
![類似の区間セットが Minitab の標準の一元配置分散分析手順の出力に表示されます ([ 統計 ] > [ 分散分析 ] > [ 一元配置 ]) ただし 上記の区間は平均の単なる個別信頼区間です 分散分析検定 (F または Welch のいずれか ) で一部の平均が異なるという結論が出ると 重なり合っていない区間を探し どの平均が異なるのかについて結論を導こうとする自然な傾向があります](/docs-images/91/107518128/images/15-0.jpg "この個別信頼区間の非公式な分析が 妥当な結論につながる場合が多くありますが 誤差の確率は分散分析検定と同様には制御されません 母集団の数によっては 差があると結論付けられる確率が 検定より著しく高くまたは低くなる場合があります その結果 2 つの方法で一致しない結論に容易に達する可能性があります 比較管理チャートは 多重比較を行うときに Welch")
15 類似の区間セットが Minitab の標準の一元配置分散分析手順の出力に表示されます ([ 統計 ] > [ 分散分析 ] > [ 一元配置 ]) ただし 上記の区間は平均の単なる個別信頼区間です 分散分析検定 (F または Welch のいずれか ) で一部の平均が異なるという結論が出ると 重なり合っていない区間を探し どの平均が異なるのかについて結論を導こうとする自然な傾向があります この個別信頼区間の非公式な分析が 妥当な結論につながる場合が多くありますが 誤差の確率は分散分析検定と同様には制御されません 母集団の数によっては 差があると結論付けられる確率が 検定より著しく高くまたは低くなる場合があります その結果 2 つの方法で一致しない結論に容易に達する可能性があります 比較管理チャートは 多重比較を行うときに Welch 検定の結果により一貫して一致するように設計されています ただし 完全な一貫性を必ずしも実現できるということではありません Minitab の Tukey-Kramer 比較や Games-Howell 比較などの多重比較の方法では ([ 統計 ] > [ 分散分析 ] > [ 一元配置 ]) 個々の平均間の差について統計的に有効な結論を導くことができます これら 2 つの方法は 各平均ペアの差の区間が示される ペアワイズ比較の方法です 推定する差がすべての区間に同時に含まれる確率は少なくとも 1 α です Tukey- Kramer の方法が等分散性の仮定に依存するのに対し Games-Howell の方法では等分散性は必要ありません 等平均性の帰無仮説が真の場合 すべての差は 0 になり Games-Howell の区間のすべてに 0 が含まれない確率は 最大でも α です したがって 有意水準 α で仮説検定を実行するのに 区間を使用できます アシスタントでは 比較管理チャートの区間を導出するために Games-Howell の区間を開始点として使用します すべての差 μ i μ j, 1 i < j k に区間セット [Lij, Uij] を与え 同じ情報を伝える 個々の平均 μ i, 1 i k の区間セット [L i, U i] を求める必要があります これには μ i μ j = d. となるように μ i [L i, U i ] と μ j [L j, U j ] が存在する場合にのみ 任意の差 d は区間 [Lij, Uij] にあることが必要です 区間のエンドポイントは次の式で関連する必要があります 一元配置分散分析 (ANOVA) 15
16 U i L j = U ij と L i U j = L ij. k = 2 の場合 差は 1 つのみですが 個別区間は 2 つあるため 正確な比較区間を得ることができます 実際 この条件を満たす区間の幅にはかなりの柔軟性があります k = 3 の場合 3 つの差と 3 つの個別区間があるので 条件を満たすことは可能ですが 区間の幅の設定に柔軟性はありません k = 4 の場合 6 つの差がありますが 個別区間は 4 つしかありません 比較区間では より少ない区間数で同じ情報を伝えるようにする必要があります 一般に k 4 の場合は 個別平均よりも差のほうが多いため 等幅など 差の区間に対して追加条件を科さないかぎり 厳密解はありません Tukey-Kramer の区間は すべてのサンプルサイズが同じ場合にのみ等幅になります 等幅は 等分散性の仮定によって生じる結果でもあります Games-Howell の区間では 等分散を仮定しないので 等幅にはなりません アシスタントでは 比較区間を定義するには近似法に頼る必要があります μ i μ j の Games-Howell の区間は x i x j ± q (k, ν ij) s 2 i n i + s 2 j n j となり ここで q (k, ν ij) はスチューデント化された範囲分布の近似の百分位数です これは 比較対象の平均数 k と ペア (i, j) に関連付けられた自由度 νij に依存します ν ij = ( s i 2 2 n ) i ( s i 2 n + s 2 j i n ) j n i 1 + (s j n ) j 2. 1 n j 1 Hochberg, Weiss, and Hart(1982) は 次の式を使用して これらのペアワイズ比較にほぼ等しくなる個別区間を求めました 値 X i は x i ± q (k, ν) s p X i (X i + X j a ij ) 2 i j を最小化するために選択されます 上の式で a ij = 1 n i + 1 n j となります 次の形式の Games-Howell の比較から区間を導出して 分散が等しくないケースにこの手法を適応します 値 d i は x i ± d i (d i + d j b ij ) 2 i j を最小化するために選択されます 上の式で b ij = q (k, ν ij) s 2 i n i + s 2 j n j となります 一元配置分散分析 (ANOVA) 16

17 解は d i = 1 b k 1 j i ij 1 b (k 1)(k 2) j i,l i,j<l jl となります 次のグラフで Welch 検定のシミュレーション結果 および 2 つの方法を使用した比較区間の結果を比較します この 2 つの方法とは 現在使用している方法に基づく Games-Howell と Minitab リリース 16 で使用された自由度の平均に基づく方法です 垂直軸は 10,000 回のシミュレーションのうち Welch 検定で帰無仮説が誤って棄却された または比較区間のすべては重なり合っていない回数の比率です これらの例の目標 α は α = です これらのシミュレーションは 標準偏差とサンプルサイズが等しくないさまざまなケースを網羅しています 水平軸に沿った各位置は 異なるケースを表します 図 2 3 つのサンプルの比較区間を計算する 2 つの方法を使用して比較した Welch 検定 一元配置分散分析 (ANOVA) 17

")
18 図 3 5 つのサンプルの比較区間を計算する 2 つの方法を使用して比較した Welch 検定 図 4 7 つのサンプルの比較区間を計算する 2 つの方法を使用して比較した Welch 検定 これらの結果は 目標値の 周辺の狭い範囲で シミュレートした α 値を示しています また Minitab リリース 17 で実装されている Games-Howell に基づく方法を使用した結果が 一元配置分散分析 (ANOVA) 18

19 Minitab リリース 16 で使用された方法よりも Welch 検定の結果に より厳密に一致することはほぼ間違いありません 区間の被覆確率が 等しくない標準偏差による影響を受けやすい可能性を示す証拠があります ただし この感度は F 検定の感度ほど極端なものではありません 次のグラフに k = 5 の場合の この依存性を示します 図 5 等しくない標準偏差を使用したシミュレーションの結果 仮説検定と比較区間の併用 まれに 帰無仮説の棄却について 仮説検定と比較が一致しない場合があります 比較区間がすべて重なり合っているのに 検定で帰無仮説が棄却されることがあります 逆に 重なり合っていない区間があるのに 検定で帰無仮説が棄却されないこともあります 真の帰無仮説が棄却される確率は両方の方法で同じなので この不一致が起こるのはまれです これが起こった場合は 最初に検定結果を検討し 比較を使用して有意な検定をさらに調べます 有意水準 α で帰無仮説が棄却される場合 少なくとも他の 1 つの区間と重なり合っていない比較区間がすべて赤でマークされます これは 対応するグループ平均が少なくとも他の 1 つのグループ平均と異なることを視覚的に示すために使用されます 検定が有意で 最も可能性が高い 差を示す場合 すべての区間が重なり合っていない場合でも 重なりの量が最小のペアが赤でマークされます ( 図 6 を参照 ) 特に 重なりが非常に小さいペアが他にある場合 これはいくぶんか任意の選択です ただし 0 に近い差に境界があるペアは他にありません 一元配置分散分析 (ANOVA) 19
20 図 6 有意な検定 サンプル間で重なり合っている場合でも区間が赤でマークされている 検定で帰無仮説が棄却されない場合 重なり合っていない区間があっても 赤でマークされる区間は 1 つもありません ( 次の図 7 を参照 ) 区間は平均に差があることを示唆しますが 帰無仮説の棄却の失敗は 帰無仮説が真であると結論付けることと同じではありません これは単に 観測された差が 原因として可能性を除外するほど大きくないということを示しています また この状況では 重なり合っていない区間の Gap は通常非常に小さくなるため 非常に小さい差でも区間と一致し 実用的な意味を持つ差があることを必ずしも示しているわけではない点に留意してください 一元配置分散分析 (ANOVA) 20
21 図 7 検定失敗 サンプル間の重なり合いがない場合でも区間が赤でマークされていない 一元配置分散分析 (ANOVA) 21
22 付録 C: サンプルサイズ 一元配置分散分析では 検定対象のパラメータはさまざまなグループまたは母集団の母集団平均 μ1 μ2 μk です パラメータがすべて等しい場合 帰無仮説が満たされます 平均間に少しでも差があれば 対立仮説が満たされます 帰無仮説が棄却される確率は 帰無仮説を満たす平均の未満になる必要があります 実際の確率は 分布の標準偏差とサンプルのサイズによって異なります 帰無仮説から偏差を検出する検出力は より小さい標準偏差またはより大きなサンプルを使用すると増大します F 検定の検出力は 非心 F 分布を使用して 標準分散が等しい正規分布の仮定で計算できます 非心パラメータは次のようになります k i=1 θ F = n i (μ i μ) 2 σ 2 ここで μ は平均の加重平均です k k i=1 μ = i=1 n i μ i / n i σ は標準偏差で 一定であると仮定します その他すべてが等しいと 検出力は θf で増加します これは 厳密な意味では 平均が帰無仮説から遠く逸脱するほど 検出力が高くなるということです F 検定とは異なり Welch 検定には検出力の単純な厳密式がありません そこで 適度に良好な 2 つの近似式を見てみます 最初の式では F 検定の検出力と類似の方法で非心 F 分布が使用されます 使用する非心パラメータは 次の形式になります ここで μ は加重平均です k μ = i=1 w i μ i j=1 w j k k θ W = w i (μ i μ) 2 i=1 ただし重みは 既知の標準偏差 σ 2 i の結果をシミュレートするのか サンプル標準偏差 s 2 i に基づいて検出力を推定するのかによって 標準偏差とサンプルサイズに依存します ( つまり 2 2 w i = n i σ i またはw i = n i s i ) 近似の検出力は 次のように計算されます ここで 分母自由度は f = k k (1 w i k i=1 j=1 w j ) (n i 1) P(F k 1,f,θw F k 1,f,1 α ) となります 次に示すように これでシミュレーションで観測される検出力に適度に良好な近似が得られます アシスタントメニューでは検出力の計算に異なる近似を使用しますが この近似から良い洞察を得ることができ アシスタントメニューで検出力を計算する平均の配置を選択するための基準となります 平均の配置 Minitab の検出力とサンプルサイズに使用した手法 ([ 統計 ] > [ 分散分析 ] > [ 一元配置 ]) に合わせて アシスタントでは検出力を評価する平均セットすべての入力は要求されません 代わりに 実用的な意味を持つ平均の差の入力を求められます 最大平均と最小平均に指定 一元配置分散分析 (ANOVA) 22
23 した量の差が生じる可能性のある平均の配置は無数にあります たとえば 次のすべてで 5 つの平均間に 10 の最大差があります μ 1 = 0 μ 2 = 5 μ 3 = 5 μ 4 = 5 μ 5 = 10 μ 1 = 5 μ 2 = 0 μ 3 = 10 μ 4 = 10 μ 5 = 0 μ 1 = 0 μ 2 = 10 μ 3 = 0 μ 4 = 0 μ 5 = 0 この他にも無数の配置があります Minitab の検出力およびサンプルサイズで使用される手法 ([ 統計 ] > [ 検出力 ] および [ サンプルサイズ ] > [ 一元配置分散分析 (ANOVA)]) に従います つまり 2 つを除くすべての平均が平均の ( 加重 ) 平均となり 残り 2 つの平均の差が規定量となるケースを抽出します ただし 分散とサンプルサイズが等しくない可能性があるため 非心パラメータ ( したがって検出力 ) は どの 2 つの平均が異なると仮定されるのかによって異なります 2 つを除くすべての平均が全体加重平均 μ に等しく 2 つの平均 ( たとえば μi > μj) の間 および 2 つの平均と全体平均の間に差がある 平均の配置 μ1 μk を検討します Δ = μ i μ j が 2 つの平均間の差を表すとします Δ i = μ i μ および Δ j = μ μ j とします したがって Δ = Δ i + Δ j となります また μ はすべての k 平均の加重平均を表し (k - 2) 個の平均は μ に等しいと仮定されるので 次のようになります μ = [ w l μ l + w i (μ + i ) l i,j k k + w j (μ j )] w l = μ + (w i i w j j ) w l. l=1 l=1 したがって w i i = w j j = w j ( i ) ゆえに i = w j w i + w j j = w i w i + w j この特定の平均の配置について Welch 検定に関連する非心パラメータを計算できます θ W = w i (μ i μ) 2 + w j (μ j μ) 2 = w iw j w j w i 2 2 (w i + w j ) 2 = w iw j 2 w i + w j この数量は 固定された wj の wi で増加し 逆の場合も同じです したがって これは 2 つの最大の重みを使用したペア (i, j) で最大化され 2 つの最小の重みを使用したペアで最小化されます すべての検出力の計算で ちょうど 2 つの平均が平均の全体加重平均と異なるという仮定のもとで 検出力が最小化および最大化される 2 つの極端なケースが検討されます ユーザーが検定の実質的な差を指定すると この差の最小および最大検出力が評価されます これらの検出力の範囲は 検出力が 60% 以下は赤 検出力が 90% 以上は緑 検出力が 60%~ 90% は黄という色分けしたバーに相対してレポートに示されます レポートカードの結果は この色分けされたスケールに相対して 検出力の範囲がどこになるのかによって異なります 一元配置分散分析 (ANOVA) 23
24 範囲全体が赤の場合 すべてのグループペアの検出力が 60% 以下で レポートカードには検出力不足の問題を示す赤のアイコンが表示されます 範囲全体が緑の場合 すべてのグループの検出力が少なくとも 90% で レポートカードには十分な検出力の状態を示す緑のアイコンが表示されます その他すべての状態は レポートカードに黄色のアイコンで示される 中間の状況として扱われます 緑の状態に一致しない場合 ユーザーが指定した差と観測されたサンプル標準偏差を所与として 緑の状態がもたらされるサンプルサイズが計算されます 推定される検出力は 重み 2 w i = n i s i. を使用するサンプルサイズによって異なります すべてのサンプルが同じサンプルサイズであると仮定される場合 最も小さい 2 つの重みは サンプル標準偏差が最も大きい 2 つのグループに対応します アシスタントでは 指定された差が最も大きな変動性を持つ 2 つのグループの間にある場合に少なくとも 90% の検出力が得られるサンプルサイズが検出されます したがって すべてのグループで少なくともこの大きさのサンプルサイズを使用すると 検出力の範囲全体が少なくとも 90% になり 緑の条件が満たされます ユーザーが検出力の計算に差を指定しない場合 アシスタントでは 計算された検出力の範囲の最大が 60% となる最大の差が検出されます この値は 検出力レポートで 60% の検出力に対応する バーの赤い部分と黄色の部分の境界にラベル表示されます また 計算された検出力の範囲の最小が 90% となる最小の差も検出されます この値は 検出力レポートで 90% の検出力に対応する バーの黄色の部分と緑の部分の境界にラベル表示されます 検出力の計算 検出力は Kulinskaya et al.(2003) による近似を使用して計算されます 次を定義します λ = k i=1 w i (μ i μ) 2 A = k i=1 h i, k B = i=1 w i (μ i μ) 2 (1 w i /W)/(n i 1) k D = i=1 w 2 i (μ i μ) 4 /(n i 1) k E = w i 3 (μ i μ) 6 /(n i 1) 2 i=1 Welch 統計量の分子 k i=1 w i (x i μ ) 2 の最初の 3 つのキュムラントは 次のように推定できます κ 1 = k 1 + λ + 2A + 2B κ 2 = 2(k 1 + 2λ + 7A + 14B + D) κ 3 = 8(k 1 + 3λ + 15A + 45B + 6D + 2E) F k 1, f, 1 α は F(k 1, f) 分布の (1 α) 分位点を表すとします W* F k 1, f, 1 α はサイズ α の Welch 検定で帰無仮説を棄却する基準です そこで q = (k 1) [1 + b = κ 1 2κ 2 2 /κ 3 2(k 2)A k 2 1 ] F k 1,f,1 α 一元配置分散分析 (ANOVA) 24
25 ( 注 : c の式は Kulinskaya et al.(2003) で括弧なしで示されています ) ν = 8κ 2 3 /κ 3 2 とすると Welch 検定の推定される近似の検出力は 次のようになります P(χ v 2 q b ) c ここで χ v 2 は自由度 ν のカイ二乗確率変数です 次の結果は 2 つの近似法の検出力と 10,000 回のシミュレーションに基づく 例の範囲のシミュレートされた検出力を比較したものです 表 3 シミュレートした検出力と比較した 2 つの近似法の検出力の計算 例 α シミュレートし た検出力 非心 F Kulinskaya et al. μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: 一元配置分散分析 (ANOVA) 25
26 例 α シミュレートし た検出力 非心 F Kulinskaya et al. μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: 一元配置分散分析 (ANOVA) 26
27 例 α シミュレートし た検出力 非心 F Kulinskaya et al. μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: 一元配置分散分析 (ANOVA) 27
28 例 α シミュレートし た検出力 非心 F Kulinskaya et al. μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: μ: σ: n: 一元配置分散分析 (ANOVA) 28

29 例 α シミュレートし た検出力 非心 F Kulinskaya et al. μ: σ: n: μ: σ: n: μ: σ: n: 上の結果を次のグラフに要約します このグラフは 各近似とシミュレーションによって推定された検出力の値の不一致を示しています 図 8 2 つの検出力の近似とシミュレーションによって推定された検出力の比較 一元配置分散分析 (ANOVA) 29
30 付録 D: 正規性 このセクションでは さまざまな非正規分布で小規模から中規模のサンプルを使用して Welch 検定および比較区間の性能を調べるシミュレーションについて説明します 次の表に 等平均性の帰無仮説のもとで さまざまなタイプの分布で行ったシミュレーションの結果を要約します これらの例では すべての標準偏差が等しく すべてのサンプルのサイズも等しくなっています サンプル数は k = 3 5 または 7 です 各セルは シミュレーション 10,000 回に基づくタイプ I の誤りの推定値を示しています 目標有意水準 ( 目標 α) は です 表 4 さまざまな分布で等しい平均を使用した Welch 検定のシミュレーション結果 サンプルサイズ n = 10 サンプルサイズ n = 15 分布 k = 3 k = 5 k = 7 k = 3 k = 5 k = 7 N(0,1) t(3) t(5) ラプラス分布 Laplace(0,1) 一様分布 Uniform(-1, 1) ベータ分布 Beta(3, 3) 指数分布 カイ二乗分布 Chi-square(3) カイ二乗分布 Chi-square(5) カイ二乗分布 Chi-square(10) ベータ分布 Beta(8, 1) タイプ I 過誤率は サンプルのサイズが 10 の場合でも すべて目標 α の 3 パーセントポイント以内になりました グループ数が多く 正規から離れた分布では 偏差が大きくなる傾向があります サンプルサイズが 10 のとき 合格確率が 2 パーセントポイント以上外れるのは k = 7 でした これは 正規よりかなり裾が短い一様分布 大きく歪んだ指数分布 カイ二乗分布 Chi-square(3) ベータ分布 Beta(8, 1) で起こりました サンプルサイズを 15 まで増加すると 一様分布の結果は著しく向上しますが 2 つの大きく歪んだ分布では向上しません 比較区間に対して同様のシミュレーションを行いました この場合のシミュレートした α は シミュレーション数 10,000 のうち 一部の区間が重なり合っていない数を指します 目標 α = です 一元配置分散分析 (ANOVA) 30
31 表 5 さまざまな分布で等しい平均を使用した比較区間のシミュレーション結果 サンプルサイズ n = 10 サンプルサイズ n = 15 分布 k = 3 k = 5 k = 7 k = 3 k = 5 k = 7 N(0,1) t(3) t(5) ラプラス分布 Laplace(0,1) 一様分布 Uniform(-1, 1) ベータ分布 Beta(3, 3) 指数分布 カイ二乗分布 Chi-square(3) カイ二乗分布 Chi-square(5) カイ二乗分布 Chi-square(10) ベータ分布 Beta(8, 1) Welch 検定と同様に タイプ I 過誤率は サンプルのサイズが 10 の場合でも すべて目標 α の 3 パーセントポイント以内になりました サンプル数が多く 正規から離れた分布では 偏差が大きくなる傾向があります サンプルサイズが 10 のとき k = 7 では過誤率が 2 パーセントポイント以上外れる場合があります (k = 5 の場合は 1 件 ) このようなケースは 自由度 3 の極端に裾の重い t 分布 ラプラス分布 大きく歪んだ指数分布およびカイ二乗分布 Chi-square(3) で起こります サンプルサイズを 15 まで増加すると 結果は著しく向上しますが t(3) と指数分布のシミュレートした α 値のみが目標から 2 パーセントポイント以上外れます ただし Welch 検定の結果とは異なり 比較区間のより大きな偏差は保守的です アシスタントの一元配置分散分析では 最大で k = 12 のサンプルを使用できるため 次にサンプル数 8 以上の結果を検討します 次の表に k = 9 グループの非正規データで Welch 検定を使用したタイプ I 過誤率を示します ここでも 目標 α = です 表 6 9 個のサンプルを使用したさまざまな分布の Welch 検定のシミュレーション結果 分布 k = 9 t(3) t(5) ラプラス分布 Laplace(0,1) 一様分布 Uniform(-1, 1) 一元配置分散分析 (ANOVA) 31
32 ベータ分布 Beta(3, 3) 84 指数分布 カイ二乗分布 Chisquare(3) カイ二乗分布 Chisquare(5) カイ二乗分布 Chisquare(10) ベータ分布 Beta(8, 1) 予想どおり 大きく歪んだ分布は 目標 α から最も大きな偏差を示しています その場合でも 指数分布の偏差は近いですが 目標からの逸脱が 4 パーセントポイントを超える過誤率はありません すべての結果が目標 α に少なくとも適度に近いため レポートカードでは サンプルのサイズ 15 は十分であるとして扱い 非正規データの問題は示されません サイズ n = 15 のサンプルは k = 12 のサンプルになると それほど正しく行われません 次に 極端に非正規な分布を使用して さまざまなサンプルサイズで行った Welch 検定のシミュレートした結果を検討します これは サンプルサイズの適度な基準を開発するのに役立ちます 表 7 12 個のサンプルを使用したさまざまな分布の Welch 検定のシミュレーション結果 n t(3) 一様分布 カイ二乗分布 Chi-square(5) 目標 α からの偏差が 2 パーセントポイントを若干上回っても許容できるならば これらの分布で n = 15 は許容範囲内です 偏差を 2 パーセントポイント未満に保つには サンプルサイズは 20 にする必要があります 次に より歪んだカイ二乗分布 Chi-square(3) と指数分布の結果を検討します 表 8 12 個のサンプルを使用したカイ二乗分布と指数分布の Welch 検定のシミュレーション結果 n カイ二乗分布 Chisquare(3) 指数分布 一元配置分散分析 (ANOVA) 32
33 n カイ二乗分布 Chisquare(3) 指数分布 これらの大きく歪んだ分布は難しい課題です 目標 α = からの偏差が 3 パーセントポイントを優に上回っても許容できるならば n = 15 は カイ二乗分布 Chi-square(3) でも十分とみなされる可能性がありますが 指数分布の場合は n = 30 により近いサイズが必要です 特定のサンプルサイズの基準はいくぶん任意であり n = 20 はさまざまな分布でうまく機能するが 極端に歪んだ分布ではかろうじてうまく機能するに過ぎないという事実は踏まえつつ サンプル数 10~12 に推奨される最小サンプルサイズとして n = 20 を使用します 極端に歪んだ分布でも偏差を小さく保つ必要がある場合は 明らかに より大きなサンプルが推奨されます 2015, 2017 Minitab Inc. All rights reserved. Minitab, Quality. Analysis. Results. and the Minitab logo are all registered trademarks of Minitab, Inc., in the United States and other countries. See minitab.com/legal/trademarks for more information. 一元配置分散分析 (ANOVA) 33
仮説検定を伴う方法では 検定の仮定が満たされ 検定に適切な検出力があり データの分析に使用される近似で有効な結果が得られることを確認することを推奨します カイ二乗検定の場合 仮定はデータ収集に固有であるためデータチェックでは対応しません Minitab は近似法の検出力と妥当性に焦点を絞っています
 MINITAB アシスタントホワイトペーパー本書は Minitab 統計ソフトウェアのアシスタントで使用される方法およびデータチェックを開発するため Minitab の統計専門家によって行われた調査に関する一連の文書の 1 つです カイ二乗検定 概要 実際には 連続データの収集が不可能な場合や難しい場合 品質の専門家は工程を評価するためのカテゴリデータの収集が必要となることがあります たとえば 製品は不良
MINITAB アシスタントホワイトペーパー本書は Minitab 統計ソフトウェアのアシスタントで使用される方法およびデータチェックを開発するため Minitab の統計専門家によって行われた調査に関する一連の文書の 1 つです カイ二乗検定 概要 実際には 連続データの収集が不可能な場合や難しい場合 品質の専門家は工程を評価するためのカテゴリデータの収集が必要となることがあります たとえば 製品は不良
Medical3
 Chapter 1 1.4.1 1 元配置分散分析と多重比較の実行 3つの治療法による測定値に有意な差が認められるかどうかを分散分析で調べます この例では 因子が1つだけ含まれるため1 元配置分散分析 one-way ANOVA の適用になります また 多重比較法 multiple comparison procedure を用いて 具体的のどの治療法の間に有意差が認められるかを検定します 1. 分析メニュー
Chapter 1 1.4.1 1 元配置分散分析と多重比較の実行 3つの治療法による測定値に有意な差が認められるかどうかを分散分析で調べます この例では 因子が1つだけ含まれるため1 元配置分散分析 one-way ANOVA の適用になります また 多重比較法 multiple comparison procedure を用いて 具体的のどの治療法の間に有意差が認められるかを検定します 1. 分析メニュー
MINITAB アシスタントホワイトペーパー本書は Minitab 統計ソフトウェアのアシスタントで使用される方法およびデータチェックを開発するため Minitab の統計専門家によって行われた調査に関する一連の文書群を構成する文書の 1 つです ゲージ R&R 分析 ( 交差 ) 概要 測定システ
 概要 測定システ") MINITAB アシスタントホワイトペーパー本書は Minitab 統計ソフトウェアのアシスタントで使用される方法およびデータチェックを開発するため Minitab の統計専門家によって行われた調査に関する一連の文書群を構成する文書の 1 つです ゲージ R&R 分析 ( 交差 ) 概要 測定システムの分析は 生産工程を適切に監視および改善するために 事実上あらゆる種類の製造業で行われています 一般的な測定システムの分析では
MINITAB アシスタントホワイトペーパー本書は Minitab 統計ソフトウェアのアシスタントで使用される方法およびデータチェックを開発するため Minitab の統計専門家によって行われた調査に関する一連の文書群を構成する文書の 1 つです ゲージ R&R 分析 ( 交差 ) 概要 測定システムの分析は 生産工程を適切に監視および改善するために 事実上あらゆる種類の製造業で行われています 一般的な測定システムの分析では
基礎統計
 基礎統計 第 11 回講義資料 6.4.2 標本平均の差の標本分布 母平均の差 標本平均の差をみれば良い ただし, 母分散に依存するため場合分けをする 1 2 3 分散が既知分散が未知であるが等しい分散が未知であり等しいとは限らない 1 母分散が既知のとき が既知 標準化変量 2 母分散が未知であり, 等しいとき 分散が未知であるが, 等しいということは分かっているとき 標準化変量 自由度 の t
基礎統計 第 11 回講義資料 6.4.2 標本平均の差の標本分布 母平均の差 標本平均の差をみれば良い ただし, 母分散に依存するため場合分けをする 1 2 3 分散が既知分散が未知であるが等しい分散が未知であり等しいとは限らない 1 母分散が既知のとき が既知 標準化変量 2 母分散が未知であり, 等しいとき 分散が未知であるが, 等しいということは分かっているとき 標準化変量 自由度 の t
JMP による 2 群間の比較 SAS Institute Japan 株式会社 JMP ジャパン事業部 2008 年 3 月 JMP で t 検定や Wilcoxon 検定はどのメニューで実行できるのか または検定を行う際の前提条件の評価 ( 正規性 等分散性 ) はどのメニューで実行できるのかと
 はどのメニューで実行できるのかと") JMP による 2 群間の比較 SAS Institute Japan 株式会社 JMP ジャパン事業部 2008 年 3 月 JMP で t 検定や Wilcoxon 検定はどのメニューで実行できるのか または検定を行う際の前提条件の評価 ( 正規性 等分散性 ) はどのメニューで実行できるのかというお問い合わせがよくあります そこで本文書では これらについて の回答を 例題を用いて説明します 1.
JMP による 2 群間の比較 SAS Institute Japan 株式会社 JMP ジャパン事業部 2008 年 3 月 JMP で t 検定や Wilcoxon 検定はどのメニューで実行できるのか または検定を行う際の前提条件の評価 ( 正規性 等分散性 ) はどのメニューで実行できるのかというお問い合わせがよくあります そこで本文書では これらについて の回答を 例題を用いて説明します 1.
ビジネス統計 統計基礎とエクセル分析 正誤表
 ビジネス統計統計基礎とエクセル分析 ビジネス統計スペシャリスト エクセル分析スペシャリスト 公式テキスト正誤表と学習用データ更新履歴 平成 30 年 5 月 14 日現在 公式テキスト正誤表 頁場所誤正修正 6 知識編第 章 -3-3 最頻値の解説内容 たとえば, 表.1 のデータであれば, 最頻値は 167.5cm というたとえば, 表.1 のデータであれば, 最頻値は 165.0cm ということになります
ビジネス統計統計基礎とエクセル分析 ビジネス統計スペシャリスト エクセル分析スペシャリスト 公式テキスト正誤表と学習用データ更新履歴 平成 30 年 5 月 14 日現在 公式テキスト正誤表 頁場所誤正修正 6 知識編第 章 -3-3 最頻値の解説内容 たとえば, 表.1 のデータであれば, 最頻値は 167.5cm というたとえば, 表.1 のデータであれば, 最頻値は 165.0cm ということになります
EBNと疫学
 推定と検定 57 ( 復習 ) 記述統計と推測統計 統計解析は大きく 2 つに分けられる 記述統計 推測統計 記述統計 観察集団の特性を示すもの 代表値 ( 平均値や中央値 ) や ばらつきの指標 ( 標準偏差など ) 図表を効果的に使う 推測統計 観察集団のデータから母集団の特性を 推定 する 平均 / 分散 / 係数値などの推定 ( 点推定 ) 点推定値のばらつきを調べる ( 区間推定 ) 検定統計量を用いた検定
推定と検定 57 ( 復習 ) 記述統計と推測統計 統計解析は大きく 2 つに分けられる 記述統計 推測統計 記述統計 観察集団の特性を示すもの 代表値 ( 平均値や中央値 ) や ばらつきの指標 ( 標準偏差など ) 図表を効果的に使う 推測統計 観察集団のデータから母集団の特性を 推定 する 平均 / 分散 / 係数値などの推定 ( 点推定 ) 点推定値のばらつきを調べる ( 区間推定 ) 検定統計量を用いた検定
講義「○○○○」
 講義 信頼度の推定と立証 内容. 点推定と区間推定. 指数分布の点推定 区間推定 3. 指数分布 正規分布の信頼度推定 担当 : 倉敷哲生 ( ビジネスエンジニアリング専攻 ) 統計的推測 標本から得られる情報を基に 母集団に関する結論の導出が目的 測定値 x x x 3 : x 母集団 (populaio) 母集団の特性値 統計的推測 標本 (sample) 標本の特性値 分布のパラメータ ( 母数
講義 信頼度の推定と立証 内容. 点推定と区間推定. 指数分布の点推定 区間推定 3. 指数分布 正規分布の信頼度推定 担当 : 倉敷哲生 ( ビジネスエンジニアリング専攻 ) 統計的推測 標本から得られる情報を基に 母集団に関する結論の導出が目的 測定値 x x x 3 : x 母集団 (populaio) 母集団の特性値 統計的推測 標本 (sample) 標本の特性値 分布のパラメータ ( 母数
統計的データ解析
 統計的データ解析 011 011.11.9 林田清 ( 大阪大学大学院理学研究科 ) 連続確率分布の平均値 分散 比較のため P(c ) c 分布 自由度 の ( カイ c 平均値 0, 標準偏差 1の正規分布 に従う変数 xの自乗和 c x =1 が従う分布を自由度 の分布と呼ぶ 一般に自由度の分布は f /1 c / / ( c ) {( c ) e }/ ( / ) 期待値 二乗 ) 分布 c
統計的データ解析 011 011.11.9 林田清 ( 大阪大学大学院理学研究科 ) 連続確率分布の平均値 分散 比較のため P(c ) c 分布 自由度 の ( カイ c 平均値 0, 標準偏差 1の正規分布 に従う変数 xの自乗和 c x =1 が従う分布を自由度 の分布と呼ぶ 一般に自由度の分布は f /1 c / / ( c ) {( c ) e }/ ( / ) 期待値 二乗 ) 分布 c
Medical3
 1.4.1 クロス集計表の作成 -l m 分割表 - 3つ以上のカテゴリを含む変数を用いて l mのクロス集計表による分析を行います この例では race( 人種 ) によってlow( 低体重出生 ) に差が認められるかどうかを分析します 人種には3つのカテゴリ 低体重出生には2つのカテゴリが含まれています 2つの変数はともにカテゴリ変数であるため クロス集計表によって分析します 1. 分析メニュー
1.4.1 クロス集計表の作成 -l m 分割表 - 3つ以上のカテゴリを含む変数を用いて l mのクロス集計表による分析を行います この例では race( 人種 ) によってlow( 低体重出生 ) に差が認められるかどうかを分析します 人種には3つのカテゴリ 低体重出生には2つのカテゴリが含まれています 2つの変数はともにカテゴリ変数であるため クロス集計表によって分析します 1. 分析メニュー
<4D F736F F D208EC08CB18C7689E68A E F AA957A82C682948C9F92E82E646F63>
 第 7 回 t 分布と t 検定 実験計画学 A.t 分布 ( 小標本に関する平均の推定と検定 ) 前々回と前回の授業では, 標本が十分に大きいあるいは母分散が既知であることを条件に正規分布を用いて推定 検定した. しかし, 母集団が正規分布し, 標本が小さい場合には, 標本分散から母分散を推定するときの不確実さを加味したt 分布を用いて推定 検定しなければならない. t 分布は標本分散の自由度 f(
第 7 回 t 分布と t 検定 実験計画学 A.t 分布 ( 小標本に関する平均の推定と検定 ) 前々回と前回の授業では, 標本が十分に大きいあるいは母分散が既知であることを条件に正規分布を用いて推定 検定した. しかし, 母集団が正規分布し, 標本が小さい場合には, 標本分散から母分散を推定するときの不確実さを加味したt 分布を用いて推定 検定しなければならない. t 分布は標本分散の自由度 f(
Microsoft PowerPoint - Statistics[B]
![Microsoft PowerPoint - Statistics[B]](/thumbs/101/151482563.jpg "Microsoft PowerPoint - Statistics[B]") 講義の目的 サンプルサイズの大きい標本比率の分布は正規分布で近似できることを理解します 科目コード 130509, 130609, 110225 統計学講義第 19/20 回 2019 年 6 月 25 日 ( 火 )6/7 限 担当教員 : 唐渡広志 ( からと こうじ ) 研究室 : email: website: 経済学研究棟 4 階 432 号室 [email protected]
講義の目的 サンプルサイズの大きい標本比率の分布は正規分布で近似できることを理解します 科目コード 130509, 130609, 110225 統計学講義第 19/20 回 2019 年 6 月 25 日 ( 火 )6/7 限 担当教員 : 唐渡広志 ( からと こうじ ) 研究室 : email: website: 経済学研究棟 4 階 432 号室 [email protected]
Excelによる統計分析検定_知識編_小塚明_5_9章.indd
 第7章57766 検定と推定 サンプリングによって得られた標本から, 母集団の統計的性質に対して推測を行うことを統計的推測といいます 本章では, 推測統計の根幹をなす仮説検定と推定の基本的な考え方について説明します 前章までの知識を用いて, 具体的な分析を行います 本章以降の知識は操作編での操作に直接関連していますので, 少し聞きなれない言葉ですが, 帰無仮説 有意水準 棄却域 などの意味を理解して,
第7章57766 検定と推定 サンプリングによって得られた標本から, 母集団の統計的性質に対して推測を行うことを統計的推測といいます 本章では, 推測統計の根幹をなす仮説検定と推定の基本的な考え方について説明します 前章までの知識を用いて, 具体的な分析を行います 本章以降の知識は操作編での操作に直接関連していますので, 少し聞きなれない言葉ですが, 帰無仮説 有意水準 棄却域 などの意味を理解して,
自動車感性評価学 1. 二項検定 内容 2 3. 質的データの解析方法 1 ( 名義尺度 ) 2.χ 2 検定 タイプ 1. 二項検定 官能検査における分類データの解析法 識別できるかを調べる 嗜好に差があるかを調べる 2 点比較法 2 点識別法 2 点嗜好法 3 点比較法 3 点識別法 3 点嗜好
 2.χ 2 検定 タイプ 1. 二項検定 官能検査における分類データの解析法 識別できるかを調べる 嗜好に差があるかを調べる 2 点比較法 2 点識別法 2 点嗜好法 3 点比較法 3 点識別法 3 点嗜好") . 内容 3. 質的データの解析方法 ( 名義尺度 ).χ 検定 タイプ. 官能検査における分類データの解析法 識別できるかを調べる 嗜好に差があるかを調べる 点比較法 点識別法 点嗜好法 3 点比較法 3 点識別法 3 点嗜好法 : 点比較法 : 点識別法 配偶法 配偶法 ( 官能評価の基礎と応用 ) 3 A か B かの判定において 回の判定でAが選ばれる回数 kは p の二項分布に従う H :
. 内容 3. 質的データの解析方法 ( 名義尺度 ).χ 検定 タイプ. 官能検査における分類データの解析法 識別できるかを調べる 嗜好に差があるかを調べる 点比較法 点識別法 点嗜好法 3 点比較法 3 点識別法 3 点嗜好法 : 点比較法 : 点識別法 配偶法 配偶法 ( 官能評価の基礎と応用 ) 3 A か B かの判定において 回の判定でAが選ばれる回数 kは p の二項分布に従う H :
Microsoft PowerPoint - e-stat(OLS).pptx
.pptx") 経済統計学 ( 補足 ) 最小二乗法について 担当 : 小塚匡文 2015 年 11 月 19 日 ( 改訂版 ) 神戸大学経済学部 2015 年度後期開講授業 補足 : 最小二乗法 ( 単回帰分析 ) 1.( 単純 ) 回帰分析とは? 標本サイズTの2 変数 ( ここではXとY) のデータが存在 YをXで説明する回帰方程式を推定するための方法 Y: 被説明変数 ( または従属変数 ) X: 説明変数
経済統計学 ( 補足 ) 最小二乗法について 担当 : 小塚匡文 2015 年 11 月 19 日 ( 改訂版 ) 神戸大学経済学部 2015 年度後期開講授業 補足 : 最小二乗法 ( 単回帰分析 ) 1.( 単純 ) 回帰分析とは? 標本サイズTの2 変数 ( ここではXとY) のデータが存在 YをXで説明する回帰方程式を推定するための方法 Y: 被説明変数 ( または従属変数 ) X: 説明変数
Probit , Mixed logit
 Probit, Mixed logit 2016/5/16 スタートアップゼミ #5 B4 後藤祥孝 1 0. 目次 Probit モデルについて 1. モデル概要 2. 定式化と理解 3. 推定 Mixed logit モデルについて 4. モデル概要 5. 定式化と理解 6. 推定 2 1.Probit 概要 プロビットモデルとは. 効用関数の誤差項に多変量正規分布を仮定したもの. 誤差項には様々な要因が存在するため,
Probit, Mixed logit 2016/5/16 スタートアップゼミ #5 B4 後藤祥孝 1 0. 目次 Probit モデルについて 1. モデル概要 2. 定式化と理解 3. 推定 Mixed logit モデルについて 4. モデル概要 5. 定式化と理解 6. 推定 2 1.Probit 概要 プロビットモデルとは. 効用関数の誤差項に多変量正規分布を仮定したもの. 誤差項には様々な要因が存在するため,
(3) 検定統計量の有意確率にもとづく仮説の採否データから有意確率 (significant probability, p 値 ) を求め 有意水準と照合する 有意確率とは データの分析によって得られた統計値が偶然おこる確率のこと あらかじめ設定した有意確率より低い場合は 帰無仮説を棄却して対立仮説
 検定統計量の有意確率にもとづく仮説の採否データから有意確率 (significant probability, p 値 ) を求め 有意水準と照合する 有意確率とは データの分析によって得られた統計値が偶然おこる確率のこと あらかじめ設定した有意確率より低い場合は 帰無仮説を棄却して対立仮説") 第 3 章 t 検定 (pp. 33-42) 3-1 統計的検定 統計的検定とは 設定した仮説を検証する場合に 仮説に基づいて集めた標本を 確率論の観点から分析 検証すること 使用する標本は 母集団から無作為抽出されたものでなければならない パラメトリック検定とノンパラメトリック検定 パラメトリック検定は母集団が正規分布に従う間隔尺度あるいは比率尺度の連続データを対象とする ノンパラメトリック検定は母集団に特定の分布を仮定しない
第 3 章 t 検定 (pp. 33-42) 3-1 統計的検定 統計的検定とは 設定した仮説を検証する場合に 仮説に基づいて集めた標本を 確率論の観点から分析 検証すること 使用する標本は 母集団から無作為抽出されたものでなければならない パラメトリック検定とノンパラメトリック検定 パラメトリック検定は母集団が正規分布に従う間隔尺度あるいは比率尺度の連続データを対象とする ノンパラメトリック検定は母集団に特定の分布を仮定しない
統計学 - 社会統計の基礎 - 正規分布 標準正規分布累積分布関数の逆関数 t 分布正規分布に従うサンプルの平均の信頼区間 担当 : 岸 康人 資料ページ :
 統計学 - 社会統計の基礎 - 正規分布 標準正規分布累積分布関数の逆関数 t 分布正規分布に従うサンプルの平均の信頼区間 担当 : 岸 康人 資料ページ : https://goo.gl/qw1djw 正規分布 ( 復習 ) 正規分布 (Normal Distribution)N (μ, σ 2 ) 別名 : ガウス分布 (Gaussian Distribution) 密度関数 Excel:= NORM.DIST
統計学 - 社会統計の基礎 - 正規分布 標準正規分布累積分布関数の逆関数 t 分布正規分布に従うサンプルの平均の信頼区間 担当 : 岸 康人 資料ページ : https://goo.gl/qw1djw 正規分布 ( 復習 ) 正規分布 (Normal Distribution)N (μ, σ 2 ) 別名 : ガウス分布 (Gaussian Distribution) 密度関数 Excel:= NORM.DIST
経済統計分析1 イントロダクション
 1 経済統計分析 9 分散分析 今日のおはなし. 検定 statistical test のいろいろ 2 変数の関係を調べる手段のひとつ適合度検定独立性検定分散分析 今日のタネ 吉田耕作.2006. 直感的統計学. 日経 BP. 中村隆英ほか.1984. 統計入門. 東大出版会. 2 仮説検定の手続き 仮説検定のロジック もし帰無仮説が正しければ, 検定統計量が既知の分布に従う 計算された検定統計量の値から,
1 経済統計分析 9 分散分析 今日のおはなし. 検定 statistical test のいろいろ 2 変数の関係を調べる手段のひとつ適合度検定独立性検定分散分析 今日のタネ 吉田耕作.2006. 直感的統計学. 日経 BP. 中村隆英ほか.1984. 統計入門. 東大出版会. 2 仮説検定の手続き 仮説検定のロジック もし帰無仮説が正しければ, 検定統計量が既知の分布に従う 計算された検定統計量の値から,
多変量解析 ~ 重回帰分析 ~ 2006 年 4 月 21 日 ( 金 ) 南慶典
 南慶典") 多変量解析 ~ 重回帰分析 ~ 2006 年 4 月 21 日 ( 金 ) 南慶典 重回帰分析とは? 重回帰分析とは複数の説明変数から目的変数との関係性を予測 評価説明変数 ( 数量データ ) は目的変数を説明するのに有効であるか得られた関係性より未知のデータの妥当性を判断する これを重回帰分析という つまり どんなことをするのか? 1 最小 2 乗法により重回帰モデルを想定 2 自由度調整済寄与率を求め
多変量解析 ~ 重回帰分析 ~ 2006 年 4 月 21 日 ( 金 ) 南慶典 重回帰分析とは? 重回帰分析とは複数の説明変数から目的変数との関係性を予測 評価説明変数 ( 数量データ ) は目的変数を説明するのに有効であるか得られた関係性より未知のデータの妥当性を判断する これを重回帰分析という つまり どんなことをするのか? 1 最小 2 乗法により重回帰モデルを想定 2 自由度調整済寄与率を求め
Microsoft Word - Stattext12.doc
 章対応のない 群間の量的データの検定. 検定手順 この章ではデータ間に 対 の対応のないつの標本から推定される母集団間の平均値や中央値の比較を行ないます 検定手法は 図. のようにまず正規に従うかどうかを調べます 但し この場合はつの群が共に正規に従うことを調べる必要があります 次に 群とも正規ならば F 検定を用いて等分散であるかどうかを調べます 等分散の場合は t 検定 等分散でない場合はウェルチ
章対応のない 群間の量的データの検定. 検定手順 この章ではデータ間に 対 の対応のないつの標本から推定される母集団間の平均値や中央値の比較を行ないます 検定手法は 図. のようにまず正規に従うかどうかを調べます 但し この場合はつの群が共に正規に従うことを調べる必要があります 次に 群とも正規ならば F 検定を用いて等分散であるかどうかを調べます 等分散の場合は t 検定 等分散でない場合はウェルチ
Kumamoto University Center for Multimedia and Information Technologies Lab. 熊本大学アプリケーション実験 ~ 実環境における無線 LAN 受信電波強度を用いた位置推定手法の検討 ~ InKIAI 宮崎県美郷
 熊本大学アプリケーション実験 ~ 実環境における無線 LAN 受信電波強度を用いた位置推定手法の検討 ~ InKIAI プロジェクト @ 宮崎県美郷町 熊本大学副島慶人川村諒 1 実験の目的 従来 信号の受信電波強度 (RSSI:RecevedSgnal StrengthIndcator) により 対象の位置を推定する手法として 無線 LAN の AP(AccessPont) から受信する信号の減衰量をもとに位置を推定する手法が多く検討されている
熊本大学アプリケーション実験 ~ 実環境における無線 LAN 受信電波強度を用いた位置推定手法の検討 ~ InKIAI プロジェクト @ 宮崎県美郷町 熊本大学副島慶人川村諒 1 実験の目的 従来 信号の受信電波強度 (RSSI:RecevedSgnal StrengthIndcator) により 対象の位置を推定する手法として 無線 LAN の AP(AccessPont) から受信する信号の減衰量をもとに位置を推定する手法が多く検討されている
Python-statistics5 Python で統計学を学ぶ (5) この内容は山田 杉澤 村井 (2008) R によるやさしい統計学 (
 この内容は山田 杉澤 村井 (2008) R によるやさしい統計学 (") http://localhost:8888/notebooks/... Python で統計学を学ぶ (5) この内容は山田 杉澤 村井 (2008) R によるやさしい統計学 (http://shop.ohmsha.co.jp/shop /shopdetail.html?brandcode=000000001781&search=978-4-274-06710-5&sort=) を参考にしています
http://localhost:8888/notebooks/... Python で統計学を学ぶ (5) この内容は山田 杉澤 村井 (2008) R によるやさしい統計学 (http://shop.ohmsha.co.jp/shop /shopdetail.html?brandcode=000000001781&search=978-4-274-06710-5&sort=) を参考にしています
第 3 回講義の項目と概要 統計的手法入門 : 品質のばらつきを解析する 平均と標準偏差 (P30) a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均
 a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均") 第 3 回講義の項目と概要 016.8.9 1.3 統計的手法入門 : 品質のばらつきを解析する 1.3.1 平均と標準偏差 (P30) a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均 :AVERAGE 関数, 標準偏差 :STDEVP 関数とSTDEVという関数 1 取得したデータそのものの標準偏差
第 3 回講義の項目と概要 016.8.9 1.3 統計的手法入門 : 品質のばらつきを解析する 1.3.1 平均と標準偏差 (P30) a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均 :AVERAGE 関数, 標準偏差 :STDEVP 関数とSTDEVという関数 1 取得したデータそのものの標準偏差
異文化言語教育評価論 ⅠA 第 4 章分散分析 (3 グループ以上の平均を比較する ) 平成 26 年 5 月 14 日 報告者 :D.M. K.S. 4-1 分散分析とは 検定の多重性 t 検定 2 群の平均値を比較する場合の手法分散分析 3 群以上の平均を比較する場合の手法 t 検定
 平成 26 年 5 月 14 日 報告者 :D.M. K.S. 4-1 分散分析とは 検定の多重性 t 検定 2 群の平均値を比較する場合の手法分散分析 3 群以上の平均を比較する場合の手法 t 検定") 異文化言語教育評価論 ⅠA 第 4 章分散分析 (3 グループ以上の平均を比較する ) 平成 26 年 5 月 14 日 報告者 :D.M. K.S. 4-1 分散分析とは 4-1-1 検定の多重性 t 検定 2 群の平均値を比較する場合の手法分散分析 3 群以上の平均を比較する場合の手法 t 検定の反復 (e.g., A, B, C の 3 群の比較を A-B 間 B-C 間 A-C 間の t 検定で行う
異文化言語教育評価論 ⅠA 第 4 章分散分析 (3 グループ以上の平均を比較する ) 平成 26 年 5 月 14 日 報告者 :D.M. K.S. 4-1 分散分析とは 4-1-1 検定の多重性 t 検定 2 群の平均値を比較する場合の手法分散分析 3 群以上の平均を比較する場合の手法 t 検定の反復 (e.g., A, B, C の 3 群の比較を A-B 間 B-C 間 A-C 間の t 検定で行う
PowerPoint プレゼンテーション
 1/X Chapter 9: Linear correlation Cohen, B. H. (2007). In B. H. Cohen (Ed.), Explaining Psychological Statistics (3rd ed.) (pp. 255-285). NJ: Wiley. 概要 2/X 相関係数とは何か 相関係数の数式 検定 注意点 フィッシャーのZ 変換 信頼区間 相関係数の差の検定
1/X Chapter 9: Linear correlation Cohen, B. H. (2007). In B. H. Cohen (Ed.), Explaining Psychological Statistics (3rd ed.) (pp. 255-285). NJ: Wiley. 概要 2/X 相関係数とは何か 相関係数の数式 検定 注意点 フィッシャーのZ 変換 信頼区間 相関係数の差の検定
ANOVA
 3 つ z のグループの平均を比べる ( 分散分析 : ANOVA: analysis of variance) 分散分析は 全体として 3 つ以上のグループの平均に差があるか ということしかわからないために, どのグループの間に差があったかを確かめるには 多重比較 という方法を用います これは Excel だと自分で計算しなければならないので, 分散分析には統計ソフトを使った方がよいでしょう 1.
3 つ z のグループの平均を比べる ( 分散分析 : ANOVA: analysis of variance) 分散分析は 全体として 3 つ以上のグループの平均に差があるか ということしかわからないために, どのグループの間に差があったかを確かめるには 多重比較 という方法を用います これは Excel だと自分で計算しなければならないので, 分散分析には統計ソフトを使った方がよいでしょう 1.
カイ二乗フィット検定、パラメータの誤差
 統計的データ解析 008 008.. 林田清 ( 大阪大学大学院理学研究科 ) 問題 C (, ) ( x xˆ) ( y yˆ) σ x πσ σ y y Pabx (, ;,,, ) ˆ y σx σ y = dx exp exp πσx ただし xy ˆ ˆ はyˆ = axˆ+ bであらわされる直線モデル上の点 ( ˆ) ( ˆ ) ( ) x x y ax b y ax b Pabx (,
統計的データ解析 008 008.. 林田清 ( 大阪大学大学院理学研究科 ) 問題 C (, ) ( x xˆ) ( y yˆ) σ x πσ σ y y Pabx (, ;,,, ) ˆ y σx σ y = dx exp exp πσx ただし xy ˆ ˆ はyˆ = axˆ+ bであらわされる直線モデル上の点 ( ˆ) ( ˆ ) ( ) x x y ax b y ax b Pabx (,
Microsoft Word - å“Ÿåłžå¸°173.docx
 回帰分析 ( その 3) 経済情報処理 価格弾力性の推定ある商品について その購入量を w 単価を p とし それぞれの変化量を w p で表 w w すことにする この時 この商品の価格弾力性 は により定義される これ p p は p が 1 パーセント変化した場合に w が何パーセント変化するかを示したものである ここで p を 0 に近づけていった極限を考えると d ln w 1 dw dw
回帰分析 ( その 3) 経済情報処理 価格弾力性の推定ある商品について その購入量を w 単価を p とし それぞれの変化量を w p で表 w w すことにする この時 この商品の価格弾力性 は により定義される これ p p は p が 1 パーセント変化した場合に w が何パーセント変化するかを示したものである ここで p を 0 に近づけていった極限を考えると d ln w 1 dw dw
様々なミクロ計量モデル†
 担当 : 長倉大輔 ( ながくらだいすけ ) この資料は私の講義において使用するために作成した資料です WEB ページ上で公開しており 自由に参照して頂いて構いません ただし 内容について 一応検証してありますが もし間違いがあった場合でもそれによって生じるいかなる損害 不利益について責任を負いかねますのでご了承ください 間違いは発見次第 継続的に直していますが まだ存在する可能性があります 1 カウントデータモデル
担当 : 長倉大輔 ( ながくらだいすけ ) この資料は私の講義において使用するために作成した資料です WEB ページ上で公開しており 自由に参照して頂いて構いません ただし 内容について 一応検証してありますが もし間違いがあった場合でもそれによって生じるいかなる損害 不利益について責任を負いかねますのでご了承ください 間違いは発見次第 継続的に直していますが まだ存在する可能性があります 1 カウントデータモデル
スライド 1
 データ解析特論第 10 回 ( 全 15 回 ) 2012 年 12 月 11 日 ( 火 ) 情報エレクトロニクス専攻横田孝義 1 終了 11/13 11/20 重回帰分析をしばらくやります 12/4 12/11 12/18 2 前回から回帰分析について学習しています 3 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える
データ解析特論第 10 回 ( 全 15 回 ) 2012 年 12 月 11 日 ( 火 ) 情報エレクトロニクス専攻横田孝義 1 終了 11/13 11/20 重回帰分析をしばらくやります 12/4 12/11 12/18 2 前回から回帰分析について学習しています 3 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える
Microsoft PowerPoint - statistics pptx
 統計学 第 回 講義 仮説検定 Part-3 06 年 6 8 ( )3 限 担当教員 唐渡 広志 ( からと こうじ ) 研究室 経済学研究棟 4 階 43 号室 email [email protected] webite htt://www3.u-toyama.ac.j/kkarato/ 講義の目的 つの 集団の平均 ( 率 ) に差があるかどうかを検定する 法を理解します keyword:
統計学 第 回 講義 仮説検定 Part-3 06 年 6 8 ( )3 限 担当教員 唐渡 広志 ( からと こうじ ) 研究室 経済学研究棟 4 階 43 号室 email [email protected] webite htt://www3.u-toyama.ac.j/kkarato/ 講義の目的 つの 集団の平均 ( 率 ) に差があるかどうかを検定する 法を理解します keyword:
不偏推定量
 不偏推定量 情報科学の補足資料 018 年 6 月 7 日藤本祥二 統計的推定 (statistical estimatio) 確率分布が理論的に分かっている標本統計量を利用する 確率分布の期待値の値をそのまま推定値とするのが点推定 ( 信頼度 0%) 点推定に ± で幅を持たせて信頼度を上げたものが区間推定 持たせた幅のことを誤差 (error) と呼ぶ 信頼度 (cofidece level)
不偏推定量 情報科学の補足資料 018 年 6 月 7 日藤本祥二 統計的推定 (statistical estimatio) 確率分布が理論的に分かっている標本統計量を利用する 確率分布の期待値の値をそのまま推定値とするのが点推定 ( 信頼度 0%) 点推定に ± で幅を持たせて信頼度を上げたものが区間推定 持たせた幅のことを誤差 (error) と呼ぶ 信頼度 (cofidece level)
Microsoft PowerPoint - stat-2014-[9] pptx
![Microsoft PowerPoint - stat-2014-[9] pptx](/thumbs/49/25555771.jpg "Microsoft PowerPoint - stat-2014-[9] pptx") 統計学 第 17 回 講義 母平均の区間推定 Part-1 014 年 6 17 ( )6-7 限 担当教員 : 唐渡 広志 ( からと こうじ ) 研究室 : 経済学研究棟 4 階 43 号室 email: [email protected] website: htt://www3.u-toyama.ac.j/kkarato/ 1 講義の目的 標本平均は正規分布に従うという性質を
統計学 第 17 回 講義 母平均の区間推定 Part-1 014 年 6 17 ( )6-7 限 担当教員 : 唐渡 広志 ( からと こうじ ) 研究室 : 経済学研究棟 4 階 43 号室 email: [email protected] website: htt://www3.u-toyama.ac.j/kkarato/ 1 講義の目的 標本平均は正規分布に従うという性質を
データ科学2.pptx
 データ科学 多重検定 2 mul%ple test False Discovery Rate 藤博幸 前回の復習 1 多くの検定を繰り返す時には 単純に個々の検定を繰り返すだけでは不十分 5% 有意水準ということは, 1000 回検定を繰り返すと, 50 回くらいは帰無仮説が正しいのに 間違って棄却されてすまうじちがあるということ ex) 1 万個の遺伝子について 正常細胞とガン細胞で それぞれの遺伝子の発現に差があるかどうかを検定
データ科学 多重検定 2 mul%ple test False Discovery Rate 藤博幸 前回の復習 1 多くの検定を繰り返す時には 単純に個々の検定を繰り返すだけでは不十分 5% 有意水準ということは, 1000 回検定を繰り返すと, 50 回くらいは帰無仮説が正しいのに 間違って棄却されてすまうじちがあるということ ex) 1 万個の遺伝子について 正常細胞とガン細胞で それぞれの遺伝子の発現に差があるかどうかを検定
解析センターを知っていただく キャンペーン
 005..5 SAS 問題設定 目的 PKパラメータ (AUC,Cmax,Tmaxなど) の推定 PKパラメータの群間比較 PKパラメータのバラツキの評価! データの特徴 非反復測定値 個体につき 個の測定値しか得られない plasma concentration 非反復測定値のイメージ図 測定時点間で個体の対応がない 着目する状況 plasma concentration 経時反復測定値のイメージ図
005..5 SAS 問題設定 目的 PKパラメータ (AUC,Cmax,Tmaxなど) の推定 PKパラメータの群間比較 PKパラメータのバラツキの評価! データの特徴 非反復測定値 個体につき 個の測定値しか得られない plasma concentration 非反復測定値のイメージ図 測定時点間で個体の対応がない 着目する状況 plasma concentration 経時反復測定値のイメージ図
青焼 1章[15-52].indd
![青焼 1章[15-52].indd](/thumbs/86/94313777.jpg "青焼 1章[15-52].indd") 1 第 1 章統計の基礎知識 1 1 なぜ統計解析が必要なのか? 人間は自分自身の経験にもとづいて 感覚的にものごとを判断しがちである 例えばある疾患に対する標準治療薬の有効率が 50% であったとする そこに新薬が登場し ある医師がその新薬を 5 人の患者に使ったところ 4 人が有効と判定されたとしたら 多くの医師はこれまでの標準治療薬よりも新薬のほうが有効性が高そうだと感じることだろう しかし
1 第 1 章統計の基礎知識 1 1 なぜ統計解析が必要なのか? 人間は自分自身の経験にもとづいて 感覚的にものごとを判断しがちである 例えばある疾患に対する標準治療薬の有効率が 50% であったとする そこに新薬が登場し ある医師がその新薬を 5 人の患者に使ったところ 4 人が有効と判定されたとしたら 多くの医師はこれまでの標準治療薬よりも新薬のほうが有効性が高そうだと感じることだろう しかし
スライド 1
 データ解析特論重回帰分析編 2017 年 7 月 10 日 ( 月 )~ 情報エレクトロニクスコース横田孝義 1 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える 具体的には y = a + bx という回帰直線 ( モデル ) でデータを代表させる このためにデータからこの回帰直線の切片 (a) と傾き (b) を最小
データ解析特論重回帰分析編 2017 年 7 月 10 日 ( 月 )~ 情報エレクトロニクスコース横田孝義 1 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える 具体的には y = a + bx という回帰直線 ( モデル ) でデータを代表させる このためにデータからこの回帰直線の切片 (a) と傾き (b) を最小
PowerPoint プレゼンテーション
 学位論文作成のための疫学 統計解析の実際 徳島大学大学院 医歯薬学研究部 社会医学系 予防医学分野 有澤孝吉 (e-mail: [email protected]) 本日の講義の内容 (SPSS を用いて ) 記述統計 ( データのまとめ方 ) 代表値 ばらつき正規確率プロット 正規性の検定標準偏差 不偏標準偏差 標準誤差の区別中心極限定理母平均の区間推定 ( 母集団の標準偏差が既知の場合
学位論文作成のための疫学 統計解析の実際 徳島大学大学院 医歯薬学研究部 社会医学系 予防医学分野 有澤孝吉 (e-mail: [email protected]) 本日の講義の内容 (SPSS を用いて ) 記述統計 ( データのまとめ方 ) 代表値 ばらつき正規確率プロット 正規性の検定標準偏差 不偏標準偏差 標準誤差の区別中心極限定理母平均の区間推定 ( 母集団の標準偏差が既知の場合
Microsoft PowerPoint - ch04j
 Ch.4 重回帰分析 : 推論 重回帰分析 y = 0 + 1 x 1 + 2 x 2 +... + k x k + u 2. 推論 1. OLS 推定量の標本分布 2. 1 係数の仮説検定 : t 検定 3. 信頼区間 4. 係数の線形結合への仮説検定 5. 複数線形制約の検定 : F 検定 6. 回帰結果の報告 入門計量経済学 1 入門計量経済学 2 OLS 推定量の標本分布について OLS 推定量は確率変数
Ch.4 重回帰分析 : 推論 重回帰分析 y = 0 + 1 x 1 + 2 x 2 +... + k x k + u 2. 推論 1. OLS 推定量の標本分布 2. 1 係数の仮説検定 : t 検定 3. 信頼区間 4. 係数の線形結合への仮説検定 5. 複数線形制約の検定 : F 検定 6. 回帰結果の報告 入門計量経済学 1 入門計量経済学 2 OLS 推定量の標本分布について OLS 推定量は確率変数
Microsoft PowerPoint - statistics pptx
 統計学 第 16 回 講義 母平均の区間推定 Part-1 016 年 6 10 ( ) 1 限 担当教員 : 唐渡 広志 ( からと こうじ ) 研究室 : 経済学研究棟 4 階 43 号室 email: [email protected] website: http://www3.u-toyama.ac.jp/kkarato/ 1 講義の目的 標本平均は正規分布に従うという性質を
統計学 第 16 回 講義 母平均の区間推定 Part-1 016 年 6 10 ( ) 1 限 担当教員 : 唐渡 広志 ( からと こうじ ) 研究室 : 経済学研究棟 4 階 43 号室 email: [email protected] website: http://www3.u-toyama.ac.jp/kkarato/ 1 講義の目的 標本平均は正規分布に従うという性質を
モジュール1のまとめ
 数理統計学 第 0 回 復習 標本分散と ( 標本 ) 不偏分散両方とも 分散 というのが実情 二乗偏差計標本分散 = データ数 (0ページ) ( 標本 ) 不偏分散 = (03 ページ ) 二乗偏差計 データ数 - 分析ではこちらをとることが多い 復習 ここまで 実験結果 ( 万回 ) 平均 50Kg 標準偏差 0Kg 0 人 全体に小さすぎる > mea(jkke) [] 89.4373 標準偏差
数理統計学 第 0 回 復習 標本分散と ( 標本 ) 不偏分散両方とも 分散 というのが実情 二乗偏差計標本分散 = データ数 (0ページ) ( 標本 ) 不偏分散 = (03 ページ ) 二乗偏差計 データ数 - 分析ではこちらをとることが多い 復習 ここまで 実験結果 ( 万回 ) 平均 50Kg 標準偏差 0Kg 0 人 全体に小さすぎる > mea(jkke) [] 89.4373 標準偏差
NLMIXED プロシジャを用いた生存時間解析 伊藤要二アストラゼネカ株式会社臨床統計 プログラミング グループグルプ Survival analysis using PROC NLMIXED Yohji Itoh Clinical Statistics & Programming Group, A
 NLMIXED プロシジャを用いた生存時間解析 伊藤要二アストラゼネカ株式会社臨床統計 プログラミング グループグルプ Survival analysis using PROC NLMIXED Yohji Itoh Clinical Statistics & Programming Group, AstraZeneca KK 要旨 : NLMIXEDプロシジャの最尤推定の機能を用いて 指数分布 Weibull
NLMIXED プロシジャを用いた生存時間解析 伊藤要二アストラゼネカ株式会社臨床統計 プログラミング グループグルプ Survival analysis using PROC NLMIXED Yohji Itoh Clinical Statistics & Programming Group, AstraZeneca KK 要旨 : NLMIXEDプロシジャの最尤推定の機能を用いて 指数分布 Weibull
ダンゴムシの 交替性転向反応に 関する研究 3A15 今野直輝
 ダンゴムシの 交替性転向反応に 関する研究 3A15 今野直輝 1. 研究の動機 ダンゴムシには 右に曲がった後は左に 左に曲がった後は右に曲がる という交替性転向反応という習性がある 数多くの生物において この習性は見受けられるのだが なかでもダンゴムシやその仲間のワラジムシは その行動が特に顕著であるとして有名である そのため図 1のような道をダンゴムシに歩かせると 前の突き当りでどちらの方向に曲がったかを見ることによって
ダンゴムシの 交替性転向反応に 関する研究 3A15 今野直輝 1. 研究の動機 ダンゴムシには 右に曲がった後は左に 左に曲がった後は右に曲がる という交替性転向反応という習性がある 数多くの生物において この習性は見受けられるのだが なかでもダンゴムシやその仲間のワラジムシは その行動が特に顕著であるとして有名である そのため図 1のような道をダンゴムシに歩かせると 前の突き当りでどちらの方向に曲がったかを見ることによって
切片 ( 定数項 ) ダミー 以下の単回帰モデルを考えよう これは賃金と就業年数の関係を分析している : ( 賃金関数 ) ここで Y i = α + β X i + u i, i =1,, n, u i ~ i.i.d. N(0, σ 2 ) Y i : 賃金の対数値, X i : 就業年数. (
 ダミー 以下の単回帰モデルを考えよう これは賃金と就業年数の関係を分析している : ( 賃金関数 ) ここで Y i = α + β X i + u i, i =1,, n, u i ~ i.i.d. N(0, σ 2 ) Y i : 賃金の対数値, X i : 就業年数. (") 統計学ダミー変数による分析 担当 : 長倉大輔 ( ながくらだいすけ ) 1 切片 ( 定数項 ) ダミー 以下の単回帰モデルを考えよう これは賃金と就業年数の関係を分析している : ( 賃金関数 ) ここで Y i = α + β X i + u i, i =1,, n, u i ~ i.i.d. N(0, σ 2 ) Y i : 賃金の対数値, X i : 就業年数. ( 実際は賃金を就業年数だけで説明するのは現実的はない
統計学ダミー変数による分析 担当 : 長倉大輔 ( ながくらだいすけ ) 1 切片 ( 定数項 ) ダミー 以下の単回帰モデルを考えよう これは賃金と就業年数の関係を分析している : ( 賃金関数 ) ここで Y i = α + β X i + u i, i =1,, n, u i ~ i.i.d. N(0, σ 2 ) Y i : 賃金の対数値, X i : 就業年数. ( 実際は賃金を就業年数だけで説明するのは現実的はない
<4D F736F F D204B208C5182CC94E497A682CC8DB782CC8C9F92E BD8F6494E48A722E646F6378>
 3 群以上の比率の差の多重検定法 013 年 1 月 15 日 017 年 3 月 14 日修正 3 群以上の比率の差の多重検定法 ( 対比較 ) 分割表で表記される計数データについて群間で比率の差の検定を行う場合 全体としての統計的有意性の有無は χ 検定により判断することができるが 個々の群間の差の有意性を判定するためには多重検定法が必要となる 3 群以上の比率の差を対比較で検定する方法としては
3 群以上の比率の差の多重検定法 013 年 1 月 15 日 017 年 3 月 14 日修正 3 群以上の比率の差の多重検定法 ( 対比較 ) 分割表で表記される計数データについて群間で比率の差の検定を行う場合 全体としての統計的有意性の有無は χ 検定により判断することができるが 個々の群間の差の有意性を判定するためには多重検定法が必要となる 3 群以上の比率の差を対比較で検定する方法としては
統計学の基礎から学ぶ実験計画法ー1
 第 部統計学の基礎と. 統計学とは. 統計学の基本. 母集団とサンプル ( 標本 ). データ (data) 3. 集団の特性を示す統計量 基本的な解析手法 3. 統計量 (statistic) とは 3. 集団を代表する統計量 - 平均値など 3.3 集団のばらつきを表す値 - 平方和 分散 標準偏差 4. ばらつき ( 分布 ) を表す関数 4. 確率密度関数 4. 最も重要な正規分布 4.3
第 部統計学の基礎と. 統計学とは. 統計学の基本. 母集団とサンプル ( 標本 ). データ (data) 3. 集団の特性を示す統計量 基本的な解析手法 3. 統計量 (statistic) とは 3. 集団を代表する統計量 - 平均値など 3.3 集団のばらつきを表す値 - 平方和 分散 標準偏差 4. ばらつき ( 分布 ) を表す関数 4. 確率密度関数 4. 最も重要な正規分布 4.3
Chapter カスタムテーブルの概要 カスタムテーブル Custom Tables は 複数の変数に基づいた多重クロス集計テーブルや スケール変数を用いた集計テーブルなど より複雑な集計表を自由に設計することができるIBM SPSS Statisticsのオプション製品です テーブ
 カスタムテーブル入門 1 カスタムテーブル入門 カスタムテーブル Custom Tables は IBM SPSS Statisticsのオプション機能の1つです カスタムテーブルを追加することで 基本的な度数集計テーブルやクロス集計テーブルの作成はもちろん 複数の変数を積み重ねた多重クロス集計テーブルや スケール変数を用いた集計テーブルなど より複雑で柔軟な集計表を作成することができます この章では
カスタムテーブル入門 1 カスタムテーブル入門 カスタムテーブル Custom Tables は IBM SPSS Statisticsのオプション機能の1つです カスタムテーブルを追加することで 基本的な度数集計テーブルやクロス集計テーブルの作成はもちろん 複数の変数を積み重ねた多重クロス集計テーブルや スケール変数を用いた集計テーブルなど より複雑で柔軟な集計表を作成することができます この章では
<4D F736F F D208EC08CB18C7689E68A E F193F18D8095AA957A C C839395AA957A814590B38B4B95AA957A2E646F63>
 第 4 回二項分布, ポアソン分布, 正規分布 実験計画学 009 年 月 0 日 A. 代表的な分布. 離散分布 二項分布大きさ n の標本で, 事象 Eの起こる確率を p とするとき, そのうち x 個にEが起こる確率 P(x) は二項分布に従う. 例さいころを 0 回振ったときに の出る回数 x の確率分布は二項分布に従う. この場合, n = 0, p = 6 の二項分布になる さいころを
第 4 回二項分布, ポアソン分布, 正規分布 実験計画学 009 年 月 0 日 A. 代表的な分布. 離散分布 二項分布大きさ n の標本で, 事象 Eの起こる確率を p とするとき, そのうち x 個にEが起こる確率 P(x) は二項分布に従う. 例さいころを 0 回振ったときに の出る回数 x の確率分布は二項分布に従う. この場合, n = 0, p = 6 の二項分布になる さいころを
データ解析
 データ解析 ( 前期 ) 最小二乗法 向井厚志 005 年度テキスト 0 データ解析 - 最小二乗法 - 目次 第 回 Σ の計算 第 回ヒストグラム 第 3 回平均と標準偏差 6 第 回誤差の伝播 8 第 5 回正規分布 0 第 6 回最尤性原理 第 7 回正規分布の 分布の幅 第 8 回最小二乗法 6 第 9 回最小二乗法の練習 8 第 0 回最小二乗法の推定誤差 0 第 回推定誤差の計算 第
データ解析 ( 前期 ) 最小二乗法 向井厚志 005 年度テキスト 0 データ解析 - 最小二乗法 - 目次 第 回 Σ の計算 第 回ヒストグラム 第 3 回平均と標準偏差 6 第 回誤差の伝播 8 第 5 回正規分布 0 第 6 回最尤性原理 第 7 回正規分布の 分布の幅 第 8 回最小二乗法 6 第 9 回最小二乗法の練習 8 第 0 回最小二乗法の推定誤差 0 第 回推定誤差の計算 第
1.民営化
 参考資料 最小二乗法 数学的性質 経済統計分析 3 年度秋学期 回帰分析と最小二乗法 被説明変数 の動きを説明変数 の動きで説明 = 回帰分析 説明変数がつ 単回帰 説明変数がつ以上 重回帰 被説明変数 従属変数 係数 定数項傾き 説明変数 独立変数 残差... で説明できる部分 説明できない部分 説明できない部分が小さくなるように回帰式の係数 を推定する有力な方法 = 最小二乗法 最小二乗法による回帰の考え方
参考資料 最小二乗法 数学的性質 経済統計分析 3 年度秋学期 回帰分析と最小二乗法 被説明変数 の動きを説明変数 の動きで説明 = 回帰分析 説明変数がつ 単回帰 説明変数がつ以上 重回帰 被説明変数 従属変数 係数 定数項傾き 説明変数 独立変数 残差... で説明できる部分 説明できない部分 説明できない部分が小さくなるように回帰式の係数 を推定する有力な方法 = 最小二乗法 最小二乗法による回帰の考え方
異文化言語教育評価論 ⅠA 教育 心理系研究のためのデータ分析入門 第 3 章 t 検定 (2 変数間の平均の差を分析 ) 平成 26 年 5 月 7 日 報告者 :M.S. I.N. 3-1 統計的検定 統計的検定 : 設定した仮説にもとづいて集めた標本を確率論の観点から分析し 仮説検証を行うこと
 平成 26 年 5 月 7 日 報告者 :M.S. I.N. 3-1 統計的検定 統計的検定 : 設定した仮説にもとづいて集めた標本を確率論の観点から分析し 仮説検証を行うこと") 異文化言語教育評価論 ⅠA 教育 心理系研究のためのデータ分析入門 第 3 章 t 検定 (2 変数間の平均の差を分析 ) 平成 26 年 5 月 7 日 報告者 :M.S. I.N. 3-1 統計的検定 統計的検定 : 設定した仮説にもとづいて集めた標本を確率論の観点から分析し 仮説検証を行うこと 使用する標本は母集団から無作為抽出し 母集団を代表している値と考える 標本同士を比較して得た結果から
異文化言語教育評価論 ⅠA 教育 心理系研究のためのデータ分析入門 第 3 章 t 検定 (2 変数間の平均の差を分析 ) 平成 26 年 5 月 7 日 報告者 :M.S. I.N. 3-1 統計的検定 統計的検定 : 設定した仮説にもとづいて集めた標本を確率論の観点から分析し 仮説検証を行うこと 使用する標本は母集団から無作為抽出し 母集団を代表している値と考える 標本同士を比較して得た結果から
untitled
 に, 月次モデルの場合でも四半期モデルの場合でも, シミュレーション期間とは無関係に一様に RMSPE を最小にするバンドの設定法は存在しないということである 第 2 は, 表で与えた 2 つの期間及びすべての内生変数を見渡して, 全般的にパフォーマンスのよいバンドの設定法は, 最適固定バンドと最適可変バンドのうちの M 2, Q2 である いずれにしても, 以上述べた 3 つのバンド設定法は若干便宜的なものと言わざるを得ない
に, 月次モデルの場合でも四半期モデルの場合でも, シミュレーション期間とは無関係に一様に RMSPE を最小にするバンドの設定法は存在しないということである 第 2 は, 表で与えた 2 つの期間及びすべての内生変数を見渡して, 全般的にパフォーマンスのよいバンドの設定法は, 最適固定バンドと最適可変バンドのうちの M 2, Q2 である いずれにしても, 以上述べた 3 つのバンド設定法は若干便宜的なものと言わざるを得ない
と 測定を繰り返した時のばらつき の和が 全体のばらつき () に対して どれくらいの割合となるかがわかり 測定システムを評価することができる MSA 第 4 版スタディガイド ジャパン プレクサス (010)p.104 では % GRR の値が10% 未満であれば 一般に受容れられる測定システムと
 に対して どれくらいの割合となるかがわかり 測定システムを評価することができる MSA 第 4 版スタディガイド ジャパン プレクサス (010)p.104 では % GRR の値が10% 未満であれば 一般に受容れられる測定システムと") .5 Gage R&R による解析.5.1 Gage R&Rとは Gage R&R(Gage Repeatability and Reproducibility ) とは 測定システム分析 (MSA: Measurement System Analysis) ともいわれ 測定プロセスを管理または審査するための手法である MSAでは ばらつきの大きさを 変動 という尺度で表し 測定システムのどこに原因があるのか
.5 Gage R&R による解析.5.1 Gage R&Rとは Gage R&R(Gage Repeatability and Reproducibility ) とは 測定システム分析 (MSA: Measurement System Analysis) ともいわれ 測定プロセスを管理または審査するための手法である MSAでは ばらつきの大きさを 変動 という尺度で表し 測定システムのどこに原因があるのか
周期時系列の統計解析 (3) 移動平均とフーリエ変換 nino 2017 年 12 月 18 日 移動平均は, 周期時系列における特定の周期成分の消去や不規則変動 ( ノイズ ) の低減に汎用されている統計手法である. ここでは, 周期時系列をコサイン関数で近似し, その移動平均により周期成分の振幅
 移動平均とフーリエ変換 nino 2017 年 12 月 18 日 移動平均は, 周期時系列における特定の周期成分の消去や不規則変動 ( ノイズ ) の低減に汎用されている統計手法である. ここでは, 周期時系列をコサイン関数で近似し, その移動平均により周期成分の振幅") 周期時系列の統計解析 3 移動平均とフーリエ変換 io 07 年 月 8 日 移動平均は, 周期時系列における特定の周期成分の消去や不規則変動 ノイズ の低減に汎用されている統計手法である. ここでは, 周期時系列をコサイン関数で近似し, その移動平均により周期成分のがどのように変化するのか等について検討する. また, 気温の実測値に移動平均を適用した結果についてフーリエ変換も併用して考察する. 単純移動平均の計算式移動平均には,
周期時系列の統計解析 3 移動平均とフーリエ変換 io 07 年 月 8 日 移動平均は, 周期時系列における特定の周期成分の消去や不規則変動 ノイズ の低減に汎用されている統計手法である. ここでは, 周期時系列をコサイン関数で近似し, その移動平均により周期成分のがどのように変化するのか等について検討する. また, 気温の実測値に移動平均を適用した結果についてフーリエ変換も併用して考察する. 単純移動平均の計算式移動平均には,
測量試補 重要事項
 重量平均による標高の最確値 < 試験合格へのポイント > 標高の最確値を重量平均によって求める問題である 士補試験では 定番 問題であり 水準測量の計算問題としては この形式か 往復観測の較差と許容範囲 の どちらか または両方がほぼ毎年出題されている 定番の計算問題であるがその難易度は低く 基本的な解き方をマスターしてしまえば 容易に解くことができる ( : 最重要事項 : 重要事項 : 知っておくと良い
重量平均による標高の最確値 < 試験合格へのポイント > 標高の最確値を重量平均によって求める問題である 士補試験では 定番 問題であり 水準測量の計算問題としては この形式か 往復観測の較差と許容範囲 の どちらか または両方がほぼ毎年出題されている 定番の計算問題であるがその難易度は低く 基本的な解き方をマスターしてしまえば 容易に解くことができる ( : 最重要事項 : 重要事項 : 知っておくと良い
IBM Software Business Analytics IBM SPSS Missing Values IBM SPSS Missing Values 空白を埋める際の適切なモデルを構築 ハイライト データをさまざまな角度から容易に検証する 欠損データの問題を素早く診断する 欠損値を推定値に
 空白を埋める際の適切なモデルを構築 ハイライト データをさまざまな角度から容易に検証する 欠損データの問題を素早く診断する 欠損値を推定値に置き換える 欠損データ タイプおよび極値を表示する 隠れたバイアスを除去する アンケート調査や市場調査 社会科学 データ マイニングなどの多くの専門家が 調査データの検証に を使用しています 欠損データを無視したり 除外したりすると 偏った無意味な結果につながる危険性があります
空白を埋める際の適切なモデルを構築 ハイライト データをさまざまな角度から容易に検証する 欠損データの問題を素早く診断する 欠損値を推定値に置き換える 欠損データ タイプおよび極値を表示する 隠れたバイアスを除去する アンケート調査や市場調査 社会科学 データ マイニングなどの多くの専門家が 調査データの検証に を使用しています 欠損データを無視したり 除外したりすると 偏った無意味な結果につながる危険性があります
Microsoft Word - 補論3.2
 補論 3. 多変量 GARC モデル 07//6 新谷元嗣 藪友良 対数尤度関数 3 章 7 節では 変量の対数尤度を求めた ここでは多変量の場合 とくに 変量について対数尤度を求める 誤差項 は平均 0 で 次元の正規分布に従うとする 単純化のため 分散と共分散は時間を通じて一定としよう ( この仮定は後で変更される ) したがって ij から添え字 を除くことができる このとき と の尤度関数は
補論 3. 多変量 GARC モデル 07//6 新谷元嗣 藪友良 対数尤度関数 3 章 7 節では 変量の対数尤度を求めた ここでは多変量の場合 とくに 変量について対数尤度を求める 誤差項 は平均 0 で 次元の正規分布に従うとする 単純化のため 分散と共分散は時間を通じて一定としよう ( この仮定は後で変更される ) したがって ij から添え字 を除くことができる このとき と の尤度関数は
Microsoft Word - 保健医療統計学112817完成版.docx
 講義で使用するので テキスト ( 地域診断のすすめ方 ) を必ず持参すること 5 4 統計処理のすすめ方 ( テキスト P. 134 136) 1. 6つのステップ 分布を知る ( 度数分布表 ヒストグラム ) 基礎統計量を求める Ø 代表値 Ø バラツキ : 範囲 ( 最大値 最小値 四分位偏位 ) 分散 標準偏差 標準誤差 集計する ( 単純集計 クロス集計 ) 母集団の情報を推定する ( 母平均
講義で使用するので テキスト ( 地域診断のすすめ方 ) を必ず持参すること 5 4 統計処理のすすめ方 ( テキスト P. 134 136) 1. 6つのステップ 分布を知る ( 度数分布表 ヒストグラム ) 基礎統計量を求める Ø 代表値 Ø バラツキ : 範囲 ( 最大値 最小値 四分位偏位 ) 分散 標準偏差 標準誤差 集計する ( 単純集計 クロス集計 ) 母集団の情報を推定する ( 母平均
Microsoft PowerPoint - 資料04 重回帰分析.ppt
 04. 重回帰分析 京都大学 加納学 Division of Process Control & Process Sstems Engineering Department of Chemical Engineering, Koto Universit [email protected] http://www-pse.cheme.koto-u.ac.jp/~kano/ Outline
04. 重回帰分析 京都大学 加納学 Division of Process Control & Process Sstems Engineering Department of Chemical Engineering, Koto Universit [email protected] http://www-pse.cheme.koto-u.ac.jp/~kano/ Outline
Microsoft PowerPoint - 測量学.ppt [互換モード]
![Microsoft PowerPoint - 測量学.ppt [互換モード]](/thumbs/92/109082022.jpg "Microsoft PowerPoint - 測量学.ppt [互換モード]") 8/5/ 誤差理論 測定の分類 性格による分類 独立 ( な ) 測定 : 測定値がある条件を満たさなければならないなどの拘束や制約を持たないで独立して行う測定 条件 ( 付き ) 測定 : 三角形の 3 つの内角の和のように, 個々の測定値間に満たすべき条件式が存在する場合の測定 方法による分類 直接測定 : 距離や角度などを機器を用いて直接行う測定 間接測定 : 求めるべき量を直接測定するのではなく,
8/5/ 誤差理論 測定の分類 性格による分類 独立 ( な ) 測定 : 測定値がある条件を満たさなければならないなどの拘束や制約を持たないで独立して行う測定 条件 ( 付き ) 測定 : 三角形の 3 つの内角の和のように, 個々の測定値間に満たすべき条件式が存在する場合の測定 方法による分類 直接測定 : 距離や角度などを機器を用いて直接行う測定 間接測定 : 求めるべき量を直接測定するのではなく,
Microsoft Word - apstattext04.docx
 4 章母集団と指定値との量的データの検定 4.1 検定手順今までは質的データの検定の方法を学んで来ましたが これからは量的データについてよく利用される方法を説明します 量的データでは データの分布が正規分布か否かで検定の方法が著しく異なります この章ではまずデータの分布の正規性を調べる方法を述べ 次にデータの平均値または中央値がある指定された値と違うかどうかの検定方法を説明します 以下の図 4.1.1
4 章母集団と指定値との量的データの検定 4.1 検定手順今までは質的データの検定の方法を学んで来ましたが これからは量的データについてよく利用される方法を説明します 量的データでは データの分布が正規分布か否かで検定の方法が著しく異なります この章ではまずデータの分布の正規性を調べる方法を述べ 次にデータの平均値または中央値がある指定された値と違うかどうかの検定方法を説明します 以下の図 4.1.1
Microsoft PowerPoint - A1.ppt [互換モード]
![Microsoft PowerPoint - A1.ppt [互換モード]](/thumbs/77/75537561.jpg "Microsoft PowerPoint - A1.ppt [互換モード]") 011/4/13 付録 A1( 推測統計学の基礎 ) 付録 A1 推測統計学の基礎 1. 統計学. カイ 乗検定 3. 分散分析 4. 相関係数 5. 多変量解析 1. 統計学 3 統計ソフト 4 記述統計学 推測統計学 検定 ノンパラメトリック検定名義 / 分類尺度順序 / 順位尺度パラメトリック検定間隔 / 距離尺度比例 / 比率尺度 SAS SPSS R R-Tps (http://cse.aro.affrc.go.jp/takezawa/r-tps/r.html)
011/4/13 付録 A1( 推測統計学の基礎 ) 付録 A1 推測統計学の基礎 1. 統計学. カイ 乗検定 3. 分散分析 4. 相関係数 5. 多変量解析 1. 統計学 3 統計ソフト 4 記述統計学 推測統計学 検定 ノンパラメトリック検定名義 / 分類尺度順序 / 順位尺度パラメトリック検定間隔 / 距離尺度比例 / 比率尺度 SAS SPSS R R-Tps (http://cse.aro.affrc.go.jp/takezawa/r-tps/r.html)
横浜市環境科学研究所
 周期時系列の統計解析 単回帰分析 io 8 年 3 日 周期時系列に季節調整を行わないで単回帰分析を適用すると, 回帰係数には周期成分の影響が加わる. ここでは, 周期時系列をコサイン関数モデルで近似し単回帰分析によりモデルの回帰係数を求め, 周期成分の影響を検討した. また, その結果を気温時系列に当てはめ, 課題等について考察した. 気温時系列とコサイン関数モデル第 報の結果を利用するので, その一部を再掲する.
周期時系列の統計解析 単回帰分析 io 8 年 3 日 周期時系列に季節調整を行わないで単回帰分析を適用すると, 回帰係数には周期成分の影響が加わる. ここでは, 周期時系列をコサイン関数モデルで近似し単回帰分析によりモデルの回帰係数を求め, 周期成分の影響を検討した. また, その結果を気温時系列に当てはめ, 課題等について考察した. 気温時系列とコサイン関数モデル第 報の結果を利用するので, その一部を再掲する.
Autodesk Inventor Skill Builders Autodesk Inventor 2010 構造解析の精度改良 メッシュリファインメントによる収束計算 予想作業時間:15 分 対象のバージョン:Inventor 2010 もしくはそれ以降のバージョン シミュレーションを設定する際
 Autodesk Inventor Skill Builders Autodesk Inventor 2010 構造解析の精度改良 メッシュリファインメントによる収束計算 予想作業時間:15 分 対象のバージョン:Inventor 2010 もしくはそれ以降のバージョン シミュレーションを設定する際に 収束判定に関するデフォルトの設定をそのまま使うか 修正をします 応力解析ソルバーでは計算の終了を判断するときにこの設定を使います
Autodesk Inventor Skill Builders Autodesk Inventor 2010 構造解析の精度改良 メッシュリファインメントによる収束計算 予想作業時間:15 分 対象のバージョン:Inventor 2010 もしくはそれ以降のバージョン シミュレーションを設定する際に 収束判定に関するデフォルトの設定をそのまま使うか 修正をします 応力解析ソルバーでは計算の終了を判断するときにこの設定を使います
0 部分的最小二乗回帰 Partial Least Squares Regression PLS 明治大学理 学部応用化学科 データ化学 学研究室 弘昌
 0 部分的最小二乗回帰 Parial Leas Squares Regressio PLS 明治大学理 学部応用化学科 データ化学 学研究室 弘昌 部分的最小二乗回帰 (PLS) とは? 部分的最小二乗回帰 (Parial Leas Squares Regressio, PLS) 線形の回帰分析手法の つ 説明変数 ( 記述 ) の数がサンプルの数より多くても計算可能 回帰式を作るときにノイズの影響を受けにくい
0 部分的最小二乗回帰 Parial Leas Squares Regressio PLS 明治大学理 学部応用化学科 データ化学 学研究室 弘昌 部分的最小二乗回帰 (PLS) とは? 部分的最小二乗回帰 (Parial Leas Squares Regressio, PLS) 線形の回帰分析手法の つ 説明変数 ( 記述 ) の数がサンプルの数より多くても計算可能 回帰式を作るときにノイズの影響を受けにくい
RMS(Root Mean Square value 実効値 ) 実効値は AC の電圧と電流両方の値を規定する 最も一般的で便利な値です AC 波形の実効値はその波形から得られる パワーのレベルを示すものであり AC 信号の最も重要な属性となります 実効値の計算は AC の電流波形と それによって
 実効値は AC の電圧と電流両方の値を規定する 最も一般的で便利な値です AC 波形の実効値はその波形から得られる パワーのレベルを示すものであり AC 信号の最も重要な属性となります 実効値の計算は AC の電流波形と それによって") 入門書 最近の数多くの AC 電源アプリケーションに伴う複雑な電流 / 電圧波形のため さまざまな測定上の課題が発生しています このような問題に対処する場合 基本的な測定 使用される用語 それらの関係について理解することが重要になります このアプリケーションノートではパワー測定の基本的な考え方やパワー測定において重要な 以下の用語の明確に定義します RMS(Root Mean Square value
入門書 最近の数多くの AC 電源アプリケーションに伴う複雑な電流 / 電圧波形のため さまざまな測定上の課題が発生しています このような問題に対処する場合 基本的な測定 使用される用語 それらの関係について理解することが重要になります このアプリケーションノートではパワー測定の基本的な考え方やパワー測定において重要な 以下の用語の明確に定義します RMS(Root Mean Square value
OpRisk VaR3.2 Presentation
 オペレーショナル リスク VaR 計量の実施例 2009 年 5 月 SAS Institute Japan 株式会社 RI ビジネス開発部羽柴利明 オペレーショナル リスク計量の枠組み SAS OpRisk VaR の例 損失情報スケーリング計量単位の設定分布推定各種調整 VaR 計量 内部損失データ スケーリング 頻度分布 規模分布 分布の補正相関調整外部データによる分布の補正 損失シナリオ 分布の統合モンテカルロシミュレーション
オペレーショナル リスク VaR 計量の実施例 2009 年 5 月 SAS Institute Japan 株式会社 RI ビジネス開発部羽柴利明 オペレーショナル リスク計量の枠組み SAS OpRisk VaR の例 損失情報スケーリング計量単位の設定分布推定各種調整 VaR 計量 内部損失データ スケーリング 頻度分布 規模分布 分布の補正相関調整外部データによる分布の補正 損失シナリオ 分布の統合モンテカルロシミュレーション
Excelによる統計分析検定_知識編_小塚明_1_4章.indd
 第2章 1 変量データのまとめ方 本章では, 記述統計の手法について説明します 具体的には, 得られたデータから表やグラフを作成し, 意昧のある統計量を算出する方法など,1 変量データのまとめ方について学びます 本章から理解を深めるための数式が出てきますが, 必ずしも, これらの式を覚える必要はありません それぞれのデータの性質や統計量の意義を理解することが重要です 円グラフと棒グラフ 1 変量質的データをまとめる方法としてよく使われるグラフは,
第2章 1 変量データのまとめ方 本章では, 記述統計の手法について説明します 具体的には, 得られたデータから表やグラフを作成し, 意昧のある統計量を算出する方法など,1 変量データのまとめ方について学びます 本章から理解を深めるための数式が出てきますが, 必ずしも, これらの式を覚える必要はありません それぞれのデータの性質や統計量の意義を理解することが重要です 円グラフと棒グラフ 1 変量質的データをまとめる方法としてよく使われるグラフは,
ファイナンスのための数学基礎 第1回 オリエンテーション、ベクトル
 時系列分析 変量時系列モデルとその性質 担当 : 長倉大輔 ( ながくらだいすけ 時系列モデル 時系列モデルとは時系列データを生み出すメカニズムとなるものである これは実際には未知である 私たちにできるのは観測された時系列データからその背後にある時系列モデルを推測 推定するだけである 以下ではいくつかの代表的な時系列モデルを考察する 自己回帰モデル (Auoregressive Model もっとも頻繁に使われる時系列モデルは自己回帰モデル
時系列分析 変量時系列モデルとその性質 担当 : 長倉大輔 ( ながくらだいすけ 時系列モデル 時系列モデルとは時系列データを生み出すメカニズムとなるものである これは実際には未知である 私たちにできるのは観測された時系列データからその背後にある時系列モデルを推測 推定するだけである 以下ではいくつかの代表的な時系列モデルを考察する 自己回帰モデル (Auoregressive Model もっとも頻繁に使われる時系列モデルは自己回帰モデル
Microsoft PowerPoint - ICS修士論文発表会資料.ppt
 2011 年 9 月 28 日 ICS 修士論文発表会 我が国の年齢階級別 リスク資産保有比率に関する研究 2011 年 3 月修了生元利大輔 研究の動機 我が国では, 若年層のリスク資産保有比率が低いと言われている. 一方,FP の一般的なアドバイスでは, 若年層ほどリスクを積極的にとり, 株式等へ投資すべきと言われている. 高齢層は本来リスク資産の保有を少なくすべきかを考察したい. Sep 28,
2011 年 9 月 28 日 ICS 修士論文発表会 我が国の年齢階級別 リスク資産保有比率に関する研究 2011 年 3 月修了生元利大輔 研究の動機 我が国では, 若年層のリスク資産保有比率が低いと言われている. 一方,FP の一般的なアドバイスでは, 若年層ほどリスクを積極的にとり, 株式等へ投資すべきと言われている. 高齢層は本来リスク資産の保有を少なくすべきかを考察したい. Sep 28,
21世紀型パラメータ設計―標準SN比の活用―
 世紀のパラメータ設計ースイッチ機構のモデル化ー 接点 ゴム 変位 スイッチ動作前 スイッチ動作後 反転ばねでスイッチの クリック感 を実現した構造 世紀型パラメータ設計 標準 SN 比の活用 0 世紀の品質工学においては,SN 比の中に, 信号因子の乱れである 次誤差 (S res ) もノイズの効果の中に加えて評価してきた.のパラメータ設計の例では, 比例関係が理想であるから, 次誤差も誤差の仲間と考えてもよかったが,
世紀のパラメータ設計ースイッチ機構のモデル化ー 接点 ゴム 変位 スイッチ動作前 スイッチ動作後 反転ばねでスイッチの クリック感 を実現した構造 世紀型パラメータ設計 標準 SN 比の活用 0 世紀の品質工学においては,SN 比の中に, 信号因子の乱れである 次誤差 (S res ) もノイズの効果の中に加えて評価してきた.のパラメータ設計の例では, 比例関係が理想であるから, 次誤差も誤差の仲間と考えてもよかったが,
日本製薬工業協会シンポジウム 生存時間解析の評価指標に関する最近の展開ー RMST (restricted mean survival time) を理解するー 2. RMST の定義と統計的推測 2018 年 6 月 13 日医薬品評価委員会データサイエンス部会タスクフォース 4 生存時間解析チー
 を理解するー 2. RMST の定義と統計的推測 2018 年 6 月 13 日医薬品評価委員会データサイエンス部会タスクフォース 4 生存時間解析チー") 日本製薬工業協会シンポジウム 生存時間解析の評価指標に関する最近の展開ー RMST (restricted mean survival time) を理解するー 2. RMST の定義と統計的推測 2018 年 6 月 13 日医薬品評価委員会データサイエンス部会タスクフォース 4 生存時間解析チーム 日本新薬 ( 株 ) 田中慎一 留意点 本発表は, 先日公開された 生存時間型応答の評価指標 -RMST(restricted
日本製薬工業協会シンポジウム 生存時間解析の評価指標に関する最近の展開ー RMST (restricted mean survival time) を理解するー 2. RMST の定義と統計的推測 2018 年 6 月 13 日医薬品評価委員会データサイエンス部会タスクフォース 4 生存時間解析チーム 日本新薬 ( 株 ) 田中慎一 留意点 本発表は, 先日公開された 生存時間型応答の評価指標 -RMST(restricted
Microsoft PowerPoint - R-stat-intro_12.ppt [互換モード]
![Microsoft PowerPoint - R-stat-intro_12.ppt [互換モード]](/thumbs/101/151921093.jpg "Microsoft PowerPoint - R-stat-intro_12.ppt [互換モード]") R で統計解析入門 (12) 生存時間解析 中篇 準備 : データ DEP の読み込み 1. データ DEP を以下からダウンロードする http://www.cwk.zaq.ne.jp/fkhud708/files/dep.csv /fkh /d 2. ダウンロードした場所を把握する ここでは c:/temp とする 3. R を起動し,2. 2 の場所に移動し, データを読み込む 4. データ
R で統計解析入門 (12) 生存時間解析 中篇 準備 : データ DEP の読み込み 1. データ DEP を以下からダウンロードする http://www.cwk.zaq.ne.jp/fkhud708/files/dep.csv /fkh /d 2. ダウンロードした場所を把握する ここでは c:/temp とする 3. R を起動し,2. 2 の場所に移動し, データを読み込む 4. データ
無党派層についての分析 芝井清久 神奈川大学人間科学部教務補助職員 統計数理研究所データ科学研究系特任研究員 注 ) 図表は 不明 無回答 を除外して作成した 設問によっては その他 の回答も除外した この分析では Q13 で と答えた有権者を無党派層と定義する Q13 と Q15-1, 2 のクロ
 図表は 不明 無回答 を除外して作成した 設問によっては その他 の回答も除外した この分析では Q13 で と答えた有権者を無党派層と定義する Q13 と Q15-1, 2 のクロ") Ⅰ 無党派層についての分析 無党派層についての分析 芝井清久 神奈川大学人間科学部教務補助職員 統計数理研究所データ科学研究系特任研究員 注 ) 図表は 不明 無回答 を除外して作成した 設問によっては その他 の回答も除外した この分析では Q13 で と答えた有権者を無党派層と定義する Q13 と Q15-1, 2 のクロス表 Q13 合計 Q15-1 男性 度数 76 78 154 行 % 49.4%
Ⅰ 無党派層についての分析 無党派層についての分析 芝井清久 神奈川大学人間科学部教務補助職員 統計数理研究所データ科学研究系特任研究員 注 ) 図表は 不明 無回答 を除外して作成した 設問によっては その他 の回答も除外した この分析では Q13 で と答えた有権者を無党派層と定義する Q13 と Q15-1, 2 のクロス表 Q13 合計 Q15-1 男性 度数 76 78 154 行 % 49.4%
JUSE-StatWorks/V5 活用ガイドブック
 4.6 薄膜金属材料の表面加工 ( 直積法 ) 直積法では, 内側に直交配列表または要因配置計画の M 個の実験, 外側に直交配列表または要因配置計画の N 個の実験をわりつけ, その組み合わせの M N のデータを解析します. 直積法を用いることにより, 内側計画の各列と全ての外側因子との交互作用を求めることができます. よって, 環境条件や使用条件のように制御が難しい ( 水準を指定できない )
4.6 薄膜金属材料の表面加工 ( 直積法 ) 直積法では, 内側に直交配列表または要因配置計画の M 個の実験, 外側に直交配列表または要因配置計画の N 個の実験をわりつけ, その組み合わせの M N のデータを解析します. 直積法を用いることにより, 内側計画の各列と全ての外側因子との交互作用を求めることができます. よって, 環境条件や使用条件のように制御が難しい ( 水準を指定できない )
Microsoft Word - lec_student-chp3_1-representative
 1. はじめに この節でのテーマ データ分布の中心位置を数値で表す 可視化でとらえた分布の中心位置を数量化する 平均値とメジアン, 幾何平均 この節での到達目標 1 平均値 メジアン 幾何平均の定義を書ける 2 平均値とメジアン, 幾何平均の特徴と使える状況を説明できる. 3 平均値 メジアン 幾何平均を計算できる 2. 特性値 集めたデータを度数分布表やヒストグラムに整理する ( 可視化する )
1. はじめに この節でのテーマ データ分布の中心位置を数値で表す 可視化でとらえた分布の中心位置を数量化する 平均値とメジアン, 幾何平均 この節での到達目標 1 平均値 メジアン 幾何平均の定義を書ける 2 平均値とメジアン, 幾何平均の特徴と使える状況を説明できる. 3 平均値 メジアン 幾何平均を計算できる 2. 特性値 集めたデータを度数分布表やヒストグラムに整理する ( 可視化する )
0 21 カラー反射率 slope aspect 図 2.9: 復元結果例 2.4 画像生成技術としての計算フォトグラフィ 3 次元情報を復元することにより, 画像生成 ( レンダリング ) に応用することが可能である. 近年, コンピュータにより, カメラで直接得られない画像を生成する技術分野が生
 に応用することが可能である. 近年, コンピュータにより, カメラで直接得られない画像を生成する技術分野が生") 0 21 カラー反射率 slope aspect 図 2.9: 復元結果例 2.4 画像生成技術としての計算フォトグラフィ 3 次元情報を復元することにより, 画像生成 ( レンダリング ) に応用することが可能である. 近年, コンピュータにより, カメラで直接得られない画像を生成する技術分野が生まれ, コンピューテーショナルフォトグラフィ ( 計算フォトグラフィ ) と呼ばれている.3 次元画像認識技術の計算フォトグラフィへの応用として,
0 21 カラー反射率 slope aspect 図 2.9: 復元結果例 2.4 画像生成技術としての計算フォトグラフィ 3 次元情報を復元することにより, 画像生成 ( レンダリング ) に応用することが可能である. 近年, コンピュータにより, カメラで直接得られない画像を生成する技術分野が生まれ, コンピューテーショナルフォトグラフィ ( 計算フォトグラフィ ) と呼ばれている.3 次元画像認識技術の計算フォトグラフィへの応用として,