線形代数演算ライブラリBLASとLAPACKの 基礎と実践1
|
|
|
- ふみな うづき
- 5 years ago
- Views:
Transcription
1 1 / 56 BLAS LAPACK 1, 2017/05/25 CMSI A
2 2 / 56 BLAS LAPACK (I) BLAS, LAPACK BLAS : - LAPACK :
3 3 / 56 ( ) 1000 ( ; 1 2 ) :...
4 3 / 56 ( ) 1000 ( ; 1 2 ) :...
5 3 / 56 ( ) 1000 ( ; 1 2 ) :...
6 3 / 56 ( ) 1000 ( ; 1 2 ) :...
7 3 / 56 ( ) 1000 ( ; 1 2 ) :...
8 4 / 56 twitter!
9 convolution( ) - C = AB Google Page Rank Ax = λx, M = UΣV 3D O AO ( ) ( ) U HU = diag(λ 1, λ 2, ) 5 / 56
10 convolution( ) - C = AB Google Page Rank Ax = λx, M = UΣV 3D O AO ( ) ( ) U HU = diag(λ 1, λ 2, ) 5 / 56
11 convolution( ) - C = AB Google Page Rank Ax = λx, M = UΣV 3D O AO ( ) ( ) U HU = diag(λ 1, λ 2, ) 5 / 56
12 convolution( ) - C = AB Google Page Rank Ax = λx, M = UΣV 3D O AO ( ) ( ) U HU = diag(λ 1, λ 2, ) 5 / 56
13 convolution( ) - C = AB Google Page Rank Ax = λx, M = UΣV 3D O AO ( ) ( ) U HU = diag(λ 1, λ 2, ) 5 / 56
14 6 / 56 The Rhind Papyrus (the Ahmes Papyrus; BC 1650 ) x + ax = b, x + ax + bx = c
")
15 7 / 56 ( 1 2 ) Gauss
16 8 / 56 ( 1 2 ) :
17 9 / 56 ( 1 2 ) +Google trans. : : 9 1 4, 4 1 4, ( )...
18 ( 1 2 ) +Google trans. : 3x + 2y + z = 39 ( ) 2x + 3y + z = 34 ( ) x + 2y + 3z = 26 ( ) ( ) ( ) ( ) 3 ( ) 2 ( ) 3 ( ) ( ) 3(2x + 3y + z = 34) 2(3x + 2y + z = 39) 5y + z = 24 ( ) 3(x + 2y + 3z = 39) 3x + 2y + z = 39 4y + 8z = 39 ( ) ( ) 5 3x + 2y + z = 39 ( ) 5y + z = 24 ( ) 20y + 40z = 195 ( ) ( )-( )x4 36z = / 56
19 11 / : = (= ) 1950 (LU )
 10 14 2800 357")
20 12 / 56 ENIAC ENIAC( Electronic Numerical Integrator and Computer 1946 ) (Wikipedia )
21 13 / 56
22 14 / ( ) (fraction) (exponent) a n 0 or 1 f raction {}}{ exponent k ( ) n 1 {}}{ ± 1 + a n 2 m 2 n= (2) = = (10) = ( ) 32 = 52
23 14 / ( ) (fraction) (exponent) a n 0 or 1 f raction {}}{ exponent k ( ) n 1 {}}{ ± 1 + a n 2 m 2 n= (2) = = (10) = ( ) 32 = 52
24 14 / ( ) (fraction) (exponent) a n 0 or 1 f raction {}}{ exponent k ( ) n 1 {}}{ ± 1 + a n 2 m 2 n= (2) = = (10) = ( ) 32 = 52
25 14 / ( ) (fraction) (exponent) a n 0 or 1 f raction {}}{ exponent k ( ) n 1 {}}{ ± 1 + a n 2 m 2 n= (2) = = (10) = ( ) 32 = 52
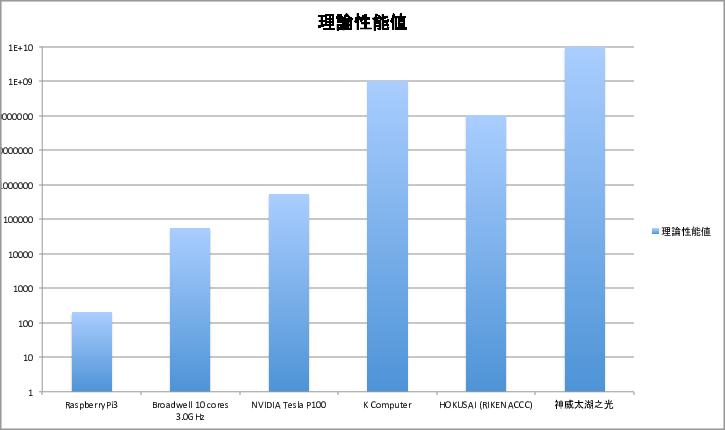
: 560GFLOPS; NVIDIA TESLA P100 5.3TFLOPS, 10PFLOPS), HOKUSAI (1PFlops), (93.")
26 15 / 56 : IEEE Standard for Floating-Point Arithmetic binary64 ( ) =Floating point operation per second G = 10 9, T = 10 12, P = :Core i7 (Broadwell, 10 cores, 3.5GHz): 560GFLOPS; NVIDIA TESLA P TFLOPS, 10PFLOPS), HOKUSAI (1PFlops), (93.01PFlops)

27 16 / 56
28 17 / 56
29 18 / 56
30 19 / 56! = 1 a + (b + c) (a + b) + c
31 19 / 56! = 1 a + (b + c) (a + b) + c
32 19 / 56! = 1 a + (b + c) (a + b) + c
33 20 / 56!! a float ( (18+a) - a ) (a) 18 (b) 0 (c)
34 20 / 56!! a float ( (18+a) - a ) (a) 18 (b) 0 (c)
35 20 / 56!! a float ( (18+a) - a ) (a) 18 (b) 0 (c)
36 20 / 56!! a float ( (18+a) - a ) (a) 18 (b) 0 (c)
37 21 / 56 (c) $ cat test.c #include <math.h> #include <stdio.h> int main() { double a = 18.0; double b = pow(2,57); printf("%lf\n", (a+b) - b); } $ gcc test.c ;./a.out ( )
38 22 / 56
39 23 / :, 0...
40 23 / :, 0...
41 23 / :, 0...
42 23 / :, 0...
43 23 / :, 0...
44 23 / :, 0...
45 24 / 56? BLAS, LAPACK?
46 24 / 56? BLAS, LAPACK?
47 24 / 56? BLAS, LAPACK?
48 24 / 56? BLAS, LAPACK?
49 24 / 56? BLAS, LAPACK?
50 24 / 56? BLAS, LAPACK?
51 25 / 56 BLAS, LAPACK: BLAS+LAPACK ( OS ) ( )!! BLAS, LAPACK!
52 25 / 56 BLAS, LAPACK: BLAS+LAPACK ( OS ) ( )!! BLAS, LAPACK!
53 25 / 56 BLAS, LAPACK: BLAS+LAPACK ( OS ) ( )!! BLAS, LAPACK!
54 25 / 56 BLAS, LAPACK: BLAS+LAPACK ( OS ) ( )!! BLAS, LAPACK!
55 25 / 56 BLAS, LAPACK: BLAS+LAPACK ( OS ) ( )!! BLAS, LAPACK!
56 25 / 56 BLAS, LAPACK: BLAS+LAPACK ( OS ) ( )!! BLAS, LAPACK!
57 25 / 56 BLAS, LAPACK: BLAS+LAPACK ( OS ) ( )!! BLAS, LAPACK!
58 25 / 56 BLAS, LAPACK: BLAS+LAPACK ( OS ) ( )!! BLAS, LAPACK!
59 26 / 56 BLAS? BLAS Basic Linear Algebra Subprograms FORTRAN77 (Reference BLAS) BLAS!
60 26 / 56 BLAS? BLAS Basic Linear Algebra Subprograms FORTRAN77 (Reference BLAS) BLAS!
61 26 / 56 BLAS? BLAS Basic Linear Algebra Subprograms FORTRAN77 (Reference BLAS) BLAS!
62 26 / 56 BLAS? BLAS Basic Linear Algebra Subprograms FORTRAN77 (Reference BLAS) BLAS!
63 26 / 56 BLAS? BLAS Basic Linear Algebra Subprograms FORTRAN77 (Reference BLAS) BLAS!
64 27 / 56 Level 1 BLAS BLAS Level 1, 2, 3 Level 1: - (+ ) (DAXPY), (DDOT) y αx + y, (1) dot x T y, (2) 15,,,, 4.
65 28 / 56 Level 2 BLAS BLAS Level 1, 2, 3 Level 2: - - (DGEMV) (DTRSV) y αax + βy, (3) x A 1 b, (4) 25, 4
66 29 / 56 Level 3 BLAS BLAS Level 1, 2, 3 Level 3 BLAS - - (DGEMM), - DSYRK, DTRSM 9 C αab + βc (5) C αaa T + βc (6) B αa 1 B (7)
67 30 / 56 BLAS : s, d, c, z LEVEL1 BLAS zrotg zdcal drotg drot drotm zdrot zswap dswap zdscal dscal zcopy dcopy zaxpy daxpy ddot zdotc zdotu dznrm2 dnrm2 dasum izasum idamax dzabs1 LEVEL2 BLAS zgemv dgemv zgbmv dgbmv zhemv zhbmv zhpmv dsymv dsbmv ztrmv zgemv dgemv zgbmv dgemv zhemv zhbmv zhpmv dsymv dsbmv dspmv ztrmv dtrmv ztbmv ztpmv dtpmv ztrsv dtrsv ztbsv dtbsv ztpsv dger zgeru zgerc zher zhpr zher2 zhpr2 dsyr dspr dsyr2 dspr2 LEVEL3 BLAS zgemm dgemm zsymm dsymm zhemm zsyrk dsyrk zherk zsyr2k dsyr2k zher2k ztrmm dtrmm ztrsm dtrsm
68 31 / 56 LAPACK? LAPACK(Linear Algebra PACKage),. BLAS. : (LU,, QR,, Schur, Schur ),, CPU OS Fortran web ! (2017/5/22 ; 1000?) github (
69 32 / 56 BLAS, LAPACK BLAS, LAPACK. Gaussian, Gamess, ADF, VASP CPLEX, NUOPT, GLPK.. Ruby, Python, Perl, Java, C, Mathematica, Maple, Matlab, R, octave, SciLab

70 33 / 56 Top 500 Top 500: Top 500, LINPACK., DGEMM -,
71 BLAS, LAPACK : BLAS, LAPACK Reference BLAS CPU OpenBLAS: Zhang Xianyi GotoBLAS2 SandyBridge ARM AMD Power, ICT Loongson-3A, 3B Intel MKL: Intel BLAS LAPACK 2012 Intel Intel OpenBLAS GotoBLAS2 ATLAS:R. Clint Whaley, BLAS 2001 BLAS, BLAS % 10% GPU BLAS, LAPACK: GPU CPU 1W 10,. MAGMA CUDA, Xeon Phi OpenCL GPU BLAS, LAPACK NVIDIA cublas 34 / 56
72 35 / 56 BLAS, LAPACK : CPU OS BLAS? C? FORTRAN? Python? Ruby? 32bit OS 64bit OS? GPU Linux MacOSX Windows Ubuntu x86
73 36 / 56 BLAS LAPACK Ubuntu BLAS, LAPACK C++ -
74 BLAS LAPACK Ubuntu BLAS LAPACK $ sudo apt-get install gfortran g++ libblas-dev liblapack-dev $ sudo apt-get install gfortran g++ libblas-dev liblapack-dev... g++ gfortran libblas-dev liblapack-dev : 0 : 0 : 0 : / 56
75 38 / DGEMM A = B = C = α = 3, β = 2, C αab + βc
76 39 / 56 - :DGEMM CBLAS BLAS void F77_dgemm(const char *transa, const char *transb, int m, int n, int k, const double * alpha, const double *A, int lda, const double * B, int ldb, const double *beta, double *C, int ldc); transa, transb, transc A, B, C Row major M, N, K alpha, beta
77 40 / 56 - I #include <stdio.h> extern "C" { #define ADD_ #include <cblas_f77.h> } //Matlab/Octave format void printmat(int N, int M, double *A, int LDA) { double mtmp; printf("[ "); for (int i = 0; i < N; i++) { printf("[ "); for (int j = 0; j < M; j++) { mtmp = A[i + j * LDA]; printf("%5.2e", mtmp); if (j < M - 1) printf(", "); } if (i < N - 1) printf("]; "); else printf("] "); } printf("]"); } int main() { int n = 3; double alpha, beta; double *A = new double[n*n]; double *B = new double[n*n]; double *C = new double[n*n]; A[0+0*n]=1; A[0+1*n]= 8; A[0+2*n]= 3; A[1+0*n]=2; A[1+1*n]=10; A[1+2*n]= 8; A[2+0*n]=9; A[2+1*n]=-5; A[2+2*n]=-1; B[0+0*n]= 9; B[0+1*n]= 8; B[0+2*n]=3; B[1+0*n]= 3; B[1+1*n]=11; B[1+2*n]=2.3; B[2+0*n]=-8; B[2+1*n]= 6; B[2+2*n]=1; C[0+0*n]=3; C[0+1*n]=3; C[0+2*n]=1.2; C[1+0*n]=8; C[1+1*n]=4; C[1+2*n]=8; C[2+0*n]=6; C[2+1*n]=1; C[2+2*n]=-2;
78 41 / 56 - II printf("# dgemm demo...\n"); printf("a =");printmat(n,n,a,n);printf("\n"); printf("b =");printmat(n,n,b,n);printf("\n"); printf("c =");printmat(n,n,c,n);printf("\n"); alpha = 3.0; beta = -2.0; F77_dgemm("n", "n", &n, &n, &n, &alpha, A, &n, B, &n, &beta, C, &n); printf("alpha = %5.3e\n", alpha); printf("beta = %5.3e\n", beta); printf("ans="); printmat(n,n,c,n); printf("\n"); printf("#check by Matlab/Octave by:\n"); printf("alpha * A * B + beta * C =\n"); delete[]c; delete[]b; delete[]a;
79 42 / 56 - dgemm_demo.cpp $ g++ dgemm_demo.cpp -o dgemm_demo -lblas -lapack., Octave Matlab & $./dgemm_demo # dgemm demo... A =[ [ 1.00e+00, 8.00e+00, 3.00e+00]; [ 2.00e+00, 1.00e+01, 8.00e+00]; [ 9.00e+00, -5.00e+00, -1.00e+00] ] B =[ [ 9.00e+00, 8.00e+00, 3.00e+00]; [ 3.00e+00, 1.10e+01, 2.30e+00]; [ -8.00e+00, 6.00e+00, 1.00e+00] ] C =[ [ 3.00e+00, 3.00e+00, 1.20e+00]; [ 8.00e+00, 4.00e+00, 8.00e+00]; [ 6.00e+00, 1.00e+00, -2.00e+00] ] alpha = 3.000e+00 beta = e+00 ans=[ [ 2.10e+01, 3.36e+02, 7.08e+01]; [ -6.40e+01, 5.14e+02, 9.50e+01]; [ 2.10e+02, 3.10e+01, 4.75e+01] ] #check by Matlab/Octave by: alpha * A * B + beta * C
80 43 / 56 - DGEMM C αab + βc void F77_dgemm(const char *transa, const char *transb, int m, int n, int k, const double * alpha, const double *A, int lda, const double * B, int ldb, const double *beta, double *C, int ldc);? 1 m, n, k 2 lda, ldb, ldc? 3 α, β 1, 0?
81 44 / 56 - DGEMM :Leading dimension (= )
82 - DGEMM :Leading dimension 45 / 56
83 46 / 56 - DGEMM :Leading dimension ( ), leading dimension LDA, LDB A(i,j) A leading dimension A(i + j lda) M N A LDA N
84 47 / 56 - DGEMM :Leading dimension A A? A (p, q) n, m leading dimension
85 LAPACK : :DSYEV A = Av i = λ i v i (i = 1, 2, 3) λ 1, λ 2, λ 3 v 1, v 2, v , , v 1 = ( , , ) v 2 = ( , , ) v 3 = ( , , ) 48 / 56
86 49 / 56 DSYEV Fortran dsyev_f77(const char *jobz, const char *uplo, int *n, double *A, int *lda, double *w, double *work, int *lwork, int *info); jobz: uplo: A, lda: A leading dimension w: ( ) work, lwork: info: =0 <0: INFO=-i i >0: INFO=i
87 #include <iostream> #include <stdio.h> extern "C" int dsyev_(const char *jobz, const char *uplo, int *n, double *a, int *lda, double *w, double *work, int *lwork, int *info); //Matlab/Octave format void printmat(int N, int M, double *A, int LDA) { double mtmp; printf("[ "); for (int i = 0; i < N; i++) { printf("[ "); for (int j = 0; j < M; j++) { mtmp = A[i + j * LDA]; printf("%5.2e", mtmp); if (j < M - 1) printf(", "); } if (i < N - 1) printf("]; "); else printf("] "); } printf("]"); } int main() { int n = 3; int lwork, info; double *A = new double[n*n]; double *w = new double[n]; //setting A matrix A[0+0*n]=1;A[0+1*n]=2;A[0+2*n]=3; A[1+0*n]=2;A[1+1*n]=5;A[1+2*n]=4; A[2+0*n]=3;A[2+1*n]=4;A[2+2*n]=6; printf("a ="); printmat(n, n, A, n); printf("\n"); lwork = -1; double *work = new double[1]; dsyev_("v", "U", &n, A, &n, w, work, &lwork, &info); lwork = (int) work[0]; delete[]work; work = new double[std::max((int) 1, lwork)]; //get Eigenvalue dsyev_("v", "U", &n, A, &n, w, work, &lwork, &info); //print out some results. printf("#eigenvalues \n"); printf("w ="); printmat(n, 1, w, 1); printf("\n"); printf("#eigenvecs \n"); printf("u ="); printmat(n, n, A, n); printf("\n"); printf("#check Matlab/Octave by:\n"); printf("eig(a)\n"); printf("u *A*U\n"); delete[]work; delete[]w; delete[]a; 50 / 56
88 51 / 56 eigenvalue_demo.cpp $ g++ eigenvalue_demo.cpp -o eigenvalue_demo -lblas -lapack -lgfortran, Octave Matlab & A =[ [ 1.00e+00, 2.00e+00, 3.00e+00];\ [ 2.00e+00, 5.00e+00, 4.00e+00];\ [ 3.00e+00, 4.00e+00, 6.00e+00] ] #eigenvalues w =[ [ -4.10e-01]; [ 1.58e+00]; [ 1.08e+01] ] #eigenvecs U =[ [ -9.14e-01, 2.16e-01, 3.42e-01];\ [ 4.01e-02, -7.93e-01, 6.08e-01];\ [ 4.03e-01, 5.70e-01, 7.16e-01] ] #Check Matlab/Octave by: eig(a) U *A*U
89 52 / 56 BLAS, LAPACK :Column major or Row major 2 1 ( ) A = column major, row major. 1, 4, 2, 5, 3, 6 column major
90 53 / 56 BLAS, LAPACK :Column major or Row major ( ) A = , 2, 3, 4, 5, 6 row major C, C++ row major
91 54 / 56 BLAS, LAPACK : 0 1? FORTRAN 1, C, C++, 0. 1 N (FORTRAN), 0 n (C,C++). x i FORTRAN X(I), C x[i 1]. A i, j FORTRAN A(I, J), C column major A[i 1 + ( j 1) lda]
92 55 / 56 BLAS, LAPACK BLAS, LAPACK C / BLAS, LAPACK
93 56 / 56 BLAS, LAPACK 1 ( ) BLAS, LAPACK 2 (GPU ) LAPACK/BLAS ( Matrix Computations Gene H. Golub and Charles F. Van Loan ( %20Matrix%20Computations.pdf) Accuracy and Stablity of NumericalAlgorithms, Nicholas J. Higham
線形代数演算ライブラリBLASとLAPACKの 基礎と実践1
 1 / 50 BLAS LAPACK 1, 2015/05/21 CMSI A 2 / 50 BLAS LAPACK (I) BLAS, LAPACK BLAS : - LAPACK : 3 / 50 ( ) 1000 ( ; 1 2 ) :... 3 / 50 ( ) 1000 ( ; 1 2 ) :... 3 / 50 ( ) 1000 ( ; 1 2 ) :... 3 / 50 ( ) 1000
1 / 50 BLAS LAPACK 1, 2015/05/21 CMSI A 2 / 50 BLAS LAPACK (I) BLAS, LAPACK BLAS : - LAPACK : 3 / 50 ( ) 1000 ( ; 1 2 ) :... 3 / 50 ( ) 1000 ( ; 1 2 ) :... 3 / 50 ( ) 1000 ( ; 1 2 ) :... 3 / 50 ( ) 1000
線形代数演算ライブラリBLASとLAPACKの 基礎と実践1
 .. BLAS LAPACK 1, 2013/05/23 CMSI A 1 / 43 BLAS LAPACK (I) BLAS, LAPACK BLAS : - LAPACK : 2 / 43 : 3 / 43 (wikipedia) V : f : V u, v u + v u + v V α K u V αu V V x, y f (x + y) = f (x) + f (y) V x K α
.. BLAS LAPACK 1, 2013/05/23 CMSI A 1 / 43 BLAS LAPACK (I) BLAS, LAPACK BLAS : - LAPACK : 2 / 43 : 3 / 43 (wikipedia) V : f : V u, v u + v u + v V α K u V αu V V x, y f (x + y) = f (x) + f (y) V x K α
11020070-0_Vol16No2.indd
 2552 チュートリアル BLAS, LAPACK 2 1 BLAS, LAPACKチュートリアル パート1 ( 簡 単 な 使 い 方 とプログラミング) 中 田 真 秀 1 読 者 の 想 定 BLAS [1], LAPACK [2] 2 線 形 代 数 の 重 要 性 について Google Page Rank 3D CPU 筆 者 紹 介 BLAS LAPACK http://accc.riken.jp/maho/
2552 チュートリアル BLAS, LAPACK 2 1 BLAS, LAPACKチュートリアル パート1 ( 簡 単 な 使 い 方 とプログラミング) 中 田 真 秀 1 読 者 の 想 定 BLAS [1], LAPACK [2] 2 線 形 代 数 の 重 要 性 について Google Page Rank 3D CPU 筆 者 紹 介 BLAS LAPACK http://accc.riken.jp/maho/
CMSI教育計算科学技術特論A_中田真秀
 線形代数演算ライブラリBLAS とLAPACKの基礎と実践 (I) BLAS, LAPACK入門編 中田 真秀 理化学研究所 情報システム本部 2019/5/23 計算科学技術特論A BLAS, LAPACK入門編 講義目的 線形代数演算をコンピュータで行うには 必ずBLAS LAPACKのお世話になる 使うには(若干)知識がいる 実際にUbuntu Linuxで試せる形で提示し 使えるよう になる
線形代数演算ライブラリBLAS とLAPACKの基礎と実践 (I) BLAS, LAPACK入門編 中田 真秀 理化学研究所 情報システム本部 2019/5/23 計算科学技術特論A BLAS, LAPACK入門編 講義目的 線形代数演算をコンピュータで行うには 必ずBLAS LAPACKのお世話になる 使うには(若干)知識がいる 実際にUbuntu Linuxで試せる形で提示し 使えるよう になる
untitled
 A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
untitled
 A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
A = QΛQ T A n n Λ Q A = XΛX 1 A n n Λ X GPGPU A 3 T Q T AQ = T (Q: ) T u i = λ i u i T {λ i } {u i } QR MR 3 v i = Q u i A {v i } A n = 9000 Quad Core Xeon 2 LAPACK (4/3) n 3 O(n 2 ) O(n 3 ) A {v i }
倍々精度RgemmのnVidia C2050上への実装と応用
 .. maho@riken.jp http://accc.riken.jp/maho/,,, 2011/2/16 1 - : GPU : SDPA-DD 10 1 - Rgemm : 4 (32 ) nvidia C2050, GPU CPU 150, 24GFlops 25 20 GFLOPS 15 10 QuadAdd Cray, QuadMul Sloppy Kernel QuadAdd Cray,
.. maho@riken.jp http://accc.riken.jp/maho/,,, 2011/2/16 1 - : GPU : SDPA-DD 10 1 - Rgemm : 4 (32 ) nvidia C2050, GPU CPU 150, 24GFlops 25 20 GFLOPS 15 10 QuadAdd Cray, QuadMul Sloppy Kernel QuadAdd Cray,
MBLAS¤ÈMLAPACK; ¿ÇÜĹÀºÅÙÈǤÎBLAS/LAPACK¤ÎºîÀ®
 MBLAS MLAPACK; BLAS/LAPACK maho@riken.jp February 23, 2009 MPACK(MBLAS/MLAPACK) ( ) (2007 ) ( ) http://accc.riken.jp/maho/ BLAS/LAPACK http://mplapack.sourceforge.net/ BLAS (Basic Linear Algebra Subprograms)
MBLAS MLAPACK; BLAS/LAPACK maho@riken.jp February 23, 2009 MPACK(MBLAS/MLAPACK) ( ) (2007 ) ( ) http://accc.riken.jp/maho/ BLAS/LAPACK http://mplapack.sourceforge.net/ BLAS (Basic Linear Algebra Subprograms)
11050427-0_Vol16No3.indd
 2599 チュートリアル BLAS, LAPACK 2 2 GPU BLAS, LAPACKチュートリアル パート2 (GPU 編 ) 中 田 真 秀 1 はじめに GPU Graphics Processing Unit BLAS, LAPACK GPU GPU NVIDIA AMD AMD RADEON HD NVIDIA NVIDIA GPU NVIDIA C2050 BLAS, LAPACK
2599 チュートリアル BLAS, LAPACK 2 2 GPU BLAS, LAPACKチュートリアル パート2 (GPU 編 ) 中 田 真 秀 1 はじめに GPU Graphics Processing Unit BLAS, LAPACK GPU GPU NVIDIA AMD AMD RADEON HD NVIDIA NVIDIA GPU NVIDIA C2050 BLAS, LAPACK
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司
![4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司](/thumbs/97/131936032.jpg "4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司") 4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
4 倍精度基本線形代数ルーチン群 QPBLAS の紹介 [index] 1. Introduction 2. Double-double algorithm 3. QPBLAS 4. QPBLAS-GPU 5. Summary 佐々成正 1, 山田進 1, 町田昌彦 1, 今村俊幸 2, 奥田洋司 3 1 1 日本原子力研究開発機構システム計算科学センター 2 理科学研究所計算科学研究機構 3 東京大学新領域創成科学研究科
211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS /1/18 a a 1 a 2 a 3 a a GPU Graphics Processing Unit GPU CPU GPU GPGPU G
 211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS211 211/1/18 GPU 4 8 BLAS 4 8 BLAS Basic Linear Algebra Subprograms GPU Graphics Processing Unit 4 8 double 2 4 double-double DD 4 4 8 quad-double
211 年ハイパフォーマンスコンピューティングと計算科学シンポジウム Computing Symposium 211 HPCS211 211/1/18 GPU 4 8 BLAS 4 8 BLAS Basic Linear Algebra Subprograms GPU Graphics Processing Unit 4 8 double 2 4 double-double DD 4 4 8 quad-double
1 (bit ) ( ) PC WS CPU IEEE754 standard ( 24bit) ( 53bit)
 ( ) PC WS CPU IEEE754 standard ( 24bit) ( 53bit)") GNU MP BNCpack tkouya@cs.sist.ac.jp 2002 9 20 ( ) Linux Conference 2002 1 1 (bit ) ( ) PC WS CPU IEEE754 standard ( 24bit) ( 53bit) 10 2 2 3 4 5768:9:; = %? @BADCEGFH-I:JLKNMNOQP R )TSVU!" # %$ & " #
GNU MP BNCpack tkouya@cs.sist.ac.jp 2002 9 20 ( ) Linux Conference 2002 1 1 (bit ) ( ) PC WS CPU IEEE754 standard ( 24bit) ( 53bit) 10 2 2 3 4 5768:9:; = %? @BADCEGFH-I:JLKNMNOQP R )TSVU!" # %$ & " #
Untitled
 VASP 2703 2006 3 VASP 100 PC 3,4 VASP VASP VASP FFT. (LAPACK,BLAS,FFT), CPU VASP. 1 C LAPACK,BLAS VASP VASP VASP VASP bench.hg VASP CPU CPU CPU northwood LAPACK lmkl lapack64, BLAS lmkl p4 LA- PACK liblapack,
VASP 2703 2006 3 VASP 100 PC 3,4 VASP VASP VASP FFT. (LAPACK,BLAS,FFT), CPU VASP. 1 C LAPACK,BLAS VASP VASP VASP VASP bench.hg VASP CPU CPU CPU northwood LAPACK lmkl lapack64, BLAS lmkl p4 LA- PACK liblapack,
理研スーパーコンピュータ・システム
 線形代数演算ライブラリ BLAS と LAPACK の基礎と実践 2 理化学研究所情報基盤センター 2013/5/30 13:00- 大阪大学基礎工学部 中田真秀 この授業の目的 対象者 - 研究用プログラムを高速化したい人 - LAPACK についてよく知らない人 この講習会の目的 - コンピュータの簡単な仕組みについて - 今後 どうやってプログラムを高速化するか - BLAS, LAPACK
線形代数演算ライブラリ BLAS と LAPACK の基礎と実践 2 理化学研究所情報基盤センター 2013/5/30 13:00- 大阪大学基礎工学部 中田真秀 この授業の目的 対象者 - 研究用プログラムを高速化したい人 - LAPACK についてよく知らない人 この講習会の目的 - コンピュータの簡単な仕組みについて - 今後 どうやってプログラムを高速化するか - BLAS, LAPACK
CPU Levels in the memory hierarchy Level 1 Level 2... Increasing distance from the CPU in access time Level n Size of the memory at each level 1: 2.2
 FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
FFT 1 Fourier fast Fourier transform FFT FFT FFT 1 FFT FFT 2 Fourier 2.1 Fourier FFT Fourier discrete Fourier transform DFT DFT n 1 y k = j=0 x j ω jk n, 0 k n 1 (1) x j y k ω n = e 2πi/n i = 1 (1) n DFT
PC Windows 95, Windows 98, Windows NT, Windows 2000, MS-DOS, UNIX CPU
 1. 1.1. 1.2. 1 PC Windows 95, Windows 98, Windows NT, Windows 2000, MS-DOS, UNIX CPU 2. 2.1. 2 1 2 C a b N: PC BC c 3C ac b 3 4 a F7 b Y c 6 5 a ctrl+f5) 4 2.2. main 2.3. main 2.4. 3 4 5 6 7 printf printf
1. 1.1. 1.2. 1 PC Windows 95, Windows 98, Windows NT, Windows 2000, MS-DOS, UNIX CPU 2. 2.1. 2 1 2 C a b N: PC BC c 3C ac b 3 4 a F7 b Y c 6 5 a ctrl+f5) 4 2.2. main 2.3. main 2.4. 3 4 5 6 7 printf printf
Minsky の電力消費量の調査 (1) ディープラーニングデモプログラム (mnist) の実行デモプログラム 添付 1 CPU 実行 シングル GPU 実行 2GPU 実行での計算時間と電力消費量を比較した 〇計算時間 CPU 実行 シングル GPU 実行複数 GPU 実行 今回は 2GPU 計
 ディープラーニングデモプログラム (mnist) の実行デモプログラム 添付 1 CPU 実行 シングル GPU 実行 2GPU 実行での計算時間と電力消費量を比較した 〇計算時間 CPU 実行 シングル GPU 実行複数 GPU 実行 今回は 2GPU 計") IBM Minsky における 電力性能比検証報告書 (Deep Learning および HPC アプリケーション ) 2017 年 1 月 ビジュアルテクノロジー株式会社 Minsky の電力消費量の調査 (1) ディープラーニングデモプログラム (mnist) の実行デモプログラム 添付 1 CPU 実行 シングル GPU 実行 2GPU 実行での計算時間と電力消費量を比較した 〇計算時間 CPU
IBM Minsky における 電力性能比検証報告書 (Deep Learning および HPC アプリケーション ) 2017 年 1 月 ビジュアルテクノロジー株式会社 Minsky の電力消費量の調査 (1) ディープラーニングデモプログラム (mnist) の実行デモプログラム 添付 1 CPU 実行 シングル GPU 実行 2GPU 実行での計算時間と電力消費量を比較した 〇計算時間 CPU
14 2 Scilab Scilab GUI インタグラフ プリタ描画各種ライブラリ (LAPACK, ODEPACK, ) SciNOTES ハードウェア (CPU, GPU) 21 Scilab SciNotes 呼び出し 3 変数ブラウザ 1 ファイルブラウザ 2 コンソール 4 コマンド履歴
 SciNOTES ハードウェア (CPU, GPU) 21 Scilab SciNotes 呼び出し 3 変数ブラウザ 1 ファイルブラウザ 2 コンソール 4 コマンド履歴") 13 2 Scilab Scilab Scilab 21 Scilab Scilab[4] INRIA C/C++, Fortran LAPACK Matlab Scilab Web http://wwwscilaborg/ 2016 4 552 Windows 10/8x MacOS X, Linux Scilab Octave Matlab (Matlab Toolbox) (Mathematica
13 2 Scilab Scilab Scilab 21 Scilab Scilab[4] INRIA C/C++, Fortran LAPACK Matlab Scilab Web http://wwwscilaborg/ 2016 4 552 Windows 10/8x MacOS X, Linux Scilab Octave Matlab (Matlab Toolbox) (Mathematica
/* sansu1.c */ #include <stdio.h> main() { int a, b, c; /* a, b, c */ a = 200; b = 1300; /* a 200 */ /* b 200 */ c = a + b; /* a b c */ }
 { int a, b, c; /* a, b, c */ a = 200; b = 1300; /* a 200 */ /* b 200 */ c = a + b; /* a b c */ }") C 2: A Pedestrian Approach to the C Programming Language 2 2-1 2.1........................... 2-1 2.1.1.............................. 2-1 2.1.2......... 2-4 2.1.3..................................... 2-6
C 2: A Pedestrian Approach to the C Programming Language 2 2-1 2.1........................... 2-1 2.1.1.............................. 2-1 2.1.2......... 2-4 2.1.3..................................... 2-6
AutoTuned-RB
 ABCLib Working Notes No.10 AutoTuned-RB Version 1.00 AutoTuned-RB AutoTuned-RB RB_DGEMM RB_DGEMM ( TransA, TransB, M, N, K, a, A, lda, B, ldb, b, C, ldc ) L3BLAS DGEMM (C a Trans(A) Trans(B) b C) (1) TransA:
ABCLib Working Notes No.10 AutoTuned-RB Version 1.00 AutoTuned-RB AutoTuned-RB RB_DGEMM RB_DGEMM ( TransA, TransB, M, N, K, a, A, lda, B, ldb, b, C, ldc ) L3BLAS DGEMM (C a Trans(A) Trans(B) b C) (1) TransA:
[1] #include<stdio.h> main() { printf("hello, world."); return 0; } (G1) int long int float ± ±
![[1] #include<stdio.h> main() { printf(hello, world.); return 0; } (G1) int long int float ± ±](/thumbs/99/143405735.jpg "[1] #include<stdio.h> main() { printf(hello, world.); return 0; } (G1) int long int float ± ±") [1] #include printf("hello, world."); (G1) int -32768 32767 long int -2147483648 2147483647 float ±3.4 10 38 ±3.4 10 38 double ±1.7 10 308 ±1.7 10 308 char [2] #include int a, b, c, d,
[1] #include printf("hello, world."); (G1) int -32768 32767 long int -2147483648 2147483647 float ±3.4 10 38 ±3.4 10 38 double ±1.7 10 308 ±1.7 10 308 char [2] #include int a, b, c, d,
PowerPoint プレゼンテーション
 応用数理概論 準備 端末上で cd ~/ mkdir cppwork cd cppwork wget http://271.jp/gairon/main.cpp wget http://271.jp/gairon/matrix.hpp とコマンドを記入. ls とコマンドをうち,main.cppとmatrix.hppがダウンロードされていることを確認. 1 準備 コンパイル c++ -I. -std=c++0x
応用数理概論 準備 端末上で cd ~/ mkdir cppwork cd cppwork wget http://271.jp/gairon/main.cpp wget http://271.jp/gairon/matrix.hpp とコマンドを記入. ls とコマンドをうち,main.cppとmatrix.hppがダウンロードされていることを確認. 1 準備 コンパイル c++ -I. -std=c++0x
A11 (1993,1994) 29 A12 (1994) 29 A13 Trefethen and Bau Numerical Linear Algebra (1997) 29 A14 (1999) 30 A15 (2003) 30 A16 (2004) 30 A17 (2007) 30 A18
 29 A12 (1994) 29 A13 Trefethen and Bau Numerical Linear Algebra (1997) 29 A14 (1999) 30 A15 (2003) 30 A16 (2004) 30 A17 (2007) 30 A18") 2013 8 29y, 2016 10 29 1 2 2 Jordan 3 21 3 3 Jordan (1) 3 31 Jordan 4 32 Jordan 4 33 Jordan 6 34 Jordan 8 35 9 4 Jordan (2) 10 41 x 11 42 x 12 43 16 44 19 441 19 442 20 443 25 45 25 5 Jordan 26 A 26 A1
2013 8 29y, 2016 10 29 1 2 2 Jordan 3 21 3 3 Jordan (1) 3 31 Jordan 4 32 Jordan 4 33 Jordan 6 34 Jordan 8 35 9 4 Jordan (2) 10 41 x 11 42 x 12 43 16 44 19 441 19 442 20 443 25 45 25 5 Jordan 26 A 26 A1
2008 ( 13 ) C LAPACK 2008 ( 13 )C LAPACK p. 1
 C LAPACK 2008 ( 13 )C LAPACK p. 1") 2008 ( 13 ) C LAPACK LAPACK p. 1 Q & A Euler http://phase.hpcc.jp/phase/mppack/long.pdf KNOPPIX MT (Mersenne Twister) SFMT., ( ) ( ) ( ) ( ). LAPACK p. 2 C C, main Asir ( Asir ) ( ) (,,...), LAPACK p.
2008 ( 13 ) C LAPACK LAPACK p. 1 Q & A Euler http://phase.hpcc.jp/phase/mppack/long.pdf KNOPPIX MT (Mersenne Twister) SFMT., ( ) ( ) ( ) ( ). LAPACK p. 2 C C, main Asir ( Asir ) ( ) (,,...), LAPACK p.
comment.dvi
 ( ) (sample1.c) (sample1.c) 2 2 Nearest Neighbor 1 (2D-class1.dat) 2 (2D-class2.dat) (2D-test.dat) 3 Nearest Neighbor Nearest Neighbor ( 1) 2 1: NN 1 (sample1.c) /* -----------------------------------------------------------------
( ) (sample1.c) (sample1.c) 2 2 Nearest Neighbor 1 (2D-class1.dat) 2 (2D-class2.dat) (2D-test.dat) 3 Nearest Neighbor Nearest Neighbor ( 1) 2 1: NN 1 (sample1.c) /* -----------------------------------------------------------------
C による数値計算法入門 ( 第 2 版 ) 新装版 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. このサンプルページの内容は, 新装版 1 刷発行時のものです.
 新装版 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. このサンプルページの内容は, 新装版 1 刷発行時のものです.") C による数値計算法入門 ( 第 2 版 ) 新装版 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. http://www.morikita.co.jp/books/mid/009383 このサンプルページの内容は, 新装版 1 刷発行時のものです. i 2 22 2 13 ( ) 2 (1) ANSI (2) 2 (3) Web http://www.morikita.co.jp/books/mid/009383
C による数値計算法入門 ( 第 2 版 ) 新装版 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. http://www.morikita.co.jp/books/mid/009383 このサンプルページの内容は, 新装版 1 刷発行時のものです. i 2 22 2 13 ( ) 2 (1) ANSI (2) 2 (3) Web http://www.morikita.co.jp/books/mid/009383
supercomputer2010.ppt
 nanri@cc.kyushu-u.ac.jp 1 !! : 11 12! : nanri@cc.kyushu-u.ac.jp! : Word 2 ! PC GPU) 1997 7 http://wiredvision.jp/news/200806/2008062322.html 3 !! (Cell, GPU )! 4 ! etc...! 5 !! etc. 6 !! 20km 40 km ) 340km
nanri@cc.kyushu-u.ac.jp 1 !! : 11 12! : nanri@cc.kyushu-u.ac.jp! : Word 2 ! PC GPU) 1997 7 http://wiredvision.jp/news/200806/2008062322.html 3 !! (Cell, GPU )! 4 ! etc...! 5 !! etc. 6 !! 20km 40 km ) 340km
1 OpenCL OpenCL 1 OpenCL GPU ( ) 1 OpenCL Compute Units Elements OpenCL OpenCL SPMD (Single-Program, Multiple-Data) SPMD OpenCL work-item work-group N
 1 OpenCL Compute Units Elements OpenCL OpenCL SPMD (Single-Program, Multiple-Data) SPMD OpenCL work-item work-group N") GPU 1 1 2 1, 3 2, 3 (Graphics Unit: GPU) GPU GPU GPU Evaluation of GPU Computing Based on An Automatic Program Generation Technology Makoto Sugawara, 1 Katsuto Sato, 1 Kazuhiko Komatsu, 2 Hiroyuki Takizawa
GPU 1 1 2 1, 3 2, 3 (Graphics Unit: GPU) GPU GPU GPU Evaluation of GPU Computing Based on An Automatic Program Generation Technology Makoto Sugawara, 1 Katsuto Sato, 1 Kazuhiko Komatsu, 2 Hiroyuki Takizawa
ex12.dvi
 1 0. C, char., char, 0,. C, ("),., char str[]="abc" ; str abc.,, str 4. str 3. char str[10]="abc" ;, str 10, str 3., char s[]="abc", t[10] ;, t = s. ASCII, 0x00 0x7F, char., "abc" 3, 1. 1 8 256, 2., 2
1 0. C, char., char, 0,. C, ("),., char str[]="abc" ; str abc.,, str 4. str 3. char str[10]="abc" ;, str 10, str 3., char s[]="abc", t[10] ;, t = s. ASCII, 0x00 0x7F, char., "abc" 3, 1. 1 8 256, 2., 2
/* do-while */ #include <stdio.h> #include <math.h> int main(void) double val1, val2, arith_mean, geo_mean; printf( \n ); do printf( ); scanf( %lf, &v
 double val1, val2, arith_mean, geo_mean; printf( \n ); do printf( ); scanf( %lf, &v") 1 http://www7.bpe.es.osaka-u.ac.jp/~kota/classes/jse.html kota@fbs.osaka-u.ac.jp /* do-while */ #include #include int main(void) double val1, val2, arith_mean, geo_mean; printf( \n );
1 http://www7.bpe.es.osaka-u.ac.jp/~kota/classes/jse.html kota@fbs.osaka-u.ac.jp /* do-while */ #include #include int main(void) double val1, val2, arith_mean, geo_mean; printf( \n );
 ARM gcc Kunihiko IMAI 2009 1 11 ARM gcc 1 2 2 2 3 3 4 3 4.1................................. 3 4.2............................................ 4 4.3........................................
ARM gcc Kunihiko IMAI 2009 1 11 ARM gcc 1 2 2 2 3 3 4 3 4.1................................. 3 4.2............................................ 4 4.3........................................
漸化式のすべてのパターンを解説しましたー高校数学の達人・河見賢司のサイト
 https://www.hmg-gen.com/tuusin.html https://www.hmg-gen.com/tuusin1.html 1 2 OK 3 4 {a n } (1) a 1 = 1, a n+1 a n = 2 (2) a 1 = 3, a n+1 a n = 2n a n a n+1 a n = ( ) a n+1 a n = ( ) a n+1 a n {a n } 1,
https://www.hmg-gen.com/tuusin.html https://www.hmg-gen.com/tuusin1.html 1 2 OK 3 4 {a n } (1) a 1 = 1, a n+1 a n = 2 (2) a 1 = 3, a n+1 a n = 2n a n a n+1 a n = ( ) a n+1 a n = ( ) a n+1 a n {a n } 1,
ストリーミング SIMD 拡張命令2 (SSE2) を使用した SAXPY/DAXPY
 を使用した SAXPY/DAXPY") SIMD 2(SSE2) SAXPY/DAXPY 2.0 2000 7 : 248600J-001 01/12/06 1 305-8603 115 Fax: 0120-47-8832 * Copyright Intel Corporation 1999, 2000 01/12/06 2 1...5 2 SAXPY DAXPY...5 2.1 SAXPY DAXPY...6 2.1.1 SIMD C++...6
SIMD 2(SSE2) SAXPY/DAXPY 2.0 2000 7 : 248600J-001 01/12/06 1 305-8603 115 Fax: 0120-47-8832 * Copyright Intel Corporation 1999, 2000 01/12/06 2 1...5 2 SAXPY DAXPY...5 2.1 SAXPY DAXPY...6 2.1.1 SIMD C++...6
bash on Ubuntu on Windows bash on Ubuntu on Windows bash on Ubuntu on Windows bash on Ubuntu on Windows bash on Ubuntu on Windows ˆ Windows10 64bit Wi
 Windows bash on Ubuntu on Windows [Windows Creators Update(1703) ] TAKE 2017-10-06 bash on Ubuntu on Windows bash on Ubuntu on Windows bash on Ubuntu on Windows bash on Ubuntu on Windows bash on Ubuntu
Windows bash on Ubuntu on Windows [Windows Creators Update(1703) ] TAKE 2017-10-06 bash on Ubuntu on Windows bash on Ubuntu on Windows bash on Ubuntu on Windows bash on Ubuntu on Windows bash on Ubuntu
インテル(R) Visual Fortran Composer XE
 Visual Fortran Composer XE") Visual Fortran Composer XE 1. 2. 3. 4. 5. Visual Studio 6. Visual Studio 7. 8. Compaq Visual Fortran 9. Visual Studio 10. 2 https://registrationcenter.intel.com/regcenter/ w_fcompxe_all_jp_2013_sp1.1.139.exe
Visual Fortran Composer XE 1. 2. 3. 4. 5. Visual Studio 6. Visual Studio 7. 8. Compaq Visual Fortran 9. Visual Studio 10. 2 https://registrationcenter.intel.com/regcenter/ w_fcompxe_all_jp_2013_sp1.1.139.exe
‚æ4›ñ
 ( ) ( ) ( ) A B C D E F G H I J K L M N O P Q R S T U V W X Y Z a b c d e f g h i j k l m n o p q r s t u v w x y z 0 1 2 3 4 5 6 7 8 9 (OUS) 9 26 1 / 28 ( ) ( ) ( ) A B C D Z a b c d z 0 1 2 9 (OUS) 9
( ) ( ) ( ) A B C D E F G H I J K L M N O P Q R S T U V W X Y Z a b c d e f g h i j k l m n o p q r s t u v w x y z 0 1 2 3 4 5 6 7 8 9 (OUS) 9 26 1 / 28 ( ) ( ) ( ) A B C D Z a b c d z 0 1 2 9 (OUS) 9
XMPによる並列化実装2
 2 3 C Fortran Exercise 1 Exercise 2 Serial init.c init.f90 XMP xmp_init.c xmp_init.f90 Serial laplace.c laplace.f90 XMP xmp_laplace.c xmp_laplace.f90 #include int a[10]; program init integer
2 3 C Fortran Exercise 1 Exercise 2 Serial init.c init.f90 XMP xmp_init.c xmp_init.f90 Serial laplace.c laplace.f90 XMP xmp_laplace.c xmp_laplace.f90 #include int a[10]; program init integer
0530cmsi教育計算科学技術特論a_中田真秀 (nakata maho's conflicted copy) (6)
 (6)") 線形代数演算ライブラリBLAS とLAPACKの基礎と実践 (II) BLAS, LAPACK実践編 中田 真秀 理化学研究所 情報システム本部 2019/5/30 計算科学技術特論A 13:00 BLAS, LAPACK実践編 講義内容 コンピュータの簡単な仕組みとボトルネック フォン ノイマン型コンピュータ フォン ノイマンボトルネック 演算バンド幅のトレンド メモリバンド幅のトレンド 演算バンド幅の理論性能
線形代数演算ライブラリBLAS とLAPACKの基礎と実践 (II) BLAS, LAPACK実践編 中田 真秀 理化学研究所 情報システム本部 2019/5/30 計算科学技術特論A 13:00 BLAS, LAPACK実践編 講義内容 コンピュータの簡単な仕組みとボトルネック フォン ノイマン型コンピュータ フォン ノイマンボトルネック 演算バンド幅のトレンド メモリバンド幅のトレンド 演算バンド幅の理論性能
07-二村幸孝・出口大輔.indd
 GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
GPU Graphics Processing Units HPC High Performance Computing GPU GPGPU General-Purpose computation on GPU CPU GPU GPU *1 Intel Quad-Core Xeon E5472 3.0 GHz 2 6 MB L2 cache 1600 MHz FSB 80 GFlops 1 nvidia
Microsoft Word - C.....u.K...doc
 C uwêííôöðöõ Ð C ÔÖÐÖÕ ÐÊÉÌÊ C ÔÖÐÖÕÊ C ÔÖÐÖÕÊ Ç Ê Æ ~ if eíè ~ for ÒÑÒ ÌÆÊÉÉÊ ~ switch ÉeÍÈ ~ while ÒÑÒ ÊÍÍÔÖÐÖÕÊ ~ 1 C ÔÖÐÖÕ ÐÊÉÌÊ uê~ ÏÒÏÑ Ð ÓÏÖ CUI Ô ÑÊ ÏÒÏÑ ÔÖÐÖÕÎ d ÈÍÉÇÊ ÆÒ Ö ÒÐÑÒ ÊÔÎÏÖÎ d ÉÇÍÊ
C uwêííôöðöõ Ð C ÔÖÐÖÕ ÐÊÉÌÊ C ÔÖÐÖÕÊ C ÔÖÐÖÕÊ Ç Ê Æ ~ if eíè ~ for ÒÑÒ ÌÆÊÉÉÊ ~ switch ÉeÍÈ ~ while ÒÑÒ ÊÍÍÔÖÐÖÕÊ ~ 1 C ÔÖÐÖÕ ÐÊÉÌÊ uê~ ÏÒÏÑ Ð ÓÏÖ CUI Ô ÑÊ ÏÒÏÑ ÔÖÐÖÕÎ d ÈÍÉÇÊ ÆÒ Ö ÒÐÑÒ ÊÔÎÏÖÎ d ÉÇÍÊ
kiso2-09.key
 座席指定はありません 計算機基礎実習II 2018 のウェブページか 第9回 ら 以下の課題に自力で取り組んで下さい 計算機基礎実習II 第7回の復習課題(rev07) 第9回の基本課題(base09) 第8回試験の結果 中間試験に関するコメント コンパイルできない不完全なプログラムなど プログラミングに慣れていない あるいは複雑な問題は 要件 をバラして段階的にプログラムを作成する exam08-2.c
座席指定はありません 計算機基礎実習II 2018 のウェブページか 第9回 ら 以下の課題に自力で取り組んで下さい 計算機基礎実習II 第7回の復習課題(rev07) 第9回の基本課題(base09) 第8回試験の結果 中間試験に関するコメント コンパイルできない不完全なプログラムなど プログラミングに慣れていない あるいは複雑な問題は 要件 をバラして段階的にプログラムを作成する exam08-2.c
Informatics 2014
 C 計算機の歴史 手回し計算機 新旧のソロバン バベッジの階差機関 スパコン ENIAC (1946) パソコン 大型汎用計算機 電卓 現在のコンピュータ Input Output Device Central Processing Unit I/O CPU Memory OS (Operating System) OS Windows 78, Vista, XP Windows Mac OS X
C 計算機の歴史 手回し計算機 新旧のソロバン バベッジの階差機関 スパコン ENIAC (1946) パソコン 大型汎用計算機 電卓 現在のコンピュータ Input Output Device Central Processing Unit I/O CPU Memory OS (Operating System) OS Windows 78, Vista, XP Windows Mac OS X
(Basic Theory of Information Processing) 1
 1") (Basic Theory of Information Processing) 1 10 (p.178) Java a[0] = 1; 1 a[4] = 7; i = 2; j = 8; a[i] = j; b[0][0] = 1; 2 b[2][3] = 10; b[i][j] = a[2] * 3; x = a[2]; a[2] = b[i][3] * x; 2 public class Array0
(Basic Theory of Information Processing) 1 10 (p.178) Java a[0] = 1; 1 a[4] = 7; i = 2; j = 8; a[i] = j; b[0][0] = 1; 2 b[2][3] = 10; b[i][j] = a[2] * 3; x = a[2]; a[2] = b[i][3] * x; 2 public class Array0
2 2.1 Mac OS CPU Mac OS tar zxf zpares_0.9.6.tar.gz cd zpares_0.9.6 Mac Makefile Mekefile.inc cp Makefile.inc/make.inc.gfortran.seq.macosx make
 Sakurai-Sugiura z-pares 26 9 5 1 1 2 2 2.1 Mac OS CPU......................................... 2 2.2 Linux MPI............................................ 2 3 3 4 6 4.1 MUMPS....................................
Sakurai-Sugiura z-pares 26 9 5 1 1 2 2 2.1 Mac OS CPU......................................... 2 2.2 Linux MPI............................................ 2 3 3 4 6 4.1 MUMPS....................................
1 1.1 C 2 1 double a[ ][ ]; 1 3x x3 ( ) malloc() 2 double *a[ ]; double 1 malloc() dou
![1 1.1 C 2 1 double a[ ][ ]; 1 3x x3 ( ) malloc() 2 double *a[ ]; double 1 malloc() dou](/thumbs/98/138757599.jpg "1 1.1 C 2 1 double a[ ][ ]; 1 3x x3 ( ) malloc() 2 double *a[ ]; double 1 malloc() dou") 1 1.1 C 2 1 double a[ ][ ]; 1 3x3 0 1 3x3 ( ) 0.240 0.143 0.339 0.191 0.341 0.477 0.412 0.003 0.921 1.2 malloc() 2 double *a[ ]; double 1 malloc() double 1 malloc() free() 3 #include #include
1 1.1 C 2 1 double a[ ][ ]; 1 3x3 0 1 3x3 ( ) 0.240 0.143 0.339 0.191 0.341 0.477 0.412 0.003 0.921 1.2 malloc() 2 double *a[ ]; double 1 malloc() double 1 malloc() free() 3 #include #include
並列計算の数理とアルゴリズム サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. このサンプルページの内容は, 初版 1 刷発行時のものです.
 並列計算の数理とアルゴリズム サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. http://www.morikita.co.jp/books/mid/080711 このサンプルページの内容は, 初版 1 刷発行時のものです. Calcul scientifique parallèle by Frédéric Magoulès and François-Xavier
並列計算の数理とアルゴリズム サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. http://www.morikita.co.jp/books/mid/080711 このサンプルページの内容は, 初版 1 刷発行時のものです. Calcul scientifique parallèle by Frédéric Magoulès and François-Xavier
KBLAS[7] *1., CUBLAS.,,, Byte/flop., [13] 1 2. (AT). GPU AT,, GPU SYMV., SYMV CUDABLAS., (double, float) (cu- FloatComplex, cudoublecomplex).,, DD(dou
![KBLAS[7] *1., CUBLAS.,,, Byte/flop., [13] 1 2. (AT). GPU AT,, GPU SYMV., SYMV CUDABLAS., (double, float) (cu- FloatComplex, cudoublecomplex).,, DD(dou](/thumbs/71/64446865.jpg "KBLAS[7] *1., CUBLAS.,,, Byte/flop., [13] 1 2. (AT). GPU AT,, GPU SYMV., SYMV CUDABLAS., (double, float) (cu- FloatComplex, cudoublecomplex).,, DD(dou") Vol.214-HPC-146 No.14 214/1/3 CUDA-xSYMV 1,3,a) 1 2,3 2,3 (SYMV)., (GEMV) 2.,, mutex., CUBLAS., 1 2,. (AT). 2, SYMV GPU., SSYMV( SYMV), GeForce GTXTitan Black 211GFLOPS( 62.8%)., ( ) (, ) DD(double-double),
Vol.214-HPC-146 No.14 214/1/3 CUDA-xSYMV 1,3,a) 1 2,3 2,3 (SYMV)., (GEMV) 2.,, mutex., CUBLAS., 1 2,. (AT). 2, SYMV GPU., SSYMV( SYMV), GeForce GTXTitan Black 211GFLOPS( 62.8%)., ( ) (, ) DD(double-double),
1 1.1 C 2 1 double a[ ][ ]; 1 3x x3 ( ) malloc() malloc 2 #include <stdio.h> #include
![1 1.1 C 2 1 double a[ ][ ]; 1 3x x3 ( ) malloc() malloc 2 #include <stdio.h> #include](/thumbs/98/138365120.jpg "1 1.1 C 2 1 double a[ ][ ]; 1 3x x3 ( ) malloc() malloc 2 #include <stdio.h> #include") 1 1.1 C 2 1 double a[ ][ ]; 1 3x3 0 1 3x3 ( ) 0.240 0.143 0.339 0.191 0.341 0.477 0.412 0.003 0.921 1.2 malloc() malloc 2 #include #include #include enum LENGTH = 10 ; int
1 1.1 C 2 1 double a[ ][ ]; 1 3x3 0 1 3x3 ( ) 0.240 0.143 0.339 0.191 0.341 0.477 0.412 0.003 0.921 1.2 malloc() malloc 2 #include #include #include enum LENGTH = 10 ; int
2 1. Ubuntu 1.1 OS OS OS ( OS ) OS ( OS ) VMware Player VMware Player jp/download/player/ URL VMware Plaeyr VMware
 OS ( OS ) VMware Player VMware Player jp/download/player/ URL VMware Plaeyr VMware") 1 2010 k-okada@jsk.t.u-tokyo.ac.jp http://www.jsk.t.u-tokyo.ac.jp/~k-okada/lecture/ 2010 4 5 Linux 1 Ubuntu Ubuntu Linux 1 Ubuntu Ubuntu 3 1. 1 Ubuntu 2. OS Ubuntu OS 3. OS Ubuntu https://wiki.ubuntulinux.jp/ubuntutips/install/installdualboot
1 2010 k-okada@jsk.t.u-tokyo.ac.jp http://www.jsk.t.u-tokyo.ac.jp/~k-okada/lecture/ 2010 4 5 Linux 1 Ubuntu Ubuntu Linux 1 Ubuntu Ubuntu 3 1. 1 Ubuntu 2. OS Ubuntu OS 3. OS Ubuntu https://wiki.ubuntulinux.jp/ubuntutips/install/installdualboot
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日
 TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
TSUBAME2.0 における GPU の 活用方法 東京工業大学学術国際情報センター丸山直也第 10 回 GPU コンピューティング講習会 2011 年 9 月 28 日 目次 1. TSUBAMEのGPU 環境 2. プログラム作成 3. プログラム実行 4. 性能解析 デバッグ サンプルコードは /work0/gsic/seminars/gpu- 2011-09- 28 からコピー可能です 1.
C 2 / 21 1 y = x 1.1 lagrange.c 1 / Laglange / 2 #include <stdio.h> 3 #include <math.h> 4 int main() 5 { 6 float x[10], y[10]; 7 float xx, pn, p; 8 in
![C 2 / 21 1 y = x 1.1 lagrange.c 1 / Laglange / 2 #include <stdio.h> 3 #include <math.h> 4 int main() 5 { 6 float x[10], y[10]; 7 float xx, pn, p; 8 in](/thumbs/88/114913715.jpg "C 2 / 21 1 y = x 1.1 lagrange.c 1 / Laglange / 2 #include <stdio.h> 3 #include <math.h> 4 int main() 5 { 6 float x[10], y[10]; 7 float xx, pn, p; 8 in") C 1 / 21 C 2005 A * 1 2 1.1......................................... 2 1.2 *.......................................... 3 2 4 2.1.............................................. 4 2.2..............................................
C 1 / 21 C 2005 A * 1 2 1.1......................................... 2 1.2 *.......................................... 3 2 4 2.1.............................................. 4 2.2..............................................
(Version: 2017/4/18) Intel CPU 1 Intel CPU( AMD CPU) 64bit SIMD Inline Assemler Windows Visual C++ Linux gcc 2 FPU SSE2 Intel CPU do
 Intel CPU 1 Intel CPU( AMD CPU) 64bit SIMD Inline Assemler Windows Visual C++ Linux gcc 2 FPU SSE2 Intel CPU do") (Version: 2017/4/18) Intel CPU (kashi@waseda.jp) 1 Intel CPU( AMD CPU) 64bit SIMD Inline Assemler Windows Visual C++ Linux gcc 2 FPU SSE2 Intel CPU double 8087 FPU (floating point number processing unit)
(Version: 2017/4/18) Intel CPU (kashi@waseda.jp) 1 Intel CPU( AMD CPU) 64bit SIMD Inline Assemler Windows Visual C++ Linux gcc 2 FPU SSE2 Intel CPU double 8087 FPU (floating point number processing unit)
joho09.ppt
 s M B e E s: (+ or -) M: B: (=2) e: E: ax 2 + bx + c = 0 y = ax 2 + bx + c x a, b y +/- [a, b] a, b y (a+b) / 2 1-2 1-3 x 1 A a, b y 1. 2. a, b 3. for Loop (b-a)/ 4. y=a*x*x + b*x + c 5. y==0.0 y (y2)
s M B e E s: (+ or -) M: B: (=2) e: E: ax 2 + bx + c = 0 y = ax 2 + bx + c x a, b y +/- [a, b] a, b y (a+b) / 2 1-2 1-3 x 1 A a, b y 1. 2. a, b 3. for Loop (b-a)/ 4. y=a*x*x + b*x + c 5. y==0.0 y (y2)
. a, b, c, d b a ± d bc ± ad = c ac b a d c = bd ac b a d c = bc ad n m nm [2][3] BASIC [4] B BASIC [5] BASIC Intel x * IEEE a e d
![. a, b, c, d b a ± d bc ± ad = c ac b a d c = bd ac b a d c = bc ad n m nm [2][3] BASIC [4] B BASIC [5] BASIC Intel x * IEEE a e d](/thumbs/84/90471282.jpg ". a, b, c, d b a ± d bc ± ad = c ac b a d c = bd ac b a d c = bc ad n m nm [2][3] BASIC [4] B BASIC [5] BASIC Intel x * IEEE a e d") 3 3 BASIC C++ 8 Tflop/s 8TB [] High precision symmetric eigenvalue computation through exact tridiagonalization by using rational number arithmetic Hikaru Samukawa Abstract: Since rational number arithmetic,
3 3 BASIC C++ 8 Tflop/s 8TB [] High precision symmetric eigenvalue computation through exact tridiagonalization by using rational number arithmetic Hikaru Samukawa Abstract: Since rational number arithmetic,
untitled
 II yacc 005 : 1, 1 1 1 %{ int lineno=0; 3 int wordno=0; 4 int charno=0; 5 6 %} 7 8 %% 9 [ \t]+ { charno+=strlen(yytext); } 10 "\n" { lineno++; charno++; } 11 [^ \t\n]+ { wordno++; charno+=strlen(yytext);}
II yacc 005 : 1, 1 1 1 %{ int lineno=0; 3 int wordno=0; 4 int charno=0; 5 6 %} 7 8 %% 9 [ \t]+ { charno+=strlen(yytext); } 10 "\n" { lineno++; charno++; } 11 [^ \t\n]+ { wordno++; charno+=strlen(yytext);}
 1 5 13 4 1 41 1 411 1 412 2 413 3 414 3 415 4 42 6 43 LU 7 431 LU 10 432 11 433 LU 11 44 12 441 13 442 13 443 SOR ( ) 14 444 14 445 15 446 16 447 SOR 16 448 16 45 17 4 41 n x 1,, x n a 11 x 1 + a 1n x
1 5 13 4 1 41 1 411 1 412 2 413 3 414 3 415 4 42 6 43 LU 7 431 LU 10 432 11 433 LU 11 44 12 441 13 442 13 443 SOR ( ) 14 444 14 445 15 446 16 447 SOR 16 448 16 45 17 4 41 n x 1,, x n a 11 x 1 + a 1n x
ex01.dvi
 ,. 0. 0.0. C () /******************************* * $Id: ex_0_0.c,v.2 2006-04-0 3:37:00+09 naito Exp $ * * 0. 0.0 *******************************/ #include int main(int argc, char **argv) { double
,. 0. 0.0. C () /******************************* * $Id: ex_0_0.c,v.2 2006-04-0 3:37:00+09 naito Exp $ * * 0. 0.0 *******************************/ #include int main(int argc, char **argv) { double
ex01.dvi
 ,. 0. 0.0. C () /******************************* * $Id: ex_0_0.c,v.2 2006-04-0 3:37:00+09 naito Exp $ * * 0. 0.0 *******************************/ #include int main(int argc, char **argv) double
,. 0. 0.0. C () /******************************* * $Id: ex_0_0.c,v.2 2006-04-0 3:37:00+09 naito Exp $ * * 0. 0.0 *******************************/ #include int main(int argc, char **argv) double
QR
 1 7 16 13 1 13.1 QR...................................... 2 13.1.1............................................ 2 13.1.2..................................... 3 13.1.3 QR........................................
1 7 16 13 1 13.1 QR...................................... 2 13.1.1............................................ 2 13.1.2..................................... 3 13.1.3 QR........................................
64bit SSE2 SSE2 FPU Visual C++ 64bit Inline Assembler 4 FPU SSE2 4.1 FPU Control Word FPU 16bit R R R IC RC(2) PC(2) R R PM UM OM ZM DM IM R: reserved
 PC(2) R R PM UM OM ZM DM IM R: reserved") (Version: 2013/5/16) Intel CPU (kashi@waseda.jp) 1 Intel CPU( AMD CPU) 64bit SIMD Inline Assemler Windows Visual C++ Linux gcc 2 FPU SSE2 Intel CPU double 8087 FPU (floating point number processing unit)
(Version: 2013/5/16) Intel CPU (kashi@waseda.jp) 1 Intel CPU( AMD CPU) 64bit SIMD Inline Assemler Windows Visual C++ Linux gcc 2 FPU SSE2 Intel CPU double 8087 FPU (floating point number processing unit)
GPU n Graphics Processing Unit CG CAD
 GPU 2016/06/27 第 20 回 GPU コンピューティング講習会 ( 東京工業大学 ) 1 GPU n Graphics Processing Unit CG CAD www.nvidia.co.jp www.autodesk.co.jp www.pixar.com GPU n GPU ü n NVIDIA CUDA ü NVIDIA GPU ü OS Linux, Windows, Mac
GPU 2016/06/27 第 20 回 GPU コンピューティング講習会 ( 東京工業大学 ) 1 GPU n Graphics Processing Unit CG CAD www.nvidia.co.jp www.autodesk.co.jp www.pixar.com GPU n GPU ü n NVIDIA CUDA ü NVIDIA GPU ü OS Linux, Windows, Mac
Microsoft Word - HOKUSAI_system_overview_ja.docx
 HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
HOKUSAI システムの概要 1.1 システム構成 HOKUSAI システムは 超並列演算システム (GWMPC BWMPC) アプリケーション演算サーバ群 ( 大容量メモリ演算サーバ GPU 演算サーバ ) と システムの利用入口となるフロントエンドサーバ 用途の異なる 2 つのストレージ ( オンライン ストレージ 階層型ストレージ ) から構成されるシステムです 図 0-1 システム構成図
Informatics 2015
 C 計算機の歴史 新旧のソロバン バベッジの階差機関 19C前半 手回し計算機 19C後半 20C後半 スパコン 1960年代 ENIAC (1946) 大型汎用計算機 1950年代 1980年代 電卓 1964 パソコン 1970年代 現在のコンピュータ Input Output Device Central Processing Unit I/O CPU Memory OS (Operating
C 計算機の歴史 新旧のソロバン バベッジの階差機関 19C前半 手回し計算機 19C後半 20C後半 スパコン 1960年代 ENIAC (1946) 大型汎用計算機 1950年代 1980年代 電卓 1964 パソコン 1970年代 現在のコンピュータ Input Output Device Central Processing Unit I/O CPU Memory OS (Operating
GPU GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1
 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1") GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
GPU 4 2010 8 28 1 GPU CPU CPU CPU GPU GPU N N CPU ( ) 1 GPU CPU GPU 2D 3D CPU GPU GPU GPGPU GPGPU 2 nvidia GPU CUDA 3 GPU 3.1 GPU Core 1 Register & Shared Memory ( ) CPU CPU(Intel Core i7 965) GPU(Tesla
( CUDA CUDA CUDA CUDA ( NVIDIA CUDA I
 GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
GPGPU (II) GPGPU CUDA 1 GPGPU CUDA(CUDA Unified Device Architecture) CUDA NVIDIA GPU *1 C/C++ (nvcc) CUDA NVIDIA GPU GPU CUDA CUDA 1 CUDA CUDA 2 CUDA NVIDIA GPU PC Windows Linux MaxOSX CUDA GPU CUDA NVIDIA
(2 Linux Mozilla [ ] [ ] [ ] [ ] URL 2 qkc, nkc ~/.cshrc (emacs 2 set path=($path /usr/meiji/pub/linux/bin tcsh b
![(2 Linux Mozilla [ ] [ ] [ ] [ ] URL 2 qkc, nkc ~/.cshrc (emacs 2 set path=($path /usr/meiji/pub/linux/bin tcsh b](/thumbs/92/108952818.jpg "(2 Linux Mozilla [ ] [ ] [ ] [ ] URL 2 qkc, nkc ~/.cshrc (emacs 2 set path=($path /usr/meiji/pub/linux/bin tcsh b") II 5 (1 2005 5 26 http://www.math.meiji.ac.jp/~mk/syori2-2005/ UNIX (Linux Linux 1 : 2005 http://www.math.meiji.ac.jp/~mk/syori2-2005/jouhousyori2-2005-00/node2. html ( (Linux 1 2 ( ( http://www.meiji.ac.jp/mind/tool/internet-license/
II 5 (1 2005 5 26 http://www.math.meiji.ac.jp/~mk/syori2-2005/ UNIX (Linux Linux 1 : 2005 http://www.math.meiji.ac.jp/~mk/syori2-2005/jouhousyori2-2005-00/node2. html ( (Linux 1 2 ( ( http://www.meiji.ac.jp/mind/tool/internet-license/
numb.dvi
 11 Poisson kanenko@mbkniftycom alexeikanenko@docomonejp http://wwwkanenkocom/ , u = f, ( u = u+f u t, u = f t ) 1 D R 2 L 2 (D) := {f(x,y) f(x,y) 2 dxdy < )} D D f,g L 2 (D) (f,g) := f(x,y)g(x,y)dxdy (L
11 Poisson kanenko@mbkniftycom alexeikanenko@docomonejp http://wwwkanenkocom/ , u = f, ( u = u+f u t, u = f t ) 1 D R 2 L 2 (D) := {f(x,y) f(x,y) 2 dxdy < )} D D f,g L 2 (D) (f,g) := f(x,y)g(x,y)dxdy (L
Informatics 2010.key
 http://math.sci.hiroshima-u.ac.jp/ ~ryo/lectures/informatics2010/ 1 2 C ATM etc. etc. (Personal Computer) 3 4 Input Output Device Central Processing Unit I/O CPU Memory 5 6 (CPU),,... etc. C, Java, Fortran...
http://math.sci.hiroshima-u.ac.jp/ ~ryo/lectures/informatics2010/ 1 2 C ATM etc. etc. (Personal Computer) 3 4 Input Output Device Central Processing Unit I/O CPU Memory 5 6 (CPU),,... etc. C, Java, Fortran...
Microsoft Word - Sample_CQS-Report_English_backslant.doc
 ***** Corporation ANSI C compiler test system System test report 2005/11/16 Japan Novel Corporation *****V43/NQP-DS-501-1 Contents Contents......2 1. Evaluated compiler......3 1.1. smp-compiler compiler...3
***** Corporation ANSI C compiler test system System test report 2005/11/16 Japan Novel Corporation *****V43/NQP-DS-501-1 Contents Contents......2 1. Evaluated compiler......3 1.1. smp-compiler compiler...3
. UNIX, Linux, KNOPPIX. C,.,., ( 1 ) p. 2
 p. 2") 2009 ( 1 ) 2009 ( 1 ) p. 1 . UNIX, Linux, KNOPPIX. C,.,.,. 2009 ( 1 ) p. 2 , +, ( ), ( ), or PC orange2, knxm2008vm, iyokan-6 KNOPPIX/Math (DVD ) 2009 ( 1 ) p. 3 ,. Mathematica (20-30 /1 ), Maple (20 /1
2009 ( 1 ) 2009 ( 1 ) p. 1 . UNIX, Linux, KNOPPIX. C,.,.,. 2009 ( 1 ) p. 2 , +, ( ), ( ), or PC orange2, knxm2008vm, iyokan-6 KNOPPIX/Math (DVD ) 2009 ( 1 ) p. 3 ,. Mathematica (20-30 /1 ), Maple (20 /1
8 / 0 1 i++ i 1 i-- i C !!! C 2
 C 2006 5 2 printf() 1 [1] 5 8 C 5 ( ) 6 (auto) (static) 7 (=) 1 8 / 0 1 i++ i 1 i-- i 1 2 2.1 C 4 5 3 13!!! C 2 2.2 C ( ) 4 1 HTML はじめ mkdir work 作業用ディレクトリーの作成 emacs hoge.c& エディターによりソースプログラム作成 gcc -o fuga
C 2006 5 2 printf() 1 [1] 5 8 C 5 ( ) 6 (auto) (static) 7 (=) 1 8 / 0 1 i++ i 1 i-- i 1 2 2.1 C 4 5 3 13!!! C 2 2.2 C ( ) 4 1 HTML はじめ mkdir work 作業用ディレクトリーの作成 emacs hoge.c& エディターによりソースプログラム作成 gcc -o fuga
1 4 2 EP) (EP) (EP)
 (EP) (EP)") 2003 2004 2 27 1 1 4 2 EP) 5 3 6 3.1.............................. 6 3.2.............................. 6 3.3 (EP)............... 7 4 8 4.1 (EP).................... 8 4.1.1.................... 18 5 (EP)
2003 2004 2 27 1 1 4 2 EP) 5 3 6 3.1.............................. 6 3.2.............................. 6 3.3 (EP)............... 7 4 8 4.1 (EP).................... 8 4.1.1.................... 18 5 (EP)
 QD library! Feature! Easy to use high precision! Easy to understand the structure of arithmetic! 2 type high precision arithmetic! Double-Double precision (pseudo quadruple precision)! Quad-Double precision
QD library! Feature! Easy to use high precision! Easy to understand the structure of arithmetic! 2 type high precision arithmetic! Double-Double precision (pseudo quadruple precision)! Quad-Double precision
Gauss
 15 1 LU LDL T 6 : 1g00p013-5 1 6 1.1....................................... 7 1.2.................................. 8 1.3.................................. 8 2 Gauss 9 2.1.....................................
15 1 LU LDL T 6 : 1g00p013-5 1 6 1.1....................................... 7 1.2.................................. 8 1.3.................................. 8 2 Gauss 9 2.1.....................................
スパコンに通じる並列プログラミングの基礎
 2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
2018.06.04 2018.06.04 1 / 62 2018.06.04 2 / 62 Windows, Mac Unix 0444-J 2018.06.04 3 / 62 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 2018.06.04 4 / 62 0444-J ( : ) 6 4 ( ) 6 5 * 6 19 SX-ACE * 6
> > <., vs. > x 2 x y = ax 2 + bx + c y = 0 2 ax 2 + bx + c = 0 y = 0 x ( x ) y = ax 2 + bx + c D = b 2 4ac (1) D > 0 x (2) D = 0 x (3
 y = ax 2 + bx + c D = b 2 4ac (1) D > 0 x (2) D = 0 x (3") 13 2 13.0 2 ( ) ( ) 2 13.1 ( ) ax 2 + bx + c > 0 ( a, b, c ) ( ) 275 > > 2 2 13.3 x 2 x y = ax 2 + bx + c y = 0 2 ax 2 + bx + c = 0 y = 0 x ( x ) y = ax 2 + bx + c D = b 2 4ac (1) D >
13 2 13.0 2 ( ) ( ) 2 13.1 ( ) ax 2 + bx + c > 0 ( a, b, c ) ( ) 275 > > 2 2 13.3 x 2 x y = ax 2 + bx + c y = 0 2 ax 2 + bx + c = 0 y = 0 x ( x ) y = ax 2 + bx + c D = b 2 4ac (1) D >
IPSJ SIG Technical Report Vol.2013-HPC-138 No /2/21 GPU CRS 1,a) 2,b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla
 2,b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla") GPU CRS 1,a),b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla K0 CUDA5.0 cusparse CRS SpMV 00 1.86 177 1. SpMV SpMV CRS Compressed Row Storage *1 SpMV GPU GPU NVIDIA Kepler
GPU CRS 1,a),b) SpMV GPU CRS SpMV GPU NVIDIA Kepler CUDA5.0 Fermi GPU Kepler Kepler Tesla K0 CUDA5.0 cusparse CRS SpMV 00 1.86 177 1. SpMV SpMV CRS Compressed Row Storage *1 SpMV GPU GPU NVIDIA Kepler
Second-semi.PDF
 PC 2000 2 18 2 HPC Agenda PC Linux OS UNIX OS Linux Linux OS HPC 1 1CPU CPU Beowulf PC (PC) PC CPU(Pentium ) Beowulf: NASA Tomas Sterling Donald Becker 2 (PC ) Beowulf PC!! Linux Cluster (1) Level 1:
PC 2000 2 18 2 HPC Agenda PC Linux OS UNIX OS Linux Linux OS HPC 1 1CPU CPU Beowulf PC (PC) PC CPU(Pentium ) Beowulf: NASA Tomas Sterling Donald Becker 2 (PC ) Beowulf PC!! Linux Cluster (1) Level 1:
スパコンに通じる並列プログラミングの基礎
 2018.09.10 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 1 / 59 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 2 / 59 Windows, Mac Unix 0444-J furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 3 / 59 Part I Unix GUI CUI:
2018.09.10 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 1 / 59 furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 2 / 59 Windows, Mac Unix 0444-J furihata@cmc.osaka-u.ac.jp ( ) 2018.09.10 3 / 59 Part I Unix GUI CUI:
I ASCII ( ) NUL 16 DLE SP P p 1 SOH 17 DC1! 1 A Q a q STX 2 18 DC2 " 2 B R b
 NUL 16 DLE SP P p 1 SOH 17 DC1! 1 A Q a q STX 2 18 DC2 2 B R b") I 4 003 4 30 1 ASCII ( ) 0 17 0 NUL 16 DLE SP 0 @ P 3 48 64 80 96 11 p 1 SOH 17 DC1! 1 A Q a 33 49 65 81 97 113 q STX 18 DC " B R b 34 50 66 8 98 114 r 3 ETX 19 DC3 # 3 C S c 35 51 67 83 99 115 s 4 EOT
I 4 003 4 30 1 ASCII ( ) 0 17 0 NUL 16 DLE SP 0 @ P 3 48 64 80 96 11 p 1 SOH 17 DC1! 1 A Q a 33 49 65 81 97 113 q STX 18 DC " B R b 34 50 66 8 98 114 r 3 ETX 19 DC3 # 3 C S c 35 51 67 83 99 115 s 4 EOT
電気通信大学 I 類 情報系 情報 ネットワーク工学専攻 CED 2018 システム利用ガイド ver1.2 CED 管理者 学術技師 島崎俊介 教育研究技師部 実験実習支援センター 2018 年 3 月 29 日 1 ログイン ログアウト手順について 1.1 ログイン手順 CentOS 1. モニ
 電気通信大学 I 類 情報系 情報 ネットワーク工学専攻 CED 2018 システム利用ガイド ver1.2 CED 管理者 学術技師 島崎俊介 教育研究技師部 実験実習支援センター 2018 年 3 月 29 日 1 ログイン ログアウト手順について 1.1 ログイン手順 CentOS 1. モニタと端末の電源を入れる 2. GNU GRUB version 2.02 Beta2-36ubuntu3
電気通信大学 I 類 情報系 情報 ネットワーク工学専攻 CED 2018 システム利用ガイド ver1.2 CED 管理者 学術技師 島崎俊介 教育研究技師部 実験実習支援センター 2018 年 3 月 29 日 1 ログイン ログアウト手順について 1.1 ログイン手順 CentOS 1. モニタと端末の電源を入れる 2. GNU GRUB version 2.02 Beta2-36ubuntu3
¹âÀºÅÙÀþ·ÁÂå¿ô±é»»¥é¥¤¥Ö¥é¥êMPACK¤Î³«È¯
 .... 2 2010/11/27@ . MPACK 0.6.7: Multiple precision version of BLAS and LAPACK http://mplapack.sourceforge.net/ @ MPACK (MBLAS and MLAPACK) BLAS/LAPACK (API) 0.6.7 (2010/8/20); 666 100 MLAPACK, MBLAS
.... 2 2010/11/27@ . MPACK 0.6.7: Multiple precision version of BLAS and LAPACK http://mplapack.sourceforge.net/ @ MPACK (MBLAS and MLAPACK) BLAS/LAPACK (API) 0.6.7 (2010/8/20); 666 100 MLAPACK, MBLAS
Krylov (b) x k+1 := x k + α k p k (c) r k+1 := r k α k Ap k ( := b Ax k+1 ) (d) β k := r k r k 2 2 (e) : r k 2 / r 0 2 < ε R (f) p k+1 :=
 x k+1 := x k + α k p k (c) r k+1 := r k α k Ap k ( := b Ax k+1 ) (d) β k := r k r k 2 2 (e) : r k 2 / r 0 2 < ε R (f) p k+1 :=") 127 10 Krylov Krylov (Conjugate-Gradient (CG ), Krylov ) MPIBNCpack 10.1 CG (Conjugate-Gradient CG ) A R n n a 11 a 12 a 1n a 21 a 22 a 2n A T = =... a n1 a n2 a nn n a 11 a 21 a n1 a 12 a 22 a n2 = A...
127 10 Krylov Krylov (Conjugate-Gradient (CG ), Krylov ) MPIBNCpack 10.1 CG (Conjugate-Gradient CG ) A R n n a 11 a 12 a 1n a 21 a 22 a 2n A T = =... a n1 a n2 a nn n a 11 a 21 a n1 a 12 a 22 a n2 = A...
tabaicho3mukunoki.pptx
 1 2 はじめに n 目的 4倍精度演算より高速な3倍精度演算を実現する l 倍精度では足りないが4倍精度は必要ないケースに欲しい l 4倍精度に比べてデータサイズが小さい Ø 少なくともメモリ律速な計算では4倍精度よりデータ 転送時間を減らすことが可能 Ø PCIeやノード間通信がボトルネックとなりやすい GPUクラスタ環境に有効か n 研究概要 l DD型4倍精度演算 DD演算 に基づく3倍精度演算
1 2 はじめに n 目的 4倍精度演算より高速な3倍精度演算を実現する l 倍精度では足りないが4倍精度は必要ないケースに欲しい l 4倍精度に比べてデータサイズが小さい Ø 少なくともメモリ律速な計算では4倍精度よりデータ 転送時間を減らすことが可能 Ø PCIeやノード間通信がボトルネックとなりやすい GPUクラスタ環境に有効か n 研究概要 l DD型4倍精度演算 DD演算 に基づく3倍精度演算
18 C ( ) hello world.c 1 #include <stdio.h> 2 3 main() 4 { 5 printf("hello World\n"); 6 } [ ] [ ] #include <stdio.h> % cc hello_world.c %./a.o
![18 C ( ) hello world.c 1 #include <stdio.h> 2 3 main() 4 { 5 printf(hello World\n); 6 } [ ] [ ] #include <stdio.h> % cc hello_world.c %./a.o](/thumbs/95/124976715.jpg "18 C ( ) hello world.c 1 #include <stdio.h> 2 3 main() 4 { 5 printf(hello World\n); 6 } [ ] [ ] #include <stdio.h> % cc hello_world.c %./a.o") 18 C ( ) 1 1 1.1 hello world.c 5 printf("hello World\n"); 6 } [ ] [ ] #include % cc hello_world.c %./a.out Hello World [a.out ] % cc hello_world.c -o hello_world [ ( ) ] (K&R 4.1.1) #include
18 C ( ) 1 1 1.1 hello world.c 5 printf("hello World\n"); 6 } [ ] [ ] #include % cc hello_world.c %./a.out Hello World [a.out ] % cc hello_world.c -o hello_world [ ( ) ] (K&R 4.1.1) #include
memo
 計数工学プログラミング演習 ( 第 3 回 ) 2017/04/25 DEPARTMENT OF MATHEMATICAL INFORMATICS 1 内容 ポインタの続き 引数の値渡しと参照渡し 構造体 2 ポインタで指されるメモリへのアクセス double **R; 型 R[i] と *(R+i) は同じ意味 意味 R double ** ポインタの配列 ( の先頭 ) へのポインタ R[i]
計数工学プログラミング演習 ( 第 3 回 ) 2017/04/25 DEPARTMENT OF MATHEMATICAL INFORMATICS 1 内容 ポインタの続き 引数の値渡しと参照渡し 構造体 2 ポインタで指されるメモリへのアクセス double **R; 型 R[i] と *(R+i) は同じ意味 意味 R double ** ポインタの配列 ( の先頭 ) へのポインタ R[i]
C のコード例 (Z80 と同機能 ) int main(void) { int i,sum=0; for (i=1; i<=10; i++) sum=sum + i; printf ("sum=%d n",sum); 2
 int main(void) { int i,sum=0; for (i=1; i<=10; i++) sum=sum + i; printf (sum=%d n,sum); 2") アセンブラ (Z80) の例 ORG 100H LD B,10 SUB A LOOP: ADD A,B DEC B JR NZ,LOOP LD (SUM),A HALT ORG 200H SUM: DEFS 1 END 1 C のコード例 (Z80 と同機能 ) int main(void) { int i,sum=0; for (i=1; i
アセンブラ (Z80) の例 ORG 100H LD B,10 SUB A LOOP: ADD A,B DEC B JR NZ,LOOP LD (SUM),A HALT ORG 200H SUM: DEFS 1 END 1 C のコード例 (Z80 と同機能 ) int main(void) { int i,sum=0; for (i=1; i
ad bc A A A = ad bc ( d ) b c a n A n A n A A det A A ( ) a b A = c d det A = ad bc σ {,,,, n} {,,, } {,,, } {,,, } ( ) σ = σ() = σ() = n sign σ sign(
 b c a n A n A n A A det A A ( ) a b A = c d det A = ad bc σ {,,,, n} {,,, } {,,, } {,,, } ( ) σ = σ() = σ() = n sign σ sign(") I n n A AX = I, YA = I () n XY A () X = IX = (YA)X = Y(AX) = YI = Y X Y () XY A A AB AB BA (AB)(B A ) = A(BB )A = AA = I (BA)(A B ) = B(AA )B = BB = I (AB) = B A (BA) = A B A B A = B = 5 5 A B AB BA A
I n n A AX = I, YA = I () n XY A () X = IX = (YA)X = Y(AX) = YI = Y X Y () XY A A AB AB BA (AB)(B A ) = A(BB )A = AA = I (BA)(A B ) = B(AA )B = BB = I (AB) = B A (BA) = A B A B A = B = 5 5 A B AB BA A
( ) ( ) ( ) 2
 ( ) ( ) 2") (Basic Theory of Information Processing) 1 1 1.1 - - ( ) ( ) ( ) 2 Engineering Transformation or ( ) Military Transformation ( ) ( ) ( ) HDTV 3 ( ) or ( ) 4 5.609 (TSUBAME2.5, 11 (2014.6)) IP ( ) ( ) (
(Basic Theory of Information Processing) 1 1 1.1 - - ( ) ( ) ( ) 2 Engineering Transformation or ( ) Military Transformation ( ) ( ) ( ) HDTV 3 ( ) or ( ) 4 5.609 (TSUBAME2.5, 11 (2014.6)) IP ( ) ( ) (
C
 C 1 2 1.1........................... 2 1.2........................ 2 1.3 make................................................ 3 1.4....................................... 5 1.4.1 strip................................................
C 1 2 1.1........................... 2 1.2........................ 2 1.3 make................................................ 3 1.4....................................... 5 1.4.1 strip................................................
スパコンに通じる並列プログラミングの基礎
 2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
2016.06.06 2016.06.06 1 / 60 2016.06.06 2 / 60 Windows, Mac Unix 0444-J 2016.06.06 3 / 60 Part I Unix GUI CUI: Unix, Windows, Mac OS Part II 0444-J 2016.06.06 4 / 60 ( : ) 6 6 ( ) 6 10 6 16 SX-ACE 6 17
Intel® Compilers Professional Editions
 2007 6 10.0 * 10.0 6 5 Software &Solutions group 10.0 (SV) C++ Fortran OpenMP* OpenMP API / : 200 C/C++ Fortran : OpenMP : : : $ cat -n main.cpp 1 #include 2 int foo(const char *); 3 int main()
2007 6 10.0 * 10.0 6 5 Software &Solutions group 10.0 (SV) C++ Fortran OpenMP* OpenMP API / : 200 C/C++ Fortran : OpenMP : : : $ cat -n main.cpp 1 #include 2 int foo(const char *); 3 int main()
6 ( ) 1 / 53
 1 / 53") 6 / 6 (2014 11 05 ) / 53 6 (2014 11 05 ) 1 / 53 nodeedge 2 u v u v (u, v) 6 (2014 11 05 ) 2 / 53 Twitter 6 (2014 11 05 ) 3 / 53 Facebook 6 (2014 11 05 ) 4 / 53 N N N 1,2,..., N (i, j )i j 10 i j 2(i, j
6 / 6 (2014 11 05 ) / 53 6 (2014 11 05 ) 1 / 53 nodeedge 2 u v u v (u, v) 6 (2014 11 05 ) 2 / 53 Twitter 6 (2014 11 05 ) 3 / 53 Facebook 6 (2014 11 05 ) 4 / 53 N N N 1,2,..., N (i, j )i j 10 i j 2(i, j
tuat1.dvi
 ( 1 ) http://ist.ksc.kwansei.ac.jp/ tutimura/ 2012 6 23 ( 1 ) 1 / 58 C ( 1 ) 2 / 58 2008 9 2002 2005 T E X ptetex3, ptexlive pt E X UTF-8 xdvi-jp 3 ( 1 ) 3 / 58 ( 1 ) 4 / 58 C,... ( 1 ) 5 / 58 6/23( )
( 1 ) http://ist.ksc.kwansei.ac.jp/ tutimura/ 2012 6 23 ( 1 ) 1 / 58 C ( 1 ) 2 / 58 2008 9 2002 2005 T E X ptetex3, ptexlive pt E X UTF-8 xdvi-jp 3 ( 1 ) 3 / 58 ( 1 ) 4 / 58 C,... ( 1 ) 5 / 58 6/23( )
1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU
![1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU](/thumbs/89/99132402.jpg "1 GPU GPGPU GPU CPU 2 GPU 2007 NVIDIA GPGPU CUDA[3] GPGPU CUDA GPGPU CUDA GPGPU GPU GPU GPU Graphics Processing Unit LSI LSI CPU ( ) DRAM GPU LSI GPU") GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
GPGPU (I) GPU GPGPU 1 GPU(Graphics Processing Unit) GPU GPGPU(General-Purpose computing on GPUs) GPU GPGPU GPU ( PC ) PC PC GPU PC PC GPU GPU 2008 TSUBAME NVIDIA GPU(Tesla S1070) TOP500 29 [1] 2009 AMD
C¥×¥í¥°¥é¥ß¥ó¥° ÆþÌç
 C (3) if else switch AND && OR (NOT)! 1 BMI BMI BMI = 10 4 [kg]) ( [cm]) 2 bmi1.c Input your height[cm]: 173.2 Enter Input your weight[kg]: 60.3 Enter Your BMI is 20.1. 10 4 = 10000.0 1 BMI BMI BMI = 10
C (3) if else switch AND && OR (NOT)! 1 BMI BMI BMI = 10 4 [kg]) ( [cm]) 2 bmi1.c Input your height[cm]: 173.2 Enter Input your weight[kg]: 60.3 Enter Your BMI is 20.1. 10 4 = 10000.0 1 BMI BMI BMI = 10
01_OpenMP_osx.indd
 OpenMP* / 1 1... 2 2... 3 3... 5 4... 7 5... 9 5.1... 9 5.2 OpenMP* API... 13 6... 17 7... 19 / 4 1 2 C/C++ OpenMP* 3 Fortran OpenMP* 4 PC 1 1 9.0 Linux* Windows* Xeon Itanium OS 1 2 2 WEB OS OS OS 1 OS
OpenMP* / 1 1... 2 2... 3 3... 5 4... 7 5... 9 5.1... 9 5.2 OpenMP* API... 13 6... 17 7... 19 / 4 1 2 C/C++ OpenMP* 3 Fortran OpenMP* 4 PC 1 1 9.0 Linux* Windows* Xeon Itanium OS 1 2 2 WEB OS OS OS 1 OS
AMD/ATI Radeon HD 5870 GPU DEGIMA LINPACK HD 5870 GPU DEGIMA LINPACK GFlops/Watt GFlops/Watt Abstract GPU Computing has lately attracted
 DEGIMA LINPACK Energy Performance for LINPACK Benchmark on DEGIMA 1 AMD/ATI Radeon HD 5870 GPU DEGIMA LINPACK HD 5870 GPU DEGIMA LINPACK 1.4698 GFlops/Watt 1.9658 GFlops/Watt Abstract GPU Computing has
DEGIMA LINPACK Energy Performance for LINPACK Benchmark on DEGIMA 1 AMD/ATI Radeon HD 5870 GPU DEGIMA LINPACK HD 5870 GPU DEGIMA LINPACK 1.4698 GFlops/Watt 1.9658 GFlops/Watt Abstract GPU Computing has
BLAS の概要
 GotoBLAS チュートリアル 後藤和茂 ( テキサス州立大学 ) 26/12/9 Kazushige Goto (TACC) 1 自己紹介 お題目 数値計算と最適化の基本事項の確認 BLAS とは? GotoBLAS の特徴 Level 1 ~Level 3 ルーチンの構造と特徴 BLAS による最適化の限界 26/12/9 Kazushige Goto (TACC) 2 自己紹介 早稲田大学電気工学修士課程卒
GotoBLAS チュートリアル 後藤和茂 ( テキサス州立大学 ) 26/12/9 Kazushige Goto (TACC) 1 自己紹介 お題目 数値計算と最適化の基本事項の確認 BLAS とは? GotoBLAS の特徴 Level 1 ~Level 3 ルーチンの構造と特徴 BLAS による最適化の限界 26/12/9 Kazushige Goto (TACC) 2 自己紹介 早稲田大学電気工学修士課程卒