[R ] ˆ ˆ ˆ R ˆ R ˆ R S C UNIX AT&T( Lucent Technologies) ( C UNIX ) ˆ CRAN ˆ URL
|
|
|
- みいか かに
- 5 years ago
- Views:
Transcription
1 uda2008/main.tex 2008/05/ EM [ ] ˆ R ˆ 1. R 2. ˆ R C Java 2008 R ˆ Mac R Windows PC Mac OK Linux ( PC vmware ˆ ˆ ˆ ˆ 2007 [ ] ˆ 2007 ˆ Google ˆ ˆ ˆ ˆ 2 4
![[R ] ˆ ˆ ˆ R http://cran.r-project.](/docs-images/81/84418577/images/2-0.jpg "org ˆ R ˆ R S C UNIX AT&T( Lucent Technologies) ( C UNIX ) ˆ 2007 3 5 CRAN 1008. 2008 4 4 1385 ˆ URL http://cran.")

![exe [R (Windows)] ˆ R ˆ SAS, SPSS, Mathematica, (matlab) [R ] 5 7 ˆ The R Project for Statistical Computing](/docs-images/81/84418577/images/2-2.jpg "http://cran.r-project.org ˆ Wiki RjpWiki http://www.okada.jp.org/rwiki/ ˆ R http://www.is.titech.ac.jp/~mase/r.")
2 [R ] ˆ ˆ ˆ R ˆ R ˆ R S C UNIX AT&T( Lucent Technologies) ( C UNIX ) ˆ CRAN ˆ URL /04/03 R R win32.exe ˆ ( R R win32.exe [R (Windows)] ˆ R ˆ SAS, SPSS, Mathematica, (matlab) [R ] 5 7 ˆ The R Project for Statistical Computing ˆ Wiki RjpWiki ˆ R PDF R Introduction to R ver Appendix A [R (Windows)] 6 ˆ R R Console GUI Rgui Font MS Gothic Apply Save R 8
![[R ] foo2 <- function(x) if(x>0) x else 0 (Windows) R (Unix ) OS % R [return] (Windows).RData (Unix ) R > q() [return] Save workspace image? [y/n/c]: y.rdata R R > > a <- 1:10 (1,2,.](/docs-images/81/84418577/images/3-0.jpg "..,10) a > a^2 a [1] 1 4 9 16 25 36 49 64 81 100 > plot(a,a^2) a a^2 > foo2(3) [1] 3 > foo2(-3) [1] 0 > help(for) for > help(\"for\") > help(\":\") : > library() > library(mass) MASS > demo() >")
3 [R ] foo2 <- function(x) if(x>0) x else 0 (Windows) R (Unix ) OS % R [return] (Windows).RData (Unix ) R > q() [return] Save workspace image? [y/n/c]: y.rdata R R > > a <- 1:10 (1,2,...,10) a > a^2 a [1] > plot(a,a^2) a a^2 > foo2(3) [1] 3 > foo2(-3) [1] 0 > help(for) for > help("for") > help(":") : > library() > library(mass) MASS > demo() > demo(graphics) > demo(image) [return] emacs ESS emacs (M-x R R ) [ ] 9 11 ˆ Trevor Hastie, Robert Tibshirani, Jerome H. Friedman, The Elements of Statistical Learning: Data Mining, Inference, and Prediction, ˆ R S) W. N. Venables, Brian D. Ripley Modern Applied Statistics with S Springer-Verlag ˆ R R ˆ R R/Rstat.pdf ˆ gakubu html > foo <- function(x) sum(x^2) foo foo(a) [1] 385 for(i in 1:10) {...} i 1,...,10 > x <- rep(0,10); for(i in 1:10) x[i] <- i^2 > x [1] [ ] gakureki-shushou.txt "Gakureki" "Shushou" "Hokkaido" "Aomori" "Iwate" "Miyagi"




4 > dat <- read.table("gakureki-shushou.txt") # > dim(dat) # ( matrix data.frame ) [1] 47 2 > dat[1:5,] # 5 Gakureki Shushou Hokkaido
5 Aomori Iwate Miyagi Akita > plot(dat) # > f <- lm(shushou ~ Gakureki, dat) # > summary(f) # Call: lm(formula = Shushou ~ Gakureki, data = dat) Residuals: Min 1Q Median 3Q Max Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) < 2e-16 *** Gakureki e-09 *** --- Signif. codes: 0 '***' '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Shushou Shushou Okinawa Saga Fukushima Shimane Yamagata Miyazaki Tottori Fukui Kagoshima Nagano Iwate Nagasaki Kumamoto Kagawa Shiga NiigataGumma Ooita Yamanashi Okayama Aomori Yamaguchi Tochigi Mie Shizuoka Gifu Ibaraki AkitaKochi Wakayama Tokushima Toyama Ehime Ishikawa Aichi Hiroshima Miyagi Hyogo Fukuoka Osaka SaitamaChiba Nara Kyoto Hokkaido Kanagawa Residual standard error: on 45 degrees of freedom Multiple R-Squared: , Adjusted R-squared: F-statistic: on 1 and 45 DF, p-value: 5.943e-09 > abline(f,col="red") # > plot(dat,type="n"); text(dat,rownames(dat)); abline(f,col="red",lty=2) # ˆ = β 0 + β 1 + ɛ 17 Tokyo Gakureki Gakureki 1 19 ˆ ˆβ 0 = 1.74, ˆβ 1 = ˆ ˆσ 0 = 0.04, ˆσ 1 = ˆ p 0 = , p 1 = R Editor ˆ ˆ [ (Windows)] ˆ R Console ˆ ˆ.R ˆ.R ˆ R GUI 18 20
 23 [")
![(I)] 2004 ˆ [ ] 22 (y =1](/docs-images/81/84418577/images/6-1.jpg "=0) log (x 369 ) ˆ P (Y")

6 ˆ ( ) ˆ ˆ R Console 21 ˆ ˆ ( ) 23 [ (I)] 2004 ˆ [ ] 22 (y =1 =0) log (x 369 ) ˆ P (Y = 1 x) P (Y = 0 x) = β 0 + β 1 x β k x k 24
7 [ ] gakureki-rikon-12.txt: Gakureki E09504 ( ) Shushou A05203 Zouka A05201 ( ) Ninzu A06102 ( :person) Kaku A06202 ( ) Tomo F01503 ( ) Tandoku A06205 ( ) 65Sai A ( ) Kfufu A06302 ( ) Ktan A06304 ( ) Konin A06601 Rikon A06602 X2000data.txt 12 > dat <- read.table("gakureki-rikon-12.txt") # > dim(dat) # [1] > pairs(dat,pch=".") # > f <- princomp(dat,cor=t) # > biplot(f) # 25 ˆ vs,,,,, 65,,, ˆ?,,,, ˆ?, ˆ 1 > ## x y > myregplot <- function(x,y,dat) { + e <- formula(paste(y,"~",x)) # y~x + plot(e,dat,type="n") # + text(dat[,x],dat[,y],rownames(dat)) # + f <- lm(e,dat) # + abline(f,col="red",lty=2) # + title(sub=paste(names(f$coef),round(f$coef,4),sep="=",collapse=", ")) + summary(f)$coef # Gakurek Shushou Zouka Ninzu Kaku Tomo Tandoku X65Sai Kfufu Ktan Konin Comp.2 Rikon Comp Kagoshima Kochi Kfufu Yamaguchi Ktan Ehime Miyazaki Ooita Wakayama Hokkaido Nagasaki Tandoku Shimane Tokushima Kumamoto Tokyo KagawaHiroshima Fukuoka Rikon Kyoto X65Sai Akita Okayama Kaku Aomori Hyogo Osaka Shushou Tottori Iwate Nagano Yamanashi Mie Saga Gumma Nara Gakureki Tomo Niigata Fukushima Ishikawa Miyagi Kanagawa Toyama Chiba Konin Yamagata Fukui GifuShizuoka Tochigi Ibaraki Aichi Okinawa Zouka Ninzu Saitama Shiga > myregplot("tomo","shushou",dat) Estimate Std. Error t value Pr(> t ) (Intercept) e-15 Tomo e-05 > myregplot("zouka","shushou",dat[-match(c("okinawa","tokyo"),rownames(dat)),]) Estimate Std. Error t value Pr(> t ) (Intercept) e-51 Zouka e-03 [ ]
8 R Shushou Okinawa Saga Fukushima Shimane Miyazaki Tottori Yamaga Fukui Kagoshima Nagano Nagasaki Kumamoto Iwate Kagawa Shiga OoitaOkayama Yamanashi Gumma Niigata Yamaguchi Aomori Ibaraki Tochigi Mie Shizuoka Gifu Wakayama EhimeKochi Aichi Tokushima Ishikawa Akita Toyama Hiroshima Hyogo Miyagi Fukuoka Osaka NaraChiba Saitama KanagawaKyoto Hokkaido Tokyo Tomo (Intercept)=1.0309, Tomo= Shushou Saga Shimane Fukushima Yamagata Tottori Miyazaki Nagano Fukui Kagoshima Nagasaki IwateKumamoto Kagawa Ooita Niigata Okayama Yamanashi Gumma Yamaguchi Aomori Mie Tochigi Ibaraki Gifu Shizuoka Kochi Akita Tokushima Wakayama EhimeToyama Ishikawa Hiroshima Miyagi Hyogo Fukuoka Nara Kyoto Shiga Aichi Osaka Chiba Saitama Kanagawa Hokkaido Zouka (Intercept)=1.4947, Zouka= > ## cp932 JIS enconding="shift-jis" > X2000.item <- read.table(file("x2000item.txt",encoding="cp932")) > dim(x2000.item) # [1] > X2000.item[1,] # 1 Imi Tani Zenkoku Bunrui A01101 ( ) 100 A 1) > X2000.item[c("E09504","A05203"),] # Gakureki Shushou Imi Tani Zenkoku Bunrui E09504 ( ) E 7) A A 5) [ ] read.table dat data.frame matrix as.matrix > dat[1:3,] # Gakureki Shushou Hokkaido Aomori Iwate > datmat <- as.matrix(dat) # > datmat[1:3,] # Gakureki Shushou Hokkaido asahi.com [ ] http: // 47 ( ) R X2000data.txt > X2000.data <- read.table("x2000data.txt") # X2000 > dim(x2000.data) # [1] > dat <- X2000.data[,c("E09504","A05203")] # > names(dat) <- c("gakureki","shushou") # (names colnames > write.table(dat,"test.txt") # X2000item.txt, X2000code.txt, X2000name.txt [ ] txt Windows (shift-jis, CR/LF ) X2000data.txt X2000item.txt Linux Mac nkf 30 Aomori Iwate > c(is.matrix(dat),is.data.frame(dat)) # [1] FALSE TRUE > c(is.matrix(datmat),is.data.frame(datmat)) # [1] TRUE FALSE > t(datmat) %*% datmat # t() %*% Gakureki Shushou Gakureki Shushou > colnames(datmat) <- c("aaa","bbb") # names > datmat[1:3,] # AAA BBB Hokkaido Aomori Iwate [ (II)] 2003 DNA ˆ (DNA ) 32
![ˆ Cluster Dendrogram Cluster Dendrogram ˆ [ ] Height 0 2 4 6 8 10 12 Nagasaki Miyazaki Wakayama Ooita Yamaguchi Ehime Kochi Kagoshima Shimane Akita Iwate](/docs-images/81/84418577/images/9-0.jpg "Niigata Yamagata Toyama Fukui Tottori Fukushima Saga Gumma Yamanashi Mie Ishikawa Nagano Aomori Okayama Kagawa Tokushima Kumamoto Nara Miyagi Shiga Gifu")
 dist(x) hclust (*, \"complete\") 4 dist(t(x)) hclust (*, \"complete\") 33 35 ˆ")
 # > x <- scale(dat) # > h1 <- hclust(dist(x)) # > plot(h1) # > h2 <- hclust(dist(t(x))) # > plot(h2) # ˆ (pvclust R ) [ (III)] 2004 Assessing the")
9 ˆ Cluster Dendrogram Cluster Dendrogram ˆ [ ] Height Nagasaki Miyazaki Wakayama Ooita Yamaguchi Ehime Kochi Kagoshima Shimane Akita Iwate Niigata Yamagata Toyama Fukui Tottori Fukushima Saga Gumma Yamanashi Mie Ishikawa Nagano Aomori Okayama Kagawa Tokushima Kumamoto Nara Miyagi Shiga Gifu Tokyo Ibaraki Tochigi Shizuoka Okinawa Hokkaido Kyoto Fukuoka Hyogo Hiroshima Aichi Saitama Chiba Kanagawa Osaka Height Ninzu Shushou Tomo X65Sai Kaku Rikon Gakureki Zouka Konin Tandoku Kfufu Ktan ˆ 12 ˆ dist() dist(x) hclust (*, "complete") 4 dist(t(x)) hclust (*, "complete") ˆ hclust() ˆ plot() > dat <- read.table("gakureki-rikon-12.txt") # > x <- scale(dat) # > h1 <- hclust(dist(x)) # > plot(h1) # > h2 <- hclust(dist(t(x))) # > plot(h2) # ˆ (pvclust R ) [ (III)] 2004 Assessing the uncertainty in hierarchical cluster analysis via multiscale bootstrap resampling ( ) ˆ (p=73 n=916 ) 34 36
10 1 1.1 X x f(x) g(x) [ 1.1] Y = g(x) E (g(x)) = g(x)f(x) dx (1.1) [ 1.2] m X x f(x) g(x) E(g(X)) = g(x)f(x) dx R m X E(X) V (X) X 1 E(X 1 ) C(X 1, X 1 ) C(X 1, X m ) X =., E(X) =., V (X) =.. X m E(X m ) C(X m, X 1 ) C(X m, X m ) C(X i, X j ) = E [(X i E(X i ))(X j E(X j ))] X i X j ρ(x i, X j ) = C(X i, X j )/ C(X i, X i )C(X j, X j ) X i V (X i ) [ 1.6] X m w R m Y = w X A A E(Y ) = w E(X), V (Y ) = w V (X)w [ 1.1] a, b R, g 1 (x), g 2 (x) E(ag 1 (X) + bg 2 (X)) = ae(g 1 (X)) + be(g 2 (X)) 37 [ 1.2] X m E(X i ) = µ V (X i ) = σ Y = m i=1 X i/m w = ( 1 m,..., 1 m ) [ 1.2] [ 1.3] X E(X) (1.1) g(x) X V (X) (1.1) g(x) E(Y ) = µ, V (Y ) = σ2 m [ 1.4] (a, b), a < b X P (a < X < b) (1.1) g(x) A I(A) = 1 I(A) = 0 (indicator function) [ 1.5] g(s) F (x) = x f(s) ds (1.1) x [ 1.1] (0, 1) X U(0, 1) f(x) = 1, 0 < x < 1, f(x) = 0 X 1 E(X) = xf(x) dx = x dx = V (X) = (x E(X)) 2 f(x) dx = (x 1 2 )2 dx = x F (x) = ds = x, 0 < x < 1; F (x) = 0, x 0; F (x) = 1, x 1 0 > sx <- 0.2 # SD(X) > m <- 1:10 # m=1,2,...,10 > sy <- sx/sqrt(m) # SD(Y) > plot(m,sy) [ 1.7] X m w R m X i i Y = w X w E(Y ) µ 1 E(Y ) = µ, m w i = 1 V (Y ) i=1 w = Σ 1 A ( A Σ 1 A ) 1 [ ] µ
11 Σ = V (X) 1 m = (1,..., 1) 1 m A = (E(X), 1 m ) m 2 [ 1.3] m E(X i ) V (X i ) X i X j ρ > ex <- c(0.2,0.15,0.1,0.05) # E(X) > sx <- c(0.2,0.2,0.1,0.05) # SD(X) > rho <- 0.3 Σ Σ 1 A C = Σ 1 A ( A Σ 1 A ) 1 > m <- length(sx) # = 4 > V <- (sx %o% sx) * (diag(m)*(1-rho) + matrix(rho,m,m)) # Sigma > B <- solve(v) # Sigma^(-1) > A <- cbind(ex,1) # A > C <- B %*% A %*% solve(t(a) %*% B %*% A) # C E(Y ) = 0.15 V (Y ) V (Y ) > w <- C %*% c(0.15,1) # > t(w) # [,1] [,2] [,3] [,4] [1,] > t(w) %*% ex # 0.15 [,1] [1,] 0.15 > sqrt(t(w) %*% V %*% w) # SD(Y) [,1] [1,] sy ey m sy E(Y ) V (Y ) - > # E(Y) SD(Y) > mysy <- function(ey) { + w <- C %*% c(ey,1) + sqrt(t(w) %*% V %*% w) > ey <- seq(-0.1,0.4,length=100) # E(Y) > sy <- sapply(ey,mysy) # SD(Y) > plot(sy,ey,type="l") > points(sx,ex,col="red") [ 1.8] x h(x) 0 E(h(X)) a > 0 E(h(X)) ap (h(x) a) ɛ > 0 E(X) = µ V (X) = σ 2 P ( X µ ɛ) σ2 ɛ 2 [ ] 1.1 f(x) X s 0, s 1,... p(x) E (g(x)) = g(s i )p(s i ) (1.2) i=0 δ(x) f(x) = p(s i )δ(s i ) i=0 (1.1) f A R f(a) = P (X A) E(g(X)) = g(x)f(dx) R (1.1) 42 44
12 1.2 Y 1, Y 2,... Y n, n = 1, 2,... [ 1.3] Y n Y (convergence in probability) ɛ > 0 lim P ( Y n Y > ɛ) = 0 (1.3) n n 0 [ 1.9] X n E(g(X 1 )) Ȳ n = 1 n g(x i ) (1.5) n i=1 p E(Ȳn) = E(g(X 1 )), Ȳ n E(g(X1 )) Y n p Y Y Zn = Y n Y ɛ > 0; lim n P ( Z n > ɛ) = 0 n (1.1) (1.5) V (g(x 1 )) V (Ȳn) = V (g(x 1 ))/n [ 1.4] X n (0, 1) X n U(0, 1) [ ] ˆ, almost surely convergent ( ) P lim Y n(ω) = Y (ω) = 1 n ˆ (convergence in distribution) y; lim n P (Y n y) = P (Y y) 45 X 1,..., X n ( ) x 1,..., x n > ## > x <- runif(10000) # U(0,1) > x[1:5] # [1] > ## > mean(x[1:10]) # 10 [1] > mean(x[1:100]) # 100 [1] > mean(x[1:1000]) # 1000 [1] ˆ ˆ Levy (1937) X k, k = 1, 2,... Y n = n k=1 X k, n = 1, 2,... [ 1.1] X n E(X 1 ) = µ n X n = 1 n X n n n i=1 X i X n p µ (1.4) (sample size) > mean(x) # (0.5) [1] > y1 <- cumsum(x)/(1:10000) # n > plot(y1,log="x"); abline(h=0.5) > ## > mean((x - mean(x))^2) # (1/12 = 0.833) [1] > ## x 0.1 > mean(x < 0.1) # P(X<0.1)=0.1 [1] > z <- x < 0.1 # 0 1 > as.numeric(z[1:100]) # 100 [1] [38] [75] > cumsum(z[1:100]) # [1] [38] [75] > y2 <- cumsum(z)/(1:10000) # n > plot(y2,log="x"); abline(h=0.1) [ ] σ 2 = V (X 1 ) V ( X n ) = σ 2 /n P ( X n µ ɛ ) σ2 nɛ
13 ら分布の収束がいえる 分布関数 p = F (q) の逆関数を q = F 1 (p) = inf F (q) p q と書く (inf は F の不連続点を考慮す [定義 1.5] るため) q は分布 F の 下側 100p パーセント点という F 1 (1 p) は上側 100p パーセント点という 経験分布を用いて F n 1 (p) は 下側 100p パーセント標本点という p = 0.5 ときが中央値 (median) であ [例 1.5] 例題 1.4で作成した x1,..., xn を再利用する > hist(x,prob=true) # ヒストグラム 確率密度表示 > y <- sort(x) # 小さい順に並べ替え > y[5000] # 経験分布の逆関数 (p=0.5) [1] > (y[5000]+y[5001])/2 # 線形補間したもの (p=0.5) [1] > quantile(x,p=0.5) # median(x) でも同じ 50% > p <- (1:10000)/10000 # , ,..., , 1 > plot(y,p,pch=".") # 経験分布関数 y y る help(quantile) を実行すれば R における標本パーセント点の実装が読める Index 図 6 左 Y n = 1 n Pn i=1 Xi 右 Y n = 1 n Pn i=1 平均 0 分散 1 の正規分布 これを標準正規分布という X N (0, 1) の密度関数は f (x) = [例 1.6] Index 1 2π I(Xi < 0.1) 2 exp( x2 ) である rnorm を利用して X1,..., X10000 N (0, 1) を生成し 標本平均 標本分散 標本中 央値 標本上側 5% 点 標本上側 2.5% 点を計算する それらを理論値 F n のかわりに F から得られる値 と比較する 49 [定義 1.4] 51 標本 x1,..., xn の経験 累積 分布関数は n F n (x) = である 対応する確率密度関数は 1X #(xi x) I(xi x) = n i=1 n (1.6) Histogram of x n 1X fˆn (x) = δ(x xi ) n i= (1.7) 0.6 p nf n (x) が2項分布に従うことを示し F n (x) の平均 分散を求めよ Density p x を固定して F n (x) を X1,..., Xn の関数とみなす このとき F n (x) F (x) を示せ また 0.4 [課題 1.10] 0.8 である 各 xi の確率が 1/n の離散分布とみなせる ½ ¾ lim sup F n (x) F (x) = 0 = 1 n x R いずれにしても 標本数を増やせば経験分布関数は分布関数に収束する と解釈できる 大数の法則では平 均値が期待値への収束することを述べていたが 期待値は分布のひとつの性質に過ぎず サンプルが持ってる P 0.0 Cantelli の定理 がいえる 0.2 p [注意] x の各点で F n (x) F (x) となるだけでなく より強く一様収束をのべる以下の結果 Glivenko y 図 7 左 ヒストグラム 右 経験分布関数 情報は分布そのものを再現できることを示している もっとも 大数の法則で g(x) を自由に選べることか x
14 > x <- rnorm(10000) # N(0,1) > mean(x) # [1] > mean((x-mean(x))^2) # [1] > quantile(x,p=c(0.5,0.95,0.975)) # 5% 2.5% 50% 95% 97.5% > qnorm(c(0.5,0.95,0.975)) # [1] > ### > library(mass) # MASS > truehist(x) # > x0 <- seq(min(x),max(x),length=10000) # x 1000 > lines(x0,dnorm(x0),col=2) # > p <- (1:10000)/10000 # , ,..., , 1 > plot(sort(x),p,pch=".") # > lines(x0,pnorm(x0),col=2) # [ 1.7] library(mass) truehist nbis Scott (1979) > truehist(x) # nbins="scott" > nclass.scott # nbins function (x) { h <- 3.5 * sqrt(stats::var(x)) * length(x)^(-1/3) ceiling(diff(range(x))/h) } 53 <environment: namespace:grdevices> > truehist(x,nbins=nclass.scott(x)*2) # 2 > truehist(x,nbins=nclass.scott(x)/2) # [ 1.11] Y = (a, b], a < b X 1,..., X n C X F (x) C n(b a) µ σ2 [ 1.12] f(x) 2 h (i) x (a, b) f(x) Y b a h ( ) h E(Y ) f(x) = f (a) + (x a) + O(h 2 ), V (Y ) = f(a) 2 nh + O(n 1 ) x 2 ( MSE(x) = V (Y ) + (E(Y ) f(x)) 2 = f (a) 2 x a + b ) 2 + f(a) 2 nh + O ( h 3 + n 1) (ii) (a, b) 1 b a b a MSE(x) dx f (a) 2 h f(a) nh (iii) 2 MSE(x) dx [f (x) 2 h f(x) ] dx = h2 f (x) 2 dx + 1 nh 12 nh p x sort(x) x x
15 (iv) h [ n ] 1/3 h = f (x) 2 dx 6 (v) f(x) σ 2 f (x) 2 1 dx = 4 πσ 3 h = (24 π) 1/3 σn 1/3 3.49σn 1/3 Scott (1979) 1.3 (0, 1) U 1, U 2,... U(0, 1) F (x) f(x) X 1, X 2,... (1.1) (1.5) [ 1.13] [ 1.8] X = F 1 (U) X F (x) f(x) = e x, F 1 (p) = log(1 p) 57 F (x) = 1 e x > ## X ~ N(0,1) > ## rnorm > u0 <- 2*runif(10000)-1 # U(-1,1) > u <- abs(u0) # U(0,1) > s <- sign(u0) # +1,-1 > v <- -log(runif(10000)) # v ~ exp(-v) > a <- u <= exp(-(v-1)^2/2) # a > x <- (s*v)[a] # > length(x) # [1] 7575 > truehist(x) # > x0 <- seq(min(x),max(x),length=10000) # x 1000 > lines(x0,dnorm(x0),col=2) # [ 1.15] m X N m (µ, Σ) ( f(x µ, Σ) = (2π) m/2 Σ 1/2 exp 1 ) 2 (x µ) Σ 1 (x µ) Σ m m A Σ = AA A A A A m Z N m (0, I m ) X = AZ + µ 59 > ## X ~ exp(-x) > ## rexp > u <- runif(10000) # U(0,1) > x <- -log(u) # X = F^{-1}(U) > truehist(x) # > x0 <- seq(min(x),max(x),length=1000) > lines(x0,exp(-x0),col=2) # [ 1.14] f(x), g(x) U U(0, 1) V g(v) X f(x) 1. x f(x) cg(x) c 2. U U(0, 1) V g(v) 3. U f(v ) cg(v ) X = V 2 (rejection method) [ 1.9] X N(0, 1) f(x) = 1 2π e x2 2, g(x) = 1 2 e x, c = f(x) cg(x) f(x)/(cg(x)) = e ( x 1)2 2 X 58 2e π x x
16 [ 1.10] X N 2 (µ, Σ) [ ] [ ] µ1 1 ρ µ =, Σ = µ 2 ρ 1 µ 1 = 5, µ 2 = 0, ρ = 0.5 > S <- matrix(c(1,0.5,0.5,1),2,2) # Sigma > S # [,1] [,2] [1,] [2,] > A <- t(chol(s)) # > A # [,1] [,2] [1,] [2,] > z <- matrix(rnorm(2*1000),2,1000) # N(0,1) 2x1000 > var(t(z)) # z [,1] [,2] [1,] [2,] > x <- A %*% z + c(5,0) # z 1000 > var(t(x)) # x [,1] [,2] [1,] [2,] > plot(z[1,],z[2,]) # z 61 z[2, ] x[2, ] z[1, ] x[1, ] z 1000 x 63 > plot(x[1,],x[2,]) # x [ 1.16] X 1, X 2,... p(x t+1 x t ) f(x) p(x t+1 x t )f(x t ) = p(x t x t+1 )f(x t+1 ) X t f(x t ) X t+1 p(x t+1 x t )f(x t ) dx t = p(x t x t+1 )f(x t+1 ) dx t = f(x t+1 ) f(x) [ ] 1. q(v x) X 1 t = 1 2. U U(0, 1) V q(v X t ) 3. { α(v, X t ) = min 1, q(x } t V )f(v ) q(v X t )f(x t ) 4. U α(v, X t ) X t+1 = V X t+1 = X t 5. t 2 x x Metrololis-Hastings f(x) 62 f(v)/f(x) (Markov Chain Monte Carlo MCMC) q(v x) (proposal distribution) (1.1) (1.5) X 0 N N = 100, 000 X 1, X 2,..., X N M < N M = 10, 000 X M+1, X M+2,..., X N N t=m+1 X t/(n M) (1.1) M burn-in ( ) [ 1.11] 1.10 MCMC MCMC 1.15 MCMC q(v x) { (2d) 2 v[1] x[1] d, v[2] x[2] d q(v x) = 0 ( d, d) q(v x) = q(x v) { α(v, x) = min 1, f(v) } f(x) 64
17 v x > N < # > rho <- 0.5 # > S <- matrix(c(1,rho,rho,1),2,2) # Sigma > mu <- c(5,0) # mu > Sinv <- solve(s) # S > myf <- function(x) exp(-0.5*(x-mu)%*%sinv%*%(x-mu)) # f(x) > d <- 0.5 # > x <- c(0,0) # > xs <- matrix(0,2,n) # > fs <- rep(0,n) # f(x) > cnt <- 0 # > for(t in 1:N) { + v <- x + (2*runif(2)-1)*d # v ~ q(v x) + a <- myf(v)/myf(x) # alpha=min(1,a) + u <- runif(1) # u ~ U(0,1) + if(u <= a) { + x <- v # v + cnt <- cnt + 1 # + xs[,t] <- x # x + fs[t] <- myf(x) # f(x) > cnt/n # [1] > plot(xs[1,],xs[2,]) # x > segments(c(0,xs[1,-n]),c(0,xs[2,-n]),xs[1,],xs[2,],col="pink") # > plot(log(fs),type="l") # log(f(x)) 65 [ 1.17] K p k (x t+1 x t ), k = 1,..., K f(x) X 1, X 2,... π k p k (x t+1 x t ) K k=1 π k = 1 f(x) [ ] 1.17 k = 1, 2,..., K, 1, 2,... p k f(x) [ 1.18] m X 1, X 2,... X f(x) m x i x[i] x x[i] m 1 x[ i] x[ i] h i (x[ i]) = f(x) dx[i] x[ i] x[i] 1. X 1 t = 1 f i (x[i] x[ i]) = 67 f(x) h i (x[ i]) 2. i 3. V f i (V X t [ i]) 4. X t+1 [i] = V X t+1 [ i] = X[ i] 5. t 2 xs[2, ] log(fs) [ ] Gibbs sampler) α = 1 [ 1.19] m X N m (µ, Σ) Y X Y m + 1 x Y ([ ]) [ ([ ]) X µ X E =, V = Y λ] Y [ Σ ] b b c Y x N ( λ + b Σ 1 (x µ), c b Σ 1 b ) xs[1, ] Index Σ e = (c b Σ 1 b) 1, d = eσ 1 b, X t log(f(x t)) 66 A = eσ 1 bb Σ 1 [ ] 1 [ Σ b Σ 1 ] + A d b = c d e 68
18 [ 1.13] x[i], i = (1, 1),..., (m, m) {+1, 1} [ 1.12] X[2] x[1] N ( µ 2 + ρ(x[1] µ 1 ), 1 ρ 2) > N < # > rho <- 0.5 # > S <- matrix(c(1,rho,rho,1),2,2) # Sigma > mu <- c(5,0) # mu > Sinv <- solve(s) # S > myf <- function(x) exp(-0.5*(x-mu)%*%sinv%*%(x-mu)) # f(x) > x <- c(0,0) # > xs <- matrix(0,2,n) # > fs <- rep(0,n) # f(x) > for(t in 1:N) { + i <- floor(runif(1)*2)+1 # + v <- mu[i]+rho*(x[-i]-mu[-i]) + rnorm(1)*sqrt(1-rho^2) # X[i] x[-i] + x[i] <- v # + xs[,t] <- x # x + fs[t] <- myf(x) # f(x) > plot(xs[1,],xs[2,]) # x > segments(c(0,xs[1,-n]),c(0,xs[2,-n]),xs[1,],xs[2,],col="pink") # > plot(log(fs),type="l") # log(f(x)) 69 H(x) = γ (i,j) x[i]x[j] (Ising model) γ > 0 f(x) exp( H(x)) h[i] = γ j:(i,j) x[j] i j f i(v x[ i]) exp(vh[i]) f i (v x[ i]) = exp(vh[i]) exp(h[i]) + exp( h[i]) i +1, 1 i i +1 cf. > N < # > m <- 50 # m*m > x0 <- matrix(runif(m*m)>0.5,m,m)*2-1 # +1,-1 > gamma <- 1.0 # gamma > 1/2.269 > x <- x0 # x > xi <- function(i) x[(i[1]-1)%%m+1,(i[2]-1)%%m+1] # x[(i[1],i[2])] > d1 <- c(1,0); d2 <- c(-1,0); d3 <- c(0,1); d4 <- c(0,-1) # > for(t in 1:N) { # + i <- trunc(runif(2)*m)+1 # i + a <- exp((xi(i+d1)+xi(i+d2)+xi(i+d3)+xi(i+d4))*gamma) # a=exp(h[i]) + p <- a/(a+(1/a)) # p=f_{i}(+1 x[-i]) + if(runif(1)<=p) v <- 1 else v <- -1 # p v=+1, (1-p) v= x[i[1],i[2]] <- v # x[i] := v > bw <- rev(gray((0:64)/64)) # 64 > image(x0,axes=f,col=bw) # > image(x,axes=f,col=bw) # N 1.4 xs[2, ] log(fs) [ 1.20] Ω i=1 D i = Ω A D i P (D i A) = P (A D i )P (D i ) j=1 P (A D j)p (D j ) P (A) > 0 [ 1.21] X, Y f(x, y) f f(x) = f(x, y) dy, f(y) = f(x, y) dx f(x y) f(y x) xs[1, ] Index X t log(f(x t)) f(y x)f(x) f(x y) = f(y x)f(x) dx f(y) >
19 ( ) { 1 ɛ y[i] = x[i] f(y[i] x[i]) = ɛ y[i] x[i] (i) x y ( f(y x) exp λ i ) x[i]y[i] λ = ɛ log( ɛ ) i x, y (ii) x ( f(x) exp γ ) x[i]x[j] (i,j) , γ > 0 (i,j) x x y x ( f(x y) exp λ x[i]y[i] + γ ) x[i]x[j] (1.8) i (i,j) x y [ 1.14] 1.24 (ii) f(x y) X 1, X 2, [ ] a X b Y f(x, y) f(y) > 0 f(y x)f(x) f(x y) = f(y x)f(x) dx R a f(x) f(x y) [ 1.22] X, Y Y x x Y X N(0, a 2 ), Y x N(x, b 2 ) X y N ( cy, cb 2), c = b2 a 2 c (i) a = 3, b = 1 (ii) a = 1, b = 3 [ 1.23] µ N(0, τ 2 ) µ n µ σ 2 x 1,..., x n N(µ, σ 2 ) x = (x x n )/n µ τ 2, σ 2 [ 1.24] x[i] y[i], i = (1, 1),..., (m, m) {+1, 1} x y x ɛ (0 < ɛ < 1) 74 y x 1.13 H(x) = γ (i,j) x[i]x[j] λ i x[i]y[i] y i λy[i] f(x y) exp( H(x)) h[i] = γ j:(i,j) x[j] + λy[i] x burn-in E(X y) MAP > ## > N < # > M < # burn-in > ns < # > m <- 50 # m*m > gamma <- 1.0 # gamma > 1/2.269 > eps < # 35% (50% ) > lambda <- 0.5*log((1-eps)/eps) # > d1 <- c(1,0); d2 <- c(-1,0); d3 <- c(0,1); d4 <- c(0,-1) # > xi <- function(i) if(i[1]>=1 && i[2]>=1 && i[1]<=m && i[2]<=m) + x[i[1],i[2]] else -1 # x[(i[1],i[2])] > ## ( ) > y0 <- matrix(-1,m,m) # y[i]=-1 > for(i1 in 1:m) for(i2 in 1:m) + if(!(abs(i1-0.5*m)<0.15*m && abs(i2-0.5*m)<0.15*m) && + sqrt((i1-0.5*m)^2+(i2-0.5*m)^2) < 0.4*m ) y0[i1,i2] <- +1 > ## 76
20 > y <- y0 # > i <- runif(m*m) < eps # > y[i] <- - y[i] # > ## > myabserr <- function(x) mean(abs(x-y0)/2) # y0 > mylogf <- function(x) { # log(f(x y)) y0 + s <- 0 + for(i1 in 1:m) for(i2 in 1:m) { + i <- c(i1,i2) + s <- s + xi(i)*(xi(i+d1)+xi(i+d2)+xi(i+d3)+xi(i+d4)) + lambda*sum(x*y)+gamma*s/2 > ## > x <- y # x > myabserr(x) # [1] 0.35 > abserrs <- rep(0,1+n/ns); logfs <- rep(0,1+n/ns) # abserr logf > abserrs[1] <- myabserr(x); logfs[1] <- mylogf(x) # > xp <- matrix(0,m,m) # > ## > for(t in 1:N) { + i <- trunc(runif(2)*m)+1 # i + a <- exp((xi(i+d1)+xi(i+d2)+xi(i+d3)+xi(i+d4))*gamma + +y[i[1],i[2]]*lambda) # a=exp(h[i]) + p <- a/(a+(1/a)) # p=f_{i}(+1 x[-i],y) + if(runif(1)<=p) v <- 1 else v <- -1 # p v=+1, (1-p) v= x[i[1],i[2]] <- v # x[i] := v + if(t>m) xp <- xp + x # x(t) + if((t %% ns) == 0) { # + j <- 1 + t %/% ns + abserrs[j] <- myabserr(x); logfs[j] <- mylogf(x) # > xn <- x # > myabserr(xn) # [1] > xp <- xp / (N-M) # > myabserr(xp) # [1] > xp2 <- sign(xp) # 2 > myabserr(xp2) # [1] > bw <- rev(gray((0:64)/64)) # 64 > image(y0,axes=f,col=bw) # > image(y,axes=f,col=bw) # > image(xp,axes=f,col=bw) # N-M > image(xp2,axes=f,col=bw) # 2 > plot(0:(n/ns),abserrs,xlab=paste("t/",ns,sep="")) # > abline(v=m/ns,lty=2) # burn-in > plot(0:(n/ns),logfs,xlab=paste("t/",ns,sep="")) # log(f(y x)) > abline(v=m/ns,lty=2) # burn-in [ 1.25] burn-in 2 ɛ =
21 > abserrs2[nf+1] # [1] > plot(0:nf,abserrs2,xlab="iteration") # > image(xf,axes=f,col=bw) # 1.5 abserrs logfs [ 1.6] t R X (moment generating function) M X (t) = E(e tx ) [ 1.27] [ 1.28] k M X (t) E(X k ) = dm M X (t) t=0 dt k X N(0, 1) M X (t) E(X k ) t/2500 t/2500 k = 2, 4, 6, 8 17 P i X t[i] x[i] /(2m2 ) log f(x t y) (1.8) exp [ 1.29] [ 1.30] X Y M X+Y (t) = M X (t)m Y (t) X 1,..., X n N(0, 1) X > mean(xp2!= y) [1] [ 1.26] 1.14 (i) (ii) (iii) γ λ N M [ 1.15] > nf <- 10 # > d0 <- c(0,0) # > d1 <- c(1,0); d2 <- c(-1,0); d3 <- c(0,1); d4 <- c(0,-1) # > d5 <- c(1,1); d6 <- c(-1,1); d7 <- c(-1,-1); d8 <- c(1,-1) # > xi9 <- function(i) c(xi(i+d0),xi(i+d1),xi(i+d2),xi(i+d3),xi(i+d4), + xi(i+d5),xi(i+d6),xi(i+d7),xi(i+d8)) # 9 > xf <- y # > abserrs2 <- rep(0,nf+1); abserrs2[1] <- myabserr(y) # > ## > for(t in 1:nf) { + x <- xf + for(i1 in 1:m) for(i2 in 1:m) xf[i1,i2] <- median(xi9(c(i1,i2))) + abserrs2[t+1] <- myabserr(xf) abserrs iteration
22 Y n = X Xn 2 M Y n (t) n Y χ 2 n 1 f(y) = 2 n e y 2 y n 2 1, y 0 2 Γ( n 2 ) Y M Y (t) M Yn (t) [ 1.32] m X E(X) = µ V (X) = Σ Y = AX + b A k m b k [ 1.33] X X N m (µ, Σ) Y [ 1.7] t R X (characteristic function) ϕ X (t) = E(e itx ) [ 1.10] Y n Y g [ ] ϕ X (t) = M X (it) i = 1 lim E(g(Y n)) = E(g(Y )) (1.9) n ϕ X (t) f f(x) ϕ X (t) Y n Y Y n d Y n F d Y Y F f(t) = Ff(t) = e itx f(x) dx, f(x) = F 1 1 f(x) = e itx f(t) dt 2π ϕ X (t) = f( t) M X (t) ϕ X (t) [ ] Y n f n (y) Y f(y) Y n d Y f n f g(x) = I(x A) (1.9) lim n f n (A) = f(a) A = (, y) lim n F n (y) = F (y) F (y) y [ 1.8] X 1 z 1 X G X (z) = E(z X ) [ ] G X (e t ) = M X (t) X G X (z) M X (t) [ 1.31] X n > 0 0 < p < 1 Y λ > 0 0 x n, y 0 p X (x) = n! x!(n x)! px (1 p) n x, p Y (y) = e λ λ y y! Y n [ 1.2] d Y X n E(X 1 ) = 0 V (X 1 ) = 1 n n Y n = 1 n n X i 1.1 Y n = n X n n i=1 ( n, ( ) M X (t) = pe t + (1 p)) MY (t) = exp λ(e t 1) Y n d N(0, 1) (1.10) [ ] E(X 1 ) = µ V (X 1 ) = σ 2 Z n = (X n µ)/σ Z n [ 1.9] m X = (X 1,..., X m ) m t = (t 1,..., t m ) M X (t) = E(e t X ) n Z d n N(0, 1) n n Zn N(0, 1) (asymptotic normality) n Z a a n N(0, 1) Zn N(0, 1/n) a X n N(µ, σ 2 /n) E( X n ) = µ V ( X n ) = σ 2 /n X n [ ] E(X k 1 ), k = 1, 2,... X 1 ϕ X1 (t) = E(e itx1 ) = 86 88
23 (it) k k=0 k! E(X1 k ) = 1 t2 2 it3 6 E(X3 1 ) + t4 24 E(X4 1 ) + ϕ Yn (t) = [ ϕ X1 (t/ n) ] n = [ 1 t2 2n lim n ϕ Yn (t) = e t2 /2 it3 6n 3/2 E(X3 1 ) + t4 24n 2 E(X4 1 ) + [ 1.16] > ## myclt: n b > ## : n= b= > ## : b > myclt <- function(n,b) { + X <- matrix(runif(n*b),n,b) # n*b U(0,1) + a <- rep(1/n,n) # 1/n n + y <- a %*% X # b + x0 <- seq(min(y),max(y),length=1000) # y truehist(y) # + lines(x0,dnorm(x0,mean=0.5,sd=sqrt(1/120)),col=2) # > myclt(5,10000) > myclt(10,10000) 19 [ 1.17] > ## myclt2: n ( p 1 1-p 0) b > ## : n= p=+1 b= > ## : b 89 ] n ] n = [1 t2 (1 + o(1)) 2n > myclt2 <- function(n,p,b) { + X <- matrix(as.numeric(runif(n*b)<p),n,b) # n*b a <- rep(1,n) # 1 n + y <- a %*% X # b + x0 <- seq(from=min(y)-0.5,to=max(y)+0.5) # truehist(y,breaks=x0) # + x0 <- seq(from=min(y),to=max(y)) # + points(x0,dbinom(x0,size=n, prob=p)) # + points(x0,dpois(x0,lambda=n*p),col=3) # + x0 <- seq(from=min(y)-0.5,to=max(y)+0.5,length=10000) # lines(x0,dnorm(x0,mean=n*p,sd=sqrt(n*p*(1-p))),col=2) # > myclt2(10,0.05,10000) > myclt2(10,0.5,10000) 20 [ 1.34] n p X (i) λ > 0 p = λ/n n X λ 1.31 M X (t) M Y (t) (ii) 0 < p < 1 n (X np)/ n 0 p(1 p) [ 1.35] X n m E(X) = 0 V (X) = Σ = (σ ij ) y y y y 19 n n = 5 n = n n = 10, p = 0.05 n = 10, p =
24 X n = n i=1 X i/n n X n d Nm (0, Σ) (1.11) [ 2.2] f(x; θ) θ 0 Θ q = f( ; θ 0 ) x q(x) = f(x; θ 0 ) N m E(X k1 1 Xkm m ), k 1,..., k m 0 ϕ n X(t) = E(e i nt X ) [ ] [ 2.1] X N(µ, σ 2 ) θ = (µ, σ 2 ), p = 2 m X N m (µ, Σ) θ = (µ, Σ), p = m(m + 3)/2 [ 2.2] k i X f i (x; θ i ) k i p(i) = π i > 0 k i=1 π i = 1 X i f(x, i; θ) = f i (x; θ i )π i θ = (π 1,..., π k 1, θ 1,..., θ k ) f(x, i; θ) = f(x i; θ)p(i; θ) i X N(µ i, σi 2) θ i = (µ i, σi 2) f i(x; θ i ) = 1 2πσ 2 i exp( (x µi)2 ) 2σi 2 [ 2.3] 2.2 X i X EM Fisher 2.1 m X q(x) X q(x) q(x) X q n m X 1,..., X n q(x) (i.i.d.=independently identically distributed) X 1,..., X n q(x) (i.i.d.) n X = (x 1,..., x n ) [ 2.1] q(x) p θ Θ R p f(x; θ) X k f(x; θ) = f i (x; θ i )π i [ 2.3] i=1 2.3 (mixture distribution) (normal mixture model) [ ] i x i x i x f(x i) i p(i) i, j f(x i, j) i j x ( X) 94 96
25 [ 2.4] 2.3 n 1 = 100, k = 3, π 1 = 0.5, π 2 = 0.3, π 3 = 0.2, µ 1 = 0, µ 2 = 4, µ 3 = 3, σ 1 = 1, σ 2 = 2, σ 3 = 1. > ### > ## : n1 > ## : k > ## : pr[1],...,pr[k-1] > ## : mu[1],...,mu[k] > ## : ss[1],...,ss[k] > ## xx1 > n1 <- 100; k <- 3 > pr <- c(0.5,0.3); mu <- c(0,4,-3); ss <- c(1,2,1)^2 > pr[k] <- 1 - sum(pr) > ## > ## x0= x (k,pr,mu,ss)= col= > drawnormmix <- function(x0,k,pr,mu,ss,col) { + ## i f(x0[t] i)*p(i),t=1,2,.. + fi <- matrix(0,length(x0),k) # fi(xt), i=1,...,k, t=1,...,n + for(i in 1:k) fi[,i] <- pr[i]*dnorm(x0,mean=mu[i],sd=sqrt(ss[i])) + ## f(x0[t]),t=1,2,... + f <- apply(fi,1,sum) # f(xt), t=1,...,n + ## + if(col!= FALSE) { + matlines(x0,fi,col=col,lty=1) # + lines(x0,f,col=col,lty=2,lwd=2) # 97 [1] > drawnormmix(x0,k,pr1,mu1,ss1,"red") # n 1 X 1 = {(x t, i t ), t = 1,..., n 1 } n 1 log L(θ X 1 ) = log (f it (x t ; θ it )π it ) 2.2 [ 2.5] 2.3 x i p(i x) t=1 π i (x; θ) = f i(x; θ i )π i f(x; θ) i î(x; θ) = arg max i=1,...,k π i(x; θ) x î(x; θ) θ ˆθ 99 + invisible(list(f=f,fi=fi)) # > ## > ii1 <- sample(k,n1,replace=true,prob=pr) # > ii1[1:30] # [1] > zz1 <- rnorm(n1) # N(0,1) > xx1 <- zz1*sqrt(ss)[ii1] + mu[ii1] # > x0 <- seq(min(xx1),max(xx1),length=400) # 400 > hist(xx1,nclas=10,prob=t) # > rug(xx1) # > f0 <- drawnormmix(x0,k,pr,mu,ss,"darkgreen")$f # (f0 ) (x, i) i = 1,..., k > ## pr1,mu1,ss1 > pr1 <- mu1 <- ss1 <- rep(0,k) # > for(i in 1:k) { + pr1[i] <- sum(ii1==i)/length(ii1) # i + x <- xx1[ii1==i] # i + mu1[i] <- mean(x) # + ss1[i] <- mean((x-mu1[i])^2) # > pr1 # pr [1] > mu1 # mu [1] > sqrt(ss1) # sqrt(ss) 98 x i i.i.d. [ 2.6] 2.4 n 2 = 300 i x î(x; ˆθ) 2.4 (x t, i t ) i > ## : n2 > ## xx2 > n2 <- 300 > ii2 <- sample(k,n2,replace=true,prob=pr) # > ii2[1:30] # [1] > zz2 <- rnorm(n2) # N(0,1) > xx2 <- zz2*sqrt(ss)[ii2] + mu[ii2] # > hist(xx2,nclass=15,prob=t) # > rug(xx2) # > drawnormmix(x0,k,pr,mu,ss,"darkgreen") # > ## i ii2 xx2 ( xx1 ii1 > a <- drawnormmix(xx2,k,pr1,mu1,ss1,false) # n1 > round(t(a$fi[1:10,]),3) # f(xx2[t] i)*p(i) 10 [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [1,] [2,] [3,] > round(a$f[1:10],3) # f(xx2[t])
26 [1] > pr2x1 <- a$fi / a$f # p(i x) > round(t(pr2x1[1:10,]),3) # 10 [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [1,] [2,] [3,] > ## ( ) : ii2x1 pr2x1 a$fi > ii2x1 <- apply(pr2x1,1,function(p) order(-p)[1]) > ii2x1[1:30] # [1] > sum(ii2x1 == ii2)/length(ii2) # [1] [ 2.7] k = 2 i = 0 (ham) i = 1 (spam) m j = 1,..., m x[j] = 1 x[j] = 0 i x p(x i) f i (x i; θ i ) = p(x[1] i)p(x[2] i) p(x[m] i) i x[j] = 1 p(x[j] i) = θ i [j] x[j] = 0 p(x[j] i) = 1 θ i [j] θ = (π 1, θ 0 [1],..., θ 0 [m], θ 1 [1],..., θ 1 [m]) 101 Naive Bayes Spambase UCI Repository of machine learning databases ~mlearn/mlrepository.html > ### > load("spam1.rda") # dat1.train,spam.train,dat1.test,spam.test > dim(dat1.train) # n=3601, m=54 [1] > t(dat1.train[1:20,1:10]) # Iword_freq_make Iword_freq_address Iword_freq_all Iword_freq_3d Iword_freq_our Iword_freq_over Iword_freq_remove Iword_freq_internet Iword_freq_order Iword_freq_mail > spam.train[1:20] # spam=1, ham=0 [1] > dim(dat1.test) # [1] > ### theta > ## x : 0,1 ( dat) > ## y : 0,1 ( spam) 103 Density Histogram of xx xx1 Density Histogram of xx xx2 21 (x t, i t), t = 1,..., n > mymle <- function(x,y) { + py1 <- mean(y) # p(y=1) + px0 <- apply(x[y==0,],2,mean) # p(x[j]=1 y=0) + px1 <- apply(x[y==1,],2,mean) # p(x[j]=1 y=1) + list(py1=py1,px0=px0,px1=px1) # theta > ### p(y=1 x) > ## th : list(py1,px0,px1) > ## x : 0,1 ( dat) > mypp <- function(th,x) { + x <- as.matrix(x) # x + x0 <- x1 <- x + for(j in seq(ncol(x))) { # j=1,...,m + a <- x[,j] + 1 # t=1,...,n j =2, =1 + x0[,j] <- c(1-th$px0[j],th$px0[j])[a] # p(x[j] y=0) + x1[,j] <- c(1-th$px1[j],th$px1[j])[a] # p(x[j] y=1) + p0 <- apply(x0,1,prod) # p(x y=0) + p1 <- apply(x1,1,prod) # p(x y=1) + th$py1*p1/(th$py1*p1 + (1-th$py1)*p0) # p(y=1 x) > ### > myppplot <- function(spam,pp,pth) { + ## + def.par <- par(no.readonly = TRUE); on.exit(par(def.par)) + layout(matrix(1:2,2,1)) + ## spam/ham + sp <- spam==1 # spam=true, ham=false + p0 <- mean(pp[!sp]>pth) # ham spam 104
27 + p1 <- mean(pp[sp]>pth) # spam spam + ## ham + hist(pp[!sp],col="blue",nclass=50,prob=t,main="ham mails", + sub=paste("p(say spam ham mail)=",round(p0,5))) + abline(v=pth,col="green") + ## spam + hist(pp[sp],col="red",nclass=50,prob=t,main="spam mails", + sub=paste("p(say spam spam mail)=",round(p1,5))) + abline(v=pth,col="green") + ## + ret <- c(pth,p0,p1) + names(ret) <- c("pth","p0","p1") + ret > ### > ## > th <- mymle(dat1.train,spam.train) # th > names(th) # [1] "py1" "px0" "px1" > th$py1 # p(y=1) [1] > round(th$px0[1:10],3) # p(x[j]=1 y=0) Iword_freq_make Iword_freq_address Iword_freq_all Iword_freq_3d Iword_freq_our Iword_freq_over Iword_freq_remove Iword_freq_internet Iword_freq_order Iword_freq_mail > round(th$px1[1:10],3) # p(x[j]=1 y=1) 105 > pth <- quantile(pp.train[spam.train==0],p=0.99) > pth # p(y=1 x)>pth spam 99% > myppplot(spam.train,pp.train,pth) # pth pth p0 p > myppplot(spam.test,pp.test,pth) # pth pth p0 p [ 2.1] 2.5 x m f i (x; θ i ) x N m (µ i, Σ i ) θ i = (µ i, Σ i ) i j π i f i (x; θ i ) > π j f i (x; θ j ) i j x S i (x) = log(π i f i (x; θ i )) [ 2.2] [ 2.3] 2.1 i Σ i = Σ x 2.5 θ = (π 1,..., π k 1, θ 1,..., θ k ) i x 107 Iword_freq_make Iword_freq_address Iword_freq_all Iword_freq_3d Iword_freq_our Iword_freq_over Iword_freq_remove Iword_freq_internet Iword_freq_order Iword_freq_mail > ## > pp.train <- mypp(th,dat1.train) # > round(pp.train[1:20],3) # p(y=1 x) > myppplot(spam.train,pp.train,0.5) # 0.5 pth p0 p > ## > pp.test <- mypp(th,dat1.test) # > round(pp.test[1:20],3) # p(y=1 x) > spam.test[1:20] # [1] > myppplot(spam.test,pp.test,0.5) # 0.5 pth p0 p > ## ham spam 0.01 Density Density ham mails pp[!sp] P(say spam ham mail)= spam mails pp[sp] P(say spam spam mail)= Density Density ham mails pp[!sp] P(say spam ham mail)= spam mails pp[sp] P(say spam spam mail)=
28 R 1 R 2 R k x R i i R = {R 1,..., R k } k P (R) = π i f i (x; θ i ) dx R i i=1 R = {R1,..., Rk } x Ri π i f i (x; θ i ) π j f j (x; θ j ), j = 1,..., k P (R ) P (R) 2.3 X = (x 1,..., x n ) f(x; θ) θ ˆθ ˆθ X f(x; θ) ˆθ [ 2.4] (X 1,..., X n ) θ L(θ X ) = f(x 1 ; θ) f(x n ; θ) [ 2.5] X 1,..., X n N(µ, σ 2 ) (i.i.d.) θ = (µ, σ 2 ) ML ˆµ ML = x, ˆσ 2 ML = n t=1 (x t x) 2 /n [ 2.6] X 1,..., X n N m (µ, Σ) (i.i.d.) θ = (θ, Σ) ˆµ ML = x, ˆΣ ML = n t=1 (x t x)(x t x) /n [ 2.7] k 2 X {1, 2,..., k} θ i = P (X = i), i = 1,..., k 1 θ = (θ 1,..., θ k 1 ) P (X = k) = 1 k 1 i=1 θ i x 1,..., x n i z i ˆθ i = z i /n (Z 1,..., Z k ) [ 2.8] 2.2 (x t, i t ), t = 1,..., n X i θ θ i i = 1,..., k π i i ˆθ i = arg max θ i n I(i t = i) log f i (x t ; θ i ), t=1 ˆπ i = z i n z i = n t=1 I(i t = i) ˆµ i = n t=1 I(i t = i)x t /z i ˆσ 2 i = n t=1 I(i t = i)(x t ˆµ i ) 2 /z i [ 2.5] θ π(θ) π(θ X ) L(θ X )π(θ) θ Θ π(θ X ) MAP Maximum A Posteriori estimator) [ 2.4] ˆθ MAP = arg max θ Θ π(θ X ) X 1,..., X n µ N(µ, 1) (i.i.d.), µ N(0, τ 2 ) µ (i) L(µ X ) exp( n 2 (µ x)2 ) x = n t=1 x t/n (ii) µ MAP ˆµ MAP = x x 1+nτ 2 [ 2.6] estimator) θ Θ L(θ X ) Maximum Likelihood ˆθ ML = arg max θ Θ L(θ X ) MAP π(θ) = 110 X 2.5 [ 2.8] i X 2.3 f(x; θ) 2.6 n 2 x t (i t θ X 2 = {x t, t = n 1 + 1,..., n 1 + n 2 } log L(θ X 2 ) = n 1+n 2 t=n 1+1 log f(x t ; θ) = n 1+n 2 t=n 1+1 ( k ) log f i (x t ; θ i )π i > ## > ## : xx2 > ## : k > ## pr2,mu2,ss2 > ## > mylik2 <- function(theta) { + pr <- theta[1:(k-1)]; mu <- theta[k:(2*k-1)]; ss <- theta[(2*k):(3*k-1)] + pr[k] <- 1 - sum(pr) + f <- drawnormmix(xx2,k,pr,mu,ss,false)$f # xx2 + -sum(log(f)) # *(-1) > ## (optim > th0 <- c(1/3,1/3,0,2,-2,1,1,1) # > opt2 <- optim(th0,mylik2,method="bfgs",control=list(trace=1,reltol=1e-14),hessian=true) initial value iter 10 value i=1
29 iter 20 value iter 30 value iter 40 value final value converged > th2 <- opt2$par > pr2 <- th2[1:(k-1)]; mu2 <- th2[k:(2*k-1)]; ss2 <- th2[(2*k):(3*k-1)] > pr2[k] <- 1 - sum(pr2) > a <- order(-pr2) # pr2 > pr2 <- pr2[a]; mu2 <- mu2[a]; ss2 <- ss2[a] # > pr2 # pr [1] > mu2 # mu [1] > sqrt(ss2) # sqrt(ss) [1] > hist(xx2,nclass=15,prob=t) # > rug(xx2) # > drawnormmix(x0,k,pr2,mu2,ss2,"blue") # > lines(x0,f0,col="darkgreen",lty=2,lwd=2) ˆθ = (ˆπ 1,..., ˆπ k 1, ˆµ 1,..., ˆµ k, ˆσ 2 1,..., σ 2 k ) i > ## i ii2 xx2 > a <- drawnormmix(xx2,k,pr2,mu2,ss2,false) # n2 x > pr2x2 <- a$fi / a$f > round(t(pr2x2[1:10,]),3) # [ 2.9] 2.9 X 1 X 2 ˆθ > ## > ## : xx1, ii1, xx2 > ## : k > ## pr3,mu3,ss3 > ## > mylik3 <- function(theta) { + pr <- theta[1:(k-1)]; mu <- theta[k:(2*k-1)]; ss <- theta[(2*k):(3*k-1)] + pr[k] <- 1 - sum(pr) + ## xx1,ii1 + fi <- drawnormmix(xx1,k,pr,mu,ss,false)$fi + f1 <- fi[seq(n1) + (ii1-1)*n1] + ## xx2 + f2 <- drawnormmix(xx2,k,pr,mu,ss,false)$f # xx2 + ## + -sum(log(c(f1,f2))) # *(-1) > ## > th0 <- c(1/3,1/3,0,2,-2,1,1,1) # > opt3 <- optim(th0,mylik3,method="bfgs",control=list(trace=1,reltol=1e-14)) # initial value [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [1,] [2,] [3,] > ## ( ) MAP : ii2x2 > ii2x2 <- apply(pr2x2,1,function(p) order(-p)[1]) > ii2x2[1:30] # [1] > sum(ii2x2 == ii2)/length(ii2) # [1] k x 1,..., x n x t x t i [ 2.9] n 1 X 1 = {(x t, i t ), t = 1,..., n 1 } n 2 X 2 = {x t, t = n 1 + 1,..., n 1 + n 2 } n 1 log L(θ X 1, X 2 ) = log L(θ X 1 ) + log L(θ X 2 ) = log (f it (x t ; θ it )π it ) + t=1 114 n 1+n 2 t=n 1+1 ( k ) log f i (x t ; θ i )π i i=1 iter 10 value iter 20 value iter 30 value iter 30 value iter 30 value final value converged > th3 <- opt3$par > pr3 <- th3[1:(k-1)]; mu3 <- th3[k:(2*k-1)]; ss3 <- th3[(2*k):(3*k-1)] > pr3[k] <- 1 - sum(pr3) > pr3 # pr [1] > mu3 # mu [1] > sqrt(ss3) # sqrt(ss) [1] > hist(xx2,nclass=15,prob=t) # > rug(xx2) # > drawnormmix(x0,k,pr3,mu3,ss3,"orange") # > lines(x0,f0,col="darkgreen",lty=2,lwd=2) > ## i ii2 xx2 > a <- drawnormmix(xx2,k,pr3,mu3,ss3,false) # n1 (x,i) n2 x > pr2x3 <- a$fi / a$f > round(t(pr2x3[1:10,]),3) # 10 [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [1,] [2,] [3,] > ## ( ) MAP : ii2x3 116
30 > ii2x3 <- apply(pr2x3,1,function(p) order(-p)[1]) > ii2x3[1:30] # [1] > sum(ii2x3 == ii2)/length(ii2) # [1] > ### > sum((c(pr1,mu1,ss1)-c(pr,mu,ss))^2) # n1 (x,i) [1] > sum((c(pr2,mu2,ss2)-c(pr,mu,ss))^2) # n2 x [1] > sum((c(pr3,mu3,ss3)-c(pr,mu,ss))^2) # n1 (x,i) n2 x [1] [ ] R optim EM n = n 1 + n 2 ˆ E (Expectation step) θ (r) t = 1,..., n 1 + n 2 i p(i t x t ) = π i (x t ; θ (r) ) π i (x t ; θ (r) ) = I(i = i t ), t = 1,..., n 1 X 1 i t )π (r) π i (x t ; θ (r) ) = f i(x t ; θ (r) i i f(x t ; θ (r) ), t = n 1 + 1,..., n ˆ M (Maximization step) π 1,..., π k ( i=1 π i = 1) π (r+1) i x t w t = = 1 n t=1 π i (x t ; θ (r) ) n t =1 π i(x t ; θ (r) ), n π i (x t ; θ (r) ) t = 1,..., n 2.4 EM [ 2.10] 2.9 r = 0, 1, 2,... r = 0 θ (r) θ (r+1) Histogram of xx2 Histogram of xx2 i = 1,..., k µ (r+1) i = σ 2 (r+1) i = n w t x t, t=1 n t=1 t = 1,..., n w t (x t µ (r+1) i ) 2, t = 1,..., n Density Density xx2 xx2 23 n 2 x t n 1 (x t, i t) n 2 x t 118 E M optim log L(θ (r) X 1, X 2 ) > ## EM > ## : xx1, ii1, xx2 > ## : k > ## pr4,mu4,ss4 > pr4 <- c(1/3,1/3,1/3); mu4 <- c(0,2,-2); ss4 <- c(1,1,1) # > nr <- 30 # > mystat <- function(pr,mu,ss) { # + lik <- mylik3(c(pr[-k],mu,ss)) # + cat(format(lik,digits=10),round(c(pr,mu,ss),3),"\n") # + c(lik,pr,mu,ss) > stat3 <- mystat(pr3,mu3,ss3) # optim mylik > stat4 <- matrix(0,1+nr,length(stat3)) # > stat4[1,] <- mystat(pr4,mu4,ss4) # 120
31 > xx <- c(xx1,xx2) # > pp1 <- matrix(0,n1,k); pp1[seq(n1)+(ii1-1)*n1] <- 1 # xx1 > t(pp1[1:10,]) # [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [1,] [2,] [3,] > ## EM > for(r in 1:nr) { # : break + a <- drawnormmix(xx2,k,pr4,mu4,ss4,false); pp2 <- a$fi/a$f # xx2 + pp <- rbind(pp1,pp2) # xx1 xx2 + pr4 <- apply(pp,2,sum)/(n1+n2) # pr + # wt <- pp/rep(apply(pp,2,sum),rep(n1+n2,k)) # + wt <- sweep(pp,2,apply(pp,2,sum),"/") # sweep + mu4 <- apply(xx*wt,2,sum) # mu + # ss4 <- apply((xx-rep(mu4,rep(n1+n2,k)))^2*wt,2,sum) # ss + ss4 <- apply(sweep(matrix(xx,n1+n2,k),2,mu4,"-")^2*wt,2,sum) # + cat(r,": ") + stat4[r+1,] <- mystat(pr4,mu4,ss4) # 1 : : : : : : : : > plot(0:nr,stat4[,1],type="b",xlab="iteration",ylab="lik") # > abline(h=stat3[1],lty=2,col="pink") # optim > matplot(0:nr,stat4[,-1],type="b",xlab="iteration",ylab="parameters") # > abline(h=stat3[-1],lty=2,col="pink") # optim [ 2.7] X Y 2.9 X = {X 1, X 2 } = {x 1,..., x n1+n 2, i 1,..., n n1 } Y = {i n1+1,..., i n1+n 2 } (X, Y) L(θ X, Y) X L(θ X ) = L(θ X, Y) dy Y 2.9 L(θ X ) EM r = 0 θ (r) θ (r+1) ˆ E (Expectation step) θ (r) X Y f(y X ; θ (r) ) f(y X ; θ (r) ) = L(θ(r) X, Y) L(θ (r) X ) Y log(l(θ X, Y)) Q(θ, θ (r) ) = log(l(θ X, Y))f(Y X ; θ (r) ) dy : : : : : : : : : : : : : : : : : : : : : : > pr4 # pr [1] > mu4 # mu [1] > sqrt(ss4) # sqrt(ss) [1] lik iteration parameters log L(θ (r) X 1, X 2), r = 0,..., optim θ (r) = (π (r) 1, π(r) 2, µ(r) 1, µ(r) 2, µ(r) (r) 3, σ2 1, σ 2 (r) 2, σ 2 (r) 3 ) iteration
32 ˆ M (Maximization step) Q(θ, θ (r) ) θ ˆθ ML ˆθ ML (X ) ˆθ ML (x 1,..., x n ) [ ] θ (r+1) = arg max Q(θ, θ (r) ) θ L(θ (r+1) X ) L(θ (r) X ) L(θ X ) = L(θ X, Y)/f(Y X ; θ) log L(θ X ) = log L(θ X, Y) log f(y X ; θ) ˆθ [ 2.8] f(x; θ) ˆθ (unbiased) E θ (ˆθ(X 1,..., X n )) = θ f(y X ; θ (r) ) log L(θ X ) = Q(θ, θ (r) ) H(θ, θ (r) ) H(θ, θ (r) ) = log(f(y X ; θ))f(y X ; θ (r) ) dy θ H(θ, θ (r) ) H(θ (r), θ (r) ) Q(θ, θ (r) ) Q(θ (r), θ (r) ) θ log L(θ X ) log L(θ (r) X ) [ ] (i) EM log L(θ X ) EM (ii) µ [ 2.1] ˆθ V θ (ˆθ(X 1,..., X n )) 1 n G(θ) 1 (2.1) G(θ) A, B A B A B (non-negative definite) m m G(θ) { } log f(x; θ) log f(x; θ) G ij (θ) = E θ θ i θ j G(θ) Fisher 127 x t log L(θ X ) [ 2.10] f(x) g(x) < x < f(x) > 0, g(x) > 0 log(g(x))f(x) dx log(f(x))f(x) dx [ ] G(θ) X t n ng(θ) Fisher 2.14 ( ) ng(θ) = E θ 2 log L θ θ [ ] E θ (ˆθ(X 1,..., X n )) = θ [ 2.11] EM 2.10 X = {x 1, x 2,..., x n } X 1, X 2,..., X n g(x) (i.i.d.) g(x) f(x; θ), θ Θ m θ = (θ 1,..., θ m ) f(x; θ) g(x) f(x; θ) X 1,..., X n X E θ ( ) V θ ( ) C θ ( ) L(θ X ) = f(x 1,..., x n ; θ) = f(x 1 ; θ)f(x 2 ; θ) f(x n ; θ) 126 θ j ˆθ i (x 1,..., x n )f(x 1,..., x n ; θ) dx 1 dx n = θ i, i = 1,..., m ˆθ i (x 1,..., x n ) log f(x 1,..., x n ; θ) f(x 1,..., x n ; θ) dx 1 dx n = θ i θ j θ j m S(x 1,..., x n ; θ) X = (X 1,..., X n ) S j (x 1,..., x n ; θ) = log f(x 1,..., x n ; θ) θ j, j = 1,..., m E θ {ˆθ(X )S(X ; θ) } = I m (2.2) 128
uda2008/main.tex 2008/05/
 uda2008/main.tex 2008/05/02 http://www.is.titech.ac.jp/~shimo/class/ 1 37 1.1.......................................................... 37 1.2....................................................... 45
uda2008/main.tex 2008/05/02 http://www.is.titech.ac.jp/~shimo/class/ 1 37 1.1.......................................................... 37 1.2....................................................... 45
第2回:データの加工・整理
 2 2018 4 13 1 / 24 1. 2. Excel 3. Stata 4. Stata 5. Stata 2 / 24 1 cross section data e.g., 47 2009 time series data e.g., 1999 2014 5 panel data e.g., 47 1999 2014 5 3 / 24 micro data aggregate data 4
2 2018 4 13 1 / 24 1. 2. Excel 3. Stata 4. Stata 5. Stata 2 / 24 1 cross section data e.g., 47 2009 time series data e.g., 1999 2014 5 panel data e.g., 47 1999 2014 5 3 / 24 micro data aggregate data 4
Copyright (c) 2004,2005 Hidetoshi Shimodaira :43:33 shimo X = x x 1p x n1... x np } {{ } p n = x (1) x (n) = [x 1,..
 2004,2005 Hidetoshi Shimodaira :43:33 shimo X = x x 1p x n1... x np } {{ } p n = x (1) x (n) = [x 1,..") Copyright (c) 2004,2005 Hidetoshi Shimodaira 2005-01-19 09:43:33 shimo 1. 2. 3. 1 1.1 X = x 11... x 1p x n1... x np } {{ } p n = x (1) x (n) = [x 1,..., x p ] x (i) x j X X 1 1 n n1 nx R dat
Copyright (c) 2004,2005 Hidetoshi Shimodaira 2005-01-19 09:43:33 shimo 1. 2. 3. 1 1.1 X = x 11... x 1p x n1... x np } {{ } p n = x (1) x (n) = [x 1,..., x p ] x (i) x j X X 1 1 n n1 nx R dat
 -- 2-- 4-- HP 3 2004 HP 6-- 5 8-- 7 / / ( / ) 10-- 77 30 39 14 2 3 3 77 14 9 2514 N 25 % 79 80 85 53 11 %DS 83 85 97 65 12 MJ/kg-wet 1.57 1.48 2.53 0.68 N=1 :40% 10.4MJ/kg-wet 2613 12-- 12 120% 10 100%
-- 2-- 4-- HP 3 2004 HP 6-- 5 8-- 7 / / ( / ) 10-- 77 30 39 14 2 3 3 77 14 9 2514 N 25 % 79 80 85 53 11 %DS 83 85 97 65 12 MJ/kg-wet 1.57 1.48 2.53 0.68 N=1 :40% 10.4MJ/kg-wet 2613 12-- 12 120% 10 100%
第6回:データセットの結合
 6 2018 5 18 1 / 29 1. 2. 3. 2 / 29 Stata Stata dta merge master using _merge master only (1): using only (2): matched (3): 3 / 29 Stata One-to-one on key variables Many-to-one on key variables One-to-many
6 2018 5 18 1 / 29 1. 2. 3. 2 / 29 Stata Stata dta merge master using _merge master only (1): using only (2): matched (3): 3 / 29 Stata One-to-one on key variables Many-to-one on key variables One-to-many
Supplementary data
 Supplementary data Supplement to: Onozuka D, Gasparrini A, Sera F, Hashizume M, Honda Y. Future projections of temperature-related excess out-of-hospital cardiac arrest under climate change scenarios in
Supplementary data Supplement to: Onozuka D, Gasparrini A, Sera F, Hashizume M, Honda Y. Future projections of temperature-related excess out-of-hospital cardiac arrest under climate change scenarios in
untitled
 2 : n =1, 2,, 10000 0.5125 0.51 0.5075 0.505 0.5025 0.5 0.4975 0.495 0 2000 4000 6000 8000 10000 2 weak law of large numbers 1. X 1,X 2,,X n 2. µ = E(X i ),i=1, 2,,n 3. σi 2 = V (X i ) σ 2,i=1, 2,,n ɛ>0
2 : n =1, 2,, 10000 0.5125 0.51 0.5075 0.505 0.5025 0.5 0.4975 0.495 0 2000 4000 6000 8000 10000 2 weak law of large numbers 1. X 1,X 2,,X n 2. µ = E(X i ),i=1, 2,,n 3. σi 2 = V (X i ) σ 2,i=1, 2,,n ɛ>0
tokei01.dvi
 2. :,,,. :.... Apr. - Jul., 26FY Dept. of Mechanical Engineering, Saga Univ., JAPAN 4 3. (probability),, 1. : : n, α A, A a/n. :, p, p Apr. - Jul., 26FY Dept. of Mechanical Engineering, Saga Univ., JAPAN
2. :,,,. :.... Apr. - Jul., 26FY Dept. of Mechanical Engineering, Saga Univ., JAPAN 4 3. (probability),, 1. : : n, α A, A a/n. :, p, p Apr. - Jul., 26FY Dept. of Mechanical Engineering, Saga Univ., JAPAN
A B P (A B) = P (A)P (B) (3) A B A B P (B A) A B A B P (A B) = P (B A)P (A) (4) P (B A) = P (A B) P (A) (5) P (A B) P (B A) P (A B) A B P
 = P (A)P (B) (3) A B A B P (B A) A B A B P (A B) = P (B A)P (A) (4) P (B A) = P (A B) P (A) (5) P (A B) P (B A) P (A B) A B P") 1 1.1 (population) (sample) (event) (trial) Ω () 1 1 Ω 1.2 P 1. A A P (A) 0 1 0 P (A) 1 (1) 2. P 1 P 0 1 6 1 1 6 0 3. A B P (A B) = P (A) + P (B) (2) A B A B A 1 B 2 A B 1 2 1 2 1 1 2 2 3 1.3 A B P (A
1 1.1 (population) (sample) (event) (trial) Ω () 1 1 Ω 1.2 P 1. A A P (A) 0 1 0 P (A) 1 (1) 2. P 1 P 0 1 6 1 1 6 0 3. A B P (A B) = P (A) + P (B) (2) A B A B A 1 B 2 A B 1 2 1 2 1 1 2 2 3 1.3 A B P (A
Part () () Γ Part ,
 () Γ Part ,") Contents a 6 6 6 6 6 6 6 7 7. 8.. 8.. 8.3. 8 Part. 9. 9.. 9.. 3. 3.. 3.. 3 4. 5 4.. 5 4.. 9 4.3. 3 Part. 6 5. () 6 5.. () 7 5.. 9 5.3. Γ 3 6. 3 6.. 3 6.. 3 6.3. 33 Part 3. 34 7. 34 7.. 34 7.. 34 8. 35
Contents a 6 6 6 6 6 6 6 7 7. 8.. 8.. 8.3. 8 Part. 9. 9.. 9.. 3. 3.. 3.. 3 4. 5 4.. 5 4.. 9 4.3. 3 Part. 6 5. () 6 5.. () 7 5.. 9 5.3. Γ 3 6. 3 6.. 3 6.. 3 6.3. 33 Part 3. 34 7. 34 7.. 34 7.. 34 8. 35
 n ξ n,i, i = 1,, n S n ξ n,i n 0 R 1,.. σ 1 σ i .10.14.15 0 1 0 1 1 3.14 3.18 3.19 3.14 3.14,. ii 1 1 1.1..................................... 1 1............................... 3 1.3.........................
n ξ n,i, i = 1,, n S n ξ n,i n 0 R 1,.. σ 1 σ i .10.14.15 0 1 0 1 1 3.14 3.18 3.19 3.14 3.14,. ii 1 1 1.1..................................... 1 1............................... 3 1.3.........................
ii 3.,. 4. F. (), ,,. 8.,. 1. (75%) (25%) =7 20, =7 21 (. ). 1.,, (). 3.,. 1. ().,.,.,.,.,. () (12 )., (), 0. 2., 1., 0,.
, ,,. 8.,. 1. (75%) (25%) =7 20, =7 21 (. ). 1.,, (). 3.,. 1. ().,.,.,.,.,. () (12 )., (), 0. 2., 1., 0,.") 24(2012) (1 C106) 4 11 (2 C206) 4 12 http://www.math.is.tohoku.ac.jp/~obata,.,,,.. 1. 2. 3. 4. 5. 6. 7.,,. 1., 2007 (). 2. P. G. Hoel, 1995. 3... 1... 2.,,. ii 3.,. 4. F. (),.. 5... 6.. 7.,,. 8.,. 1. (75%)
24(2012) (1 C106) 4 11 (2 C206) 4 12 http://www.math.is.tohoku.ac.jp/~obata,.,,,.. 1. 2. 3. 4. 5. 6. 7.,,. 1., 2007 (). 2. P. G. Hoel, 1995. 3... 1... 2.,,. ii 3.,. 4. F. (),.. 5... 6.. 7.,,. 8.,. 1. (75%)
 Gift Selection Catalog ご注文例 美味しい卵かけごはんを食べてほしい おすすめセット以外の組み合わせでご注文の場合は 単品番号でご注文ください IWATE YAMAGUCHI KUMAMOTO MIYAZAKI KAGAWA SHIZUOKA AICHI KANAGAWA TOKYO IBARAKI GUNMA SAITAMA GIFU MIE SHIGA KYOTO
Gift Selection Catalog ご注文例 美味しい卵かけごはんを食べてほしい おすすめセット以外の組み合わせでご注文の場合は 単品番号でご注文ください IWATE YAMAGUCHI KUMAMOTO MIYAZAKI KAGAWA SHIZUOKA AICHI KANAGAWA TOKYO IBARAKI GUNMA SAITAMA GIFU MIE SHIGA KYOTO
(lm) lm AIC 2 / 1
 lm AIC 2 / 1") W707 s-taiji@is.titech.ac.jp 1 / 1 (lm) lm AIC 2 / 1 : y = β 1 x 1 + β 2 x 2 + + β d x d + β d+1 + ϵ (ϵ N(0, σ 2 )) y R: x R d : β i (i = 1,..., d):, β d+1 : ( ) (d = 1) y = β 1 x 1 + β 2 + ϵ (d > 1) y
W707 s-taiji@is.titech.ac.jp 1 / 1 (lm) lm AIC 2 / 1 : y = β 1 x 1 + β 2 x 2 + + β d x d + β d+1 + ϵ (ϵ N(0, σ 2 )) y R: x R d : β i (i = 1,..., d):, β d+1 : ( ) (d = 1) y = β 1 x 1 + β 2 + ϵ (d > 1) y
I, II 1, A = A 4 : 6 = max{ A, } A A 10 10%
 1 2006.4.17. A 3-312 tel: 092-726-4774, e-mail: hara@math.kyushu-u.ac.jp, http://www.math.kyushu-u.ac.jp/ hara/lectures/lectures-j.html Office hours: B A I ɛ-δ ɛ-δ 1. 2. A 1. 1. 2. 3. 4. 5. 2. ɛ-δ 1. ɛ-n
1 2006.4.17. A 3-312 tel: 092-726-4774, e-mail: hara@math.kyushu-u.ac.jp, http://www.math.kyushu-u.ac.jp/ hara/lectures/lectures-j.html Office hours: B A I ɛ-δ ɛ-δ 1. 2. A 1. 1. 2. 3. 4. 5. 2. ɛ-δ 1. ɛ-n
II No.01 [n/2] [1]H n (x) H n (x) = ( 1) r n! r!(n 2r)! (2x)n 2r. r=0 [2]H n (x) n,, H n ( x) = ( 1) n H n (x). [3] H n (x) = ( 1) n dn x2 e dx n e x2
![II No.01 [n/2] [1]H n (x) H n (x) = ( 1) r n! r!(n 2r)! (2x)n 2r. r=0 [2]H n (x) n,, H n ( x) = ( 1) n H n (x). [3] H n (x) = ( 1) n dn x2 e dx n e x2](/thumbs/101/149159646.jpg "II No.01 [n/2] [1]H n (x) H n (x) = ( 1) r n! r!(n 2r)! (2x)n 2r. r=0 [2]H n (x) n,, H n ( x) = ( 1) n H n (x). [3] H n (x) = ( 1) n dn x2 e dx n e x2") II No.1 [n/] [1]H n x) H n x) = 1) r n! r!n r)! x)n r r= []H n x) n,, H n x) = 1) n H n x) [3] H n x) = 1) n dn x e dx n e x [4] H n+1 x) = xh n x) nh n 1 x) ) d dx x H n x) = H n+1 x) d dx H nx) = nh
II No.1 [n/] [1]H n x) H n x) = 1) r n! r!n r)! x)n r r= []H n x) n,, H n x) = 1) n H n x) [3] H n x) = 1) n dn x e dx n e x [4] H n+1 x) = xh n x) nh n 1 x) ) d dx x H n x) = H n+1 x) d dx H nx) = nh
6.1 (P (P (P (P (P (P (, P (, P.
 (011 30 7 0 ( ( 3 ( 010 1 (P.3 1 1.1 (P.4.................. 1 1. (P.4............... 1 (P.15.1 (P.16................. (P.0............3 (P.18 3.4 (P.3............... 4 3 (P.9 4 3.1 (P.30........... 4 3.
(011 30 7 0 ( ( 3 ( 010 1 (P.3 1 1.1 (P.4.................. 1 1. (P.4............... 1 (P.15.1 (P.16................. (P.0............3 (P.18 3.4 (P.3............... 4 3 (P.9 4 3.1 (P.30........... 4 3.
 ( 30 ) 30 4 5 1 4 1.1............................................... 4 1.............................................. 4 1..1.................................. 4 1.......................................
( 30 ) 30 4 5 1 4 1.1............................................... 4 1.............................................. 4 1..1.................................. 4 1.......................................
ii 3.,. 4. F. ( ), ,,. 8.,. 1. (75% ) (25% ) =7 24, =7 25, =7 26 (. ). 1.,, ( ). 3.,...,.,.,.,.,. ( ) (1 2 )., ( ), 0., 1., 0,.
, ,,. 8.,. 1. (75% ) (25% ) =7 24, =7 25, =7 26 (. ). 1.,, ( ). 3.,...,.,.,.,.,. ( ) (1 2 )., ( ), 0., 1., 0,.") (1 C205) 4 10 (2 C206) 4 11 (2 B202) 4 12 25(2013) http://www.math.is.tohoku.ac.jp/~obata,.,,,..,,. 1. 2. 3. 4. 5. 6. 7. 8. 1., 2007 ( ).,. 2. P. G., 1995. 3. J. C., 1988. 1... 2.,,. ii 3.,. 4. F. ( ),..
(1 C205) 4 10 (2 C206) 4 11 (2 B202) 4 12 25(2013) http://www.math.is.tohoku.ac.jp/~obata,.,,,..,,. 1. 2. 3. 4. 5. 6. 7. 8. 1., 2007 ( ).,. 2. P. G., 1995. 3. J. C., 1988. 1... 2.,,. ii 3.,. 4. F. ( ),..
6.1 (P (P (P (P (P (P (, P (, P.101
 (008 0 3 7 ( ( ( 00 1 (P.3 1 1.1 (P.3.................. 1 1. (P.4............... 1 (P.15.1 (P.15................. (P.18............3 (P.17......... 3.4 (P................ 4 3 (P.7 4 3.1 ( P.7...........
(008 0 3 7 ( ( ( 00 1 (P.3 1 1.1 (P.3.................. 1 1. (P.4............... 1 (P.15.1 (P.15................. (P.18............3 (P.17......... 3.4 (P................ 4 3 (P.7 4 3.1 ( P.7...........
ii 3.,. 4. F. (), ,,. 8.,. 1. (75% ) (25% ) =9 7, =9 8 (. ). 1.,, (). 3.,. 1. ( ).,.,.,.,.,. ( ) (1 2 )., ( ), 0. 2., 1., 0,.
, ,,. 8.,. 1. (75% ) (25% ) =9 7, =9 8 (. ). 1.,, (). 3.,. 1. ( ).,.,.,.,.,. ( ) (1 2 )., ( ), 0. 2., 1., 0,.") 23(2011) (1 C104) 5 11 (2 C206) 5 12 http://www.math.is.tohoku.ac.jp/~obata,.,,,.. 1. 2. 3. 4. 5. 6. 7.,,. 1., 2007 ( ). 2. P. G. Hoel, 1995. 3... 1... 2.,,. ii 3.,. 4. F. (),.. 5.. 6.. 7.,,. 8.,. 1. (75%
23(2011) (1 C104) 5 11 (2 C206) 5 12 http://www.math.is.tohoku.ac.jp/~obata,.,,,.. 1. 2. 3. 4. 5. 6. 7.,,. 1., 2007 ( ). 2. P. G. Hoel, 1995. 3... 1... 2.,,. ii 3.,. 4. F. (),.. 5.. 6.. 7.,,. 8.,. 1. (75%
k2 ( :35 ) ( k2) (GLM) web web 1 :
 ( k2) (GLM) web web 1 :") 2012 11 01 k2 (2012-10-26 16:35 ) 1 6 2 (2012 11 01 k2) (GLM) kubo@ees.hokudai.ac.jp web http://goo.gl/wijx2 web http://goo.gl/ufq2 1 : 2 2 4 3 7 4 9 5 : 11 5.1................... 13 6 14 6.1......................
2012 11 01 k2 (2012-10-26 16:35 ) 1 6 2 (2012 11 01 k2) (GLM) kubo@ees.hokudai.ac.jp web http://goo.gl/wijx2 web http://goo.gl/ufq2 1 : 2 2 4 3 7 4 9 5 : 11 5.1................... 13 6 14 6.1......................
untitled
 17 5 13 1 2 1.1... 2 1.2... 2 1.3... 3 2 3 2.1... 3 2.2... 5 3 6 3.1... 6 3.2... 7 3.3 t... 7 3.4 BC a... 9 3.5... 10 4 11 1 1 θ n ˆθ. ˆθ, ˆθ, ˆθ.,, ˆθ.,.,,,. 1.1 ˆθ σ 2 = E(ˆθ E ˆθ) 2 b = E(ˆθ θ). Y 1,,Y
17 5 13 1 2 1.1... 2 1.2... 2 1.3... 3 2 3 2.1... 3 2.2... 5 3 6 3.1... 6 3.2... 7 3.3 t... 7 3.4 BC a... 9 3.5... 10 4 11 1 1 θ n ˆθ. ˆθ, ˆθ, ˆθ.,, ˆθ.,.,,,. 1.1 ˆθ σ 2 = E(ˆθ E ˆθ) 2 b = E(ˆθ θ). Y 1,,Y
統計学のポイント整理
 .. September 17, 2012 1 / 55 n! = n (n 1) (n 2) 1 0! = 1 10! = 10 9 8 1 = 3628800 n k np k np k = n! (n k)! (1) 5 3 5 P 3 = 5! = 5 4 3 = 60 (5 3)! n k n C k nc k = npk k! = n! k!(n k)! (2) 5 3 5C 3 = 5!
.. September 17, 2012 1 / 55 n! = n (n 1) (n 2) 1 0! = 1 10! = 10 9 8 1 = 3628800 n k np k np k = n! (n k)! (1) 5 3 5 P 3 = 5! = 5 4 3 = 60 (5 3)! n k n C k nc k = npk k! = n! k!(n k)! (2) 5 3 5C 3 = 5!
微分積分 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. このサンプルページの内容は, 初版 1 刷発行時のものです.
 微分積分 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. ttp://www.morikita.co.jp/books/mid/00571 このサンプルページの内容は, 初版 1 刷発行時のものです. i ii 014 10 iii [note] 1 3 iv 4 5 3 6 4 x 0 sin x x 1 5 6 z = f(x, y) 1 y = f(x)
微分積分 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. ttp://www.morikita.co.jp/books/mid/00571 このサンプルページの内容は, 初版 1 刷発行時のものです. i ii 014 10 iii [note] 1 3 iv 4 5 3 6 4 x 0 sin x x 1 5 6 z = f(x, y) 1 y = f(x)
I A A441 : April 21, 2014 Version : Kawahira, Tomoki TA (Kondo, Hirotaka ) Google
 Google") I4 - : April, 4 Version :. Kwhir, Tomoki TA (Kondo, Hirotk) Google http://www.mth.ngoy-u.c.jp/~kwhir/courses/4s-biseki.html pdf 4 4 4 4 8 e 5 5 9 etc. 5 6 6 6 9 n etc. 6 6 6 3 6 3 7 7 etc 7 4 7 7 8 5 59
I4 - : April, 4 Version :. Kwhir, Tomoki TA (Kondo, Hirotk) Google http://www.mth.ngoy-u.c.jp/~kwhir/courses/4s-biseki.html pdf 4 4 4 4 8 e 5 5 9 etc. 5 6 6 6 9 n etc. 6 6 6 3 6 3 7 7 etc 7 4 7 7 8 5 59
確率論と統計学の資料
 5 June 015 ii........................ 1 1 1.1...................... 1 1........................... 3 1.3... 4 6.1........................... 6................... 7 ii ii.3.................. 8.4..........................
5 June 015 ii........................ 1 1 1.1...................... 1 1........................... 3 1.3... 4 6.1........................... 6................... 7 ii ii.3.................. 8.4..........................
201711grade1ouyou.pdf
 2017 11 26 1 2 52 3 12 13 22 23 32 33 42 3 5 3 4 90 5 6 A 1 2 Web Web 3 4 1 2... 5 6 7 7 44 8 9 1 2 3 1 p p >2 2 A 1 2 0.6 0.4 0.52... (a) 0.6 0.4...... B 1 2 0.8-0.2 0.52..... (b) 0.6 0.52.... 1 A B 2
2017 11 26 1 2 52 3 12 13 22 23 32 33 42 3 5 3 4 90 5 6 A 1 2 Web Web 3 4 1 2... 5 6 7 7 44 8 9 1 2 3 1 p p >2 2 A 1 2 0.6 0.4 0.52... (a) 0.6 0.4...... B 1 2 0.8-0.2 0.52..... (b) 0.6 0.52.... 1 A B 2
ii
 ii iii 1 1 1.1..................................... 1 1.2................................... 3 1.3........................... 4 2 9 2.1.................................. 9 2.2...............................
ii iii 1 1 1.1..................................... 1 1.2................................... 3 1.3........................... 4 2 9 2.1.................................. 9 2.2...............................
数理統計学Iノート
 I ver. 0/Apr/208 * (inferential statistics) *2 A, B *3 5.9 *4 *5 [6] [],.., 7 2004. [2].., 973. [3]. R (Wonderful R )., 9 206. [4]. ( )., 7 99. [5]. ( )., 8 992. [6],.., 989. [7]. - 30., 0 996. [4] [5]
I ver. 0/Apr/208 * (inferential statistics) *2 A, B *3 5.9 *4 *5 [6] [],.., 7 2004. [2].., 973. [3]. R (Wonderful R )., 9 206. [4]. ( )., 7 99. [5]. ( )., 8 992. [6],.., 989. [7]. - 30., 0 996. [4] [5]
st.dvi
 9 3 5................................... 5............................. 5....................................... 5.................................. 7.........................................................................
9 3 5................................... 5............................. 5....................................... 5.................................. 7.........................................................................
(2 X Poisso P (λ ϕ X (t = E[e itx ] = k= itk λk e k! e λ = (e it λ k e λ = e eitλ e λ = e λ(eit 1. k! k= 6.7 X N(, 1 ϕ X (t = e 1 2 t2 : Cauchy ϕ X (t
![(2 X Poisso P (λ ϕ X (t = E[e itx ] = k= itk λk e k! e λ = (e it λ k e λ = e eitλ e λ = e λ(eit 1. k! k= 6.7 X N(, 1 ϕ X (t = e 1 2 t2 : Cauchy ϕ X (t](/thumbs/67/56612994.jpg "(2 X Poisso P (λ ϕ X (t = E[e itx ] = k= itk λk e k! e λ = (e it λ k e λ = e eitλ e λ = e λ(eit 1. k! k= 6.7 X N(, 1 ϕ X (t = e 1 2 t2 : Cauchy ϕ X (t") 6 6.1 6.1 (1 Z ( X = e Z, Y = Im Z ( Z = X + iy, i = 1 (2 Z E[ e Z ] < E[ Im Z ] < Z E[Z] = E[e Z] + ie[im Z] 6.2 Z E[Z] E[ Z ] : E[ Z ] < e Z Z, Im Z Z E[Z] α = E[Z], Z = Z Z 1 {Z } E[Z] = α = α [ α ]
6 6.1 6.1 (1 Z ( X = e Z, Y = Im Z ( Z = X + iy, i = 1 (2 Z E[ e Z ] < E[ Im Z ] < Z E[Z] = E[e Z] + ie[im Z] 6.2 Z E[Z] E[ Z ] : E[ Z ] < e Z Z, Im Z Z E[Z] α = E[Z], Z = Z Z 1 {Z } E[Z] = α = α [ α ]
V 0 = + r pv (H) + qv (T ) = + r ps (H) + qs (T ) = S 0 X n+ (T ) = n S n+ (T ) + ( + r)(x n n S n ) = ( + r)x n + n (d r)s n = ( + r)v n + V n+(h) V
 + qv (T ) = + r ps (H) + qs (T ) = S 0 X n+ (T ) = n S n+ (T ) + ( + r)(x n n S n ) = ( + r)x n + n (d r)s n = ( + r)v n + V n+(h) V") I (..2) (0 < d < + r < u) X 0, X X = 0 S + ( + r)(x 0 0 S 0 ) () X 0 = 0, P (X 0) =, P (X > 0) > 0 0 H, T () X 0 = 0, X (H) = 0 us 0 ( + r) 0 S 0 = 0 S 0 (u r) X (T ) = 0 ds 0 ( + r) 0 S 0 = 0 S 0 (d r)
I (..2) (0 < d < + r < u) X 0, X X = 0 S + ( + r)(x 0 0 S 0 ) () X 0 = 0, P (X 0) =, P (X > 0) > 0 0 H, T () X 0 = 0, X (H) = 0 us 0 ( + r) 0 S 0 = 0 S 0 (u r) X (T ) = 0 ds 0 ( + r) 0 S 0 = 0 S 0 (d r)
untitled
 3 3. (stochastic differential equations) { dx(t) =f(t, X)dt + G(t, X)dW (t), t [,T], (3.) X( )=X X(t) : [,T] R d (d ) f(t, X) : [,T] R d R d (drift term) G(t, X) : [,T] R d R d m (diffusion term) W (t)
3 3. (stochastic differential equations) { dx(t) =f(t, X)dt + G(t, X)dW (t), t [,T], (3.) X( )=X X(t) : [,T] R d (d ) f(t, X) : [,T] R d R d (drift term) G(t, X) : [,T] R d R d m (diffusion term) W (t)
( )/2 hara/lectures/lectures-j.html 2, {H} {T } S = {H, T } {(H, H), (H, T )} {(H, T ), (T, T )} {(H, H), (T, T )} {1
/2 hara/lectures/lectures-j.html 2, {H} {T } S = {H, T } {(H, H), (H, T )} {(H, T ), (T, T )} {(H, H), (T, T )} {1") ( )/2 http://www2.math.kyushu-u.ac.jp/ hara/lectures/lectures-j.html 1 2011 ( )/2 2 2011 4 1 2 1.1 1 2 1 2 3 4 5 1.1.1 sample space S S = {H, T } H T T H S = {(H, H), (H, T ), (T, H), (T, T )} (T, H) S
( )/2 http://www2.math.kyushu-u.ac.jp/ hara/lectures/lectures-j.html 1 2011 ( )/2 2 2011 4 1 2 1.1 1 2 1 2 3 4 5 1.1.1 sample space S S = {H, T } H T T H S = {(H, H), (H, T ), (T, H), (T, T )} (T, H) S
 X G P G (X) G BG [X, BG] S 2 2 2 S 2 2 S 2 = { (x 1, x 2, x 3 ) R 3 x 2 1 + x 2 2 + x 2 3 = 1 } R 3 S 2 S 2 v x S 2 x x v(x) T x S 2 T x S 2 S 2 x T x S 2 = { ξ R 3 x ξ } R 3 T x S 2 S 2 x x T x S 2
X G P G (X) G BG [X, BG] S 2 2 2 S 2 2 S 2 = { (x 1, x 2, x 3 ) R 3 x 2 1 + x 2 2 + x 2 3 = 1 } R 3 S 2 S 2 v x S 2 x x v(x) T x S 2 T x S 2 S 2 x T x S 2 = { ξ R 3 x ξ } R 3 T x S 2 S 2 x x T x S 2
I L01( Wed) : Time-stamp: Wed 07:38 JST hig e, ( ) L01 I(2017) 1 / 19
 : Time-stamp: Wed 07:38 JST hig e, ( ) L01 I(2017) 1 / 19") I L01(2017-09-20 Wed) : Time-stamp: 2017-09-20 Wed 07:38 JST hig e, http://hig3.net ( ) L01 I(2017) 1 / 19 ? 1? 2? ( ) L01 I(2017) 2 / 19 ?,,.,., 1..,. 1,2,.,.,. ( ) L01 I(2017) 3 / 19 ? I. M (3 ) II,
I L01(2017-09-20 Wed) : Time-stamp: 2017-09-20 Wed 07:38 JST hig e, http://hig3.net ( ) L01 I(2017) 1 / 19 ? 1? 2? ( ) L01 I(2017) 2 / 19 ?,,.,., 1..,. 1,2,.,.,. ( ) L01 I(2017) 3 / 19 ? I. M (3 ) II,
renshumondai-kaito.dvi
 3 1 13 14 1.1 1 44.5 39.5 49.5 2 0.10 2 0.10 54.5 49.5 59.5 5 0.25 7 0.35 64.5 59.5 69.5 8 0.40 15 0.75 74.5 69.5 79.5 3 0.15 18 0.90 84.5 79.5 89.5 2 0.10 20 1.00 20 1.00 2 1.2 1 16.5 20.5 12.5 2 0.10
3 1 13 14 1.1 1 44.5 39.5 49.5 2 0.10 2 0.10 54.5 49.5 59.5 5 0.25 7 0.35 64.5 59.5 69.5 8 0.40 15 0.75 74.5 69.5 79.5 3 0.15 18 0.90 84.5 79.5 89.5 2 0.10 20 1.00 20 1.00 2 1.2 1 16.5 20.5 12.5 2 0.10
newmain.dvi
 数論 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. http://www.morikita.co.jp/books/mid/008142 このサンプルページの内容は, 第 2 版 1 刷発行当時のものです. Daniel DUVERNEY: THÉORIE DES NOMBRES c Dunod, Paris, 1998, This book is published
数論 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. http://www.morikita.co.jp/books/mid/008142 このサンプルページの内容は, 第 2 版 1 刷発行当時のものです. Daniel DUVERNEY: THÉORIE DES NOMBRES c Dunod, Paris, 1998, This book is published
..3. Ω, Ω F, P Ω, F, P ). ) F a) A, A,..., A i,... F A i F. b) A F A c F c) Ω F. ) A F A P A),. a) 0 P A) b) P Ω) c) [ ] A, A,..., A i,... F i j A i A
![..3. Ω, Ω F, P Ω, F, P ). ) F a) A, A,..., A i,... F A i F. b) A F A c F c) Ω F. ) A F A P A),. a) 0 P A) b) P Ω) c) [ ] A, A,..., A i,... F i j A i A](/thumbs/93/112175219.jpg "..3. Ω, Ω F, P Ω, F, P ). ) F a) A, A,..., A i,... F A i F. b) A F A c F c) Ω F. ) A F A P A),. a) 0 P A) b) P Ω) c) [ ] A, A,..., A i,... F i j A i A") .. Laplace ). A... i),. ω i i ). {ω,..., ω } Ω,. ii) Ω. Ω. A ) r, A P A) P A) r... ).. Ω {,, 3, 4, 5, 6}. i i 6). A {, 4, 6} P A) P A) 3 6. ).. i, j i, j) ) Ω {i, j) i 6, j 6}., 36. A. A {i, j) i j }.
.. Laplace ). A... i),. ω i i ). {ω,..., ω } Ω,. ii) Ω. Ω. A ) r, A P A) P A) r... ).. Ω {,, 3, 4, 5, 6}. i i 6). A {, 4, 6} P A) P A) 3 6. ).. i, j i, j) ) Ω {i, j) i 6, j 6}., 36. A. A {i, j) i j }.
1 No.1 5 C 1 I III F 1 F 2 F 1 F 2 2 Φ 2 (t) = Φ 1 (t) Φ 1 (t t). = Φ 1(t) t = ( 1.5e 0.5t 2.4e 4t 2e 10t ) τ < 0 t > τ Φ 2 (t) < 0 lim t Φ 2 (t) = 0
 = Φ 1 (t) Φ 1 (t t). = Φ 1(t) t = ( 1.5e 0.5t 2.4e 4t 2e 10t ) τ < 0 t > τ Φ 2 (t) < 0 lim t Φ 2 (t) = 0") 1 No.1 5 C 1 I III F 1 F 2 F 1 F 2 2 Φ 2 (t) = Φ 1 (t) Φ 1 (t t). = Φ 1(t) t = ( 1.5e 0.5t 2.4e 4t 2e 10t ) τ < 0 t > τ Φ 2 (t) < 0 lim t Φ 2 (t) = 0 0 < t < τ I II 0 No.2 2 C x y x y > 0 x 0 x > b a dx
1 No.1 5 C 1 I III F 1 F 2 F 1 F 2 2 Φ 2 (t) = Φ 1 (t) Φ 1 (t t). = Φ 1(t) t = ( 1.5e 0.5t 2.4e 4t 2e 10t ) τ < 0 t > τ Φ 2 (t) < 0 lim t Φ 2 (t) = 0 0 < t < τ I II 0 No.2 2 C x y x y > 0 x 0 x > b a dx
1 8, : 8.1 1, 2 z = ax + by + c ax by + z c = a b +1 x y z c = 0, (0, 0, c), n = ( a, b, 1). f = n i=1 a ii x 2 i + i<j 2a ij x i x j = ( x, A x), f =
, n = ( a, b, 1). f = n i=1 a ii x 2 i + i<j 2a ij x i x j = ( x, A x), f =") 1 8, : 8.1 1, z = ax + by + c ax by + z c = a b +1 x y z c = 0, (0, 0, c), n = ( a, b, 1). f = a ii x i + i
1 8, : 8.1 1, z = ax + by + c ax by + z c = a b +1 x y z c = 0, (0, 0, c), n = ( a, b, 1). f = a ii x i + i
2000年度『数学展望 I』講義録
 2000 I I IV I II 2000 I I IV I-IV. i ii 3.10 (http://www.math.nagoya-u.ac.jp/ kanai/) 2000 A....1 B....4 C....10 D....13 E....17 Brouwer A....21 B....26 C....33 D....39 E. Sperner...45 F....48 A....53
2000 I I IV I II 2000 I I IV I-IV. i ii 3.10 (http://www.math.nagoya-u.ac.jp/ kanai/) 2000 A....1 B....4 C....10 D....13 E....17 Brouwer A....21 B....26 C....33 D....39 E. Sperner...45 F....48 A....53
: , 2.0, 3.0, 2.0, (%) ( 2.
 ( 2.") 2017 1 2 1.1...................................... 2 1.2......................................... 4 1.3........................................... 10 1.4................................. 14 1.5..........................................
2017 1 2 1.1...................................... 2 1.2......................................... 4 1.3........................................... 10 1.4................................. 14 1.5..........................................
(3) (2),,. ( 20) ( s200103) 0.7 x C,, x 2 + y 2 + ax = 0 a.. D,. D, y C, C (x, y) (y 0) C m. (2) D y = y(x) (x ± y 0), (x, y) D, m, m = 1., D. (x 2 y
 (2),,. ( 20) ( s200103) 0.7 x C,, x 2 + y 2 + ax = 0 a.. D,. D, y C, C (x, y) (y 0) C m. (2) D y = y(x) (x ± y 0), (x, y) D, m, m = 1., D. (x 2 y") [ ] 7 0.1 2 2 + y = t sin t IC ( 9) ( s090101) 0.2 y = d2 y 2, y = x 3 y + y 2 = 0 (2) y + 2y 3y = e 2x 0.3 1 ( y ) = f x C u = y x ( 15) ( s150102) [ ] y/x du x = Cexp f(u) u (2) x y = xey/x ( 16) ( s160101)
[ ] 7 0.1 2 2 + y = t sin t IC ( 9) ( s090101) 0.2 y = d2 y 2, y = x 3 y + y 2 = 0 (2) y + 2y 3y = e 2x 0.3 1 ( y ) = f x C u = y x ( 15) ( s150102) [ ] y/x du x = Cexp f(u) u (2) x y = xey/x ( 16) ( s160101)
1 1.1 ( ). z = a + bi, a, b R 0 a, b 0 a 2 + b 2 0 z = a + bi = ( ) a 2 + b 2 a a 2 + b + b 2 a 2 + b i 2 r = a 2 + b 2 θ cos θ = a a 2 + b 2, sin θ =
. z = a + bi, a, b R 0 a, b 0 a 2 + b 2 0 z = a + bi = ( ) a 2 + b 2 a a 2 + b + b 2 a 2 + b i 2 r = a 2 + b 2 θ cos θ = a a 2 + b 2, sin θ =") 1 1.1 ( ). z = + bi,, b R 0, b 0 2 + b 2 0 z = + bi = ( ) 2 + b 2 2 + b + b 2 2 + b i 2 r = 2 + b 2 θ cos θ = 2 + b 2, sin θ = b 2 + b 2 2π z = r(cos θ + i sin θ) 1.2 (, ). 1. < 2. > 3. ±,, 1.3 ( ). A
1 1.1 ( ). z = + bi,, b R 0, b 0 2 + b 2 0 z = + bi = ( ) 2 + b 2 2 + b + b 2 2 + b i 2 r = 2 + b 2 θ cos θ = 2 + b 2, sin θ = b 2 + b 2 2π z = r(cos θ + i sin θ) 1.2 (, ). 1. < 2. > 3. ±,, 1.3 ( ). A
.. ( )T p T = p p = T () T x T N P (X < x T ) N = ( T ) N (2) ) N ( P (X x T ) N = T (3) T N P T N P 0
T p T = p p = T () T x T N P (X < x T ) N = ( T ) N (2) ) N ( P (X x T ) N = T (3) T N P T N P 0") 20 5 8..................................................2.....................................3 L.....................................4................................. 2 2. 3 2. (N ).........................................
20 5 8..................................................2.....................................3 L.....................................4................................. 2 2. 3 2. (N ).........................................
100sen_Eng_h1_4
 Sapporo 1 Hakodate Japan 5 2 3 Kanazawa 15 7 Sendai Kyoto Kobe 17 16 10 9 18 20 Hiroshima 11 8 32 31 21 28 26 19 Fukuoka 33 25 13 35 34 23 22 14 12 40 37 27 24 29 41 38 Tokyo 36 42 44 39 30 Nagoya Shizuoka
Sapporo 1 Hakodate Japan 5 2 3 Kanazawa 15 7 Sendai Kyoto Kobe 17 16 10 9 18 20 Hiroshima 11 8 32 31 21 28 26 19 Fukuoka 33 25 13 35 34 23 22 14 12 40 37 27 24 29 41 38 Tokyo 36 42 44 39 30 Nagoya Shizuoka
I, II 1, 2 ɛ-δ 100 A = A 4 : 6 = max{ A, } A A 10
 1 2007.4.13. A 3-312 tel: 092-726-4774, e-mail: hara@math.kyushu-u.ac.jp, http://www.math.kyushu-u.ac.jp/ hara/lectures/lectures-j.html Office hours: B A I ɛ-δ ɛ-δ 1. 2. A 0. 1. 1. 2. 3. 2. ɛ-δ 1. ɛ-n
1 2007.4.13. A 3-312 tel: 092-726-4774, e-mail: hara@math.kyushu-u.ac.jp, http://www.math.kyushu-u.ac.jp/ hara/lectures/lectures-j.html Office hours: B A I ɛ-δ ɛ-δ 1. 2. A 0. 1. 1. 2. 3. 2. ɛ-δ 1. ɛ-n
都道府県別パネル・データを用いた均衡地価の分析: パネル共和分の応用
 No.04-J-7 4 3 * yumi.saita@boj.or.jp ** towa.tachibana@boj.or.jp *** **** toshitaka.sekine@boj.or.jp 103-8660 30 * ** *** London School of Economics **** : Λ y z x 4 3 / 1 (panel cointegration) Meese and
No.04-J-7 4 3 * yumi.saita@boj.or.jp ** towa.tachibana@boj.or.jp *** **** toshitaka.sekine@boj.or.jp 103-8660 30 * ** *** London School of Economics **** : Λ y z x 4 3 / 1 (panel cointegration) Meese and
II 2 II
 II 2 II 2005 yugami@cc.utsunomiya-u.ac.jp 2005 4 1 1 2 5 2.1.................................... 5 2.2................................. 6 2.3............................. 6 2.4.................................
II 2 II 2005 yugami@cc.utsunomiya-u.ac.jp 2005 4 1 1 2 5 2.1.................................... 5 2.2................................. 6 2.3............................. 6 2.4.................................
Microsoft PowerPoint - Sample info
 List of Microbial Libraries ExMyco StrMyco PowKinoco Contact us http://www.hyphagenesis.co.jp info@hyphagenesis.co.jp HyphaGenesis Inc. 2 37, Tamagawagakuen 6 chome, Machida, Tokyo 194 0041 Tel: 042(860)6258
List of Microbial Libraries ExMyco StrMyco PowKinoco Contact us http://www.hyphagenesis.co.jp info@hyphagenesis.co.jp HyphaGenesis Inc. 2 37, Tamagawagakuen 6 chome, Machida, Tokyo 194 0041 Tel: 042(860)6258
x () g(x) = f(t) dt f(x), F (x) 3x () g(x) g (x) f(x), F (x) (3) h(x) = x 3x tf(t) dt.9 = {(x, y) ; x, y, x + y } f(x, y) = xy( x y). h (x) f(x), F (x
 g(x) = f(t) dt f(x), F (x) 3x () g(x) g (x) f(x), F (x) (3) h(x) = x 3x tf(t) dt.9 = {(x, y) ; x, y, x + y } f(x, y) = xy( x y). h (x) f(x), F (x") [ ] IC. f(x) = e x () f(x) f (x) () lim f(x) lim f(x) x + x (3) lim f(x) lim f(x) x + x (4) y = f(x) ( ) ( s46). < a < () a () lim a log xdx a log xdx ( ) n (3) lim log k log n n n k=.3 z = log(x + y ),
[ ] IC. f(x) = e x () f(x) f (x) () lim f(x) lim f(x) x + x (3) lim f(x) lim f(x) x + x (4) y = f(x) ( ) ( s46). < a < () a () lim a log xdx a log xdx ( ) n (3) lim log k log n n n k=.3 z = log(x + y ),
,. Black-Scholes u t t, x c u 0 t, x x u t t, x c u t, x x u t t, x + σ x u t, x + rx ut, x rux, t 0 x x,,.,. Step 3, 7,,, Step 6., Step 4,. Step 5,,.
 9 α ν β Ξ ξ Γ γ o δ Π π ε ρ ζ Σ σ η τ Θ θ Υ υ ι Φ φ κ χ Λ λ Ψ ψ µ Ω ω Def, Prop, Th, Lem, Note, Remark, Ex,, Proof, R, N, Q, C [a, b {x R : a x b} : a, b {x R : a < x < b} : [a, b {x R : a x < b} : a,
9 α ν β Ξ ξ Γ γ o δ Π π ε ρ ζ Σ σ η τ Θ θ Υ υ ι Φ φ κ χ Λ λ Ψ ψ µ Ω ω Def, Prop, Th, Lem, Note, Remark, Ex,, Proof, R, N, Q, C [a, b {x R : a x b} : a, b {x R : a < x < b} : [a, b {x R : a x < b} : a,
R John Fox R R R Console library(rcmdr) Rcmdr R GUI Windows R R SDI *1 R Console R 1 2 Windows XP Windows * 2 R R Console R ˆ R
 Rcmdr R GUI Windows R R SDI *1 R Console R 1 2 Windows XP Windows * 2 R R Console R ˆ R") R John Fox 2006 8 26 2008 8 28 1 R R R Console library(rcmdr) Rcmdr R GUI Windows R R SDI *1 R Console R 1 2 Windows XP Windows * 2 R R Console R ˆ R GUI R R R Console > ˆ 2 ˆ Fox(2005) jfox@mcmaster.ca
R John Fox 2006 8 26 2008 8 28 1 R R R Console library(rcmdr) Rcmdr R GUI Windows R R SDI *1 R Console R 1 2 Windows XP Windows * 2 R R Console R ˆ R GUI R R R Console > ˆ 2 ˆ Fox(2005) jfox@mcmaster.ca
10:30 12:00 P.G. vs vs vs 2
 1 10:30 12:00 P.G. vs vs vs 2 LOGIT PROBIT TOBIT mean median mode CV 3 4 5 0.5 1000 6 45 7 P(A B) = P(A) + P(B) - P(A B) P(B A)=P(A B)/P(A) P(A B)=P(B A) P(A) P(A B) P(A) P(B A) P(B) P(A B) P(A) P(B) P(B
1 10:30 12:00 P.G. vs vs vs 2 LOGIT PROBIT TOBIT mean median mode CV 3 4 5 0.5 1000 6 45 7 P(A B) = P(A) + P(B) - P(A B) P(B A)=P(A B)/P(A) P(A B)=P(B A) P(A) P(A B) P(A) P(B A) P(B) P(A B) P(A) P(B) P(B
ohpmain.dvi
 fujisawa@ism.ac.jp 1 Contents 1. 2. 3. 4. γ- 2 1. 3 10 5.6, 5.7, 5.4, 5.5, 5.8, 5.5, 5.3, 5.6, 5.4, 5.2. 5.5 5.6 +5.7 +5.4 +5.5 +5.8 +5.5 +5.3 +5.6 +5.4 +5.2 =5.5. 10 outlier 5 5.6, 5.7, 5.4, 5.5, 5.8,
fujisawa@ism.ac.jp 1 Contents 1. 2. 3. 4. γ- 2 1. 3 10 5.6, 5.7, 5.4, 5.5, 5.8, 5.5, 5.3, 5.6, 5.4, 5.2. 5.5 5.6 +5.7 +5.4 +5.5 +5.8 +5.5 +5.3 +5.6 +5.4 +5.2 =5.5. 10 outlier 5 5.6, 5.7, 5.4, 5.5, 5.8,
untitled
 18 1 2,000,000 2,000,000 2007 2 2 2008 3 31 (1) 6 JCOSSAR 2007pp.57-642007.6. LCC (1) (2) 2 10mm 1020 14 12 10 8 6 4 40,50,60 2 0 1998 27.5 1995 1960 40 1) 2) 3) LCC LCC LCC 1 1) Vol.42No.5pp.29-322004.5.
18 1 2,000,000 2,000,000 2007 2 2 2008 3 31 (1) 6 JCOSSAR 2007pp.57-642007.6. LCC (1) (2) 2 10mm 1020 14 12 10 8 6 4 40,50,60 2 0 1998 27.5 1995 1960 40 1) 2) 3) LCC LCC LCC 1 1) Vol.42No.5pp.29-322004.5.
18 ( ) I II III A B C(100 ) 1, 2, 3, 5 I II A B (100 ) 1, 2, 3 I II A B (80 ) 6 8 I II III A B C(80 ) 1 n (1 + x) n (1) n C 1 + n C
 I II III A B C(100 ) 1, 2, 3, 5 I II A B (100 ) 1, 2, 3 I II A B (80 ) 6 8 I II III A B C(80 ) 1 n (1 + x) n (1) n C 1 + n C") 8 ( ) 8 5 4 I II III A B C( ),,, 5 I II A B ( ),, I II A B (8 ) 6 8 I II III A B C(8 ) n ( + x) n () n C + n C + + n C n = 7 n () 7 9 C : y = x x A(, 6) () A C () C P AP Q () () () 4 A(,, ) B(,, ) C(,,
8 ( ) 8 5 4 I II III A B C( ),,, 5 I II A B ( ),, I II A B (8 ) 6 8 I II III A B C(8 ) n ( + x) n () n C + n C + + n C n = 7 n () 7 9 C : y = x x A(, 6) () A C () C P AP Q () () () 4 A(,, ) B(,, ) C(,,
The Environmental Monitoring 2017 Surface water [1] Total PCBs /surface water (pg/l) Monitored year :2017 stats Detection Frequency (site) :46/47(Miss
![The Environmental Monitoring 2017 Surface water [1] Total PCBs /surface water (pg/l) Monitored year :2017 stats Detection Frequency (site) :46/47(Miss](/thumbs/103/157571288.jpg "The Environmental Monitoring 2017 Surface water [1] Total PCBs /surface water (pg/l) Monitored year :2017 stats Detection Frequency (site) :46/47(Miss") Surface water [1] Total PCBs /surface water (pg/l) Detection Frequency (site) :46/47(Missing value :0) Geometric mean 84 Detection Frequency (sample) :46/47(Missing value :0) Median 79 Detection limit
Surface water [1] Total PCBs /surface water (pg/l) Detection Frequency (site) :46/47(Missing value :0) Geometric mean 84 Detection Frequency (sample) :46/47(Missing value :0) Median 79 Detection limit
 211 kotaro@math.titech.ac.jp 1 R *1 n n R n *2 R n = {(x 1,..., x n ) x 1,..., x n R}. R R 2 R 3 R n R n R n D D R n *3 ) (x 1,..., x n ) f(x 1,..., x n ) f D *4 n 2 n = 1 ( ) 1 f D R n f : D R 1.1. (x,
211 kotaro@math.titech.ac.jp 1 R *1 n n R n *2 R n = {(x 1,..., x n ) x 1,..., x n R}. R R 2 R 3 R n R n R n D D R n *3 ) (x 1,..., x n ) f(x 1,..., x n ) f D *4 n 2 n = 1 ( ) 1 f D R n f : D R 1.1. (x,
x (x, ) x y (, y) iy x y z = x + iy (x, y) (r, θ) r = x + y, θ = tan ( y ), π < θ π x r = z, θ = arg z z = x + iy = r cos θ + ir sin θ = r(cos θ + i s
 x y (, y) iy x y z = x + iy (x, y) (r, θ) r = x + y, θ = tan ( y ), π < θ π x r = z, θ = arg z z = x + iy = r cos θ + ir sin θ = r(cos θ + i s") ... x, y z = x + iy x z y z x = Rez, y = Imz z = x + iy x iy z z () z + z = (z + z )() z z = (z z )(3) z z = ( z z )(4)z z = z z = x + y z = x + iy ()Rez = (z + z), Imz = (z z) i () z z z + z z + z.. z
... x, y z = x + iy x z y z x = Rez, y = Imz z = x + iy x iy z z () z + z = (z + z )() z z = (z z )(3) z z = ( z z )(4)z z = z z = x + y z = x + iy ()Rez = (z + z), Imz = (z z) i () z z z + z z + z.. z
I A A441 : April 15, 2013 Version : 1.1 I Kawahira, Tomoki TA (Shigehiro, Yoshida )
") I013 00-1 : April 15, 013 Version : 1.1 I Kawahira, Tomoki TA (Shigehiro, Yoshida) http://www.math.nagoya-u.ac.jp/~kawahira/courses/13s-tenbou.html pdf * 4 15 4 5 13 e πi = 1 5 0 5 7 3 4 6 3 6 10 6 17
I013 00-1 : April 15, 013 Version : 1.1 I Kawahira, Tomoki TA (Shigehiro, Yoshida) http://www.math.nagoya-u.ac.jp/~kawahira/courses/13s-tenbou.html pdf * 4 15 4 5 13 e πi = 1 5 0 5 7 3 4 6 3 6 10 6 17
³ÎΨÏÀ
 2017 12 12 Makoto Nakashima 2017 12 12 1 / 22 2.1. C, D π- C, D. A 1, A 2 C A 1 A 2 C A 3, A 4 D A 1 A 2 D Makoto Nakashima 2017 12 12 2 / 22 . (,, L p - ). Makoto Nakashima 2017 12 12 3 / 22 . (,, L p
2017 12 12 Makoto Nakashima 2017 12 12 1 / 22 2.1. C, D π- C, D. A 1, A 2 C A 1 A 2 C A 3, A 4 D A 1 A 2 D Makoto Nakashima 2017 12 12 2 / 22 . (,, L p - ). Makoto Nakashima 2017 12 12 3 / 22 . (,, L p
keisoku01.dvi
 2.,, Mon, 2006, 401, SAGA, JAPAN Dept. of Mechanical Engineering, Saga Univ., JAPAN 4 Mon, 2006, 401, SAGA, JAPAN Dept. of Mechanical Engineering, Saga Univ., JAPAN 5 Mon, 2006, 401, SAGA, JAPAN Dept.
2.,, Mon, 2006, 401, SAGA, JAPAN Dept. of Mechanical Engineering, Saga Univ., JAPAN 4 Mon, 2006, 401, SAGA, JAPAN Dept. of Mechanical Engineering, Saga Univ., JAPAN 5 Mon, 2006, 401, SAGA, JAPAN Dept.
2011de.dvi
 211 ( 4 2 1. 3 1.1............................... 3 1.2 1- -......................... 13 1.3 2-1 -................... 19 1.4 3- -......................... 29 2. 37 2.1................................ 37
211 ( 4 2 1. 3 1.1............................... 3 1.2 1- -......................... 13 1.3 2-1 -................... 19 1.4 3- -......................... 29 2. 37 2.1................................ 37
2 G(k) e ikx = (ik) n x n n! n=0 (k ) ( ) X n = ( i) n n k n G(k) k=0 F (k) ln G(k) = ln e ikx n κ n F (k) = F (k) (ik) n n= n! κ n κ n = ( i) n n k n
 e ikx = (ik) n x n n! n=0 (k ) ( ) X n = ( i) n n k n G(k) k=0 F (k) ln G(k) = ln e ikx n κ n F (k) = F (k) (ik) n n= n! κ n κ n = ( i) n n k n") . X {x, x 2, x 3,... x n } X X {, 2, 3, 4, 5, 6} X x i P i. 0 P i 2. n P i = 3. P (i ω) = i ω P i P 3 {x, x 2, x 3,... x n } ω P i = 6 X f(x) f(x) X n n f(x i )P i n x n i P i X n 2 G(k) e ikx = (ik) n
. X {x, x 2, x 3,... x n } X X {, 2, 3, 4, 5, 6} X x i P i. 0 P i 2. n P i = 3. P (i ω) = i ω P i P 3 {x, x 2, x 3,... x n } ω P i = 6 X f(x) f(x) X n n f(x i )P i n x n i P i X n 2 G(k) e ikx = (ik) n
waseda2010a-jukaiki1-main.dvi
 November, 2 Contents 6 2 8 3 3 3 32 32 33 5 34 34 6 35 35 7 4 R 2 7 4 4 9 42 42 2 43 44 2 5 : 2 5 5 23 52 52 23 53 53 23 54 24 6 24 6 6 26 62 62 26 63 t 27 7 27 7 7 28 72 72 28 73 36) 29 8 29 8 29 82 3
November, 2 Contents 6 2 8 3 3 3 32 32 33 5 34 34 6 35 35 7 4 R 2 7 4 4 9 42 42 2 43 44 2 5 : 2 5 5 23 52 52 23 53 53 23 54 24 6 24 6 6 26 62 62 26 63 t 27 7 27 7 7 28 72 72 28 73 36) 29 8 29 8 29 82 3
講義のーと : データ解析のための統計モデリング. 第3回
 Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
151021slide.dvi
 : Mac I 1 ( 5 Windows (Mac Excel : Excel 2007 9 10 1 4 http://asakura.co.jp/ books/isbn/978-4-254-12172-8/ (1 1 9 1/29 (,,... (,,,... (,,, (3 3/29 (, (F7, Ctrl + i, (Shift +, Shift + Ctrl (, a i (, Enter,
: Mac I 1 ( 5 Windows (Mac Excel : Excel 2007 9 10 1 4 http://asakura.co.jp/ books/isbn/978-4-254-12172-8/ (1 1 9 1/29 (,,... (,,,... (,,, (3 3/29 (, (F7, Ctrl + i, (Shift +, Shift + Ctrl (, a i (, Enter,
1 Tokyo Daily Rainfall (mm) Days (mm)
 Days (mm)") ( ) r-taka@maritime.kobe-u.ac.jp 1 Tokyo Daily Rainfall (mm) 0 100 200 300 0 10000 20000 30000 40000 50000 Days (mm) 1876 1 1 2013 12 31 Tokyo, 1876 Daily Rainfall (mm) 0 50 100 150 0 100 200 300 Tokyo,
( ) r-taka@maritime.kobe-u.ac.jp 1 Tokyo Daily Rainfall (mm) 0 100 200 300 0 10000 20000 30000 40000 50000 Days (mm) 1876 1 1 2013 12 31 Tokyo, 1876 Daily Rainfall (mm) 0 50 100 150 0 100 200 300 Tokyo,
( 28 ) ( ) ( ) 0 This note is c 2016, 2017 by Setsuo Taniguchi. It may be used for personal or classroom purposes, but not for commercial purp
 ( ) ( ) 0 This note is c 2016, 2017 by Setsuo Taniguchi. It may be used for personal or classroom purposes, but not for commercial purp") ( 28) ( ) ( 28 9 22 ) 0 This ote is c 2016, 2017 by Setsuo Taiguchi. It may be used for persoal or classroom purposes, but ot for commercial purposes. i (http://www.stat.go.jp/teacher/c2epi1.htm ) = statistics
( 28) ( ) ( 28 9 22 ) 0 This ote is c 2016, 2017 by Setsuo Taiguchi. It may be used for persoal or classroom purposes, but ot for commercial purposes. i (http://www.stat.go.jp/teacher/c2epi1.htm ) = statistics
2 1,2, , 2 ( ) (1) (2) (3) (4) Cameron and Trivedi(1998) , (1987) (1982) Agresti(2003)
 (1) (2) (3) (4) Cameron and Trivedi(1998) , (1987) (1982) Agresti(2003)") 3 1 1 1 2 1 2 1,2,3 1 0 50 3000, 2 ( ) 1 3 1 0 4 3 (1) (2) (3) (4) 1 1 1 2 3 Cameron and Trivedi(1998) 4 1974, (1987) (1982) Agresti(2003) 3 (1)-(4) AAA, AA+,A (1) (2) (3) (4) (5) (1)-(5) 1 2 5 3 5 (DI)
3 1 1 1 2 1 2 1,2,3 1 0 50 3000, 2 ( ) 1 3 1 0 4 3 (1) (2) (3) (4) 1 1 1 2 3 Cameron and Trivedi(1998) 4 1974, (1987) (1982) Agresti(2003) 3 (1)-(4) AAA, AA+,A (1) (2) (3) (4) (5) (1)-(5) 1 2 5 3 5 (DI)
インターネットを活用した経済分析 - フリーソフト Rを使おう
 R 1 1 1 2017 2 15 2017 2 15 1/64 2 R 3 R R RESAS 2017 2 15 2/64 2 R 3 R R RESAS 2017 2 15 3/64 2-4 ( ) ( (80%) (20%) 2017 2 15 4/64 PC LAN R 2017 2 15 5/64 R R 2017 2 15 6/64 3-4 R 15 + 2017 2 15 7/64
R 1 1 1 2017 2 15 2017 2 15 1/64 2 R 3 R R RESAS 2017 2 15 2/64 2 R 3 R R RESAS 2017 2 15 3/64 2-4 ( ) ( (80%) (20%) 2017 2 15 4/64 PC LAN R 2017 2 15 5/64 R R 2017 2 15 6/64 3-4 R 15 + 2017 2 15 7/64
DVIOUT
 A. A. A-- [ ] f(x) x = f 00 (x) f 0 () =0 f 00 () > 0= f(x) x = f 00 () < 0= f(x) x = A--2 [ ] f(x) D f 00 (x) > 0= y = f(x) f 00 (x) < 0= y = f(x) P (, f()) f 00 () =0 A--3 [ ] y = f(x) [, b] x = f (y)
A. A. A-- [ ] f(x) x = f 00 (x) f 0 () =0 f 00 () > 0= f(x) x = f 00 () < 0= f(x) x = A--2 [ ] f(x) D f 00 (x) > 0= y = f(x) f 00 (x) < 0= y = f(x) P (, f()) f 00 () =0 A--3 [ ] y = f(x) [, b] x = f (y)
 IA hara@math.kyushu-u.ac.jp Last updated: January,......................................................................................................................................................................................
IA hara@math.kyushu-u.ac.jp Last updated: January,......................................................................................................................................................................................
Microsoft Word - 信号処理3.doc
 Junji OHTSUBO 2012 FFT FFT SN sin cos x v ψ(x,t) = f (x vt) (1.1) t=0 (1.1) ψ(x,t) = A 0 cos{k(x vt) + φ} = A 0 cos(kx ωt + φ) (1.2) A 0 v=ω/k φ ω k 1.3 (1.2) (1.2) (1.2) (1.1) 1.1 c c = a + ib, a = Re[c],
Junji OHTSUBO 2012 FFT FFT SN sin cos x v ψ(x,t) = f (x vt) (1.1) t=0 (1.1) ψ(x,t) = A 0 cos{k(x vt) + φ} = A 0 cos(kx ωt + φ) (1.2) A 0 v=ω/k φ ω k 1.3 (1.2) (1.2) (1.2) (1.1) 1.1 c c = a + ib, a = Re[c],
.. F x) = x ft)dt ), fx) : PDF : probbility density function) F x) : CDF : cumultive distribution function F x) x.2 ) T = µ p), T : ) p : x p p = F x
 = x ft)dt ), fx) : PDF : probbility density function) F x) : CDF : cumultive distribution function F x) x.2 ) T = µ p), T : ) p : x p p = F x") 203 7......................................2................................................3.....................................4 L.................................... 2.5.................................
203 7......................................2................................................3.....................................4 L.................................... 2.5.................................
1308
 国内コンビニエンスストアコンビニエンスストアの店舗数店舗数の推移 推移 Number of stores in Japan *1 2012 年度 1H/FY FY2012 2013 年度 1H/FY FY2013 2013 年度計画 /FY FY2013 2013(Forecast Forecast) 2012.3.1-2012.8.31 2013.3.1-2013.8.31 2013.3.1-2014.2.28
国内コンビニエンスストアコンビニエンスストアの店舗数店舗数の推移 推移 Number of stores in Japan *1 2012 年度 1H/FY FY2012 2013 年度 1H/FY FY2013 2013 年度計画 /FY FY2013 2013(Forecast Forecast) 2012.3.1-2012.8.31 2013.3.1-2013.8.31 2013.3.1-2014.2.28
1311
 国内コンビニエンスストアコンビニエンスストアの店舗数店舗数の推移 推移 Number of stores in Japan *1 2012 年度 3Q/FY FY2012 2013 年度 3Q/FY FY2013 2013 年度計画 /FY FY2013 2013(Forecast Forecast) 2012.3.1-2012.11.30 2013.3.1-2013.11.30 2013.3.1-2014.2.28
国内コンビニエンスストアコンビニエンスストアの店舗数店舗数の推移 推移 Number of stores in Japan *1 2012 年度 3Q/FY FY2012 2013 年度 3Q/FY FY2013 2013 年度計画 /FY FY2013 2013(Forecast Forecast) 2012.3.1-2012.11.30 2013.3.1-2013.11.30 2013.3.1-2014.2.28
医系の統計入門第 2 版 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. このサンプルページの内容は, 第 2 版 1 刷発行時のものです.
 医系の統計入門第 2 版 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. http://www.morikita.co.jp/books/mid/009192 このサンプルページの内容は, 第 2 版 1 刷発行時のものです. i 2 t 1. 2. 3 2 3. 6 4. 7 5. n 2 ν 6. 2 7. 2003 ii 2 2013 10 iii 1987
医系の統計入門第 2 版 サンプルページ この本の定価 判型などは, 以下の URL からご覧いただけます. http://www.morikita.co.jp/books/mid/009192 このサンプルページの内容は, 第 2 版 1 刷発行時のものです. i 2 t 1. 2. 3 2 3. 6 4. 7 5. n 2 ν 6. 2 7. 2003 ii 2 2013 10 iii 1987
.3. (x, x = (, u = = 4 (, x x = 4 x, x 0 x = 0 x = 4 x.4. ( z + z = 8 z, z 0 (z, z = (0, 8, (,, (8, 0 3 (0, 8, (,, (8, 0 z = z 4 z (g f(x = g(
 06 5.. ( y = x x y 5 y 5 = (x y = x + ( y = x + y = x y.. ( Y = C + I = 50 + 0.5Y + 50 r r = 00 0.5Y ( L = M Y r = 00 r = 0.5Y 50 (3 00 0.5Y = 0.5Y 50 Y = 50, r = 5 .3. (x, x = (, u = = 4 (, x x = 4 x,
06 5.. ( y = x x y 5 y 5 = (x y = x + ( y = x + y = x y.. ( Y = C + I = 50 + 0.5Y + 50 r r = 00 0.5Y ( L = M Y r = 00 r = 0.5Y 50 (3 00 0.5Y = 0.5Y 50 Y = 50, r = 5 .3. (x, x = (, u = = 4 (, x x = 4 x,
1 15 R Part : website:
 1 15 R Part 4 2017 7 24 4 : website: email: http://www3.u-toyama.ac.jp/kkarato/ kkarato@eco.u-toyama.ac.jp 1 2 2 3 2.1............................... 3 2.2 2................................. 4 2.3................................
1 15 R Part 4 2017 7 24 4 : website: email: http://www3.u-toyama.ac.jp/kkarato/ kkarato@eco.u-toyama.ac.jp 1 2 2 3 2.1............................... 3 2.2 2................................. 4 2.3................................
店舗の状況 Number of stores 国内コンビニエンスストアの店舗数の推移 Number of convenience stores in Japan * 2017 年度 /FY 年度 /FY 年度 ( 計画 )/FY2019 (Forecast) 20
/FY2019 (Forecast) 20") 国内コンビニエンスストアの店舗数の推移 Number of convenience stores in Japan * 2017 年度 /FY2017 2018 年度 /FY2018 2019 年度 ( 計画 )/FY2019 (Forecast) 2017.3.1-2018.2.28 2018.3.1-2019.2.28 2019.3.1-2020.2.29 単体 Non-consolidated
国内コンビニエンスストアの店舗数の推移 Number of convenience stores in Japan * 2017 年度 /FY2017 2018 年度 /FY2018 2019 年度 ( 計画 )/FY2019 (Forecast) 2017.3.1-2018.2.28 2018.3.1-2019.2.28 2019.3.1-2020.2.29 単体 Non-consolidated
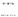 25 7 18 1 1 1.1 v.s............................. 1 1.1.1.................................. 1 1.1.2................................. 1 1.1.3.................................. 3 1.2................... 3
25 7 18 1 1 1.1 v.s............................. 1 1.1.1.................................. 1 1.1.2................................. 1 1.1.3.................................. 3 1.2................... 3
,,,17,,, ( ),, E Q [S T F t ] < S t, t [, T ],,,,,,,,
![,,,17,,, ( ),, E Q [S T F t ] < S t, t [, T ],,,,,,,,](/thumbs/91/105754403.jpg ",,,17,,, ( ),, E Q [S T F t ] < S t, t [, T ],,,,,,,,") 14 5 1 ,,,17,,,194 1 4 ( ),, E Q [S T F t ] < S t, t [, T ],,,,,,,, 1 4 1.1........................................ 4 5.1........................................ 5.........................................
14 5 1 ,,,17,,,194 1 4 ( ),, E Q [S T F t ] < S t, t [, T ],,,,,,,, 1 4 1.1........................................ 4 5.1........................................ 5.........................................
資料1-1(3)
") Table1. Average Time Spent on Activities for All Persons Sample size Population 10 years and over (1000) Sleep Personal care Meals Commuting to and from school or work Work Schoolwork Housework Caring
Table1. Average Time Spent on Activities for All Persons Sample size Population 10 years and over (1000) Sleep Personal care Meals Commuting to and from school or work Work Schoolwork Housework Caring
 20 9 19 1 3 11 1 3 111 3 112 1 4 12 6 121 6 122 7 13 7 131 8 132 10 133 10 134 12 14 13 141 13 142 13 143 15 144 16 145 17 15 19 151 1 19 152 20 2 21 21 21 211 21 212 1 23 213 1 23 214 25 215 31 22 33
20 9 19 1 3 11 1 3 111 3 112 1 4 12 6 121 6 122 7 13 7 131 8 132 10 133 10 134 12 14 13 141 13 142 13 143 15 144 16 145 17 15 19 151 1 19 152 20 2 21 21 21 211 21 212 1 23 213 1 23 214 25 215 31 22 33
() n C + n C + n C + + n C n n (3) n C + n C + n C 4 + n C + n C 3 + n C 5 + (5) (6 ) n C + nc + 3 nc n nc n (7 ) n C + nc + 3 nc n nc n (
 n C + n C + n C + + n C n n (3) n C + n C + n C 4 + n C + n C 3 + n C 5 + (5) (6 ) n C + nc + 3 nc n nc n (7 ) n C + nc + 3 nc n nc n (") 3 n nc k+ k + 3 () n C r n C n r nc r C r + C r ( r n ) () n C + n C + n C + + n C n n (3) n C + n C + n C 4 + n C + n C 3 + n C 5 + (4) n C n n C + n C + n C + + n C n (5) k k n C k n C k (6) n C + nc
3 n nc k+ k + 3 () n C r n C n r nc r C r + C r ( r n ) () n C + n C + n C + + n C n n (3) n C + n C + n C 4 + n C + n C 3 + n C 5 + (4) n C n n C + n C + n C + + n C n (5) k k n C k n C k (6) n C + nc
A
 A 2563 15 4 21 1 3 1.1................................................ 3 1.2............................................. 3 2 3 2.1......................................... 3 2.2............................................
A 2563 15 4 21 1 3 1.1................................................ 3 1.2............................................. 3 2 3 2.1......................................... 3 2.2............................................
 20 6 4 1 4 1.1 1.................................... 4 1.1.1.................................... 4 1.1.2 1................................ 5 1.2................................... 7 1.2.1....................................
20 6 4 1 4 1.1 1.................................... 4 1.1.1.................................... 4 1.1.2 1................................ 5 1.2................................... 7 1.2.1....................................
() Remrk I = [0, ] [x i, x i ]. (x : ) f(x) = 0 (x : ) ξ i, (f) = f(ξ i )(x i x i ) = (x i x i ) = ξ i, (f) = f(ξ i )(x i x i ) = 0 (f) 0.
![() Remrk I = [0, ] [x i, x i ]. (x : ) f(x) = 0 (x : ) ξ i, (f) = f(ξ i )(x i x i ) = (x i x i ) = ξ i, (f) = f(ξ i )(x i x i ) = 0 (f) 0.](/thumbs/89/98384840.jpg "() Remrk I = [0, ] [x i, x i ]. (x : ) f(x) = 0 (x : ) ξ i, (f) = f(ξ i )(x i x i ) = (x i x i ) = ξ i, (f) = f(ξ i )(x i x i ) = 0 (f) 0.") () 6 f(x) [, b] 6. Riemnn [, b] f(x) S f(x) [, b] (Riemnn) = x 0 < x < x < < x n = b. I = [, b] = {x,, x n } mx(x i x i ) =. i [x i, x i ] ξ i n (f) = f(ξ i )(x i x i ) i=. (ξ i ) (f) 0( ), ξ i, S, ε >
() 6 f(x) [, b] 6. Riemnn [, b] f(x) S f(x) [, b] (Riemnn) = x 0 < x < x < < x n = b. I = [, b] = {x,, x n } mx(x i x i ) =. i [x i, x i ] ξ i n (f) = f(ξ i )(x i x i ) i=. (ξ i ) (f) 0( ), ξ i, S, ε >
TOP URL 1
 TOP URL http://amonphys.web.fc.com/ 3.............................. 3.............................. 4.3 4................... 5.4........................ 6.5........................ 8.6...........................7
TOP URL http://amonphys.web.fc.com/ 3.............................. 3.............................. 4.3 4................... 5.4........................ 6.5........................ 8.6...........................7
t χ 2 F Q t χ 2 F 1 2 µ, σ 2 N(µ, σ 2 ) f(x µ, σ 2 ) = 1 ( exp (x ) µ)2 2πσ 2 2σ 2 0, N(0, 1) (100 α) z(α) t χ 2 *1 2.1 t (i)x N(µ, σ 2 ) x µ σ N(0, 1
 f(x µ, σ 2 ) = 1 ( exp (x ) µ)2 2πσ 2 2σ 2 0, N(0, 1) (100 α) z(α) t χ 2 *1 2.1 t (i)x N(µ, σ 2 ) x µ σ N(0, 1") t χ F Q t χ F µ, σ N(µ, σ ) f(x µ, σ ) = ( exp (x ) µ) πσ σ 0, N(0, ) (00 α) z(α) t χ *. t (i)x N(µ, σ ) x µ σ N(0, ) (ii)x,, x N(µ, σ ) x = x+ +x N(µ, σ ) (iii) (i),(ii) z = x µ N(0, ) σ N(0, ) ( 9 97.
t χ F Q t χ F µ, σ N(µ, σ ) f(x µ, σ ) = ( exp (x ) µ) πσ σ 0, N(0, ) (00 α) z(α) t χ *. t (i)x N(µ, σ ) x µ σ N(0, ) (ii)x,, x N(µ, σ ) x = x+ +x N(µ, σ ) (iii) (i),(ii) z = x µ N(0, ) σ N(0, ) ( 9 97.
DAA09
 > summary(dat.lm1) Call: lm(formula = sales ~ price, data = dat) Residuals: Min 1Q Median 3Q Max -55.719-19.270 4.212 16.143 73.454 Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) 237.1326
> summary(dat.lm1) Call: lm(formula = sales ~ price, data = dat) Residuals: Min 1Q Median 3Q Max -55.719-19.270 4.212 16.143 73.454 Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) 237.1326
) ] [ h m x + y + + V x) φ = Eφ 1) z E = i h t 13) x << 1) N n n= = N N + 1) 14) N n n= = N N + 1)N + 1) 6 15) N n 3 n= = 1 4 N N + 1) 16) N n 4
![) ] [ h m x + y + + V x) φ = Eφ 1) z E = i h t 13) x << 1) N n n= = N N + 1) 14) N n n= = N N + 1)N + 1) 6 15) N n 3 n= = 1 4 N N + 1) 16) N n 4](/thumbs/92/107866707.jpg ") ] [ h m x + y + + V x) φ = Eφ 1) z E = i h t 13) x << 1) N n n= = N N + 1) 14) N n n= = N N + 1)N + 1) 6 15) N n 3 n= = 1 4 N N + 1) 16) N n 4") 1. k λ ν ω T v p v g k = π λ ω = πν = π T v p = λν = ω k v g = dω dk 1) ) 3) 4). p = hk = h λ 5) E = hν = hω 6) h = h π 7) h =6.6618 1 34 J sec) hc=197.3 MeV fm = 197.3 kev pm= 197.3 ev nm = 1.97 1 3 ev
1. k λ ν ω T v p v g k = π λ ω = πν = π T v p = λν = ω k v g = dω dk 1) ) 3) 4). p = hk = h λ 5) E = hν = hω 6) h = h π 7) h =6.6618 1 34 J sec) hc=197.3 MeV fm = 197.3 kev pm= 197.3 ev nm = 1.97 1 3 ev
y π π O π x 9 s94.5 y dy dx. y = x + 3 y = x logx + 9 s9.6 z z x, z y. z = xy + y 3 z = sinx y 9 s x dx π x cos xdx 9 s93.8 a, fx = e x ax,. a =
 [ ] 9 IC. dx = 3x 4y dt dy dt = x y u xt = expλt u yt λ u u t = u u u + u = xt yt 6 3. u = x, y, z = x + y + z u u 9 s9 grad u ux, y, z = c c : grad u = u x i + u y j + u k i, j, k z x, y, z grad u v =
[ ] 9 IC. dx = 3x 4y dt dy dt = x y u xt = expλt u yt λ u u t = u u u + u = xt yt 6 3. u = x, y, z = x + y + z u u 9 s9 grad u ux, y, z = c c : grad u = u x i + u y j + u k i, j, k z x, y, z grad u v =
(pdf) (cdf) Matlab χ ( ) F t
 (cdf) Matlab χ ( ) F t") (, ) (univariate) (bivariate) (multi-variate) Matlab Octave Matlab Matlab/Octave --...............3. (pdf) (cdf)...3.4....4.5....4.6....7.7. Matlab...8.7.....9.7.. χ ( )...0.7.3.....7.4. F....7.5. t-...3.8....4.8.....4.8.....5.8.3....6.8.4....8.8.5....8.8.6....8.9....9.9.....9.9.....0.9.3....0.9.4.....9.5.....0....3
(, ) (univariate) (bivariate) (multi-variate) Matlab Octave Matlab Matlab/Octave --...............3. (pdf) (cdf)...3.4....4.5....4.6....7.7. Matlab...8.7.....9.7.. χ ( )...0.7.3.....7.4. F....7.5. t-...3.8....4.8.....4.8.....5.8.3....6.8.4....8.8.5....8.8.6....8.9....9.9.....9.9.....0.9.3....0.9.4.....9.5.....0....3
.3 ˆβ1 = S, S ˆβ0 = ȳ ˆβ1 S = (β0 + β1i i) β0 β1 S = (i β0 β1i) = 0 β0 S = (i β0 β1i)i = 0 β1 β0, β1 ȳ β0 β1 = 0, (i ȳ β1(i ))i = 0 {(i ȳ)(i ) β1(i ))
 β0 β1 S = (i β0 β1i) = 0 β0 S = (i β0 β1i)i = 0 β1 β0, β1 ȳ β0 β1 = 0, (i ȳ β1(i ))i = 0 {(i ȳ)(i ) β1(i ))") Copright (c) 004,005 Hidetoshi Shimodaira 1.. 3. 4. 004-10-01 16:15:07 shimo cat(" 1: "); c(mea(), mea()) cat(" : "); mmea
Copright (c) 004,005 Hidetoshi Shimodaira 1.. 3. 4. 004-10-01 16:15:07 shimo cat(" 1: "); c(mea(), mea()) cat(" : "); mmea
(Basic of Proability Theory). (Probability Spacees ad Radom Variables , (Expectatios, Meas) (Weak Law
. (Probability Spacees ad Radom Variables , (Expectatios, Meas) (Weak Law") I (Radom Walks ad Percolatios) 3 4 7 ( -2 ) (Preface),.,,,...,,.,,,,.,.,,.,,. (,.) (Basic of Proability Theory). (Probability Spacees ad Radom Variables...............2, (Expectatios, Meas).............................
I (Radom Walks ad Percolatios) 3 4 7 ( -2 ) (Preface),.,,,...,,.,,,,.,.,,.,,. (,.) (Basic of Proability Theory). (Probability Spacees ad Radom Variables...............2, (Expectatios, Meas).............................