スライド 1
|
|
|
- ありさ かつま
- 5 years ago
- Views:
Transcription
1 SAS による二項比率の差の非劣性検定の正確な方法について 武藤彬正宮島育哉榊原伊織株式会社タクミインフォメーションテクノロジー Eact method of non-inferiority test for two binomial proportions using SAS Akimasa Muto Ikuya Miyajima Iori Sakakibara Takumi Information Technology Inc.
2 要旨 : 本発表では SAS プロシジャを用いた二項比率の差の非劣性検定について紹介した後 プロシジャに導入されていない正確な検定手法について紹介するとともに そのプログラムを提供する また 保守的になりすぎず検出力を高めた手法について紹介するとともに そのプログラムを提供する キーワード :Non-inferiority Test, Binomial, Eact, FREQ Procedure
3 発表の構成. 非劣性検定とは. 非劣性検定手法の紹介.. 近似法 < Wald & Hauck-Anderson & Farrington-Manning >.. 正確法 < Eact Method >.3. 正確近似法 < Eact Like Method > 3. 各手法の特徴 3.. 第一種の過誤 < Type I Error > 3.. 検出力 < Power > 4. Program 紹介 4.. 正確法 & 正確近似法
4 . 非劣性検定とは
5 非劣性検定とは 非劣性検定は 新規の薬剤の有効率 が既存の薬剤 の有効率に比べて ある程度 ( 非劣性マージン :Δ 0 > 0) 以上には劣っていないことを示す検定である 有効率の差とその信頼区間を図示すると 次の 3 パターンが考えられる Case : 0を超え 優越性 Case: -Δ 0 を超え 非劣性 Case3: -Δ 0 以下で 劣性
6 検定統計量について 検定統計量 = ( ˆ ˆ ) V 標準偏差には未知のパラメーターが含まれており 複数の推定方法がある 標本比率を最尤推定値とみなし そのまま使う方法 補正を加えた推定量を使用する方法 制限付き最尤推定量の使用する方法 (Farrington and Manning, 990) 0
7 p-value の算出方法について 検定統計量の値から p-value を算出する方法が 3 つある 近似的な方法 EXACT な方法 3 Eact Like な方法 (Kang and Chen, 000) 検定統計量 p-value の算出法どの組み合わせがより良い?
8 何が良い手法か? Type I Error を起こす確率安全性の指標 α 超えず 近いほど良い 検出力感度の指標高いほど良い つまり Type I Error を起こす確率が α を超えず 名目の水準に近く 検出力が高い統計手法が優れた統計手法である
9 . 非劣性検定手法の紹介

10 Notation X および X は それぞれ独立した二項分布に従う確率変数とする 非劣性検定での 帰無仮説と対立仮説は 非劣性マージン Δ 0 を用いて次のように表わせる


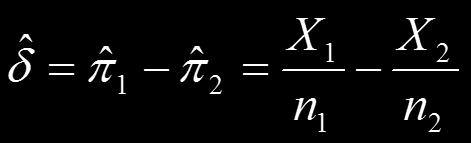
11 Notation 母比率の差 標本比率の差 帰無仮説での期待値 の分散
12 . 近似法 <Wald> 検定統計量 Z W とは独立しているとみなした場合 とがそれぞれ最尤推定量となる これを利用した Wald 検定統計量は 次の式で表せる Z W ( ˆ ˆ ) 0 ˆ ( ˆ ) ˆ ( ˆ ) n n
 ~ ( ~ ) ~ )( ( ~ ) ˆ ˆ ( n n Z F 0 0 0 ), ( n n H n n X X P Farrington, C.P. and G.")
13 <Farrington and Manning> 検定統計量 Z F 帰無仮説のもとでの制限付き最尤推定量 : を利用 Farrington and Manning 検定統計量は 求めたを用いることで次のように表せる ) ~ ( ~ ) ~ )( ( ~ ) ˆ ˆ ( n n Z F ), ( n n H n n X X P Farrington, C.P. and G. Manning (990).
14 <Hauck-Anderson> 検定統計量 Z H とは独立しているとみなした場合 とがそれぞれ最尤推定量となる 連続調整 : ccを加える Z H ( ˆ ˆ ) 0 cc ˆ ( ˆ ) ˆ ( ˆ ) n n ただし cc /(min(, n )) n とする Hauck, W. W. and Anderson, S. (986).
15 FREQ Procedure による非劣性検定 tables ステートメントの riskdiff オプションから非劣性検定を指定 PROC FREQ data = < 入力データ > ; tables < 群変数 > * < 応答変数 > / riskdiff ( noninf margin = < 非劣性マージン > method = < 手法 > var = < sample mull > ) alpha = < 有意水準 > ; weight < 度数変数 > RUN ; 手法の指定 : method = WALD FM HA 有意水準 : 0 ~ 未満非劣性マージン : 0 ~
16 FREQ Procedure による非劣性検定の例 入力データ InData 群応答度数非劣性マージン : 0. 有意水準 : 0.05 (5%) drug resp freq A 50 A 70 B 40 B 40 検定手法 : WALD 検定統計量 : Z W 分散の推定方法 : Sample drug resp A : 新薬 B : 既存薬 : 有効 : 無効
17 非劣性検定 Program の例 PROC FREQ data = InData ; tables drug*resp / riskdiff( noninf margin = 0.5 method = WALD var = SAMPLE ) alpha = 0.05 ; weight freq ; RUN ; var = の指定が可能な手法は WALD のみ 他の検定手法では SAMPLE の指定で分散の算出が行われる
18 非劣性検定 Program の実行結果 FREQ プロシジャ drug * resp の統計量 Noninferiority Analysis for the Proportion (Risk) Difference H0: P - P <= -Margin Ha: P - P > -Margin Margin = 0.5 Wald Method Proportion Difference ASE (Sample) Z Pr > Z 非劣性の限界 90% 信頼区間
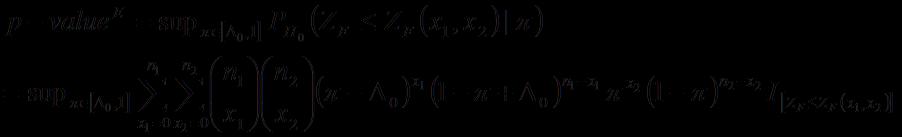
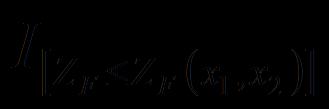
19 . 正確法 <Eact> 検定統計量 Z F 帰無仮説のもとで取り得るすべての母比率について観測値より稀な観測値の組み合わせをとる確率を算出 得られた確率の内 上極限を p-value とする ただし : 定義関数とする
20 <Eact> Program の流れ 検定実行各群のデータ 帰無仮説から各群の最尤推定を計算する最尤推定のときの検定統計量 Z F を計算する帰無仮説の元で すべてのPの値について 下の計算する すべての X,X の組み合わせに対して 尤度と検定統計量 Z F (X,X ) を計算する Z F Z F (X,X ) を満たすような尤度の合計を計算する すべての P の中で尤度の合計が最大のものを p-value とし 判定を行う
21 <Eact> Program その 最尤推定の計算 a = N + M ; b = (-) * ( N + M + + y + Delta * ( N + * M ) ) ; c = M * ( delta ** ) + Delta * ( * y + N + M ) + + y ; d = - * y * Delta * ( + Delta ) ; v = ( b / ( 3 * a ) ) ** 3 - b * c / ( 6 * ( a ** ) ) + d / ( * a ) ; u = sign(v) * sqrt( b ** / ( 3 * a ) ** - c / ( 3 * a ) ) ; wcos = v / ( u ** 3 ) ; w = ( pi + arcos( wcos ) ) / 3 ; PL = * u * cos( w ) - b / ( 3 * a ) ;
22 <Eact> Program その p-value の計算 do pcnt = 0.00 to ( - Delta ) by 0.00 ; Pv_cnt = 0 ; do i = 0 to N ; do yi = 0 to M ; nc = comb(n,i) ; mcy = comb(m,yi) ; Ph0 = nc * mcy * ( p ** i ) * ( ( - p ) ** ( N - i ) ) * ( ( p + delta ) ** yi ) * ( ( - p - delta ) ** ( M - yi) ) ; Omega = sqrt( ( p * ( - p ) ) / N + ( ( p + Delta ) * ( - p - Delta ) ) / M) ; Pi = i / N ; Pi = yi / M ; Zi = ( Pi - Pi + Delta ) / Omega ; if Z <= Zi then Pv_cnt = sum( Pv_cnt, Ph0 ) ; end ; end ; if Pvalue < Pv_cnt then Pvalue = Pv_cnt ; end ;
23 .3 正確近似法 <Eact Like> 検定統計量 Z F この方法は Eact な方法と異なり 帰無仮説のもとでの最尤推定値を用いて p-value を算出し 検定を行う 帰無仮説のもとで 観測値より推定されたの最尤推定量をとし p-value を算出する式を示す ,, ~ ~ ~ ~ ~, n n Z Z n n F F H L F F I n n Z Z P value p Kang, S. and J. J. Chen(000).
24 <Eact Like> Program の流れ 検定実行各群のデータ 帰無仮説から各群の最尤推定を計算する最尤推定のときの検定統計量 Z F を計算する帰無仮説の元で 最尤推定について 下の計算する すべての X,X の組み合わせに対して 尤度と検定統計量 Z F (X,X ) を計算する Z F Z F (X,X ) を満たすような尤度の合計を計算する 尤度の合計を p-value とし 判定を行う
25 <Eact Like> Program p-value の計算 do i = 0 to N ; do yi = 0 to M ; nc = comb(n,i) ; mcy = comb(m,yi) ; Ph0 = nc * mcy * p ** i * ( - p ) ** ( N - i ) * ( p + Delta ) ** yi * ( - p - Delta ) ** ( M - yi) ; Omega = sqrt( ( p * ( - p ) ) / N + ( ( p + Delta ) * ( - p - Delta ) ) / M) ; Pi = i / N ; Pi = yi / M ; Zi = ( Pi - Pi + delta ) / Omega ; if Z <= Zi then Pv_cnt = sum( Pv_cnt, Ph0 ) ; end ; end ; Pvalue = Pv_cnt ;
26 3. 各手法の特徴
27 3.. 第一種の過誤 < Type I Error > Balance Data p = 0.7 vs p = 0.8 (Δ 0 =0.) F : Farrington Manning L : Eact Like E : Eact
28 3.. 検出力 < Power > Balance Data N = N = 50 (Δ 0 =0.5) F : Farrington Manning L : Eact Like E : Eact
29 検定手法の特徴 近似的な方法は 例数が少ない場合に Type I Error を起こす確率が有意水準を上回ってしまう Eact Like な方法は 近似的な方法に比べ保守的であり Type I Error を起こす確率が有意水準を上回ることが少ない Eact な方法は Type I Error を起こす確率が有意水準を上回ることはないが 近似を用いた方法に比べかなり保守的である 検出力は近似的な手法が高く 比率 0.4~0.6 で下がっている
30 4. Program 紹介
31 4. 正確法 & 正確近似法 Macro Program の紹介 %* *; %MACRO Noninf_EXL(N=,=,M=,y=,Alpha=,Delta=,Method=) ; %* *; DATA Noninf_EXL ; keep N M y Alpha Delta Ph Ph RiskDiff PL PL Pvalue Decison ; %* 初期設定 *; N = &N ; = & ; M = &M ; y = &y ; Alpha = &Alpha ; Delta = &Delta ; pi = constant("pi") ; p_intval = 0.00 ; %* 各群の比率 比率の差を算出 *; Ph = / N ; Ph = y / M ; RiskDiff = Ph - Ph ;
32 %* 二項比率の差の最尤推定を算出 P を推定 *; a = N + M ; b = (-) * ( N + M + + y + Delta * ( N + * M ) ) ; c = M * ( Delta ** ) + Delta * ( * y + N + M ) + + y ; d = - * y * Delta * ( + Delta ) ; v = ( b / ( 3 * a ) ) ** 3 - b * c / ( 6 * ( a ** ) ) + d / ( * a ) ; u = sign(v) * sqrt( b ** / ( 3 * a ) ** - c / ( 3 * a ) ) ; %* v が極小の場合の処理 *; if v = 0 then w = ( Pi + arcos( 0 ) ) / 3 ; else do ; wcos = v / ( u ** 3 ) ; w = ( pi + arcos( wcos ) ) / 3 ; end ; PL = * u * cos( w ) - b / ( 3 * a ) ; %* 推定値から検定統計量を算出 *; PL = PL - Delta; PL = PL ; Omega = sqrt(( PL * ( - PL ) ) / N + ( PL * ( - PL )) / M) ; Z = ( Ph - Ph + Delta ) / Omega ;
33 Eact Method %if %upcase( &Method ) = EXACT %then %do ; %* Eact Method *; %* P-value の算出 *; %* 各 p = p で 各 i,yi の組合せの尤度 統計量算出 P-value を計算 *; Pvalue = 0 ; sta_cnt = Delta / p_intval ; end_cnt = / p_intval ; do pcnt = sta_cnt to end_cnt by ; P = pcnt * p_intval ; Pv_cnt = 0 ; do i = 0 to N ; do yi = 0 to M ; nc = comb( N, i ) ; mcy = comb( M, yi ) ;
34 * 尤度の計算 0 の 0 乗のための処理を追加 *; if ( P - Delta = 0 ) and ( i = 0 ) then e = ; else e = ( P - Delta ) ** i ; if ( - P + Delta = 0 ) and ( N - i = 0 ) then f = ; else f = ( - P + Delta ) ** ( N - i ) ; if ( P - Delta = 0 ) and ( yi = 0 ) then g = ; else g = P ** yi ; if ( - P = 0 ) and ( M - yi = 0 ) then h = ; else h = ( - P ) ** ( M - yi) ; Ph0 = nc * mcy * e * f * g * h ; Omega = sqrt( ( P * ( - P ) ) / N + ( ( P - Delta ) * ( - P + Delta ) ) / M) ; Pi = i / N ; Pi = yi / M ; Zi = ( Pi - Pi + Delta ) / Omega ; if Z <= Zi then Pv_cnt = sum( Pv_cnt, Ph0 ) ; end ; end ; if Pvalue < Pv_cnt then Pvalue = Pv_cnt ; end ;
35 Eact Like Method %end ; %else %if %upcase( &Method ) = ELIKE %then %do ; * Eact Like Method *; * P = PL で ある i,yi のときの尤度 統計量算出 P-value を計算 *; P = PL ; Pv_cnt = 0 ; do i = 0 to N ; do yi = 0 to M ; nc = comb( N, i ) ; mcy = comb( M, yi ) ;
36 %* 尤度の計算 0^0 のための処理を追加 *; if ( P - Delta = 0 ) and ( i = 0 ) then e = ; else e = ( P - Delta ) ** i ; if ( - P + Delta = 0 ) and ( N - i = 0 ) then f = ; else f = ( - P + Delta ) ** ( N - i ) ; if ( P - Delta = 0 ) and ( yi = 0 ) then g = ; else g = P ** yi ; h = ( - P ) ** ( M - yi) ; Ph0 = nc * mcy * e * f * g * h ; Omega = sqrt( ( ( P - Delta ) * ( - P + Delta ) ) / N + ( P * ( - P ) ) / M) ; Pi = i / N ; Pi = yi / M ; Zi = ( Pi - Pi + Delta ) / Omega ; if Z <= Zi then Pv_cnt = sum( Pv_cnt, Ph0 ) ; end ; end ; Pvalue = Pv_cnt ; %end ;
37 %* P-value の切り上げ *; Pvalue = ceilz( Pvalue * 0000 ) / 0000 ; %* 有意水準との判定 *; if Pvalue <= Alpha then Decison = "*" ; else Decison = "" ; output Noninf_EXL ; RUN ; Report Output %* *; %MEND Noninf_EXL ; %* *;
38 %* Report Output *; PROC REPORT data = Noninf_EXL nowd ls = 50 ps = 30 center split="/" ; column ( "InData Information /" ( "Group" N Ph ) ( "Group" M y Ph ) ( "RiskDiff" RiskDiff ) ) ( "Estimate / under the Null Hypothesis /" PL PL Delta ) ( "Non-Inferiority / &Method Test /" Alpha Pvalue Decison ) ; define N / display width = 8 center "N" ; define / display width = 8 center "Sample" ; define Ph / display width = center "Proportion" ; define M / display width = 8 center "N" ; define y / display width = 8 center "Sample" ; define Ph / display width = center "Proportion" ; define RiskDiff / display width = 4 center "Group-Group" ; define PL / display width = 8 center "Group" format = 8.4 ; define PL / display width = 8 center "Group" format = 8.4 ; define Delta / display width = 8 center "Delta" ; define Alpha / display width = 8 center "Alpha" ; define Pvalue / display width = 8 center "P-Value" format = 8.4 ; define Decison / display width = 8 center "Decison" ; RUN ;
39 マクロの実行 %Noninf_EXL(N=0,M=84,=64,y=5,Alpha=0.05,Delta=0.,Method=Elike) ; マクロ実行結果 InData Information Group Group RiskDiff N Sample Proportion N Sample Proportion Group-Group Estimate Non-Inferiority under the Null Hypothesis Elike Test Group Group Delta Alpha P-Value Decison *
40 Reference Farrington, C.P. and G. Manning (990). Test statistics and sample size formulae for comparative binomial trials with null hypothesis of non-zero risk difference or non-unity relative risk. Statistics in Medicine, 9, pp Hauck, W. W. and Anderson, S. (986). A comparison of largesample confidence interval methods for the difference of two binomial probabilities, The American Statistician, 40, Kang, S. and J. J. Chen(000). An approimate unconditional test of non-inferiority between two proportions. Statistics In Medicine, 9, pp
41 ご清聴ありがとうございました
スライド 1
 SASによる二項比率における正確な信頼区間の比較 原茂恵美子 1) 武藤彬正 1) 宮島育哉 2) 榊原伊織 2) 1) 株式会社タクミインフォメーションテクノロジーシステム開発推進部 2) 株式会社タクミインフォメーションテクノロジービジネスソリューション部 Comparison of Five Exact Confidence Intervals for the Binomial Proportion
SASによる二項比率における正確な信頼区間の比較 原茂恵美子 1) 武藤彬正 1) 宮島育哉 2) 榊原伊織 2) 1) 株式会社タクミインフォメーションテクノロジーシステム開発推進部 2) 株式会社タクミインフォメーションテクノロジービジネスソリューション部 Comparison of Five Exact Confidence Intervals for the Binomial Proportion
<4D F736F F F696E74202D204D C982E682E892B290AE82B582BD838A E8DB782CC904D978A8BE68AD482C98AD682B782E988EA8D6C8E402E >
 SAS ユーザー総会 2017 Mantel-Haenszel 法により調整したリスク差の信頼区間に関する一考察 武田薬品工業株式会社日本開発センター生物統計室佐々木英麿 舟尾暢男 要旨 Mantel-Haenszel 法により調整したリスク差に関する以下の信頼区間の算出方法を紹介し 各信頼区間の被覆確率をシミュレーションにより確認することで性能評価を行う Greenland 信頼区間 Sato 信頼区間
SAS ユーザー総会 2017 Mantel-Haenszel 法により調整したリスク差の信頼区間に関する一考察 武田薬品工業株式会社日本開発センター生物統計室佐々木英麿 舟尾暢男 要旨 Mantel-Haenszel 法により調整したリスク差に関する以下の信頼区間の算出方法を紹介し 各信頼区間の被覆確率をシミュレーションにより確認することで性能評価を行う Greenland 信頼区間 Sato 信頼区間
Microsoft PowerPoint - SAS2012_ZHANG_0629.ppt [互換モード]
![Microsoft PowerPoint - SAS2012_ZHANG_0629.ppt [互換モード]](/thumbs/99/142650241.jpg "Microsoft PowerPoint - SAS2012_ZHANG_0629.ppt [互換モード]") SAS による生存時間解析の実務 張方紅グラクソ スミスクライン ( 株 バイオメディカルデータサイエンス部 Practice of Survival Analysis sing SAS Fanghong Zhang Biomedical Data Science Department, GlaxoSmithKline K.K. 要旨 : SASによる生存時間解析の実務経験を共有する. データの要約
SAS による生存時間解析の実務 張方紅グラクソ スミスクライン ( 株 バイオメディカルデータサイエンス部 Practice of Survival Analysis sing SAS Fanghong Zhang Biomedical Data Science Department, GlaxoSmithKline K.K. 要旨 : SASによる生存時間解析の実務経験を共有する. データの要約
Microsoft PowerPoint - 【配布・WEB公開用】SAS発表資料.pptx
 生存関数における信頼区間算出法の比較 佐藤聖士, 浜田知久馬東京理科大学工学研究科 Comparison of confidence intervals for survival rate Masashi Sato, Chikuma Hamada Graduate school of Engineering, Tokyo University of Science 要旨 : 生存割合の信頼区間算出の際に用いられる各変換関数の性能について被覆確率を評価指標として比較した.
生存関数における信頼区間算出法の比較 佐藤聖士, 浜田知久馬東京理科大学工学研究科 Comparison of confidence intervals for survival rate Masashi Sato, Chikuma Hamada Graduate school of Engineering, Tokyo University of Science 要旨 : 生存割合の信頼区間算出の際に用いられる各変換関数の性能について被覆確率を評価指標として比較した.
y = x 4 y = x 8 3 y = x 4 y = x 3. 4 f(x) = x y = f(x) 4 x =,, 3, 4, 5 5 f(x) f() = f() = 3 f(3) = 3 4 f(4) = 4 *3 S S = f() + f() + f(3) + f(4) () *4
 = x y = f(x) 4 x =,, 3, 4, 5 5 f(x) f() = f() = 3 f(3) = 3 4 f(4) = 4 *3 S S = f() + f() + f(3) + f(4) () *4") Simpson H4 BioS. Simpson 3 3 0 x. β α (β α)3 (x α)(x β)dx = () * * x * * ɛ δ y = x 4 y = x 8 3 y = x 4 y = x 3. 4 f(x) = x y = f(x) 4 x =,, 3, 4, 5 5 f(x) f() = f() = 3 f(3) = 3 4 f(4) = 4 *3 S S = f()
Simpson H4 BioS. Simpson 3 3 0 x. β α (β α)3 (x α)(x β)dx = () * * x * * ɛ δ y = x 4 y = x 8 3 y = x 4 y = x 3. 4 f(x) = x y = f(x) 4 x =,, 3, 4, 5 5 f(x) f() = f() = 3 f(3) = 3 4 f(4) = 4 *3 S S = f()
情報工学概論
 確率と統計 中山クラス 第 11 週 0 本日の内容 第 3 回レポート解説 第 5 章 5.6 独立性の検定 ( カイ二乗検定 ) 5.7 サンプルサイズの検定結果への影響練習問題 (4),(5) 第 4 回レポート課題の説明 1 演習問題 ( 前回 ) の解説 勉強時間と定期試験の得点の関係を無相関検定により調べる. データ入力 > aa
確率と統計 中山クラス 第 11 週 0 本日の内容 第 3 回レポート解説 第 5 章 5.6 独立性の検定 ( カイ二乗検定 ) 5.7 サンプルサイズの検定結果への影響練習問題 (4),(5) 第 4 回レポート課題の説明 1 演習問題 ( 前回 ) の解説 勉強時間と定期試験の得点の関係を無相関検定により調べる. データ入力 > aa
Microsoft PowerPoint - sc7.ppt [互換モード]
![Microsoft PowerPoint - sc7.ppt [互換モード]](/thumbs/91/107013389.jpg "Microsoft PowerPoint - sc7.ppt [互換モード]") / 社会調査論 本章の概要 本章では クロス集計表を用いた独立性の検定を中心に方法を学ぶ 1) 立命館大学経済学部 寺脇 拓 2 11 1.1 比率の推定 ベルヌーイ分布 (Bernoulli distribution) 浄水器の所有率を推定したいとする 浄水器の所有の有無を表す変数をxで表し 浄水器をもっている を 1 浄水器をもっていない を 0 で表す 母集団の浄水器を持っている人の割合をpで表すとすると
/ 社会調査論 本章の概要 本章では クロス集計表を用いた独立性の検定を中心に方法を学ぶ 1) 立命館大学経済学部 寺脇 拓 2 11 1.1 比率の推定 ベルヌーイ分布 (Bernoulli distribution) 浄水器の所有率を推定したいとする 浄水器の所有の有無を表す変数をxで表し 浄水器をもっている を 1 浄水器をもっていない を 0 で表す 母集団の浄水器を持っている人の割合をpで表すとすると
基礎統計
 基礎統計 第 11 回講義資料 6.4.2 標本平均の差の標本分布 母平均の差 標本平均の差をみれば良い ただし, 母分散に依存するため場合分けをする 1 2 3 分散が既知分散が未知であるが等しい分散が未知であり等しいとは限らない 1 母分散が既知のとき が既知 標準化変量 2 母分散が未知であり, 等しいとき 分散が未知であるが, 等しいということは分かっているとき 標準化変量 自由度 の t
基礎統計 第 11 回講義資料 6.4.2 標本平均の差の標本分布 母平均の差 標本平均の差をみれば良い ただし, 母分散に依存するため場合分けをする 1 2 3 分散が既知分散が未知であるが等しい分散が未知であり等しいとは限らない 1 母分散が既知のとき が既知 標準化変量 2 母分散が未知であり, 等しいとき 分散が未知であるが, 等しいということは分かっているとき 標準化変量 自由度 の t
統計的データ解析
 統計的データ解析 011 011.11.9 林田清 ( 大阪大学大学院理学研究科 ) 連続確率分布の平均値 分散 比較のため P(c ) c 分布 自由度 の ( カイ c 平均値 0, 標準偏差 1の正規分布 に従う変数 xの自乗和 c x =1 が従う分布を自由度 の分布と呼ぶ 一般に自由度の分布は f /1 c / / ( c ) {( c ) e }/ ( / ) 期待値 二乗 ) 分布 c
統計的データ解析 011 011.11.9 林田清 ( 大阪大学大学院理学研究科 ) 連続確率分布の平均値 分散 比較のため P(c ) c 分布 自由度 の ( カイ c 平均値 0, 標準偏差 1の正規分布 に従う変数 xの自乗和 c x =1 が従う分布を自由度 の分布と呼ぶ 一般に自由度の分布は f /1 c / / ( c ) {( c ) e }/ ( / ) 期待値 二乗 ) 分布 c
日本製薬工業協会シンポジウム 生存時間解析の評価指標に関する最近の展開ー RMST (restricted mean survival time) を理解するー 2. RMST の定義と統計的推測 2018 年 6 月 13 日医薬品評価委員会データサイエンス部会タスクフォース 4 生存時間解析チー
 を理解するー 2. RMST の定義と統計的推測 2018 年 6 月 13 日医薬品評価委員会データサイエンス部会タスクフォース 4 生存時間解析チー") 日本製薬工業協会シンポジウム 生存時間解析の評価指標に関する最近の展開ー RMST (restricted mean survival time) を理解するー 2. RMST の定義と統計的推測 2018 年 6 月 13 日医薬品評価委員会データサイエンス部会タスクフォース 4 生存時間解析チーム 日本新薬 ( 株 ) 田中慎一 留意点 本発表は, 先日公開された 生存時間型応答の評価指標 -RMST(restricted
日本製薬工業協会シンポジウム 生存時間解析の評価指標に関する最近の展開ー RMST (restricted mean survival time) を理解するー 2. RMST の定義と統計的推測 2018 年 6 月 13 日医薬品評価委員会データサイエンス部会タスクフォース 4 生存時間解析チーム 日本新薬 ( 株 ) 田中慎一 留意点 本発表は, 先日公開された 生存時間型応答の評価指標 -RMST(restricted
こんにちは由美子です
 Sample size power calculation Sample Size Estimation AZTPIAIDS AIDSAZT AIDSPI AIDSRNA AZTPr (S A ) = π A, PIPr (S B ) = π B AIDS (sampling)(inference) π A, π B π A - π B = 0.20 PI 20 20AZT, PI 10 6 8 HIV-RNA
Sample size power calculation Sample Size Estimation AZTPIAIDS AIDSAZT AIDSPI AIDSRNA AZTPr (S A ) = π A, PIPr (S B ) = π B AIDS (sampling)(inference) π A, π B π A - π B = 0.20 PI 20 20AZT, PI 10 6 8 HIV-RNA
ECCS. ECCS,. ( 2. Mac Do-file Editor. Mac Do-file Editor Windows Do-file Editor Top Do-file e
 1 1 2015 4 6 1. ECCS. ECCS,. (https://ras.ecc.u-tokyo.ac.jp/guacamole/) 2. Mac Do-file Editor. Mac Do-file Editor Windows Do-file Editor Top Do-file editor, Do View Do-file Editor Execute(do). 3. Mac System
1 1 2015 4 6 1. ECCS. ECCS,. (https://ras.ecc.u-tokyo.ac.jp/guacamole/) 2. Mac Do-file Editor. Mac Do-file Editor Windows Do-file Editor Top Do-file editor, Do View Do-file Editor Execute(do). 3. Mac System
青焼 1章[15-52].indd
![青焼 1章[15-52].indd](/thumbs/86/94313777.jpg "青焼 1章[15-52].indd") 1 第 1 章統計の基礎知識 1 1 なぜ統計解析が必要なのか? 人間は自分自身の経験にもとづいて 感覚的にものごとを判断しがちである 例えばある疾患に対する標準治療薬の有効率が 50% であったとする そこに新薬が登場し ある医師がその新薬を 5 人の患者に使ったところ 4 人が有効と判定されたとしたら 多くの医師はこれまでの標準治療薬よりも新薬のほうが有効性が高そうだと感じることだろう しかし
1 第 1 章統計の基礎知識 1 1 なぜ統計解析が必要なのか? 人間は自分自身の経験にもとづいて 感覚的にものごとを判断しがちである 例えばある疾患に対する標準治療薬の有効率が 50% であったとする そこに新薬が登場し ある医師がその新薬を 5 人の患者に使ったところ 4 人が有効と判定されたとしたら 多くの医師はこれまでの標準治療薬よりも新薬のほうが有効性が高そうだと感じることだろう しかし
仮説検定を伴う方法では 検定の仮定が満たされ 検定に適切な検出力があり データの分析に使用される近似で有効な結果が得られることを確認することを推奨します カイ二乗検定の場合 仮定はデータ収集に固有であるためデータチェックでは対応しません Minitab は近似法の検出力と妥当性に焦点を絞っています
 MINITAB アシスタントホワイトペーパー本書は Minitab 統計ソフトウェアのアシスタントで使用される方法およびデータチェックを開発するため Minitab の統計専門家によって行われた調査に関する一連の文書の 1 つです カイ二乗検定 概要 実際には 連続データの収集が不可能な場合や難しい場合 品質の専門家は工程を評価するためのカテゴリデータの収集が必要となることがあります たとえば 製品は不良
MINITAB アシスタントホワイトペーパー本書は Minitab 統計ソフトウェアのアシスタントで使用される方法およびデータチェックを開発するため Minitab の統計専門家によって行われた調査に関する一連の文書の 1 つです カイ二乗検定 概要 実際には 連続データの収集が不可能な場合や難しい場合 品質の専門家は工程を評価するためのカテゴリデータの収集が必要となることがあります たとえば 製品は不良
スライド 1
 生存時間解析における Lakatos の症例数設計法の有用性の評価 魚住龍史, * 水澤純基 浜田知久馬 日本化薬株式会社医薬データセンター 東京理科大学工学部経営工学科 Evaluation of availability about sample size formula by Lakatos on survival analysis Ryuji Uozumi,, * Junki Mizusawa,
生存時間解析における Lakatos の症例数設計法の有用性の評価 魚住龍史, * 水澤純基 浜田知久馬 日本化薬株式会社医薬データセンター 東京理科大学工学部経営工学科 Evaluation of availability about sample size formula by Lakatos on survival analysis Ryuji Uozumi,, * Junki Mizusawa,
DATA Sample1 /**/ INPUT Price /* */ DATALINES
 3180, 3599, 3280, 2980, 3500, 3099, 3200, 2980, 3380, 3780, 3199, 2979, 3680, 2780, 2950, 3180, 3200, 3100, 3780, 3200 DATA Sample1 /**/ INPUT Price @@ /* @@1 */ DATALINES 3180 3599 3280 2980 3500 3099
3180, 3599, 3280, 2980, 3500, 3099, 3200, 2980, 3380, 3780, 3199, 2979, 3680, 2780, 2950, 3180, 3200, 3100, 3780, 3200 DATA Sample1 /**/ INPUT Price @@ /* @@1 */ DATALINES 3180 3599 3280 2980 3500 3099
RSS Higher Certificate in Statistics, Specimen A Module 3: Basic Statistical Methods Solutions Question 1 (i) 帰無仮説 : 200C と 250C において鉄鋼の破壊応力の母平均には違いはな
 帰無仮説 : 200C と 250C において鉄鋼の破壊応力の母平均には違いはな") RSS Higher Certiicate in Statistics, Specimen A Module 3: Basic Statistical Methods Solutions Question (i) 帰無仮説 : 00C と 50C において鉄鋼の破壊応力の母平均には違いはない. 対立仮説 : 破壊応力の母平均には違いがあり, 50C の方ときの方が大きい. n 8, n 7, x 59.6,
RSS Higher Certiicate in Statistics, Specimen A Module 3: Basic Statistical Methods Solutions Question (i) 帰無仮説 : 00C と 50C において鉄鋼の破壊応力の母平均には違いはない. 対立仮説 : 破壊応力の母平均には違いがあり, 50C の方ときの方が大きい. n 8, n 7, x 59.6,
第7章
 5. 推定と検定母集団分布の母数を推定する方法と仮説検定の方法を解説する まず 母数を一つの値で推定する点推定について 推定精度としての標準誤差を説明する また 母数が区間に存在することを推定する信頼区間も取り扱う 後半は統計的仮説検定について述べる 検定法の基本的な考え方と正規分布および二項確率についての検定法を解説する 5.1. 点推定先に述べた統計量は対応する母数の推定値である このように母数を一つの値およびベクトルで推定する場合を点推定
5. 推定と検定母集団分布の母数を推定する方法と仮説検定の方法を解説する まず 母数を一つの値で推定する点推定について 推定精度としての標準誤差を説明する また 母数が区間に存在することを推定する信頼区間も取り扱う 後半は統計的仮説検定について述べる 検定法の基本的な考え方と正規分布および二項確率についての検定法を解説する 5.1. 点推定先に述べた統計量は対応する母数の推定値である このように母数を一つの値およびベクトルで推定する場合を点推定
Medical3
 1.4.1 クロス集計表の作成 -l m 分割表 - 3つ以上のカテゴリを含む変数を用いて l mのクロス集計表による分析を行います この例では race( 人種 ) によってlow( 低体重出生 ) に差が認められるかどうかを分析します 人種には3つのカテゴリ 低体重出生には2つのカテゴリが含まれています 2つの変数はともにカテゴリ変数であるため クロス集計表によって分析します 1. 分析メニュー
1.4.1 クロス集計表の作成 -l m 分割表 - 3つ以上のカテゴリを含む変数を用いて l mのクロス集計表による分析を行います この例では race( 人種 ) によってlow( 低体重出生 ) に差が認められるかどうかを分析します 人種には3つのカテゴリ 低体重出生には2つのカテゴリが含まれています 2つの変数はともにカテゴリ変数であるため クロス集計表によって分析します 1. 分析メニュー
自動車感性評価学 1. 二項検定 内容 2 3. 質的データの解析方法 1 ( 名義尺度 ) 2.χ 2 検定 タイプ 1. 二項検定 官能検査における分類データの解析法 識別できるかを調べる 嗜好に差があるかを調べる 2 点比較法 2 点識別法 2 点嗜好法 3 点比較法 3 点識別法 3 点嗜好
 2.χ 2 検定 タイプ 1. 二項検定 官能検査における分類データの解析法 識別できるかを調べる 嗜好に差があるかを調べる 2 点比較法 2 点識別法 2 点嗜好法 3 点比較法 3 点識別法 3 点嗜好") . 内容 3. 質的データの解析方法 ( 名義尺度 ).χ 検定 タイプ. 官能検査における分類データの解析法 識別できるかを調べる 嗜好に差があるかを調べる 点比較法 点識別法 点嗜好法 3 点比較法 3 点識別法 3 点嗜好法 : 点比較法 : 点識別法 配偶法 配偶法 ( 官能評価の基礎と応用 ) 3 A か B かの判定において 回の判定でAが選ばれる回数 kは p の二項分布に従う H :
. 内容 3. 質的データの解析方法 ( 名義尺度 ).χ 検定 タイプ. 官能検査における分類データの解析法 識別できるかを調べる 嗜好に差があるかを調べる 点比較法 点識別法 点嗜好法 3 点比較法 3 点識別法 3 点嗜好法 : 点比較法 : 点識別法 配偶法 配偶法 ( 官能評価の基礎と応用 ) 3 A か B かの判定において 回の判定でAが選ばれる回数 kは p の二項分布に従う H :
NLMIXED プロシジャを用いた生存時間解析 伊藤要二アストラゼネカ株式会社臨床統計 プログラミング グループグルプ Survival analysis using PROC NLMIXED Yohji Itoh Clinical Statistics & Programming Group, A
 NLMIXED プロシジャを用いた生存時間解析 伊藤要二アストラゼネカ株式会社臨床統計 プログラミング グループグルプ Survival analysis using PROC NLMIXED Yohji Itoh Clinical Statistics & Programming Group, AstraZeneca KK 要旨 : NLMIXEDプロシジャの最尤推定の機能を用いて 指数分布 Weibull
NLMIXED プロシジャを用いた生存時間解析 伊藤要二アストラゼネカ株式会社臨床統計 プログラミング グループグルプ Survival analysis using PROC NLMIXED Yohji Itoh Clinical Statistics & Programming Group, AstraZeneca KK 要旨 : NLMIXEDプロシジャの最尤推定の機能を用いて 指数分布 Weibull
Medical3
 Chapter 1 1.4.1 1 元配置分散分析と多重比較の実行 3つの治療法による測定値に有意な差が認められるかどうかを分散分析で調べます この例では 因子が1つだけ含まれるため1 元配置分散分析 one-way ANOVA の適用になります また 多重比較法 multiple comparison procedure を用いて 具体的のどの治療法の間に有意差が認められるかを検定します 1. 分析メニュー
Chapter 1 1.4.1 1 元配置分散分析と多重比較の実行 3つの治療法による測定値に有意な差が認められるかどうかを分散分析で調べます この例では 因子が1つだけ含まれるため1 元配置分散分析 one-way ANOVA の適用になります また 多重比較法 multiple comparison procedure を用いて 具体的のどの治療法の間に有意差が認められるかを検定します 1. 分析メニュー
(3) 検定統計量の有意確率にもとづく仮説の採否データから有意確率 (significant probability, p 値 ) を求め 有意水準と照合する 有意確率とは データの分析によって得られた統計値が偶然おこる確率のこと あらかじめ設定した有意確率より低い場合は 帰無仮説を棄却して対立仮説
 検定統計量の有意確率にもとづく仮説の採否データから有意確率 (significant probability, p 値 ) を求め 有意水準と照合する 有意確率とは データの分析によって得られた統計値が偶然おこる確率のこと あらかじめ設定した有意確率より低い場合は 帰無仮説を棄却して対立仮説") 第 3 章 t 検定 (pp. 33-42) 3-1 統計的検定 統計的検定とは 設定した仮説を検証する場合に 仮説に基づいて集めた標本を 確率論の観点から分析 検証すること 使用する標本は 母集団から無作為抽出されたものでなければならない パラメトリック検定とノンパラメトリック検定 パラメトリック検定は母集団が正規分布に従う間隔尺度あるいは比率尺度の連続データを対象とする ノンパラメトリック検定は母集団に特定の分布を仮定しない
第 3 章 t 検定 (pp. 33-42) 3-1 統計的検定 統計的検定とは 設定した仮説を検証する場合に 仮説に基づいて集めた標本を 確率論の観点から分析 検証すること 使用する標本は 母集団から無作為抽出されたものでなければならない パラメトリック検定とノンパラメトリック検定 パラメトリック検定は母集団が正規分布に従う間隔尺度あるいは比率尺度の連続データを対象とする ノンパラメトリック検定は母集団に特定の分布を仮定しない
SAS_2014_zhang_3
 生物学的同等性試験における例数設計 : 正確 近似と漸近 張方紅 安藤英一グラクソ スミスクライン 株 バイオメディカルデータサイエンス部 Sample size for bioequivalence rials: Exac approximae and asympoic mehods Fanghong Zhang and Hidekazu Ando Biomedical Daa Science Deparmen
生物学的同等性試験における例数設計 : 正確 近似と漸近 張方紅 安藤英一グラクソ スミスクライン 株 バイオメディカルデータサイエンス部 Sample size for bioequivalence rials: Exac approximae and asympoic mehods Fanghong Zhang and Hidekazu Ando Biomedical Daa Science Deparmen
2 H23 BioS (i) data d1; input group patno t sex censor; cards;
 data d1; input group patno t sex censor; cards;") H BioS (i) data d1; input group patno t sex censor; cards; 0 1 0 0 0 0 1 0 1 1 0 4 4 0 1 0 5 5 1 1 0 6 5 1 1 0 7 10 1 0 0 8 15 0 1 0 9 15 0 1 0 10 4 1 0 0 11 4 1 0 1 1 5 1 0 1 1 7 0 1 1 14 8 1 0 1 15 8
H BioS (i) data d1; input group patno t sex censor; cards; 0 1 0 0 0 0 1 0 1 1 0 4 4 0 1 0 5 5 1 1 0 6 5 1 1 0 7 10 1 0 0 8 15 0 1 0 9 15 0 1 0 10 4 1 0 0 11 4 1 0 1 1 5 1 0 1 1 7 0 1 1 14 8 1 0 1 15 8
講義「○○○○」
 講義 信頼度の推定と立証 内容. 点推定と区間推定. 指数分布の点推定 区間推定 3. 指数分布 正規分布の信頼度推定 担当 : 倉敷哲生 ( ビジネスエンジニアリング専攻 ) 統計的推測 標本から得られる情報を基に 母集団に関する結論の導出が目的 測定値 x x x 3 : x 母集団 (populaio) 母集団の特性値 統計的推測 標本 (sample) 標本の特性値 分布のパラメータ ( 母数
講義 信頼度の推定と立証 内容. 点推定と区間推定. 指数分布の点推定 区間推定 3. 指数分布 正規分布の信頼度推定 担当 : 倉敷哲生 ( ビジネスエンジニアリング専攻 ) 統計的推測 標本から得られる情報を基に 母集団に関する結論の導出が目的 測定値 x x x 3 : x 母集団 (populaio) 母集団の特性値 統計的推測 標本 (sample) 標本の特性値 分布のパラメータ ( 母数
データ構造の作成 一時 SAS データセットと永久 SAS データセットの作成 テキストファイルから SAS データセットを作成するための DATA ステップの使用例 : Data NewData; Infile "path.rawdata"; Input <pointer-control> var
 SAS Base Programming for SAS 9 データへのアクセス フォーマット入力とリスト入力を使用したローデータ ファイルの読み込み 文字データと数値データ 標準と非標準の数値データの識別文字および 標準 非標準の固定長データを読み取るための フォーマット入力のINPUTステートメントの使用 :INPUT 変数名入力形式 ; 文字および 標準 非標準のフリーフォーマットデータを読み込むための
SAS Base Programming for SAS 9 データへのアクセス フォーマット入力とリスト入力を使用したローデータ ファイルの読み込み 文字データと数値データ 標準と非標準の数値データの識別文字および 標準 非標準の固定長データを読み取るための フォーマット入力のINPUTステートメントの使用 :INPUT 変数名入力形式 ; 文字および 標準 非標準のフリーフォーマットデータを読み込むための
統計学 - 社会統計の基礎 - 正規分布 標準正規分布累積分布関数の逆関数 t 分布正規分布に従うサンプルの平均の信頼区間 担当 : 岸 康人 資料ページ :
 統計学 - 社会統計の基礎 - 正規分布 標準正規分布累積分布関数の逆関数 t 分布正規分布に従うサンプルの平均の信頼区間 担当 : 岸 康人 資料ページ : https://goo.gl/qw1djw 正規分布 ( 復習 ) 正規分布 (Normal Distribution)N (μ, σ 2 ) 別名 : ガウス分布 (Gaussian Distribution) 密度関数 Excel:= NORM.DIST
統計学 - 社会統計の基礎 - 正規分布 標準正規分布累積分布関数の逆関数 t 分布正規分布に従うサンプルの平均の信頼区間 担当 : 岸 康人 資料ページ : https://goo.gl/qw1djw 正規分布 ( 復習 ) 正規分布 (Normal Distribution)N (μ, σ 2 ) 別名 : ガウス分布 (Gaussian Distribution) 密度関数 Excel:= NORM.DIST
Kumamoto University Center for Multimedia and Information Technologies Lab. 熊本大学アプリケーション実験 ~ 実環境における無線 LAN 受信電波強度を用いた位置推定手法の検討 ~ InKIAI 宮崎県美郷
 熊本大学アプリケーション実験 ~ 実環境における無線 LAN 受信電波強度を用いた位置推定手法の検討 ~ InKIAI プロジェクト @ 宮崎県美郷町 熊本大学副島慶人川村諒 1 実験の目的 従来 信号の受信電波強度 (RSSI:RecevedSgnal StrengthIndcator) により 対象の位置を推定する手法として 無線 LAN の AP(AccessPont) から受信する信号の減衰量をもとに位置を推定する手法が多く検討されている
熊本大学アプリケーション実験 ~ 実環境における無線 LAN 受信電波強度を用いた位置推定手法の検討 ~ InKIAI プロジェクト @ 宮崎県美郷町 熊本大学副島慶人川村諒 1 実験の目的 従来 信号の受信電波強度 (RSSI:RecevedSgnal StrengthIndcator) により 対象の位置を推定する手法として 無線 LAN の AP(AccessPont) から受信する信号の減衰量をもとに位置を推定する手法が多く検討されている
EBNと疫学
 推定と検定 57 ( 復習 ) 記述統計と推測統計 統計解析は大きく 2 つに分けられる 記述統計 推測統計 記述統計 観察集団の特性を示すもの 代表値 ( 平均値や中央値 ) や ばらつきの指標 ( 標準偏差など ) 図表を効果的に使う 推測統計 観察集団のデータから母集団の特性を 推定 する 平均 / 分散 / 係数値などの推定 ( 点推定 ) 点推定値のばらつきを調べる ( 区間推定 ) 検定統計量を用いた検定
推定と検定 57 ( 復習 ) 記述統計と推測統計 統計解析は大きく 2 つに分けられる 記述統計 推測統計 記述統計 観察集団の特性を示すもの 代表値 ( 平均値や中央値 ) や ばらつきの指標 ( 標準偏差など ) 図表を効果的に使う 推測統計 観察集団のデータから母集団の特性を 推定 する 平均 / 分散 / 係数値などの推定 ( 点推定 ) 点推定値のばらつきを調べる ( 区間推定 ) 検定統計量を用いた検定
解析センターを知っていただく キャンペーン
 005..5 SAS 問題設定 目的 PKパラメータ (AUC,Cmax,Tmaxなど) の推定 PKパラメータの群間比較 PKパラメータのバラツキの評価! データの特徴 非反復測定値 個体につき 個の測定値しか得られない plasma concentration 非反復測定値のイメージ図 測定時点間で個体の対応がない 着目する状況 plasma concentration 経時反復測定値のイメージ図
005..5 SAS 問題設定 目的 PKパラメータ (AUC,Cmax,Tmaxなど) の推定 PKパラメータの群間比較 PKパラメータのバラツキの評価! データの特徴 非反復測定値 個体につき 個の測定値しか得られない plasma concentration 非反復測定値のイメージ図 測定時点間で個体の対応がない 着目する状況 plasma concentration 経時反復測定値のイメージ図
1 I EViews View Proc Freeze
 EViews 2017 9 6 1 I EViews 4 1 5 2 10 3 13 4 16 4.1 View.......................................... 17 4.2 Proc.......................................... 22 4.3 Freeze & Name....................................
EViews 2017 9 6 1 I EViews 4 1 5 2 10 3 13 4 16 4.1 View.......................................... 17 4.2 Proc.......................................... 22 4.3 Freeze & Name....................................
カイ二乗フィット検定、パラメータの誤差
 統計的データ解析 008 008.. 林田清 ( 大阪大学大学院理学研究科 ) 問題 C (, ) ( x xˆ) ( y yˆ) σ x πσ σ y y Pabx (, ;,,, ) ˆ y σx σ y = dx exp exp πσx ただし xy ˆ ˆ はyˆ = axˆ+ bであらわされる直線モデル上の点 ( ˆ) ( ˆ ) ( ) x x y ax b y ax b Pabx (,
統計的データ解析 008 008.. 林田清 ( 大阪大学大学院理学研究科 ) 問題 C (, ) ( x xˆ) ( y yˆ) σ x πσ σ y y Pabx (, ;,,, ) ˆ y σx σ y = dx exp exp πσx ただし xy ˆ ˆ はyˆ = axˆ+ bであらわされる直線モデル上の点 ( ˆ) ( ˆ ) ( ) x x y ax b y ax b Pabx (,
様々なミクロ計量モデル†
 担当 : 長倉大輔 ( ながくらだいすけ ) この資料は私の講義において使用するために作成した資料です WEB ページ上で公開しており 自由に参照して頂いて構いません ただし 内容について 一応検証してありますが もし間違いがあった場合でもそれによって生じるいかなる損害 不利益について責任を負いかねますのでご了承ください 間違いは発見次第 継続的に直していますが まだ存在する可能性があります 1 カウントデータモデル
担当 : 長倉大輔 ( ながくらだいすけ ) この資料は私の講義において使用するために作成した資料です WEB ページ上で公開しており 自由に参照して頂いて構いません ただし 内容について 一応検証してありますが もし間違いがあった場合でもそれによって生じるいかなる損害 不利益について責任を負いかねますのでご了承ください 間違いは発見次第 継続的に直していますが まだ存在する可能性があります 1 カウントデータモデル
症例数設定? What is sample size estimation? 医療機器臨床試験のコンサルティングで最も相談件数が多いのは 症例数の設定 Many a need of consulting for device clinical trial is sample size estimat
 医療機器臨床試験における 例数設計のいろは Sample size estimation for clinical trials of devices -First education- 株式会社バイオスタティスティカルリサ - チ古川敏仁 Furukawa Toshihito, Biostatistical Research 2005 年 9 月 3 日第 2 回医療機器臨床試験研究会 Copyright(C)
医療機器臨床試験における 例数設計のいろは Sample size estimation for clinical trials of devices -First education- 株式会社バイオスタティスティカルリサ - チ古川敏仁 Furukawa Toshihito, Biostatistical Research 2005 年 9 月 3 日第 2 回医療機器臨床試験研究会 Copyright(C)
際 正規分布に従わない観測値に対して通常の t 検定を適用した場合 どのような不都合が生じるかを考える 一般に通常の t 検定や Wilcoxon 検定などの仮説検定を行う場合 2つの処理の間に差がないことが真実であるにもかかわらず差があると主張する過誤確率 ( 第 1 種の過誤確率 ) 2つの処理
 2つの処理") 連載 第 2 回 医学データの統計解析の基本 2 つの平均の比較 * 朝倉こう子 濱﨑俊光 Fundamentals of statistical analysis in biomedical research:two-sample tests for comparing means 1 基礎研究や臨床研究を問わず医学研究において 新しい化合物や治療法を発見し その性能を特徴づける場合 何らかの対照
連載 第 2 回 医学データの統計解析の基本 2 つの平均の比較 * 朝倉こう子 濱﨑俊光 Fundamentals of statistical analysis in biomedical research:two-sample tests for comparing means 1 基礎研究や臨床研究を問わず医学研究において 新しい化合物や治療法を発見し その性能を特徴づける場合 何らかの対照
 Autumn 2007 1 5 8 12 14 14 15 %!SASROOT/sassetup SAS Installation Setup Welcome to SAS Setup, the program used to install and maintain your SAS software. SAS Setup guides you through a series of menus
Autumn 2007 1 5 8 12 14 14 15 %!SASROOT/sassetup SAS Installation Setup Welcome to SAS Setup, the program used to install and maintain your SAS software. SAS Setup guides you through a series of menus
Microsoft Word - å“Ÿåłžå¸°173.docx
 回帰分析 ( その 3) 経済情報処理 価格弾力性の推定ある商品について その購入量を w 単価を p とし それぞれの変化量を w p で表 w w すことにする この時 この商品の価格弾力性 は により定義される これ p p は p が 1 パーセント変化した場合に w が何パーセント変化するかを示したものである ここで p を 0 に近づけていった極限を考えると d ln w 1 dw dw
回帰分析 ( その 3) 経済情報処理 価格弾力性の推定ある商品について その購入量を w 単価を p とし それぞれの変化量を w p で表 w w すことにする この時 この商品の価格弾力性 は により定義される これ p p は p が 1 パーセント変化した場合に w が何パーセント変化するかを示したものである ここで p を 0 に近づけていった極限を考えると d ln w 1 dw dw
Stata 11 Stata ROC whitepaper mwp anova/oneway 3 mwp-042 kwallis Kruskal Wallis 28 mwp-045 ranksum/median / 31 mwp-047 roctab/roccomp ROC 34 mwp-050 s
 BR003 Stata 11 Stata ROC whitepaper mwp anova/oneway 3 mwp-042 kwallis Kruskal Wallis 28 mwp-045 ranksum/median / 31 mwp-047 roctab/roccomp ROC 34 mwp-050 sampsi 47 mwp-044 sdtest 54 mwp-043 signrank/signtest
BR003 Stata 11 Stata ROC whitepaper mwp anova/oneway 3 mwp-042 kwallis Kruskal Wallis 28 mwp-045 ranksum/median / 31 mwp-047 roctab/roccomp ROC 34 mwp-050 sampsi 47 mwp-044 sdtest 54 mwp-043 signrank/signtest
<4D F736F F D208EC08CB18C7689E68A E F AA957A82C682948C9F92E82E646F63>
 第 7 回 t 分布と t 検定 実験計画学 A.t 分布 ( 小標本に関する平均の推定と検定 ) 前々回と前回の授業では, 標本が十分に大きいあるいは母分散が既知であることを条件に正規分布を用いて推定 検定した. しかし, 母集団が正規分布し, 標本が小さい場合には, 標本分散から母分散を推定するときの不確実さを加味したt 分布を用いて推定 検定しなければならない. t 分布は標本分散の自由度 f(
第 7 回 t 分布と t 検定 実験計画学 A.t 分布 ( 小標本に関する平均の推定と検定 ) 前々回と前回の授業では, 標本が十分に大きいあるいは母分散が既知であることを条件に正規分布を用いて推定 検定した. しかし, 母集団が正規分布し, 標本が小さい場合には, 標本分散から母分散を推定するときの不確実さを加味したt 分布を用いて推定 検定しなければならない. t 分布は標本分散の自由度 f(
こんにちは由美子です
 Analysis of Variance 2 two sample t test analysis of variance (ANOVA) CO 3 3 1 EFV1 µ 1 µ 2 µ 3 H 0 H 0 : µ 1 = µ 2 = µ 3 H A : Group 1 Group 2.. Group k population mean µ 1 µ µ κ SD σ 1 σ σ κ sample mean
Analysis of Variance 2 two sample t test analysis of variance (ANOVA) CO 3 3 1 EFV1 µ 1 µ 2 µ 3 H 0 H 0 : µ 1 = µ 2 = µ 3 H A : Group 1 Group 2.. Group k population mean µ 1 µ µ κ SD σ 1 σ σ κ sample mean
untitled
 WinLD R (16) WinLD https://www.biostat.wisc.edu/content/lan-demets-method-statistical-programs-clinical-trials WinLD.zip 2 2 1 α = 5% Type I error rate 1 5.0 % 2 9.8 % 3 14.3 % 5 22.6 % 10 40.1 % 3 Type
WinLD R (16) WinLD https://www.biostat.wisc.edu/content/lan-demets-method-statistical-programs-clinical-trials WinLD.zip 2 2 1 α = 5% Type I error rate 1 5.0 % 2 9.8 % 3 14.3 % 5 22.6 % 10 40.1 % 3 Type
Proc luaを初めて使ってみた -SASでの処理を条件に応じて変える- 淺井友紀 ( エイツーヘルスケア株式会社 ) I tried PROC LUA for the first time Tomoki Asai A2 Healthcare Corporation
 I tried PROC LUA for the first time Tomoki Asai A2 Healthcare Corporation") Proc luaを初めて使ってみた -SASでの処理を条件に応じて変える- 淺井友紀 ( エイツーヘルスケア株式会社 ) I tried PROC LUA for the first time Tomoki Asai A2 Healthcare Corporation 要旨 : 実行されるコードを分岐 繰り返すためには SAS マクロが用いられてきた 本発表では SAS マクロではなく Proc Lua
Proc luaを初めて使ってみた -SASでの処理を条件に応じて変える- 淺井友紀 ( エイツーヘルスケア株式会社 ) I tried PROC LUA for the first time Tomoki Asai A2 Healthcare Corporation 要旨 : 実行されるコードを分岐 繰り返すためには SAS マクロが用いられてきた 本発表では SAS マクロではなく Proc Lua
Python-statistics5 Python で統計学を学ぶ (5) この内容は山田 杉澤 村井 (2008) R によるやさしい統計学 (
 この内容は山田 杉澤 村井 (2008) R によるやさしい統計学 (") http://localhost:8888/notebooks/... Python で統計学を学ぶ (5) この内容は山田 杉澤 村井 (2008) R によるやさしい統計学 (http://shop.ohmsha.co.jp/shop /shopdetail.html?brandcode=000000001781&search=978-4-274-06710-5&sort=) を参考にしています
http://localhost:8888/notebooks/... Python で統計学を学ぶ (5) この内容は山田 杉澤 村井 (2008) R によるやさしい統計学 (http://shop.ohmsha.co.jp/shop /shopdetail.html?brandcode=000000001781&search=978-4-274-06710-5&sort=) を参考にしています
<4D F736F F D204B208C5182CC94E497A682CC8DB782CC8C9F92E BD8F6494E48A722E646F6378>
 3 群以上の比率の差の多重検定法 013 年 1 月 15 日 017 年 3 月 14 日修正 3 群以上の比率の差の多重検定法 ( 対比較 ) 分割表で表記される計数データについて群間で比率の差の検定を行う場合 全体としての統計的有意性の有無は χ 検定により判断することができるが 個々の群間の差の有意性を判定するためには多重検定法が必要となる 3 群以上の比率の差を対比較で検定する方法としては
3 群以上の比率の差の多重検定法 013 年 1 月 15 日 017 年 3 月 14 日修正 3 群以上の比率の差の多重検定法 ( 対比較 ) 分割表で表記される計数データについて群間で比率の差の検定を行う場合 全体としての統計的有意性の有無は χ 検定により判断することができるが 個々の群間の差の有意性を判定するためには多重検定法が必要となる 3 群以上の比率の差を対比較で検定する方法としては
スライド 1
 データ解析特論重回帰分析編 2017 年 7 月 10 日 ( 月 )~ 情報エレクトロニクスコース横田孝義 1 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える 具体的には y = a + bx という回帰直線 ( モデル ) でデータを代表させる このためにデータからこの回帰直線の切片 (a) と傾き (b) を最小
データ解析特論重回帰分析編 2017 年 7 月 10 日 ( 月 )~ 情報エレクトロニクスコース横田孝義 1 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える 具体的には y = a + bx という回帰直線 ( モデル ) でデータを代表させる このためにデータからこの回帰直線の切片 (a) と傾き (b) を最小
ビジネス統計 統計基礎とエクセル分析 正誤表
 ビジネス統計統計基礎とエクセル分析 ビジネス統計スペシャリスト エクセル分析スペシャリスト 公式テキスト正誤表と学習用データ更新履歴 平成 30 年 5 月 14 日現在 公式テキスト正誤表 頁場所誤正修正 6 知識編第 章 -3-3 最頻値の解説内容 たとえば, 表.1 のデータであれば, 最頻値は 167.5cm というたとえば, 表.1 のデータであれば, 最頻値は 165.0cm ということになります
ビジネス統計統計基礎とエクセル分析 ビジネス統計スペシャリスト エクセル分析スペシャリスト 公式テキスト正誤表と学習用データ更新履歴 平成 30 年 5 月 14 日現在 公式テキスト正誤表 頁場所誤正修正 6 知識編第 章 -3-3 最頻値の解説内容 たとえば, 表.1 のデータであれば, 最頻値は 167.5cm というたとえば, 表.1 のデータであれば, 最頻値は 165.0cm ということになります
Statistical inference for one-sample proportion
 RAND 関数による擬似乱数の生成 魚住龍史 * 浜田知久馬東京理科大学大学院工学研究科経営工学専攻 Generating pseudo-random numbers using RAND function Ryuji Uozumi * and Chikuma Hamada Department of Management Science, Graduate School of Engineering,
RAND 関数による擬似乱数の生成 魚住龍史 * 浜田知久馬東京理科大学大学院工学研究科経営工学専攻 Generating pseudo-random numbers using RAND function Ryuji Uozumi * and Chikuma Hamada Department of Management Science, Graduate School of Engineering,
Microsoft PowerPoint - e-stat(OLS).pptx
.pptx") 経済統計学 ( 補足 ) 最小二乗法について 担当 : 小塚匡文 2015 年 11 月 19 日 ( 改訂版 ) 神戸大学経済学部 2015 年度後期開講授業 補足 : 最小二乗法 ( 単回帰分析 ) 1.( 単純 ) 回帰分析とは? 標本サイズTの2 変数 ( ここではXとY) のデータが存在 YをXで説明する回帰方程式を推定するための方法 Y: 被説明変数 ( または従属変数 ) X: 説明変数
経済統計学 ( 補足 ) 最小二乗法について 担当 : 小塚匡文 2015 年 11 月 19 日 ( 改訂版 ) 神戸大学経済学部 2015 年度後期開講授業 補足 : 最小二乗法 ( 単回帰分析 ) 1.( 単純 ) 回帰分析とは? 標本サイズTの2 変数 ( ここではXとY) のデータが存在 YをXで説明する回帰方程式を推定するための方法 Y: 被説明変数 ( または従属変数 ) X: 説明変数
Microsoft Word - Stattext12.doc
 章対応のない 群間の量的データの検定. 検定手順 この章ではデータ間に 対 の対応のないつの標本から推定される母集団間の平均値や中央値の比較を行ないます 検定手法は 図. のようにまず正規に従うかどうかを調べます 但し この場合はつの群が共に正規に従うことを調べる必要があります 次に 群とも正規ならば F 検定を用いて等分散であるかどうかを調べます 等分散の場合は t 検定 等分散でない場合はウェルチ
章対応のない 群間の量的データの検定. 検定手順 この章ではデータ間に 対 の対応のないつの標本から推定される母集団間の平均値や中央値の比較を行ないます 検定手法は 図. のようにまず正規に従うかどうかを調べます 但し この場合はつの群が共に正規に従うことを調べる必要があります 次に 群とも正規ならば F 検定を用いて等分散であるかどうかを調べます 等分散の場合は t 検定 等分散でない場合はウェルチ
untitled
 146,650 168,577 116,665 122,915 22,420 23,100 7,564 22,562 140,317 166,252 133,581 158,677 186 376 204 257 5,594 6,167 750 775 6,333 2,325 298 88 5,358 756 1,273 1,657 - - 23,905 23,923 1,749 489 1,309
146,650 168,577 116,665 122,915 22,420 23,100 7,564 22,562 140,317 166,252 133,581 158,677 186 376 204 257 5,594 6,167 750 775 6,333 2,325 298 88 5,358 756 1,273 1,657 - - 23,905 23,923 1,749 489 1,309
Microsoft Word - 計量研修テキスト_第5版).doc
.doc") Q10-2 テキスト P191 1. 記述統計量 ( 変数 :YY95) 表示変数として 平均 中央値 最大値 最小値 標準偏差 観測値 を選択 A. 都道府県別 Descriptive Statistics for YY95 Categorized by values of PREFNUM Date: 05/11/06 Time: 14:36 Sample: 1990 2002 Included
Q10-2 テキスト P191 1. 記述統計量 ( 変数 :YY95) 表示変数として 平均 中央値 最大値 最小値 標準偏差 観測値 を選択 A. 都道府県別 Descriptive Statistics for YY95 Categorized by values of PREFNUM Date: 05/11/06 Time: 14:36 Sample: 1990 2002 Included
こんにちは由美子です
 1 2 . sum Variable Obs Mean Std. Dev. Min Max ---------+----------------------------------------------------- var1 13.4923077.3545926.05 1.1 3 3 3 0.71 3 x 3 C 3 = 0.3579 2 1 0.71 2 x 0.29 x 3 C 2 = 0.4386
1 2 . sum Variable Obs Mean Std. Dev. Min Max ---------+----------------------------------------------------- var1 13.4923077.3545926.05 1.1 3 3 3 0.71 3 x 3 C 3 = 0.3579 2 1 0.71 2 x 0.29 x 3 C 2 = 0.4386
Excelによる統計分析検定_知識編_小塚明_5_9章.indd
 第7章57766 検定と推定 サンプリングによって得られた標本から, 母集団の統計的性質に対して推測を行うことを統計的推測といいます 本章では, 推測統計の根幹をなす仮説検定と推定の基本的な考え方について説明します 前章までの知識を用いて, 具体的な分析を行います 本章以降の知識は操作編での操作に直接関連していますので, 少し聞きなれない言葉ですが, 帰無仮説 有意水準 棄却域 などの意味を理解して,
第7章57766 検定と推定 サンプリングによって得られた標本から, 母集団の統計的性質に対して推測を行うことを統計的推測といいます 本章では, 推測統計の根幹をなす仮説検定と推定の基本的な考え方について説明します 前章までの知識を用いて, 具体的な分析を行います 本章以降の知識は操作編での操作に直接関連していますので, 少し聞きなれない言葉ですが, 帰無仮説 有意水準 棄却域 などの意味を理解して,
Chapter カスタムテーブルの概要 カスタムテーブル Custom Tables は 複数の変数に基づいた多重クロス集計テーブルや スケール変数を用いた集計テーブルなど より複雑な集計表を自由に設計することができるIBM SPSS Statisticsのオプション製品です テーブ
 カスタムテーブル入門 1 カスタムテーブル入門 カスタムテーブル Custom Tables は IBM SPSS Statisticsのオプション機能の1つです カスタムテーブルを追加することで 基本的な度数集計テーブルやクロス集計テーブルの作成はもちろん 複数の変数を積み重ねた多重クロス集計テーブルや スケール変数を用いた集計テーブルなど より複雑で柔軟な集計表を作成することができます この章では
カスタムテーブル入門 1 カスタムテーブル入門 カスタムテーブル Custom Tables は IBM SPSS Statisticsのオプション機能の1つです カスタムテーブルを追加することで 基本的な度数集計テーブルやクロス集計テーブルの作成はもちろん 複数の変数を積み重ねた多重クロス集計テーブルや スケール変数を用いた集計テーブルなど より複雑で柔軟な集計表を作成することができます この章では
帳票 Mockup からの RTF 用テンプレート SAS プログラム自動作成ツール Taiho TLF Automated Tool の紹介 伊藤衡気 1 栗矢芳之 2 銭本敦 2 ( 株式会社タクミインフォメーションテクノロジー 1 大鵬薬品工業株式会社 2 )
") 帳票 Mockup からの RTF 用テンプレート SAS プログラム自動作成ツール Taiho TLF Automated Tool の紹介 伊藤衡気 1 栗矢芳之 2 銭本敦 2 ( 株式会社タクミインフォメーションテクノロジー 1 大鵬薬品工業株式会社 2 ) 要旨 : Excelで作成したTLF Mockupから RTF 出力用のSASマクロプログラムを 自動で作成するツール Taiho TLF
帳票 Mockup からの RTF 用テンプレート SAS プログラム自動作成ツール Taiho TLF Automated Tool の紹介 伊藤衡気 1 栗矢芳之 2 銭本敦 2 ( 株式会社タクミインフォメーションテクノロジー 1 大鵬薬品工業株式会社 2 ) 要旨 : Excelで作成したTLF Mockupから RTF 出力用のSASマクロプログラムを 自動で作成するツール Taiho TLF
解答のポイント 第 1 章問 1 ポイント仮に1 年生全員の数が 100 人であったとする.100 人全員に数学の試験を課して, それらの 100 人の個人個人の点数が母集団となる. 問 2 ポイント仮に10 人を抽出するとする. 学生に1から 100 までの番号を割り当てたとする. 箱の中に番号札
 解答のポイント 第 1 章問 1 ポイント仮に1 年生全員の数が 100 人であったとする.100 人全員に数学の試験を課して, それらの 100 人の個人個人の点数が母集団となる. 問 2 ポイント仮に10 人を抽出するとする. 学生に1から 100 までの番号を割り当てたとする. 箱の中に番号札を入れまず1 枚取り出す ( 仮に1 番とする ). 最初に1 番の学生を選ぶ. その1 番の札を箱の中に戻し,
解答のポイント 第 1 章問 1 ポイント仮に1 年生全員の数が 100 人であったとする.100 人全員に数学の試験を課して, それらの 100 人の個人個人の点数が母集団となる. 問 2 ポイント仮に10 人を抽出するとする. 学生に1から 100 までの番号を割り当てたとする. 箱の中に番号札を入れまず1 枚取り出す ( 仮に1 番とする ). 最初に1 番の学生を選ぶ. その1 番の札を箱の中に戻し,
現代日本論演習/比較現代日本論研究演習I「統計分析の基礎」
 URL: http://tsigeto.info/statg/ I () 3 2016 2 ( 7F) 1 : (1); (2) 1998 (70 20% 6 9 ) (30%) ( 2) ( 2) 2 1. (4/14) 2. SPSS (4/21) 3. (4/28) [] 4. (5/126/2) [1, 4] 5. (6/9) 6. (6/166/30) [2, 5] 7. (7/78/4)
URL: http://tsigeto.info/statg/ I () 3 2016 2 ( 7F) 1 : (1); (2) 1998 (70 20% 6 9 ) (30%) ( 2) ( 2) 2 1. (4/14) 2. SPSS (4/21) 3. (4/28) [] 4. (5/126/2) [1, 4] 5. (6/9) 6. (6/166/30) [2, 5] 7. (7/78/4)
kubostat2018d p.2 :? bod size x and fertilization f change seed number? : a statistical model for this example? i response variable seed number : { i
 kubostat2018d p.1 I 2018 (d) model selection and kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2018 06 25 : 2018 06 21 17:45 1 2 3 4 :? AIC : deviance model selection misunderstanding kubostat2018d (http://goo.gl/76c4i)
kubostat2018d p.1 I 2018 (d) model selection and kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2018 06 25 : 2018 06 21 17:45 1 2 3 4 :? AIC : deviance model selection misunderstanding kubostat2018d (http://goo.gl/76c4i)
Microsoft Word - Power_Analysis_Jp_ docx
 Power Analysis using G*Power Version 1.0 013 年 3 月 03 日 評価学博士 佐々木亮 サンプルサイズの検討方法 1. 最低のサンプルサイズサンプルサイズに関する考え方 統計分析を用いた調査報告書では サンプルサイズとして 30 あるいは 5 を用いている場合が頻繁に見られる 事前 事後比較のための 1 群の t 検定では まさに 30 あるいは 5 が必要ということになり
Power Analysis using G*Power Version 1.0 013 年 3 月 03 日 評価学博士 佐々木亮 サンプルサイズの検討方法 1. 最低のサンプルサイズサンプルサイズに関する考え方 統計分析を用いた調査報告書では サンプルサイズとして 30 あるいは 5 を用いている場合が頻繁に見られる 事前 事後比較のための 1 群の t 検定では まさに 30 あるいは 5 が必要ということになり
ODS GRAPHICS ON; ODS GRAPHICS ON; PROC TTEST DATA=SASHELP.CLASS SIDE=2 DIST=NORMAL H0=58 PLOTS(ONLY SHOWH0)=(SUMMARY); VAR HEIGHT;
=(SUMMARY); VAR HEIGHT;") Summer 2009 1 8 12 14 16 16 16 ODS GRAPHICS ON; ODS GRAPHICS ON; PROC TTEST DATA=SASHELP.CLASS SIDE=2 DIST=NORMAL H0=58 PLOTS(ONLY SHOWH0)=(SUMMARY); VAR HEIGHT; PROC SGPLOT DATA=SASHELP.PRDSALE; HBAR
Summer 2009 1 8 12 14 16 16 16 ODS GRAPHICS ON; ODS GRAPHICS ON; PROC TTEST DATA=SASHELP.CLASS SIDE=2 DIST=NORMAL H0=58 PLOTS(ONLY SHOWH0)=(SUMMARY); VAR HEIGHT; PROC SGPLOT DATA=SASHELP.PRDSALE; HBAR
統計学 Ⅱ( 章 ( 区間推定のシミュレーション 母平均 μ の区間推定 X ~ N, のとき X T ~ 自由度 1の t分布 1 自由度 -1のt 分布の97.5% 点 :t.975 P t T t この式に T を代入する t.975 母集団
 統計学 Ⅱ(16 11-1 章 11 章母集団パラメータの推定 1. 信頼区間 (1 点推定と区間推定 ( 区間推定のシミュレーション (3 母平均 μの信頼区間 (4 母比率 pの信頼区間 (5 母比率 pのより厳密な信頼区間. 点推定量の特性 (1 標本平均 X の持つ望ましい性質 ( 不偏性 (3 推定量の分散と有効性 (4 平均 乗誤差 MEと最小分散性 (5 一致性 (6 チェビシェフの不等式
統計学 Ⅱ(16 11-1 章 11 章母集団パラメータの推定 1. 信頼区間 (1 点推定と区間推定 ( 区間推定のシミュレーション (3 母平均 μの信頼区間 (4 母比率 pの信頼区間 (5 母比率 pのより厳密な信頼区間. 点推定量の特性 (1 標本平均 X の持つ望ましい性質 ( 不偏性 (3 推定量の分散と有効性 (4 平均 乗誤差 MEと最小分散性 (5 一致性 (6 チェビシェフの不等式
Excelにおける回帰分析(最小二乗法)の手順と出力
の手順と出力") Microsoft Excel Excel 1 1 x y x y y = a + bx a b a x 1 3 x 0 1 30 31 y b log x α x α x β 4 version.01 008 3 30 Website:http://keijisaito.info, E-mail:master@keijisaito.info 1 Excel Excel.1 Excel Excel
Microsoft Excel Excel 1 1 x y x y y = a + bx a b a x 1 3 x 0 1 30 31 y b log x α x α x β 4 version.01 008 3 30 Website:http://keijisaito.info, E-mail:master@keijisaito.info 1 Excel Excel.1 Excel Excel
Mantel-Haenszelの方法
 Mantel-Haenszel 2008 6 12 ) 2008 6 12 1 / 39 Mantel & Haenzel 1959) Mantel N, Haenszel W. Statistical aspects of the analysis of data from retrospective studies of disease. J. Nat. Cancer Inst. 1959; 224):
Mantel-Haenszel 2008 6 12 ) 2008 6 12 1 / 39 Mantel & Haenzel 1959) Mantel N, Haenszel W. Statistical aspects of the analysis of data from retrospective studies of disease. J. Nat. Cancer Inst. 1959; 224):
スライド 1
 データ解析特論第 10 回 ( 全 15 回 ) 2012 年 12 月 11 日 ( 火 ) 情報エレクトロニクス専攻横田孝義 1 終了 11/13 11/20 重回帰分析をしばらくやります 12/4 12/11 12/18 2 前回から回帰分析について学習しています 3 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える
データ解析特論第 10 回 ( 全 15 回 ) 2012 年 12 月 11 日 ( 火 ) 情報エレクトロニクス専攻横田孝義 1 終了 11/13 11/20 重回帰分析をしばらくやります 12/4 12/11 12/18 2 前回から回帰分析について学習しています 3 ( 単 ) 回帰分析 単回帰分析では一つの従属変数 ( 目的変数 ) を 一つの独立変数 ( 説明変数 ) で予測する事を考える
Microsoft PowerPoint - statistics pptx
 統計学 第 回 講義 仮説検定 Part-3 06 年 6 8 ( )3 限 担当教員 唐渡 広志 ( からと こうじ ) 研究室 経済学研究棟 4 階 43 号室 email kkarato@eco.u-toyama.ac.j webite htt://www3.u-toyama.ac.j/kkarato/ 講義の目的 つの 集団の平均 ( 率 ) に差があるかどうかを検定する 法を理解します keyword:
統計学 第 回 講義 仮説検定 Part-3 06 年 6 8 ( )3 限 担当教員 唐渡 広志 ( からと こうじ ) 研究室 経済学研究棟 4 階 43 号室 email kkarato@eco.u-toyama.ac.j webite htt://www3.u-toyama.ac.j/kkarato/ 講義の目的 つの 集団の平均 ( 率 ) に差があるかどうかを検定する 法を理解します keyword:
(.3) 式 z / の計算, alpha( ), sigma( ) から, 値 ( 区間幅 ) を計算 siki.3<-fuctio(, alpha, sigma) elta <- qorm(-alpha/) sigma /sqrt() elta [ 例 ]., 信頼率 として, サイ
![(.3) 式 z / の計算, alpha( ), sigma( ) から, 値 ( 区間幅 ) を計算 siki.3<-fuctio(, alpha, sigma) elta <- qorm(-alpha/) sigma /sqrt() elta [ 例 ]., 信頼率 として, サイ](/thumbs/91/105783221.jpg "(.3) 式 z / の計算, alpha( ), sigma( ) から, 値 ( 区間幅 ) を計算 siki.3<-fuctio(, alpha, sigma) elta <- qorm(-alpha/) sigma /sqrt() elta [ 例 ]., 信頼率 として, サイ") 区間推定に基づくサンプルサイズの設計方法 7.7. 株式会社応用数理研究所佐々木俊久 永田靖 サンプルサイズの決め方 朝倉書店 (3) の 章です 原本とおなじ 6 種類を記述していますが 平均値関連 4 つをから4 章とし, 分散の つを 5,6 章に順序を変更しました 推定手順 サンプルサイズの設計方法は, 原本をそのまま引用しています R(S-PLUS) 関数での計算方法および例を追加しました.
区間推定に基づくサンプルサイズの設計方法 7.7. 株式会社応用数理研究所佐々木俊久 永田靖 サンプルサイズの決め方 朝倉書店 (3) の 章です 原本とおなじ 6 種類を記述していますが 平均値関連 4 つをから4 章とし, 分散の つを 5,6 章に順序を変更しました 推定手順 サンプルサイズの設計方法は, 原本をそのまま引用しています R(S-PLUS) 関数での計算方法および例を追加しました.
Exam : A JPN Title : SAS Base Programming for SAS 9 Vendor : SASInstitute Version : DEMO Get Latest & Valid A JPN Exam's Question and Answ
 Actual4Test http://www.actual4test.com Actual4test - actual test exam dumps-pass for IT exams Exam : A00-211-JPN Title : SAS Base Programming for SAS 9 Vendor : SASInstitute Version : DEMO Get Latest &
Actual4Test http://www.actual4test.com Actual4test - actual test exam dumps-pass for IT exams Exam : A00-211-JPN Title : SAS Base Programming for SAS 9 Vendor : SASInstitute Version : DEMO Get Latest &
Microsoft PowerPoint - Statistics[B]
![Microsoft PowerPoint - Statistics[B]](/thumbs/101/151482563.jpg "Microsoft PowerPoint - Statistics[B]") 講義の目的 サンプルサイズの大きい標本比率の分布は正規分布で近似できることを理解します 科目コード 130509, 130609, 110225 統計学講義第 19/20 回 2019 年 6 月 25 日 ( 火 )6/7 限 担当教員 : 唐渡広志 ( からと こうじ ) 研究室 : email: website: 経済学研究棟 4 階 432 号室 kkarato@eco.u-toyama.ac.jp
講義の目的 サンプルサイズの大きい標本比率の分布は正規分布で近似できることを理解します 科目コード 130509, 130609, 110225 統計学講義第 19/20 回 2019 年 6 月 25 日 ( 火 )6/7 限 担当教員 : 唐渡広志 ( からと こうじ ) 研究室 : email: website: 経済学研究棟 4 階 432 号室 kkarato@eco.u-toyama.ac.jp
ディスカッションの目的と背景 2
 第 5 回 DSRT 医薬品の臨床試験および製造販売後調査におけるベイズ統計学の活用について 議題 5:PIII 非劣性試験における ベイズ統計学の利用可能性 ( 予習資料 ) 1 ディスカッションの目的と背景 2 議論の背景と目的 背景 : 医薬品開発において非劣性試験を行う場合, 以下の状況が想定できると考える 実対照群の 有効性に対する情報 が十分に蓄積されている 実対照群の 有効性に対する情報
第 5 回 DSRT 医薬品の臨床試験および製造販売後調査におけるベイズ統計学の活用について 議題 5:PIII 非劣性試験における ベイズ統計学の利用可能性 ( 予習資料 ) 1 ディスカッションの目的と背景 2 議論の背景と目的 背景 : 医薬品開発において非劣性試験を行う場合, 以下の状況が想定できると考える 実対照群の 有効性に対する情報 が十分に蓄積されている 実対照群の 有効性に対する情報
Microsoft Word - sample_adv-programming.docx
 サンプル問題 以下のサンプル問題は包括的ではなく 必ずしも試験を構成するすべての種類の問題を表すとは限りません 問題は 個人が認定試験を受ける準備ができているかどうかを評価するためのものではありません SAS Advanced Programming for SAS 9 問題 1 次の SAS データセット ONE と TWO があります proc sql; select one.*, sales
サンプル問題 以下のサンプル問題は包括的ではなく 必ずしも試験を構成するすべての種類の問題を表すとは限りません 問題は 個人が認定試験を受ける準備ができているかどうかを評価するためのものではありません SAS Advanced Programming for SAS 9 問題 1 次の SAS データセット ONE と TWO があります proc sql; select one.*, sales
数値計算法
 数値計算法 011/5/5 林田清 ( 大阪大学大学院理学研究科 ) レポート課題 1( 締め切りは 5/5) 平均値と標準偏差を求めるプログラム 入力 : データの数 データ データは以下の 10 個 ( 例えばある月の最高気温 ( )10 日分 ) 34.3,5.0,3.,34.6,.9,7.7,30.6,5.8,3.0,31.3 出力 :( 標本 ) 平均値 標準偏差 ソースプログラムと出力結果をメイルの本文にして
数値計算法 011/5/5 林田清 ( 大阪大学大学院理学研究科 ) レポート課題 1( 締め切りは 5/5) 平均値と標準偏差を求めるプログラム 入力 : データの数 データ データは以下の 10 個 ( 例えばある月の最高気温 ( )10 日分 ) 34.3,5.0,3.,34.6,.9,7.7,30.6,5.8,3.0,31.3 出力 :( 標本 ) 平均値 標準偏差 ソースプログラムと出力結果をメイルの本文にして
Microsoft Word - 計量研修テキスト_第5版).doc
.doc") Q9-1 テキスト P166 2)VAR の推定 注 ) 各変数について ADF 検定を行った結果 和文の次数はすべて 1 である 作業手順 4 情報量基準 (AIC) によるラグ次数の選択 VAR Lag Order Selection Criteria Endogenous variables: D(IG9S) D(IP9S) D(CP9S) Exogenous variables: C Date:
Q9-1 テキスト P166 2)VAR の推定 注 ) 各変数について ADF 検定を行った結果 和文の次数はすべて 1 である 作業手順 4 情報量基準 (AIC) によるラグ次数の選択 VAR Lag Order Selection Criteria Endogenous variables: D(IG9S) D(IP9S) D(CP9S) Exogenous variables: C Date:
切断安定分布による資産収益率のファットテイル性のモデル化とVaR・ESの計測手法におけるモデル・リスクの数値的分析
 日本銀行金融高度化センターワークショップ リスク計測の高度化 ~ テイルリスクの把握 ~ 説明資料 1 切断安定分布による資産収益率のファットテイル性のモデル化と VR VaR の計測手法における モデル リスクの数値的分析 2013 年 2 月 28 日日本銀行金融機構局金融高度化センター磯貝孝 要旨 ( 分析の枠組み ) 日経平均株価の日次収益率の母分布を切断安定分布として推計 同分布からのランダム
日本銀行金融高度化センターワークショップ リスク計測の高度化 ~ テイルリスクの把握 ~ 説明資料 1 切断安定分布による資産収益率のファットテイル性のモデル化と VR VaR の計測手法における モデル リスクの数値的分析 2013 年 2 月 28 日日本銀行金融機構局金融高度化センター磯貝孝 要旨 ( 分析の枠組み ) 日経平均株価の日次収益率の母分布を切断安定分布として推計 同分布からのランダム
Kaplan-Meierプロットに付加情報を追加するマクロの作成
 Kaplan-Meier 1, 2,3 1 2 3 A SAS macro for extended Kaplan-Meier plots Kengo Nagashima 1, Yasunori Sato 2,3 1 Department of Parmaceutical Technochemistry, Josai University 2 School of Medicine, Chiba University
Kaplan-Meier 1, 2,3 1 2 3 A SAS macro for extended Kaplan-Meier plots Kengo Nagashima 1, Yasunori Sato 2,3 1 Department of Parmaceutical Technochemistry, Josai University 2 School of Medicine, Chiba University
untitled
 Summer 2008 1 7 12 14 16 16 16 SAS Academic News B-8 4 B-9 6 B-11 7 B-15 10 DATA _NULL_; dlm=","; char1="" char2="" char3="15" char4="a",,15,a results=catx(dlm, OF char1-char4); PUT results; DATA
Summer 2008 1 7 12 14 16 16 16 SAS Academic News B-8 4 B-9 6 B-11 7 B-15 10 DATA _NULL_; dlm=","; char1="" char2="" char3="15" char4="a",,15,a results=catx(dlm, OF char1-char4); PUT results; DATA
数値計算法
 数値計算法 008 4/3 林田清 ( 大阪大学大学院理学研究科 ) 実験データの統計処理その 誤差について 母集団と標本 平均値と標準偏差 誤差伝播 最尤法 平均値につく誤差 誤差 (Error): 真の値からのずれ 測定誤差 物差しが曲がっていた 測定する対象が室温が低いため縮んでいた g の単位までしかデジタル表示されない計りで g 以下 計りの目盛りを読み取る角度によって値が異なる 統計誤差
数値計算法 008 4/3 林田清 ( 大阪大学大学院理学研究科 ) 実験データの統計処理その 誤差について 母集団と標本 平均値と標準偏差 誤差伝播 最尤法 平均値につく誤差 誤差 (Error): 真の値からのずれ 測定誤差 物差しが曲がっていた 測定する対象が室温が低いため縮んでいた g の単位までしかデジタル表示されない計りで g 以下 計りの目盛りを読み取る角度によって値が異なる 統計誤差
k2 ( :35 ) ( k2) (GLM) web web 1 :
 ( k2) (GLM) web web 1 :") 2012 11 01 k2 (2012-10-26 16:35 ) 1 6 2 (2012 11 01 k2) (GLM) kubo@ees.hokudai.ac.jp web http://goo.gl/wijx2 web http://goo.gl/ufq2 1 : 2 2 4 3 7 4 9 5 : 11 5.1................... 13 6 14 6.1......................
2012 11 01 k2 (2012-10-26 16:35 ) 1 6 2 (2012 11 01 k2) (GLM) kubo@ees.hokudai.ac.jp web http://goo.gl/wijx2 web http://goo.gl/ufq2 1 : 2 2 4 3 7 4 9 5 : 11 5.1................... 13 6 14 6.1......................
 Autumn 2005 1 9 13 14 16 16 DATA _null_; SET sashelp.class END=eof; FILE 'C: MyFiles class.txt'; /* */ PUT name sex age; IF eof THEN DO; FILE LOG; /* */ PUT '*** ' _n_ ' ***'; END; DATA _null_;
Autumn 2005 1 9 13 14 16 16 DATA _null_; SET sashelp.class END=eof; FILE 'C: MyFiles class.txt'; /* */ PUT name sex age; IF eof THEN DO; FILE LOG; /* */ PUT '*** ' _n_ ' ***'; END; DATA _null_;
Microsoft Word - 計量研修テキスト_第5版).doc
.doc") Q8-1 テキスト P131 Engle-Granger 検定 Dependent Variable: RM2 Date: 11/04/05 Time: 15:15 Sample: 1967Q1 1999Q1 Included observations: 129 RGDP 0.012792 0.000194 65.92203 0.0000 R -95.45715 11.33648-8.420349
Q8-1 テキスト P131 Engle-Granger 検定 Dependent Variable: RM2 Date: 11/04/05 Time: 15:15 Sample: 1967Q1 1999Q1 Included observations: 129 RGDP 0.012792 0.000194 65.92203 0.0000 R -95.45715 11.33648-8.420349
Microsoft PowerPoint - R-stat-intro_12.ppt [互換モード]
![Microsoft PowerPoint - R-stat-intro_12.ppt [互換モード]](/thumbs/101/151921093.jpg "Microsoft PowerPoint - R-stat-intro_12.ppt [互換モード]") R で統計解析入門 (12) 生存時間解析 中篇 準備 : データ DEP の読み込み 1. データ DEP を以下からダウンロードする http://www.cwk.zaq.ne.jp/fkhud708/files/dep.csv /fkh /d 2. ダウンロードした場所を把握する ここでは c:/temp とする 3. R を起動し,2. 2 の場所に移動し, データを読み込む 4. データ
R で統計解析入門 (12) 生存時間解析 中篇 準備 : データ DEP の読み込み 1. データ DEP を以下からダウンロードする http://www.cwk.zaq.ne.jp/fkhud708/files/dep.csv /fkh /d 2. ダウンロードした場所を把握する ここでは c:/temp とする 3. R を起動し,2. 2 の場所に移動し, データを読み込む 4. データ
Microsoft Word - StatsDirectMA Web ver. 2.0.doc
 Web version. 2.0 15 May 2006 StatsDirect ver. 2.0 15 May 2006 2 2 2 Meta-Analysis for Beginners by using the StatsDirect ver. 2.0 15 May 2006 Yukari KAMIJIMA 1), Ataru IGARASHI 2), Kiichiro TSUTANI 2)
Web version. 2.0 15 May 2006 StatsDirect ver. 2.0 15 May 2006 2 2 2 Meta-Analysis for Beginners by using the StatsDirect ver. 2.0 15 May 2006 Yukari KAMIJIMA 1), Ataru IGARASHI 2), Kiichiro TSUTANI 2)
5 Armitage x 1,, x n y i = 10x i + 3 y i = log x i {x i } {y i } 1.2 n i i x ij i j y ij, z ij i j 2 1 y = a x + b ( cm) x ij (i j )
 x ij (i j )") 5 Armitage. x,, x n y i = 0x i + 3 y i = log x i x i y i.2 n i i x ij i j y ij, z ij i j 2 y = a x + b 2 2. ( cm) x ij (i j ) (i) x, x 2 σ 2 x,, σ 2 x,2 σ x,, σ x,2 t t x * (ii) (i) m y ij = x ij /00 y
5 Armitage. x,, x n y i = 0x i + 3 y i = log x i x i y i.2 n i i x ij i j y ij, z ij i j 2 y = a x + b 2 2. ( cm) x ij (i j ) (i) x, x 2 σ 2 x,, σ 2 x,2 σ x,, σ x,2 t t x * (ii) (i) m y ij = x ij /00 y
Microsoft PowerPoint - stat-2014-[9] pptx
![Microsoft PowerPoint - stat-2014-[9] pptx](/thumbs/49/25555771.jpg "Microsoft PowerPoint - stat-2014-[9] pptx") 統計学 第 17 回 講義 母平均の区間推定 Part-1 014 年 6 17 ( )6-7 限 担当教員 : 唐渡 広志 ( からと こうじ ) 研究室 : 経済学研究棟 4 階 43 号室 email: kkarato@eco.u-toyama.ac.j website: htt://www3.u-toyama.ac.j/kkarato/ 1 講義の目的 標本平均は正規分布に従うという性質を
統計学 第 17 回 講義 母平均の区間推定 Part-1 014 年 6 17 ( )6-7 限 担当教員 : 唐渡 広志 ( からと こうじ ) 研究室 : 経済学研究棟 4 階 43 号室 email: kkarato@eco.u-toyama.ac.j website: htt://www3.u-toyama.ac.j/kkarato/ 1 講義の目的 標本平均は正規分布に従うという性質を
Microsoft Word - apstattext04.docx
 4 章母集団と指定値との量的データの検定 4.1 検定手順今までは質的データの検定の方法を学んで来ましたが これからは量的データについてよく利用される方法を説明します 量的データでは データの分布が正規分布か否かで検定の方法が著しく異なります この章ではまずデータの分布の正規性を調べる方法を述べ 次にデータの平均値または中央値がある指定された値と違うかどうかの検定方法を説明します 以下の図 4.1.1
4 章母集団と指定値との量的データの検定 4.1 検定手順今までは質的データの検定の方法を学んで来ましたが これからは量的データについてよく利用される方法を説明します 量的データでは データの分布が正規分布か否かで検定の方法が著しく異なります この章ではまずデータの分布の正規性を調べる方法を述べ 次にデータの平均値または中央値がある指定された値と違うかどうかの検定方法を説明します 以下の図 4.1.1
Dependent Variable: LOG(GDP00/(E*HOUR)) Date: 02/27/06 Time: 16:39 Sample (adjusted): 1994Q1 2005Q3 Included observations: 47 after adjustments C -1.5
) Date: 02/27/06 Time: 16:39 Sample (adjusted): 1994Q1 2005Q3 Included observations: 47 after adjustments C -1.5") 第 4 章 この章では 最小二乗法をベースにして 推計上のさまざまなテクニックを検討する 変数のバリエーション 係数の制約係数にあらかじめ制約がある場合がある たとえばマクロの生産関数は 次のように表すことができる 生産要素は資本と労働である 稼動資本は資本ストックに稼働率をかけることで計算でき 労働投入量は 就業者数に総労働時間をかけることで計算できる 制約を掛けずに 推計すると次の結果が得られる
第 4 章 この章では 最小二乗法をベースにして 推計上のさまざまなテクニックを検討する 変数のバリエーション 係数の制約係数にあらかじめ制約がある場合がある たとえばマクロの生産関数は 次のように表すことができる 生産要素は資本と労働である 稼動資本は資本ストックに稼働率をかけることで計算でき 労働投入量は 就業者数に総労働時間をかけることで計算できる 制約を掛けずに 推計すると次の結果が得られる
異文化言語教育評価論 ⅠA 第 4 章分散分析 (3 グループ以上の平均を比較する ) 平成 26 年 5 月 14 日 報告者 :D.M. K.S. 4-1 分散分析とは 検定の多重性 t 検定 2 群の平均値を比較する場合の手法分散分析 3 群以上の平均を比較する場合の手法 t 検定
 平成 26 年 5 月 14 日 報告者 :D.M. K.S. 4-1 分散分析とは 検定の多重性 t 検定 2 群の平均値を比較する場合の手法分散分析 3 群以上の平均を比較する場合の手法 t 検定") 異文化言語教育評価論 ⅠA 第 4 章分散分析 (3 グループ以上の平均を比較する ) 平成 26 年 5 月 14 日 報告者 :D.M. K.S. 4-1 分散分析とは 4-1-1 検定の多重性 t 検定 2 群の平均値を比較する場合の手法分散分析 3 群以上の平均を比較する場合の手法 t 検定の反復 (e.g., A, B, C の 3 群の比較を A-B 間 B-C 間 A-C 間の t 検定で行う
異文化言語教育評価論 ⅠA 第 4 章分散分析 (3 グループ以上の平均を比較する ) 平成 26 年 5 月 14 日 報告者 :D.M. K.S. 4-1 分散分析とは 4-1-1 検定の多重性 t 検定 2 群の平均値を比較する場合の手法分散分析 3 群以上の平均を比較する場合の手法 t 検定の反復 (e.g., A, B, C の 3 群の比較を A-B 間 B-C 間 A-C 間の t 検定で行う
Microsoft Word doc
 . 正規線形モデルのベイズ推定翠川 大竹距離減衰式 (PGA(Midorikawa, S., and Ohtake, Y. (, Attenuation relationships of peak ground acceleration and velocity considering attenuation characteristics for shallow and deeper earthquakes,
. 正規線形モデルのベイズ推定翠川 大竹距離減衰式 (PGA(Midorikawa, S., and Ohtake, Y. (, Attenuation relationships of peak ground acceleration and velocity considering attenuation characteristics for shallow and deeper earthquakes,
要旨 : データステップ及び SGPLOT プロシジャにおける POLYGON/TEXT ステートメントを利用した SAS プログラムステップフローチャートを生成する SAS プログラムを紹介する キーワード :SGPLOT, フローチャート, 可視化 2
 SAS プログラムの可視化 - SAS プログラムステップフローチャート生成プログラムの紹介 - 福田裕章 1 ( 1 MSD 株式会社 ) Visualization of SAS programs Hiroaki Fukuda MSD K.K. 要旨 : データステップ及び SGPLOT プロシジャにおける POLYGON/TEXT ステートメントを利用した SAS プログラムステップフローチャートを生成する
SAS プログラムの可視化 - SAS プログラムステップフローチャート生成プログラムの紹介 - 福田裕章 1 ( 1 MSD 株式会社 ) Visualization of SAS programs Hiroaki Fukuda MSD K.K. 要旨 : データステップ及び SGPLOT プロシジャにおける POLYGON/TEXT ステートメントを利用した SAS プログラムステップフローチャートを生成する
「スウェーデン企業におけるワーク・ライフ・バランス調査 」報告書
 1 2004 12 2005 4 5 100 25 3 1 76 2 Demoskop 2 2004 11 24 30 7 2 10 1 2005 1 31 2 4 5 2 3-1-1 3-1-1 Micromediabanken 2005 1 507 1000 55.0 2 77 50 50 /CEO 36.3 37.4 18.1 3-2-1 43.0 34.4 / 17.6 3-2-2 78 79.4
1 2004 12 2005 4 5 100 25 3 1 76 2 Demoskop 2 2004 11 24 30 7 2 10 1 2005 1 31 2 4 5 2 3-1-1 3-1-1 Micromediabanken 2005 1 507 1000 55.0 2 77 50 50 /CEO 36.3 37.4 18.1 3-2-1 43.0 34.4 / 17.6 3-2-2 78 79.4
H22 BioS (i) I treat1 II treat2 data d1; input group patno treat1 treat2; cards; ; run; I
 I treat1 II treat2 data d1; input group patno treat1 treat2; cards; ; run; I") H BioS (i) I treat II treat data d; input group patno treat treat; cards; 8 7 4 8 8 5 5 6 ; run; I II sum data d; set d; sum treat + treat; run; sum proc gplot data d; plot sum * group ; symbol c black
H BioS (i) I treat II treat data d; input group patno treat treat; cards; 8 7 4 8 8 5 5 6 ; run; I II sum data d; set d; sum treat + treat; run; sum proc gplot data d; plot sum * group ; symbol c black
Microsoft Word - Stattext11.doc
 章母集団と指定値との量的データの検定. 検定手順 前章で質的データの検定手法について説明しましたので ここからは量的データの検定について話します 量的データの検定は少し分量が多くなりますので 母集団と指定値との検定 対応のない 群間の検定 対応のある 群間の検定 と 3つに章を分けて話を進めることにします ここでは 母集団と指定値との検定について説明します 例えば全国平均が分かっている場合で ある地域の標本と全国平均を比較するような場合や
章母集団と指定値との量的データの検定. 検定手順 前章で質的データの検定手法について説明しましたので ここからは量的データの検定について話します 量的データの検定は少し分量が多くなりますので 母集団と指定値との検定 対応のない 群間の検定 対応のある 群間の検定 と 3つに章を分けて話を進めることにします ここでは 母集団と指定値との検定について説明します 例えば全国平均が分かっている場合で ある地域の標本と全国平均を比較するような場合や
Microsoft Word - 補論3.2
 補論 3. 多変量 GARC モデル 07//6 新谷元嗣 藪友良 対数尤度関数 3 章 7 節では 変量の対数尤度を求めた ここでは多変量の場合 とくに 変量について対数尤度を求める 誤差項 は平均 0 で 次元の正規分布に従うとする 単純化のため 分散と共分散は時間を通じて一定としよう ( この仮定は後で変更される ) したがって ij から添え字 を除くことができる このとき と の尤度関数は
補論 3. 多変量 GARC モデル 07//6 新谷元嗣 藪友良 対数尤度関数 3 章 7 節では 変量の対数尤度を求めた ここでは多変量の場合 とくに 変量について対数尤度を求める 誤差項 は平均 0 で 次元の正規分布に従うとする 単純化のため 分散と共分散は時間を通じて一定としよう ( この仮定は後で変更される ) したがって ij から添え字 を除くことができる このとき と の尤度関数は
α β *2 α α β β α = α 1 β = 1 β 2.2 α 0 β *3 2.3 * *2 *3 *4 (µ A ) (µ P ) (µ A > µ P ) 10 (µ A = µ P + 10) 15 (µ A = µ P +
 (µ P ) (µ A > µ P ) 10 (µ A = µ P + 10) 15 (µ A = µ P +") Armitage 1 1.1 2 t *1 α β 1.2 µ x µ 2 2 2 α β 2.1 1 α β α ( ) β *1 t t 1 α β *2 α α β β α = α 1 β = 1 β 2.2 α 0 β 1 0 0 1 1 5 2.5 *3 2.3 *4 3 3.1 1 1 1 *2 *3 *4 (µ A ) (µ P ) (µ A > µ P ) 10 (µ A = µ P
Armitage 1 1.1 2 t *1 α β 1.2 µ x µ 2 2 2 α β 2.1 1 α β α ( ) β *1 t t 1 α β *2 α α β β α = α 1 β = 1 β 2.2 α 0 β 1 0 0 1 1 5 2.5 *3 2.3 *4 3 3.1 1 1 1 *2 *3 *4 (µ A ) (µ P ) (µ A > µ P ) 10 (µ A = µ P
ChIP-seq
 ChIP-seq 1 ChIP-seq 解析原理 ChIP サンプルのフラグメントでは タンパク質結合部位付近にそれぞれ Forward と Reverse のリードがマップされることが予想される ChIP のサンプルでは Forward と Reverse のリードを 3 側へシフトさせ ChIP のピークを算出する コントロールサンプルでは ChIP のサンプルとは異なり 特定の場所に多くマップされないため
ChIP-seq 1 ChIP-seq 解析原理 ChIP サンプルのフラグメントでは タンパク質結合部位付近にそれぞれ Forward と Reverse のリードがマップされることが予想される ChIP のサンプルでは Forward と Reverse のリードを 3 側へシフトさせ ChIP のピークを算出する コントロールサンプルでは ChIP のサンプルとは異なり 特定の場所に多くマップされないため
1 P2 P P3P4 P5P8 P9P10 P11 P12
 1 P2 P14 2 3 4 5 1 P3P4 P5P8 P9P10 P11 P12 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 & 11 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 1! 3 2 3! 4 4 3 5 6 I 7 8 P7 P7I P5 9 P5! 10 4!! 11 5 03-5220-8520
1 P2 P14 2 3 4 5 1 P3P4 P5P8 P9P10 P11 P12 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 & 11 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 1! 3 2 3! 4 4 3 5 6 I 7 8 P7 P7I P5 9 P5! 10 4!! 11 5 03-5220-8520
<4D F736F F F696E74202D2091BD8F6494E48A7282CC8AEE916282C B C815B F96405F947A957A97702E >
 第 27 回創薬情報研究会 多重比較の基礎とゲートキーピング法 日本開発センタークリニカルデータサイエンス部舟尾暢男 おわび 後で読み返していただいた際に理解しやすい様 細かなところまで説明するよう努めました そのため 内容が盛りだくさんとなってしまい 早口で説明させていただくこととなります ご容赦下さい また 全てをお話してしまうと時間が大幅に超過してしまいますので本講演では タイトルに があるスライド
第 27 回創薬情報研究会 多重比較の基礎とゲートキーピング法 日本開発センタークリニカルデータサイエンス部舟尾暢男 おわび 後で読み返していただいた際に理解しやすい様 細かなところまで説明するよう努めました そのため 内容が盛りだくさんとなってしまい 早口で説明させていただくこととなります ご容赦下さい また 全てをお話してしまうと時間が大幅に超過してしまいますので本講演では タイトルに があるスライド
Microsoft Word - Stattext13.doc
 3 章対応のある 群間の量的データの検定 3. 検定手順 この章では対応がある場合の量的データの検定方法について学びます この場合も図 3. のように最初に正規に従うかどうかを調べます 正規性が認められた場合は対応がある場合の t 検定 正規性が認められない場合はウィルコクソン (Wlcoxo) の符号付き順位和検定を行ないます 章で述べた検定方法と似ていますが ここでは対応のあるデータ同士を引き算した値を用いて判断します
3 章対応のある 群間の量的データの検定 3. 検定手順 この章では対応がある場合の量的データの検定方法について学びます この場合も図 3. のように最初に正規に従うかどうかを調べます 正規性が認められた場合は対応がある場合の t 検定 正規性が認められない場合はウィルコクソン (Wlcoxo) の符号付き順位和検定を行ないます 章で述べた検定方法と似ていますが ここでは対応のあるデータ同士を引き算した値を用いて判断します
Microsoft Word - Time Series Basic - Modeling.doc
 時系列解析入門 モデリング. 確率分布と統計的モデル が確率変数 (radom varable のとき すべての実数 R に対して となる確 率 Prob( が定められる これを の関数とみなして G( Prob ( とあらわすとき G( を確率変数 の分布関数 (probablt dstrbuto ucto と呼 ぶ 時系列解析で用いられる確率変数は通常連続型と呼ばれるもので その分布関数は (
時系列解析入門 モデリング. 確率分布と統計的モデル が確率変数 (radom varable のとき すべての実数 R に対して となる確 率 Prob( が定められる これを の関数とみなして G( Prob ( とあらわすとき G( を確率変数 の分布関数 (probablt dstrbuto ucto と呼 ぶ 時系列解析で用いられる確率変数は通常連続型と呼ばれるもので その分布関数は (
経済統計分析1 イントロダクション
 1 経済統計分析 9 分散分析 今日のおはなし. 検定 statistical test のいろいろ 2 変数の関係を調べる手段のひとつ適合度検定独立性検定分散分析 今日のタネ 吉田耕作.2006. 直感的統計学. 日経 BP. 中村隆英ほか.1984. 統計入門. 東大出版会. 2 仮説検定の手続き 仮説検定のロジック もし帰無仮説が正しければ, 検定統計量が既知の分布に従う 計算された検定統計量の値から,
1 経済統計分析 9 分散分析 今日のおはなし. 検定 statistical test のいろいろ 2 変数の関係を調べる手段のひとつ適合度検定独立性検定分散分析 今日のタネ 吉田耕作.2006. 直感的統計学. 日経 BP. 中村隆英ほか.1984. 統計入門. 東大出版会. 2 仮説検定の手続き 仮説検定のロジック もし帰無仮説が正しければ, 検定統計量が既知の分布に従う 計算された検定統計量の値から,