バイオインフォマティクス特論3
|
|
|
- そうすけ いなくら
- 3 years ago
- Views:
Transcription
1 藤 博幸
2 平均と標準偏差を推測する の科学者 の科学者のコードの改造
3 ベイズ統計で実践モデリング 4.1 平均と標準偏差を推測する 第 4 章ガウス分布を使った推論
4 データは n 個の独 な観測値 x 1, x 2, x n 例 : ある細胞の遺伝 の発現量を 温度 時間などの条件を全く同じ状態で独 に n 回計測ガウス分布に従うと仮定 このデータが従うガウス分布の平均と標準偏差を推測しよう 注意 :Jags では ガウス分布は 平均と精度 ( 精度は標準偏差の逆数 ) の 2 つにパラメータで表される
5 μ σ x 1 x 2 x 3... x n
6 プレート記法によるグラフィカルモデル μ σ x i i data
7 連続値 離散値 観測変数 ( 確率変数 ) 観測変数 依存関係
8 μ σ 尤度 仮定からデータ x i は同じ正規分布に従うので n 尤度 =Πdnorm(x i, µ, 1/σ 2 ) i=1 x i i data モデルとしては x i ~ Gaussian(µ, 1/σ 2 ) と表現
9 事前分布 μ σ µ は平均 0 で 精度が小さい (= 分散が大きい ) 正規分布に従うとする µ ~ Gaussian(0, 0.001) x i i data σ は 上限を 10 に設定して 一様分布で表現 σ ~ Uniform(0, 10) 無情報事前分布 あるいはそれに近い形で表現
10 x <- seq(-10, 10, 0.01) plot(x, dnorm(x, 0, ),ty='l', ylim=c(0,10^(-10000)))
11 Jags でのモデルの記述 Gaussian.txt μ x i σ i data # Inferring the Mean and Standard Deviation # of a Gaussian model{ # Data Come From A Gaussian for (i in 1:n){ x[i] ~ dnorm(mu,lambda) } # Priors mu ~ dnorm(0,.001) sigma ~ dunif(0,10) lambda <- 1/pow(sigma,2) }
12 Gaussian_jags.R 変数のクリア # clears workspace: rm(list=ls()) Rate_1.txt と Rate_1_jags.R のあるディレクトリへの移動 # sets working directories: setwd("/users/toh/desktop/code/parameterestimation/gaussian") library(r2jags) パッケージの読み込み x <- c(1.1, 1.9, 2.3, 1.8) n <- length(x) 観測変数の設定 data <- list("x", "n") # to be passed on to JAGS
13 μ と σ の初期値の設定 myinits <- list( list(mu = 0, sigma = 1)) # parameters to be monitored: parameters <- c("mu", "sigma") # The following command calls JAGS with specific options. # For a detailed description see the R2jags documentation. samples <- jags(data, inits=myinits, parameters, model.file="gaussian.txt", n.chains=1, n.iter=1000, n.burnin=1, n.thin=1, DIC=T) # Now the values for the monitored parameters are in the "samples" object, # ready for inspection. mu <- samples$bugsoutput$sims.list$mu sigma <- samples$bugsoutput$sims.list$sigma モニターするパラメータの設定 Jags を呼び出して μ と σ をサンプリング
14 traceplot(samples) par(cex.main = 1.5, mar = c(5, 6, 4, 5) + 0.1, mgp = c(3.5, 1, 0), cex.lab = 1.5, font.lab = 2, cex.axis = 1.3, bty = "n", las=1) Nbreaks <- 80 y <- hist(mu, Nbreaks, plot=f) plot(c(y$breaks, max(y$breaks)), c(0,y$density,0), type="s", lwd=2, lty=1, xlim=c(0,15), ylim=c(0,3), xlab="rate", ylab="posterior Density") par(cex.main = 1.5, mar = c(5, 6, 4, 5) + 0.1, mgp = c(3.5, 1, 0), cex.lab = 1.5, font.lab = 2, cex.axis = 1.3, bty = "n", las=1) Nbreaks <- 80 y <- hist(sigma, Nbreaks, plot=f) plot(c(y$breaks, max(y$breaks)), c(0,y$density,0), type="s", lwd=2, lty=1, xlim=c(0,8), ylim=c(0,5), xlab="rate", ylab="posterior Density")

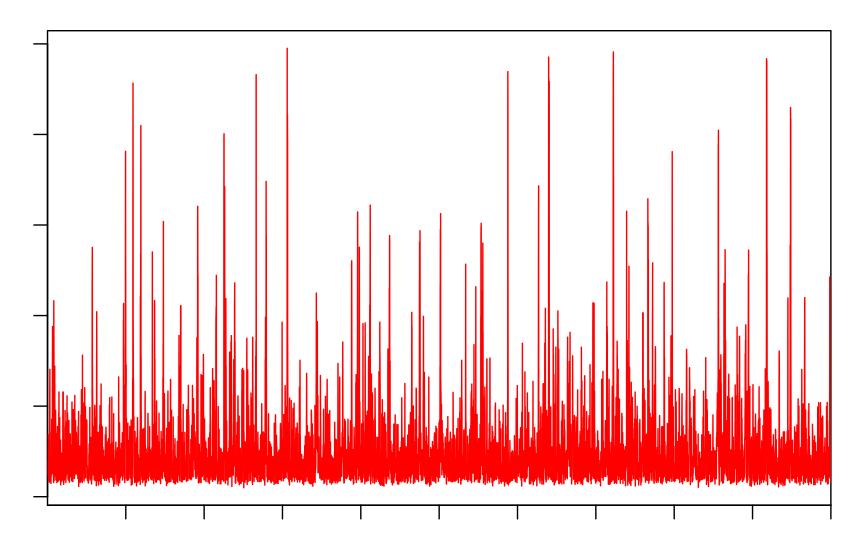
15 μ のトレース σ のトレース
16 μ の事後分布 σ の事後分布
17 μ の要約 σ の要約 summary(mu) V1 Min. : st Qu.: Median : Mean : rd Qu.: Max. : summary(sigma) V1 Min. : st Qu.: Median : Mean : rd Qu.: Max. : density(mu)$x[which(density(mu)$y==max(density(mu)$y))] [1] density(sigma)$x[which(density(sigma)$y==max(density(sigma)$y))] [1]
18 ベイズ統計で実践モデリング の科学者 第 4 章ガウス分布を使った推論
19 実験スキルの きく異なる 7 の科学者が 全員同じ量について測定を う 直感的には最初の 2 は適性を いた研究者この量の真の値は 10 をわずかに下回る程度と考えられる この測定量についての事後分布を求めて 測定される量について推論する 副次的には 7 の科学者の測定スキルをついて推論する
20 σ i 仮定 (1) 全ての科学者の測定はガウス分布に従う (2) 全員同じ量を測定しているので それぞれのガウス分布は同じ平均値を持つ λ i (3) 標準偏差の違いで実験スキルの違いを表現 μ x i i 番 のデータ プレート表記でのグラフィカルモデル
21 σ 1 σ 2 σ 3 σ 4 σ 5 σ 6 σ 7 λ 1 λ 2 λ 3 λ 4 λ 5 λ 6 λ 7 x 1 x 2 x 3 x 4 x 5 x 6 x 7 μ
22 # The Seven Scientists model{ # Data Come From Gaussians With Common Mean But Different Precisions for (i in 1:n){ x[i] ~ dnorm(mu,lambda[i]) 尤度の要素の設定 } # Priors mu ~ dnorm(0,.001) for (i in 1:n){ 事前分布の設定 lambda[i] ~ dgamma(.001,.001) sigma[i] <- 1/sqrt(lambda[i]) } }
23 事前分布の形 x <- seq(0, 1.0, 0.001) plot(x, dgamma(x, 0.001, 0.001), ty='l') 先の例では標準偏差の事前分布として 様分布を使ったが 今回は精度の事前分布としてガンマ分布を使
24 SevenScientists_jags.R # clears workspace: rm(list=ls()) 変数のクリア Rate_1.txt と Rate_1_jags.R のあるディレクトリへの移動 # sets working directories: setwd("/users/toh/desttop/code/parameterestimation/gaussian") library(r2jags) パッケージの読み込み x <- c( ,3.570,8.191,9.898,9.603,9.945,10.056) n <- length(x) data <- list("x", "n") # to be passed on to JAGS 観測変数の設定
25 myinits <- list( list(mu = 0, lambda = rep(1,n))) # parameters to be monitored: parameters <- c("mu", "sigma") μ と λ の初期値の設定 モニターするパラメータの設定 Jags を呼び出して μ と σ をサンプリング # The following command calls JAGS with specific options. # For a detailed description see the R2jags documentation. samples <- jags(data, inits=myinits, parameters, model.file ="SevenScientists.txt", n.chains=1, n.iter=1000, n.burnin=1, n.thin=1, DIC=T) # Now the values for the monitored parameters are in the "samples" object, # ready for inspection.
26 MCMC のサンプリングのトレース traceplot(samples) σ は 7 分出てくる
27 μ の事後分布のヒストグラム par(cex.main = 1.5, mar = c(5, 6, 4, 5) + 0.1, mgp = c(3.5, 1, 0), cex.lab = 1.5, font.lab = 2, cex.axis = 1.3, bty = "n", las=1) Nbreaks <- 80 y <- hist(mu, Nbreaks, plot=f) plot(c(y$breaks, max(y$breaks)), c(0,y$density,0), type="s", lwd=2, lty=1, xlim=c(0,15), ylim=c(0,3), xlab="rate", ylab="posterior Density")
28 μ の要約 summary(mu) V1 Min. : st Qu.: Median : Mean : rd Qu.: Max. :10.658
29 σ の事後分布のヒストグラム Nbreaks <- 80 hist(sigma[,1], Nbreaks) hist(sigma[,7], Nbreaks)
30 σ の要約 summary(sigma) V1 V2 V3 V4 V5 V6 V7 Min. : Min. : Min. : Min. : Min. : Min. : Min. : st Qu.: st Qu.: st Qu.: st Qu.: st Qu.: st Qu.: st Qu.: Median : Median : Median : Median : Median : Median : Median : Mean : Mean : Mean : Mean : Mean : Mean : Mean : rd Qu.: rd Qu.: rd Qu.: rd Qu.: rd Qu.: rd Qu.: rd Qu.: Max. : Max. : Max. : Max. : Max. : Max. : Max. : と だけでなく 3 もスキルに問題がありそう
31 モード ( 最頻値 ) を出 for (i in 1:n) { print(density(sigma[,i])$x[which(density(sigma[,i])$y==max(density(sigma[,i])$y))]) } [1] [1] [1] [1] [1] [1] [1] 結果が 平均やメジアン ( 中央値 ) ほど安定していない MCMC のステップ数 ( サンプル数 ) が少ないせいか?
32 ステップ数 ( サンプル数 ) が少ないバーンイン やシンニングが考慮されていない 正確な不変分布 ( 事後分布 ) が得られていないのでは?
33 burn in を100 ß--- n.burnin thinningを50 ß--- n.thin MCMCの全ステップ数を ß--- n.iter chainを2にして 初期値を与える ß-- n.chains SevenScientistsv2_jags.R (=SevenScientists_jags.R をコピーしたもの ) を書き換える 2 回目の Rate_1_jags.R を参考にできる モデルは同じなので SevenScientists.txt は変更しなくて良い
34 (1) 実 部分を書き換える samples <- jags(data, inits=myinits, parameters, model.file ="SevenScientists.txt", n.chains=1, n.iter=1000, n.burnin=1, n.thin=1, DIC=T) samples <- jags(data, inits=myinits, parameters, model.file ="SevenScientists.txt", n.chains=2, n.iter=100000, n.burnin=100, n.thin=50, DIC=T)
35 (2) 2 つの連鎖の初期値を与える myinits <- list( list(mu = 0, lambda = rep(1,n))) myinits <- list( list(mu = 0, lambda = rep(1,n)), list(mu = 10.0, lamda = rep(10, n)))
36 結果の要約 print(samples) Inference for Bugs model at "SevenScientists.txt", fit using jags, 2 chains, each with 1e+05 iterations (first 100 discarded), n.thin = 50 n.sims = 3996 iterations saved mu.vect sd.vect 2.5% 25% 50% 75% 97.5% Rhat n.eff mu sigma[1] sigma[2] sigma[3] sigma[4] sigma[5] sigma[6] sigma[7] deviance For each parameter, n.eff is a crude measure of effective sample size, and Rhat is the potential scale reduction factor (at convergence, Rhat=1). DIC info (using the rule, pd = var(deviance)/2) pd = 14.1 and DIC = 37.3 DIC is an estimate of expected predictive error (lower deviance is better).
37 mixing の確認 traceplot traceplot(samples)
38 MCMC の 2 つの連鎖をそれぞれ取り出す mu <- samples$bugsoutput$sims.array[,,2] max(mu) # [1] min(mu) # [1] plot(mu[,1],ylim=c(7,14),ty='l',col=2) par(new=t) plot(mu[,2],ylim=c(7,14),ty='l',col=4)
39
40 summary(mu[,1]) Min. 1st Qu. Median Mean 3rd Qu. Max summary(mu[,2]) Min. 1st Qu. Median Mean 3rd Qu. Max density(mu[,1])$x[which(density(mu[,1])$y==max(density(mu[,1])$y))] [1] density(mu[,2])$x[which(density(mu[,2])$y==max(density(mu[,2])$y))] [1]
41 Nbreaks <- 80 x <- hist(mu[,1],nbreaks,plot=f) y <- hist(mu[,2],nbreaks,plot=f) plot(c(x$breaks, max(x$breaks)), c(0,x$density,0), type="s", lwd=2, lty=1, xlim=c(7,12), ylim=c(0,7), xlab="mu", ylab="posterior Density", col=2) par(new=t) plot(c(y$breaks, max(y$breaks)), c(0,y$density,0), type="s", lwd=2, lty=1, xlim=c(7,12), ylim=c(0,7), xlab="mu", ylab="posterior Density", col=4) 2 つの MCMC で得られた μ の事後分布がほぼ同じ形に収束していることがわかる
42 sigma <- samples$bugsoutput$sims.array[,,3:9] max(sigma[,,7]) # [1] min(sigma[,,7]) # [1] plot(sigma[,1,7],ylim=c(0,790),ty='l',col=2) par(new=t) plot(sigma[,2,7],ylim=c(0,790),ty='l',col=4)
43
44 for (i in 1:7) { print(i) for (j in 1:2) { print(summary(sigma[,j,i])) print(density(sigma[,j,i])$x[which(density(sigma[,j,i])$y==max(density(sigma[,j,i])$y))]) } print("//") } [1] 1 Min. 1st Qu. Median Mean 3rd Qu. Max [1] Min. 1st Qu. Median Mean 3rd Qu. Max [1] [1] "//" [1] 2 Min. 1st Qu. Median Mean 3rd Qu. Max [1] Min. 1st Qu. Median Mean 3rd Qu. Max [1] [1] "//"
45 [1] 3 Min. 1st Qu. Median Mean 3rd Qu. Max [1] Min. 1st Qu. Median Mean 3rd Qu. Max [1] [1] "//" [1] 4 Min. 1st Qu. Median Mean 3rd Qu. Max [1] Min. 1st Qu. Median Mean 3rd Qu. Max [1] [1] "//" [1] 5 Min. 1st Qu. Median Mean 3rd Qu. Max [1] Min. 1st Qu. Median Mean 3rd Qu. Max [1] [1] "//"
46 [1] 6 Min. 1st Qu. Median Mean 3rd Qu. Max [1] Min. 1st Qu. Median Mean 3rd Qu. Max [1] [1] "//" [1] 7 Min. 1st Qu. Median Mean 3rd Qu. Max [1] Min. 1st Qu. Median Mean 3rd Qu. Max [1] [1] "//"
バイオインフォマティクス特論4
 藤 博幸 1-3-1. ピアソン相関係数 1-3-2. 致性のカッパ係数 1-3-3. 時系列データにおける変化検出 ベイズ統計で実践モデリング 5.1 ピアソン係数 第 5 章データ解析の例 データは n ペアの独 な観測値の対例 : 特定の薬剤の投与量と投与から t 時間後の注 する遺伝 の発現量 2 つの変数間の線形の関係性はピアソンの積率相関係数 r で表現される t 時間後の注 する遺伝
藤 博幸 1-3-1. ピアソン相関係数 1-3-2. 致性のカッパ係数 1-3-3. 時系列データにおける変化検出 ベイズ統計で実践モデリング 5.1 ピアソン係数 第 5 章データ解析の例 データは n ペアの独 な観測値の対例 : 特定の薬剤の投与量と投与から t 時間後の注 する遺伝 の発現量 2 つの変数間の線形の関係性はピアソンの積率相関係数 r で表現される t 時間後の注 する遺伝
バイオインフォマティクス特論12
 藤 博幸 事後予測分布 パラメータの事後分布に従って モデルがどんなデータを期待するかを予測する 予測分布が観測されたデータと 致するかを確認することで モデルの適切さを確認できる 前回と同じ問題で事後予測を う 3-1-1. 個 差を考えない場合 3-1-2. 完全な個 差を考える場合 3-1-3. 構造化された個 差を考える場合 ベイズ統計で実践モデリング 10.1 個 差を考えない場合 第 10
藤 博幸 事後予測分布 パラメータの事後分布に従って モデルがどんなデータを期待するかを予測する 予測分布が観測されたデータと 致するかを確認することで モデルの適切さを確認できる 前回と同じ問題で事後予測を う 3-1-1. 個 差を考えない場合 3-1-2. 完全な個 差を考える場合 3-1-3. 構造化された個 差を考える場合 ベイズ統計で実践モデリング 10.1 個 差を考えない場合 第 10
kubo2015ngt6 p.2 ( ( (MLE 8 y i L(q q log L(q q 0 ˆq log L(q / q = 0 q ˆq = = = * ˆq = 0.46 ( 8 y 0.46 y y y i kubo (ht
 kubo2015ngt6 p.1 2015 (6 MCMC kubo@ees.hokudai.ac.jp, @KuboBook http://goo.gl/m8hsbm 1 ( 2 3 4 5 JAGS : 2015 05 18 16:48 kubo (http://goo.gl/m8hsbm 2015 (6 1 / 70 kubo (http://goo.gl/m8hsbm 2015 (6 2 /
kubo2015ngt6 p.1 2015 (6 MCMC kubo@ees.hokudai.ac.jp, @KuboBook http://goo.gl/m8hsbm 1 ( 2 3 4 5 JAGS : 2015 05 18 16:48 kubo (http://goo.gl/m8hsbm 2015 (6 1 / 70 kubo (http://goo.gl/m8hsbm 2015 (6 2 /
2014ESJ.key
 http://www001.upp.so-net.ne.jp/ito-hi/stat/2014esj/ Statistical Software for State Space Models Commandeur et al. (2011) Journal of Statistical Software 41(1) State Space Models in R Petris & Petrone (2011)
http://www001.upp.so-net.ne.jp/ito-hi/stat/2014esj/ Statistical Software for State Space Models Commandeur et al. (2011) Journal of Statistical Software 41(1) State Space Models in R Petris & Petrone (2011)
12/1 ( ) GLM, R MCMC, WinBUGS 12/2 ( ) WinBUGS WinBUGS 12/2 ( ) : 12/3 ( ) :? ( :51 ) 2/ 71
 GLM, R MCMC, WinBUGS 12/2 ( ) WinBUGS WinBUGS 12/2 ( ) : 12/3 ( ) :? ( :51 ) 2/ 71") 2010-12-02 (2010 12 02 10 :51 ) 1/ 71 GCOE 2010-12-02 WinBUGS kubo@ees.hokudai.ac.jp http://goo.gl/bukrb 12/1 ( ) GLM, R MCMC, WinBUGS 12/2 ( ) WinBUGS WinBUGS 12/2 ( ) : 12/3 ( ) :? 2010-12-02 (2010 12
2010-12-02 (2010 12 02 10 :51 ) 1/ 71 GCOE 2010-12-02 WinBUGS kubo@ees.hokudai.ac.jp http://goo.gl/bukrb 12/1 ( ) GLM, R MCMC, WinBUGS 12/2 ( ) WinBUGS WinBUGS 12/2 ( ) : 12/3 ( ) :? 2010-12-02 (2010 12
kubostat1g p. MCMC binomial distribution q MCMC : i N i y i p(y i q = ( Ni y i q y i (1 q N i y i, q {y i } q likelihood q L(q {y i } = i=1 p(y i q 1
 kubostat1g p.1 1 (g Hierarchical Bayesian Model kubo@ees.hokudai.ac.jp http://goo.gl/7ci The development of linear models Hierarchical Bayesian Model Be more flexible Generalized Linear Mixed Model (GLMM
kubostat1g p.1 1 (g Hierarchical Bayesian Model kubo@ees.hokudai.ac.jp http://goo.gl/7ci The development of linear models Hierarchical Bayesian Model Be more flexible Generalized Linear Mixed Model (GLMM
Stanによるハミルトニアンモンテカルロ法を用いたサンプリングについて
 Stan によるハミルトニアンモンテカルロ法を用いたサンプリングについて 10 月 22 日中村文士 1 目次 1.STANについて 2.RでSTANをするためのインストール 3.STANのコード記述方法 4.STANによるサンプリングの例 2 1.STAN について ハミルトニアンモンテカルロ法に基づいた事後分布からのサンプリングなどができる STAN の HP: mc-stan.org 3 由来
Stan によるハミルトニアンモンテカルロ法を用いたサンプリングについて 10 月 22 日中村文士 1 目次 1.STANについて 2.RでSTANをするためのインストール 3.STANのコード記述方法 4.STANによるサンプリングの例 2 1.STAN について ハミルトニアンモンテカルロ法に基づいた事後分布からのサンプリングなどができる STAN の HP: mc-stan.org 3 由来
日心TWS
 2017.09.22 (15:40~17:10) 日本心理学会第 81 回大会 TWS ベイジアンデータ解析入門 回帰分析を例に ベイジアンデータ解析 を体験してみる 広島大学大学院教育学研究科平川真 ベイジアン分析のステップ (p.24) 1) データの特定 2) モデルの定義 ( 解釈可能な ) モデルの作成 3) パラメタの事前分布の設定 4) ベイズ推論を用いて パラメタの値に確信度を再配分ベイズ推定
2017.09.22 (15:40~17:10) 日本心理学会第 81 回大会 TWS ベイジアンデータ解析入門 回帰分析を例に ベイジアンデータ解析 を体験してみる 広島大学大学院教育学研究科平川真 ベイジアン分析のステップ (p.24) 1) データの特定 2) モデルの定義 ( 解釈可能な ) モデルの作成 3) パラメタの事前分布の設定 4) ベイズ推論を用いて パラメタの値に確信度を再配分ベイズ推定
kubo2017sep16a p.1 ( 1 ) : : :55 kubo ( ( 1 ) / 10
 : : :55 kubo ( ( 1 ) / 10") kubo2017sep16a p.1 ( 1 ) kubo@ees.hokudai.ac.jp 2017 09 16 : http://goo.gl/8je5wh : 2017 09 13 16:55 kubo (http://goo.gl/ufq2) ( 1 ) 2017 09 16 1 / 106 kubo (http://goo.gl/ufq2) ( 1 ) 2017 09 16 2 / 106
kubo2017sep16a p.1 ( 1 ) kubo@ees.hokudai.ac.jp 2017 09 16 : http://goo.gl/8je5wh : 2017 09 13 16:55 kubo (http://goo.gl/ufq2) ( 1 ) 2017 09 16 1 / 106 kubo (http://goo.gl/ufq2) ( 1 ) 2017 09 16 2 / 106
講義のーと : データ解析のための統計モデリング. 第2回
 Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
Microsoft PowerPoint - R-stat-intro_20.ppt [互換モード]
![Microsoft PowerPoint - R-stat-intro_20.ppt [互換モード]](/thumbs/95/123289731.jpg "Microsoft PowerPoint - R-stat-intro_20.ppt [互換モード]") と WinBUGS R で統計解析入門 (20) ベイズ統計 超 入門 WinBUGS と R2WinBUGS のセットアップ 1. 本資料で使用するデータを以下からダウンロードする http://www.cwk.zaq.ne.jp/fkhud708/files/r-intro/r-stat-intro_data.zip 2. WinBUGS のホームページから下記ファイルをダウンロードし WinBUGS14.exe
と WinBUGS R で統計解析入門 (20) ベイズ統計 超 入門 WinBUGS と R2WinBUGS のセットアップ 1. 本資料で使用するデータを以下からダウンロードする http://www.cwk.zaq.ne.jp/fkhud708/files/r-intro/r-stat-intro_data.zip 2. WinBUGS のホームページから下記ファイルをダウンロードし WinBUGS14.exe
kubostat2017j p.2 CSV CSV (!) d2.csv d2.csv,, 286,0,A 85,0,B 378,1,A 148,1,B ( :27 ) 10/ 51 kubostat2017j (http://goo.gl/76c4i
 d2.csv d2.csv,, 286,0,A 85,0,B 378,1,A 148,1,B ( :27 ) 10/ 51 kubostat2017j (http://goo.gl/76c4i") kubostat2017j p.1 2017 (j) Categorical Data Analsis kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2017 11 15 : 2017 11 08 17:11 kubostat2017j (http://goo.gl/76c4i) 2017 (j) 2017 11 15 1 / 63 A B C D E F G
kubostat2017j p.1 2017 (j) Categorical Data Analsis kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2017 11 15 : 2017 11 08 17:11 kubostat2017j (http://goo.gl/76c4i) 2017 (j) 2017 11 15 1 / 63 A B C D E F G
ベイズ統計入門
 ベイズ統計入門 条件付確率 事象 F が起こったことが既知であるという条件の下で E が起こる確率を条件付確率 (codtoal probablt) という P ( E F ) P ( E F ) P( F ) 定義式を変形すると 確率の乗法公式となる ( E F ) P( F ) P( E F ) P( E) P( F E) P 事象の独立 ある事象の生起する確率が 他のある事象が生起するかどうかによって変化しないとき
ベイズ統計入門 条件付確率 事象 F が起こったことが既知であるという条件の下で E が起こる確率を条件付確率 (codtoal probablt) という P ( E F ) P ( E F ) P( F ) 定義式を変形すると 確率の乗法公式となる ( E F ) P( F ) P( E F ) P( E) P( F E) P 事象の独立 ある事象の生起する確率が 他のある事象が生起するかどうかによって変化しないとき
一般化線形 (混合) モデル (2) - ロジスティック回帰と GLMM
 モデル (2) - ロジスティック回帰と GLMM") .. ( ) (2) GLMM kubo@ees.hokudai.ac.jp I http://goo.gl/rrhzey 2013 08 27 : 2013 08 27 08:29 kubostat2013ou2 (http://goo.gl/rrhzey) ( ) (2) 2013 08 27 1 / 74 I.1 N k.2 binomial distribution logit link function.3.4!
.. ( ) (2) GLMM kubo@ees.hokudai.ac.jp I http://goo.gl/rrhzey 2013 08 27 : 2013 08 27 08:29 kubostat2013ou2 (http://goo.gl/rrhzey) ( ) (2) 2013 08 27 1 / 74 I.1 N k.2 binomial distribution logit link function.3.4!
k2 ( :35 ) ( k2) (GLM) web web 1 :
 ( k2) (GLM) web web 1 :") 2012 11 01 k2 (2012-10-26 16:35 ) 1 6 2 (2012 11 01 k2) (GLM) kubo@ees.hokudai.ac.jp web http://goo.gl/wijx2 web http://goo.gl/ufq2 1 : 2 2 4 3 7 4 9 5 : 11 5.1................... 13 6 14 6.1......................
2012 11 01 k2 (2012-10-26 16:35 ) 1 6 2 (2012 11 01 k2) (GLM) kubo@ees.hokudai.ac.jp web http://goo.gl/wijx2 web http://goo.gl/ufq2 1 : 2 2 4 3 7 4 9 5 : 11 5.1................... 13 6 14 6.1......................
講義のーと : データ解析のための統計モデリング. 第3回
 Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
/22 R MCMC R R MCMC? 3. Gibbs sampler : kubo/
 2006-12-09 1/22 R MCMC R 1. 2. R MCMC? 3. Gibbs sampler : kubo@ees.hokudai.ac.jp http://hosho.ees.hokudai.ac.jp/ kubo/ 2006-12-09 2/22 : ( ) : : ( ) : (?) community ( ) 2006-12-09 3/22 :? 1. ( ) 2. ( )
2006-12-09 1/22 R MCMC R 1. 2. R MCMC? 3. Gibbs sampler : kubo@ees.hokudai.ac.jp http://hosho.ees.hokudai.ac.jp/ kubo/ 2006-12-09 2/22 : ( ) : : ( ) : (?) community ( ) 2006-12-09 3/22 :? 1. ( ) 2. ( )
DAA04
 # plot(x,y, ) plot(dat$shoesize, dat$h, main="relationship b/w shoesize and height, xlab = 'shoesize, ylab='height, pch=19, col='red ) Relationship b/w shoesize and height height 150 160 170 180 21 22
# plot(x,y, ) plot(dat$shoesize, dat$h, main="relationship b/w shoesize and height, xlab = 'shoesize, ylab='height, pch=19, col='red ) Relationship b/w shoesize and height height 150 160 170 180 21 22
60 (W30)? 1. ( ) 2. ( ) web site URL ( :41 ) 1/ 77
? 1. ( ) 2. ( ) web site URL ( :41 ) 1/ 77") 60 (W30)? 1. ( ) kubo@ees.hokudai.ac.jp 2. ( ) web site URL http://goo.gl/e1cja!! 2013 03 07 (2013 03 07 17 :41 ) 1/ 77 ! : :? 2013 03 07 (2013 03 07 17 :41 ) 2/ 77 2013 03 07 (2013 03 07 17 :41 ) 3/ 77!!
60 (W30)? 1. ( ) kubo@ees.hokudai.ac.jp 2. ( ) web site URL http://goo.gl/e1cja!! 2013 03 07 (2013 03 07 17 :41 ) 1/ 77 ! : :? 2013 03 07 (2013 03 07 17 :41 ) 2/ 77 2013 03 07 (2013 03 07 17 :41 ) 3/ 77!!
@i_kiwamu Bayes - -
 Bayes RStan 1 2012 12 1 R @ @i_kiwamu Bayes - - Stan / RStan Bayes Stan Development Team - Andrew Gelman, Bob Carpenter, Matt Hoffman, Ben Goodrich, Michael Malecki, Daniel Lee and Chad Scherrer Open source
Bayes RStan 1 2012 12 1 R @ @i_kiwamu Bayes - - Stan / RStan Bayes Stan Development Team - Andrew Gelman, Bob Carpenter, Matt Hoffman, Ben Goodrich, Michael Malecki, Daniel Lee and Chad Scherrer Open source
スライド 1
 WinBUGS 入門 水産資源学におけるベイズ統計の応用ワークショップ 2007 年 8 月 2-3 日, 中央水研 遠洋水産研究所外洋資源部 鯨類管理研究室 岡村寛 WinBUGS とは BUGS (Bayesian Inference Using Gibbs Sampling) の Windows バージョン フリーのソフトウェア Gibbs samplingを利用した事後確率からのサンプリングを行う
WinBUGS 入門 水産資源学におけるベイズ統計の応用ワークショップ 2007 年 8 月 2-3 日, 中央水研 遠洋水産研究所外洋資源部 鯨類管理研究室 岡村寛 WinBUGS とは BUGS (Bayesian Inference Using Gibbs Sampling) の Windows バージョン フリーのソフトウェア Gibbs samplingを利用した事後確率からのサンプリングを行う
講義のーと : データ解析のための統計モデリング. 第5回
 Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
Title 講義のーと : データ解析のための統計モデリング Author(s) 久保, 拓弥 Issue Date 2008 Doc URL http://hdl.handle.net/2115/49477 Type learningobject Note この講義資料は, 著者のホームページ http://hosho.ees.hokudai.ac.jp/~kub ードできます Note(URL)http://hosho.ees.hokudai.ac.jp/~kubo/ce/EesLecture20
DAA03
 par(mfrow=c(1,2)) # figure Dist. of Height for Female Participants Dist. of Height for Male Participants Density 0.00 0.02 0.04 0.06 0.08 Density 0.00 0.02 0.04 0.06 0.08 140 150 160 170 180 190 Height
par(mfrow=c(1,2)) # figure Dist. of Height for Female Participants Dist. of Height for Male Participants Density 0.00 0.02 0.04 0.06 0.08 Density 0.00 0.02 0.04 0.06 0.08 140 150 160 170 180 190 Height
kubostat2017e p.1 I 2017 (e) GLM logistic regression : : :02 1 N y count data or
 GLM logistic regression : : :02 1 N y count data or") kubostat207e p. I 207 (e) GLM kubo@ees.hokudai.ac.jp https://goo.gl/z9ycjy 207 4 207 6:02 N y 2 binomial distribution logit link function 3 4! offset kubostat207e (https://goo.gl/z9ycjy) 207 (e) 207 4
kubostat207e p. I 207 (e) GLM kubo@ees.hokudai.ac.jp https://goo.gl/z9ycjy 207 4 207 6:02 N y 2 binomial distribution logit link function 3 4! offset kubostat207e (https://goo.gl/z9ycjy) 207 (e) 207 4
 2009 5 1...1 2...3 2.1...3 2.2...3 3...10 3.1...10 3.1.1...10 3.1.2... 11 3.2...14 3.2.1...14 3.2.2...16 3.3...18 3.4...19 3.4.1...19 3.4.2...20 3.4.3...21 4...24 4.1...24 4.2...24 4.3 WinBUGS...25 4.4...28
2009 5 1...1 2...3 2.1...3 2.2...3 3...10 3.1...10 3.1.1...10 3.1.2... 11 3.2...14 3.2.1...14 3.2.2...16 3.3...18 3.4...19 3.4.1...19 3.4.2...20 3.4.3...21 4...24 4.1...24 4.2...24 4.3 WinBUGS...25 4.4...28
kubostat7f p GLM! logistic regression as usual? N? GLM GLM doesn t work! GLM!! probabilit distribution binomial distribution : : β + β x i link functi
 kubostat7f p statistaical models appeared in the class 7 (f) kubo@eeshokudaiacjp https://googl/z9cjy 7 : 7 : The development of linear models Hierarchical Baesian Model Be more flexible Generalized Linear
kubostat7f p statistaical models appeared in the class 7 (f) kubo@eeshokudaiacjp https://googl/z9cjy 7 : 7 : The development of linear models Hierarchical Baesian Model Be more flexible Generalized Linear
kubostat2017c p (c) Poisson regression, a generalized linear model (GLM) : :
 Poisson regression, a generalized linear model (GLM) : :") kubostat2017c p.1 2017 (c), a generalized linear model (GLM) : kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2017 11 14 : 2017 11 07 15:43 kubostat2017c (http://goo.gl/76c4i) 2017 (c) 2017 11 14 1 / 47 agenda
kubostat2017c p.1 2017 (c), a generalized linear model (GLM) : kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2017 11 14 : 2017 11 07 15:43 kubostat2017c (http://goo.gl/76c4i) 2017 (c) 2017 11 14 1 / 47 agenda
kubostat2015e p.2 how to specify Poisson regression model, a GLM GLM how to specify model, a GLM GLM logistic probability distribution Poisson distrib
 kubostat2015e p.1 I 2015 (e) GLM kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2015 07 22 2015 07 21 16:26 kubostat2015e (http://goo.gl/76c4i) 2015 (e) 2015 07 22 1 / 42 1 N k 2 binomial distribution logit
kubostat2015e p.1 I 2015 (e) GLM kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2015 07 22 2015 07 21 16:26 kubostat2015e (http://goo.gl/76c4i) 2015 (e) 2015 07 22 1 / 42 1 N k 2 binomial distribution logit
kubostat2017b p.1 agenda I 2017 (b) probability distribution and maximum likelihood estimation :
 probability distribution and maximum likelihood estimation :") kubostat2017b p.1 agenda I 2017 (b) probabilit distribution and maimum likelihood estimation kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2017 11 14 : 2017 11 07 15:43 1 : 2 3? 4 kubostat2017b (http://goo.gl/76c4i)
kubostat2017b p.1 agenda I 2017 (b) probabilit distribution and maimum likelihood estimation kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2017 11 14 : 2017 11 07 15:43 1 : 2 3? 4 kubostat2017b (http://goo.gl/76c4i)
MCMCについて
 MCMC について 水産資源学におけるベイズ統計の応用ワークショップ 2007 年 8 月 2-3 日, 中央水研 遠洋水産研究所外洋資源部 鯨類管理研究室 岡村寛 事後分布からサンプルする Pr(θ 1, θ 2, θ 3, ) θ 1 は重要. あとは必要だけど直接的じゃないというようなとき, P(θ 1 x)= P(θ 1,, θ n x)dθ 2 dθ n を計算したい. モンテカルロ近似
MCMC について 水産資源学におけるベイズ統計の応用ワークショップ 2007 年 8 月 2-3 日, 中央水研 遠洋水産研究所外洋資源部 鯨類管理研究室 岡村寛 事後分布からサンプルする Pr(θ 1, θ 2, θ 3, ) θ 1 は重要. あとは必要だけど直接的じゃないというようなとき, P(θ 1 x)= P(θ 1,, θ n x)dθ 2 dθ n を計算したい. モンテカルロ近似
Microsoft PowerPoint slide2forWeb.ppt [互換モード]
![Microsoft PowerPoint slide2forWeb.ppt [互換モード]](/thumbs/96/126561931.jpg "Microsoft PowerPoint slide2forWeb.ppt [互換モード]") 講義内容 9..4 正規分布 ormal dstrbuto ガウス分布 Gaussa dstrbuto 中心極限定理 サンプルからの母集団統計量の推定 不偏推定量について 確率変数, 確率密度関数 確率密度関数 確率密度関数は積分したら. 平均 : 確率変数 分散 : 例 ある場所, ある日時での気温の確率. : 気温, : 気温 が起こる確率 標本平均とのアナロジー 類推 例 人の身長の分布と平均
講義内容 9..4 正規分布 ormal dstrbuto ガウス分布 Gaussa dstrbuto 中心極限定理 サンプルからの母集団統計量の推定 不偏推定量について 確率変数, 確率密度関数 確率密度関数 確率密度関数は積分したら. 平均 : 確率変数 分散 : 例 ある場所, ある日時での気温の確率. : 気温, : 気温 が起こる確率 標本平均とのアナロジー 類推 例 人の身長の分布と平均
統計学 - 社会統計の基礎 - 正規分布 標準正規分布累積分布関数の逆関数 t 分布正規分布に従うサンプルの平均の信頼区間 担当 : 岸 康人 資料ページ :
 統計学 - 社会統計の基礎 - 正規分布 標準正規分布累積分布関数の逆関数 t 分布正規分布に従うサンプルの平均の信頼区間 担当 : 岸 康人 資料ページ : https://goo.gl/qw1djw 正規分布 ( 復習 ) 正規分布 (Normal Distribution)N (μ, σ 2 ) 別名 : ガウス分布 (Gaussian Distribution) 密度関数 Excel:= NORM.DIST
統計学 - 社会統計の基礎 - 正規分布 標準正規分布累積分布関数の逆関数 t 分布正規分布に従うサンプルの平均の信頼区間 担当 : 岸 康人 資料ページ : https://goo.gl/qw1djw 正規分布 ( 復習 ) 正規分布 (Normal Distribution)N (μ, σ 2 ) 別名 : ガウス分布 (Gaussian Distribution) 密度関数 Excel:= NORM.DIST
k3 ( :07 ) 2 (A) k = 1 (B) k = 7 y x x 1 (k2)?? x y (A) GLM (k
 2 (A) k = 1 (B) k = 7 y x x 1 (k2)?? x y (A) GLM (k") 2012 11 01 k3 (2012-10-24 14:07 ) 1 6 3 (2012 11 01 k3) kubo@ees.hokudai.ac.jp web http://goo.gl/wijx2 web http://goo.gl/ufq2 1 3 2 : 4 3 AIC 6 4 7 5 8 6 : 9 7 11 8 12 8.1 (1)........ 13 8.2 (2) χ 2....................
2012 11 01 k3 (2012-10-24 14:07 ) 1 6 3 (2012 11 01 k3) kubo@ees.hokudai.ac.jp web http://goo.gl/wijx2 web http://goo.gl/ufq2 1 3 2 : 4 3 AIC 6 4 7 5 8 6 : 9 7 11 8 12 8.1 (1)........ 13 8.2 (2) χ 2....................
Rによる計量分析:データ解析と可視化 - 第3回 Rの基礎とデータ操作・管理
 R 3 R 2017 Email: gito@eco.u-toyama.ac.jp October 23, 2017 (Toyama/NIHU) R ( 3 ) October 23, 2017 1 / 34 Agenda 1 2 3 4 R 5 RStudio (Toyama/NIHU) R ( 3 ) October 23, 2017 2 / 34 10/30 (Mon.) 12/11 (Mon.)
R 3 R 2017 Email: gito@eco.u-toyama.ac.jp October 23, 2017 (Toyama/NIHU) R ( 3 ) October 23, 2017 1 / 34 Agenda 1 2 3 4 R 5 RStudio (Toyama/NIHU) R ( 3 ) October 23, 2017 2 / 34 10/30 (Mon.) 12/11 (Mon.)
今日の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか
 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか") 時系列データ解析でよく見る あぶない モデリング 久保拓弥 (北海道大 環境科学) 1/56 今日の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか (危 1) 時系列データを GLM で (危 2) 時系列Yt 時系列 Xt 相関は因果関係ではない 問題の一部
時系列データ解析でよく見る あぶない モデリング 久保拓弥 (北海道大 環境科学) 1/56 今日の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか (危 1) 時系列データを GLM で (危 2) 時系列Yt 時系列 Xt 相関は因果関係ではない 問題の一部
DAA09
 > summary(dat.lm1) Call: lm(formula = sales ~ price, data = dat) Residuals: Min 1Q Median 3Q Max -55.719-19.270 4.212 16.143 73.454 Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) 237.1326
> summary(dat.lm1) Call: lm(formula = sales ~ price, data = dat) Residuals: Min 1Q Median 3Q Max -55.719-19.270 4.212 16.143 73.454 Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) 237.1326
Microsoft Word - Time Series Basic - Modeling.doc
 時系列解析入門 モデリング. 確率分布と統計的モデル が確率変数 (radom varable のとき すべての実数 R に対して となる確 率 Prob( が定められる これを の関数とみなして G( Prob ( とあらわすとき G( を確率変数 の分布関数 (probablt dstrbuto ucto と呼 ぶ 時系列解析で用いられる確率変数は通常連続型と呼ばれるもので その分布関数は (
時系列解析入門 モデリング. 確率分布と統計的モデル が確率変数 (radom varable のとき すべての実数 R に対して となる確 率 Prob( が定められる これを の関数とみなして G( Prob ( とあらわすとき G( を確率変数 の分布関数 (probablt dstrbuto ucto と呼 ぶ 時系列解析で用いられる確率変数は通常連続型と呼ばれるもので その分布関数は (
スライド 1
 2018 年 5 月 8 日 @ 統計モデリング 統計モデリング 第四回配布資料 文献 : a) A. J. Dobson and A. G. Barnett: An Introduction to Generalized Linear Models. 3rd ed., CRC Press. b) H. Dung, et al: Monitoring the Transmission of Schistosoma
2018 年 5 月 8 日 @ 統計モデリング 統計モデリング 第四回配布資料 文献 : a) A. J. Dobson and A. G. Barnett: An Introduction to Generalized Linear Models. 3rd ed., CRC Press. b) H. Dung, et al: Monitoring the Transmission of Schistosoma
Probit , Mixed logit
 Probit, Mixed logit 2016/5/16 スタートアップゼミ #5 B4 後藤祥孝 1 0. 目次 Probit モデルについて 1. モデル概要 2. 定式化と理解 3. 推定 Mixed logit モデルについて 4. モデル概要 5. 定式化と理解 6. 推定 2 1.Probit 概要 プロビットモデルとは. 効用関数の誤差項に多変量正規分布を仮定したもの. 誤差項には様々な要因が存在するため,
Probit, Mixed logit 2016/5/16 スタートアップゼミ #5 B4 後藤祥孝 1 0. 目次 Probit モデルについて 1. モデル概要 2. 定式化と理解 3. 推定 Mixed logit モデルについて 4. モデル概要 5. 定式化と理解 6. 推定 2 1.Probit 概要 プロビットモデルとは. 効用関数の誤差項に多変量正規分布を仮定したもの. 誤差項には様々な要因が存在するため,
情報工学概論
 確率と統計 中山クラス 第 11 週 0 本日の内容 第 3 回レポート解説 第 5 章 5.6 独立性の検定 ( カイ二乗検定 ) 5.7 サンプルサイズの検定結果への影響練習問題 (4),(5) 第 4 回レポート課題の説明 1 演習問題 ( 前回 ) の解説 勉強時間と定期試験の得点の関係を無相関検定により調べる. データ入力 > aa
確率と統計 中山クラス 第 11 週 0 本日の内容 第 3 回レポート解説 第 5 章 5.6 独立性の検定 ( カイ二乗検定 ) 5.7 サンプルサイズの検定結果への影響練習問題 (4),(5) 第 4 回レポート課題の説明 1 演習問題 ( 前回 ) の解説 勉強時間と定期試験の得点の関係を無相関検定により調べる. データ入力 > aa
Microsoft Word - 計量研修テキスト_第5版).doc
.doc") Q10-2 テキスト P191 1. 記述統計量 ( 変数 :YY95) 表示変数として 平均 中央値 最大値 最小値 標準偏差 観測値 を選択 A. 都道府県別 Descriptive Statistics for YY95 Categorized by values of PREFNUM Date: 05/11/06 Time: 14:36 Sample: 1990 2002 Included
Q10-2 テキスト P191 1. 記述統計量 ( 変数 :YY95) 表示変数として 平均 中央値 最大値 最小値 標準偏差 観測値 を選択 A. 都道府県別 Descriptive Statistics for YY95 Categorized by values of PREFNUM Date: 05/11/06 Time: 14:36 Sample: 1990 2002 Included
データ科学2.pptx
 データ科学 多重検定 2 mul%ple test False Discovery Rate 藤博幸 前回の復習 1 多くの検定を繰り返す時には 単純に個々の検定を繰り返すだけでは不十分 5% 有意水準ということは, 1000 回検定を繰り返すと, 50 回くらいは帰無仮説が正しいのに 間違って棄却されてすまうじちがあるということ ex) 1 万個の遺伝子について 正常細胞とガン細胞で それぞれの遺伝子の発現に差があるかどうかを検定
データ科学 多重検定 2 mul%ple test False Discovery Rate 藤博幸 前回の復習 1 多くの検定を繰り返す時には 単純に個々の検定を繰り返すだけでは不十分 5% 有意水準ということは, 1000 回検定を繰り返すと, 50 回くらいは帰無仮説が正しいのに 間違って棄却されてすまうじちがあるということ ex) 1 万個の遺伝子について 正常細胞とガン細胞で それぞれの遺伝子の発現に差があるかどうかを検定
Microsoft PowerPoint - 14回パラメータ推定配布用.pptx
 パラメータ推定の理論と実践 BEhavior Study for Transportation Graduate school, Univ. of Yamanashi 山梨大学佐々木邦明 最尤推定法 点推定量を求める最もポピュラーな方法 L n x n i1 f x i 右上の式を θ の関数とみなしたものが尤度関数 データ (a,b) が得られたとき, 全体の平均がいくつとするのがよいか 平均がいくつだったら
パラメータ推定の理論と実践 BEhavior Study for Transportation Graduate school, Univ. of Yamanashi 山梨大学佐々木邦明 最尤推定法 点推定量を求める最もポピュラーな方法 L n x n i1 f x i 右上の式を θ の関数とみなしたものが尤度関数 データ (a,b) が得られたとき, 全体の平均がいくつとするのがよいか 平均がいくつだったら
数値計算法
 数値計算法 008 4/3 林田清 ( 大阪大学大学院理学研究科 ) 実験データの統計処理その 誤差について 母集団と標本 平均値と標準偏差 誤差伝播 最尤法 平均値につく誤差 誤差 (Error): 真の値からのずれ 測定誤差 物差しが曲がっていた 測定する対象が室温が低いため縮んでいた g の単位までしかデジタル表示されない計りで g 以下 計りの目盛りを読み取る角度によって値が異なる 統計誤差
数値計算法 008 4/3 林田清 ( 大阪大学大学院理学研究科 ) 実験データの統計処理その 誤差について 母集団と標本 平均値と標準偏差 誤差伝播 最尤法 平均値につく誤差 誤差 (Error): 真の値からのずれ 測定誤差 物差しが曲がっていた 測定する対象が室温が低いため縮んでいた g の単位までしかデジタル表示されない計りで g 以下 計りの目盛りを読み取る角度によって値が異なる 統計誤差
10
 z c j = N 1 N t= j1 [ ( z t z ) ( )] z t j z q 2 1 2 r j /N j=1 1/ N J Q = N(N 2) 1 N j j=1 r j 2 2 χ J B d z t = z t d (1 B) 2 z t = (z t z t 1 ) (z t 1 z t 2 ) (1 B s )z t = z t z t s _ARIMA CONSUME
z c j = N 1 N t= j1 [ ( z t z ) ( )] z t j z q 2 1 2 r j /N j=1 1/ N J Q = N(N 2) 1 N j j=1 r j 2 2 χ J B d z t = z t d (1 B) 2 z t = (z t z t 1 ) (z t 1 z t 2 ) (1 B s )z t = z t z t s _ARIMA CONSUME
¥¤¥ó¥¿¡¼¥Í¥Ã¥È·×¬¤È¥Ç¡¼¥¿²òÀÏ Âè2²ó
 2 2015 4 20 1 (4/13) : ruby 2 / 49 2 ( ) : gnuplot 3 / 49 1 1 2014 6 IIJ / 4 / 49 1 ( ) / 5 / 49 ( ) 6 / 49 (summary statistics) : (mean) (median) (mode) : (range) (variance) (standard deviation) 7 / 49
2 2015 4 20 1 (4/13) : ruby 2 / 49 2 ( ) : gnuplot 3 / 49 1 1 2014 6 IIJ / 4 / 49 1 ( ) / 5 / 49 ( ) 6 / 49 (summary statistics) : (mean) (median) (mode) : (range) (variance) (standard deviation) 7 / 49
RとExcelを用いた分布推定の実践例
 R Excel 1 2 1 2 2011/11/09 ( IMI) R Excel 2011/11/09 1 / 12 (1) R Excel (2) ( IMI) R Excel 2011/11/09 2 / 12 R Excel R R > library(fitdistrplus) > x fitdist(x,"norm","mle")
R Excel 1 2 1 2 2011/11/09 ( IMI) R Excel 2011/11/09 1 / 12 (1) R Excel (2) ( IMI) R Excel 2011/11/09 2 / 12 R Excel R R > library(fitdistrplus) > x fitdist(x,"norm","mle")
今回 次回の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ Danger!! (危 1) 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか これは次回)
 時系列データの GLM あてはめ (危 2) 時系列Yt 時系列 Xt 各時刻の個体数 気温 とか これは次回)") 生態学の時系列データ解析でよく見る あぶない モデリング 久保拓弥 mailto:kubo@ees.hokudai.ac.jp statistical model for time-series data 2017-07-03 kubostat2017 (h) 1/59 今回 次回の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ Danger!! (危 1) 時系列データの
生態学の時系列データ解析でよく見る あぶない モデリング 久保拓弥 mailto:kubo@ees.hokudai.ac.jp statistical model for time-series data 2017-07-03 kubostat2017 (h) 1/59 今回 次回の要点 あぶない 時系列データ解析は やめましょう! 統計モデル のあてはめ Danger!! (危 1) 時系列データの
森林水文 水資源学 2 2. 水文統計 豪雨があった時, 新聞やテレビのニュースで 50 年に一度の大雨だった などと報告されることがある. 今争点となっている川辺川ダムは,80 年に 1 回の洪水を想定して治水計画が立てられている. 畑地かんがいでは,10 年に 1 回の渇水を対象として計画が立て
 . 水文統計 豪雨があった時, 新聞やテレビのニュースで 50 年に一度の大雨だった などと報告されることがある. 今争点となっている川辺川ダムは,80 年に 回の洪水を想定して治水計画が立てられている. 畑地かんがいでは,0 年に 回の渇水を対象として計画が立てられる. このように, 水利構造物の設計や, 治水や利水の計画などでは, 年に 回起こるような降雨事象 ( 最大降雨強度, 最大連続干天日数など
. 水文統計 豪雨があった時, 新聞やテレビのニュースで 50 年に一度の大雨だった などと報告されることがある. 今争点となっている川辺川ダムは,80 年に 回の洪水を想定して治水計画が立てられている. 畑地かんがいでは,0 年に 回の渇水を対象として計画が立てられる. このように, 水利構造物の設計や, 治水や利水の計画などでは, 年に 回起こるような降雨事象 ( 最大降雨強度, 最大連続干天日数など
NLMIXED プロシジャを用いた生存時間解析 伊藤要二アストラゼネカ株式会社臨床統計 プログラミング グループグルプ Survival analysis using PROC NLMIXED Yohji Itoh Clinical Statistics & Programming Group, A
 NLMIXED プロシジャを用いた生存時間解析 伊藤要二アストラゼネカ株式会社臨床統計 プログラミング グループグルプ Survival analysis using PROC NLMIXED Yohji Itoh Clinical Statistics & Programming Group, AstraZeneca KK 要旨 : NLMIXEDプロシジャの最尤推定の機能を用いて 指数分布 Weibull
NLMIXED プロシジャを用いた生存時間解析 伊藤要二アストラゼネカ株式会社臨床統計 プログラミング グループグルプ Survival analysis using PROC NLMIXED Yohji Itoh Clinical Statistics & Programming Group, AstraZeneca KK 要旨 : NLMIXEDプロシジャの最尤推定の機能を用いて 指数分布 Weibull
untitled
 MCMC 2004 23 1 I. MCMC 1. 2. 3. 4. MH 5. 6. MCMC 2 II. 1. 2. 3. 4. 5. 3 I. MCMC 1. 2. 3. 4. MH 5. 4 1. MCMC 5 2. A P (A) : P (A)=0.02 A B A B Pr B A) Pr B A c Pr B A)=0.8, Pr B A c =0.1 6 B A 7 8 A, :
MCMC 2004 23 1 I. MCMC 1. 2. 3. 4. MH 5. 6. MCMC 2 II. 1. 2. 3. 4. 5. 3 I. MCMC 1. 2. 3. 4. MH 5. 4 1. MCMC 5 2. A P (A) : P (A)=0.02 A B A B Pr B A) Pr B A c Pr B A)=0.8, Pr B A c =0.1 6 B A 7 8 A, :
ii 3.,. 4. F. (), ,,. 8.,. 1. (75% ) (25% ) =9 7, =9 8 (. ). 1.,, (). 3.,. 1. ( ).,.,.,.,.,. ( ) (1 2 )., ( ), 0. 2., 1., 0,.
, ,,. 8.,. 1. (75% ) (25% ) =9 7, =9 8 (. ). 1.,, (). 3.,. 1. ( ).,.,.,.,.,. ( ) (1 2 )., ( ), 0. 2., 1., 0,.") 23(2011) (1 C104) 5 11 (2 C206) 5 12 http://www.math.is.tohoku.ac.jp/~obata,.,,,.. 1. 2. 3. 4. 5. 6. 7.,,. 1., 2007 ( ). 2. P. G. Hoel, 1995. 3... 1... 2.,,. ii 3.,. 4. F. (),.. 5.. 6.. 7.,,. 8.,. 1. (75%
23(2011) (1 C104) 5 11 (2 C206) 5 12 http://www.math.is.tohoku.ac.jp/~obata,.,,,.. 1. 2. 3. 4. 5. 6. 7.,,. 1., 2007 ( ). 2. P. G. Hoel, 1995. 3... 1... 2.,,. ii 3.,. 4. F. (),.. 5.. 6.. 7.,,. 8.,. 1. (75%
症例数設定? What is sample size estimation? 医療機器臨床試験のコンサルティングで最も相談件数が多いのは 症例数の設定 Many a need of consulting for device clinical trial is sample size estimat
 医療機器臨床試験における 例数設計のいろは Sample size estimation for clinical trials of devices -First education- 株式会社バイオスタティスティカルリサ - チ古川敏仁 Furukawa Toshihito, Biostatistical Research 2005 年 9 月 3 日第 2 回医療機器臨床試験研究会 Copyright(C)
医療機器臨床試験における 例数設計のいろは Sample size estimation for clinical trials of devices -First education- 株式会社バイオスタティスティカルリサ - チ古川敏仁 Furukawa Toshihito, Biostatistical Research 2005 年 9 月 3 日第 2 回医療機器臨床試験研究会 Copyright(C)
Microsoft Word - lec_student-chp3_1-representative
 1. はじめに この節でのテーマ データ分布の中心位置を数値で表す 可視化でとらえた分布の中心位置を数量化する 平均値とメジアン, 幾何平均 この節での到達目標 1 平均値 メジアン 幾何平均の定義を書ける 2 平均値とメジアン, 幾何平均の特徴と使える状況を説明できる. 3 平均値 メジアン 幾何平均を計算できる 2. 特性値 集めたデータを度数分布表やヒストグラムに整理する ( 可視化する )
1. はじめに この節でのテーマ データ分布の中心位置を数値で表す 可視化でとらえた分布の中心位置を数量化する 平均値とメジアン, 幾何平均 この節での到達目標 1 平均値 メジアン 幾何平均の定義を書ける 2 平均値とメジアン, 幾何平均の特徴と使える状況を説明できる. 3 平均値 メジアン 幾何平均を計算できる 2. 特性値 集めたデータを度数分布表やヒストグラムに整理する ( 可視化する )
Microsoft PowerPoint - 統計科学研究所_R_重回帰分析_変数選択_2.ppt
 重回帰分析 残差分析 変数選択 1 内容 重回帰分析 残差分析 歯の咬耗度データの分析 R で変数選択 ~ step 関数 ~ 2 重回帰分析と単回帰分析 体重を予測する問題 分析 1 身長 のみから体重を予測 分析 2 身長 と ウエスト の両方を用いて体重を予測 分析 1 と比べて大きな改善 体重 に関する推測では 身長 だけでは不十分 重回帰分析における問題 ~ モデルの構築 ~ 適切なモデルで分析しているか?
重回帰分析 残差分析 変数選択 1 内容 重回帰分析 残差分析 歯の咬耗度データの分析 R で変数選択 ~ step 関数 ~ 2 重回帰分析と単回帰分析 体重を予測する問題 分析 1 身長 のみから体重を予測 分析 2 身長 と ウエスト の両方を用いて体重を予測 分析 1 と比べて大きな改善 体重 に関する推測では 身長 だけでは不十分 重回帰分析における問題 ~ モデルの構築 ~ 適切なモデルで分析しているか?
したがって このモデルではの長さをもつ潜在履歴 latent history が存在し 同様に と指標化して扱うことができる 以下では 潜在的に起こりうる履歴を潜在履歴 latent history 実際にデ ータとして記録された履歴を記録履歴 recorded history ということにする M
 Bayesian Inference with ecological applications Chapter 10 Bayesian Inference with ecological applications 輪読会 潜在的な事象を扱うための多項分布モデル Latent Multinomial Models 本章では 記録した頻度データが多項分布に従う潜在的な変数を集約したものと考えられるときの
Bayesian Inference with ecological applications Chapter 10 Bayesian Inference with ecological applications 輪読会 潜在的な事象を扱うための多項分布モデル Latent Multinomial Models 本章では 記録した頻度データが多項分布に従う潜在的な変数を集約したものと考えられるときの
R-introduction.R
 による統計解析 三中信宏 minaka@affrc.go.jp http://leeswijzer.org 305-8604 茨城県つくば市観音台 3-1-3 国立研究開発法人農業 食品産業技術総合研究機構農業環境変動研究センター統計モデル解析ユニット専門員 租界 R の門前にて : 統計言語 R との極私的格闘記録 http://leeswijzer.org/r/r-top.html 教科書と参考書
による統計解析 三中信宏 minaka@affrc.go.jp http://leeswijzer.org 305-8604 茨城県つくば市観音台 3-1-3 国立研究開発法人農業 食品産業技術総合研究機構農業環境変動研究センター統計モデル解析ユニット専門員 租界 R の門前にて : 統計言語 R との極私的格闘記録 http://leeswijzer.org/r/r-top.html 教科書と参考書
確率分布 - 確率と計算 1 6 回に 1 回の割合で 1 の目が出るさいころがある. このさいころを 6 回投げたとき,1 度も 1 の目が出ない確率を求めよ. 5 6 /6 6 =15625/46656= (5/6) 6 = ある市の気象観測所での記録では, 毎年雨の降る
 6 = ある市の気象観測所での記録では, 毎年雨の降る") 確率分布 - 確率と計算 6 回に 回の割合で の目が出るさいころがある. このさいころを 6 回投げたとき 度も の目が出ない確率を求めよ. 5 6 /6 6 =565/46656=.48 (5/6) 6 =.48 ある市の気象観測所での記録では 毎年雨の降る日と降らない日の割合は概ね :9 で一定している. 前日に発表される予報の精度は 8% で 残りの % は実際とは逆の天気を予報している.
確率分布 - 確率と計算 6 回に 回の割合で の目が出るさいころがある. このさいころを 6 回投げたとき 度も の目が出ない確率を求めよ. 5 6 /6 6 =565/46656=.48 (5/6) 6 =.48 ある市の気象観測所での記録では 毎年雨の降る日と降らない日の割合は概ね :9 で一定している. 前日に発表される予報の精度は 8% で 残りの % は実際とは逆の天気を予報している.
Medical3
 Chapter 1 1.4.1 1 元配置分散分析と多重比較の実行 3つの治療法による測定値に有意な差が認められるかどうかを分散分析で調べます この例では 因子が1つだけ含まれるため1 元配置分散分析 one-way ANOVA の適用になります また 多重比較法 multiple comparison procedure を用いて 具体的のどの治療法の間に有意差が認められるかを検定します 1. 分析メニュー
Chapter 1 1.4.1 1 元配置分散分析と多重比較の実行 3つの治療法による測定値に有意な差が認められるかどうかを分散分析で調べます この例では 因子が1つだけ含まれるため1 元配置分散分析 one-way ANOVA の適用になります また 多重比較法 multiple comparison procedure を用いて 具体的のどの治療法の間に有意差が認められるかを検定します 1. 分析メニュー
スライド 1
 2019 年 5 月 7 日 @ 統計モデリング 統計モデリング 第四回配布資料 ( 予習用 ) 文献 : a) A. J. Dobson and A. G. Barnett: An Introduction to Generalized Linear Models. 3rd ed., CRC Press. b) H. Dung, et al: Monitoring the Transmission
2019 年 5 月 7 日 @ 統計モデリング 統計モデリング 第四回配布資料 ( 予習用 ) 文献 : a) A. J. Dobson and A. G. Barnett: An Introduction to Generalized Linear Models. 3rd ed., CRC Press. b) H. Dung, et al: Monitoring the Transmission
統計研修R分散分析(追加).indd
.indd") http://cse.niaes.affrc.go.jp/minaka/r/r-top.html > mm mm TRT DATA 1 DM1 2537 2 DM1 2069 3 DM1 2104 4 DM1 1797 5 DM2 3366 6 DM2 2591 7 DM2 2211 8
http://cse.niaes.affrc.go.jp/minaka/r/r-top.html > mm mm TRT DATA 1 DM1 2537 2 DM1 2069 3 DM1 2104 4 DM1 1797 5 DM2 3366 6 DM2 2591 7 DM2 2211 8
Variational Auto Encoder
 Variational Auto Encoder nzw 216 年 12 月 1 日 1 はじめに 深層学習における生成モデルとして Generative Adversarial Nets (GAN) と Variational Auto Encoder (VAE) [1] が主な手法として知られている. 本資料では,VAE を紹介する. 本資料は, 提案論文 [1] とチュートリアル資料 [2]
Variational Auto Encoder nzw 216 年 12 月 1 日 1 はじめに 深層学習における生成モデルとして Generative Adversarial Nets (GAN) と Variational Auto Encoder (VAE) [1] が主な手法として知られている. 本資料では,VAE を紹介する. 本資料は, 提案論文 [1] とチュートリアル資料 [2]
青焼 1章[15-52].indd
![青焼 1章[15-52].indd](/thumbs/86/94313777.jpg "青焼 1章[15-52].indd") 1 第 1 章統計の基礎知識 1 1 なぜ統計解析が必要なのか? 人間は自分自身の経験にもとづいて 感覚的にものごとを判断しがちである 例えばある疾患に対する標準治療薬の有効率が 50% であったとする そこに新薬が登場し ある医師がその新薬を 5 人の患者に使ったところ 4 人が有効と判定されたとしたら 多くの医師はこれまでの標準治療薬よりも新薬のほうが有効性が高そうだと感じることだろう しかし
1 第 1 章統計の基礎知識 1 1 なぜ統計解析が必要なのか? 人間は自分自身の経験にもとづいて 感覚的にものごとを判断しがちである 例えばある疾患に対する標準治療薬の有効率が 50% であったとする そこに新薬が登場し ある医師がその新薬を 5 人の患者に使ったところ 4 人が有効と判定されたとしたら 多くの医師はこれまでの標準治療薬よりも新薬のほうが有効性が高そうだと感じることだろう しかし
Microsoft PowerPoint - 基礎・経済統計6.ppt
 . 確率変数 基礎 経済統計 6 確率分布 事象を数値化したもの ( 事象ー > 数値 の関数 自然に数値されている場合 さいころの目 量的尺度 数値化が必要な場合 質的尺度, 順序的尺度 それらの尺度に数値を割り当てる 例えば, コインの表が出たら, 裏なら 0. 離散確率変数と連続確率変数 確率変数の値 連続値をとるもの 身長, 体重, 実質 GDP など とびとびの値 離散値をとるもの 新生児の性別
. 確率変数 基礎 経済統計 6 確率分布 事象を数値化したもの ( 事象ー > 数値 の関数 自然に数値されている場合 さいころの目 量的尺度 数値化が必要な場合 質的尺度, 順序的尺度 それらの尺度に数値を割り当てる 例えば, コインの表が出たら, 裏なら 0. 離散確率変数と連続確率変数 確率変数の値 連続値をとるもの 身長, 体重, 実質 GDP など とびとびの値 離散値をとるもの 新生児の性別
講義「○○○○」
 講義 信頼度の推定と立証 内容. 点推定と区間推定. 指数分布の点推定 区間推定 3. 指数分布 正規分布の信頼度推定 担当 : 倉敷哲生 ( ビジネスエンジニアリング専攻 ) 統計的推測 標本から得られる情報を基に 母集団に関する結論の導出が目的 測定値 x x x 3 : x 母集団 (populaio) 母集団の特性値 統計的推測 標本 (sample) 標本の特性値 分布のパラメータ ( 母数
講義 信頼度の推定と立証 内容. 点推定と区間推定. 指数分布の点推定 区間推定 3. 指数分布 正規分布の信頼度推定 担当 : 倉敷哲生 ( ビジネスエンジニアリング専攻 ) 統計的推測 標本から得られる情報を基に 母集団に関する結論の導出が目的 測定値 x x x 3 : x 母集団 (populaio) 母集団の特性値 統計的推測 標本 (sample) 標本の特性値 分布のパラメータ ( 母数

¥¤¥ó¥¿¡¼¥Í¥Ã¥È·×¬¤È¥Ç¡¼¥¿²òÀÏ Âè2²ó
 2 212 4 13 1 (4/6) : ruby 2 / 35 ( ) : gnuplot 3 / 35 ( ) 4 / 35 (summary statistics) : (mean) (median) (mode) : (range) (variance) (standard deviation) 5 / 35 (mean): x = 1 n (median): { xr+1 m, m = 2r
2 212 4 13 1 (4/6) : ruby 2 / 35 ( ) : gnuplot 3 / 35 ( ) 4 / 35 (summary statistics) : (mean) (median) (mode) : (range) (variance) (standard deviation) 5 / 35 (mean): x = 1 n (median): { xr+1 m, m = 2r
kubostat2018d p.2 :? bod size x and fertilization f change seed number? : a statistical model for this example? i response variable seed number : { i
 kubostat2018d p.1 I 2018 (d) model selection and kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2018 06 25 : 2018 06 21 17:45 1 2 3 4 :? AIC : deviance model selection misunderstanding kubostat2018d (http://goo.gl/76c4i)
kubostat2018d p.1 I 2018 (d) model selection and kubo@ees.hokudai.ac.jp http://goo.gl/76c4i 2018 06 25 : 2018 06 21 17:45 1 2 3 4 :? AIC : deviance model selection misunderstanding kubostat2018d (http://goo.gl/76c4i)
Microsoft Word - Meta70_Preferences.doc
 Image Windows Preferences Edit, Preferences MetaMorph, MetaVue Image Windows Preferences Edit, Preferences Image Windows Preferences 1. Windows Image Placement: Acquire Overlay at Top Left Corner: 1 Acquire
Image Windows Preferences Edit, Preferences MetaMorph, MetaVue Image Windows Preferences Edit, Preferences Image Windows Preferences 1. Windows Image Placement: Acquire Overlay at Top Left Corner: 1 Acquire
スライド 1
 担当 : 田中冬彦 016 年 4 月 19 日 @ 統計モデリング 統計モデリング 第二回配布資料 文献 : A. J. Dobson and A. G. Barnett: An Introduction to Generalized Linear Models 3rd ed., CRC Press. 配布資料の PDF は以下からも DL できます. 短縮 URL http://tinyurl.com/lxb7kb8
担当 : 田中冬彦 016 年 4 月 19 日 @ 統計モデリング 統計モデリング 第二回配布資料 文献 : A. J. Dobson and A. G. Barnett: An Introduction to Generalized Linear Models 3rd ed., CRC Press. 配布資料の PDF は以下からも DL できます. 短縮 URL http://tinyurl.com/lxb7kb8
様々なミクロ計量モデル†
 担当 : 長倉大輔 ( ながくらだいすけ ) この資料は私の講義において使用するために作成した資料です WEB ページ上で公開しており 自由に参照して頂いて構いません ただし 内容について 一応検証してありますが もし間違いがあった場合でもそれによって生じるいかなる損害 不利益について責任を負いかねますのでご了承ください 間違いは発見次第 継続的に直していますが まだ存在する可能性があります 1 カウントデータモデル
担当 : 長倉大輔 ( ながくらだいすけ ) この資料は私の講義において使用するために作成した資料です WEB ページ上で公開しており 自由に参照して頂いて構いません ただし 内容について 一応検証してありますが もし間違いがあった場合でもそれによって生じるいかなる損害 不利益について責任を負いかねますのでご了承ください 間違いは発見次第 継続的に直していますが まだ存在する可能性があります 1 カウントデータモデル
memo
 数理情報工学特論第一 機械学習とデータマイニング 4 章 : 教師なし学習 3 かしまひさし 鹿島久嗣 ( 数理 6 研 ) kashima@mist.i.~ DEPARTMENT OF MATHEMATICAL INFORMATICS 1 グラフィカルモデルについて学びます グラフィカルモデル グラフィカルラッソ グラフィカルラッソの推定アルゴリズム 2 グラフィカルモデル 3 教師なし学習の主要タスクは
数理情報工学特論第一 機械学習とデータマイニング 4 章 : 教師なし学習 3 かしまひさし 鹿島久嗣 ( 数理 6 研 ) kashima@mist.i.~ DEPARTMENT OF MATHEMATICAL INFORMATICS 1 グラフィカルモデルについて学びます グラフィカルモデル グラフィカルラッソ グラフィカルラッソの推定アルゴリズム 2 グラフィカルモデル 3 教師なし学習の主要タスクは
Microsoft PowerPoint - SPECTPETの原理2012.ppt [互換モード]
![Microsoft PowerPoint - SPECTPETの原理2012.ppt [互換モード]](/thumbs/94/121508518.jpg "Microsoft PowerPoint - SPECTPETの原理2012.ppt [互換モード]") 22 年国家試験解答 1,5 フーリエ変換は線形変換 FFT はデータ数に 2 の累乗数を要求するが DFT は任意のデータ数に対応 123I-IMP Brain SPECT FBP with Ramp filter 123I-IMP Brain SPECT FBP with Shepp&Logan filter 99mTc-MIBI Myocardial SPECT における ストリークアーチファクト
22 年国家試験解答 1,5 フーリエ変換は線形変換 FFT はデータ数に 2 の累乗数を要求するが DFT は任意のデータ数に対応 123I-IMP Brain SPECT FBP with Ramp filter 123I-IMP Brain SPECT FBP with Shepp&Logan filter 99mTc-MIBI Myocardial SPECT における ストリークアーチファクト
EBNと疫学
 推定と検定 57 ( 復習 ) 記述統計と推測統計 統計解析は大きく 2 つに分けられる 記述統計 推測統計 記述統計 観察集団の特性を示すもの 代表値 ( 平均値や中央値 ) や ばらつきの指標 ( 標準偏差など ) 図表を効果的に使う 推測統計 観察集団のデータから母集団の特性を 推定 する 平均 / 分散 / 係数値などの推定 ( 点推定 ) 点推定値のばらつきを調べる ( 区間推定 ) 検定統計量を用いた検定
推定と検定 57 ( 復習 ) 記述統計と推測統計 統計解析は大きく 2 つに分けられる 記述統計 推測統計 記述統計 観察集団の特性を示すもの 代表値 ( 平均値や中央値 ) や ばらつきの指標 ( 標準偏差など ) 図表を効果的に使う 推測統計 観察集団のデータから母集団の特性を 推定 する 平均 / 分散 / 係数値などの推定 ( 点推定 ) 点推定値のばらつきを調べる ( 区間推定 ) 検定統計量を用いた検定
yamadaiR(cEFA).pdf
.pdf") R 2012/10/05 Kosugi,E.Koji (Yamadai.R) Categorical Factor Analysis by using R 2012/10/05 1 / 9 Why we use... 3 5 Kosugi,E.Koji (Yamadai.R) Categorical Factor Analysis by using R 2012/10/05 2 / 9 FA vs
R 2012/10/05 Kosugi,E.Koji (Yamadai.R) Categorical Factor Analysis by using R 2012/10/05 1 / 9 Why we use... 3 5 Kosugi,E.Koji (Yamadai.R) Categorical Factor Analysis by using R 2012/10/05 2 / 9 FA vs
スライド 1
 205 年 4 月 28 日 @ 統計モデリング 統計モデリング 第三回配布資料 文献 : A. J. Dobso ad A. G. Barett: A Itroducto to Geeralzed Lear Models. 3rd ed., CRC Press. J. J. Faraway: Etedg the Lear Model wth R. CRC Press. 配布資料の PDF は以下からも
205 年 4 月 28 日 @ 統計モデリング 統計モデリング 第三回配布資料 文献 : A. J. Dobso ad A. G. Barett: A Itroducto to Geeralzed Lear Models. 3rd ed., CRC Press. J. J. Faraway: Etedg the Lear Model wth R. CRC Press. 配布資料の PDF は以下からも
ビジネス統計 統計基礎とエクセル分析 正誤表
 ビジネス統計統計基礎とエクセル分析 ビジネス統計スペシャリスト エクセル分析スペシャリスト 公式テキスト正誤表と学習用データ更新履歴 平成 30 年 5 月 14 日現在 公式テキスト正誤表 頁場所誤正修正 6 知識編第 章 -3-3 最頻値の解説内容 たとえば, 表.1 のデータであれば, 最頻値は 167.5cm というたとえば, 表.1 のデータであれば, 最頻値は 165.0cm ということになります
ビジネス統計統計基礎とエクセル分析 ビジネス統計スペシャリスト エクセル分析スペシャリスト 公式テキスト正誤表と学習用データ更新履歴 平成 30 年 5 月 14 日現在 公式テキスト正誤表 頁場所誤正修正 6 知識編第 章 -3-3 最頻値の解説内容 たとえば, 表.1 のデータであれば, 最頻値は 167.5cm というたとえば, 表.1 のデータであれば, 最頻値は 165.0cm ということになります
/ *1 *1 c Mike Gonzalez, October 14, Wikimedia Commons.
 2010 05 22 1/ 35 2010 2010 05 22 *1 kubo@ees.hokudai.ac.jp *1 c Mike Gonzalez, October 14, 2007. Wikimedia Commons. 2010 05 22 2/ 35 1. 2. 3. 2010 05 22 3/ 35 : 1.? 2. 2010 05 22 4/ 35 1. 2010 05 22 5/
2010 05 22 1/ 35 2010 2010 05 22 *1 kubo@ees.hokudai.ac.jp *1 c Mike Gonzalez, October 14, 2007. Wikimedia Commons. 2010 05 22 2/ 35 1. 2. 3. 2010 05 22 3/ 35 : 1.? 2. 2010 05 22 4/ 35 1. 2010 05 22 5/
第 3 回講義の項目と概要 統計的手法入門 : 品質のばらつきを解析する 平均と標準偏差 (P30) a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均
 a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均") 第 3 回講義の項目と概要 016.8.9 1.3 統計的手法入門 : 品質のばらつきを解析する 1.3.1 平均と標準偏差 (P30) a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均 :AVERAGE 関数, 標準偏差 :STDEVP 関数とSTDEVという関数 1 取得したデータそのものの標準偏差
第 3 回講義の項目と概要 016.8.9 1.3 統計的手法入門 : 品質のばらつきを解析する 1.3.1 平均と標準偏差 (P30) a) データは平均を見ただけではわからない 平均が同じだからといって 同一視してはいけない b) データのばらつきを示す 標準偏差 にも注目しよう c) 平均 :AVERAGE 関数, 標準偏差 :STDEVP 関数とSTDEVという関数 1 取得したデータそのものの標準偏差
スライド 1
 第 13 章系列データ 2015/9/20 夏合宿 PRML 輪読ゼミ B4 三木真理子 目次 2 1. 系列データと状態空間モデル 2. 隠れマルコフモデル 2.1 定式化とその性質 2.2 最尤推定法 2.3 潜在変数の系列を知るには 3. 線形動的システム この章の目標 : 系列データを扱う際に有効な状態空間モデルのうち 代表的な 2 例である隠れマルコフモデルと線形動的システムの性質を知り
第 13 章系列データ 2015/9/20 夏合宿 PRML 輪読ゼミ B4 三木真理子 目次 2 1. 系列データと状態空間モデル 2. 隠れマルコフモデル 2.1 定式化とその性質 2.2 最尤推定法 2.3 潜在変数の系列を知るには 3. 線形動的システム この章の目標 : 系列データを扱う際に有効な状態空間モデルのうち 代表的な 2 例である隠れマルコフモデルと線形動的システムの性質を知り
統計的データ解析
 統計的データ解析 011 011.11.9 林田清 ( 大阪大学大学院理学研究科 ) 連続確率分布の平均値 分散 比較のため P(c ) c 分布 自由度 の ( カイ c 平均値 0, 標準偏差 1の正規分布 に従う変数 xの自乗和 c x =1 が従う分布を自由度 の分布と呼ぶ 一般に自由度の分布は f /1 c / / ( c ) {( c ) e }/ ( / ) 期待値 二乗 ) 分布 c
統計的データ解析 011 011.11.9 林田清 ( 大阪大学大学院理学研究科 ) 連続確率分布の平均値 分散 比較のため P(c ) c 分布 自由度 の ( カイ c 平均値 0, 標準偏差 1の正規分布 に従う変数 xの自乗和 c x =1 が従う分布を自由度 の分布と呼ぶ 一般に自由度の分布は f /1 c / / ( c ) {( c ) e }/ ( / ) 期待値 二乗 ) 分布 c
言語モデルの基礎 2
 自然言語処理プログラミング勉強会 1 1-gram 言語モデル Graham Neubig 奈良先端科学技術大学院大学 (NAIST) 1 言語モデルの基礎 2 言語モデル 英語の音声認識を行いたい時に どれが正解 英語音声 W1 = speech recognition system W2 = speech cognition system W3 = speck podcast histamine
自然言語処理プログラミング勉強会 1 1-gram 言語モデル Graham Neubig 奈良先端科学技術大学院大学 (NAIST) 1 言語モデルの基礎 2 言語モデル 英語の音声認識を行いたい時に どれが正解 英語音声 W1 = speech recognition system W2 = speech cognition system W3 = speck podcast histamine
「統 計 数 学 3」
 関数の使い方 1 関数と引数 関数の構造 関数名 ( 引数 1, 引数 2, 引数 3, ) 例 : マハラノビス距離を求める関数 mahalanobis(data,m,v) 引数名を指定して記述する場合 mahalanobis(x=data, center=m, cov=v) 2 関数についてのヘルプ 基本的な関数のヘルプの呼び出し? 関数名 例 :?mean 例 :?mahalanobis 指定できる引数を確認する関数
関数の使い方 1 関数と引数 関数の構造 関数名 ( 引数 1, 引数 2, 引数 3, ) 例 : マハラノビス距離を求める関数 mahalanobis(data,m,v) 引数名を指定して記述する場合 mahalanobis(x=data, center=m, cov=v) 2 関数についてのヘルプ 基本的な関数のヘルプの呼び出し? 関数名 例 :?mean 例 :?mahalanobis 指定できる引数を確認する関数
Microsoft Word - 1 color Normalization Document _Agilent version_ .doc
 color 実験の Normalization color 実験で得られた複数のアレイデータを相互比較するためには Normalization( 正規化 ) が必要です 2 つのサンプルを異なる色素でラベル化し 競合ハイブリダイゼーションさせる 2color 実験では 基本的に Dye Normalization( 色素補正 ) が適用されますが color 実験では データの特徴と実験の目的 (
color 実験の Normalization color 実験で得られた複数のアレイデータを相互比較するためには Normalization( 正規化 ) が必要です 2 つのサンプルを異なる色素でラベル化し 競合ハイブリダイゼーションさせる 2color 実験では 基本的に Dye Normalization( 色素補正 ) が適用されますが color 実験では データの特徴と実験の目的 (
& 3 3 ' ' (., (Pixel), (Light Intensity) (Random Variable). (Joint Probability). V., V = {,,, V }. i x i x = (x, x,, x V ) T. x i i (State Variable),
, (Light Intensity) (Random Variable). (Joint Probability). V., V = {,,, V }. i x i x = (x, x,, x V ) T. x i i (State Variable),") .... Deeping and Expansion of Large-Scale Random Fields and Probabilistic Image Processing Kazuyuki Tanaka The mathematical frameworks of probabilistic image processing are formulated by means of Markov
.... Deeping and Expansion of Large-Scale Random Fields and Probabilistic Image Processing Kazuyuki Tanaka The mathematical frameworks of probabilistic image processing are formulated by means of Markov
日本製薬工業協会シンポジウム 生存時間解析の評価指標に関する最近の展開ー RMST (restricted mean survival time) を理解するー 2. RMST の定義と統計的推測 2018 年 6 月 13 日医薬品評価委員会データサイエンス部会タスクフォース 4 生存時間解析チー
 を理解するー 2. RMST の定義と統計的推測 2018 年 6 月 13 日医薬品評価委員会データサイエンス部会タスクフォース 4 生存時間解析チー") 日本製薬工業協会シンポジウム 生存時間解析の評価指標に関する最近の展開ー RMST (restricted mean survival time) を理解するー 2. RMST の定義と統計的推測 2018 年 6 月 13 日医薬品評価委員会データサイエンス部会タスクフォース 4 生存時間解析チーム 日本新薬 ( 株 ) 田中慎一 留意点 本発表は, 先日公開された 生存時間型応答の評価指標 -RMST(restricted
日本製薬工業協会シンポジウム 生存時間解析の評価指標に関する最近の展開ー RMST (restricted mean survival time) を理解するー 2. RMST の定義と統計的推測 2018 年 6 月 13 日医薬品評価委員会データサイエンス部会タスクフォース 4 生存時間解析チーム 日本新薬 ( 株 ) 田中慎一 留意点 本発表は, 先日公開された 生存時間型応答の評価指標 -RMST(restricted

< E6D6364>
 東京経大学会誌 第 274 号 田島博和 1. はじめに 確率的離散選択の代表的なモデルであるロジットモデルは, マーケティングや消費者行動の分野でも, 消費者のブランド選択行動等を記述するために古くから用いられてきた [Malhotra, 1984; 片平 杉田, 1994; 土田, 2010 ほか ] 最近では,MCMC(Markov-Chain Monte-Carlo) アルゴリズムを用いたベイズ推定により,
東京経大学会誌 第 274 号 田島博和 1. はじめに 確率的離散選択の代表的なモデルであるロジットモデルは, マーケティングや消費者行動の分野でも, 消費者のブランド選択行動等を記述するために古くから用いられてきた [Malhotra, 1984; 片平 杉田, 1994; 土田, 2010 ほか ] 最近では,MCMC(Markov-Chain Monte-Carlo) アルゴリズムを用いたベイズ推定により,
DAA02
 c(var1,var2,...,varn) > x x [1] 1 2 3 4 > x2 x2 [1] 1 2 3 4 5 6 7 8 c(var1,var2,...,varn) > y=c('a0','a1','b0','b1') > y [1] "a0" "a1" "b0" "b1 > z=c(x,y) > z [1] "1" "2"
c(var1,var2,...,varn) > x x [1] 1 2 3 4 > x2 x2 [1] 1 2 3 4 5 6 7 8 c(var1,var2,...,varn) > y=c('a0','a1','b0','b1') > y [1] "a0" "a1" "b0" "b1 > z=c(x,y) > z [1] "1" "2"
1 R Windows R 1.1 R The R project web R web Download [CRAN] CRAN Mirrors Japan Download and Install R [Windows 9
![1 R Windows R 1.1 R The R project web R web Download [CRAN] CRAN Mirrors Japan Download and Install R [Windows 9](/thumbs/99/142039515.jpg "1 R Windows R 1.1 R The R project web R web Download [CRAN] CRAN Mirrors Japan Download and Install R [Windows 9") 1 R 2007 8 19 1 Windows R 1.1 R The R project web http://www.r-project.org/ R web Download [CRAN] CRAN Mirrors Japan Download and Install R [Windows 95 and later ] [base] 2.5.1 R - 2.5.1 for Windows R
1 R 2007 8 19 1 Windows R 1.1 R The R project web http://www.r-project.org/ R web Download [CRAN] CRAN Mirrors Japan Download and Install R [Windows 95 and later ] [base] 2.5.1 R - 2.5.1 for Windows R
PowerPoint プレゼンテーション
 パーティクルフィルタ 理論と特性 11.1 パーティクルフィルタの理論的導出 状態遷移とマルコフ性 p x k x 1:k 1, y 1:k 1 = f x k x k 1 p y k x 1:k, y 1:k 1 k = 0,1, = h y k x k x 1:k x 1, x 2,, x k y 1:k y 1, y 2,, y k 確率分布で表現される現時刻の状態が, 前時刻までの状態と観測の条件付き確率によって定まる.
パーティクルフィルタ 理論と特性 11.1 パーティクルフィルタの理論的導出 状態遷移とマルコフ性 p x k x 1:k 1, y 1:k 1 = f x k x k 1 p y k x 1:k, y 1:k 1 k = 0,1, = h y k x k x 1:k x 1, x 2,, x k y 1:k y 1, y 2,, y k 確率分布で表現される現時刻の状態が, 前時刻までの状態と観測の条件付き確率によって定まる.
Microsoft PowerPoint - statistics08_03.ppt [互換モード]
![Microsoft PowerPoint - statistics08_03.ppt [互換モード]](/thumbs/91/105352863.jpg "Microsoft PowerPoint - statistics08_03.ppt [互換モード]") 授業担当 : 徳永伸一 東京医科歯科大学教養部 数学講座 前回 ( 第 2 回 ) の授業の概要 : 第 1 回 ( 教科書第 9 章 順列 組合せと確率 ほぼ全部 ) の復習 教科書第 10 章 記述統計 S. TOKUNAGA 2 1 Overview 確率 (9 章 ) 記述統計 (10 章 ) 情報の要約 表やグラフで表す 代表値 ( 平均など ) や散布度 ( 分散など ) を求める 確率モデル
授業担当 : 徳永伸一 東京医科歯科大学教養部 数学講座 前回 ( 第 2 回 ) の授業の概要 : 第 1 回 ( 教科書第 9 章 順列 組合せと確率 ほぼ全部 ) の復習 教科書第 10 章 記述統計 S. TOKUNAGA 2 1 Overview 確率 (9 章 ) 記述統計 (10 章 ) 情報の要約 表やグラフで表す 代表値 ( 平均など ) や散布度 ( 分散など ) を求める 確率モデル
1 1 ( ) ( 1.1 1.1.1 60% mm 100 100 60 60% 1.1.2 A B A B A 1
 ( 1.1 1.1.1 60% mm 100 100 60 60% 1.1.2 A B A B A 1") 1 21 10 5 1 E-mail: qliu@res.otaru-uc.ac.jp 1 1 ( ) ( 1.1 1.1.1 60% mm 100 100 60 60% 1.1.2 A B A B A 1 B 1.1.3 boy W ID 1 2 3 DI DII DIII OL OL 1.1.4 2 1.1.5 1.1.6 1.1.7 1.1.8 1.2 1.2.1 1. 2. 3 1.2.2
1 21 10 5 1 E-mail: qliu@res.otaru-uc.ac.jp 1 1 ( ) ( 1.1 1.1.1 60% mm 100 100 60 60% 1.1.2 A B A B A 1 B 1.1.3 boy W ID 1 2 3 DI DII DIII OL OL 1.1.4 2 1.1.5 1.1.6 1.1.7 1.1.8 1.2 1.2.1 1. 2. 3 1.2.2
(lm) lm AIC 2 / 1
 lm AIC 2 / 1") W707 s-taiji@is.titech.ac.jp 1 / 1 (lm) lm AIC 2 / 1 : y = β 1 x 1 + β 2 x 2 + + β d x d + β d+1 + ϵ (ϵ N(0, σ 2 )) y R: x R d : β i (i = 1,..., d):, β d+1 : ( ) (d = 1) y = β 1 x 1 + β 2 + ϵ (d > 1) y
W707 s-taiji@is.titech.ac.jp 1 / 1 (lm) lm AIC 2 / 1 : y = β 1 x 1 + β 2 x 2 + + β d x d + β d+1 + ϵ (ϵ N(0, σ 2 )) y R: x R d : β i (i = 1,..., d):, β d+1 : ( ) (d = 1) y = β 1 x 1 + β 2 + ϵ (d > 1) y
2016 年熊本地震の余震の確率予測 Probability aftershock forecasting of the M6.5 and M7.3 Kumamoto earthquakes of 2016 東京大学生産技術研究所統計数理研究所東京大学地震研究所 Institute of Indus
 2016 年熊本地震の余震の確率予測 Probability aftershock forecasting of the M6.5 and M7.3 Kumamoto earthquakes of 2016 東京大学生産技術研究所統計数理研究所東京大学地震研究所 Institute of Industrial Science, University of Tokyo The Institute of
2016 年熊本地震の余震の確率予測 Probability aftershock forecasting of the M6.5 and M7.3 Kumamoto earthquakes of 2016 東京大学生産技術研究所統計数理研究所東京大学地震研究所 Institute of Industrial Science, University of Tokyo The Institute of
_KyoukaNaiyou_No.4
 理科教科内容指導論 I : 物理分野 物理現象の定量的把握第 4 回 ( 実験 ) データの眺め ~ 統計学の基礎続き 統計のはなし 基礎 応 娯楽 (Best selected business books) 村平 科技連出版社 1836 円 前回の復習と今回以降の 標 東京 学 善 郎 Web サイトより データ ヒストグラム 代表値 ( 平均値 最頻値 中間値 ) 分布の散らばり 集団の分布
理科教科内容指導論 I : 物理分野 物理現象の定量的把握第 4 回 ( 実験 ) データの眺め ~ 統計学の基礎続き 統計のはなし 基礎 応 娯楽 (Best selected business books) 村平 科技連出版社 1836 円 前回の復習と今回以降の 標 東京 学 善 郎 Web サイトより データ ヒストグラム 代表値 ( 平均値 最頻値 中間値 ) 分布の散らばり 集団の分布
14 化学実験法 II( 吉村 ( 洋 mmol/l の半分だったから さんの測定値は くんの測定値の 4 倍の重みがあり 推定値 としては 0.68 mmol/l その標準偏差は mmol/l 程度ということになる 測定値を 特徴づけるパラメータ t を推定するこの手
 14 化学実験法 II( 吉村 ( 洋 014.6.1. 最小 乗法のはなし 014.6.1. 内容 最小 乗法のはなし...1 最小 乗法の考え方...1 最小 乗法によるパラメータの決定... パラメータの信頼区間...3 重みの異なるデータの取扱い...4 相関係数 決定係数 ( 最小 乗法を語るもう一つの立場...5 実験条件の誤差の影響...5 問題...6 最小 乗法の考え方 飲料水中のカルシウム濃度を
14 化学実験法 II( 吉村 ( 洋 014.6.1. 最小 乗法のはなし 014.6.1. 内容 最小 乗法のはなし...1 最小 乗法の考え方...1 最小 乗法によるパラメータの決定... パラメータの信頼区間...3 重みの異なるデータの取扱い...4 相関係数 決定係数 ( 最小 乗法を語るもう一つの立場...5 実験条件の誤差の影響...5 問題...6 最小 乗法の考え方 飲料水中のカルシウム濃度を
win版8日目
 8 日目 : 項目のチェック (2) 1 日 30 分くらい,30 日で何とか R をそこそこ使えるようになるための練習帳 :Win 版 昨日は, 平均値などの基礎統計量を計算する試行錯誤へご招待しましたが (?), 今日は簡 単にやってみます そのためには,psych というパッケージが必要となりますが, パッケー ジのインストール & 読み込みの詳しい方法は, 後で説明します 以下の説明は,psych
8 日目 : 項目のチェック (2) 1 日 30 分くらい,30 日で何とか R をそこそこ使えるようになるための練習帳 :Win 版 昨日は, 平均値などの基礎統計量を計算する試行錯誤へご招待しましたが (?), 今日は簡 単にやってみます そのためには,psych というパッケージが必要となりますが, パッケー ジのインストール & 読み込みの詳しい方法は, 後で説明します 以下の説明は,psych
スライド 1
 担当 : 田中冬彦 2018 年 4 月 17 日 @ 統計モデリング 統計モデリング 第二回配布資料 文献 : A. J. Dobson and A. G. Barnett: An Introduction to Generalized Linear Models 3rd ed., CRC Press. 配布資料の PDF は以下からも DL できます. 短縮 URL http://tinyurl.com/lxb7kb8
担当 : 田中冬彦 2018 年 4 月 17 日 @ 統計モデリング 統計モデリング 第二回配布資料 文献 : A. J. Dobson and A. G. Barnett: An Introduction to Generalized Linear Models 3rd ed., CRC Press. 配布資料の PDF は以下からも DL できます. 短縮 URL http://tinyurl.com/lxb7kb8
PackageSoft/R-033U.tex (2018/March) R:
 R:") ................................................................................ R: 2018 3 29................................................................................ R AI R https://cran.r-project.org/doc/contrib/manuals-jp/r-intro-170.jp.pdf
................................................................................ R: 2018 3 29................................................................................ R AI R https://cran.r-project.org/doc/contrib/manuals-jp/r-intro-170.jp.pdf